 Marco Bilucaglia
Marco Bilucaglia Mara Bellati
Mara Bellati Alessandro Fici
Alessandro Fici Vincenzo Russo
Vincenzo Russo Margherita Zito
Margherita Zito- 1Behavior and Brain Laboratory IULM – Neuromarketing Research Center, Università IULM, Milan, Italy
- 2Department of Business, Law, Economics and Consumer Behaviour “Carlo A. Ricciardi, ” Università IULM, Milan, Italy
- 3Department of Philosophy and Cultural Heritage, Ca' Foscari University, Venice, Italy
Flavor, a multimodal perception based on taste, smell, and tactile cues, plays a significant role in consumer preferences and purchase intentions toward coffee. In this exploratory study, we assessed the potential of electroencephalography (EEG) and machine learning (ML) techniques to predict coffee sensory attributes. We extracted spectral and temporal features from a professional panel while tasting coffee samples and basic water solutions. We trained multiple Least-Squares Boosted Trees (LSBoost) and optimized their hyperparameters through a 100-step Bayesian approach based on a Leave-One-Subject-Out (LOSO) scheme. The models achieved, overall, high predictive accuracy (MAE < 0.75 on a 0 − 10 scale) and medium-to-large robustness (Cohen'sd>0.6) with respect to mean and lasso benchmark regressors. Feature importance analysis revealed that spectral powers and Hjorth's parameters within parietal, central, and frontal regions were the most predictive. Our findings endorse the use of EEG-based ML models as an alternative to traditional flavor evaluation methods, such as Descriptive Sensory Analysis (DSA).
1 Introduction
Coffee stands as the major component of the global hot drink market, with a worldwide production exceeding 176 million bags and consumption reaching 7 billion kilograms (Kim Y. et al., 2025). Among over 60 coffee plant species, only 10 are extensively cultivated, with Coffea arabica (arabica), Coffea canephora (robusta), and Coffea liberica being the most prevalent (Feria-Morales, 2002). Arabica and robusta make up 99% of global production (Jayakumar et al., 2017) and commercial coffee typically results from blending their beans in varying proportions (Seninde and Chambers, 2020).
Consumer preference and purchasing intentions for coffee are mainly driven by subjective factors, such as taste, aroma, and body (Li et al., 2019). These elements belong to the broader concept of flavor, a multimodal experience in which gustatory, olfactory, trigeminal, and somatosensory inputs are individually processed before being integrated (Small, 2012). Gustatory signals ascend via the nucleus of the solitary tract (NST) and ventroposteromedial nucleus (VPM) to the primary taste cortex in the rostral insula and adjoining frontal operculum, where the identity and intensity of basic tastes, as well as oral texture and temperature, are encoded. Retronasal olfactory inputs, initially processed in the piriform cortex, converge with gustatory signals in the orbitofrontal cortex (OFC), which also integrates oral somatosensory and trigeminal inputs such as viscosity, temperature, irritation, and astringency (Rolls, 2005). Within the OFC, convergent inputs give rise to multimodal flavor representations, in which sensory modalities are integrated and assigned hedonic value. At the same time, projections to the amygdala and anterior cingulate cortex (ACC) further embed these representations within affective and motivational systems (Small, 2012).
Flavor assessment often relies on Descriptive Sensory Analysis (DSA), wherein expert panels assign numerical scores to standardized sensory attributes (Yang and Lee, 2019). Various coffee attributes have been suggested (Spencer et al., 2016). However, only bitter, sour, sweet, and astringent (i.e., mouth-drying sensation) have established reference solutions (Batali et al., 2022).
Based on self-reports, DSA can be confounded by physiological and psychological biases. Physiological phenomena include sensory adaptation and multimodal enhancement/suppression. Psychological phenomena include expectation, stimulus/proximity/logical errors, habituation, halo effect, presentation order, mutual suggestion, and central/extreme rating tendency (Stone et al., 2021; Civille et al., 2024). To mitigate these risks, international standards (e.g., ISO 13299, ISO 11132, and ISO 8586) and the scientific literature recommend extraneous cues blinding, randomized or Williams-balanced presentations, adequate rests/rinses alternation, and ongoing panel performance monitoring (Sipos et al., 2021). Additionally, direct techniques based on bioelectrical measures have recently been advocated (Torrico et al., 2023; Rodrigues et al., 2024).
Previous studies have explored the use of electroencephalography (EEG) for flavor assessment. Global field power and scalp topographies (Crouzet et al., 2015), as well as phase in the delta band (Wallroth et al., 2018) and spectral powers in alpha and theta bands (Yang et al., 2023) have emerged as candidate neurometrics. Similar results, involving alpha, beta, and theta powers, have been observed in coffee tasting tasks (Hsu and Chen, 2021; Tonacci et al., 2024). However, their correlational—rather than causal—nature poses a risk of reverse inference problems (Poldrack, 2006). Pattern-decoding methods based on Machine Learning (ML) models have been suggested to mitigate this issue (Nathan and Del Pinal, 2017). Furthermore, being free of rigid theoretical assumptions, ML methods could also be helpful in revealing latent structures in the data, providing new theoretical insights and hypotheses (Verzelli et al., 2024).
Research on flavor prediction with ML and EEG data is still limited (see the following Section 2 for details). Most of the studies employed basic water solutions as eliciting stimuli, and the few examining coffee focused on other target variables than taste. Moreover, nearly all existing models were classifiers to discriminate among basic tastes (e.g., sour, sweet, bitter, salty, umami, and neutral) instead of predicting the intensity level of sensory attributes. Therefore, such models are ill-suited to replace or even complement traditional DSA.
To address these limitations, we performed an exploratory study recording the EEG data from expert coffee tasters while they tasted both reference solutions and coffee samples. We trained multiple tree-based ensemble regressors to predict the intensity level of bitter, sweet, acid and astringent, achieving high performances and robustness against benchmark models. We interpreted the fitted models, identifying as most informative, spectral and temporal features within parietal, central and frontal regions.
2 Related work
As previously mentioned, most of the past studies on taste prediction using EEG data and ML methods trained classifiers to discriminate among basic water solutions. De et al. (2023) fed temporal (maximum/minimum values, mean, kurtosis and skewness) and spectral [Power Spectral Densities (PSDs) in theta, delta, alpha and beta bands] features into a Long Short-Term Memory Recurrent Neural Network (LSTM-RNN) to discriminate sour, sweet, bitter, salty, umami, and neutral solutions from 46 subjects. They obtained an accuracy of 97.16%. Xia et al. (2024) employed a Convolutional Neural Network (CNN) with spatiotemporally augmented raw EEG data to identify sour, sweet, bitter, and salty solutions from 20 subjects. They reached 99.5% of accuracy. Li et al. (2025) trained a Support Vector Machine (SVM) with spectral features (wavelet decompositions in α and θ bands) to classify sour, sweet, bitter, salty, and umami solutions from 22 subjects. They reported a maximum accuracy of 76.13%. Vo et al. (2023) trained a feed-forward Neural Network (NN) using spectral features (powers in delta, theta, alpha, beta, and gamma bands) to discriminate between salty and sour solutions from 15 people. The accuracy was 84.36%.
Only one study moved from discrimination to intensity level prediction. Zhao et al. (2022) contrasted linear, tree, and ensemble regressors, trained with temporal and information-related features (energy, absolute mean value, and wavelet entropy), to predict the intensity level of sour, sweet, bitter, salty, and umami from 10 subjects. The best model, Extreme Gradient Boosting (XGBoost), achieved a goodness-of-fit (measured through the R2 coefficient), ranging from −0.22 to 0.18.
Two studies focused on other-than-basic water solutions. González-España et al. (2023) aimed to discriminate wine vs. water and wine vs. wine tasting tasks of 10 participants through an SVM with temporal and spatial features (global field powers and channel averages). They reported accuracies greater than the chance level of 70% for both predictions. Naser and Aydemir (2024) trained a k-Nearest Neighbors (kNN) and a Random Forest (RF) with temporal and spectral features (mean value of the Hilbert-transformed EEG signal and level-2 wavelet coefficients) to discriminate four food substances (oils of Orange, Mint, Thyme, and Clove) from 10 subjects. The highest accuracy, obtained with the kNN, was 87.5%.
Coffee was selected as an eliciting stimulus in two studies. However, as previously mentioned, the target belonged to other aspects than taste. Maram et al. (2023) trained a CNN with raw EEG data to classify the preference of 3 coffee brands from 12 participants, obtaining an accuracy of 83.43%. Xu et al. (2021) compared several Bayesian Regression (BR) models, trained with spectral features (powers in theta, alpha, beta, and gamma bands), to predict the emotional responses to tasting tasks from 32 subjects. The best model achieved a goodness-of-fit [measured through the Watanabe-Akaike Information Criterion (WAIC)] of 963.55.
3 Materials and methods
3.1 Study population
A total of 15 subjects (9 females) in the age range 24–59 years (M = 40.13, SD = 13.80) took part in the experiment. They were recruited as professional coffee tasters with proficiency in DSA and grouped as trained (T, less than 3 years of experience) or experts (E, more than 3 years of experience). Despite the sample size being below the average when compared to the surveyed past studies (i.e. 19.67 ± 12.31, range: 10 − 46), it was still in line with DSA studies that typically consist of 5–15 experts (Gacula and Rutenbeck, 2006).
The participants resulted group- and gender-balanced in terms of mean age [t(13) = 0.818, p = 0.428 and t(13) = 1.034, p = 0.320, respectively]. However, the groups resulted in an unbalanced in terms of gender proportion [E: 2 females, T: 7 females, χ2(1) = 5.402, p = 0.020].
A sensitivity analysis performed with G*Power (Faul et al., 2007) considering a within-between design with 2 groups, 8 measures, and standard parameters (α = 0.05, 1−β = 0.95, ϵ = 1, ρ = 0.5) confirmed a minimum detectable effect size of f = 0.302, interpreted as medium-to-large (Cohen, 1992).
The study was approved by the Ethical Committee of Universitá IULM (approval number: 0067814). All the procedures adhered to the guidelines of the Helsinki Declaration, and informed consent was secured from each participant.
3.2 Instrumentation
The EEG was acquired using the NVX-52 device (Medical Computer System Ltd.) from 38 Ag/AgCl scalp electrodes, 2 Ag/AgCl ear clips (A1 and A2), and 1 adhesive Ag/AgCl patch placed on the left mastoids (M1). The electrode positioning, detailed in Bilucaglia et al. (2024), followed the 10-10 system (Nuwer, 2018), and the montage was monopolar, reference-free, and grounded to M1. Neorec software (Medical Computer System Ltd) was used to record the data at a sample frequency of 2kHz and a resolution of 24bits.
The iMotions software (iMotions A/S) was used to deliver the experiment instructions and collect the sensory evaluations.
Data synchronization was ensured by a transistor-to-transistor (TTL) pulse, sent by iMotions at the beginning of the experiment and fed into the NVX-52 by means of the ESB synchronization box (Bilucaglia et al., 2020).
All computations were carried out on a workstation equipped with an AMD Ryzen™ Threadripper PRO 5975WX CPU (32 cores, 64 threads, 3.6 GHz base clock) and 256 GB of DDR4-3,200 MHz ECC. No GPU acceleration was used. Code was executed in MATLAB R2024b (The Mathworks, Inc.) with Statistics and Machine Learning Toolbox 12.3.
3.3 Experimental protocol
The experiment consisted of a starting 60s eye-closed baseline (BSL) and two experimental phases, namely benchmark (Be) and coffee (Co).
The Be phase involved 4 tasting trials with solutions of sucrose (20g/l), caffeine (0.6g/l), citric acid (0.6g/l), and potassium aluminum sulfate (1g/l), to elicit sweet, bitter acid, and astringent flavors respectively (Anbarasan et al., 2022). Micro-filtered mineral water was used as diluent. According to Rousmans et al. (2000), the exact concentration of the solutions was determined from a previous pilot test.
According to Abubakar et al. (2020), the Co phase involved four tasting trials with coffees at various arabica/robusta ratios (100:0, 80:20, 85:15, and 70:30).
The phase order was fixed (i.e., first Be and then Co), and the tasting trials were randomized within each phase.
The administration of liquids was masked. The Be solutions were served at room temperature, while the Co at approximately 60°C. According to Di Flumeri et al. (2017), participants were instructed to rinse the palate with a glass of water before any tasting trial (WR task) and to keep the liquid (solution or coffee) in the mouth for 10s (TL task) before swallowing. At the end of each tasting trial, subjective ratings for bitter, astringent, sweet, and acid attributes were collected on a 0 − 10 scale.
The following Figure 1 summarizes the experimental protocol.
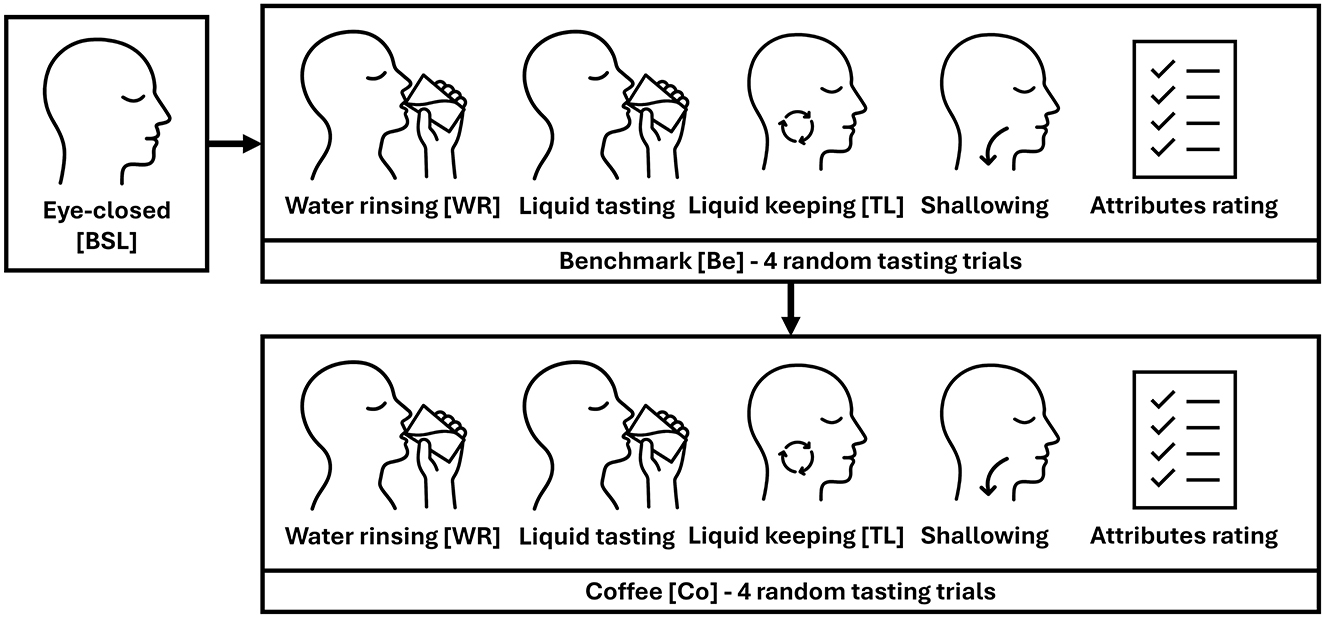
Figure 1. Schematic representation of the experimental protocol.
3.4 Data processing
Data processing was performed using the EEGLab toolbox (Delorme and Makeig, 2004). The EEG was resampled at 512Hz and filtered in the 0.1 − 40Hz band (IV zero-phase Butterworth filter). Power line interference (50 and 100Hz) was reduced through the CleanLine, a multi-taper-based regression technique (Bokil et al., 2010), while non-stationary artifacts were corrected using the Artifact Subspace Reconstruction (ASR) method (Chang et al., 2020) with standard cutoff parameter (κ = 20). ASR represents the gold standard for handling high-amplitude artifacts, such as those related to locomotor tasks in real-world and Mobile Brain Imaging (MoBI) contexts (Kim H. et al., 2025). Independent component analysis (ICA) decomposition was carried out using the second-order blind identification (SOBI) algorithm (Urigüen and Garcia-Zapirain, 2015) on a resampled (100Hz) and heavily filtered (1 − 30Hz, IV order zero-phase Butterworth filter) copy of the data. According to Bilucaglia et al. (2024), the resulting weight matrix was multiplied by the original data to obtain the independent components (ICs). The ICLabel classifier (Pion-Tonachini et al., 2019) was used to detect artifactual ICs as those with not-brain probability Pr{!brain}≥0.9. On average, 3.8 ± 1.373 (min = 2, max = 7) artifactual ICs over 38 were identified and removed. Finally, a re-reference to the approximately zero ideal potential was performed through the Representational State Transfer (REST) algorithm (Yao, 2001).
The cleaned EEG was offline aligned to the starting TTL pulse and epoched according to the experimental phases (i.e., EYC and TL tasks of Be and Co). The following Figure 2 shows a representative segment of raw and pre-processed EEG data.
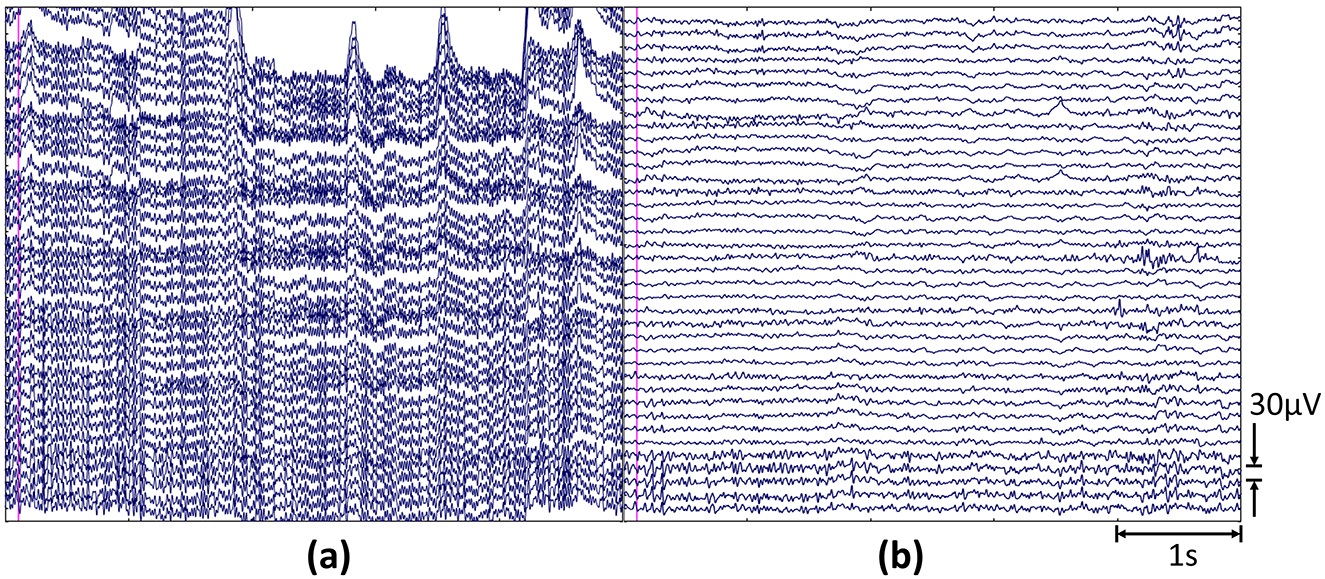
Figure 2. Representative 5s−long segments showing the (a) raw and (b) pre-processed EEG signal. The data refer to the TL task of As solution, with onset marked by the pink vertical line.
For each subject, the Individual Alpha Frequency (IAF) was computed as the center of gravity of the Power Spectral Density (PSD) in the extended (7.5 − 12.5Hz) alpha band (Klimesch, 1999). As PSD, the average occipital Welch's PSD (1s−long Hamming window at 50% of overlapping) estimated in the BSL epoch was considered (Bilucaglia et al., 2019). The IAF served to define the following subject-specific δ, θ, α, β, and γ EEG bands (Borghini et al., 2019):
3.5 Feature extraction
Features were extracted exclusively from WR and TL epochs, thereby excluding non-task-related activity that could also have been potentially contaminated by residual muscle artifacts. For each channel C and band B = {δ, θ, α, β, γ}, normalized spectral powers pC, B were computed as (Bilucaglia et al., 2022):
where xC(f) is the Welch's PSD (1s−long Hamming window with 50% of overlapping).
Additionally, the following activity (AC), mobility (MC), and complexity (CC) temporal parameters were computed as (Hjorth, 1970):
where σ{·} is the temporal variance operator.
Expertise level (group) and age were also considered, since their impact on flavor evaluation has been previously reported (Croijmans and Majid, 2016; Mojet, 2003).
The feature vectors (306 − long) were finally obtained by concatenating spectral (38 × 5 = 190) and temporal (38 × 3 = 114) vectors, as well as age and group (categorical: T, E) scalars. For each tasting trial T and each phase P, the TL vectors xT, P were normalized with respect to the WL vectors yT, P as:
where ⊘ represents the Hadamard (i.e., element-wise) division operator.
Three datasets corresponding to the Be and Co phases (60 × 306 each) as well as the BeCo (120 × 360) consisting of the normalized TL vectors were finally built. The target variables y, consisting of the attribute ratings, were transformed as log(1+y), following general recommendations for ratio scales (Keene, 1995).
3.6 Model training and evaluation
The selected model was LSBoost, a least-squares variant of Boosted Trees (Friedman, 2001). It was chosen for the enhanced predictive performance, as a non-linear ensemble method, and because it incorporates feature selection within the weak learners (Decision Trees, DTs). Regressors belonging to the boosted trees family have been previously shown to outperform in EEG prediction tasks (Hussain et al., 2019; He et al., 2022; Isabona et al., 2022).
LSBoost's tunable hyperparameters included the number of learners (n) and the learning rate (ρ), while DTs' ones included the leaf size (ls) and the maximum number of splits (ns). Since the dataset pre-processing is known to impact the performance of the EEG-based prediction models (Apicella et al., 2023; Tryon et al., 2025), different standardization techniques (S) were also considered. They included the subject-wise z-score and min-max normalisations, as well as a non-linear transformation based on the median value (Arevalillo-Herráez et al., 2019) and the lack of standardization (none).
The best hyperparameters were obtained through a Bayesian optimization (Snoek et al., 2012), considering the cross-validated Mean Absolute Error (MAE) as objective function . This solved the following Combined Algorithm Selection and Hyperparameter (CASH) problem (Kotthoff et al., 2017):
where n∈[1 − 500], ρ∈[0.01, 1], ls, ns∈[1 − 100] and S∈{z-score, minmax, median, none}.
The maximum number of evaluations was set to 100 and the seed was fixed at rng(1), to ensure replicability.
The cross-validation followed a Leave-One-Subject-Out (LOSO) (Fazli et al., 2009) scheme to address the subject-wise data dependence.
As baselines for a robust model evaluation, a regressor constantly predicting the training set's mean target (Me) and a lasso regressor (LR) (Tibshirani, 1996) were additionally fitted following the same LOSO approach. The lasso's penalisation term λ was set at (Bühlmann and Van De Geer, 2011, p. 14):
where n = 56 and p = 306 are the dimensions of the training set.
The cross-validated MAEs of LSBoost vs. Me and LBoost vs. LR were compared by means of the following Cohen's d-scores (Goulet-Pelletier and Cousineau, 2018):
where , m(·) and s(·) are the mean and standard deviation of the cross-validated MAEs, respectively. Cutoffs for small, medium, and large differences are placed at 0.2, 0.5, and 0.8, respectively (Cohen, 1992).
The significance at α = 0.05 level of each d coefficient was assessed from its 95% Confidence Intervals, estimated from a non-central t distribution (Goulet-Pelletier and Cousineau, 2018).
To assess the predictive power of the features, models showing significant dMe, LR coefficients were trained on the complete datasets using optimal hyperparameters. Then, LSBoost's feature importance scores were extracted, normalized to the total importance score, and then summed across the channels. According to Bilucaglia et al. (2019), a topographic map showing the feature importance distribution was then obtained by averaging the scores across datasets, targets, and models.
4 Results
Four models reported significant improvements from the benchmarks, with an overall MAE of 0.537 ± 0.073 (anti-log:0.714 ± 0.124) and d scores of dMe = 0.858 ± 0.341, dLR = 0.897 ± 0.326. The targets were Bi (trained on Be), Sw (on Be), Ac (on Co), and As (on BeCo).
The Ac prediction obtained the best MAE (Co: 0.459 ± 0.178), while Sw the worst one (Be: 0.600 ± 0.282). The highest robustness against benchmark regressors was achieved by Bi trained on Be (dMe = 1.344, dLR = 1.372), while the lowest one was observed for Sw trained on Be (dMe = 0.651, dLR = 0.660).
The following Table 1 reports the best hyperparameters and the training time (in seconds) of the significant models, split for dataset and target. The following Table 2 summarizes the performances (cross-validated MAEs and Cohen's d coefficients) of the significant models, split for datasets and targets.
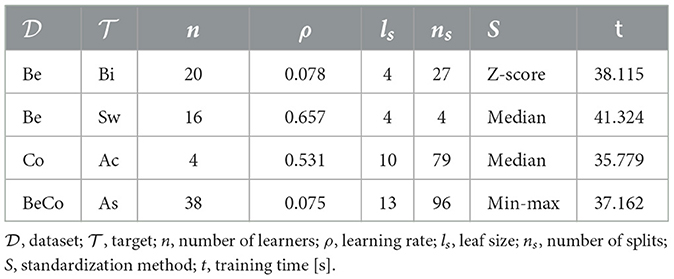
Table 1. Significant models with best hyper-parameters and training time (in seconds) split for dataset and target.
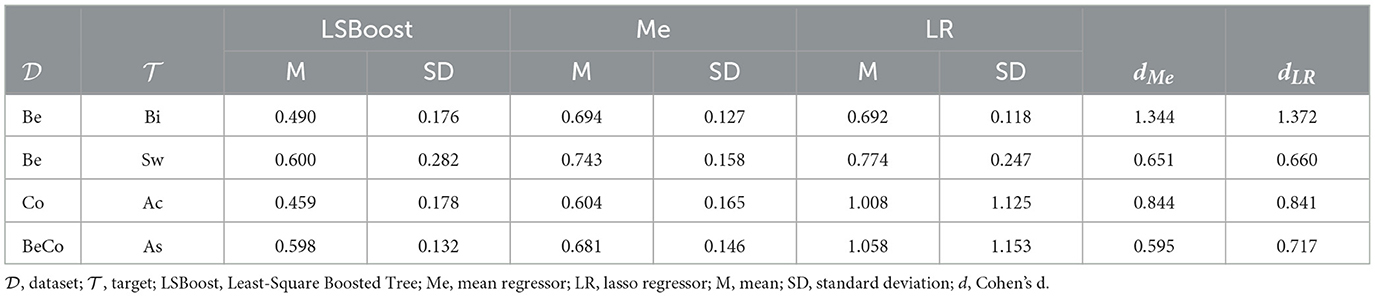
Table 2. Performances of the significant models split for the dataset and target.
Both spectral and temporal features contributed to the predictions, but their importance scores varied substantially across datasets and targets. The highest median score was observed for pα (Med = 0.139, IQR = 0.190), whereas the lowest was for M (Med = 0.034, IQR = 0.037). Age and Group appeared as predictors in two models each: Age in Sw with Be and Ac with Co, while Group in Ac with Co and As with BeCo. Group achieved the highest importance, not only compared to Age but also across all features (Med = 0.252, IQR = 0.136). Table 3 summarizes the channel-averaged feature importance scores, split by dataset and target.

Table 3. Feature importance scores, split for dataset and target.
The topographic plot in Figure 3 qualitatively identified central, occipital, parietal, and frontal regions as most important for the overall prediction.
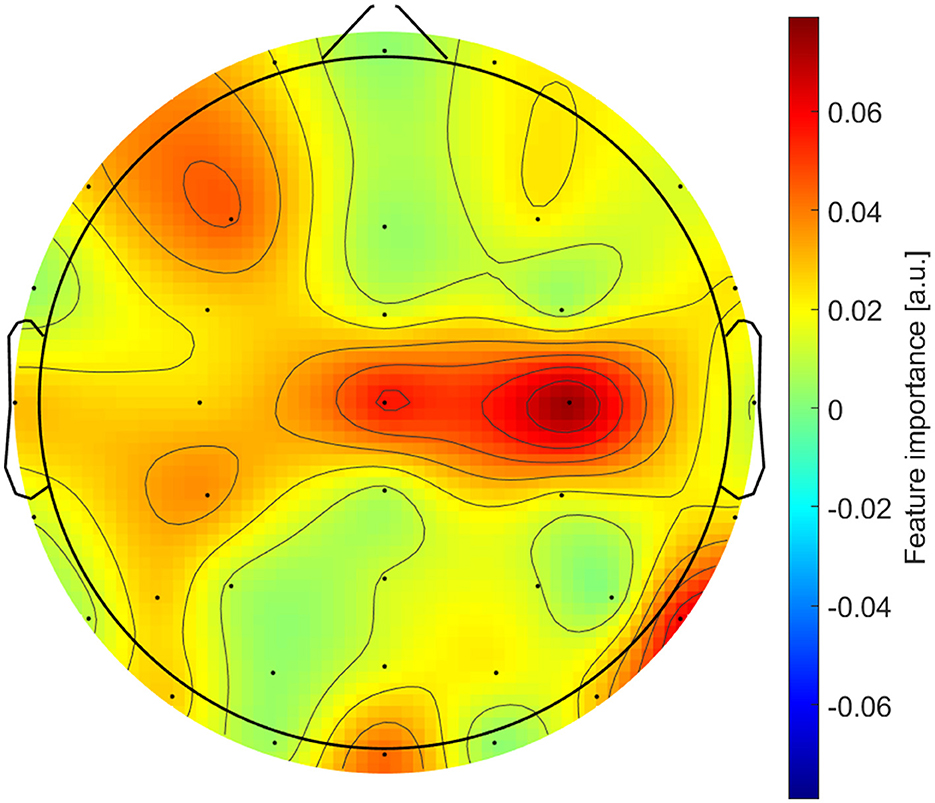
Figure 3. Topographic distribution of the feature importance scores.
5 Discussion
In this study, we trained Least-Squares Boosted Trees (LSBoost) with spectral and temporal EEG features to predict sensory attributes—bitterness (Bi), sweetness (Sw), acidity (Ac), and astringency (As)—of Coffee (Co) and basic solutions (Be). The best configuration of hyperparameters and data normalization was obtained through a Bayesian optimisation approach, following a Leave-One-Subject-Out (LOSO) scheme. The LSBoost's performances were compared with mean (Me) and lasso (LR) regressors through Cohen's d coefficients, and the feature importance for type and channel was assessed from the trees' coefficients.
The significant models achieved high performances, with an average anti-log MAE of about 7% of the scale range and a medium-to-large (dMe, LR>0.5) (Cohen, 1992) robustness against the benchmarks. The lowest MAE of Ac is in line with previous studies that identified sour as the best predictable flavor, with the highest R2 coefficient in Zhao et al. (2022) and the second (after salty) highest accuracy in Li et al. (2025). Compared to other dimensions, Sw has already shown poor performances (De et al., 2023) and low feature discriminability (Xia et al., 2024), supporting the obtained highest MAE and lowest d coefficients. Finally, the robustness of Bi against benchmarks may reflect the well-known evolutionary adaptation in vertebrates toward heightened bitter taste sensitivity for early toxin detection and avoidance (Wooding et al., 2021).
The feature importance of pα, pβ, and pγ is in line with past studies that effectively trained ML models using spectral powers in α, β, and γ bands (De et al., 2023; Vo et al., 2023). The role of pδ, and pθ as key predictors is supported by previous research studies that identified differences in δ and θ bands during flavor evaluation (Wallroth et al., 2018; Yang et al., 2023). Overall, the involvement of EEG features from specific central, parietal, and frontal regions has already been observed in predictive (Li et al., 2025) and experimental (Lejap et al., 2024) studies. The contribution of temporal parameters, represented by C, M and A, matches the good performance of past deep-learning models (e.g., CNNs and RNNs) trained with the raw EEG signal (De et al., 2023; Xia et al., 2024). Finally, the significance of Group and Age could be related to the previously reported influence of expertise (Croijmans and Majid, 2016) and aging (Mojet, 2003) on sensory evaluations. However, the reasons why they impacted only in two models require further investigation.
This study acknowledges some limitations. First, despite being in line with DSA studies that typically involve 5–15 experts (Gacula and Rutenbeck, 2006), the sample size must still be considered limited. Increasing it in both magnitude and heterogeneity (e.g., adding non-expert tasters and accounting for their coffee-consumption frequency) would potentially improve not only the performance but also the generalisability of the models. An increase in dataset size would also yield less noisy results, which is particularly relevant in chemo-sensory studies. In fact, despite the use of advanced denoising techniques and the selection of short epochs with minimal muscular artifacts, the data quality in the present study should still be regarded as suboptimal. Second, the experiment has not accounted for confounders given by the fixed Be-Co order, the temperature difference between the Be and Co samples, as well as potential visual cues (e.g., the colors of the liquids), potentially biasing the sensory analyses (Delwiche, 2023). Future confirmatory studies should be, thus, based on a fully-randomized and truly-blind design. Third, our models were trained and validated in a single session per subject. Although being standard practice in multivariate-pattern-analysis with brain-imaging data (Taxali et al., 2021), it prevented us from quantifying the test-retest reliability of the models. Future works should acquire longitudinal recordings—at least a second session separated by days or weeks—to determine the stability of features and models over time.
Nevertheless, our exploratory study endorses the use of regression techniques based on EEG data in flavor assessment, as an alternative to self-report sensory evaluations.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
The studies involving humans were approved by Ethical Committee of Universitá IULM. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study. Written informed consent was obtained from the individual(s) for the publication of any potentially identifiable images or data included in this article.
Author contributions
MBi: Writing – original draft, Writing – review & editing, Formal analysis, Methodology. MBe: Investigation, Conceptualization, Writing – review & editing. AF: Writing – review & editing, Data curation, Conceptualization. VR: Funding acquisition, Writing – review & editing, Supervision. MZ: Writing – review & editing, Supervision, Project administration.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. The authors declare that this study received funding from Lavazza Group. The funder was not involved in the study design, collection, analysis, interpretation of data, the writing of this article or the decision to submit it for publication.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declared that they were an editorial board member of Frontiers, at the time of submission. This had no impact on the peer review process and the final decision.
Generative AI statement
The author(s) declare that Gen AI was used in the creation of this manuscript. Generative AI (ChatGPT by OpenAI) was used solely for (i) grammar and typos corrections and (ii) generating elements of Figure 1 (schematic representations of the experimental protocol).
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Abubakar, Y., Gemasih, T., Muzaifa, M., Hasni, D., and Sulaiman, M. (2020). Effect of blend percentage and roasting degree on sensory quality of arabica-robusta coffee blend. IOP Conf. Ser. Earth Environ. Sci. 425:12081. doi: 10.1088/1755-1315/425/1/012081
Anbarasan, R., Gomez Carmona, D., and Mahendran, R. (2022). Human taste-perception: brain computer interface (BCI) and its application as an engineering tool for taste-driven sensory studies. Food Eng. Rev. 14, 408–434. doi: 10.1007/s12393-022-09308-0
Apicella, A., Isgr, F., Pollastro, A., and Prevete, R. (2023). On the effects of data normalization for domain adaptation on EEG data. Eng. Appl. Artif. Intell. 123:106205. doi: 10.1016/j.engappai.2023.106205
Arevalillo-Herráez, M., Cobos, M., Roger, S., and García-Pineda, M. (2019). Combining inter-subject modeling with a subject-based data transformation to improve affect recognition from EEG signals. Sensors 19:2999. doi: 10.3390/s19132999
Batali, M. E., Lim, L. X., Liang, J., Yeager, S. E., Thompson, A. N., Han, J., et al. (2022). Sensory analysis of full immersion coffee: cold brew is more floral, and less bitter, sour, and rubbery than hot brew. Foods 11:2440. doi: 10.3390/foods11162440
Bilucaglia, M., Laureanti, R., Circi, R., Zito, M., Bellati, M., Fici, A., et al. (2022). “Spectral differences in resting-state EEG associated to individual emotional styles,” in 2022 44th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC) (Glasgow: IEEE), 4052–4055. doi: 10.1109/EMBC48229.2022.9871191
Bilucaglia, M., Laureanti, R., Zito, M., Circi, R., Fici, A., Rivetti, F., et al. (2019). “Looking through blue glasses: bioelectrical measures to assess the awakening after a calm situation,” in 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC) (Berlin: IEEE), 526–529. doi: 10.1109/EMBC.2019.8856486
Bilucaglia, M., Masi, R., Stanislao, G. D., Laureanti, R., Fici, A., Circi, R., et al. (2020). Esb: a low-cost EEG synchronization box. HardwareX 8:e00125. doi: 10.1016/j.ohx.2020.e00125
Bilucaglia, M., Zito, M., Fici, A., Casiraghi, C., Rivetti, F., Bellati, M., et al. (2024). I dare: iulm dataset of affective responses. Front. Hum. Neurosci. 18:1347327. doi: 10.3389/fnhum.2024.1347327
Bokil, H., Andrews, P., Kulkarni, J. E., Mehta, S., and Mitra, P. P. (2010). Chronux: a platform for analyzing neural signals. J. Neurosci. Methods 192, 146–151. doi: 10.1016/j.jneumeth.2010.06.020
Borghini, G., Aricó, P., Flumeri, G. D., Sciaraffa, N., and Babiloni, F. (2019). Correlation and similarity between cerebral and non-cerebral electrical activity for user's states assessment. Sensors 19:704. doi: 10.3390/s19030704
Bühlmann, P., and Van De Geer, S. (2011). Statistics for High-Dimensional Data: Methods, Theory and Applications. Springer Science and Business Media: New York. doi: 10.1007/978-3-642-20192-9
Chang, C.-Y., Hsu, S.-H., Pion-Tonachini, L., and Jung, T.-P. (2020). Evaluation of artifact subspace reconstruction for automatic artifact components removal in multi-channel EEG recordings. IEEE Trans. Biomed. Eng. 67, 1114–1121. doi: 10.1109/TBME.2019.2930186
Civille, G. V., Carr, B. T., and Osdoba, K. E. (2024). Sensory Evaluation Techniques. Boca Raton, FL: CRC Press. doi: 10.1201/9781003352082
Croijmans, I., and Majid, A. (2016). Not all flavor expertise is equal: the language of wine and coffee experts. PLoS ONE 11:e0155845. doi: 10.1371/journal.pone.0155845
Crouzet, S. M., Busch, N. A., and Ohla, K. (2015). Taste quality decoding parallels taste sensations. Curr. Biol. 25, 890–896. doi: 10.1016/j.cub.2015.01.057
De, S., Mukherjee, P., Konar, D., and Roy, A. H. (2023). “EEG-based taste perception classification using pca enhanced attention-tlstm neural network,” in 2023 4th International Conference on Communication, Computing and Industry 6.0 (C216) (Bangalore: IEEE), 1–6. doi: 10.1109/C2I659362.2023.10430968
Delorme, A., and Makeig, S. (2004). EEGLAB: an open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 134, 9–21. doi: 10.1016/j.jneumeth.2003.10.009
Delwiche, J. (2023). “Psychological considerations in sensory analysis,” in The Sensory Evaluation of Dairy Products, eds. S. Clark, M. Drake, and K. Kaylegian (Springer Cham), 9–17. doi: 10.1007/978-3-031-30019-6_2
Di Flumeri, G., Arico, P., Borghini, G., Sciaraffa, N., Maglione, A. G., Rossi, D., et al. (2017). “EEG-based approach-withdrawal index for the pleasantness evaluation during taste experience in realistic settings,” in 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC) (Jeju: IEEE), 3228–3231. doi: 10.1109/EMBC.2017.8037544
Faul, F., Erdfelder, E., Lang, A. G., and Buchner, A. (2007). G*power 3: a flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behav. Res. Methods 39, 175–191. doi: 10.3758/BF03193146
Fazli, S., Popescu, F., Danóczy, M., Blankertz, B., Müller, K.-R., and Grozea, C. (2009). Subject-independent mental state classification in single trials. Neural Netw. 22, 1305–1312. doi: 10.1016/j.neunet.2009.06.003
Feria-Morales, A. M. (2002). Examining the case of green coffee to illustrate the limitations of grading systems/expert tasters in sensory evaluation for quality control. Food Qual. Prefer. 13, 355–367. doi: 10.1016/S0950-3293(02)00028-9
Friedman, J. H. (2001). Greedy function approximation: a gradient boosting machine. Ann. Stat. 29, 1189–1232. doi: 10.1214/aos/1013203451
Gacula, M., and Rutenbeck, S. (2006). Sample size in consumer test and descriptive analysis. J. Sens. Stud. 21, 129–145. doi: 10.1111/j.1745-459X.2006.00055.x
González-España, J. J., Back, K.-J., Reynolds, D., and Contreras-Vidal, J. L. (2023). “Decoding taste from EEG: gustatory evoked potentials during wine tasting,” in 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC) (Honolulu, HI: IEEE), 4253–4258. doi: 10.1109/SMC53992.2023.10394408
Goulet-Pelletier, J.-C., and Cousineau, D. (2018). A review of effect sizes and their confidence intervals, part I: the cohen'sd family. Quant. Methods Psychol. 14, 242–265. doi: 10.20982/tqmp.14.4.p242
He, J., Yang, L., Liu, D., and Song, Z. (2022). Automatic recognition of high-density epileptic EEG using support vector machine and gradient-boosting decision tree. Brain Sci. 12:1197. doi: 10.3390/brainsci12091197
Hjorth, B. (1970). EEG analysis based on time domain properties. Electroencephalogr. Clin. Neurophysiol. 29, 306–310. doi: 10.1016/0013-4694(70)90143-4
Hsu, L., and Chen, Y.-J. (2021). Does coffee taste better with latte art? A neuroscientific perspective. Br. Food J. 123, 1931–1946. doi: 10.1108/BFJ-07-2020-0612
Hussain, L., Saeed, S., Idris, A., Awan, I. A., Shah, S. A., Majid, A., et al. (2019). Regression analysis for detecting epileptic seizure with different feature extracting strategies. Biomed. Eng./Biomed. Tech. 64, 619–642. doi: 10.1515/bmt-2018-0012
Isabona, J., Imoize, A. L., and Kim, Y. (2022). Machine learning-based boosted regression ensemble combined with hyperparameter tuning for optimal adaptive learning. Sensors 22:3776. doi: 10.3390/s22103776
Jayakumar, M., Rajavel, M., Surendran, U., Gopinath, G., and Ramamoorthy, K. (2017). Impact of climate variability on coffee yield in India—with a micro-level case study using long-term coffee yield data of humid tropical kerala. Clim. Change 145, 335–349. doi: 10.1007/s10584-017-2101-2
Keene, O. N. (1995). The log transformation is special. Stat. Med. 14, 811–819. doi: 10.1002/sim.4780140810
Kim, H., Chang, C.-Y., Kothe, C., Iversen, J. R., and Miyakoshi, M. (2025). Juggler's ASR: unpacking the principles of artifact subspace reconstruction for revision toward extreme mobi. J. Neurosci. Methods 420:110465. doi: 10.1016/j.jneumeth.2025.110465
Kim, Y., An, J., and Lee, J. (2025). The espresso protocol as a tool for sensory quality evaluation. Food Res. Int. 202:115670. doi: 10.1016/j.foodres.2025.115670
Klimesch, W. (1999). EEG alpha and theta oscillations reflect cognitive and memory performance: a review and analysis. Brain Res. Rev. 29, 169–195. doi: 10.1016/S0165-0173(98)00056-3
Kotthoff, L., Thornton, C., Hoos, H. H., Hutter, F., and Leyton-Brown, K. (2017). Auto-weka 2.0: automatic model selection and hyperparameter optimization in weka. J. Mach. Learn. Res. 18, 1–5.
Lejap, M. Y. L., Wibawa, A. D., and Mukti, P. H. (2024). “EEG brain heatmap visualization for sweet and sour tasting,” in 2024 International Seminar on Intelligent Technology and Its Applications (ISITIA) (Mataram: IEEE), 367–372. doi: 10.1109/ISITIA63062.2024.10668352
Li, H., Feng, X., Liu, Z., Wang, W., Tian, L., Xu, D., et al. (2025). The influence of different flavor peptides on brain perception via scalp electroencephalogram and development of a taste model. Food Chem. 465:141953. doi: 10.1016/j.foodchem.2024.141953
Li, J., Streletskaya, N. A., and Gmez, M. I. (2019). Does taste sensitivity matter? The effect of coffee sensory tasting information and taste sensitivity on consumer preferences. Food Qual. Prefer. 71, 447–451. doi: 10.1016/j.foodqual.2018.08.006
Maram, M., Khalil, M. A., and George, K. (2023). “Analysis of consumer coffee brand preferences using brain-computer interface and deep learning,” in 2023 IEEE 7th International Conference on Information Technology, Information Systems and Electrical Engineering (ICITISEE) (Purwokerto: IEEE), 227–232. doi: 10.1109/ICITISEE58992.2023.10404368
Mojet, J. (2003). Taste perception with age: generic or specific losses in supra-threshold intensities of five taste qualities? Chem. Senses 28, 397–413. doi: 10.1093/chemse/28.5.397
Naser, A., and Aydemir, Ö. (2024). Enhancing EEG signal classification with a novel random subset channel selection approach: applications in taste, odor, and motor imagery analysis. IEEE Access 12, 145608–145618. doi: 10.1109/ACCESS.2024.3473810
Nathan, M. J., and Del Pinal, G. (2017). The future of cognitive neuroscience? Reverse inference in focus. Philos. Compass 12:e12427. doi: 10.1111/phc3.12427
Nuwer, M. R. (2018). 10-10 electrode system for EEG recording. Clin. Neurophysiol. 129:1103. doi: 10.1016/j.clinph.2018.01.065
Pion-Tonachini, L., Kreutz-Delgado, K., and Makeig, S. (2019). Iclabel: an automated electroencephalographic independent component classifier, dataset, and website. Neuroimage 198, 181–197. doi: 10.1016/j.neuroimage.2019.05.026
Poldrack, R. A. (2006). Can cognitive processes be inferred from neuroimaging data? Trends Cogn. Sci. 10, 59–63. doi: 10.1016/j.tics.2005.12.004
Rodrigues, S. S. Q., Dias, L. G., and Teixeira, A. (2024). Emerging methods for the evaluation of sensory quality of food: technology at service. Curr. Food Sci. Technol. Rep. 2, 77–90. doi: 10.1007/s43555-024-00019-7
Rolls, E. (2005). Taste, olfactory, and food texture processing in the brain, and the control of food intake. Physiol. Behav. 85, 45–56. doi: 10.1016/j.physbeh.2005.04.012
Rousmans, S., Robin, O., Dittmar, A., and Vernet-Maury, E. (2000). Autonomic nervous system responses associated with primary tastes. Chem. Senses 25, 709–718. doi: 10.1093/chemse/25.6.709
Seninde, D. R., and Chambers, E. (2020). Coffee flavor: a review. Beverages 6:44. doi: 10.3390/beverages6030044
Sipos, L., Nyitrai, A., Hitka, G., Friedrich, L. F., and Kókai, Z. (2021). Sensory panel performance evaluation—comprehensive review of practical approaches. Appl. Sci. 11:11977. doi: 10.3390/app112411977
Small, D. M. (2012). Flavor is in the brain. Physiol. Behav. 107, 540–552. doi: 10.1016/j.physbeh.2012.04.011
Snoek, J., Larochelle, H., and Adams, R. P. (2012). “Practical bayesian optimization of machine learning algorithms,” in Advances in Neural Information Processing Systems 25 (NIPS 2012), 1–9.
Spencer, M., Sage, E., Velez, M., and Guinard, J. (2016). Using single free sorting and multivariate exploratory methods to design a new coffee taster's flavor wheel. J. Food Sci. 81, S2997–S3005. doi: 10.1111/1750-3841.13555
Stone, H., Bleibaum, R. N., and Thomas, H. A. (2021). Sensory Evaluation Practices. San Diego, CA: Academic Press.
Taxali, A., Angstadt, M., Rutherford, S., and Sripada, C. (2021). Boost in test-retest reliability in resting state fmri with predictive modeling. Cereb. Cortex 31, 2822–2833. doi: 10.1093/cercor/bhaa390
Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B Stat. Methodol. 58, 267–288. doi: 10.1111/j.2517-6161.1996.tb02080.x
Tonacci, A., Taglieri, I., Sanmartin, C., Billeci, L., Crifaci, G., Ferroni, G., et al. (2024). Taste the emotions: pilot for a novel, sensors-based approach to emotional analysis during coffee tasting. J. Sci. Food Agric. 105, 1420–1429. doi: 10.1002/jsfa.13172
Torrico, D. D., Mehta, A., and Borssato, A. B. (2023). New methods to assess sensory responses: a brief review of innovative techniques in sensory evaluation. Curr. Opin. Food Sci. 49:100978. doi: 10.1016/j.cofs.2022.100978
Tryon, J., Guillermo Colli Alfaro, J., and Trejos, A. L. (2025). Effects of image normalization on CNN-based EEG–MG fusion. IEEE Sens. J. 25, 20894–20906. doi: 10.1109/JSEN.2025.3559438
Urigüen, J. A., and Garcia-Zapirain, B. (2015). EEG artifact removal—state-of-the-art and guidelines. J. Neural Eng. 12:31001. doi: 10.1088/1741-2560/12/3/031001
Verzelli, P., Tchumatchenko, T., and Kotaleski, J. H. (2024). Editorial overview: computational neuroscience as a bridge between artificial intelligence, modeling and data. Curr. Opin. Neurobiol. 84:102835. doi: 10.1016/j.conb.2023.102835
Vo, H.-T.-T., Nguyen, T.-N.-Q., Cuong, D. D., and Van Huynh, T. (2023). “Classification taste-EEG signals using base neural network,” in 2023 RIVF International Conference on Computing and Communication Technologies (RIVF) (Hanoi: IEEE), 107–111. doi: 10.1109/RIVF60135.2023.10471803
Wallroth, R., Höchenberger, R., and Ohla, K. (2018). Delta activity encodes taste information in the human brain. Neuroimage 181, 471–479. doi: 10.1016/j.neuroimage.2018.07.034
Wooding, S. P., Ramirez, V. A., and Behrens, M. (2021). Bitter taste receptors. Evol. Med. Public Health 9, 431–447. doi: 10.1093/emph/eoab031
Xia, X., Yang, Y., Shi, Y., Zheng, W., and Men, H. (2024). Decoding human taste perception by reconstructing and mining temporal-spatial features of taste-related EEGs. Appl. Intell. 54, 3902–3917. doi: 10.1007/s10489-024-05374-5
Xu, K., Katahira, K., Yamazaki, Y., Zhang, F., Nishida, N., Tamai, Y., et al. (2021). “Estimating beverage preference based on subjective emotional reactions and EEG activity,” in 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC) (Tokyo: IEEE), 366–372.
Yang, J., and Lee, J. (2019). Application of sensory descriptive analysis and consumer studies to investigate traditional and authentic foods: a review. Foods 8:54. doi: 10.3390/foods8020054
Yang, T., Zhang, P., Xing, L., Hu, J., Feng, R., Zhong, J., et al. (2023). Insights into brain perceptions of the different taste qualities and hedonic valence of food via scalp electroencephalogram. Food Res. Int. 173:113311. doi: 10.1016/j.foodres.2023.113311
Yao, D. (2001). A method to standardize a reference of scalp EEG recordings to a point at infinity. Physiol. Meas. 22, 693–711. doi: 10.1088/0967-3334/22/4/305
Keywords: coffee flavor prediction, electroencephalography (EEG), machine learning (ML), ensemble learning, boosted-tree regression, Descriptive Sensory Analysis (DSA)
Citation: Bilucaglia M, Bellati M, Fici A, Russo V and Zito M (2025) Tuning into flavor: predicting coffee sensory attributes from EEG with boosted-tree regression models. Front. Hum. Neurosci. 19:1661214. doi: 10.3389/fnhum.2025.1661214
Received: 07 July 2025; Accepted: 17 September 2025;
Published: 09 October 2025.
Edited by:
Filippo Brighina, University of Palermo, ItalyReviewed by:
Alessandro Tonacci, National Research Council (CNR), ItalyNazan Turhan, İzmir University of Economics, Türkiye
Tianyi Yang, Nanjing University of Aeronautics and Astronautics, China
Copyright © 2025 Bilucaglia, Bellati, Fici, Russo and Zito. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Marco Bilucaglia, bWFyY28uYmlsdWNhZ2xpYUBzdHVkZW50aS5pdWxtLml0