 Daniele Malpetti1,2,†
Daniele Malpetti1,2,† Marco Scutari1*†
Marco Scutari1*† Francesco Gualdi1,2,†
Francesco Gualdi1,2,† Jessica van Setten3
Jessica van Setten3 Sander van der Laan4,5
Sander van der Laan4,5 Saskia Haitjema4
Saskia Haitjema4 Aaron Mark Lee6Isabelle Hering7Francesca Mangili1,2
Aaron Mark Lee6Isabelle Hering7Francesca Mangili1,2
- 1Istituto Dalle Molle di Studi sull’Intelligenza Artificiale (IDSIA), USI-SUPSI, Polo Universitario Lugano, Lugano, Switzerland
- 2Swiss Institute of Bioinformatics (SIB), Lugano, Switzerland
- 3Department of Cardiology, University Medical Center Utrecht, University of Utrecht, Utrecht, Netherlands
- 4Central Diagnostics Laboratory, University Medical Center Utrecht, University of Utrecht, Utrecht, Netherlands
- 5Department of Genome Sciences, University of Virginia, Charlottesville, VA, United States
- 6William Harvey Research Institute, NIHR Barts Biomedical Research Centre, Queen Mary University of London, London, United Kingdom
- 7Étude Hering, DPO Associates SARL, Nyon, Switzerland
Federated learning leverages data across institutions to improve clinical discovery while complying with data-sharing restrictions and protecting patient privacy. This paper provides a gentle introduction to this approach in bioinformatics, and is the first to review key applications in proteomics, genome-wide association studies (GWAS), single-cell and multi-omics studies in their legal as well as methodological and infrastructural challenges. As the evolution of biobanks in genetics and systems biology has proved, accessing more extensive and varied data pools leads to a faster and more robust exploration and translation of results. More widespread use of federated learning may have a similar impact in bioinformatics, allowing academic and clinical institutions to access many combinations of genotypic, phenotypic and environmental information that are undercovered or not included in existing biobanks.
1 Introduction
Sharing personal information has been increasingly regulated in both the EU [with the GDPR and the AI act; (1, 2)] and the US [with HIPAA and the National AI Initiative Act; (3, 4)] to mitigate the personal and societal risks associated with their use, particularly in connection with machine learning and AI models (5). These regulations make multi-centre studies and similar endeavours more challenging, impacting biomedical and clinical research.
Federated learning [FL; (6, 7)] is a technical solution intended to reduce the impact of these restrictions. FL allows multiple parties to collaboratively train a global machine learning model using their respective data without sharing it themselves, and without any meaningful model performance degradation. Instead, parties only share model updates, making it impractical to reconstruct personal information when the appropriate secure computational measures are implemented (8).
This approach strengthens security by keeping sensitive information local, improves privacy by minimising data exposure even between the parties involved, and limits risk of data misuse by allowing each party to retain complete control over its data (9). If enough parties are involved, FL may access larger and more varied data pools than centralised biobanks can provide. This is particularly true if there are legal (or other) barriers to data centralisation, resulting in more accurate and robust models than those produced by any individual party.
FL has proven to be a valuable tool for biomedical research and is expected to gain further traction in the years to come. Its use has improved breast density classification models [accuracy up by 6%, generalisability up by 46%; (10)], COVID-19 outcome prediction at both 24h and 72h [up 16% and 38%; (11)] and rare tumour segmentation [up by 23%–33% and 15%; (12)] compared to single-party analyses. A consortium of ten pharmaceutical companies found that FL improved structure-activity relationship (QSAR) models for drug discovery [both up 12% (13)]. Early-stage applications building predictive models from electronic health records (14) have also confirmed no practical performance degradation compared to pooling data from all parties.
To achieve such results, a real-world implementation of FL must overcome several methodological, infrastructural and legal issues. However, biomedical FL literature reviews (15, 16, among others) are predominantly high-level and considered simulated rather than real-world implementations. Here, we will cover federated methods designed explicitly for bioinformatics and discuss the infrastructure they require, as well as how they meet legal requirements. While various legal frameworks may apply depending on jurisdiction, we place particular emphasis on the European General Data Protection Regulation (GDPR). This focus reflects not only our EU-based perspective but also the GDPR’s comprehensive scope, stringent requirements, and influence as a global benchmark for data protection in research and technology. In reviewing the literature, we selected papers that study practical analysis problems (as opposed to proposing methodologies in the abstract) for proteomics, genome-wide association studies (GWAS), and single-cell and multi-omics data. We also considered papers that discuss their feasibility, trade-offs, and performance compared to centralised analyses, and were published after 2016. We used Google Scholar to find and retrieve them.
To this end, we have structured the remainder of the paper as follows: We first review the fundamental concepts and design decisions of FL in Section 2, including different topologies (Section 2.1), hardware and software (Section 2.2), data layouts in different parties (Sections 2.3 and 2.4), security (Section 2.5) and privacy concerns (Section 2.6). In Section 3, we contrast and compare bioinformatics FL methods for proteomics and differential expression (Section 3.1), genome-wide association studies (GWAS; Section 3.2), single-cell RNA sequencing (Section 3.3), multiomics (Section 3.4) and medical imaging (Section 3.5) applications. We conclude the section with notable examples of ready-to-use software tools (Section 3.6). Section 4 provides examples of federated operations common in bioinformatics. Finally, we discuss the legal implications of using FL (Section 5) before summarising our perspective in Section 7.
2 Federated learning
FL is a collaborative approach to machine learning model training, where multiple institutions form a consortium to jointly train a shared model by exchanging model updates rather than individual patient data. Typically, FL involves data holders (called “clients”) sharing their local contributions with a server (6) as outlined in Figure 1. The server then creates and shares back a global model, inviting the data holders to update and resubmit their contributions. This process is iterative and involves several rounds of model update exchanges. Unlike traditional centralised computing, FL does not store patient data in a central location. Instead, patient data remain under the control of the respective data owners at their sites, enhancing privacy.
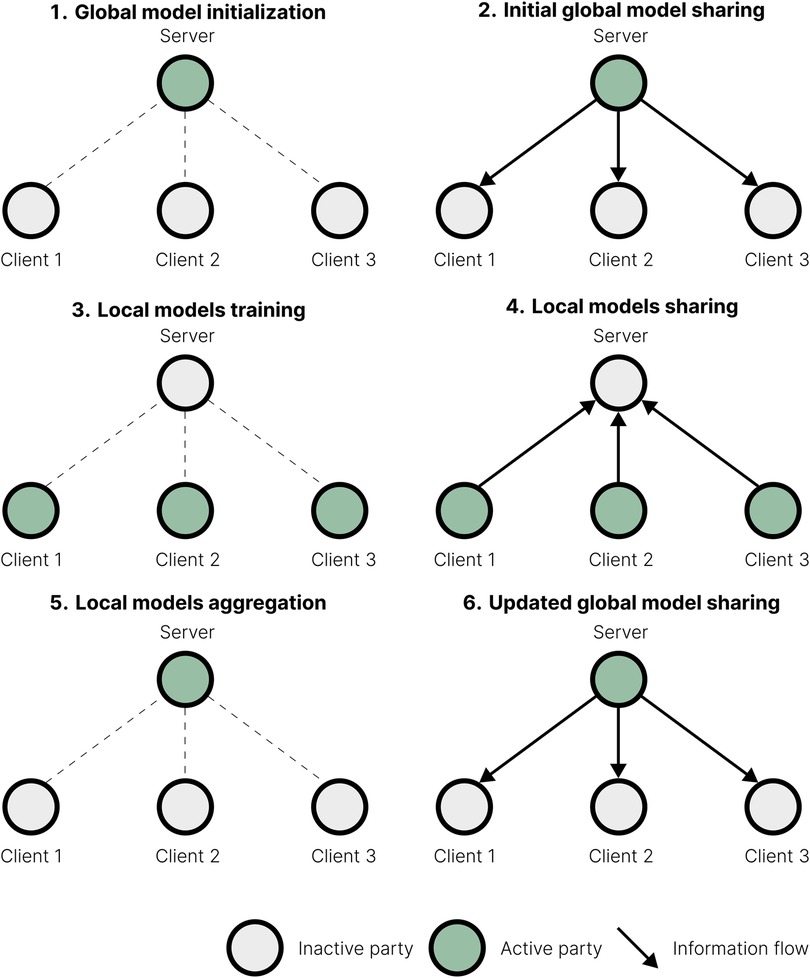
Figure 1. Overview of a typical federated learning (FL) workflow. (1) The central server initialises a global model. (2) The server shares the global model parameters with consortium parties, referred to as clients. (3) Each client initialises a local model from the global model parameters and updates it by training it on its local data. (4) Clients send their updated local model parameters back to the server. (5) The server aggregates local model parameters it collected to construct a new global model. (6) The server redistributes the updated global model parameters to clients to start the next training round. Steps (3)–(6) are repeated iteratively until a predefined stopping criterion is met. Active parties in each step are in green, and the arrows show the direction of information flow within the consortium.
FL has similarities with distributed computing, meta-analysis, and trusted research environments (TREs), but also has key differences, which we highlight below. Table 1 provides a comparative overview of these approaches.
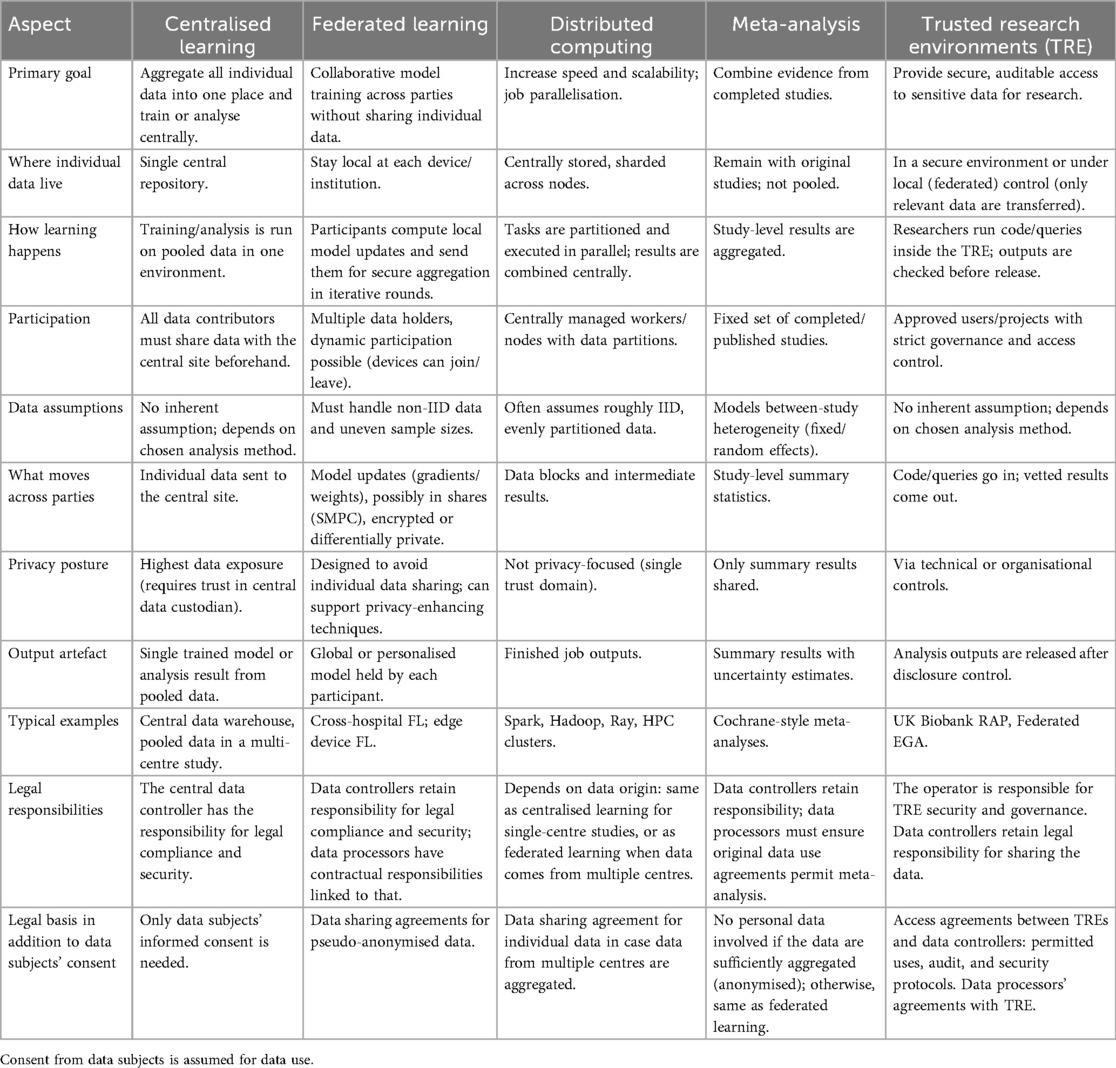
Table 1. Methodological comparison of centralised learning, federated learning, distributed computing, meta-analysis, and trusted research environments.
Distributed computing (DC) (17) divides a computational task among multiple machines to enhance processing speed and efficiency. Typically, DC starts from a centrally managed data set spread across multiple machines, which is assumed to contain independent and identically distributed observations. Each machine is tasked to process a comparable quantity of data. In contrast, clients independently join FL with their locally held data, which may vary significantly in quantity and distribution. While sharing some techniques with FL, distributed computing aims for computational efficiency and lacks its privacy focus.
On the other hand, meta-analyses (18) aggregate results across previously completed studies using statistical methods to account for their variations, thus allowing researchers to synthesise findings without accessing personal data and preserve the privacy of individual data sets. Here, FL collaboratively trains a joint model using distributed data to iteratively update it while meta-analysis constructs it in a single step from the pre-existing results. Multiple studies on sequencing data have demonstrated that FL produces results closer to centralised analysis than from meta-analysis (19, 20).
TREs (21) provide access to data within a controlled, secure computing environment for conducting analyses, almost always disallowing data sharing. Some TREs have a centralised data location and governance; an example is the Research Analysis Platform (RAP), the TRE for the UK Biobank [UKB; (22)]. Others, such as FEGA (23), are decentralised. Each institution maintains its data locally; only the relevant data are securely transferred to the computing environment when the analysis is authorised. Unlike FL, the learning process is not distributed across the data holders. Thus, the trade-off between TREs and FL is between a centralised, trusted entity with extensive computational facilities that can place substantial restrictions on the analysis, and a consortium that requires all parties to apply governance guidelines and provide compute, but can scale both data access and privacy guarantees.
2.1 Topologies
The topology of the FL consortium is determined by the number of participating parties and their defined interactions. Some examples are illustrated in Figure 2. The most common is the centralised topology, where multiple data-holding parties (the clients) collaboratively train a shared machine learning model through a central server (the aggregator) that iteratively collects model updates from each client, updates the global model, and redistributes it back to the clients. Typically, clients do not communicate directly; they only communicate with the central server. In contrast, a decentralised topology (24) lacks a dedicated aggregation server. All consortium parties can potentially serve as model trainers and aggregators, interacting through peer-to-peer communication. Hybrid configurations include, for instance, using two servers: one server handles aggregation of noisy local models, while the other performs auxiliary tasks, such as noise aggregation (25). Clients can communicate with the servers, and servers can communicate with each other, but clients cannot communicate with each other.
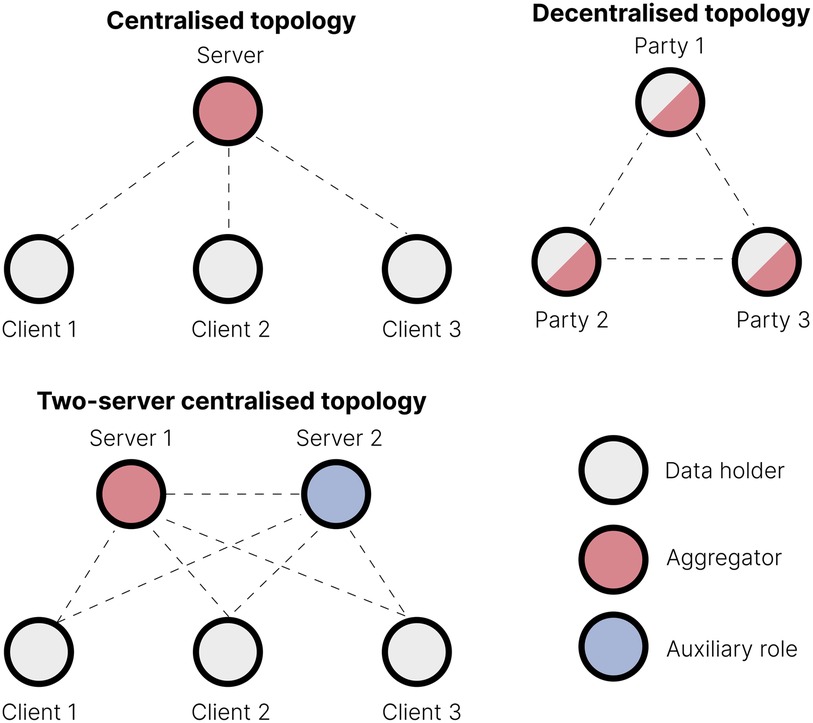
Figure 2. Different FL topologies. In centralised topologies, the data holders are typically referred to as clients, reflecting their interaction with a central server. In decentralised topologies, where no central entity exists, the participants are often called parties.
We will focus on the standard centralised topology and its two-server variant here because, to our knowledge, no bioinformatics applications use decentralised topologies.
2.2 Hardware and software
Hardware, software and models should be chosen with knowledge of the data and inputs from domain and machine learning specialists to design an effective machine learning pipeline (26).
In terms of infrastructure, FL requires computational resources for each client and server. The optimal hardware configuration depends on the models to be trained; at a minimum, each client must be able to produce model updates from local data, and each server must be able to aggregate those updates and manage the consortium. Connection bandwidth is not necessarily critical: to date, client-server communications contain only a few megabytes of data, reaching 150MB only for large computer vision models, and can be made more compact through compression and model quantisation (27). On the other hand, latency may be a bottleneck if it limits the hardware utilisation.
As for software, several dedicated FL frameworks, many of which are comparatively analysed in (28), provide structured tools and environments for developing, deploying, and managing federated machine learning models. While some frameworks, such as Tensorflow Federated [TFF; (29)], specialise in particular models, others support a broader range of approaches. Notable open-source examples include PySyft (30) and Flower (31). Both are supported by active communities and integrate with PyTorch to train complex models. PySyft is a multi-language library focusing on advanced privacy-preserving techniques, including differential privacy and homomorphic encryption. Flower is an FL framework: its modular design and ease of customisation make it particularly useful for large-scale and multi-omics studies involving heterogeneous devices and clients. We will provide examples using these frameworks in Section 3 before discussing frameworks explicitly designed for bioinformatics in Section 3.6.
Other frameworks target healthcare and biomedical applications, but not bioinformatics specifically. For instance, OpenFL (32) is designed to facilitate FL on sensitive EHRs and medical imaging data; it supports different data partitioning schemes (Section 2.4) but struggles with heterogeneous cross-device FL (Section 2.3). NVIDIA Clara, which was used in Dayan et al. (11), has similar limitations.
2.3 Usage scenarios: cross-device and cross-silo
FL applications take different forms in different domains. Many small, low-powered clients, such as wearable medical devices from the Internet of Things, may produce the data needed to train the federated machine learning model. Such cross-device communications are often unreliable: passing lightweight model updates instead of individual data largely addresses connectivity issues and privacy risks.
FL may also involve a small number of parties, each possessing large amounts of sensitive data (33), stored within their “data silos”. This setting, often called the emphcross-silo scenario, is common in healthcare and bioinformatics. Here, the main priority is to minimise the privacy risks associated with data sharing and comply with regulations. Additionally, minimising large data transfers is also computationally advantageous when modelling large volumes of information, such as whole-genome sequences.
These two scenarios differ in how they handle model updates. In the cross-silo scenario, all (few) data holders in the consortium must participate in each update. In contrast, we can rely on a subset of (the many) data holders in the cross-device scenario because each holds a smaller share of the overall data. This article focuses on the cross-silo scenario, as nearly all bioinformatics applications fall within this framework.
2.4 Data partitioning and heterogeneity
Data may be partitioned along two axes: each party may record the same features for different samples or features describing the same samples (Figure 3). In the first scenario, known as horizontal FL, different parties may each possess genomic sequencing data from different individuals. In contrast, in vertical FL, one party may hold data from one omic type (say, genomic data), while another may have data from a different phenotype or omic type (say, proteomic data) for the same individuals. Horizontal FL is by far the most prevalent approach in bioinformatics.
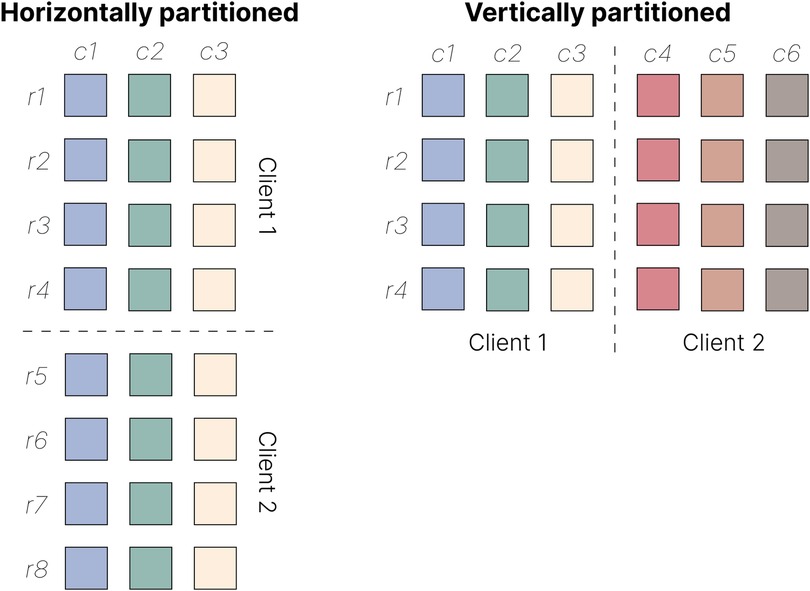
Figure 3. Horizontal and vertical data partitioning in FL. In horizontal FL (left), clients hold data sets with the same features (c1–c3) but different subsets of samples (r1–r8). In vertical FL (right), clients hold data sets with different features (c1–c6) but the same set of samples (r1–r4).
Significant variations in sample size and feature distributions between data holders often exist. This heterogeneity allows FL to better capture the variability of the underlying population, resulting in transferable models that generalise well (34). Clearly, if data holders collect observations from distinct populations, any federated model trained from them must be correctly specified to capture population structure and avoid bias in inference and prediction. If the populations are known, we can train targeted population-specific models alongside the global one (35). Otherwise, we can use clustering to identify them from the available data (36). Accounting for variations in measurements, definitions and distributions to harmonise data across parties is also fundamental but is much more challenging because access to data is restricted, even more so than in meta-analysis (27).
2.5 Security and privacy
FL reduces some privacy and security risks by design by passing model updates between parties instead of centralising data in a single location. However, it does not eliminate them completely.
In terms of privacy, deep learning models are the most problematic in machine learning because of their ability to memorise training data. They leak individual observations during training [through model updates; (37)], after training [through their parameters; (38)] and during inference [membership attacks; (39, 40)]. More broadly, individual reidentification is an issue for genetic data (41) and all the models learned from them. For instance, (42) has demonstrated that it is possible to identify an individual from the linear model learned in an association study from just 25 genes. However, such works make unrealistic assumptions on the level of access to the models and the data (43): even basic infrastructure security measures and the distributed nature of the data will make such identification difficult under the best circumstances. The privacy-enhancing techniques discussed in Section 2.6 can make such efforts wholly impractical.
As for security, we must consider different threat models, understanding what information requires protection, their vulnerabilities, and how to mitigate or respond to threats. Internal and external threats to the consortium should be treated equally with security in depth design and implementation decisions that consider parties untrusted. Security threats, such as membership attacks and model inversion attacks (44), can originate equally from parties and external adversaries that seek to abuse the model inference capabilities to extract information about the data. On the other hand, adversarial attacks are more likely to originate from consortium parties that seek to introduce carefully crafted data or model updates into the training process to produce a global model with undesirable behaviour. Some examples are data poisoning (45), manipulation (46) and Byzantine attacks (47).
Encrypting communication channels, implementing strict authentication (to verify each party’s identity) and authorisation (to control which information and resources each party has access to or shares) schemes, and keeping comprehensive access logs for audit can secure any machine learning pipeline, including federated ones. Similarly, using an experiment tracking platform makes it possible to track data provenance, audit both the data and the training process and ensure the reproducibility of results (26). These measures must be complemented by federated models resistant to these threats at training and inference time, as thoroughly discussed in Yin et al. (48).
2.6 Privacy-enhancing techniques
Privacy-enhancing techniques improve the confidentiality of sensitive information during training. We summarise the most relevant below, illustrating them in Figure 4.

Figure 4. Example of privacy-preserving sum computation in FL using three different techniques. Note that although differential privacy is described in Section 2.6, it is not included in this example, as it would not be suitable for such a calculation.
Homomorphic encryption [HE; (49)] is a cryptographic technique that enables computations to be performed directly on encrypted data (ciphertexts) without requiring decryption. The outcome of operations on ciphertexts matches the result of performing the same operations on the corresponding non-encrypted values (plaintexts) when decrypted. HE can be either fully homomorphic (FHE), which allows for arbitrary computations, or partially homomorphic (PHE), which supports only a specific subset of mathematical operations. For instance, the Paillier PHE scheme (50) only supports additive operations on encrypted data. FHE requires considerable computational resources for encryption and decryption. PHE is less flexible but computationally more efficient, making it a common choice in practical applications.
Secure multiparty computation [SMPC; (51)] is a peer-to-peer protocol allowing multiple parties to compute a function over their data collaboratively, similarly to Figure 2 (centre). Each data holder divides their data into random shares and distributes them among all parties in the consortium, thus ensuring that no single party can access the complete data set. The shares are then combined during the computation process, often with the assistance of a server, to produce the correct result while preserving data privacy. SMPC ensures high security with exact results and keeps data private throughout the computation process. However, SMPC is computationally intensive and requires peer-to-peer communication, leading to high communication overhead. Its complexity also increases with the number of participants, limiting scalability.
Another approach to securing FL is using an aggregator and a compensator server in a centralised two-server topology [Figure 2, right; (25)]. Each client adds a noise pattern to their local data, sharing the former with the compensator (which aggregates all noise patterns) and the latter with the aggregator (which aggregates the noisy data and trains the model). The aggregator then obtains the overall noise pattern from the compensator and removes it from the aggregated noisy data, allowing for denoised model training. This two-server approach is efficient: it requires neither extensive computation in the clients nor peer-to-peer communication. However, it makes infrastructure more complex and requires trust in both servers not to collude to compromise the privacy of individual contributions.
Unlike the above methods, which are encryption-based methods ensuring data confidentiality during transmission or storage, differential privacy, another popular technique for data-protection in federated learning, is not an encryption system but rather a technique that focuses on privacy by ensuring that the output of data analysis does not leak sensitive information about the underlying dataset. Differential privacy [DP; (52)] achieves this through a mathematical framework designed to ensure analyses remain statistically consistent, regardless of whether any specific individual’s data is included or excluded. This property guarantees that sensitive information about individuals cannot be inferred from the results up to a preset “privacy budget” worth of operations. DP is typically implemented by introducing noise into the data (53, 54), weight clipping in the training process (55, 56) or predictions (57, 58) to obfuscate individual contributions. The amount of noise must be carefully calibrated to balance predictive accuracy and privacy within the analysis: too little noise undermines privacy, and too much reduces performance. This effect is more pronounced within specific subgroups underrepresented in the training set (59).
3 Federated learning in bioinformatics
Most FL literature focuses on general algorithms and is motivated by applications other than bioinformatics, such as digital twins for smart cities (60), smart industry (61) and open banking and finance (62). Even the clinical literature mainly focuses on different types of data and issues (11, 63). Here, we highlight and discuss notable examples of FL designed specifically for bioinformatics, summarised in Table 2. They are all in the early stages of development, so their reliability, reproducibility, and scalability are open questions. However, they hint at the potential of FL to perform better than meta-analysis and single-client analyses on real-world data, comparing favourably to centralised data analyses where data are pooled in a central location while addressing data sharing and use concerns (15, 20).
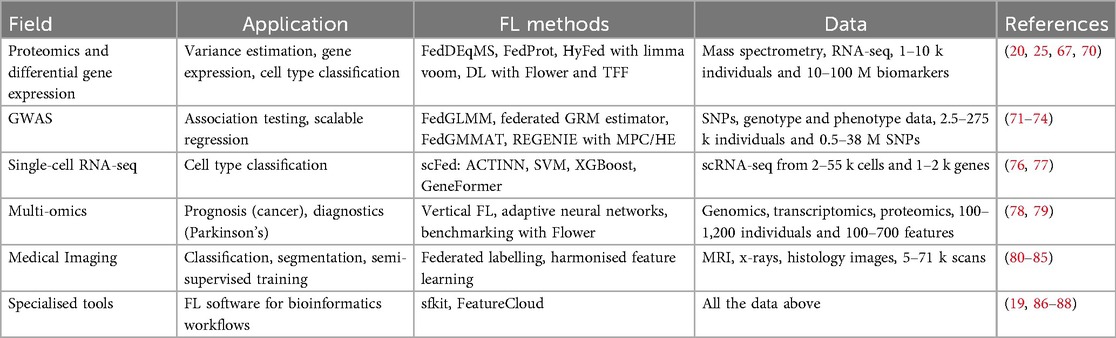
Table 2. Summary of key federated learning applications in bioinformatics.
3.1 Proteomics and differential gene expression
Proteomics studies the complex protein dynamics that govern cellular processes and their interplay with physiological and pathological states, such as cancer (64), to improve risk assessment, treatment selection and patient monitoring. Differential expression analyses focus specifically on comparing expression levels across different conditions, tissues, or cell types to identify genes with statistically significant differences (65).
In addition to the issues discussed in Section 2, FL in proteomics must overcome the challenge of integrating data from different platforms (66) while accounting for imbalanced samples and batch effects. Cai et al. (67) produced a federated implementation of DEqMS [FedProt; (68)] for variance estimation in mass spectrometry-based data that successfully identifies top differentially-abundant proteins in two real-world data sets using label-free quantification and tandem mass tags.
Zolotareva et al. (20) implemented a federated limma voom pipeline (69) on top of HyFed (25), which uses the aggregator-compensator two-server topology we described earlier. This approach was demonstrated on two extensive RNA-seq data sets, proving robust to heterogeneity across clients and batch effects. Hannemann et al. (70) trained a federated deep-learning model for cell type classification using both Flower and TFF and different architectures, with similar results.
3.2 Genome-wide association studies
Genome-wide association studies (GWAS) aim to identify genomic variants statistically associated with a qualitative (say, a case-control label) or quantitative trait (say, body mass index). These studies mainly use regression models, which can be largely trained using general-purpose federated regression implementations with minor modifications to address scalability and correct for population structure [see, for instance, (43)].
Li et al. (71) has developed the most complete adaptation of these models to federated GWAS in the literature: it provides linear and logistic regressions with fixed and random effects and accounts for population structure via a genomic relatedness matrix. Wang et al. (72) further provides a federated estimator for the genomic relatedness matrix. Finally, Li et al. (73) describes the federated association tests for the genomic variants associated with this model. All these steps incorporate HE to ensure privacy in the GWAS.
As an alternative, Cho et al. (74) built on REGENIE (75) to avoid using a genomic relatedness matrix and increase the scalability of GWAS while using MPC and HE to secure the data. Despite the overhead introduced by the encryption, this approach is efficient enough to work on a cohort of 401 k individuals from the UK Biobank and 90 million single-nucleotide polymorphisms (SNPs) in less than 5 h.
3.3 Single-cell RNA sequencing
Single-cell RNA sequencing (scRNA-seq) measures gene expression at the cellular level, rather than aggregating it at the tissue level as in bulk RNA sequencing, and identifies the distinct expression profiles of individual cell populations within tissues (89, 90).
Wang et al. (76) developed scFed, a unified FL framework integrating four algorithms for cell type classification from scRNA-seq data: the ACTINN neural network (91), explicitly designed for this task; a linear support vector machine; XGBoost based on Li et al. (77); and the GeneFormer transformer (92). They evaluated scFed on eight data sets evenly distributed among 2–20 clients, suggesting that the federated approach has a predictive accuracy comparable to that obtained by pooling the data and better than that in individual clients. However, the overhead during training increases with the number of clients, limiting the scalability to larger consortia. More recently, Bakhtiari et al. (93) introduced FedscGen, a federated implementation of scGen (94), a variational autoencoder-based method for batch effect correction. FedscGen employs secure SMPC for privacy-preserving aggregation and achieves results that closely match those obtained under centralised training.
3.4 Multi-omics
Proteomics, genomics, and transcriptomics capture different aspects of biological processes. Integrating large data sets from different omics offers deeper insights into their underlying mechanisms (95). Vertical FL allows multiple parties to combine various features of the same patients into multimodal omics data sets without exposing sensitive information (96). For instance, Wang et al. (78) trained a deep neural network with an adaptive optimisation module for cancer prognosis evaluation from multi-omics data. The neural network performs feature selection while the adaptive optimisation module prevents overfitting, a common issue in small high-dimensional samples (97). This method performs better than a single-omic analysis, but the improvement in predictive accuracy is strongly model-dependent. Another example is Danek et al. (79), who built a diagnostic model for Parkinson’s disease: they provided a reproducible setup for evaluating several multi-omics models trained on pre-processed, harmonised and artificially horizontally federated data using Flower. Their study identifies a general but not substantial reduction in FL performance compared to centrally trained models, which increases with the number of clients and is variably affected by client heterogeneity.
3.5 Medical imaging
Medical imaging studies the human body’s interior to diagnose abnormalities in its anatomy and physiology from digital images such as those obtained by radiography, magnetic resonance and ultrasound devices (98). It is the most common application of FL in the medical literature (16). As a result, protocols for image segmentation and diagnostic prediction are well documented. Notable case studies target breast cancer (10), melanomas (83), cardiovascular disease (84), COVID-19 (11, 85).
Machine learning applications that use medical imaging data typically face challenges, including incomplete or inaccurate labelling and the normalisation of images from different scanners and different protocols. Bdair et al. (80) explored a federated labelling scheme in which clients produced ground-truth labels for skin lesions in a privacy-preserving manner, improving classification accuracy. Yan et al. (81) also proposed an efficient scheme to use data sets mainly comprising unlabelled images, focusing on chest x-rays. Furthermore, Jiang et al. (82) apply FL to learn a harmonised feature set from heterogeneous medical images, improving both the classification and segmentation of histology and MRI scans.
3.6 Ready-to-use FL tools for bioinformatics
The need for user-friendly FL implementations of common bioinformatics workflows has driven the creation of secure collaborative analysis tools (87, 88, 99). Two notable examples are sfkit and FeatureCloud.
The sfkit framework (19) facilitates federated genomic analyses by implementing GWAS, principal component analysis (PCA), genetic relatedness and a modular architecture to complement them as needed. It provides a web interface featuring a project bulletin board, chat functions, study parameter configurations and results sharing. State-of-the-art cryptographic tools for privacy preservation based on SMPC and HE ensure data protection (100).
FeatureCloud (86) is an integrated solution that enables end users without programming experience to build custom workflows. It provides modules to run on the clients and servers in the consortium. Unlike sfkit, FeatureCloud allows users to publish applications in its app store, including regression models, random forests and neural networks. Developers must also document how privacy guarantees are implemented in their apps.
4 Practical insights on federation
This section offers practical insights to help readers interested in building a federated and secure analogue of an existing bioinformatics algorithm. We focus on horizontal FL with the centralised topology from Figure 2 (left). Consider different clients, each possessing a local data set , where . Each data set contains samples, denoted as , where represents the sample index, and represents the features for each sample. We denote a row (column) of the matrix as (). This describes a distributed data set of observations:
The following sections assume that an FL consortium has been established, the necessary infrastructure is operational, and an appropriate FL framework has been selected and installed. It is also assumed that a secure aggregation protocol has been chosen, such as those described in Section 2.6 and Figure 4. The choice of a specific secure aggregation protocol may depend on several factors, including technology and infrastructure (e.g., the availability of a particular FL topology that drives the choice), as well as privacy risks and scalability concerns, as discussed in Section 2.6. In the following sections, we provide a general overview of sum-based mathematical operations built upon a secure aggregation protocol, as well as operations involving federated averaging [FedAvg; (6)].
Coding examples using Flower (31) are available in our GitHub repository (https://github.com/IDSIA/FL-Bioinformatics). We chose Flower because it has a shallow learning curve for new FL users and provides a good balance between simplicity and flexibility when implementing custom algorithms. Riedel et al. (28) also identified Flower as a promising framework because it has a large, active, and growing community of developers and scientists, as well as extensive tutorials and documentation. In our examples, secure summation is performed using the secure aggregation protocol SecAgg+ (101). This protocol combines encryption with SMPC, using a multiparty approach in which each client interacts with only a subset of the others. It is particularly suitable for several FL contexts, as it is robust to client dropout and highly scalable. In particular, a relevant aspect of the bioinformatics domain is that it scales linearly with the size of the vectors to be aggregated (102).
4.1 Sum-based computations
Let be real numbers stored by individual clients. We define the secure sum of these numbers, performed through the selected secure aggregation protocol, as . We can build on this simple, secure sum to construct a wide range of operations. However, note that as the complexity of operations increases, the amount of information revealed to the server may also increase. Sum-based operations include:
• The overall sample size of the distributed data set as from the local sample sizes .
• The mean value of the th feature, given , as
Each client computes the inner sum on their local data, whereas the outer one is a secure sum aggregated across clients by the server.
• The variance of the th feature, given and , as
which can be used to standardise the th feature as .
• The Pearson correlation coefficient of two features and , given and , as
• The matrix , as , where is a secure element-wise sum. This matrix is equivalent to the covariance matrix for standardised data sets and is commonly used for PCA.
Beyond these general-purpose examples, many operations specific to bioinformatics pipelines also rely on simple sums. These operations are often straightforward generalisations or compositions of the examples introduced above.
In differential gene expression studies, for instance, filtering out weakly expressed genes is standard practice. Weakly expressed genes can be defined as those whose expression values fall below a specified threshold in, for instance, 70% of the samples. Let be a vector belonging to client , where each vector component represents the number of samples in which the expression level of the gene (e.g., counts) exceeds the threshold . The server can securely calculate and identify weakly expressed genes as those whose corresponding components of are smaller than 0.7.
A fundamental preliminary step in a GWAS is identifying the minor allele and its frequency. Let , , , and be vectors belonging to client , where each component corresponds to a specific SNP. The components of , , , represent the number of samples in which nucleotides , , , are observed, respectively. The server can securely compute the aggregated allele counts across all clients as and similarly , , (where can also be computed by difference from and the other three vectors). For each SNP, the minor allele is determined by comparing the corresponding components of , , , : the allele with the smaller value is designated as the minor allele. This operation is crucial because the minor allele within a single client’s population may differ from the minor allele when considering the whole distributed data set. Ensuring a consistent definition of the minor allele across all clients is essential for reliable downstream analyses.
4.2 Federated averaging computations
FedAvg is a widely used algorithm for training deep neural networks in FL. It iteratively computes a weighted average of model parameters across clients, with weights proportional to the local sample sizes . Thus, it can be applied to any parametric model, including linear models.
FedAvg proceeds as illustrated in Figure 1. The server first broadcasts an initial global model with parameters . At each step of the algorithm, clients start with the global model and perform local updates to produce updated local models . The global model is updated after each round of local training as the weighted sum of the local models:
where we use the secure sum for aggregation (FedAvg is itself a sum-based operation). After aggregation, the updated global model is distributed back to the clients.
However, many bioinformatics pipelines rely on linear models rather than deep learning models. One commonly used model is logistic regression, which is applied in tasks such as gene expression analysis and GWAS. A federated implementation of logistic regression can be achieved by starting with a standard implementation and applying FedAvg, which aggregates the local models after a specified number of iterations performed by the local logistic regressions.
5 Legal aspects of federated learning
The legal frameworks used within FL consortia are rarely discussed in the literature. Ballhausen et al. (103) describes both the technical and legal aspects of a European pilot study implementing a federated statistical analysis by secure multiparty computation. They established agreements between parties similar to those between participants in a multi-centre clinical trial, as using SMPC and exchanging model gradients was legally considered data pseudonymisation (rather than anonymisation). FL was determined to require the same level of data protection as regular data sharing, which is also the most conservative course of action suggested in Truong et al. (9) and Lieftink et al. (104). All clients jointly controlled the consortium and were responsible for determining the purpose and means of processing, including obtaining approval from the respective Ethics Committees. Sun et al. (105) similarly describes the server in their consortium as a trusted and secure environment, supported by a legal joint controller agreement between the data owners.
Following Ballhausen et al. (103), establishing an FL consortium could be expected to require all participating and involved parties to execute agreements that regulate their interactions, the so-called DPA or DSA (data protection/processing/sharing agreements). Doing so will establish the level of trust between parties and their responsibilities towards each other, third parties, and patients. Risk aversion suggests that it should include a data-sharing clause to allow for the sharing of information, similar to a centralised analysis, as described in Figure 1. No party has access to the data of other parties. Still, it is theoretically possible that, in some cases, the model updates shared during FL could be deanonymised by malicious internal or external attackers (9). Parties may then be reluctant to treat that information as non-personally identifiable without formal mathematical proof of anonymisation and prefer to establish data protection responsibilities with a data-sharing agreement. In the EU (GDPR), but also other jurisdictions (national data protection laws), “all the means reasonably likely to be used should be considered to determine whether a natural person is identifiable” (1). Securing infrastructure in depth using best practices from information technology, defensive software engineering, and data by secure computing and encryption can make malicious attacks impractical with current technologies [security by design and by default; (106, 107)]. In addition, when FL involves models other than deep neural networks, if the contributions of individual parties are well balanced across the consortium and include a sufficiently large number of individuals, the information exchanged may very well be the same summary information routinely published as supplementary material to academic journal publications (108). A recent systematic literature review of privacy attacks in FL has also highlighted that many of them are only feasible under unrealistic assumptions (8). Therefore, reducing the amount of information shared during FL and using secure computing must be considered to provide increased protection against data leaks and misuse. Advertising such measures as a key feature of the FL consortium will make partners and patients more comfortable with contributing to federated studies [see, for instance, (103)]. Lieftink et al. (104), which investigated how FL aligns with GDPR in public health, also acknowledges that FL mitigates many privacy risks by enforcing purpose limitation, data use and information exchange minimisation, integrity and confidentiality (at a cost, as discussed in Section 2.4).
Furthermore, consortium parties must agree on how to assign intellectual property (IP) rights. Bioinformatics research often has practical applications in industry, which may involve patenting the results and apportioning any financial gains arising from their use. Parties in the consortium jointly control it and should share any gains from it (109). FL consortia are no different in this respect. From a technical standpoint, watermarking techniques for tracking data provenance and plagiarism have been adapted to FL (110) to identify data and model theft.
Additionally, the agreement establishing the FL consortium must outline its relationships with third parties and their corresponding legal obligations. Third parties that have access to the infrastructure may be required to sign a data processing agreement to guarantee the safety and privacy of data. In many countries in Europe, as well as in the US, patients have the right to withdraw their consent to use their data at any time. This, in turn, may require implementing procedures to remove individual data points from future federated analyses.
We summarised these considerations in Table 1, along with the key differences from the alternatives we discussed in Section 2. FL provides increased protection against data and model leaks, which should reduce the perceived risk for parties and patients in contributing to the consortium. However, out of an abundance of caution, establishing a consortium-wide data-sharing agreement may help allocate and reduce party responsibilities in the event of a privacy breach. The use of FL has a limited impact on other legal aspects of collaborative analysis, such as IP handling and requirements for third parties, because it is a technical solution that does not change the fundamental legal rights and responsibilities of the parties involved in the consortium. Table 3 summarises the key legal and procedural steps required to implement federated learning in biomedical research, as detailed above.
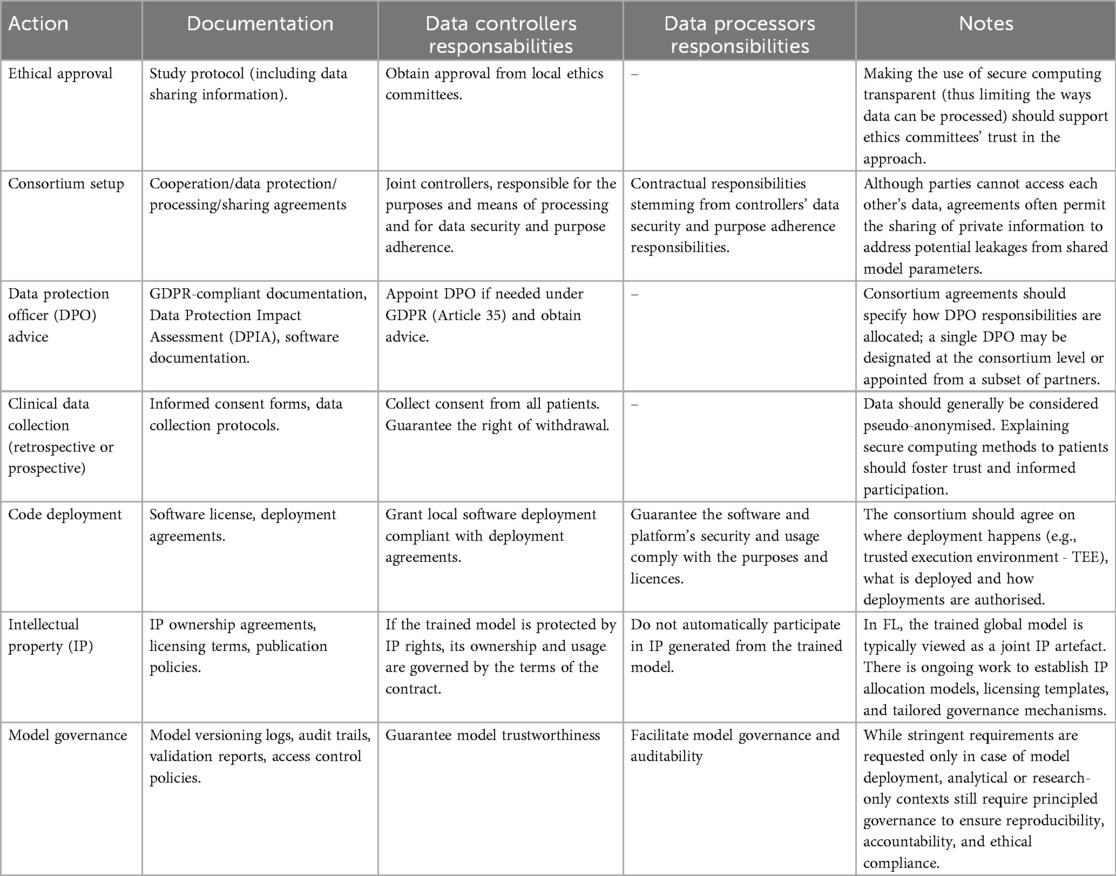
Table 3. Overview of legal, procedural, and technical actions in federated learning, with relevance to governance, data, and software.
We now proceed to discuss how FL facilitates compliance with the key requirements of GDPR (1) through its architecture. Data providers, which have a complete control over and a more intimate knowledge of the data they collected as well as a direct connection to data subjects, act in a “data controller” role (Articles 4 and 24), taking “appropriate technical and organisational measures” (Article 25) to ensure privacy and security, thus minimising the risk of data breaches. Therefore, they can directly scrutinise their use, notify data subjects about it to request consent (Article 9); allow them to withdraw their data (Article 7); ensure lawful, fair and transparent processing (Articles 12–15); and directly assess risks to data subjects and minimise them through appropriate legal agreements. Consortium parties, which include both data controllers (as clients) and data processors (as servers, compute facilities, as defined in Article 4), are also required to use the techniques described in Section 2.5 to ensure data security and privacy beyond what is provided by base FL (privacy by design, Articles 24, 25 and 32). For the same reasons, FL facilitates compliance with the EU AI Act (2). Some of its requirements strengthen those in the GDPR, such as data minimisation, localisation, transparency, auditability, security, and data quality. Additionally, the EU AI Act requires efforts to mitigate bias, ensure the robustness of models, implement human oversight, and assess high-risk systems. Data controllers are in the best position to ensure these requirements are met. Collectively, they can provide more representative samples that are less prone to bias and fairness issues. Finally, the presence of multiple data controllers in the consortium also implies that these requirements are verified by several independent parties.
In contrast, the US AI Act is more flexible in its requirements, which are left to sector-specific agencies to define and enforce. It focuses more on party self-regulation and harm remediation rather than universal legal mandates and prevention. As a result, cross-border EU-US consortia should rely on the EU-US Data Protection Framework (111) or put in additional safeguards as required by the GDPR (Article 46). Even so, FL’s privacy stance naturally fits well with the practical implementation of the US AI Act.
6 Challenges and future directions
Federated learning (FL) has evolved rapidly over its relatively short lifetime, becoming a widely adopted methodology across diverse domains. In a recent article (112), which includes several authors of the seminal FL paper (6), the progress of the field is reviewed, and key challenges for its future development are outlined. The authors propose a refined definition of FL centred on privacy principles and analyse how core concepts such as data minimisation, anonymisation, transparency and control, verifiability, and auditability have evolved and are expected to play a major role in the future. They identify three primary challenges for the field: scaling FL to support large and multimodal models, overcoming operational difficulties arising from device heterogeneity and synchronisation constraints (particularly relevant in cross-device FL), and addressing the current lack of verifiability in deployed systems. As a potential means to address this latter aspect, the authors highlight trusted execution environments (TEEs) (113) as a promising technology. A TEE is a secure area within a processor that executes code and processes data in isolation from other software, protecting it from tampering or unauthorised access even if the main operating system is compromised.
Complementing these insights, other surveys examine additional aspects of the anticipated future developments in federated learning (FL) research. Wen et al. (114) call for more efficient encryption schemes and greater overall efficiency in FL, including strategies to reduce communication costs between clients and servers. They also emphasise the importance of novel aggregation strategies that can better handle client heterogeneity. In the context of multimodal FL, aggregation must often reconcile contributions when clients supply only partially overlapping modalities, which represents an additional complexity beyond standard heterogeneity. Yurdem et al. (115) highlight the emerging paradigm of FL as a Service, in which federated learning training is conducted through ready-to-use platforms such as FeatureCloud (86) and sfkit (19), discussed in Section 3.6. This approach allows institutions to participate in collaborative model development with minimal software and deployment effort, thereby simplifying implementation and facilitating cross-organisational collaboration. Looking ahead, the emergence of federated foundation models is expected to define the next phase of research in this field. Their development will require progress across several key dimensions, including improving efficiency through advanced aggregation methods and optimised computational and communication frameworks; strengthening trustworthiness by increasing robustness to attacks; and enhancing incentive mechanisms that reward clients according to the quality of the models provided. Collectively, these advances are expected to be essential for making large-scale federated models practical and scalable while maintaining manageable communication costs (116).
The prospects of federated learning in bioinformatics depend on how the legal and technical landscape will develop. Further legislation will progressively regulate the use of machine learning and AI models, defining and restricting how data can be shared and used. As its effects percolate through protocol and product development, many aspects of federated learning will likely take a more definite shape.
Firstly, the security and privacy risks are likely to become more clearly defined. Jurisprudence will naturally shift from general guiding principles, such as the EU AI Act, to practical compliance rule sets as products based on federated learning enter the market. How to assess sensitive aspects of data (re)use will also likely be standardised (117), using the vast collection of available data and model cards as a starting point (118, 119). What threat models are relevant, what security measures are appropriate at the infrastructure level, and what attacks are feasible will then become clear, possibly confirming the irrelevance of many that have been speculated in the literature (43). The evolution of encryption and differential privacy techniques may also allow different types of data to be treated as anonymised, depending on their nature and the theoretical guarantees of those techniques. Some data (say, single-cell transcriptomics) are intrinsically more difficult to tie to a specific individual than others (say, whole genome sequences), and different privacy-enhancing techniques are more effective than others at mitigating various types of risk.
Secondly, the evolution of data and models will require periodic reevaluation of the trade-offs discussed in this paper. The ever-increasing volumes of data used to train federated models will eventually force a cost-benefit analysis for resource-intensive techniques like HE and MPC; lighter approaches may be the only feasible choice at scale, provided regulations permit their use. Modelling approaches will undergo a similar selection process, as they will be required to evolve to handle new biological and clinical data types in larger quantities and across multiple modalities. In this respect, we foresee that federated learning in bioinformatics may diverge from the mainstream, which has largely standardised on deep learning models (15, 16). Historically, bioinformatics has produced distinct model classes for different types of data. Federating them, optimising them, and assessing their privacy risks will require significant research and engineering efforts before they are suitable for practical applications.
7 Conclusions
Independent research efforts in several bioinformatics domains have shown federated learning to be an effective tool to improve clinical discovery while minimising data sharing (10, 12, 13, among others). FL enables access to larger and more diverse data pools, resulting in faster and more robust exploration and interpretation of results. At the same time, it provides enhanced data privacy and can seamlessly incorporate advanced, encrypted and secure computation techniques. Despite the increased computational requirements and reduced ability to explore and troubleshoot issues with the data (104), the benefits of FL may outweigh these additional costs.
Therefore, federated learning can potentially mitigate the risks associated with national regulations if implemented in a manner that is secure by design and by default. Its use may also make patients and institutions more confident in participating in clinical studies by reducing privacy and data misuse risks. However, the reliable use of federated learning and its effective translation into clinical practice require a concerted effort by machine learning, clinical, and information technology specialists. All their skills are necessary to accurately evaluate the associated risks and expand its practical applications in bioinformatics beyond the early-stage applications reviewed in this paper.
Author contributions
DM: Investigation, Writing – review & editing, Conceptualization, Methodology, Writing – original draft. MS: Conceptualization, Investigation, Writing – review & editing, Writing – original draft, Methodology. FG: Methodology, Writing – review & editing, Writing – original draft. JS: Writing – review & editing, Writing – original draft. SL: Funding acquisition, Writing – original draft, Writing – review & editing, Project administration. SH: Writing – review & editing, Writing – original draft. AL: Writing – original draft, Funding acquisition, Writing – review & editing, Project administration. IH: Writing – original draft, Writing – review & editing. FM: Conceptualization, Writing – review & editing, Writing – original draft, Funding acquisition, Project administration.
Funding
The author(s) declare financial support was received for the research and/or publication of this article. This work was supported by the European Union Horizon 2020 programme [101136962]; UK Research and Innovation (UKRI) under the UK Government’s Horizon Europe funding guarantee [10098097, 10104323] and the Swiss State Secretariat for Education, Research and Innovation (SERI).
Conflict of interest
Author IH was employed by company DPO Associates SARL.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
3. US Congress. Health Insurance Portability and Accountability Act of 1996 (1996). Pub. L. No. 104-191, 110 Stat. 1936.
4. US Congress. National Artificial Intelligence Initiative Act of 2020 (2020). Public Law No: 116-283, Division E
5. Cath C, Wachter S, Mittelstadt B, Taddeo M, Floridi L. Artificial intelligence and the ‘good society’: the US, EU, and UK approach. Sci Eng Ethics. (2018) 24:505–28. doi: 10.1007/s11948-017-9901-7
6. McMahan B, Moore E, Ramage D, Hampson S. Communication-efficient learning of deep networks from decentralized data. In: Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (2017). p. 1273–82.
7. Ludwig H, Baracaldo N, Federated Learning: A Comprehensive Overview of Methods and Applications. Berlin: Springer (2022).
8. Wainakh A, Zimmer E, Subedi S, Keim J, Grube T, Karuppayah S, et al.Federated learning attacks revisited: a critical discussion of gaps, assumptions, and evaluation setups. Sensors. (2022) 23:31. doi: 10.3390/s23010031
9. Truong N, Sun K, Wang S, Guitton F, Guo Y. Privacy preservation in federated learning: an insightful survey from the GDPR perspective. Comput Secur. (2021) 110:102402. doi: 10.1016/j.cose.2021.102402
10. Roth HR, Chang K, Singh P, Neumark N, Li W, Gupta V, et al.. Federated learning for breast density classification: a real-world implementation. In: Domain Adaptation and Representation Transfer, and Distributed and Collaborative Learning: 2nd MICCAI Workshop, DART 2020, and 1st MICCAI Workshop, DCL 2020. Springer (2020). p. 181–91.
11. Dayan I, Roth HR, Zhong A, Harouni A, Gentili A, Abidin AZ, et al.Federated learning for predicting clinical outcomes in patients with COVID-19. Nat Med. (2021) 27:1735–43. doi: 10.1038/s41591-021-01506-3
12. Pati S, Baid U, Edwards B, Sheller M, Wang S, Reina GA, et al.Federated learning enables big data for rare cancer boundary detection. Nat Commun. (2022) 13:7346. doi: 10.1038/s41467-022-33407-5
13. Heyndrickx W, Mervin L, Morawietz T, Sturm N, Friedrich L, Zalewski A, et al.MELLODDY: cross-pharma federated learning at unprecedented scale unlocks benefits in QSAR without compromising proprietary information. J Chem Inf Model. (2023) 64:2331–44. doi: 10.1021/acs.jcim.3c00799
14. Brisimi TS, Chen R, Mela T, Olshevsky A, Paschalidis IC, Shi W. Federated learning of predictive models from federated electronic health records. Int J Med Inform. (2018) 112:59–67. doi: 10.1016/j.ijmedinf.2018.01.007
15. Xu J, Glicksberg BS, Su C, Walker P, Bian J, Wang F. Federated learning for healthcare informatics. J Healthc Inform Res. (2020) 5:1–19. doi: 10.1007/s41666-020-00082-4
16. Chowdhury A, Kassem H, Padoy N, Umeton R, Karargyris A. A review of medical federated learning: applications in oncology and cancer research. In: Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries: 7th International Workshop, BrainLes 2021, 24th MICCAI Conference (2022). p. 3–24.
17. Zomaya AY, Parallel Computing for Bioinformatics and Computational Biology: Models, Enabling Technologies, and Case Studies. Hoboken: John Wiley & Sons (2006).
18. Toro-Domínguez D, Villatoro-Garciá JA, Martorell-Marugán J, Román-Montoya Y, Alarcón-Riquelme ME, Carmona-Saéz P. A survey of gene expression meta-analysis: methods and applications. Brief Bioinformatics. (2021) 22:1694–705. doi: 10.1093/bib/bbaa019
19. Mendelsohn S, Froelicher D, Loginov D, Bernick D, Berger B, Cho H. Sfkit: a web-based toolkit for secure and federated genomic analysis. Nucleic Acids Res. (2023) 51:W535–41. doi: 10.1093/nar/gkad464
20. Zolotareva O, Nasirigerdeh R, Matschinske J, Torkzadehmahani R, Bakhtiari M, Frisch T, et al.Flimma: a federated and privacy-aware tool for differential gene expression analysis. Genome Biol. (2021) 22:1–26. doi: 10.1186/s13059-021-02553-2
21. Kavianpour S, Sutherland J, Mansouri-Benssassi E, Coull N, Jefferson E. Next-generation capabilities in trusted research environments: interview study. J Med Internet Res. (2022) 24:e33720. doi: 10.2196/33720
22. Sudlow C, Gallacher J, Allen N, Beral V, Burton P, Danesh J, et al.UK biobank: an open access resource for identifying the causes of a wide range of complex diseases of middle and old age. PLoS Med. (2015) 12:e1001779. doi: 10.1371/journal.pmed.1001779
23. Federated European Genome-phenome Archive. Federated European Genome-Phenome Archive (FEGA) (2024) (accessed October 30, 2024).
24. Beltrán ETM, Pérez MQ, Sánchez PMS, Bernal SL, Bovet G, Pérez MG, et al.Decentralized federated learning: fundamentals, state of the art, frameworks, trends, and challenges. IEEE Commun Surv Tutor. (2023) 5:2983–3013.
25. Nasirigerdeh R, Torkzadehmahani R, Matschinske J, Baumbach J, Rueckert D, Kaissis G. Hyfed: a hybrid federated framework for privacy-preserving machine learning. arXiv [Preprint]. arXiv:2105.10545 (2021).
26. Scutari M, Malvestio M, The Pragmatic Programmer for Machine Learning: Engineering Analytics and Data Science Solutions. London: Chapman & Hall (2023).
27. Camajori Tedeschini B, Savazzi S, Stoklasa R, Barbieri L, Stathopoulos I, Nicoli M, et al.Decentralized federated learning for healthcare networks: a case study on tumor segmentation. IEEE Access. (2022) 10:8693–708. doi: 10.1109/ACCESS.2022.3141913
28. Riedel P, Schick L, von Schwerin R, Reichert M, Schaudt D, Hafner A. Comparative analysis of open-source federated learning frameworks—a literature-based survey and review. Int J Mach Learn Cybern. (2024) 15:5257–78. doi: 10.1007/s13042-024-02234-z
29. Google. TensorFlow federated: machine learning on decentralized data (2024). Available online at: https://www.tensorflow.org/federated (Accessed June 10, 2025).
30. Ziller A, Trask A, Lopardo A, Szymkow B, Wagner B, Bluemke E, et al.. Pysyft: a library for easy federated learning. In: Federated Learning Systems: Towards Next-Generation AI (2021). p. 111–39.
31. Beutel DJ, Topal T, Mathur A, Qiu X, Fernandez-Marques J, Gao Y, et al.. Flower: a friendly federated learning research framework. arXiv [Preprint]. arXiv:2007.14390 (2020).
32. Foley P, Sheller MJ, Edwards B, Pati S, Riviera W, Sharma M, et al.OpenFL: the open federated learning library. Phys Med Biol. (2022) 67:214001. doi: 10.1088/1361-6560/ac97d9
33. Huang C, Huang J, Liu X. Cross-silo federated learning: challenges and opportunities. arXiv [Preprint]. arXiv:2206.12949 (2022).
34. Sheller MJ, Edwards B, Reina GA, Martin J, Pati S, Kotrotsou A, et al.Federated learning in medicine: facilitating multi-institutional collaborations without sharing patient data. Sci Rep. (2020) 10:12598. doi: 10.1038/s41598-020-69250-1
35. Tan AZ, Yu H, Cui L, Yang Q. Towards personalized federated learning. IEEE Trans Neural Netw Learn Syst. (2022) 34:9587–603. doi: 10.1109/TNNLS.2022.3160699
36. Sattler F, Muller K, Samek W. Clustered federated learning: model-agnostic distributed multitask optimization under privacy constraints. IEEE Trans Neural Netw Learn Syst. (2021) 32:3710–22. doi: 10.1109/TNNLS.2020.3015958
37. Geiping J, Bauermeister H, Dröge H, Moeller M. Inverting gradients-how easy is it to break privacy in federated learning? Adv Neural Inf Process Syst. (2020) 33:16937–47.
38. Haim N, Vardi G, Yehudai G, Shamir O, Irani M. Reconstructing training data from trained neural networks. Adv Neural Inf Process Syst. (2022) 35:22911–24.
39. Shokri R, Stronati M, Song C, Shmatikov V. Membership inference attacks against machine learning models. In: 2017 IEEE Symposium on Security and Privacy (2017). p. 3–18.
40. Hu H, Salcic Z, Sun L, Dobbie G, Yu PS, Zhang X. Membership inference attacks on machine learning: a survey. ACM Comput Surv. (2022) 54:1–37. doi: 10.1145/3523273
41. Homer N, Szelinger S, Redman M, Duggan D, Tembe W, Muehling J, et al.Resolving individuals contributing trace amounts of DNA to highly complex mixtures using high-density SNP genotyping microarrays. PLoS Genet. (2008) 4:e1000167. doi: 10.1371/journal.pgen.1000167
42. Cai R, Hao Z, Winslett M, Xiao X, Yang Y, Zhang Z, et al.Deterministic identification of specific individuals from GWAS results. Bioinformatics. (2015) 31:1701–7. doi: 10.1093/bioinformatics/btv018
43. Kolobkov D, Mishra Sharma S, Medvedev A, Lebedev M, Kosaretskiy E, Vakhitov R. Efficacy of federated learning on genomic data: a study on the UK biobank and the 1000 genomes project. Front Big Data. (2024) 7:1266031. doi: 10.3389/fdata.2024.1266031
44. Fredrikson M, Jha S, Ristenpart T. Model inversion attacks that exploit confidence information and basic countermeasures. In: Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security (2015). p. 1322–33.
45. Sun G, Cong Y, Dong J, Wang Q, Lyu L, Liu J. Data poisoning attacks on federated machine learning. IEEE Internet Things J. (2022) 9:11365–75. doi: 10.1109/JIOT.2021.3128646
46. Jagielski M, Oprea A, Biggio B, Liu C, Nita-Rotaru C, Li B. Manipulating machine learning: poisoning attacks and countermeasures for regression learning. In: 2018 IEEE Symposium on Security and Privacy (Sp) (2018). p. 19–35.
47. Li B, Wang P, Shao Z, Liu A, Jiang Y, Li Y. Defending Byzantine attacks in ensemble federated learning: a reputation-based phishing approach. Future Gener Comput Syst. (2023) 147:136–48. doi: 10.1016/j.future.2023.05.002
48. Yin X, Zhu Y, Hu J. A comprehensive survey of privacy-preserving federated learning: a taxonomy, review, and future directions. ACM Comput Surv. (2021) 54:1–36. doi: 10.1145/3460427
49. Gentry C. Fully homomorphic encryption using ideal lattices. In: Proceedings of the Forty-First Annual ACM Symposium on Theory of Computing (2009). p. 169–78.
50. Paillier P. Public-key cryptosystems based on composite degree residuosity classes. In: International Conference on the Theory and Applications of Cryptographic Techniques (1999). p. 223–38.
51. Zhao C, Zhao S, Zhao M, Chen Z, Gao C, Li H, et al.Secure multi-party computation: theory, practice and applications. Inf Sci (Ny). (2019) 476:357–72. doi: 10.1016/j.ins.2018.10.024
52. Ficek J, Wang W, Chen H, Dagne G, Daley E. Differential privacy in health research: a scoping review. J Am Med Inform Assoc. (2021) 28:2269–76. doi: 10.1093/jamia/ocab135
53. Schein A, Wu ZS, Schofield A, Zhou M, Wallach H. Locally private Bayesian inference for count models. In: Proceedings of the 36th International Conference on Machine Learning (2019). p. 5638–48.
54. Cai K, Lei X, Wei J, Xiao X. Data synthesis via differentially private Markov random fields. Proc VLDB Endow. (2021) 14:2190–202. doi: 10.14778/3476249.3476272
55. Abadi M, Chu A, Goodfellow I, McMahan HB, Mironov I, Talwar K, et al.. Deep learning with differential privacy. In: Proceedings of the 2016 ACM Sigsac Conference on Computer and Communications Security (2016). p. 308–18.
56. Jayaraman B, Evans D. Evaluating differentially private machine learning in practice. In: 28th Usenix Security Symposium (Usenix Security 19) (2019). p. 1895–912.
57. Nissim K, Raskhodnikova S, Smith A. Smooth sensitivity and sampling in private data analysis. In: Proceedings of the Thirty-Ninth Annual ACM Symposium on Theory of Computing (2007). p. 75–84.
58. Dwork C, Feldman V. Privacy-preserving prediction. In: Proceedings of the 31st Conference on Learning Theory (2018). p. 1693–702.
59. Bagdasaryan E, Poursaeed O, Shmatikov V. Differential privacy has disparate impact on model accuracy. Adv Neural Inf Process Syst. (2019) 32:15479–88.
60. Ramu SP, Boopalan P, Pham Q, Maddikunta PKR, Huynh-The T, Alazab M, et al.Federated learning enabled digital twins for smart cities: concepts, recent advances, and future directions. Sustain Cities Soc. (2022) 79:103663. doi: 10.1016/j.scs.2021.103663
61. Zhang W, Yang D, Wu W, Peng H, Zhang N, Zhang H, et al.Optimizing federated learning in distributed industrial IoT: a multi-agent approach. IEEE J Sel Areas Commun. (2021) 39:3688–703. doi: 10.1109/JSAC.2021.3118352
62. Long G, Tan Y, Jiang J, Zhang C, Federated Learning for Open Banking. Berlin: Springer (2020). p. 240–54. Chap. 17.
63. van Rooden SM, van der Werff SD, van Mourik MSM, Lomholt F, Møller KL, Valk S, et al.Federated systems for automated infection surveillance: a perspective. Antimicrob Resist Infect Control. (2024) 13:113. doi: 10.1186/s13756-024-01464-8
64. Maes E, Mertens I, Valkenborg D, Pauwels P, Rolfo C, Baggerman G. Proteomics in cancer research: are we ready for clinical practice? Crit Rev Oncol Hematol. (2015) 96:437–48. doi: 10.1016/j.critrevonc.2015.07.006
65. Rodriguez-Esteban R, Jiang X. Differential gene expression in disease: a comparison between high-throughput studies and the literature. BMC Med Genom. (2017) 10:1–10. doi: 10.1186/s12920-017-0293-y
66. Rieke N, Hancox J, Li W, Milletari F, Roth HR, Albarqouni S, et al.The future of digital health with federated learning. npj Digit Med. (2020) 3:1–7. doi: 10.1038/s41746-020-00323-1
67. Cai Z, Poulos RC, Liu J, Zhong Q. Machine learning for multi-omics data integration in cancer. Iscience. (2022) 25:103798. doi: 10.1016/j.isci.2022.103798
68. Zhu Y, Orre LM, Tran YZ, Mermelekas G, Johansson HJ, Malyutina A, et al.DEqMS: a method for accurate variance estimation in differential protein expression analysis. Mol Cell Proteom. (2020) 19:1047–57. doi: 10.1074/mcp.TIR119.001646
69. Law CW, Chen Y, Shi W, Smyth GK. Voom: precision weights unlock linear model analysis tools for RNA-seq read counts. Genome Biol. (2014) 15:1–17. doi: 10.1186/gb-2014-15-2-r29
70. Hannemann A, Ewald J, Seeger L, Buchmann E. Federated learning on transcriptomic data: model quality and performance trade-offs. In: International Conference on Computational Science (2024). p. 279–93.
71. Li W, Tong J, Anjum MM, Mohammed N, Chen Y, Jiang X. Federated learning algorithms for generalized mixed-effects model (GLMM) on horizontally partitioned data from distributed sources. BMC Med Inform Decis Mak. (2022) 22:269. doi: 10.1186/s12911-022-02014-1
72. Wang S, Kim M, Li W, Jiang X, Chen H, Harmanci A. Privacy-aware estimation of relatedness in admixed populations. Brief Bioinform. (2022) 23:bbac473. doi: 10.1093/bib/bbac473
73. Li W, Chen H, Jiang X, Harmanci A. FedGMMAT: federated generalized linear mixed model association tests. PLoS Comput Biol. (2024) 20:e1012142. doi: 10.1371/journal.pcbi.1012142
74. Cho H, Froelicher D, Chen J, Edupalli M, Pyrgelis A, Troncoso-Pastoriza JR, et al.Secure and federated genome-wide association studies for biobank-scale datasets. Nat Genet. (2025) 57:809–14. doi: 10.1038/s41588-025-02109-1
75. Mbatchou J, Barnard L, Backman J, Marcketta A, Kosmicki JA, Ziyatdinov A, et al.Computationally efficient whole-genome regression for quantitative and binary traits. Nat Genet. (2021) 53:1097–103. doi: 10.1038/s41588-021-00870-7
76. Wang S, Shen B, Guo L, Shang M, Liu J, Sun Q, et al.Scfed: federated learning for cell type classification with scRNA-seq. Brief Bioinform. (2024) 25:bbad507. doi: 10.1093/bib/bbad507
77. Li Q, Wu Z, Cai Y, Han Y, Yung CM, Fu T, et al.FedTree: a federated learning system for trees. Proc Mach Learn Syst. (2023) 5:89–103.
78. Wang Q, He M, Guo L, Chai H. AFEI: adaptive optimized vertical federated learning for heterogeneous multi-omics data integration. Brief Bioinform. (2023) 24:bbad269. doi: 10.1093/bib/bbad269
79. Danek BP, Makarious MB, Dadu A, Vitale D, Lee PS, Singleton AB, et al.Federated learning for multi-omics: a performance evaluation in Parkinson’s disease. Patterns. (2024) 5:100945. doi: 10.1016/j.patter.2024.100945
80. Bdair T, Navab N, Albarqouni S. Semi-supervised federated peer learning for skin lesion classification. Mach Learn Biomed Imaging. (2022) 1:1–37. doi: 10.59275/j.melba.2022-8g82
81. Yan R, Qu L, Wei Q, Huang S, Shen L, Rubin DL, et al.Label-efficient self-supervised federated learning for tackling data heterogeneity in medical imaging. IEEE Trans Med Imaging. (2023) 42:1932–43. doi: 10.1109/TMI.2022.3233574
82. Jiang M, Wang Z, Dou Q. Harmofl: harmonizing local and global drifts in federated learning on heterogeneous medical images. Proc AAAI Conf Artif Intell. (2022) 36:1087–95. doi: 10.1609/aaai.v36i1.19993
83. Haggenmüller S, Schmitt M, Krieghoff-Henning E, Hekler A, Maron RC, Wies C, et al.Federated learning for decentralized artificial intelligence in melanoma diagnostics. JAMA Dermatol. (2024) 160:303. doi: 10.1001/jamadermatol.2023.5550
84. Linardos A, Kushibar K, Walsh S, Gkontra P, Lekadir K. Federated learning for multi-center imaging diagnostics: a simulation study in cardiovascular disease. Sci Rep. (2022) 12:3551. doi: 10.1038/s41598-022-07186-4
85. Yang D, Xu Z, Li W, Myronenko A, Roth HR, Harmon S, et al.Federated semi-supervised learning for COVID region segmentation in chest CT using multi-national data from China, Italy, Japan. Med Image Anal. (2021) 70:101992. doi: 10.1016/j.media.2021.101992
86. Matschinske J, Späth J, Bakhtiari M, Probul N, Majdabadi MMK, Nasirigerdeh R, et al.The featurecloud platform for federated learning in biomedicine: unified approach. J Med Internet Res. (2023) 25:e42621. doi: 10.2196/42621
87. Berger B, Cho H. Emerging technologies towards enhancing privacy in genomic data sharing. Genome Biol. (2019) 20:128. doi: 10.1186/s13059-019-1741-0
88. Froelicher D, Troncoso-Pastoriza JR, Raisaro JL, Cuendet MA, Sousa JS, Cho H, et al.Truly privacy-preserving federated analytics for precision medicine with multiparty homomorphic encryption. Nat Commun. (2021) 12:5910. doi: 10.1038/s41467-021-25972-y
89. Hwang B, Lee JH, Bang D. Single-cell RNA sequencing technologies and bioinformatics pipelines. Exp Mol Med. (2018) 50:1–14. doi: 10.1038/s12276-018-0071-8
90. Papalexi E, Satija R. Single-cell RNA sequencing to explore immune cell heterogeneity. Nat Rev Immunol. (2018) 18:35–45. doi: 10.1038/nri.2017.76
91. Ma F, Pellegrini M. ACTINN: automated identification of cell types in single cell RNA sequencing. Bioinformatics. (2020) 36:533–8. doi: 10.1093/bioinformatics/btz592
92. Theodoris CV, Xiao L, Chopra A, Chaffin MD, Al Sayed ZR, Hill MC, et al.Transfer learning enables predictions in network biology. Nature. (2023) 618:616–24. doi: 10.1038/s41586-023-06139-9
93. Bakhtiari M, Bonn S, Theis F, Zolotareva O, Baumbach J. FedscGEN: privacy-preserving federated batch effect correction of single-cell RNA sequencing Data. Genome Biol. (2025) 26:216. doi: 10.1186/s13059-025-03684-6
94. Lotfollahi M, Wolf FA, Theis FJ. scGEN predicts single-cell perturbation responses. Nat Methods. (2019) 16:715–21. doi: 10.1038/s41592-019-0494-8
95. Civelek M, Lusis AJ. Systems genetics approaches to understand complex traits. Nat Rev Genet. (2014) 15:34–48. doi: 10.1038/nrg3575
96. Liu Y, Kang Y, Zou T, Pu Y, He Y, Ye X, et al.Vertical federated learning: concepts, advances, and challenges. IEEE Trans Knowl Data Eng. (2024) 36:3615–34. doi: 10.1109/TKDE.2024.3352628
97. Rajput D, Wang W, Chen C. Evaluation of a decided sample size in machine learning applications. BMC Bioinform. (2023) 24:48. doi: 10.1186/s12859-023-05156-9
98. Suetens P, Fundamentals of Medical Imaging. 3rd ed. Cambridge: Cambridge University Press (2017).
99. Wan Z, Hazel JW, Clayton EW, Vorobeychik Y, Kantarcioglu M, Malin BA. Sociotechnical safeguards for genomic data privacy. Nat Rev Genet. (2022) 23:429–45. doi: 10.1038/s41576-022-00455-y
100. Mouchet CV, Bossuat J, Troncoso-Pastoriza JR, Hubaux J. Lattigo: a multiparty homomorphic encryption library in go. In: Proceedings of the 8th Workshop on Encrypted Computing and Applied Homomorphic Cryptography (2020). p. 64–70.
101. Bell JH, Bonawitz KA, Gascón A, Lepoint T, Raykova M. Secure single-server aggregation with (Poly) logarithmic overhead. In: Proceedings of the 2020 ACM Sigsac Conference on Computer and Communications Security (2020). p. 1253–69.
102. Li KH, de Gusmão PPB, Beutel DJ, Lane ND. Secure aggregation for federated learning in flower. In: Proceedings of the 2nd ACM International Workshop on Distributed Machine Learning (2021). p. 8–14.
103. Ballhausen H, Corradini S, Belka C, Bogdanov D, Boldrini L, Bono F, et al.Privacy-friendly evaluation of patient data with secure multiparty computation in a European pilot study. npj Digit Med. (2024) 7:280. doi: 10.1038/s41746-024-01293-4
104. Lieftink N, Kroon M, Haringhuizen GB, Wong A, van de Burgwal LHM. The potential of federated learning for public health purposes: a qualitative analysis of GDPR compliance, Europe, 2021. Eurosurveillance. (2024) 29:2300695. doi: 10.2807/1560-7917.ES.2024.29.38.2300695
105. Sun C, van Soest J, Koster A, Eussen SJ, Schram MT, Stehouwer CD, et al.Studying the association of diabetes and healthcare cost on distributed data from the Maastricht Study and Statistics Netherlands using a privacy-preserving federated learning infrastructure. J Biomed Inform. (2022) 134:104194. doi: 10.1016/j.jbi.2022.104194
106. Volini GA. A deep dive into technical encryption concepts to better understand cybersecurity & data privacy legal & policy issues. J Intell Prop Law. (2020) 28:291.
107. Martin YD, Kung A. Methods and tools for GDPR compliance through privacy and data protection engineering. In: IEEE European Symposium on Security and Privacy Workshops (2018). p. 108–11.
108. Jégou R, Bachot C, Monteil C, Boernert E, Chmiel J, Boucher M, et al.Capability and accuracy of usual statistical analyses in a real-world setting using a federated approach. PLoS ONE. (2024) 19:e0312697. doi: 10.1371/journal.pone.0312697
109. Minssen T, Pierce J, Big Data and Intellectual Property Rights in the Health and Life Sciences. Cambridge: Cambridge University Press (2018). p. 311–23. Chap. 21.
110. Tekgul BGA, Xia Y, Marchal S, Asokan N. WAFFLE: watermarking in federated learning. In: 40th International Symposium on Reliable Distributed Systems (2021). p. 310–20.
111. International Trade Administration, US Department of Commerce. Data Privacy Framework (2025). Available online at: https://www.dataprivacyframework.gov/ (Accessed June 10, 2025).
112. Daly K, Eichner H, Kairouz P, McMahan HB, Ramage D, Xu Z. Federated learning in practice: reflections and projections. arXiv [Preprint]. arXiv:2410.08892 (2025).
113. Sabt M, Achemlal M, Bouabdallah A. Trusted execution environment: what it is, and what it is not. In: 2015 IEEE Trustcom/BigDataSE/ISPA (2015). p. 57–64.
114. Wen J, Zhang Z, Lan Y, Cui Z, Cai J, Zhang W. A survey on federated learning: challenges and applications. Int J Mach Learn Cybern. (2023) 14:513–35. doi: 10.1007/s13042-022-01647-y
115. Yurdem B, Kuzlu M, Gullu MK, Catak FO, Tabassum M. Federated learning: overview, strategies, applications, tools and future directions. Heliyon. (2024) 10:e38137. doi: 10.1016/j.heliyon.2024.e38137
116. Ren C, Yu H, Peng H, Tang X, Zhao B, Yi L, et al.Advances and open challenges in federated foundation models. IEEE Commun Surv Tutor. (2025) 1. doi: 10.1109/COMST.2025.3552524
117. Gilbert S, Adler R, Holoyad T, Weicken E. Could transparent model cards with layered accessible information drive trust and safety in health AI? npj Digit Med. (2025) 8:124. doi: 10.1038/s41746-025-01482-9
118. Coalition for Health AI. Applied Model Card (2024). Available online at: https://www.chai.org/workgroup/applied-model (Accessed June 10, 2025).
Keywords: federated machine learning, exposome, secure distributed analysis, data privacy, collaborative genomics
Citation: Malpetti D, Scutari M, Gualdi F, van Setten J, van der Laan S, Haitjema S, Lee AM, Hering I and Mangili F (2025) Technical and legal aspects of federated learning in bioinformatics: applications, challenges and opportunities. Front. Digit. Health 7:1644291. doi: 10.3389/fdgth.2025.1644291
Received: 10 June 2025; Accepted: 30 October 2025;
Published: 18 November 2025.
Edited by:
Emmanouil Spanakis, Foundation for Research and Technology Hellas (FORTH), GreeceReviewed by:
Uwe Aickelin, The University of Melbourne, AustraliaKonstantina Athanasopoulou, National and Kapodistrian University of Athens, Greece
Copyright: © 2025 Malpetti, Scutari, Gualdi, van Setten, van der Laan, Haitjema, Lee, Hering and Mangili. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Marco Scutari, c2N1dGFyaUBibmxlYXJuLmNvbQ==
†These authors have contributed equally to this work