 Xiao-Lin Wu1,2*
Xiao-Lin Wu1,2* George R. Wiggans1
George R. Wiggans1 H. Duane Norman1
H. Duane Norman1 Asha M. Miles3
Asha M. Miles3 Curtis P. Van Tassell3
Curtis P. Van Tassell3 Ransom L. Baldwin VI3Javier Burchard1João Dürr1
Ransom L. Baldwin VI3Javier Burchard1João Dürr1- 1Council on Dairy Cattle Breeding, Bowie, MD, United States
- 2Department of Animal and Dairy Sciences, University of Wisconsin, Madison, WI, United States
- 3USDA, Agricultural Research Service, Animal Genomics and Improvement Laboratory, Beltsville, MD, United States
Cost-effective milking plans have been adapted to supplement the standard supervised twice-daily monthly testing scheme since the 1960s. Various methods have been proposed to estimate daily milk yields (DMY), focusing on yield correction factors. The present study evaluated the performance of existing statistical methods, including a recently proposed exponential regression model, for estimating DMY using 10-fold cross-validation in Holstein and Jersey cows. The initial approach doubled the morning (AM) or evening (PM) yield as estimated DMY in AM-PM plans, assuming equal 12-h AM and PM milking intervals. However, in reality, AM milking intervals tended to be longer than PM milking intervals. Additive correction factors (ACF) provided additive adjustments beyond twice AM or PM yields. Hence, an ACF model equivalently assumed a fixed regression coefficient or a multiplier of “2.0” for AM or PM yields. Similarly, a linear regression model was viewed as an ACF model, yet it estimated the regression coefficient for a single milk yield from the data. Multiplicative correction factors (MCF) represented daily to partial milk yield ratios. Hence, multiplying a yield from single milking by an appropriate MCF gave a DMY estimate. The exponential regression model was analogous to an exponential growth function with the yield from single milking as the initial state and the rate of change tuned by a linear function of milking interval. In the present study, all the methods had high precision in the estimates, but they differed considerably in biases. Overall, the MCF and linear regression models had smaller squared biases and greater accuracies for estimating DMY than the ACF models. The exponential regression model had the greatest accuracies and smallest squared biases. Model parameters were compared. Discretized milking interval categories led to a loss of accuracy of the estimates. Characterization of ACF and MCF revealed their similarities and dissimilarities and biases aroused by unequal milking intervals. The present study focused on estimating DMY in AM-PM milking plans. Yet, the methods and relevant principles are generally applicable to cows milked more than two times a day.
Introduction
Accurate milking data are essential for herd management and genetic improvement in dairy cattle. In reality, lactation (305 days) yields are not directly measured, but they are calculated from the test-day yields, either with or without explicitly imputing DMY for non-test dates (VanRaden, 1997; Cole and VanRaden; Cole et al., 2009). For genetic evaluation programs, the standardization of lactation yields is practiced, ensuring that milking records are comparable between cows. The latter goal is to adjust variation due to, for example, the number of milking per day, lactation length, and age and month of calving (McDaniel, 1973; Schutz and Norman, 1994; Norman et al., 1995). Hence, the accuracies of test-day yields form the basis for the accuracies of lactation yields and the following standardization of lactation yields for genetic evaluation programs.
Nevertheless, test-day yields are not directly measured either. In the US, reduced-cost milking plans started to displace the standard supervised twice-daily, monthly testing scheme in the 1960s, motivated by reducing visits by a DHIA supervisor (Puttnam and Gilmore, 1968). Typically, cows are milked two or more times on a test day, but not all these milkings are measured. Porzio (1953) was the first to propose sampling the morning (AM) and evening (PM) milkings alternately on test days throughout lactation in the mountainous areas of Italy. This was known as the AM-PM milking plan, and the daily yield was taken to be approximately two times the yield of a single milking, assuming equal 12-h intervals for AM and PM milkings. In practice, however, AM and PM milking intervals can be different, and milk secretion rates may vary between day and night. Morning milking intervals tend to be longer than afternoon milking intervals. Hence, AM milk yields are usually higher than PM milk yields (Puttnam and Gilmore, 1970).
Various methods have been proposed to estimate daily milk, fat, and protein yields. The landmark developments date to the 1980s and 1990s, focusing on adjustment criteria in two broad categories, namely, additive (ACFs) and multiplicative correction factors (MCFs). ACFs provide additive adjustments beyond the two times AM or PM yields as the estimate of daily yields. Everett and Wadell (1970a) showed that the difference between AM and PM yields was a function of milking interval and days in milk (DIM). Significant factors affecting differences varied with cattle breeds, which also include lactation months, herd production, age classes, and so on (Everett and Wadell, 1970b). Hence, ACFs are evaluated by the average differences between AM and PM yields milk, say, in AM-PM milking plans, for various milking interval classes (MICs), and other categorical variables.
On the other hand, MCFs are ratios of daily yield to yield from a single milking, computed for each MIC. MCFs are also referred to as ratio factors. Multiplying a yield from a single milking by an appropriate ratio factor gives an estimate of daily yield. Various MCF forms have been proposed, yet the statistical interpretations differ (Wu et al., 2022). Shook et al. (1980) described the MCF as reciprocals of the AM or PM portions of daily yields, subject to quadratic smoothing. DeLorenzo and Wiggans (1986) proposed deriving MCF for AM-PM milking plans based on a linear regression model without intercept. They assumed heterogeneous means and variances and fitted separate regression models to each MIC. Wiggans (1986) proposed deriving MCFs for cows milked three times a day by regressing single-to-daily yield ratio on milking interval. Additional predictors such as DIM can be included in the model when applicable. MCF models are statistically challenged by “the ratio problem” because they have a ratio variable (i.e., proportional daily yield) as the dependent variable in the data density (Wiggans, 1986) or the smoothing functions (Shook et al., 1980; DeLorenzo and Wiggans, 1986). Consequences included possible biases in two aspects: omitted variable bias and measurement error bias (Lien et al., 2017). The former bias happens because main model effects are missing if the model is re-arranged by multiplying the denominator variable to both sides of the model equation. The latter bias occurs when there are measurement errors with the denominator variable of the response. Furthermore, the MCF models postulated a rational function between daily milky yield and milking, in which the numerator is 1, and the denominator is a linear function (DeLorenzo and Wiggans, 1986; Wiggans, 1986) or a quadratic function (Shook et al., 1980) of milking interval.
Previous studies almost exclusively assessed the accuracy of estimated daily yield in the same datasets from which the correction factors were derived (Putnam and Gilmore, 1968, 1970; Smith and Person, 1981; Liu et al., 2000). This type of in-sample evaluation essentially reflected more model-fitting accuracy than prediction accuracy. In the present study, our primary goal was to evaluate the performance of existing statistical models, including the recently proposed exponential regression model (Wu et al., 2022), in Holstein and Jersey cattle by cross-validation. Secondary goals included comparing model parameters and characterizing ACF and MCF obtained from various models, relative to the initial approach assuming a fixed multiplicative factor of 2.0 for AM or PM yields. Cross-validation, also referred to as out-of-sample testing, is a model validation technique for assessing how the results of a statistical analysis will generalize to an independent dataset (Stone, 1974; Geisser, 1993). Briefly, one round of cross-validation involves partitioning a sample of data into complementary subsets, performing the analysis on one subset (i.e., training set), and validating the analysis on the other subset (i.e., validation or testing set). To access variability, multiple rounds of cross-validation are performed using different partitions, and the validation results are combined by averaging over the rounds to give an estimate of the model’s predictive performance. Hence, cross-validation combines (averages) measures of fitness in prediction to derive a more accurate estimate of model prediction performance. Because cross-validation is a resampling method that uses different portions of the data to train and test a model across iterations, it also allows inferring the error origins by decomposing an MSE into the variance of the estimate and squared bias. The inverse of the variance provides a measure of precision for the estimates.
Materials and Methods
AM-PM Milking Data
Milking records were extracted from the data repositories maintained by the Council for Dairy Cattle Breeding (CDCB). The data consisted of 9,218 milking records from 6,533 cows in 27 herds in 11 states, USA, collected from 2006 through 2009 (Table 1). Most milking records consisted of 82.7% Holsteins and 13.1% Jersey (13.1%) cows. The remaining (4.2%) milking records represented multiple breeds, including Ayrshire (0.7%), Brown Swiss (2.4%), Milking Shorthorn (0.01%), Red and White Holstein (0.04%), and unknown breeds (0.87%). Milking records from Holstein and Jersey cows were used in the present study. Data editing excluded records with missing or incomplete values for relevant columns (e.g., AM or PM milking yield, AM or PM milking interval, parity, lactation year or month, days in milk (DIM), and herd locations). The final dataset retained 7,544 Holstein milking records from 23 herds and 1,194 Jersey milking records from 9 herds. Approximately, one-third of records (30.6–39.9%) represented the first parity cows and two-thirds (59.4–69.4%) were the second parity cows in the two breeds. Milking records collected from parity 3 and greater were rate (0–10.7%).
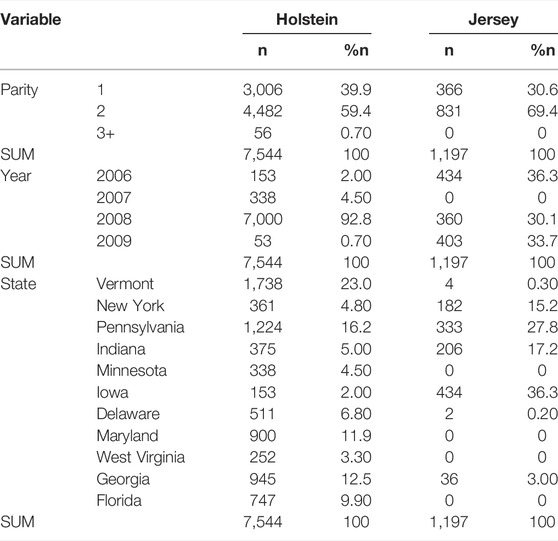
TABLE 1. Number (n) and percentage (%n) of milking records by parities, lactation years, and states in the Holstein and Jersey cattle, respectively.
Statistical Methods
Model 0 (M0): Doubling AM or PM Milking Yield
The initial AM-PM milking plan alternately sampled AM or PM milking on a test day throughout lactation, and the daily yield was obtained by doubling single milk weighed on each test day (Porzio, 1953). That is,
where
Model 1 (M1): ACF Model With Discrete Variables
Additive correction factors are evaluated by the expected values of the differences between AM and PM yields, computed locally for each MIC, coupled with other categorical variables such as lactation months (Everett and Wadell, 1970b). For example, let
where
Given the computed ACF and a single milk yield that has been measured for cow i (denoted by
In the aforementioned equation, we see that an ACF model is equivalent to a regression model assuming a fixed regression coefficient (2.0) for AM or PM yield. ACF models can be fit on AM or PM milk yields separately or jointly.
Model 2 (M2A,B): ACF Model With Continuous Variables
An ACF model can also be fitted with continuous variables for milking interval (denoted by
where
Given the estimated model parameters, DMY is estimated by
where
where
With the latter approach (denoted by M2B), DMY is estimated through the ACF.
Model 3 (M3A,B): Linear Regression With Linear Milking Interval and DIM
The linear model approach treats DMY as the response variable. Let
In (9),
Linear regression also offers two methods of estimating DMY. First, DMY for a cow can be estimated directly given the estimated model parameters in (9), as follows:
The aforementioned equation is referred to as the model M3A. Second, ACF can be computed on discretized MIC, following the same formula as (7), and then DMY are estimated by the following (denoted by M3B):
Model 4 (M4): Linear Regression With Linear and Quadratic Milking Interval and DIM
Linear regression models can be defined with varying complexity (Liu et al., 2000; Schaeffer et al., 2000). In the present study, we also evaluated a linear regression model with linear and quadratic variables for milking interval and DIM:
Given the estimated model parameters, DMY is estimated directly as follows:
MCF could be derived similar to M2B, yet considering the quadratic terms, but they were not evaluated in the present study.
Model 5 (M5): The 1980 Shook-Jensen-Dickimson MCF model
Shook et al. (1980) described MCF by the inverse of AM or PM proportion of daily milk yield. For example, MCF given PM yields are formulated as follows:
where
In the aforementioned equation,
Given the estimated PM MCF, the AM MCF can be computed indirectly (Shook et al., 1980), but this approach was not taken in the present study. Instead, we computed AM and PM MCF directly from the AM or PM milking data. Similar to (14), MCF given AM yields are formulated to be the inverses of the AM portion of daily yield, computed for each AM MIC (
Given the MCF (
Model 6 (M6): The 1986 DeLorenzo and Wiggans MCF model
DeLorenzo and Wiggans (1986) derived MCF for cows milked twice a day based on a linear regression without intercept. They assumed heterogeneous means and variances and fitted separate linear regression models for different MIC.
In (18),
Given the computed MCF, DMY is estimated by
Model 7 (M7A,B): The 1986 Wiggans MCF model
Wiggans (1986) proposed to derive MCF for cows milked three times a day by modeling the single-to-daily milk yield ratio as a linear function of milking interval and DIM when applicable:
The aforementioned model also applies to cows milked more than three times and, arguably, it applies to cows milked twice a day. In the latter case, however, the model is subject to the violation of linearity with a longer milking interval (Schmidt, 1960). In the present study, DMY is estimated directly based on the estimated model parameters from (21) or through computed MCF according to Wiggans (1986). In the former case (denoted by M7A), DMYs are computed directly given the estimated model parameters, as follows:
In the latter case (denoted by M7B), MCF are obtained by locally taking the expected value on both sides of Equation 21, assuming
Similarly, by taking the first-order Taylor series approximation of (21), that is,
Model 8 (M8A,B): Exponential Regression Model
Considering milking interval and days in milk, the exponential regression model for estimating DMY takes the following form (Wu et al., 2022):
By noting
where
The model parameters can be estimated by taking the following logarithm transformation:
As a direct approach. DMY is estimated, given the model parameter estimates (
Alternatively, MCF is computed locally for discretized MIC (Wu et al., 2022):
where
The logarithm linear regression also suggests that ACF can be computed for estimating
Cross-Validation of Accuracy
The performance of eight selected models and two strategies (Table 2) was evaluated for estimating DMY in the Holstein and Jersey milking datasets. The eight models included two ACF models, one with discrete MIC (M1) and the other with a continuous variable for milking interval (M2), a linear regression model M3 and M4, and three MCF models (M5, M6, and M7), according to Shook et al. (1980), DeLorenzo and Wiggans (1986), and Wiggans (1986), respectively, and the exponential regression model (M8), with doubling AM or PM (M0) as the benchmark model for comparison. For the two strategies, a model labeled “A” (M2A, M3A, M7A, and M8A) estimated DMY directly, given the estimates of model parameters, whereas a model labeled “B” (M2B, M3B, M7B, and M8B) estimated DMY indirectly via the computed ACF or MCF. Accuracy and decomposed mean squared errors (MSE) were evaluated for each model or model–strategy combination by cross-validation. Briefly, each dataset was divided into 10 approximately equal subsets. Then, nine subsets were pooled for training, and the remaining subset was used for testing the accuracy. The cross-validation process rotated 10 times, with each subset used for testing once and only once. To facilitate inference of the variance of the estimates, cross-validations were replicated 30 times, each with randomly selected subsets of data samples for training and testing.

The correlation between the estimate and actual DMY and the following R2 accuracy:
Here,
To infer the origin of errors, the mean squared error (MSE) of DMY estimates from the 10-fold cross-validation was decomposed into the variance (
In the aforementioned equation,
Cubic Smoothing Splines
Cubic smoothing splines of the individual R2 accuracies and actual daily milk yields, respectively, were also fitted to provide approximations with weaker assumptions for relevant comparisons. Statistically, smoothing splines are function estimates (denoted by
Let
In the aforementioned equation,
Results and Discussion
Summary of Milking Data for Holstein and Jersey Cows
In the Holstein cows, the mean and median of AM milking intervals were 12.3 h and 12.1 h, respectively, whereas the mean and median of PM milking intervals were 11.6 h and 11.9 h, respectively. The AM milking intervals had a wider range (5.6–23.67 h) than the PM milking intervals (5.0–18.4 h) (Figure 1A). A paired t-test showed that the mean AM milking interval was significantly longer than the mean PM milking interval in the Holsteins cows (t = 27.3, p < 2.2e-16). The mean difference between AM and PM milking intervals was 0.688 h, with a 95% confidential interval between 0.639 h and 0.738 h. Similarly, the mean and median of AM milking intervals in the Jersey cows were 13.0 h and 12.9 h, respectively. The mean and median of PM milking intervals were 11.1 h and 11.0 h, respectively. The AM milking interval was significantly longer than the PM milking interval based on a paired t-test (t = 44.2; p < 2.2e-16). The mean difference between AM and PM milking interval in the Jersey cows was 1.87 h, with a 95% confidential interval between 1.79 h and 1.95 h. The AM milking interval range (9.6–23.5 h) was also larger than the PM milking interval range (1.4–14.3 h) in Jersey cows (Figure 1B). The distribution of AM and PM milking intervals was approximately symmetric and bell shaped in the Holstein and Jersey cows, respectively (Figure 1).
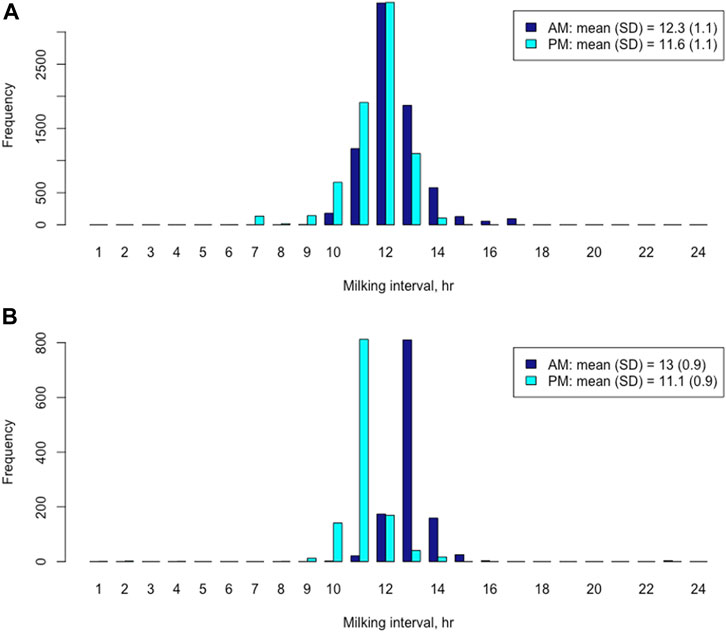
FIGURE 1. Distributions of morning (AM) and evening (PM) milking interval time in Holstein cows (A) and Jersey cows (B), respectively.
Longer AM milking intervals led to greater average AM milk yields (Figure 2). In the Holstein cows, the mean AM milk yield (16.4 kg) was significantly larger than the average PM milk yield (15.3 kg) (t = 23.5; p < 2.2e-16) (Figure 2A). The mean difference between AM and PM milk yield was 2.49 kg, with a 95% confidential interval between 2.29 and 2.70 kg, in the Holstein cows. Similarly, the mean AM milk yield (12.7 kg) was significantly larger than the average PM milk yield (11.0 kg) (t = 22.2; p < 2.2e-16) in the Jersey cows (Figure 2B). The mean difference between AM and PM milk yield was 3.87 kg, with a 95% confidential interval between 3.53 and 4.21 kg, in the Jersey cows.
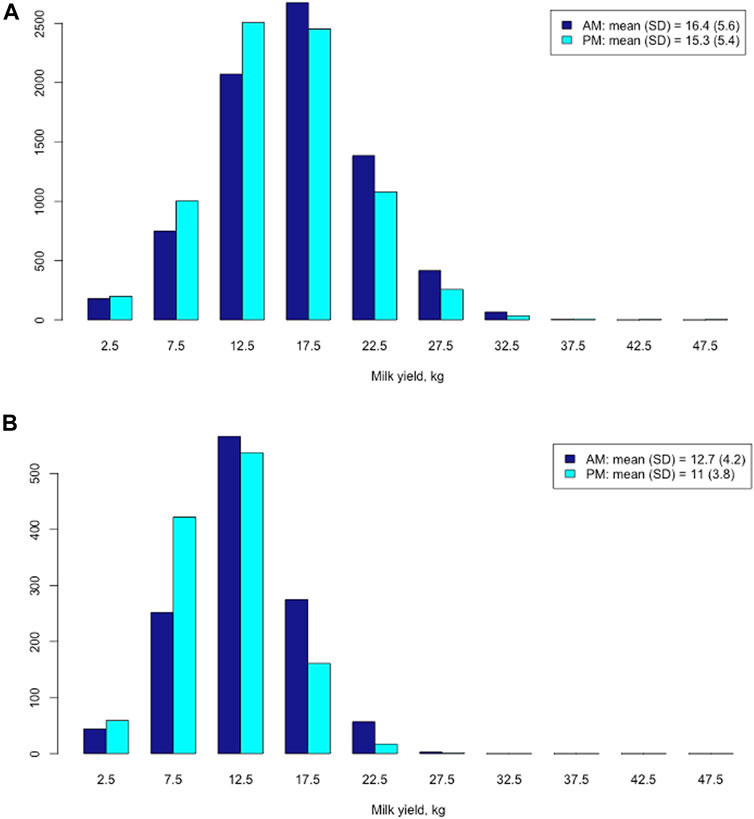
FIGURE 2. Distribution of morning (AM) and evening (PM) milk yields in Holstein cows (A) and Jersey cows (B), respectively.
Comparing Decomposed Mean Squared Errors and Accuracies
Accuracy and precision are two primary measures of observational or estimation errors. For estimating DMY, accuracy tells how close an estimated DMY is to the actual value, whereas precision shows how well the estimates agree with each other. Precision was measured by the inverse of the variance of DMY estimates. The smaller the variance, the greater the precision. Decomposed MSE were shown in Table 3. All the methods had close to zero variances for the DMY estimates, meaning they all had high precision of the estimated DMY. The variance of DMY estimates was not greater than 0.003 in Holstein cows and less than 0.03 in Jersey cows. The MSE were dominated by the portion of squared bias in Holstein and Jersey cows. Model M0 (doubling AM or PM milk yields) had the largest squared biases and the largest MSE, which were more than two times their counterparts for all the other models in Holstein and Jersey cows. Comparably speaking, the ACF models had larger squared biases and MSE than the MCF and linear regression models. The exponential regression model (M8A) had the smallest squared biases and the smallest MSE. Not including the model M0, the root MSE was between 3.18 and 3.38 kg in the Holstein cows and between 2.46 and 2.63 kg in the Jersey cows. The root MSE roughly agreed with two or three Schutz and Norman (2011), who reported a range of root MSE between 2.07 and 2.85 kg for cows milked twice a day. Higher root MSE for estimating DMY were reported in cows milked times a day (Schutz et al., 2008). It is worth mentioning that we used a 10-fold cross-validation, whereas Schutz and Norman (2011) employed an in-sample evaluation. Often, cross-validations tend to report higher errors than in-sample evaluations when applied to the same dataset. In-sample errors are the errors we get on the same data we used to train the prediction model, which tends to be optimistic, compared to the errors we would get from a new sample. The latter is referred to as out-of-sample errors. The reason is overfitting with in-sample evaluation (Harkins and Douglas, 2004). Overfitting occurs when the trained predictive model becomes sensitive to the noise in the sample. As a result, the function will perform well on the training set but not perform well on new data. The more overfitting occurs, the worse the predictive model will generalize to new data. When we get a new dataset, there will be different noises, so the accuracy will go down to some extent. Hence, in-sample errors are always less than out-of-sample errors, which leads to overestimated accuracy. Yet, the fact is, once we build a model on a sample of data that we have collected, we might want to test the realistic expectation of the predictive model as to how well it will perform on new data.
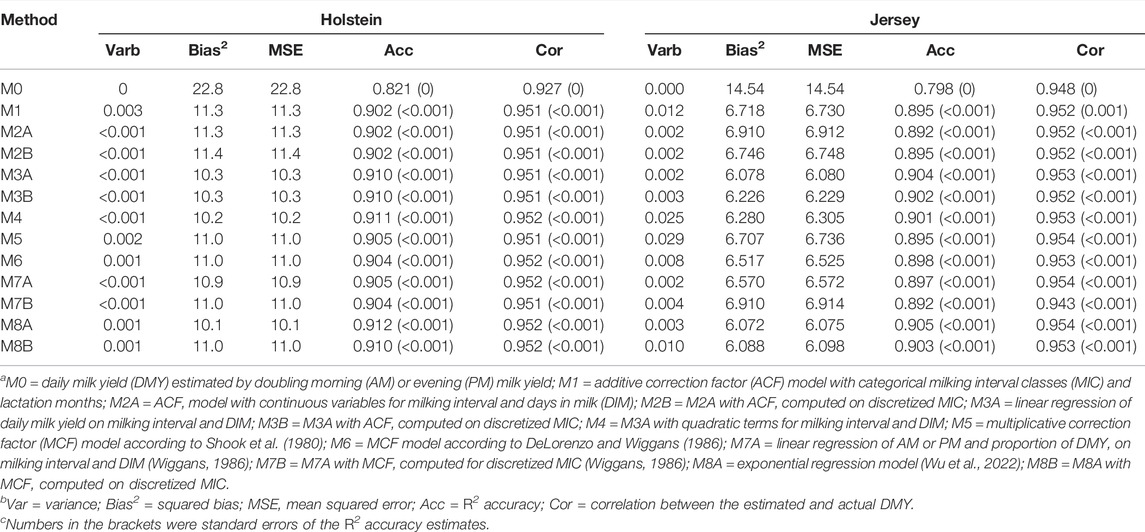
TABLE 3. Decomposed mean squared error, R2 accuracy, and correlation between estimated and actual daily milk yield obtained from 10-fold cross-validation a,b,c.
The standard deviation of the mean R2 accuracy between the 30 CV replicates was 0 for M0 and less than 0.001 for all the remaining methods. Exactly, the standard deviation of R2 accuracies between cross-validation replicates ranged between 0.00002 and 0.0001 for these methods in Holstein cows and between 0.0001 and 0.0005 in Jersey cows. By this definition, the R2 accuracy is viewed as a population parameter. Based on paired t-test, we showed that the exponential regression model had highly significant mean R2 accuracy than each of the existing methods (Holsteins: t = 584.8–37281; p < 2.2–16; Jerseys: 1178.5–5861.4; p < 2.2e-16). The model M0 had the lowest R2 accuracy (0.821 in Holstein cows and 0.798 in Jersey cows). Compared to model M0, the ACF and MCF models, including the linear regression models, highly significantly improved the accuracies for estimating DMY (Holsteins: t = 8658.1–37281; p < 2.2e-16; Jerseys: 11.67–5861.4; p < 1.8e-12). The MCF and linear regression models had slightly higher accuracies of DMY estimates (0.904–0.912 in Holstein cows and 0.892–0.905 in Jersey cows) than the ACF models (0.902–0.910 in Holstein cows and 0.892–0.904 in Jersey cows). The exponential regression models, M8A and M8B, had the greatest R2 accuracies of DMY estimates (0.910–0.912 in Holstein cows and 0.903–0.905 in Jersey cows). Based on a similar criterion, Liu et al. (2000) reported slightly higher R2 accuracies (0.885) for doubling AM or PM approach in the German Holstein cows than ours in the US Holstein cows (0.821). The accuracies of estimated DMY (0.902–0.912) in the US Holstein cows that we obtained using the DeLorenzo and Wiggans (1986) model were within the accuracy range (0.900–0.914) in German Holstein cows obtained by Liu et al. (2000) using the same model. In addition to the genetic differences between German and the US Holstein cows, the accuracies of estimated DMY can vary with evaluation methods. Liu et al. (2000) employed in-sample evaluation, whereas we evaluated the accuracies by 10-fold cross-validation. As mentioned earlier, the accuracy obtained from cross-validation tends to be lower than that from in-sample evaluation because the former evaluations are prone to overfitting (Harkins and Douglas, 2004). Thus, comparing various methods is valid only when applied to the same dataset with the same evaluation strategy.
Correlation has been widely used to measure prediction accuracy, e.g., in genomic prediction and machine learning. However, correlation is not as informative as the R2 accuracy for evaluating the performance of various models to estimate DMY. In the present study, all the models had similarly high correlations (0.951–0.952 in Holstein cows and 0.952–0.954 in Jersey cows) between the estimated and actual DMY, except that the model M0 had significantly lower corrections (0.927 in Holstein cows and 0.948 in Jersey cows). The standard deviation (i.e., standard error) of correlations between cross-validation replicates were all less than 0.0005. In statistics, correlation measures the degree of dependence between two random variables. Yet, correlation is not a precise measure of accuracy for two evident reasons. First, a correlation can be negative, but a valid accuracy measure is non-negative. Second and more importantly, a correlation does not account for estimation biases, meaning that two methods having identical corrections can vary drastically in the biases of the estimates. Hence, we recommend using the R2 accuracy, instead of correction, as the measure of accuracy for estimating DMY.
A couple of reasons are worth noting for the lower accuracies with the ACF models than linear regression models. First, an ACF model is equivalent to assuming a fixed regression coefficient for partial milk yield, which can limit its predictability. For example, consider the models M2A and M2B. With some re-arrangements, these two models can be re-arranged into linear regression models of DMY on milk interval and DIM, plus a variable for AM or PM milk yield with a fixed regression coefficient (
Concerning an ACF or MCF model with continuous variables for milking intervals and DIM, discretizing a continuous variable to a categorical variable often leads to loss of information (and, therefore, accuracy) to some extent. Wu et al. (2022) showed analytically that computing ACF and MCF on discretized MIC led to a loss of accuracy of DMY estimates. This phenomenon was empirically observed in the Holstein and Jersey cows in the present study when comparing four pairs of models: M2A versus M2B, M3A versus M3B, M7A versus M7B, and M8A versus M8B. Each pair had the same model settings except that DMY were estimated with different strategies. The models labeled “A” (M2A, M3A, M7A, and M8A) estimated DMY directly based on estimated model parameters. Instead, the models labeled “B” (M2B, M3B, M7B, and M8B) computed ACF or MCF for discretized MICs after data fitting. Then, DMY were estimated through the calculated ACF or MCF. The models in group A consistently had smaller MSE and better accuracies than their counterparts in group B (Table 3). These results were an indication that discretizing milking interval time led to a loss of accuracy in estimated DMY. Hence, computing ACF or MCF without accounting for the loss due to discretizing MIC may be suboptimal when the linearity holds.
Relative to model M0 (doubling AM or PM milk yields), ACF and MCF models have considerably improved the DMY accuracy. To probe into the details, we computed the R2 accuracies for individual cows based on three selected models, M0 (doubling AM or PM yields), one ACF model (M2B), and one MCF model (M7B). It came to our attention that mean individual R2 accuracies were higher than the average R2 accuracy population-wise across the 30 replicates. The distributions of individual R2 accuracies in the Holstein cows obtained from these three models are shown in Figure 3. In particular, the distribution of individual R accuracies for the model M0 had a thicker tail than that for the model M2B or M7B. This was an indication that doubling AM or PM milk yields as the estimated DMY led to a higher percentage of the estimated DMY with lower accuracies, compared to the ACF and MCF models. The percentage of individual R2 accuracies ≥ 0.90 were 59.6% (M0), 81.6% (M2B), and 83.4% (M7B). Average individual R2 accuracy was 0.934 for M2B and 0.937 for M7B, respectively; both were substantially higher than the average individual R2 accuracy (0.873) for M0. The medians of the R2 accuracies were 0.927 for M0, 0.976 for M2B, and 0.980 for M7B, respectively, in the Holstein cows. The medians were consistently larger than the means. The MCF model (M7B) had a slightly higher mean R2 accuracy than the ACF model (M2B). Unlike the standard deviations of the average R2 accuracies between cross-validation replicates, which were all close to zero, the standard deviation of the individual R2 accuracy was 0.135 for M0, 0.116 for M2B, and 0.115 for M7B. By Student’s t-test, the mean R2 accuracies between M2B and M7B was not significantly different (t = 1.69, p = 0.091), yet they both were highly significantly greater than the mean R2 accuracy of M0 (t = 29.4–31.1, p < 2.2e-16). Similar trends were observed in Jersey cows.
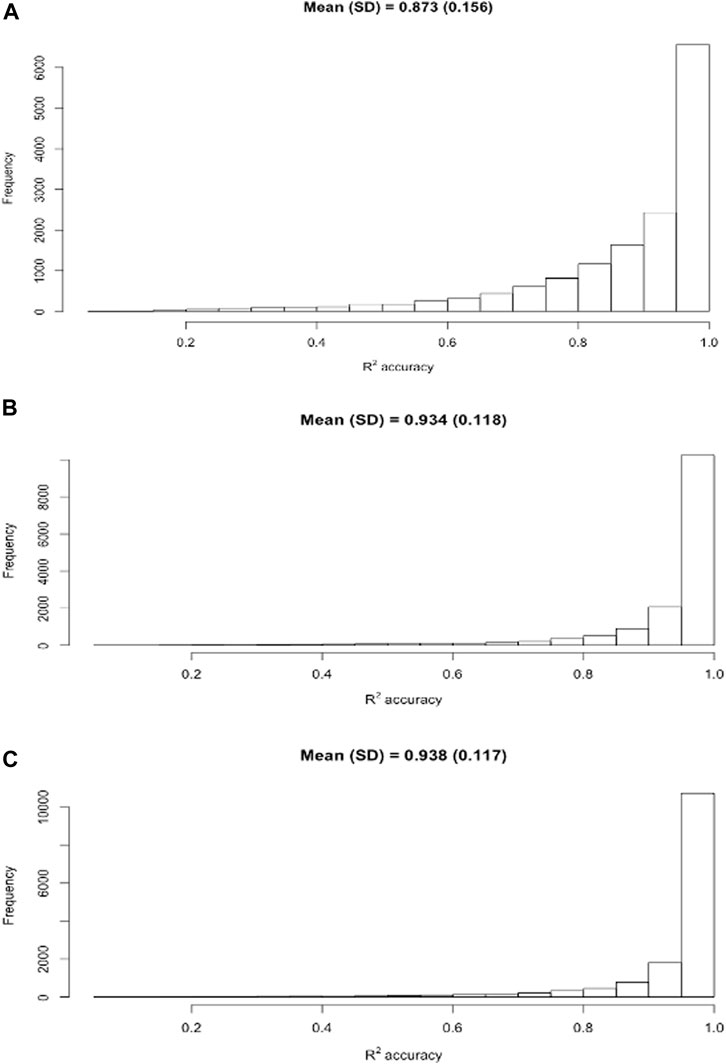
FIGURE 3. Distribution of individual R2 accuracies of the estimated daily milk yield obtained using three models, M0 (A), M2B (B), and M7B (C), respectively. M0 = two times AM or PM yield as the estimate of test-day milk yield; M2B = additive correction factor model implemented by regressing the difference between AM and PM yields on milking interval and days in milk; M7B = multiplicative correction factor model according to Wiggans (1986).
Furthermore, the cubic smoothing spline (CSS) means of individual R2 accuracies obtained from the three models were plotted against milking interval time in hours. (Figure 4). All three models had comparable means of individual R2 accuracies when AM and PM milking intervals were approximately 12 h. Still, the average individual R2 accuracy with the model M0 dropped drastically as the milking interval deviated from 12 h. The further it deviated from 12 h, the lower the average R2 accuracy it had. In contrast, average individual R2 accuracies for models M2B and M7B remained consistently high for milking intervals between 10 h and 16 h. They dropped slightly outside that range due to insufficient milking data. Hence, doubling AM or PM yield is equivalent to assuming a fixed multiplicative factor of 2.0 for AM and PM milk yields. It is valid (or approximately so) only for equal (12–12 h) AM and PM milking intervals but subject to large errors with unequal AM and PM milking intervals. Instead, ACF and MCF effectively provided adjustments to unequal milking intervals, leading to substantially improved DMY accuracies.
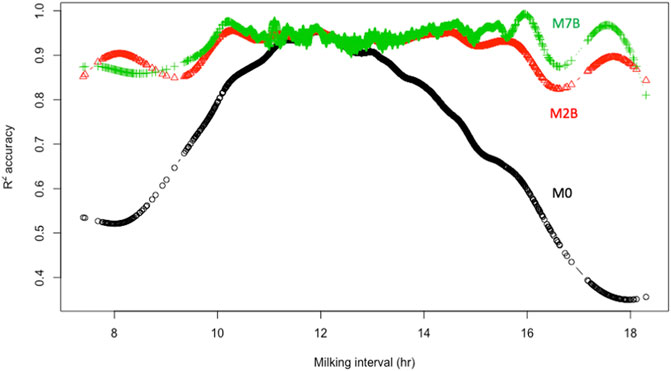
FIGURE 4. Relationships between smooth splines means of individual R2 accuracies of the estimated daily milk yield and milking interval for three models, M0, M2B, and M7B. M0 = two times AM or PM yield as the estimate of test-day milk yield; M2B = additive correction factor model implemented by regressing the difference between AM and PM yields on milking interval and days in milk; M7B = multiplicative correction factor model according to Wiggans (1986).
Comparing Model Parameters
Model parameters were estimated and compared for four selected models (M2A, M3A, M7A, and M8A) using all milking data in Holstein and Jersey cows; each was implemented for AM or PM milkings separately and jointly (Table 4). The first two models, M2A and M3A, are the baseline models for the ACF models M2B and M3B. Both models (M2A and M3A) were implemented similarly yet with slightly different modeling assumptions. The model M2A equivalently assumed a fixed regression coefficient “2.0” for AM or PM milk yields, whereas the model M3A estimated the regression coefficient for AM or PM yield from the data. For example, the estimated regression coefficient with model M3A was 1.749 in Holstein cows and 1.750 in Jersey cows when AM and PM milk yields were analyzed jointly. Hence, the model M2A provided additive adjustments to two times AM or PM milk yields as the DMY estimates, whereas the model M3A provided additive adjustments to approximately 1.75 times AM or PM milk yields as the estimated DMY. Owing to this difference, other model parameters varied between both models. Overall, the model M3A had a slightly larger intercept than the model M2A in both datasets. The regression coefficients for milking intervals were all negative for both models. The absolute value of the regression coefficient for milking interval in the model M2A was larger than that in the model M3A. The model M3A would coincide precisely with the ACF model M2A if we could fix the regression coefficient for AM or PM milk yield to be 2.0 in the model M3A.
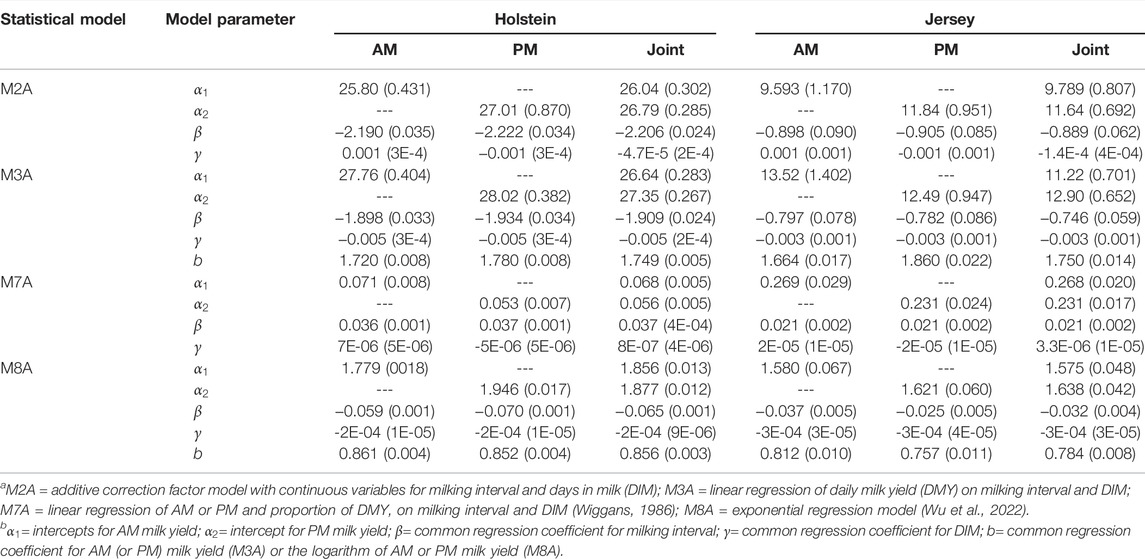
TABLE 4. Estimated parameters obtained from four models (M2A, M3A, M7A, and M8A), each implemented separately or jointly for known morning (AM) or evening (PM) milk yields a,b.
The models M7A and M8A are the baseline models for the MCF models, M7B and M8B. The MCF models represented substantially different modeling strategies (Table 2). For example, the former model (M7A) fitted AM or PM proportion of DMY as a linear function of milking interval and days in milk (Wiggans, 1986). In contrast, the latter (M8A) was an exponential regression model (Wu et al., 2022). We show that the model M8A was equivalent to a linear regression of the logarithm DMY on milking interval, days in milk, and the logarithm AM (or PM) milk yields through reparameterization. When AM and PM milk yields were analyzed jointly, the regression coefficient for milking interval was positive (0.037 in Holstein cows and 0.021 in Jersey cows) in the model M7A, whereas it was negative (0.065 in Holstein cows and 0.032 in Jersey cows) in the model M8A. The regression coefficient for the logarithm AM (or PM) milk yield was less than 1.0 (0.856 in Holstein cows and 0.784 in Jersey cows) in the model M8A.
Analyzing AM and PM milk yields separately led to slightly different model parameters in Holstein and Jersey cows (Table 4). Overall, the joint model had a smaller standard deviation of model parameters because the size of the data used to estimate these parameters doubled. Therefore, the joint analysis improved the precision of estimated model parameters by pooling AM and PM milk yields. Nevertheless, the accuracies of estimated DMY from separate analyses for AM or PM milkings increased only slightly compared to the joint analyses. Plots of actual and estimated DMY for the exponential regression model (M8A), implemented separately or jointly for AM and PM milkings, are shown in Figure 5B,C compared to the mode M0 (Figure 5A). The plots showed slight stratification between AM and PM milkings, which explained why separate analyses had better, although slightly, linear regression fits between the actual and estimated DMY than joint analyses. For the model M8A, separate analyses had smaller intercepts and the regression coefficient was closer to 1, indicating improved accuracies with the separate analyses. However, the extent of improved accuracies was very slight. The R2 accuracy was 0.9151 for the separate accounting and 0.9147 for the joint analysis; both rounded to 0.915. Here, we show that the accuracy obtained from the in-sample evaluation was higher than that (0.912) from the 10-fold cross-validation. Similarly, the R2 accuracies from separate analyses were almost identical to or slightly better than joint analyses for the other models. For example, the R2 accuracies were 0.9040 with the joint analysis and 0.9042 with the separate analysis for the model M2A, 0.9128 (joint) and 0.9131 (separate) for the model M3A, and 0.9062 (joint) and 0.9063 (separate) for the model M7A. The differences in the R2 accuracies were seen only in the third or fourth decimal points. Compared to model M8A, model M0 had considerably larger intercepts and the regression coefficients deviated substantially from 1.0. In other words, the model M8A has improved the DMY accuracies substantially compared to model M0. Similar conclusions hold all the ACF and MCF models and linear regression models, compared to doubling AM or PM yield as the daily yields.
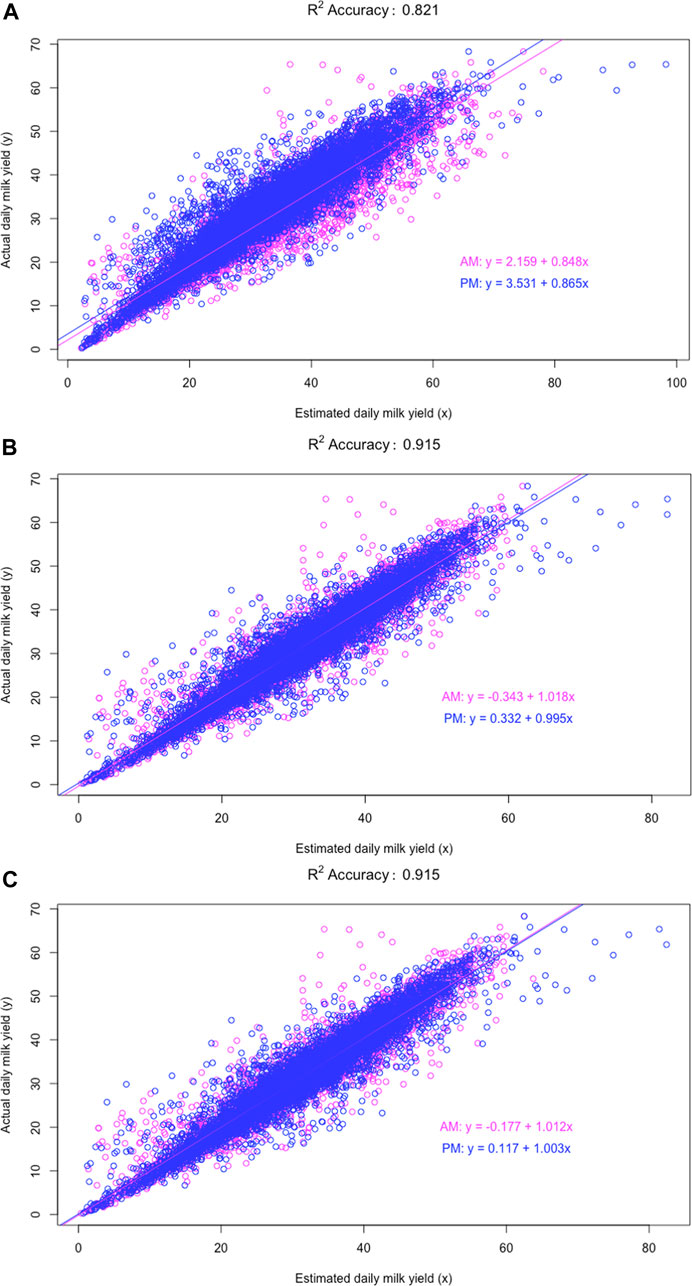
FIGURE 5. Scatterplot and linear regression fits of the actual daily milk yield against estimated daily milk yields under three scenarios: (A) estimating daily milk yield (DMY) by doubling morning (AM) or evening (PM) milk yields (model M0); (B) estimating DMY for known morning (AM) and evening (PM) milkings separately using the exponential regression model (model M8A; separate analysis); (C) estimating DMY for known AM and PM milkings jointly using the exponential regression model (model M8A; joint analysis).
Average DMY by milking intervals between 9 and 15 h were computed based on the estimated model parameters by joint analyses for the four selected models (M2A, M3A, M7A, and M8A), compared to the model M0 and the CSS means of actual DMY over milking interval (Figure 6). All the methods gave an average DMY comparable to the CSS means when AM and PM milking intervals were equal (12–12 h for AM and PM milking intervals). Still, they showed larger deviations with unequal AM and PM milkings. The model M0 had the largest deviations from the CSS means of DMY. Overall, the model M0 underestimated DMY with milking interval <12 h and overestimated DMY with milking interval >12 h. The more the AM (PM) milking interval departed from 12 h, the larger its deviation from the actual DMY. For the model M0, the average absolute deviation from the SCC means was 3.23 kg in Holstein and Jersey cows. Nevertheless, the deviations were much smaller for the ACF models (M2A and M3A) and the MCF models (M7A and M8A). The exponential regression model M8A had the smallest average absolute deviations from the CSS means of DMY (0.543 kg in the Holstein cows and 0.598 in the Jersey cows). For the other models M2A, M3A, and M7A, the average absolute deviation from the CSS mean varied from 0.568 (M3A) to 0.773 (M2A) in the Holstein cows and from 0.649 (M3A) to 0.914 (M2A) in the Jersey cows. These results also showed that the relation between the smoothed average DMY and milking interval time from 9 h to 15 h was not precisely linear (Figure 6). Early studies showed that DMY (including fat and solid-not-fat) were not linear with intervals beyond 12 h (Ragsdale et al., 1924; Bailey et al., 1955; Elliott and Brumby, 1955; Schmidt, 1960). In particular, Atashi and Hostens (2021) showed that milk and component productions, in relation to the interval between the current milking and the previous milking, showed an exponential increase at the beginning and later leveled off to an asymptote. This exponential behavior for milk production was assumed to be the result of cell degradation and milk present in the udder (Neal and Thornley, 1983).
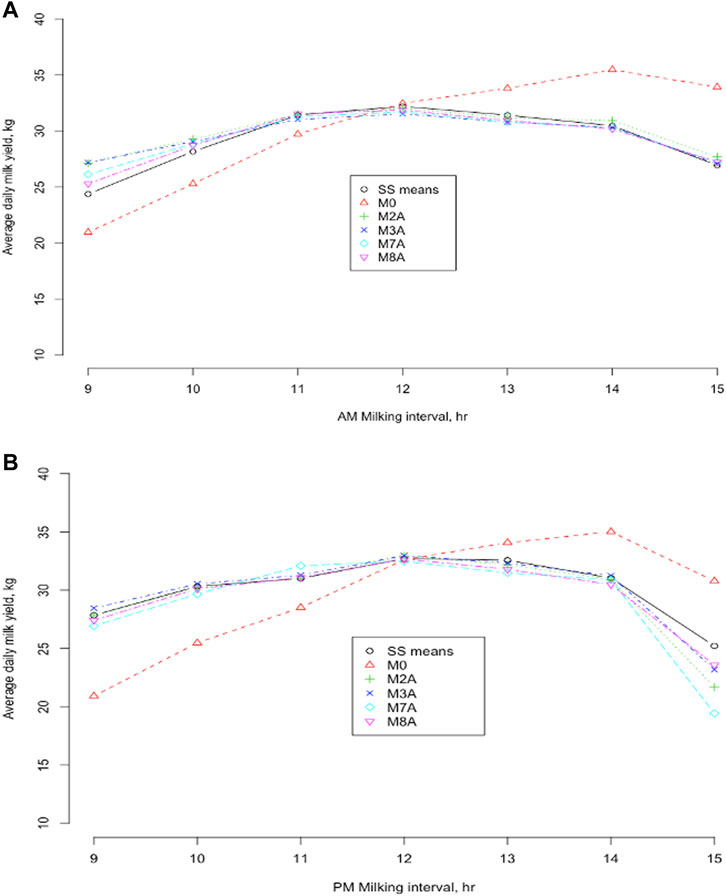
FIGURE 6. Average daily milk yields were obtained from five models and smooth spline (SS) means of the daily milk yield against morning (A) and evening (B) milking intervals from 9 to 15 h, respectively. M0 = daily milk yield (DMY) estimated as two times AM or PM yield; M2A = linear regression of the difference between morning (AM) and evening (PM) milk yields on milking interval and days in milk (DIM); M3A = linear regression of DMY on the milking interval and DIM; M7A = linear regression of AM or PM proportion of DMY on milking interval and DIM (Wiggans, 1986); M8A = exponential regression model (Wu et al., 2022).
Comparing Additive and Multiplicative Correction Factors
Additive and multiplicative factors were computed based on the parameter values of the data density functions or smoothing functions. Plots of ACF and MCF by MIC are shown in Figure 7. The ACF models were implemented with slightly different model assumptions, yet they resulted in drastically different ACF values in two groups (Figure 7A). The two classic ACF models, M1 and M2B, equivalently assumed a fixed regression coefficient of 2.0 for AM or PM milk yield. Hence, both models gave roughly comparable ACF per MIC, except that ACF from M2B were smoothed, but those from M1 were not (Figure 7A). The M1 model had considerably large fluctuations of ACF when the milking interval was less than 9 h or greater than 15 h due to insufficient milking records. Instead, the model M2B fitted the data on a continuous variable for milking interval, and ACF were computed on discretized MIC regardless of the data size for a specific MIC. Hence, the model M2B was robust to insufficient milking records per MIC, provided that the data are sufficient in general. Within MIC, the sum of AM and PM ACF for each model was close to zero (which ranged −0.031 with M1 to −0.108 with M2B). The ACF computed from the linear regression model (M3B) were considerably larger than those based on the two ACF models (M1 and M2B). This was because the estimated regression coefficients (approximately 1.75; Table 4) from the linear regression models were less than the fixed regression coefficients (2.0) assumed in the ACF model. Hence, the classic ACF models provided additive adjustments to two times AM or PM milk yields as the estimated DMY. Still, the linear regression models provided additive adjustments to approximately 1.75 times AM or PM milk yields. Because of this difference, the ACF from the linear regression model should be larger than those from the ACF models. The sum of AM and PM ACF within MIC was greater than zero (i.e., 8.24 kg) for the model M3B, with the average ACF being 4.11 kg, in the Holstein cows. The average ACF from the linear regression model can be verified as follows. In the Holstein cows, the average AM and PM milk yields were 16.4 and 15.3 kg, respectively. The regression coefficients for AM and PM milk yields by the separate analyses were 1.72 and 1.78, respectively. Hence, the average difference in ACF between the linear regression model and the ACF model was approximately estimated to be
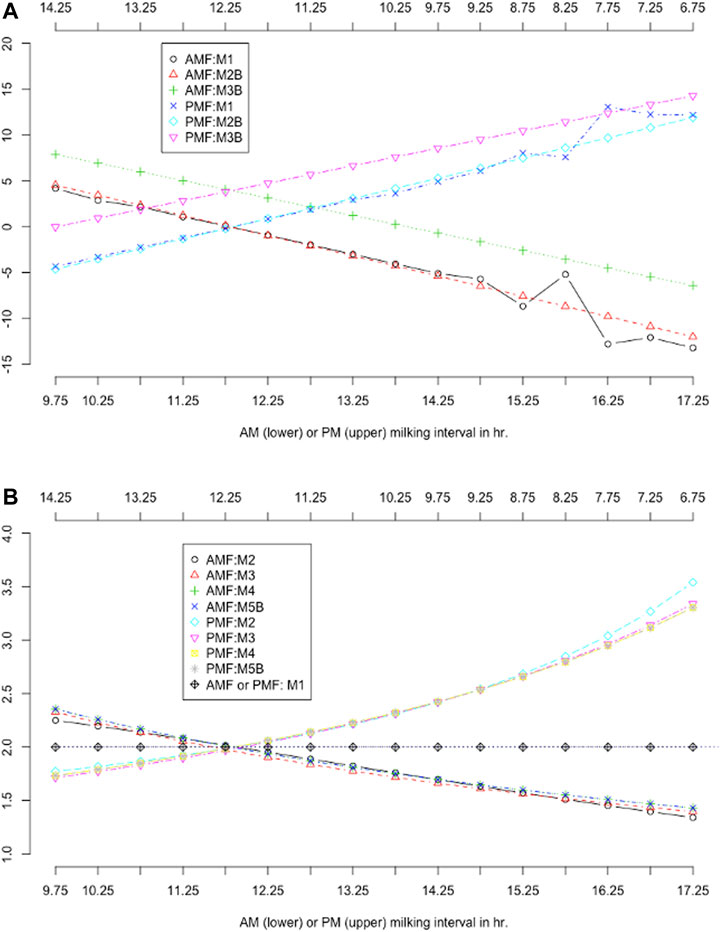
FIGURE 7. Comparison of additive correction factors (A) and multiplicative correction factors (B) obtained using different models. AMF = morning milk yield correction factors; PMF = evening milk yield correction factors. M0 = daily milk yield (DMY) estimated as two times AM or PM yield; M1 = additive correction factors (ACF) model with categorical milking interval (MIC) and lactation months; M2B = ACF model with continuous milking interval and days in milk (DIM); M3B = linear regression of DMY on milking interval and DIM, with ACFs computed for discretized MIC; M5 = multiplicative correction factor (MCF) model according to Shook et al. (1980); M6 = MCF model according to DeLorenzo and Wiggans (1986); M7B = MCF model according to Wiggans (1986); M8B = MCF model based on the exponential regression model (Wu et al., 2022).
With equal (12–12 h) AM and PM milking intervals, the ACF obtained from the M1 and M2B models were all close to zero (0.09–0.123 kg in Holstein cows and -0.67–0.41 kg in Jersey cows). Because these two models each assumed a fixed regression coefficient of 2.0 for the AM or PM milk yield, we concluded that doubling AM or PM milk yields provided an approximate estimate of DMY with equal AM and PM milking intervals. Put in another way. With equal AM and PM milking intervals, the additive correction amount was zero beyond two-time AM or PM milk yield as the estimated DMY. The results agreed with some early studies. For example, Everet and Wadell (1970b) showed that the mean AM excluding PM milk production was -0.51–0.19 kg in Holstein cows and −0.35–0.27 kg in Jersey cows with approximately equal AM and PM milking intervals (720–749 min). In the present study, the average AM minus PM milk yield was 1.13 kg in Holstein cows and 1.75 kg in Jersey cows. Similarly, Everet and Wadell (1970b) reported that the average AM minus PM milk yield in Holstein cows was 1.28 kg in Holstein cows and 0.89 kg in Jersey cows. Both studies agreed with each other concerning the average AM minus PM milk yield, despite a 50-year gap. Nevertheless, the ranges of AM minus PM milk yield (and ACF) in our study were significantly larger than the ranges in Everet and Wadell (1970b) because daily milk production has increased considerably over the past decades.
Unlike the ACF model, the MCF models implemented substantially different modeling strategies (Table 2). Nevertheless, the computed MCF from various models all corresponded to ratios of daily-to-single milk yields, despite their statistical interpretations varied (Wu et al., 2022). Hence, MCF obtained using various methods were approximately comparable in the Holstein cows (Figure 7B). MCF agreed well between the four MCF models given AM milking between 11 and 15 h, or PM milking between 9 and 13 h. Yet, large differences were observed out of this range. MCF were approximately 2.0 when AM and PM milking intervals were both 12 h. The AM MCF was greater than 2.0 when the AM milking interval was less than 12, and it was less than 2.0 when the AM milking interval was greater than 12 h. A precisely opposite trend was observed with the PM MCF. These results again suggested that two times AM or PM milk yield was an approximate estimate of DMY with equal AM and PM milking intervals. Still, such approximation did not hold with uneven AM and PM milking intervals. Similar results were observed in Jersey cows as well.
Conclusion
Estimated milk yields by doubling AM or PM milk yields were taken approximately assuming equal AM and PM milking intervals, but they were subject to large errors when AM and PM milking intervals were unequal. The more deviations of AM and PM milking intervals from 12–12 h, the larger errors it generated. ACF and MCF provided effective adjustments to the estimated DMY with unequal AM and PM milkings. ACF provided additive adjustments, evaluated by the expected difference between AM and PM milk yield for each MIC and other categorical variables when applicable. An ACF model equivalently assumed a fixed multiplier (2.0) for AM or PM milk yields. In reality, ACF models with many discrete variables are challenged by insufficient or missing data points for specific MIC categories. Similarly, a linear regression model was implemented as an ACF model which nevertheless estimated the multiplier (regression coefficient) for AM or PM milk yield from the data. Relaxing the limitation on the fixed multiplier for AM and PM milkings allowed linear regression models to fit and predict the data better than ACF models. Multiplicative correction factors were computed by ratios of daily yield to yield from a single milking. Thus, multiplying a known AM or PM yield by an MCF gave an estimated DMY. Overall, the MCF models outperformed the ACF models, providing more accurate DMY estimates in the Holstein and Jersey cows. Nevertheless, computed ACF or MCF on discretized milking interval time suffered from losing information, leading to larger errors and lower accuracies. The exponential regression model (Wu et al., 2022) had the smallest MSE and the greatest accuracies of DMY estimates. This new model is analogous to an exponential growth (or decay) function for DMY with the observed yield from single milking as the initial state and the change rate tuned by a linear function of milking interval and other variables when applicable. This exponential regression model provides a promising alternative tool for estimating DMY.
The present study represented a preliminary effort to revisit the existing statistical methods for estimating DMY, compared to the newly proposed exponential regression model, using milking data collected between 2006 and 2009. In a continuing effort, large-scaled high-resolution milking data are being collected for follow-up studies, jointly supported by the US Council on Dairy Cattle Breeding, the USDA Agricultural Genomics and Improvement Laboratories, and the National Dairy Herd Information Association. This is a 3-year data collection project. We expect that MCF in use will be updated by then. Finally, we illustrated the methods for estimating DMY in AM and PM milking plans. Yet, these methods and principles are generally applicable, either directly or with necessary modifications, to cows milked more than two times a day.
Data Availability Statement
The data analyzed in this study are subject to the following licenses/restrictions: The Holstein and Jersey milking record data maintained by CDCB are not publicly available, but can be requested to JD, subject to signing an official agreement for non-commercial use only. Requests to access these datasets should be directed to Joao Durr, ZHVyckB1c2NkY2IuY29t">Joao,ZHVyckB1c2NkY2IuY29t.
Author Contributions
X-LW conceived and designed this study, with a series of discussion meetings with GW, HDN, AM, CVT, RB, JB, and JD. X-LW carried out the data extraction and data analyses and drafted this manuscript. All authors have reviewed and approved the final manuscript.
Funding
This project was financially supported by CDCB, a non-profit organization for dairy genetic/genomic evaluations and data storage.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Bailey, G. L., Clough, P. A., and Dodd, F. H. (1955). The Rate of Secretion of Milk and Fat. J. Dairy Res. 22, 22–36. doi:10.1017/s0022029900007512
Cole, J. B., Null, D. J., and VanRaden, P. M. (2009). Best Prediction of Yields for Long Lactations. J. Dairy Sci. 92, 1796–1810. doi:10.3168/jds.2007-0976
Craven, P., and Wahba, G. (1979). Smoothing Noisy Data with Spline Functions. Numer. Math. 31, 377–403.
DeLorenzo, M. A., and Wiggans, G. R. (1986). Factors for Estimating Daily Yield of Milk, Fat, and Protein from a Single Milking for Herds Milked Twice a Day. J. Dairy Sci. 69, 2386–2394. doi:10.3168/jds.s0022-0302(86)80678-6
Elliott, G. M., and Brumby, P. J. (1955). Rate of Milk Secretion with Increasing Interval between Milking. Nature 176, 350–351. doi:10.1038/176350a0
Everett, R. W., and Wadell, L. H. (1970a). Relationship between Milking Intervals and Individual Milk Weights. J. Dairy Sci. 53, 548–553. doi:10.3168/jds.s0022-0302(70)86251-8
Everett, R. W., and Wadell, L. H. (1970b). Sources of Variation Affecting the Difference between Morning and Evening Daily Milk Production. J. Dairy Sci. 53, 1424–1429. doi:10.3168/jds.s0022-0302(70)86410-4
Hawkins, D. M., and Douglas, M. (2004). The Problem of Overfitting. J. Chem. Inf. Comput. Sci. 44, 1–12. doi:10.1021/ci0342472
Lien, D., Hu, Y., and Liu, L. (2017). A Note on Using Ratio Variables in Regression Analysis. Econ. Lett. 150, 114–117. doi:10.1016/j.econlet.2016.11.019
Liu, Z., Reents, R., Reents, R., Reinhardt, F., and Kuwan, K. (2000). Approaches to Estimating Daily Yield from Single Milk Testing Schemes and Use of a.m.-p.M. Records in Test-Day Model Genetic Evaluation in Dairy Cattle. J. Dairy Sci. 83, 2672–2682. doi:10.3168/jds.s0022-0302(00)75161-7
McDaniel, B. T. (1973). Merits and Problems of Adjusting to Other Than Mature Age. J. Dairy Sci. 56, 959–967. doi:10.3168/jds.s0022-0302(73)85286-5
Neal, H. D. S. C., and Thornley, J. H. M. (1983). The Lactation Curve in Cattle: A Mathematical Model of the Mammary Gland. J. Agric. Sci. 101, 389–400. doi:10.1017/s0021859600037710
Norman, H. D., Meinert, T. R., Schultz, M. M., and Wright, J. R. (1995). Age and Seasonal Effects on Holstein Yield for Four Regions of the United States over Time. J. Dairy Sci. 78, 1855–1861. doi:10.3168/jds.s0022-0302(95)76810-2
Putnam, D. N., and Gilmore, H. C. (1970). Factors to Adjust Milk Production to a 24-hourbasiswhen Milking Intervals Are Unequal. J. Dairy Sci. 53, 685.
Putnam, D. N., and Gilmore, H. C. (1968). The Evaluation of an Alternate AM-PM Monthly Testing Plan and its Application for Use in the DHIA Program. J. Dairy Sci. 51, 985.
Ragsdale, A. C., Turner, C. W., and Brody, S. (1924). The Rate of Milk Secretion as Affected by an Accumulation of Milk in the Mammary Gland. J. Dairy Sci. 7, 249–254. doi:10.3168/jds.s0022-0302(24)94019-7
Schaeffer, L. R., Jamrozik, J., Van Dorp, R., Kelton, D. F., and Lazenby, D. W. (2000). Estimating Daily Yields of Cows from Different Milking Schemes. Livest. Prod. Sci. 65, 219–227. doi:10.1016/s0301-6226(00)00153-6
Schmidt, G. H. (1960). Effect of Milking Intervals on the Rate of Milk and Fat Secretion. J. Dairy Sci. 43, 213–219. doi:10.3168/jds.s0022-0302(60)90143-0
Schutz, M. M., Bewley, J. M., and Norman, H. D. (2010). Derivation of Factors to Estimate Daily Milk Yield from One Milking of Cows Milked Three Times Daily. J. Dairy Sci. 93 (E-Suppl. 1), 595.
Schutz, M. M., Bewley, J. M., and Norman, H. D. (2008). Derivation of Factors to Estimate Daily Yield from Single Milkings for Holsteins Milked Two or Three Times Daily. J. Dairy Sci. 91 (E-Suppl. 1), 106–107.
Schutz, M. M., and Norman, H. D. (1994). Adjustment of Jersey Milk, Fat, and Protein Records across Time for Calving Age and Season. J. Dairy Sci. 72 (E-Suppl. 1), 267.
Schutz, M. M., and Norman, H. D. (2011). Verification of Factors to Estimate Daily Milk Yield from One Milking of Cows Milked Twice Daily. J. Dairy Sci. 94 (E-Suppl. 1), 28–29.
Shook, G., Jensen, E. L., and Dickinson, F. N. (1980). Factors for Estimating Sample-Day Yield in Am-Pm Sampling Plans. DHI Lett. 56, 25–30.
Smith, J. W., and Pearson, R. E. (1981). Development and Evaluation of Alternate Testing Procedures for Official Records. J. Dairy Sci. 64, 466–474. doi:10.3168/jds.s0022-0302(81)82595-7
Stone, M. (1974). Cross-validatory Choice and Assessment of Statistical Predictions. J. R. Stat. Soc. Ser. B Methodol. 36, 111–133. doi:10.1111/j.2517-6161.1974.tb00994.x
VanRaden, P. M. (1997). Lactation Yields and Accuracies Computed from Test Day Yields and (Co)variances by Best Prediction. J. Dairy Sci. 80, 3015–3022. doi:10.3168/jds.s0022-0302(97)76268-4
Wiggans, G. R. (1986). Estimating Daily Yields of Cows Milked Three Times a Day. J. Dairy Sci. 69, 2935–2940. doi:10.3168/jds.s0022-0302(86)80749-4
Keywords: dairy cattle, days in milk, lactation, exponential growth function, milking interval
Citation: Wu X-L, Wiggans GR, Norman HD, Miles AM, Van Tassell CP, Baldwin RL, Burchard J and Dürr J (2022) Statistical Methods Revisited for Estimating Daily Milk Yields: How Well do They Work?. Front. Genet. 13:943705. doi: 10.3389/fgene.2022.943705
Received: 14 May 2022; Accepted: 23 June 2022;
Published: 10 August 2022.
Edited by:
Li Ma, University of Maryland, United StatesReviewed by:
Jose Denis-Robichaud, Independent researcherNavid Ghavi Hossein-Zadeh, University of Guilan, Iran
Copyright © 2022 Wu, Wiggans, Norman, Miles, Van Tassell, Baldwin, Burchard and Dürr. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xiao-Lin Wu, bmljay53dUB1c2NkY2IuY29t