 Bo Zhou
Bo Zhou Haisu Yu
Haisu Yu Xiangrui Zeng
Xiangrui Zeng Xiaoyan Yang
Xiaoyan Yang Jing Zhang
Jing Zhang Min Xu
Min Xu- 1Department of Biomedical Engineering, Yale University, New Haven, CT, United States
- 2Computational Biology Department, Carnegie Mellon University, Pittsburgh, PA, United States
- 3Computer Science Department, University of California, Irvine, Irvine, CA, United States
Cryo-electron Tomography (cryo-ET) generates 3D visualization of cellular organization that allows biologists to analyze cellular structures in a near-native state with nano resolution. Recently, deep learning methods have demonstrated promising performance in classification and segmentation of macromolecule structures captured by cryo-ET, but training individual deep learning models requires large amounts of manually labeled and segmented data from previously observed classes. To perform classification and segmentation in the wild (i.e., with limited training data and with unseen classes), novel deep learning model needs to be developed to classify and segment unseen macromolecules captured by cryo-ET. In this paper, we develop a one-shot learning framework, called cryo-ET one-shot network (COS-Net), for simultaneous classification of macromolecular structure and generation of the voxel-level 3D segmentation, using only one training sample per class. Our experimental results on 22 macromolecule classes demonstrated that our COS-Net could efficiently classify macromolecular structures with small amounts of samples and produce accurate 3D segmentation at the same time.
1. Introduction
Cryo-Electron Tomography (cryo-ET) has made possible the observation of cellular organelles and macromolecular structures at nano-meter resolution with native conformations (Lučić et al., 2013). Without disrupting the cell, cryo-ET can visualize both known and unknown cellular structures in situ1 and reveals their spatial and organizational relationships (Oikonomou and Jensen, 2017). Using cryo-ET, it is possible to capture 3D structural information of diverse macromolecular structures inside a given scanned sample.
To analyze the macromolecular structures in cryo-ET, two major subsequent steps need to occur. First, we need to extract the subtomograms2 and average those that belong to the same macromolecular class, in order to generate a high Signal-to-Noise Ratio (SNR) subtomogram for clear visualization (Zhang, 2019). Second, it is desirable to obtain the macromolecule segmentation in subtomograms to analyze the macromolecular structure parameters such as size distribution and shape. However, the macromolecular structures are highly heterogeneous and contain large quantities of subtomograms. In the past, biologists would spend large amounts of time on a set of tomograms to manually classify and segment subtomograms, but manual annotation is time-consuming and susceptible to the biases of individual biologists. Therefore, it is desirable to automatically classify the extracted subtomograms into subset of macromolecule with similar structure, and automatically generate the macromolecular segmentation.
To automate the process as well as to achieve objective analysis, deep learning methods for classification (Che et al., 2017; Xu et al., 2017; Guo et al., 2018; Zhao et al., 2018; Li et al., 2019, 2020) and segmentation (Chen et al., 2017; Liu et al., 2018; Zhou et al., 2018) have been developed for cryo-ET. Xu et al. (2017) proposed to use Inception3D network and DSRF3D network for cryo-ET subtomogram classification. Then, Chen et al. (2017) further improved the DSRF3D network with residual connection design. Guo et al. (2018) developed a cryo-ET classification model compression technique to reduce the model size while maintaining the classification performance. Zhao et al. (2018) developed a classification model visualization technique for explaining the model's attention on the classified subtomograms. For cryo-ET segmentation, Che et al. (2017) utilized independent 2D CNNs for cryo-ET tomogram components segmentation. Liu et al. (2018) built a SSN3D net for subtomogram segmentation via supervised training with large amounts of segmentation data. While previous deep learning models on cryo-ET improved the accuracy and efficiency on classification and segmentation, there are still two major bottlenecks: (1) as supervised classification methods, previous algorithms still require large amount of manually annotated training data for deep model's training, and (2) previous algorithms need to be trained again to apply to a new dataset of different classes. The open question is: Is it possible to design a generalizable cryo-ET subtomogram classification model that requires only a small reference dataset (such as one manually picked sample in each class) and match the given subtomogram to a reference class, while performing generalizable subtomogram segmentation?
Inspired by one-shot learning models which aim to learn information about object categories from one, or only a few training images (Fe-Fei et al., 2003; Koch et al., 2015), In this work, we develop a Cryo-ET One-Shot Network (COS-Net) that is able to (1) classify macromolecular structure using only a very small amount of samples, (2) simultaneously segment structural regions in a subtomogram based on the classification network, and (3) be readily and directly applied to classify and segment novel structures without needing to be re-trained. Using our COS-Net, biologists can classify and segment thousands of subtomograms by only manually picking a few representative subtomograms as support classes. When there is a need to classify new subtomogram datasets with novel structures, the support classes can be readily changed to accommodate without the need to train the model again. Moreover, unlike previous one-shot learning and few-shot learning algorithms that only address the classification task, our COS-Net can generate both classification and 3D segmentation with application in 3D imaging data of cryo-ET.
Our COS-Net is a Siamese network with pairs of volume encoders, volume decoders, and feature encoders. Given a support set of subtomograms and a target subtomogram, volume encoders first extract the volume's feature presentations. Then, the feature encoders transform the feature presentations for the next stage: one-shot learning. In the meantime, the volume decoders decode the feature presentations to generate the coarse attention/segmentation of the subtomograms. Our COS-Net with additional attention guidance from segmentation information allows better feature embedding for one-shot learning, and thus could provide better one-shot classification performance. During the test stage, we also developed a customized subtomogram processing pipeline to refine the coarse attention/segmentation from COS-Net based on 3D Conditional Random Field (3D-CRF) (Krähenbühl and Koltun, 2011). Our experimental results demonstrated that our method can effectively classify observed or novel macromolecular structures and produce accurate segmentation mask.
2. Methods
The general structure of our COS-Net is shown in Figure 1. The COS-Net is a Siamese network with two encoding-decoding streams. First, each stream consists of one volume encoder, one volume decoder, and one feature encoder. The volume encoders, volume decoders, and feature encoders shared weights between the dual streams. The design of our volume encoders, volume decoders, and feature encoders are illustrated in Figure 2 and are discussed in detail in our next section. Denoting the input for the upper stream as XS that is our support set with dimensions of N × K, where N is the number of classes and K is sample per class, support set XS consists of N classes of macromolecules with K samples per class. In our one-shot learning scheme, K = 1. The upper volume encoder takes the support set XS as input and generates the latent representation of the support set with:
where FS1 is the latent representation of the support set XS and is the volume encoder function. Then, the support set's latent representations FS1 are simultaneously fed into the volume decoder and feature encoder :
where MS is the predicted segmentation of the support set, and FS2 is the feature for next stage one-shot learning. Similarly, denoting the input for the lower stream as XT that is our target set with dimensions of 1 × K, target set XT consists of 1 classes of macromolecules with K samples per class. In our one-shot learning scheme, K = 1. Similarly, the same volume encoder takes the target set XT as input and generates the latent representation of the target set with:
where FT1 is the latent representation of the target set XT. Then, the target set's latent representations FT1 are simultaneously fed into the shared weights volume decoder and feature encoder :
where MT is the predicted segmentation of the target set, and FT2 is the feature for next stage one-shot learning. Given the features FS2 from support set and the features FT2 from target set, we compute the L1 distance between the features to calculate the similarity between the support set features FS2 and the target set features FT2 with:
where Fdis is the feature distance. Fdis is then input into a fully connected layer followed by a softmax function:
where Fout is the final output with one-shot prediction indicating that the target data matches with which specific class in the support set.
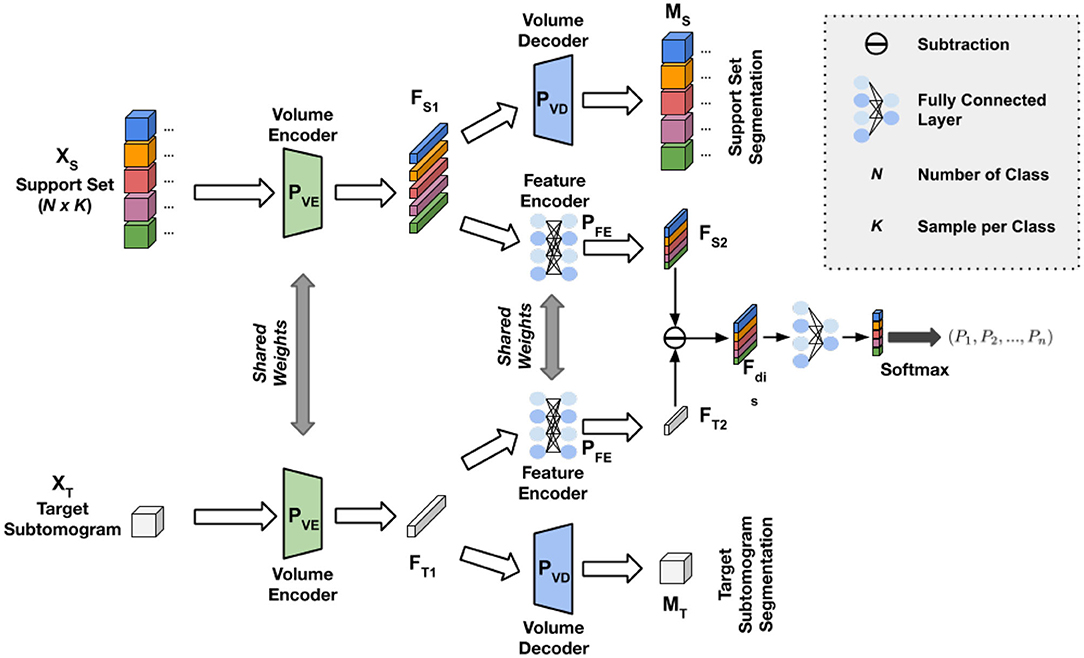
Figure 1. Illustration of our Cryo-ET One-Shot Network (COS-Net) structure. The data input consists of subtomogram support set and target subtomogram. The network consists of pairs of volume encoders , volume decoder , and feature encoder with details illustrated in Figure 2.
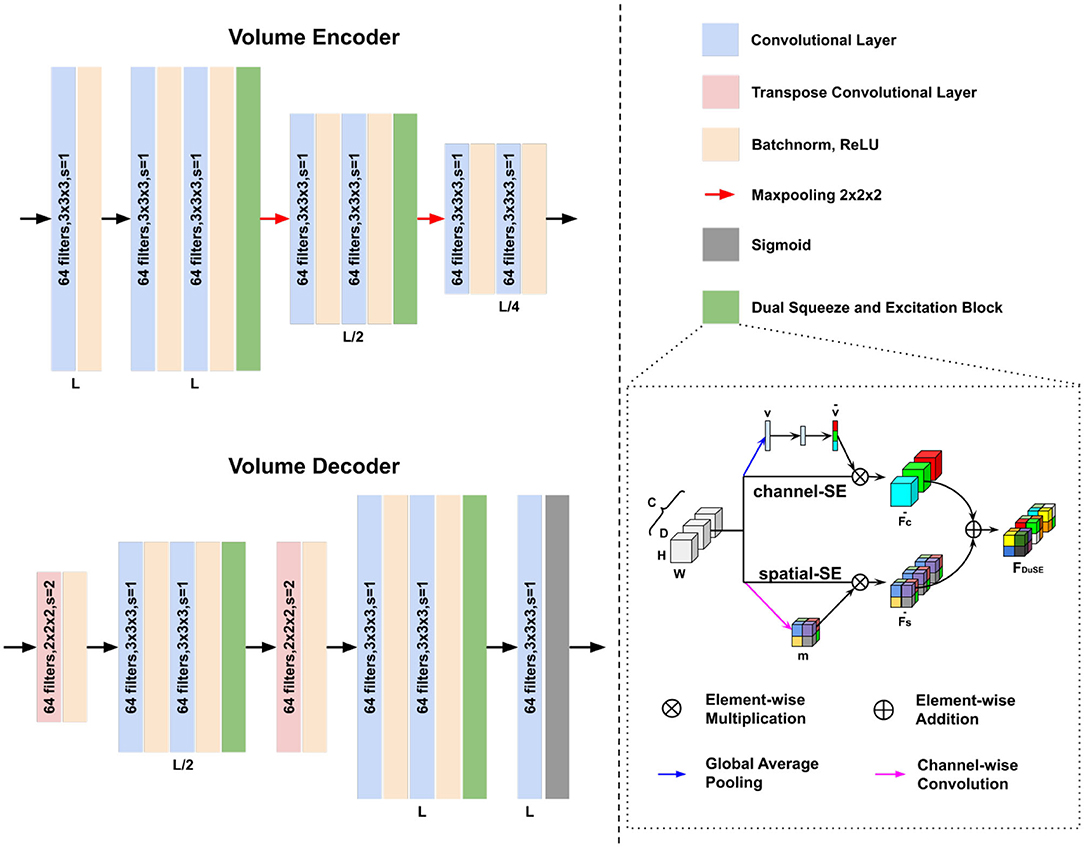
Figure 2. Architectures of our volume encoder and volume decoder in Figure 1. The Dual Squeeze-and-Excitation (DuSE) block is illustrated on the bottom right.
Sub-networks Design: We use a 512 × 512 fully connected layer as our feature encoder. The volume encoder and decoder design are shown in Figure 2. Our volume encoder and volume decoder consist of three level of 3D convolution layers. Unlike conventional convolutional encoder and decoder, we concatenate a Dual Squeeze-and-Excitation (DuSE) block at each level's output in order to re-calibrate the features channel-wise and spatial-wise. More specifically, as illustrated in Figure 2 bottom right, our DuSE block contains two 3D Squeeze-and-Excitation branches for spatial-Squeeze-channel-Excitation (scSE) and channel-Squeeze-spatial-Excitation (csSE), respectively (Hu et al., 2018; Roy et al., 2018).
For scSE, we spatial-wise squeeze the input feature map using global average pooling, where the feature map is formulated as F = [f1, f2, …, fC] here with denoting the individual feature channel. We flatten the global average pooling output, generating v ∈ ℝC with its z-th element:
where vector v embeds the spatial-wise global information. Then, v is feed into two fully connected layers with weights of and , producing the channel-wise calibration vector:
where η and σ are the ReLU and Sigmoid activation function, respectively. The calibration vector is applied to the input feature map using channel-wise multiplication, namely channel-Excitation:
where indicates the importance of the i-th feature channel and lies in [0, 1]. With scSE embedded into our network, the calibration vector adaptively learns to emphasize the important feature channels while playing down the others.
In csSE, we formulate our feature map as F = [f1, 1, 1, …, fi, j, k, …, fH, W, D], where fi, j, k ∈ ℝC indicates the feature at spatial location (i, j, k) with i ∈ {1, …, H}, j ∈ {1, …, W}, and k ∈ {1, …, D}. We channel-wise squeeze the input feature map using a convolutional kernel with weights of , generating a volume tensor m = w3 ⊛ F with m ∈ ℝH×W×D. Each fi, j, k is a linear combination of all feature channel at spatial location (i, j, k). Then, the spatial-wise calibration volume that lies in [0, 1] and can be written as:
where σ is the Sigmoid activation function. Applying the calibration volume to the input feature map, we have:
where calibration parameter of provides the relative importance of a spatial information of a given feature map. Similarly, with csSE embedded into our network, the calibration volume learns to stress the most important spatial locations while ignores the irrelevant ones.
Finally, channel-wise calibration and spatial-wise calibration are combined via element-wise addition: . With the two SE branch fusion, feature at (i, j, k, c) possess high activation only when it receives high activation from both scSE and csSE. Our DuSE encourages the networks to re-calibrate the feature map such that more accurate and relevant feature map can be learned.
Training Strategy and Losses: We design a customized training strategy to train our COS-Net, such that the training procedure matches the inference at test time. Specifically, two support set are randomly generated during the training procedure. Within N classes, the same n classes are randomly sampled for each support set. 1 subtomogram is randomly sampled from these classes to form a n-way-1-shot scheme. The ground-truth one-shot classification label is generated by matching the class labels from the two support set, i.e., 1 for matched class label and 0 for unmatched class label.
Our training loss consists of two parts, including a Binary Cross Entropy (BCE) loss for one-shot classification learning and a Dice Similarity Coefficient (DSC) loss for one-shot segmentation. Denoting the ground-truth one-shot classification label as Fgt, the BCE loss can be written as:
Denoting the ground-truth subtomogram segmentation for the two support set as Mgt1 and Mgt2, the segmentation loss can be written as:
where MS1 and MS2 are the predicted segmentation from COS-Net. The total loss thus can be formulated as:
In testing, one of the support sets during training can be replaced with the target subtomogram for direct inference.
Attention-guided Segmentation: The segmentation predicted from COS-Net is a probability distribution, which is used for guiding our final segmentation. Specifically, the volume decoder's output is a probability distribution ranging between 0 and 1. We use a 3D Conditional Random Field (CRF) to refine and generate the final 3D subtomogram segmentation. The CRF aims to optimize the following objective function:
where ψu is the unary potential that encourages the CRF output to be loyal to the probability distribution from the COS-Net. ψp is the pairwise potential between label on voxel i and j and can be expanded as:
where μ(xi, xj) is the compatibility transformation and depends on the labels xi and xj such that μ(xi, xj) = 1 if xi≠xj, and 0 otherwise. Ii and Ij are the intensity value at voxel location i and j. pi and pj are the spatial coordinates of voxel i and j. w1, w2, σα, σβ, and σγ are learnable parameters for CRF. This term penalizes pixels with similar position p and intensity x but with different label.
3. Experiments and Results
3.1. Data Preparation
We prepared a realistically simulated dataset with known macromolecular structures by reconstructing the tomographic image using the projection images (Pei et al., 2016). The limiting factors of cryo-ET, such as noise, missing wedge, and electron optical factors (Modulation Transfer Function, Contrast Transfer Function) were all properly included. The simulation process mimicked the experimental cellular sample imaging condition and tomographic reconstruction process. We took into account the randomness of macromolecule structural poses. The packed volume containing macromolecular structures were projected to a series of 2D projection images with specified tilt angle steps. The resulting projection images were convolved to include optical factors and then back-projected to obtain the reconstructed 3D simulated tomogram. 22 distinct macromolecular structures are chosen from the Proterin Databank (PDB) with their PDB ID information (Berman et al., 2000) of atomic coordinates and connectivity, and secondary structure assignments. We choose very representative macromolecules such as ribosome (4V4Q), proteasome (3DY4), and RNA polymerase (2GHO), which are well-studied due to their abundance and importance in cellular functions. Each simulated tomogram of 600 × 600 × 300 voxels contains 10,000 randomly distributed macromolecules. Given the true position of these macromolecules inside tomograms, we collected 5,835 subtomograms of size 32 × 32 × 32, belonging to 22 structural classes. The dataset with 22 distinct classes was split into a training set with 14 classes and a test set with 8 classes. Three datasets with different levels of signal-to-noise ratio (SNR) were used, including SNR = ∞, SNR = 1, 000, and SNR = 0.5.
3.2. Classification Results
Table 1 summarizes the one-shot classification performance with different sub-network setup. We evaluated the one-shot classification accuracy under different noise level and various one-shot training schemes. First, comparing the COS-Net with and without volume decoder for guiding the one-shot classification, with volume decoder can significantly improve the classification accuracy for sub-networks with or without DuSE block. For example, using the SNR = 1, 000 dataset, the 2way-1shot COS-Net with DuSE improve the accuracy from 0.928 to 0.939 by adding the volume decoder. Second, comparing the COS-Net with and without DuSE block, adding DuSE block to volume encoder/decoder can also improve the classification accuracy. However, the classification accuracy decreases as the SNR decreases, due to the structural details being degraded by noise. Meanwhile, the classification accuracy also decreases as the number of classes (way) increase.
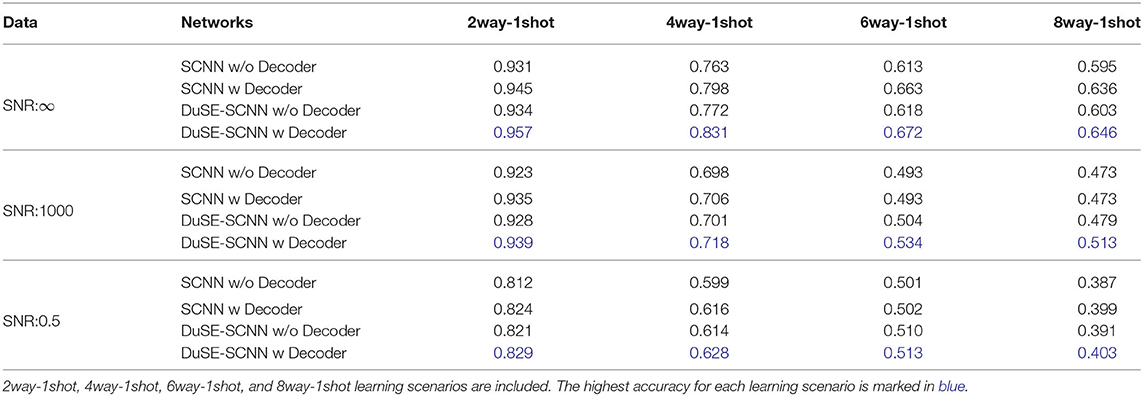
Table 1. The one-shot classification accuracy on three dataset with three different SNR levels.
3.3. Segmentation Results
The segmentation performance of our attention-guided segmentation is evaluated using the same test set as in the classification section based on DSC:
where Mpred is our generated segmentation, and Mgt is the ground-truth segmentation. Segmentation results with different training schemes on SNR = 1, 000 dataset are visualized in Figure 3. As we can see, our method can generate accurate 3D segmentation that does not rely on unseen classes' pixel-level or image-level training data. It is also worth notice that our method can achieve robust and consistent segmentation performance over different way one shot learning schemes. Besides, a comparison of segmentation results with and without DuSE block on eight different macromolecule classes is visualized in Figure 4. While segmentation with DuSE block does not significantly outperforms segmentation without DuSE block, they both produce reasonable segmentation of macromolecules.

Figure 3. Illustration of segmentation results on all three test classes using COS-Net with DuSESCNN. The macromolecule PDB ID is indicated for each classes on the left. The ground truth segmentation (second column) is compared against COS-Net with 2way-1shot, 4way-1shot, 6way-1shot scenarios from second to fifth column. The enlarged images on selected 2D slices are visualized at the bottom.
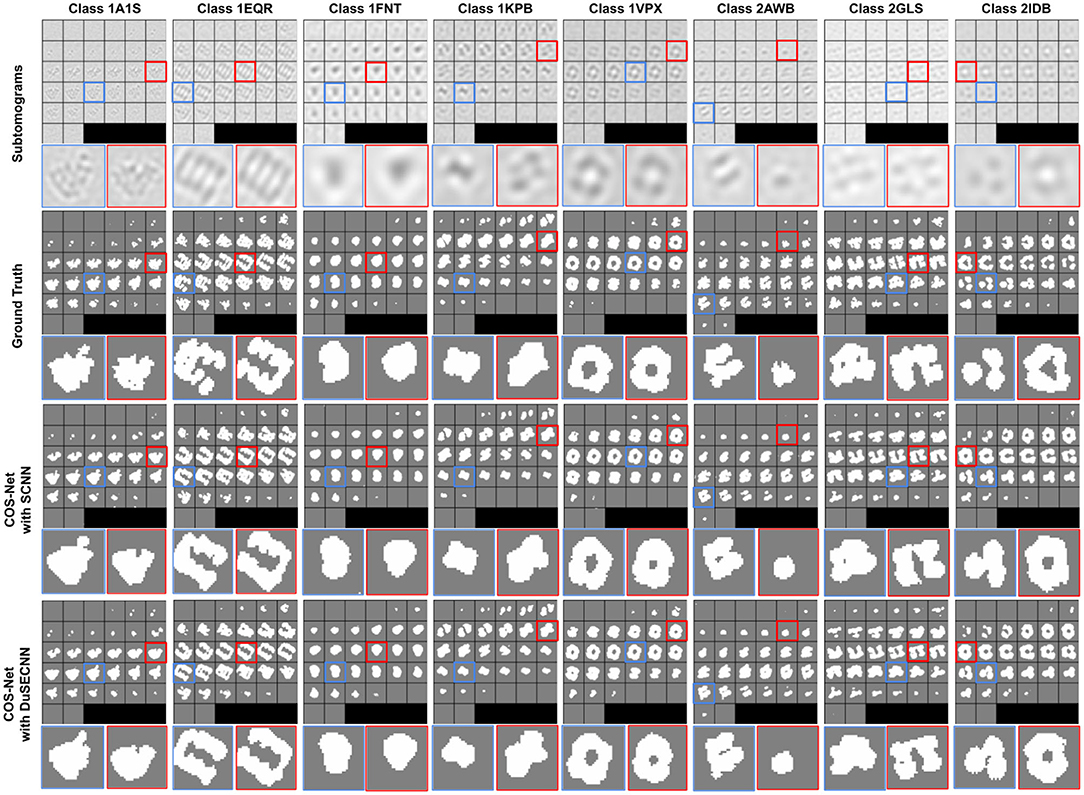
Figure 4. Illustration of segmentation results on all eight test classes using 2way-1shot. The macromolecular PDB ID is indicated for each classes on the top. The ground truth segmentation (second row) is compared against COS-Net with SCNN (third row) and COS-Net with DuSESCNN (fourth row). The enlarged images on selected 2D slices are visualized at the bottom.
The quantitative results using SNR = 1, 000 and SNR = ∞ datasets are summarized in Tables 2, 3, respectively. As we can observe, for all 8 unseen classes, our COS-Net is able to generate reasonable 3D segmentation. For SNR = ∞ data, the DSC of our COS-Net with DuSE are all > 0.92 for all classes, indicating accurate 3D macromolecule segmentation. For SNR = 1, 000, the DSC of COS-Net with DuSE are > 0.84. The decrease in segmentation performance is due to the increased noise level that degrades the macromolecule structure details. However, as illustrated in Figure 3, our COS-Net can still generate reasonable 3D segmentation for unseen classes.
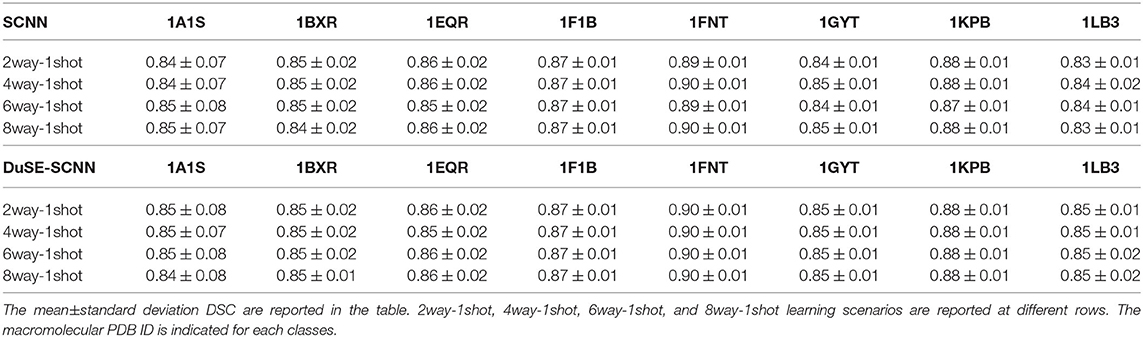
Table 2. The segmentation results for all eight test classes on SNR = 1,000 dataset.
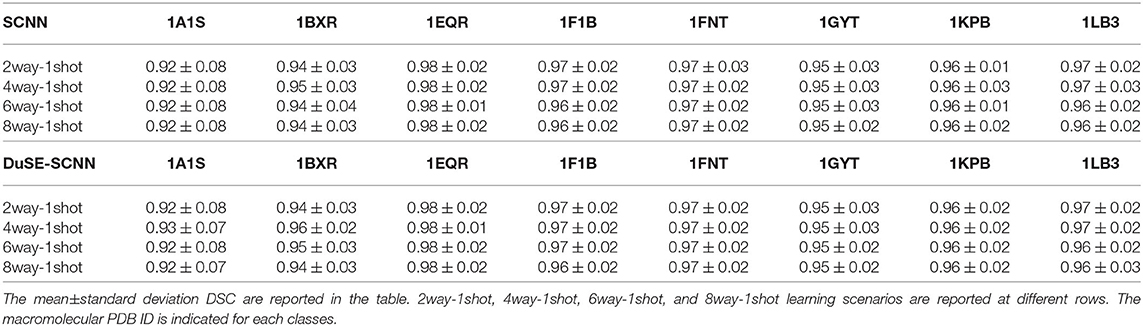
Table 3. The segmentation results for all eight test classes on SNR = ∞ dataset.
4. Discussion and Conclusion
In this work, we developed a one-shot learning framework for cryo-ET where simultaneous classification and segmentation can be performed for seen or unseen macromolecule subtomograms. Specifically, we developed a COS-Net to learn the class matching between a support set consisting of multiple classes with only 1 sample per class and a target subtomogram. In COS-Net, the segmentation attention is utilized to better guide the one-shot classification. In the mean time, the volume decoder of COS-Net allows us to generate the coarse segmentation of the macromolecule in the subtomogram. Then, 3D CRF is utilized to refine the 3D macromolecule segmentation from COS-Net.
We demonstrated the successful application of our COS-Net on a cryo-ET dataset consisting of 22 macromolecule classes. First, our method demonstrated accurate one-shot classification performance over dataset with different noise levels. Even with SNR as low as 0.5, the classification accuracy is over 0.8 in a 2way-1shot classification scheme. As compared to previous supervised cryo-ET classification methods with classification accuracy of about 0.9, our method is able to achieve comparable performance without using large-scale high-quality labeled data (Liu et al., 2018; Che et al., 2019). Second, our method can produce high-quality 3D segmentation for unseen macromolecules under different one-shot classification schemes. As we can observe in Table 3, our COS-Net can produce 3D segmentation with DSC> 0.84 on all test macromolecules over all one-shot schemes. As compared to previous supervised segmentation methods, our segmentation performance is comparable to these supervised cryo-ET segmentation models with DSC of about 0.88, which require segmentation ground truth on seen macromolecule classes for training (Liu et al., 2018; Che et al., 2019). Therefore, our method provides a solution of both accurate classification and segmentation for unseen macromolecule classes.
The presented work can potentially be further improved from the following perspectives. First of all, the classification accuracy decreases as the number of classes in the support set increases. As more classes are involved in the class matching procedure and only one sample is used for each classes, the classification difficulty will naturally increase. However, our COS-Net can be extended from one-shot to few-shot if more samples are available for each class, and this strategy could potentially improve the classification accuracy. Moreover, the macromolecule alignment is not considered in the current one-shot classification pipeline. The macromolecule in the support set and target set may not be aligned, i.e., they have different orientations before feeding into our network, which could potentially decrease the classification accuracy. Subtomogram pre-processing by alignment of macromolecule in subtomograms could potentially further improve our classification accuracy and will be a focus in our future work (Lü et al., 2019; Zeng and Xu, 2020). Second, the cryo-ET imaging data is reconstructed from limited angle conditions. The subtomogram image quality could be degraded by the limited angle reconstruction artifacts and potentially impact the downstream COS-Net's performance. Deep learning based limited angle reconstruction algorithms could be incorporated to mitigate these artifacts and potentially further improve our performance (Zhou et al., 2019, 2020). Third, our study is performed based on realistically simulated cryo-ET dataset with sufficient amounts of macromolecule classes for one-shot learning studies. Currently, real cryo-ET data does not provide sufficient amounts of classes for one-shot learning studies, and we will include it in our future studies.
In summary, we developed a COS-Net for one-shot classification and segmentation in cryo-ET, which enables the classification and segmentation for unseen macromolecules in the wild. We believe our algorithm is an important step toward the large-scale and systematic in situ analysis of macromolecular structure in single cells captured by cryo-ET.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author Contributions
BZ: conceptualization, methodology, software, visualization, validation, formal analysis, and writing original draft. HY: methodology, software, visualization, validation, formal analysis, and writing original draft. XZ: conceptualization, methodology, and writing—review and editing. XY: software, visualization, validation, and formal analysis. JZ: writing—review and editing, and supervision. MX: conceptualization, methodology, writing—review and editing, and supervision. All authors contributed to the article and approved the submitted version.
Funding
This work was supported in part by U.S. National Institutes of Health (NIH) grants P41GM103712, R01GM134020, and K01MH123896, U.S. National Science Foundation (NSF) grants DBI-1949629 and IIS-2007595, AMD COVID-19 HPC Fund, and Mark Foundation 19-044-ASP. BZ was supported by the Biomedical Engineering Ph.D. fellowship from Yale University. XZ was supported by a fellowship from Carnegie Mellon University's Center for Machine Learning and Health.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We would like to thank Erica Chiang at Carnegie Mellon University for improving the manuscript.
Footnotes
1. ^At their original locations.
2. ^Small cubic subvolumes containing one macromolecular structure.
References
Berman, H. M., Bhat, T. N., Bourne, P. E., Feng, Z., Gilliland, G., Weissig, H., et al. (2000). The protein data bank and the challenge of structural genomics. Nat. Struct. Mol. Biol. 7, 957–959. doi: 10.1038/80734
Che, C., Lin, R., Zeng, X., Elmaaroufi, K., Galeotti, J., and Xu, M. (2017). Improved deep learning based macromolecules structure classification from electron cryo tomograms. arXiv preprint arXiv:1707.04885.
Che, C., Xian, Z., Zeng, X., Gao, X., and Xu, M. (2019). “Domain randomization for macromolecule structure classification and segmentation in electron cyro-tomograms,” in 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) (San Diego, CA: IEEE), 6–11.
Chen, M., Dai, W., Sun, S. Y., Jonasch, D., He, C. Y., Schmid, M. F., et al. (2017). Convolutional neural networks for automated annotation of cellular cryo-electron tomograms. Nat. Methods 14:983. doi: 10.1038/nmeth.4405
Fe-Fei, L., and Fergus, Perona. (2003). “A bayesian approach to unsupervised one-shot learning of object categories,” in Computer Vision, 2003. Proceedings. Ninth IEEE International Conference on (Madison, WI: IEEE), 1134–1141.
Guo, J., Zhou, B., Zeng, X., Freyberg, Z., and Xu, M. (2018). “Model compression for faster structural separation of macromolecules captured by cellular electron cryo-tomography,” in International Conference Image Analysis and Recognition (Póvoa de Varzim: Springer), 144–152.
Hu, J., Shen, L., and Sun, G. (2018). “Squeeze-and-excitation networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Salt Lake City, UT), 7132–7141.
Koch, G., Zemel, R., and Salakhutdinov, R. (2015). “Siamese neural networks for one-shot image recognition,” in ICML Deep Learning Workshop (Lille), Vol. 2.
Krähenbühl, P., and Koltun, V. (2011). “Efficient inference in fully connected crfs with gaussian edge potentials,” in Advances in Neural Information Processing Systems (Granada), 109–117.
Li, R., Yu, L., Zhou, B., Zeng, X., Wang, Z., Yang, X., et al. (2020). Few-shot learning for classification of novel macromolecular structures in cryo-electron tomograms. PLoS Comput. Biol. 16:e1008227. doi: 10.1371/journal.pcbi.1008227
Li, R., Zeng, X., Sigmund, S. E., Lin, R., Zhou, B., Liu, C., et al. (2019). Automatic localization and identification of mitochondria in cellular electron cryo-tomography using faster-rcnn. BMC Bioinformatics 20:132. doi: 10.1186/s12859-019-2650-7
Liu, C., Zeng, X., Lin, R., Liang, X., Freyberg, Z., Xing, E., et al. (2018). “Deep learning based supervised semantic segmentation of electron cryo-subtomograms,” in 2018 25th IEEE International Conference on Image Processing (ICIP) (Athens: IEEE), 1578–1582.
Lü, Y., Zeng, X., Zhao, X., Li, S., Li, H., Gao, X., et al. (2019). Fine-grained alignment of cryo-electron subtomograms based on mpi parallel optimization. BMC Bioinformatics 20:443. doi: 10.1186/s12859-019-3003-2
Lučić, V., Rigort, A., and Baumeister, W. (2013). Cryo-electron tomography: the challenge of doing structural biology in situ. J. Cell. Biol. 202, 407–419. doi: 10.1083/jcb.201304193
Oikonomou, C. M., and Jensen, G. J. (2017). Cellular electron cryotomography: toward structural biology in situ. Annu. Rev. Biochem. 86, 873–896. doi: 10.1146/annurev-biochem-061516-044741
Pei, L., Xu, M., Frazier, Z., and Alber, F. (2016). Simulating cryo electron tomograms of crowded cell cytoplasm for assessment of automated particle picking. BMC Bioinformatics 17:405. doi: 10.1186/s12859-016-1283-3
Roy, A. G., Navab, N., and Wachinger, C. (2018). Recalibrating fully convolutional networks with spatial and channel “squeeze and excitation” blocks. IEEE Trans. Med. Imaging 38, 540–549. doi: 10.1109/TMI.2018.2867261
Xu, M., Chai, X., Muthakana, H., Liang, X., Yang, G., Zeev-Ben-Mordehai, T., et al. (2017). Deep learning-based subdivision approach for large scale macromolecules structure recovery from electron cryo tomograms. Bioinformatics 33, i13–i22. doi: 10.1093/bioinformatics/btx230
Zeng, X., and Xu, M. (2020). “Gum-net: unsupervised geometric matching for fast and accurate 3d subtomogram image alignment and averaging,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (Seattle, WA), 4073–4084.
Zhang, P. (2019). Advances in cryo-electron tomography and subtomogram averaging and classification. Curr. Opin. Struct. Biol. 58, 249–258. doi: 10.1016/j.sbi.2019.05.021
Zhao, G., Zhou, B., Wang, K., Jiang, R., and Xu, M. (2018). “Respond-cam: analyzing deep models for 3d imaging data by visualizations,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Granada: Springer), 485–492.
Zhou, B., Guo, Q., Wang, K., Zeng, X., Gao, X., and Xu, M. (2018). “Feature decomposition based saliency detection in electron cryo-tomograms,” in 2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) (Madrid: IEEE), 2467–2473.
Zhou, B., Lin, X., and Eck, B. (2019). “Limited angle tomography reconstruction: synthetic reconstruction via unsupervised sinogram adaptation,” in International Conference on Information Processing in Medical Imaging (Hong Kong: Springer), 141–152.
Keywords: one shot learning, cryo-ET, macromolecule classification, macromolecular segmentation, attention
Citation: Zhou B, Yu H, Zeng X, Yang X, Zhang J and Xu M (2021) One-Shot Learning With Attention-Guided Segmentation in Cryo-Electron Tomography. Front. Mol. Biosci. 7:613347. doi: 10.3389/fmolb.2020.613347
Received: 02 October 2020; Accepted: 09 December 2020;
Published: 12 January 2021.
Edited by:
Gaurav Malviya, University of Glasgow, United KingdomReviewed by:
Nikolay Mikhaylovich Borisov, Moscow Institute of Physics and Technology, RussiaAnindya Ghosh, University of Arkansas at Little Rock, United States
Copyright © 2021 Zhou, Yu, Zeng, Yang, Zhang and Xu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Min Xu, bXh1MUBjcy5jbXUuZWR1