 Alexander Partin1*
Alexander Partin1* Thomas Brettin1
Thomas Brettin1 Yitan Zhu1
Yitan Zhu1 James M. Dolezal2Sara Kochanny2
James M. Dolezal2Sara Kochanny2 Alexander T. Pearson2Maulik Shukla1Yvonne A. Evrard3
Alexander T. Pearson2Maulik Shukla1Yvonne A. Evrard3 James H. Doroshow4
James H. Doroshow4 Rick L. Stevens1,5
Rick L. Stevens1,5- 1Division of Data Science and Learning, Argonne National Laboratory, Lemont, IL, United States
- 2Section of Hematology/Oncology, Department of Medicine, University of Chicago Medical Center, Chicago, IL, United States
- 3Frederick National Laboratory for Cancer Research, Leidos Biomedical Research, Inc., Frederick, MD, United States
- 4Division of Cancer Therapeutics and Diagnosis, National Cancer Institute, Bethesda, MD, United States
- 5Department of Computer Science, The University of Chicago, Chicago, IL, United States
Patient-derived xenografts (PDXs) are an appealing platform for preclinical drug studies. A primary challenge in modeling drug response prediction (DRP) with PDXs and neural networks (NNs) is the limited number of drug response samples. We investigate multimodal neural network (MM-Net) and data augmentation for DRP in PDXs. The MM-Net learns to predict response using drug descriptors, gene expressions (GE), and histology whole-slide images (WSIs). We explore whether combining WSIs with GE improves predictions as compared with models that use GE alone. We propose two data augmentation methods which allow us training multimodal and unimodal NNs without changing architectures with a single larger dataset: 1) combine single-drug and drug-pair treatments by homogenizing drug representations, and 2) augment drug-pairs which doubles the sample size of all drug-pair samples. Unimodal NNs which use GE are compared to assess the contribution of data augmentation. The NN that uses the original and the augmented drug-pair treatments as well as single-drug treatments outperforms NNs that ignore either the augmented drug-pairs or the single-drug treatments. In assessing the multimodal learning based on the MCC metric, MM-Net outperforms all the baselines. Our results show that data augmentation and integration of histology images with GE can improve prediction performance of drug response in PDXs.
1. Introduction
With recent advancements in applications of artificial intelligence in medicine and biology, predictive modeling has gradually become one of the primary directions in cancer research for analytically predicting the response of tumors to anticancer treatments (1, 2). In particular, conventional machine learning (ML) and deep learning (DL) methods have been widely investigated for building computational drug response prediction models for cancer cell lines with large datasets of omics profiles (3). The complex heterogeneities of cancer that occur within and between tumors present a major obstacle to successful discovery of robust biomarkers and therapies (4, 5). Patient-derived tumor xenografts (PDXs) are a contemporary biological model that is created by grafting cancerous tissue, obtained from human tumor specimens, into immunodeficient mice. The in vivo environment of PDXs helps preserve tumor heterogeneity as compared to in vitro cell lines, and therefore, is presumed to better mimic the response of human patients with certain cancer types. PDXs continue to gain reputation for studying cancer and investigating drug response in preclinical drug studies (6–8).
Predicting the response of tumors to drug treatments with accurate and robust computational models provides a modern approach for identifying top candidates for preclinical drug screening experiments or personalized cancer treatments. A variety of ML and DL approaches have been explored with high-throughput drug screens and cell lines (9, 10). Alternatively, our literature search retrieved only two publications that have used only PDX data to train prediction models for drug response (11, 12). Both studies used the Novartis PDX data (NIBR PDXE), which were generated using a 1 x 1 x 1 experimental design (13, 14), where each drug was tested against each patient PDX model using only one entumored mouse per model. Nguyen et al. (11) used an optimal model complexity (OMC) strategy with random forests to build drug response models for 26 treatment-cancer type combinations. They considered three genomic feature types in their analyses, including gene expressions (GE), copy-number alterations (CNAs), and single-nucleotide variants (SNVs). While considering a single feature type at a time, they used OMC to determine an optimal subset of features to obtain the best performing model for each treatment-cancer type pair. They showed that for the majority of cases, models developed with OMC outperform models that used all the available features. In another study, Kim et al. proposed PDXGEM, a pipeline that identifies biomarkers predictive of drug response in PDX and then uses the identified markers to train prediction models (12). To identify predictive genes based on GE and drug response, the pipeline utilizes a strategy similar to co-expression extrapolation (COXEN) (15, 16), and consequently selects the genes whose co-expression patterns are best preserved between PDXs and patient tumors. They trained prediction models using random forests for six treatment-tumor type combinations and then predicted response in patients.
A primary challenge in modeling drug response with PDXs is the limited availability of drug response data. The sample size of PDXs is usually orders of magnitude smaller than the analogous cell line datasets. It has been shown that increasing the amount of training samples improves generalization performance of supervised learning models in vision and text applications (17, 18), as well as drug response models in cell lines (19, 20). Collecting PDX response data, either through experiments or integration of multiple datasets, carries considerable technical and financial challenges. Alternatively, instead of directly increasing the sample size, the volume of data can be expanded by representing each sample with multiple feature types. Multimodal architectures that integrate genomic and histology images have been shown to improve prognosis prediction of patients with cancer as compared with unimodal architectures that learn only from a single data modality (i.e., feature type) (21–23). Another possible direction to address the limited sample size is data augmentation. Augmentation techniques have been extensively explored with image and text data, but not much with drug response. While augmenting images has become a common practice, tabular datasets such as omics profiles lack standardized augmentation methods.
In this study, we investigate two approaches for predicting drug response in PDX, including multimodal learning and data augmentation. We explore a multimodal neural network (MM-Net) that learns to predict drug response in PDXs using GE and histology whole-slide images (WSIs), two feature types representing cancer tissue, and molecular descriptors that represent drugs. The multimodal architecture is designed to take four feature sets as inputs: (1) GE, (2) histology images, and (3,4) molecular descriptors of a pair of drugs. We benchmark the prediction performance of MM-Net against three baselines: (1) NN trained with drug descriptors and GE, (2) NN trained with drug descriptors and WSIs, and (3) LightGBM model (24) trained with drug descriptors and GE. With multimodal learning, our goal is to explore whether the integration of histology images with GE improves the prediction performance as compared with models that use GE features alone. For data augmentation, we homogenize the drug representation of single-drug and drug-pair treatments in order to combine them into a single dataset. Moreover, we introduce an augmentation method that doubles the sample size of all drug-pair treatments. The proposed augmentations allow us to combine single-drug and drug-pair treatments to train MM-Net and the baselines without changing the architectures and the dataset. We explore the contribution of augmented data for improving the prediction of drug response.
This paper provides unique contributions compared with existing works that train drug response models with PDX data (11, 12). First, we build general drug response models for PDXs across multiple cancer types and drug treatments. Alternatively, prediction models in Kim et al. (12) and Nguyen et al. (11) are built for specific combinations of cancer type and drug treatment. Thus, our study targets a more challenging task. Second, we utilize PDX histology images with multimodal architecture which has not yet been studied for drug response prediction in PDX. Our study presents a framework for integrating image data with genomic measurements and drug chemical structure for predicting treatment effect. Third, we combine multiple treatments into a single dataset by homogenizing single-drug and drug-pair treatments and utilize drug features for training models. This provides an advantage over existing works which built prediction models for unique combinations of drugs and cancer types, and therefore, disregard drug features when model training. Furthermore, we propose an augmentation method for drug-pairs that doubles the sample size of the drug-pair treatments in the dataset. Fourth, existing studies built prediction models using the PDXE drug screening data which were generated using a 1 x 1 x 1 experimental design, i.e., one mouse per model per treatment. In contrast, we utilized the PDMR dataset where treatment response is measured by comparing a group of treated mice to a group of untreated mice. The group approach allows assessing the variability of response across mice and might be considered as more reliable in capturing tumor heterogeneity.
2. Materials and methods
2.1. Data
2.1.1. Experimental design of drug efficacy in PDX
We used unpublished PDX drug response data from the NCI Patient-Derived Models Repository (PDMR; http://pdmr.cancer.gov). The NCI PDMR performs histopathology assessment, whole-exome sequencing and RNA-Seq analysis of a subset of tumors from each PDX model to establish baseline histology and omic characterization for each model. To date, over six hundred unique PDX models have been characterized and data made available through the public website. Baseline pathology and omic characterization from 487 models were used for this analysis. The efficacy of drug treatments in PDMR is measured through controlled group experiments. Figure 1 illustrates the process of obtaining primary tumor specimen from a patient, engrafting tumor tissue into PDX models, performing baseline characterization, expanding tumor tissue over multiple passages within a lineage, and then using the expanded tumors in drug treatment experiments. A total of 96 PDX models from 89 unique patients were used for the experiments. The tumors are grown subcutaneously in NOD.Cg-Prkdcscid Il2rgtm1Wjl/SzJ (NSG) host mice and staged to an approximate tumor weight of 200 mm3 for the drug studies. The control group is treated with a vehicle only (i.e., a solution that delivers drugs to the treated animals). The preclinical dataset includes twelve single-drug and 36 drug-pair treatment arms (the drugs are still in preclinical and/or clinical investigations and their names and properties are expected to be released in the future). Median tumor volume over time for each vehicle or treatment group is used for response assessment. The GE profiles and WSIs were aggregated and preprocessed for the downstream ML and DL analysis.
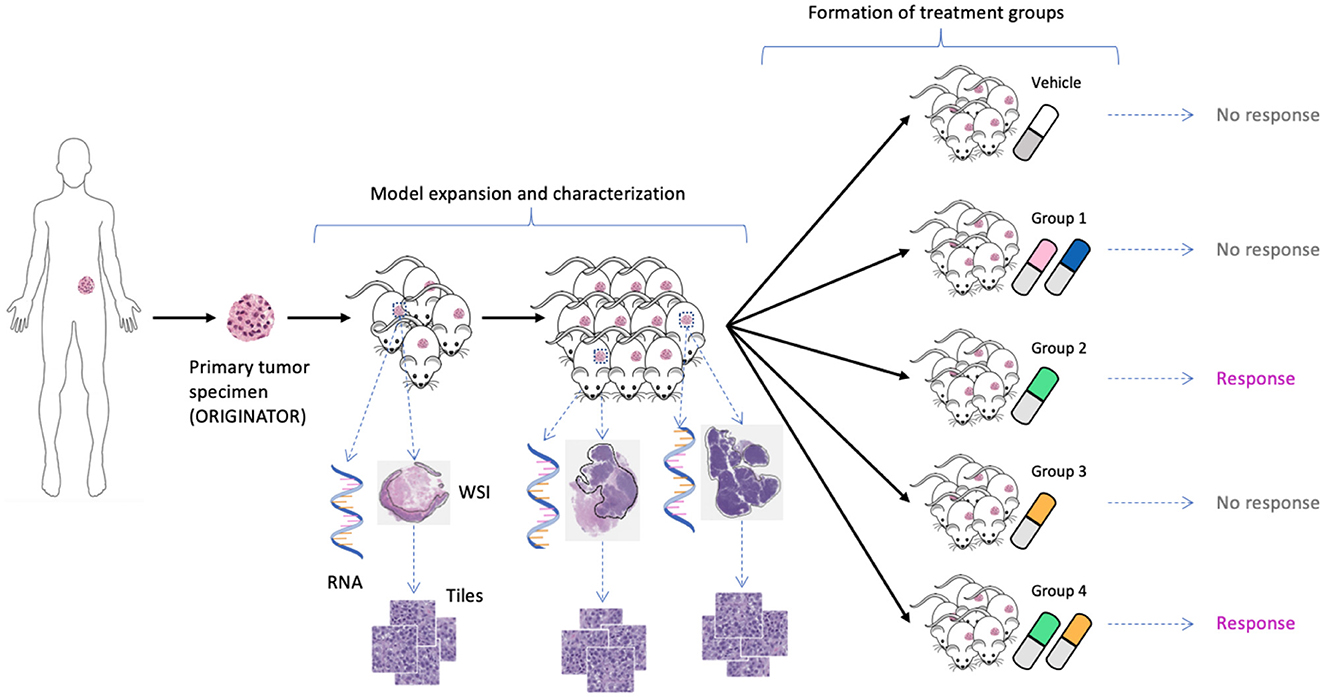
Figure 1. Expansion of tumor tissue from the source specimen (ORIGINATOR) to mice across multiple passages. Mice originated from the same specimen are divided into a control group and multiple treatment groups. Tumors from certain mice were histologically and molecularly profiled, resulting in whole-slide images and omics profiles.
2.1.2. Drug response in PDX
The growth of tumor volume over time represents the response of PDX tumors to drug treatments, as shown in Figure 2. There are several methods available in the literature for encoding drug response in PDXs which include both continuous and categorical types, but no consensus currently exists regarding which type or actual representation is better (6, 25). Continuous metrics include percent change in tumor volume, area under the tumor growth curve, best tumor response, best average response, and more. In this study we chose to use the binary representation of response which aligns with other drug response prediction studies that are mentioned earlier (11, 12), and the RECIST criteria, an existing standard for encoding response in patients (26). The group approach intends to capture the variability of PDX drug response across mice of the same lineage (25). Median tumor volume per treatment group is assessed relative to the control group to create a binary variable representing response. Specifically, for each drug treatment experiment, a single experienced preclinical study analyst assessed the curves of median tumor volume over time for each treatment arm, and assigned label “1” for response (regression of at least 30% from staging for more than one consecutive time point at any point during the study) and label “0” for non-response. In essence, a modified RECIST score for regression vs. no regression was used to label the response. Thus, a single best response value was assigned for each treatment arm.
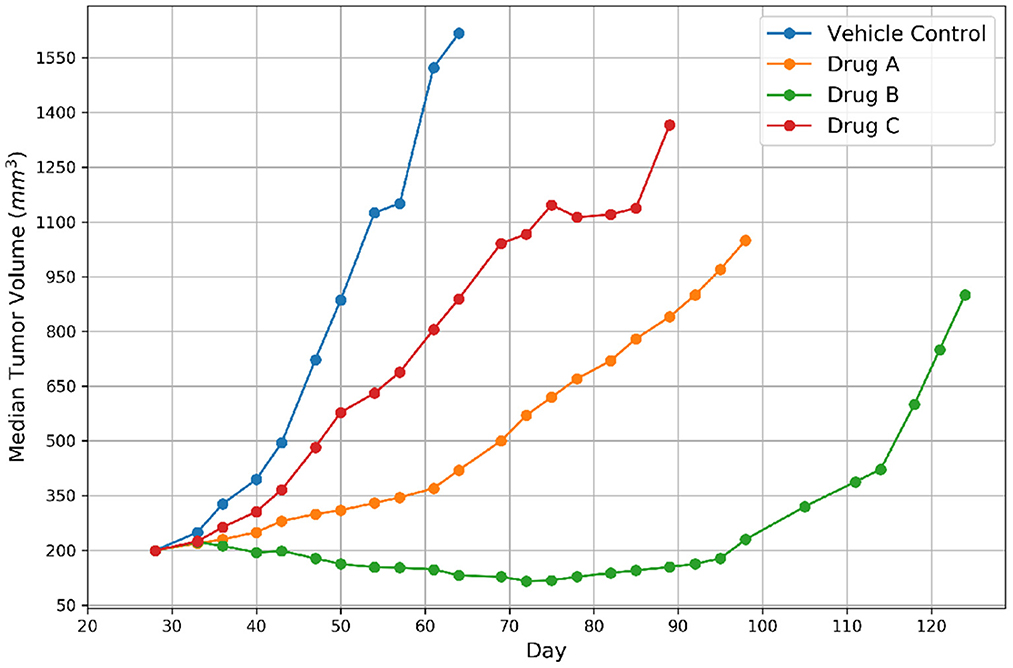
Figure 2. Representative tumor growth curves for vehicle control and three drugs. The label of response was assigned to Drug B because the tumor achieved regression and non-response was assigned to the remaining drugs.
2.1.3. Data generation
Three feature types were used for model training, including drug descriptors, GE, and histology image tiles.
Gene expressions. Gene expressions have been considered to provide more predictive power than other omics data types for drug response prediction (DRP) (27), and therefore, are often used to represent cancer in DRP models, either standalone or in a combination with other multiomics (28). However, the high dimensionality of gene expressions and the relatively small sample size can lead to overfitting (2). To address this issue, several gene selection methods have been utilized, including filtering genes based on variability across samples (29–31) or using gene subsets such as LINCS (10, 32–36) or COSMIC (35, 37–40) that are known to be associated with cancer and/or treatment response. We are not aware of any systematic analysis that studied which filtering method better addresses overfitting and improves prediction generalization. In this study, we filtered the RNA-seq data by selecting 942 landmark genes discovered by the Library of Integrated Network-Based Cellular Signatures (LINCS) project. The LINCS genes have been shown to comprehensively characterize and infer the gene expression variation of more than 80% of the whole transcriptome (32). We used TPM (transcripts per kilobase million) expression values of these genes, which were transformed by log2x+1, where x is the TPM value of a gene. The log transformed TPM values of each gene were then standardized to have a zero mean and a unit standard deviation across all gene expression profiles.
Drug descriptors. We used the Dragon software package (version 7.0) to calculate numerical descriptors of drug molecular structure. The software calculates various types of molecular descriptors, such as atom types, estimations of molecular properties, topological and geometrical descriptors, functional groups and fragment counts, and drug-like indices. A total of 1,993 descriptors were used for the analysis after removing descriptors with missing values. We standardized the descriptor values across drugs to have a zero mean and a unit standard deviation.
Histology images. During PDX model expansion, entumored mice were sacrificed between 1,000 and 2,000 mm3 for collection of tumors for representative model characterization including histopathological examination. Hematoxylin and Eosin (H&E) stained pathology slides were digitized into WSIs using an Aperio AT2 digital whole slide scanner (Leica Biosystems) at 20x magnification. A board-certified pathologist from Frederick National Laboratory of Cancer Research reviewed the slides to ensure the PDX models were consistent with the original patient diagnosis. Tumor regions of interest (ROIs) were annotated within the image slides using QuPath (41) by a single University of Chicago pathologist.
Whole slide images were processed into individual tiles using the Slideflow software package (42, 43), as shown in Figure 3. Image tiles were extracted from within annotated ROIs in a grid pattern at 302 μm by 302 μm with no overlap, then downsampled to 299 pixels by 299 pixels, resulting in an effective optical magnification of 10x. Background tiles were removed with grayscale filtering, where each tile is converted to the HSV color space and removed if more than 60% of its pixels have a hue value of less than 0.05. Image tiles then underwent digital stain normalization using the Reinhard method (44) and were subsequently standardized to give each image a mean of zero with a variance of one.
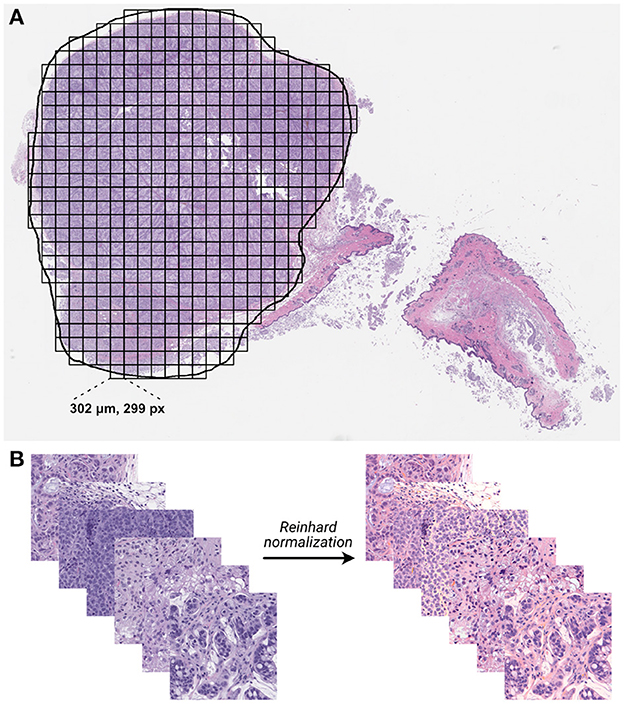
Figure 3. Whole-slide histology image processing. (A) Whole-slide images were annotated with region of interest (ROI) outlines, and image tiles were extracted from within ROIs in a grid-wise fashion. (B) Extracted non-background tiles underwent digital stain normalization using the Reinhard method (44).
2.1.4. Constructing PDX drug response dataset
In constructing the drug response dataset, we populated samples from each group experiment with the corresponding response label. Each sample that was molecularly and histologically profiled consists of three feature types and a binary response value. The feature types include drug descriptors, GE, and histology tiles, as illustrated in Figure 4. Table 1 lists the summary statistics of the dataset.
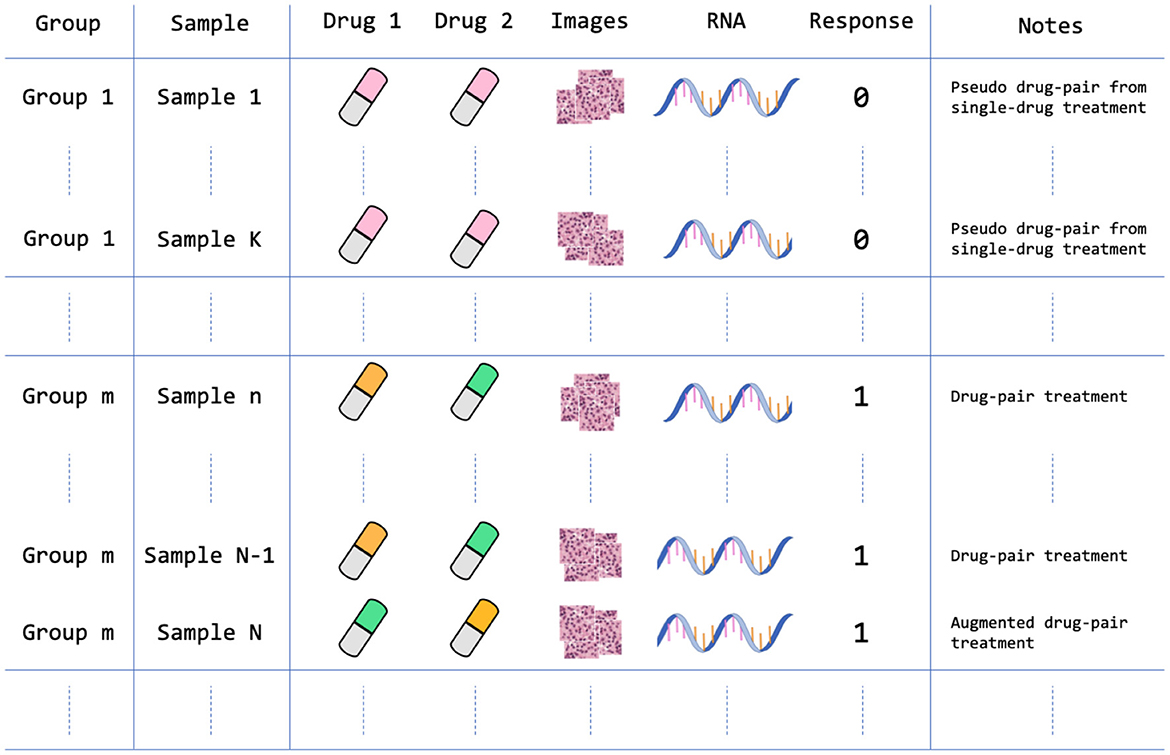
Figure 4. Data arrangement of the PDX drug response dataset. The dataset contains 959 treatment groups after homogenizing and augmenting the drug experiments as described in Section 2.1.4. For example, Sample 1 is a single-drug treatment that is structured as a pseudo drug-pair treatment where Drug 1 and Drug 2 features are the same feature vectors; Sample N is an augmented version of Sample N-1, in which the positions of drug feature vectors are switched. Note that each sample contains multiple histology image tiles that were extracted from a large WSI.
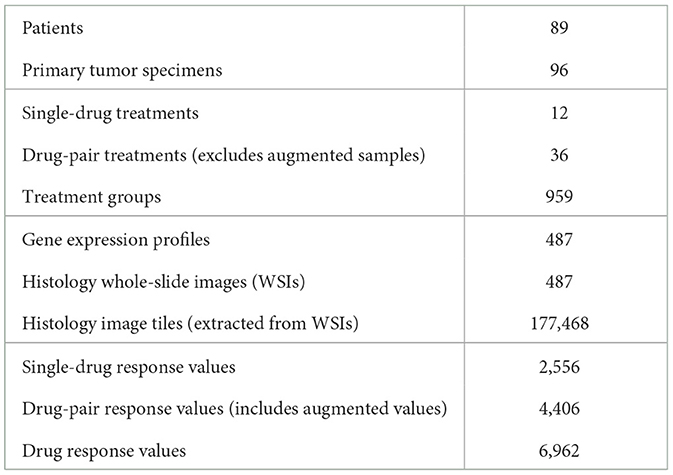
Table 1. Summary of the PDX drug response dataset used for building prediction models.
The PDMR preclinical dataset contains experiments of single-drug treatments and drug pairs. In order to include both single-drug and drug-pair treatments in the dataset, and ensure consistent dimensionality of drug features, we homogenized single-drug treatments by duplicating drug descriptors to form a pseudo drug-pair that includes two identical drug feature vectors. In this case, the samples of single-drug and drug-pair treatments will follow the same input dimensionality for all ML models. Moreover, because switching the position of drug features in drug-pair treatments should not change the drug response, we augmented all drug-pair samples by switching the position of the two drugs while keeping the drug response value unchanged. Such data augmentation doubles the number of drug-pair samples in the dataset.
Following the integration of group samples into the dataset and the augmentation of drug-pair treatments, the drug response dataset contains 6,962 samples. The total number of treatment groups in the dataset is 959 with 917 non-response and 42 response groups. The dataset contains three feature types (modalities): two vectors of drug descriptors (a vector for each drug), GE profile, and histology tiles. Each sample consists of a unique combination of drug descriptors and GE profiles. However, each such sample contains multiple image tiles from a corresponding histology slide. Concretely, each sample consists of a GE profile, vector of descriptors for drug 1 and drug 2, and multiple image tiles as shown in Figure 4. We store the data in TFRecords (TensorFlow file format) which enables efficient data prefetching and loading, and therefore, considerably decreases the training and inference time.
2.1.5. Data splits
Data leakage can lead to overly optimistic predictions (45). Two primary characteristics of our dataset may lead to leakage if random splitting is used to generate training, validation, and test sets. First, a drug response label is assigned to all the samples in the entire treatment group. To prevent leakage, we make sure that samples from the same treatment group always appear together in one of the training, validation, or test sets. Second, the augmented drug-pair samples represent, in reality, the same experiment, and therefore, are also placed together when generating the splits. With this strategy, we generated 100 data splits for the analysis (10-fold cross-validation repeated ten times with different random seeds), where the tissue features (GE profiles and WSIs) of the same treatment group are kept together and not shared across training, validation, and test sets of each data split.
2.2. Prediction models
We explore the performance of MM-Net, shown in Figure 5, in predicting the drug response in PDXs. The model takes preprocessed feature sets as inputs, including drug descriptors, GE, and histology tiles, and passes them through subnetworks of layers. The encoded features from the subnetworks are merged via a concatenation layer and propagated to the output for predicting a binary drug response.
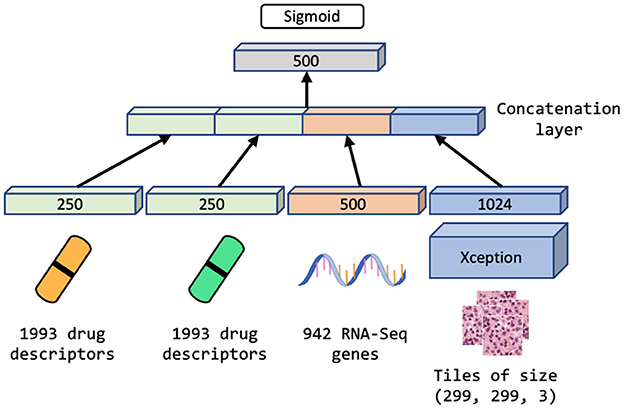
Figure 5. Multimodal neural network (MM-Net) learns from drug descriptors, gene expressions, and tiles generated from whole-slide images, to predict drug response in PDXs.
Since the dataset is highly redundant in terms of GE and drug features as shown in Figure 4 and Table 1 (there are 48 unique drug treatments and 487 unique expression sets), we use a single layer of trainable weights to encode these features with the goal to mitigate overfitting. The image tiles are passed through a subnetwork of convolutional layers of the Xception model (46) with weights pre-trained on ImageNet (47). The output from the convolutional neural network (CNN) is passed through a series of dense layers before being concatenated with the encoded GE and drug descriptor representations.
We compare the performance of MM-Net with three unimodal baselines that use either GE or WSI as tumor features: (1) UME-Net, NN that uses GE, (2) UMH-Net, NN that uses histology tiles, and (3) LGBM, LightGBM that uses GE. Note that all models use drug descriptors.
2.3. Training and evaluation
We used a randomized search to obtain a set of hyperparameters (HPs) for UME-Net, including optimizer, learning rate, and layer dimensions that encode GE and drug descriptors. The values of these HPs were also used for MM-Net. A few remaining HPs that are unique to MM-Net were determined in a separate search using the MM-Net architecture. Another randomized search was performed to obtain the HPs for LGBM such as the number of leaves in the decision tree and the number of trees.
To mitigate overfitting, we used the early stopping mechanism in TensorFlow and LightBGM where model trainings terminate automatically if the predictions on a validation set have not been improved for a predefined number of training iterations. The early stopping parameter was set to 10 epochs for all NNs and 100 boosting rounds for the LGBM. All NNs were trained for 400 training epochs which triggered early stopping and ensured model convergence. To further address overfitting, we applied standard image augmentation methods such as rotation and horizontal flipping to histology tiles during the training of MM-Net and UMH-Net.
Since the dataset is highly imbalanced in terms of drug response distribution, we used a weighted loss function that penalizes more heavily incorrect predictions of the response samples as opposed to the non-response samples. For training MM-Net, we used only 10% of the image tiles that were available in each WSI, because our preliminary experiments revealed that the prediction performance does not improve if additional tiles are used. The 10% of the tiles have been drawn at random from each WSI.
For model evaluation, we used three performance metrics for binary classification tasks, including Matthews correlation coefficient (MCC), area under the receiver operating characteristic curve (AUROC), and area under the precision-recall curve (AUPRC). We calculated the metrics based on a test set of each one of the 100 splits. To compute each metric for a given test set, we aggregated all the sample predictions in the test set. In the case of baseline models where each tumor sample is represented by a GE vector, the prediction model generates in a single probability value for each sample. However, in the case of MM-Net where each tumor sample is represented by multiple image tiles in addition to the GE profile, the prediction model generates a single probability value for each image tile which results in multiple predicted probability values for a single sample. To conform with the output of the baseline models, the tile predictions from MM-Net were aggregated via mean to provide a single probability value for each sample. Note that while only 10% of the available tiles were used for training MM-Net, all tiles in the test set were used to compute predictions and subsequently obtain the performance metrics.
3. Results
A total of six prediction models were analyzed, as summarized in Table 2. The models differ in terms of the feature sets and the samples that were used for training and validation (binary columns in Table 2). All models were evaluated across the same 100 data splits. Figure 6 shows the performance metrics, including MCC, AUPRC, and AUROC where each data point is a metric value calculated for a given split. The average score of each model was aggregated via mean across the splits for each metric (listed in Table 2).

Table 2. Performance metrics including MCC, AUPRC, and AUROC are listed for drug response prediction models (UME-Net, UME-Netorg, UME-Netpairs, UMH-Net, MM-Net, and LGBM).
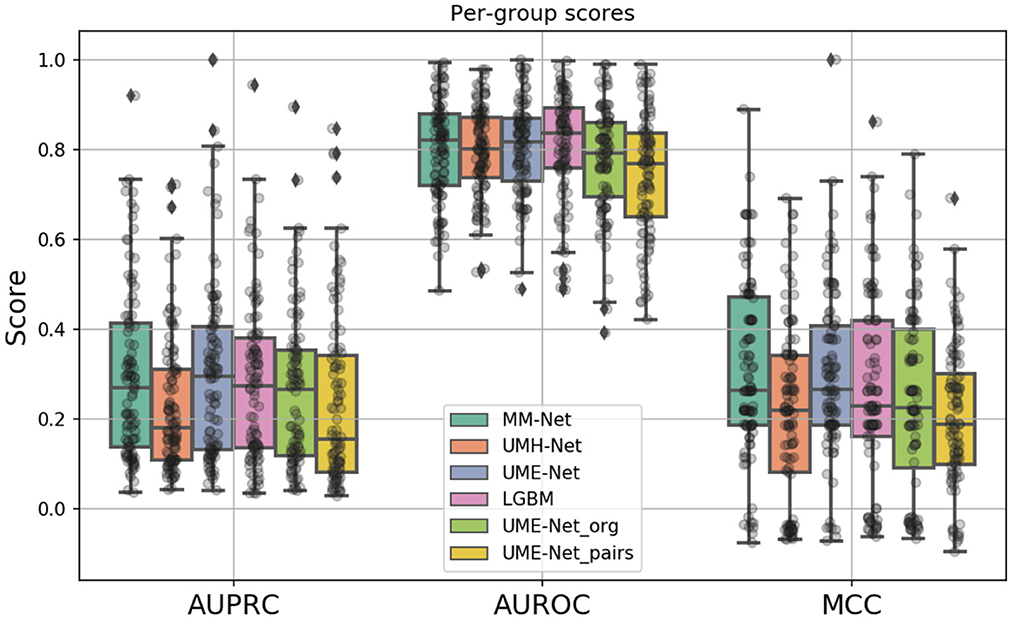
Figure 6. Boxplots showing the distribution of scores for the investigated drug response prediction models. The differences between the models are summarized in Table 2.
In constructing the drug response dataset, we used two approaches to increase the number of response values, as described in Section 2.1.4. We analyzed the effect of these two methods on the prediction performance by comparing three unimodal NNs that were trained with GE and drug descriptors on subsets of the dataset: (1) UME-Net, trained with the full dataset that includes the original and the augmented drug-pair treatments as well as single-drug treatments, (2) UME-Netpairs, trained with only drug-pair samples which include the original and the augmented samples, and (3) UME-Netorg, trained with the original single-drug and drug-pair samples that exclude the augmented drug-pair samples. Figure 6 shows the prediction performance of using the different training subsets across the data splits where each data point is a metric value calculated for a given split. While the distribution of scores across the splits is quite substantial, removing either subset of samples (i.e., single-drug samples or augmented drug-pairs) results in a significant decline in prediction performance, as demonstrated by two statistical tests, including paired t-test and Wilcoxon signed-rank test (p < 0.05). In other words, augmentation methods lead to a significant improvement in performance of the NNs when trained with GE and descriptors. Hence, we used the full set of the available training samples for the analyses of multimodal learning.
The MM-Net architecture, shown in Figure 5, was compared against three baseline models, including UME-Net, UMH-Net, and LGBM. The performance metrics represent the ability of the models to generalize to a test set of unseen observations. Statistical tests (paired t-test and Wilcoxon signed-rank test) were performed to assess statistical difference between the models across the 100 data splits. Based on the aggregated MCC score, MM-Net statistically significantly outperforms all the baselines (p < 0.05 for both tests) except for UME-Net. When considering the AUPRC, MM-Net outperforms UMH-Net but there is no significant difference when comparing MM-Net with UME-Net or LGBM. No statistical significance was observed when comparing MM-Net with the other models. All the performance scores and statistical tests are provided in Supplementary Table S1.
As compared to DL models that are trained with cell line data, all models in Table 2 generally exhibit a relatively lower performance. For example, the average AUPRC is around 0.27 in Table 2 (all precision-recall curves are provided in the Supplementary material) but models trained on cell lines can exhibit AUPRC of 0.7 and above (48). Yet, we can observe a large spread of scores for all models and metrics (Figure 6). This indicates that for certain data splits, the models exhibit very high generalization performance, while for other splits, the models almost entirely fail to learn a meaningful mapping function for predicting drug response. In practical scenarios, where the goal is to design a highly generalizable model, a careful analysis should be conducted to determine the training and validation sets that adequately represent the test set. Subsequently, the threshold of the classifier can be determined depending on the error rate that the stakeholders can tolerate which will ultimately depend on the specific application that the model was designed for (e.g., precision oncology, drug development, etc.). In our analysis, however, the objective was to conduct large-scale trainings across multiple data splits and examine the overall capacity of MM-Net in predicting drug response across multiple cancer types and treatments. We observe that for certain dataset splits, MM-Net outperforms the baselines but for other splits it underperforms, as shown in Figure 7. An in-depth investigation is further required to understand in which cases MM-Net trained with WSI significantly improves prediction generalization.
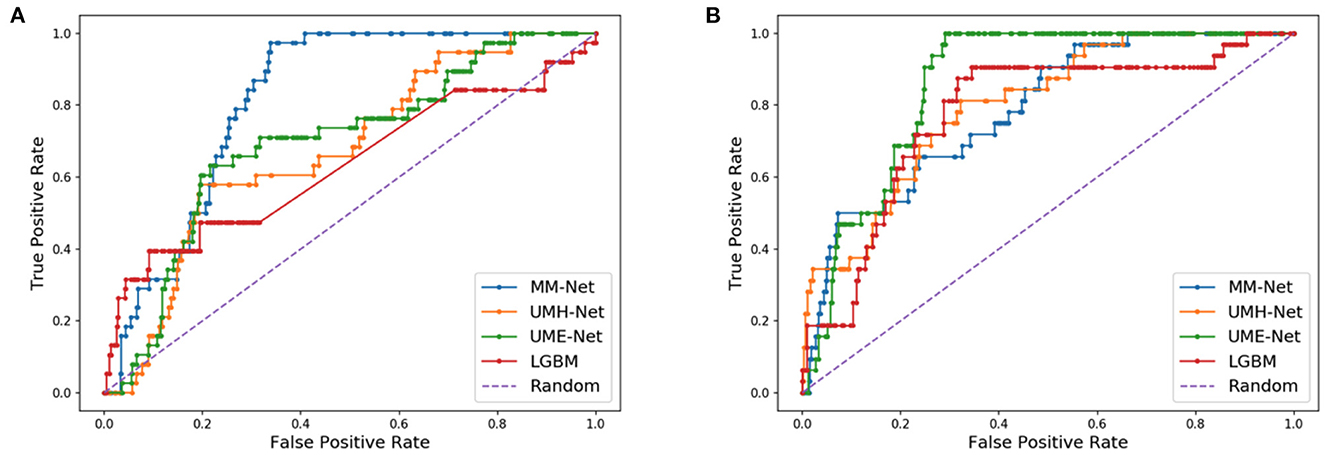
Figure 7. Receiver operating characteristic (ROC) curves for two different data splits. (A) MM-Net outperforms the baseline models. (B) MM-Net underperforms the baseline models.
4. Discussion
In this study, we investigated data augmentation methods and a multimodal architecture for predicting drug response in PDXs. We utilized the PDMR drug response dataset of single-drug and drug-pair treatments that were generated in controlled group experiments with PDX models of multiple cancer types. To assess the utility of the proposed methods, we conducted a large-scale analysis by training MM-Net and three baseline models over 100 data splits that contain GE profiles, histology image tiles, and molecular drug descriptors. We demonstrated that data augmentation methods lead to a significant improvement in drug response predictions across all performance metrics (MCC, AUPRC, and AUROC). Alternatively, the MM-Net model exhibits statistically significant improvement in prediction performance only when measured by the MCC.
The data splitting strategy and the choice of performance metrics play an important role in the downstream analysis when evaluating the utility of prediction models for practical applications. The dataset size and its diversity in terms of PDX models and treatments allowed us to generate multiple data splits while mitigating data leakage between training, validation, and test sets. Since each split comprises unique GE and histology images, we face a challenging prediction problem as opposed to a situation in which the samples are randomly split. Alternative splitting strategies may involve a careful choice of a single test set with the goal to reduce the distributional shift between training and test sets (49). Instead of carefully assembling the most representative test set, we chose to conduct a large-scale analysis to assess the empirical range of prediction performance with NNs and LGBM. The results show a large spread of scores across the splits, indicating that for certain data splits the models exhibit high prediction performance, while for other splits, the learning of models fails. When we specifically focus on the performance of MM-Net as compared with the baselines, we discover that in 46 out of the 100 splits, the MM-Net outperformed the UME-Net baseline. This observation implies that for certain data splits, the histology images boost the generalization performance of the prediction model, and therefore, its potential utility in preclinical and clinical settings. A further investigation is required to better understand the cases and data characteristics in which histology images improve response prediction.
Technological progress in digital pathology and high-throughput omic profiling have led researchers to generate big data repositories of histology images and omics data, as well as algorithms to jointly analyze these diverse data types. Several papers have explored multimodal architectures that combine histology images with omics data for predicting survival outcomes of cancer patients. Mobadersany et al. demonstrated that a CNN-based supervised learning model combined with cox regression accurately predicts survival outcomes of glioma patients from histology and mutation data (21). Cheerla et al. proposed an unsupervised learning method to learn a low-dimensional representation for each feature type and, consequently, concatenated the learned representations to predict survival outcome of cancer patients (22). They have also demonstrated on 20 cancer types that a custom dropout layer that randomly drops an entire feature vector improves predictions. Building upon existing works, Chen et al. introduced a supervised architecture for multimodal fusion of histology and omics data to predict patient survival and applied their method to glioma and clear cell renal cell carcinoma patients (23). The model uses graph convolutional network (GCN) and CNN to encode histology image data and feed-forward network for mutation data. Each encoded feature vector is passed through an attention mechanism and subsequently fused via a Kronecker product. The cox regression is finally used to predict patient survival. While these papers do not consider drug treatments in their analysis, they exploit modern approaches for enhancing predictions of multimodal NNs with histology and omics data and can be further explored for drug response prediction.
A wide spectrum of methods is available in vision applications for inducing changes in images that allow for data augmentation (50). In this study, we exploit the lack of invariance to permutation as the means to augment the sample size. Recently, additional methods have been proposed for augmenting transcriptomic data which can potentially be combined and provide further improvement in predicting drug response (51–53). Considering the scale of existing PDX datasets, data fusion and augmentation provide promising research directions for enhancing predictive capabilities with PDXs. However, special care should be taken because high-dimensional feature sets can often lead to severe overfitting and poor generalization. Presumably to mitigate overfitting, Nguyen et al. (11) and Kim et al. (12) used feature selection methods to reduce the dimensionality of PDX data while considering a single omics feature type at a time. Therefore, multimodal learning exhibits a tradeoff between enriching the feature space via multimodal fusion and overfitting. To alleviate this tradeoff, alternative methods can be explored to reduce the feature space while incorporating multiple feature types (54). With the methods proposed in this study and ongoing research into novel augmentation and fusion techniques, PDX pharmaco-omic datasets may become more suitable for modern deep learning techniques and further increase interest for building prediction models to advance precision oncology.
5. Conclusions
Deep learning methods have shown promising results in predicting drug response in cancer cell lines. While PDXs are presumed to better mimic human cancer, drug response datasets with this cancer model are substantially smaller as compared to cell line datasets. We investigate multimodal learning and data augmentation methods to address the challenge of limited drug response sample size. Our results suggest that data augmentation and integration of histology images and gene expressions can improve prediction performance of drug response in PDXs.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found at: https://pdmr.cancer.gov/database/default.htm.
Ethics statement
The animal study was reviewed and approved by FNLCR is accredited by the Association for Assessment and Accreditation of Laboratory Animal Care International and follows the Public Health Service Policy for the Care and Use of Laboratory Animals. All studies were conducted according to an approved animal care and use committee protocol in accordance with procedures outlined in the Guide for Care and Use of Laboratory Animals 8th Edition.
Author contributions
APa, TB, YZ, and RS: conceptualization. APa, YZ, JDol, SK, MS, and YE: data curation. APa and YZ: formal analysis. RS: funding acquisition. APa and YE: investigation and methodology. TB, APe, YE, and RS: project administration and resources. APa, YZ, and JDol: software. YE and JDor: validation. APa: writing—original draft preparation. APa, TB, YZ, JDol, APe, YE, and RS: writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
This has been funded in whole or in part with Federal funding by the NCI-DOE Collaboration established by the U.S. Department of Energy (DOE) and the National Cancer Institute (NCI) of the National Institutes of Health, Cancer Moonshot Task Order No. 75N91019F00134 and under Frederick National Laboratory for Cancer Research Contract 75N91019D00024. This work was performed under the auspices of the U.S. Department of Energy by Argonne National Laboratory under Contract DE-AC02-06-CH11357, Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344, Los Alamos National Laboratory under Contract 89233218CNA000001, and Oak Ridge National Laboratory under Contract DE-AC05-00OR22725. Argonne National Laboratory's work on the Preclinical Modeling High-Performance Computing Artificial Intelligence project was supported in whole or in part by Leidos Biomedical Research, Inc., under PRJ1009868.
Conflict of interest
YE was employed by Leidos Biomedical Research, Inc.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmed.2023.1058919/full#supplementary-material
References
1. Ballester PJ, Stevens R, Haibe-Kains B, Huang RS, Aittokallio T. Artificial intelligence for drug response prediction in disease models. Brief Bioinform. (2021) 2021:bbab450. doi: 10.1093/bib/bbab450
2. Adam G, Rampášek L, Safikhani Z, Smirnov P, Haibe-Kains B, Goldenberg A. Machine learning approaches to drug response prediction: challenges and recent progress. NPJ Precis Oncol. (2020) 4:19. doi: 10.1038/s41698-020-0122-1
3. Sharifi-Noghabi H, Jahangiri-Tazehkand S, Smirnov P, Hon C, Mammoliti A, Nair SK, et al. Drug sensitivity prediction from cell line-based pharmacogenomics data: guidelines for developing machine learning models. Brief Bioinform. (2021) 22:bbab294. doi: 10.1093/bib/bbab294
4. Fisher R, Pusztai L, Swanton C. Cancer heterogeneity: implications for targeted therapeutics. Br J Cancer. (2013) 108:479–85. doi: 10.1038/bjc.2012.581
5. Seoane J, Mattos-Arruda LD. The challenge of intratumour heterogeneity in precision medicine. J Internal Med. (2014) 276:41–51. doi: 10.1111/joim.12240
6. Evrard YA, Srivastava A, Randjelovic J, Doroshow JH, Dean DA, Morris JS, et al. Systematic establishment of robustness and standards in patient-derived xenograft experiments and analysis. Cancer Res. (2020) 80:2286–97. doi: 10.1158/0008-5472.CAN-19-3101
7. Goto T. Patient-derived tumor xenograft models: toward the establishment of precision cancer medicine. J Pers Med. (2020) 10:64. doi: 10.3390/jpm10030064
8. Yoshida GJ. Applications of patient-derived tumor xenograft models and tumor organoids. J Hematol Oncol. (2020) 13:4. doi: 10.1186/s13045-019-0829-z
9. Chiu YC, Chen HIH, Gorthi A, Mostavi M, Zheng S, Huang Y, et al. Deep learning of pharmacogenomics resources: moving towards precision oncology. Brief Bioinform. (2020) 21:2066–83. doi: 10.1093/bib/bbz144
10. Zhu Y, Brettin T, Evrard YA, Partin A, Xia F, Shukla M, et al. Ensemble transfer learning for the prediction of anti-cancer drug response. Sci Rep. (2020) 10:1–11. doi: 10.1038/s41598-020-74921-0
11. Nguyen LC, Naulaerts S, Bruna A, Ghislat G, Ballester PJ. Predicting cancer drug response in vivo by learning an optimal feature selection of tumour molecular profiles. Biomedicines. (2021) 9:319. doi: 10.3390/biomedicines9101319
12. Kim Y, Kim D, Cao B, Carvajal R, Kim M. PDXGEM: patient-derived tumor xenograft-based gene expression model for predicting clinical response to anticancer therapy in cancer patients. BMC Bioinform. (2020) 21:288. doi: 10.1186/s12859-020-03633-z
13. Migliardi G, Sassi F, Torti D, Galimi F, Zanella ER, Buscarino M, et al. Inhibition of MEK and PI3K/mTOR suppresses tumor growth but does not cause tumor regression in patient-derived xenografts of RAS-mutant colorectal carcinomas. Clin Cancer Res. (2012) 18:2515–25. doi: 10.1158/1078-0432.CCR-11-2683
14. Gao H, Korn JM, Ferretti S, Monahan JE, Wang Y, Singh M, et al. High-throughput screening using patient-derived tumor xenografts to predict clinical trial drug response. Nat Med. (2015) 21:1318–25. doi: 10.1038/nm.3954
15. Smith SC, Baras AS, Lee JK, Theodorescu D. The COXEN principle: translating signatures of in vitro chemosensitivity into tools for clinical outcome prediction and drug discovery in cancer. Cancer Res. (2010) 70:1753–8. doi: 10.1158/0008-5472.CAN-09-3562
16. Zhu Y, Brettin T, Evrard YA, Xia F, Partin A, Shukla M, et al. Enhanced co-expression extrapolation (COXEN) gene selection method for building anti-cancer drug response prediction models. Genes. (2020) 11:1070. doi: 10.3390/genes11091070
17. Hestness J, Narang S, Ardalani N, Diamos G, Jun H, Kianinejad H, et al. Deep learning scaling is predictable, empirically. arXiv:171200409 [cs, stat]. (2017). doi: 10.48550/arXiv.1712.00409
18. Rosenfeld JS, Rosenfeld A, Belinkov Y, Shavit N. A constructive prediction of the generalization error across scales. In: ICLR. (2020). Available online at: https://iclr.cc/Conferences/2020
19. Partin A, Brettin T, Evrard YA, Zhu Y, Yoo H, Xia F, et al. Learning curves for drug response prediction in cancer cell lines. BMC Bioinform. (2021) 22:1. doi: 10.1186/s12859-021-04163-y
20. Xia F, Allen J, Balaprakash P, Brettin T, Garcia-Cardona C, Clyde A, et al. A cross-study analysis of drug response prediction in cancer cell lines. Brief Bioinform. (2022) 23:bbab356. doi: 10.1093/bib/bbab356
21. Mobadersany P, Yousefi S, Amgad M, Gutman DA, Barnholtz-Sloan JS, Velázquez Vega JE, et al. Predicting cancer outcomes from histology and genomics using convolutional networks. Proc Natl Acad Sci USA. (2018) 115:E2970-E2979. doi: 10.1073/pnas.1717139115
22. Cheerla A, Gevaert O. Deep learning with multimodal representation for pancancer prognosis prediction. Bioinformatics. (2019) 35:446–54. doi: 10.1093/bioinformatics/btz342
23. Chen RJ, Lu MY, Wang J, Williamson DFK, Rodig SJ, Lindeman NI, et al. Pathomic fusion: an integrated framework for fusing histopathology and genomic features for cancer diagnosis and prognosis. IEEE Trans Med Imaging. (2019) 44:757–70. doi: 10.1109/TMI.2020.3021387
24. Ke G, Meng Q, Finley T, Wang T, Chen W, Ma W, et al. LightGBM: a highly efficient gradient boosting decision tree. In: Advances in Neural Information Processing Systems.. Curran Associates, Inc. (2017) 30, 3146–3154. Availble online at: http://citebay.com/how-to-cite/light-gradient-boosting-machine/
25. Mer AS, Ba-Alawi W, Smirnov P, Wang YX, Brew B, Ortmann J, et al. Integrative pharmacogenomics analysis of patient-derived xenografts. Cancer Res. (2019) 79:4539–50. doi: 10.1158/0008-5472.CAN-19-0349
26. Schwartz LH, Litière S, Vries Ed, Ford R, Gwyther S, Mandrekar S, et al. RECIST 1.1–Update and clarification: From the RECIST committee. Eur J Cancer. (2016) 62:132–7. doi: 10.1016/j.ejca.2016.03.081
27. Costello JC, Heiser LM, Georgii E, Gönen M, Menden MP, Wang NJ, et al. A community effort to assess and improve drug sensitivity prediction algorithms. Nat Biotechnol. (2014) 32:1202–12. doi: 10.1038/nbt.2877
28. Partin A, Brettin TS, Zhu Y, Narykov O, Clyde A, Jamie O, et al. Deep learning methods for drug response prediction in cancer: predominant and emerging trends. Front Med. (2023) 10:1086097. doi: 10.3389/fmed.2023.1086097
29. Ahmed KT, Park S, Jiang Q, Yeu Y, Hwang T, Zhang W. Network-based drug sensitivity prediction. BMC Med Genomics. (2020) 13:193. doi: 10.1186/s12920-020-00829-3
30. Jia P, Hu R, Pei G, Dai Y, Wang YY, Zhao Z. Deep generative neural network for accurate drug response imputation. Nat Commun. (2021) 12:1740. doi: 10.1038/s41467-021-21997-5
31. Hostallero DE, Li Y, Emad A. Looking at the BiG picture: incorporating bipartite graphs in drug response prediction. Bioinformatics. (2022) 38:3609–20. doi: 10.1093/bioinformatics/btac383
32. Subramanian A, Narayan R, Corsello SM, Peck DD, Natoli TE, Lu X, et al. A next generation connectivity map: L1000 platform and the first 1,000,000 profiles. Cell. (2017) 171:1437–52. doi: 10.1016/j.cell.2017.10.049
33. Rampasek L, Hidru D, Smirnov P, Haibe-Kains B, Goldenberg A. Dr.VAE: improving drug response prediction via modeling of drug perturbation effects. Bioinformatics. (2019) 35:3743–51. doi: 10.1093/bioinformatics/btz158
34. Deng L, Cai Y, Zhang W, Yang W, Gao B, Liu H. Pathway-guided deep neural network toward interpretable and predictive modeling of drug sensitivity. J Chem Inf Model. (2020) 60:4497–505. doi: 10.1021/acs.jcim.0c00331
35. Zuo Z, Wang P, Chen X, Tian L, Ge H, Qian D. SWnet: a deep learning model for drug response prediction from cancer genomic signatures and compound chemical structures. BMC Bioinform. (2021) 22:434. doi: 10.1186/s12859-021-04352-9
36. Kim S, Bae S, Piao Y, Jo K. Graph convolutional network for drug response prediction using gene expression data. Mathematics. (2021) 9:772. doi: 10.3390/math9070772
37. Forbes SA, Beare D, Boutselakis H, Bamford S, Bindal N, Tate J, et al. COSMIC: somatic cancer genetics at high-resolution. Nucleic Acids Res. (2017) 45:D777–83. doi: 10.1093/nar/gkw1121
38. Liu Q, Hu Z, Jiang R, Zhou M. DeepCDR: a hybrid graph convolutional network for predicting cancer drug response. Bioinformatics. (2020) 36:i911–8. doi: 10.1093/bioinformatics/btaa822
39. Zhu Y, Ouyang Z, Chen W, Feng R, Chen DZ, Cao J, et al. TGSA: protein-protein association-based twin graph neural networks for drug response prediction with similarity augmentation. Bioinformatics. (2021) 38:461–8. doi: 10.1093/bioinformatics/btab650
40. Ma T, Liu Q, Li H, Zhou M, Jiang R, Zhang X. DualGCN: a dual graph convolutional network model to predict cancer drug response. BMC Bioinform. (2022) 23:129. doi: 10.1186/s12859-022-04664-4
41. Bankhead P, Loughrey MB, Fernández JA, Dombrowski Y, McArt DG, Dunne PD, et al. QuPath: open source software for digital pathology image analysis. Sci Rep. (2017) 7:16878. doi: 10.1038/s41598-017-17204-5
42. Dolezal JM, Trzcinska A, Liao CY, Kochanny S, Blair E, Agrawal N, et al. Deep learning prediction of BRAF-RAS gene expression signature identifies noninvasive follicular thyroid neoplasms with papillary-like nuclear features. Modern Pathol. (2021) 34:862–74. doi: 10.1038/s41379-020-00724-3
43. Dolezal JM, Kochanny S, Howard F. Jamesdolezal/slideflow: Slideflow 1.0 - Official Public Release (1.0.4). Zenodo. (2021). doi: 10.5281/zenodo.5718806
44. Reinhard E, Adhikhmin M, Gooch B, Shirley P. Color transfer between images. IEEE Comput Graphics Appl. (2001) 21:34–41. doi: 10.1109/38.946629
45. Kaufman S, Rosset S, Perlich C. Leakage in data mining: formulation, detection, and avoidance. ACM Trans Knowl Discovery Data. (2012) 6:579. doi: 10.1145/2382577.2382579
46. Chollet F. Xception: deep learning with depthwise separable convolutions. arXiv:161002357 [cs]. (2017) doi: 10.1109/CVPR.2017.195
47. Deng J, Dong W, Socher R, Li LJ, Li K, Fei-Fei L. ImageNet: a large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, FL: IEEE (2009). p. 248–55.
48. Jiang L, Jiang C, Yu X, Fu R, Jin S, Liu X. DeepTTA: a transformer-based model for predicting cancer drug response. Brief Bioinform. (2022) 23:bbac100. doi: 10.1093/bib/bbac100
49. Stacke K, Eilertsen G, Unger J, Lundstrom C. Measuring domain shift for deep learning in histopathology. IEEE J Biomed Health Inform. (2021) 25:325–36. doi: 10.1109/JBHI.2020.3032060
50. Shorten C, Khoshgoftaar TM. A survey on image data augmentation for deep learning. J Big Data. (2019) 6:60. doi: 10.1186/s40537-019-0197-0
51. Moreno-Barea FJ, Jerez JM, Franco L. GAN-Based data augmentation for0prediction improvement using gene expression data in0cancer. In:Groen D, de Mulatier C, Paszynski M, Krzhizhanovskaya VV, Dongarra JJ, Sloot PMA, editors. Computational Science-ICCS 2022 Lecture Notes in Computer Science. Cham: Springer International Publishing (2022). p. 28–42.
52. Kircher M, Chludzinski E, Krepel J, Saremi B, Beineke A, Jung K. Augmentation of transcriptomic data for improved classification of patients with respiratory diseases of viral origin. Int J Mol Sci. (2022) 23:2481. doi: 10.3390/ijms23052481
53. Huang HH, Rao H, Miao R, Liang Y. A novel meta-analysis based on data augmentation and elastic data shared lasso regularization for gene expression. BMC Bioinform. (2022) 23:353. doi: 10.1186/s12859-022-04887-5
Keywords: drug response prediction, histology whole-slide images, gene expression, multimodal deep learning, preclinical drug studies, data augmentation, patient-derived xenograft (PDX)
Citation: Partin A, Brettin T, Zhu Y, Dolezal JM, Kochanny S, Pearson AT, Shukla M, Evrard YA, Doroshow JH and Stevens RL (2023) Data augmentation and multimodal learning for predicting drug response in patient-derived xenografts from gene expressions and histology images. Front. Med. 10:1058919. doi: 10.3389/fmed.2023.1058919
Received: 30 September 2022; Accepted: 10 February 2023;
Published: 07 March 2023.
Edited by:
Ken Chen, University of Texas MD Anderson Cancer Center, United StatesReviewed by:
Carl-Magnus Svensson, Leibniz Institute for Natural Product Research and Infection Biology, GermanyShaoheng Liang, Rice University, United States
Copyright © 2023 Partin, Brettin, Zhu, Dolezal, Kochanny, Pearson, Shukla, Evrard, Doroshow and Stevens. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Alexander Partin, YXBhcnRpbkBhbmwuZ292