 P. Taylor
P. Taylor Ze He
Ze He Noah Bilgrien
Noah Bilgrien Hava T. Siegelmann
Hava T. Siegelmann- 1College of Information and Computer Sciences, University of Massachusetts, Amherst, MA, USA
- 2Neuroscience and Behavior Program, University of Massachusetts, Amherst, MA, USA
- 3Department of Mechanical and Industrial Engineering, University of Massachusetts, Amherst, MA, USA
Objective: We aimed to elucidate how our domain-general cuing algorithm improved multitasking performance and changed behavioral strategies in human operators.
Background: Though many gaze-control systems have been designed, previous real-time gaze-aware assistance systems were not both successful and domain-general. It is largely unknown what constitutes optimal search efficiency using the eyes, or ideal control using the mouse. It is unclear what the best coordinating strategies are between these two modalities. Our previously developed closed-loop multitasking aid drastically improved multitasking performance, though the behavioral mechanisms through which it acted were unknown.
Methods: We performed in-depth analyses and generated novel eye tracking and mouse movement measures, to explore the complex effects of our helpful system on gaze and motor behavior.
Results: Our overlay cuing algorithm improved control efficiency and reduced well-known biases in search patterns. This system also reduced micromanaging behavior, with humans rationally relying more on imperfect automation in experimental assistance cue conditions. We showed that mouse and gaze were more independently specialized in the helpful cuing condition than in control conditions. Specifically, with our aid, the gaze performed more global movement, and the mouse performed more local clustered movement. Further, the gaze shifted toward search over processing with the helpful cuing system. We also illustrated a relationship between the mouse and the gaze, such that in these studies, “the hand was quicker than the eye.”
Conclusion: Overall, results suggested that our cuing system improved performance and reduced short-term working memory load on humans by delegating it to the computer in real time. Further, it reduced the number of required repeated decisions by an estimate of about one per second. It also enabled the gaze to specialize for improved visual search behavior, and the mouse to specialize for improved control.
1. Introduction
The vast majority of people are poor multitaskers (Watson and Strayer, 2010). To make matters worse, some of those who score worst on measures of multitasking performance tend to perceive that they are better at multitasking, with a negative correlation between perception and ability in large studies (Sanbonmatsu et al., 2013). These issues are particularly important, since in every day work-life, multitasking may often be necessary or efficient for a variety of human labor.
Tracking a participant’s eye movements while multitasking is an especially good way to glean optimal cognitive strategies. Much work has shown that eye tracking to determine point of gaze can reliably convey the location at which humans’ visual attention is currently directed (Just and Carpenter, 1976; Nielsen and Pernice, 2010). Locus of attention is a factor that can illustrate which of multiple tasks a participant is currently attending to, as well as many other details. Further, measuring where humans look tends to be highly informative of what is interesting to them in a particular scene (Buswell, 1935; Yarbus, 1967), and can be helpful for inferring cognitive strategies. Generally, gaze appears deeply intertwined with cognitive processes. For example, eye movements during an actual event have been shown to resemble those during the recollection of a similar event (de’Sperati, 2003). Even though “looked but did not see” events have been experimentally recorded in special circumstances, typically even brief gazes are informative about attention. For example, the location of very small unintentional eye movements called microsaccades may index intention to look at a non-fixated location or even mere interest in a non-fixated location in the form of covert attention (Hafed and Clark, 2002).
Multitasking principles also apply when managing multiple items in working memory (Heathcote et al., 2014). The canonical number of items capable of maintenance in working memory is 7 ± 2 (Miller, 1956), though this is likely a high estimate, whereas the real-world version, running memory, is likely around 5 chunks of “familiar information” (Moray, 1980). For working memory, another cognitive construct that is difficult to measure and discussed at length below, eye movement paradigms have revealed how visual search tasks can be interfered with when working memory is being taxed (Downing, 2000; Oh and Kim, 2004; Woodman and Luck, 2004).
Though many paradigms have been developed to study multitasking using eye tracking, most traditional applications of eye tracking are not used in real time, but instead to augment training, or simply to observe optimal strategies. For an example of training, post-experiment analysis of gaze data can be used to determine an attention strategy of the best-performing participants or groups. Then, these higher-performing strategies can be taught during training sessions at a later date (Rosch and Vogel-Walcutt, 2013). Implemented examples include educating health care professionals on visual scanning patterns associated with reduced incidence of medical documentation errors (Marquard et al., 2011; He et al., 2014), and training novice drivers’ gaze behaviors to mimic more experienced drivers with lower crash risk (Taylor et al., 2013). As eye tracking methods become more popular, they have been applied in the field of human–computer interaction and usability (Jaimes and Sebe, 2007; Strandvall, 2009; Drewes, 2010), as well as human–robot interaction (Atienza and Zelinsky, 2002; Bhuiyan et al., 2004; Majaranta et al., 2011), though in this area, guiding principles for optimal gaze strategies are still nascent.
Real-time reminders for tasks can improve user performance (Moray, 1981). Generally, real-time cuing of goals can speed or increase the accuracy of detection (Eriksen and Collins, 1969). Highlighting display elements in a multi-display may assist in directing attention (Fisher and Tan, 1989; Hammer, 1999), though eye tracking may often be critical to reliably automate such reminders for many tasks. As described above, there is little previous work developing real-time eye tracking assistance, with most research focused on training, evaluation, or basic hypothesis testing. The real-time systems developed previously, elaborated extensively in the Discussion below (Section 4.5), were lacking in domain-generality, utility, and flexibility. For example, one previous application-specific approach has been to cue the gaze history itself, as a form of bookmark of where has been visited (Ohno, 2004). There appears to be a need for an assistive device for managing multiple visual tasks, which is domain-general, transparent, intuitive, non-interfering, non-command, improves control (without replacing direct control), and adaptively extrapolates to a variety of circumstances. Somewhat counter-intuitively, in the current experiment we explicitly and simply cued the inverse of gaze recency. Thus, we evaluated a system that successfully addressed the need for domain-general multitasking assistance (Figure 1). The goal of this paper is to illustrate the mechanistic means by which this system influenced human strategies for multitasking.
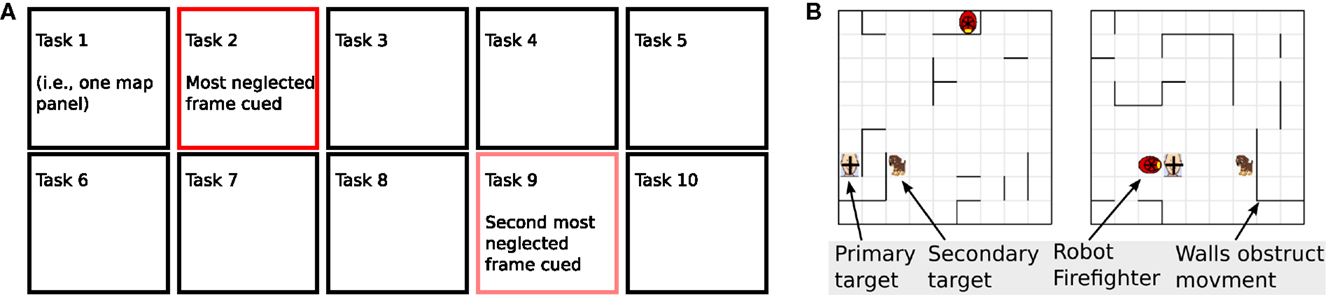
Figure 1. Diagram of the general cuing system employed. (A) Panels of tasks compose a visual array (10 tasks depicted here). A dark red frame cues the most neglected map panel task (looked at longest ago), while pale red highlights the next most neglected map panel task. (B) Participants controlled firefighting robots to rescue targets on map panel tasks (2 displayed). Robots were displayed as red firefighter helmets, each traveling through one separate map panel task to rescue targets. Participants received points for rescuing targets via contact. Each robot remained within its own separate map panel task, and navigated independently of other robots and other panels. Occasional human intervention could improve upon error-prone semi-autonomous movement. In our experiment, each task was an independent robot game task.
The structure of our paper is as follows: the Materials and Methods section details the design of our cuing system, our previous evaluation of its basic effectiveness toward improving multitasking performance, the participant details, technical implementation, and statistical procedures. All of our measures (except one) were novel and custom to this circumstance. Thus, the algorithms for analysis were not included in the Methods section, but instead were interleaved with the Results below for better readability, and since these analysis methods are new contributions themselves. Then, the Section Discussion includes both the findings in the context of the engineering psychology literature and in-depth review of the related eye tracking work. We end the paper with brief conclusions and suggestions of wider application.
2. Materials and Methods
2.1. Experiment: The Game and Conditions
In a previous paper, we demonstrated that cuing participants with the inverse of eye-gaze recency (the most neglected task at the moment) drastically improved users’ performance (Taylor et al., 2015). The eye tracker continuously notified the computer and game software of the location of gaze. Frame cues for the most neglected map panel were automatically quickly removed and re-updated if a participant gazed at any map panel task.
To evaluate this system, participants played a multi-agent game (Ember’s game): they managed multiple simulated robotic firefighters simultaneously to save rescue victims. The semi-random automated movement of the robot would eventually rescue some targets, though occasional human intervention could speed rescue times. Each participant session had 7 experimental blocks, and the number of robots they managed increased from 4 to 10 across the 7 blocks, e.g., they managed 4 robots in Block-1, 5 robots in Block-2, and 10 robots in Block-7. Each robot moved in a separate map panel task. An image of the game and eye tracking algorithm design was included in Figure 1, and with full detail in Taylor et al. (2015). To optimize performance, a participant must divide their attention across many independent map panel tasks.
This study adopted a between subject design with one independent variable, the type of frame cuing each of multiple simultaneous map panel tasks. Participants were randomly assigned to one of the three conditions (one test and two control), determined by three frame cue types: (1) “On” condition: helpful gaze history frame cues surrounded the most neglected task (test experimental condition), (2) “Random” condition: randomly moving frames, which were the same physical stimulus, but without any relationship to the gaze (an “active” control condition), and (3) “Off” condition: no frames (an “absent” control condition). All other game parameters were equal across conditions.
In our previous study, we analyzed data collected from participants’ eye movements, mouse movements, and task performance (score). The system displayed large improvements in performance in the On (Helpful frame cue) condition over both controls. In addition, the Helpful frame cue group demonstrated faster reaction times and showed reduced pupil dilation as a proxy for reduced cognitive load (Taylor et al., 2015). Given the simple nature of the frame cue aid, this performance improvement is likely to be similarly seen in many multitasking scenarios. Specifically, it likely extrapolates to many tasks where a user must engage with multiple separate visual processes or agents simultaneously, and the probability that any single task entity needs user interaction increases with duration of time since the user’s last interaction with that same task. Overall, our solution as described in Taylor et al. (2015), appears to be uniquely assistive, domain-general, non-interfering, purely gaze-aware, improves pre-existing control, and most importantly, yielded improvements in task performance with very large effect sizes. However, we did not fully explore how these improvements manifested mechanistically. Therefore, in this current work, we investigated and compared the visual scanning patterns and motor control behaviors between the three experimental groups, to further explore the mechanisms of benefit.
2.2. Participants
A total of 44 human subjects participated in Ember’s game. All procedures complied with departmental and university guidelines for research with human participants and were approved by the university institutional review board, and participants provided written informed consent. Participants were recruited from the university population at large and were compensated for their time with $5 USD. Data were not excluded based on behavioral task performance in order to obtain a generalizable sample of individual variation on performance of the task while avoiding a restriction of range (Myers et al., 2010). Two participants with vision correction causing poor calibration quality for entire blocks were excluded, leaving 42 subjects. No data were excluded within this remaining pool of subjects. Each participant reported extent of past video game experience, current vision correction if any, age, and sleep measures for the previous several days; this was done after rather than before experimental task participation to prevent bias. The statistics describing these demographic surveys were detailed below at the end of the Analysis and Results section. Further participant details were provided in Taylor et al. (2015).
2.3. Technical Implementation and Data Logging
We used a desk-mounted GazePoint GP3 eye tracker positioned directly under the computer monitor to pinpoint the users’ point of gaze, i.e., the point on the screen the user was fixating. All experimental presentation procedures, data collection, and analyses were fully automated. Python and PyGame were used to program the experiment, and interfaced with the eye tracker’s open standard API via TCP/IP, generously provided by GazePoint (http://www.gazept.com). The eye tracker has an accuracy of about [0.5–1] degrees of visual angle, and error was minimized by re-calibrating after every 150 s block. Data logging included the status of all experimental variables on every refresh (at 30 Hz) during experimental trials. Behavioral data were indexed by the location and status of all game elements, such as robot location, path location, target location, and time of target detection. Eye data were indexed by left and right point of gaze on the screen (x, y coordinates) at the refresh rate frequency, the calibration quality data (error quantity) before every new block, and pupil dilation of left and right eye diameter in milliliters at every time-step. Mouse location (x, y coordinates) was recorded at the same frequency for comparison with gaze data. Full technical experimental procedures were described in Taylor et al. (2015).
2.4. Statistical Procedures
Most statistics were displayed within figures themselves, either (1) as SEM bars, which in our experiment conservatively indicate statistically significant differences between groups by approximating t-tests if SEM bars are not overlapping between conditions, as explained below, (2) as pairwise t-tests superimposed on map bias task arrays, (3) as Pearson’s product moment correlation coefficient r and p-values superimposed on scatter plots, (4) and as effect sizes calculated via Cohen’s d (Table 1).
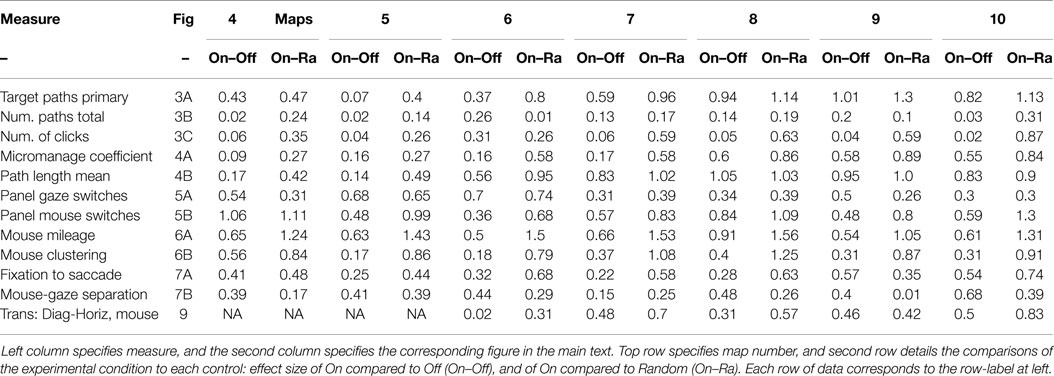 Table 1. Effect sizes presented as Cohen’s d.
Table 1. Effect sizes presented as Cohen’s d.
The t-statistic is defined as the difference between the means of two compared groups, divided by the SEM, (u1–u2)/SEM. Thus, within the parameters of this experiment (and above any typical n) it is a mathematical necessity that when the SEM bars do not overlap, a t-test on those same data would be significant above an alpha criterion of around p < 0.03 for a one-tailed t-test for effects in the expected direction (as most were in this experiment).
The low number of tests within proposed statistical families, the presence of consistent global trends, and guidelines cited here below, all argue against correcting any values for multiple comparisons (Rothman, 1990; Saville, 1990; Perneger, 1998; Feise, 2002; Gelman et al., 2012). Further, many statisticians do not recommend numerically correcting for multiple comparisons (Rothman, 1990; Saville, 1990). Rather, it is often suggested to document individual uncorrected comparisons and descriptive statistics (e.g., SEM or effect sizes), while being transparent that no correction was performed. Further, it should be noted that our conclusions rested not upon a single test, but upon globally uniform patterns.
Automated data processing and plotting were programed in the R-project statistical environment (Core Team, 2013).
3. Analysis and Results
3.1. Compliance with Gaze Assistance was Confirmed
3.1.1. Procedure and Justification
To determine whether participants actually used the assistive frame cue, we employed two overlapping measures to see how quickly participants responded to frame cues, one with the eyes, and another with the mouse: (1) For the eyes, we calculated the mean duration of the most neglected frame cue, for each of the 7 blocks (i.e., 4, 5, …, 10 map task panels) in the treatment group, only in the Helpful “On” condition. This duration was defined as an interval from when the most neglected cue frame started to highlight a map panel task to when that frame disappeared from that panel (Figure 2A). Since a cue frame disappeared from a panel immediately after that panel received the participant’s point of gaze, the duration is an estimate of the cue-to-eye response time. (2) For the mouse, we calculated the mean time between the most neglected frame cue starting to highlight a map panel task and a mouse clicking on that panel. We calculated this measure for each of the 7 blocks in “On” and “Random” groups (Figure 2B).
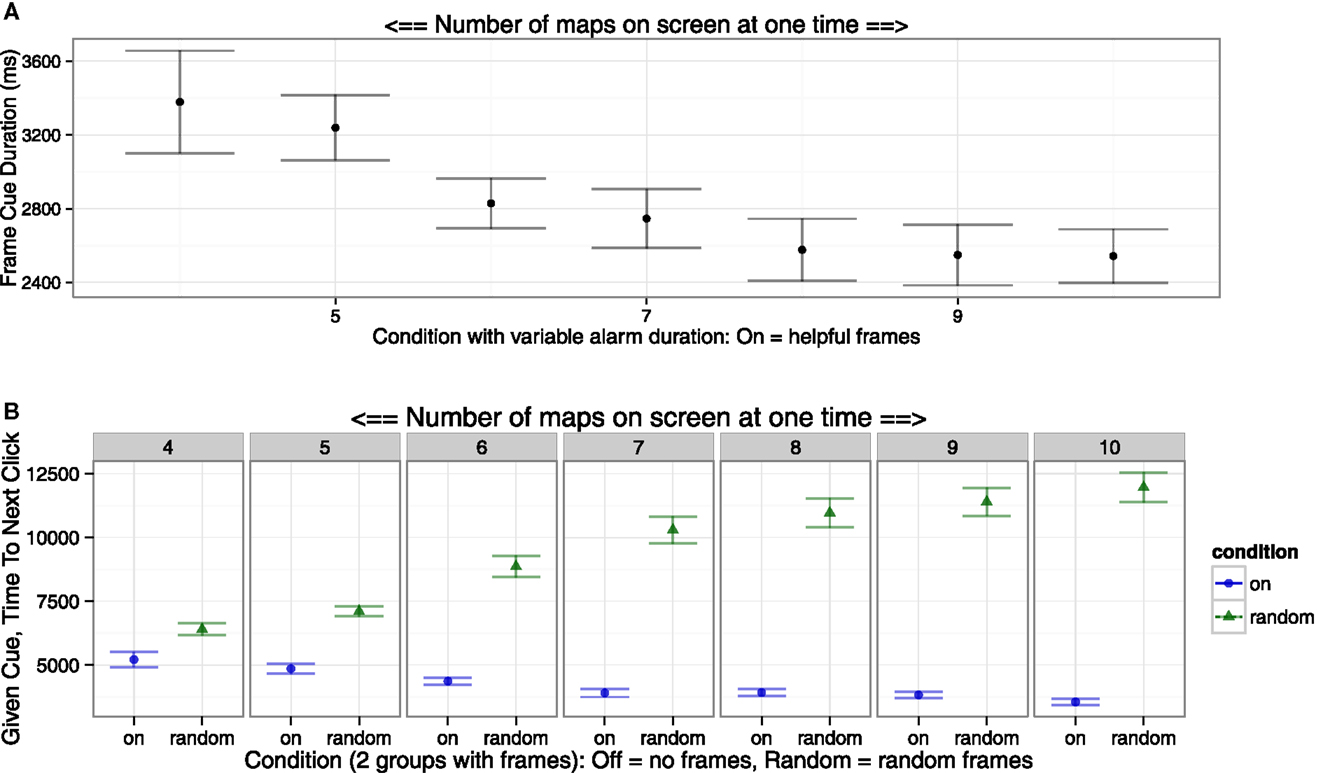
Figure 2. Participants followed the Helpful frame cue eye aid on average. (A) The duration of time a frame cue highlighted the most neglected map panel task served as an estimate of the time since the frame cue appeared until the participant looked at the cued map panel task. (B) Another similar duration was calculated: given that a frame cue was on the map panel task, the mean duration until participants clicked on that map panel task. Both results confirmed that participants were using the frame cues as instructed.
3.1.2. Result
The duration from the cue starting until the gaze or click interaction with that map task was reduced as map number increased (Figures 2A,B), perhaps reaching a lower threshold. Participants in the On group subjectively reported using the Helpful cues via verbal self-report during and after the experiment.
3.1.3. Interpretation
The decreasing durations for the Helpful frame cue condition suggested that the users were consistently looking at, and taking action (clicking), on the highlighted map panel tasks, confirming usage of the Helpful frame cue. This decrease in time means that participants utilized the cuing system to a greater degree over time, until an observed ceiling of compliance. The increasing duration in the Random condition associated with increased map task numbers, suggesting participants were choosing which map panel task to look at independently of the frame highlighting. This was as expected, since the participants in the Random condition were instructed that the frames were irrelevant to game-play.
3.2. Mouse and Click Efficiency Measures were Improved
3.2.1. Procedure and Justification
Multiple measures of mouse and click efficiency were calculated to determine the strategies employed by users in the better-performing Helpful frame cue condition: (1) The total number of paths users set to send the robot to primary targets was calculated; (2) the total number of paths was calculated as a baseline reference; (3) the total number of clicks was calculated as another baseline reference.
3.2.2. Result
The number of paths the users set to send the robot directly to primary targets was higher (better) with Helpful frames compared to both controls, while the Random condition had the lowest (worst) values (Figure 3A). The total number of paths set for robots to go to any location was not appreciably different between conditions (Figure 3B), and the total number of clicks in the block was not appreciably different (Figure 3C).
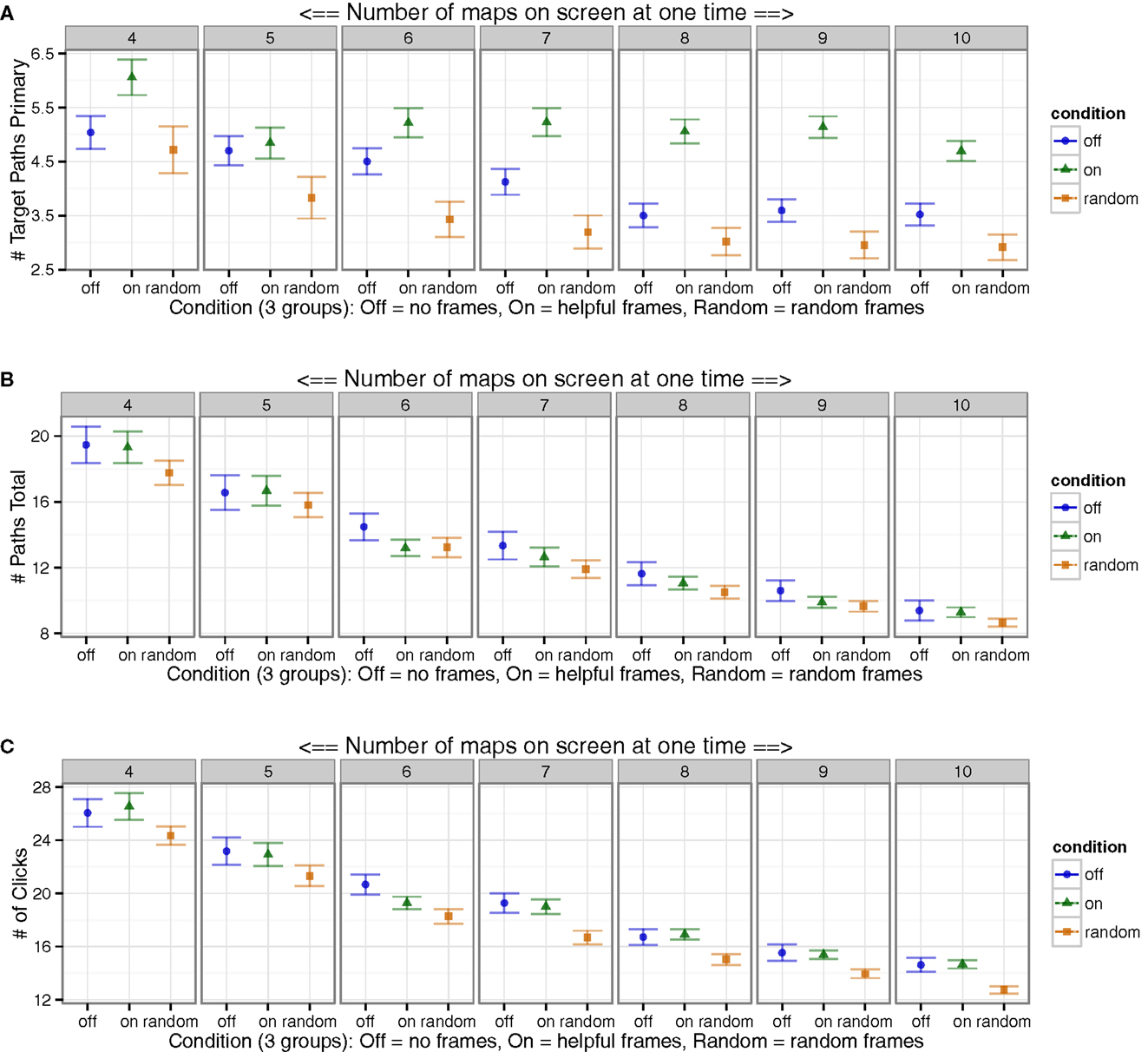
Figure 3. Participants clicked more efficiently. (A) Participants in Helpful frame conditions set a greater number of paths to targets (number of times the robot was sent directly to the target by the human). By contrast, there were no convincing effects for (B) total number of paths (number of locations the robot was directed toward by the human), or (C) total number of clicks (all clicks within the block, whether relevant or not). Overall, participants displayed an improved efficiency of strategy in their clicks.
3.2.3. Interpretation
Use of the eye tracking cuing system improved strategic efficiency of user’s mouse interaction with the task. Since it appeared that relevant clicks were increased in number over irrelevant clicks in the Helpful condition, these measures inspired the next analysis to explore micromanaging.
3.3. Micromanaging Measures were Reduced
3.3.1. Procedure and Justification
When performing the task a user could have either sequentially specified many intermediate path goals along the way to a target, or sent the semi-automated robot directly toward a primary rescue target with a single click at its ultimate goal. These two strategies illustrate the range of behaviors for “micromanaging” the robot’s location and path. Two measures of micromanaging were defined. (1) The ratio of clicking directly on-target path goals (clicking on the target) versus clicking on non-target (intermediate location) path goals was computed. This proportion resulted in our micromanaging coefficient, with lower numbers indicating less micromanaging (Figure 4A). (2) Another measure related to micromanaging was defined as the average length of a path. Path length was the mean distance from the robot’s current location, to the end-goal of the path set for that robot (Figure 4B).
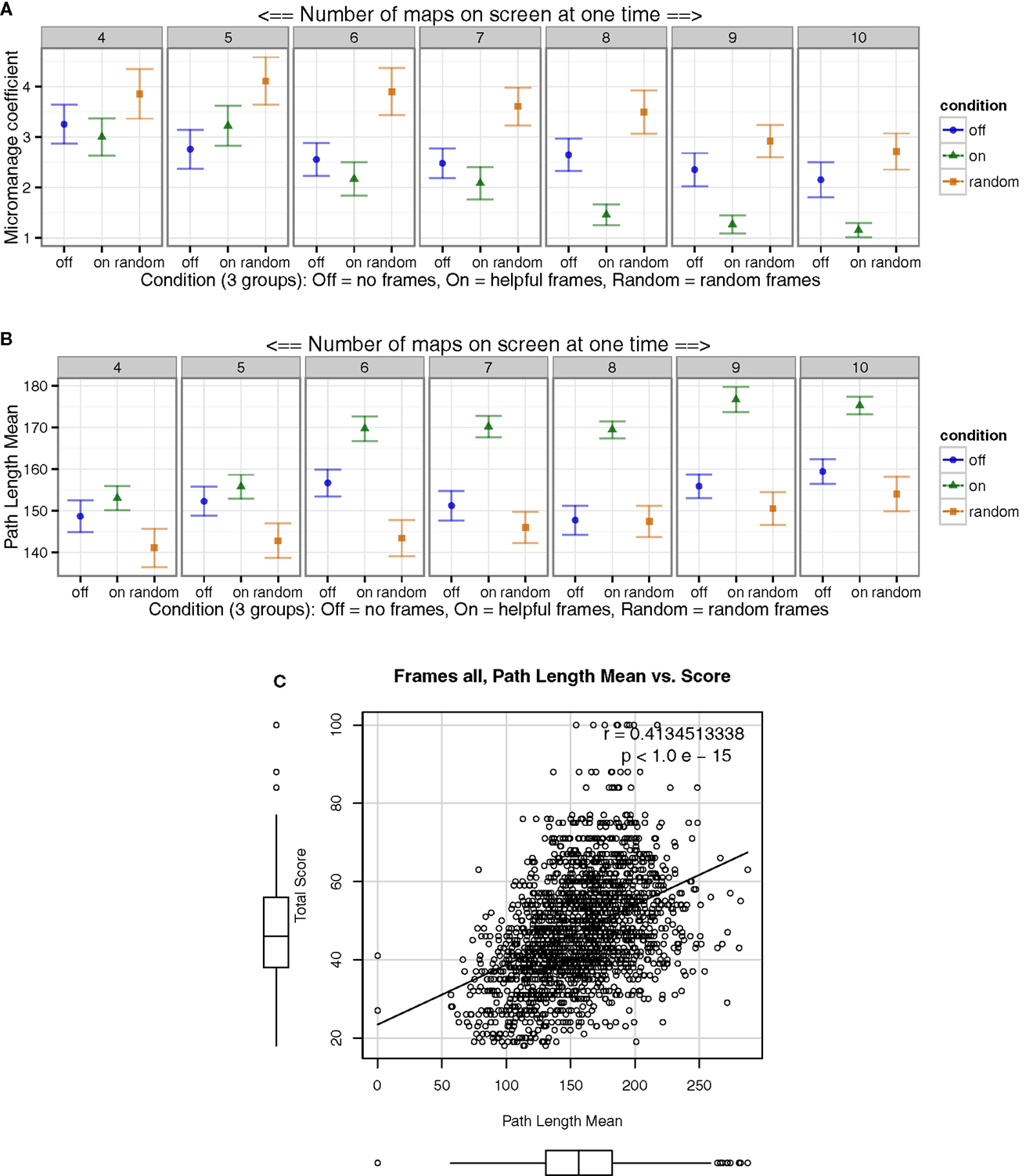
Figure 4. Micromanaging was reduced with Helpful frame cues. (A) Helpful frame groups micromanaged less than controls, by setting larger percentages of paths directly from the robot to the target, rather than specifying intermediate points along the way first. (B) We calculated a mean path length using the distance the robot had to cross to get to each assigned target location. Participants set longer more direct paths with the Helpful frames. (C) When including all, conditions, individuals, and blocks, in this analysis, longer paths associated with better performance, such that individuals who set longer paths tended to perform better. Overall, participants in the Helpful frame cue condition sent the robot more directly to targets, which allowed the robot algorithm to make micro-decisions.
3.3.2. Result
The Helpful frame cue condition demonstrated less micromanaging behavior than the Off frames condition, which in turn demonstrated less than the Random condition (Figure 4A). Path length was longer in the Helpful frame cue condition (Figure 4B). Interestingly, when averaging across all conditions, to plot all individual data points, longer path length was associated with higher total scores (Figure 4C).
3.3.3. Interpretation
These results highlighted the importance of utilizing automated systems to their fullest extent, often even when such automation is incomplete and error prone. Some robots heading directly to targets likely took inefficient paths, whereas other robots were not directed to targets at all, the latter being a much more important task to satisfy. This cuing system reduced such irrational perseverance and micromanaging behavior, and improved reliance on the semi-autonomous robots. Participants in the Helpful condition appeared to rely more on the robot’s sub-optimal automation.
3.4. Large-Scale Movement was Greater for Gaze and Reduced for Mouse
3.4.1. Procedure and Justification
To ascertain information about the type of movement strategies, the mouse and gaze were performing across conditions, the global and local dynamics of eye movements were explored. Multiple measures were calculated: (1) For both the mouse and the gaze, the number of times the mouse or gaze switched between map panel tasks in the array of 4–10 panels was calculated for each condition. The larger this number, the greater the global movement, and large-scale task switching. (2) A related measure was generated by taking the mean time that the mouse or gaze spent within a single map panel task, before leaving it and moving to the next map panel task, averaged across all map panel tasks in a single block.
3.4.2. Result
The Helpful frames increased the number of macro-level map panel task switches for gaze relative to the two control conditions (Figure 5A, left Y-axis). Fascinatingly, a similar measure for mouse movement yielded the opposite pattern, with reduced global mouse movement (Figure 5B, left Y-axis). This opposite pattern was confirmed in another related measure. With Helpful frames less eye time was spent per panel on average (Figure 5A, right Y-axis), while for the mouse, the opposite was true with more time per panel (Figure 5B, right Y-axis). Note that right Y-axes display inverted values. This increased activity of the gaze for global movement was also associated with higher total scores when comparing across all individuals in the study (Figure 5C).
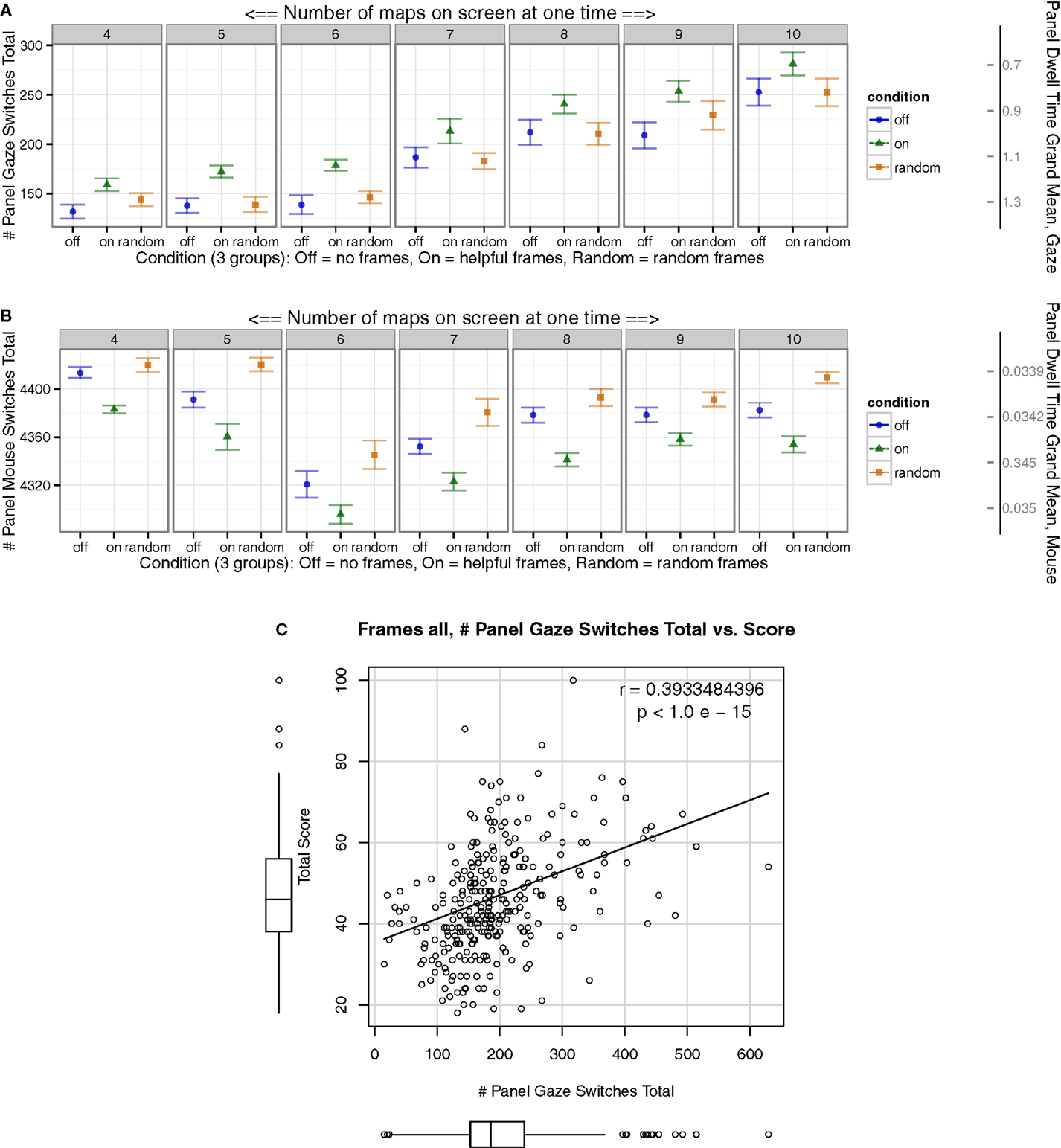
Figure 5. Participants’ gaze and mouse switches across map panel tasks (left Y-axis) and mean time spent on each map panel task before continuing (right Y-axis). [(A)-left] Gaze switched map tasks more frequently over the whole trial in the Helpful “On” condition compared to controls. [(B)-left] Mouse switched map tasks less frequently over the whole trial in the Helpful “On” condition compared to controls. [(A)-right]. Note: inverted scale. Participants spent less time gazing at each panel in the experimental “On” conditions, and [(B)-right] more time for mouse. (C) Number of gaze map panel task switches positively associated with better score across all observations. Overall, the gaze demonstrated more global movement, while the mouse showed reduced global movement.
3.4.3. Interpretation
These results suggested that gaze movements were more distributed, long range, or global, while the mouse made fewer macro-level map panel task transitions, perhaps for more efficient task switching. These results inspired the next measure, extending the investigation of mouse movements.
3.5. Mouse Movements Appeared more Local and Clustered
3.5.1. Procedure and Justification
To further characterize the global–local properties of mouse movements, these were analyzed using two measures: (1) The total cumulative distance covered by the mouse traversing the computer monitor over the course of a block, for each condition and block, was computed. (2) A novel measure of mouse-clustering was defined. Mouse movements were classified into clusters by setting an upper limit on the Euclidean distance (>2 cm) between a minimum number of sequential adjacent fixation coordinates, which spanned roughly 100 ms. We then quantified the proportion of mouse movements not in clusters (large movements) versus within clusters (small adjacent movements). The proportion of adjacent long movements (>2 cm) versus shorter movements estimated the degree to which mouse movements were clustered. Larger values indicate greater proportion of long movements, and smaller values indicate greater clustering (smaller movements).
3.5.2. Result
Surprisingly, despite the above discussed decrease in global mouse movement (number of panel mouse switches), an increase in mouse mileage was observed in the Helpful experimental condition, indicating more local movement relative to global movement with the mouse (Figure 6A). With Helpful frames, more clustered micro-movements were observed compared to the control conditions, and the Random condition showed an exaggerated decrease of mouse micro-movements with less clustering (Figure 6B). Greater cumulative mouse mileage over all observations was positively associated with higher total scores (Figure 6C).
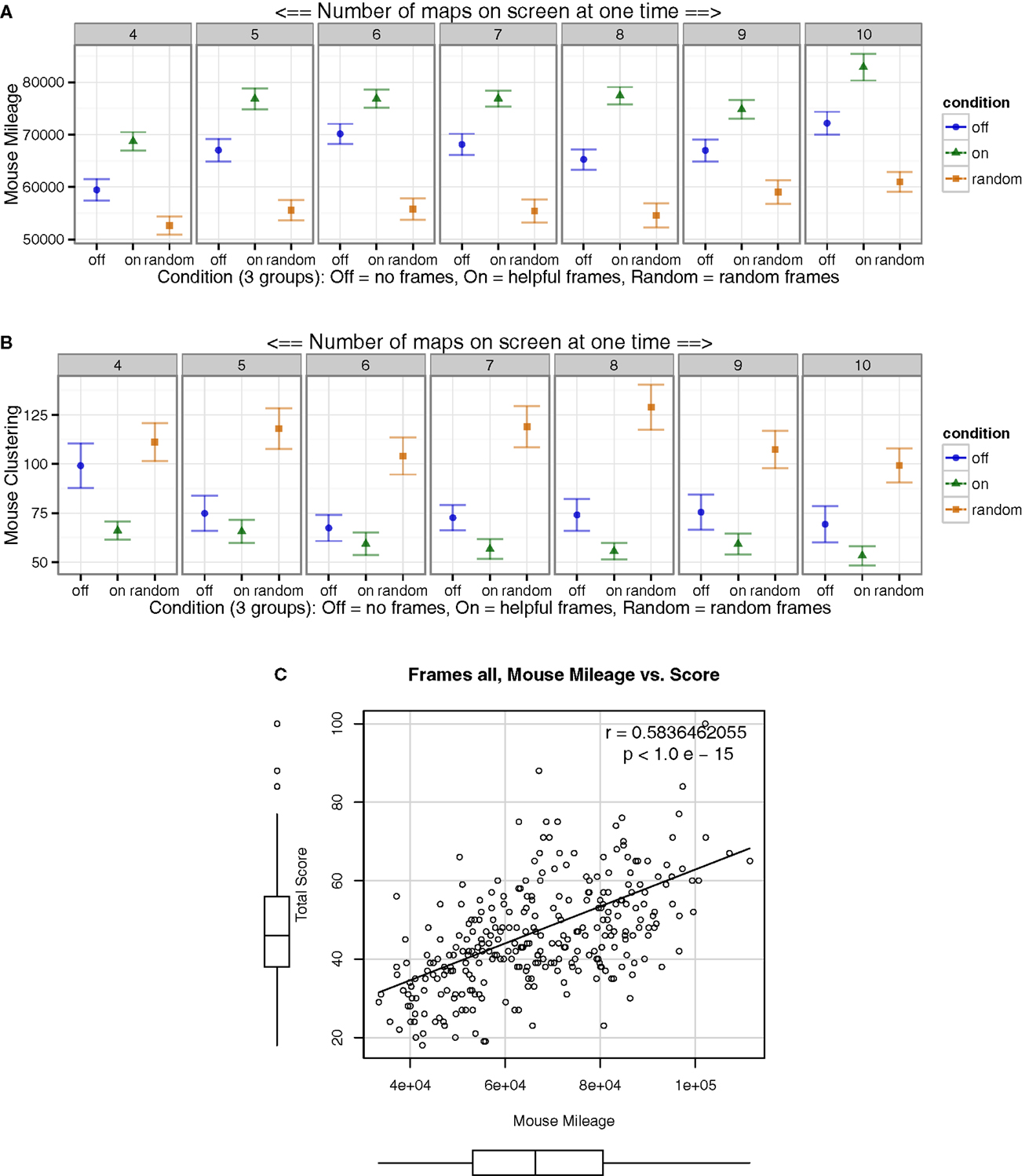
Figure 6. Mouse movements were more local and more clustered in the experimental “On” condition compared to controls. (A) Over the course of a block, the mouse traversed more total distance, in pixels, in “On” condition compared to controls. (B) Measures of mouse clustering were developed, with higher ratios indicating a greater proportion of larger distributed movements, and smaller numbers indicating increased proportion of clustered small movements. Y-axis plotted the ratio of long-range mouse movements/short-range adjacent movements. Mouse movements were more clustered in the Helpful experimental condition. (C) Greater mouse mileage associated with better performance. Overall, Helpful frame groups showed an increase in local mouse activity.
3.5.3. Interpretation
There was an observed opposite pattern in the gaze and mouse measures for map panel task switches (previously), which agreed with the current result of higher mouse mileage when compared to lower mouse global switches. Together, these indicated a functional specialization. Specifically, the mouse and gaze could work more independently; i.e., the gaze could search broadly, and the mouse could move in a more clustered local manner. In conclusion, with Helpful frames compared to other conditions, the eye-gaze appeared to specialize for global search, while the mouse for local movement.
3.6. Measures of Gaze Demonstrated more Saccades and Fewer Fixations
3.6.1. Procedure and Justification
Much previous work defines the basic terminology for eye-gaze patterns (Goldberg and Kotval, 1999; Jacob and Karn, 2003; Poole and Ball, 2006). A fixation is defined as a consistent gaze position within roughly two degrees of visual angle with a minimum duration (usually 100–200 ms), and velocity lower than a threshold (around 15–100°/s). Saccades are fast movements of the eyes, ranging from 20 to 100 ms depending on experimental context. A gaze is defined as a series of repeated contiguous fixations within an area of interest; a fixation occurring outside the area of interest ends the gaze. Search behavior can be characterized by breaking down punctuated eye movements to particular locations by their duration, into fixations (typically >120 ms) and saccades (typically <120 ms). Fixation and saccade measurements have been shown to be informative of attentional processing (Velichkovsky et al., 2000; Velichkovsky, 2002; Unema et al., 2005). Importantly, the fixation-to-saccade ratio has be used as an index of processing (fixation) versus search (saccades) (Goldberg and Kotval, 1999); higher ratios indicate either more processing and/or less search activity than lower ratios.
To further explore search behavior, two measures were computed: (1) We estimated the fixation-to-saccade ratio. Fixations were gazes lasting >120 ms, within roughly 1 cm, while any shorter duration movements were classified as saccades. (2) To explore the temporal relationship between the mouse and gaze during search, a measure of how long the mouse and gaze were separated before reuniting was calculated, the mouse-gaze separation duration. Specifically, when the mouse and gaze overlapped in 2D space (were on the same square centimeter), they were classified as overlapping. The mean duration between these overlap events was computed, to represent the duration of time the mouse and gaze spent separate. The average duration in time between these overlap events (i.e., the mean duration of time-segments where the mouse and gaze were separate) was plotted (Figure 7B).
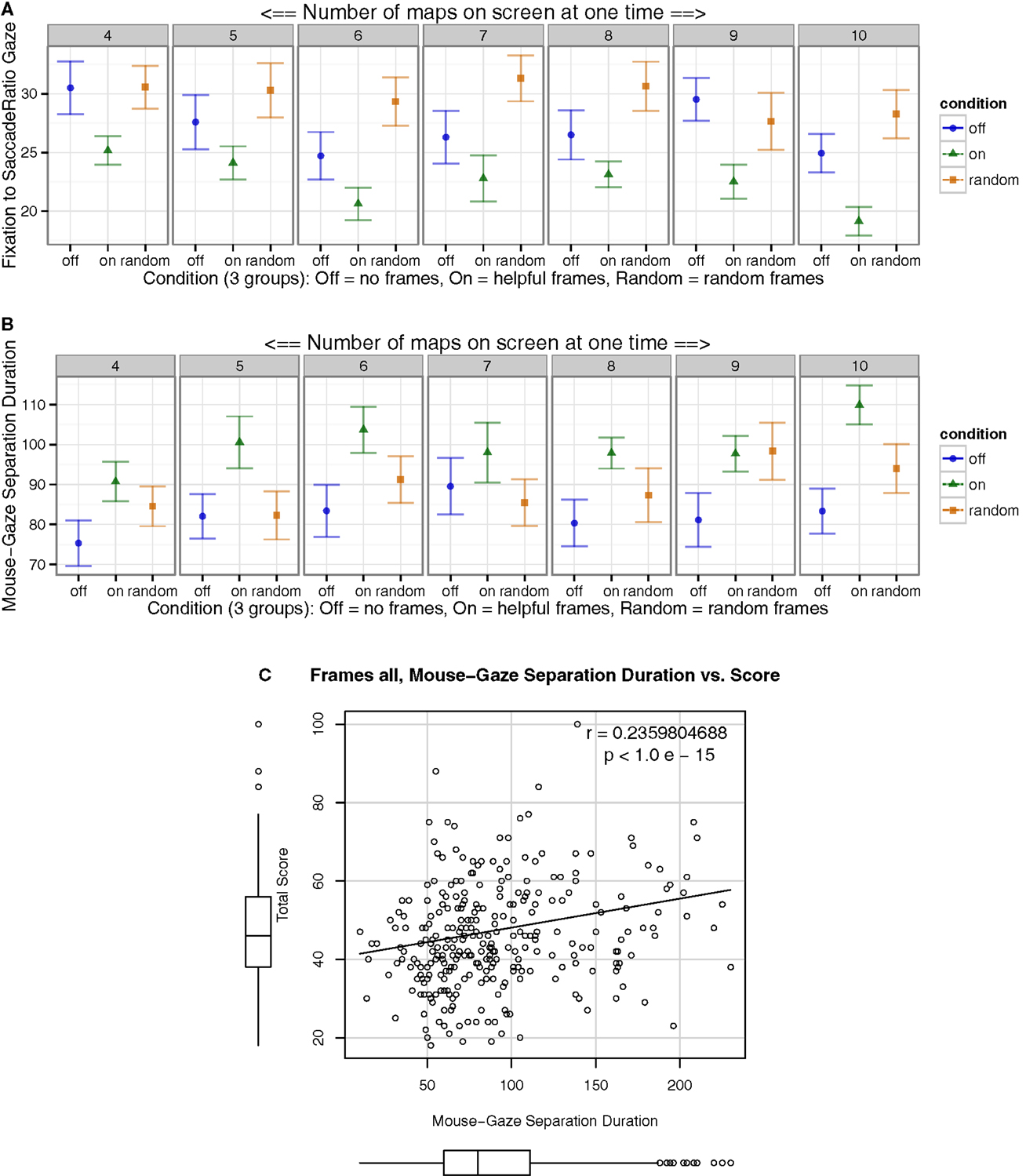
Figure 7. Gaze, “search” versus “processing.” (A) Results indicated more short saccades or fewer long fixations in experimental “On” condition. (B) In Helpful frame conditions, the duration of contiguous time the mouse and gaze were separate before reuniting (i.e., are close) was longer. Thus, the mouse and gaze were nearby less frequently with Helpful frames than controls. (C) Mouse-gaze separation duration associated with better performance. Overall, in the Helpful frames condition, the gaze appeared to specialize for search behavior, and the mouse and gaze remained distant longer.
3.6.2. Result
In the Helpful frames condition, the fixation-to-saccade ratio was lower, with a smaller proportion of fixations or greater proportion of saccades (Figure 7A). Further, the Random condition had larger ratios than the Off condition. With Helpful frames the duration in mean time the mouse and gaze were separate for a contiguous block before reuniting, was larger compared to controls (Figure 7B). Though the Random condition may have had a longer mouse-gaze separation duration than Off, these differences were not consistent. Greater duration of time between this spatial overlap of mouse and gaze positively associated with higher total scores (Figure 7C).
3.6.3. Interpretation
More short saccades and fewer long fixations would be classically interpreted to mean that participants searched more and processed less, respectively. These results indicated that the eye gaze may have specialized for search behavior (saccades) over processing (fixations), which could then be more efficient and directed. This was congruent with the above finding of greater global movement of the eyes with Helpful frames. This further supports the notion that the mouse and gaze were able to be functionally and spatially independent to a greater degree in the Helpful frames condition. This indicates a functional specialization of the mouse and gaze in the Helpful frames condition.
3.7. Gaze, Mouse, and Click Timing: The Hand is Quicker than the Eye
3.7.1. Procedure and Justification
To further elucidate mouse-gaze relationships, three more novel measures were defined: (1) Mouse-gaze distance around click. It was predicted that the mouse and gaze would be closer in 2D space around the time of a click, relative to when clicks were not occurring. To test this prediction, the distance between the mouse and gaze was plotted as a function of time, time-locked to the click, averaged across all clicks and across all blocks (Figure 8A). Time-locking refers to using a consistent time-point of reference for the purpose of averaging in relation to that point. In order to calculate the mean distance time series, for each click, we collected the time series of mouse and gaze position information 200 ms before and after that click, and computed the mouse-gaze distance during that period surrounding the click. For example, there were many clicks for each participant over the course of the experiment. For every click in each condition, we calculated mouse-gaze distances between the 200 ms before and after the click, generating as many time-series as clicks. The time-course of mouse-gaze distance was averaged over all these instances while time-locked to the click. To do so, for each point in time within the window (33 ms increments), we calculated the average distance at that equivalent time point across all time series. Following this procedure, we were able to generate a single distance time series for each condition. This measure was inspired by event related potential (ERP) analyses derived from electroencephalogram (EEG) recordings of neuronal activity. In those analysis, EEG waveforms are averaged time-locked to a particular event of interest to increase the signal to noise (SNR) of the neurological correlates of that event, when the neurological event is minuscule relative to background noise. This method applied here served to increase the SNR of factors related to clicks (mouse-gaze distance), revealing the small statistical relationship between mouse and gaze, in relation to the timing of clicks. (2) Mouse-click distance around click. A similar measure was calculated where the location of the click was treated as fixed, and artificially distributed to the entire “mouse” time-line, and then compared to the gaze over the same duration. In other words, the distance between the gaze and the click itself was plotted over the time just before and after the click. (3) Time-stepped mouse-gaze correlation. To further explore whether the gaze follows the mouse, or the opposite, a measure of mouse-gaze correlation was computed over parametrically varied artificial time-shifts. For a mouse position point and a gaze position at the same point of time, we first calculated their distance, and this was the 0 delay scenario. Then, we shifted the time series of mouse positions forward, e.g., the original time 0 became now −33 ms, denoted as delay −33 ms, and used the new mouse position and gaze position at the adjacent point in time to calculate mouse-gaze distance. In other words, the coordinates for the mouse at time-step t = 0, were used to calculate a distance from the gaze, at the same time-step (t = 0), or at later or earlier time-steps (t = −33 ms or +33 ms.). First, the mouse coordinates at t = 0 were compared to the gaze coordinates at t = 0. Then, the mouse coordinates at t = +33 ms were compared to the gaze location at t = 0. This was iterated forward and backward in time. The delay with the minimum distance in this plot was the timing at which the mouse and gaze were closest (most correlated) in space, out of all possible artificial time-shifts we calculated. The average distance between mouse and gaze was plotted as a function of the time-offset (Figure 8B).
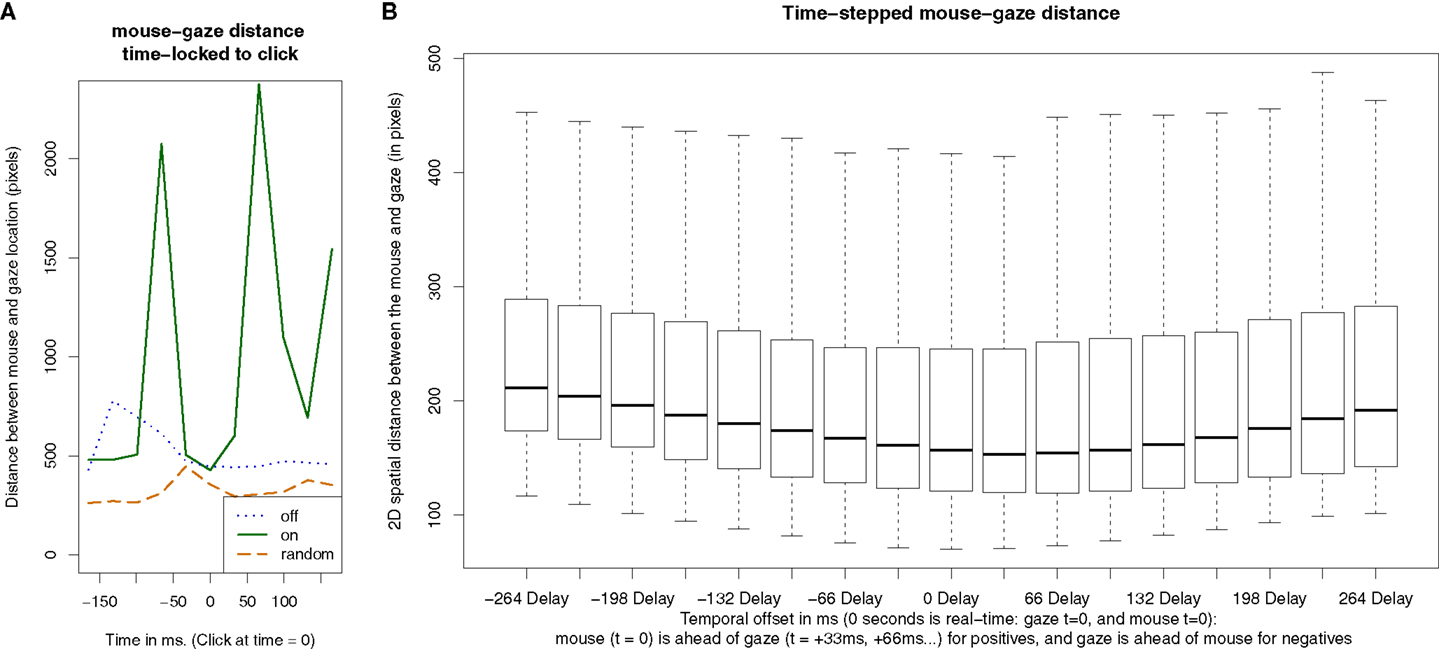
Figure 8. Mouse-gaze-click temporal relationships. (A) Mean mouse-gaze distance time-locked to the click across all trials (see text for details). Y-axis is 2D spatial distance between mouse and gaze. In the Helpful condition, participants’ mouse and gaze worked more independently, apparently moving further apart between clicks. Based on minima in distance relative to click (+20 to +55 ms), mouse might have slightly lead or preceded gaze. (B) Mouse and gaze distance, as a function of repeated artificial shift in time to compare location, either comparing present to past locations of mouse and gaze, or present to future locations. Y-axis is 2D distance between mouse and gaze. 0 delay is real (actual) time for both mouse and gaze. Based on which offset minimizes distance (mouse ahead of gaze by 33 or 66 ms), mouse location may predict gaze location in time. It is important to note that, on the right half of the plot, the coordinates in mouse distance are at t = 0 with the gaze following at later time-steps (33 ms increments), and on the left half of the plot the gaze is at t = 0 with the mouse following at later time-steps. Overall, both measures indirectly suggested that the mouse may have lead the gaze.
3.7.2. Result
The mouse and gaze appeared distant from each other, except when they came close immediately after a click (Figure 8A). In the Helpful “On” frames condition, the mouse and gaze were much further apart immediately preceding and following the click. The distance between mouse and gaze may have been closest around 25–50 ms after the click, congruent with the possibility that the mouse location may lead or predict the location of the gaze (Figure 8A). Gaze-click distance (not graphically depicted) results appeared equivalent to mouse-gaze distance plots (Figure 8A). Time-stepped mouse-gaze correlations demonstrated that the mouse and gaze were closest when the mouse lead the gaze by 33 ms (Figure 8B).
3.7.3. Interpretation
The mouse-gaze-click analysis further extended the earlier observation that the mouse and gaze may have been functionally specialized to a greater degree in the Helpful frames “On” condition. An equivalence of gaze-click-click and gaze-mouse-click plots indicated that the mouse stills, slowing movement just before the click to a greater degree than the gaze, which continues to move up until the click. The click analyses and the time-stepped correlation both indicate, but do not necessitate, the conclusion that the mouse preceded the gaze. These two findings supported the adage that the “the hand is quicker than the eye,” and previous studies (Land et al., 1999; Ishida and Sawada, 2004). Some studies have also found that when manipulating objects the eyes follow the hand (Ballard et al., 1992). Note, we only assert that the measured variable of mouse predicts the measured eye-gaze location, not that one causes the other. A causal model might include covert attention and internal motor-planning, which cause both the hand to move and the eyes to follow. These ideas are congruent with the role of intention and covert attention preceding eye movements, e.g., as is demonstrated in parafoveal preview (scanning the upcoming words with non-foveal retina) benefiting reading speeds. Mouse-gaze-click measures suggested a greater independence of function of mouse and gaze for the Helpful conditions.
3.8. Commonly Occurring Horizontal Transition Biases were Reduced
3.8.1. Procedure and Justification
Much previous work has demonstrated that human observers have a bias toward horizontal detection and transition over a diagonal, even when diagonal transitions are optimal (Megaw and Richardson, 1979; Parasuraman, 1986; Donk, 1994; Bellenkes et al., 1997). It has been hypothesized that the human visual system has a bias and enhanced ability to process horizontal search or change (over vertical) due to the overwhelming experience of most land dwelling vertebrates with information varying more in horizontal plane than the vertical; alternatively, the majority of written languages are read on a horizontal plane, with years of reading experience also providing extensive practice with horizontal visual shifts. To determine which specific biases users were overcoming in mouse movements, we calculated full transition matrices, for each block and condition. Each mouse transition matrix contained the frequency of mouse transition from every map panel task, to every other map panel task, over the entire block. These matrices were then used to calculate horizontal and diagonal transition counts for the mouse. These were then used to compute the proportion of mouse cursor transitions diagonally versus horizontally (Figure 9).
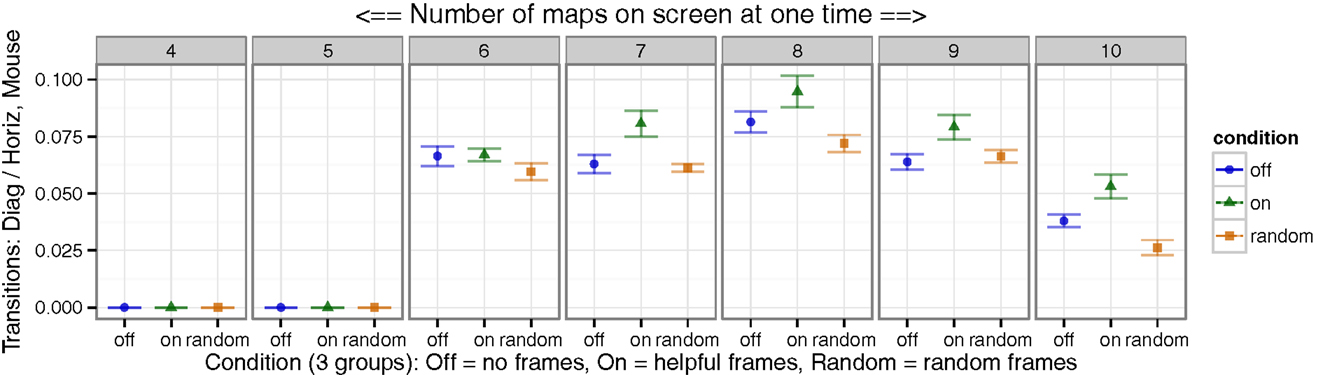
Figure 9. Mouse transitional frequencies were less biased horizontally. Since horizontal transitions are typically over-represented in humans, we measured the ratio of diagonal map-to-map transitions, over horizontal transitions. Greater diagonal relative to horizontal transitions were observed for mouse movement in the Helpful condition. For blocks with only 4 or 5 map panel tasks, all fit on one row, and thus there were no diagonal transitions. The Helpful group displayed reduced common toward horizontal search behaviors.
3.8.2. Result
With Helpful frames, participants transitioned more frequently between map panel tasks diagonally relative to horizontally in the Helpful frames condition compared to controls (Figure 9).
3.8.3. Interpretation
In addition to our previous demonstration of reducing global bias (Taylor et al., 2015), this finding further suggested that the Helpful frames may have reduced common biases and improved rational search behavior.
3.9. Effect Sizes
To measure effect sizes, Cohen’s d was computed for the comparison of each control to the experimental condition. Traditional specifications classify effect sizes as: small at around <0.2, medium ranging from 0.3–0.6, and large >0.6–0.8. With Cohens d around 1, a difference between the means is large, at one full SD. With a Cohen’s d value of 1, it is also the case that there is a 76% chance that a participant sampled randomly from our experimental condition will have a higher score than a participant chosen randomly from a control condition (i.e., probability of superiority), and that 84% of our experimental group is above the mean of a control group (i.e., Cohen’s U3 percentage). Many of our theoretically relevant effects demonstrated large effect sizes around 1 or greater (Table 1).
3.10. Participant Sample Statistics
We confirmed that there were no incidental differences between subject groups in each condition for measured features known to influence experimental performance. To do so, we tested the null hypothesis that each group had the same population mean using ANOVA for the following measures: (A) hours of sleep in the previous week did not differ (F = 0.2, p < 0.8), (B) mean age in years was 26 and did not differ (F = 1.2, p < 0.3), and (C) multiple measures of video game experience did not vary between conditions, as measured by post-experimental surveys assessing multiple measures of gaming frequency (F = 0.8, p < 0.5 – days/year; F = 0.8, p < 0.5 – h/week), and gaming history (F = 0.1, p < 0.9 – duration; F = 0.5, p < 0.6 – age started playing). Full details were included in Taylor et al. (2015).
4. Discussion and Related Work
4.1. Divided Attention and Bias, Supervisory Sampling, and Search
Dividing attention over multiple tasks or entities is notoriously problematic for most humans (Watson and Strayer, 2010). For example, operators have been found to be overly biased to the most important elements of a display (Bellenkes et al., 1997). Biases for search and scanning patterns appear in the upper left of a display, hypothesized as an artifact of western left-to-right reading (Megaw and Richardson, 1979). Operators are biased to use horizontal over diagonal eye movements and scanning patterns, even when diagonal scanning was optimal (Donk, 1994). Search also tends to be overly biased toward central regions of available visual space, termed an “edge effect” (Parasuraman, 1986). To remedy some problems with divided attention, augmented displays have been the subject of extensive study, such as classic experiments with heads up displays (HUD), which superimposed important information transparently over the frontal field of view (Weintraub, 1992; Newman, 1995; Wickens, 1997; Wickens and Seidler, 1997), with mixed results, such that care must be taken when designing such assistive systems.
In supervisory control sampling tasks, where operators perform something like instrument scanning or sampling (Moray, 1981, 1986), expertise improves sampling probabilities (Bellenkes et al., 1997). Sampling reminders for these tasks similarly improve user performance (Moray, 1981). This functions in part because generally, cuing targets can speed or increase the accuracy of detection (Eriksen and Collins, 1969). Highlighting display elements in a multi-display may assist in directing attention (Fisher and Tan, 1989; Hammer, 1999). Cuing for target detection has been studied in the real world in helmet displays, finding that cues were helpful for expected targets, but harmful for unexpected targets (Yeh et al., 1998). In theoretical support of external cuing, it has been suggested that exogenously captured attention drives faster saccades than endogenously intended reaction times as measured by saccades (Kean and Lambert, 2003). Predictive displays show operators what possible future states might arise (Kelley, 1968; Gallaher et al., 1977; Lintern et al., 1990). Preview of which element to attend to next may ameliorate delays for rapid decision making (Grossman, 1960; Elkind and Sprague, 1961; Reid and Drewell, 1972; Grunwald, 1985). Our algorithm took advantage of many of these principles, using a simple external cue, which applies domain-generally.
4.2. Task Switching
The costs for task switching are many: the rapid decision making required, the code-switching needed to switch between tasks, and the observed perseverance bias for continuing tasks longer than ideal (Jersild, 1927; Sheridan, 1972; Moray, 1986; Rogers and Monsell, 1995; Schutte and Trujillo, 1996). For tracking or decision tasks, a limit has been observed where human operators can not reliably make greater than two decisions per second (Craik, 1948; Elkind and Sprague, 1961; Fitts and Posner, 1967; Debecker and Desmedt, 1970). Our system potentially eliminates one decision per second, or per map switch, a non-trivial benefit.
Irrational perseverance is also illustrated by a past study showing that when noticing a problem with one element, operators failed to continue monitoring all tasks well, and did not move on effectively (Moray and Rotenberg, 1989), which may have been observed with our control conditions micromanaging more. For task management, it has been shown that operators’ planning strategies are not elaborate or ideal, and are typically overly simplified (Liao and Moray, 1993; Raby and Wickens, 1994; Laudeman and Palmer, 1995), because these planning strategies are resource intensive and require high cognitive workload (Tulga and Sheridan, 1980). Confusion between tasks when task switching is greater for sub-tasks which are similar when compared to sub-tasks which are dissimilar (Hirst and Kalmar, 1987), perhaps due to what is termed outcome conflict (Navon, 1984; Navon and Miller, 1987). Outcome conflict is complementary but different from the multiple resource model (Wickens et al., 1986), where different types of sensory input to an operator interfere less than similar input (Tayyari and Smith, 1987; Martin et al., 1988). Our system was particularly helpful for managing multiple similar tasks.
To ameliorate task switching costs, visual external cues for task switching may assist operators (Allport et al., 1994; Wickens, 1997). Cuing important or neglected tasks can be helpful (Wiener and Curry, 1980; Funk, 1996; Hammer, 1999); however, doing so successfully in a domain-general manner has not been accomplished. Secondary tasks have long been used to index workload for a primary task (Rolfe, 1973; Ogden et al., 1979); while indirectly these results speak to the benefit of eliminating the secondary task (tracking gaze history) in our game. Therefore, for high workload situations (like 8 or more maps here) it may be optimal to have a computer-externalized planning strategy.
Our studies took advantage of these phenomena to optimize the primary task, when a secondary task is also helpful to perform, but can be performed by the computer. Our frame cue aid may allow for more full focus on a single map, with more effective and rapid task switching between maps.
4.3. Working Memory
With multiple entities to track and evaluate, past studies showed that the human user is often limited by functional working memory load. Different working memory resources are thought to exist for different modalities or mental processes; for example, visual working memory has been proposed to be stored in what is called the visuospatial sketchpad (Salway and Logie, 1995), with dissociable memory components for different modalities (e.g., auditory) or even visual domains (Logie and Pearson, 1997). Without rehearsal, the typical duration of working memory is 10–20s, though with more items in a set to remember the set decays even faster (Brown, 1958; Peterson and Peterson, 1959; Melton, 1963; Moray, 1986). The classically proposed number of items capable of maintenance in working memory is seven chunks of familiar information, plus or minus two (Miller, 1956). However, artificial lab experiments produced an unrealistically high estimate of seven items, whereas the real-world version of working memory (running memory) is probably closer to five chunks of familiar information (Moray, 1980). Expertise expands working memory for items for which the expert has experience, for example, in chess (Chase and Simon, 1973; Groot, 1978; Gobet, 1998) or computer programing (Vessey, 1985; Ye and Salvendy, 1994; Barfield, 1997), in part via chunking (Anderson and Neely, 1996a,b; Anderson et al., 1996). In summary, a single human is capable, in principle, of monitoring multiple semi-autonomous operations, but the number is limited, in part, by running memory capacity. We expanded this functional capacity for multi-agent management tasks, by delegating working memory requirements to the computer.
With industrial relevance, vigilance tasks are hypothesized to produce continuous loads on working memory (Parasuraman, 1979; Deaton and Parasuraman, 1988). Working memory updating is error prone when updating a similar variable repeatedly (as in map location) as opposed to different variables (Yntema, 1963). Items in working memory can experience retroactive interference where items presented later interfere with the first, as well as proactive interference where items presented before an item to be remembered interfere (McGeoch, 1936; Keppel and Underwood, 1962; Anderson and Neely, 1996a), while up to 10 s between item presentation is needed to offset these interference effects. Maintaining an item in working memory is interfered with by having participants attempt to maintain a second similar set of items, more than if the second set of items is dissimilar to the first (McGeoch, 1936; Bailey, 1989; Anderson and Neely, 1996a,b). For example, presenting new spatial information interferes with previously presented spatial information, compared to interference from non-spatial information (Hole, 1996). Particularly for a spatial task-like robot manipulation, spatial working memory is taxed by performing multiple spatial tasks at one time. Short-term or working memory capacity is further limited by the fact that keeping track of which items need to be re-checked (secondary task) uses the same cognitive resources as the spatial manipulation task (primary task), further limiting task performance by the necessity of remembering attention history.
To perform optimally the user must, among other things, remember where was monitored last, since the longer the time that has elapsed since a check, the greater the probability of a situation requiring human assistance; this, however, is also a spatial working memory task. With high numbers of tasks, working memory load increases, as measured by blunting typical assistance via peripheral preview (Tulga and Sheridan, 1980). Previous studies have shown it can be practically helpful to supplement working memory with an external display, e.g., air traffic control (Wiener and Nagel, 1988) or cockpit display of traffic information (CDTI) (Hart and Loomis, 1980).
Our algorithm aids multitasking in a domain-general manner, for the first time. It is likely that one mechanism of action was via the delegation of short-term working memory to the computer in real time, freeing cognitive resources from a secondary task, so that the resources can be invested in the primary task.
4.4. Augmented Cognition, Human-Agent, Human–Robot, Human–Swarm Interaction, and Automation Assistance
Extensive research has been performed under DARPA initiatives to further real-time assistance for technical scenarios (St. John et al., 2004). In such studies of augmented cognition, assistance often involves detection and utilization of the human operator’s mental state to optimize performance (Dorneich et al., 2003; Schmorrow and McBride, 2004; Erdogmus et al., 2005; Greitzer, 2005; Ivory et al., 2005; Miller and Dorneich, 2006; Carlson et al., 2007; Fuchs et al., 2007b; Kollmorgen, 2007; Schmorrow and Reeves, 2007; Barber et al., 2008; Ushakov and Bubeev, 2008; Vogel-Walcutt et al., 2008; Agarwal and Dagli, 2013; Kolsch et al., 2013; Abbass et al., 2014; Putze and Schultz, 2014).
Similarly, human–robot interaction must be optimized for human performance; such studies take the form of designing command interfaces, optimizing naturalness, gesture-based communication, hardware design, and social considerations (Waldherr et al., 2000; Goodrich and Schultz, 2007; Lavine et al., 2007; Pfeifer et al., 2007; Bicho et al., 2011; Goodrich et al., 2011a,b; Lenzi et al., 2011; Sciutti et al., 2012; Canning and Scheutz, 2013; Kondo et al., 2013; Murphy and Schreckenghost, 2013; Tiberio et al., 2013; Trafton et al., 2013). Human–robot interactions are not always singular, and there has been progress in the design and communication of human–robot teams (Cuevas et al., 2007; Fiore et al., 2011). These multi-agent communications become even more complex when considering autonomous swarm-based agents, and some studies have begun to make progress in improving human control of swarms (Naghsh et al., 2008; Hashimoto et al., 2009; Marjovi et al., 2009; Ducatelle et al., 2011; Penders et al., 2011; Giusti et al., 2012a,b; Goodrich et al., 2012, 2013; Kerman et al., 2012; Kolling et al., 2012, 2013; Nagi et al., 2012; Brambilla et al., 2013; Mi and Yang, 2013). We build upon these studies by demonstrating a method to improve human control over multiple automated agents.
Though simple cuing can assist users in knowing what to attend to in multitasking scenarios (Seidlits et al., 2003; Boucheix and Lowe, 2010; Groen and Noyes, 2010; Ozcelik et al., 2010), the highly complex multitasking needed to manage multiple autonomous agents, requires more advanced computational assistance. For more abstract or complex tasks, proceduralization is a term used to define systematic externalized systems for improving decision making (Bazerman, 1998), often with computer assistance (Dawes et al., 1989), which our system does. Computerized displays to assist users in decision making are often domain-specific expert systems (Shortliffe, 1983; Chignell and Peterson, 1988; Schkade and Kleinmuntz, 1994; Stone et al., 1997), whereas our system is domain-general. Automation assistance has been developed to assist human users in managing automation when the tasks are complex and dynamic (Endsley, 1999; Inagaki, 2003; Kaber and Endsley, 2004), which our algorithm would assist with as well.
4.5. Real-Time Eye Tracking: Pupil Size, Contingent, Gaze-Control, and Gaze-Aware
Gaze location can be used to modify a display or physical device in real-time, depending on either pupil size or on the location of gaze itself, with both summarized in the following five parts: (1) Augmented cognition, (2) Contingency, (3) Gaze-control, (4) Gaze-aware systems, and (5) Previous limitations.
4.5.1. Augmented Cognition: Real-Time Assessment and Utilization of Pupil Size, as a Theoretical Proxy for Cognitive Load
The DARPA augmented cognition initiative has considered the use of gaze tracking as a potentially important for assisting users in military scenarios (Crosby et al., 2003; Marshall and Raley, 2004; Nicholson et al., 2005; Fuchs et al., 2007a; Stanney et al., 2009). The majority of these studies used pupil dilation as a measure of cognitive load (Marshall, 2002; Marshall et al., 2003; St John et al., 2003; Taylor et al., 2003; Raley et al., 2004; St. John et al., 2004; Johnson et al., 2005; Mathan et al., 2005; Russo et al., 2005; Ververs et al., 2005; De Greef et al., 2007; Coyne et al., 2009), while only few attempted to actually develop the technical infrastructure for real-time assistance via gaze location (Barber et al., 2008), though none produced results using gaze location.
4.5.2. Contingent: Gaze-Based Real-Time Display Updating, as an Experimental Tool
Contingent (interactive) eye tracking is defined as modifying a display or process in real-time based on gaze location, and has previously been used in lab experiments, though often as an impediment, not for the point of optimizing performance. Early in the development of the technology, the fields of linguistics and reading employed paradigms like the moving window paradigm (Reder, 1973; McConkie and Rayner, 1975), which impedes the user in real-time by replacing the upcoming periphery with noise or random letters, for example, while reading, to eliminate parafoveal preview; alternately one can also blur the periphery. The moving mask paradigm is the opposite, blurring the fovea (Rayner and Bertera, 1979); the moving mask paradigm has been used to study visual learning (Castelhano and Henderson, 2008) and visual search (Miellet et al., 2010). Another method is the parafoveal magnification paradigm (Miellet et al., 2009), which involves magnifying the periphery, to compensate for reduced resolution in the periphery, and is also used in reading studies to manipulate parafoveal preview. Others have created a central hole allowing visibility only at the fovea, like seeing through a telescope (Shimojo et al., 2003). In light of the fact that breaking or harming performance can serve as an excellent experimental probe, these paradigms were successful. However, none improved human performance on a practical task in real-time.
4.5.3. Gaze Control: Computer, Robot, and Swarm Control
A very large quantity of work on gaze-based paradigms, which are intended to control computerized systems, wheelchairs, or other robots with the eyes, exists. These have been pioneered both inside academia and out, for groups of individuals with diseases like amyotrophic lateral sclerosis (ALS), a peripheral motor-neuron disease paralyzing the body, while leaving eye movements in tact. These studies most often involve the movement of a cursor, wheelchair, and accessories via the point of gaze, while defining a variety of mouse-click paradigms, including blinks and others, as well as the use of gaze location to control computer graphical menus, zooming of windows, or context-sensitive presentation of information (Jacob, 1990, 1991, 1993a,b; Jakob, 1998; Zhai et al., 1999; Tanriverdi and Jacob, 2000; Ashmore et al., 2005; Laqua et al., 2007; Liu et al., 2012; Sundstedt, 2012; Hild et al., 2013; Wankhede et al., 2013). These paradigms have been extended to improve upon human control of robots (Carlson and Demiris, 2009), as well as humans controlling swarms (Couture-Beil et al., 2010; Monajjemi et al., 2013). Our study may assist those attempting to control multiple robots or swarms, since the algorithm may improve a variety of such control systems.
Many of these gaze control-based paradigms are very beneficial, and some include gaze-aware features, though we would like to distinguish the purely gaze-aware from the purely control or control which has some additional assistive function. The experiments presented here demonstrate a gaze-aware system, which can improve performance, without direct input, and may assist operators in a variety of scenarios, both control and non-control. We now progress to further discussion of gaze-aware components.
4.5.4. Gaze-Aware: Command vs. Assistance, Domain-Specific vs. General, and Descriptive vs. Predictive
Most gaze-display paradigms have some control component, though some displays are purely gaze-aware but not intended for user assistance: for example, video compression is used in gaze contingent displays (GCDs) to maintain image resolution while compressing the periphery and to optimize computational resources (Reingold et al., 2003; Duchowski et al., 2004; Loschky and Wolverton, 2007). Despite the fact that they do not assist the user, these systems illustrate many good features of user-assisting systems: being non-intrusive, intuitive, transparent, and non-command, features which are currently underrepresented in gaze or attentive user interfaces (AUIs).
Most of the currently existing gaze-aware systems or AUIs actually also include an active control component, for example, in the selection of which window to interact with, or which menu item to enlarge. Many of these attentive or gaze-aware interfaces are also quite domain-specific, with examples including reading, menu selection, scrolling, or information presentation (Bolt, 1981; Starker and Bolt, 1990; Sibert and Jacob, 2000; Hyrskykari et al., 2003; Fono and Vertegaal, 2004, 2005; Iqbal and Bailey, 2004; Ohno, 2004, 2007; Spakov and Miniotas, 2005; Hyrskykari, 2006; Merten and Conati, 2006; Kumar et al., 2007; Buscher et al., 2008; Bulling et al., 2011).
In robot interaction, most real-time eye interfaces have been designed to mimic gaze for social or communicative reasons (Staudte and Crocker, 2008, 2009, 2011; Jones and Schmidlin, 2011; Boucher et al., 2012; Kohlbecher et al., 2012). Only few human–robot studies took gaze location into consideration for improving human task performance (DeJong et al., 2011), which involved improving human performance in spatial transformations using robotic arms.
A common theme in gaze-aware interfaces is to attempt to predict the users’ preferences or gaze location in domain-specific scenarios, such as map scanning, reading, eye-typing, or entertainment media (Goldberg and Schryver, 1993, 1995; Salvucci, 1999; Qvarfordt and Zhai, 2005; Bee et al., 2006; Buscher and Dengel, 2008; Jie and Clark, 2008; Xu et al., 2008; Hwang et al., 2013). Some of these attempts at prediction may generalize well to forecasting wider subsets of real-world tasks (Hwang et al., 2013), though still require intelligent computer vision, image processing, and adaptation of algorithms for new tasks to be predicted optimally. For a paradigm to be domain-general to the greatest degree, it must eliminate specific prediction, relying upon description, or generalized probability distributions over the display space.
Though some have attempted domain-general systems, such attempts have interfered with the user by obscuring the display inflexibly (e.g., make everything looked at entirely opaque), or only apply to a specific subset of behavior, such as within some types of search (Pavel et al., 2003; Roy et al., 2004; Bosse et al., 2007). Our system addresses many of these limitations, in that it does not require the computer have content knowledge (e.g., vision), is domain-general, intuitive, closed-loop, non-predictive, and most importantly, effective.
4.5.5. Obviousness and Previous Limitations
Given the seeming obviousness of our solution, it is notable that despite the need and benefit from this situation-blind multitasking aid, no others exist to date. The benefits were non-trivial, with very large statistical effect sizes, and potential for wide generalization. Previous eye trackers cost upwards of $20,000 USD, which often prohibited this as a feasible solution. However, recently eye trackers have come down in price, with the eye tracker used in this study being printed on a 3D printer, with an open API, while many others have now published designs for open and inexpensive hardware (Babcock and Pelz, 2004; Li et al., 2006; Lemahieu and Wyns, 2011).
4.6. Conclusion
In part, previous applications attempted to predict human intentions, to better provide the human with what they wanted. For general benefits, it is more efficient to eliminate prediction, and define domain-general probability utility over the visual display, such that the display is transparent, non-interfering, and assistive. Our application may function via delegating short-term memory load to the computer, and reducing the number of repeated decisions the user needed to make. Highlighting the gaze history on multiple tracking tasks could theoretically improve performance on many tasks where the probability of task relevance relates to the delay since gaze, even in complex ways. The design of the assistive algorithms tested here demonstrated clearly greater application-independence than any previous AUIs or gaze-aware interfaces. Rather than enable novel control means, these experiments demonstrated an overlay procedure to transparently accelerate normal interaction or pre-existing control, likely generalizing to a wide variety of multi-agent applications.
Author Contributions
PT designed experiment, with assistance from NB, HS, and ZH. NB programmed experiment, with contributions and edits by PT. PT and ZH ran human subjects. ZH and PT programmed data analysis. PT wrote manuscript, with contributions from HS, ZH, and NB. HS supervised all research.
Data Sharing
Source code for the experimental game will be provided upon request, under the open GPLv3 license.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Funding
We thank the Office of Naval Research, award: N00014-09-1-0069.
References
Abbass, H. A., Tang, J., Amin, R., Ellejmi, M., and Kirby, S. (2014). “Augmented cognition using real-time EEG-based adaptive strategies for air traffic control,” in Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Vol. 58 (Chicago, IL: SAGE), 230–234. doi:10.1177/1541931214581048
Agarwal, S., and Dagli, C. H. (2013). Augmented cognition in human-system interaction through coupled action of body sensor network and agent based modeling. Procedia Comput. Sci. 16, 20–28. doi:10.1016/j.procs.2013.01.003
Allport, D., Styles, E., and Hsieh, S. (1994). “Shifting intentional set: exploring the dynamic control of tasks,” in Attention and Performance 15: Conscious and Nonconscious Information Processing, eds C. Umilt and M. Moscovitch (Cambridge, MA: The MIT Press), 421–452.
Anderson, J., and Neely, J. (1996a). “Chapter 8 – interference and inhibition in memory retrieval,” in Memory, eds E. L. Bjork and R. A. Bjork (San Diego, CA: Academic Press), 237–313.
Anderson, J. R., Reder, L. M., and Lebiere, C. (1996). Working memory: activation limitations on retrieval. Cogn. Psychol. 30, 221–256. doi:10.1006/cogp.1996.0007
Anderson, M. C., and Neely, J. H. (1996b). “Chapter 8 – interference and inhibition in memory retrieval,” in Memory, eds E. L. Bjork and R. A. Bjork (San Diego, CA: Academic Press), 237–313.
Ashmore, M., Duchowski, A. T., and Shoemaker, G. (2005). Efficient Eye Pointing with a Fisheye Lens, Vol. 05. Waterloo, ON: Canadian Human-Computer Communications Society, School of Computer Science, University of Waterloo, 203–210.
Atienza, R., and Zelinsky, A. (2002). “Active gaze tracking for human-robot interaction,” in Proceedings of the 4th IEEE International Conference on Multimodal Interfaces (Washington, DC: IEEE Computer Society), 261. doi:10.1109/ICMI.2002.1167004
Babcock, J. S., and Pelz, J. B. (2004). “Building a lightweight eyetracking headgear,” in Proceedings of the 2004 Symposium on Eye Tracking Research & Applications (New York, NY: ACM). 109–114. doi:10.1145/968363.968386
Bailey, R. (1989). Human Performance Engineering: Using Human Factors/Ergonomics to Achieve Computer System Usability. Englewood-Cliffs, NJ: Prentice Hall.
Ballard, D. H., Hayhoe, M. M., Li, F., Whitehead, S. D., Frisby, J. P., Taylor, J. G., et al. (1992). Hand-eye coordination during sequential tasks [and discussion]. Philos. Trans. R. Soc. Lond. B Biol. Sci. 337, 331–339. doi:10.1098/rstb.1992.0111
Barber, D., Davis, L., Nicholson, D., Finkelstein, N., and Chen, J. Y. (2008). The Mixed Initiative Experimental (MIX) Testbed for Human Robot Interactions with Varied Levels of Automation. Technical Report. Orlando, FL: DTIC Document.
Barfield, W. (1997). Skilled performance on software as a function of domain expertise and program organization. Percept. Mot. Skills 85, 1471–1480. doi:10.2466/pms.1997.85.3f.1471
Bee, N., Prendinger, H., Andrè, E., and Ishizuka, M. (2006). “Automatic preference detection by analyzing the gaze ‘cascade effect’,” in Electronic Proceedings of the 2nd conference on communication by gaze interaction (Turin: COGAIN), 61–64.
Bellenkes, A. H., Wickens, C. D., and Kramer, A. F. (1997). Visual scanning and pilot expertise: the role of attentional flexibility and mental model development. Aviat. Space Environ. Med. 68, 569–579.
Bhuiyan, M., Ampornaramveth, V., Muto, S.-Y, and Ueno, H. (2004). On tracking of eye for human-robot interface. Int. J. Robot. Autom. 19, 42–54. doi:10.2316/Journal.206.2004.1.206-2605
Bicho, E., Erlhagen, W., Louro, L., and Costa e Silva, E. (2011). Neuro-cognitive mechanisms of decision making in joint action: a human-robot interaction study. Hum. Mov. Sci. 30, 846–868. doi:10.1016/j.humov.2010.08.012
Bolt, R. A. (1981). “Gaze-orchestrated dynamic windows,” in SIGGRAPH ’81 (New York, NY: ACM), 109–119.
Bosse, T., Van Doesburg, W., van Maanen, P.-P., and Treur, J. (2007). “Augmented metacognition addressing dynamic allocation of tasks requiring visual attention,” in Foundations of Augmented Cognition. eds D. Schmorrow and L. Reeves (Berlin Heidelberg: Springer), 166–175. doi:10.1007/978-3-540-73216-7_19
Boucheix, J.-M., and Lowe, R. K. (2010). An eye tracking comparison of external pointing cues and internal continuous cues in learning with complex animations. Learn. Instruct. 20, 123–135. doi:10.1016/j.learninstruc.2009.02.015
Boucher, J.-D., Pattacini, U., Lelong, A., Bailly, G., Elisei, F., Fagel, S., et al. (2012). I reach faster when I see you look: gaze effects in human-human and human-robot face-to-face cooperation. Front. Neurorobot. 6:3. doi:10.3389/fnbot.2012.00003
Brambilla, M., Ferrante, E., Birattari, M., and Dorigo, M. (2013). Swarm robotics: a review from the swarm engineering perspective. Swarm Intell. 7, 1–41. doi:10.1007/s11721-012-0075-2
Brown, J. (1958). Some tests of the decay theory of immediate memory. Q. J. Exp. Psychol. 10, 12–21. doi:10.1080/17470215808416249
Bulling, A., Roggen, D., and Troester, G. (2011). What’s in the eyes for context-awareness? IEEE Pervasive Comput. 10, 48–57. doi:10.1109/MPRV.2010.49
Buscher, G., and Dengel, A. (2008). “Attention-based document classifier learning,” in Document Analysis Systems, 2008. DAS’08. The Eighth IAPR International Workshop on (Nara: IEEE), 87–94.
Buscher, G., Dengel, A., and van Elst, L. (2008). “Query expansion using gaze-based feedback on the subdocument level,” in SIGIR ’08 (New York, NY: ACM), 387–394. doi:10.1145/1390334.1390401
Buswell, G. (1935). How People Look at Pictures: A Study of the Psychology and Perception in Art. Oxford: Univ. Chicago Press.
Canning, C., and Scheutz, M. (2013). Functional near-infrared spectroscopy in human-robot interaction. J. Hum. Robot Interact. 2, 62–84. doi:10.5898/JHRI.2.3.Canning
Carlson, R. A., Gray, W. D., Kirlik, A., Kirsh, D., Payne, S. J., and Neth, H. (2007). “Immediate interactive behavior: how embodied and embedded cognition uses and changes the world to achieve its goal,” in Proceedings of the 29th Annual Conference of the Cognitive Science Society (Nashville, TN), 33–34.
Carlson, T., and Demiris, Y. (2009). Using Visual Attention to Evaluate Collaborative Control Architectures for Human Robot Interaction. 38–43.
Castelhano, M. S., and Henderson, J. M. (2008). Stable individual differences across images in human saccadic eye movements. Can. J. Exp. Psychol. 62, 1–14. doi:10.1037/1196-1961.62.1.1
Chase, W. G., and Simon, H. A. (1973). “The mind’s eye in chess,” in Visual Information Processing, Vol. xiv. ed. W. G. Chase (Oxford: Academic), 555
Chignell, M. H., and Peterson, J. G. (1988). Strategic issues in knowledge engineering. J. Hum. Fact. Ergon. Soc. 30, 381–394. doi:10.1177/001872088803000402
Core Team, R. (2013). R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing.
Couture-Beil, A., Vaughan, R. T., and Mori, G. (2010). “Selecting and commanding individual robots in a multi-robot system,” in Computer and Robot Vision (CRV), 2010 Canadian Conference on (Ottawa, ON: IEEE), 159–166. doi:10.1109/CRV.2010.28
Coyne, J., Baldwin, C., Cole, A., Sibley, C., and Roberts, D. (2009). “Applying real time physiological measures of cognitive load to improve training,” in Foundations of Augmented Cognition. Neuroergonomics and Operational Neuroscience. eds D. Schmorrow, I. Estabrooke, and M. Grootjen (Springer Berlin: Springer), 469–478. doi:10.1007/978-3-642-02812-0_55
Craik, K. J. W. (1948). Theory of the human operator in control systems. Br. J. Psychol. 38, 142–148. doi:10.1111/j.2044-8295.1948.tb01149.x
Crosby, M. E., Iding, M. K., and Chin, D. N. (2003). “Research on task complexity as a foundation for augmented cognition,” in International Conference on System Sciences, 2003. Proceedings of the 36th Annual Hawaii (Hawaii: IEEE), 9.
Cuevas, H. M., Fiore, S. M., CAlDWEll, B. S., and StRAtER, L. (2007). Augmenting team cognition in human-automation teams performing in complex operational environments. Aviat. Space Environ. Med. 78(Suppl. 1), B63–B70.
Dawes, R. M., Faust, D., and Meehl, P. E. (1989). Clinical versus actuarial judgment. Science 243, 1668–1674. doi:10.1126/science.2648573
De Greef, T., van Dongen, K., Grootjen, M., and Lindenberg, J. (2007). “Augmenting cognition: reviewing the symbiotic relation between man and machine,” in Foundations of Augmented Cognition. eds D. Schmorrow and L. Reeves (Berlin Heidelberg: Springer), 439–448. doi:10.1007/978-3-540-73216-7_51
Deaton, J., and Parasuraman, R. (1988). Effects of Task Demands and Age on Vigilance and Subjective Workload. Anaheim, CA.
Debecker, J., and Desmedt, J. E. (1970). Maximum capacity for sequential one-bit auditory decisions. J. Exp. Psychol. 83, 366. doi:10.1037/h0028848
DeJong, B., Colgate, J., and Peshkin, M. (2011). “Mental transformations in human-robot interaction,” in Mixed Reality and Human-Robot Interaction. ed. X. Wang (Netherlands: Springer), 35–51. doi:10.1007/978-94-007-0582-1_3
de’Sperati, C. (2003). “The inner-workings of dynamic visuo-spatial imagery as revealed by spontaneous eye movements,” in The Mind’s Eye: Cognitive and Applied Aspects of Eye Movement Research. eds R. Radach, J. Hyona, and H. Deubel (Oxford: Elsevier).
Donk, M. (1994). Human monitoring behavior in a multiple-instrument setting: independent sampling, sequential sampling or arrangement-dependent sampling. Acta Psychol. 86, 31–55. doi:10.1016/0001-6918(94)90010-8
Dorneich, M. C., Whitlow, S. D., Ververs, P. M., and Rogers, W. H. (2003). “Mitigating cognitive bottlenecks via an augmented cognition adaptive system,” in Systems, Man and Cybernetics, 2003. IEEE International Conference on, Vol. 1 (Washington, DC: IEEE), 937–944.
Downing, P. E. (2000). Interactions between visual working memory and selective attention. Psychol. Sci. 11, 467–473. doi:10.1111/1467-9280.00290
Ducatelle, F., Di Caro, G. A., Pinciroli, C., Mondada, F., and Gambardella, L. M. (2011). “Communication assisted navigation in robotic swarms: self-organization and cooperation,” in Intelligent Robots and Systems (IROS), 2011 IEEE/RSJ International Conference on (San Francisco, CA), 4981–4988.
Duchowski, A. T., Cournia, N., and Murphy, H. (2004). Gaze-contingent displays: a review. Cyberpsychol. Behav. 7, 621–634. doi:10.1089/cpb.2004.7.621
Elkind, J., and Sprague, L. (1961). Transmission of information in simple manual control systems. IRE Trans. Hum. Fact. Electron. HFE-2, 58–60. doi:10.1109/THFE2.1961.4503299
Endsley, M. R. (1999). Level of automation effects on performance, situation awareness and workload in a dynamic control task. Ergonomics 42, 462–492. doi:10.1080/001401399185595
Erdogmus, D., Adami, A., Pavel, M., Lan, T., Mathan, S., Whitlow, S., et al. (2005). “Cognitive state estimation based on EEG for augmented cognition, in neural engineering,” in Neural Engineering, 2005. Conference Proceedings. 2nd International IEEE EMBS Conference on (Arlington, VA: IEEE), 566–569. doi:10.1109/CNE.2005.1419686
Eriksen, C. W., and Collins, J. F. (1969). Temporal course of selective attention. J. Exp. Psychol. 80(2, Pt.1), 254–261. doi:10.1037/h0027268
Feise, R. J. (2002). Do multiple outcome measures require p-value adjustment? BMC Med. Res. Methodol. 2:8. doi:10.1186/1471-2288-2-8
Fiore, S. M., Badler, N. L., Boloni, L., Goodrich, M. A., Wu, A. S., and Chen, J. (2011). Human-robot teams collaborating socially, organizationally, and culturally. Proc. Hum. Fact. Ergon. Soc. Annu. Meet. 55, 465–469.
Fisher, D. L., and Tan, K. C. (1989). Visual displays: the highlighting paradox. Hum. Factors 31, 17–30. doi:10.1177/001872088903100102
Fono, D., and Vertegaal, R. (2004). “EyeWindows: using eye-controlled zooming windows for focus selection,” in Proceedings of UIST 2004. In Video Proceedings. New Mexico: ACM, Santa Fe.
Fono, D., and Vertegaal, R. (2005). “EyeWindows: evaluation of eye-controlled zooming windows for focus selection,” in CHI ’05 (New York, NY: ACM), 151–160.
Fuchs, S., Hale, K. S., and Axelsson, P. (2007a). “Augmented cognition can increase human performance in the control room,” in Human Factors and Power Plants and HPRCT 13th Annual Meeting, 2007 IEEE 8th (Monterey, CA: IEEE), 128–132.
Fuchs, S., Hale, K. S., Stanney, K. M., Juhnke, J., and Schmorrow, D. D. (2007b). Enhancing mitigation in augmented cognition. J. Cogn. Eng. Decis. Mak. 1, 309–326. doi:10.1518/155534307X255645
Funk, K., and McCoy, B. (1996). “A functional model of flightdeck agenda management,” in Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Vol. 40, 254–258. doi:10.1177/154193129604000424
Gallaher, P. D., Hunt, R. A., and Williges, R. C. (1977). A regression approach to generate aircraft predictor information. Hum. Factors 19, 549–555. doi:10.1177/001872087701900603
Gelman, A., Hill, J., and Yajima, M. (2012). Why we (usually) don’t have to worry about multiple comparisons. J. Res. Educ. Eff. 5, 189–211. doi:10.1080/19345747.2011.618213
Giusti, A., Nagi, J., Gambardella, L. M., Bonardi, S., and Di Caro, G. A. (2012a). “Human-swarm interaction through distributed cooperative gesture recognition,” in Proceedings of the Seventh Annual ACM/IEEE International Conference on Human-Robot Interaction. 401–402. doi:10.1145/2157689.2157818
Giusti, A., Nagi, J., Gambardella, L. M., and Di Caro, G. A. (2012b). “Distributed consensus for interaction between humans and mobile robot swarms (demonstration),” in Proceedings of the 11th International Conference on Autonomous Agents and Multiagent Systems, Vol. 3 (Richland, SC: International Foundation for Autonomous Agents and Multiagent Systems), 1503–1504.
Gobet, F. (1998). Expert memory: a comparison of four theories. Cognition 66, 115–152. doi:10.1016/S0010-0277(98)00020-1
Goldberg, J. H., and Kotval, X. P. (1999). Computer interface evaluation using eye movements: methods and constructs. Int. J. Ind. Ergon. 24, 631–645. doi:10.1016/S0169-8141(98)00068-7
Goldberg, J. H., and Schryver, J. C. (1993). Eye-gaze control of the computer interface: discrimination of zoom intent. Proc. Hum. Fact. Ergon. Soc. Annu. Meet. 37, 1370–1374. doi:10.1518/107118193784162272
Goldberg, J. H., and Schryver, J. C. (1995). Eye-gaze-contingent control of the computer interface: methodology and example for zoom detection. Behav. Res. Methods Instrum. Comput. 27, 338–350. doi:10.3758/BF03200428
Goodrich, M. A., Kerman, S., and Jung, S.-Y. (2012). “On leadership and influence in human-swarm interaction,” in AAAI Fall Symposium: Human Control of Bioinspired Swarms.
Goodrich, M. A., Kerman, S., Pendleton, B., and Sujit, P. B. (2013). What Types of Interactions do Bio-Inspired Robot Swarms and Flocks Afford a Human? Robotics. 105.
Goodrich, M. A., Pendleton, B., Sujit, P. B., and Pinto, J. (2011a). “Toward human interaction with bio-inspired robot teams,” in Systems, Man, and Cybernetics (SMC), 2011 IEEE International Conference on (IEEE), 2859–2864.
Goodrich, M. A., Sujit, P. B., Kerman, S., Pendleton, B., and Pinto, J. (2011b). Enabling Human Interaction with Bio-Inspired Robot Teams: Topologies, Leaders, Predators, and Stakeholders. Technical Report. Brigham Young University-HCMI.
Goodrich, M. A., and Schultz, A. C. (2007). Human-robot interaction: a survey. Found. Trends Hum. Comput. Interact. 1, 203–275. doi:10.1561/1100000005
Greitzer, F. L. (2005). “Extending the reach of augmented cognition to real-world decision making tasks,” in Proceedings of the HCI International 2005/Augmented Cognition Conference. Las Vegas.
Groen, M., and Noyes, J. (2010). Solving problems: how can guidance concerning task-relevancy be provided? Comput. Human Behav. 26, 1318–1326. doi:10.1016/j.chb.2010.04.004
Groot, A. D. D. (1978). Thought and Choice in Chess. The Hague: Amsterdam University Press. doi:10.5117/9789053569986
Grossman, E. R. F. W. (1960). The information-capacity of the human motor-system in pursuit tracking. Q. J. Exp. Psychol. 12, 01–16. doi:10.1080/17470216008416694
Grunwald, A. J. (1985). Predictor laws for pictorial flight displays. J. Guid. Control Dyn. 8, 545–552. doi:10.2514/3.20021
Hafed, Z. M., and Clark, J. J. (2002). Microsaccades as an overt measure of covert attention shifts. Vision Res. 42, 2533–2545. doi:10.1016/S0042-6989(02)00263-8
Hammer, J. (1999). “Human factors of functionality and intelligent avionics,” in Handbook of Human Factors in Aviation, eds D. Garland, J. Wise and V. Hopkin (Mahwah, NJ: Erlbaum), 549–565.
Hart, S. G., and Loomis, L. L. (1980). Evaluation of the potential format and content of a cockpit display of traffic information. Hum. Factors 22, 591–604. doi:10.1177/001872088002200508
Hashimoto, H., Yokota, S., Sasaki, A., Ohyama, Y., and Kobayashi, H. (2009). “Cooperative interaction of walking human and distributed robot maintaining stability of swarm,” in Human System Interactions, 2009. HSI’09. 2nd Conference on (Catania: IEEE), 24–27.
He, Z., Marquard, J., and Henneman, P. L. (2014). How do Interruptions Impact Nurses’ Visual Scanning Patterns When Using Barcode Medication Administration systems?. Washington, DC: American Medical Informatics Association, 1768–1776.
Heathcote, A., Eidels, A., Houpt, J. W., Coleman, J., Watson, J., Strayer, D., et al. (2014). “Multi-tasking in working memory,” in Proceedings of the 36th Annual Conference of the Cognitive Science Society (Quebec City), 601–606.
Hild, J., Mller, E., Klaus, E., Peinsipp-Byma, E., and Beyerer, J. (2013). “Evaluating multi-modal eye gaze interaction for moving object selection,” in Proceedings of ACHI (Nice: IARIA), 454–459.
Hirst, W., and Kalmar, D. (1987). Characterizing attentional resources. J. Exp. Psychol. 116, 68–81. doi:10.1037/0096-3445.116.1.68
Hole, G. (1996). Decay and interference effects in visuospatial short-term memory. Perception 25, 53–64. doi:10.1068/p250053
Hwang, B., Jang, Y.-M., Mallipeddi, R., and Lee, M. (2013). Probing of human implicit intent based on eye movement and pupillary analysis for augmented cognition. Int. J. Imaging Syst. Technol. 23, 114–126. doi:10.1002/ima.22046
Hyrskykari, A. (2006). Eyes in Attentive Interfaces: Experiences from Creating iDict, a Gaze-Aware Reading Aid. Ph.D. thesis, University of Tampere, Finland.
Hyrskykari, A., Majaranta, P., and Räihä, K.-J. (2003). “Proactive response to eye movements,” in INTERACT, Vol. 3 (IOS Press), 129–136.
Inagaki, T. (2003). “Adaptive automation: sharing and trading of control,” in Handbook of Cognitive Task Design, Vol. 8. ed. E. Hollnagel (Mahwah, NJ: Lawrence Erlbaum Associates), 147–169.
Iqbal, S. T., and Bailey, B. P. (2004). “Using eye gaze patterns to identify user tasks,” in The Grace Hopper Celebration of Women in Computing, 5–10.
Ishida, F., and Sawada, Y. (2004). Human hand moves proactively to the external stimulus: an evolutional strategy for minimizing transient error. Phys. Rev. Lett. 93, 16. doi:10.1103/PhysRevLett.93.168105
Ivory, M. Y., Martin, A. P., Megraw, R., and Slabosky, B. (2005). “Augmented cognition: an approach to increasing universal benefit from information technology,” in Proc. 1st International Conference on Augmented Cognition (Citeseer).
Jacob, R., and Karn, K. (2003). “Eye tracking in human-computer interaction and usability research: ready to deliver the promises,” in The Mind’s eye: Cognitive The Mind’s Eye: Cognitive and Applied Aspects of Eye Movement Research, Vol. 2, 573–603.
Jacob, R. J. (1990). “What you look at is what you get: Eye movement-based interaction techniques,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (New York, NY: ACM), 11–18. doi:10.1145/97243.97246
Jacob, R. J. (1993a). Eye movement-based human-computer interaction techniques: toward non-command interfaces. Adv. Hum. Comput. Interact. 4, 151–190.
Jacob, R. J. (1993b). Hot topics-eye-gaze computer interfaces: what you look at is what you get. Computer 26, 65–66. doi:10.1109/MC.1993.274943
Jacob, R. J. K. (1991). The use of eye movements in human-computer interaction techniques: what you look at is what you get. ACM Trans. Inf. Syst. 9, 152–169. doi:10.1145/123078.128728
Jaimes, A., and Sebe, N. (2007). Multimodal human-computer interaction: a survey. Comput. Vis. Image Understand. 108, 116–134. doi:10.1016/j.cviu.2006.10.019
Jakob, R. J. K. (1998). “The use of eye movements in human-computer interaction techniques: what you look at is what you get,” in Readings in Intelligent User Interfaces, eds M. T. Maybury and W. Wahlster (Morgan Kaufmann), 65–83.
Jie, L., and Clark, J. J. (2008). Video game design using an eye-movement-dependent model of visual attention. ACM Trans. Multimedia Comput. Commun. Appl. 4, 1–22. doi:10.1145/1386109.1386115
Johnson, M., Kulkarni, K., Raj, A., Carff, R., and Bradshaw, J. M. (2005). “Ami: an adaptive multi-agent framework for augmented cognition,” in Proceedings of the 11th International Conference in Human Computer Interaction, AUGCOG Conference (Las Vegas), 22–27.
Jones, K. S., and Schmidlin, E. A. (2011). Human-robot interaction: toward usable personal service robots. Rev. Hum. Fact. Ergon. 7, 100–148. doi:10.1177/1557234X11410388
Just, M. A., and Carpenter, P. A. (1976). Eye fixations and cognitive processes. Cogn. Psychol. 8, 441–480. doi:10.1016/0010-0285(76)90015-3
Kaber, D. B., and Endsley, M. R. (2004). The effects of level of automation and adaptive automation on human performance, situation awareness and workload in a dynamic control task. Theor. Issues Ergon. Sci. 5, 113–153. doi:10.1080/1463922021000054335
Kean, M., and Lambert, A. (2003). The influence of a salience distinction between bilateral cues on the latency of target-detection saccades. Br. J. Psychol. 94, 373–388. doi:10.1348/000712603767876280
Keppel, G., and Underwood, B. J. (1962). Proactive inhibition in short-term retention of single items. J. Verbal. Learn. Verbal. Behav. 1, 153–161. doi:10.1016/S0022-5371(62)80023-1
Kerman, S., Brown, D., and Goodrich, M. A. (2012). “Supporting human interaction with robust robot swarms,” in Resilient Control Systems (ISRCS), 2012 5th International Symposium on (Salt Lake City, UT: IEEE) 197–202.
Kohlbecher, S., Wiese, E., Bartl, K., Blume, J., Bannat, A., and Schneider, E. (2012). “Studying gaze-based human robot interaction: An experimental platform,” in 7th ACM/IEEE International Conference on Human-Robot Interaction. Boston, MA.
Kolling, A., Nunnally, S., and Lewis, M. (2012). “Towards human control of robot swarms,” in Proceedings of the seventh annual ACM/IEEE international conference on human-robot interaction (Boston, MA: ACM), 89–96.
Kolling, A., Sycara, K., Nunnally, S., and Lewis, M. (2013). Human swarm interaction: an experimental study of two types of interaction with foraging swarms. J. Hum. Robot Interact. 2, 104–129. doi:10.5898/JHRI.2.2.Kolling
Kollmorgen, L. S. (2007). A case for operational approach in advanced research projects the augmented cognition story. Aviat. Space Environ. Med. 78(Suppl. 1), B1–B3.
Kolsch, M., Wachs, J., and Sadagic, A. (2013). “Visual analysis and filtering to augment cognition,” in Foundations of Augmented Cognition. ed. C. Fidopiastis (Berlin Heidelber: Springer), 695–702. doi:10.1007/978-3-642-39454-6_74
Kondo, Y., Takemura, K., Takamatsu, J., and Ogasawara, T. (2013). A gesture-centric android system for multi-party human-robot interaction. J. Hum. Robot Interact. 2, 133–151. doi:10.5898/JHRI.2.1.Kondo
Kumar, M., Winograd, T., and Paepcke, A. (2007). “Gaze-enhanced scrolling techniques,” in CHI EA ’07 (New York, NY: ACM), 2531–2536.
Land, M., Mennie, N., and Rusted, J. (1999). The roles of vision and eye movements in the control of activities of daily living. Perception 28, 1311–1328. doi:10.1068/p2935
Laqua, S., Bandara, S. U., and Sasse, M. A. (2007). “GazeSpace: eye gaze controlled content spaces,” in BCS-HCI ’07 (Swinton: British Computer Society), 55–58.
Laudeman, I., and Palmer, E. (1995). Quantitative measurement of observed workload in the analysis of aircrew performance. Int. J. Aviat. Psychol. 5, 187–197. doi:10.1207/s15327108ijap0502_4
Lavine, M. S., Voss, D., and Coontz, R. (2007). A robotic future. Science 318, 1083–1083. doi:10.1126/science.318.5853.1083
Lemahieu, W., and Wyns, B. (2011). Low cost eye tracking for human-machine interfacing. Journal of Eyetracking, Visual Cognition and Emotion 1, 1–12.
Lenzi, T., Vitiello, N., Rossi, S. M. M. D., Persichetti, A., Giovacchini, F., Roccella, S., et al. (2011). Measuring human-robot interaction on wearable robots: a distributed approach. Mechatronics 21, 1123–1131. doi:10.1016/j.mechatronics.2011.04.003
Li, D., Babcock, J., and Parkhurst, D. J. (2006). “Openeyes: a low-cost head-mounted eye-tracking solution,” in Proceedings of the 2006 symposium on Eye tracking research & applications (ACM), 95–100.
Liao, J., and Moray, N. (1993). A simulation study of human performance deterioration and mental workload. Trav. Hum. 56, 321–344. doi:10.1080/15389581003747522
Lintern, G., Roscoe, S. N., and Sivier, J. E. (1990). Display principles, control dynamics, and environmental factors in pilot training and transfer. Hum. Factors 32, 299–317. doi:10.1177/001872089003200304
Liu, S. S., Rawicz, A., Rezaei, S., Ma, T., Zhang, C., Lin, K., et al. (2012). An eye-gaze tracking and human computer interface system for people with ALS and other locked-in diseases. J. Med. Biol. Eng. 32, 111–116. doi:10.5405/jmbe.813
Logie, R., and Pearson, D. (1997). The inner eye and the inner scribe of visuo-spatial working memory: evidence from developmental fractionation. Eur. J. Cogn. Psychol. 9, 241–257. doi:10.1080/713752559
Loschky, L. C., and Wolverton, G. S. (2007). How late can you update gaze-contingent multiresolutional displays without detection? ACM Trans. Multimedia Comput. Commun. Appl. 3, 1–10. doi:10.1145/1314303.1314310
Majaranta, P., Aoki, H., Donegan, M., Hansen, D. W., Hansen, J. P., Hyrskykari, A., et al. (2011). Gaze Interaction and Applications of Eye Tracking: Advances in Assistive Technologies. IGI Global.
Marjovi, A., Marques, L., and Penders, J. (2009). “Guardians robot swarm exploration and firefighter assistance,” Workshop on NRS in IEEE/RSJ international conference on Intelligent Robots and Systems (IROS). St Louis.
Marquard, J. L., Henneman, P. L., He, Z., Jo, J., Fisher, D. L., and Henneman, E. A. (2011). Nurses’ behaviors and visual scanning patterns may reduce patient identification errors. J. Exp. Psychol. 17, 247–256. doi:10.1037/a0025261
Marshall, L., and Raley, C. (2004). Platform-Based Design of Augmented Cognition Systems. Technical Report. Maryland: University of Maryland ISR.
Marshall, S. P. (2002). “The index of cognitive activity: measuring cognitive workload, in human factors and power plants,” in Proceedings of the 2002 IEEE 7th Conference on (Scottsdale: IEEE), 7–5.
Marshall, S. P., Pleydell-Pearce, C. W., and Dickson, B. T. (2003). “Integrating psychophysiological measures of cognitive workload and eye movements to detect strategy shifts, in system sciences,” in Proceedings of the 36th Annual Hawaii International Conference on, Vol. 6. (Hawaii: IEEE), 6.
Martin, R. C., Wogalter, M. S., and Forlano, J. G. (1988). Reading comprehension in the presence of unattended speech and music. J. Mem. Lang. 27, 382–398. doi:10.1016/0749-596X(88)90063-0
Mathan, S., Dorneich, M., and Whitlow, S. (2005). “Automation etiquette in the augmented cognition context,” in Proceedings of the 11th International Conference on Human-Computer Interaction (1st AnnualAugmented Cognition International) (Mahwah, NJ: Lawrence Erlbaum).
McConkie, G. W., and Rayner, K. (1975). The span of the effective stimulus during a fixation in reading. Percept. Psychophys. 17, 578–586. doi:10.3758/BF03203972
McGeoch, J. (1936). Studies in retroactive inhibition: VII. Retroactive inhibition as a function of the length and frequency of presentation of the interpolated lists. J. Educ. Psychol. 86, 256–266.
Megaw, E. D., and Richardson, J. (1979). Target uncertainty and visual scanning strategies. Hum. Factors 21, 303–315. doi:10.1177/001872087902100305
Melton, A. W. (1963). Implications of short-term memory for a general theory of memory. J. Verbal. Learn. Verbal. Behav. 2, 1–21. doi:10.1016/S0022-5371(63)80063-8
Merten, C., and Conati, C. (2006). “Eye-tracking to model and adapt to user meta-cognition in intelligent learning environments,” in Proceedings of the 11th International Conference on Intelligent User Interfaces (New York, NY: ACM), 39–46. doi:10.1145/1111449.1111465
Mi, Z.-Q., and Yang, Y. (2013). Human-robot interaction in UVs swarming: a survey. Int. J. Comput. Sci. Issues 10, 273.
Miellet, S., O’Donnell, P. J., and Sereno, S. C. (2009). Parafoveal magnification: visual acuity does not modulate the perceptual span in reading. Psychol. Sci. 20, 721–728. doi:10.1111/j.1467-9280.2009.02364.x
Miellet, S., Zhou, X., He, L., Rodger, H., and Caldara, R. (2010). Investigating cultural diversity for extrafoveal information use in visual scenes. J. Vis. 10, 21. doi:10.1167/10.6.21
Miller, C. A., and Dorneich, M. C. (2006). “From associate systems to augmented cognition: 25 years of user adaptation in high criticality systems,” in Foundations of Augmented Cognition 2nd Edition Augmented Cognition: Past, Present & Future. Arlington, VA: Strategic Analysis, Inc & ACI Society.
Miller, G. A. (1956). The magical number seven, plus or minus two: some limits on our capacity for processing information. Psychological Review 63, 81–97. doi:10.1037/h0043158
Monajjemi, V. M., Wawerla, J., Vaughan, R., and Mori, G. (2013). “Hri in the sky: Creating and commanding teams of uavs with a vision-mediated gestural interface,” in Intelligent Robots and Systems (IROS), 2013 IEEE/RSJ International Conference on (Tokyo: IEEE)
Moray, N. (1980). Human Information Processing in Monitoring and Supervisory Control. Technical Report. (Cambridge, MA: MIT, Man-Machine Systems).
Moray, N. (1981). “The role of attention in the detection of errors and the diagnosis of failures in man-machine systems,” in Human Detection and Diagnosis of System Failures, Vol. 15. eds J. Rasmussen and W. B. Rouse (Springer), 185–198. doi:10.1007/978-1-4615-9230-3_13
Moray, N. (1986). “Monitoring behavior and supervisory control,” in Handbook of Perception and Human Performance, Vol. 2: Cognitive Processes and Performance, eds K. R. Boff, L. Kaufman, and J. P. Thomas (Oxford: John Wiley & Sons), 1–51.
Moray, N., and Rotenberg, I. (1989). Fault management in process control: eye movements and action. Ergonomics 32, 11. doi:10.1080/00140138908966910
Murphy, R. R., and Schreckenghost, D. (2013). “Survey of metrics for human-robot interaction,” in Human-Robot Interaction (HRI), 2013 8th ACM/IEEE International Conference on (IEEE), 197–198.
Myers, J. L., Well, A. D., and Lorch, R. F. Jr. (2010). Research Design and Statistical Analysis, Third Edn. New York, NY: Routledge.
Naghsh, A. M., Gancet, J., Tanoto, A., and Roast, C. (2008). “Analysis and design of human-robot swarm interaction in firefighting,” in Robot and Human Interactive Communication, 2008. RO-MAN 2008. The 17th IEEE International Symposium on (Munich: IEEE), 255–260.
Nagi, J., Ngo, H., Giusti, A., Gambardella, L. M., Schmidhuber, J., and Di Caro, G. A. (2012). “Incremental learning using partial feedback for gesture-based human-swarm interaction,” in RO-MAN, 2012 IEEE (Paris: IEEE), 898–905.
Navon, D. (1984). Resources: theoretical soup stone? Psychol. Rev. 91, 216–234. doi:10.1037/0033-295X.91.2.216
Navon, D., and Miller, J. (1987). Role of outcome conflict in dual-task interference. J. Exp. Psychol. 13, 435–448. doi:10.1037/0096-1523.13.3.435
Nicholson, D., Lackey, S., Arnold, R., and Scott, K. (2005). Augmented Cognition Technologies Applied to Training: A Roadmap for the Future. Technical Report, DTIC Document.
Ogden, G. D., Levine, J. M., and Eisner, E. J. (1979). Measurement of workload by secondary tasks. Hum. Factors 21, 529–548. doi:10.1177/001872087902100502
Oh, S.-H., and Kim, M.-S. (2004). The role of spatial working memory in visual search efficiency. Psychon. Bull. Rev. 11, 275–281. doi:10.3758/BF03196570
Ohno, T. (2004). “EyePrint: support of document browsing with eye gaze trace,” in ICMI ’04 (New York, NY: ACM), 16–23. doi:10.1145/1027933.1027937
Ohno, T. (2007). EyePrint: using passive eye trace from reading to enhance document access and comprehension. Int. J. Hum. Comput. Interact. 23, 71–94. doi:10.1080/10447310701362934
Ozcelik, E., Arslan-Ari, I., and Cagiltay, K. (2010). Why does signaling enhance multimedia learning? Evidence from eye movements. Comput. Human Behav. 26, 110–117. doi:10.1016/j.chb.2009.09.001
Parasuraman, R. (1979). Memory load and event rate control sensitivity decrements in sustained attention. Science 205, 924–927. doi:10.1126/science.472714
Parasuraman, R. (1986). “Vigilance, monitoring, and search,” in Handbook of Perception and Human Performance, Vol. 2: Cognitive Processes and Performance, eds K. R. Boff, L. Kaufman and J. P. Thomas (Oxford: John Wiley & Sons), 1–39.
Pavel, M., Wang, G., and Li, K. (2003). “Augmented cognition: allocation of attention, in system sciences,” in System Sciences, 2003. Proceedings of the 36th Annual Hawaii International Conference on (Washington, DC: IEEE), 6.
Penders, J., Alboul, L., Witkowski, U., Naghsh, A., Saez-Pons, J., Herbrechtsmeier, S., et al. (2011). A robot swarm assisting a human fire-fighter. Adv. Robot. 25, 93–117. doi:10.1163/016918610X538507
Perneger, T. V. (1998). What’s wrong with Bonferroni adjustments. BMJ 316, 1236–1238. doi:10.1136/bmj.316.7139.1236
Peterson, L., and Peterson, M. J. (1959). Short-term retention of individual verbal items. J. Exp. Psychol. 58, 193–198. doi:10.1037/h0049234
Pfeifer, R., Lungarella, M., and Iida, F. (2007). Self-organization, embodiment, and biologically inspired robotics. Science 318, 1088–1093. doi:10.1126/science.1145803
Poole, A., and Ball, L. J. (2006). Eye tracking in HCI and usability research. Encyclopedia Hum. Comput. Interact. 1, 211–219. doi:10.1016/j.cmpb.2008.06.008
Putze, F., and Schultz, T. (2014). Adaptive cognitive technical systems. J. Neurosci. Methods 234, 108–115. doi:10.1016/j.jneumeth.2014.06.029
Qvarfordt, P., and Zhai, S. (2005). “Conversing with the user based on eye-gaze patterns,” in CHI ’05 (New York, NY: ACM), 221–230.
Raby, M., and Wickens, C. (1994). Strategic behavior, workload, and performance in task scheduling. Int. J. Aviat. Psychol. 4, 211–240.
Raley, C., Stripling, R., Kruse, A., Schmorrow, D., and Patrey, J. (2004). Augmented cognition overview: improving information intake under stress. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 48, 1150–1154.
Rayner, K., and Bertera, J. H. (1979). Reading without a fovea. Science 206, 468–469. doi:10.1126/science.504987
Reder, S. M. (1973). On-line monitoring of eye-position signals in contingent and noncontingent paradigms. Behav. Res. Methods Instrument. 5, 218–228. doi:10.3758/BF03200168
Reid, D., and Drewell, N. (1972). “A pilot model for tracking with preview,” Proceedings of the 8th Annual Conference on Manual Control (DTIC Document), 191–206.
Reingold, E. M., Loschky, L. C., McConkie, G. W., and Stampe, D. M. (2003). Gaze-contingent multiresolutional displays: an integrative review. Hum. Factors 45, 307–328. doi:10.1518/hfes.45.2.307.27235
Rogers, R. D., and Monsell, S. (1995). Costs of a predictible switch between simple cognitive tasks. J. Exp. Psychol. 124, 207–231. doi:10.1037/0096-3445.124.2.207
Rolfe, J. (1973). The Secondary Task as a Measure of Mental Workload: Measurement of Man at Work. London: Taylor & Francis.
Rosch, J. L., and Vogel-Walcutt, J. J. (2013). A review of eye-tracking applications as tools for training. Cogn. Tech. Work 15, 313–327. doi:10.1007/s10111-012-0234-7
Rothman, K. J. (1990). No adjustments are needed for multiple comparisons. Epidemiology 1, 43–46. doi:10.1097/00001648-199001000-00010
Roy, D., Ghitza, Y., Bartelma, J., and Kehoe, C. (2004). “Visual memory augmentation: using eye gaze as an attention filter,” in Wearable Computers, 2004. ISWC 2004. Eighth International Symposium on, Vol. 1. (Washington, DC: IEEE), 128–131.
Russo, M. B., Stetz, M. C., and Thomas, M. L. (2005). Monitoring and predicting cognitive state and performance via physiological correlates of neuronal signals. Aviat. Space Environ. Med. 76(Suppl. 1), C59–C63.
Salvucci, D. D. (1999). “Inferring intent in eye-based interfaces: tracing eye movements with process models,” in CHI ’99 (New York, NY: ACM), 254–261.
Salway, A. F. S., and Logie, R. H. (1995). Visuospatial working memory, movement control and executive demands. Br. J. Psychol. 86, 253–269. doi:10.1111/j.2044-8295.1995.tb02560.x
Sanbonmatsu, D. M., Strayer, D. L., Medeiros-Ward, N., and Watson, J. M. (2013). Who multi-tasks and why? Multi-tasking ability, perceived multi-tasking ability, impulsivity, and sensation seeking. PLoS ONE 8:e54402. doi:10.1371/journal.pone.0054402
Saville, D. J. (1990). Multiple comparison procedures: the practical solution. Am. Stat. 44, 174–180. doi:10.2307/2684163
Schkade, D. A., and Kleinmuntz, D. N. (1994). Information displays and choice processes: differential effects of organization, form, and sequence. Organ. Behav. Hum. Decis. Process 57, 319–337. doi:10.1006/obhd.1994.1018
Schmorrow, D. D., and Reeves, L. M. (2007). 21st century human-system computing: augmented cognition for improved human performance. Aviat. Space Environ. Med. 78(Suppl. 1), B7–B11.
Schutte, P. C., and Trujillo, A. C. (1996). Flight crew task management in non-normal situations. Proc. Hum. Fact. Ergon. Soc. Annu. Meet. 40, 244–248.
Sciutti, A., Bisio, A., Nori, F., Metta, G., Fadiga, L., Pozzo, T., et al. (2012). Measuring human-robot interaction through motor resonance. Int. J. Soc. Robot. 4, 223–234. doi:10.1007/s12369-012-0143-1
Seidlits, S. K., Reza, T., Briand, K. A., and Sereno, A. B. (2003). Voluntary spatial attention has different effects on voluntary and reflexive saccades. ScientificWorldJournal 3, 881–902. doi:10.1100/tsw.2003.72
Sheridan, T. B. (1972). On how often the supervisor should sample. IEEE Trans. Syst. Man Cybern. 2, 140–145.
Shimojo, S., Simion, C., Shimojo, E., and Scheier, C. (2003). Gaze bias both reflects and influences preference. Nat. Neurosci. 6, 1317–1322. doi:10.1038/nn1150
Shortliffe, E. (1983). Medical Consultation Systems: Designing for Human-Computer Communications. New York, NY: Academic Press.
Sibert, L. E., and Jacob, R. J. K. (2000). “Evaluation of eye gaze interaction,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (New York, NY: ACM), 281–288. doi:10.1145/332040.332445
Spakov, O., and Miniotas, D. (2005). “Gaze-based selection of standard-size menu items,” in ICMI ’05 (New York, NY: ACM), 124–128. doi:10.1145/1088463.1088486
St. John, M., Kobus, D., Morrison, J., and Schmorrow, D. (2004). Overview of the DARPA augmented cognition technical integration experiment. Int. J. Hum. Comput. Interact. 17, 131–149. doi:10.1207/s15327590ijhc1702_2
St John, M., Kobus, D. A., and Morrison, J. G. (2003). DARPA Augmented Cognition Technical Integration Experiment (TIE). Technical Report. DTIC Document.
Stanney, K. M., Schmorrow, D. D., Johnston, M., Fuchs, S., Jones, D., Hale, K. S., et al. (2009). Augmented cognition: an overview. Rev. Hum. Factors Ergon. 5, 195–224. doi:10.1518/155723409X448062
Starker, I., and Bolt, R. A. (1990). “A gaze-responsive self-disclosing display,” in CHI ’90 (New York, NY: ACM), 3–10. doi:10.1145/97243.97245
Staudte, M., and Crocker, M. (2008). “The utility of gaze in spoken human-robot interaction,” in Proceedings of Workshop on Metrics for Human-Robot Interaction 2008 (Amsterdam: Citeseer), 53–59.
Staudte, M., and Crocker, M. W. (2009). “Visual attention in spoken human-robot interaction,” Proceedings of the 4th ACM/IEEE International Conference on Human Robot Interaction. (New York, NY: ACM), 77–84. doi:10.1145/1514095.1514111
Staudte, M., and Crocker, M. W. (2011). Investigating joint attention mechanisms through spoken human-robot interaction. Cognition 120, 268–291. doi:10.1016/j.cognition.2011.05.005
Stone, E. R., Frank, J., and Parker, A. M. (1997). Effects of numerical and graphical displays on professed risk-taking behavior. J. Exp. Psychol. 3, 243–256. doi:10.1037/1076-898X.3.4.243
Strandvall, T. (2009). “Eye tracking in human-computer interaction and usability research,” in Human-Computer Interaction – INTERACT 2009, volume 5727 of Lecture Notes in Computer Science, eds T. Gross, J. Gulliksen, P. Kotzé, L. Oestreicher, and P. Palanque, et al. (Berlin Heidelberg: Springer), 936–937.
Sundstedt, V. (2012). Gazing at games: an introduction to eye tracking control. Synth. Lect. Comput. Graph. Anim. 5, 1–113. doi:10.2200/S00395ED1V01Y201111CGR014
Tanriverdi, V., and Jacob, R. J. K. (2000). “Interacting with eye movements in virtual environments,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (New York, NY: ACM), 265–272.
Taylor, P., Bilgrien, N., He, Z., and Siegelmann, H. T. (2015). Eyeframe: real-time memory aid improves human multitasking via domain-general eye tracking procedures. Hum. Media Interact. 2:17. doi:10.3389/fict.2015.00017
Taylor, R. M., Brown, L., and Dickson, B. (2003). From Safety Net to Augmented Cognition: Using Flexible Autonomy Levels for On-Line Cognitive Assistance and Automation. Technical Report, DTIC Document.
Taylor, T., Pradhan, A., Divekar, G., Romoser, M., Muttart, J., Gomez, R., et al. (2013). The view from the road: the contribution of on-road glance-monitoring technologies to understanding driver behavior. Accid. Anal. Prev. 58, 175–186. doi:10.1016/j.aap.2013.02.008
Tayyari, F., and Smith, J. L. (1987). Effect of music on performance in human-computer interface. Proc. Hum. Fact. Ergon. Soc. Annu. Meet. 31, 1321–1325. doi:10.1177/154193128703101205
Tiberio, L., Cesta, A., and Belardinelli, M. (2013). Psychophysiological methods to evaluate user’s response in human robot interaction: a review and feasibility study. Robotics 2, 92–121. doi:10.3390/robotics2020092
Trafton, G., Hiatt, L., Harrison, A., Tanborello, F., Khemlani, S., and Schultz, A. (2013). ACT-r-e: an embodied cognitive architecture for human-robot interaction. J. Hum. Robot Interact. 2, 30–55. doi:10.5898/JHRI.2.1.Trafton
Tulga, M., and Sheridan, T. (1980). Dynamic decisions and work load in multitask supervisory control. IEEE Trans. Syst. Man Cybern. 10, 217–232. doi:10.1109/TSMC.1980.4308481
Unema, P. J. A., Pannasch, S., Joos, M., and Velichkovsky, B. M. (2005). Time course of information processing during scene perception: the relationship between saccade amplitude and fixation duration. Vis. Cogn. 12, 473–494. doi:10.1080/13506280444000409
Ushakov, I., and Bubeev, Y. (2008). Psychophysiological approaches to the research and restoration of mental health of military in extreme conditions. Int. J. Psychophysiol. 69, 142–143. doi:10.1016/j.ijpsycho.2008.05.348
Velichkovsky, B. M. (2002). Heterarchy of cognition: the depths and the highs of a framework for memory research. Memory 10, 405–419. doi:10.1080/09658210244000234
Velichkovsky, B. M., Dornhoefer, S. M., Pannasch, S., and Unema, P. J. (2000). “Visual fixations and level of attentional processing,” in ETRA ’00 (New York, NY: ACM), 79–85.
Ververs, P. M., Whitlow, S., Dorneich, M., and Mathan, S. (2005). “Building Honeywell’s adaptive system for the augmented cognition program,” in 1st International Conference on Augmented Cognition (Las Vegas, NV).
Vessey, I. (1985). Expertise in debugging computer programs: a process analysis. Int. J. Man Mach. Stud. 23, 459–494. doi:10.1016/S0020-7373(85)80054-7
Vogel-Walcutt, J. J., Schatz, S., Bowers, C., Gebrim, J. B., and Sciarini, L. W. (2008). Augmented cognition and training in the laboratory: DVTE system validation. Proc. Hum. Fact. Ergon. Soc. Annu. Meet. 52, 187–191. doi:10.1177/154193120805200308
Waldherr, S., Romero, R., and Thrun, S. (2000). A gesture based interface for human-robot interaction. Autonomous Robots 9, 151–173.
Wankhede, H. S., Chhabria, S. A., and Dharaskar, R. V. (2013). Human computer interaction using eye and speech: The hybrid approach. Int. J. Emer Sci Eng. 54–58.
Watson, J. M., and Strayer, D. L. (2010). Supertaskers: profiles in extraordinary multitasking ability. Psychon. Bull. Rev. 17, 479–485. doi:10.3758/PBR.17.4.479
Weintraub, D. J. (1992). Human Factors Issues in Head-Up Display Design: The Book of HUD. Technical Report. DTIC Document.
Wickens, C. D. (1997). Computational Models of Human Performance in the Design and Layout of Controls and Displays (Crew System Ergonomics Information Analysis Center (CSERIAC). Wright-Patterson AFB, OH: CSERIAC).
Wickens, C. D., Hyman, F., Dellinger, J., Taylor, H., and Meador, M. (1986). The Sternberg memory search task as an index of pilot workload. Ergonomics 29, 1371–1383. doi:10.1080/00140138608967252
Wickens, C. D., and Seidler, K. S. (1997). Information access in a dual-task context: testing a model of optimal strategy selection. J. Exp. Psychol. 3, 196–215. doi:10.1037/1076-898X.3.3.196
Wiener, E. L., and Curry, R. E. (1980). Flight-Deck automation: promises and problems. Ergonomics 23, 995–1011. doi:10.1080/00140138008924809
Wiener, E. L., and Nagel, D. C. (1988). Human Factors in Aviation. Houston, TX: Gulf Professional Publishing.
Woodman, G. F., and Luck, S. J. (2004). Visual search is slowed when visuospatial working memory is occupied. Psychon. Bull. Rev. 11, 269–274. doi:10.3758/BF03196569
Xu, S., Jiang, H., and Lau, F. C. (2008). “Personalized online document, image and video recommendation via commodity eye-tracking,” in RecSys ’08 (New York, NY: ACM), 83–90.
Ye, N., and Salvendy, G. (1994). Quantitative and qualitative differences between experts and novices in chunking computer software knowledge. Int. J. Hum. Comput. Interact. 6, 105–118. doi:10.1080/10447319409526085
Yeh, M., Wickens, C. D., and Seagull, F. J. (1998). Conformality and target cueing: presentation of symbology in augmented reality. Proc. Hum. Fact. Ergon. Soc. Annu. Meet. 42, 1526–1530. doi:10.1177/154193129804202113
Zhai, S., Morimoto, C., and Ihde, S. (1999). “Manual and gaze input cascaded (MAGIC) pointing,” in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (Pittsburgh, PA: ACM), 246–253.
Keywords: eye tracking, automation, gaze-aware, multitasking, task switching, monitoring, working memory, human–computer interaction
Citation: Taylor P, He Z, Bilgrien N and Siegelmann HT (2015) Human strategies for multitasking, search, and control improved via real-time memory aid for gaze location. Front. ICT 2:15. doi: 10.3389/fict.2015.00015
Received: 08 June 2015; Accepted: 07 August 2015;
Published: 07 September 2015
Edited by:
Javier Jaen, Universitat Politecnica de Valencia, SpainReviewed by:
João Dinis Freitas, Microsoft Language Development Center, PortugalRubén San Segundo Hernández, Universidad Politécnica de Madrid, Spain
Copyright: © 2015 Taylor, He, Bilgrien and Siegelmann. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: P. Taylor, Biologically Inspired Neural and Dynamical Systems Laboratory, College of Information and Computer Sciences, Neuroscience and Behavior Program, University of Massachusetts, 140 Governors Drive, Amherst, MA 01003, USA,cHRheWxvckBjcy51bWFzcy5lZHU=