 Shaiban Ahmed
Shaiban Ahmed David Le
David Le Taeyoon Son1
Taeyoon Son1 Xincheng Yao
Xincheng Yao- 1Department of Biomedical Engineering, University of Illinois Chicago, Chicago, IL, United States
- 2Department of Ophthalmology and Visual Science, University of Illinois Chicago, Chicago, IL, United States
Chromatic dispersion is a common problem to degrade the system resolution in optical coherence tomography (OCT). This study is to develop a deep learning network for automated dispersion compensation (ADC-Net) in OCT. The ADC-Net is based on a modified UNet architecture which employs an encoder-decoder pipeline. The input section encompasses partially compensated OCT B-scans with individual retinal layers optimized. Corresponding output is a fully compensated OCT B-scan with all retinal layers optimized. Two numeric parameters, i.e., peak signal to noise ratio (PSNR) and structural similarity index metric computed at multiple scales (MS-SSIM), were used for objective assessment of the ADC-Net performance and optimal values of 29.95 ± 2.52 dB and 0.97 ± 0.014 were obtained respectively. Comparative analysis of training models, including single, three, five, seven and nine input channels were implemented. The mode with five-input channels was observed to be optimal for ADC-Net training to achieve robust dispersion compensation in OCT.
Introduction
Optical coherence tomography (OCT) is a non-invasive imaging modality that can provide three-dimensional information for clinical assessment (1, 2). By providing micrometer scale resolution to visualize retinal neurovasculature, it has been widely used for fundamental research and clinical management of eye conditions (3–5). Given the reciprocal relationship between the axial resolution and bandwidth of the light source, high resolution OCT requires a broadband light source (6, 7). However, the broadband light source induces chromatic dispersion, i.e., light wavelength dependence of the optical pathlength difference between the sample and the reference arms. The reference arm generally houses a reference mirror that has a uniform reflectance profile, but the sample arm usually contains dispersive media (such as a biological tissue). Optical dispersion induces phase shifts among different wavelength signals in OCT detection, and thus degrades the axial resolution. Dispersion can also produce chirping noise and hence reduce the quality of the OCT image. Both hardware and numeric methods have been developed for dispersion compensation to enhance OCT image quality.
The hardware-based method involves additional dispersive media, such as water, BK7 glass (8), fused silica (9), etc. in the reference arm to balance the dispersion in the sample arm. Physical dispersion compensation can also be achieved by using grating-based group and phase delay detectors (10). Faster speed and a higher range of tunability were achieved by using acousto-optic modulator (11) and tunable optical fiber stretchers (12). However, hardware compensation leads to a bulky optical system due to the need of additional components. Moreover, the hardware compensation is typically effective only when the sample subject is stable with a fixed dispersion.
Numerical dispersion compensation has been established as a useful alternative to hardware-based techniques. Numeric dispersion correction is based on the digital processing of OCT spectrogram, providing the flexibility of adjustable correction values of the dispersion induced phase error. Fercher et al. (13) proposed a numeric compensation technique where a depth-dependent kernel was correlated with the spectrogram to compensate dispersion. However, this method relies on the availability of information related to the dispersive characteristics of the sample which can vary for biological tissues. Fractional Fourier transform for dispersion compensation was introduced by Lippok et al. (14) where the performance is dependent on the accuracy of the value of an order parameter and acquiring this value for biological samples can be challenging. A spectral domain phase correction method, where the spectral density function is multiplied with a phase term, was demonstrated by Cense et al. (15). However, to determine the precise phase term, isolated reflections from a reference interface with a uniform reflectance profile, which might not be available in clinical setup, are required. A numeric algorithm based on the optimization of a sharpness function, which was termed to be divided by the number of intensity points above a specified threshold, was presented by Wojtkowski et al. (16) where a pair of dispersion compensation coefficients were derived to compensate dispersion in the entire B-scan. But due to the depth varying changes in biological tissues, the dispersion effect can vary at different depths and hence a single pair of dispersion compensation coefficients may not be able to compensate dispersion for all depths effectively in one B-scan.
Entropy information of the signal acquired in the spatial domain was utilized as the sharpness metric by Hofer et al. (17) to compensate dispersion. However, the numeric techniques which are based on sharpness metrics are susceptible to the prevalent speckle noise in OCT B-scans and can lead to overestimation or underestimation when the system lacks high sensitivity. A depth-reliant method was proposed by Pan et al. (18) where an analytical formula was developed to estimate the second-order dispersion compensation coefficients in different depths based on a linear fitting approach. But this method relies on the accurate estimation of second order coefficients at specific depths and the analytical formula can differ for different biological subjects. Besides, the lower degree of freedom available in a linear fitting method can lead to inaccurate estimation of the coefficients at different depths. Spectroscopic analysis of A-scan's spectrogram was conducted to estimate and correct dispersion by Ni et al. (19) where information entropy estimated from a centroid image was used as a sharpness metric. However, this technique leads to lower resolution and requires a region of analysis without transversely oriented and regularly arranged nanocylinder. In general, these classical numerical methods can be computationally extensive when it comes to the widescale application as they are usually designed based on specific conditions and may require additional optimization for the generalized application. Hence these methods may lead to computational complexity in real-time application.
Deep learning has garnered popularity in medical image processing (20–24), with demonstrated feasibility for real-time application due to its capability to handle large datasets, computational efficiency, high accuracy, and flexibility for widescale application. Deep learning-based algorithms have been used in image denoising (25, 26), segmentation (27–31), classification (32–34), etc. In this study, we propose a deep learning network for automated dispersion compensation (ADC-Net) that is based on a modified UNet architecture. Input to ADC-Net comprises OCT B-scans which are compensated by different second-order dispersion coefficients and hence are partially compensated for certain retinal layers only. The output is a fully compensated OCT B-scan image optimized for all retinal layers. We quantitatively analyzed the proposed model using two parameters namely MS-SSIM and PSNR. Comparative analysis of training models, including single, three, five, seven and nine input channels were implemented. The source code along with necessary instructions on how to implement it have been provided here: github.com/dleninja/adcnet.
Materials and Methods
This study has been conducted in compliance with the ethical regulations reported in the Declaration of Helsinki and has been authorized by the institutional review board of the University of Illinois at Chicago.
Data Acquisition
Five healthy human subjects (mean age: 30 ± 4.18 years; mean refractive error: −2.28 ± 1.53D) were recruited to acquire the OCT images for training and testing the proposed ADC-Net. These subjects had no history of ocular medical conditions. All human subjects affirmed their willful consent before participating in the experimental study. Moreover, two patients diagnosed with proliferative diabetic retinopathy (DR) were recruited for technical validation of the ADC-Net performance on OCT with eye conditions. Patient 1 was a 58-year-old female diagnosed with proliferative DR without macular edema. Patient 2 was a 68-year-old male also diagnosed with proliferative DR but with macular edema. Data were acquired from the left eye for both the patients. For OCT imaging, the illumination power on the cornea was 600 mW which is within the limit set by the American National Standards Institute. The light source used for this experiment was a near infrared (NIR) superluminescent diode (D-840-HPI, Superlum, Cork, Ireland). A pupil camera and a dim red light were used for localizing the retina and as a fixation target, respectively. The purpose of the fixation target is to minimize voluntary eye movements. Axial and lateral pixel resolutions were achieved as 1.5 and 5.0 mm respectively. The OCT spectrometer that was used for data recording consisted of a line-scan CCD camera. The total number of pixels in the CCD camera was 2,048 pixels and the line rate was 70,000 Hz. The recording speed for OCT imaging was 100 B-scans per second with a frame resolution of 300 A-lines per B-Scan. A total of 9 OCT volumes were captured. Each OCT volume consists of 1200 B-scans. Seven of these OCT volumes (8400 B-scans) were used for training the model, and another two (2400 B-scans) were used as testing set.
Dispersion Compensation
The signal acquisition in OCT involves recording the spectrogram obtained by interfering back-reflected light from different interfaces of the sample with the back-reflected light from the reference mirror. The fringe pattern generated by this interference signal is detected by the spectrometer and corresponding OCT signal can be represented by the following equation (18):
In this equation, In(k) and Ir(k) represent the back-reflected light intensity obtained from the n-th sample layer and reference arm respectively. The wavenumber is denoted by k while the difference in optical path length is denoted by Δzn. The phase term ϕ(k.Δzn) denotes the phase difference between the sample interfaces and the reference mirror and this includes the higher order dispersive terms. We can express the phase term as:
Where βn represents dispersion coefficient, while a2 and a3 are second and third order dispersion compensation coefficients. While nn is the sample's n-th layer's refractive index, nn,g is the effective group refractive index. Numeric dispersion compensation can be done by modifying the phase term through the addition of a phase correction term which eliminates the dispersive phase. The following equation shows second and third order dispersion compensation phase correction:
Where a2 and a3 can be adjusted to compensate second-order group velocity and third-order phase dispersion. However, since dispersion in biological tissue is different at different depths, dispersion compensation using a single pair of second and third-order coefficients might not be sufficient for all depths. Numerically estimating and applying different compensation coefficients for different depths can be computationally extensive for widescale application. In following Section Model Architecture, we present ADC-Net, a deep learning-based dispersion compensation algorithm for automated implementation of full depth compensation. Input to ADC-Net can be of single or multiple channels of partially compensated B-scans. These partially compensated B-scans can be obtained by using the phase correction method in Equation (3). For simplicity, we have compensated the B-scans using second order compensation only. All depth dispersion compensated ground truth data were also crafted from an array of partially compensated B-scans and the detailed procedure is elaborated in Section Data Pre-Processing.
Model Architecture
The ADC-Net is a fully convolutional network (FCN) based on a modified UNet algorithm, which consists of an encoder-decoder architecture (Figure 1). The input to the ADC-Net can be of a single channel or a multichannel system. Each input is an OCT B-scan image which was compensated by different second-order dispersion compensation coefficients and hence the B-scans in each channel are optimally compensated at different layers or depths. The output is dispersion compensated OCT B-scans where all layers in different depths are compensated effectively.
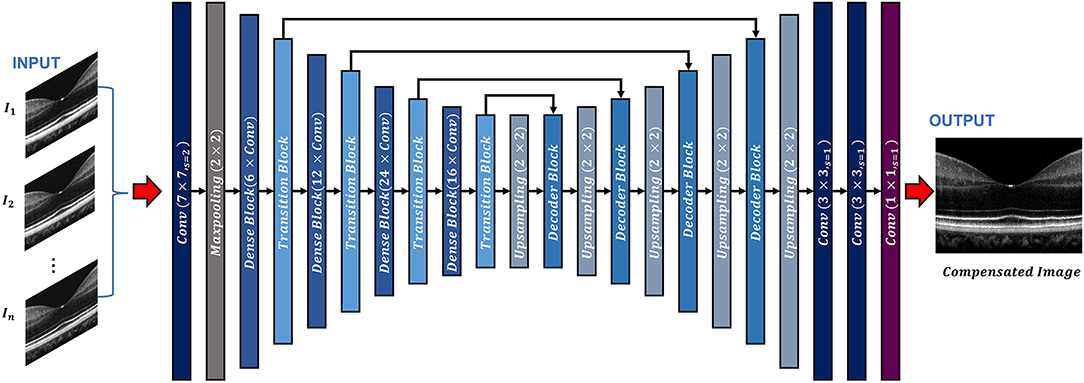
Figure 1. Overview of the ADC-Net architecture. Conv stands for convolution operation. The input section is comprised of OCT B-scans compensated by different second order coefficients (n = 3, 5, 7, and 9 for three, five, seven, and nine input channel models. A single image is used as input for the single input channel model). The output image is a corresponding fully compensated OCT B-scan.
The encoder segment is a combination of convolutional, max pooling, dense, and transitional blocks. The primary function of the decoder segment is to deduce useful features from the image. To ensure precise feature localization and mapping for generating output images, bridging between the encoder and the decoder is established. The convolution blocks, which perform summing operations, constitute the dense blocks. The skip connections, which alleviate the vanishing gradient problem, are used to link each subsequent block to previous blocks. A transition block is connected to each dense block, which is to reduce the dimension of output feature map.
The decoder segment consists of up-sampling operations along with the decoder blocks. Using the decoder block, the outputs obtained from the convolution operation of the fitting transition blocks and the up-sampling operations are concatenated. Image features can then be localized precisely by convolving the generated feature maps.
In the ADC-Net, two types of functions, namely batch normalization function and ReLU activation function trail all the convolution operations. On the other hand, a SoftMax activation function follows the terminal convolutional layer.
Moreover, transfer learning is employed to avoid overfitting errors by utilizing the ImageNet dataset. The ImageNet dataset is a visual database that consists of millions of everyday images. These images differ from the OCT B-scans but facilitate in training the CNN model to learn about simple features such as edges, color codes, geometric shapes, etc. in the primary layers and complex features in the deeper layers by utilizing CNN's bottom-up hierarchical learning structure. Transfer learning can then facilitate the network to relay these simple features to learn complex features which are related to the OCT B-scans. A fully connected layer that consists of 1,000 neurons along with a SoftMax activation function exists in the pre-trained encoder network model. When the pre-training was concluded (after achieving about 75% classification accuracy on the ImageNet validation dataset), the fully connected layer was removed. The decoder network was then fed with transitional outputs from the encoder network. Adam optimizer which had a learning rate of 0.0001 was used to train the FCN model along with a dice loss function. The proposed network has a deeper layer and utilizes lesser parameters compared to the classical UNet model which ensures higher learning capability with reduced computational burden and thus makes it more robust. It is similar to a previously reported model (33) where it has been shown that this network can generate higher mean IOU and F1 scores when compared to classical UNet architecture.
The hardware environment used for implementing the proposed ADC-Net had Windows 10 operating system equipped with NVIDIA Quadro RTX Graphics Processing Unit (GPU). The software model was written on Python (v3.7.1) utilizing Keras (v2.2.4) with Tensorflow (v1.31.1) backend.
Data Pre-processing
Figure 2 briefly illustrates the ground truth preparation method for a single B-scan. Raw OCT data were acquired using the SD-OCT system described in Section Data Acquisition. An array of B-scans ranging from I1 to IN (In this study, N = 5) were reconstructed from the same raw data frame using the usual procedure that involves background subtraction, k-space linearization, dispersion compensation, FFT, etc. However, each of the B-scans were compensated with different second order dispersion compensation coefficients ranging from C1 to CN (N = 5). Technical rationale of numeric compensation has been explained in Section Dispersion Compensation. Since the tissue structure in a biological subject differ at different depths, the dispersion effect also varies accordingly and thus a single second order coefficient can effectively compensate dispersion errors at a specific layer only. Thus, required values of second order dispersion compensation co-efficient, ranging from C1 to CN, were selected empirically so that dispersion at all depths were compensated optimally. In I1, the region demarcated by the red box along the inner retina had been dispersion compensated and optimized using C1. However, as we move further away from the inner layers the dispersion effects appear to be more prominent due to ineffective compensation. Image IN on the contrary has the region demarcated by the yellow box at the outer retina optimized and well compensated. To prepare the ground truth B-scan, the red and yellow demarcated region from I1 and IN were extracted and stitched in proper sequence to obtain dispersion compensated layers at the inner and outer retina. Similarly, the remaining layers acquired from I2 to IN−1 which were compensated by C2 to CN−1 respectively. Optimally compensated layers were extracted and stitched sequentially to obtain the all-depth compensated ground truth B-scan. To prepare the training and test data for the single, three, five, seven, and nine input channel models, 1, 3, 5, 7, and 9 arrays of B-scans were re-constructed respectively from each raw volume while each array were compensated with different second order dispersion compensation coefficients. These coefficients were selected in equal intervals between C1 to CN. To acquire the OCT data and for digital image processing, LabView (National Instruments) and MATLAB 2021 software environments were used, respectively.
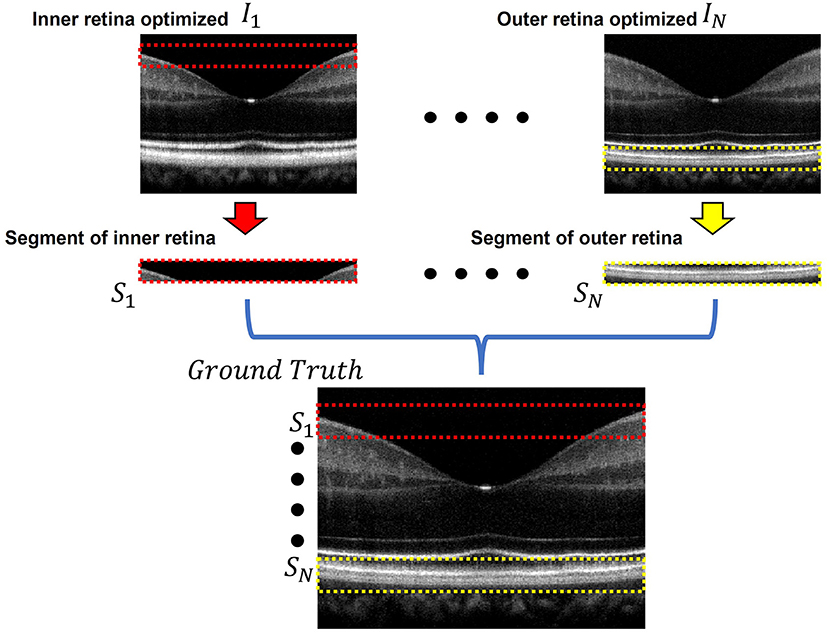
Figure 2. Ground truth preparation. An array of images ranging from I1 to IN were utilized to prepare the ground truth image. Each image was compensated by a single second order co-efficient ranging from C1 to CN. Well compensated layers from each image were extracted and stitched together to form the ground truth image. In I1 the inner retinal segment (demarcated by the dashed red box) is better compensated compared to the inner retinal segment in IN. On the other hand, the outer retinal segment in IN (demarcated by the dashed yellow box) is better compensated compared to that of I1. The ground truth was prepared by stitching the inner retinal segment S1 from I1 and outer retinal segment SN from IN. The adjacent layers were similarly extracted and stitched from the subsequent images between I1 and IN.
Quantitative Parameters
Two parameters, namely peak signal to noise ratio (PSNR) and structural similarity index metric at multiple scales (MS-SSIM) were used for quantitative analysis and objective assessment of our proposed method. The two parameters are defined as follows:
Peak Signal to Nose Ratio
PSNR can be defined as the ratio of maximum signal strength to the corrupting background noise which was computed using the following equation (35):
Where s is the maximum pixel intensity value in the reconstructed image. Mean squared error (MSE) between the reference image f (ground truth) and reconstructed image g (output) can be defined by the following equation:
Where M, N denotes the number of rows and columns while (fij − gij) denote the pixel-wise error difference between f and g.
Structural Similarity Index Metric at Multiple Scale
MS-SSIM was computed to quantify the structural similarities between the ground truth and the corresponding output images obtained from the ADC-Net when implemented with different input channels models. MS-SSIM utilizes three visual perception parameters namely the luminance, contrast and structural parameters when calculated at multiple scales and thus it incorporates detailed image information at different resolutions and visual perceptions which make it a robust and accurate quality metric.
If x and y denote two image patches which are to be compared, the luminance parameter is defined by (36):
The contrast parameter is defined by:
The structural parameter is defined by:
Where μx and μy represent the mean, σxy represents the co-variance, σx and σy represent the standard deviation of x and y respectively. The constants C1, C2, and C3 can be obtained by:
Where, L is the pixel dynamic image range and K1 (0.01) and K2 (0.03) are two scalar constants. Thus, SSIM can be defined as:
In order to obtain multi scale SSIM, an iterative approach is employed where the reference and the output images are scaled M-1 times and down sampled by a factor of 2 after each iteration. The contrast and structural parameter are calculated at each scale while the luminance parameter is computed only at the M-th scale. The final quantitative parameter is obtained by the combining the values obtained at all the scales using the following relation:
Results
Qualitative Assessment
Figure 3A shows representative OCT B-scan images obtained from different input channels models along with a raw uncompensated OCT B-scan. For better visualization, 6 neighboring B-scans at the macula region of a human retina were averaged and the images are displayed on a logarithmic scale. Figure 3A1 represents the uncompensated image and due to the dispersion effect, the B-scan suffers from low axial resolution and the different retinal layers appear to be blurry and overlapping as the detailed structural information is lost. Figures 3A2–A6 illustrate the representative OCT B-scans obtained from single to nine input channels models respectively. In Figure 3A2, which was obtained from the single input channel model, even though the inner retinal layer appears to be well compensated, the central and outer bands suffer from blurring and the dispersion effect is not optimally compensated. When the input was increased to 3, 5, 7, and 9 B-scans, the quality of the output image was enhanced. As shown in Figures 3A3–A6, both the inner and outer layers were better compensated compared to single input channel model and showed sharp microstructural information. As described in Section Data Acquisition, input models with 3, 5, 7, and 9 input channels had input B-scans with both inner and outer retinal layers compensated. However, 5, 7, and 9 input channels performed slightly better compensation compared to the model with 3 input channels and this improvement can be better visualized in Figure 3B which were generated for a detailed illustration of the differences in performance of the different models. To generate these images, pixel-wise, intensity difference between the corresponding ground truth and Figures 3A1–A6 were computed, and the resultant intensity differential images were displayed in a jet colourmap. Here, the bright regions indicate higher differences in intensity while the darker blue region indicates lower to no difference. These images serve two purposes. First, the pixel wise extent of dissimilarity between each of the images and the ground truth can be observed. The lesser difference with the ground truth means higher similarity and thus indicates better performance. Second, the detailed differences in performance between the different input models and the uncompensated image can be better visualized using the difference between these images and the ground truth as a qualitative metric. Figure 3B1 shows that the uncompensated image depicts more difference from the compensated ground truth due to lack of dispersion compensation. While Figure 3B2 shows slightly better performance but more bright regions at the outer retina depict that the single input model could not compensate dispersion properly at the lower depths. Figure 3B3 illustrates that the model with three input channels performed better than the single input channel model. However, Figures 3B4–B6 show almost similar performance and the least amount of difference with the ground truth and thus the higher performance than the other two models.
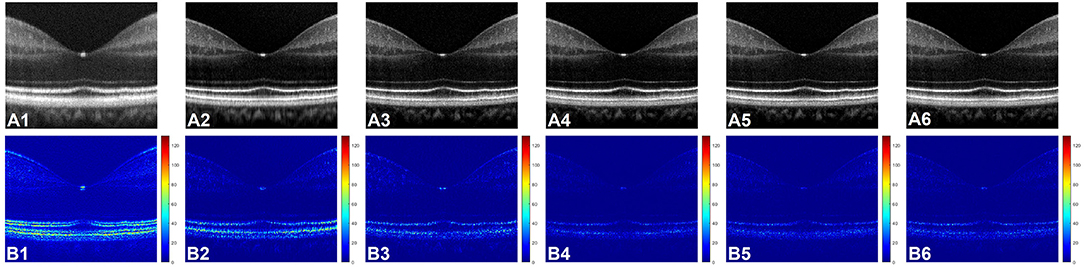
Figure 3. (A) Representative OCT of a human retina with no dispersion compensation (A1), and dispersion compensated by single (A2), three (A3), five (A4), seven (A5), and nine (A6) input channel models. (B) Corresponding differential intensity images which were generated by computing the pixel-to-pixel intensity differences between the ground truth image and the images in (A1–A6), respectively.
Quantitative Assessment
The two quantitative parameters described in Section Quantitative Parameterswere calculated from the resultant images obtained from different input channels models along with the corresponding uncompensated images to perform a quantitative assessment of the proposed ADC-Net. Before computing the quantitative parameters, the four repetitive B-scans at the same locations were averaged. MS-SSIM and PSNR were calculated, and the result is graphically represented in Figure 4. Mean values with standard deviation were used for representative purpose. In Figure 4, UC represents uncompensated images while M1, M3, M5, M7, and M9 represent the output obtained from single, three, five, seven, and nine input channels models respectively. In Figure 4A, we can observe that the lowest mean MS-SSIM score was obtained for UC (0.85 ± 0.025) which depicts the least similarity with the ground truth image. Due to the dispersion effect the image quality degrades significantly without compensation. The MS-SSIM score obtained from the single input channel model (M1) is 0.94 ± 0.021 which shows an improved performance in terms of dispersion compensation compared to the raw uncompensated image. The similarity score for three (M3) and five (M5) input channels models show a gradual improvement in performance with MS-SSIM values of 0.95 ± 0.018 and 0.97 ± 0.016 respectively. However, the graph flattens after M5 as seven (M7) and nine (M9) input channels models show a similarity score of 0.97 ± 0.014 and 0.97 ± 0.014 which are within the 1 standard deviation range of the five-input channels model. We can observe a similar trend in Figure 4B which depicts the mean PSNR. Highest PSNR of 29.95 ± 2.52 dB was calculated for the five input channels model (M5) while seven and nine input channels model had a mean PSNR of 29.91 ± 2.134 dB and 29.64 ± 2.259 dB respectively. Output from the three input channels model recorded a slightly lower PSNR value of 27.49 ± 1.606 dB and the downward slope continued for the single input channel model (M1) with a mean value of 25.86 ± 1.677 dB and the least PSNR of 20.99 ± 0.021 dB was observed for the uncompensated B-scans.
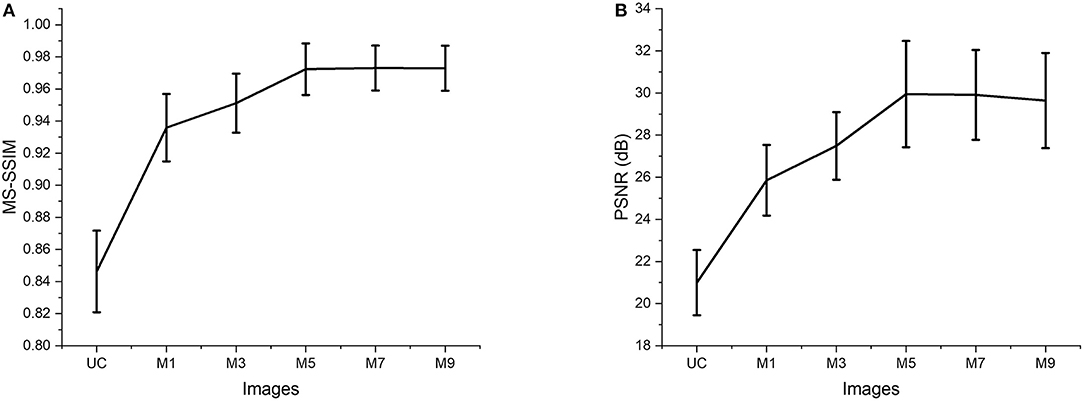
Figure 4. Quantitative evaluation of MS-SSIM (A) and PSNR (B). Average values are used for the graphical representation. UC represents the uncompensated images; M1, M3, M5, M7, and M9 represent the images acquired from ADC-Net with the single, three, five, seven, and nine input channel models.
Intensity Profile Analysis
Figure 5 illustrates comparative reflectance intensity profile analysis of the outer retina. The yellow vertical line in Figure 5A shows the retinal region for OCT intensity profile analysis (Figure 5B). Figure 5B illustrates axial intensity profiles at the parafovea and encompasses the outer retinal bands. Six neighboring B-scans were averaged and 5 adjacent A-lines at the region of interest were averaged from the averaged B-scan before generating the intensity profiles. Figure 5A is displayed in logarithmic scale for enhanced visualization, but the intensity profile analysis in Figure 5B is shown in linear scale. The intensity profiles are depicted in Figure 5 where GT and UC represent the intensity profiles obtained from the ground truth and the uncompensated images, respectively. Whereas M1, M3, M5, M7, and M9 stand for the intensity profiles obtained from single, three, five, seven, and nine input channels models respectively.
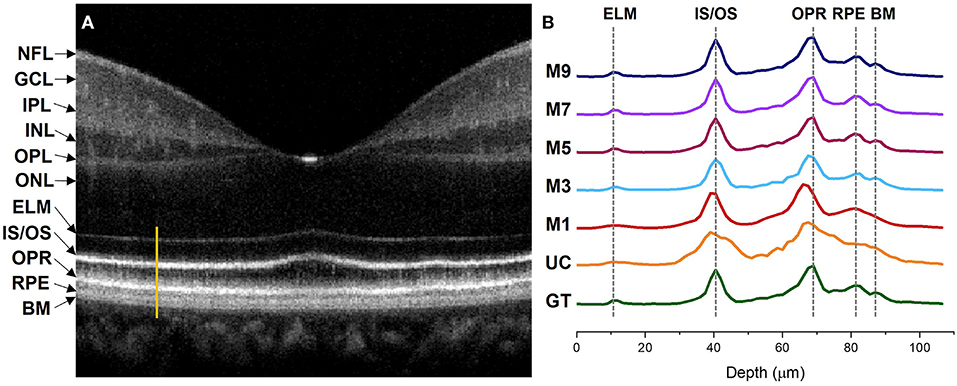
Figure 5. Intensity profile analysis of the outer retinal bands. (A) OCT B-scan of a human retina at the macula region with different retinal layers labeled accordingly. The bright orange line represents the A-line segment of the outer retina at the parafovea region where the intensity profiles in (B) were computed. (B) Intensity profiles generated from different image models. GT, ground truth; UC, uncompensated; M1, single input channel; M3, three input channels; M5, five input channels; M7, seven input channels; M9, nine input channels; NFL, nerve fiber layer; GCL, ganglion cell layer; IPL, inner plexiform layer; INL, inner nuclear layer; OPL, outer plexiform layer; INL, outer nuclear layer; ELM, external limiting membrane; IS/OS, inner segment/outer segment junction; OPR, outer plexiform layer; RPE, retinal pigment epithelium; BM, bruch's membrane.
The ELM band profile is known to reflect the point spread function (PSF), i.e., the axial resolution. From GT we can observe a sharper and narrower PSF at the ELM layer when compared to UC and M1, where the PSF is flat and wider. The ELM band profile becomes slightly better for M3, but M5, M7, and M9 depict thinner and analogous band profile to GT. Blurred RPE band profiles can also be observed for UC and M1 at the RPE which overlaps with the Bruch's Membrane (BM) region (37). On the contrary, GT, M3, M5, M7, and M9 show sharper peaks which can be distinguished separately. This means that the RPE and Bruch's membrane can be observed separately from the reconstructed images. The IS/OS and OPR bands in UC have distinguishable peaks but still depict thicker profiles, compared to GT. M1 and M3 show slightly thinner IS/OS and OPR bands, compared to UC. On the other hand, GT, M5, M7, and M9 depict sharper and thinner OCT band profiles.
Dispersion can also shift the location of the interfaces in a multilayered sample which can affect the depth measurement of different layers (38). We comparatively evaluate the peak locations of the ELM, IS/OS, OPR, and RPE in the intensity profiles demonstrated in Figure 5 to assess the performance of our proposed method in terms of depth measurement where the GT was taken as the reference of assessment. The GT's peak location at the ELM and IS/OS layer aligns with M3, M5, M7, and M9. However, the peak location for M3 shifts at the OPR and RPE when compared to the peak location of the GT where M5, M7, and M9 demonstrate aligned peaks with the GT. For M1 and UC, the peaks observed at ELM and RPE are flat and overlapping while the peaks are shifted at the IS/OS and OPR layer.
Automated Dispersion Compensation in 3D Volume OCT
Figure 6 illustrated the performance of the ADC-Net model for automated processing of 3D volume OCT. Figure 6A shows an OCT enface image. For 3D volumetric OCT, with the model of five input channels, the ADC-Net was used to compensate for individual B-scans sequentially. Figures 6B,C show three representative B-scans before (Figure 6B) and after (Figure 6C) dispersion compensation. Figures 6C1–C3 have higher contrast, sharpness and retain better structural integrity when compared to the uncompensated images in Figures 6B1–B3.
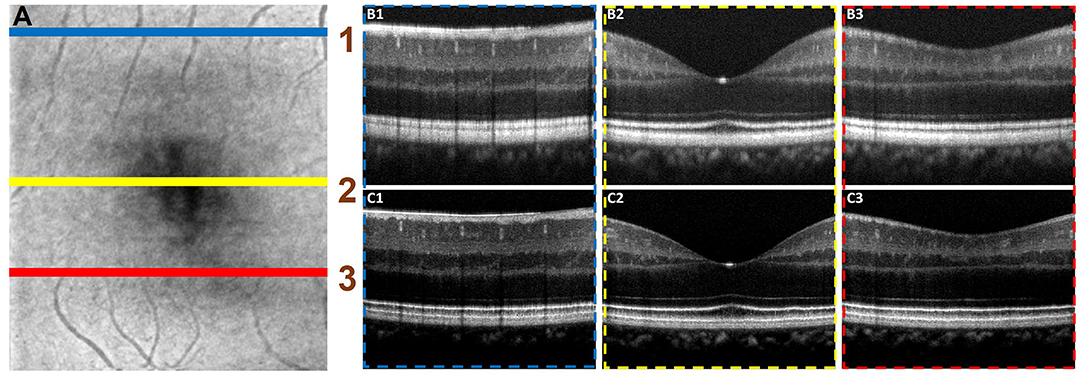
Figure 6. Automated processing of 3D volume OCT dataset. (A) Depicts an enface image with the horizontal lines, line 1 (blue), line 2 (yellow), and line 3 (red), demarcating the regions from where representative B-scans were extracted. The corresponding B-scans are shown in (B,C). The compensated B-scans (C1–C3) demonstrate higher sharpness, contrast and better visibility of structural layers when compared to the raw uncompensated B-scans (B1–B3).
Performance Validation With OCT Images of DR
Performance of the proposed ADC-Net was also assessed using OCT images with eye conditions. Two OCT volumes acquired from two different subjects diagnosed with DR were used for this technical validation. Patient details have been discussed in Section Data Acquisition. and the representative B-scans have been illustrated in Figure 7. Figures 7A1,B1 depicts the raw uncompensated images obtained from patient 1 and 2, respectively. Figures 7A2,B2 depicts the corresponding compensated B-scans obtained from our proposed ADC-Net when implemented using 5 input channels. Compared to the uncompensated B-scans, Figures 7A2,B2 depict better contrast and signal quality, and the retinal layers are sharper and can be visualized more effectively. The distortion in retinal layers can also be depicted from the compensated images.
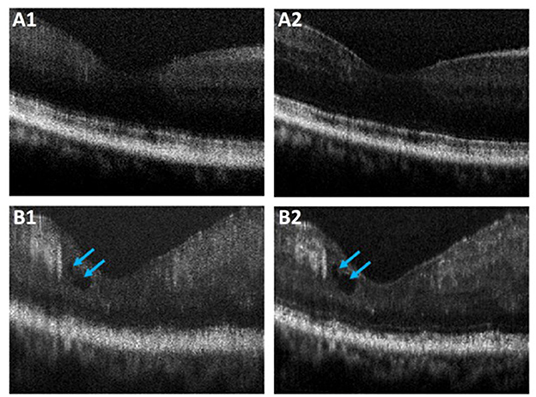
Figure 7. Representative OCT B-scans of proliferative diabetic retinopathy (DR) patients without (A) and with (B) macular edema (blue arrowheads). The compensated B-scans (A2,B2) obtained from the proposed ADC-Net illustrate higher contrast and sharpness compared to the raw uncompensated B-scans (A1,B1).
Discussion
Dispersion compensation is necessary to obtain high axial resolution and retain detailed structural information in OCT. Traditional numeric dispersion compensation approaches can be computationally expensive. Numerically devised methods also require optimization based on specific contexts, and thus may lack flexibility for generalized application. The demonstrated ADC-Net can be automated for real-time implementation due to its higher computational flexibility and simplicity. Once trained with the optimum number of input channels and well-crafted ground truth data, ADC-Net can automatically compensate dispersion effectively and generate OCT B-scans with high quality. We made the proposed ADC-Net available through an open-source platform (github.com/dleninja/adcnet-) for easy accessibility to a robust and automated dispersion compensation algorithm.
The performance of ADC-Net peaked when employed using five, seven, and nine input channels models. While a single input channel model performed better than a raw uncompensated image in terms of image resolution, the output images still depicted blurring effects. The output obtained from the three input channels model was better than the single input channel model but slightly worse than the five, seven, and nine input channels.
Since the proposed FCN is built on a modified UNet structure and follows an encoder-decoder pipeline, the model trains itself by acquiring features from the input and the ground truth data to reconstruct dispersion compensated images. For a single input channel model, the input B-scans were compensated by a single second-order dispersion compensation co-efficient which can optimize dispersion in a specific retinal layer only. For our experiment, the second-order dispersion compensation parameter was selected close to C1 and thus the input B-scans had optimum compensation along with the inner retinal layer only. Consequently, the output B-scans had the inner retinal layer optimized only. The input model with three input channels had three arrays of B-scans and each array was compensated by different second-order dispersion compensation coefficients which were selected equally spaced between C1 to CN. The three input channels thus provided more information related to more layers being compensated and thus the model performed better compared to the single input channel model. Similarly, for five, seven, and nine input channels models, the input channels had more B-scans with more layers being compensated which in terms provided more features to the model to train itself better. Hence the performance was better compared to single and three input channels models. However, quantitative analysis revealed that five, seven, and nine input channels models depict similar performance, and thus optimum all-depth dispersion can be obtained using five input channels.
The dispersion effect broadens OCT band profiles and thus degrade the axial resolution. In a well-compensated OCT image, such as the ground truth image, this blur effect would be minimized, corresponding to thinner and sharper band profiles. On the other hand, as illustrated in the intensity profile obtained from the uncompensated image, the band profiles would be thicker due to dispersion effect which in terms would affect the image resolution. This would impact the thickness measurement of the retinal bands as they would appear to be thicker than the actual value. From our proposed ADC-Net we obtained sharp and thin OCT band profiles from input models with five, seven, and nine channels which were analogous to the intensity profile obtained from the ground truth image. The peaks for the outer retinal layers were also aligned which shows the promise for accurate depth measurement. Hence the proposed ADC-Net demonstrates its capability to generate B-scans with high resolution that can retain intricate structural information. Implementation of this automated process can be beneficial in clinical assessment and ophthalmic research by providing accurate retinal thickness and depth measurement in healthy and diagnosed patients. Artificial intelligence may reduce the technical complexities and streamlining tasks in a clinical setting.
The major challenge of our proposed ADC-Net is the availability of finetuned ground truth data which requires all depth compensation. However, once the required values of the coefficients for different depths and ranges are obtained for one volume, it can be applied to other volumes directly. Thus, for one OCT system, calibrating the system once would be enough. Once our proposed ADC-Net is trained with all depth compensated ground truth, it can automatically generate fully compensated B-scans with retinal layers optimized. Therefore, this ADC-Net process can be effectively implemented for real-time application. The performance of the ADC-Net has been validated with OCT images acquired from both healthy and diseased eyes. We are aware that the OCT image quality of diseased eyes in Figure 7 was relatively poor, compared to that of healthy subjects. However, the feasibility of automatically generating dispersion compensated images from diseased eyes has been validated with the ADC-Net.
In conclusion, a deep learning network ADC-Net has been validated for automated dispersion compensation in OCT. The ADC-Net is based on a redesigned UNet architecture which employs an encoder-decoder pipeline. With input of partially compensated OCT B-scans with individual retinal layers optimized, the ADC-Net can output a fully compensated OCT B-scans with all retinal layers optimized. The partially compensated OCT B-scans can be produced automatically, after a system calibration to estimate the dispersion range. Comparative analysis of training models, including single, three, five, seven and nine input channels were implemented. The five-input channels implementation was observed to be sufficient for ADC-Net training to achieve robust dispersion compensation in OCT.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation. Source code for implementing ADC-Net is available at: https://github.com/dleninja/adcnet.
Ethics Statement
The studies involving human participants were reviewed and approved by Institutional Review Board of the University of Illinois at Chicago. The patients/participants provided their written informed consent to participate in this study.
Author Contributions
SA contributed to data processing, analysis, model implementation, and manuscript preparation. DL contributed to network design, model implementation, and manuscript preparation. TS contributed to experimental design, data acquisition, and manuscript preparation. TA contributed to data processing. GM contributed to the data collection of the diseased patients. XY supervised the project and contributed to manuscript preparation. All authors contributed to the article and approved the submitted version.
Funding
This research was supported in part by National Institutes of Health (NIH) (R01 EY023522, R01 EY029673, R01 EY030101, R01 EY030842, and P30 EY001792), Richard and Loan Hill endowment, and Unrestricted grant from Research to prevent blindness.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Huang D, Swanson EA, Lin CP, Schuman JS, Stinson WG, Chang W, et al. Optical coherence tomography. Science. (1991) 254:1178–81. doi: 10.1126/science.1957169
2. Fujimoto JG, Brezinski ME, Tearney GJ, Boppart SA, Bouma B, Hee MR, et al. Optical biopsy and imaging using optical coherence tomography. Nat Med. (1995) 1:970–2. doi: 10.1038/nm0995-970
3. Wojtkowski M, Bajraszewski T, Gorczyńska I, Targowski P, Kowalczyk A, Wasilewski W, et al. Ophthalmic imaging by spectral optical coherence tomography. Am J Ophthalmol. (2004) 138:412–9. doi: 10.1016/j.ajo.2004.04.049
4. Gao SS, Jia Y, Zhang M, Su JP, Liu G, Hwang TS, et al. Optical coherence tomography angiography. Invest Ophthalmol Vis Sci. (2016) 57:OCT27–36. doi: 10.1167/iovs.15-19043
5. Yao X, Son T, Kim T-H, Lu Y. Functional optical coherence tomography of retinal photoreceptors. Exp Biol Med. (2018) 243:1256–64. doi: 10.1177/1535370218816517
6. Povazay B, Bizheva K, Unterhuber A, Hermann B, Sattmann H, Fercher AF, et al. Submicrometer axial resolution optical coherence tomography. Opt Lett. (2002) 27:1800–2. doi: 10.1364/OL.27.001800
7. Unterhuber A, PovaŽay B, Hermann B, Sattmann H, Drexler W, Yakovlev V, et al. Compact, low-cost Ti: Al 2 O 3 laser for in vivo ultrahigh-resolution optical coherence tomography. Opt Lett. (2003) 28:905–7. doi: 10.1364/OL.28.000905
8. Yao XC, Yamauchi A, Perry B, George JS. Rapid optical coherence tomography and recording functional scattering changes from activated frog retina. Appl Opt. (2005) 44:2019–23. doi: 10.1364/AO.44.002019
9. Drexler W, Morgner U, Ghanta RK, Kärtner FX, Schuman JS, Fujimoto JG. Ultrahigh-resolution ophthalmic optical coherence tomography. Nat Med. (2001) 7:502–7. doi: 10.1038/86589
10. Tearney G, Bouma B, Fujimoto J. High-speed phase-and group-delay scanning with a grating-based phase control delay line. Opt Lett. (1997) 22:1811–3. doi: 10.1364/OL.22.001811
11. Xie T, Wang Z, Pan Y. Dispersion compensation in high-speed optical coherence tomography by acousto-optic modulation. Appl Opt. (2005) 44:4272–80. doi: 10.1364/AO.44.004272
12. Iyer S, Coen S, Vanholsbeeck F. Dual-fiber stretcher as a tunable dispersion compensator for an all-fiber optical coherence tomography system. Opt Lett. (2009) 34:2903–5. doi: 10.1364/OL.34.002903
13. Fercher AF, Hitzenberger CK, Sticker M, Zawadzki R, Karamata B, Lasser T. Numerical dispersion compensation for partial coherence interferometry and optical coherence tomography. Opt Express. (2001) 9:610–5. doi: 10.1364/OE.9.000610
14. Lippok N, Coen S, Nielsen P, Vanholsbeeck F. Dispersion compensation in fourier domain optical coherence tomography using the fractional Fourier transform. Opt Express. (2012) 20:23398–413. doi: 10.1364/OE.20.023398
15. Cense B, Nassif NA, Chen TC, Pierce MC, Yun S-H, Park BH, et al. Ultrahigh-resolution high-speed retinal imaging using spectral-domain optical coherence tomography. Opt Express. (2004) 12:2435–47. doi: 10.1364/OPEX.12.002435
16. Wojtkowski M, Srinivasan VJ, Ko TH, Fujimoto JG, Kowalczyk A, Duker JS. Ultrahigh-resolution, high-speed, Fourier domain optical coherence tomography and methods for dispersion compensation. Opt Express. (2004) 12:2404–22. doi: 10.1364/OPEX.12.002404
17. Hofer B, PovaŽay B, Hermann B, Unterhuber A, Matz G, Drexler W. Dispersion encoded full range frequency domain optical coherence tomography. Opt Express. (2009) 17:7–24. doi: 10.1364/OE.17.000007
18. Pan L, Wang X, Li Z, Zhang X, Bu Y, Nan N, et al. Depth-dependent dispersion compensation for full-depth Oct image. Opt Express. (2017) 25:10345–54. doi: 10.1364/OE.25.010345
19. Ni G, Zhang J, Liu L, Wang X, Du X, Liu J, et al. Detection and compensation of dispersion mismatch for frequency-domain optical coherence tomography based on a-scan's spectrogram. Opt Express. (2020) 28:19229–41. doi: 10.1364/OE.393870
20. Lakhani P, Sundaram B. Deep learning at chest radiography: automated classification of pulmonary tuberculosis by using convolutional neural networks. Radiology. (2017) 284:574–82. doi: 10.1148/radiol.2017162326
21. Mohsen H, El-Dahshan E-SA, El-Horbaty E-SM, Salem A-BM. Classification using deep learning neural networks for brain tumors. Future Comput Inform J. (2018) 3:68–71. doi: 10.1016/j.fcij.2017.12.001
22. Baltruschat IM, Nickisch H, Grass M, Knopp T, Saalbach A. Comparison of deep learning approaches for multi-label chest X-Ray classification. Sci Rep. (2019) 9:1–10. doi: 10.1007/s41906-018-0376-1
23. Tanaka H, Chiu S-W, Watanabe T, Kaoku S, Yamaguchi T. Computer-aided diagnosis system for breast ultrasound images using deep learning. Phys Med Biol. (2019) 64:235013. doi: 10.1088/1361-6560/ab5093
24. Riquelme D, Akhloufi MA. Deep learning for lung cancer nodules detection and classification in Ct scans. AI. (2020) 1:28–67. doi: 10.3390/ai1010003
25. Devalla SK, Subramanian G, Pham TH, Wang X, Perera S, Tun TA, et al. A Deep learning approach to denoise optical coherence tomography images of the optic nerve head. Sci Rep. (2019) 9:1–13. doi: 10.1038/s41598-019-51062-7
26. Mehdizadeh M, MacNish C, Xiao D, Alonso-Caneiro D, Kugelman J, Bennamoun M. Deep feature loss to denoise oct images using deep neural networks. J Biomed Opt. (2021) 26:046003. doi: 10.1117/1.JBO.26.4.046003
27. Wang Z, Camino A, Hagag AM, Wang J, Weleber RG, Yang P, et al. Automated detection of preserved photoreceptor on optical coherence tomography in choroideremia based on machine learning. J Biophotonics. (2018) 11:e201700313. doi: 10.1002/jbio.201700313
28. Guo Y, Hormel TT, Xiong H, Wang B, Camino A, Wang J, et al. Development and validation of a deep learning algorithm for distinguishing the nonperfusion area from signal reduction artifacts on oct angiography. Biomed Opt Express. (2019) 10:3257–68. doi: 10.1364/BOE.10.003257
29. Guo Y, Hormel TT, Xiong H, Wang J, Hwang TS, Jia Y. Automated segmentation of retinal fluid volumes from structural and angiographic optical coherence tomography using deep learning. Transl Vis Sci Technol. (2020) 9:54. doi: 10.1167/tvst.9.2.54
30. Wang J, Hormel TT, You Q, Guo Y, Wang X, Chen L, et al. Robust non-perfusion area detection in three retinal plexuses using convolutional neural network in oct angiography. Biomed Opt Express. (2020) 11:330–45. doi: 10.1364/BOE.11.000330
31. Guo Y, Hormel TT, Gao L, You Q, Wang B, Flaxel CJ, et al. Quantification of nonperfusion area in montaged wide-field optical coherence tomography angiography using deep learning in diabetic retinopathy. Ophthalmol Sci. (2021) 1:100027. doi: 10.1016/j.xops.2021.100027
32. Alam M, Le D, Lim JI, Chan RV, Yao X. Supervised machine learning based multi-task artificial intelligence classification of retinopathies. J Clin Med. (2019) 8:872. doi: 10.3390/jcm8060872
33. Alam M, Le D, Son T, Lim JI, Yao X. Av-Net: deep learning for fully automated artery-vein classification in optical coherence tomography angiography. Biomed Opt Express. (2020) 11:5249–57. doi: 10.1364/BOE.399514
34. Qiao L, Zhu Y, Zhou H. Diabetic retinopathy detection using prognosis of microaneurysm and early diagnosis system for non-proliferative diabetic retinopathy based on deep learning algorithms. IEEE Access. (2020) 8:104292–302. doi: 10.1109/ACCESS.2020.2993937
35. Hore A, Ziou D. Image quality metrics: Psnr Vs. Ssim. In: Proceedings of 2010 20th International Conference on Pattern Recognition. Istanbul: IEEE (2010). p. 2366–9. doi: 10.1109/ICPR.2010.579
36. Wang Z, Simoncelli EP, Bovik AC. Multiscale structural similarity for image quality assessment. In: Proceedings of The Thirty Seventh Asilomar Conference on Signals, Systems & Computers. Pacific Grove, CA: IEEE (2003). p. 1398–402. doi: 10.1109/ACSSC.2003.129216
37. Yao X, Son T, Kim T-H, Le D. Interpretation of anatomic correlates of outer retinal bands in optical coherence tomography. Exp Biol Med. (2021) 246:15353702211022674. doi: 10.1177/15353702211022674
Keywords: dispersion compensation, deep learning, fully convolutional network (FCN), automated approach, optical coherence tomography
Citation: Ahmed S, Le D, Son T, Adejumo T, Ma G and Yao X (2022) ADC-Net: An Open-Source Deep Learning Network for Automated Dispersion Compensation in Optical Coherence Tomography. Front. Med. 9:864879. doi: 10.3389/fmed.2022.864879
Received: 28 January 2022; Accepted: 14 March 2022;
Published: 08 April 2022.
Edited by:
Peng Xiao, Sun Yat-sen University, ChinaReviewed by:
Pengfei Zhang, Dalian University of Technology, ChinaWeiye Song, Shandong University, China
Copyright © 2022 Ahmed, Le, Son, Adejumo, Ma and Yao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xincheng Yao, eGN5QHVpYy5lZHU=