 Meritxell Deulofeu1,2
Meritxell Deulofeu1,2 Esteban García-Cuesta3,4Eladia María Peña-Méndez5José Elías Conde5Orlando Jiménez-Romero1,2
Esteban García-Cuesta3,4Eladia María Peña-Méndez5José Elías Conde5Orlando Jiménez-Romero1,2 Enrique Verdú1María Teresa Serrando1,2Victoria Salvadó6*
Enrique Verdú1María Teresa Serrando1,2Victoria Salvadó6* Pere Boadas-Vaello1,2*
Pere Boadas-Vaello1,2*- 1Research Group of Clinical Anatomy, Embryology and Neuroscience (NEOMA), Department of Medical Sciences, University of Girona, Girona, Spain
- 2ICS-IAS Girona Clinical Laboratory, Santa Caterina Hospital, Parc Sanitari Martí i Julià, Salt, Spain
- 3Science, Computation, and Technology Department, School of Architecture, Design, and Engineering, European University of Madrid, Madrid, Spain
- 4Instant Biosensing Technologies, Carson, NV, United States
- 5Analytical Chemistry Division, Department of Chemistry, Faculty of Science, University of La Laguna, La Laguna, Spain
- 6Department of Chemistry, Faculty of Science, University of Girona, Girona, Spain
The high infectivity of SARS-CoV-2 makes it essential to develop a rapid and accurate diagnostic test so that carriers can be isolated at an early stage. Viral RNA in nasopharyngeal samples by RT-PCR is currently considered the reference method although it is not recognized as a strong gold standard due to certain drawbacks. Here we develop a methodology combining the analysis of from human nasopharyngeal (NP) samples by matrix-assisted laser desorption/ionization time-of-flight mass spectrometry (MALDI-TOF MS) with the use of machine learning (ML). A total of 236 NP samples collected in two different viral transport media were analyzed with minimal sample preparation and the subsequent mass spectra data was used to build different ML models with two different techniques. The best model showed high performance in terms of accuracy, sensitivity and specificity, in all cases reaching values higher than 90%. Our results suggest that the analysis of NP samples by MALDI-TOF MS and ML is a simple, safe, fast and economic diagnostic test for COVID-19.
Introduction
The COVID-19 pandemic not only represents a major health crisis, but has also had unprecedented economic repercussions. According to the most recent available report of the World Health Organization (1), the cumulative number of reported cases of SARS-CoV-2 infections worldwide has now reached over 98 million people and over 2 million people have died of the disease since the start of the COVID-19 pandemic in December 2019. Moreover, it has been estimated that the gross domestic product may drop by more than 10-15% in some countries (2). Taking into consideration how rapidly the COVID-19 pandemic has spread, often through the transmission of SARS-CoV-2 by asymptomatic individuals (3), fast and economic diagnostic tools are essential for the control of this devastating pandemic.
While several diagnostic and surveillance technologies for SARS-CoV-2 have been either developed or used during the COVID-19 pandemic (4–6), real-time reverse transcription polymerase chain reaction (RT-PCR) is currently still the validated assay for early diagnosis in patients with suspected SARS-CoV-2 infection (7). However, there are certain concerns regarding RT-PCR (8) as the gold standard analytical methodology for pandemic control. PCR-based strategies are costly, require a lot of technical personnel and laboratories, and the analysis time is relatively long, limiting the number of samples that can be processed daily. Although some of these problems can be overcome by using saliva for COVID-19 diagnosis and a dual RT-qPCR test, the time needed to obtain results remains high (9, 10). Moreover, most countries do not have sufficient laboratory resources and, due to the enormous global demand, are not able to obtain a sufficient supply of PCR kits. Given this situation, new alternative methodologies need to be developed.
A useful bioanalytical methodology that would allow most of these limitations to be overcome is matrix-assisted laser desorption/ionization mass spectrometry coupled to a TOF analyzer (MALDI-TOF MS). This technique is the current tool for rapid, accurate, and cost-effective identification of cultured bacteria and fungi in clinical microbiology (11, 12) and even though it is not routinely used in hospitals to identify viruses, it has been shown to be useful for this purpose (13, 14). Although some MALDI-TOF MS methodologies need time-consuming sample preparation, such as protein or nucleotide extraction, simpler protocols are possible. For example, protocols that consist only of the mixing of a diluted sample with the matrix have been successfully applied to differentiate samples from myeloma patients and healthy subjects (15). In that study, the analyses of biological samples by MALDI-TOF MS allowed the patterns or fingerprints of different biological samples to be obtained, which could be further used to differentiate between samples (e.g., control vs. disease samples).
The large amount of data obtained using MS spectra fingerprints requires the combination of powerful statistical strategies (13) and artificial intelligence methods in order to be able to identify the diagnostic pattern. These strategies have been successfully applied in medicine and biomedicine (15, 16). The fingerprint (pattern recognition) approach avoids tedious biological sample work and eliminates the need to identify biomarkers, so considerably reducing the analysis time (17). With regards to the use of biomarkers, it should also be noted that single biomarkers are generally considered as insufficient and so it is often necessary to search for a combination of several different biomarkers to perform effective clinical diagnosis (18, 19).
A method based on recording the MALDI mass spectra of nasal swab samples previously tested for SARS-CoV-2 by RT–qPCR and their subsequent analysis by machine learning (ML) has recently been proposed for large-scale SARS-CoV-2 testing (20). In this study, samples were analyzed after adding a CHCA solution as a matrix and irradiating the MALDI plates with an ultraviolet light for 20 min to inactivate the viruses. However, in addition to the problems regarding this methodology discussed by SoRelle et al. (21), other aspects such as the application of safer sample inactivation protocols, the use of different viral transport media and the development of more robust machine learning protocols have required further progress.
In light of the above, the present work has aimed to develop a new methodology based on MALDI-TOF MS analyses of nasopharyngeal samples coupled to methods of artificial intelligence, allowing COVID-19 to be identified. We have employed a variety of machine learning approaches to analyze the pattern spectra (fingerprint) of nasopharyngeal samples in the two most widely used types of virus transport media. The methodology developed as a result of these approaches is a promising tool not only in the battle to control the spread of COVID-19 but also for post-pandemic testing in local settings to prevent future major outbreaks.
The hypothesis of the present work was that there is a MALDI-TOF mass spectral pattern (fingerprint) that can be assigned as a signature accurately characterizing negative and positive samples for SARS-CoV-2 infection. The application of a machine learning (ML) approach to the fingerprint mass spectra of positive and negative samples of SARS-CoV-2 infection will allow the development of a fast and efficient approach to support clinical decisions.
Materials and Methods
Chemicals
Sinapinic acid was used as a matrix for MALDI-TOF MS analysis and was purchased from Bruker Daltonics (Bremen, Germany; #8201345). Trifluoroacetic acid (TFA) was purchased from Scharlab (#AC31420100; peptide synthesis grade) and acetonitrile (mass spectrometry grade) was purchased from VWR (#83640.29). Protein Calibration Standard I (#8206355) was used for MALDI-TOF MS calibration and was purchased from Bruker Daltonics (Bremen, Germany).
Sample Collection
A total of 237 nasopharyngeal samples were provided by the ICS-IAS Girona Clinical Laboratory (Parc Sanitari Martí i Julià; Salt, Catalonia, Spain), according to IDIBGI Biobank (Biobanc IDIBGI, B.0000872) agreement, to carry out the present study, which was approved by the Clinical Research Ethics Committee of the Doctor Josep Trueta Hospital in Girona (ref#2020.088). A consecutive non-probabilistic model was chased since samples were provided when available at several time points during the first COVID19 wave (April–July of 2020). Such samples were provided either in DeltaSwab ViCUM (#304273; DeltaLab) or DeltaSwab Virus (#304295; DeltaLab) virus transport medium. Concretely 149 samples were provided in DeltaSwab ViCUM and 88 in DeltaSwab Virus. Before delivering, they were processed in the Molecular area of the territorial laboratory of Girona under biosafety II conditions to perform both the chemical inactivation and the PCR diagnostics. The sample inactivation was performed using Ribospin vRD Buffer VL (GeneAll, Korea), which its principal component is guanidine thiocyanate in a concentration of 60–70%, by mixing 300 ul of the buffer with 300 ul of the transport medium where the NP sample was collected. The RT-PCR diagnosis was performed using two different methodological platforms which detect 2 targets (N and E qRT-PCR methodology, Xpert SARS-CoV-2, Cepheid, US) or 4 targets (N, E, S and RpRd genes, Allplex 2019-nCoV assay, Seegen, South Korea). After sample inactivation and the RT-PCR analysis samples were send to the laboratory of NEOMA research group.
Sample Preparation for MS
Inactivated samples, previously tested by RT-PCR in the ICS-IAS Girona Clinical Laboratory, were then processed for MS analysis in the laboratory of NEOMA research group of the University of Girona.
All samples were first diluted 10 times with Milli-Q water. Theyhe were then mixed in 1:1 ratio with a solution of sinapinic acid (SA) containing 20 mg SA/mL in 60%:40% (v/v) acetonitrile (ACN): milli-Q water with 0.3% trifluoroacetic acid (TFA). TFA was added in order to increase the ionization. Finally, 1 ul of the mixture was spotted on a purified stainless-steel target plate (MTP 384 target ground steel; Bruker Daltonics, Bremen, Germany) in triplicates and allowed to dry at room temperature before being analyzed by MALDI-TOF MS. To avoid carry-over contamination, the target plate was regularly cleaned in an ultrasonic bath using a specific cleaning procedure with ultrapure solvents sequentially in this order: 2-propanol, MilliQ water, 2-propanol and TA30 (350 ml ACN: 350 ml TFA 0.1%).
Acquisition of Mass Spectra
Mass spectra were acquired using Autoflex maX with Time-Of-Flight (TOF) analyzer from Bruker Daltonics (Bruker Daltonics, Bremen, Germany). Ionization was achieved by irradiation with a solid phase laser (with patented Smartbeam technology) operating at 2,000 Hz. All spectra were acquired automatically using a regular raster (in random walk mode) and 20 shots were made in each raster spot; locations were calibrated prior to each run. Sample mass spectra was the sum of 1,800 satisfactory shots taken in 300 shots steps. All measurements were carried out in a positive linear mode and each spectrum was externally calibrated using a standard mixture of peptides (Standard Protein I, Bruker Daltonics). All mass spectra were acquired using FlexControl software (Bruker Daltonics, Germany) and each spectrum consisted of more than 25,000 m/z values with the corresponding intensities in the mass range from 5 to 20 kDa. The smoothing of mass spectra by Savitzky-Golay method, the baseline subtraction by Top-Hat method and the recalibration of each mass spectrum was performed using the FlexAnalysis 3.4 software (Bruker Daltonics, Germany). The same software was used to export all the m/z values with the corresponding intensities into ASCII format for its further analysis using machine learning approaches.
Machine Learning
To classify the positive and negative samples a machine learning approach was adopted. The learned model represents the best solution given the data samples obtained by MALDI-TOF MS. To study the performance, two of the most well-known and successfully applied techniques were selected. Extreme Gradient Boosting Trees (XBOOST) (22) and Support Vector Machines (SVMs) (23) were tested using different parameters to obtain their best results to the problem. A cross-validation (CV) was applied to study the performance of both XBOOST and SVM. In standard CV, instances are distributed randomly into CV partitions. But our study involved three replicas of the same sample and they were related. Therefore, in this study we considered the 3 replicas of the same individual as a unique sample in the CV phase. Also, a number of K = 10-folders was used because the number of samples was small, but a minimum of four positive and negative examples were added as a constraint for each fold to ensure that there are samples of at least two different individuals. Note that previous to the CV process, 10% of the samples were randomly separated to perform the test using the best model selected using CV. The test was done 20 times to avoid bias in the results and guarantee that the results are independent of the samples selected in the training phase (double-blind test).
Because the number of available features was large (29,393 m/z values) it is expected that many of them were highly correlated and some of them may contain irrelevant information. To overcome some of the problems that arise using high-dimensional data, all the experiments were performed using principal component analysis (PCA) as dimensionality reduction technique. Then, to analyze what was the optimal number of dimensions, the SVM and XBOOST methods were evaluated for 5, 10, and 50 projected features.
Both SVM and XBOOST have some hyper-parameters that require tuning in order to improve results. Three hyperparameters were fitted:
• Number of estimators (XBOOST): 50 and 10
• Tree depth (XBOOST): 5 and 10
• Subsample (XBOOST): between 50 and 80% in steps of 10%
• Learning rate (XBOOST): 0.01 and 0.05
• Kernel (SVM): radial base and linear functions
• Gamma (SVM): 0.01, 0.001 and 0.0001
• C-penalty parameter (SVM): 1 and 10
In order to tune the hyper-parameters, a systematic procedure known as grid-search was used. This method tries all possible combinations of hyper-parameter values. Models for each hyper-parameter combination are trained with the training partition and evaluated with the validation partition. The best combination on the validation set is selected.
Finally, F1-Score was used as a performance measure (Equation 1) to select the most suitable developed model. This criterion is very appealing when the positive and negative classes are unbalanced and we are interested in minimizing the probability that a random positive sample is included into the negative sample classification area and vice versa.
Results and Discussion
Based on the hypothesis of differences in the fingerprints of positive and negative samples, a machine learning (ML) approach was adopted to build a model for the fast and efficient classification of these two groups of samples. Different experiments were designed to test the ability of MALDI-TOF MS to extract these spectral patterns from the data obtained from human nasopharyngeal (NP) and enable it to detect patients infected by SARS-CoV-2.
The Optimization of the MALDI Parameters
It is well-known that several factors can influence the results obtained by MALDI-TOF MS, including matrix and sample preparation (24). Moreover, finding the mass range in which the most relevant information can be found is also an important step. Therefore, the optimization of the methodology was first carried out with the objective to find the optimal matrix, sample dilution and mass range in order to develop a simple procedure that would allow the maximum number of peaks to be obtained with acceptable resolutions and intensities. Firstly, undiluted samples were analyzed but no signals at different mass-to-charge (m/z) values were observed in the mass spectra. When samples were diluted 10 times, rich mass spectra with acceptable resolution and intensities were obtained. Since the idea was to develop a simple and fast methodology, the analysis of the low mass range (<1,000 Da) was discarded due to the high background noise generated by the matrix (25, 26). Finally, we selected the mass spectra in the 5 to 20 kDa range. This mass spectra range was also used by Nachtigall et al. (20) in developing a similar methodology. In contrast we decided to use Sinapinic Acid (SA) for MALDI TOF MS sample analysis as this is particularly recommended for larger mass range (27).
First Experiment: Using All Collected Samples
Initially, the transport media in which the nasopharyngeal (NP) samples were collected was not considered as a main experimental criterion. In other words, all spectra acquired from samples collected in either DeltaSwab-ViCUM or DeltaSwab-Virus transport media were used without splitting samples by the transporter. Therefore, different strategies of ML analysis were performed using the whole dataset composed of the m/z values, in the 5 to 20 kDa range, and their corresponding intensities for each sample. A total of 708 mass spectra were obtained by MALDI-TOF analysis, corresponding to samples that were previously analyzed by RT-PCR, resulting in 180 positive and 528 negative samples for SARS-CoV-2 infection.
The mass spectra assigned by PCR as positive samples presented differences both in the intensity of signals and the m/z values in comparison to the spectra of PCR negative samples. Despite the differences exhibited, no specific biomarkers for any of the positive or negative PCR sample groups were found (Figure 1A). The ML approach was then applied to analyze the data from the entire range of the selected m/z pattern (fingerprint) without applying any variable selection method. Six models were constructed using both XGBOOST and support vector machine (SVM) algorithms with different numbers of principal components (PCs) (5, 10 or 50 PCs) to identify the conditions that would tend toward lower variance. When training the different models, performance analyses showed that the models' accuracies, sensitivities, and specificities did not vary significantly between the different number of PCs. Based on the metric F1-score, which is the harmonic-mean of precision and recall, the best model for this experiment was obtained by SVM + 10PCs. The model was able to perform better than baseline (F1-Score = 0.639 ± 0.056) (Table 1), showing the existence of a general pattern associated to the mass spectra. These results can also be observed in the precision-recall (PR) curve (Figure 1B), providing insights that suggest the best model. Overall, the resulting model reached an 0.580 ± 0.110 and 0.739 ± 0.065 of sensitivity and specificity, respectively. This model was then applied to perform the test process. Figures 1C,D shows the matrix confusion of this experiment with the summary of the predicted results for all the samples used to perform the test.
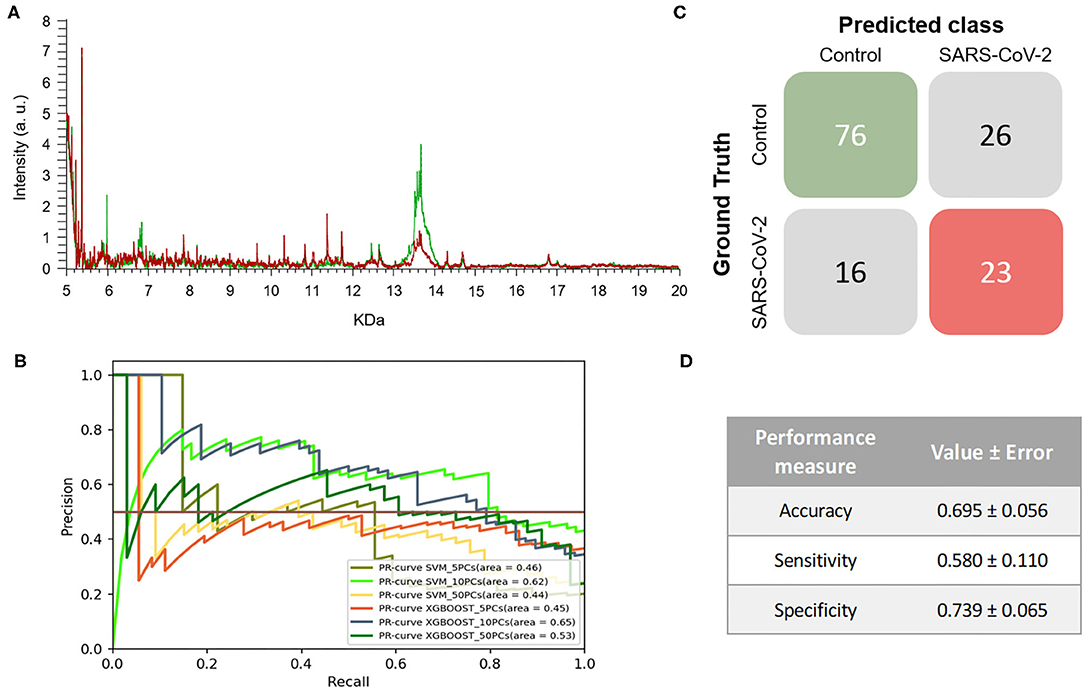
Figure 1. Results of the first experiment. (A) Representative mass spectra of NP samples for SARS-CoV-2: positive (red) and negative (green). (B) Precision-recall curve from the different models. (C) Average confusion matrix and (D) average performance metrics including the standard deviation (note that the test was performed 20 times selecting random different samples for each iteration) of the best model (SVM + 10PCs cross-validation K = 10).
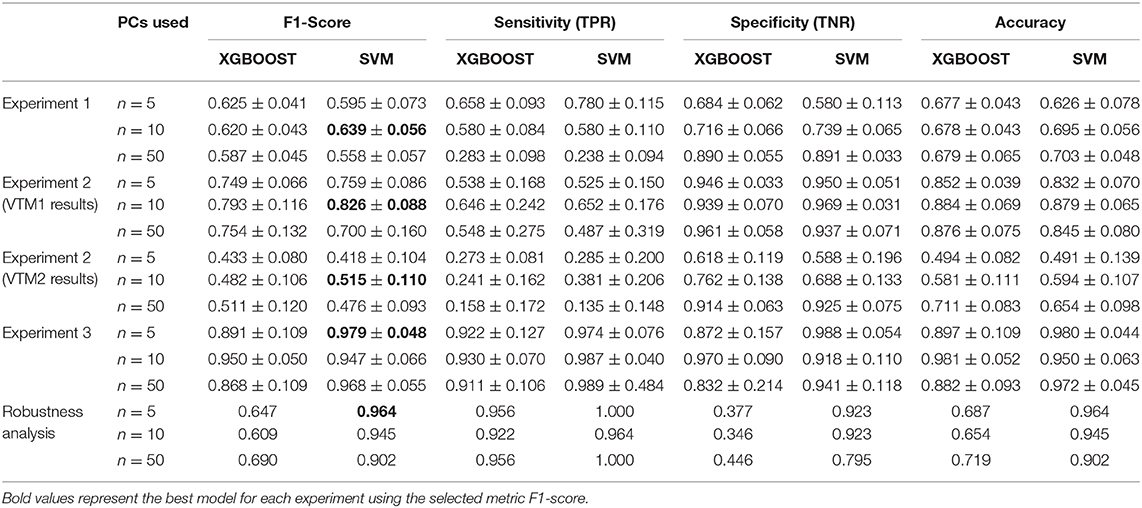
Table 1. Model learning (cross validation results K = 10) of all the models tested in the different experiments.
The results demonstrated that the developed a methodology, without considering the viral transport media, enables SARS-CoV-2-positive and -negative samples to be discriminated with around 70% accuracy, 60% sensitivity and 74% specificity. Although these percentages may be lower than the expectations, it is worth noting that RT-PCR for COVID-19 diagnosis only reaches clinical sensitivities of between 38 and 78% (28, 29). In the case of RT-PCR in nasopharyngeal swabs, sensitivity has not been found to exceed 70% (30, 31). Therefore, our first developed model using two different transport media would be as useful as RT-PCR in monitoring the spread of COVID-19 during a pandemic in which both incidence and prevalence are high. It is important to note that the mass spectra of the samples used to train and develop the different ML models were classified in the control group and in the COVID-19 group based on the previous RT-PCR result. However, there is a high rate of false negatives in RT-PCR results, estimated at between 2 and 29% by Arevalo-Rodriguez et al. (32), which may hinder the learning, validation and testing steps of the classification model. The drawbacks of RT-PCR as a diagnostic test for COVID-19 and the lack of a clear gold-standard complicates the evaluation of new methodologies (8, 33, 34).
Interestingly, the optimized model for the prediction of SARS-CoV-2-positive and negative samples shows a greater ability to detect negative samples than positive ones (despite the standard deviation of the sensitivity being quite large for the different tests performed). These results may indicate that the developed model has a dependence on factors such as the heterogeneity of the samples and the noise of the data. This heterogeneity of the data in this first experiment may be caused by the different viral transport media used for sample collection. The high demand during the COVID-19 pandemic for the specific transport media for SARS-CoV-2, resulted in the use of alternative viral transport media, following the recommendations of the FDA, that had the effect of increasing the heterogeneity of the samples received in the laboratories (35).
Second Experiment: Splitting Samples by the Viral Transport Media
To test the hypothesis that the heterogeneity of the data was a result of the different viral transport media that were used, the dataset was split by DeltaSwab-ViCUM (viral transport medium 1, VTM1) and DeltaSwab-Virus (viral transport medium 2, VTM2).
As for VTM1, 443 mass spectra (111 and 332 from samples that were positive and negative for SARS-CoV-2, respectively) were obtained from NP samples collected in this viral transport media. As observed in the first experiment, the spectra of the two groups present differences in certain regions (Figure 2A). The same ML strategy as was used in the previous section was then applied to analyze the information from the corresponding pattern of the mass spectra (fingerprint). The results did not vary substantially between the different ML models applied to perform the analysis (Figure 2B and Table 1). However, of the different models tested the best results in terms of the F1-score were obtained when the SVM using 10 PCs (F1-score = 0.826 ± 0.088) was applied (Table 1).
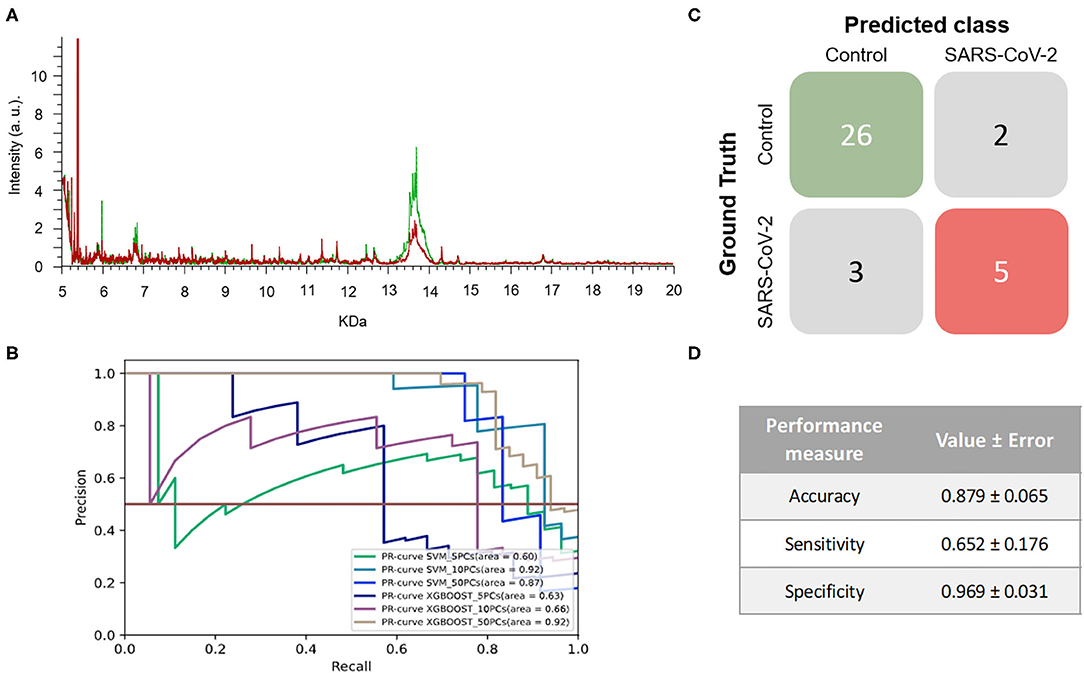
Figure 2. Results for DeltaSwab-ViCUM (VTM1). (A) Representative mass spectra of NP samples for SARS-CoV-2: positive (red) and negative (green). (B) Precision-recall curve from the different models. (C) Average confusion matrix and (D) average performance metrics including their standard deviation (the test was performed 20 times selecting randomly different samples for each iteration) of the best model (SVM + 10PCs cross-validation K = 10).
On the other hand, 264 mass spectra [69 positive and 195 negative for SARS-CoV-2, respectively] were obtained from NP samples collected in VTM2. In this case, no clear differences were observed between the spectral pattern of positive and negative samples (Figure 3A). After analyzing the spectral data by the different ML models, the best model was obtained for SVM using 10PCs (F1-score = 0.515±0.110) (Figure 3B and Table 1).
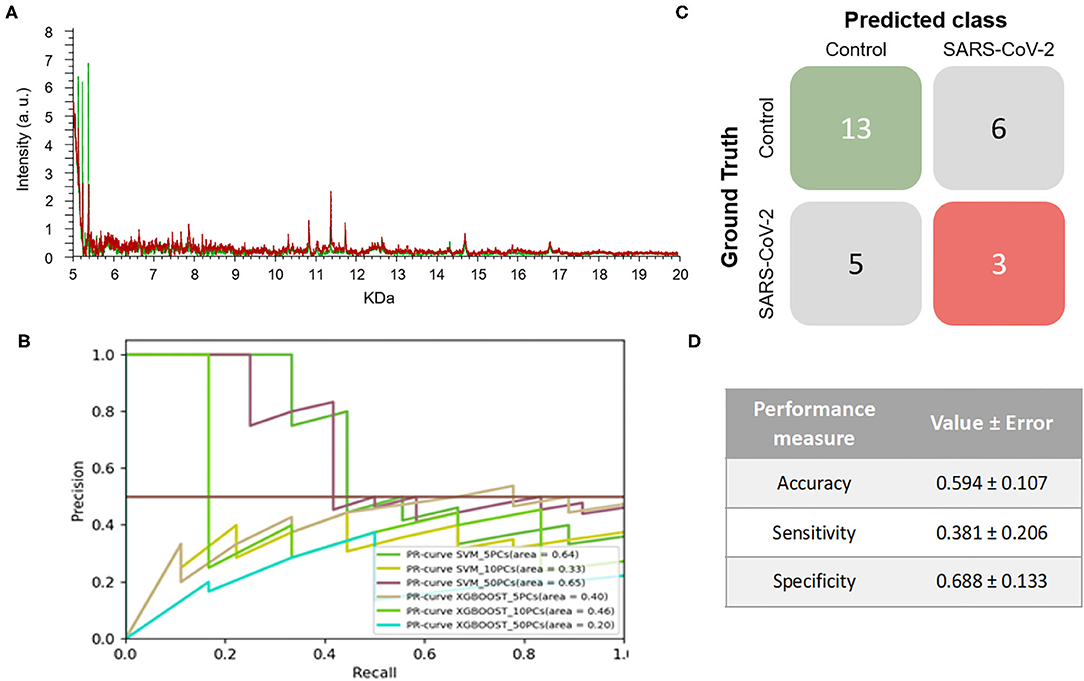
Figure 3. Results for DeltaSwab-Virus (VTM2). (A) Representative mass spectra of NP samples for SARS-CoV-2: positive (red) and negative (green). (B) Precision-recall curve from the different models. (C) Average confusion matrix and (D) average performance metrics including their standard deviation (the test was performed 20 times selecting randomly different samples for each iteration) of the best model (SVM + 10 PCs cross-validation K = 10).
The results obtained relating to the performance of the two best models clearly differed. Accuracy (VTM1 = 0.879 ± 0.065 vs. VTM2 = 0.594 ± 0.107), sensitivity (VTM1 = 0.652 ± 0.176 vs. VTM2 = 0.381 ± 0.206), and specificity (VTM1 = 0.969 ± 0.031 vs. VTM2 = 0.688 ± 0.133) all varied significantly between the two transport media (Figures 2C,D, 3C,D). The model that gave the best results was the one with VTM1, reaching 88, 65, and 97% for accuracy, sensitivity and specificity, respectively. The results prove that these two virus transporters behave differently and that VTM1 is better suited for the detection of SARS-CoV-2 infected samples. This finding that the model is reagent-dependent is unsurprising as the use of different analytical platforms in clinical laboratories require specific sample collectors and reagents in order to obtain accurate results.
Analyzing the results more deeply, it can be seen that despite the promising results related to VTM1 in this second experiment, there was still a significant standard deviation value in the sensitivity (±0.176), suggesting either internal VTM1 heterogeneity and noisy samples. This heterogeneity might be due to the nucleic acid amplification technique used for their analysis since different PCR platforms were used in the clinical laboratory. The main difference between the used platforms in this study lies in the number of the targets detected by PCR amplification related to viral structural proteins. At that time of the pandemic that we collected the samples, two targets (N and E qRT-PCR methodology, Xpert SARS-CoV-2, Cepheid, US) or four targets (N, E, S and RpRd genes, Allplex 2019-nCoV assay, Seegen, South Korea) were detected, considering both platforms methodologically equivalents. However, these platforms provide positive or negative results for the SARS-CoV-2 detection by using different diagnostic algorithms (true positive is considered when we observe at least two targets amplified). It has to be highlighted that the sensibility and the specificity of the RT-PCR is assay-dependent (6, 30, 33, 36). So, it is important to remark that the analytical sensitivity and specificity of these platforms, which are both qualitative, can change due to the difference in the number of the targets detected.
Despite this methodological platform variability, we hypothesize that the greatest source of heterogeneity might be the moment during the pandemic at which the samples were collected. It is known that disease prevalence plays an important role in the accuracy of a specific test (33, 37, 38). The prevalence of COVID-19 was different during the peak of the pandemic than at the beginning of the de-escalation phase when the incidence of infections was much lower. Remarkably, the available number of SARS-CoV-2-positive samples for analysis was extremely low when compared with the negative ones. As a result, the class imbalance observed in the dataset was due to the low number of samples collected at the beginning of the de-escalation phase.
In light of the above, we decided to split the samples collected in viral transport media 1 into two groups based on the moment during the pandemic at which they were collected. Hence, in a third experiment, samples collected during the peak of the pandemic period were used for ML calculations due to their greater homogeneity, while those collected later during the de-escalated phase when the incidence of infections was much lower were discarded for this purpose.
Third Experiment Focusing on DeltaSwab-ViCUM Transport Media
For this third experiment, NP samples collected in VTM1 between April and the beginning of May were analyzed. A total of 173 mass spectra (89 and 84 from samples that were positive and negative for SARS-CoV-2, respectively) were obtained and analyzed in this experiment.
When the mass spectra of positives NP samples were compared with the mass spectra of the negative ones, noticeable differences were observed in the profile of the mass spectra (Figure 4A). None of the performance measures varied significantly with the different numbers of PCs selected nor with the different ML approaches. Although all of the models showed good results, the one with the highest F1-score was the SVM using 5 PCs (F1-score = 0.979 ± 0.048) and so this was considered to be the best model (Figure 4B and Table 1). These results were not only highly precise but also had low variability, demonstrating that the learned models are independent of the training data selected and valid for SARS-CoV-2 infection detection in future samples. The average confusion matrix (Figures 4C,D) shows the high performance obtained for both negative and positive samples in terms of accuracy, sensitivity and specificity, in all cases reaching values higher than 90% (0.981 ± 0.052, 0.993 ± 0.040, and 0.974 ± 0.085, respectively).
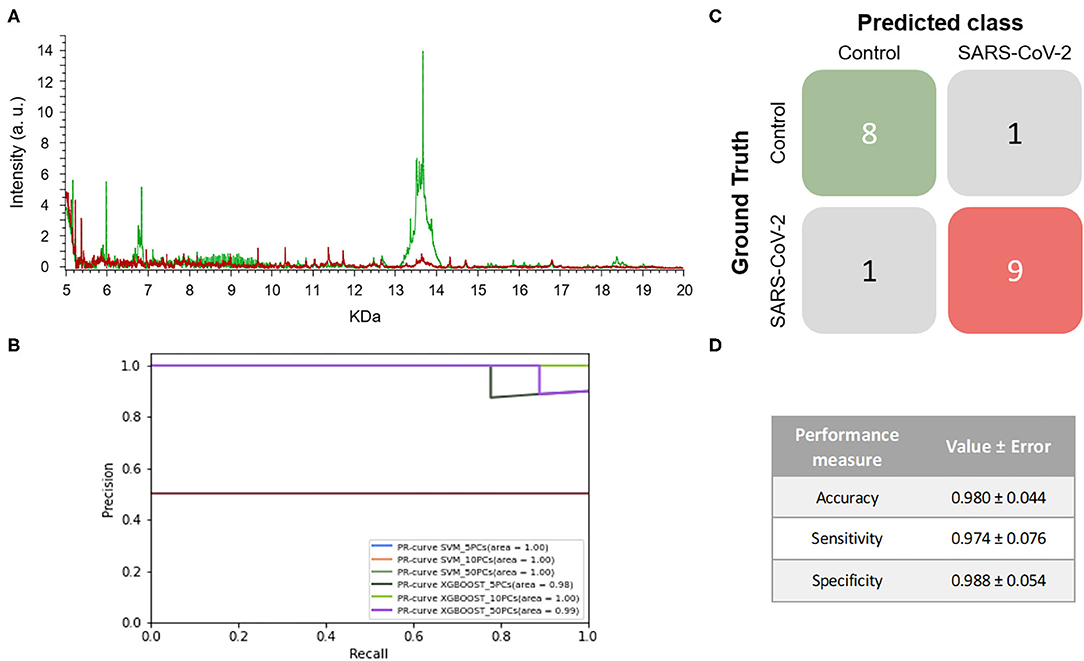
Figure 4. Results for DeltaSwab-ViCUM (VTM1) within the high incidence pandemic period. (A) Representative mass spectra of NP samples for SARS-CoV-2: positive (red) and negative (green). (B) Precision-recall curve from the different models. (C) Average confusion matrix and (D) average performance metrics including their standard deviation (the test was performed 20 times selecting randomly different samples for each iteration) of the best model (SVM + 5PCs cross-validation K = 10).
Considering the promising results obtained in this third experiment, a final experiment was performed to evaluate the robustness of the methodology in which the results of an independent set of samples were tested.
Robustness Analysis and Applicability
As has been said, two different sample sets were acquired during the peak of the pandemic. Since the final objective is to develop a methodology that is able to discriminate between a SARS-CoV-2-positive and -negative sample, we needed to test whether an independent data set was correctly classified using the model that was built using a different sample set.
With all the previous results described above, we decided to test the methodology using the same samples as in the third experiment, consisting of NP samples collected in VTM1 during the peak of the pandemic but selecting different time periods to train and test. Thereof, these group of samples consists of two independent sample sets. The first set (Set 1; S1) consisted of NP samples collected in VTM1 at the end of April 2020 while the second set (Set 2; S2) corresponded to those samples collected in the same transport media at the beginning of May. Unlike the third experiment where all samples were considered as a single group, in this experiment the 89 mass spectra (45 positive and 44 negative) of the samples of set 1 (S1) were used to train a model and the 84 mass spectra (45 positive and 39 negative) of set 2 were used to test it.
The mass spectra of the two sets of samples are shown in Figure 5A. As can be seen, the positive and negative samples for SARS-CoV-2 infection have clearly distinct fingerprints. In this experiment, the best model, which was the SVM using 5 PCs, had a F1-score of 0.964 (Figure 5B and Table 1). Excellent results were obtained in terms of accuracy, sensitivity and specificity, reaching values of 97, 100 and 92%, respectively (Figure 5C). Moreover, these high values with low variation errors showed the robustness of the developed methodology when used for the detection of SARS-CoV-2-positive samples.
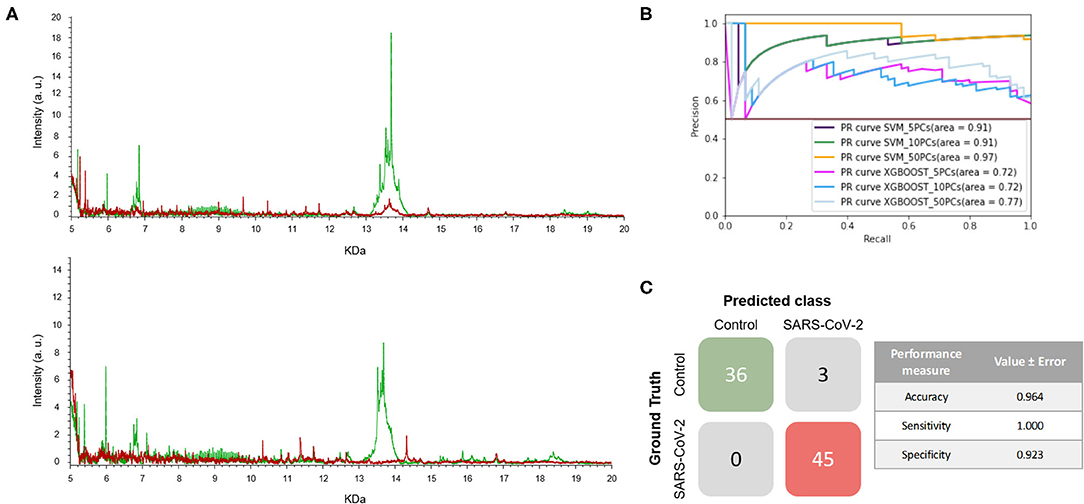
Figure 5. Developed methodology robustness. (A) Representative mass spectra of NP samples [positive (red) and negative (green)] for SARS-CoV-2 of S1 (top mass spectra) and S2 (down mass spectra). (B) Precision-recall curve from the different models. (C) Matrix confusion showing the summary of the results of all the samples used in the test phases and performance measures of the best model (SVM + 5PCs cross-validation K = 10). Note that no errors are included given that the results correspond to a single test set.
Overall, our results demonstrate that the developed method represents a promising method for the detection of SARS-CoV-2-positive samples. As it can be seen, the best results are achieved using the VTM1. However, a similar methodology was also described by Nachtigall et al. (20) where another viral transport media (Cary-Blair transport medium) was used. In contrast to what we have undertaken here, they did not study neither the effect that the use of different viral transport media might have in the results nor performed double-blind test in the ML. Another difference is that the samples used in our study were chemically inactivated whereas only ultraviolet irradiation was performed in their study. This detail is of great significance given that SARS-CoV-2 is extremely infectious and working with inactivated samples not only reduces the risk of in-lab infection during the experimental procedure but also reduces the mental stress that could be experienced by laboratory staff (39). In line with our results, an earlier study has also found that using inactivated samples does not interfere with RT-PCR results (40).
Due to the high infectivity rate of SARS-CoV-2, an accurate and rapid diagnosis of both symptomatic and asymptomatic patients is needed to reduce the spread of the virus (31, 40). Different diagnostic methodologies have been developed, each with its own specific applications as well as its own its advantages and drawbacks (5). However, all these methodologies share certain limitations: low sensitivity, high rate of false negatives, high dependence on the moment of the diagnostic window in which the sample is collected, etc. (8, 28, 30, 34, 41). Given that asymptomatic infected people can also spread the virus, a rapid and economic screening test is needed to detect those SARS-CoV-2-positive patients without symptoms (3, 5, 42). Considering the cost of materials per specimen, we estimate that the cost of MALDI-TOF MS will be no more than 25% of the cost of RT-PCR analysis. With regards to the length of time required to receive results, the turn-around-time of a conventional RT-PCR in which an RNA extraction phase is also needed is around 6 h (40) whereas the analysis of the NP samples by MALDI-TOF MS takes less than a third part of this. Therefore, the use of MALDI-TOF -MS analysis, which is widely available in clinical laboratories, as a screening technique for SARS-CoV-2 infection detection will offer enormous savings both in time and cost.
As said, community prevalence and pre-test probability have an important effect on the positive and negative predictive value of a diagnostic test (37, 38). Under a clinical point of view, this pandemic situation has been one of the most challenging experiences in the laboratories; recruiting resources, reagents, methodological platforms and personal staff has been the most difficult goal to achieve for the very last months. Nowadays, this new situation is extremely demanding due to the high incidence and prevalence in the general population. Vaccines are ready to be used as immunological protection against SARS-CoV-2 (43) so we will probably notice shortly a descent of the cases. In this future and new scenario and with lower prevalence in the population, we will need a strong and accurate methodology that provides results requiring less time and investment. MALDI-TOF is the best option available in clinical laboratories that can reach this purpose. Moreover, this equipment is commonly found in clinical laboratories also in the developing countries, which means that the implementation of the developed methodology would not require a huge economic cost.
Finally, in order to estimate the benefit to society of this innovation, we have used the online calculator of the BMJ (33) applying our best developed model. Firstly, a pandemic situation was simulated taking an estimated prevalence of COVID-19 in Europe of 80%, which was a pre-test probability calculated by the WHO. If 100 people were tested, and only 1 false negative and 1 false positive were obtained (Figure 6A), the probability of having COVID-19 if the test is negative is only 5%. To simulate the results in a post-pandemic situation, the pre-test probability was set at 16% which is the estimated prevalence of the influenza virus in Europe. In this case, only 3 false positives and no false negatives were obtained (Figure 6B). These two simulations strongly support our own conclusion that the developed methodology, consisting in the analysis NP samples by MALDI-TOF-MS in combination with machine learning approaches, is suitable to diagnose COVID-19 patients not only in pandemic situations but also in an epidemic situation as a screening tool in the first steps of diagnosis.
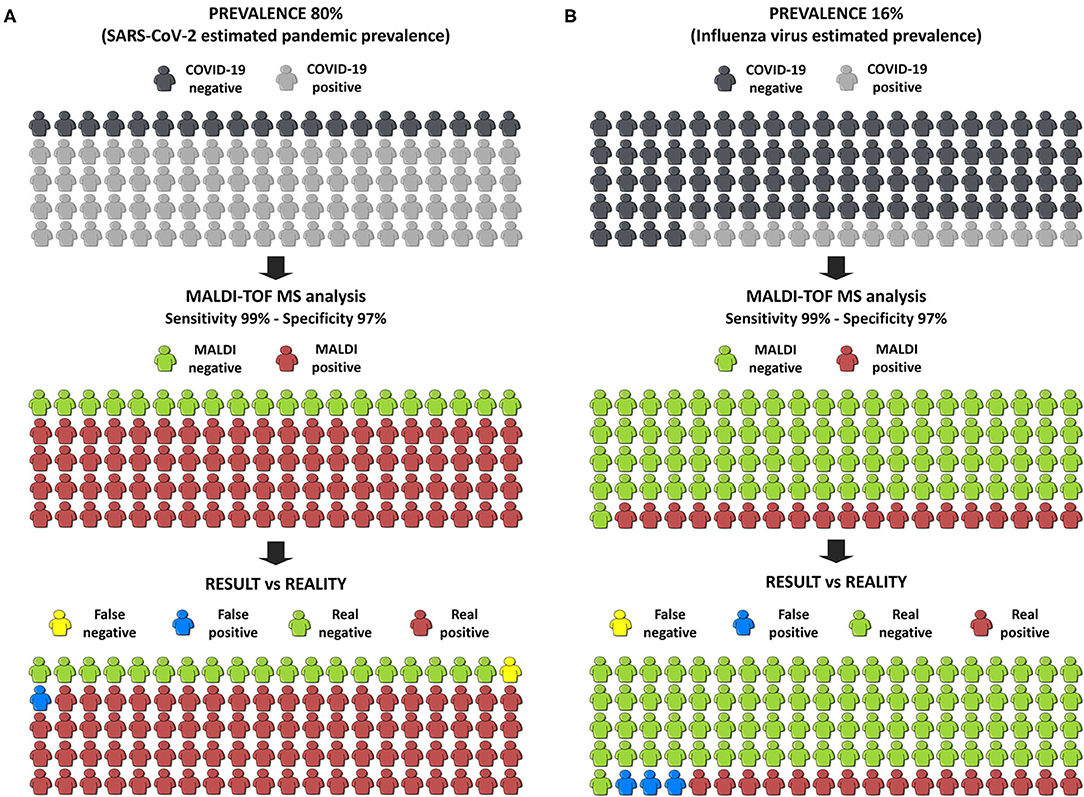
Figure 6. Infographic of the simulation of the results in the society. (A) Simulation in a pandemic situation. (B) Simulation in a post-pandemic situation.
Data Availability Statement
The datasets presented in this article are not readily available because the data that support the findings of this study are available from the corresponding author upon reasonable request. Requests to access the datasets should be directed to Pere Boadas-Vaello, cGVyZS5ib2FkYXNAdWRnLmVkdQ==.
Ethics Statement
The studies involving human participants were reviewed and approved by Clinical Research Ethics Committee of the Doctor Josep Trueta Hospital in Girona (ref#2020.088). Written informed consent for participation was not required for this study in accordance with the national legislation and the institutional requirements.
Author Contributions
PB-V, MD, and VS conceived the experiments, supported by EV and MS. OJ-R and MS were in charge of the NP samples inactivation and management. MALDI-MS experiments were carried out by MD and PB-V. Spectra analyses were carried out by MD, EP-M, and JC. Machine learning analyses were performed by EG-C and MD. All authors were involved in interpretation of the data and they contributed to both critical discussion of the results and elaboration of the manuscript. All authors listed above have contributed sufficiently to be included as authors.
Funding
The present work was supported by SAUN—Santander Universidades-CRUE, grant PEDIEC from FONDO SUPERA COVID-19 call.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors would like to thank the ICS-IAS Girona Clinical Laboratory staff for the RT–PCR assessments and we want to particularly acknowledge the patients and the IDIBGI Biobank (Biobanc IDIBGI, B.0000872), integrated in the Spanish National Biobanks Network, for their collaboration. Also we thank the staff of the Universitat de Girona Research Technical Services where the MALDI-TOF MS measurements were performed.
References
1. World Health Organization (WHO). Coronavirus disease (COVID-2019) situation reports. 29 December, 2020. Available online at: https://www.who.int/publications/m/item/weekly-epidemiological-update—27-january-2021 (accessed January 30, 2021).
2. Zaman KT, Islam H, Khan AN, Shweta DS, Rahman A, Masud J, et al. COVID-19 pandemic burden on global economy: a paradigm shift. Preprints (2020). doi: 10.20944/preprints202005.0461.v1
3. Bai Y, Yao L, Wei T, Tian F, Jin DY, Chen L, et al. Presumed asymptomatic carrier transmission of COVID-19. JAMA. (2020) 323:1406–7. doi: 10.1001/jama.2020.2565
4. Ji T, Liu Z, Wang G, Guo X, Akbar Khan S, Lai C, et al. Detection of COVID-19: A review of the current literature and future perspectives. Biosens Bioelectron. (2020) 166:112455. doi: 10.1016/j.bios.2020.112455
5. Wu SY, Yau HS, Yu MY, Tsang HF, Chan LWC, Cho WCS, et al. The diagnostic methods in the COVID-19 pandemic, today and in the future. Expert Rev Mol Diagn. (2020) 20:985–93. doi: 10.1080/14737159.2020.1816171
6. Udugama B, Kadhiresan P, Kozlowski HN, Malekjahani A, Osborne M, Li VYC, et al. Diagnosing COVID-19: the disease and tools for detection. ACS Nano. (2020) 14:3822–35. doi: 10.1021/acsnano.0c02624
7. World Health Organization (WHO). Laboratory testing for coronavirus disease 2019 (COVID-19) in suspected human cases: interim guidance, 2 March 2020. Available online at: https://apps.who.int/iris/handle/10665/331329 (accessed December 20, 2020).
8. Tahamtan A, Ardebili A. Real-time RT-PCR in COVID-19 detection: issues affecting the results. Expert Rev Mol Diagn. (2020) 20:453–4. doi: 10.1080/14737159.2020.1757437
9. Williams E, Bond K, Zhang B, Putland M, Williamson DA. Saliva as a non-invasive specimen for detection of SARS-CoV-2. J Clin Microbiol. (2020) 58:e00776-20. doi: 10.1128/JCM.00776-20
10. Pasomsub E, Watcharananan SP, Boonyawat K, Janchompoo P, Wongtabtim G, Suksuwan W, et al. Saliva sample as a non-invasive specimen for the diagnosis of coronavirus disease 2019: a cross-sectional study. Clin Microbiol Infect. (2020) 27:285.e1–285.e4. doi: 10.1016/j.cmi.2020.05.001
11. Reeve MA, Bachmann D. MALDI-TOF MS protein fingerprinting of mixed samples. Biol Methods Protoc. (2019) 4:bpz013. doi: 10.1093/biomethods/bpz013
12. Welker M, van Belkum A, Girard V, Charrier JP, Pincus D. An update on the routine application of MALDI-TOF MS in clinical microbiology. Expert Rev Proteomics. (2019) 16:695–710. doi: 10.1080/14789450.2019.1645603
13. Majchrzykiewicz-Koehorst JA, Heikens E, Trip H, Hulst AG, de Jong AL, Viveen MC, et al. Paauw, Rapid and generic identification of influenza A and other respiratory viruses with mass spectrometry. J Virol Methods. (2015) 213:75–83. doi: 10.1016/j.jviromet.2014.11.014
14. Calderaro A, Arcangeletti MC, Rodighiero I, Buttrini M, Montecchini S, Vasile Simone R, et al. Identification of different respiratory viruses, after a cell culture step, by matrix assisted laser desorption/ionization time of flight mass spectrometry (MALDI-TOF MS). Sci Rep. (2016) 6:36082. doi: 10.1038/srep36082
15. Deulofeu M, Kolárová L, Salvadó V, María Peña-Méndez E, Almáši M, Štork M, et al. Rapid discrimination of multiple myeloma patients by artificial neural networks coupled with mass spectrometry of peripheral blood plasma. Sci Rep. (2019) 9:7975. doi: 10.1038/s41598-019-44215-1
16. Amato F, López A, Peña-Méndez EM, Vanhara P, Hampl A, Havel J. Artificial neural networks in medical diagnosis. J Appl Biomed. (2013) 11:47–58. doi: 10.2478/v10136-012-0031-x
17. Marchetti-Deschmann M, Allmaier G. Mass spectrometry — one of the pillars of proteomics. J Proteomics. (2011) 74:915–9. doi: 10.1016/j.jprot.2011.04.024
18. Bäckryd E, Ghafouri B, Carlsson AK, Olausson P, Gerdle B. Multivariate proteomic analysis of the cerebrospinal fluid of patients with peripheral neuropathic pain and healthy controls—a hypothesis-generating pilot study. J Pain Res. (2015) 8:321–33. doi: 10.2147/JPR.S82970
19. Sisignano M, Lötsch J, Parnham MJ, Geisslinger G. Potential biomarkers for persistent and neuropathic pain therapy. Pharmacol Ther. (2019) 199:16–29. doi: 10.1016/j.pharmthera.2019.02.004
20. Nachtigall FM, Pereira A, Trofymchuk OS, Santos LS. Detection of SARS-CoV-2 in nasal swabs using MALDI-MS. Nat Biotechnol. (2020) 38:1168–73. doi: 10.1038/s41587-020-0644-7
21. SoRelle JA, Patel K, Filkins L, Park JY. Mass spectrometry for COVID-19. Clin Chem. (2020) 66:1367–8. doi: 10.1093/clinchem/hvaa222
22. Friedman JH. Greedy function approximation: a gradient boosting machine. Ann Stat. (2001) 29:1189–232. doi: 10.1214/aos/1013203451
23. Boser BE, Guyon IM, Vapnik VN. A training algorithm for optimal margin classifiers. In: Proceedings of the fifth annual workshop on Computational learning theory (COLT '92) (Pittsburgh, PA). (1992).
24. Albalat A, Stalmach A, Bitsika V, Siwy J, Schanstra JP, Petropoulos AD, et al. Improving peptide relative quantification in MALDI-TOF MS for biomarker assessment. Proteomics. (2013) 13:2967–75. doi: 10.1002/pmic.201300100
25. Hossain M, Limbach PA. A comparison of MALDI matrices. In: Cole RB, editor. Electrospray and MALDI Mass Spectrometry. Fundamentals, Instrumentation, Practicalities, and Biological Applications. New Jersey, NJ: Wiley (2010). p. 214–244.
26. Chen Y, Gao D, Bai H, Liu H, Lin S, Jiang Y. Carbon dots and 9aa as a binary matrix for the detection of small molecules by matrix-assisted laser desorption/ionization mass spectrometry. J Am Soc Mass Spectrom. (2016) 27:1227–35. doi: 10.1007/s13361-016-1396-y
27. Harvey DJ. Mass spectrometry: ionization methods overview. In: Worsfold P, Townshend A, Poole C, Miró M, editors. Encyclopedia of Analytical Science. Amsterdam: Elsevier (2013). p. 350–9.
28. Zitek T. The appropriate use of testing for COVID-19. West J Emerg Med. (2020) 21:470–2. doi: 10.5811/westjem.2020.4.47370
29. Waller JV, Kaur P, Tucker A, Lin KK, Diaz MJ, Henry TS, et al. Diagnostic tools for coronavirus disease (COVID-19): comparing CT and RT-PCR viral nucleic acid testing. AJR Am J Roentgenol. (2020) 215:834–8. doi: 10.2214/AJR.20.23418
30. Lippi G, Mattiuzzi C, Bovo C, Plebani M. Current laboratory diagnostics of coronavirus disease 2019 (COVID-19). Acta Biomed. (2020) 91:137–45. doi: 10.23750/abm.v91i2.9548
31. Basso D, Aita A, Navaglia F, Franchin E, Fioretto P, Moz S, et al. SARS-CoV-2 RNA identification in nasopharyngeal swabs: issues in pre-analytics. Clin Chem Lab Med. (2020) 58:1579–86. doi: 10.1515/cclm-2020-0749
32. Arevalo-Rodriguez I, Buitrago-Garcia D, Simancas-Racines D, Zambrano-Achig P, Del Campo R, Ciapponi A, et al. False-negative results of initial RT-PCR assays for COVID-19: a systematic review. PLoS ONE. (2020) 15:e0242958. doi: 10.1371/journal.pone.0242958
33. Watson J, Whiting PF, Brush JE. Brush, interpreting a covid-19 test result. BMJ. (2020) 369:m1808. doi: 10.1136/bmj.m1808
34. Feng W, Newbigging AM, Le C, Pang B, Peng H, Cao Y, et al. Molecular diagnosis of COVID-19: challenges and research needs. Anal Chem. (2020) 92:10196–209. doi: 10.1021/acs.analchem.0c02060
35. Rogers AA, Baumann RE, Borillo GA, Kagan RM, Batterman HJ, Galdzicka MM, et al. Evaluation of transport media and specimen transport conditions for the detection of SARS-CoV-2 by use of real-time reverse transcription-PCR. J Clin Microbiol. (2020) 58:e00708–20. doi: 10.1128/JCM.00708-20
36. Axell-House DB, Lavingia R, Rafferty M, Clark E, Amirian ES, Chiao EY. The estimation of diagnostic accuracy of tests for COVID-19: a scoping review. J Infect. (2020) 81:681–97. doi: 10.1016/j.jinf.2020.08.043
37. Shyu D, Dorroh J, Holtmeyer C, Ritter D, Upendran A, Kanna R, et al. Laboratory tests for COVID-19: a review of peer-reviewed publications and implications for clinical use. Mo Med. (2020) 117:184–95.
38. Tu YP, O'Leary TJ. Testing for severe acute respiratory syndrome-coronavirus 2: challenges in getting good specimens, choosing the right test, and interpreting the results. Crit Care Med. (2020) 48:1680–9. doi: 10.1097/CCM.0000000000004594
39. Wang Y, Song W, Zhao Z, Chen P, Liu J, Li C. The impacts of viral inactivating methods on quantitative RT-PCR for COVID-19. Virus Res. (2020) 285:197988. doi: 10.1016/j.virusres.2020.197988
40. Long C, Xu H, Shen Q, Zhang X, Fan B, Wang C, et al. Diagnosis of the Coronavirus disease (COVID-19): rRT-PCR or CT? Eur J Radiol. (2020) 126:108961. doi: 10.1016/j.ejrad.2020.108961
41. Bohn MK, Lippi G, Horvath A, Sethi S, Koch D, Ferrari M, et al. Molecular, serological, and biochemical diagnosis and monitoring of COVID-19: IFCC taskforce evaluation of the latest evidence. Clin Chem Lab Med. (2020) 58:1037–52. doi: 10.1515/cclm-2020-0722
42. Gao Z, Xu Y, Sun C, Wang X, Guo Y, Qiu S, et al. A systematic review of asymptomatic infections with COVID-19. J Microbiol Immunol Infect. (2020) 54:12–6. doi: 10.1016/j.jmii.2020.05.001
Keywords: MALDI-TOF MS analysis, machine learning, SARS-CoV-2, NP samples, viral transport media
Citation: Deulofeu M, García-Cuesta E, Peña-Méndez EM, Conde JE, Jiménez-Romero O, Verdú E, Serrando MT, Salvadó V and Boadas-Vaello P (2021) Detection of SARS-CoV-2 Infection in Human Nasopharyngeal Samples by Combining MALDI-TOF MS and Artificial Intelligence. Front. Med. 8:661358. doi: 10.3389/fmed.2021.661358
Received: 30 January 2021; Accepted: 11 March 2021;
Published: 01 April 2021.
Edited by:
Reza Lashgari, Institute for Research in Fundamental Sciences, IranReviewed by:
Armand Paauw, Netherlands Organisation for Applied Scientific Research, NetherlandsMinjin Wang, Sichuan University, China
Copyright © 2021 Deulofeu, García-Cuesta, Peña-Méndez, Conde, Jiménez-Romero, Verdú, Serrando, Salvadó and Boadas-Vaello. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Pere Boadas-Vaello, cGVyZS5ib2FkYXNAdWRnLmVkdQ==; Victoria Salvadó, dmljdG9yaWEuc2FsdmFkb0B1ZGcuZWR1