 Jana Obšteter
Jana Obšteter Janez Jenko
Janez Jenko Gregor Gorjanc
Gregor Gorjanc- 1Department of Animal Science, Agricultural Institute of Slovenia, Ljubljana, Slovenia
- 2Geno Breeding and A. I. Association, Hamar, Norway
- 3The Roslin Institute and Royal (Dick) School of Veterinary Studies, University of Edinburgh, Edinburgh, United Kingdom
- 4Biotechnical Faculty, University of Ljubljana, Ljubljana, Slovenia
This paper evaluates the potential of maximizing genetic gain in dairy cattle breeding by optimizing investment into phenotyping and genotyping. Conventional breeding focuses on phenotyping selection candidates or their close relatives to maximize selection accuracy for breeders and quality assurance for producers. Genomic selection decoupled phenotyping and selection and through this increased genetic gain per year compared to the conventional selection. Although genomic selection is established in well-resourced breeding programs, small populations and developing countries still struggle with the implementation. The main issues include the lack of training animals and lack of financial resources. To address this, we simulated a case-study of a small dairy population with a number of scenarios with equal available resources yet varied use of resources for phenotyping and genotyping. The conventional progeny testing scenario collected 11 phenotypic records per lactation. In genomic selection scenarios, we reduced phenotyping to between 10 and 1 phenotypic records per lactation and invested the saved resources into genotyping. We tested these scenarios at different relative prices of phenotyping to genotyping and with or without an initial training population for genomic selection. Reallocating a part of phenotyping resources for repeated milk records to genotyping increased genetic gain compared to the conventional selection scenario regardless of the amount and relative cost of phenotyping, and the availability of an initial training population. Genetic gain increased by increasing genotyping, despite reduced phenotyping. High-genotyping scenarios even saved resources. Genomic selection scenarios expectedly increased accuracy for young non-phenotyped candidate males and females, but also proven females. This study shows that breeding programs should optimize investment into phenotyping and genotyping to maximize return on investment. Our results suggest that any dairy breeding program using conventional progeny testing with repeated milk records can implement genomic selection without increasing the level of investment.
Introduction
This paper evaluates the potential of maximizing genetic gain in dairy cattle breeding by optimizing investment into phenotyping and genotyping. Breeding programs strive to maximize genetic gain, which is a function of selection intensity, accuracy of selection, genetic variation, and generation interval. The conventional dairy breeding program uses an expensive and time-consuming progeny test. Genomic selection (Meuwissen et al., 2001; Schaeffer, 2006) achieves the same genetic progress faster and cheaper through a substantially reduced generation interval, increased accuracy of selection for young animals, and increased selection intensity of males (Schaeffer, 2006; Obšteter et al., 2019). Despite lower accuracy of sire selection compared to the conventional selection, genomic selection doubles the rate of genetic gain per year in dairy cattle (Wiggans et al., 2017).
All breeding programs operate with a limited resources allocated to breeding activities with the aim to maximize return on investment. Genomic selection is now a de-facto standard in leading breeding programs but is still challenging to implement in small national breeding programs or in developing countries. While leading breeding programs can service some small national breeding, developing countries require tailored breeding goals that will respond to the rapidly rising demand for a sustainable dairy production in local environment (Ducrocq et al., 2018; Marshall et al., 2019; Mrode et al., 2019). We hypothesize that these breeding programs need to evaluate priorities and could optimize the allocation of resources for phenotyping and genotyping to maximize return on investment. We base this hypothesis on the following simple examples (Supplementary Table S1).
The accuracy of conventional (pedigree-based) estimates of breeding values increases with increasing heritability and increasing number of phenotypic records per animal or its closest relatives (e.g., Mrode, 2005). For example, for a female-expressed trait with 0.25 heritability, the accuracy as a function of the number of repeated records per lactation (n) is 0.89 (n = 10), 0.81 (n = 5), 0.70 (n = 2), and 0.62 (n = 1). The corresponding accuracies for 100 sires tested on the total of 10,000 daughters are, respectively, 0.98 (n = 10), 0.97 (n = 5), 0.96 (n = 2), and 0.93 (n = 1).
The accuracy of genome-based estimates of breeding values similarly increases with increasing heritability and increasing number of phenotypic records per genotyped animal. It also increases with increasing training population, decreasing genetic distance between training and prediction individuals, and decreasing number of effective genome segments (Daetwyler et al., 2008; Goddard, 2009; Clark et al., 2011; Goddard et al., 2011). Following the previous example, assume 10,000 effective genome segments, 0.25 heritability, and a training population of 10,000 cows. The accuracy of genomic prediction for non-phenotyped animals as a function of the number of repeated records per lactation in the training population (n) is 0.76 (n = 10), 0.71 (n = 5), 0.63 (n = 2), or 0.56 (n = 1). These examples show diminishing returns with repeated phenotyping and a scope for optimizing return on investment in genomic breeding programs.
The accuracy of genomic prediction as a function of the number of genotyped and phenotyped cows (N) and the number of repeated records per lactation (n) is then 0.84 (N = 20,000, n = 5), 0.90 (N = 50,000, n = 2), or 0.93 (N = 100,000, n = 1). While these genomic prediction accuracies are lower than those generated with progeny testing, shorter generation interval enables larger genetic gain per unit of time (Schaeffer, 2006).
Previous studies also explored the value of adding females to the training population (Van Grevenhof et al., 2012; Gonzalez-Recio et al., 2014). They concluded that accuracy has diminishing returns with increasing the number of genotyped and phenotyped animals in the training population, hence additional females are most valuable when training population is small. However, real breeding programs involve overlapping generations, individuals with a mix of phenotype, pedigree, and genotype information, various selection intensities, and other dynamic components. Thus, evaluating the optimal allocation of resources into phenotyping and genotyping is beyond these simple examples.
The above examples suggest that repeated phenotyping could serve as an internal financial reserve to enable dairy breeding programs to implement genomic selection and maximize return on investment. In dairy breeding the most repeatedly and extensively recorded phenotypes are milk production traits. There are different milk recording methods that differ in the recording frequency (International Committee for Animal Recording, 2017). The recording interval ranges from daily recording to recording every 9 weeks, which translates to between 310 and 5 records per lactation. The different recording methods have different costs, which vary considerably between recording systems, countries, and even their regions. For example, some organizations require payment of a participation fee plus the cost per sample, while others include the fee in the sample cost, or cover the costs in other ways. There is also a huge variability in the way dairy breeding programs are funded. Some are funded by farmers and breeding companies while in some countries data recording or breeding are subsidized by state or charities. There are also situations where farmers do not record phenotypes and all genetic progress is generated in “research” nucleus herds.
The aim of this study was to evaluate the potential of maximizing genetic gain by optimizing investment into phenotyping and genotyping in dairy breeding programs. Although studies exist that aimed to optimize the allocation of resources to genotyping and phenotyping in plant breeding programs (Lorenz, 2013; Riedelsheimer and Melchinger, 2013; Lin et al., 2017), no such studies exist for animal or dairy breeding programs. In animal breeding, studies did explore economic efficiency of genomic selection, but with respect to other goals: to maximize imputation accuracy (Huang et al., 2012); to optimize selection accuracy with respect to economic efficiency (Azizian et al., 2016); to maximize discounted profit or monetary genetic gain (König et al., 2009; Thomasen et al., 2014a); or to evaluate the cost-efficiency of genotyping females (Thomasen et al., 2014b). Since milk production traits are example of repeated phenotypes with diminishing returns, we aimed to optimize investment into milk recording and genotyping. To this end we have compared a dairy breeding program with conventional progeny testing and several genomic breeding programs under equal financial resources. To implement genomic selection, we reduced the number of milk records per lactation and invested the saved resources into genotyping. We compared the breeding programs in a case-study of a small cattle population where implementing genomic selection is challenging. The results show that reallocating a part of phenotyping resources to genotyping increases genetic gain regardless of the cost and amount of genotyping, and the availability of an initial training population.
Materials and Methods
The study aimed to evaluate the effect of different investment into phenotyping and genotyping with a simulation of a case-study of a small dairy breeding program. The simulation mimicked a real dairy cattle population of ∼22,500 animals analyzed in Obšteter et al. (2019). Here we evaluated 36 genomic selection against the conventional selection scenario, all with equal available resources, but varying extent of phenotyping and genotyping. The conventional selection scenario implemented progeny testing and collected 11 phenotypic records per lactation, while genomic selection scenarios reduced phenotyping and invested the saved resources into genotyping. The genomic selection scenarios differed in (i) the number of phenotypic records per lactation; (ii) the relative cost of phenotyping and genotyping;, and (iii) the availability of an initial training population. All scenarios were compared on genetic gain and accuracy of selection.
Simulation of the Base Population, Phenotype, and Historical Breeding
The simulation mimicked a small dairy cattle breeding program of∼22,500 animals with ∼10,500 cows. The introduction of effective genomic selection in such populations is challenging due to costs of assembling a training population and limited number of training animals. We used this population as a case-study to optimize investment into phenotyping and genotyping. The dairy breeding program aimed at improving production traits, which we simulated as a single polygenic trait. We used a coalescent process to simulate genome comprised of 10 cattle-like chromosomes, each with 108 base pairs, 1,000 randomly chosen causal loci, and 2,000 randomly chosen marker loci. We sampled the effects of causal loci from a normal distribution and use them to calculate animal’s breeding value (ai) for dairy performance (yijkl), which was affected also by a permanent environment (pi), herd (hj), herd-year (hyjk), herd-test-day (htdjkl), and residual environmental (eijkl) effects:
We sampled permanent environment effects from a normal distribution with zero mean and variance equal to the base population additive genetic variance (σ2a). We sampled herd, herd-year, and herd-test-day effects each from a normal distribution with zero mean and variance of 1/3 σ2a. Finally, we sampled residual environment effects from a normal distribution with zero mean and variance of σ2a. This sampling scheme gave a trait with 0.25 heritability and 0.50 repeatability. With the simulated genome and phenotype architecture we have initiated a dairy cattle breeding program and ran it for 20 years of conventional selection with progeny-testing based on 11 cow phenotypic records per lactation. The detailed parameters of the simulation are described in Obšteter et al. (2019). In summary, in the breeding program we selected 3,849 out of 4,320 new-born females. We selected 139 bull dams out of cows in the second, third, and fourth lactation. We generated 45 male calves from matings of bull dams and progeny tested sires (elite matings). Out of these we chose 8 for progeny testing of which 4 were eventually selected as sires for widespread insemination of cows. We made all selection decisions based on pedigree-based estimates of breeding values. The 20 years represented historical breeding and provided a starting point for evaluating future breeding scenarios, which we ran for additional 20 years.
Scenarios
We evaluated 36 genomic selection scenarios with varying extent of phenotyping and genotyping against the conventional selection scenario, all with equal available resources. The conventional selection scenario continued the breeding scheme from the historical breeding. It used progeny testing and 11 phenotypic records per lactation (named C11), corresponding to the standard ICAR recording interval of 4 weeks (International Committee for Animal Recording, 2017). We assumed that this scenario represented the total resources for generating data. We then created genomic selection scenarios by distributing resources between phenotyping and genotyping–we reduced phenotyping and invested the saved resources into genotyping. In genomic selection scenarios we selected females as in the conventional selection scenario and males on genomic estimates of breeding values. The number of genomically tested candidate males varied according to the genotyping resources in a specific scenario. We selected 5 males with the highest genomic estimates of breeding value as sires for widespread insemination of cows. We evaluated the genomic selection scenarios with a varying number of phenotypic records per lactation, relative cost of phenotyping to genotyping, and the availability of an initial training population.
In genomic selection scenarios we reduced the number of phenotypic records per lactation to between 10 and 1. Three of them followed ICAR standards of 9, 8, and 5 records per lactation, corresponding to recording intervals of 5, 6, and 9 weeks. Additionally, we tested the non-standard 10, 2, and 1 records per lactation. We named the scenarios as “GX” with X being the number of records per lactation. Genomic selection scenarios next varied the relative cost of phenotyping ($P) to genotyping ($G). The cost of phenotyping was the cost of 11 phenotypic records per lactation. The cost of genotyping was the cost of genotyping one animal. We applied quantity discount to the cost of phenotyping–by increasing the number of records per lactation, the cost per record decreased by 6%. For example, if the price per record was €1 when collecting only one record per lactation, the cost per record dropped to €0.94 when collecting two records per lactation. Conservatively we kept the cost of genotyping constant. Based on a survey of several breeding programs, milk recording organizations, and genotyping providers we have considered three ratios of the cost of phenotyping vs. the cost of genotyping, $P:$G (CRV Netherlands, 2020; CRV New Zealand, 2020; ICBF, 2020; LIC, 2020; Progressive Genetics, 2020; personal communication). The 2:1 ratio represented costly phenotyping, 1:1 equal cost of phenotyping and genotyping, and 1:2 represented costly genotyping. The reduction in the number of phenotypic records per lactation and $P:$G dictated the resources available for genotyping and hence the number of genotyped animals (Table 1). For example, assuming that the cost per milk record is €1.78 when we collect 11 phenotypic records per lactation, the total cost per lactation sums to €19.55 (€1.78 ∗ 11). This represents $P. When we collect 10 phenotypic records per lactation, the cost per record increases to €1.89, which sums to the total cost of €18.91 per lactation. This second scenario saves €0.64 (€19.55–€18.91) per lactation that can be go toward genotyping. Applying this to our simulated populations with 10,852 active cows, we therefore save €6,945 which suffices for genotyping 356 animals every year when $P:$G = 1:1.
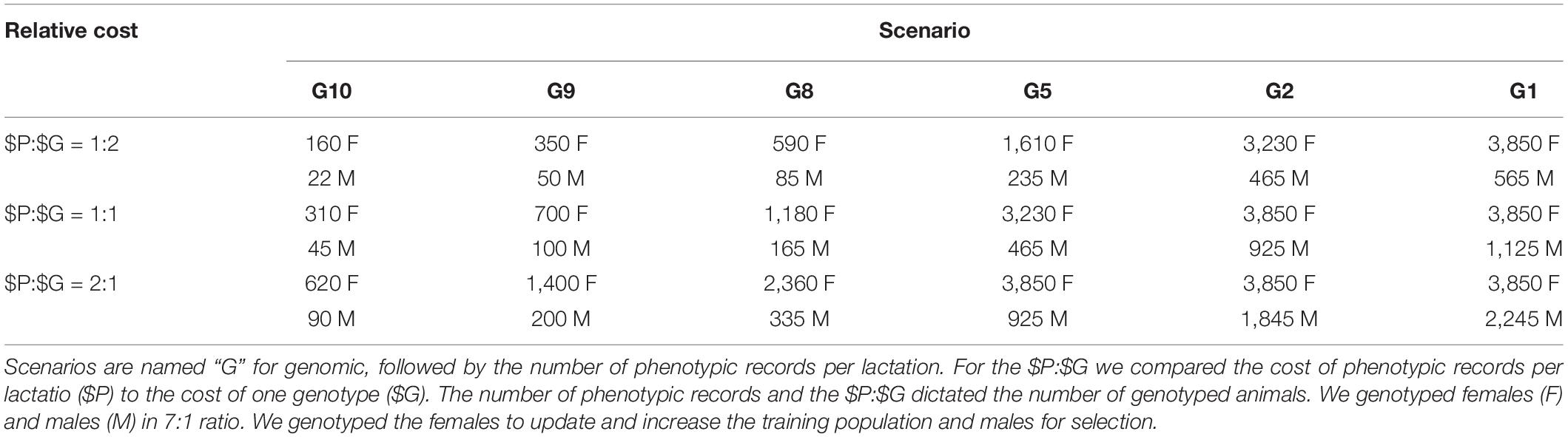
Table 1. Number of genotyped animals per year by scenario and relative cost of phenotyping to genotyping ($P:$G).
We invested the saved resources into genotyping females and males in ratio 7:1 based on our previous work (Obšteter et al., 2019). To update the training population, we genotyped a designated number (Table 1) of randomly chosen first-parity cows. This maximized the accuracy of genomic prediction, since it reduced genetic distance between training and prediction population, prevented the loss of investment with culled heifers, and minimized the time to obtain a phenotype linked to a genotype. To maximize the genetic gain, we genotyped a designated number (Table 1) of male calves with the highest parent average, including all male calves from elite matings. In scenarios where the resources for genotyping females were larger than the cost of genotyping all first-parity cows, we did not reallocate the excess of resources to genotyping males for consistency (we saved resources in those cases).
Lastly, we created scenarios with and without an initial training population for genomic prediction. When we assumed an initial training population was available, we genotyped all active cows (10,852) and elite sires (80) before the first genomic selection of males. When an initial training population was not available, we yearly genotyped a designated number of first-parity cows until the training population reached 2,000 cows. Once we reached this goal, we started to genotype both females and males as specified in Table 1. At that point we started genomic selection of males.
Estimation of Breeding Values
We selected animals based on their breeding values estimated from a pedigree or single-step genomic repeatability model with breeding value, permanent environment, and herd-year as random effects. We did not fit the herd-test-day effect as data structure of this small population did not enable its accurate estimation. Since we simulated dairy performance, we included only the phenotypic information of the female animals. We estimated breeding values once a year with blupf90 (Misztal et al., 2018) with default settings. We updated the training population every year with newly genotyped first-parity cows and candidate males. We kept the first parity cows in the training population through their subsequent lactations, hence the training population also included multiparious cow. We also kept the candidate males so the training population included all elite sires. In the estimation we included all available phenotypic and pedigree records for all active, phenotyped, or genotyped animals, and additional three generations of ancestral pedigree data. Three additional generations is the default option in blupf90 and have been shown to improve convergence without harming prediction accuracy (Pocrnic et al., 2017). We used at most 25,000 genotype records due to a limit in the academic software version. When we accumulated more than 25,000 genotyped animals, we removed genotypes of the oldest animals in favor of the latest genotyped cows and male selection candidates. We did not remove any phenotypic information.
Analysis of Scenarios
All scenarios had equal available resources. We compared the scenarios based on their final genetic gain, which indicated return on the investment, accuracy of selection, and selection intensity. We measured the genetic gain as an average true breeding value by year of birth and standardized it to have zero mean and unit standard genetic deviation in the first year of comparison. We measured the accuracy of breeding values as the correlation between true and estimated breeding values. We measured the accuracy separately for four groups of animals: (i) candidate males (genotyped and non-phenotyped); (ii) proven males (currently used in artificial insemination); (iii) candidate females (non-genotyped and non-phenotyped);, and (iv) proven females (all active phenotyped cows and bull dams). We also computed the intensities of male selection. In conventional and genomic selection sires are selected in two stages. The first stage selects males for progeny or genomic testing. The second stage selects elite sires. We computed the intensities of two-stage selection (i) by integrating standard bivariate distribution as , where x is the parent average, y is the genomic breeding value, and ρ is the correlation between the variables (Young, 1964; Jopson et al., 2004). We computed the correlation ρ by dividing the scenario-specific accuracy of parent average by the accuracy of genomic prediction. Tx is the standardized cut-off for the proportion of all new-born male calves selected for genomic testing (p1) based on parent average in the first selection stage. Ty is the standardized cut-off for the proportion of all newborn males selected as sires (p2) based on genomic breeding values in the second selection stage. We repeated simulation of the base population and each scenario 10 times and summarized them with mean and standard deviation across the replicates. We used Tukey’s multiple comparison test to test the significance of the difference between means.
Results
Genomic selection scenarios increased the genetic gain compared to the conventional selection scenario regardless of the number of phenotypic records per lactation, relative cost of phenotyping to genotyping, and the availability of an initial training population. Genomic selection scenarios with an initial training population achieved up to 143% higher genetic gain than the conventional selection scenario, despite reduced phenotyping. Genetic gain increased with increasing investment into genotyping. Genomic selection scenarios increased accuracy for non-phenotyped candidate males and females, and proven females. Scenarios without an initial training population showed the same trends for genetic gain and accuracy. Although these scenarios had a slightly smaller genetic gain due to delayed implementation of genomic selection, they still increased the genetic gain of the conventional selection scenario by up to 134%. We present these results in more details in the following sub-sections separately for settings with and without an initial training population available.
Genetic Gain With an Initial Training Population
Genomic selection scenarios with an initial training population increased the genetic gain of the conventional selection scenario using the same resources. The genetic gain increased with increasing investment in genotyping, despite reduced phenotyping (Figure 1 and Supplementary Table S2). We show the corresponding intensities of sire selection in Supplementary Table S3. In the $P:$G = 1:1 setting, the genomic selection scenarios increased the genetic gain of the conventional selection scenario between 79 and 143%. By reducing the number of phenotypic records from 11 (C11) to 10 per lactation (G10), we saved resources for genotyping 355 animals per year (45 candidate males). This small change increased male selection intensity from 0.10 to 0.26 and coupled with a shorter generation interval increased the genetic gain by 79% (from 3.01 to 5.41). By reducing the number of phenotypic records to nine or eight per lactation (G9 or G8), we, respectively saved resources to genotype 800 or 1,345 animals per year (100 or 165 candidate males). This, respectively increased male selection intensity to 0.39 or 0.49, and genetic gain by 109 or 120% (from 3.01 to 6.30 or 6.62). We achieved the highest genetic gain, between 135 and 143% of the conventional selection scenario (between 7.07 and 7.33), when we collected between five and one phenotypic records per lactation (G5, G2, and G1). In these three scenarios we saved resources for genotyping between 3,230 and 3,850 (all) cows and between 465 and 1,125 candidate males per year, and achieved male selection intensity between 0.77 and 0.92.
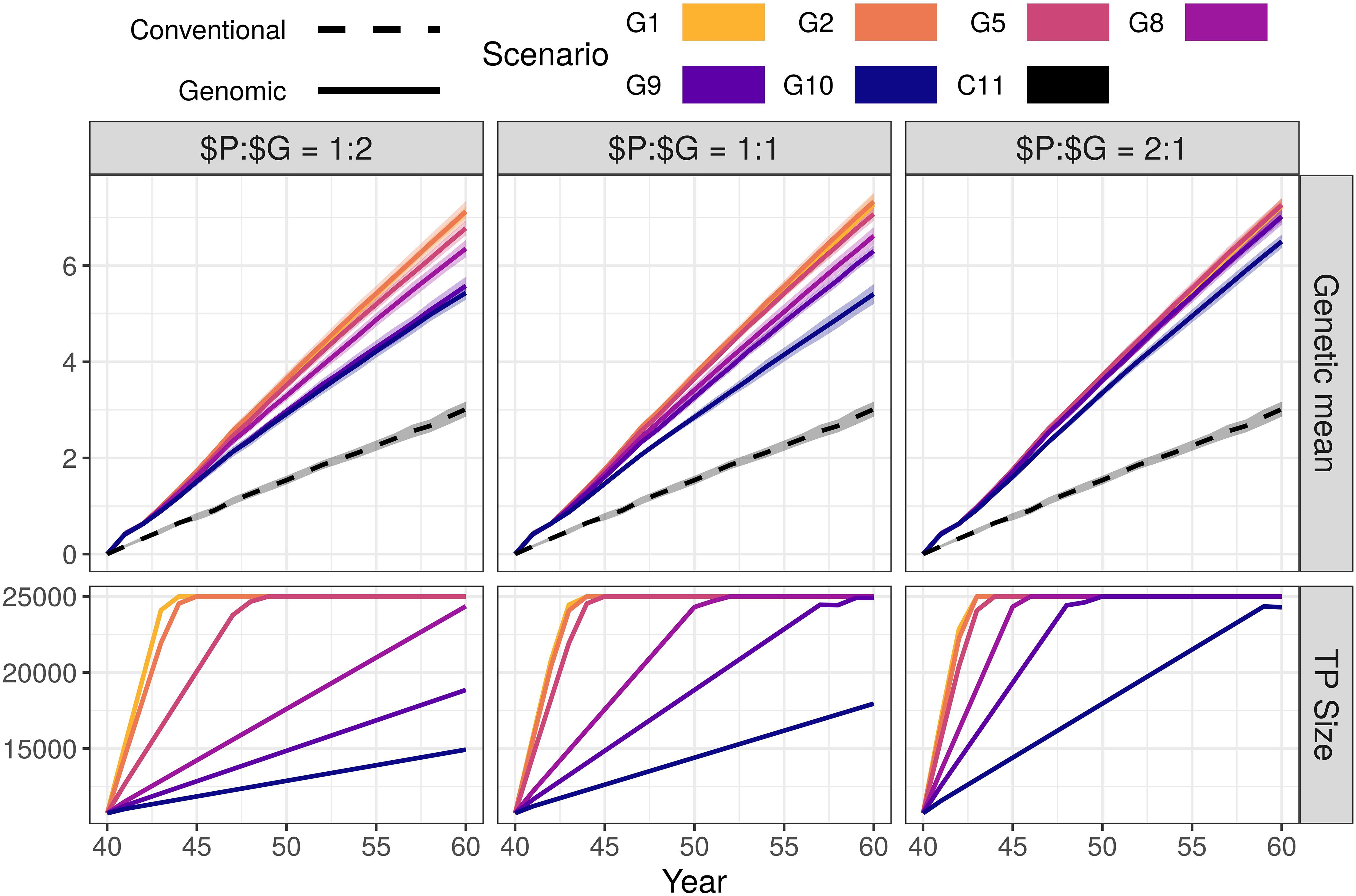
Figure 1. Genetic gain and training population size by scenario and relative cost of phenotyping to genotyping ($P:$G) with an initial training population (TP). The figure presents the means (lines) and 95% confidence intervals (polygons) across 10 replicates for the conventional (C) and genomic (G) selection scenarios, with numbers indicating the number of phenotypic records per lactation. For the $P:$G we compared the cost of 11 phenotypic records per lactation to the cost of one genotype.
Changing the relative cost of phenotyping to genotyping did not change the trend in genetic gain. In the G10 scenario of the $P:$G = 1:2 setting we yearly genotyped 182 animals (22 candidate males) and increased the genetic gain by 80% (from 3.01 to 5.43). In the G10 scenario of the $P:$G = 2:1 setting we yearly genotyped 710 animals (90 males candidates) and increased the genetic gain by 116% (from 3.01 to 6.50). When we maximized the investment into genotyping (G1), we genotyped between 565 and 2,245 candidate males and all females. This achieved a comparable genetic gain, between 136 and 143% of the conventional selection scenario, regardless of the relative cost of phenotyping to genotyping and male selection intensities.
The high-genotyping scenarios achieved the observed genetic gain without using all the resources (marked bold in Supplementary Table S2). In these scenarios the resources designated to genotyping females exceeded the cost of genotyping all females. These savings could cover 11 phenotypic records per lactation for between additional 169 and 5,950 animals, or between 85 and 11,900 additional genotypes.
In Figure 1 we also show the growth of the training population for genomic prediction. The training population started with ∼10,000 individuals and grew until reaching 25,000 individuals. The increase was not linear through all generations, since the procedure for choosing the training animals changed when the training population exceed 25,000 (only latest females and candidate males included).
Accuracy With an Initial Training Population
Compared to the conventional selection scenario, genomic selection scenarios increased accuracy for young non-phenotyped and genotyped candidate males, non-phenotyped, and non-genotyped candidate females, and proven females, but decreased accuracy for proven males (Figure 2 and Supplementary Table S4). In the $P:$G = 1:1 setting, the accuracy for young genomically tested candidate males ranged between 0.90 and 0.91 regardless of the amount of phenotyping and genotyping. This accuracy was between 0.53 and 0.54 higher compared to the pre-selection for progeny testing and between 0.03 and 0.04 lower compared to the sire selection in the conventional selection scenario. In contrast, the accuracy for proven males decreased with decreasing investment into phenotyping and was between 0.11 and 0.23 lower than in conventional selection scenario. We observed the lowest accuracy for proven males (0.63) when we invested the most into genotyping (G1) and the highest (0.75) when we invested the most into phenotyping (G10).
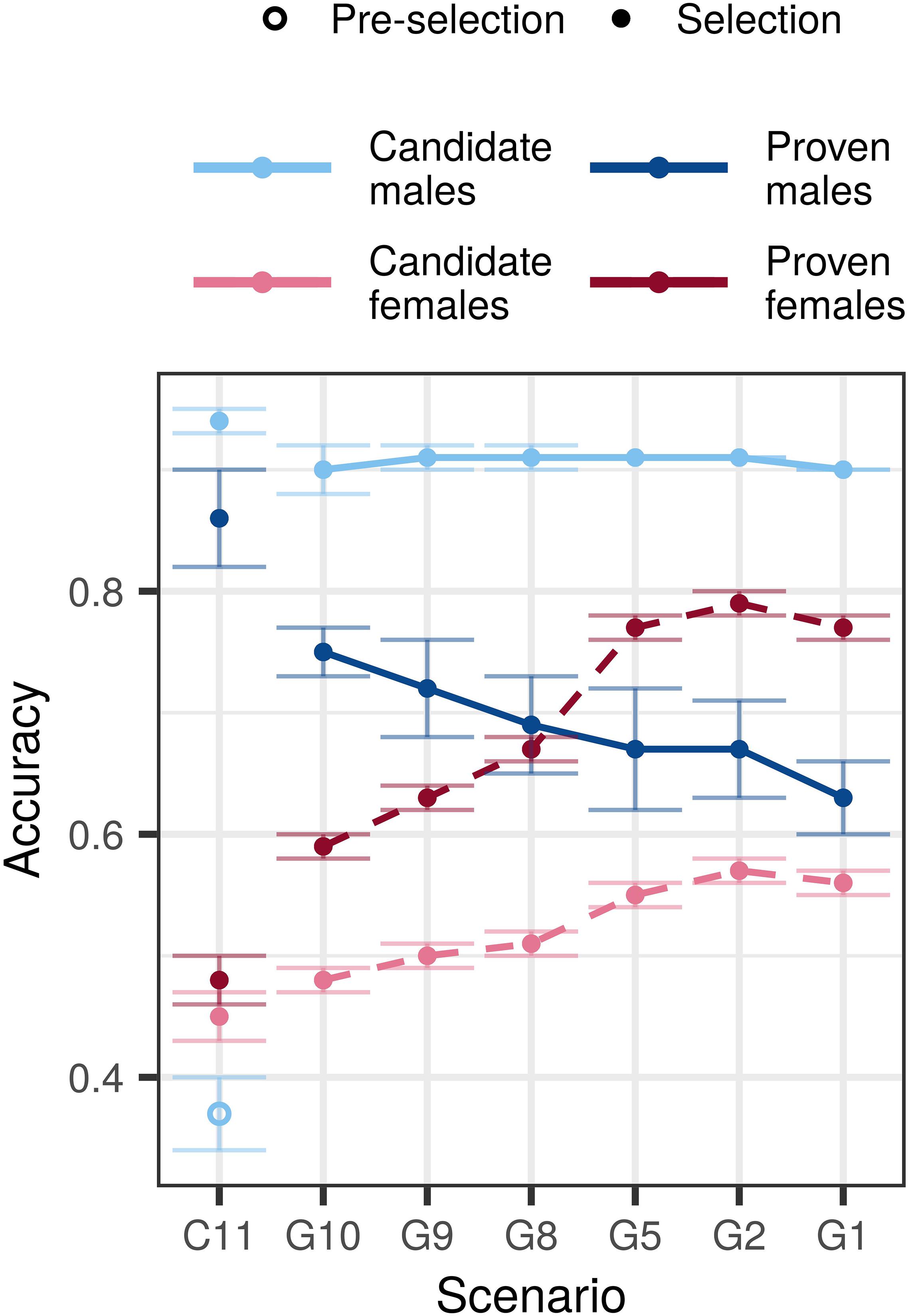
Figure 2. Accuracy by scenario with an initial training population and equal cost of phenotyping and genotyping. The figure presents the means (lines) and 95% confidence intervals (error bars) across 10 replicates for the conventional (C) and genomic (G) selection scenarios with numbers indicating the number of phenotypic records per lactation. The cost of phenotyping was defined as the cost of 11 phenotypic records per lactation, and the cost of genotyping as the cost of one genotype. Conventional selection implemented two-stage selection for males, hence we present the accuracy of pre-selection for progeny testing (empty point) and the accuracy of sire selection (solid point).
The accuracy for non-genotyped candidate and proven females increased with increasing genotyping, despite reduced phenotyping. We observed the highest accuracy for candidate (0.55–0.57) and proven females (0.77–0.79) when we recorded between five and one phenotypic record per lactation and invested the rest into genotyping. Compared to the conventional selection scenario, the genomic selection scenarios increased the accuracy between 0.03 and 0.11 for candidate females, and between 0.11 and 0.29 for proven females.
Changing the relative cost of phenotyping to genotyping affected primarily the accuracy for candidate and proven females. For the majority of scenarios we observed the highest accuracy in the $P:$G = 2:1 setting, that enabled more genotyping. We observed the largest difference of 0.06 for candidate and 0.12 for proven females when we changed the relative cost of phenotyping from half to twice the cost of genotyping. Changing the relative costs, however, did not change the accuracy trends.
Scenarios Without an Initial Training Population
Genetic Gain
Genomic selection scenarios without an initial training population also achieved higher genetic gain than the conventional selection scenario with equal available resources. The trends were in line with what we observed with an initial training population, that is, increasing genotyping increased genetic gain despite reduced phenotyping (Figure 3). However, all corresponding scenarios achieved between 2 and 28% smaller genetic gain than when an initial training population was available (Supplementary Table S2).
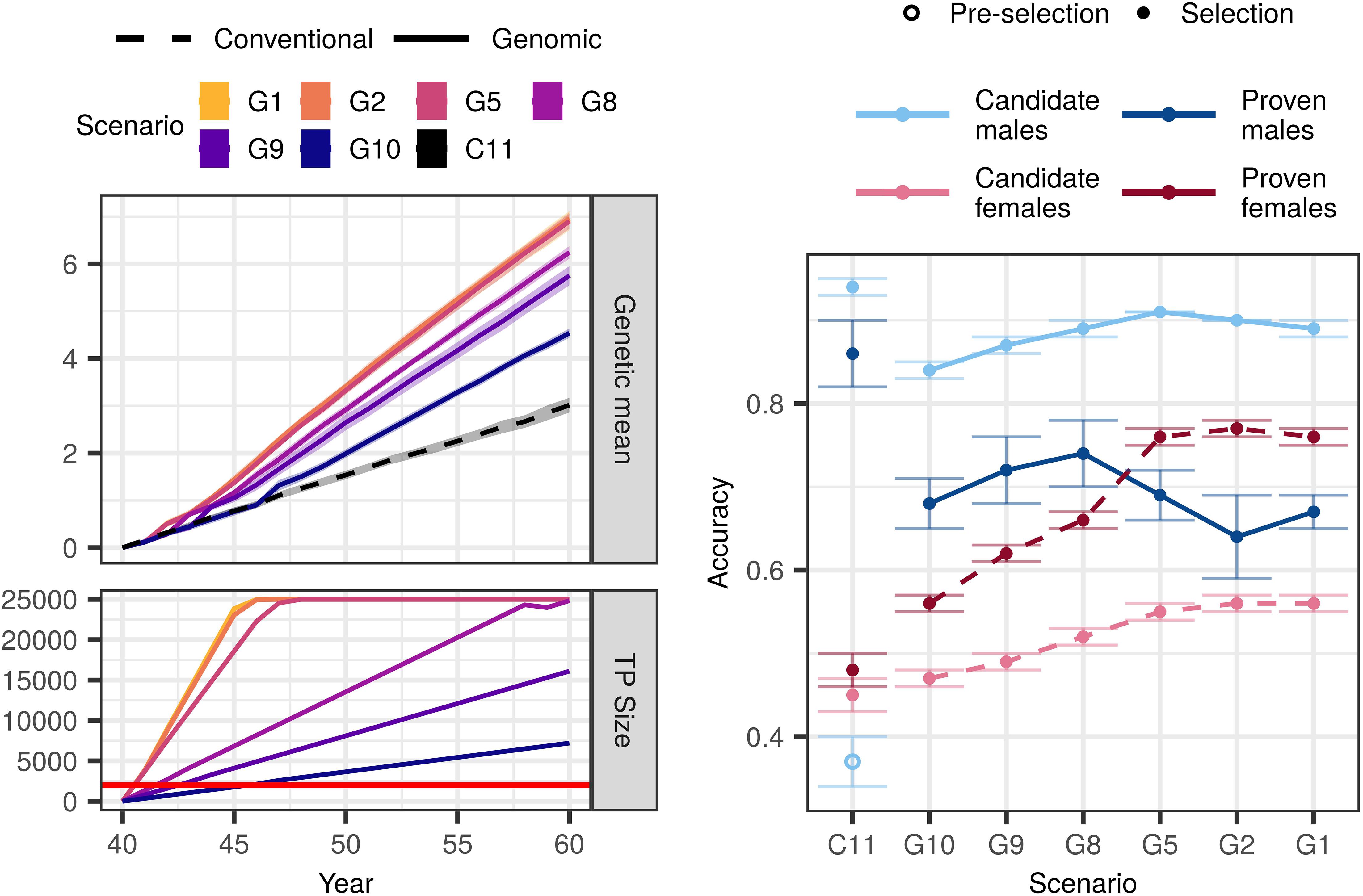
Figure 3. Genetic gain, training population size, and accuracy by scenario without an initial training population (TP) and equal cost of phenotyping and genotyping. The figure presents the means (lines or points) and 95% confidence intervals (polygons or error-bars) across 10 replicates for the conventional (C) and genomic (G) selection scenarios with numbers indicating the number of phenotypic records per lactation. The cost of phenotyping was defined as the cost of 11 phenotypic records per lactation, and the cost of genotyping as the cost of one genotype. The red line marks the condition of required 2,000 training animals to start genomic selection. Conventional selection implemented two-stage selection for males, hence we present the accuracy of the pre-selection for progeny testing (empty point) and the accuracy of sire selection (solid point).
In the $P:$G = 1:1 setting, genomic selection scenarios increased the genetic gain of the conventional selection scenario between 51 and 131%. Compared to when we had an initial training population, the corresponding scenarios achieved between 2 and 16% lower genetic gain. This difference was the largest when we invested the least into genotyping (G10). In this scenario we needed 6 years to build a training population of 2,000 cows and implement genomic selection, since we only genotyped 355 cows per year. We observed the smallest difference in the scenario that collected two phenotypic records per lactations (G2) and implemented genomic selection in the first year.
Changing the relative cost of phenotyping to genotyping did not change the overall trend. In the $P:$G = 1:2 setting, the genomic selection scenarios increased genetic gain of the conventional selection scenario between 31 and 126%. That was between 4 and 28% less than corresponding scenarios with an initial training population. In the $P:$G = 2:1 setting, the genomic selection scenarios increased the genetic gain of the conventional selection scenario between 86 and 134%, which was between 3 and 14% less than corresponding scenarios with an initial training population.
Accuracy
Similar to the scenarios with an initial training population, genomic selection scenarios without it increased the accuracy for non-phenotyped candidate males and females, and proven females (Figure 3 and Supplementary Table S4). In the $P:$G = 1:1 setting the accuracy for candidate males ranged between 0.84 and 0.91. In contrast to scenarios with an initial training population, the accuracy increased with increasing investment into genotyping. The accuracy for proven males ranged between 0.64 and 0.74. Contrary to when we had an initial training population, we observed no clear trend of either increasing or decreasing accuracy with decreasing investment into phenotyping. For candidate females the accuracy ranged between 0.47 and 0.56, and for proven females between 0.56 and 0.76. For both the accuracies followed the trends of when we had an initial training population, this is increasing genotyping increased the accuracy.
Changing the relative cost of phenotyping to genotyping affected the accuracy for non-genotyped candidate and proven females, and candidate males. Decreasing the relative cost of genotyping to phenotyping increased the accuracy in the majority of the scenarios, particularly the low-genotyping ones.
Discussion
Our results show that any dairy breeding program using conventional progeny testing with repeated milk records can implement genomic selection without extra costs. While breeding programs have established funding for phenotyping, not all of them have established funding for genotyping. We show that by reallocating a part of phenotyping resources into genotyping, breeding programs can implement genomic selection and substantially increase genetic gain regardless of the amount and cost of genotyping, and availability of an initial training population. However, increasing investment in genotyping has diminishing returns, which suggests that breeding programs should optimize the investment into phenotyping and genotyping to maximize return on investment for selection and management. The results raise four discussion points: (1) how optimizing the investment in phenotyping and genotyping affects genetic gain; (2) how optimizing the investment in phenotyping and genotyping affects accuracy; (3) implications for dairy breeding programs;, and (4) limitations of the study. We first discuss the results under equal cost of phenotyping and genotyping, and an initial training population available. We then discuss changes at different costs and no initial training population.
Genetic Gain With an Initial Training Population
Genomic vs. Conventional Selection
Implementing genomic selection by optimizing the investment in phenotyping and genotyping increased genetic gain compared to the conventional selection, mainly due to reduced generation interval in sire selection paths. This improvement is in agreement with previous theoretical studies (Schaeffer, 2006; Pryce et al., 2010; Obšteter et al., 2019). Empirical studies confirm this; in the US Holstein population the generation interval for the sires of sires and sires of dams paths recently decreased between 25 and 50% compared to the conventional selection (García-Ruiz et al., 2016). Van Grevenhof et al. (2012) also showed that when genomic selection halves the generation interval, a training population with ∼2,000 individuals with own performance or ∼3,500 individuals with 10 progeny gives comparable response as conventional selection for a trait with intermediate heritability.
Another major advantage of the genomic selection scenarios was increased intensity of sire selection. A costly and lengthy progeny-testing limits the number of tested candidate males in conventional selection. Genomic selection significantly reduces the cost of testing (Schaeffer, 2006) and thus allows for testing more candidate males. In the US Holstein population, genomic selection improved the selection differential for all traits, particularly for traits with low heritability, such as health and fertility (García-Ruiz et al., 2016).
Increasing the Investment Into Genotyping
Genetic gain increased with increased investment into genotyping. This was mainly due to higher intensity of sire selection, since more resources for genotyping allowed us to test more candidate males while selecting the same number. A larger investment into genotyping also increased the update and total size of the training population, which increased the accuracy of female selection (we discuss this in the next sub-section).
The genetic gain had diminishing return relationship with investment into genotyping. This has important implications for dairy breeding programs, since they use phenotypes also for management, and we discuss this separately. In our study, investing resources of more than six phenotypic records into genotyping did not significantly improve the genetic gain. There are three reasons for this. First, increasing female training population has diminishing return relationship with genetic gain (Van Grevenhof et al., 2012; Gonzalez-Recio et al., 2014). Since scenarios with an initial training population started with ∼10,000 genotyped and phenotyped cows, enlarging the training population had a marginal effect. Consequently, the accuracy of sire selection in genomic selection scenario was high regardless of the amount of genotyping. Second, increasing investment into genotyping did not proportionally increase the size of the training population due to the limit of 25,000 animals of the training population. And third, the intensity of sire selection had diminishing return with increasing number of genotyped candidate males. This agrees with Reiner-Benaim et al. (2017) that showed an increased genetic gain with increasing the number of tested candidate males, but with a diminishing return. While they achieved the maximum profit with four selected sires out of 1,721 tested candidates, they achieved 99 or 90% of the maximum profit with, respectively, 740 or 119 tested candidates. The same three reasons enabled comparable maximum genetic gain regardless of the relative price of phenotyping to genotyping. In general, selecting less than 2% of the tested males and updating the training population with at least 35% of first-parity cows resulted in the maximum genetic gain.
While genetic gain increased with the number of cows in training population, it did not increase with the number of repeated records. The scenarios with the largest genetic gain therefore had a training population with many cows and few repeated records (Supplementary Figure S1). However, since we used the single-step genomic prediction, the phenotypes of the non-genotyped animals contributed to the estimation as well. Effectively, all scenarios thus operated with the same number of phenotyped animals.
We should emphasize, that some of the high-genotyping scenarios achieved the observed genetic gain at a lower total cost, since they could not use all the saved resources for genotyping females in the studied population. The saved resources could be invested back into phenotyping females for milk production or novel traits, genotyping more candidate males, or other breeding actions.
Accuracy With an Initial Training Population
Despite reduced phenotyping, genomic selection scenarios increased the accuracy for young non-phenotyped calves and cows. When the accuracy of parent average is already high, genomic prediction increases primarily the accuracy of the Mendelian sampling term. But when the accuracy of parent average is low, such as for the offspring of parents with little or no own or progeny information, genomic information increases accuracy both for the parent average and the Mendelian sampling term (Daetwyler et al., 2007; Wolc et al., 2011).
Accuracy for Males
For candidate males, genomic prediction more than doubled the accuracy compared to the parent average used for pre-selection of male calves for progeny testing. This is in agreement with twofold accuracy increase in dairy (Schaeffer, 2006) and layers (Wolc et al., 2011). Within the genomic selection scenarios, the accuracy for candidate males was high regardless of the amount of genotyping and phenotyping for two reasons. First, the accuracy of their parent average was high, since we tested offspring of elite matings. Second, starting with an initial 10,000 training population gave an adequate accuracy that was additionally boosted by using all available information jointly through the single-step genomic prediction. Using single-step genomic prediction also removed the bias due to pre-selection (Jibrila et al., 2020).
In contrast, reducing phenotyping decreased the accuracy of proven males. We believe this is due to two reasons. First, since proven males are the very best animals, their breeding values are close together in the tail of the distribution. Due to small differences between the proven males, each additional phenotypic record helps to differentiate them and thus increases the accuracy. Second, as we invested more into genotyping, the training population grew quicker and reached the limit of 25,000. At this point we removed proven males’ in favor of proven females’ genotypes, hence prediction for proven males depended only on daughters’ data and no longer on their own genotype. However, since this is the accuracy after the selection has already been made, it is not of great interest for breeding.
Accuracy for Females
Genomic selection scenarios increased the accuracy for proven females compared to the conventional selection scenario. Besides increasing the accuracy of Mendelian sampling term, using genomic information increases genetic connectedness between individuals from different management units (Yu et al., 2017; Powell et al., 2019). Increased connectedness in turn increases the accuracy of prediction regardless of the heritability and the number of causal loci or markers (Yu et al., 2018). This improvement is important because we selected bull dams for elite mating from proven females.
The accuracy for proven females increased with increasing investment into genotyping, despite reduced phenotyping due to three reasons. First, more proven females had both genomic and phenotypic information, which increased the accuracy of their estimated breeding values. Second, more genotyped proven females increased genetic connectedness (Yu et al., 2018). And third, investing more into genotyping translated into larger training population and its yearly update. As shown by previous studies (Van Grevenhof et al., 2012; Gonzalez-Recio et al., 2014), the accuracy of genomic prediction increases with increasing the size of a female training population. They showed that the accuracy of 0.70 is achieved with ∼20,000 animals as in our study. Same studies shown that, as with genetic gain, accuracy had a diminishing return with the size of the training population. We observed plateau in accuracy when we invested more than six phenotypic records (out of 11) into genotyping.
Accuracy for candidate females followed the trend for proven females, but at lower values. Candidate females were not genotyped nor phenotyped, hence their accuracy mainly reflected the accuracy of their parent average. Increasing genotyping increased the accuracy for proven females and in turn increased the accuracy of candidate females’ parent average. The benefit of this increase was not large, since the intensity of female selection was low. However, there is potential for this benefit to be larger with sexed semen and embryo transfer.
Scenario Without an Initial Training Population
Genetic Gain
We also considered that some populations do not have access to an initial training population and have to initialize one themselves. These genomic selection scenarios still increased genetic gain compared to the conventional selection scenario, but achieved lower genetic gain than corresponding scenarios with an initial training population available. Increasing the investment into genotyping compensated for starting without a training population in two ways. First, it shortened the time to obtain the targeted 2,000 genotypes required to implement genomic selection down to 1 year in high-genotyping scenarios. Second, it shortened the time to build a training population in which an additional record had negligible effect on accuracy (Gonzalez-Recio et al., 2014).
Accuracy
Accuracy in scenarios without an initial training population closely followed the trends of the corresponding scenarios with an initial training population available. We observed minor differences in the low genotyping scenarios that had reduced accuracy for candidate and proven males. We attribute this to a smaller training population. Buch et al. (2012) showed that for new traits and large-scale recording, we can achieve 75% of the maximum genomic accuracy within first 2–3 years of recording. In our study we shortened this period even more by including the historical data through the single-step genomic prediction.
Implications
The results suggest that any dairy breeding program using conventional progeny testing with repeated milk records can implement genomic selection without extra costs by optimizing the investment of resources into breeding actions. Here we propose funding the genotyping with a part of resources for milk recording, since we can manipulate the number of repeated records. Breeding programs could reduce phenotyping for a different trait that they record repeatedly and is perhaps less crucial for management. They could also reallocate the funds from another breeding action.
Additionally, we could optimize which individuals to genotype and phenotype, as well as the computational costs. Selective phenotyping was shown to increase the accuracy of genomic prediction up to 20% with small sample sizes in plant breeding (Heslot and Feoktistov, 2017; Akdemir and Isidro-Sánchez, 2019). Similarly, selective genotyping of cows from the distribution tails has been shown to increase the accuracy of genomic prediction by 15% (Jenko et al., 2017). We expect this would further increase the return on investment, but increase the complexity of optimization. Regarding computing costs, the problem of a large number of genotypes can be alternatively solved by using methods with reduced computational costs. Examples of such methods are the algorithm for proven and young (Misztal et al., 2014) and singular value decomposition of the genotype matrix (Ødegård et al., 2018). Also, as shown in our study, we can achieve large genetic gain with a relatively small training population of recent genotypes.
The economic efficiency of breeding programs strongly depends on which stakeholders fund which breeding action. Different programs have different investment schemes, often complex. The scenarios presented in this paper are of little value for programs where funding for phenotyping and genotyping is disconnected. Similarly, optimizing the investment into phenotyping is not of interest for breeding programs with abundant use of automated milking systems where the cost of phenotyping does not depend on the number of records. However, in populations with small herds the use of automated milking systems is limited. Further on, genomic selection could benefit some settings more than others. For example, genomic information is especially important for generating genetic connectedness in systems with small herd sizes, geographically dispersed farms, and limited use of artificial insemination, often found in low- to mid-income countries (Powell et al., 2019). The same benefits are expected for small ruminant programs that do not actively exchange sires between herds (Kasap et al., 2018).
High cost of genotyping diminishes the benefit of the proposed solutions. The relative cost of phenotyping to genotyping at which genomic selection is not beneficial to conventional selection depends on a number of factors: (i) the number of females in the recorded population, since it dictates the savings from reducing the phenotyping; (ii) the number of phenotypic records the breeders are willing to sacrifice; (iii) the availability of an initial training population;, and (iv) the ratio of genotyped males and females. In our case, if $P:$G was 1:10, we would save resources to genotype between 36 (10 phenotypic records) and 900 (one phenotypic record) animals. While such numbers of genotyped animals could allow for efficient genomic selection if we had an initial training population and genotyped only males, it would probably not be viable if we had to build the training population ourselves.
We did not account for the benefits of genotyping besides genomic selection. Genomic information has additional value for (i) parentage verification, parentage discovery, or correction of parentage errors; (ii) management of monogenic diseases and traits, which can prevent economic losses caused by spreading lethal alleles or create economic gain by adding value to the products; (iii) better monitoring and control of inbreeding (Sonesson et al., 2012) and optimization of matings (Obšteter et al., 2019); (iv) determination of animals’ breed composition, which serves to identify the most appropriate breed or cross-breed in a production system, or improve the structure of the training population (Marshall et al., 2019). Additional uses of genotypes increase the return on investment beyond what we measured in this study. Another important point to note is also, that while phenoypes serve to improve a single trait, genotypes serve to improve the genetic gain for all selected trait.
Limitations of the Study
Reducing the Number of Phenotypic Records
Balancing phenotyping and genotyping can lead to conflicts between managing production (short-term goal) and achieving genetic gain (long-term goal). Producers use phenotypic records to manage animals’ health, reproduction and feed composition, which affect the success of dairy cattle production in the short-term. Besides managing production, milk recording is also important from an environmental perspective (Verbiè et al., 2019), but so is genetic improvement. In general, about half of phenotypic improvement is due to management and half due to selection (Dekkers and Hospital, 2002).
The ownership of the data that drives dairy improvement is a matter of discussion in many breeding programs. When data collection is subsidized, the data are usually free for management and genetic improvement. Finding optimal frequency of recording for management and genetic improvement in such systems is crucial for optimal return on investment. When data collection is paid by producers, they can be available to breeding organizations for free or at a cost. Depending on the cost breeding organizations can save some resources by purchasing smaller number of repeated phenotypes per individual and genotype more selection candidates instead.
While genotype data is currently largely used for selection, the same data could also support management (predicting feed requirements, disease liability, etc.). Therefore, evaluating the value of phenotype and genotype data is complex and beyond the scope of this study. One possible way forward would be to compare variance between herd-test day effects and genetic variance to contrast the value of managing production and genetic gain in addition to comparing phenotypic and genetic trends (Dekkers and Hospital, 2002).
In practice, test day records are also used to compute the 305 day milk yield (International Committee for Animal Recording, 2020). The longest sampling interval tested in our study and still approved by ICAR was 9 weeks, which yielded five records per lactation. Previous studies showed that the correlation of predicting 305 day milk using five records per lactation with using either weekly or 11 records per lactation was between 0.98 and 0.99 (Pool and Meuwissen, 1999; Berry et al., 2005). However, some studies showed that prediction using less than 11 records can yield substantial bias (Gantner et al., 2008).
Single Additive Trait
We simulated milk yield as a single polygenic trait with additive genetic as well as herd, permanent environment, and residual environmental effects. We did not simulate nor account for non-additive genetic effects that also affect dairy performance (Fuerst and Sölkner, 1994; Ertl et al., 2014; Jiang et al., 2017). We note that we simulated permanent environment effects, which capture non-additive genetic effects and other individual specific environmental effects. The simplified simulation of the phenotype affected the observed accuracies that were higher than recorded in practice. We also simulated milk yield in different lactations as a single trait with constant heritability, whereas genetic correlation between different lactations and through the lactation is not unity (Meyer, 1984; Swalve and Vleck, 1987; Dong and van Vleck, 1989). If genetic correlation is less than one, the repeatability of the phenotype decreases and the value of a repeated record and its contribution to accuracy diminishes.
We simulated a trait with heritability of 0.25, since the majority of production traits recorded repeatedly show intermediate heritability. Previous studies also provide insights in how changing the heritability of the phenotype would affect the results. On one hand, at a lower heritability we would need more females in the training population until the contribution of additional female was negligible (Gonzalez-Recio et al., 2014). On the other hand, genomic selection is less affected by the heritability than conventional selection and hence more beneficial for traits with low heritability (Lillehammer et al., 2011; García-Ruiz et al., 2016).
Genomic Selection of Females
We did not use genomic selection for females, nor did we use reproductive technologies such as sexing semen or embryo transfer. This would further decrease the generation interval, increase selection intensity on female side, and in turn increase genetic gain of genomic selection scenarios even more (Pryce et al., 2010; García-Ruiz et al., 2016). Such an implementation of genomic selection requires only a minor modification of the design used in this study–genotyping heifers instead of first-parity cows. However, if breeding program funds are used in an optimal sense, we would still suggest genotyping phenotyped females, while farmers can at extra genotype heifers. Since most females are kept it probably would not make difference in terms of training population, and would slightly increase genetic gain. Reproductive technologies require a larger modification and investment. Some of the scenarios saved resource and could invest into these technologies.
Data Availability Statement
We have now made the data publicly available and can be found at: https://doi.org/10.6084/m9.figshare.c.5281625.v1.
Author Contributions
JO designed the study, ran the simulation, analyzed the data, interpreted the results, and wrote the manuscript. JJ participated in study design, results interpretation, and manuscript revision. GG initiated and supervised the work and contributed to all its stages. All authors contributed to the article and approved the submitted version.
Funding
JO acknowledges support from Agricultural Institute of Slovenia and core financing of Slovenian Research Agency (grant P4-0133). GG acknowledges support from the BBSRC to the Roslin Institute (BBS/E/D/30002275) and The University of Edinburgh’s Data-Driven Innovation Chancellor’s fellowship.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We acknowledge I. Pocrnić (The Roslin Institute, University of Edinburgh) for his help in interpreting the results and comments on the manuscript.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fgene.2021.637017/full#supplementary-material
References
Akdemir, D., and Isidro-Sánchez, J. (2019). Design of training populations for selective phenotyping in genomic prediction. Sci. Rep. 9:1446. doi: 10.1038/s41598-018-38081-6
Azizian, S., Shadparvar, A. A., Hossein-Zadeh, N. G., and Joezy-Shekalgorabi, S. (2016). Effect of increasing accuracy of genomic evaluations on economic efficiency of dairy cattle breeding programmes. Ital. J. Anim. Sci. 15, 379–385. doi: 10.1080/1828051X.2016.1210484
Berry, D. P., Olori, V. E., Cromie, A. R., Veerkamp, R. F., Rath, M., and Dillon, P. (2005). Accuracy of predicting milk yield from alternative milk recording schemes. Anim. Sci. 801, 53–60. doi: 10.1079/ASC34880053
Buch, L. H., Kargo, M., Berg, P., Lassen, J., and Sørensen, A. C. (2012). The value of cows in reference populations for genomic selection of new functional traits. Animal 6, 880–886. doi: 10.1017/S1751731111002205
Clark, S. A., Hickey, J. M., and van der Werf, J. H. J. (2011). Different models of genetic variation and their effect on genomic evaluation. Genet. Sel. Evol. 43:18. doi: 10.1186/1297-9686-43-18
CRV Netherlands (2020). MPR. Available online at: https://www.crv4all.nl/service/melkproductieregistratie/https:/www.crv4all.nl/service/melkproductieregistratie/ (accessed January 5, 2020).
CRV New Zealand (2020). CRV Herd testing. Available online at: https://www.crv4all.co.nz/service/crv-herd-testing/ (accessed January 5, 2020).
Daetwyler, H. D., Villanueva, B., Bijma, P., and Woolliams, J. A. (2007). Inbreeding in genome-wide selection. J. Anim. Breed. Genet. 124, 369–376. doi: 10.1111/j.1439-0388.2007.00693.x
Daetwyler, H. D., Villanueva, B., and Woolliams, J. A. (2008). Accuracy of predicting the genetic risk of disease using a genome-wide approach. PLoS One 3:e3395. doi: 10.1371/journal.pone.0003395
Dekkers, J. C. M., and Hospital, F. (2002). The use of molecular genetics in the improvement of agricultural populations. Nat. Rev. Genet. 3, 22–32. doi: 10.1038/nrg701
Dong, M. C., and van Vleck, L. D. (1989). Correlations among first and second lactation milk yield and calving interval. J. Dairy Sci. 72, 1933–1936. doi: 10.3168/jds.S0022-0302(89)79313-9
Ducrocq, V., Laloe, D., Swaminathan, M., Rognon, X., Tixier-Boichard, M., and Zerjal, T. (2018). Genomics for ruminants in developing countries: from principles to practice. Front. Genet. 9:251. doi: 10.3389/fgene.2018.00251
Ertl, J., Legarra, A., Vitezica, Z. G., Varona, L., Edel, C., Emmerling, R., et al. (2014). Genomic analysis of dominance effects on milk production and conformation traits in Fleckvieh cattle. Genet. Sel. Evol. 46:40. doi: 10.1186/1297-9686-46-40
Fuerst, C., and Sölkner, J. (1994). Additive and nonadditive genetic variances for milk yield, fertility, and lifetime performance traits of dairy cattle. J. Dairy Sci. 77, 1114–1125. doi: 10.3168/jds.S0022-0302(94)77047-8
Gantner, V., Jovanovac, S., Raguž, N., Klopčič, M., and Solić, D. (2008). Prediction of lactation milk yield using various milk recording methods. Biotechnol. Anim. Husb. 24, 9–18. doi: 10.2298/bah0804009g
García-Ruiz, A., Cole, J. B., VanRaden, P. M., Wiggans, G. R., Ruiz-López, F. J., and Tassell, C. P. V. (2016). Changes in genetic selection differentials and generation intervals in US Holstein dairy cattle as a result of genomic selection. Proc.Natl. Acade. Sci. U.S.A. 113, E3995–E4004. doi: 10.1073/pnas.1519061113
Goddard, M. (2009). Genomic selection: prediction of accuracy and maximisation of long term response. Genetica 136, 245–257. doi: 10.1007/s10709-008-9308-0
Goddard, M. E., Hayes, B. J., and Meuwissen, T. H. E. (2011). Using the genomic relationship matrix to predict the accuracy of genomic selection. J Anim. Breed. Genet. 128, 409–421. doi: 10.1111/j.1439-0388.2011.00964.x
Gonzalez-Recio, O., Coffey, M. P., and Pryce, J. E. (2014). On the value of the phenotypes in the genomic era. J. Dairy Sci. 97, 7905–7915. doi: 10.3168/jds.2014-8125
Heslot, N., and Feoktistov, V. (2017). Optimization of selective phenotyping and population design for genomic prediction. BioRxiv[Preprint] 172064. doi: 10.1101/172064
Huang, Y., Hickey, J. M., Cleveland, M. A., and Maltecca, C. (2012). Assessment of alternative genotyping strategies to maximize imputation accuracy at minimal cost. Genet. Sel. Evol. 44:25. doi: 10.1186/1297-9686-44-25
ICBF (2020). Milk Recording Service Options. Available online at: https://www.icbf.com/wp/?page_id=291 (accessed January 5, 2020).
International Committee for Animal Recording (2017). Section 02—Cattle Milk Recording. Overview. In ICAR Guidelines. Rome: ICAR.
International Committee for Animal Recording (2020). Section 02—Cattle Milk Recording. Procedure 2—Computing Lactation Yield. In ICAR Guidelines. Rome: ICAR.
Jenko, J., Wiggans, G. R., Cooper, T. A., Eaglen, S. A. E., de, W. G., Luff, L., et al. (2017). Cow genotyping strategies for genomic selection in a small dairy cattle population. J. Dairy Sci. 100, 439–452. doi: 10.3168/jds.2016-11479
Jiang, J., Shen, B., O’Connell, J. R., VanRaden, P. M., Cole, J. B., and Ma, L. (2017). Dissection of additive, dominance, and imprinting effects for production and reproduction traits in Holstein cattle. BMC Genom. 18:425. doi: 10.1186/s12864-017-3821-4
Jibrila, I., Ten Napel, J., Vandenplas, J., Veerkamp, R. F., and Calus, M. P. L. (2020). Investigating the impact of preselection on subsequent single-step genomic BLUP evaluation of preselected animals. Genet. Sel. Evol. 52:42. doi: 10.1186/s12711-020-00562-6
Jopson, N. B., Amer, P. R., and McEwan, J. M. (2004). “Comparison of two-stage selection breeding programmes for terminal sire sheep,” in Proceedings of the New Zealand Society of Animal Production, Vol. 64, (Hamilton), 212–216.
Kasap, A., Mioc, B., Hickey, J. M., and Gorjanc, G. (2018). “Genetic connectedness in the U.S. sheep industry,” in Proceedings of the Book of Abstracts of the 69th Annual Meeting of the European Federation of Animal Science, (Wageningen: Wageningen Academic Publishers), 590. doi: 10.3920/978-90-8686-871-1
König, S., Simianer, H., and Willam, A. (2009). Economic evaluation of genomic breeding programs. J Dairy Sci. 92, 382–391. doi: 10.3168/jds.2008-1310
LIC (2020). Herd Test Prices. Available online at: https://www.lic.co.nz/products-and-services/herd-testing/herd-test-prices/ (accessed January 5, 2020).
Lillehammer, M., Meuwissen, T. H. E., and Sonesson, A. K. (2011). A comparison of dairy cattle breeding designs that use genomic selection. J Dairy Sci. 94, 493–500. doi: 10.3168/jds.2010-3518
Lin, Z., Wang, J., Cogan, N. O., Pembleton, L. W., Badenhorst, P., Forster, J. W., et al. (2017). Optimizing resource allocation in a genomic breeding program for perennial ryegrass to balance genetic gain, cost, and inbreeding. Crop Sci. 57, 243–252. doi: 10.2135/cropsci2016.07.0577
Lorenz, A. J. (2013). Resource allocation for maximizing prediction accuracy and genetic gain of genomic selection in plant breeding: a simulation experiment. G3 (Bethesda, Md.) 3, 481–491. doi: 10.1534/g3.112.004911
Marshall, K., Gibson, J. P., Mwai, O., Mwacharo, J. M., Haile, A., Getachew, T., et al. (2019). Livestock genomics for developing Countries – African examples in practice. Front. Genet. 10:297. doi: 10.3389/fgene.2019.00297
Meuwissen, T. H. E., Hayes, B. J., and Goddard, M. E. (2001). Prediction of total genetic value using genome-wide dense marker maps. Genetics. 157, 1819–1829.
Meyer, K. (1984). Estimates of genetic parameters for milk and fat yield for the first three lactations in British Friesian cows. Anim. Sci. 38, 313–322. doi: 10.1017/S0003356100041519
Misztal, I., Legarra, A., and Aguilar, I. (2014). Using recursion to compute the inverse of the genomic relationship matrix. J. Dairy Sci. 97, 3943–3952. doi: 10.3168/jds.2013-7752
Misztal, I., Tsuruta, S., Lourenco, D. A. L., Masuda, Y., Aguilar, I., Legarra, A., et al. (2018). Manual for BLUPF90 family programs. University of Georgia. Available online at: http://nce.ads.uga.edu/wiki/doku.php?id=documentation (accessed January 5, 2021).
Mrode, R. A. (2005). Linear Models for the Prediction of Animal Breeding Values (Second edition). Wallingford: CAB International.
Mrode, R., Ojango, J. M. K., Okeyo, A. M., and Mwacharo, J. M. (2019). Genomic selection and use of molecular tools in breeding programs for indigenous and crossbred cattle in developing countries: current status and future prospects. Front. Genet. 9:964. doi: 10.3389/fgene.2018.00694
Obšteter, J., Jenko, J., Hickey, J. M., and Gorjanc, G. (2019). Efficient use of genomic information for sustainable genetic improvement in small cattle populations. J. Dairy Sci. 102, 9971–9982. doi: 10.3168/jds.2019-16853
Ødegård, J., Indahl, U., Strandén, I., and Meuwissen, T. H. E. (2018). Large-scale genomic prediction using singular value decomposition of the genotype matrix. Genet. Sel. Evol. 50:6. doi: 10.1186/s12711-018-0373-2
Pocrnic, I., Lourenco, D., Bradford, H., Chen, C. Y., and Misztal, I. (2017). Technical note: Impact of pedigree depth on convergence of single-step genomic BLUP in a purebred swine population. J. Anim. Sci. 95, 3391–3395. doi: 10.2527/jas.2017.1581
Pool, M. H., and Meuwissen, T. H. E. (1999). Prediction of daily milk yields from a limited number of test days using test day models. J. Dairy Sci. 82, 1555–1564. doi: 10.3168/jds.S0022-0302(99)75383-X
Powell, O., Mrode, R., Gaynor, C. R., Johnsson, M., Gorjanc, G., and Hickey, J. M. (2019). Genomic data enables genetic evaluation using data recorded on LMIC smallholder dairy farms. BioRxiv[Preprint] 827956. doi: 10.1101/827956
Progressive Genetics (2020). Milk recording. Available online at: https://www.progressivegenetics.ie/milk-recording/ (accessed January 5, 2020).
Pryce, J. E., Goddard, M. E., Raadsma, H. W., and Hayes, B. J. (2010). Deterministic models of breeding scheme designs that incorporate genomic selection. J. Dairy Sci. 93, 5455–5466. doi: 10.3168/jds.2010-3256
Reiner-Benaim, A., Ezra, E., and Weller, J. I. (2017). Optimization of a genomic breeding program for a moderately sized dairy cattle population. J. Dairy Sci. 100, 2892–2904. doi: 10.3168/jds.2016-11748
Riedelsheimer, C., and Melchinger, A. E. (2013). Optimizing the allocation of resources for genomic selection in one breeding cycle. Theor. Appl. Genet. 126, 2835–2848. doi: 10.1007/s00122-013-2175-9
Schaeffer, L. R. (2006). Strategy for applying genome-wide selection in dairy cattle. J. Anim. Breed. Genet. 123, 218–223. doi: 10.1111/j.1439-0388.2006.00595.x
Sonesson, A. K., Woolliams, J. A., and Meuwissen, T. H. E. (2012). Genomic selection requires genomic control of inbreeding. Genet. Sel. Evol. 44:27. doi: 10.1186/1297-9686-44-27
Swalve, H., and Vleck, L. D. V. (1987). Estimation of genetic (Co) variances for milk yield in first three lactations using an animal model and restricted maximum likelihood. J. Dairy Sci. 70, 842–849. doi: 10.3168/jds.S0022-0302(87)80082-6
Thomasen, J. R., Egger-Danner, C., Willam, A., Guldbrandtsen, B., Lund, M. S., and Sørensen, A. C. (2014a). Genomic selection strategies in a small dairy cattle population evaluated for genetic gain and profit. J. Dairy Sci. 97:470. doi: 10.3168/jds.2013-6599
Thomasen, J. R., Sørensen, A. C., Lund, M. S., and Guldbrandtsen, B. (2014b). Adding cows to the reference population makes a small dairy population competitive. J. Dairy Sci. 97, 5822–5832. doi: 10.3168/jds.2014-7906
Van Grevenhof, E. M., Van Arendonk, J. A. M., and Bijma, P. (2012). Response to genomic selection: The Bulmer effect and the potential of genomic selection when the number of phenotypic records is limiting. Genet. Sel. Evoul. 44:26. doi: 10.1186/1297-9686-44-26
Verbiè, J., Jenko, J., Jeretina, J., and Babnik, D. (2019). “Milk urea concentration as a tool to reduce the nitrogen footprint of milk production in conditions of small scale farming,” in Proceedings of the 4th liveAGE meeting. Towards Precision Livestock Husbandry and Its Potential to Mitigate Ammonia and GHG Emissions: Abstracts’ Leaflet, Galilee.
Wiggans, G. R., Cole, J. B., Hubbard, S. M., and Sonstegard, T. S. (2017). Genomic selection in dairy cattle: the USDA experience. Annu. Rev. Anim. Biosci. 5, 309–327. doi: 10.1146/annurev-animal-021815-111422
Wolc, A., Arango, J., Settar, P., Fulton, J. E., O’Sullivan, N. P., Preisinger, R., et al. (2011). Persistence of accuracy of genomic estimated breeding values over generations in layer chickens. Genet. Sel. Evol. 43:23. doi: 10.1186/1297-9686-43-23
Young, S. (1964). Multi-stage selection for genetic gain. Heredity 19, 131–145. doi: 10.1038/hdy.1964.11
Yu, H., Spangler, M. L., Lewis, R. M., and Morota, G. (2017). Genomic relatedness strengthens genetic connectedness across management units. G3 (Bethesda) 7, 3543–3556. doi: 10.1534/g3.117.300151
Keywords: genomic selection, dairy breeding program, small populations, optimized investment, return on investment
Citation: Obšteter J, Jenko J and Gorjanc G (2021) Genomic Selection for Any Dairy Breeding Program via Optimized Investment in Phenotyping and Genotyping. Front. Genet. 12:637017. doi: 10.3389/fgene.2021.637017
Received: 02 December 2020; Accepted: 14 January 2021;
Published: 10 February 2021.
Edited by:
Nick V. L. Serão, Iowa State University, United StatesReviewed by:
Francisco Peñagaricano, University of Wisconsin-Madison, United StatesFrancesco Tiezzi, North Carolina State University, United States
Copyright © 2021 Obšteter, Jenko and Gorjanc. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jana Obšteter, amFuYS5vYnN0ZXRlckBraXMuc2k=