 Tim Beck1,2*
Tim Beck1,2* Tom Shorter1†
Tom Shorter1† Yan Hu3,4†
Yan Hu3,4† Zhuoyu Li3†Shujian Sun3†
Zhuoyu Li3†Shujian Sun3† Casiana M. Popovici3,4†Nicholas A. R. McQuibban3,5
Casiana M. Popovici3,4†Nicholas A. R. McQuibban3,5 Filip Makraduli3
Filip Makraduli3 Cheng S. Yeung3
Cheng S. Yeung3 Thomas Rowlands1
Thomas Rowlands1 Joram M. Posma2,3*
Joram M. Posma2,3*- 1Department of Genetics and Genome Biology, University of Leicester, Leicester, United Kingdom
- 2Health Data Research UK (HDR UK), London, United Kingdom
- 3Section of Bioinformatics, Division of Systems Medicine, Department of Metabolism, Digestion and Reproduction, Imperial College London, London, United Kingdom
- 4Department of Surgery and Cancer, Imperial College London, London, United Kingdom
- 5Centre for Integrative Systems Biology and Bioinformatics (CISBIO), Department of Life Sciences, Imperial College London, London, United Kingdom
To analyse large corpora using machine learning and other Natural Language Processing (NLP) algorithms, the corpora need to be standardized. The BioC format is a community-driven simple data structure for sharing text and annotations, however there is limited access to biomedical literature in BioC format and a lack of bioinformatics tools to convert online publication HTML formats to BioC. We present Auto-CORPus (Automated pipeline for Consistent Outputs from Research Publications), a novel NLP tool for the standardization and conversion of publication HTML and table image files to three convenient machine-interpretable outputs to support biomedical text analytics. Firstly, Auto-CORPus can be configured to convert HTML from various publication sources to BioC. To standardize the description of heterogenous publication sections, the Information Artifact Ontology is used to annotate each section within the BioC output. Secondly, Auto-CORPus transforms publication tables to a JSON format to store, exchange and annotate table data between text analytics systems. The BioC specification does not include a data structure for representing publication table data, so we present a JSON format for sharing table content and metadata. Inline tables within full-text HTML files and linked tables within separate HTML files are processed and converted to machine-interpretable table JSON format. Finally, Auto-CORPus extracts abbreviations declared within publication text and provides an abbreviations JSON output that relates an abbreviation with the full definition. This abbreviation collection supports text mining tasks such as named entity recognition by including abbreviations unique to individual publications that are not contained within standard bio-ontologies and dictionaries. The Auto-CORPus package is freely available with detailed instructions from GitHub at: https://github.com/omicsNLP/Auto-CORPus.
Introduction
Natural language processing (NLP) is a branch of artificial intelligence that uses computers to process, understand, and use human language. NLP is applied in many different fields including language modeling, speech recognition, text mining, and translation systems. In the biomedical realm NLP has been applied to extract, for example, medication data from electronic health records and patient clinical history from free-text (unstructured) clinical notes, to significantly speed up processes that would otherwise be extracted manually by experts (1, 2). Biomedical research publications, although semi-structured, pose similar challenges with regards to extracting and integrating relevant information (3). The full-text of biomedical literature is predominately made available online in the accessible and reusable HTML format, however, some publications are only available as PDF documents which are more difficult to reuse. Efforts to resolve the problem of publication text accessibility across science in general includes work by the Semantic Scholar search engine to convert PDF documents to HTML formats (4). Whichever process is used to obtain a suitable HTML file, before the text can be processed using NLP, heterogeneously structured HTML requires standardization and optimization. BioC is a simple JSON (and XML) format for sharing and reusing text data that has been developed by the text mining community to improve system interoperability (5). The BioC data model consists of collections of documents divided into data elements such as publication sections and associated entity and relation annotations. PubMed Central (PMC) makes full-text articles from its Open Access and Author Manuscript collections available in BioC format (6). To our knowledge there are no services available to convert PMC publications that are not part of these collections to BioC. Additionally, there is a gap in available software to convert publishers' publication HTML to BioC, creating a bottleneck in many biomedical literature text mining workflows caused by having to process documents in heterogenous formats. To bridge this gap, we have developed an Automated pipeline for Consistent Outputs from Research Publications (Auto-CORPus) that can be configured to process any HTML publication structure and transform the corresponding publications to BioC format.
During information extraction, the publication section context of an entity will assist with entity prioritization. For example, an entity identified in the Results Section may be regarded as a higher priority novel finding than one identified in the Introduction Section. However, the naming and the sequential order of sections within research articles differ between publications. A Methods section, for example, may be found at different locations relative to other sections and identified using a range of synonyms such as experimental section, experimental procedures, and methodology. The Information Artifact Ontology (IAO) was created to serve as a domain-neutral resource for the representation of types of information content entities such as documents, databases, and digital images (7). Auto-CORPus applies IAO annotations to BioC file outputs to standardize the description of sections across all processed publications.
Vast amounts of biomedical data are contained in publication tables which can be large and multi-dimensional where information beyond a standard two-dimensional matrix is conveyed to a human reader. For example, a table may have subsections or entirely new column headers to merge multiple tables into a single structure. Milosevic and colleagues developed a methodology to analyse complex tables that are represented in XML format and perform a semantic analysis to classify the data types used within a table (8). The outputs from the table analysis are stored in esoteric XML or database models. The communal BioC format on the other hand has limited support for tables, for example the PMC BioC JSON output includes table data in PMC XML format, introducing file parsing complexity. In addition to variations in how tables are structured, there is variability amongst table filetypes. Whereas, publication full-text is contained within a single HTML file, tables may be contained within that full-text file (inline tables), or individual tables may be contained in separate HTML files (linked tables). We have defined a dedicated table JSON format for representing table data from both formats of table. The contents of individual cells are unambiguously identified and thus can be used in entity and relation annotations. In developing the Auto-CORPus table JSON format, we adopted a similar goal to the BioC community, namely, a simple format to maximize interoperability and reuse of table documents and annotations. The table JSON reuses the BioC data model for entity and relation annotations, ensuring that table and full-text annotations can share the same BioC syntax. Auto-CORPus transforms both inline and linked HTML tables to the machine interpretable table JSON format.
Abbreviations and acronyms are widely used in publication text to reduce space and avoid prolix. Abbreviations and their definitions are useful in text mining to identify lexical variations of words describing identical entities. However, the frequent use of novel abbreviations in texts presents a challenge for the curators of biomedical lexical ontologies to ensure they are continually updated. Several algorithms have been developed to extract abbreviations and their definitions from biomedical text (9–11). Abbreviations within publications can be defined when they are declared within the full-text, and in some publications, are included in a dedicated abbreviations section. Auto-CORPus adapts an abbreviation detecting methodology (12) and couples it with IAO section detection to comprehensively extract abbreviations declared in the full-text and in the abbreviations section. For each publication, Auto-CORPus generates an abbreviations dictionary JSON file.
The aim of this article is to describe the open Auto-CORPus python package and the text mining use cases that make it a simple user-friendly application to create machine interpretable biomedical literature files, from a single publication to a large corpus. The authors share the common interest of progressing text mining capabilities across the biomedical literature domain and contribute omics and health data use cases related to their expertise in Genome-Wide Association Study (GWAS) and Metabolome-Wide Association Study (MWAS) data integration and analytics (see Author Contributions Section). The following sections describe the technical details about the algorithms developed and the benchmarking undertaken to assess the quality of the three Auto-CORPus outputs generated for each publication: BioC full-text, Auto-CORPus tables, and Auto-CORPus abbreviations JSON files.
Materials and Methods
Data for Algorithm Development
We used a set of 3,279 full-text HTML and 1,041 linked table files to develop and test the algorithms described in this section. Files for 1,200 Open Access (OA) GWAS publications whose data exists in the GWAS Central database (13) were downloaded from PMC in March 2020. A further 1,241 OA PMC publications of MWAS and metabolomics studies on cancer, gastrointestinal diseases, metabolic syndrome, sepsis and neurodegenerative, psychiatric, and brain illnesses were also downloaded to ensure the methods are not biased toward one domain, more information is available in the Supplementary Material. This formed a collection of 2,441 publications that will be referred to as the “OA dataset.” We also downloaded publisher-specific full-text files, and linked table data were available, for publications whose data exists in the GWAS Central database. This collection of 838 full-text and 1,041 table HTML files will be referred to as the “publisher dataset.” Table 1 lists the publishers and journals included in the publisher dataset and the number of publications that overlap with the OA dataset. This also includes publications from non-biomedical fields to evaluate the application in other domains.
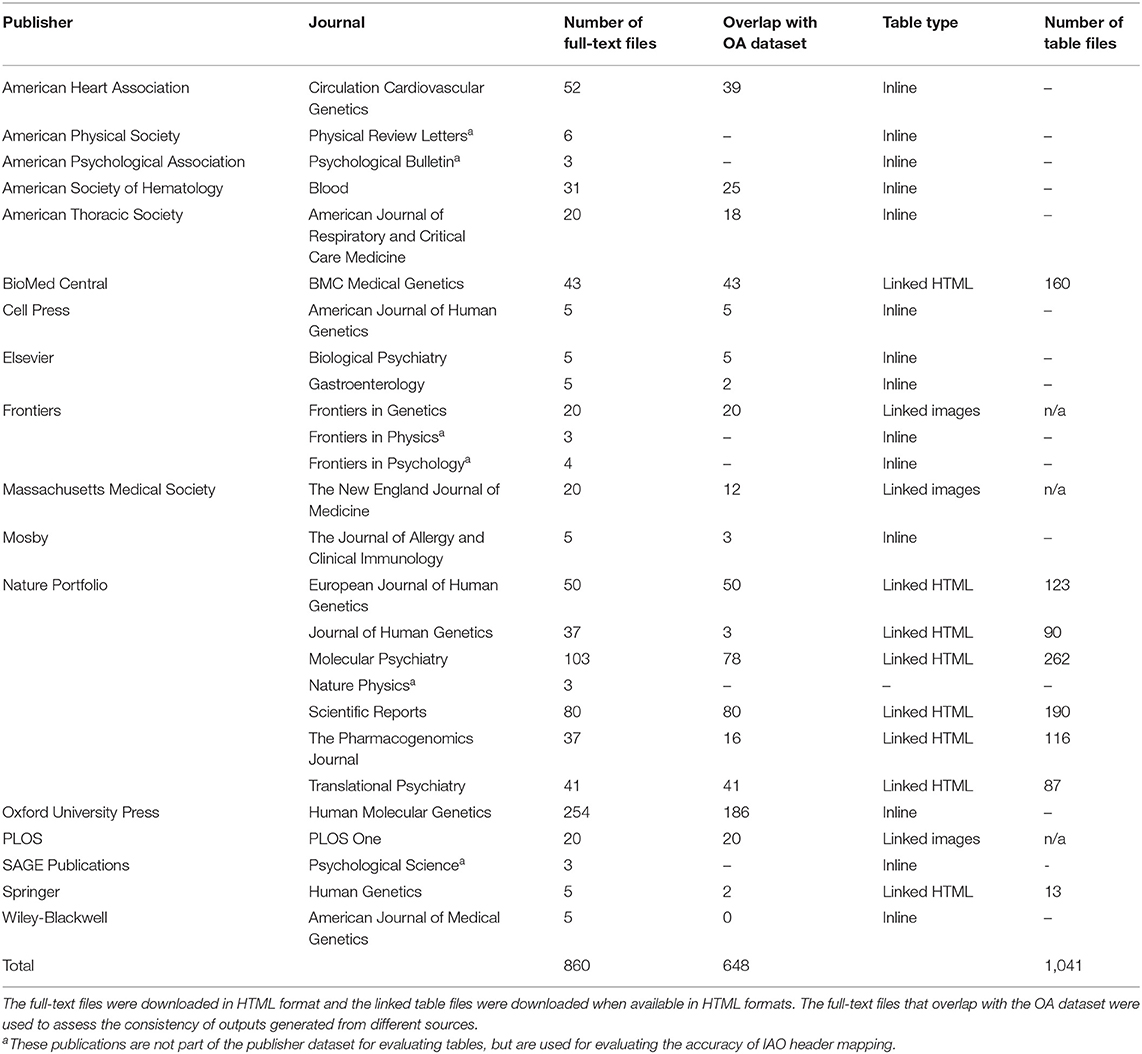
Table 1. Publishers and journals included in the publisher dataset.
Algorithms for Processing Publication Full-Text HTML
An Auto-CORPus configuration file is set by the user to define the heading and paragraph HTML elements used in the publication files to be processed. Regular expressions can be used within the configuration file allowing a group of publications with a similar but not an identical structure to be defined by a single configuration file, for example when processing publications from journals by the same publisher. The heading elements are used to delineate the content of the publication sections and the BioC data structure is populated with publication text. All HTML tags including text formatting (e.g., emphasized words, superscript, and subscript) are removed from the publication text. Each section is automatically annotated using IAO (see Section Algorithms for Classifying Publication Sections With IAO Terms) and the BioC data structure is output in JSON format. The BioC specification requires “key files” to accompany BioC data files to specify how the data files should be interpreted (5). We provide key files to define the data elements in the Auto-CORPus JSON output files for full-text, tables, and abbreviations (https://github.com/omicsNLP/Auto-CORPus/tree/main/keyFiles). Figure 1 gives an example of the BioC JSON output and the abbreviations and tables outputs are described below.

Figure 1. An extract of the Auto-CORPus BioC JSON created from the PMC3606015 full-text HTML file. Each section is annotated with IAO terms. The “autocorpus_fulltext.key” file describes the contents of the full-text JSON file (https://github.com/omicsNLP/Auto-CORPus/blob/main/keyFiles/autocorpus_fulltext.key).
Abbreviations in the full-text are found using an adaptation of a previously published methodology and implementation (12). The method finds all brackets within a publication and if there are two or more non-digit characters within brackets it considers if the string in the brackets could be an abbreviation. It searches for the characters present in the brackets in the text on either side of the brackets one by one. The first character of one of these words must contain the first character within the bracket, and the other characters within that bracket must be contained by other words that follow the first word whose first character is the same as the first character in that bracket. An example of the Auto-CORPus abbreviations JSON is given in Figure 2 which shows that the output from this algorithm is stored along with the abbreviations defined in the publication abbreviations section (if present).

Figure 2. An extract from the Auto-CORPus abbreviations JSON created from the PMC4068805 full-text HTML file. For each abbreviation the corresponding long form definition is given along with the algorithm(s) used to detect the abbreviation. Most of the abbreviations shown were independently identified in both the full-text and in the abbreviations section of the publication. A variation in the definition of “RP” was detected: in the abbreviations section this was defined as “reverse phase,” however in the full-text this was defined as “reversed phase.” The “autocorpus_abbreviations.key” file describes the contents of the abbreviations JSON file (https://github.com/omicsNLP/Auto-CORPus/blob/main/keyFiles/autocorpus_abbreviations.key).
Algorithms for Classifying Publication Sections With IAO Terms
A total of 21,849 section headers were extracted from the OA dataset and directed path graphs (DPGs) were created for each publication (Figure 3). DPGs are a linear chain without any cycles. For example, at this point in this article the main headers are abstract (one paragraph) followed by introduction (five paragraphs) and materials and methods (four paragraphs, three sub-headers)—this would make up a DPG with three nodes (abstract, introduction, materials and methods) and two directed edges. For our Introduction Section, while the individual five paragraphs within a section would all be mapped to the main header (introduction), only one node would appear in the DPG (relating to the header itself) without any self-edges. The individual DPGs were then combined into a directed graph (digraph, Supplementary Figure 2) and the extracted section headers were mapped to IAO (v2020-06-10) document part terms using the Lexical OWL Ontology Matcher (LOOM) method (14). Fuzzy matching using the fuzzywuzzy python package (v0.17.0) was then used to map headers to the preferred section header terms and synonyms, with a similarity threshold of 0.8 (e.g., the typographical error “experemintal section” in PMC4286171 is correctly mapped to methods section). This threshold was evaluated by two independent researchers who confirmed all matches for the OA dataset were accurate. Digraphs consist of nodes (entities, headers) and edges (links between nodes) and the weight of the nodes and edges is proportional to the number of publications in which these are found. Here the digraph consists of 372 unique nodes and 806 directed edges (Supplementary Figure 1).
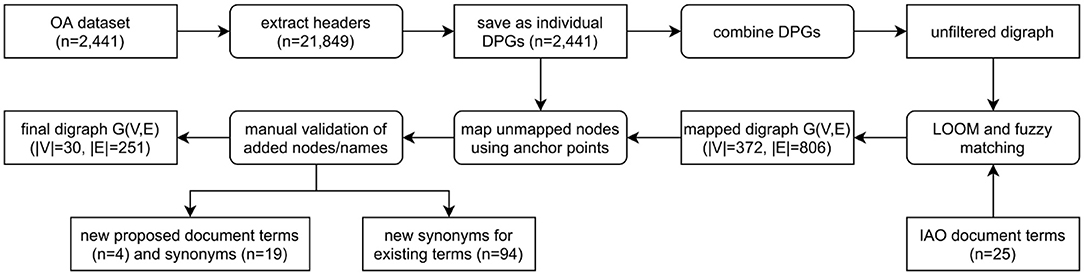
Figure 3. Flow diagram demonstrating the process of classifying publication sections with IAO terms. The unfiltered digraph is visualized in Supplementary Figure 1, and the process of combining DPGs and mapping unmapped nodes using anchor points in Supplementary Figure 2. DPG, directed path graph; G(V,E), graph(vertex, edge); IAO, information artifact ontology.
However, after direct IAO mapping and fuzzy matching, unmapped headers still existed. To map these headings, we developed a new method using both the digraph and the individual DPGs. The headers are not repeated within a document/DPG, they are sequential/a chain and have a set order that can be exploited. Unmapped headers are assigned a section based on the digraph and the headers in the publication (DPG) that could be mapped (anchor headers), an example is given in Supplementary Figure 2 where a header cannot be mapped to IAO terms. Any unmapped header that is mapped to an existing IAO term in this manner does not result in a self-edge in the network as subsequent repeated headers are collapsed into a single node. Auto-CORPus uses the LOOM, fuzzy matching and digraph prediction algorithms to annotate publication sections with IAO terms in the BioC full-text file. Paragraphs can be mapped to multiple IAO terms in case of publications without main-text headers (based on digraph prediction) or with ambiguous headers (based on fuzzy matching and/or digraph prediction).
New IAO Terms and Synonyms
We used the IAO classification algorithms to identify potential new IAO terms and synonyms. Three hundred and forty-eight headings from the OA dataset were mapped to IAO terms during the fuzzy matching or mapped based on the digraph using the publication structure and anchor headers. These headings were considered for inclusion in IAO as term synonyms. We manually evaluated each heading and Table 2 lists the 94 synonyms we identified for existing IAO terms.

Table 2. New synonyms identified for existing IAO terms from the fuzzy and digraph mappings of 2,441 publications.
Diagraph nodes that were not mapped to IAO terms but formed heavily weighted “ego-networks,” indicating the same heading was found in many publications, were manually evaluated for inclusion in IAO as new terms. For example, based on the digraph, we assigned data and data description to be synonyms of the materials section. The same process was applied to ego-networks from other nodes linked to existing IAO terms to add additional synonyms to simplify the digraph. Figure 4 shows the ego-network for abstract, and four main categories and one potential new synonym (precis, in red) were identified. From the further analysis of all ego-networks, four new potential terms were identified: disclosure, graphical abstract, highlights, and participants—the latter is related to, but deemed distinct from, the existing patients section (IAO:0000635). Table 3 details the proposed definition and synonyms for these terms. The terms and synonyms described here will be submitted to the IAO, with our initial submission of one term and 59 synonyms accepted and included in IAO previously (v2020-12-09) (https://github.com/information-artifact-ontology/IAO/issues/234). Figure 5 shows the resulting digraph with only existing and newly proposed section terms. A major unmapped node is associated data, which is a header specific for PMC articles that appears at the beginning of each article before the abstract. In addition, IAO has separate definitions for materials (IAO:0000633), methods (IAO:0000317), and statistical methods (IAO:0000644) sections, hence they are separate nodes in the graph. The introduction is often followed by these headers to reflect the methods section (and synonyms), however there is also a major directed edge from introduction directly to results to account for materials and methods placed after the discussion and/or conclusion sections in some publications.
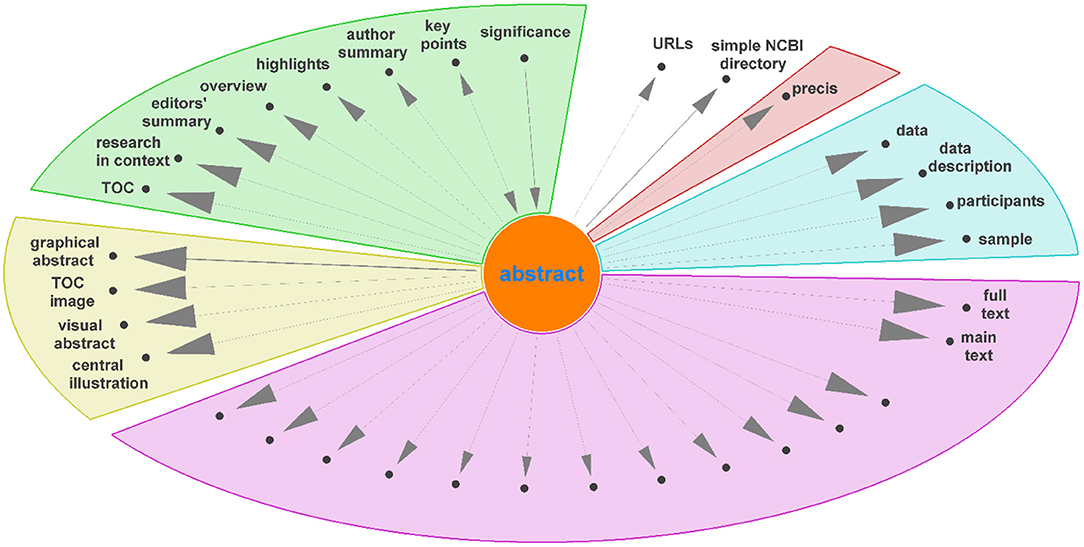
Figure 4. Unmapped nodes in the digraph (Figure 3) connected to “abstract” as ego node, excluding corpus specific nodes, grouped into different categories. Unlabeled nodes are titles of paragraphs in the main text.

Table 3. (A) Proposed new IAO terms to define publication sections that were derived from analyzing the sections of 2,441 publications. (B) Proposed new IAO terms to define parts of a table section. Elements in italics have previously been submitted by us for inclusion into IAO and added in the v2020-12-09 IAO release.
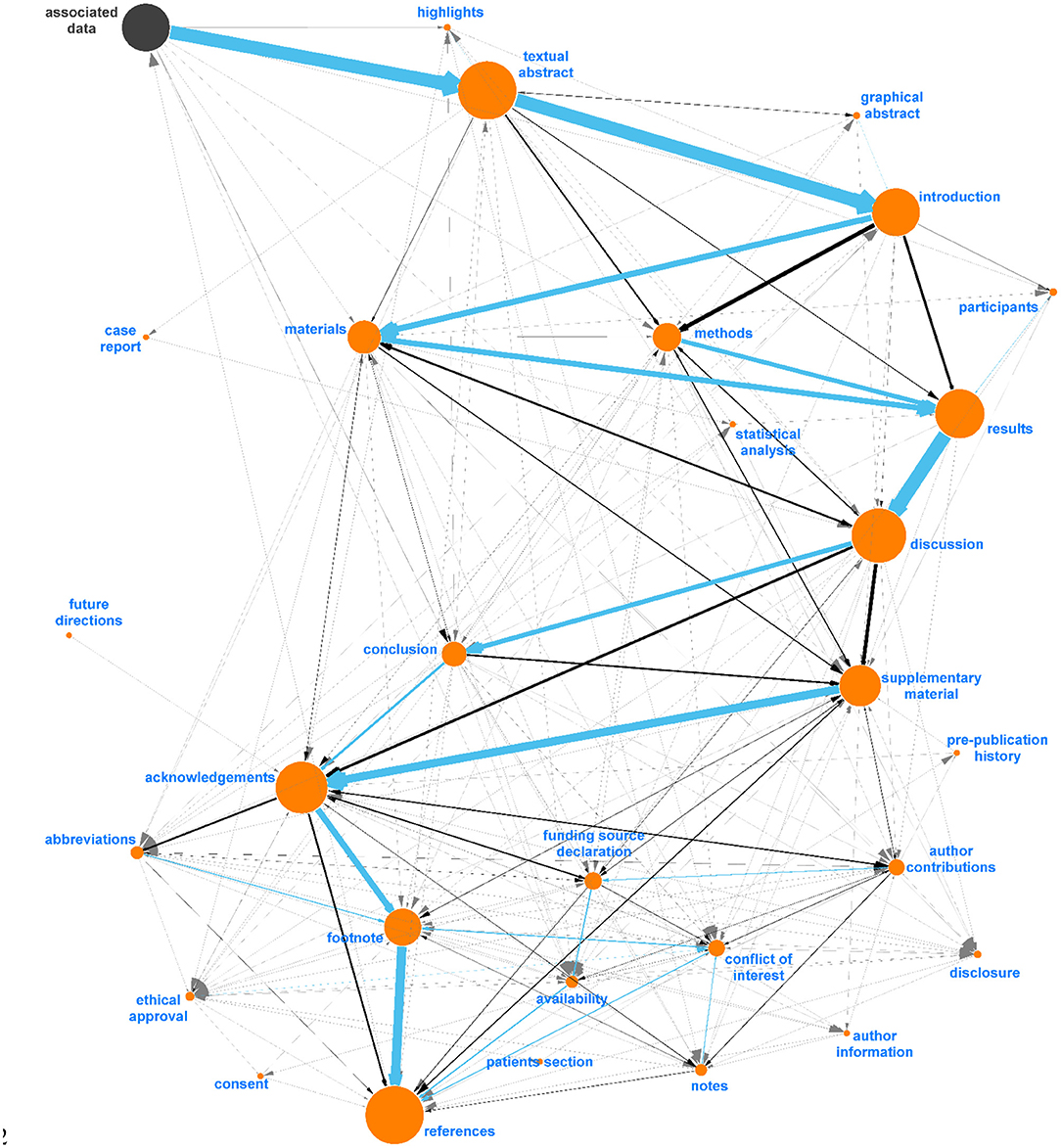
Figure 5. Final digraph model used in Auto-CORPus to classify paragraphs after fuzzy matching to IAO terms (v2020-06-10). This model includes new (proposed) section terms and each section contains new synonyms identified in this analysis. “Associated Data” is included as this is a PMC-specific header found before abstracts and can be used to indicate the start of most articles, all IAO terms are indicated in orange.
Algorithms for Processing Tables
Auto-CORPus Table JSON Design
The BioC format does not specify how table content should be structured, leaving this open to the interpretation of implementers. For example, the PMC BioC JSON output describes table content using PMC XML (see the “pmc.key” file at https://ftp.ncbi.nlm.nih.gov/pub/wilbur/BioC-PMC/pmc.key). Including markup language within JSON objects presents data parsing challenges and interoperability barriers with non-PMC table data representations. We developed a simple table JSON format that is agnostic to the publication table source, can store multi-dimensional table content from complex table structures, and applies BioC design principles (5) to enable the annotation of entities and relations between entities. The table JSON stores table metadata of title, caption and footer. The table content is stored as “column headers” and “data rows.” The format supports the use of IAO to define the table metadata and content sections, however additional IAO terms are required to define table metadata document parts. Table 3 includes the proposed definition and synonyms for these terms. To compensate for currently absent IAO terms, we have defined three section type labels: table title, table caption and table footer. To support the text mining of tables, each column header and data row cell has an identifier that can be used to identify entities in annotations. Tables can be arranged into subsections, thus the table JSON represents this and includes subsection headings. Figure 6 gives an example of table metadata and content stored in the Auto-CORPus table JSON format. In addition to the Auto-CORPus key files, we make a table JSON schema available for the validation of table JSON files and to facilitate the use of the format in text analytics software and pipelines.

Figure 6. Extracts of the Auto-CORPus table JSON file generated to store metadata and content for an example table. (A) The parts of a table stored in table JSON. The section titles are underlined. The table shown is the PMC version (PMC4245044) of Table 1 from (15). (B) The title and caption table metadata stored in table JSON. (C) Each column heading in the table content is split between two rows, so the strings from both cells are concatenated with a pipe symbol in the table JSON. Headers that span multiple columns of sub-headers are replicated in each header cell as here with the pipe symbol. (D) The table content for the first row from the first section is shown in table JSON. Superscript characters are identified using HTML markup. (E) The footer table metadata stored in table JSON. The “autocorpus_tables.key” file describes the contents of the tables JSON file (https://github.com/omicsNLP/Auto-CORPus/blob/main/keyFiles/autocorpus_tables.key).
Processing Table HTML
Tables can used within HTML documents for formatting web page layouts and are distinct from the data tables processed by Auto-CORPus. The configuration file set by the user identifies the HTML elements used to define data table containers, which include title, caption, footer, and table content. The files processed can either be a full-text HTML file for inline tables and/or separate HTML files for individual linked tables. The Auto-CORPus algorithm for processing tables is based on the functional and structural table analysis method described by Milosevic et al. (8). The cells that contain navigational information such as column headers and section headings are identified. If a column has header strings contained in cells spanning multiple rows, the strings are concatenated with a pipe character separator to form a single column header string. The “super row” is a single text string that spans a complete row (multiple columns) within the table body. The “index column” is a single text string in the first column (sometimes known as a stub) within the table body when either only the first column does not have a header, or the cell spans more than one row. The presence of a super row or index column indicates a table section division where the previous section (if present) ends, and a new section starts. The super row or index column text string provides the section name. A nested array data structure of table content is built to relate column headers to data rows, working from top to bottom and left to right, with section headings occurring in between and grouping data rows. The algorithm extracts the table metadata of title, footer and caption. Table content and metadata are output in the table JSON format. The contents of table cells can be either string or number data types (we consider “true” and “false” booleans as strings) and are represented in the output file using the respective JSON data type. Cells that contain only scientific notation are converted to exponential notation and stored as a JSON number data type. All HTML text formatting is removed, however this distorts the meaning of positive exponents in text strings, for example n = 103 is represented as n = 103. To preserve the meaning of exponents within text strings, superscript characters are identified using superscript HTML element markup, for example n = 10 <sup>3</sup>.
Some publication tables contain content that could be represented in two or more separate tables. These multi-dimensional tables use the same gridlines, but new column headers are declared after initial column headers and data rows have appeared in the table. New column headers are identified by looking down columns and classifying each cell as one of three types: numerical, textual, and a mix of numbers and text. The type for a column is determined by the dominant cell type of all rows in a column excluding super rows. After the type of all columns are determined, the algorithm loops through all rows except super rows, and if more than half of cells in the row do not match with the columns' types, the row is identified as a new header row, and the rows that follow the new headers are then regarded as a sub-table. Auto-CORPus represents sub-tables as distinct tables in the table JSON, with identical metadata to the initial table. Tables are identified by the table number used in the publication, so since sub-tables will share their table number with the initial table, a new identifier is created for sub-tables with the initial table number, an underscore, then a sub-table number such as “1_1.”
Comparative Analysis of Outputs
The correspondence between PMC BioC and Auto-CORPus BioC outputs were compared to evaluate whether all information present in the PMC BioC output also appears in the Auto-CORPus BioC output. This was done by analyzing the number of characters in the PMC BioC JSON that appear in the same order in the Auto-CORPus BioC JSON using the longest common subsequence method. With this method, overlapping sequences of characters that vary in length are extracted from the PMC BioC string to find a matching sequence in the Auto-CORPus string. With this method it can occur that a subsequence from the PMC BioC matches to multiple parts of the Auto-CORPus BioC string (e.g., repeated words). This is mitigated by evaluating matches of overlapping/adjacent subsequences which should all be close to each other as they appear in the PMC BioC text.
This longest common subsequence method was applied to each individual paragraph of the PMC BioC input and compared with the Auto-CORPus BioC paragraphs. This method was chosen over other string metric algorithms, such as the Levenshtein distance or cosine-similarity, due to it being non-symmetric/unidirectional (the Auto-CORPus BioC output strings contain more information (e.g., figure/table links, references) than the PMC BioC output) and ability to directly extract different characters.
Results
Data for the Evaluation of Algorithms
We attempted to download PMC BioC JSON format for all 1,200 GWAS PMC publications in our OA dataset, but only 766 were available as BioC from the NCBI server. We refer to this as the “PMC BioC dataset.” For the 766 PMC articles where we could obtain a NCBI BioC file, we processed the equivalent PMC HTML files using Auto-CORPus. We used only the BioC output files and refer to this as the “Auto-CORPus BioC dataset.” To compare the Auto-CORPus BioC and table outputs for PMC and publisher-specific versions, we accessed 163 Nature Communication and 5 Nature Genetics articles that overlap with the OA dataset and were not present in the publisher dataset, so they were unseen data. These journals have linked tables, so full-text and all linked table HTML files were accessed (367 linked table files). Auto-CORPus configuration files were setup for the journals to process the publisher-specific files and the BioC and table JSON output files were collated into what we refer to as the “linked table dataset.” The equivalent PMC HTML files from the OA dataset were also processed by Auto-CORPus and the BioC and table JSON files form the “inline table dataset.”
Performance of Auto-CORPus Full-Text Processing
The proportion of characters from 3,195 full-text paragraphs in the PMC BioC dataset that also appear in the Auto-CORPus BioC dataset in the same order in the paragraph string were evaluated using the longest common subsequence method. The median and interquartile range of the (left-skewed) similarity are 100% and 100–100%, respectively. Differences between the Auto-CORPus and PMC outputs are shown in Table 4 and relate to how display items, abbreviations and links are stored, and different character encodings. A structural difference between the two outputs is in how section titles are associated to passage text. In PMC BioC the section titles (and subtitles) are distinct from the passages they describe as both are treated as equivalent text. The section title occurs once in the file and the passage(s) it refers to follows it. In Auto-CORPus BioC the (first level) section titles (and subtitles) are linked directly with the passage text they refer to, and are included for each paragraph. Auto-CORPus uses IAO to classify text sections so, for example, the introduction title and text are grouped into a section annotated as introduction, rather than splitting these into two subsections (introduction title and introduction text as separate entities in the PMC BioC output) which would not fit with the IAO structure.
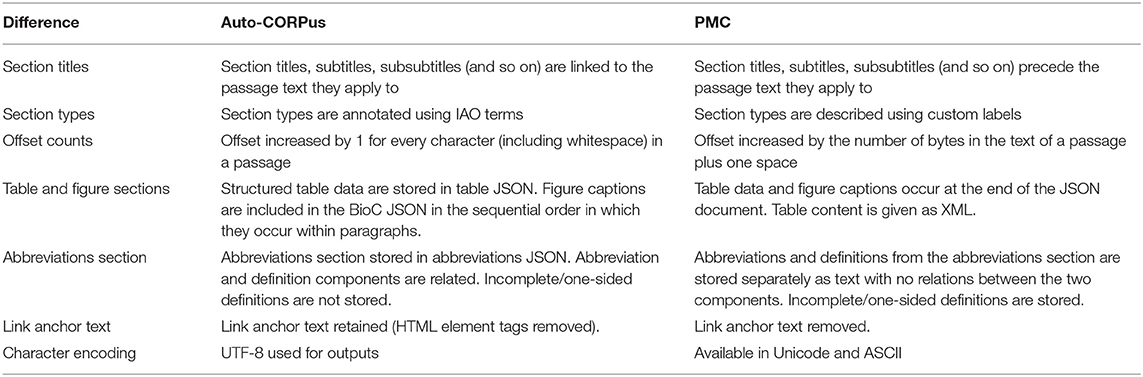
Table 4. Differences between the Auto-CORPus BioC and PMC BioC JSON outputs.
The Auto-CORPus BioC output includes the figure captions where they appear in the text and a separate table JSON file to store the table data, whereas the PMC BioC adds these data at the end of the JSON document and provides table content as a block of XML. Abbreviation sections are not included in the Auto-CORPus BioC output since Auto-CORPus provides a dedicated abbreviations JSON output. In the PMC BioC format the abbreviations and definitions are not related, whereas in the Auto-CORPus abbreviations JSON output the two elements are related. If an abbreviation does not contain a definition in the abbreviations section (perhaps due to an editorial error), PMC BioC will include the undefined thus meaningless abbreviation string, whereas Auto-CORPus will ignore it. Link anchor text to figures, tables, references and URLs are retained in the Auto-CORPus output but removed in the PMC BioC output. The most common differences between the two BioC versions is the encodings/strings used to reflect different whitespace characters and other special characters, with the remaining content being identical.
The proportion of characters from 9,468 full-text paragraphs in the publisher dataset that also appear in the Auto-CORPus PMC BioC dataset in the same order in the paragraph string were evaluated. The median and interquartile range of the (left-skewed) similarity is also 100 and 100–100%, respectively, and differences between the PMC and publisher-versions are the same as those previously observed and reported in Table 4.
Last, we evaluated the section title mapping to IAO terms for publication from non-biomedical domains (physics, psychology). We observed that not all publications from these domains have standardized headers that can be mapped directly or with fuzzy matching and require the digraph to map headers. Most headers are mapped correctly either to one or multiple (potential) IAO terms (Supplementary Table 1). Only one publication contained a mismatch where two sections were mapped to introduction and methods sections, respectively, where each of these contained sub-headers that relate to introduction, methods and results. In two physics publications we encountered the case where the “proportional to” sign (∝) could not be mapped by the encoder.
Performance of Auto-CORPus Table Processing
We assessed the accuracy of the table JSON output generated from non-PMC linked tables compared with table JSON output generated from the equivalent PMC HTML with inline tables. The comparative analysis method described above was used for comparing BioC output from the linked table and inline table datasets, except here it was applied to both strings (bidirectional, taking the maximum value of both outcomes). This is equivalent to the Levenshtein similarity applied to transform the larger string into the smaller string, with the exception that the different characters for both comparisons are retained for identifying the differences. The correspondence between table JSON files in the linked table and inline table datasets was calculated as the number of characters correctly represented in the publishers table JSON output relative to the PMC versions [also using the (symmetric) longest common subsequence method]. Both the text and table similarity are represented as the median (inter-quartile range) to account for non-normal distributions of the data. Any differences identified during these analyses were at the paragraph or table row level, enabling manual investigation of these sections in a side-by-side comparison of the files.
The proportion of characters from 367 tables in the linked table dataset that also appear in the inline table dataset in the same order in the cell or text string were evaluated. The median and interquartile range of the (left-skewed) similarity is 100 and 99.79–100.00%, respectively. We found that there were structural differences between some of the output files where additional data rows were present in the JSON files generated from the publisher's files. This occurred because cell value strings in tables from the publisher's files were split across two rows, however in the PMC version the string was formatted (wrapped) to be contained within a single row. The use of different table structures to contain the same data resulted in accurate but differing table JSON outputs. Most of the differences between table content and metadata values pertain to the character encoding used in the different table versions. For example, we have found different uses of hyphen/em dash/en dash/minus symbols between different versions, and Greek letters were represented differently in the different table versions. Other differences are related to how numbers are represented in scientific notation. If a cell contains a number only, then it is represented as a JSON number data type in the output. However, if the cell contains non-numeric characters, then there is no standardization of the cell text and the notation used (e.g., the × symbol or E notation) will be reproduced in the JSON output. When there is variation in notation between sources, the JSON outputs will differ. Other editorial differences include whether thousands are represented with or without commas and how whitespace characters are used. Despite these variations there was no information loss between processed inline and linked tables.
Application: NER on GWAS Publications
Our intention is that Auto-CORPus supports information extraction from the biomedical literature. To demonstrate the use of Auto-CORPus outputs within a real-world application and aligned to the authors' expertise to support the evaluation of the results, we applied named-entity recognition (NER) to the Auto-CORPus BioC full-text output to extract GWAS metadata. Study metadata are included in curated GWAS databases, such as GWAS Central, and the ability to extract these entities automatically could provide a valuable curation aid. Full details of the method and the rationale behind the application is provided in the Supplementary Methods. In summary, we filtered out sentences in the methods sections from the BioC full-text output that contain information on the genotyping platforms, assays, total number of genetic variants, quality control and imputation that were used. We trained five separate algorithms for NER (one for each metadata type) using 700 GWAS publications and evaluated these on 500 GWAS publications of the test set. The F1-scores for the five tasks are between 0.82 and 1.00 (Supplementary Table 2) with examples given in Supplementary Figure 4.
Discussion
Strengths and Limitations
We have shown that Auto-CORPus brings together and bolsters several disjointed standards (BioC and IAO) and algorithmic components (for processing tables and abbreviations) of scientific literature analytics into a convenient and reliable tool for standardizing full-text and tables. The BioC format is a useful but not ubiquitous standard for representing text and annotations. Auto-CORPus enables the transformation of the widely available HTML format into BioC JSON following the setup of a configuration file associated with the structure of the HTML documents. The use of the configuration file drives the flexibility of the package, but also restricts use to users who are confident exploring HTML document structures. We make available the configuration files used in the evaluations described in this paper. To process additional sources, an upfront time investment is required from the user to explore the HTML structure and set the configuration file. We will be increasing the number of configuration files available for larger publishers, and we help non-technical users by providing documentation to explain how to setup configuration files. We welcome configuration files submitted by users and the documentation describes the process for users to submit files. Configuration files contain a section for tracking contributions made to the file, so the names of authors and editors can be logged. Once a configuration file has been submitted and tested, the file will be included within the Auto-CORPus package and the user credited (should they wish) with authorship of the file.
The inclusion of IAO terms within the Auto-CORPus BioC output standardizes the description of publication sections across all processed sources. The digraph that is used to assign unmapped paragraph headers to standard IAO terms was constructed using both GWAS and MWAS literature to avoid training it to be used for a single domain only. We have tested the algorithms on PMC articles from three different physics and three psychology journals to confirm the BioC JSON output and IAO term recognition extend beyond only biomedical literature. Virtually all header terms from these articles were mapped to relevant IAO terms even when not all headers could be mapped, however some sections were mapped to multiple IAO terms based on paths in the digraph. Since ontologies are stable but not static, any resource or service that relies on one ontology structure could become outdated or redundant as the ontology is updated. We will rerun the fuzzy matching of headers to IAO terms and regenerate the digraph as new terms are introduced to the document part branch of IAO. We have experience of this when our first group of term suggestions based on the digraph were included into the IAO.
The BioC output of abbreviations contains the abbreviation, definition and the algorithm(s) by which each pair was identified. One limitation of the current full-text abbreviation algorithm is that it searches for abbreviations in brackets and therefore will not find abbreviations for which the definition is in brackets, or abbreviations that are defined without use of brackets. The current structure of the abbreviation JSON allows additional methods to be included alongside the two methods currently used. Adding further algorithms to find different types of abbreviation in the full-text is considered as part of future work.
Auto-CORPus implements a method for extracting table structures and data that was developed to extract table information from XML formatted tables (8). The use of the configuration file for identifying table containers enables the table processing to be focused on relevant data tables and exclude other tables associated with web page formatting. Auto-CORPus is distinct from other work in this field that uses machine learning methods to classify the types of information within tables (16). Auto-CORPus table processing is agnostic to the extracted variables, with the only distinction made between numbers and strings for the pragmatic reason of correctly formatting the JSON data type. The table JSON files could be used in downstream analysis (and annotation) of cell information types, but the intention of Auto-CORPus is to provide the capability to generate a faithful standardized output from any HTML source file. We have shown high accuracy (>99%) for the tables we have processed with a configuration file and the machine learning method was shown to recover data from ~86% of tables (16). Accurate extraction is possible across more data sources with the Auto-CORPus rule-based approach, but a greater investment in setup time is required.
Auto-CORPus focuses on HTML versions of articles as these are readily and widely available within the biomedical domain. Currently the processing of PDF documents is not supported, but the work by the Semantic Scholar group to convert PDF documents to HTML is encouraging as they observed that 87% of PDF documents processed showed little to no readability issues (4). The ability to leverage reliable document transformation will have implications for processing supplementary information files and broader scientific literature sources which are sometimes only available in PDF format, and therefore will require conversion to the accessible and reusable HTML format.
Future Research and Conclusions
We found that the tables for some publications are made available as images (see Table 1), so could not be processed by Auto-CORPus. To overcome this gap in publication table standardization, we are refining a plugin for Auto-CORPus that provides an algorithm for processing images of tables. The algorithm leverages Google's Tesseract optical character recognition engine to extract text from preprocessed table images. An overview of the table image processing pipeline is available in Supplementary Figure 3. During our preliminary evaluation of the plugin, it achieved an accuracy of ~88% when processing a collection of 200 JPG and PNG table images taken from 23 different journals. Although encouraging, there are caveats in that the image formats must be of high resolution, the algorithm performs better on tables with gridlines than tables without gridlines, special characters are rarely interpreted correctly, and cell text formatting is lost. We are fine tuning the Tesseract model by training new datasets on biomedical data. An alpha release of the table image processing plugin is available with the Auto-CORPus package.
The authors are involved in omics health data NLP projects that use Auto-CORPus within text mining pipelines to standardize and optimize biomedical literature ahead of entity and relation annotations and have given examples in the Supplementary Material of how the Auto-CORPus output was used to train these algorithms. The BioC format supports the stand-off annotation of linguistic features such as tokens, part-of-speech tags and noun phrases, as well as the annotation of relations between these elements (5). We are developing machine learning methods to automatically extract genome-wide association study (GWAS) data from peer-reviewed literature. High quality annotated datasets are required to develop and train NLP algorithms and validate the outputs. We are developing a GWAS corpus that can be used for this purpose using a semi-automated annotation method. The GWAS Central database is a comprehensive collection of summary-level GWAS findings imported from published research papers or submitted by study authors (13). For GWAS Central studies, we used Auto-CORPus to standardize the full-text publication text and tables. In an automatic annotation step, for each publication, all GWAS Central association data was retrieved. Association data consists of three related entities: a phenotype/disease description, genetic marker, and an association P-value. A named entity recognition algorithm identifies the database entities in the Auto-CORPus BioC and table JSON files. The database entities and relations are mapped back onto the text, by expressing the annotations in BioC format and appending these to the relevant BioC element in the JSON files. The automatic annotations are then manually evaluated using the TeamTat text annotation tool which provides a user-friendly interface for annotating entities and relations (17). We use TeamTat to manually inspect the automatic annotations and modify or remove incorrect annotations, in addition to including new annotations that were not automatically generated. TeamTat accepts BioC input files and outputs in BioC format, thus the Auto-CORPus files that have been automatically annotated are suitable for importing into TeamTat. Work to create the GWAS corpus is ongoing, but the convenient semi-automatic process for creating high-quality annotations from biomedical literature HTML files described here could be adapted for creating other gold-standard corpora.
In related work, we are developing a corpus for MWAS for metabolite named-entity recognition to enable the development of new NLP tools to speed up literature review. As part of this, the active development focuses on extending Auto-CORPus to analyse preprint literature and Supplementary Materials, improving the abbreviation detection, and development of more configuration files. Our preliminary work on preprint literature has shown we can map paragraphs in Rxiv versions to paragraphs in the peer-reviewed manuscript with the high accuracy (average similarity of paragraphs >95%). Another planned extension is to classify paragraphs based on the text in the case where headers are mapped to multiple IAO terms. The flexibility of the Auto-CORPus configuration file enables researchers to use Auto-CORPus to process publications and data from a broad variety of sources to create reusable corpora for many use cases in biomedical literature and other scientific fields.
Data Availability Statement
Publicly available datasets were analyzed in this study. The Auto-CORPus package is freely available from GitHub (https://github.com/omicsNLP/Auto-CORPus) and can be deployed on local machines as well as using high-performance computing to process publications in batch. A step-by-step guide to detail how to use Auto-CORPus is supplied with the package. Data from both Open Access (via PubMed Central) and publisher repositories are used, the latter were downloaded within university library licenses and cannot be shared.
Author Contributions
TB and JP designed and supervised the research and wrote the manuscript. TB contributed the GWAS use case and JP contributed the MWAS/metabolomics use cases. TS developed the BioC outputs and led the coding integration aspects. YH developed the section header standardization algorithm and implemented the abbreviation recognition algorithm. ZL developed the table image recognition and processing algorithm. SS developed the table extraction algorithm and main configuration file. CP developed configuration files for preprint texts. NM developed the NER algorithms for GWAS entity recognition. NM, FM, CY, ZL, and CP tested the package and performed comparative analysis of outputs. TR refined standardization of full-texts and contributed algorithms for character set conversions. All authors read, edited, and approved the manuscript.
Funding
This work has been supported by Health Data Research (HDR) UK and the Medical Research Council via an UKRI Innovation Fellowship to TB (MR/S003703/1) and a Rutherford Fund Fellowship to JP (MR/S004033/1).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
We thank Mohamed Ibrahim (University of Leicester) for identifying different configurations of tables for different HTML formats.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fdgth.2022.788124/full#supplementary-material
References
1. Sheikhalishahi S, Miotto R, Dudley JT, Lavelli A, Rinaldi F, Osmani V. Natural language processing of clinical notes on chronic diseases: systematic review. JMIR Med Inform. (2019) 7:e12239. doi: 10.2196/12239
2. Jackson RG, Patel R, Jayatilleke N, Kolliakou A, Ball M, Gorrell G, et al. Natural language processing to extract symptoms of severe mental illness from clinical text: the Clinical Record Interactive Search Comprehensive Data Extraction (CRIS-CODE) project. BMJ Open. (2017) 7:e012012. doi: 10.1136/bmjopen-2016-012012
3. Erhardt RA, Schneider R, Blaschke C. Status of text-mining techniques applied to biomedical text. Drug Discov Today. (2006) 11:315–25. doi: 10.1016/j.drudis.2006.02.011
4. Wang LL, Cachola I, Bragg J, Yu-Yen Cheng E, Haupt C, Latzke M, et al. Improving the accessibility of scientific documents: current state, user needs, and a system solution to enhance scientific PDF accessibility for blind and low vision users. arXiv e-prints: arXiv:2105.00076 (2021). Available online at: https://arxiv.org/pdf/2105.00076.pdf
5. Comeau DC, Islamaj Dogan R, Ciccarese P, Cohen KB, Krallinger M, Leitner F, et al. BioC: a minimalist approach to interoperability for biomedical text processing. Database. (2013) 2013:bat064. doi: 10.1093/database/bat064
6. Comeau DC, Wei CH, Islamaj Dogan R, Lu Z. PMC text mining subset in BioC: about three million full-text articles and growing. Bioinformatics. (2019) 35:3533–5. doi: 10.1093/bioinformatics/btz070
7. Ceusters W. An information artifact ontology perspective on data collections and associated representational artifacts. Stud Health Technol Inform. (2012) 180:68–72. doi: 10.3233/978-1-61499-101-4-68
8. Milosevic N, Gregson C, Hernandez R, Nenadic G. Disentangling the structure of tables in scientific literature. In: Métais E, Meziane F, Saraee M, Sugumaran V, Vadera S, editors. Natural Language Processing and Information Systems. Cham: Springer International Publishing (2016). p. 162–74. doi: 10.1007/978-3-319-41754-7_14
9. Craven M, Kumlien J. Constructing biological knowledge bases by extracting information from text sources. In: International Conference on Intelligent Systems for Molecular Biology. Heidelberg (1999) p. 77–86.
10. Blaschke C, Andrade MA, Ouzounis C, Valencia A. Automatic extraction of biological information from scientific text: protein-protein interactions. In: International Conference on Intelligent Systems for Molecular Biology. Heidelberg (1999) p. 60–7.
11. Andrade MA, Valencia A. Automatic annotation for biological sequences by extraction of keywords from MEDLINE abstracts. Development of a prototype system. Proc Int Conf Intell Syst Mol Biol. (1997) 5:25–32.
12. Schwartz AS, Hearst MA. A simple algorithm for identifying abbreviation definitions in biomedical text. Pac Symp Biocomput. (2003) 8:451–62. Available online at: https://psb.stanford.edu/psb-online/proceedings/psb03/schwartz.pdf
13. Beck T, Shorter T, Brookes AJ. GWAS Central: a comprehensive resource for the discovery and comparison of genotype and phenotype data from genome-wide association studies. Nucleic Acids Res. (2020) 48:D933–40. doi: 10.1093/nar/gkz895
14. Ghazvinian A, Noy NF, Musen MA. Creating mappings for ontologies in biomedicine: simple methods work. AMIA Annu Symp Proc. (2009) 2009:198–202.
15. Keller MF, Reiner AP, Okada Y, van Rooij FJ, Johnson AD, Chen MH, et al. Trans-ethnic meta-analysis of white blood cell phenotypes. Hum Mol Genet. (2014) 23:6944–60. doi: 10.1093/hmg/ddu401
16. Milosevic N, Gregson C, Hernandez R, Nenadic G. A framework for information extraction from tables in biomedical literature. Int J Docum Anal Recogn. (2019) 22:55–78. doi: 10.1007/s10032-019-00317-0
Keywords: natural language processing, text mining, biomedical literature, semantics, health data
Citation: Beck T, Shorter T, Hu Y, Li Z, Sun S, Popovici CM, McQuibban NAR, Makraduli F, Yeung CS, Rowlands T and Posma JM (2022) Auto-CORPus: A Natural Language Processing Tool for Standardizing and Reusing Biomedical Literature. Front. Digit. Health 4:788124. doi: 10.3389/fdgth.2022.788124
Received: 01 October 2021; Accepted: 21 January 2022;
Published: 15 February 2022.
Edited by:
Patrick Ruch, Geneva School of Business Administration, SwitzerlandReviewed by:
Denis Newman-Griffis, University of Pittsburgh, United StatesCeyda Kasavi, Marmara University, Turkey
Copyright © 2022 Beck, Shorter, Hu, Li, Sun, Popovici, McQuibban, Makraduli, Yeung, Rowlands and Posma. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Tim Beck, dGIxNDNAbGVpY2VzdGVyLmFjLnVr; Joram M. Posma, am1wMTExQGljLmFjLnVr
†These authors have contributed equally to this work