 Ina Koch
Ina Koch Joachim Nöthen1†
Joachim Nöthen1† Enrico Schleiff
Enrico Schleiff- 1Department of Molecular Bioinformatics, Institute of Computer Science, Cluster of Excellence “Macromolecular Complexes”, Goethe-University Frankfurt, Frankfurt am Main, Germany
- 2Department of Biosciences, Institute of Molecular Biosciences, Molecular Cell Biology of Plants, Cluster of Excellence “Macromolecular Complexes”, Goethe-University Frankfurt, Frankfurt am Main, Germany
Motivation: Arabidopsis thaliana is a well-established model system for the analysis of the basic physiological and metabolic pathways of plants. Nevertheless, the system is not yet fully understood, although many mechanisms are described, and information for many processes exists. However, the combination and interpretation of the large amount of biological data remain a big challenge, not only because data sets for metabolic paths are still incomplete. Moreover, they are often inconsistent, because they are coming from different experiments of various scales, regarding, for example, accuracy and/or significance. Here, theoretical modeling is powerful to formulate hypotheses for pathways and the dynamics of the metabolism, even if the biological data are incomplete. To develop reliable mathematical models they have to be proven for consistency. This is still a challenging task because many verification techniques fail already for middle-sized models. Consequently, new methods, like decomposition methods or reduction approaches, are developed to circumvent this problem.
Methods: We present a new semi-quantitative mathematical model of the metabolism of Arabidopsis thaliana. We used the Petri net formalism to express the complex reaction system in a mathematically unique manner. To verify the model for correctness and consistency we applied concepts of network decomposition and network reduction such as transition invariants, common transition pairs, and invariant transition pairs.
Results: We formulated the core metabolism of Arabidopsis thaliana based on recent knowledge from literature, including the Calvin cycle, glycolysis and citric acid cycle, glyoxylate cycle, urea cycle, sucrose synthesis, and the starch metabolism. By applying network decomposition and reduction techniques at steady-state conditions, we suggest a straightforward mathematical modeling process. We demonstrate that potential steady-state pathways exist, which provide the fixed carbon to nearly all parts of the network, especially to the citric acid cycle. There is a close cooperation of important metabolic pathways, e.g., the de novo synthesis of uridine-5-monophosphate, the γ-aminobutyric acid shunt, and the urea cycle. The presented approach extends the established methods for a feasible interpretation of biological network models, in particular of large and complex models.
1. Introduction
Arabidopsis thaliana (A. thaliana) is a popular model organism in plant biology (Van Norman and Benfey, 2009). A. thaliana was the first plant with sequenced genome (Arabidopsis-Genome-Initiative, 2000), and a large mutant collection (Sessions et al., 2002; Alonso et al., 2003) provides the optimal base for genetic and physiological analysis of this model system. It further is characterized by a short generation time, small plant size, diploid genetics, and a large number of offspring, which is of high advantage for breeding for research (Meinke et al., 1998; Koornneef and Meinke, 2010 and references therein). Most of the current information on plant metabolism is based on this model system (Lunn, 2007). Beside the academic interest in understanding the metabolism of plants, there is a broad interest to improve nutritional quality of crops and agricultural productivity to generate phytopharmaceutical substances and to increase the production of nutraceutical biomolecules and pharmaceutical proteins of commercial interest (Hur et al., 2013). The development of network models based on these investigations (Dersch and Beckers, 2016) represents a useful approach for the analysis and simulation of the metabolism. Nowadays, the Path2Models database contains 125 models for A. thaliana (Büchel et al., 2013). To develop a mathematical model, the single reactions are typically extracted from databases such as AraCyc (Mueller et al., 2003; Zhang et al., 2005), and/or KEGG (Kanehisa et al., 2008).
Various models of the metabolism of A. thaliana exist. Several approaches concern gene regulatory networks (Lucas and Brady, 2013). For example, a method based on Bayesian networks was formulated to investigate root cell differentiation (Bruex et al., 2012), and a network, focusing on stress response in leaves, was developed (Hickman et al., 2013). The power of these networks has been documented, for example, by identification of new factors involved. Using a recently developed statistical linear regression technique, novel genes were detected which are involved in the mucilage biosynthesis (Vasilevski et al., 2012).
In this paper, we focus on recent research results of metabolic modeling approaches of A. thaliana. The first steady-state Metabolic Flux Analysis (MFA) maps for A. thaliana were introduced in 2008 (Williams et al., 2008), using a heterotrophic cell suspension grown under two different oxygen concentrations as experimental data source. The results suggest a possible alteration of metabolite abundance without changes in the balance between respiratory and biosynthetic flux or a major rearrangement of the network. Based on this study, further investigations have been followed, in particular on the flux in the pentose phosphate pathway (Masakapalli et al., 2010). Three new models were derived, which differ in the compartmental organization of the pentose phosphate pathway. The measured data fit to each of the three models in an acceptable manner, which necessitate further investigations in addition to the MFA. This underlines the problems of metabolic flux analysis (Masakapalli et al., 2010). Several genome-scale flux models have been developed for A. thaliana, for example, by Poolman et al. (2009), de Oliveira Dal'Molin et al. (2010), Radrich et al. (2010), and Mintz-Oron et al. (2012).
The Poolman model is based on the AraCyc database (Mueller et al., 2003) and was automatically extracted. It consists of 1,253 metabolites and 1,406 reactions, involving the production of biomass components, such as nucleotides, amino acids, lipid, starch, and cellulose in the proportion experimentally observed in a heterotrophic suspension culture. After the removal of reactions that are not necessary to maintain a steady state, 855 reactions remain. Additionally, the authors provide a steady-state model of 232 reactions that exhibit only nonzero flux values.
Similarly, de Oliveira Dal'Molin et al. (2010) automatically extract a core reaction system called AraGEM from the KEGG database to generate a model. The model is compartmentalized into cytosol, mitochondrion, plastid, perixome, and vacuole. Additional information is manually integrated from databases, such as AraPerox (Reumann et al., 2004) and SUBA (Arabidopsis Subcellular Database, Heazlewood et al., 2007). The model contains 1,567 reactions and 1,748 metabolites. A two-dimensional annotation provides links from the reactions to the genes. The authors modify 36 reactions by manual curation to give a consistent stoichiometry. To achieve a desired functionality, they introduce 148 biomass drains and inter-organelle transporters.
The Radrich model represents a high-quality core consensus model obtained by a systematic comparison of compounds and reactions between the databases KEGG and AraCyc. Various levels of consensus lead to three submodels of different quality, the core model of 753 reactions and 914 metabolites with highest reliability, the intermediate model of 1,388 reactions and 1,248 metabolites, and the complete model of 2,315 reactions and 2,328 metabolites. The core model is the intersection between the two databases, containing every metabolite and reaction, which is present in both databases. In the intermediate model, every reaction is present, for which either all educts or all products are part of the core model. The complete model is the union of both databases. The Mintz-Oron model was semi-automatically derived from KEGG and AraCyc, including compartmental information from the Arabidopsis Subcellular Database, SUBA (Heazlewood et al., 2007), and tissue-specific localization data from the literature. It consists of 1,363 reactions and 1,078 metabolites. The authors predicted a total of 942 out of 1,363 inspected reactions to take place in every tissue. These reactions include reactions of the primary metabolite pathways, such as the glycolysis, the pentose phosphate pathway, and the fatty acid, nucleotide, and amino acid metabolism. The model is validated by comparison of experimental data with predicted flux values. All presented models use the databases AraCyc and/or KEGG as starting points for automatic network generation.
We chose Petri nets (PNs) as mathematical formalism for network construction, analysis, and simulation. PNs are mainly applied in computer science, for example, to model distributed systems. Many sound, rigorous analysis and simulation methods of PNs have been evolved over decades for various applications (Billington and Reisig, 1996). Some of these concepts and algorithms have been successfully applied to biochemical systems, including metabolic networks (Koch et al., 2005), signal transduction networks (Sackmann et al., 2006), gene regulatory networks (Matsuno et al., 2000), protein complex assembly (Bortfeldt et al., 2011), and combinations of them (Grunwald et al., 2008; Koch et al., 2011).
To motivate the work, we aimed to develop a consistent metabolic model that reflects the steady-state condition and the basic dynamic behavior. Thus, the model becomes suitable for rigorous mathematical analyses and can serve as basis for quantitative analyses. Our work was motivated by a hand-built PN model for the metabolism of barley Hordeum vulgare, integrating biochemical, physiological, proteomic, and genomic data derived from the literature and databases (Grafahrend-Belau et al., 2009). We followed the paper's strategy and built a model for A. thaliana by successively adding metabolites and reactions from the literature (Nöthen, 2009). We systematically expanded the PN to develop a new model based on the current experimental knowledge on the metabolism of A. thaliana and to investigate the structural and dynamic properties of the model. To check a metabolic model for consistency and correctness, we considered special network properties (Heiner and Koch, 2004). For biochemical systems, a correct biological interpretation of submodules at steady state was mainly applied. The computation of such submodules was based on minimal semi-positive transition invariants (TIs), also known as elementary modes (Schuster and Hilgetag, 1994). For the definition, see Section 2.1. Minimal semi-positive integer solutions were of interest (Schrijver, 1998; Koch and Ackermann, 2013) leading to a complexity that does not allow the computation of all solutions, even if the the power of supercomputers is used. Today, several alternative methods for the exploration of the inherent flux states of large systems exist (Koch and Ackermann, 2013).
The paper is organized as follows. In the Section 2, we introduce Petri nets and describe the network verification and the network reduction techniques we used, including the common transition pairs and invariant transition pairs. In Section 3, we give the complete PN and the reduced PN model of the central metabolism in A. thaliana. We explain an example for a network reduction and for a TI, and discuss the Maximal Common Transition sets, covering the analyses of functional modules. The supplementary file Table 1.pdf contains the metabolites, the reactions, and the output reactions, including the literature references. The supplementary file Table 2.pdf contains the tables, indicating each reduction step. The supplementary file Supplementary Material Data Sheet 1 includes all Petri net models.
2. Materials and Methods
In the following, we briefly describe the methods for network reduction and network decomposition given in the Petri net formalism.
2.1. Petri Nets
Petri nets (PNs) are based on a concept of communication of automation originally introduced by Carl Adam Petri (Petri, 1962) in his dissertation in 1962 for mathematical modeling of causal systems with concurrent processes. PN provide a flexible, well-defined, mathematical formalism for various modeling types, ranging from qualitative to quantitative modeling. Here, we introduce the basic definitions and notations that are necessary to understand the paper. For a more detailed introduction, see Murata (1989), Baumgarten (1996), and Koch et al. (2011).
The first biological application of PNs was published in 1993 by Reddy et al. (1993). PNs has been used to model various biochemical systems, such as metabolic networks (Koch et al., 2005), signal transduction networks (Sackmann et al., 2006), gene regulatory networks (Matsuno et al., 2000), protein complex assembly (Bortfeldt et al., 2011), and combinations of them (Grunwald et al., 2008). The PN formalism has been also used for stochastic modeling, applying the Gillespie's algorithm (Gillespie, 1977), and for kinetic modeling, applying mass action kinetics and/or Michaelis-Menten kinetics. For a review, see Koch et al. (2011).
Petri nets are directed, bipartite, labeled graphs. They consist of two disjunctive sets of vertices, P and T, respectively. The elements in P are the places graphically represented as circles, and the elements in T are the transitions graphically represented as rectangles. Places stand for the passive system's elements, for example, chemical compounds, metabolites, proteins, and protein complexes. Instances of them are represented by tokens, which define discrete entities. Since the movement of tokens realizes the dynamics of a PN, we introduce the concept of tokens in Section 2.1.1. Transitions are the active system's elements, for example, chemical reactions, degradation processes, and complex assembly processes. Places and transitions are connected by directed, labeled edges. Edges between vertices of the same type are not allowed. Usually, the edges are labeled or weighted, respectively, by integer numbers. In the following, we call a directed, bipartite graph net or net graph, see Definition 2.1. To define a Petri net, we extend that definition, compare Definition 2.2.
Definition 2.1. Net or net graph.
A net or net graph is a triple N = (P, T, F) with
P ∩ T = ∅ and
F ⊆ (P × T) ∪ (T × P)).
We call the elements of P and T places and transitions, respectively. They are the vertices or nodes of the net. We call the elements of the flow relation, F, edges or arcs.
Regarding a net vertex, we define two sets of neighbor vertices, the set of all pre-vertices •x: = {y | (y, x) ∈ F} and the set of all post-vertices x•: = {y | (x, y) ∈ F}. Accordingly, we write for a set of pre-places, •t, for a set of post-places, t•, for a set of pre-transitions, •p, and for a set of post-transitions, p•.
We call edges that are going in two opposite directions as read arcs or test arcs. Using read arcs, we can model, for example, catalytic reactions, where the catalyst is necessary to activate the transition (reaction), but will not be consumed, when the transition takes place. A PN without read arcs is a pure PN.
Definition 2.2. Petri net. A Petri net or Place/Transition net or P/T net is a six-tuple Y = (P, T, F, K, W, M0), if
• (P, T, F) is a net,
• K : P → ℕ ∪ {∞} (capacities of the places, possibly infinite),
• W : F → ℕ (edge weights or label of the edges), and
• M0:P → ℕ0 (initial marking) with ∀p ∈ P : M0(p) ≤ K(p).
2.1.1. The Dynamics of P/T Nets
The dynamics of a net is performed by movable objects called tokens which are located on the places and will be removed according to the firing rule. If N is a P/T net, a mapping of the M : P → ℕ0 with ∀p ∈ P : M(p) ≤ K(p) is called a marking of N. We graphically represent the number of tokens of a place, M(p), under a marking, M, by M(p) dots (tokens) on the place, p. We write the capacities ≠∞ and edge weights ≠1 at the places and edges, respectively. The token distribution over all places define a certain state of the net. is the set of all markings of N. In the following, let M be a fixed marking of N. The number of the tokens can be restricted by the capacity of the place. In most biological applications, the capacity is set to infinite. Additionally, we introduce logical vertices to get an improved layout. A logical vertex has copies of the same name in the graphical representation of the model. Using logical vertices, we can draw PNs in a clearly-arranged way. For example, in metabolic networks, ATP participates in many reactions. This leads to many crossing edges if we model only one place for ATP. To avoid these crossing edges, we copy the place for ATP and mark it as logic place.
In this paper, we consider the classical Place/Transition PN (P/T net). The firing rules do not include time relations. A transition fires, or for biochemical networks, a reaction takes place, if the transition is activated or has concession, i.e., if the pre-places carry at least as many tokens as indicated by the weights of the corresponding edges and if the capacity of the post-places is large enough as indicated by he corresponding edge weights. At the moment of firing, the tokens of the pre-places will be consumed, and the tokens on the post-places will be produced, both according to the corresponding edge weights. A new system's state is achieved. The numbers of tokens and the edge weights implement quantitative properties although the system is still discrete. If always at least one transition of the PN is activated, the PN contains no deadlock and is called to be deadlock-free.
Definition 2.3. Activated transition. A transition, t ∈ T, is activated or has concession under M, written as , if
• ∀p ∈ •t : M(p) ≥ W(p, t),
• ∀p ∈ t• : M(p) ≤ K(p) − W(t, p).
We say that t fires from M to M′ and write , if t is activated under M, and M′ arises from M by removal of tokens from the pre-places and production of tokens on the post-places according to the corresponding edge weights:
Transitions without pre-places are always activated. We call them input transitions. Accordingly, we call transitions without post-places output transitions. Input and output transitions were used to model the interface to the system's environment. Figure 1 illustrates an example of a pure PN and its firing behavior.
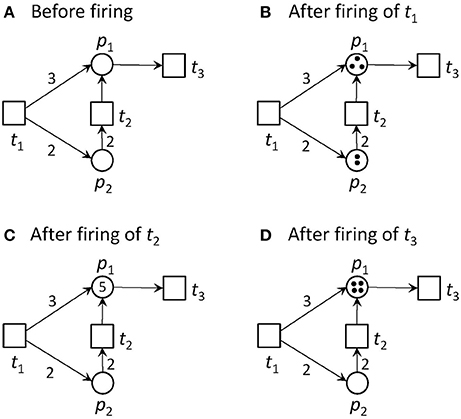
Figure 1. A Petri net and its firing possibilities. (A) The PN consists of two places and three transitions. Place p2 is pre-place of t2, and p1 is post-place of t2. t1 and t2 are pre-transitions of p1, and t3 is post-transition of p1. Transition t1 is an input transition, meaning that it has no pre-places and is, thus, always activated. Transition t3 is an output transition, meaning that it has no post-places. In the first step, only transition t1 is activated. Transition t2 would need two tokens on place p2 to become activated, and t3 would need one token to get concession. The capacities of all places are infinite. (B) The new state defined by the token distribution after firing of t1. Place p1 gets three tokens and p2 two tokens. Additionally to t1, t2 and t3 are activated, because their pre-conditions defined by the edge weights are fulfilled, and the post-condition is valid too. (C) The new state after firing of t2. For the reachability analysis, also the case of firing t3 first, will be considered. In the simulation, one of the activated transitions is randomly chosen to fire next. Now, t1 and t3 are activated. (D) The new state after firing of t3. One token was removed from the PN, because t3 has no post-place.
2.1.2. Linear Invariants
Using linear invariants, we can define specific dynamic properties of the network. These properties are valid in every system state. They can be used for model verification, but also for model decomposition and network reduction. For PNs, we define the place invariants (PI) for the passive part and the transition invariants (TI) for the active part. The definitions of both invariant types are based on the incidence matrix, we also know as stoichiometry matrix for metabolic networks. This m × n matrix, C, for m places and n transitions indicates for each place, pi ∈ P, the change in the number of tokens, △m, when a transition, tj ∈ T, fires.
Definition 2.4. Incidence matrix. Let N be a P/T net. The corresponding incidence matrix C is defined by: ∀ 1 ≤ i ≤ m, 1 ≤ j ≤ n
Note that for a PN without read arcs, we can remove \F−1 and the third condition. Contrary, for all cases, the third case, Ci, j = W(tj, pi), if(tj, pi) ∈ F, would be sufficient, if we consider W as complete mapping to (P × T) ∪ (T × P) and set the weights of non-existing edges to 0.
We developed the software tool MonaLisa especially designed for PN applications to biological systems (Einloft et al., 2013). Additionally to an intuitive editor, the tool provides many useful analysis functions based on PNs as well as on graph theory. It allows for classical discrete modeling as well as for stochastic modeling (Balazki et al., 2015).
Definition 2.5. Place invariant (PI). Let N be a P/T net and C the corresponding incidence matrix. A place invariant of N is an m-tuple x ∈ ℤm with CTx = 0.
Definition 2.6. Transition invariant (TI). Let N be a P/T net and C the corresponding incidence matrix. A transition invariant of N is an n-tuple y ∈ ℤn with Cy = 0.
We are interested in the minimal, semi-positive, integer solutions; integer, because we are working at discrete level, semi-positive because there is no interpretation of negative solutions, and minimal because such equation systems can have an infinite number of solutions. In the following, we consider minimal, semi-positive, integer PIs and TIs, writing shortly PIs and TIs, respectively. For discussion of the computational problem, see Schrijver (1998) and Koch and Ackermann (2013).
The support of a vector, x, is represented by the non-zero entries of the vector written as supp(x). An invariant x is called minimal, if its support does not contain the support of any other invariant z, i.e.,
and the greatest common divisor of all non-zero entries of x is one. Whereas PIs reflect a token or substance conservation, the TIs describe basic functional modules of the system's dynamics at steady state (Lautenbach, 1973; Schuster and Hilgetag, 1994; Schuster et al., 2002). These functional modules have to be checked for their biological correctness. The firing of the transitions of a TI in the given frequency reproduces the initial state. Thus, a TI is also called a Parikh vector. If every place or every transition, respectively, is member of at least one PI or TI, respectively, the PN is covered by PIs (CPI) or covered by TIs (CTI), respectively. The CTI property indicates the network's completeness or consistency. A transition which is not member of at least one TI does not contribute to the systems behavior. Thus, it could be removed without influencing the overall systems behavior. A TI or PI, respectively, defines a connected subnet, consisting of its support, the support's pre- and post-places or pre- and post-transitions, respectively, and all edges in between.
TIs can be classified according to the type of the participating transitions. The classes of TIs are motivated by the involved input and output transitions. We consider the following types of TIs:
• trivial: a reversible reaction, which is split into a forward and a backward transition.
• INOUT: contains at least one input transition and one output transition.
• IN: contains an input transition, but no output transition.
• OUT: contains an output transition, but no input transition.
• CYC: contains neither an input nor an output transitions forming a cycle in the model.
The explanations for some of the different types of invariants are intuitive. In a metabolic PN, containing reversible reactions, it is not possible to avoid trivial TIs. TIs of the type INOUT represent pathways through the network, a succession of consecutive biochemical reactions, transforming given educts (metabolites produced by input transitions) to the corresponding products (metabolites consumed by output transitions). TIs of the types IN or OUT contain only input or output transitions, respectively. These TIs emerge from internal production or consumption, respectively, of secondary metabolites. TIs of type CYC contain neither input nor output transitions at all. Their firings form cycles in the PN.
Figure 2 gives the incidence matrix and the equation systems for PI and TI computation of the PN example of Figure 1.
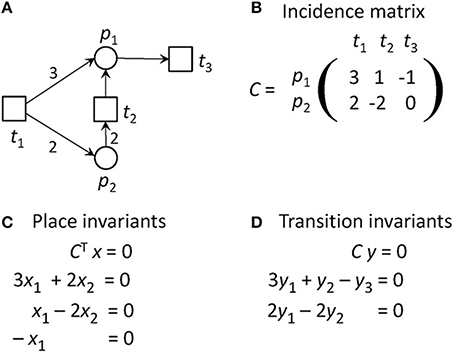
Figure 2. The definitions of invariants of the PN in Figure 1A. (A) The PN in Figure 1A. (B) The incidence matrix, C, of the PN. The matrix indicates how many tokens are removed from or consumed on the places when a transition fires. For example, if t1 fires, three tokens will be produces on p1 and two tokens on p2. (C) The equation system to compute the place invariants. (D) The equation system to compute the transition invariants. The PN has no place invariants, but is covered by transition invariants. It has one TI = {t1, t2, 4 t3}, meaning that t1 and t2 have to fire each once and t3 four times, before the original state will be reached again.
2.1.3. Maximal Common Transition Sets (MCT-Sets)
To support the biological interpretation of TIs, we group the transitions into Maximal Common Transition sets (MCT-sets, MCTS) by their occurrence in the minimal TIs: ∀i, j ∈ {1, …, m} the transitions, ti and tj, are grouped into the same MCT-set, if and only if they participate in exactly the same minimal TIs, i.e., all TIs x hold:
whereas χ{0} denotes the characteristic function, binary indicating whether an argument is equal to zero. This grouping leads to maximal sets of transitions, whereat each set of transitions ϑ holds:
whereas X denotes the set of all minimal TIs, x.
This grouping represents an equivalence relation in T, the set of transitions, which leads to a partition of T. The equivalence classes ϑ correspond to the MCT-sets. MCT-sets define also subnets as TIs, but they have not to be connected. The subnets defined by MCT-sets are disjunctive. They represent a further decomposition method of large biochemical networks into rather small subnets at steady state, which often correspond to functional units. Each of the MCT-sets may represent a building block with a special biological meaning.
2.2. Network Verification
Network verification is a crucial part in the process of model construction. For biological PNs, beside structural and behavioral properties such as the connectivity (Heiner and Koch, 2004; Koch et al., 2011), another important property is the biological interpretability of the TIs (Heiner and Koch, 2004; Koch et al., 2005; Grunwald et al., 2008) and the MCT-sets (Sackmann et al., 2006; Grafahrend-Belau et al., 2008).
The CTI property results from the TIs. This property can be seen as one indicator for the consistency and completeness of a network. It is of particular importance that a biological network is CTI, because this property ensures that each reaction may contribute to the basic system behavior (Koch and Heiner, 2008) while the steady state of the system is preserved.
We assume that metabolic networks reach a steady state. This steady-state assumption is reflected in the computation of the TIs. A TI represents a set of reactions whose enzymes ensure the steady-state condition. Only one missing reaction would lead to a disturbance of the steady state of the system. Moreover, each TI should represent a functional module in the overall network dynamics. The verification or interpretation for a biological meaning of each functional module, i.e., of each TI, represents a method to verify large networks with regard to their correctness. In this context, the computability of all TIs is a big problem, for even middle-sized networks, i.e., consisting of some hundreds of vertices and thousands of edges (Ackermann and Koch, 2011). To handle this problem, we applied network reduction techniques.
2.2.1. Network Reduction
Network reduction methods should reduce the complexity of the system, conserving main properties and the main behavior of the network. Reduction techniques are essential for network verification and analysis of big, complex systems. In computer science, the question for the correctness of algorithms, their running times, and other theoretical aspects of the reduction process are of great interest (Arnborg et al., 1993). Reduction has been employed in the analysis of complex networks in the Petri net community during the last decades. Various methods for the structural reduction of series of transitions and places have been developed (Lee-kwang et al., 1987). In this reduction process, surrounding vertices were summarized under conservation of special PN properties. Other techniques rely on the sharing properties of two or more vertices. Parallel transitions or places are connected to the same sets of pre-places and post-places or pre-transitions and post-transitions, respectively. Then, these parallel structures can be merged (Murata, 1989). Other methods try to integrate deadlock-avoiding policies, for example, in flexible manufacturing systems (Uzam, 2004). Beside these structural reduction methods, there exist also dynamical techniques for PNs (Berthelot, 1987).
In systems biology, reduction techniques are used at the topological level as well as at steady-state level. All these techniques help to verify and analyze biochemical networks. Investigations on metabolic networks (Reddy et al., 1993) apply reduction techniques of parallel structures. One approach establishes a matrix-based method to study the hierarchical organization of metabolic networks (Ravasz et al., 2002). To reduce the size of the matrix, non-branching pathways in the metabolic network of Escherichia coli are replaced by single reactions, resulting in a decrease of complexity.
Here, we used topological reduction techniques as well as steady-state reduction techniques. We considered topological reduction techniques that preserve the CTI-property (Ackermann et al., 2012). To reduce chains of transitions, we defined Common Transition Pairs (CTPs) as two transitions, ti and tj, connected by a place called a connecting place, pc, see Figure 3. We deleted the transition tj as well as the connecting place, pc. The transition, ti, absorbed the properties of the deleted transition, tj, i.e., all its pre-places, •ti, and post-places, ti•, as well as the corresponding connecting edges.
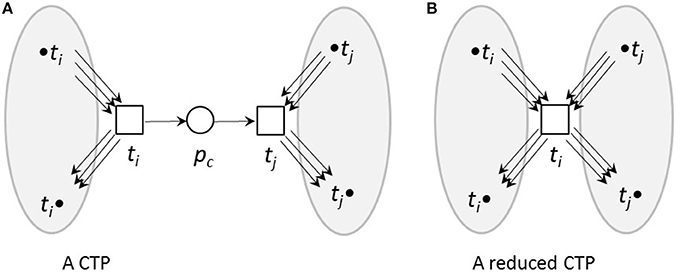
Figure 3. A CTP (A) and its reduced form (B). (A) A common transition pair, CTP, (ti, tj). The connecting place pc has one pre-transition ti and one post-transition tj. (B) The net after a CTP reduction. The transition tj as well as the connecting place pc were deleted. The transition ti absorbed the properties of the deleted transition tj, i.e., its pre-places, •ti, and post-places, ti•, as well as the corresponding edges.
To reduce reversible reactions, we defined Invariant Transition Pairs (ITPs) as two transitions, ti and tj, representing the forward and backward reaction, respectively, of a reversible reaction and connecting two places, pi and pj, see Figures 4, 5 for an example. We deleted the ITP (ti, tj), as well as the place pj. The place pi absorbed the properties of the deleted place pj, i.e., all its pre-transitions, •pi, and post-transitions, pj•, as well as the corresponding connecting edges and the markings.
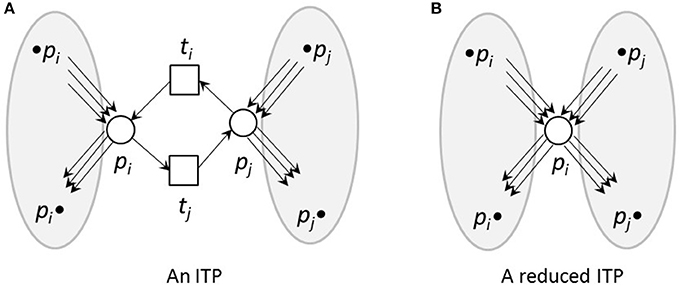
Figure 4. An ITP (A) and its reduced form (B). (A) An invariant transition pair, ITP (ti, tj). Both transitions have exactly one pre-place and one post-place. The post-place of transition ti is the pre-place of transition tj and vice versa. (B) Net reduction of an ITP. The ITP ti, tj as well as the place pj were deleted. The remaining place pi absorbed the properties of the deleted place pj, i.e., its pre-transitions, •pi and •pj, and post-transitions,pi• and pj•, as well as the corresponding edges and markings.
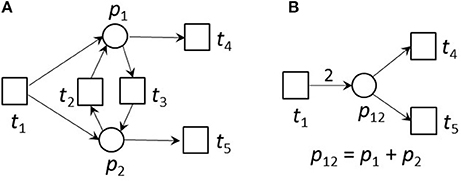
Figure 5. An example for an ITP (A) and its reduced form (B). (A) An example of a small network that is CTI and contains an ITP (ti, tj). (B) The reduced network of (A). Place p12 absorbed the edges of places p1 and p2 of the original net. The transitions t2 and t3 were neglected. The weight of edge t1, p12 was the sum of the weights of the edges t1, p1 and t1, p2 of the unreduced net in (A). The reduced net has the two TIs, (t1 + 2t4) and (t1 + 2t5). Extensions of these invariants gave the TIs,(t1 + t3 + 2t4) and (t1 + t2 + 2t5) of the original net. The TI, (t1 + t4 + t5), is not minimal for the reduced net and will not be generated.
To indicate a reduction, we changed in each reduction the names of the reactions and the metabolites. If two reactions were merged in a CTP reduction, we provided a new name for the merged transition, e.g., “ctp(ti+tj)”. If we identified, for example, the two reactions E151 and E152 connected by metabolite 87 as a potentially reducible CTP, we connected all edges from reaction E152 to reaction E151, removed metabolite 87 and reaction E152, and renamed reaction E151 to ctp(E151 + E152).
If the reduction was based on an ITP, we renamed the merged metabolites. According to the CTP reduction, we connected the names of the two metabolites in the same way preceeded by an ITP. If we reduce, for example, the reactions E24_f and E24_b, which connect the metabolites 76 and 50, by an ITP reduction, we would connect all edges from metabolite 50 to metabolite 76, remove the reactions E24_f and E24_b and the metabolite 50, and rename metabolite 76 to itp(76 + 50).
Additionally, we reduced parallel reactions, i.e., if two transitions had the same input place and the same output place, and the same weights on the corresponding edges, we combined both transitions into one without changing the net behavior (Murata, 1989). We adopted this rule for the analysis of biochemical networks (Reddy et al., 1993). We used this technique to further reduce the complexity of the model by reducing parallel pairs of transitions, but we applied it to those with only one pre-place and one post-place and edges of weight 1. The reduction procedure was recursive. It was possible that, e.g., the place itp(76 + 50) could be identified as an ITP with another place in the next step. Each step of the reduction could be followed by the nomenclature and produced a timescale of reductions, compare with the Tables 1–9 in the supplementary file Table 2.pdf.
A place or transition that had no connections left was removed from the model. It was possible to remove the just reduced CTP, i.e., the transition ti ∈ T, if the transition pair, (ti, tj], was additionally a reversible reaction for all other places connected to it. When this situation appeared, each ingoing edge for each connected place would cancel an outgoing edge of the same place, and, therefore, cancel all edges from and to ti ∈ T. After an ITP reduction, it was possible that another ITP was removed, if it connects the same pi and pj. For every other potential ITP, the reduction of the first ITP resulted into two transitions connected to the reduced place pi ∈ P with an ingoing and outgoing edge. We then removed these transitions, because they were no longer connected to the model.
3. Results and Discussion
3.1. The Petri Net Model
We developed the PN model based on the literature, i.e., each reaction (transition) is experimentally proven. The complete PN model consists of 134 metabolites and 243 reactions, which are connected via 572 edges. Figure 6 on the top gives a schematic illustration of the model. The metabolites within the PN were numbered. Their names are listed in the Supplementary file Table 1.pdf. The reactions, including the literature references, are compiled in the Tables 2–13 in the Supplementary file Table 1.pdf. The interface to the environment was modeled by 29 reactions indicated by an IN or OUT in the prefix of their names. The input reactions create the substrates glycine (metabolite = place 18), D-fructose (place 63), D-galactose (place 73), coenzyme A (CoA, place 93), acetyl-CoA (place 92), ammonia (place 29), or citrulline (place 94). In turn, the output reactions create 22 metabolites (see Table 14 in the Supplementary file Table 1.pdf). 18 output transitions were connected to sink metabolites.
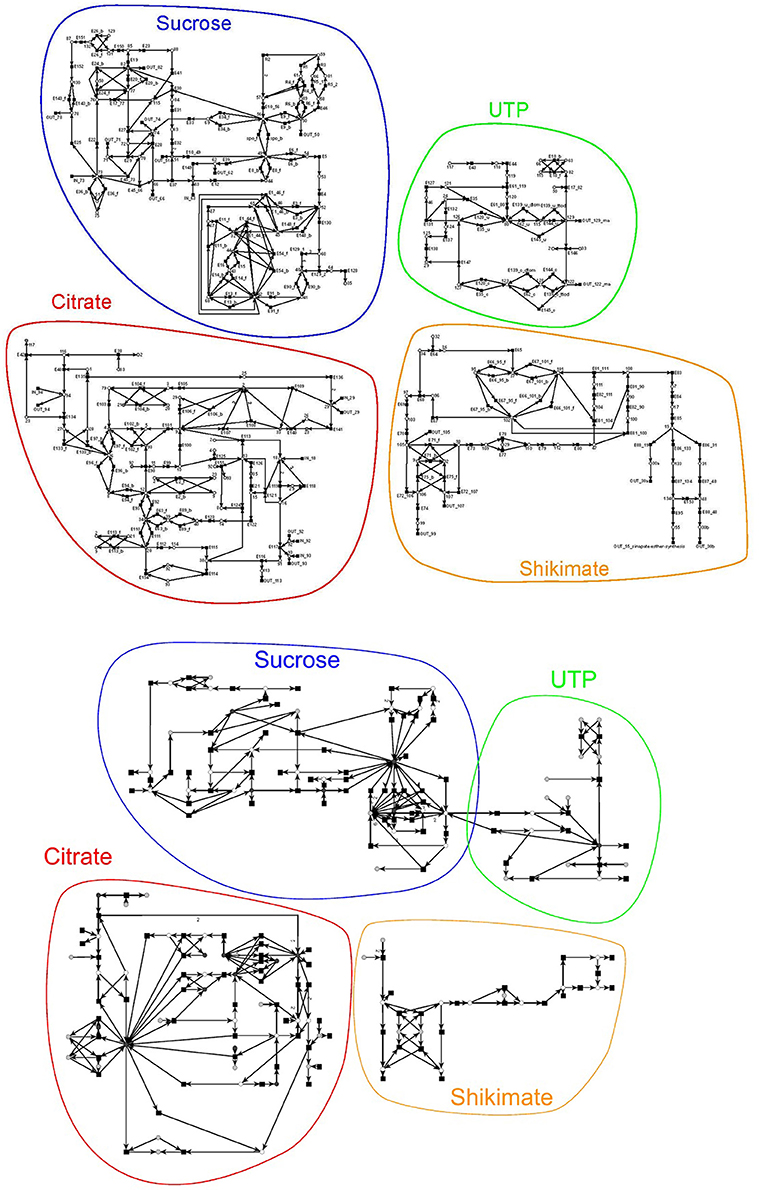
Figure 6. Schemas of the original and reduced PN model adapted from Nöthen (2014). It is a coarse-grained representation of the metabolism of A. thaliana. The original model (on the top) consists of 134 metabolites and 242 reactions connected via 569 edges and the reduced model (on the bottom) of 60 metabolites, 131 reactions, and 329 edges. The models were manually subdivided into four subnets, the sucrose, the UTP, the citrate, and the shikimate net. The subnets are highlighted in the same color and name.
Four metabolites were connected to both, an input and output transition, forming external metabolites (CoA, ammonia, acetyl-CoA, and citrulline). The biosynthesis of CoA was not modeled, and thus, the precursor of CoA, pantothenate (Raman and Rathinasabapathi, 2004), is not present in the PN. Similarly, acetyl-CoA is a product of the β-oxidation of fatty acids in A. thaliana (Fulda et al., 2002) which is not part of the model as well. Nitrate and a ammonia were taken up by roots and transported to photosynthetic tissues (Chalot et al., 2006). In leaves, ammonium is the primary nitrogen source for glutamine synthesis in the cytosol or chloroplasts, while nitrogen is either stored in vacuoles or converted to ammonium for further processing. For intracellular transport of ammonium between mitochondria and chloroplasts, a so-called ornithine-citrulline shuttle is proposed (Linka and Weber, 2005), which is also discussed to represent an efficient transport system for carbon dioxide from mitochondria to chloroplasts in form of citrulline. We modeled the external setting of citrulline to dissolve an occurring deadlock, consisting of the metabolites 94 (citrulline), 27 (L-arginino-succinate), 28 (arginine), and 1 (ornithine). Considering the four metabolites that serve as input and output, the PN consumed 3 input metabolites to produce 18 output metabolites.
For this complete PN, we were not able to compute the TIs. To verify the PN we first manually divided the complete PN into four smaller subnetworks of known biological meaning, for which we could separately compute the TIs. We chose four subnets of biological relevance according to the literature: (1) the sucrose (Figure 6, blue), (2) the citrate (red), (3) the shikimate (yellow), and (4) the UTP subnet (green). The names of the subnets represent the key metabolites of each subnet. The sucrose subnet was supplied with D-fructose and D-galactose as input from the environment, while the other five input metabolites were fed into the citrate subnet. In turn, nine metabolites were exported from the sucrose subnet, five from the citrate subnet, five from the shikimate subnet, and three from the UTP subnet.
3.1.1. The Sucrose Subnet
The sucrose subnet consists of 44 metabolites and 103 reactions (Figure 7). The subnet contains seven additional input reactions and 22 additional output reactions to generate a sufficient outlet of products. The metabolites involved in these reactions link the sucrose network with the other parts of the PN. 18 output transitions were connected to sink metabolites.
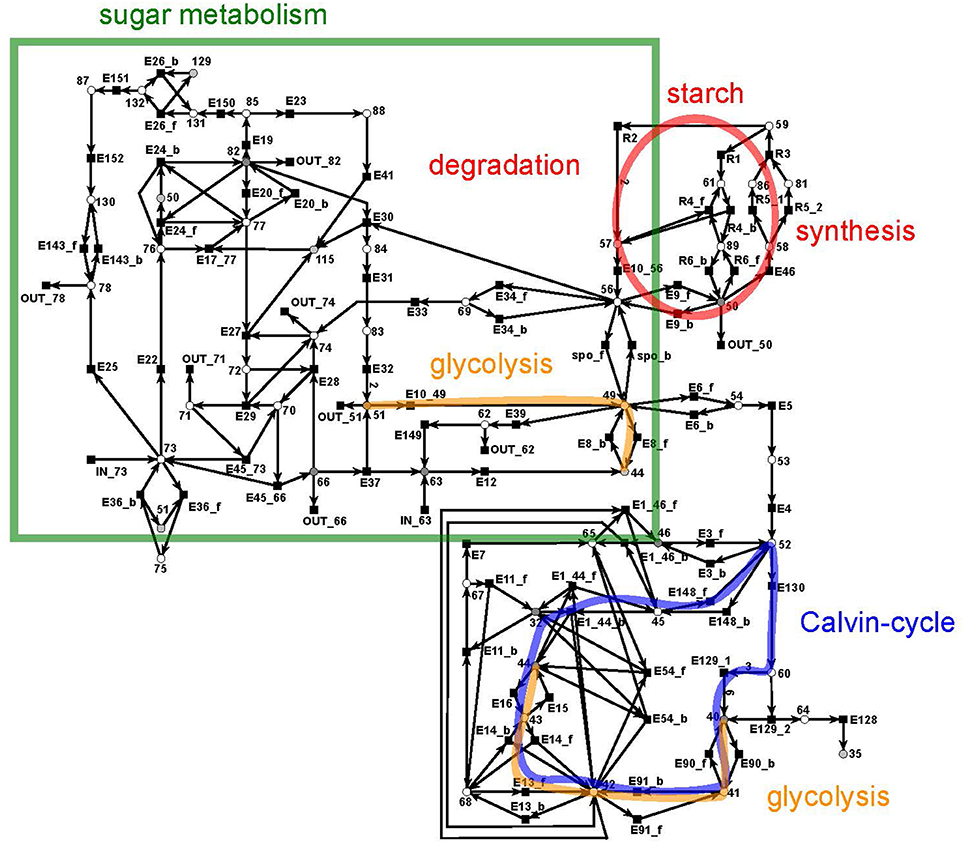
Figure 7. The PN model of the sucrose subnet adapted from Nöthen (2014). It covers the Calvin cycle (blue), part of the glycolysis (yellow), the sugar metabolism (green box), and the starch synthesis and degradation (red circle).
The sucrose subnet consists of four pathways, the Calvin cycle (Figure 7, blue), the sugar metabolism (red), the glycolysis (yellow), and the starch metabolism (green). The Calvin cycle is central for carbon fixation in plants, while the sugar metabolism accomplishes the synthesis and degradation of sucrose (metabolite 66) and UDP-glucose (metabolite 82). The glycolysis (yellow, orange) appeared to be disconnected in the layout, but the reactions of the glycolysis were combined via the logical place 44 (β-D-fructose 6-phosphate). However, only a part of the glycolysis pathway belongs to the sucrose network—the reaction cascade from D-glucose (metabolite 51) to glycerate 3-phosphate (metabolite 40). In turn, the other part of the glycolysis pathway is integrated in the citrate subnet. Thus, a transfer metabolite was required for the complementation of this cycle.
3.1.2. The Starch Metabolism
The metabolism became obvious by inspecting the synthesis and degradation of starch in detail based on Figure 7 (red). The priming, chain-addition polymerization, polymer degradation, irreversible poly-condensation, and granule formation of starch are complex enzymatic processes. The mechanisms underlying these processes are not yet fully understood for A. thaliana (Szydlowski et al., 2009). While constructing the PN (Figure 8), we did not account for the diverse structures of starch macromolecules and for the chain length distribution. Thus, we lumped the diversity of starch macromolecules to a single unique metabolite named starch (metabolite 59). This simplification was supported by a biologically intuitive view of the coarse-grained structure of the net. We adopted previously presented suggestions (Kossmann and Lloyd, 2000; Guy et al., 2008; Fettke et al., 2009) to model the starch metabolism as a pure, deadlock-free PN. To indicate deviations of reactions from the activity of single enzymes we replaced the prefix E (for enzyme) by R (for reaction) in the names of such reactions. More precisely, in Figure 9, two molecules of ADP-glucose (metabolite 58) form one molecule of starch (metabolite 59) via amylose (metabolite 86) and amylopectin (metabolite 81) (Kossmann and Lloyd, 2000). The breakdown of one unit of starch produces two units of α-D-glucose (metabolite 57) or, alternatively, via maltose (metabolite 61) only one unit of α-D-glucose and one unit of heteroglycan (metabolite 89) (Fettke et al., 2009). Heteroglycan is freely convertible to α-D-glucose 1-phosphate (metabolite 50). Also α-D-glucose can be converted via α-D-glucose 6-phosphate (metabolite 56) to α-D-glucose 1-phosphate (metabolite 50). α-D-glucose 1-phosphate is represented by a logical place (gray-filled circle). Thus, the metabolite α-D-glucose 1-phosphate can be produced and consumed by several reactions also outside the sucrose subnet. The reaction, E46, transforms α-D-glucose 1-phosphate to ADP-glucose, which can be consumed for further production of starch.
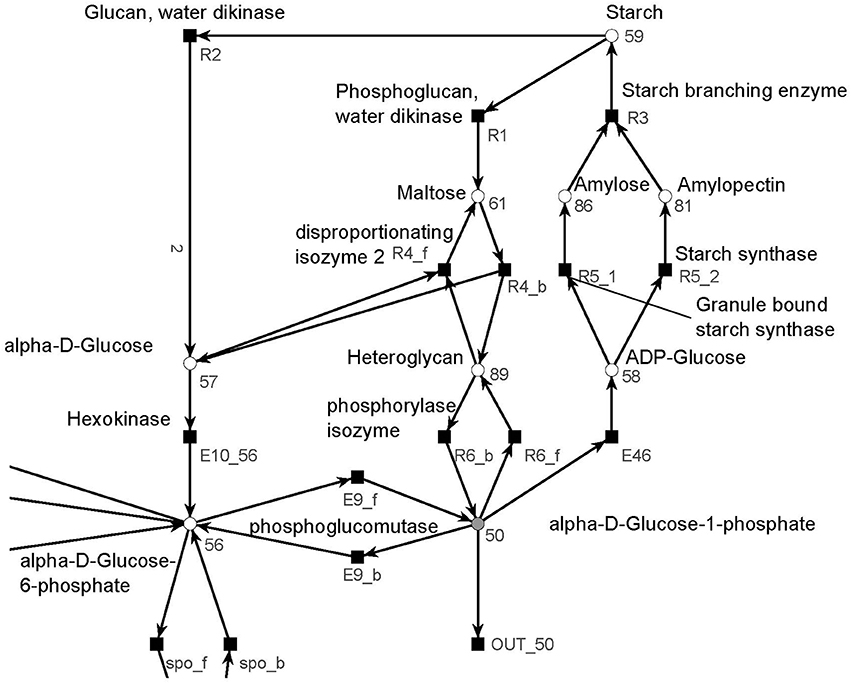
Figure 8. The PN model of the starch subnet adapted from Nöthen (2014). It covers the starch synthesis and degradation.
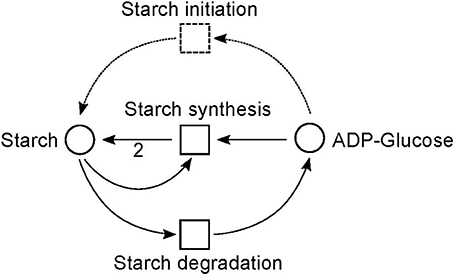
Figure 9. The simplified PN model of the initiation, synthesis, and degradation of starch adapted from Nöthen (2014). The PN is not pure, because the place Starch is a pre-place as well a post-place of the transition Starch synthesis. The starch initiation (dashed lines) was required to avoid a deadlock. In the presence of glucose, the metabolite starch is able to auto-catalyze the production of more starch until no starch is present in the system, e.g., all starch has been degraded. Without the starch initiation, the production of starch would be blocked, producing a deadlock.
Due to the polymer character of the starch molecule, it was difficult to model its synthesis and degradation in detail. There is literature (Kossmann and Lloyd, 2000; Lu and Sharkey, 2006; Guy et al., 2008; Reiter, 2008; Fettke et al., 2009) available that describes the reaction cascade of the starch metabolism without special focus on the polymeric structure of starch. We put special effort into the curation of the thermodynamic feasibility of the starch pathway by an adaption of the stoichiometric parameters in the cascade in such a way that no substance was created or consumed (comparable to the procedure in Poolman et al., 2009). This thermodynamic feasibility was supported by the two cyclic TIs, one for each degradation pathway, which together covered the starch metabolism.
3.1.3. The Citrate Subnet
The citrate subnet consists of 43 metabolites and 79 reactions (Figure 10). The subnet contains two additional input and five additional output reactions that connect the citrate network with the other parts of the PN.
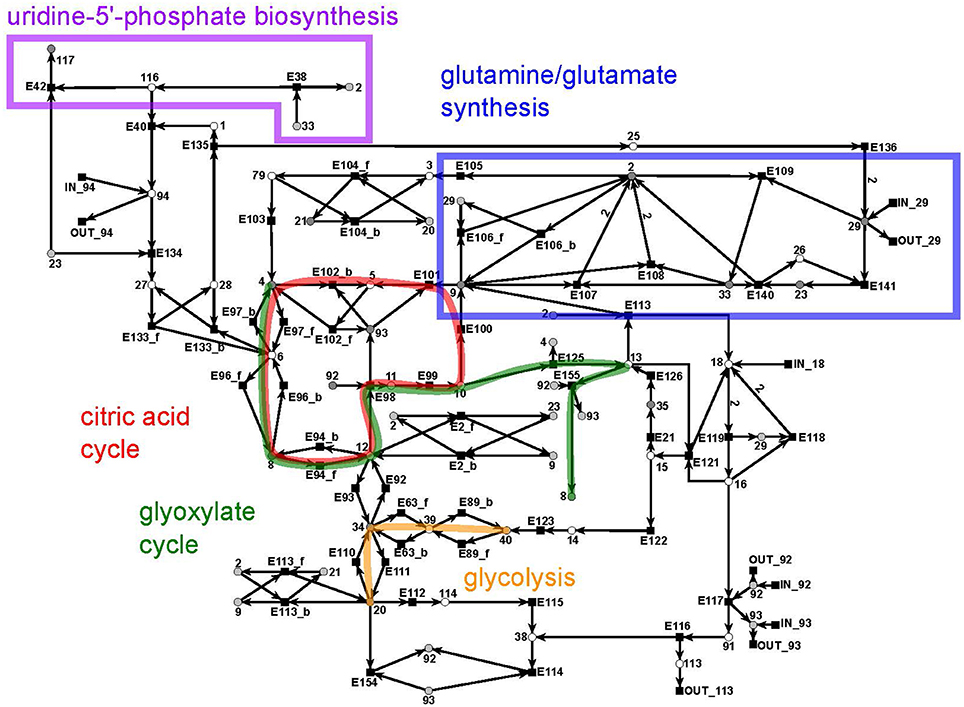
Figure 10. The PN model of the citrate subnet adapted from Nöthen (2014). It covers the citric acid cycle (red), the glyoxylate cycle (green), part of the biosynthesis of uridine 5′-phosphate (purple box), the biosynthesis of glutamate and glutamine (blue box), and part of the glycolysis (yellow).
This subnet specifies the biosynthesis of glutamate (metabolite 2) and glutamine (metabolite 33) (blue), the citric acid cycle (red), and the glyoxylate cycle (green), part of the biosynthesis of uridine 5′-phosphate (violet), and completes the pathway of glycolysis (yellow). Glutamine and glutamate play a central role in the transfer of ammonia (metabolite 29). The citric acid cycle is part of the energy metabolism in aerobic species. The glyoxylate cycle (glyoxylate: metabolite 13) plays a major role in the anabolic synthesis of carbohydrates. The reactions of glycolysis complement the part of the cycle integrated in the sucrose subnet by converting glycerate 3-phosphate (metabolite 40) to pyruvate (metabolite 20) (yellow). The biosynthesis of uridine 5′-phosphate (uridine mono phosphate, UMP) is only partially present in this subnet and was completed in the UTP subnet (purple).
3.1.4. The Shikimate Subnet
The shikimate pathway (Figure 11) consists of 39 metabolites and 46 reactions. It indicates the synthesis of shikimate (metabolite 102: red) as precursor for the synthesis of aromatic amino acids, e.g., phenylalanine (metabolite 109: green) (Herrmann and Weaver, 1999). In turn, shikimate and phenylalanine are precursors for phenylpropanoids (blue) which, in turn, are precursors for the lignin (metabolites 30a and 30b) synthesis. The synthesis of lignin is e.g., explicitly included as a part of the biomass function in a genome scale flux balance model of maize (Zea mays) (Saha et al., 2011). We divide lignin into two compounds, 30a and 30b, representing guaiacyl lignin and syringyl lignin, respectively. Guaiacyl lignin is believed to be synthesized from coniferyl alcohol (metabolite 19) while syringyl lignin is produced from sinapyl alcohol (metabolite 48) (Humphreys and Chapple, 2002).
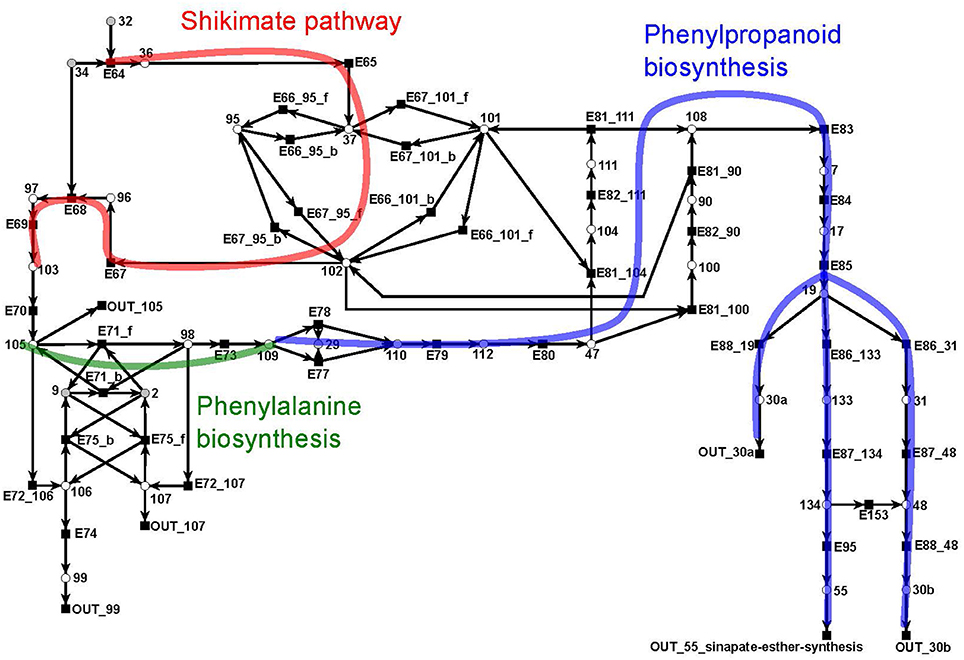
Figure 11. The PN model of the shikimate subnet adapted from Nöthen (2014). It covers the shikimate pathway (red), the biosynthesis of phenylalanine (green), and of phenylpropanoid (blue).
3.1.5. The UTP Subnet
The UTP subnet is depicted in (Figure 12, red). It consists of 25 metabolites and 29 reactions. The connection with the other parts of the PN was achieved by three additional output reactions (Table 14 in the Supplementary file Table 1.pdf).
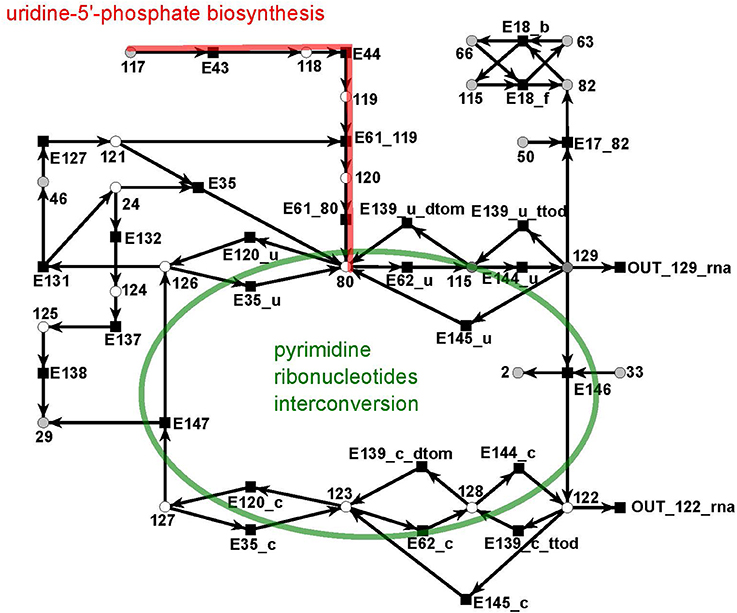
Figure 12. The PN model of the UTP subnet adapted from Nöthen (2014). It covers part of the synthesis of uridine 5′-phosphate, UMP, (red), and the interconversion of the pyrimidine ribonucleotides. The interconversion are the reversible transformation of UMPP, UDP, and UTP and CMP, CDP, and CTP into each other. Additionally, it contains the CTP synthesis CTP from UTP and degradation of CMP to UMP.
The subnet contains the completion of biosynthesis of UMP (Figure 12, red) that is initiated within the citrate subnet by consuming N-carbamoyl-L-phosphate (metabolite 117) to produce UMP (metabolite 80). The second major part of this subnet describes the interconversion of the pyrimidine ribonucleotides, i.e., the connection between UMP, UDP, and UTP and between CMP, CDP, and CTP, and the synthesis of CTP from UTP and the degradation of CMP to UMP (green).
3.2. The Reduced Petri Net Model
3.2.1. Removal of Metabolites
To limit the network complexity as far as possible, all small metabolites like water and carbon dioxide, catalytic substances like ions, and cofactors like NAD/NADH and the energy-providing compounds like ATP were omitted from the model. Hereby, the model was reduced by 19 metabolites and 274 edges. Studies have proven that hubs are less conserved than compounds which connect different modules (Guimera and Amaral, 2005), suggesting that a model without cofactors and small metabolites is more suitable than a model which lacks essential connections between the different biological modules. A complexity reduction by removing such smaller metabolites was preferred to a restriction of the overall network size. Several of the small metabolites, namely CoA and UDP, remained in the network due to suggestions of our coworkers (Schleiff, 2010, personal communication). To prove that the reduced network was still a real-world network, we compared the distributions of vertex degrees of the reduced network with that of the network based on the AraCyc database. After excluding all metabolites with a vertex degree greater than 74, we could show that the distribution of vertex degrees of the AraCyc network was very similar to the one of the PN model. This indicated that the reduced PN model was also a real-world model.
We applied ITPs (Invariant Transition Pairs) and CTPs (Common Transition Pairs) using an extended version of a previously published algorithm (Ackermann et al., 2012; Nöthen, 2014). We searched first for CTPs and then for ITPs in a parallel running implementation. If any of these structures were encountered, the net was reduced and followed by a search for a CTP. We considered the following cases: (1) there are CTPs that as well form ITPs. This is the case, if a place is connected to the rest of the network only via an ITP-forming transition pair. Then, the algorithm reduces the ITP first. (2) A special case of an ITP is given, if a certain metabolite is connected to an input and output transition. The PN model contains several external metabolites which fulfill these special ITP rules.
86 CTPs, 62 ITPs, and 2 parallel reduction steps were performed. All steps were listed in the supplementary file Table 2.pdf in the Tables 1–9. The number of metabolites was reduced from 134 to 60, the number of reactions from 243 to 131, and the number of edges from 572 to 329.
Figure 6 depicts in a schematic way the original PN model (on the top) and the model after reduction (on the bottom). We exemplarily demonstrated the interpretation of the results of the reduction procedure, choosing a place following from a series of ITP reductions. The place represented a conglomeration of substances involved in the Calvin cycle, the glycolysis, and the citric acid cycle. It combined the compounds succinate (metabolite 4), fumarate (metabolite 6), malate (metabolite 8), oxalacetate(metabolite 12), pyruvate (metabolite 20), phosphoenolpyruvate (metabolite 34), glycerate 2-phosphate (metabolite 39), glycerate 3-phosphate (metabolite 40), glycerate 1,3-bisphosphate (metabolite 41), glyceraldehyde 3-phosphate (metabolite 42), and dihydroxyacetone phosphate (metabolite 68) into the same place. These reduction steps additionally removed the transitions E13, E14, E15, E90, and E91, while the transitions E11 and E14 remained in the reduced PN. The first four metabolites were part of the citric acid cycle. Out of the remaining seven metabolites which were part of the glycolysis, there were five, namely glycerate 2-phosphate (metabolite 39), glycerate 3-phosphate (metabolite 40), glycerate 1,3-bisphosphate (metabolite 41), glyceraldehyde 3-phosphate (metabolite 42), and dihydroxyacetone phosphate (metabolite 68), which were also part of the Calvin cycle.
In plastids of A. thaliana, the glycolysis and the Calvin cycle shared several enzymes (Peltier et al., 2006): phosphogylcerate kinase (transition E90, reversible), glyceraldehyde 3-phosphatedehydrogenase (transition E91, reversible), triosephosphate isomerase (transition E13, reversible), seduheptulosebisphosphate aldolase (transitions E11 and E14, both reversible), and fructose bisphosphatase (transition E15, reversible by transition E16). The sharing of these reactions suggested that the participating compounds were shared as well. In this case, the shared metabolites would be: glycerate 3-phosphate (metabolite 40), glycerate 1,3-bisphosphate (metabolite 41), glyceraldehyde 3-phosphate (metabolite 42), D-fructose 1,6-bisphosphate (metabolite 43), D-fructose 6-phosphate (metabolite 44), and dihydroxyacetone phosphate (metabolite 68) besides D-fructose 1,6-bisphosphate (metabolite 43) and D-fructose 6-phosphate (metabolite 44). The absence of D-fructose 1,6-bisphosphate (metabolite 43) and D-fructose 6-phosphate (metabolite 44) in the reduced place was caused by restrictions in the reduction process. A merging of places by an ITP reduction was only allowed if all involved edges had a weight of 1. This was not the case for the reactions connecting metabolite 43 with 42 and 68 (transition E14). The merging of parts of the citric acid cycle, namely succinate (metabolite 4), fumarate (metabolite 6), malate (metabolite 8), and oxalacetate (metabolite 12), was inspired by the reversible reactions between the compounds, which was the main idea behind an ITP reduction. The combination of this part of the citric acid cycle and the last steps of the glycolysis, producing phosphoenolpyruvate and pyruvate, was induced by the synthesis pathway of oxalacetate from phosphoenolpyruvate (Dey and Harborne, 1997). Considering these biological aspects, the reduction process made sense.
Additionally, parallel structures of connections between two metabolites were merged as described in other PN analyses (Murata, 1989; Reddy et al., 1993). After 86 CTP and 62 ITP reduction steps, the resulting reduced network consists of 60 metabolites (45% of originally 134), 131 reactions (54% of originally 243), and 329 edges (58% of originally 572).
3.3. Transition Invariant Analysis
The problem of enumerating all minimal TIs can not be solved in polynomial time. The overall complexity of this task is still not clear, and the decision problem, whether two transitions occur in the same TI, is NP-complete (Acuña et al., 2010).
The complete model was too complex for the computation of all the TIs. Several weeks of computation time on an AMD OpteronTM 2.2 GHz with 32 GB RAM did not lead to any result. Therefore, we decomposed the PN into four biologically motivated subnetworks, which form two modules, the sucrose module, combining the sucrose and the UTP subnetwork, and the citrate module, combining the citrate and the shikimate subnet. Additionally, we reduced the complete network, preserving the CTI property. We computed the complete set of TIs for the two modules and for the reduced network. All these networks were covered by TIs. Table 1 compiles the number of TIs for the two modules, the reduced network, and for all TI types.
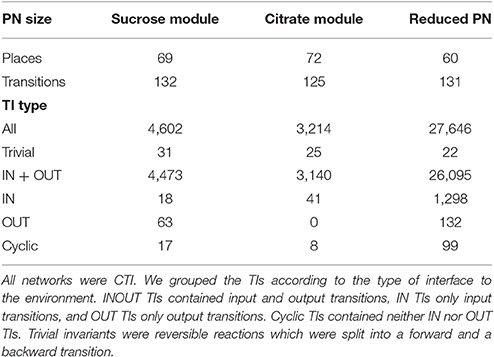
Table 1. The numbers of places, transitions, and TIs in the modules and in the reduced network.
The explanations for some of the different types of invariants were intuitive. In a metabolic PN, which usually contains reversible reactions, it was not possible to avoid trivial TIs. The condition of minimality ensures that no other invariant contains both of the transitions of the reversible reaction. TIs mainly represent pathways through the network, a succession of consecutive biochemical reactions, transforming given educts (metabolites produced by input transitions) to the corresponding products (metabolites consumed by output transitions). All TIs, containing OUT only, which exist in the sucrose module, could be explained easily.
We could show that a mapping of reduced invariants to invariants of the unreduced net will be possible.
The PN model did not include secondary metabolites, such that carbon dioxide was not modeled. In the Calvin cycle (Bassham et al., 1954; Calvin, 1956), carbon dioxide is bound to ribulose-1,5-biphosphate by ribulose-1,5-biphosphate carboxylase oxygenase (Parry et al., 2003; Raines, 2003; Roy and Andrews, 2004). This process produces two trioses from one pentose, thereby raising the number of carbons in the system. Due to deleted carbon dioxide, we modeled the Calvin cycle without an explicit input transition for carbon dioxide. All OUT TIs contained one of the two transitions modeled rubisco (E129_1 and E129_2) and thereby an implicit IN TI of carbon dioxide. This implicit modeling reduced all OUT TIs to INOUT pathways. Transition E129_1 modeled the carboxylation reaction (Calvin cycle) of rubisco, and transition E129_2 the oxygenation reaction (photorespiration) (Eckardt, 2005). All other modules did not possess OUT TIs. The OUT TIs of the reduced model were comparable to those of the sucrose subnet.
3.3.1. An Example for a Cyclic Transition Invariant
All cyclic TIs were as well artifacts, resulting from missing metabolites and cofactors. Figure 13 illustrates an example of a cyclic TI. The modeled starch metabolism requires ATP and α-D-glucose 1-phosphate (metabolite 50) to form ADP-Glucose (metabolite 58) and pyrophosphate by transition E46 (Kossmann and Lloyd, 2000; Streb and Zeeman, 2012). ATP and pyrophosphate were not modeled, otherwise this reaction would had required ATP and produced pyrophosphate. This led to two options, (1) ATP and pyrophosphate were directly provided and removed, and (2) ATP and pyrophosphate were produced and consumed throughout the network. Both cases resulted directly or indirectly in the involvement of input and output transitions leading to an INOUT TI.
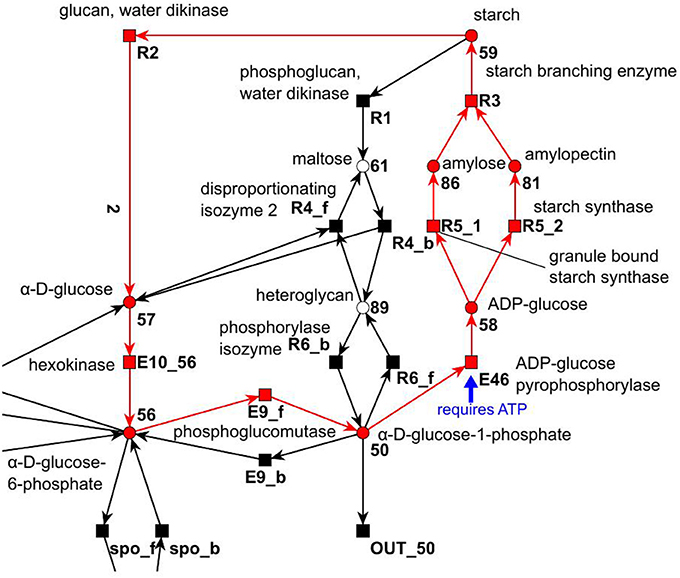
Figure 13. Example of a cyclic TI that describes part of the starch synthesis and degradation. The cycle evolves out of a silent input transition. The underlying reaction of transition E46 produces ADP-glucose and pyrophosphate from ATP and α-D-glucose 1-phosphate (Streb and Zeeman, 2012).
IN TIs were as well caused by substances, which were not modeled. In the sucrose subnet, all IN TIs were artifacts of the modeling of the pentose phosphate pathway. Transition E4 produces a carbon dioxide (Kruger and von Schaewen, 2003) in the pentose phosphate pathway from metabolite 53 (6-phospho gluconate). As carbon dioxide was not modeled, this had the function of a hidden export. This behavior corresponded to the OUT TIs, which were artifacts of the missing modeling of carbon dioxide as well.
3.3.2. Exemplary Inspection of a Single Transition Invariant
Here, we want to illustrate an exemplary inspection of a single TI of the reduced model, consisting of twelve reactions. As the reduction process merges reactions, the number of traversed reactions in the original PN could be higher. Table 2 illustrated the considered exemplary TI and listed the syntheses of substrates a reaction was involved in. Several biological pathways could be combined to form a single TI (Koch et al., 2005). The considered TI produced UTP for the synthesis of RNA from D-fructose (metabolite 63) and ammonia (metabolite 29). To biologically verify this pathway combination, we had to demonstrate that each part of the TI could be biologically explained. The product of the TI was two UTPs, which was removed from the network by the transition OUT_129_rna. The used compounds for this product were three D-fructoses provided by IN_63 and four ammonia provided by IN_29. In plants, one UMP was synthesized from four different compounds: one bicarbonate, one glutamine, one 5-phosphoribosyl 1-pyrophosphate, and one L-aspartate (Zrenner et al., 2006). UTP was then synthesized from UMP by adding phosphor groups. The metabolite bicarbonate was not modeled in the PN. It was demonstrated in the following that each of the three remaining modeled compounds was synthesized and used in a biologically explainable way. Two L-aspartate were synthesized by firing of transition E2_f (aspartate aminotransferase) two times. The substrates of this reaction were oxalacetate and glutamate and the products L-aspartate and α-ketoglutarate (Wilkie and Warren, 1998; Graindorge et al., 2010). In the reduction process, several pathways, leading to oxalacetate, were affected, resulting in a merged metabolite, which represents various compounds. The affected pathways were the glycerate 3-phosphate synthesis, the oxalacetate synthesis, and the glycolysis.

Table 2. Exemplary TI in the reduced model.
5-phosphoribosyl 1-pyrophosphate can be synthesized from D-fructose, via D-fructose 6-phosphate and D-ribose 5-phosphate (Dey and Harborne, 1997; Buchanan et al., 2000; Berg et al., 2002; Zrenner et al., 2006). This pathway structure was represented in the TI by the reactions E12 (fructokinase, synthesis of D-fructose 6-phosphate), ctp(E5 + E4) (6-phosphogluconolactonase and phosphogluconate dehydrogenase, synthesis of D-ribose 5-phosphate), and E127 (5-phosphoribosyl 1-pyrophosphatesynthase, synthesis of 5-phosphoribosyl 1-pyrophosphate). Please note that a number of reactions in the overall synthesis of 5-phosphoribosyl 1-pyrophosphate was affected by the reduction process, and the precursor of transition E127 combined several compounds. The remaining reactions, E106_f and E109, were required to regenerate two glutamate and two glutamine, thereby using four ammonia. Glutamine is an important part of the nitrogen metabolism of conifers (Cánovas et al., 2007), and α-ketoglutarate is a known nitrogen transporter in plants (Temple et al., 1998). As glutamate is convertible in both, glutamine and α-ketoglutarate (Aubert et al., 2001; Forde and Lea, 2007), it seems to share these nitrogen-transportation duties. In the TI, the regeneration of glutamate and glutamine, respectively, from α-ketoglutarate and glutamate and in the process, consuming ammonia, resembled this biological interpretation, see Figures 14, 15. These findings proved this TI to be a combination of parts of the nitrogen economy, the oxalacetate synthesis, the synthesis of 5-phosphoribosyl 1-pyrophosphate, and the synthesis of pyrimidines. Altogether, these were the important steps to synthesize UTP (Zrenner et al., 2006). Each part of the inspected TI could be biologically interpreted, which proved the possibility of the network to model these syntheses in a steady-state sustaining manner.
Figure 14. Overview of an examplary TI (pink) of the reduced PN that expresses a combination of parts of the nitrogen economy, the oxalacetate synthesis, the synthesis of 5-phosphoribosyl 1-pyrophosphate, and the synthesis of pyrimidines.
Figure 15. The top right part of an examplary TI (pink) of the reduced PN, see Figure 14.
3.4. MCT-Sets
MCT-sets represent the smallest biologically meaningful entities in which a network can be decomposed (Sackmann et al., 2006). We give several examples of MCT-sets of the reduced PN model and their biological counterparts. This additionally provides a possibility of comparison between the biologically motivated subnets and the reduced network.
3.4.1. MCTS 1 and the Sucrose Module
This MCTS consists of the transitions Import117fromB/fromCit, E43, E44, E61_119, and E61_80. All these transitions formed the reaction chain that leads to uridine 5′-phosphate (Zrenner et al., 2006). The import transition added carbamoyl aspartate to the modules, which was produced by transition E42 in the citrate module. De novo synthesis of uridine 5′-phosphate is highly energy consuming and in some tissues partly replaced by the recycling of already built compounds. Nevertheless, de novo synthesis of UMP is still needed to replenish the nucleotide stock (Moffatt and Ashihara, 2002). In the reduced network, this complete synthesis pathway was merged into one transition, called ctp(ctp(E42 + E43) + ctp(E44 + ctp(E61_119 + E61_80))). In the recursive reduction process, all of the reactions, forming the de novo synthesis of uridine 5–phosphate, fulfilled the conditions necessary for a CTP reduction. As transition E42 was part of the citrate module it could not be part of this MCTS. Nevertheless, the possible CTP reduction of the complete reaction chain, including E42, suggested a strong connection between the reactions of the uridine 5′ phosphate de novo synthesis and could indicate an MCTS in the PN, covering all of them.
3.4.2. MCTS 2 and the Citrate Module
MCTS 2 consists of the transitions E103, E104_f, E105, and E113_f. This configuration occurred in the citrate module of the biologically driven decomposition as well as in the reduced network. Compared to the decompositions and the original network, the connections of the transitions have changed during the reduction process. In the subnets, the transitions form the reactions:
•
•
•
•
with 2 = glutamate, 3 = γ-aminobutyric acid (GABA), 4 = succinate, 9 = α-ketoglutarate, 20 = pyruvate, 21 = phosphoenolpyruvate, and 79 = succinate semialdehyde. In the reduced network, the metabolites 4 and 20 were combined by an ITP reduction, forming a new place. The connections of this new place were the combined connections of the merged original places, i.e., the new place connected to E103 (as metabolite 4), E104_f (as metabolite 20), and E113_f (as metabolite 20) and led to the reduced reaction system
•
•
•
•
with 2 = glutamate, 3 = γ-aminobutyric acid (GABA), 9 = α-ketoglutarate, 21 = phosphoenolpyruvate, 79 = succinate semialdehyde, and X = the merged place (4 + 20). While the pathways for these transitions mentioned in the AraCyc database are glutamate degradation (E10, E104_f, and E105), and alanine degradation (E113f), other literature declare them as the GABA shunt (Bouché and Fromm, 2004). Finding an MCTS of these reactions strongly suggested a close interaction between them, indicating a possible network behavior consistent with the literature, because GABA is sufficient as sole nitrogen source for effective growth of A. thaliana (Breitkreuz et al., 1999), and the GABA shunt seems to play an important role in the reaction to oxidative stress (Bouché et al., 2003; Bouché and Fromm, 2004).
3.4.3. MCTS 3 and the Citrate Module
This MCTS constitutes of the transitions E40, E133_f, E134, E135, and E136 in the citrate module. The transitions E40, E133_f, E134, and E135 formed the urea cycle (Tischner et al., 2007), and transition E136 modeled the degradation of urea (metabolite 25, Sirko and Brodzik, 2000). This MCTS is a collection of transitions forming and degrading urea. In the reduced network, two CTP reductions took place in this cycle. Initially, E135 and E40 were condensed to ctp(E135 + E40), which was further flattened to ctp(ctp(E135 + E40) + E136) by the inclusion of E136. Together with E134 and E133_f, this new reduced transition formed an MCTS in the reduced network. Urea is an important nitrogen source for plants (Polacco and Holland, 1993) and mainly believed to be predominantly synthesized by the urea cycle (Reinbothe and Mothes, 1962). This MCTS suggested the importance of the urea metabolism in the PN model of the core metabolism of A. thaliana.
4. Conclusion
In this paper, we presented a new semi-quantitative Petri net model of the metabolism of A. thaliana based on recent literature. Similar to a network of barley (Grafahrend-Belau et al., 2009), the model was manually developed and curated. To ensure the model's consistency, we used PN-based reduction and biologically motivated as well as graph-based decomposition and analysis techniques.
The final size of the complete PN model was 134 metabolites, 243 reactions, and 572 edges. The complexity of this model did not allow to compute all its transition invariants, which form the base for further analysis. To get a manageable set of TIs, we followed two strategies. First, we divided the model into four biology-driven subnetworks, the sucrose, the citrate, the UTP, and the shikimate subnetwork, and defined two modules, each consisting of two subnetworks. The sucrose module covers the sucrose and the UTP subnetwork, while the citrate module compiles the citrate and the shikimate subnetwork. The second strategy followed a graph-theoretic reduction of the model, applying common transition pairs and invariant transition pairs. Through the reduction, the network size decreased by ~50%. For all three subnetworks, we computed the TIs, easily showing that the subnetworks were CTI. To handle the amount of 27,646 TIs for the reduced model, we classified the TIs into trivial, INOUT, IN, OUT, and cyclic TIs. Because we could not discuss all the 27,646 TIs, we considered exemplarily one cyclic TI that describes a part of the starch synthesis and degradation and one TI that expresses a combination of parts of the nitrogen economy, the oxalacetate synthesis, the synthesis of 5-phosphoribosyl 1-pyrophosphate, and the synthesis of pyrimidines.
We demonstrated that the carbon fixation phase and the regeneration phase of the Calvin cycle strongly depends on each other. Additionally, potential steady-state pathways exist, which provided the fixed carbon to nearly all parts of the network, especially to the citric acid cycle. Moreover, the analysis showed a close cooperation of important metabolic pathways, e.g., the de novo synthesis of uridine-5–monophosphate, the γ-aminobutyric acid shunt, and the urea cycle.
The presented model provides a solid basis for further refinement, for example, by concentrations, gene expression data, and kinetic data for a quantitative analysis.
Author Contributions
ES and IK initiated and supervised the project. JN has performed the network construction and analysis. All authors wrote the manuscript.
Funding
The project received funding from the Volkswagenstiftung to ES, from the LOEWE program Ubiquitin Networks (Ub-Net) of the State of Hesse (Germany) to IK and from the DFG Excellence Cluster CEF-Macromolecular Complexes to ES and IK.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The reviewer GR and handling editor declared their shared affiliation, and the handling editor states that the process nevertheless met the standards of a fair and objective review.
Acknowledgments
We would like to thank Oliver Mirus and Stefan Simm for guiding during the initial phase of the project and Jens Einloft for many fruitful discussions.
Supplementary Material
The Supplementary Material for this article can be found online at: http://journal.frontiersin.org/article/10.3389/fgene.2017.00085/full#supplementary-material
References
Ackermann, J., Einloft, J., Nöthen, J., and Koch, I. (2012). Reduction techniques for network validation in systems biology. J. Theor. Biol. 315, 71–80. doi: 10.1016/j.jtbi.2012.08.042
Ackermann, J., and Koch, I. (2011). “Network decomposition in biology–computational challenges,” in Proceedings of the Comference Models of Computation in Context. Computability in Europe, vol. 7, eds H. Ganchev, B. Löwe, D. Normann, I. Soskov, and M. Soskova (Sofia: St. Kliment Ohridski University Press), 39–48.
Acuña, V., Marchetti-Spaccamela, A., Sagot, M.-F., and Stougie, L. (2010). A note on the complexity of finding and enumerating elementary modes. Biosystems 99, 210–214. doi: 10.1016/j.biosystems.2009.11.004
Alonso, J., Stepanova, A., Leisse, T., Kim, C., Chen, H., Shinn, P., et al. (2003). Genome-wide insertional mutagenesis of Arabidopsis thaliana. Science 301, 653–657. doi: 10.1126/science.1086391
Arabidopsis-Genome-Initiative (2000). Analysis of the genome sequence of the flowering plant Arabidopsis thaliana. Nature 408, 796–815. doi: 10.1038/35048692
Arnborg, S., Courcelle, B., Proskurowski, A., and Seese, D. (1993). An algebraic theory of graph reduction. J. ACM 40, 1134–1164. doi: 10.1145/174147.169807
Aubert, S., Bligny, R., Douce, R., Gout, E., Ratcliffe, R., and Roberts, J. (2001). Contribution of glutamate dehydrogenase to mitochondrial glutamate metabolism studied by 13C and 31P nuclear magnetic resonance. J. Exp. Bot. 52, 37–45. doi: 10.1093/jxb/52.354.37
Balazki, P., Lindauer, K., Einloft, J., Ackermann, J., and Koch, I. (2015). MonaLisa for stochastic simulations of Petri net models of biochemical systems. BMC Bioinformatics 16:215. doi: 10.1186/s12859-015-0596-y
Bassham, J. A., Benson, A. A., Kay, L. D., Harris, A. Z., Wilson, A. T., and Calvin, M. (1954). The path of carbon in photosynthesis. XXI. The cyclic regeneration of carbon dioxide acceptor1. J. Amer. Chem. Soc. 76, 1760–1770. doi: 10.1021/ja01636a012
Baumgarten, B. (1996). Petri Nets Basics and Applications (in German), 2nd Edn. Heidelberg; Berlin: Spektrum Akademischer Verlag.
Berg, J. M., Tymoczko, J. L., and Stryer, L. (2002). Biochemistry, 5th Edn. New York, NY: W. H. Freeman.
Berthelot, G. (1987). “Transformations and decompositions of nets,” in Petri Nets: Central Models and Their Properties, Advances in Petri Nets, Lecture Notes in Computer Science, eds W. Brauer, W. Reisig, and G. Rozenberg (Berlin; Heidelberg: Springer), 359–376.
Billington, J., and Reisig, W. (1996). Application and Theory of Petri Nets. vol. 1091. Lecture notes Computer Science. Berlin; Heidelberg: Springer.
Bortfeldt, R. H., Schuster, S., and Koch, I. (2011). Exhaustive analysis of the modular structure of the spliceosomal assembly network: a Petri net approach. Stud. Health Technol. Inform. 162, 244–278.
Bouché, N., Fait, A., Bouchez, D., Møller, S. G., and Fromm, H. (2003). Mitochondrial succinic-semialdehyde dehydrogenase of the γ-aminobutyrate shunt is required to restrict levels of reactive oxygen intermediates in plants. Proc. Natl. Acad. Sci. U.S.A. 100, 6843–6848. doi: 10.1073/pnas.1037532100
Breitkreuz, K. E., Shelp, B. J., Fischer, W. N., Schwacke, R., and Rentsch, D. (1999). Identification and characterization of GABA, proline and quaternary ammonium compound transporters from Arabidopsis thaliana. FEBS Lett. 450, 280–284. doi: 10.1016/S0014-5793(99)00516-5
Bruex, A., Kainkaryam, R. M., Wieckowski, Y., Kang, Y. H., Bernhardt, C., Xia, Y., et al. (2012). A gene regulatory network for root epidermis cell differentiation in Arabidopsis. PLoS Genet. 8:e1002446. doi: 10.1371/journal.pgen.1002446
Buchanan, B. B., Gruissem, W., and Jones, R. L. (2000). Biochemistry & Molecular Biology of Plants. Rockville, MD: American Society of Plant Physiologists.
Büchel, F., Rodriguez, N., Swainston, N., Wrzodek, C., Czauderna, T., Keller, K., et al. (2013). Path2Models: large-scale generation of computational models from biochemical pathway maps. BMC Syst. Biol. 7:116. doi: 10.1186/1752-0509-7-116
Calvin, M. (1956). The photosynthetic carbon cycle. J. Chem. Soc. (Resumed) 1895–1915. doi: 10.1039/jr9560001895
Cánovas, F. M., Avila, C., Cantón, F. R., Cañas, R. A., and de la Torre, F. (2007). Ammonium assimilation and amino acid metabolism in conifers. J. Exp. Bot. 58, 2307–2318. doi: 10.1093/jxb/erm051
Chalot, M., Blaudez, D., and Brun, A. (2006). Ammonia: a candidate for nitrogen transfer at the mycorrhizal interface. Trends Plant Sci. 11, 263–266. doi: 10.1016/j.tplants.2006.04.005
de Oliveira Dal'Molin, C. G., Quek, L.-E., Palfreyman, R. W., Brumbley, S. M., and Nielsen, L. K. (2010). AraGEM, a genome-scale reconstruction of the primary metabolic network in Arabidopsis. Plant Physiol. 152, 579–589. doi: 10.1104/pp.109.148817
Dersch, L. M., and Beckers, V. W. C. (2016). Green pathways: metabolic network analysis of plant systems. Metab. Eng. 34, 1–24. doi: 10.1016/j.ymben.2015.12.001
Eckardt, N. A. (2005). Photorespiration revisited. Plant Cell Online 17, 2139–2141. doi: 10.1105/tpc.105.035873
Einloft, J., Ackermann, J., Nöthen, J., and Koch, I. (2013). MonaLisa - visualization and analysis of functional modules in biochemical networks. Bioinformatics 29, 1469–1470. doi: 10.1093/bioinformatics/btt165
Fettke, J., Hejazi, M., Smirnova, J., Höchel, E., Stage, M., and Steup, M. (2009). Eukaryotic starch degradation: integration of plastidial and cytosolic pathways. J. Exp. Bot. 60, 2907–2922. doi: 10.1093/jxb/erp054
Forde, B. G., and Lea, P. J. (2007). Glutamate in plants: metabolism, regulation, and signalling. J. Exp. Bot. 58, 2339–2358. doi: 10.1093/jxb/erm121
Fulda, M., Shockey, J., Werber, M., Wolter, F. P., and Heinz, E. (2002). Two long-chain acyl-CoA synthetases from Arabidopsis thaliana involved in peroxisomal fatty acid β-oxidation. Plant J. 32, 93–103. doi: 10.1046/j.1365-313X.2002.01405.x
Gillespie, D. (1977). Exact stochastic simulation of coupled chemical reactions. J. Phys. Chem. 81, 2340–2361. doi: 10.1021/j100540a008
Grafahrend-Belau, E., Schreiber, F., Heiner, M., Sackmann, A., Junker, B., Grunwald, S., et al. (2008). Modularization of biochemical networks based on classification of Petri net t-invariants. BMC Bioinformatics 9:90. doi: 10.1186/1471-2105-9-90
Grafahrend-Belau, E., Schreiber, F., Koschützki, D., and Junker, B. H. (2009). Flux balance analysis of barley seeds: a computational approach to study systemic properties of central metabolism. Plant Physiol. 149, 585–598. doi: 10.1104/pp.108.129635
Graindorge, M., Giustini, C., Jacomin, A. C., Kraut, A., Curien, G., and Matringe, M. (2010). Identification of a plant gene encoding glutamate/aspartate-prephenate aminotransferase: the last homeless enzyme of aromatic amino acids biosynthesis. FEBS Lett. 584, 4357–4360. doi: 10.1016/j.febslet.2010.09.037
Grunwald, S., Speer, A., Ackermann, J., and Koch, I. (2008). Petri net modelling of gene regulation of the Duchenne muscular dystrophy. Biosystems 92, 189–205. doi: 10.1016/j.biosystems.2008.02.005
Guimera, R., and Amaral, L. A. N. (2005). Functional cartography of complex metabolic networks. Nature 433, 895–900. doi: 10.1038/nature03288
Guy, C., Kaplan, F., Kopka, J., Selbig, J., and Hincha, D. K. (2008). Metabolomics of temperature stress. Physiol. Plant. 132, 220–235.
Heazlewood, J. L., Verboom, R. E., Tonti-Filippini, J., Small, I., and Millar, A. H. (2007). SUBA: the Arabidopsis subcellular database. Nucl. Acids Res. 35(Suppl 1), D213–D218. doi: 10.1093/nar/gkl863
Heiner, M., and Koch, I. (2004). “Petri net based model validation in systems biology,” in Applications and Theory of Petri Nets 2004, volume 3099 of Lecture Notes Computer Science, eds J. Cortadella and W. Reisig (Berlin; Heidelberg: Springer), 216–237.
Herrmann, K. M., and Weaver, L. M. (1999). The shikimate pathway. Ann. Rev. Plant Biol. 50, 473–503. doi: 10.1146/annurev.arplant.50.1.473
Hickman, R., Hill, C., Penfold, C. A., Breeze, E., Bowden, L., Moore, J. D., et al. (2013). A local regulatory network around three NAC transcription factors in stress responses and senescence in Arabidopsis leaves. Plant J. 75, 26–39. doi: 10.1111/tpj.12194
Humphreys, J. M., and Chapple, C. (2002). Rewriting the lignin roadmap. Curr. Opin. Plant Biol. 5, 224–229. doi: 10.1016/S1369-5266(02)00257-1
Hur, M., Campbell, A., Almeida-de Macedo, M., Li, L., Ransom, N., Jose, A., et al. (2013). A global approach to analysis and interpretation of metabolic data for plant natural product discovery. Nat. Prod. Rep. 30, 565–583. doi: 10.1039/c3np20111b
Kanehisa, M., Araki, M., Goto, S., Hattori, M., Hirakawa, M., Itoh, M., et al. (2008). KEGG for linking genomes to life and the environment. Nucl. Acids Res. 36(Suppl. 1), D480–D484. doi: 10.1093/nar/gkm882
Koch, I., and Ackermann, J. (2013). On functional module detection in metabolic networks. Metabolites 3, 673–700. doi: 10.3390/metabo3030673
Koch, I., and Heiner, M. (2008). “Petri nets,” in Analysis of Biological Networks, eds B. H. Junker and F. Schreiber (Wiley), 139–180.
Koch, I., Junker, B. H., and Heiner, M. (2005). Application of Petri net theory for modelling and validation of the sucrose breakdown pathway in the potato tuber. Bioinformatics 21, 1219–1226. doi: 10.1093/bioinformatics/bti145
Koch, I., Reisig, W., and Schreiber, F. editors (2011). Modeling in Systems Biology: The Petri Net Approach, volume 16 of Computational Biology, 1st Edn. London: Springer.
Koornneef, M., and Meinke, D. (2010). The development of Arabidopsis as a model plant. Plant J, 61, 909–921. doi: 10.1111/j.1365-313X.2009.04086.x
Kossmann, J., and Lloyd, J. (2000). Understanding and influencing starch biochemistry. Crit. Rev. Biochem. Mol. Biol. 35, 141–196. doi: 10.1080/07352680091139204
Kruger, N. J., and von Schaewen, A. (2003). The oxidative pentose phosphate pathway: structure and organisation. Curr. Opin. Plant Biol. 6, 236–246. doi: 10.1016/S1369-5266(03)00039-6
Lautenbach, K. (1973). Exakte Bedingungen der Lebendigkeit für eine Klasse von Petri-Netzen. Number 82. St. Augustin: Gesellschaft für Mathematik und Datenverarbeitung.
Lee-kwang, H., Favrel, J., and Baptiste, P. (1987). Generalized Petri net reduction method. IEEE Trans. Syst. 17, 297–303. doi: 10.1109/tsmc.1987.4309041
Linka, M., and Weber, A. P. (2005). Shuffling ammonia between mitochondria and plastids during photorespiration. Trends Plant Sci. 10, 461–465. doi: 10.1016/j.tplants.2005.08.002
Lu, Y., and Sharkey, T. (2006). The importance of maltose in transitory starch breakdown. Plant Cell Environ. 29, 353–366. doi: 10.1111/j.1365-3040.2005.01480.x
Lucas, M. D., and Brady, S. M. (2013). Gene regulatory networks in the Arabidopsis root. Curr. Opin. Plant Biol. 16, 50–55. doi: 10.1016/j.pbi.2012.10.007
Lunn, J. (2007). Compartmentation in plant metabolism. J. Exp. Bot. 58, 35–47. doi: 10.1093/jxb/erl134
Masakapalli, S. K., Le Lay, P., Huddleston, J. E., Pollock, N. L., Kruger, N. J., and Ratcliffe, R. G. (2010). Subcellular flux analysis of central metabolism in a heterotrophic Arabidopsis cell suspension using steady-state stable isotope labeling. Plant Physiol. 152, 602–619. doi: 10.1104/pp.109.151316
Matsuno, H., Doi, A., Nagasaki, M., and Miyano, S. (2000). “Hybrid Petri net representation of gene regulatory network,” in Pacific Symposium Biocomputing, vol. 87 (Singapore: World Scientific Press), 338–349.
Meinke, D., Cherry, J., Dean, C., Rounsley, S., and Koornneef, M. (1998). Arabidopsis thaliana: a model plant for genome analysis. Science 282, 662–665. doi: 10.1126/science.282.5389.662
Mintz-Oron, S., Meir, S., Malitsky, S., Ruppin, E., Aharoni, A., and Shlomi, T. (2012). Reconstruction of Arabidopsis metabolic network models accounting for subcellular compartmentalization and tissue-specificity. Proc. Natl. Acad. Sci. U.S.A. 109, 339–344. doi: 10.1073/pnas.1100358109
Moffatt, B. A., and Ashihara, H. (2002). Purine and pyrimidine nucleotide synthesis and metabolism. Arabidopsis Book/Amer. Soc. Plant Biol. 1:e0018. doi: 10.1199/tab.0018
Mueller, L. A., Zhang, P., and Rhee, S. Y. (2003). AraCyc: a biochemical pathway database for Arabidopsis. Plant Physiol. 132, 453–460. doi: 10.1104/pp.102.017236
Murata, T. (1989). Petri nets: properties, analysis and applications. Proc. IEEE 77, 541–580. doi: 10.1109/5.24143
Nöthen, J. (2009). Metabolische Netzwerke in Pflanzen. Johann Wolfgang Goethe-University Frankfurt am Main, Diploma Thesis.
Nöthen, J. (2014). Mathematical Modeling of Arabidopsis thaliana with Focus on Network Decomposition and Reduction. Johann Wolfgang Goethe-University Frankfurt am Main, Ph.D. thesis.
Parry, M. A. J., Andralojc, P. J., Mitchell, R. A. C., Madgwick, P. J., and Keys, A. J. (2003). Manipulation of Rubisco: the amount, activity, function and regulation. J. Exp. Bot. 54, 1321–1333. doi: 10.1093/jxb/erg141
Peltier, J.-B., Cai, Y., Sun, Q., Zabrouskov, V., Giacomelli, L., Rudella, A., et al. (2006). The oligomeric stromal proteome of Arabidopsis thaliana chloroplasts. Mol. Cell. Proteomics 5, 114–133. doi: 10.1074/mcp.M500180-MCP200
Petri, C. A. (1962). Communication with Automats. German. Ph.D. Thesis, Technische Hochschule Darmstadt, in German.
Poolman, M. G., Miguet, L., Sweetlove, L. J., and Fell, D. A. (2009). A genome-scale metabolic model of Arabidopsis and some of its properties. Plant Physiol. 151, 1570–1581. doi: 10.1104/pp.109.141267
Radrich, K., Tsuruoka, Y., Dobson, P., Gevorgyan, A., Swainston, N., Baart, G., et al. (2010). Integration of metabolic databases for the reconstruction of genome-scale metabolic networks. BMC Syst. Biol. 4:114. doi: 10.1186/1752-0509-4-114
Raines, C. (2003). The Calvin cycle revisited. Photosynthesis Res. 75, 1–10. doi: 10.1023/A:1022421515027
Raman, S. B., and Rathinasabapathi, B. (2004). Pantothenate synthesis in plants. Plant Sci. 167, 961–968. doi: 10.1016/j.plantsci.2004.06.019
Ravasz, E., Somera, A. L., Mongru, D. A., Oltvai, Z. N., and Barabási, A.-L. (2002). Hierarchical organization of modularity in metabolic networks. Science 297, 1551–1555. doi: 10.1126/science.1073374
Reddy, V. N., Mavrovouniotis, M. L., and Liebman, M. N. (1993). “Petri net representations in metabolic pathways,” in Proceedings ISMB, eds L. Hunter, D. B. Searls, and J. W. Shavlik (Menlo Park, CA: AAAI Press), 328–336.
Reinbothe, H., and Mothes, K. (1962). Urea, ureides, and guanidines in plants. Annu. Rev. Plant Physiol. 13, 129–149. doi: 10.1146/annurev.pp.13.060162.001021
Reiter, W. (2008). Biochemical genetics of nucleotide sugar interconversion reactions. Curr. Opin. Plant Biol. 11, 236–243. doi: 10.1016/j.pbi.2008.03.009
Reumann, S., Ma, C., Lemke, S., and Babujee, L. (2004). AraPerox: a database of putative Arabidopsis proteins from plant peroxisomes. Plant Physiol. 136, 2587–2608. doi: 10.1104/pp.104.043695
Roy, H., and Andrews, T. (2004). “Rubisco: assembly and mechanism,” in Photosynthesis, volume 9 of Advances in Photosynthesis and Respiration, eds R. C. Leegood, T. D. Sharkey, and S. Caemmerer (Dordrecht: Springer), 53–83.
Sackmann, A., Heiner, M., and Koch, I. (2006). Application of Petri net based analysis techniques to signal transduction pathways. BMC Bioinformatics 7:482. doi: 10.1186/1471-2105-7-482
Saha, R., Suthers, P. F., and Maranas, C. D. (2011). Zea mays iRS1563: a comprehensive genome-scale metabolic reconstruction of maize metabolism. PLoS ONE 6:e21784. doi: 10.1371/journal.pone.0021784
Schuster, S., and Hilgetag, C. (1994). On elementary flux modes in biochemical reaction systems at steady state. J. Biol. Syst. 2, 165–182. doi: 10.1142/S0218339094000131
Schuster, S., Hilgetag, C., Woods, J., and Fell, D. (2002). Reaction routes in biochemical reaction systems: algebraic properties, validated calculation procedure and example from nucleotide metabolism. J. Math. Biol. 45, 153–181. doi: 10.1007/s002850200143
Sessions, A., Burke, E., Presting, G., George Aux, G., McElver, J., Patton, D., et al. (2002). A high-throughput Arabidopsis reverse genetics system. Plant Cell 14, 2985–2994. doi: 10.1105/tpc.004630
Sirko, A., and Brodzik, R. (2000). Plant ureases: roles and regulation. Acta Biochim. Polonica 47, 1189–9115.
Streb, S., and Zeeman, S. C. (2012). Starch metabolism in Arabidopsis. Arabidopsis Book/Amer Soc. Plant Biol. 10:e0160. doi: 10.1199/tab.0160
Szydlowski, N., Ragel, P., Raynaud, S., Lucas, M. M., Roldán, I., Montero, M., et al. (2009). Starch granule initiation in Arabidopsis requires the presence of either class IV or class III starch synthases. Plant Cell Online 21, 2443–2457. doi: 10.1105/tpc.109.066522
Temple, S. J., Vance, C. P., and Gantt, J. S. (1998). Glutamate synthase and nitrogen assimilation. Trends Plant Sci. 3, 51–56.
Tischner, R., Galli, M., Heimer, Y. M., Bielefeld, S., Okamoto, M., Mack, A., et al. (2007). Interference with the citrulline-based nitric oxide synthase assay by argininosuccinate lyase activity in Arabidopsis extracts. FEBS J. 274, 4238–4245. doi: 10.1111/j.1742-4658.2007.05950.x
Uzam, M. (2004). The use of the Petri net reduction approach for an optimal deadlock prevention policy for flexible manufacturing systems. Int. J. Adv. Manufact. Technol. 23, 204–219. doi: 10.1007/s00170-002-1526-5
Van Norman, J. M., and Benfey, P. N. (2009). Arabidopsis thaliana as a model organism in systems biology. Wiley Interdiscip. Rev. Syst. Biol. Med. 1, 372–379. doi: 10.1002/wsbm.25
Vasilevski, A., Giorgi, F. M., Bertinetti, L., and Usadel, B. (2012). LASSO modeling of the Arabidopsis thaliana seed/seedling transcriptome: a model case for detection of novel mucilage and pectin metabolism genes. Mol. Biosyst. 8, 2566–2574. doi: 10.1039/c2mb25096a
Wilkie, S. E., and Warren, M. J. (1998). Recombinant expression, purification, and characterization of three isoenzymes of aspartate aminotransferase from Arabidopsis thaliana. Protein Exp. Purif. 12, 381–389. doi: 10.1006/prep.1997.0845
Williams, T. C., Miguet, L., Masakapalli, S. K., Kruger, N. J., Sweetlove, L. J., and Ratcliffe, R. G. (2008). Metabolic network fluxes in heterotrophic Arabidopsis cells: stability of the flux distribution under different oxygenation conditions. Plant Physiol. 148, 704–718. doi: 10.1104/pp.108.125195
Zhang, P., Foerster, H., Tissier, C. P., Mueller, L., Paley, S., Karp, P. D., et al. (2005). MetaCyc and AraCyc. Metabolic pathway databases for plant research. Plant Physiol. 138, 27–37. doi: 10.1104/pp.105.060376
Keywords: systems biology, Petri net, Arabidopsis thaliana metabolism, model verification, network reduction, transition invariant, common transition pairs, invariant transition pairs
Citation: Koch I, Nöthen J and Schleiff E (2017) Modeling the Metabolism of Arabidopsis thaliana: Application of Network Decomposition and Network Reduction in the Context of Petri Nets. Front. Genet. 8:85. doi: 10.3389/fgene.2017.00085
Received: 18 April 2016; Accepted: 06 June 2017;
Published: 30 June 2017.
Edited by:
Julio Vera González, University Hospital Erlangen, GermanyReviewed by:
Vincenzo Manca, University of Verona, ItalyGuido Santos Rosales, University of La Laguna, Spain
Copyright © 2017 Koch, Nöthen and Schleiff. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ina Koch, aW5hLmtvY2hAYmlvaW5mb3JtYXRpay51bmktZnJhbmtmdXJ0LmRl
Enrico Schleiff, c2NobGVpZmZAYmlvLnVuaS1mcmFua2Z1cnQuZGU=
†Shared first authorship.