 Keisuke Ejima
Keisuke Ejima Nianjun Liu
Nianjun Liu Luis Miguel Mestre
Luis Miguel Mestre Gustavo de los Campos
Gustavo de los Campos David B. Allison
David B. Allison- 1Department of Epidemiology and Biostatistics, Indiana University School of Public Health-Bloomington, Bloomington, IN, United States
- 2Lee Kong Chian School of Medicine, Nanyang Technological University, Singapore, Singapore
- 3Department of Global Health Policy, Graduate School of Medicine, The University of Tokyo, Tokyo, Japan
- 4Department of Epidemiology and Biostatistics, Michigan State University, East Lansing, MI, United States
- 5Department of Statistics and Probability, Michigan State University, East Lansing, MI, United States
- 6Institute for Quantitative Health Science and Engineering, Michigan State University, East Lansing, MI, United States
Mendelian randomization (MR) has become a common tool used in epidemiological studies. However, when confounding variables are correlated with the instrumental variable (in this case, a genetic/variant/marker), the estimation can remain biased even with MR. We propose conditioning on parental mating types (a function of parental genotypes) in MR to eliminate the need for one set of assumptions, thereby plausibly reducing such bias. We illustrate a situation in which the instrumental variable and confounding variables are correlated using two unlinked diallelic genetic loci: one, an instrumental variable and the other, a confounding variable. Assortative mating or population admixture can create an association between the two unlinked loci, which can violate one of the necessary assumptions for MR. We simulated datasets involving assortative mating and population admixture and analyzed them using three different methods: 1) conventional MR, 2) MR conditioning on parental genotypes, and 3) MR conditioning on parental mating types. We demonstrated that conventional MR leads to type I error rate inflation and biased estimates for cases with assortative mating or population admixtures. In the presence of non-additive effects, MR with an adjustment for parental genotypes only partially reduced the type I error rate inflation and bias. In contrast, conditioning on parental mating types in MR eliminated the type I error inflation and bias under these circumstances. Conditioning on parental mating types is a useful strategy to reduce the burden of assumptions and the potential bias in MR when the correlation between the instrument variable and confounders is due to assortative mating or population stratification but not linkage.
Introduction
Randomized experiments, often called randomized controlled trials, are the gold standard for drawing causal inferences. In randomized experiments, observational units (e.g., subjects) are randomly assigned to different levels of the variable being used to assess the causal effect, e.g., the treatment. The randomization process eliminates the influence of potential confounding variables on the exposure variable (e.g., treatment or control). Therefore, we can conclude that the observed difference in outcomes between groups in randomized controlled trials is purely caused by the treatment (barring stochastic variations). However, randomized experiments are not always ethical, feasible, or practical (Sanson-Fisher et al., 2007).
Observational studies do not always yield unbiased estimates of effects because of their lack of random assignment. Of the multiple limitations that these studies have, herein, we will only consider the bias due to confounding.
To mitigate confounding, researchers often include potential confounders in analyses as covariates in regression models or stratify analyses by confounders. Figure 1A depicts a general causal model with an exposure variable (
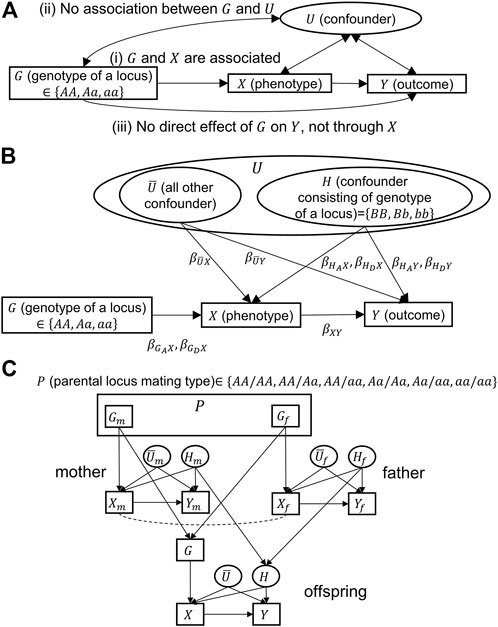
FIGURE 1. Causal models for Mendelian randomization. Directional and bidirectional arrows correspond to causal and associational relationships, respectively.
Mendelian randomization (MR) was proposed to address the issue of unmeasured confounders in observational studies (Smith and Ebrahim, 2003; Boutwell and Adams, 2020; Sanderson et al., 2022). MR uses genotypic (
However, MR rests on three assumptions (Emdin et al., 2017): “1) the genetic variant is associated with the risk factor; 2) the genetic variant is not associated with confounders; and 3) the genetic variant influences the outcome only through the risk factor.” In Figure 1A, these assumptions correspond to the following: 1)
Unfortunately, the violation of assumptions, especially the violation of assumption (2), is quite plausible: the genotype (
This paper consists of two parts. First, we demonstrate that the estimation using conventional MR (without conditioning on parental mating types) could lead to biased estimates, when there is a correlation between the instrumental variable and confounding variables due to assortative mating or population stratification. Second, we propose the use of parental mating types in conventional MR and to assess the utility of this approach.
Materials and methods
Mechanisms violating assumptions for MR: Assortative mating and population stratification
First, we define the variables, parameters, and error terms used in the simulation and analyses (summarized in Table 1), with explicit mathematical expressions and causal mechanisms. There are six variables:
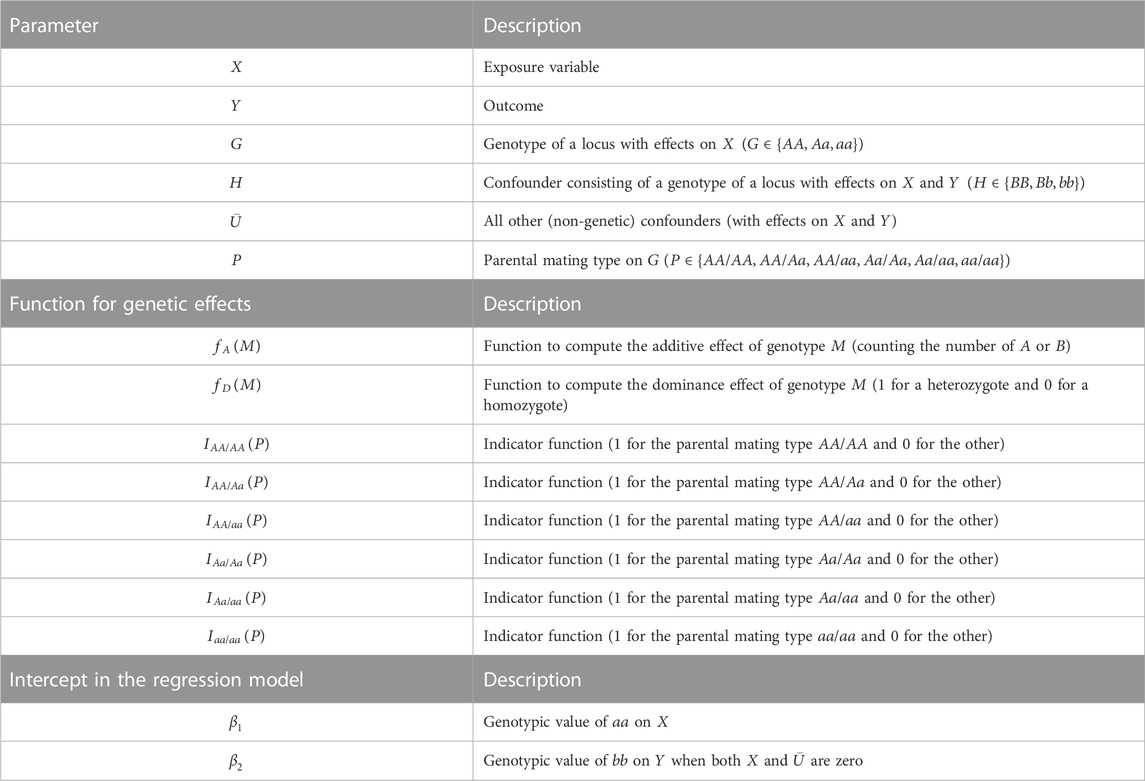
TABLE 1. Summary of variables, functions, and intercepts in regression models.
Figure 1B is a causal model in which the confounding variable set,
Situation 1: Assortative mating
In human and other animal populations, the choice of a mate does not plausibly occur at random. One may be more likely to mate with another who has specific phenotypes, resulting in non-random or assortative mating (Anonymous, 1903). For example, assortative mating for body mass index (BMI) or body fatness (i.e., individuals with a high BMI or body fatness are more likely to mate with one another, as are individuals with low BMI or body fatness) is widely observed (Allison et al., 1996; Silventoinen et al., 2003; Jackson et al., 2007). We modeled assortative mating as being dependent on the exposure variable
Briefly, the correlation between
Situation 2: Population stratification
Population stratification occurs and can create genotype–phenotype associations in the absence of linkage or a causal effect of the specific genotype on the specific phenotype, when a population consists of multiple subpopulations (Freedman et al., 2004) and some subpopulations have different allele frequencies and phenotypic distributions. By using the framework given in Figure 1C without assortative mating, we assume two different subpopulations. Therefore, within each subpopulation, three assumptions are held for conventional MR. The difference between the two populations is that they have different allele frequencies. If data from the two subpopulations were analyzed as a single population without accounting for the population substructure, they would yield a spurious association between
Correcting the bias in MR: Conditioning on parental mating types
Assuming the aforementioned two situations, the conventional MR estimation procedure can lead to biased estimates because MR assumption (2) is violated. To eliminate the bias, we propose conditioning on the parental mating type
In the following, we show details of three methods: conventional MR, MR conditioning on parental genotypes [a method proposed by Hartwig et al. (2018)], and MR conditioning on parental mating types (which we propose in this study). It should be noted that unmeasurable variables (variables in ovals, given in Figure 1C) do not appear in any of the analyses.
Conventional MR
1) Conventional MR uses the following model:
2) Then, the regression of
MR conditioning on parental genotypes
To correct for the bias in MR, Hartwig et al. (2018) proposed conditioning on parental genotypes. The analysis proceeds as follows:
1) MR conditioning on parental genotypes uses the following model:
2) The regression of
MR conditioning on parental mating types
Hartwig et al. (2018) assumed an additive model and, thus, used a parental genotype as an instrumental variable. However, if the effect of the parental genotype on an offspring’s phenotype is non-additive, using a parental mating type, i.e., a combination of parental genotypes taking one of the six possible values (Figure 1C), is more appropriate. The corresponding analysis proceeds as follows:
1) MR conditioning on parental mating types uses the following model:
2) The regression of
Simulations
To demonstrate the potential bias when conventional MR is used due to the violation of the MR assumption (2) and the utility of using parental mating types to eliminate the bias, we performed simulations considering assortative mating and population stratification.
For the simulation of each situation, we created data for 1,000 trio (father–mother–offspring) families (500 trios each for the population for situation 2) for a single simulation and performed three different analyses on each dataset. We repeated the process 1,000 times for each parameter setting. The type I error rate (when
Simulation 1: Assortative mating
The following is a step-by-step protocol and parameter setting for the simulation:
1) Allele frequencies of
2) The confounding variables for parents,
3) The exposure variables of parents,
4) The outcome of parents,
5) Proportion
6) The genotype of the offspring,
7) The exposure,
The sensitivity of the type I error rate and bias was assessed by changing
Simulation 2: Population stratification
The simulation setting for simulation 2 is similar to simulation 1 save for a couple of differences: 1) no assortative mating and 2) we assume two populations (i.e., subpopulation 1 and subpopulation 2) with different allele frequencies. Allele frequencies of
Results
The type I error rate for simulation 1 is shown in Figure 2A. Type I error inflation was observed for conventional MR and MR conditioning on parental genotypes, and it increased as the proportion involved in assortative mating increased. Type I error inflation was not observed for MR conditioning on parental mating types. Type I error inflation was mitigated by conditioning on parental genotypes to some extent, which still remained. The type I error rate for simulation 2 is shown in Figure 2B. Type I error inflation was observed for both conventional MR and MR conditioning on parental genotypes but not for MR conditioning on parental mating types. As shown in simulation 1, conditioning on parental genotypes reduced but did not eliminate type I error rate inflation. Interestingly, we observed a large type I error inflation when allele frequencies for the subpopulation were intermediate (0.5). This is because we assumed that homozygous genotypes (i.e.,
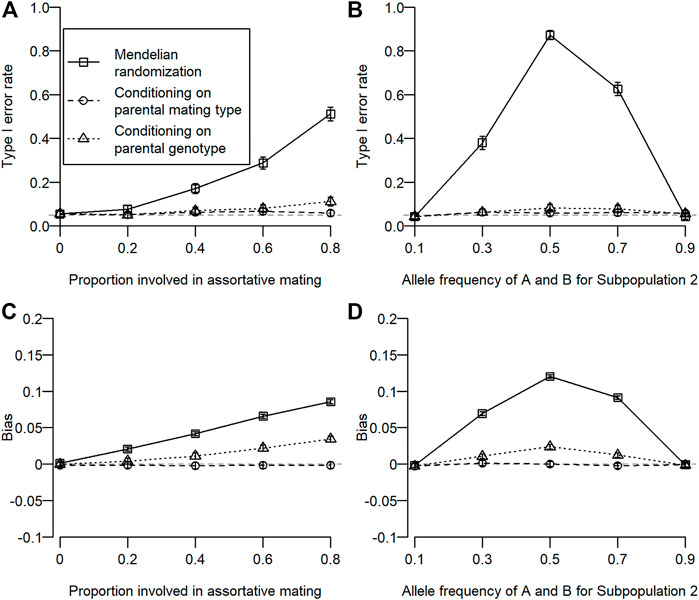
FIGURE 2. Type I error rate and bias of estimated coefficients for three different types of MR. Open squares, open circles, and open triangles correspond to conventional MR, MR conditioning on parental mating types, and MR conditioning on parental genotypes, respectively. For simulation 1, the proportion of the population involved in assortative mating was changed from 0 to 0.8. For simulation 2, allele frequencies of
The bias of the estimated coefficient is shown in Figures 2C, D. We observed similar results for the bias in estimation as in type I error rates. When type I error rate inflation was observed, a statistically significant bias was also observed, and magnitudes of type I error rate inflation and absolute bias were positively associated.
Discussion
MR has become a common approach for causal inference in epidemiology, as genetic data become more accessible owing to fast and efficient DNA sequencing technology and as journals and funding bodies encourage data sharing (Levey et al., 2009; Bloom et al., 2014; Loder and Groves, 2015). However, as for most epidemiological approaches, MR has essential assumptions we need to check before performing analysis. Among them, the assumption of no association between genetic variants used in MR and confounders [MR assumption (2)] could be violated or is difficult to check in practice. First, we demonstrated that MR produces inflation in type I error rates and a biased estimation in realistic settings where the assumption is violated. We introduced two plausible situations: assortative mating and population stratification. The sensitivity of type I error rates and estimation bias was assessed by changing parameters relevant to the violation of the MR assumption. As expected, we observed type I error inflation and estimation bias in these realistic settings when conventional MR was used, and such inflations and biases worsened as violations became more severe. They were mitigated by conditioning on parental genotypes to some extent; however, type I error inflation remained. Second, we proposed the use of parental mating types for a valid association inference for these two situations. We successfully confirmed that conditioning on parental mating types solves the problem in both situations.
We noted that we are not the first to propose the idea of considering parental genetic information in an epidemiological study. The idea was originally proposed in testing for linkages in the presence of associations (Allison, 1997). Redden et al. suggested using parental mating types in the inference of genotype–phenotype associations (Redden and Allison, 2006). Later, Liu et al. (2015) extended the idea to testing causal effects of a fetal drive. In this work, they showed the relationship between this idea and MR. In MR, the genetic variant needs to be a causal variant. However, it may be difficult to verify this assumption in practice, if not impossible. Conditioning on parental mating types is one way to identify causal genetic variants, thus relaxing assumptions, specifically assumption (2) of MR (resulting in the strengthening of MR). In the context of MR, Hartwig et al. proposed using parental genotypes in the case of assortative mating, which violates MR assumption (3) (Hartwig et al., 2018). They proposed two methods to integrate parental genotypes in MR analyses. The first method is to adjust conventional MR by parental allele scores, which we used in this study. The second method is to use parental non-transmitted allele scores and the offspring allele score as instrumental variables of parental and offspring exposure variables. They demonstrated that both methods provide unbiased estimates of the exposure–outcome association and avoid type I error inflation even under strong assortative mating conditions. The difference between the study by Hartwig et al. and ours is that we assumed that the locus influencing the outcome (
We list a few limitations of our approach. One apparent limitation is the data availability. Most genetic epidemiological research studies do not have (or is not designed to collect) parental genetic data (i.e., mother–father–offspring). However, because family trio data collection is considered to be a powerful tool for identifying rare diseases, even outside the context of MR, and owing to technological advancements in gene sequencing, the collection of family trio data may become more common (Infante-Rivard et al., 2009). In a recent study, Young et al. proposed imputing parental genotypes to reduce biases in GWA studies (Young et al., 2022). The imputation strategy presented in this study provides an opportunity to implement methods we proposed here for MR in situations where parental genotypes are not directly available. In this work, we propose that conditioning on parental genetic mating types can reduce assumptions needed for MR. We illustrate this key principle using a simulation study involving one locus with dominance effects. However, the approach we propose is general and does not require dominance effects. Indeed, our approach will also work under an additive model because the additive model is a special case of the more general model we use for conditioning. However, if the mode of action of the locus is strictly additive, conditioning on a parental allele dosage may be enough to reduce the bias. Therefore, in future studies, we plan to assess the superiority of conditioning on parental mating types relative to conditioning on allele dosages. Furthermore, we plan to assess the principle we proposed in a broader range of realistic circumstances. We are, particularly, interested in investigating two situations. The first is to evaluate the performance of the proposed approach in a multi-locus context for models involving epistatic interactions, which seem common (Zhu et al., 2015). The second situation is one where there is a selection bias on the exposure,
However, regardless of the limitations suggested previously, conditioning on parental mating types in MR can strengthen assumptions and help avoid type I error inflation and bias, when a heritable confounding variable is associated with the instrumental variable in MR.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found in: Zenodo (doi: 10.5281/zenodo.6972710).
Author contributions
DA conceived the research idea. KE, LM, GC, and NL implemented the simulation and performed the analyses. DA and GC oversaw data analyses. All authors were involved in the writing of the manuscript and gave final approval of submitted and published versions.
Funding
This work was supported in part by the National Institutes of Health (Grant numbers R25HL124208, R25DK099080, and R01AG057703 to DA; Grant numbers R03DE024198 and R03DE025646 to NL), the National Science Foundation (Grant number DMS 2002865 to NL), and the Japan Society for Promotion of Science KAKENHI (Grant number 18K18146 to KE).
Acknowledgments
The authors would like to thank Brian Boutwell (the University of Mississippi) for invaluable comments.
Conflict of Interest
DA and his institutions (Indiana University and the Indiana University Foundation) have received consulting fees, donations, grants, and contracts or promises for the same, from numerous not-for-profit, for-profit (including food, pharmaceutical, litigation, dietary supplement, and other entities), and government organizations with interests in health, causal inference, genetics, and statistics; however, none of these could reasonably be taken to represent a conflict of interest with this statistical methodology paper.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Allison, D. B., Neale, M. C., Kezis, M. I., Alfonso, V. C., Heshka, S., and Heymsfield, S. B. (1996). Assortative mating for relative weight: Genetic implications. Behav. Genet. 26 (2), 103–111. doi:10.1007/BF02359888
Allison, D. B. (1997). Transmission-disequilibrium tests for quantitative traits. Am. J. Hum. Genet. 60 (3), 676–690.
Anonymous (1903). Assortative mating in man: A cooperative study. Biometrika 2 (4), 481–498. doi:10.1093/biomet/2.4.481
Bloom, T., Ganley, E., and Winker, M. (2014). Data access for the open access literature: PLOS's data policy. PLoS Biol. 12 (2), e1001797. doi:10.1371/journal.pbio.1001797
Boutwell, B. B., and Adams, C. D. (2020). A research note on mendelian randomization and causal inference in criminology: Promises and considerations. J. Exp. Criminol. 18, 171–182. doi:10.1007/s11292-020-09436-9
Emdin, C. A., Khera, A. V., and Kathiresan, S. (2017). Mendelian randomization. JAMA 318 (19), 1925–1926. doi:10.1001/jama.2017.17219
Freedman, M. L., Reich, D., Penney, K. L., McDonald, G. J., Mignault, A. A., Patterson, N., et al. (2004). Assessing the impact of population stratification on genetic association studies. Nat. Genet. 36 (4), 388–393. doi:10.1038/ng1333
Hardy, G. H. (1908). Mendelian propositions in a mixed population. Science 28 (706), 49–50. doi:10.1126/science.28.706.49
Hartwig, F. P., Davies, N. M., and Davey Smith, G. (2018). Bias in Mendelian randomization due to assortative mating. Genet. Epidemiol. 42 (7), 608–620. doi:10.1002/gepi.22138
Infante-Rivard, C., Mirea, L., and Bull, S. B. (2009). Combining case-control and case-trio data from the same population in genetic association analyses: Overview of approaches and illustration with a candidate gene study. Am. J. Epidemiol. 170 (5), 657–664. doi:10.1093/aje/kwp180
Jackson, D. M., Stewart, J., Djafarian, K., and Speakman, J. R. (2007). Assortative mating for obesity. Am. J. Clin. Nutr. 86 (2), 316–323. doi:10.1093/ajcn/86.2.316
Levey, A., Stevens, L., Schmid, C., Zhang, Y., Castro, A., Feldman, H., et al. (2009). A new equation to estimate glomerular filtration rate. Ann. Intern Med. 150 (9), 604–612. doi:10.7326/0003-4819-150-9-200905050-00006
Liu, N., Archer, E., Srinivasasainagendra, V., and Allison, D. B. (2015). A statistical framework for testing the causal effects of fetal drive. Front. Genet. 5, 464. doi:10.3389/fgene.2014.00464
Loder, E., and Groves, T. (2015). The BMJ requires data sharing on request for all trials. BMJ 350, h2373. doi:10.1136/bmj.h2373
Pearl, J., Glymour, M., and Jewell, N. P. (2016). Causal inference in statistics: A primer. New York, NY: John Wiley & Sons.
Redden, D. T., and Allison, D. B. (2006). The effect of assortative mating upon genetic association studies: Spurious associations and population substructure in the absence of admixture. Behav. Genet. 36 (5), 678–686. doi:10.1007/s10519-006-9060-0
Sanderson, E., Glymour, M. M., Holmes, M. V., Kang, H., Morrison, J., Munafò, M. R., et al. (2022). Mendelian randomization. Nat. Rev. Methods Prim. 2 (1), 6–21. doi:10.1038/s43586-021-00092-5
Sanson-Fisher, R. W., Bonevski, B., Green, L. W., and D’Este, C. (2007). Limitations of the randomized controlled trial in evaluating population-based health interventions. Am. J. Prev. Med. 33 (2), 155–161. doi:10.1016/j.amepre.2007.04.007
Silventoinen, K., Kaprio, J., Lahelma, E., Viken, R. J., and Rose, R. J. (2003). Assortative mating by body height and BMI: Finnish twins and their spouses. Am. J. Hum. Biol. 15 (5), 620–627. doi:10.1002/ajhb.10183
Smith, G. D., and Ebrahim, S. (2003). Mendelian randomization': Can genetic epidemiology contribute to understanding environmental determinants of disease? Int. J. Epidemiol. 32 (1), 1–22. doi:10.1093/ije/dyg070
Young, A. I., Nehzati, S. M., Benonisdottir, S., Okbay, A., Jayashankar, H., Lee, C., et al. (2022). Mendelian imputation of parental genotypes improves estimates of direct genetic effects. Nat. Genet. 54 (6), 897–905. doi:10.1038/s41588-022-01085-0
Keywords: Mendelian randomization, genetic epidemiology, causal inference, study design, linkage disequilibrium
Citation: Ejima K, Liu N, Mestre LM, de los Campos G and Allison DB (2023) Conditioning on parental mating types can reduce necessary assumptions for Mendelian randomization. Front. Genet. 14:1014014. doi: 10.3389/fgene.2023.1014014
Received: 08 August 2022; Accepted: 17 February 2023;
Published: 06 March 2023.
Edited by:
Simon Charles Heath, Center for Genomic Regulation (CRG), SpainReviewed by:
Adrienne Tin, University of Mississippi Medical Center, United StatesKarl Skorecki, Bar-Ilan University, Israel
Copyright © 2023 Ejima, Liu, Mestre, de los Campos and Allison. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: David B. Allison, YWxsaXNvbkBpdS5lZHU=