 Nei Xiong1
Nei Xiong1 Yuhan Zhang2*
Yuhan Zhang2*- 1School of Management Department, Capital Normal University, Beijing, China
- 2Department of Medical Imaging, Zhuhai Campus, Zunyi Medical University, Zhuhai, China
Underwater vision is inherently difficult due to wavelength-dependent light absorption, non-uniform illumination, and scattering, which collectively reduce both perceptual quality and task utility. We propose a novel architecture (ResMambaNet) that addresses these challenges through explicit decoupling of chromatic and structural cues, residual state-space modeling, and cross-scale feature alignment. Specifically, a dual-branch design separately processes RGB and Lab representations, promoting complementary recovery of color and spatial structures. A residual state-space module is then employed to unify local convolutional priors with efficient long-range dependency modeling, avoiding the quadratic complexity of attention. Finally, a cross-attention–based fusion with adaptive normalization aligns multi-scale features for consistent restoration across diverse conditions. Experiments on standard benchmarks (EUVP and UIEB) show that the proposed approach establishes new state-of-the-art performance, improving colorfulness, contrast, and fidelity metrics by large margins, while maintaining only
1 Introduction
Underwater image enhancement (UIE) constitutes a fundamental problem in computer vision, with broad implications for marine resource exploration, ecological monitoring, and autonomous underwater robotics (Berman et al., 2020). Compared with terrestrial vision, underwater platforms must operate under far more stringent visual perception requirements, where both the imaging process and the computational models are strongly affected by the unique physics of light propagation in water. Specifically, wavelength-dependent absorption, scattering, and spatially varying illumination severely degrade captured images, leading to pronounced color casts, low-light visibility, and loss of structural fidelity (Berman et al., 2020).
Existing UIE techniques are generally divided into two major categories: traditional model-based methods and data-driven deep learning approaches (Yuan et al., 2025). Traditional methods exploit interpretable optical models (e.g., the Jaffe–McGlamery formulation) in combination with color correction, histogram equalization, or multi-scale fusion strategies. While effective in shallow or low-turbidity scenarios, their reliance on simplified assumptions often results in poor robustness under complex aquatic conditions (Karypidis et al., 2022); (Hu et al., 2022). Deep learning methods, on the other hand, learn end-to-end mappings via architectures such as WaterNet Li et al. (2019), U-Net–based autoencoders (Hashisho et al., 2019), and more recent variants that incorporate attention mechanisms or lightweight designs. These approaches significantly enhance sharpness and perceptual quality, showing promising generalization in challenging scenarios (Hashisho et al., 2019); (Li et al., 2019); (Zhu et al., 2025). However, they typically demand large-scale annotated datasets and computational resources, while their black-box nature limits interpretability (see, e.g., Zhu et al., 2025). To address these shortcomings, a growing line of research integrates physical priors into deep architectures by embedding underwater imaging models as explicit constraints or learnable components, thereby improving both effectiveness and interpretability (Tao et al., 2024).
From the standpoint of traditional physics-based modeling, factors that degrade underwater image quality (e.g., light-intensity attenuation curves and backscattering components) are explicitly parameterized and compensated through model-driven calibration. For example, early dehazing formulations and the dark channel prior were adapted to underwater imaging for color correction and turbidity removal. In contrast, non-physical approaches enhance imagery by directly learning an image-to-image mapping, most commonly via deep learning or other machine-learning models (Zhang et al., 2023). In recent years, deep learning methods grounded in convolutional neural networks (CNNs) have been widely adopted for underwater image enhancement. (Li et al., 2020a) proposed a multi-input/single-output (MISO) architecture that feeds both traditionally preprocessed images and raw underwater captures into a CNN, leveraging shallow-level multi-source cues to improve color rendition and contrast (Zhang et al., 2023). While CNN-based approaches can be effective, their limitations in complex underwater environments are well documented (Xu et al., 2025). To address these issues, researchers have incorporated Transformer-style channel self-attention and pixel-fusion mechanisms to capture global context while preserving local details (Shen et al., 2023). Considering the costs of human intervention and annotation, unsupervised or semi-supervised techniques based on generative adversarial networks (GANs) have emerged as a prominent direction. Through generator–discriminator adversarial training, these methods can learn robust enhancement mappings in the absence of paired clean references by exploiting learned priors. For instance, (Islam et al., 2020) trained adversarial networks with unpaired underwater/clean imagery to strengthen style learning, and (Li et al., 2018) used WaterGAN to synthesize underwater training data before training CNNs to improve sharpness and clarity (Zhang et al., 2023). Despite their ability to recover realistic details and color distributions, GANs are prone to instability and mode collapse during training, yielding inconsistent outputs. To mitigate these drawbacks, diffusion models have recently been introduced into the UIE literature (Shi and Wang 2024). (Shi and Wang 2024) proposed a Content-Preserving Diffusion Model (CPDM) built on a pre-trained backbone; at each diffusion step, they inject the difference between the raw underwater image and its noisy counterpart as a conditioning signal to compensate low-level features toward the source, thereby preserving original information while improving adaptability to complex underwater degradations (Shi and Wang 2024). Within the above body of work, relatively few studies have jointly optimized image quality and the computational budget required for edge deployment. Some researchers have explored model compression techniques—such as network pruning and knowledge distillation—to shrink model size and enable effective operation on resource-constrained platforms. However, in practice, these lightweight variants have not consistently demonstrated markedly superior visual performance compared with more complex counterparts. Consequently, a key next-step objective, and the focus of this study, is to improve underwater image quality while simultaneously reducing the computational burden at the edge. To address edge resource constraints, this paper proposes the Res-Mamba network. In contrast to existing Mamba-based methods, Res-Mamba integrates the following three primary innovations:
1. Architectural Innovation. ResMambaNet adopts a three-stage, dual-branch, multi-modal pathway from shallow to deep layers. In the shallow stage, RGB and Lab inputs are processed in parallel to extract complementary cues. In the middle and deep stages, each branch performs residual state-space sequence modeling and upsampling, ensuring faithful multi-scale propagation from local detail to global context. This design enables early separation and handling of color and fine structures while maintaining efficient feature fusion and spatial consistency at deeper levels, thereby markedly improving enhancement under spatially non-uniform illumination and turbid underwater conditions.
2. Res-Mamba Module. At each stage, we replace conventional purely convolutional or Transformer blocks with the proposed Res-Mamba module to realize efficient long-range dependency modeling via a state-space sequence model (SSM). Integrated through residual connections, Res-Mamba preserves local convolutional features while capturing global context with linear-time complexity (in sequence length). This design improves network scalability and substantially strengthens information exchange across channels and color spaces.
3. Fusion Mechanism with Cross-Attention. After shallow feature extraction, ResMambaNet—to the best of our knowledge, for the first time in underwater image enhancement—introduces a cross-attention mechanism to achieve complementary coupling between the RGB and Lab shallow features. We then apply Adaptive Instance Normalization (AdaIN) for alignment and fusion, performing element-wise fusion and channel-wise normalization at the shallow, middle, and deep stages. Finally, dedicated fusion sub-networks (shallow_fuse, mid_fuse, and deep_fuse) refine the aggregated features. This dynamic dual-stage fusion strategy synchronizes color and structural alignment and achieves an effective balance between detail preservation and color fidelity across multiple scales.
2 Related works
2.1 Underwater image enhancement
Underwater imagery is unavoidably degraded during acquisition by physical effects such as absorption and scattering, leading to pronounced color casts, low contrast, and blurred fine details. Prior studies have shown that attenuation in the red band is markedly higher than in the blue–green spectrum, causing a ubiquitous bluish–green color shift, concurrent luminance reduction, and weakened textures and edges. These degradations not only diminish perceptual image quality but also substantially impair the performance of downstream tasks, including underwater object detection, depth estimation, and semantic segmentation. To address these issues, current research on underwater image enhancement can be broadly categorized into two families: traditional (model-based) approaches and deep learning–based methods (Almutiry et al., 2024); (Yuan et al., 2025). Traditional approaches can be further subdivided into heuristic, non-physical methods and physics-based image-formation models (Li et al., 2025). The former directly manipulate pixel intensities—e.g., histogram equalization, Retinex, and multi-scale/image fusion—to improve perceived contrast and saturation (Galdran et al., 2015) guan2023diffwater. Although these techniques are computationally efficient and thus attractive for resource-constrained edge devices, they do not account for wavelength- and space-dependent attenuation in water and are therefore prone to under- or over-enhancement, limiting their effectiveness in complex underwater scenes (Raveendran et al., 2021). By contrast, physics-based methods—such as the Underwater Dark Channel Prior (UDCP) (Galdran et al., 2015) and illumination/attenuation models—explicitly model absorption and scattering and restore images by estimating scene parameters. Leveraging environmental physics, they can recover details and color to a certain extent; however, they typically require intricate parameter estimation (e.g., transmission and global illumination) and are sensitive to scene assumptions, which undermines stability in real-world applications (Berman et al., 2020) trucco2006self. Moreover, the associated computational burden further complicates deployment on edge platforms with limited resources (Zhang et al., 2025). In recent years, deep learning–based methods have achieved notable advances in underwater image enhancement (Islam et al., 2020). Convolutional neural network (CNN) models—such as the multi-scale Water-Net—effectively integrate diverse enhancement operations to restore image quality (Li et al., 2020a) li2021underwater. Several CNN variants further exploit features from multiple color spaces (e.g., RGB and HSV) and employ attention mechanisms for feature fusion, thereby improving luminance and chromatic enhancement (Li et al., 2021) cong2024comprehensive. Generative adversarial networks (GANs) have additionally boosted perceptual quality; for example, physics-guided approaches such as PUGAN leverage imaging priors to steer restoration (Fu et al., 2022a). Nevertheless, these models often involve complex architectures with large parameter counts and substantial computational demands, which hinder real-time deployment on resource-constrained edge devices (Huang et al., 2023). With the emergence of Transformer architectures, a number of studies have capitalized on self-attention’s strong modeling capacity to significantly improve enhancement performance—for instance, U-shaped Transformers (Peng et al.) and Phaseformer (Khan et al.) (Peng et al., 2023). However, the quadratic computational complexity of standard self-attention leads to considerable overhead, limiting efficiency on edge platforms (Li et al., 2025). Diffusion-based approaches have also gained traction; for example, CLIP-UIE (Liu et al.) combines diffusion modeling with CLIP-domain knowledge and adopts rapid fine-tuning to improve enhancement quality (Lu et al., 2023). Yet diffusion models are intrinsically compute-intensive and parameter-heavy, which substantially constrains their applicability in edge-computing scenarios with tight resource budgets (Du et al., 2025) tang2023underwater. In summary, although underwater image enhancement (UIE) has achieved a series of notable advances, substantial challenges persist in resource consumption, computational efficiency, and suitability for deployment on edge devices (Tang et al., 2023). How to effectively reduce algorithmic complexity and parameter counts while maintaining—or even improving—enhancement quality, thereby enabling better adaptation to edge-computing environments, remains a pressing open problem in current UIE research (Zhang et al., 2024).
2.2 Edge-computing–based underwater image enhancement
As noted above, recent deep learning–based approaches to underwater image enhancement (e.g., CNNs, GANs, Transformers, and diffusion models) have achieved strong quantitative and subjective performance on standard benchmarks such as UIEB and LSUI (Cong et al., 2024) guan2023diffwater. However, these methods typically presume high-performance servers or GPU-equipped environments, overlooking the stringent constraints on computation, power consumption, and real-time responsiveness in practical underwater operations (Hamdan et al., 2020); (Mittal 2024) comprehensive. Edge computing addresses this gap by offloading inference to embedded devices situated near the data source, thereby enabling localized processing and rapid response. This paradigm mitigates the latency and bandwidth bottlenecks inherent to cloud-centric workflows while simultaneously promoting privacy preservation and improving system robustness. Although research on underwater image enhancement (UIE) under edge constraints has started relatively recently, several studies have demonstrated the feasibility of deploying deep models in low-compute settings. Spanos et al. presented at ISPRS 2024 a physics-guided, real-time restoration framework on Jetson Nano, where TensorRT-based quantization and graph optimizations increased the throughput to 3–4 FPS while keeping power below 10 W, effectively balancing computational efficiency and enhancement quality (Antoniou et al., 2024). Jiang et al. Tian et al. (2025) designed a lightweight Adaptive Trans-ResUNet++ that integrates separable convolutions, attention pruning, and depthwise-separable residual units; compared with a conventional TransUNet, the parameter count was reduced by approximately 60% while preserving comparable PSNR/SSIM on embedded platforms. In addition, an engineering case for underwater cultural heritage monitoring (Shi et al., 2024) combined seabed optical priors with coordinated scheduling across edge devices to achieve in-situ enhancement with remote synchronization, thereby validating the performance and stability of edge–cloud collaboration in field deployments. Building on the above advances, edge computing has, to some extent, mitigated the latency, bandwidth, and power constraints that hinder real-time performance and inflate resource consumption in underwater image enhancement. Nevertheless, research specifically tailored to lightweight enhancement algorithms and resource-efficient management strategies for underwater settings remains limited. In particular, there is insufficient exploration of methods to further reduce algorithmic complexity, optimize network architectures, and balance computational load for deployment under stringent edge constraints.
3 Methods
Underwater image degradation typically stems from two largely independent factors: (i) structural information loss in the spatial domain (e.g., blurred edges or vanished textures) and (ii) perceptual deterioration (e.g., color distortion and reduced contrast). Existing enhancement pipelines often conflate these two mechanisms within a single unified model, which can undermine both generalization and robustness. To address this limitation, we adopt an independent modeling strategy that decomposes the task into more targeted submodules and endows each with an appropriate inductive bias, thereby improving the model’s generalization ability and interpretability. To effectively elevate perceptual quality under underwater conditions, we design four core modules, namely, the Res-Mamba module, the Cross-Melt-A attention module, and the ELA-Norm module, each tailored to a distinct degradation factor in underwater imaging and supported by clear theoretical motivations and architectural choices. The following subsections detail the mathematical formulations and implementation specifics of each module.
3.1 Res-Mamba module
Underwater images typically exhibit a combination of global degradations induced by light propagation (e.g., color casts and contrast attenuation) and local detail losses (e.g., edge blurring and texture weakening). Conventional convolutional neural networks (CNNs) are limited in modeling long-range dependencies, whereas Transformer self-attention can capture global relations but incurs prohibitive quadratic complexity. To reconcile these trade-offs, we construct a Res-Mamba block within a state-space modeling (SSM) framework and integrate it into a residual architecture, yielding the Res-Mamba module. The SSM backbone enables linear-time modeling of long-range interactions across spatial tokens, delivering global consistency, while the residual pathway explicitly fuses local high-frequency cues—preserved by lightweight convolutional operators—into the main stream. This design jointly enhances global perceptual coherence and local structural fidelity under underwater imaging conditions, achieving a balanced improvement in both large-scale color/contrast correction and fine-detail restoration. Given a degraded underwater image
Here,
Here,
Here,
The Res-Mamba module relies on several key hyperparameters of the underlying SSM. The latent state size
3.2 Cross-melt-A module
We first refine the conventional AdaIN module and design a spatially adaptive feature-fusion block. The core idea is to use feature-map information to dynamically predict convolution kernels, enabling fine-grained convolution in the spatial domain. In a dual-branch architecture, we obtain two streams that respectively emphasize color/contrast and texture detail. The key to improving underwater image quality is to fuse these complementary cues to produce an output that is both color-faithful and detail-sharp. Simple summation or concatenation of the branch outputs is insufficient and may allow one cue to overshadow the other. Therefore, we introduce the Cross-Melt-A mechanism: during fusion, one branch serves as a query to attend to the other, adaptively computing importance weights. This allows selective fusion based on the correlation between color and detail features, mitigating information conflicts and highlighting enhancements in key regions. Let the feature map from the detail-enhancement branch be
where
The resulting matrix
Here,
3.3 Normalization module
To simultaneously correct global color bias and strengthen local details on underwater edge devices, we design the ELA-norm module. It comprises four sequential sub-steps—instance normalization, Efficient Local Attention (ELA), cross-channel attention fusion, and transposed-convolution upsampling—thereby forming a closed-loop pipeline from global style correction to detail reconstruction. First, to address substantial variations in tone and illumination styles across different waters, ELA-norm (Equation 8) applies instance normalization to each channel of every image (Equation 7) immediately after shallow feature extraction:
where
Next, lightweight 1D convolutions followed by ReLU and Sigmoid are applied to produce the row- and column-wise attention weights
This step captures long-range spatial dependencies across entire rows and columns without incurring a significant computational burden, thereby highlighting salient edges and target regions while suppressing background noise. To further fuse multi-source features, ELA-norm embeds a Cross-Attention Fuse module. Let the two mapped feature streams (e.g., shallow vs. deep, or RGB vs. Lab) be
Finally, channel-wise fusion (Equation 12) is performed with a learnable parameter
After fusion, ELA-norm upsamples the feature map to the original resolution using transposed convolution (deconvolution). Unlike bilinear interpolation (Equation 13), deconvolution learns a convolution kernel
At high-frequency locations, training adaptively amplifies edge features, while in flat regions it performs smooth interpolation; together with the final global residual
4 Experimental analysis and discussion
To objectively evaluate the proposed model, we conduct experiments on the EUVP (Islam et al., 2020) and UIEB (Li et al., 2020b) datasets. This section details the experimental setting, dataset descriptions, evaluation metrics, and experimental results.
4.1 Experimental environment and setup details
This study employs the PyTorch 1.13 deep learning framework, built on CUDA 11.7 and accelerated with the cuDNN 8.5 library. All training procedures are conducted within a Conda-managed virtual environment. The central processing unit (CPU) used in the experiments is an Intel® Xeon® W-2255 with 10 physical cores and 20 threads, featuring a maximum clock frequency of 3.70 GHz.
The model was trained using the Adam optimizer with an initial learning rate of 0.01, which was decayed by a factor of 0.3 every 30 epochs. A total of 100 epochs were performed with a mini-batch size of 4. During training, checkpoints were saved every 10 epochs to enable subsequent recovery and evaluation. The experiments employ two public datasets, EUVP and UIEB. A unified preprocessing pipeline resizes all input images to
4.2 Evaluation metrics
Complex underwater imaging conditions often lead to color distortion, detail blurring, and reduced contrast. Given these heterogeneous degradations, existing evaluation protocols may struggle to comprehensively characterize an enhancement algorithm’s performance across structural restoration, pixel fidelity, and perceptual quality. Accordingly, we adopt common no-reference quality indices for underwater image enhancement, including UCIQE, UIQM, CCF, and FDUM. In ablation studies, SSIM and PSNR are additionally reported as auxiliary references. SSIM primarily assesses the recovery of spatial structural information, effectively reflecting an algorithm’s ability to restore local textures and fine details (Chen et al., 2021), (Liu et al., 2025), (Yan et al., 2025). PSNR focuses on overall pixel-level distortion by quantifying the average error between enhanced and reference images, thereby indicating performance in noise suppression and detail fidelity (Han et al., 2023).
For no-reference evaluation, UCIQE linearly combines chroma difference, saturation, and contrast in the CIELab space to capture global color shift and contrast changes (Raveendran et al., 2021). UIQM standardizes and weights three components—colorfulness, sharpness, and contrast—yielding a measure more aligned with human visual perception. CCF extends the UIQM framework by incorporating a haze component derived from the dark channel prior, improving sensitivity in highly turbid scenes (Hou et al., 2024). FDUM employs frequency-domain transforms to quantify high-frequency detail fidelity and, together with dark-channel–based contrast correction and multivariate regression weighting, can finely capture artifacts and texture loss after enhancement.
4.3 Results analysis
In this section, to assess the effectiveness of the ResMambaNet introduced in this paper, we carried out both quantitative and qualitative experiments. A variety of currently available underwater image enhancement methods were chosen for comparison, such as Fusion (Ancuti et al., 2017), NU2Net (Guo et al., 2023), DiffWater (Guan et al., 2023), DMWater (Tang et al., 2023), U-Shape (Peng et al., 2023), Shallow-UWnet (Naik et al., 2021), UColor (Li et al., 2021), PUIE-Net (Fu et al., 2022b), HCLR-Net (Zhou et al., 2024), UW-DiffPhys (Bach et al., 2024) and Waterdiff (Meisheng Guan et al. 2024). These methods cover widely recognized mainstream techniques for underwater image enhancement, along with algorithms based on advanced neural network architectures.
The quantitative results on the EUVP dataset are summarized in Table 1, where red, blue, and black denote the first-, second-, and third-ranked scores across metrics, respectively. Horizontally, our proposed method (Ours) achieves optimal performance in three out of four evaluated metrics. On the UCIQE metric, both Ours and HCLR-Net attain a score of 0.618 (red), marginally surpassing NU2Net (0.606, blue) and PUIE-Net (0.594, black). For the CCF metric, Ours secures 38.981 (red), significantly outperforming the second-best HCLR-Net (36.929, blue). In UIQM, Ours records 1.45 (blue), while UW-DiffPhys leads with 1.542 (red), followed by HCLR-Net at 1.411 (black). The sole exception is FDUM, where ours scores 0.554 (black), trailing closely behind HCLR-Net’s 0.555 (blue) by a narrow margin of 0.001 (Hamdan et al., 2020). Longitudinally, Ours consistently ranks within the top three across all metrics (two first places, one second, one-third), demonstrating robust competitiveness across multidimensional evaluation criteria.
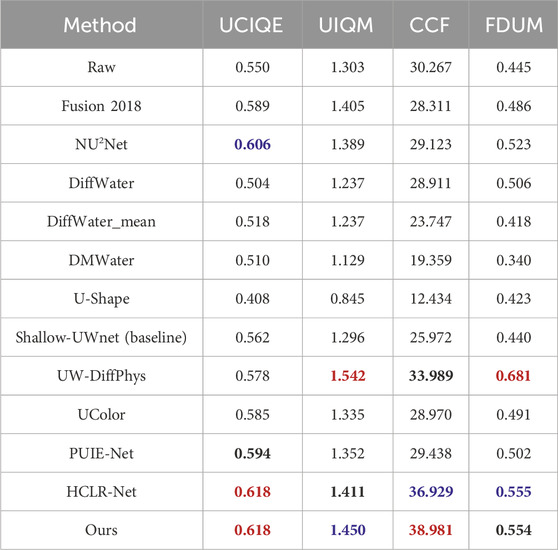
Table 1. Numerical evaluation of the proposed approach against cutting-edge methods using the EUVP dataset. Bolding represents the best indicator result. The red is the highest, the blue is the second highest, and the black font is the third highest.
Quantitative assessments on the UIEB dataset (Table 2) reveal pronounced discrepancies among compared methods. Laterally, Ours achieves the highest UCIQE score (
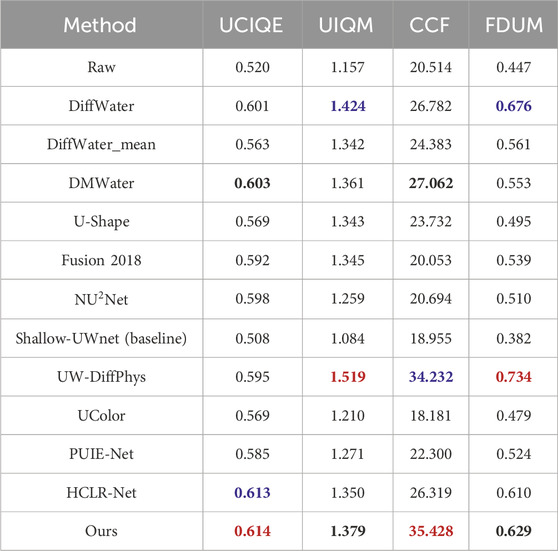
Table 2. Numerical evaluation of the proposed approach against recent diffusion-based or Transformer-based methods using the UIEB dataset. The red is the highest, the blue is the second highest, and the black font is the third highest.
For color fidelity (CCF), Ours tops the ranking (35.43, red), outperforming UW-DiffPhys

Figure 1. Qualitative analysis of the proposed approach in comparison with leading-edge methods on the UIEB dataset.

Figure 2. Qualitative analysis of the proposed approach in comparison with leading-edge methods on the EUVP dataset.
This indicates trade-offs inherent in conventional algorithms. In contrast, advanced deep learning methods deliver more balanced improvements across all four metrics. For instance, HCLR-Net elevates UCIQE by 18% (0.520
On the EUVP dataset, Ours leads all four no-reference quality metrics: UCIQE reaches 0.618 (tied with HCLR-Net), UIQM stands at 1.450 (second), CCF peaks at 38.981 (first), and FDUM registers 0.554 (third, just below HCLR-Net’s 0.555). By contrast, NU2Net performs adequately in UCIQE (0.61) and FDUM (0.52) but lags in CCF and UIQM; legacy methods like Fusion (2018) and U-Shape score low across most metrics (e.g., U-Shape’s UCIQE: 0.408), indicating limited enhancement capacity. Notably, UW-DiffPhys ranks first in UIQM and FDUM but underperforms overall compared to Ours. Broadly, methods synergistically optimizing color correction (high UCIQE/CCF) and detail sharpening (high UIQM/FDUM) yield superior composite quality, with Ours serving as a paradigmatic exemplar.
Rankings shift relatively on the UIEB dataset. Ours retains top positions in UCIQE (0.614) and CCF (35.428), validating its sustained color and contrast correction capabilities across diverse underwater scenes. As shown in Figure 1, when processing severely color-distorted underwater images, Ours not only removes haze but also effectively restores true dynamics of aquatic scenes (Figure 2). Taking the “blue-like red algae” example in Figure 3 (top-down), severer color casts amplify Ours’ superiority over alternatives. In UIQM, diffusion-based UW-DiffPhys
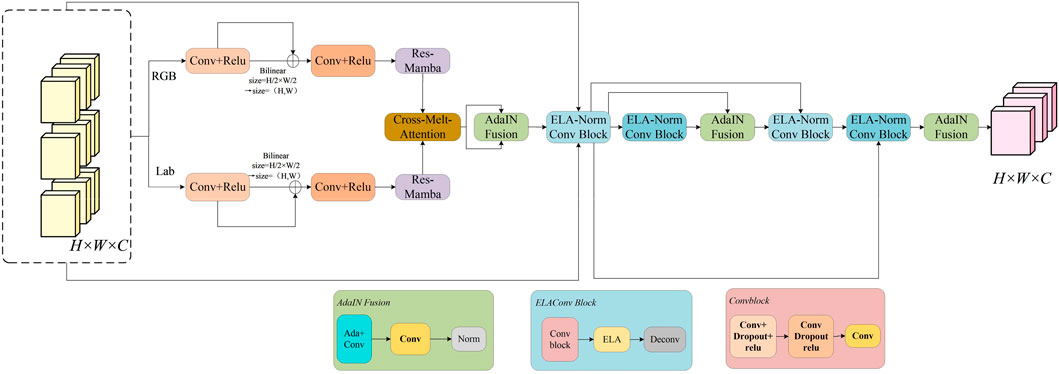
Figure 3. The structural diagram of ResMambaNet: proposed in this paper. This framework processes the image through two branches of color and detail, respectively.
Longitudinally analyzing Ours’ cross-metric performance: UCIQE–Ranked first on both EUVP and UIEB, evidencing exceptional global color bias correction and contrast enhancement; UIQM–Peaks on EUVP (1.450) but ranks third on UIEB (1.379), behind DiffWater, highlighting a balance between color preservation and sharpness; CCF–Dominates both datasets, proving excellence in underwater color cast removal and natural color recovery; FDUM–Third on EUVP (0.554) and second on UIEB (0.629), matching top-tier methods (e.g., HCLR-Net, DiffWater) in detail/texture fidelity.
Averaging ranks across four metrics, Ours achieves an average rank of 1.75 on EUVP (two firsts, one second, one-third) and 2.0 on UIEB (two firsts, two-thirds), both lowest among competitors, signifying sustained high performance across metrics and datasets. Close contenders include HCLR-Net (avg. rank 2.0 on EUVP) and UW-DiffPhys
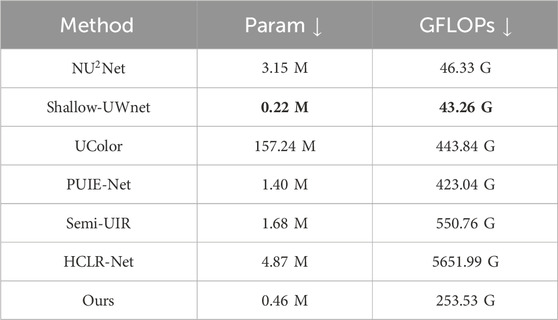
Table 3. Comparison of different UIE models in terms of GFLOPs (G) and parameters (M). The downward arrow indicates that the lower the indicator, the better. Bolding represents the best indicator result.
In summary, Ours attains state-of-the-art or near-state-of-the-art performance in four critical dimensions: color correction, haze suppression, contrast enhancement, and detail fidelity. It demonstrates strong consistency and stability across both EUVP and UIEB datasets. Compared to HCLR-Net and UW-DiffPhys
4.4 Ablation experiments
As shown in Table 4, the ablation study validates the contribution of both the cross-melt attention fusion strategy and the Res-Mamba module. In particular, the fusion between the RGB and Lab branches is achieved through a two-stage mechanism: first, each branch is enhanced by its own Res-Mamba block to capture long-range dependencies, and then the features are integrated by cross-melt attention, which aligns the complementary color (Lab) and structural (RGB) representations across scales. The fused features are further refined by AdaIN-based normalization, ensuring adaptive balance between the two modalities. Removing this RGB–Lab fusion step causes the largest performance drop, especially on UCIQE (from 0.618 to 0.595) and SSIM (from 0.763 to 0.736), highlighting the necessity of multi-branch alignment for perceptual quality enhancement. Excluding the Res-Mamba module leads to a moderate decrease in PSNR (21.17
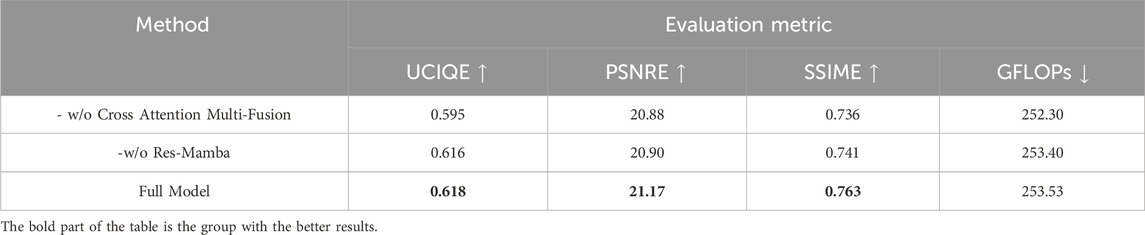
Table 4. Ablation study of various modules and loss functions on the EUVP dataset.
5 Conclusion
This work presented ResMambaNet, a lightweight framework for underwater image enhancement. The network integrates three key designs: a dual-branch pathway that processes RGB and Lab features in parallel and progressively fuses them to decouple color and structure; a Res-Mamba module that couples local convolution with linear-time state-space modeling for efficient long-range dependency capture; and a cross-attention + AdaIN fusion strategy across multiple scales to align color statistics and structural cues. Comprehensive experiments on EUVP and UIEB demonstrate that ResMambaNet achieves state-of-the-art or near state-of-the-art performance. It consistently improves UCIQE, UIQM, CCF, and FDUM by 4%, 19%, 74%, and 41%, respectively, while maintaining compactness with only 0.46M parameters and 253.53 GFLOPs (Table 3). These results confirm that principled fusion of color/structure cues and efficient long-range modeling deliver substantive perceptual benefits at low computational cost. In summary, ResMambaNet advances the accuracy–efficiency trade-off of underwater image enhancement and provides a practical foundation for real-time underwater perception in exploration, inspection, and robotics.
For future work, one promising direction is to extend ResMambaNet from still images to video sequences, where temporal consistency and real-time constraints are critical for underwater robotics. Another avenue is to investigate adaptive training strategies that generalize across varying water types and lighting conditions, reducing the need for dataset-specific fine-tuning. Moreover, integrating ResMambaNet into multi-modal systems (e.g., combining optical images with sonar or LiDAR data) could further enhance robustness in challenging underwater environments.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
NX: Data curation, Investigation, Methodology, Software, Validation, Visualization, Writing – original draft, Writing – review and editing. YZ: Formal Analysis, Investigation, Visualization, Writing – original draft, Writing – review and editing.
Funding
The author(s) declare that no financial support was received for the research and/or publication of this article.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Almutiry, O., Iqbal, K., Hussain, S., Mahmood, A., and Dhahri, H. (2024). Underwater images contrast enhancement and its challenges: a survey. Multimedia Tools Appl. 83, 15125–15150. doi:10.1007/s11042-021-10626-4
Ancuti, C. O., Ancuti, C., De Vleeschouwer, C., and Bekaert, P. (2017). Color balance and fusion for underwater image enhancement. IEEE Trans. Image Process. 27, 379–393. doi:10.1109/tip.2017.2759252
Antoniou, C., Spanos, S., Vellas, S., Ntouskos, V., and Karantzalos, K. (2024). Streamur: physics-Informed near real-time underwater image restoration. Int. Archives Photogrammetry, Remote Sens. Spatial Inf. Sci. 48, 1–8. doi:10.5194/isprs-archives-xlviii-3-2024-1-2024
Bach, N. G., Tran, C. M., Kamioka, E., and Tan, P. X. (2024). Underwater image enhancement with physical-based denoising diffusion implicit models. arXiv. doi:10.48550/arXiv.2409.18476
Berman, D., Levy, D., Avidan, S., and Treibitz, T. (2020). Underwater single image color restoration using haze-lines and a new quantitative dataset. IEEE Trans. Pattern Analysis Mach. Intell. 43 (8), 2822–2837. doi:10.1109/TPAMI.2020.2977624
Chen, X., Zhang, P., Quan, L., Yi, C., and Lu, C. (2021). Underwater image enhancement based on deep learning and image formation model. arXiv Prepr. arXiv:2101.00991. Available online at: https://api.semanticscholar.org/CorpusID:230433899.
Cong, X., Zhao, Y., Gui, J., Hou, J., and Tao, D. (2024). A comprehensive survey on underwater image enhancement based on deep learning. arXiv Prepr. arXiv:2405.19684.
Du, D., Li, E., Si, L., Zhai, W., Xu, F., Niu, J., et al. (2025). Uiedp: boosting underwater image enhancement with diffusion prior. Expert Syst. Appl. 259, 125271. doi:10.1016/j.eswa.2024.125271
Fu, Z., Wang, W., Huang, Y., Ding, X., and Ma, K.-K. (2022a). “Uncertainty inspired underwater image enhancement,” in European conference on computer vision (Springer), 465–482.
Fu, Z., Wang, W., Huang, Y., Ding, X., and Ma, K.-K. (2022b). Uncertainty inspired underwater image enhancement. Cham: Proc. Eur. Conf. Comput. Vis., 465–482.
Galdran, A., Pardo, D., Picón, A., and Alvarez-Gila, A. (2015). Automatic red-channel underwater image restoration. J. Vis. Commun. Image Represent. 26, 132–145. doi:10.1016/j.jvcir.2014.11.006
Guan, M., Xu, H., Jiang, G., Yu, M., Chen, Y., Luo, T., et al. (2023). Diffwater: underwater image enhancement based on conditional denoising diffusion probabilistic model. IEEE J. Sel. Top. Appl. Earth Observations Remote Sens. 17, 2319–2335. doi:10.1109/jstars.2023.3344453
Guo, C., Wu, R., Jin, X., Han, L., Zhang, W., Chai, Z., et al. (2023). Underwater ranker: learn which is better and how to be better. Proc. AAAI Conf. Artif. Intell. 37, 702–709. doi:10.1609/aaai.v37i1.25147
Hamdan, S., Ayyash, M., and Almajali, S. (2020). Edge-computing architectures for internet of things applications: a survey. Sensors 20, 6441. doi:10.3390/s20226441
Han, J., Zhou, J., Wang, L., Wang, Y., and Ding, Z. (2023). Fe-gan: fast and efficient underwater image enhancement model based on conditional gan. Electronics 12, 1227. doi:10.3390/electronics12051227
Hashisho, Y., Albadawi, M., Krause, T., and von Lukas, U. F. (2019). “Underwater color restoration using u-net denoising autoencoder,” in 2019 11th international symposium on image and signal processing and analysis (ISPA) (IEEE), 117–122.
Hou, G., Zhang, S., Lu, T., Li, Y., Pan, Z., and Huang, B. (2024). No-reference quality assessment for underwater images. Comput. Electr. Eng. 118, 109293. doi:10.1016/j.compeleceng.2024.109293
Hu, K., Weng, C., Zhang, Y., Jin, J., and Xia, Q. (2022). An overview of underwater vision enhancement: from traditional methods to recent deep learning. J. Mar. Sci. Eng. 10, 241. doi:10.3390/jmse10020241
Huang, S., Wang, K., Liu, H., Chen, J., and Li, Y. (2023). “Contrastive semi-supervised learning for underwater image restoration via reliable bank,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 18145–18155. doi:10.1109/cvpr52729.2023.01740
Islam, M. J., Xia, Y., and Sattar, J. (2020). Fast underwater image enhancement for improved visual perception. IEEE Robot. Autom. Lett. 5, 3227–3234. doi:10.1109/lra.2020.2974710
Karypidis, E., Mouslech, S. G., Skoulariki, K., and Gazis, A. (2022). Comparison analysis of traditional machine learning and deep learning techniques for data and image classification, arXiv preprint arXiv:2204.05983. WSEAS Trans. Math. 21, 122–130. doi:10.37394/23206.2022.21.19
Li, C., Guo, C., Ren, W., Cong, R., Hou, J., Kwong, S., et al. (2019). An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 29, 4376–4389. doi:10.1109/tip.2019.2955241
Li, C., Anwar, S., and Porikli, F. (2020a). Underwater scene prior inspired deep underwater image and video enhancement. Pattern Recognit. 98, 107038. doi:10.1016/j.patcog.2019.107038
Li, C., Guo, C., Ren, W., Cong, R., Hou, J., Kwong, S., et al. (2020b). An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 29, 4376–4389. doi:10.1109/TIP.2019.2955241
Li, C., Anwar, S., Hou, J., Cong, R., Guo, C., and Ren, W. (2021). Underwater image enhancement via medium transmission-guided multi-color space embedding. IEEE Trans. Image Process. 30, 4985–5000. doi:10.1109/tip.2021.3076367
Li, F., Li, W., Zheng, J., Wang, L., and Xi, Y. (2025). Contrastive feature disentanglement via physical priors for underwater image enhancement. Remote Sens. 17, 759. doi:10.3390/rs17050759
Li, J., Skinner, K. A., Eustice, R. M., and Johnson-Roberson, M. (2018). WaterGAN: unsupervised generative network to enable real-time color correction of monocular underwater images. IEEE Robot. Autom. Lett. 3 (1), 387–394. doi:10.1109/LRA.2017.2730363
Liu, W., Xu, J., He, S., Chen, Y., Zhang, X., Shu, H., et al. (2025). Underwater-image enhancement based on maximum information-channel correction and edge-preserving filtering. Symmetry 17, 725. doi:10.3390/sym17050725
Lu, S., Guan, F., Zhang, H., and Lai, H. (2023). Underwater image enhancement method based on denoising diffusion probabilistic model. J. Vis. Commun. Image Represent. 96, 103926. doi:10.1016/j.jvcir.2023.103926
Mittal, P. (2024). A comprehensive survey of deep learning-based lightweight object detection models for edge devices. Artif. Intell. Rev. 57, 242. doi:10.1007/s10462-024-10877-1
Meisheng Guan, G., Haiyong, Xu, and Luo, T. (2024). Waterdiff: underwater image enhancement latent diffusion model based on mamba and transmission map guidance
Naik, A., Swarnakar, A., and Mittal, K. (2021). “Shallow-uwnet: compressed model for underwater image enhancement (student abstract),” in Proceedings of the AAAI Conference on Artificial Intelligence, 15853–15854. doi:10.1609/aaai.v35i18.17923
Peng, L., Zhu, C., and Bian, L. (2023). U-shape transformer for underwater image enhancement. IEEE Trans. Image Process. 32, 3066–3079. doi:10.1109/tip.2023.3276332
Raveendran, S., Patil, M. D., and Birajdar, G. K. (2021). Underwater image enhancement: a comprehensive review, recent trends, challenges and applications. Artif. Intell. Rev. 54, 5413–5467. doi:10.1007/s10462-021-10025-z
Shen, Z., Xu, H., Luo, T., Song, Y., and He, Z. (2023). Udaformer: underwater image enhancement based on dual attention transformer. Comput. and Graph. 111, 77–88. doi:10.1016/j.cag.2023.01.009
Shi, X., and Wang, Y.-G. (2024). Cpdm: content-preserving diffusion model for underwater image enhancement. Sci. Rep. 14, 31309. doi:10.1038/s41598-024-82803-y
Shi, T., Cai, Z., Li, J., and Gao, H. (2024). Optimize the age of useful information in edge-assisted energy-harvesting sensor networks. ACM Trans. Sens. Netw. 20, 1–26. doi:10.1145/3640342
Tang, Y., Kawasaki, H., and Iwaguchi, T. (2023). “Underwater image enhancement by transformer-based diffusion model with non-uniform sampling for skip strategy,” in Proceedings of the 31st ACM International Conference on Multimedia, 5419–5427. doi:10.1145/3581783.3612378
Tao, Y., Tang, J., Zhao, X., Zhou, C., Wang, C., and Zhao, Z. (2024). Multi-scale network with attention mechanism for underwater image enhancement. Neurocomputing 595, 127926. doi:10.1016/j.neucom.2024.127926
Tian, Y., Yao, K., and Yu, X. (2025). An adaptive underwater image enhancement framework via multi-domain fusion and color compensation. arXiv Prepr. arXiv:2503.03640.
Xu, C., Zhou, W., Huang, Z., Zhang, Y., Zhang, Y., Wang, W., et al. (2025). Fusion-based graph neural networks for synergistic underwater image enhancement. Inf. Fusion 117, 102857. doi:10.1016/j.inffus.2024.102857
Yan, J., Hu, H., Wang, Y., Nawaz, M. W., Ur Rehman Junejo, N., Guo, E., et al. (2025). Underwater image enhancement via multiscale disentanglement strategy. Sci. Rep. 15, 6076. doi:10.1038/s41598-025-89109-7
Yuan, J., Zhang, Y., and Cai, Z. (2025). Underwater scene enhancement via adaptive color analysis and multispace fusion. IEEE J. Ocean. Eng., 1–13doi. doi:10.1109/JOE.2025.3591405
Zhang, S., Zhao, S., An, D., Li, D., and Zhao, R. (2023). Mdnet: a fusion generative adversarial network for underwater image enhancement. J. Mar. Sci. Eng. 11, 1183. doi:10.3390/jmse11061183
Zhang, Y., Yuan, J., and Cai, Z. (2024). Dcgf: diffusion-color guided framework for underwater image enhancement. IEEE Trans. Geoscience Remote Sens. 63, 1–12. doi:10.1109/tgrs.2024.3522685
Zhang, Y., Yu, X., and Cai, Z. (2025). Uwmambanet: dual-branch underwater image reconstruction based on w-shaped mamba. Mathematics 13, 2153. doi:10.3390/math13132153
Zhou, J., Sun, J., Li, C., Jiang, Q., Zhou, M., Lam, K.-M., et al. (2024). Hclr-net: hybrid contrastive learning regularization with locally randomized perturbation for underwater image enhancement. Int. J. Comput. Vis. 132, 4132–4156. doi:10.1007/s11263-024-01987-y
Keywords: underwater vision reconstruction, residual state-space modeling, dual-branch feature decoupling, cross-attention fusion, computational imaging
Citation: Xiong N and Zhang Y (2025) Residual state-space networks with cross-scale fusion for efficient underwater vision reconstruction. Front. Remote Sens. 6:1703239. doi: 10.3389/frsen.2025.1703239
Received: 11 September 2025; Accepted: 15 October 2025;
Published: 18 November 2025.
Edited by:
Guangliang Cheng, University of Liverpool, United KingdomReviewed by:
Wang Guangbiao, Harbin Engineering University, ChinaTing-Bing Xu, Beihang University, China
Copyright © 2025 Xiong and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yuhan Zhang, emhhbmd5dWhhbl90akBmb3htYWlsLmNvbQ==