 Amir Reza Alizad-Rahvar
Amir Reza Alizad-Rahvar Safar Vafadar2
Safar Vafadar2- 1School of Biological Sciences, Institute for Research in Fundamental Sciences (IPM), Tehran, Iran
- 2Laboratory of Biological Complex Systems and Bioinformatics (CBB), Institute of Biochemistry and Biophysics, University of Tehran, Tehran, Iran
- 3Department of Genetics, Royan Institute for Reproductive Biomedicine, The Academic Center for Education, Culture, and Research (ACECR), Tehran, Iran
- 4Department of Medical Genetics, National Institute for Genetic Engineering and Biotechnology, Tehran, Iran
After lifting the COVID-19 lockdown restrictions and opening businesses, screening is essential to prevent the spread of the virus. Group testing could be a promising candidate for screening to save time and resources. However, due to the high false-negative rate (FNR) of the RT-PCR diagnostic test, we should be cautious about using group testing because a group's false-negative result identifies all the individuals in a group as uninfected. Repeating the test is the best solution to reduce the FNR, and repeats should be integrated with the group-testing method to increase the sensitivity of the test. The simplest way is to replicate the test twice for each group (the 2Rgt method). In this paper, we present a new method for group testing (the groupMix method), which integrates two repeats in the test. Then we introduce the 2-stage sequential version of both the groupMix and the 2Rgt methods. We compare these methods analytically regarding the sensitivity and the average number of tests. The tradeoff between the sensitivity and the average number of tests should be considered when choosing the best method for the screening strategy. We applied the groupMix method to screening 263 people and identified 2 infected individuals by performing 98 tests. This method achieved a 63% saving in the number of tests compared to individual testing. Our experimental results show that in COVID-19 screening, the viral load can be low, and the group size should not be more than 6; otherwise, the FNR increases significantly. A web interface of the groupMix method is publicly available for laboratories to implement this method.
1. Introduction
In the post-COVID-19 era, most countries are trying to lift their lockdown restrictions. However, an infected person can remain completely asymptomatic and spread the virus. Hence, it is essential to increase screening tests to identify and quarantine the infected person and identify any other person who has been exposed to that individual. Unfortunately, the testing capacity of many countries is not sufficient, and they have to save their capacity for the second or even the third wave of the coronavirus outbreak.
In this situation, the group testing (or pool testing) technique can immediately and dramatically increase worldwide testing capacity by decreasing the required number of individual tests in a population. In this technique, separate samples are mixed together to create a sample pool. After a single diagnostic test has been performed on each group of samples, a negative result indicates that everyone in the group is uninfected; otherwise, at least one of the samples in the group is infected. Then, in conventional group testing (1, 2), an individual test on each sample in the infected group is performed to identify the infected samples. With this method, the number of tests is decreased by not testing the individual samples in an uninfected group.
Although different types of reverse-transcription polymerase chain reaction (RT-PCR) tests are the predominant diagnostic methods for detecting SARS-CoV-2, the accuracy of these methods for COVID-19 is still unknown (3). False positives are rare for RT-PCR testing when primers and probes are designed appropriately. There are many reports of specificity of 100% for SARS-CoV-2 RT-PCR assays, based on the in vitro cross-reactivity assessment (4–6). However, the clinical specificity, which is affected by the contamination of laboratory equipment and reagents or human error, could be less than 100%. Overall, the false positive rate (FPR) of SARS-CoV-2 RT-PCR diagnosis, without human error and contamination, can be considered to be zero.
The major problem in COVID-19 diagnosis with RT-PCR is false negatives. A false-negative rate (FNR) of up to 50% has been reported for RT-PCR-based SARS-CoV-2 diagnostic testing (4), but an FNR of 10–20% is more frequent in the reports (6, 7). An unsuitable type of sample [e.g., a throat swab rather than a nasal swab (8)] and inadequate or inappropriate specimen collection, storage, and transport are responsible for a large portion of this high FNR. Moreover, the FNR of SARS-CoV-2 RT-PCR diagnosis is affected by the number of days that have elapsed since an individual first became infected. Indeed, the FNR is about 67 and 38% on day 4 and on the day of symptom onset (day 5), respectively. Three days after symptom onset (day 8), the FNR decreases to 20%, and then, it gradually increases again to 66% on day 21 (9).
A false-negative result puts the whole society at risk by falsely indicating that an infected person does not have an infection. Hence, this person, might move around the community and infect others. False negatives in group testing are much riskier than in individual testing. If a group of specimens is infected, each sample in the group can potentially be infected. Consequently, if the test result of this infected pool is a false negative, this result indicates that every person with a specimen in the pool is infection-free. Also, the mixing of specimens in group testing makes an infected specimen become diluted by the uninfected samples. Therefore, if the group size is not determined wisely, the infected specimen becomes undetectable, and the sensitivity of the test is reduced, resulting in false negatives (the dilution effect). Hence, the group testing methods must be made resistant to false-negative results. Unfortunately, the main focus of most of the studies in the field of group testing is only on reducing the average number of tests. Hence, more studies are needed to mitigate the effect of false negatives and increase the sensitivity of the test in group testing. This paper aims to address this need.
In this work, we propose a new method of group testing, called the groupMix method, for mitigating the false negatives. We propose 1-stage and 2-stage sequential versions of this method. In (10), the authors propose a method for false-negative mitigation of SARS-CoV-2 group testing. We propose a 2-stage version of this method and compare the sensitivity and the average number of tests of 1-stage and 2-stage versions of this method with those of the groupMix method. Then we present our experimental test results for COVID-19 screening by using the groupMix method. Finally, we introduce our web interface, which will help laboratories to implement the groupMix method.
2. Group Testing Methods
In the case of individual testing, the best practice to mitigate the effect of false negatives is to repeat the test (11). If the false-positive results are ignored, a person can be diagnosed as positive if either test is positive. Assume that there is no human error and contamination resulting in false positive, and the FNR of the RT-PCR test is 20% and the test errors are independent. In this case, if we repeat the test for an individual twice independently by getting two samples, the chance of obtaining two false-negative results drops to 4%. Consequently, the sensitivity of the test increases from 80% (for a single test) to 96% (for two tests). Inspired by this easy method of false-negative mitigation for individual testing, this test repetition could be integrated into the group-testing procedure to mitigate the effect of false negatives in the detection of infected groups. For instance, an adaptive screening procedure is introduced in (12) so that the negative groups of each stage are re-tested. If both tests of a group are negative, this group is considered as a negative group. Recently, a group testing method has been proposed for SARS-CoV-2 in (10) for false-negative mitigation. Here, we call this method 2-replicate group testing, denoted by 2Rgt. We introduce this method in the next section, and then, we propose a 2-stage sequential version of it to reduce its required number of tests. We will compare the results of our proposed method, groupMix, with 2Rgt's results.
2.1. Model and Notation
Assume that the prevalence (prior probability) of the disease in the population is p. We want to test N independent specimens by using group testing. The group size, i.e., the number of specimens in each pool, is n. The optimum group size, nopt, minimizes the average number of tests, . The FNR of the diagnostic method for a single test is denoted by fN, and the FPR is negligible. It is assumed that testing the pooled sample does not change fN. In other words, the group size n is determined wisely to prevent the dilution effect and a drop in the sensitivity.
Denoting a group of samples by G, G = 0 means that all samples in G are uninfected. In contrast, G = 1 implies that G is a positive group; i.e., it has at least one infected specimen. By observing the results of group tests in different methods, we identify a group as infected or uninfected, denoted by Ĝ = 1 and Ĝ = 0, respectively. Here, we define two types of sensitivity. The sample-level sensitivity, Ss, refers to the probability of detecting an infected sample as positive. On the other hand, the group-level sensitivity, Sg, refers to the probability of positive detection of an infected group; i.e., P(Ĝ = 1 |G = 1). To be able to detect an infected sample, its corresponding pool should be diagnosed positive first, and then, its individual test should also be positive. Therefore, Ss = Sg(1−fN). In comparing different methods of group testing, we compare Sg values to measure the accuracy of the methods.
2.2. GroupMix Method
The schematic diagram of the groupMix method is depicted in Figure 1. This method has the following steps.
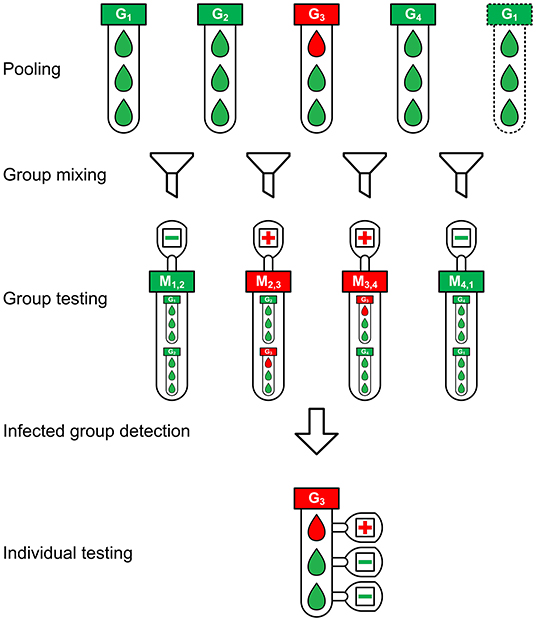
Figure 1. The schematic diagram of the groupMix method for non-conservative infected group detection.
1) Pooling: We make groups of samples with the group size of n. Therefore, we have m = ⌈N/n⌉ groups. We label each group as Gi where 1 ≤ i ≤ m, and we call them primary groups.
2) Group mixing: Each primary group Gi (2 ≤ i ≤ m−1) is mixed with Gi−1 and Gi+1 separately, giving the mixed groups Mi−1, i and Mi, i+1, respectively, a group size of 2n. In the case of the first (G1) and last (Gm) groups, we mix them together and make Mm, 1. With this form of mixing, each group exists in two mixed groups. Hence, each group will be tested twice by testing the mixed groups.
3) Group testing: Each mixed group will be tested to identify the infected mixed groups. This form of group mixing results in m mixed groups, which equals the number of the primary groups Gi. Therefore, in this step, we need m tests.
4) Infected group detection: In this step, we detect the infected primary groups from the test results of the mixed groups. Different approaches can be applied for this purpose, based on the level of compromising the false negatives and the tradeoff between sensitivity and the number of tests. Assume that we want to detect the infected group in Figure 1. Here, M2,3 and M3,4 are positive. We can have the following detection approaches.
• Conservative group detection: In a conservative approach, M2,3 = 1 indicates that both Ĝ2 and Ĝ3 should be considered as infected because both can cause a positive result for M2,3. However, Ĝ2 = 1 should also make the test result for M1,2 positive. Here, we assume pessimistically that the observed value of M1,2 = 0 is a false-negative result. Similarly, M3,4 = 1 results in Ĝ3 = 1 and Ĝ4 = 1. Hence, with this approach, the primary groups Ĝ2, Ĝ3, and Ĝ4 should be detected as positive in Figure 1. Here, Ĝ2 = 1 and Ĝ4 = 1 are false positives due to our detection algorithm. Consequently, this method makes algorithmic false positives, increasing the number of tests. However, this approach results in . In summary, in conservative group detection, we consider Ĝi = 1 and Ĝi+1 = 1 provided that Mi, i+1 = 1.
• Non-conservative group detection: To reduce the number of algorithmic false positives, and consequently, to decrease the number of tests in conservative group detection, we should be tolerant of false negatives. To achieve this goal, we can detect only more probable infected groups, with the cost of less sensitivity. In this way, both M2,3 and M3,4 in Figure 1 are positive, most likely because G3 = 1. Although these positive results can also occur if G2 = 1 and G4 = 1, the lack of M1,2 = 1 and M4,1 = 1 makes it unlikely that G2 and G4 will both equal 1. In this approach, if, for example, G2 is truly positive and M1,2 = 0 is a false-negative result, we will miss Ĝ2 = 1, resulting in less sensitivity. We will propose a 2-stage sequential version of this method to resolve this problem and increase the sensitivity.
If there is not any false-negative result, we should always see a pair of positive mixed groups for an infected group Gi, i.e., Mi−1, i and Mi, i+1. Therefore, provided that we observe only a single positive mixed group, i.e., Mi−1, i = 0, Mi, i+1 = 1, and Mi+1, i+2 = 0, then the other mixed group of the pair is not diagnosed positive because of the false-negative result. Hence, a single positive mixed group Mi, i+1 indicates that both Gi and Gi+1 can potentially be infected. Consequently, we consider both groups positive to test all of their specimens individually in the next step.
In summary, we have the following rules in non-conservative group detection.
1. Provided that the test result of both Mi−1, i and Mi, i+1 are positive, Ĝi is considered as a positive group; otherwise, it is negative.
2. If we have a single positive mixed group, e.g., Mi, i+1, both Ĝi and Ĝi+1 are considered as infected.
5) Individual testing: The specimens of all primary groups that are detected positive (Ĝi = 1) are tested individually.
In Figure 1, there are N = 12 samples with one infected sample. The pooling of samples is performed with a group size of n = 3. Hence, there are m = 4 primary groups in which G3 is infected. Figure 1 depicts the non-conservative group detection. We need 4 tests in the group-testing step and 3 individual tests in the last step, or a total of 7 tests. Using the conservative group detection, we need 4 tests in the group-testing step and 9 more individual tests, or a total of 13 tests. We can see the effect of the algorithmic false positives in increasing the number of tests.
2.3. Sequential groupMix Method
We propose a 2-stage sequential version of the non-conservative groupMix method, denoted by 2S-groupMix, to increase its sensitivity. As explained in section 2.2, some cases are undetected by the non-conservative group detection. For instance, assume that G1 = 0, G2 = 1, G3 = 0, and G4 = 1. In this case, if we observe M1,2 = 0 (a false negative), M2,3 = 1, M3,4 = 1, and M4,1 = 1, the non-conservative method detects Ĝ3 = 1 and Ĝ4 = 1. Here, Ĝ2 = 1 is not detected because of the false-negative result. Since Ĝ3 = 1 is an algorithmic false positive, the individual test of its specimens will not show any infected sample. This observation indicates that M2,3 = 1 could be due to G2 = 1, and implicitly shows that M1,2 = 0 is a false negative. Therefore, in the second stage, Ĝ2 is considered infected, and its specimens are tested individually. In this way, the sensitivity of the non-conservative groupMix method is increased by performing the second stage. In summary, the 2S-groupMix method is as follows.
1. Perform the groupMix method by using the non-conservative group detection.
2. Assume that the test of a mixed group is positive in the previous stage (e.g., Mi, i+1 = 1), and that only one of its primary groups is detected as a positive group (for example, Ĝi = 0 and Ĝi+1 = 1). Provided that the individual tests on the samples of the detected group (i.e., Gi+1) are all negative, perform the individual test on the specimens of the other undetected primary group (i.e., Gi).
Since this approach is a sequential method, we need to spend more time to increase the sensitivity of the test. In other words, there is a tradeoff between the test time and the sensitivity.
2.4. 2-Replicate Group Test
In 2-replicate group test (2Rgt) method, each group is tested twice. Provided that the result of at least one of the tests is positive, this group is diagnosed as a positive group. In this case, . Note that the 2Rgt method has no algorithmic false positive.
In the case of Figure 1, we need 11 tests if we use the 2Rgt method, while 7 and 13 tests are required if we use the non-conservative and the conservative groupMix method, respectively.
2.5. Sequential 2-Replicate Group Test
Here, we present a 2-stage sequential version of the 2Rgt method, denoted by 2S-2Rgt, to reduce the number of tests, while the sensitivity of the test, i.e., , remains the same. The drawback of the 2Rgt method is that it uses two tests for each group and increases the required number of tests. Since observing only one positive result out of two tests is enough to consider a group as infected, we can separate these two tests on each group and avoid the second test for positive groups of the first stage. The summary of this method is as follows.
1. Test all groups once and identify the positive groups as infected.
2. Perform the second test only on the negative groups of the first stage and identify the positive groups.
3. Individually test the specimens of the positive groups of stages 1 and 2.
In this way, we reduce the number of tests by saving the second test of the infected groups identified in the first stage.
3. Analytical Results
In this section, we present the results of the analytical analysis of the different group-testing methods regarding Sg, and the average number of tests per sample, . The proof for the analyses is available in Appendix A (Supplementary Material). All analytical results are verified by simulation. In the following results, it is assumed that the FNR of the diagnostic test is 10%.
3.1. The Effect of Group Size on and Sg
First, we consider the effect of the group size on and Sg in Figure 2 for FNR = 10% and p = 2%. This figure has two different y-axes. The right axis shows Sg for the non-conservative (NC), conservative (C), and 2-stage sequential (2S) groupMix methods, the 2Rgt and 2S-2Rgt methods, and the conventional method. The left axis shows for the NC-groupMix and the 2S-groupMix methods. This figure indicates that for these specific values of FNR and prevalence, nopt, which minimizes the average number of tests, is 7.
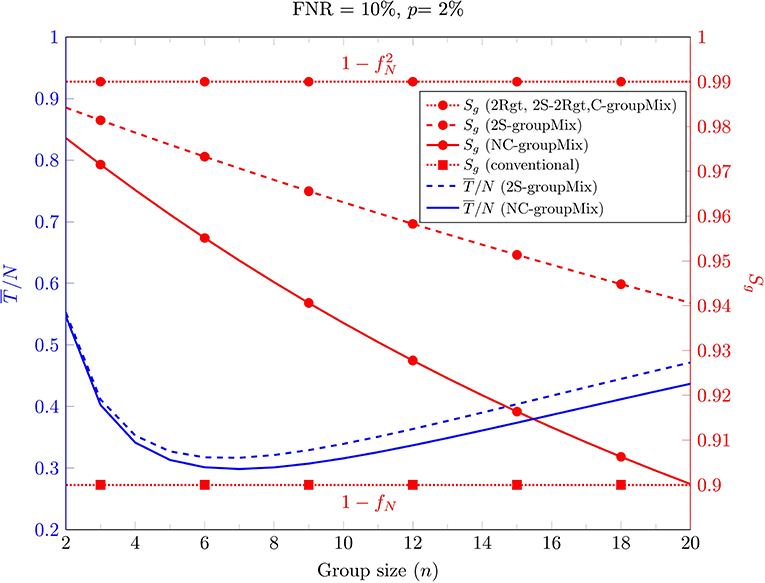
Figure 2. The average number of tests per sample (left y-axis, blue curves) and group-level sensitivity Sg (right y-axis, red curves) of different methods against the group size.
Moreover, Figure 2 shows that Sg of both the C-groupMix and 2Rgt methods is independent of n, equal to , which is 0.99 for fN = 0.1. Similarly, the conventional group-test method has the fixed group-level sensitivity Sg = 1−fN over n. However, Sg in NC- and 2S-groupMix methods varies with n. In other words, with smaller value of n, a larger value of Sg is achieved. In this figure, it is obvious that there is a tradeoff between Sg and for n ≤ 7.
If the primary concern in group testing is only to reduce the average number of tests , then the group size should minimize . However, in practice, using the optimum value of n may not be possible in the presence of problems like the dilution effect. For example, the study in (13) shows that for detecting SARS-CoV-2 with the standard kits and protocols, a single infected sample can be detected in pools of up to 32 samples, with an estimated FNR of 10%. This finding could be valid for the specimen of an active symptomatic patient. However, in COVID-19 screening, we usually deal with asymptomatically-infected or pre-symptomatic individuals or people with very mild or atypical symptoms. These cases may not have a high viral load and detectable amounts of the virus in their specimen.
Consequently, in the screening scenario, the maximum group size could be much less than 32. Our experiments show that a group size of 6 is a good choice for group testing in COVID-19 screening; otherwise, the viral load in the pool becomes very low, and the FNR increases dramatically. A thorough investigation is required to determine the maximum group size for COVID-19 screening rather than for diagnostic testing for detecting active symptomatic patients.
3.2. Optimum Group Size
Figure 3A depicts nopt against the prevalence percentage p for FNR = 10%. In the case of the groupMix methods, nopt refers to the optimum group size of the primary group, i.e., Gi. Hence, the optimum size of the mixed group tested by the diagnostic method is 2nopt. Theoretically, the smaller values of p allow us to have larger groups of specimens. However, as we discussed above, the use of larger groups can reduce the sensitivity of the test.
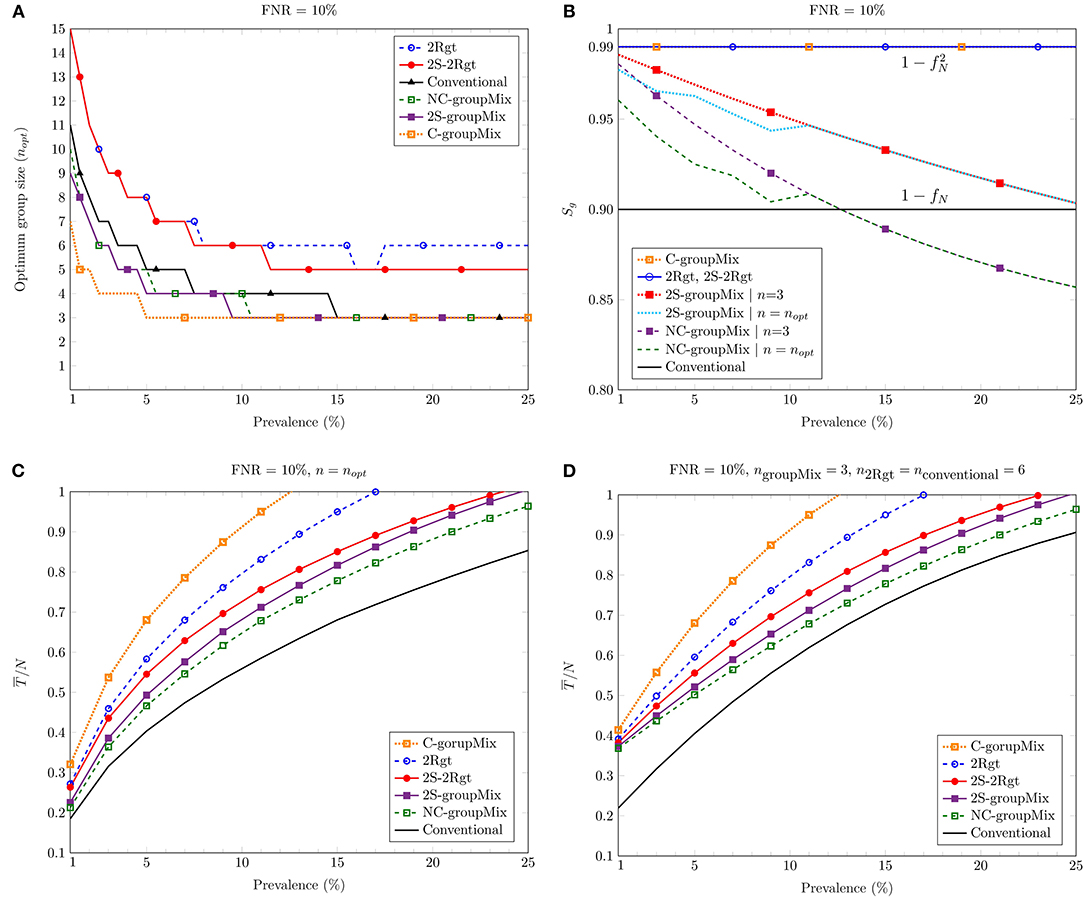
Figure 3. Comparing different methods against the percentage of prevalence: (A) the optimum group size nopt to minimize the average number of tests; (B) the group-level sensitivity Sg of the methods; (C) the average number of tests per sample for n = nopt; (D) the average number of tests per sample for the group (or the mixed group in the groupMix method) size of 6.
3.3. Group-Level Sensitivity
Figure 3B shows Sg vs. p for FNR = 10%. Overall, Sg of the C-groupMix, 2Rgt, and 2S-2Rgt methods does not vary with p and has the fixed value of . Similarly, the conventional group-test method has the p-independent sensitivity of Sg = 1−fN. However, when we utilize the non-conservative infected group detection in the groupMix method, i.e., the NC- and 2S-groupMix methods, Sg is a decreasing function of p. In non-conservative group detection, the sensitivity is compromised by accepting more false negatives to reduce the number of algorithmic false positives. The undetected cases in the non-conservative method occur more in higher values of p, resulting in less sensitivity. Even after a specific value of p, e.g., p > 0.13 for the NC-groupMix method and the FNR of 10%, Sg becomes less than that of the conventional method. Therefore, the usage of the NC-groupMix method is acceptable for small values of p, say, less than 5%. Moreover, Figure 3B depicts that the 2S-groupMix method improves Sg significantly compared to the NC-groupMix method.
As we saw in Figure 2, Sg of the C-groupMix, the 2Rgt, and the conventional methods does not vary with n. On the contrary, Sg of the NC-groupMix and the 2S-groupMix methods depends on n. For these two methods, we see Sg in Figure 3B for two cases of n = 3 (i.e., a mixed group size of 6) and n = nopt. For FNR = 10%, nopt equals 3 for p greater than about 10%, resulting in the same Sg for two different cases of group size. For smaller values of prevalence, nopt>3. Since Sg of the NC-groupMix and the 2S-groupMix methods is a decreasing function of n (Figure 2), the group testing with n = nopt is less sensitive than n = 3 for p < 10%.
3.4. Average Number of Tests
Figure 3C depicts the average number of tests per sample, , against the prevalence percentage p for n = nopt. As discussed earlier, in a COVID-19 screening scenario, the group size should not be more than 6 to prevent the dilution effect. Hence, Figure 3D shows of different methods vs. p for ngroupMix = 3 (the size of the mixed group is 6), n2Rgt = 6, and nconventional = 6. As these figures show, all methods proposed for false-negative mitigation require more tests compared to the conventional method.
Among the 1-stage methods, the NC-groupMix method needs the least average number of tests. However, as mentioned before, its sensitivity reduces with p, and after a specific value of p, its sensitivity becomes even worse than that of the conventional group test method. Therefore, it is reasonable to use the NC-groupMix method for small values of p, say p < 5%, to have both high sensitivity and less number of tests. In a comparison between the 1-stage C-groupMix and the 1-stage 2Rgt methods, which both have the same sensitivity of , the C-groupMix method needs more tests due to algorithmic false positives. Therefore, if the goal is to reach by using a 1-stage method, the 2Rgt method is preferred.
In the case of the 2-stage sequential methods, the average number of tests in the 2S-2Rgt method is less than that of the 2Rgt method. This reduction in the number of tests occurs because, in the 2S-2Rgt method, we perform the second test only for the negative groups in the first stage, rather than using two tests for each group in 2Rgt. In contrast, in groupMix methods using the non-conservative infected group detection, the 2S-groupMix needs more tests compared to the 1-stage NC-groupMix method. This increase in the number of tests occurs because the sequential version performs the full NC-groupMix test in the first stage, followed by the second stage.
In a comparison between the 2S-groupMix and the 2S-2Rgt methods, the former needs fewer tests than the latter. However, the sensitivity of the 2S-groupMix method is less than that of the 2S-2Rgt, and reduces with an increase of p. Therefore, there is a tradeoff between Sg and in decisions about choosing a 2-stage sequential group-test method for false-negative mitigation.
Considering the maximum group size (or the size of the mixed group in the groupMix method) of 6, compared to individual testing at 1% prevalence, we save 60% at the FNR of 10% for all proposed methods to mitigate the false negatives. For the optimum group size, this saving is between 70 and 80% at 1% prevalence, but it may result in less sensitive tests.
Overall, in choosing the best group-testing method to mitigate the false-negative results, we should determine the desired level of sensitivity and the amount of saving in the number of the tests. Moreover, the expected time of the test determines whether the sequential method should be used.
4. Experimental Methods
We performed COVID-19 screening in the Institute for Research in Fundamental Sciences (IPM), Tehran, Iran. A total of 263 individuals participated in the screening on 5 different days. These groups consisted of 78, 30, 31, 66, and 58 individuals, respectively. Swabs from the throat were collected and sent to the Clinical Genetic Laboratory at the Royan Institute, Tehran, Iran. Samples were collected between June 15 and 30, 2020.
The samples were pooled into the primary groups with a size of 3 prior to RNA extraction. Then, the primary groups were mixed according to the groupMix method's procedure, resulting in mixed groups of size 6.
A volume of 200 μL of the sample was mixed with 600 μL Lysis buffer, and RNA was extracted by using the Norgen Cell-Free RNA Purification Kit (Cat. No: 56300). 50 μL of Elution buffer was used in the extraction procedure.
The Novel Coronavirus (2019-nCoV) Real-Time Multiplex kit (Liferiver, Cat. No: ZJ0009) was utilized for real-time RT-PCR diagnosis. This kit detects the presence of SARS-CoV-2 RNA by detecting the three genes N, OFR1ab, and E. Reactions were heated to 45°C for 10 min (1 cycle) for reverse transcription and denatured in 95°C for 90 s (1 cycle). Then, 45 cycles of amplification were carried out in 95°C for 15 s and 58°C for 30 s. Fluorescence was measured at 58°C. The 1-stage NC-groupMix method was performed to detect the infected specimens.
This study was approved by the ethical committee of the Royan institute with a waiver of informed consent due to de-identified nature of the data.
5. Experimental Results
On the second, fourth, and fifth days, all groups with 30, 66, and 58 individuals were negative. For these days, we performed 10, 22, and 20 tests, respectively. Therefore, we saved 67, 67, and 66% in the number of tests, compared to individual testing.
In the first group, consisting of 78 individuals, we had 26 primary and mixed groups. With the NC-groupMix method, only the mixed group M20,21 was positive. Since we should always have a pair of positive mixed groups, this result indicates that one mixed group is a false negative. Therefore, both primary groups G20 and G21 were candidates to be infected. Ultimately, by performing the individual test on these primary groups, one specimen in G20 was identified as infected. Consequently, we performed 32 tests to detect one infected sample out of 78 samples. Indeed, we had a 59% saving in the number of tests, compared to individual testing.
Regarding the third group consisting of 31 individuals, the mixed groups M4,5 and M5,6 were positive. Hence, G5 was detected as the infected group. The individual test on G5 revealed the presence of one infected sample in this group. Hence, we detected this infected sample by using 14 tests (i.e., a 55% saving).
In conclusion, 2 positive samples were successfully identified out of 263 by using 98 tests, i.e., a 63% saving in the number of tests compared to individual testing. Since the average prevalence in this population was about 0.8%, the average group-level sensitivity Sg of this screening was very close to 1−fN2.
6. Discussion and Conclusion
In this paper, we investigated false-negative mitigation in group testing, focusing on massive testing for COVID-19 screening. Group testing is receiving attention as a strategy that can save time or resources for COVID-19 testing. Indeed, group testing is reasonable for screening since the percentage of infected people is very low, resulting in substantial savings. However, the high rate of false-negative results in RT-PCR-based COVID-19 diagnostic tests has been widely addressed recently as an important public health-related problem. This problem needs more attention in group testing because a false-negative result for a group of potentially infected individuals does not lead to isolating them, and they can quickly spread the virus in their community.
To mitigate the false-negative results and to increase the sensitivity of the group testing, we studied different strategies for repeating the test. By implementing r replicates in the test design, we can achieve the maximum group-level sensitivity of , but there is a tradeoff between the sensitivity and the average number of tests; hence, we can reduce the average number of tests by compromising the false negatives. However, this compromising is negligible for the very low percentage of infected samples that usually occurs in screening.
Typically, in group-testing studies, researchers propose different methods for pooling and identifying the infected groups. Then, they find the optimum group size to minimize the average number of tests. However, we explained that in COVID-19 screening, the high viral load might not be available because we are dealing with asymptomatic, pre-symptomatic, or mild-symptomatic people. This fact is crucial in group testing because the dilution effect in the pooling of specimens can cause more false-negative cases. Therefore, the theoretical optimum group size of different methods may yield a severe dilution effect and high FNR in the screening scenario. Our experimental studies showed that the maximum group size in COVID-19 screening should be 6. However, systematic studies are still required to determine the maximum group size for COVID-19 screening. Moreover, by filtering out symptomatic individuals and testing them individually, we can increase the performance and sensitivity of the test. For further studies, we can pool specimens based on the age and medical background of individuals and investigate the effect of these factors on the performance of the group-testing method.
7. groupMix Web Interface
A web interface is developed to help laboratories implement the NC-groupMix method. This website is freely accessible at http://groupmix.ipm.ir. This web interface will be elaborated in Appendix B (Supplementary Material).
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author/s.
Ethics Statement
The studies involving human participants were reviewed and approved by The Ethical Committee of the Royan Institute. The patients/participants provided their written informed consent to participate in this study.
Author Contributions
AA-R developed, analyzed, and simulated the methods, wrote the manuscript, and tested the web interface functionality. SV developed the web interface. MT performed the laboratory tests and provided the laboratory methods for writing the manuscript. MS conceived the study and guided its method development. All authors read and approved the final manuscript.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmed.2021.661277/full#supplementary-material
References
1. Dorfman R. The detection of defective members of large populations. Ann Math Statist. (1943) 14:436–40. doi: 10.1214/aoms/1177731363
2. Cahoon-Young B, Chandler A, Livermore T, Gaudino J, Benjamin R. Sensitivity and specificity of pooled versus individual sera in a human immunodeficiency virus antibody prevalence study. J Clin Microbiol. (1989) 27:1893–95. doi: 10.1128/JCM.27.8.1893-1895.1989
3. Bachelet VC. Do we know the diagnostic properties of the tests used in COVID-19? A rapid review of recently published literature. Medwave. (2020) 20:e7890. doi: 10.5867/medwave.2020.03.7891
4. Cohen AN, Kessel B. False positives in reverse transcription PCR testing for SARS-CoV-2. medRxiv [Preprint]. (2020). doi: 10.1101/2020.04.26.20080911
5. Corman VM, Landt O, Kaiser M, Molenkamp R, Meijer A, Chu DK, et al. Detection of 2019 novel coronavirus (2019-nCoV) by real-time RT-PCR. Euro Surveill. (2020) 25:23–30. doi: 10.2807/1560-7917.ES.2020.25.3.2000045
6. Broughton JP, Deng X, Yu G, Fasching CL, Servellita V, Singh J, et al. CRISPR-Cas12-based detection of SARS-CoV-2. Nat Biotechnol. (2020) 38:870–4. doi: 10.1038/s41587-020-0513-4
7. Li D, Wang D, Dong J, Wang N, Huang H, Xu H, et al. False-negative results of real-time reverse-transcriptase polymerase chain reaction for severe acute respiratory syndrome coronavirus 2: role of deep-learning-based CT diagnosis and insights from two cases. Korean J Radiol. (2020) 21:505–8. doi: 10.3348/kjr.2020.0146
8. Yang Y, Yang M, Shen C, Wang F, Yuan J, Li J, et al. Evaluating the accuracy of different respiratory specimens in the laboratory diagnosis and monitoring the viral shedding of 2019-nCoV infections. medRxiv [Preprint]. (2020). doi: 10.1101/2020.02.11.20021493
9. Kucirka LM, Lauer SA, Laeyendecker O, Boon D, Lessler J. Variation in false-negative rate of reverse transcriptase polymerase chain reaction-based SARS-CoV-2 tests by time since exposure. Ann Intern Med. (2020) 173:262–7. doi: 10.7326/M20-1495
10. Hanel R, Thurner S. Boosting test-efficiency by pooled testing for SARS-CoV-2-formula for optimal pool size. PLoS ONE. (2020) 15:e0240652. doi: 10.1371/journal.pone.0240652
11. Ramdas K, Darzi A, Jain S. ‘Test, re-test, re-test': using inaccurate tests to greatly increase the accuracy of COVID-19 testing. Nat Med. (2020). doi: 10.1038/s41591-020-0891-7 .[Epub ahead of print].
12. Litvak E, Tu XM, Pagano M. Screening for the presence of a disease by pooling sera samples. J Am Stat Assoc. (1994) 89:424–34. doi: 10.1080/01621459.1994.10476764
Keywords: COVID-19 screening, false-negative mitigation, groupMix, group testing, pool testing, RT-PCR, SARS-CoV-2, sensitivity
Citation: Alizad-Rahvar AR, Vafadar S, Totonchi M and Sadeghi M (2021) False Negative Mitigation in Group Testing for COVID-19 Screening. Front. Med. 8:661277. doi: 10.3389/fmed.2021.661277
Received: 30 January 2021; Accepted: 06 April 2021;
Published: 10 May 2021.
Edited by:
Atefeh Abedini, Shahid Beheshti University of Medical Sciences, IranReviewed by:
Hossein Peyvandi, University of Surrey, United KingdomPegah Khosravi, Cornell University, United States
Copyright © 2021 Alizad-Rahvar, Vafadar, Totonchi and Sadeghi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Amir Reza Alizad-Rahvar, YWxpemFkQGlwbS5pcg==; Mehdi Sadeghi, c2FkZWdoaUBuaWdlYi5hYy5pcg==