 Yingjian Xiong
Yingjian Xiong Xuhua Shi
Xuhua Shi- Faculty of Electrical Engineering and Computer Science, Ningbo University, Ningbo, Zhejiang, China
Crude Oil Distillation Unit (CDU) is one of the most important separation installations in the petroleum refinery industries. In this work, a Bi-level Surrogate column model Aided Constrained Optimization Design (Bi-SACOD) is proposed for time-consuming objectives and constraints in the evolutionary optimization design of CDUs. The main components of Bi-SACOD include bi-level surrogate model construction (Bi-SMC), bi-level model management (Bi-MM), and particle swarm optimization (PSO) mixed-integer constrained evolutionary (PSO-MICE) search. Bi-SMC implements surrogate column model construction and feasible domain identification. Bi-MM combines surrogate column models with rigorous CDU simulations to perform model management, and PSO-MICE implements optimum search works. The optimization results of the CDUs indicate that Bi-SACOD outperforms the single-level surrogate column model approaches, and are more consistent with the rigorous CDU model optimization approach, whereas the evaluation numbers of the time-consuming rigorous models are significantly reduced.
Introduction
Crude oil distillation is the most widely used separation process in the petroleum refinery industry. Recently, the optimal design of crude oil distillation units (CDUs) has attracted considerable research interest, while the component structural units, such as the pump-around flow system, side strippers, and a large number of equilibrium stages, incorporate the overhead reflux drums make the design of CDUs a complex task (Ibrahim et al.,2021). Combining CDU models and optimization-based design can determine the best configuration of CDUs (Xin et al., 2020), moreover, evolutionary optimization approaches provide probable ways for simultaneous optimization of structural and operating parameters for CDUs, and can achieve better optimization results (Ibrahim et al., 2021; Ibrahim et al., 2018). While optimizing the structural and operating parameters of CDUs will face the problems of a large number of constraints, time-consuming objectives and constraints, continuous and discrete decision variables, and limited samples, these will make great challenges for traditional optimization methodologies.
Generally, three main categories of CDU models have been used to simulate the complex distillation columns, namely, rigorous, simplified, and statistical models, and have recently been incorporated in approaches considering structural and operational optimization designs. Rigorous models provide more accurate predictions than simplified and statistical models. However, implementing them in an optimization algorithm is more challenging because of the large number of non-linear equations and the need to start the calculations from a perfect initial guess in order to avoid convergence problems (Kunru et al., 2020). Besides, simplified models have also been applied to the optimization of CDUs (Alattas et al., 2011). Simplified models have the advantage of being more robust and converging faster than rigorous models. However, they may have large errors and often cannot predict the behaviors of complex CDUs accurately, also, they are highly sensitive to initial guesses. Further, some statistical models, such as polynomial regression, support vector regression (SVM), and artificial neural networks (ANNs), have become popular in the optimization of CDUs (Lopez et al., 2013; Ibrahim et al., 2018; Xin et al., 2021). In (Xin et al., 2021) and (Lopez et al., 2013), the authors constructed SVM and polynomial regression models, respectively, to search for the optimal conditions for economic profit. Ibrahim et al. designed a distillation column configuration and its operating conditions using a mixed-integer non-linear program approach to maximize heat recovery (Ibrahim et al., 2018). Statistical models are more robust and more straightforward than rigorous and simplified distillation models, however, one of the main problems of this modeling is sampling, since the quality of the model depends on the quality of the data used, poor-quality sampling models will cause large model errors and affect the optimization results.
Recently, the studies on the surrogate models have shown that local surrogate models cannot assist the algorithm escaping from the local optimum, while bi-level models, i.e., global-local models are expected to take advantages of the global and local surrogate models, generally outperform most individual surrogates in terms of accuracy and efficiency in complex optimization problems (Zhou et al., 2007; Wang et al., 2017; Zhong et al., 2019). Zhou et al. presented a global-local surrogate-assisted evolutionary algorithm for expensive constrained optimization problems (Zhou et al., 2007). Wang et al. introduced the global-local model management to improve the approximation quality of the surrogate model without increasing the size of the training dataset (Wang et al., 2017). And Zhong et al. proposed an adaptive step-size global and local search strategy (GLSS) for operation optimization of hydrocracking process (Zhong et al., 2019). Therefore, in this work, an approach, termed as Bi-level Surrogate column model Aided Constrained Optimization Design (Bi-SACOD), is proposed by combining global-local surrogate column models and rigorous CDU models for fitness evaluations. Since Gaussian process (also known as the Kriging) has better global statistical characteristics (Wang et al., 2017), in the global surrogate-aided phase, we construct Kriging model to smooth out the local optima to speed up the search, while in the local phase, RBF model is often used to further approximate the fitness landscape (Zhou et al., 2007). The global-local surrogate column model management incorporated with the SVM feasibility learning approach is implemented to search for the column structural variables and operating conditions to maximize the total economic profit in this work.
The remainder of this article is organized as follows. Section 2 is the preliminary, which describes global and local surrogate models and distillation MESH equations. In Section 3, a detailed optimization formulation is presented including bi-level surrogate column model construction, bi-level model management, and PSO mixed-integer constraint evolutionary search methodology. Section 4 is the results and discussion. The conclusions of the future work are finally presented in Section 5.
Preliminary
Kriging surrogate global model
The Kriging models based on the optimal linear unbiased estimation method, which is composed of two parts: a polynomial expression and a deviation from that polynomial:
Where
Where σ2 is the variance of the response process;
RBF surrogate local model
Let
Where
Distillation MESH equations
As we know, distillation columns are chief devices for the CDU processes. In the construction of rigorous distillation models, a series of equations, such as the mass balance equations, enthalpy balance equations, equilibrium, and the summation equations collectively termed as MESH equations are applied by stage-by-stage modeling considerations (Chen, 2008).The MESH equations which are comprised of a large number of equations are applied on each stage in a column. For example, if a column has
BI-SACOD approach
Bi-SACOD which is proposed in this paper integrates surrogates and support vector machines to handle time-consuming objectives and constraints, it consists of three parts: Bi-level Surrogate column Model Construction (Bi-SMC), Bi-level Model Management (Bi-MM), and PSO Mixed-Integer Constraint Evolutionary (PSO-MICE) search. Bi-SMC mainly implements the constructing or updating of the global-local surrogate model. Bi-MM combines global and local surrogates with rigorous CDU simulations for the model management, and global and local optimal samples searching is performed using PSO-MICE strategy.
Bi-SMC and Bi-MM
Data generation and sampling are critical points for online Bi-SMC (Wang et al., 2017). For data generation, we use time-consuming rigorous CDU simulations via a commercial simulation platform Aspen Plus in this paper, three following aspects are considered: selecting industrial input and output variables, generating initial random samples, and infilling input variables in the evolution process (Ibrahim et al., 2017). For each input variable set, the corresponding outputs can be obtained by simulating the rigorous CDU models. In this work, both structural and operational input variables are selected and adjusted to improve the performance of the crude distillation column, meanwhile, the chosen output variables are related to the optimization objectives and constraints.
Model management involves how to manipulate the surrogate models to ensure that the designers acquire a reasonable solution during the search process. Figure 1 illustrates the bi-level surrogate model search diagram, where the solid line indicates the expensive model to be optimized, in the top-level, global surrogate column models are used to smooth out the local optima to speed up the search, the hollow circles represent the potential samples from the global dataset, whereas in the lower-level, the local surrogate column models which are constructed from the best m% of the global dataset are utilized to approximate the fitness landscape accurately, the solid circles denote the potential samples from the local dataset. Therefore, the search for the optimal expensive model can be conducted by finding the optimal solution of the local surrogate model.
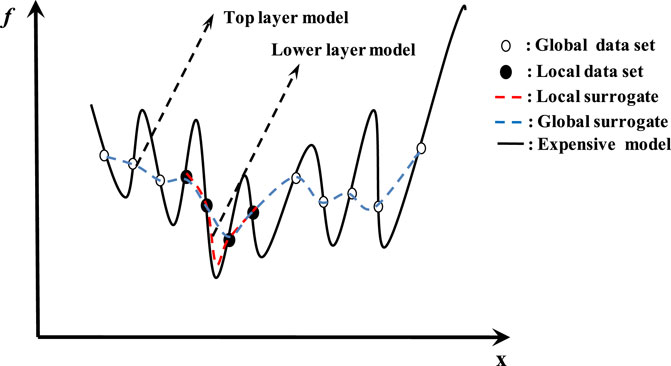
FIGURE 1. Bi-level surrogate model search diagram.
PSO-MICE search
Here, we apply a PSO Mixed-Integer Constraint Evolutionary (PSO-MICE) strategy to search for the CDU’s global and local potential samples. The velocity and position updating for the particles is described in Eqs 7–9. For all the continuous and discrete decision variables, two ways are employed to deal with the updating. If all the individuals satisfy the constrained feasible domain, for discrete variables, the updating is shown in Eqs 7, 9 respectively, where
where
Confronted with the distillation time-consuming MESH equations, here, we adopt the SVM-feasibility approach to solve constraint handling for both the global and the local searching processes. New individuals generated by PSO-MICE are separated into two families, i.e., feasible and infeasible solutions by SVM classifier (Ibrahim et al., 2018). Only a winner individual is eligible to update its velocity and position shown in Eqs 7–9.
Implementational description
The initial industrial CDU used in this study consists of a main column with 60 stages, one condenser, three side strippers, and three pump arounds (i.e., the top circulation reflux and two middle circulation refluxes), as illustrated in Figure 2. The preheated crude oil enters the column at the 52nd stage, numbered from the top downwards, with the condenser as the first stage. In addition to the two conventional products from the top and bottom of the column, i.e., from unstabilized naphtha (UN) and long residue (LR), the distillation unit processes 0.16 m3/s of crude into four products, including light naphtha (LN), heavy naphtha (HN), light gas oil (LGO), and heavy gas oil (HGO), and the residue. The main column has five sections with 8, 12, 14, 10, and 8 sieve trays, respectively. The HN, LGO, and HGO side strippers have 8, 7, and 8 trays in order. The distillation uses steam at 250°C as the stripping agent. The column’s steam flow rate is approximately 220 kmol/h, the reflux ratio is 3.2, and the operating pressure is 1.0 Mpa, respectively. The optimization objective, in this case, is to maximize the profit. Additionally, the constraints considered in the process include the lower and upper bounds of the optimization variables, and the T5% and T95% True Boiling Point (TBP) temperatures. The problem of how to maximize the profit can be expressed as follows:
where
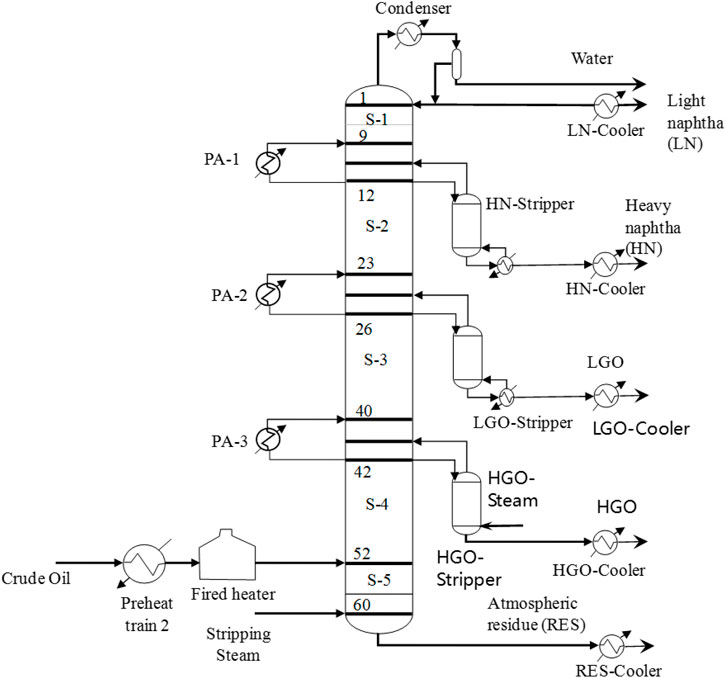
FIGURE 2. Crude oil distillation column.
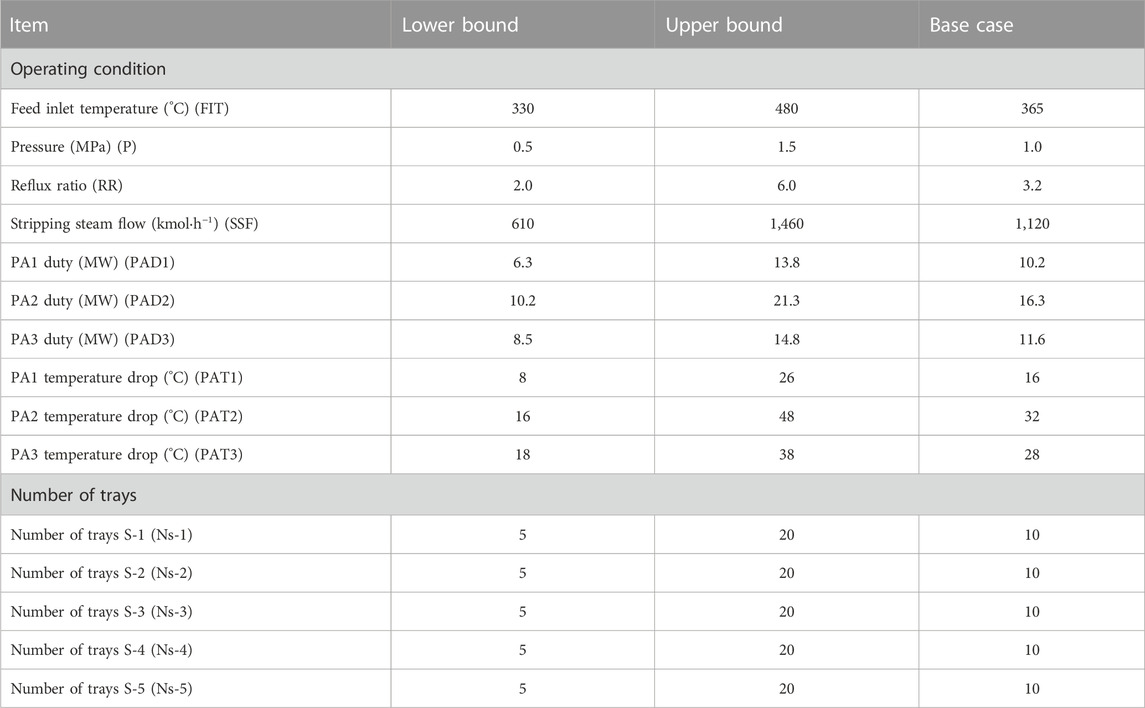
TABLE 1. Base case values of the selected decision variables.
For each product, three kinds of models are considered, the definitions are as follows:
①
②
③
where
Figure 3 illustrates the framework of the proposed approach. First, the initial population
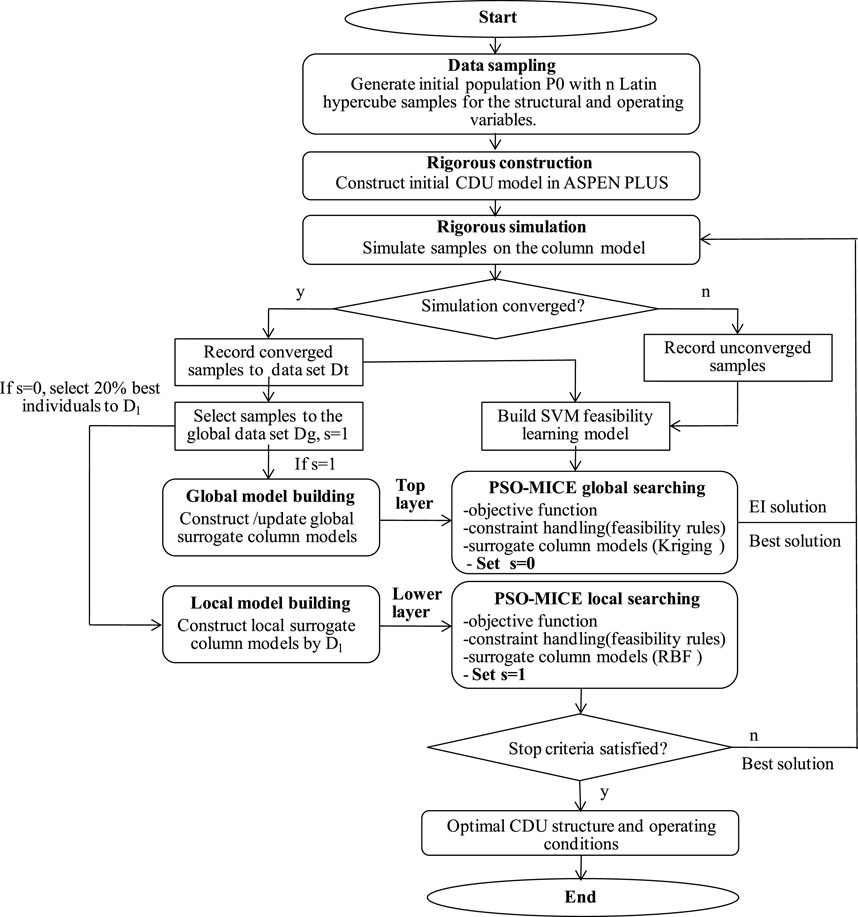
FIGURE 3. The framework of the Bi-SACOD.
The individuals of the global database
Results and discussion
To evaluate the effectiveness of the combination search strategy of global and local surrogate column models in bi-SACOD, we compare the proposed approach with the PSO-Original-Only, PSO-Sur-Kriging, PSO-Sur-RBF, and SVM-ANN (Ibrahim et al., 2018) algorithms. PSO-Original-Only is a common CDU optimization approach with the rigorous CDU model evaluation only, searching by the traditional PSO algorithm. PSO-Sur-Kriging and PSO-Sur-RBF are approaches only employing the Kriging and RBF surrogate column models respectively. It should be noted that the Kriging and RBF surrogate models used in this work are implemented using the SURROGATES toolbox (Viana and Goel, 2010). SVM-ANN is an ANN surrogate combined with the SVM feasibility penalty constraint-handling method that is recently proposed (Ibrahim et al., 2018). Besides, the parameters of bi-SACOD are set as follows: NP = 80, c1 = c2 = 0.5,
To further compare the proposed algorithm with other methods, the following three performance metrics are implemented:
1) Success rate (SR): This represents the percentage of successful runs that can find feasible solutions within the given maximum number of generations.
2) Number of rigorous model evaluations (REs): This is an important performance metric for the time-consuming optimization system. It denotes the number of CDU rigorous model evaluations to reach successful conditions.
3) Convergence speed (CS): This can be described as follows:
where
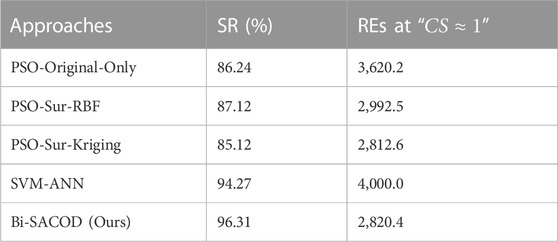
TABLE 2. Comparative performance metrics of the algorithms for average of 20 runs.
It is clear that only Bi-SACOD and SVM-ANN could obtain their optimal solutions with a high success rate (SR); Bi-SACOD saves the number of REs up to 2,820, considerably smaller than that of SVM-ANN. Although the REs at
Figure 4A plots the CDU average economic profit profiles in the 20 runs of the comparative algorithms. It indicates that PSO-Original-Only achieved the highest profit, while Bi-SACOD is the second. PSO-Sur-RBF reached a slightly higher profit than PSO-Sur-Kriging, while the convergence speed of PSO-Sur-Kriging is marginally higher than that of PSO-Sur-RBF, this is probably because the local optimum is trapped with the search of PSO-Sur-Kriging. As far as the number of original CDU evaluations is concerned, as shown in Table 2. The rigorous model evaluations number of the PSO-Original-Only is 3,620.2, while the evaluation number of Bi-SACOD, PSO-Sur-Kriging, and PSO-Sur-RBF is 2,820.4, 2,812.6, and 2,992.5 in order. Therefore, the original model evaluation number of Bi-SACOD is considerably smaller than that of the PSO-Original-Only method.
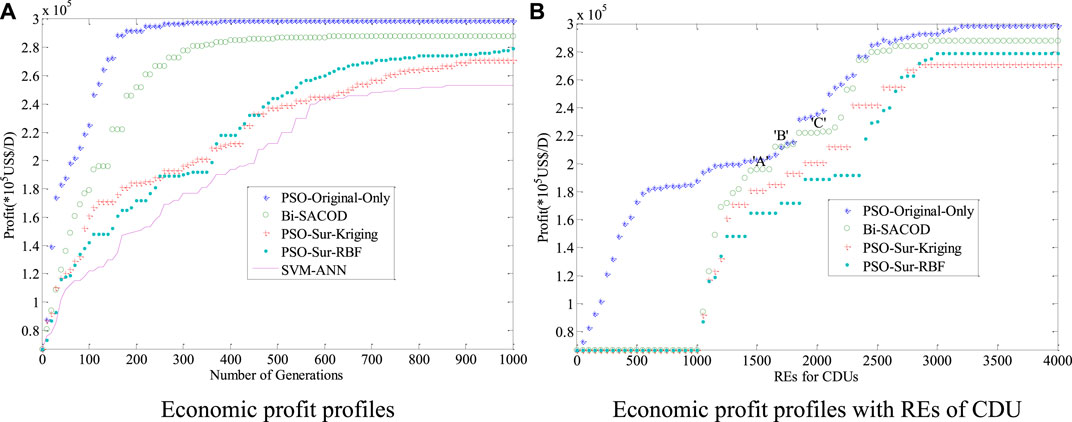
FIGURE 4. Optimization results for the comparative approaches. (A) Economic profit profiles (B) Economic profit profiles with REs of CDU.
Figure 4B illustrates the CDU column comparative economic profit profiles with the REs of the original model simulation. As shown in Figure 4B, REs from 0 to 1,000 formed the data-sampling period, and the profit of the CDU is maintained in the initial state before optimization. The slow change in the profit of Bi-SACOD labeled as “A”, “B”, and “C” attributed to the fact that it is in the local searching state. Figure 4B indicates that the plot of Bi-SACOD is remarkably more consistent with that of the PSO-Original-Only method.
Table 3 reflects the contributions of the proposed algorithm. We can see from Table 3 that in the case of the Bi-SACOD approach, the economic profit could reach USD 2.88 × 105/day, which is closer to the profit of the PSO-Original-Only method (USD 2.99 × 105/day), while the number of rigorous model evaluations of Bi-SACOD is considerably reduced.
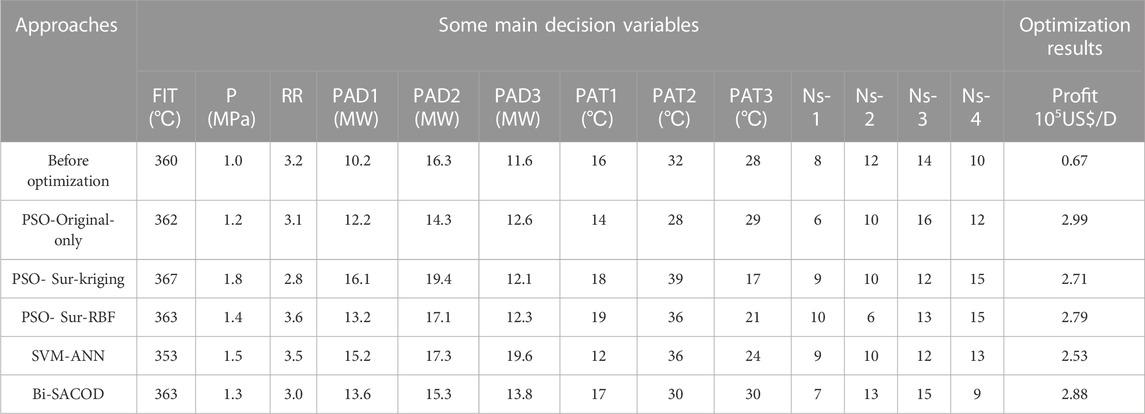
TABLE 3. Comparison of the optimization results.
Conclusion
The evolutionary optimization design of CDUs is challenging due to its mixed-integer variables with time-consuming objectives and constraints. The presented work focuses on Bi-SACOD approach for time-consuming objectives and constraints of CDUs’ design. The main contributions of this work include:1) For time consuming optimization design, we construct a two-level global-local surrogate column model for CDU optimization, in which global Kriging models are adopted to smooth out the local optima to speed up the search, and RBF local models are used to further approximate the fitness landscape. 2) Confronted with the distillation time-consuming MESH equations, we apply a PSO mixed-Integer constraint evolutionary strategy and simultaneously adopt SVM-feasibility approach to solve constraint handling for both the global and local searching processes. The optimization results of the CDUs show that Bi-SACOD outperforms the single-level surrogate column model approaches, and are more consistent with the rigorous CDU model optimization approach, whereas the number of evaluations for time-consuming rigorous models is significantly reduced. In our follow-up research, we will further improve the proposed method and extend it to other types of distillation units.
Data availability statement
The original contributions presented in the study are included inthe article/supplementary material; further inquiries can be directed to the corresponding author.
Author contributions
YX: Methodology, Software, Data curation, Verification, and Writing—original draft and revising. XS: Conceptualization, Project administration, and Writing—reviewing and editing. YM: Verification. YC: Resources. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by the National Natural Science Foundation of China under Grant Nos. 61773225 and 61803214; the K. C. Wong Magna Fund in Ningbo University, China.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Alattas, A., Grossmann, I., and Palou-Rivera, I. (2011). Integration of nonlinear crude distillation unit models in refinery planning optimizationfinery planning optimization. Industrial Eng. Chem. Res. 50 (11), 6860–6870. doi:10.1021/ie200151e
Chatterjee, A., and Siarry, P. (2006). Nonlinear inertia weight variation for dynamic adaptation in particle swarm optimization. Comput. &Operations Res. 33 (3), 859–871. doi:10.1016/j.cor.2004.08.012
Chen, L. (2008). Heat-integrated crude oil distillation design. Ph.D. Thesis. Manchester, UK. The University of Manchester, 35–39.
Ibrahim, D., Jobson, M., and Gonzalo, G. (2017). Optimization-based design of crude oil distillation units using rigorous simulation models. Industrial Eng. Chem. Res. 56 (23), 6728–6740. doi:10.1021/acs.iecr.7b01014
Ibrahim, D., Jobson, M., Li, J., and Guillen-Gosalbez, G. (2018). Optimization-based design of crude oil distillation units using surrogate column models and a support vector machine. Chem. Eng. Res. Des. 134, 212–225. doi:10.1016/j.cherd.2018.03.006
Ibrahim, D., Jobson, M., Jie, L., and Gonzalo, G. (2021). Optimal design of flexible heat-integrated crude oil distillation units using surrogate models. Chem. Eng. Res. Des. 165, 280–297. doi:10.1016/j.cherd.2020.09.014
Kunru, Y., Shirun, L., Chang, H., Bingjian, Z., Qinglin, C., and Ming, P. (2020). Improving energy saving of crude oil distillation units with optimal operations. J. Clean. Prod. 263, 121340–121349. doi:10.1016/j.jclepro.2020.121340
Lopez, D. C., Hoyos, L. J., Mahecha, C. A., Arellano-Garcia, H., and Wozny, G. (2013). Optimization model of crude oil distillation units for optimal crude oil blending and operating conditions. Industrial Eng. Chem. Res. 52, 12993–13005. doi:10.1021/ie4000344
Viana, F., and Goel, T. (2010). Surrogates toolbox user’s guide. Available at: http://fchegury.googlepages.com, Tech. Rep.
Wang, H., Jin, Y., and Doherty, J. (2017). Committee-based active learning for surrogate-assisted particle swarm optimization of expensive problems. IEEE Trans. Cybern. 47 (9), 2664–2677. doi:10.1109/tcyb.2017.2710978
Xin, D., Xiaoqiang, W., Renchu, H., Wenli, D., Weimin, Z., Liang, Z., et al. (2020). Data-driven robust optimization for crude oil blending under uncertainty. Comput. Chem. Eng. 136 (8), 106595-1–106595-7. doi:10.1016/j.compchemeng.2019.106595
Xin, D., Liang, Z., Zhi, L., Wenli, D., Weimin, Z., Renchu, H., et al. (2021). A data-driven approach for crude oil scheduling optimization under product yield uncertainty. Chem. Eng. Sci. 246, 116971–116979. doi:10.1016/j.ces.2021.116971
Zhong, W., Qiao, C., Peng, X., Li, Z., Fan, C., and Qian, F. (2019). Operation optimization of hydrocracking process based on Kriging surrogate model. Control Eng. Pract. 85, 34–40. doi:10.1016/j.conengprac.2019.01.001
Keywords: optimization design, surrogate models, crude oil distillation unit, evolutionary optimization, bi-level surrogate models
Citation: Xiong Y, Shi X, Ma Y and Chen Y (2023) Optimization design of crude oil distillation unit using bi-level surrogate model. Front. Control. Eng. 4:1162318. doi: 10.3389/fcteg.2023.1162318
Received: 09 February 2023; Accepted: 03 March 2023;
Published: 31 March 2023.
Edited by:
Lingjian Ye, Huzhou University, ChinaReviewed by:
Qinqin Fan, Shanghai Maritime University, ChinaXiaofeng Yuan, Central South University, China
Copyright © 2023 Xiong, Shi, Ma and Chen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xuhua Shi, c2hpeHVodWFAbmJ1LmVkdS5jbg==