 Louisa Jane Di Felice
Louisa Jane Di Felice Ada Diaconescu
Ada Diaconescu Payam Zahadat
Payam Zahadat Patricia Mellodge
Patricia Mellodge- 1Department of Economic History, Institutions, Politics and World Economy, Universitat de Barcelona, Barcelona, Spain
- 2Department of Computer Science and Networks, LTCI, Télécom Paris, Institut Polytechnique de Paris, Palaiseau, France
- 3Robotics, Evolution and Artificial Life Lab, IT University of Copenhagen, Copenhagen, Denmark
- 4Department of Electrical and Computer Engineering, University of Hartford, Hartford, CT, United States
Complex adaptive systems (CAS) can be described as system of information flows that dynamically interact across scales to adapt and survive. CAS often consist of many components that work toward a shared goal and interact across different informational scales through feedback loops, leading to their adaptation. In this context, understanding how information is transmitted among system components and across scales becomes crucial for understanding the behavior of CAS. Shannon entropy, a measure of syntactic information, is often used to quantify the size and rarity of messages transmitted between objects and observers, but it does not measure the value that information has for each observer. For this, semantic and pragmatic information have been conceptualized as describing the influence on an observer’s knowledge and actions. Building on this distinction, we describe the architecture of multi-scale information flows in CAS through the concept of multi-scale feedback systems and propose a series of syntactic, semantic, and pragmatic information measures to quantify the value of information flows for adaptation. While the measurement of values is necessarily context-dependent, we provide general guidelines on how to calculate semantic and pragmatic measures and concrete examples of their calculation through four case studies: a robotic collective model, a collective decision-making model, a task distribution model, and a hierarchical oscillator model. Our results contribute to an informational theory of complexity that aims to better understand the role played by information in the behavior of multi-scale feedback systems.
1 Introduction
Complex adaptive systems (CAS), such as organisms, societies, and socio-cyber-physical systems, self-organize and adapt to survive and achieve goals. Their viability and behavior depend on their ability to perceive and adapt to their internal states and external environment. Perception and adaptation are often modulated by feedback loops (Kephart and Chess, 2003; Müller-Schloer et al., 2011; Lalanda et al., 2013a; Haken and Portugali, 2016) which are based on the exchange of matter, energy, and information. When material and energy flows are perceived by system entities, we refer to these entities as agents. Material and energy flows become information flows when agents perceive them and use that perception to change their knowledge or behavior. Perception does not require consciousness, only the capacity to receive information and adapt to it—a part of an engineered system, an ant, or a cell can all be described as agents. In this view, all material and energy flows are potential information flows, and all parts of a CAS become informational. This is in line with informational structural realism (Floridi, 2008), which considers the world as the “…totality of informational objects dynamically interacting with each other” (p.219). The dynamic interactions turn material flows into informational ones, with agents transforming sources into informational inputs (Jablonka, 2002; Uexküll Von, 2013). The presence of a goal is what distinguishes physical from informational patterns: while physical interactions can have no set purpose (Roederer et al., 2005), the agent extracting information from a source does so with a goal. Still, information flows are not decoupled from energy and matter, as perception, communication, and adaptation require the storage of information onto a physical substrate, although information can be tightly or loosely coupled to its substrate (Feistel and Ebeling, 2016).
The content and dynamics of information flows are central to CAS behavior (Atmanspacher, 1991). The environmental information needed for a CAS to maintain its viability can be measured (Kolchinsky and Wolpert, 2018), determining the subset of system–environment information used for its survival (Sowinski et al., 2023). Depending on the granularity selected to perceive a CAS, collections of entities can also be described as systems (e.g., a flock of birds, not just an individual bird) (Krakauer et al., 2020). In this case, considering the information flows generated and circulated within a system is necessary to understand its adaptive behavior—a CAS using the same amount of environmental information may behave differently depending on how that information is circulated and used among its parts and on how new information is generated within the system. Collective CAS with many components tend to operate across different scales and to circulate information through feedback cycles (Simon, 1991; Ahl and Allen, 1996; Pattee, 1973). Our goal is to conceptualize what it means for information to flow through a collective CAS and to measure how that information is used for the system’s adaptation. For this, we focus on CAS formed by interacting components that operate under a collective goal and across different scales.
The term scale usually refers to spatial scales, temporal scales, or organizational levels. We consider that all observations can be modeled as a flow of information from an observed object to an observer. In this context, we define an informational scale as the granularity, level of detail, or resolution at which an object is observed (Diaconescu et al., 2021b). This definition unifies spatial, temporal, and organizational scales under an information perspective. For example, if information is related to time, the scale could represent the frequency of observation or the size of the interval over which the object is observed. If it is related to space, such as when observing a terrain, scale could represent the smallest area that can be distinguished. Using this general definition of scale, collective CAS can be described as systems where information from the local scale can be abstracted to generate global information about the collective state, and individual agents can observe this coarse-grained information locally and adapt to it. We refer to CAS that contain such multi-scale feedback cycles as multi-scale feedback systems (MSFS) (Diaconescu et al., 2019; Diaconescu et al., 2021a). Multi-scale feedback cycles help avoid scalability issues by allowing agents to coordinate without exchanging detailed information, relying instead on the local availability of global information (Flack et al., 2013). While at a higher scale information is less granular, this does not make higher scales less complex (Flack, 2021), but it does reduce the amount of information that the micro-scale has to process for its own adaptation. Bottom-up information abstraction is often referred to as coarse-graining, while top-down reification is referred to as downward causation (Flack, 2017).
The goal of this study is to propose a series of information measures that can be used to understand the behavior of MSFS. Given the complex information dynamics in CAS, as well as the plurality of the concept of information (Floridi, 2005), measuring information flows and their impacts is a non-trivial task. As information circulates through an MSFS and its environment, agents perceive it and act upon it by adapting their knowledge and behavior. These three processes—information communication and perception, knowledge update, and action update—can be mapped onto three categories of information measures: syntactic, semantic, and pragmatic (Morris, 1938). Measures of syntactic information quantify the amount of information transmitted to an agent. Among these, Shannon entropy quantifies the amount of information in a source and can be interpreted as a measure of compressibility, uncertainty, or resource use (Shannon, 1948; Tribus and McIrvine, 1971; Timpson, 2013). While relevant to message transmission, syntactic measures provide no indication about the actual meaning or usefulness of the message to each specific agent. These are described by semantic and pragmatic information measures. Semantic information measures quantify the impact of observed information on an agent’s knowledge or model, and pragmatic information measures quantify the impact of the observed information on the agent’s actions, including communication with other agents. The former focus on the agent’s state and the latter on its behavior (Haken and Portugali, 2016). Although pragmatic information measures are sometimes included in the semantic category (Kolchinsky and Wolpert, 2018) and vice versa (Gernert, 2006), we consider them as separate and interrelated. As the measures consider the value of information to an agent, they are necessarily relative (Von Uexküll, 2013), requiring a case-dependent approach for their measurement.
Building on previous studies (Diaconescu et al., 2019; Mellodge et al., 2021; Diaconescu et al., 2021a), we propose a series of syntactic, semantic, and pragmatic information measures for CAS, focusing on MSFS. We summarize the key aspects of MSFS and develop a series of guidelines that can be used to measure the impact and value of information in such systems. We offer examples of the calculation of information measures through four case studies: a robotic collective model, a collective decision-making model, a task distribution model, and a hierarchical oscillator model. The breadth of these case studies allows us to generalize the role of the proposed information measures to build towards a better understanding of the role of information in CAS.
2 Background: information measures
While agents turn material flows into information, information is still tied to a physical substrate (Walker, 2014). The information perceived by the agent can be more or less decoupled from its substrate. When it is tightly coupled, it can be referred to as structural information. When it becomes less dependent on it and can be encoded differently onto alternative substrates, it can be referred to as “symbolic information” (Feistel and Ebeling, 2016; Bellman and Goldberg, 1984). Beyond the physicality of the information carrier, resources are also needed when information is stored, interpreted, or transformed. Shannon entropy applies to the communication of messages (Shannon, 1948). It is observer-dependent since (i) it requires the existence of an observer perceiving the message and (ii) probability distributions depend on the observer’s knowledge of the system (Lewis, 1930). Alternatively, algorithmic information theory (Grunwald and Vitanyi, 2008) proposes a universal measure for the irreducible information content of an object. The object’s algorithmic, or Kolmogorov, complexity (Ming Li, 2019) is its most compressed, self-contained representation. It can be defined as the length of the shortest binary computer program that generates the object. Kolmogorov complexity only depends on the description language or universal Turing machine running the program. While Shannon entropy measures the quantity of information within an average object from a probabilistic set, Kolmogorov complexity measures the absolute information within an individual object without requiring prior knowledge of its probabilistic distribution.
Applying these concepts to human cognition, Dessalles (2013) considers the importance of information to human observers in terms of its interest, surprise, memorability, or relevance. This is assessed in terms of the difference between the perceived and expected algorithmic complexity of an observed object. Similarly, Dessalles (2010) measures an observer’s emotion about an event depending on the difference between its stakes and the causal complexity of its occurrence. Despite their richness and wide application range, the above information measures exclusively focus on the content of the informational object(s) taken in isolation, irrespective of their actual usage by an agent. This makes them insufficient for assessing the importance of information flows to an agent which employs them to self-adapt. The limitations of syntactic information measures are argued by many (Brillouin, 1962; Atmanspacher, 1991; Nehaniv, 1999; Gernert, 2006), leading to different approaches to measure semantic and pragmatic information. Semantic information is particularly relevant for biology (Jablonka, 2002). Kolchinsky and Wolpert (2018) focus on system viability and measure the environmental information needed for a system to survive, referred to as the viability value of information. For pragmatic information measures, Weizsäcker and Weizsäcker (1972) first noted that any measure of pragmatic information should be zero when novelty or confirmation are zero. “Novelty” refers to whether the message contains any new information for the receiver, and “confirmation” refers to whether the message is understandable. Weinberger (2002) proposed a formal definition of pragmatic information that also tends to zero when novelty or confirmation are zero, noting that this idea was shared by Atmanspacher (1991) and is in line with Crutchfield’s complexity. Frank (2003) argues that pragmatic information can only be measured with respect to an action. They argue that if two different maps are used to navigate from one place to another (one map being more detailed than the other) resulting in the same route, then the pragmatic information of those two maps is the same. This ignores the amount of energy needed to extract information from a message—also referred to as negentropy (Brillouin, 1953). In the MSFS context, we find it useful to distinguish between semantic and pragmatic information (impact on knowledge and impact on action). This helps assess the importance of information for a CAS that acquires knowledge to adapt and achieve goals. In engineering, this applies to autonomic computing (Kephart and Chess, 2003; Lalanda et al., 2013b), organic computing (Müller-Schloer et al., 2011; Müller-Schloer and Tomforde, 2017), self-adaptive systems (Weyns, 2021; Wong et al., 2022), self-integrating systems (Bellman et al., 2021), and self-aware systems (Kounev et al., 2017).
3 Multi-scale feedback systems
3.1 Overview
In MSFS, information observed at the micro-scale merges into macro-information. Information at the macro-scale has a coarser granularity than at the micro-scale, with a loss of information that can be due to an abstraction function (e.g., the information from the micro-scale being averaged out) or to the sampling frequency of micro-information. Macro-information has a larger scope than each information source at the micro-scale. This limits resource requirements for the micro-scale to adapt to collective information. We refer to information abstracted from micro to macro as state information and to information that flows back from macro to micro as control information. When control information is reified from macro to micro, it can become more detailed (e.g., adding new information flows specific to the micro-scale) or more abstracted (e.g., several decisions at the macro-scale resulting in the same action at the micro-). Figure 1a shows a multi-scale feedback cycle, including information abstraction, information reification, and adaptation. Processing may also take place at different scales of the feedback cycle whenever an agent observes information and updates its knowledge.
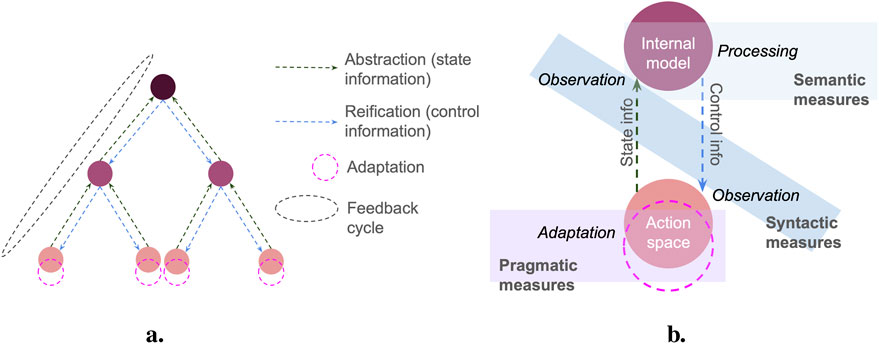
Figure 1. Main MSFS elements. (a) MSFS across three scales, with a single feedback cycle. (b) Syntactic, semantic, and pragmatic information measure domains
Macro-information can take different forms depending on how it is coupled to its physical substrate.
The above macro-categories allow for a broad range of CAS to be described as MSFS, with the underlying mechanism being a feedback cycle connecting a minimum of two scales and with the micro-scale adapting based on macro-information.
The abstraction of information allows for CAS that follow an MSFS architecture to scale (Diaconescu et al., 2019). Generally, MSFS should be dimensioned in terms of number of scales, number of entities per scale, and number of inter-entity connections to avoid communication bottlenecks between entities and storage and processing bottlenecks within entities. For example, if an entity receives too much information relative to its resources, the entity should be replicated, with each replica receiving only part of the initial information flow and with an extra, higher-scale entity observing and coordinating these replicas. This can be achieved for all entity macro-types described above. Figure 1b shows the adaptation of a micro-agent with respect to macro-information. The micro-agent is connected to the scales above and below by a flow of state information going upward and control information going downward. Additional flows may exist (e.g., communication among micro-agents). The transmission and observation of these information flows are described by syntactic information measures. When an agent processes information, it may subsequently change its knowledge (its internal model or the output generated by that model) and the action it generates. Processing can happen at different scales. Figure 1b shows a macro-agent processing information and sending the ensuing control information. The micro-agent could also observe the macro-information and process it for its adaptation. The impact of the information flow on an agent’s knowledge is measured by semantic information measures. Changes in the resulting action are measured by pragmatic information measures. Both types of measure can be assessed for one or multiple agents for a single scale or the whole system. Their estimation helps correlate the effects of observed information on knowledge and action with the agent’s (or system’s) adaptation dynamics toward the goal(s).
3.2 Information measures
Information values are observer-dependent (Brillouin, 1953). To measure them, the purpose of the information flow needs to be specified. This can be system viability (Kolchinsky and Wolpert, 2018) or utility toward a goal. In general, value is measured by comparing how the system performs toward a goal state with and without information (Gould, 1974). As all elements in a CAS are informational, various comparison scenarios can be developed. For MSFS, the impact of feedback cycles on agents’ knowledge and actions is calculated by comparing the system at different times. The relevant gap for comparison, depending on the application, can be a single time-step, a single feedback cycle, or multiple cycles. We define the time at which the information measure is calculated as
We provide general guidelines for the calculation of information measures, to be tailored via specific equations to each domain and case study. There are three steps in the construction and interpretation of information values. First, the system state at time
These guidelines can be used to generate specific equations for different case studies and domains. The exact calculations of each measure and its units depend on the system, as we will show through our four case studies. Moreover, not all measures are relevant to every system—for instance, it may not be possible to identify a ground truth for
4 Case studies
4.1 Overview
Figure 2 shows a multi-scale representation of the four case studies: robotic collective (RC) (2a), collective decision-making (CD) (2b), task distribution (TD) (2c), and hierarchical oscillators (HO) (2d).
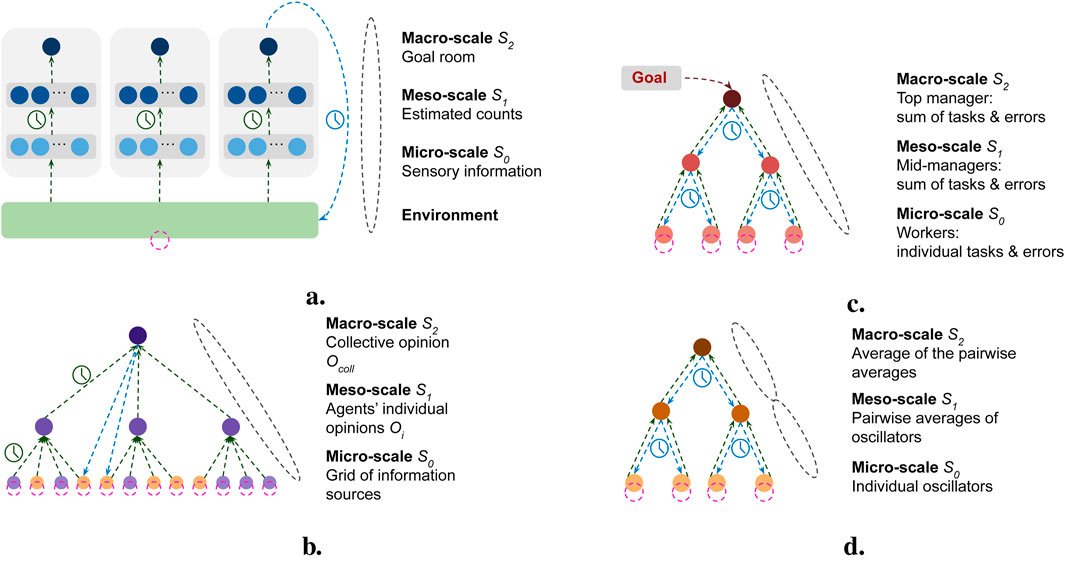
Figure 2. Multi-scale representation of the four case studies. (a) Robotic collective; (b) collective decision-making; (c) task distribution; (d) hierarchical oscillators. Green arrows show abstracted flows of state information, blue arrows show flows of control information, and pink dotted circles show the adaptation. Clocks (blue or green) denote which flows have a delay. In (b), the macro-scale sends control information to each micro-scale agent—only two flows are shown for simplicity. Similarly in (a), where each gray box represents an individual robot, only one flow connecting the robot to the environment is shown.
4.1.1 Robotic collective multi-scale overview
The RC model (Figure 2a) is based on the simulation of a swarm of robots that self-distribute across multiple rooms in proportion to the amount of collectible objects in each room, as in Zahadat (2023). Each robot acts as a micro-agent equipped with sensors that provide it with the lowest scale of information related to the number of robots and objects in the rooms based on the sensing of the environment; this forms the micro-scale
4.1.2 Collective decision-making multi-scale overview
The CD model simulates a system in which a group of agents makes a collective decision about the size of two tasks by observing their environment. The environment is composed of a fixed set of information sources, each showing one of the two tasks:
4.1.3 Task distribution multi-scale overview
This system aims to distribute a set of tasks of two types across a set of workers. We consider a small system with three scales for traceability reasons (Figure 2c). Larger instances were presented elsewhere (Diaconescu et al., 2021a). At the micro-scale
4.1.4 Hierarchical oscillators multi-scale overview
The HO case study simulates a system of communicating oscillators whose goal is to achieve synchronized oscillation. This system is based on the differential equation model for coupled biochemical oscillators presented in Kim et al. (2010), extended to a hierarchical structure (Mellodge et al., 2021). A single oscillator consists of two interacting components
4.2 Robotic collective
This case study is based on Zahadat (2023), where a homogeneous robotic swarm is designed to self-distribute across four interconnected rooms proportional to the quantity of collectible objects in each room. The four-room layout forms a ring, with each room connected to two others. Here, 200 collectible objects are distributed across four rooms, with 70 objects in each of the first two rooms and 30 in each of the remaining two rooms. The robotic swarm, consisting of 100 robots, is initially distributed uniformly across all rooms. The robots can only detect objects beneath their circular bodies, and their communication range with other robots is twice their diameter. The robots are autonomous and use a variation of the response threshold algorithm (Theraulaz et al., 1998) to independently decide in which room they want to belong: their goal room. The decision is regularly updated based on the robot’s internal model of the environment’s state. Each robot models only the state of the current room and the two rooms connected to that, collectively called the robot’s relevant rooms. The locomotion behavior of the robots is a collision-avoiding random walk, modulated by the current and the goal room: robots can cross room boundaries freely unless they are in their goal room.
We consider the multi-scale feedback generated by the information flowing through the robots’ internal processing structures and feeding back to them via the environment (Figure 2a).
The robot then selects the room with the largest estimated demand as its goal:
4.2.1 Comparison strategies
The information processing described above forms our main strategy in this study. We use two configurations for this strategy: main strategy with sensing horizon of
Comparing the measures between the main and ground truth strategies reflects the effects of the estimation algorithm, particularly regarding sub-optimal accuracy and time delays. In the random strategy, estimated counts are generated by sampling from a uniform distribution, normalized across rooms. Since this strategy lacks feedback loops, it allows us to evaluate the benefits of feedback in achieving the system’s goal.
4.2.2 Information measures
4.2.2.1 Calculations
4.2.2.1.1 Syntactic information
The amount of memory resources that a robot needs to store information at each scale is used as a measure of
4.2.2.1.2 Semantic information
For the semantic delta
where
To calculate the semantic truth value
4.2.2.1.2.1 Estimated counts sub-model
We calculate a measure of discrepancy between the estimated and actual counts over time. The estimated count vector
where
4.2.2.1.2.2 Highest demand full sub-model
To measure the discrepancy between the internal models and the actual demands, we check whether the demand estimation for the relevant rooms is sufficient to select the room with the highest actual demand as their goal. To quantify this, we calculate the normalized count of robots whose goal room does not match the room with the highest actual demand among the relevant rooms:
where
4.2.2.1.2.3 Highest demand partial sub-model
When examining the robots’ internal model for estimated demands (data not shown), we observed a strong tendency to identify the local room as having the highest demand. In practice, this means that the robots often choose their local room as their goal and only occasionally target one of the neighboring rooms. The measure here is the same as for the full model but only considers cases where the model does not identify the local room as having the highest demand.
where
4.2.2.1.3 Pragmatic information
The pragmatic goal value
The values
4.2.2.2 Results
The results are pooled from 100 repetitions of independent experimental runs and are presented as the average of all runs, with or without standard deviation for visualization clarity. Figure 3a shows
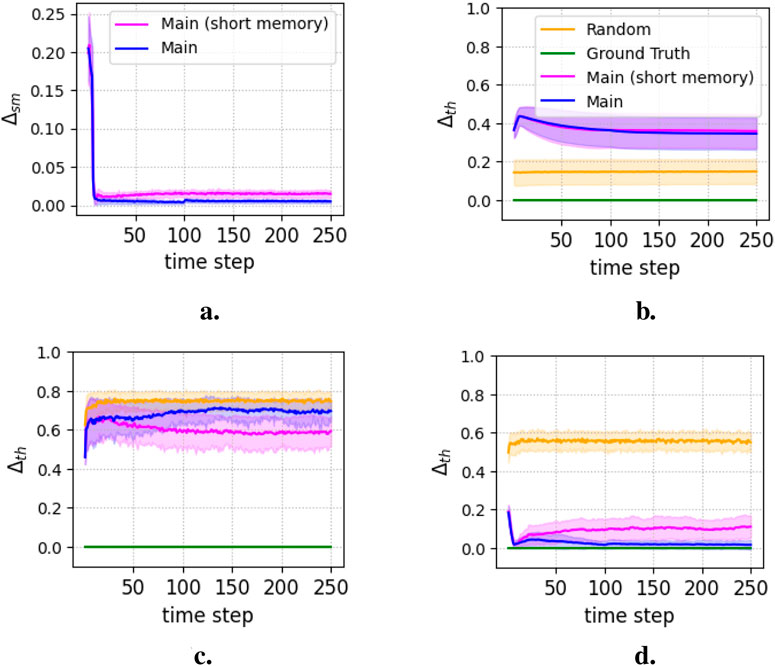
Figure 3. Semantic delta,
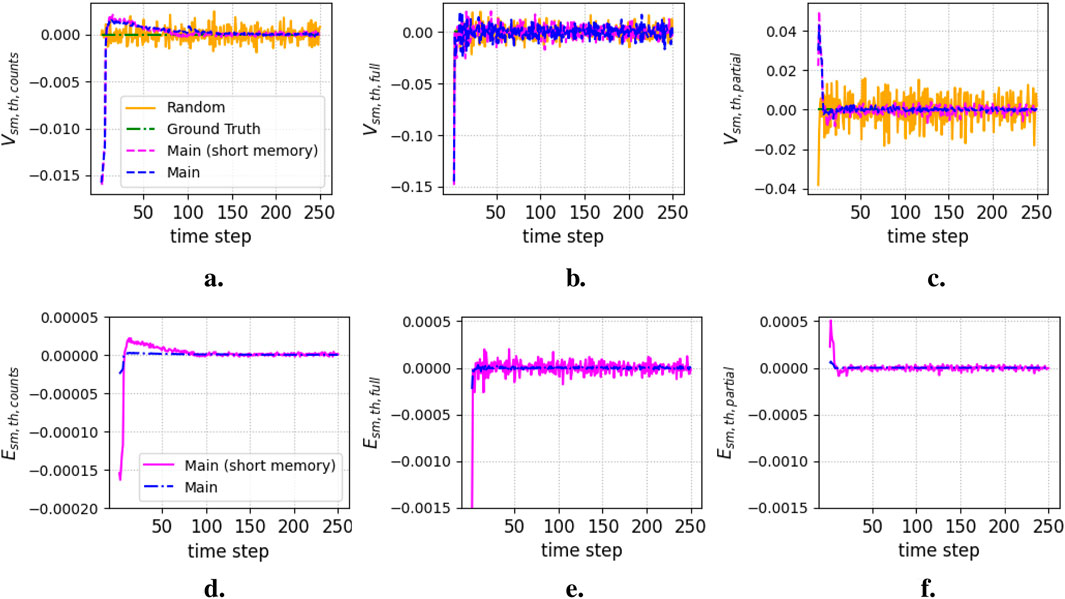
Figure 4. Semantic truth values (Equation 11) and efficiencies (Equation 12) for the three model components. (a)
Figures 5, 6 compare the pragmatic measures. Figure 5 shows the distance between the actual and desired distributions of robots across the rooms. The random strategy performs the worst, while the main strategy with the long memory achieves the best performance, followed by the short memory strategy. The ground truth strategy performs worse than the main strategies, despite relying on precise models. This is likely due to movement delays, causing late overreactions to perceived issues. This suggests a lack of critical models, possibly related to the spatial organization of robots and their interactions within rooms, which are essential for effective coordination but remain inaccessible to the robot. In contrast, the main strategies demonstrate that partial and imprecise information distributed across robots, rather than attempting an unattainable complete model, leads to better collective behavior.
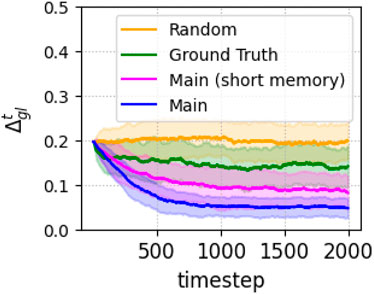
Figure 5. Pragmatic delta (Equation 13) of the various strategies.
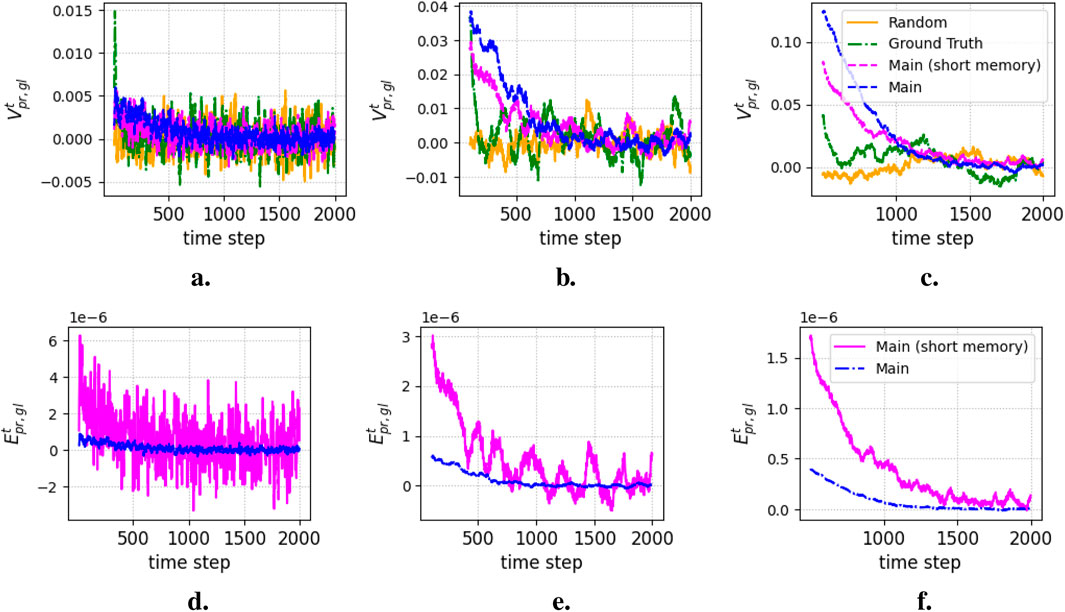
Figure 6. Pragmatic goal values (Equation 14) and efficiencies (Equation 15) of the various strategies. (a)
Figures 6a–c depict the extent to which the robots’ distribution in the rooms approaches the desired distribution over periods of 10, 100, and 500 timesteps. This indicates a pattern similar to that in Figure 5, with large initial adaptations that subsequently oscillate around zero, stabilizing the system. Figures 6d–f illustrate the efficiencies of the main strategies, highlighting the higher resource efficiency of the short memory strategy, particularly over longer feedback cycles.
4.3 Collective decision-making
4.3.1 Model description
The CD model is partially based on Di Felice and Zahadat (2022). It is a simplified representation of decision-making in small, consensus-based groups (
After
4.3.2 Comparison strategies
We refer to the decision-making strategy described above as the consensus strategy. To evaluate it, we implement three reference strategies, randomizing different abstraction steps: opinion formation, consensus formation, or both.
Comparing the consensus strategy with randomOP highlights the value of evidence-based opinion formation. Comparison with randomCN shows the advantage of the consensus process once opinions have been formed, and comparison with randomTOT evaluates the usefulness of the entire feedback cycle.
4.3.3 Experiments
Parameters
Figure 7 shows examples of the main types of behavior that can be observed in each simulation. Figure 8 shows average behaviors over the 36,000 simulations for each strategy. Long-lasting simulations (with
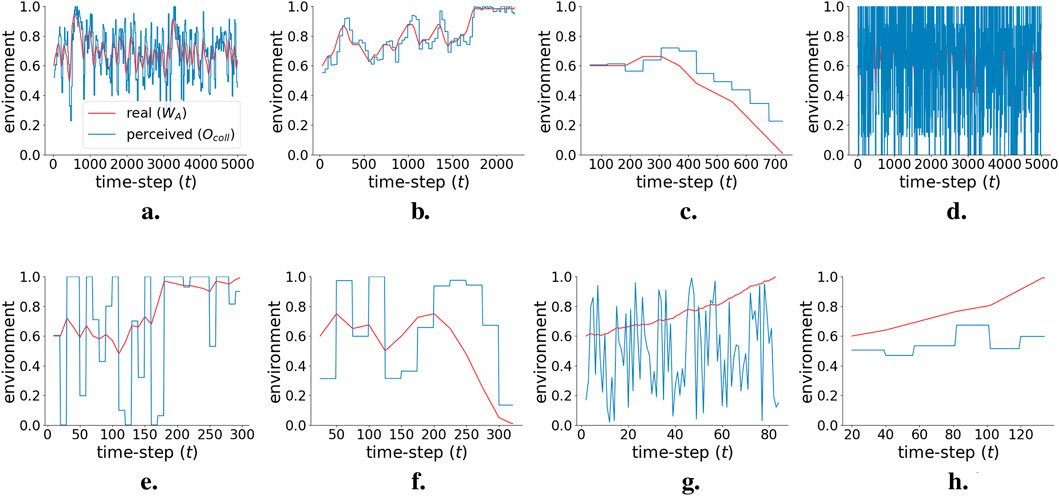
Figure 7. Examples of individual simulations, showing the evolution of
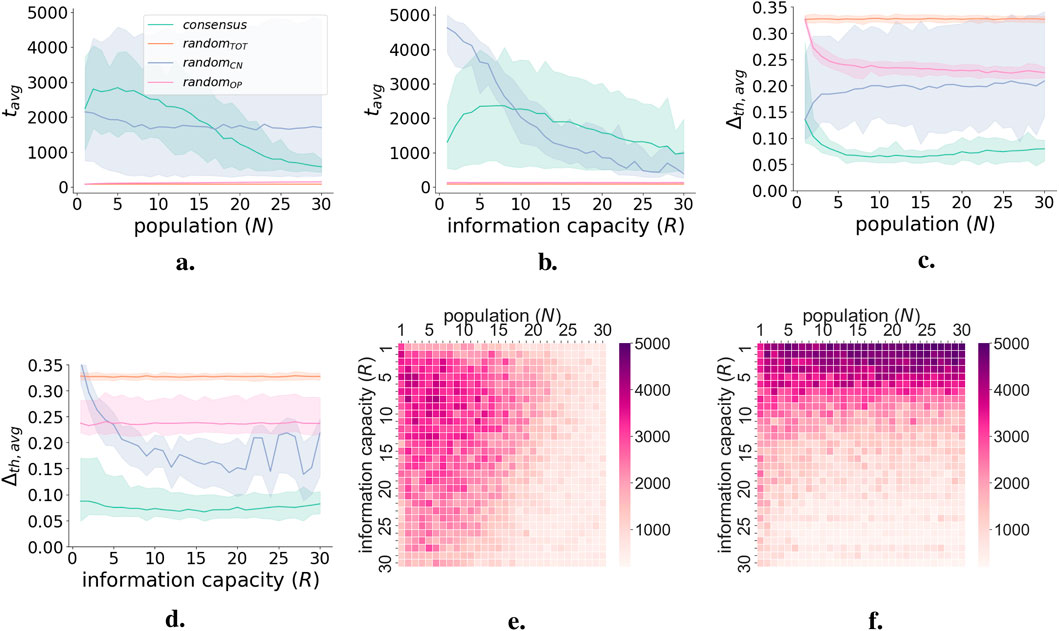
Figure 8. Comparison of average behavior across strategies. (a) Average simulation length (
Figures 8c and d show the average delta of truth
4.3.4 Information measures
4.3.4.1 Calculations
We consider
4.3.4.1.1 Syntactic information
We calculate the amount of resources needed to store information at the meso-scale
Where
Similarly, the entropy of
Where
Similar calculations are carried out for the three random strategies; full details are included in the Supplementary Material, as well as graphs showing how
4.3.4.1.2 Semantic information
For the semantic delta
Where
Then
4.3.4.1.3 Pragmatic information
The pragmatic delta
It is a proxy of how stable the environment is, with a higher value reflecting larger environmental change. The pragmatic goal value
We then calculate
Similar to
4.3.4.2 Results
Figure 9 shows the average information measures as a function of
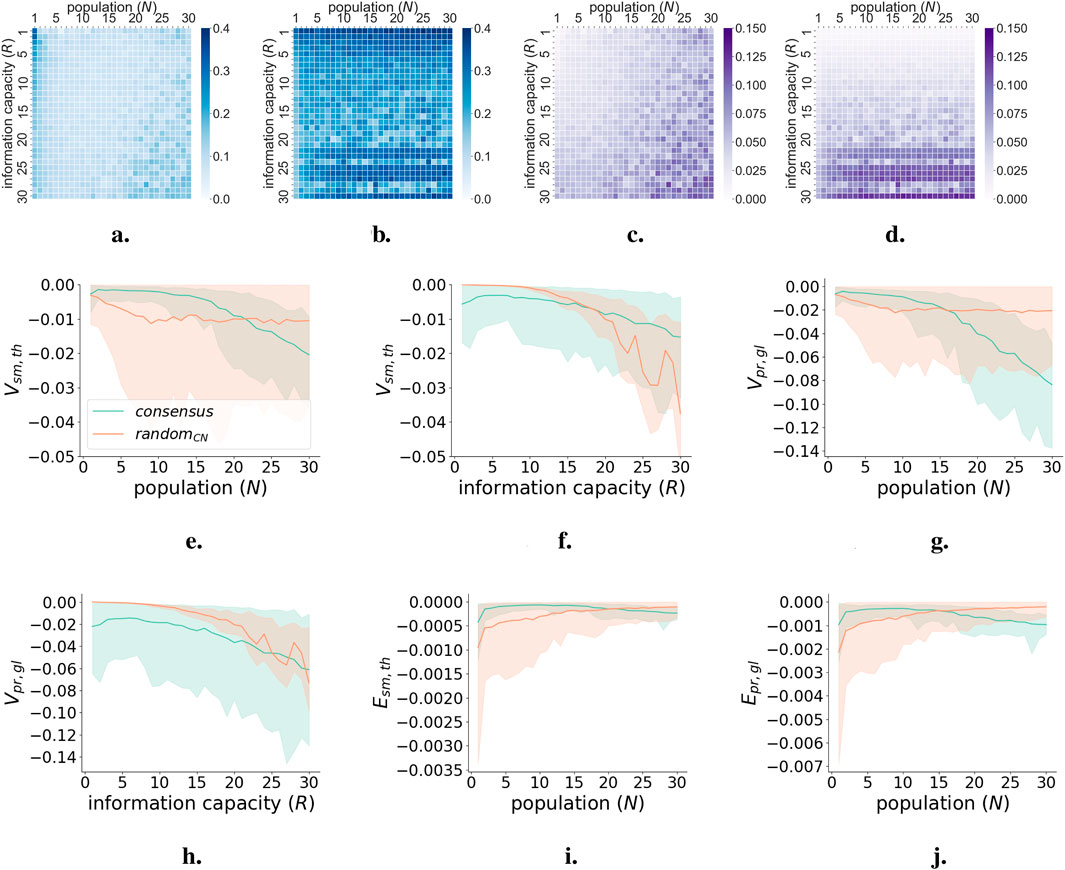
Figure 9. Semantic and pragmatic information measures for collective decision-making case study. (a) Semantic delta
4.4 Task distribution
4.4.1 Model description
This model is a simplified version of the ABM in Diaconescu et al. (2021a), aiming to achieve a given task distribution among a set of agents. We exemplify a small system to facilitate the formal analysis of information flows. The system contains
Each manager
The system uses the Blackboard (BB) strategy (simplified from Diaconescu et al. (2021a) —see Supplementary Material for further details), forming a multi-scale feedback cycle via the following information flows.
The BB simulation repeats this cycle recursively until the goal is reached, and it is maintained for
4.4.2 Comparison strategies
We define several alternative strategies for reference.
We selected these alternative strategies based on the following considerations.
4.4.3 Experiments
In the initial state, all workers perform
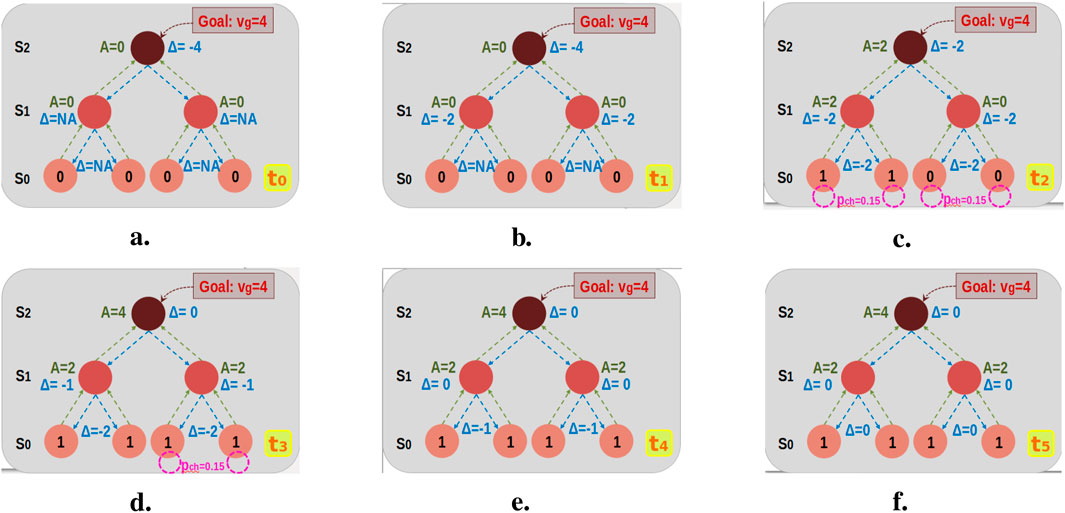
Figure 10. Task-distribution scenario
4.4.4 Information measures
We define information measures through generic equations and then illustrate them in specific cases. We consider all measures for BB and Md and only syntactic content and pragmatic values for RS, RB, and St, as they lack multi-scale coordination. Table 1 summarizes results for syntactic
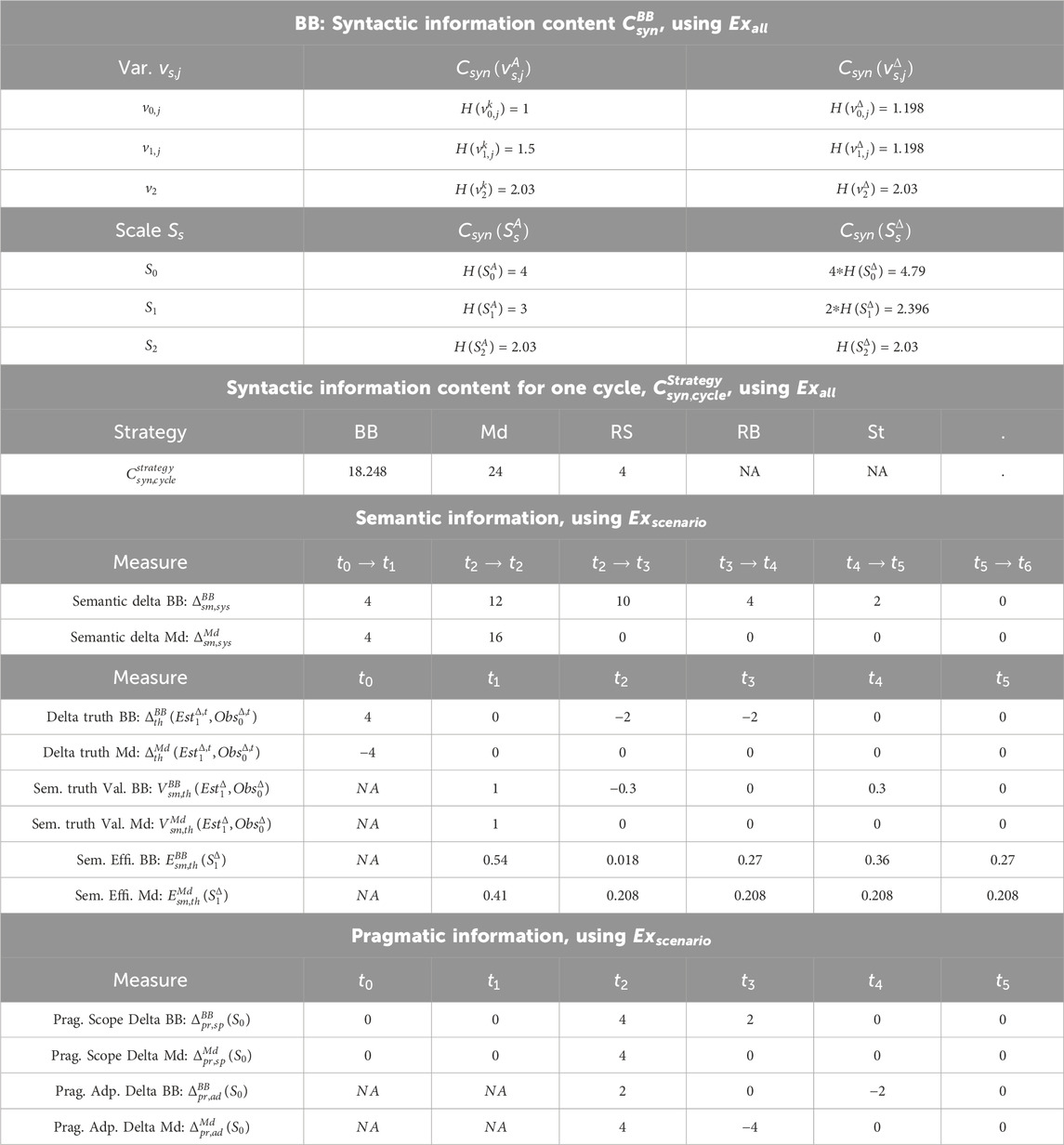
Table 1. Information measures for the task distribution case. Syntactic content and pragmatic values rely on the probabilistic analysis of all possible behaviors via
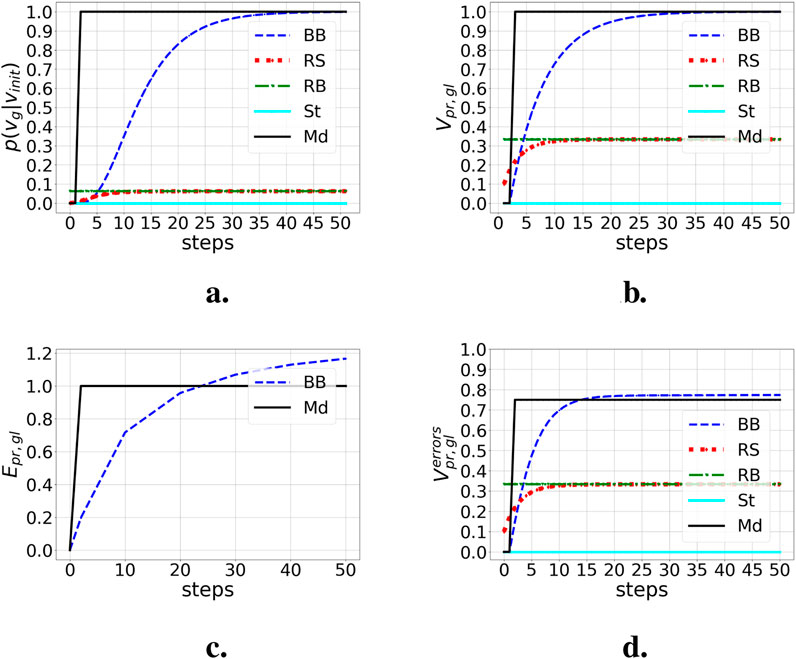
Figure 11. Probabilities of goal convergence and pragmatic goal values within 50 steps from initial state
4.4.4.1 Syntactic information
We estimate the syntactic information content
For any variable
For an entire scale
We then estimate the amount of information “lost” or “gained” via inter-scale abstraction or reification:
For example, BB’s abstraction flow loses
In all cases, resource use depends on the number of variables at each scale:
For BB, the control flow’s resource usage is larger than its information content:
Finally, we consider the syntactic content of an entire feedback cycle (see Table 1):
4.4.4.2 Semantic information
The semantic delta
For the entire system,
Using
We calculate the semantic truth value
First, we estimate the delta of truth
We consider
Using
Second, we assign values
With
Maximum
Third, we calculate
We have
We estimate the efficiency of the semantic truth value
We normalize
4.4.4.2.1 Pragmatic information
We focus on evaluating how mid-managers’ control of information
We consider two types of pragmatic delta
The pragmatic scope delta
In BB and Md, workers may only switch tasks when receiving control information; otherwise they stay idle. Hence, no information implies
In
The pragmatic adaptation delta
Here,
In
We estimate the pragmatic goal value
We assign state values
We evaluate the pragmatic adaptation value
We start from state
The likelihood that BB reaches the goal in one step is 0.0005. We can then obtain state-transition probabilities over
Finally, we assess the pragmatic goal value
The maximum value
Using
To emphasize the role of multi-scale information flows separately from their processing strategies, we introduce an error for BB and Md: worker
We assess the efficiency of the pragmatic goal value
This gives the pragmatic efficiency values in Figure 11c. Md surpasses BB in efficiency as it converges faster, yet as BB consumes less resources to maintain the goal, it will become slightly more efficient than Md over the longer term (
4.5 Hierarchical oscillators
4.5.1 Model description
This case study is based on the model of coupled biochemical oscillators in Kim et al. (2010), which was extended to a hierarchy of oscillators in Mellodge et al. (2021). Coupled biochemical oscillators are observed throughout many systems in nature (e.g., cellular processes involving circadian rhythms). A single oscillator consists of two interacting components
For the hierarchical oscillator system, the differential equation model from Kim et al. (2010) was extended to form multiple scales of oscillators that communicate their
where
and
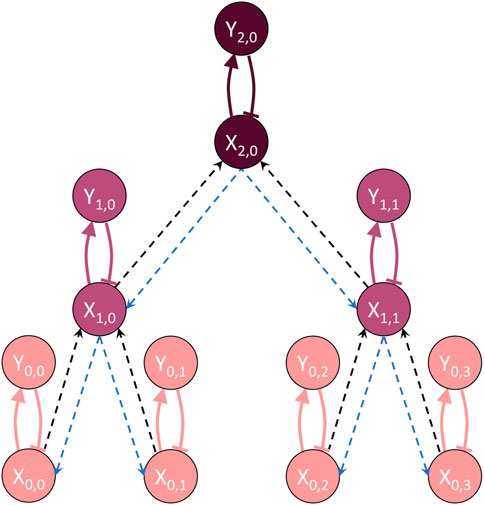
Figure 12. Hierarchical oscillator system with three scales. Each oscillator is an
In this system, communication occurs across scales only (i.e., oscillators at a given scale do not communicate directly with each other). The abstracted information contained in oscillator
4.5.2 Comparison strategies
To illustrate the information measures, we focus on two HO systems, both of which use NN type coupling but have two different scales (two- and three-scale). Both systems have four oscillators at the bottom scale
The system is simulated using a time-delay ordinary differential equations (ODE) solver (details in Supplementary Material). The initial
To calculate
4.5.3 Information measures
4.5.3.1 Calculations
Since the HO system is modeled using differential equations which are continuous-time descriptions of the system behavior, the measures which use comparisons between
4.5.3.1.1 Syntactic information
Due to the continuous nature of
where
where
The JS divergence provides a metric to measure the difference between probability distributions.
Using this definition,
4.5.3.1.2 Semantic information
This case study does not involve changes to the differential equation model itself, so the semantic delta measures how much change there is to the knowledge
The ground truth
The semantic truth value is then calculated as
The efficiency is calculated by dividing the semantic truth value by
4.5.3.1.3 Pragmatic information
An action taken by an oscillator is to change its
Since the goal is to achieve synchronized oscillation at the lowest scale, the result is identical concentrations of
where
The efficiency is calculated by dividing the pragmatic goal value by
4.5.3.2 Results
Figure 13 shows
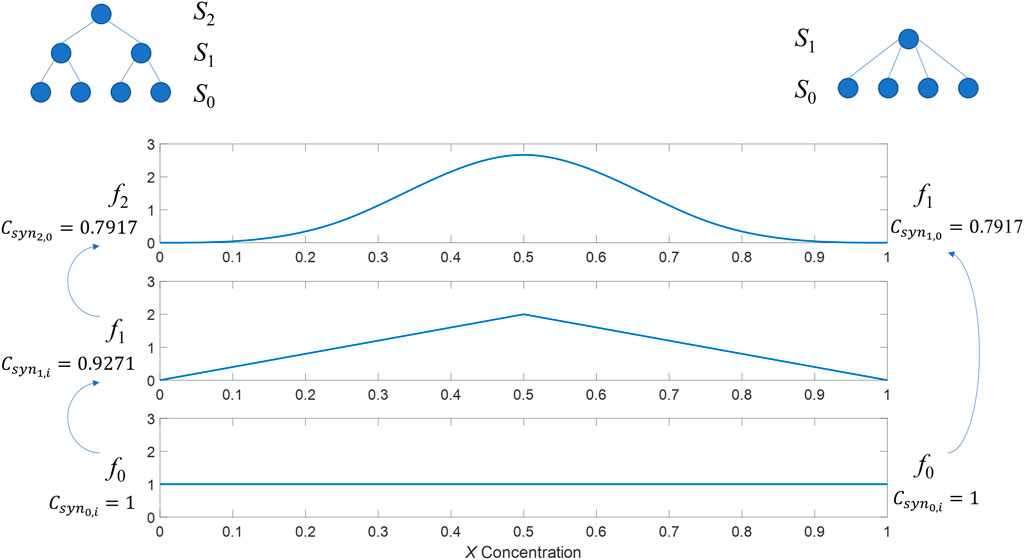
Figure 13. Calculated values for syntactic information. Left side of the figure depicts the three-scale system, right side depicts two-scale system.
Figure 14a shows the
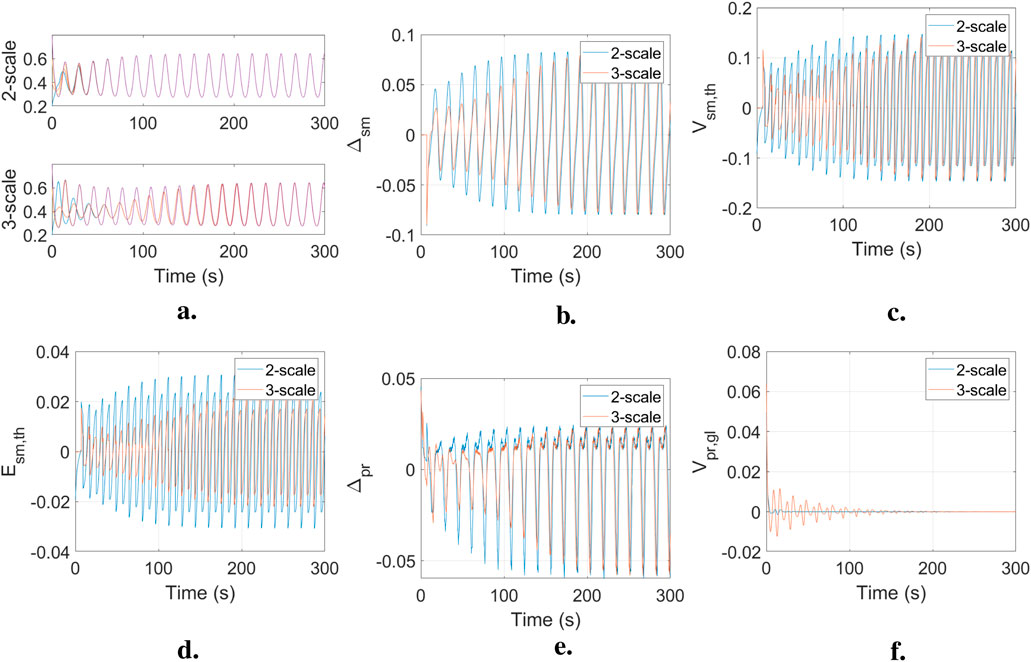
Figure 14. Results for the two hierarchical oscillator systems. Blue line shows the two-scale system and red line shows the three-scale system. (a)
Figures 14b–f show the information measures for the two HO system plotted together for comparison. As information is passed through the system in the form of
For the semantic delta, positive values indicate that the knowledge used by the oscillators to act is growing. Larger magnitudes indicate faster knowledge change. The three-scale system exhibits a smaller
For the semantic truth value, positive values indicate that the average knowledge among the oscillators is getting closer to the ground truth. As with the
For the pragmatic delta, larger magnitudes indicate a larger change in the oscillator’s adaptation. The two-scale system achieves more change in adaptation during the pre-synchronization period, while the two systems have identical
5 Discussion and conclusion
CAS typically consist of many components that interact with each other across at least two scales (Ahl and Allen, 1996; Salthe, 1993), adapting through feedback loops to reach a shared goal (Flack et al., 2013). In such MSFS, there is always a loss of syntactic information when abstracting from the micro to the macro scale. Conversely, control information flowing from the macro to the micro can be either further abstracted (e.g., different macro-states may issue the same micro-controls), stay the same (e.g., through top-down forwarding), or gain information (e.g., through extra micro-scale context). Syntactic information measures, including Shannon entropy, can be used to quantify the size of these information flows and the amount of information abstracted across scales (as shown in the hierarchical oscillator and task distribution case studies). As information becomes more symbolic, the relevance of syntactic measures decreases, calling for value-oriented measures.
We propose a non-exhaustive set of information measures within the syntactic, semantic, and pragmatic categories, exemplified their usage through four cases of MSFS, although the measures could be applied more generally to all types of CAS, including single-scale CAS. Feedback is central to the behavior of all adaptive information-processing systems. Whenever there is a feedback cycle, there is a system that adapts and an information flow controlling that system. The inherent delays and uncertainties of the adapting system and its environment play a key part in the efficacy and efficiency of the feedback cycle. When the feedback spans multiple scales, affecting components that function at different granularities of time and information, it becomes increasingly divicult to adjust its operation to the multitude of delays and uncertainties. The presence of multiple feedback cycles that operate simultaneously between different scales exacerbates this difficulty. To deal with such increased complexity, parts of the system become quasi-independent (Simon, 2012), with minimal information flows coordinating them to reach a shared goal. Tracking information flows and their mutual influences throughout such MSFS becomes essential for understanding their behavior and/or adjusting their design. Using different types of information measures, which can be calculated for the whole system or at single scales, can help us understand such increased complexity in MSFS. This requires identifying a goal. Goals can be determined at different scales and can be exogenous or endogenous, depending on where the observer is placed. Observer identification is necessary for all types of information measures, including syntactic, while the goal choice is needed to measure informational values (semantic and pragmatic).
Such information measures are interrelated and best understood when considered simultaneously. Disturbances on the information flow (measured syntactically) have an impact on knowledge (measured semantically) and adaptation (measured pragmatically). In our examples, these disturbances were due to time delays or partial (and/or imperfect) information collection. Time delays can occur in information communication and processing or in system adaptation. Within feedback cycles, they can be tracked by comparing changes in actual state measures and in their semantic and pragmatic values over time at different scales. Depending on the system characteristics, delays can be beneficial in achieving the goal. This is so when the delay in the feedback cycle matches a slow and inaccurate adaptation process. In the robotic collective, for example, adaptation delays caused by the robots’ spatial dynamics compensated for inaccuracies in their collective state information that influence their movement. In the collective decision-making case, inaccurate information (i.e., an inaccurate collective opinion
Partial or imperfect information leads to inaccurate collective knowledge. Studying the delta of truth
In the collective decision-making model, semantic and pragmatic measures tracked the impact of varying system parameters (the number of agents
These examples provide initial insights into how coupled information measures can be used to understand the behavior of CAS. Specific calculations and measure sub-types are dependent on the chosen case study and application domain; expanding these will help further generalize the definition of information measures and their calculations. Here, including case studies featuring experimental data would be particularly valuable. This can help system analysts and designers study the value of information flows for system properties, such as reactivity, stability, and scalability. When paired with reinforcement learning methods, such insights can help improve systems’ real-time adaptation. Large language models (LLMs), for example, may learn to correlate the information measures with adaptation performance indicators, enabling the system to adapt its control processes, which is in line with recent approaches to implementing LLMs within multi-agent systems (Bo et al., 2024; De Curtò and De Zarzà, 2025). The proposed semantic information measures could also be employed to assess the impact of collected information on a system’s LLM in terms of actual changes and consequent performance. Beyond system analysis and performance, identifying how different patterns of information flows correlate with the behavior and evolution of CAS across scales can help characterize existing CAS through a unified informational lens (Krakauer et al., 2020) and understand fundamental regularities across such systems, contributing to a deeper theoretical understanding of the informational nature of CAS.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors without undue reservation.
Author contributions
LJDF: Methodology, Writing – review and editing, Writing – original draft, Investigation, Conceptualization, Formal Analysis, Visualization, Data curation, Project administration. AD: Data curation, Visualization, Methodology, Conceptualization, Investigation, Writing – review and editing, Formal Analysis, Writing – original draft. PZ: Writing – review and editing, Data curation, Writing – original draft, Conceptualization, Investigation, Methodology, Visualization, Formal Analysis. PM: Conceptualization, Data curation, Writing – review and editing, Methodology, Writing – original draft, Formal Analysis, Investigation, Visualization.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. LJDF acknowledges funding by the Margarita Salas program of the Spanish Ministry of Universities, funded by the European Union-NextGeneraionEU.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fcpxs.2025.1612142/full#supplementary-material
References
Ahl, V., and Allen, T. F. (1996). Hierarchy theory: a vision, vocabulary, and epistemology. Columbia University Press.
Bellman, K. L., and Goldberg, L. J. (1984). Common origin of linguistic and movement abilities. Am. J. Physiology-Regulatory, Integr. Comp. Physiology 246, R915–R921. doi:10.1152/ajpregu.1984.246.6.R915
Bellman, K. L., Diaconescu, A., and Tomforde, S. (2021). Special issue on self-improving self integration. Future Gener. Comput. Syst. 119, 136–139. doi:10.1016/J.FUTURE.2021.02.010
Bo, X., Zhang, Z., Dai, Q., Feng, X., Wang, L., Li, R., et al. (2024). Reflective multi-agent collaboration based on large language models. Adv. Neural Inf. Process. Syst. 37, 138595–138631.
Brillouin, L. (1953). The negentropy principle of information. J. Appl. Phys. 24, 1152–1163. doi:10.1063/1.1721463
Brillouin, L., and Gottschalk, C. M. (1962). Science and information theory. Phys. Today 15, 68. doi:10.1063/1.3057866
De Curtò, J., and De Zarzà, I. (2025). Llm-driven social influence for cooperative behavior in multi-agent systems. IEEE Access. 44330–44342. doi:10.1109/ACCESS.2025.3548451
Dessalles, J.-L. (2010). “Emotion in good luck and bad luck: predictions from simplicity theory,” in Proceedings of the 32nd annual conference of the cognitive science society. Editors S. Ohlsson, and R. Catrambone (Austin, TX: Cognitive Science Society), 1928–1933.
Dessalles, J.-L. (2013). “Algorithmic simplicity and relevance,” in Algorithmic probability and friends - lnai 7070. Editor D. L. Dowe (Berlin: Springer Verlag), 119–130. doi:10.1007/978-3-642-44958-1_9
Diaconescu, A., Di Felice, L. J., and Mellodge, P. (2019). “Multi-scale feedbacks for large-scale coordination in self-systems,” in 2019 IEEE 13th international conference on self-adaptive and self-organizing systems (SASO) (IEEE), 137–142.
Diaconescu, A., Di Felice, L. J., and Mellodge, P. (2021a). Exogenous coordination in multi-scale systems: how information flows and timing affect system properties. Future Gener. Comput. Syst. 114, 403–426. doi:10.1016/j.future.2020.07.034
Diaconescu, A., Di Felice, L. J., and Mellodge, P. (2021b). “An information-oriented view of multi-scale systems,” in 2021 IEEE international conference on autonomic computing and self-organizing systems companion (ACSOS-C) (IEEE), 154–159.
Di Felice, L. J., and Zahadat, P. (2022). “An agent-based model of collective decision-making in correlated environments,” in Proceedings of the 4th International Workshop on Agent-Based Modelling of Human Behaviour (ABMHuB’22).
Feistel, R., and Ebeling, W. (2016). Entropy and the self-organization of information and value. Entropy 18, 193. doi:10.3390/e18050193
Fetzer, J. H. (2004). Information: does it have to be true? Minds Mach. 14, 223–229. doi:10.1023/b:mind.0000021682.61365.56
Flack, J. C. (2017). Coarse-graining as a downward causation mechanism. Philosophical Trans. R. Soc. A Math. Phys. Eng. Sci. 375, 20160338. doi:10.1098/rsta.2016.0338
Flack, J. C., Erwin, D., Elliot, T., and Krakauer, D. C. (2013). Timescales, symmetry, and uncertainty reduction in the origins of hierarchy in biological systems. In Evolution cooperation and complexity (Editors K Sterelny, R Joyce, B Calcott, and B Fraser), 45–74. Cambridge, MA: MIT Press.
Floridi, L. (2005). Is semantic information meaningful data? Philosophy phenomenological Res. 70, 351–370. doi:10.1111/j.1933-1592.2005.tb00531.x
Floridi, L. (2008). A defence of informational structural realism. Synthese 161, 219–253. doi:10.1007/s11229-007-9163-z
Frank, A. U. (2003). Pragmatic information content—how to measure the information in a route. Found. Geogr. Inf. Sci. 47.
Gernert, D. (2006). Pragmatic information: historical exposition and general overview. Mind Matter 4(2):, 141–167.
Gould, J. P. (1974). Risk, stochastic preference, and the value of information. J. Econ. Theory 8, 64–84. doi:10.1016/0022-0531(74)90006-4
Grunwald, P. D., and Vitanyi, P. M. (2008). “Algorithmic information theory,” in Philosophy of information (Elsevier).
Haken, H., and Portugali, J. (2016). Information and self-organization. Entropy 19, 18. doi:10.3390/e19010018
Jablonka, E. (2002). Information: its interpretation, its inheritance, and its sharing. Philosophy Sci. 69, 578–605. doi:10.1086/344621
Kephart, J., and Chess, D. (2003). The vision of autonomic computing. Computer 36, 41–50. doi:10.1109/MC.2003.1160055
Kim, J.-R., Shin, D., Jung, S. H., Heslop-Harrison, P., and Cho, K.-H. (2010). A design principle underlying the synchronization of oscillations in cellular systems. J. Cell Sci. 123, 537–543. doi:10.1242/jcs.060061
Kolchinsky, A., and Wolpert, D. H. (2018). Semantic information, autonomous agency and non-equilibrium statistical physics. Interface focus 8, 20180041. doi:10.1098/rsfs.2018.0041
Kounev, S., Lewis, P. R., Bellman, K. L., Bencomo, N., Cámara, J., Diaconescu, A., et al. (2017). “The notion of self-aware computing,” in Self-aware computing systems. Editors S. Kounev, J. O. Kephart, A. Milenkoski, and X. Zhu (Springer International Publishing), 3–16. doi:10.1007/978-3-319-47474-8_1
Krakauer, D., Bertschinger, N., Olbrich, E., Flack, J. C., and Ay, N. (2020). The information theory of individuality. Theory Biosci. 139, 209–223. doi:10.1007/s12064-020-00313-7
Kullback, S., and Leibler, R. A. (1951). On information and sufficiency. Ann. Math. statistics 22, 79–86. doi:10.1214/aoms/1177729694
Lalanda, P., McCann, J., and Diaconescu, A. (2013a). “Autonomic computing: principles, design and implementation,” in Undergraduate topics in computer science. Springer London.
Lalanda, P., McCann, J. A., and Diaconescu, A. (2013b). “Autonomic computing - principles, design and implementation,” in Undergraduate topics in computer science. Springer. doi:10.1007/978-1-4471-5007-7
Lewis, G. N. (1930). The symmetry of time in physics. Science 71, 569–577. doi:10.1126/science.71.1849.569
Lin, J. (1991). Divergence measures based on the shannon entropy. IEEE Trans. Inf. Theory 37, 145–151. doi:10.1109/18.61115
Mellodge, P., Diaconescu, A., and Di Felice, L. J. (2021). “Timing configurations affect the macro-properties of multi-scale feedback systems,” in 2021 IEEE international conference on autonomic computing and self-organizing systems (ACSOS) (Los Alamitos, CA, USA: IEEE Computer Society), 100–109. doi:10.1109/ACSOS52086.2021.00032
Ming Li, P. V. (2019). “An introduction to Kolmogorov complexity and its applications,” in Texts in computer science. Springer Cham. doi:10.1007/978-3-030-11298-1
Morris, C. (1938). Foundations of the theory of signs. In International encyclopedia of unified science. Chicago: Chicago University Press. 1–59.
Müller-Schloer, C., Schmeck, H., and Ungerer, T. (2011). “Organic computing — a paradigm shift for complex systems,” in Autonomic systems. Springer Basel.
Müller-Schloer, C., and Tomforde, S. (2017). “Organic computing – technical systems for survival in the real world,” in Autonomic systems.
Nehaniv, C. L. (1999). “Meaning for observers and agents,” in Proceedings of the 1999 IEEE international symposium on intelligent control intelligent systems and semiotics (cat. No. 99CH37014) (IEEE), 435–440.
Nielsen, F. (2019). On the jensen–shannon symmetrization of distances relying on abstract means. Entropy 21, 485. doi:10.3390/e21050485
Salthe, S. N. (1993). Development and evolution: complexity and change in biology. Cambridge, MA: Mit Press.
Shannon, C. E. (1948). A mathematical theory of communication. Bell Syst. Tech. J. 27, 379–423. doi:10.1002/j.1538-7305.1948.tb01338.x
Simon, H. A. (1991). The architecture of complexity. Boston, MA: Springer US. doi:10.1007/978-1-4899-0718-9_31
Simon, H. A. (2012). “The architecture of complexity,” in The roots of logistics (Springer), 335–361.
Sowinski, D. R., Carroll-Nellenback, J., Markwick, R. N., Piñero, J., Gleiser, M., Kolchinsky, A., et al. (2023). Semantic information in a model of resource gathering agents. PRX Life 1, 023003. arXiv preprint arXiv:2304.03286. doi:10.1103/prxlife.1.023003
Theraulaz, G., Bonabeau, E., and Deneubourg, J.-L. (1998). Response threshold reinforcement and division of labour in insect societies, Proceedings of the Royal Society B: Biological Sciences, 265(1393):327–332.
Timpson, C. G. (2013). Quantum information theory and the foundations of quantum mechanics. Oxford: OUP.
Tribus, M., and McIrvine, E. C. (1971). Energy and information. Sci. Am. 225, 179–188. doi:10.1038/scientificamerican0971-179
Uexküll von, J. (2013). A Foray Into the Worlds of Animals and Humans: With a Theory of Meaning. Minneapolis, MN: University of Minnesota Press.
Walker, S. I. (2014). Top-down causation and the rise of information in the emergence of life. Information 5, 424–439. doi:10.3390/info5030424
Weinberger, E. D. (2002). A theory of pragmatic information and its application to the quasi-species model of biological evolution. Biosystems 66, 105–119. doi:10.1016/s0303-2647(02)00038-2
Weizsäcker, E. U. v., and Weizsäcker, C. v. (1972). Wiederaufnahme der begrifflichen frage: Was ist information. Nova Acta Leopoldina 37, 535–555.
Weyns, D. (2021). “Basic principles of self-adaptation and conceptual model,”. John Wiley and Sons, Ltd, 1–15. doi:10.1002/9781119574910.ch1
Wong, T., Wagner, M., and Treude, C. (2022). Self-adaptive systems: a systematic literature review across categories and domains. Inf. Softw. Technol. 148, 106934. doi:10.1016/j.infsof.2022.106934
Keywords: adaptation, syntactic, semantic, pragmatic, complexity, feedback systems, scalability, multi-scale systems
Citation: Di Felice LJ, Diaconescu A, Zahadat P and Mellodge P (2025) The value of information in multi-scale feedback systems. Front. Complex Syst. 3:1612142. doi: 10.3389/fcpxs.2025.1612142
Received: 15 April 2025; Accepted: 23 June 2025;
Published: 29 August 2025.
Edited by:
Pierluigi Contucci, University of Bologna, ItalyReviewed by:
Godwin Osabutey, University of Modena and Reggio Emilia, ItalyJ. de Curtò, Barcelona Supercomputing Center, Spain
Copyright © 2025 Di Felice, Diaconescu, Zahadat and Mellodge. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ada Diaconescu, YWRhLmRpYWNvbmVzY3VAdGVsZWNvbS1wYXJpcy5mcg==