Abstract
A Proportional Integral Derivative (PID) controller is commonly used to carry out tasks like position tracking in the industrial robot manipulator controller; however, over time, the PID integral gain generates degradation within the controller, which then produces reduced stability and bandwidth. A proportional derivative (PD) controller has been proposed to deal with the increase in integral gain but is limited if gravity is not compensated for. In practice, the dynamic system non-linearities frequently are unknown or hard to obtain. Adaptive controllers are online schemes that are used to deal with systems that present non-linear and uncertainties dynamics. Adaptive controller use measured data of system trajectory in order to learn and compensate the uncertainties and external disturbances. However, these techniques can adopt more efficient learning methods in order to improve their performance. In this work, a nominal control law is used to achieve a sub-optimal performance, and a scheme based on a cascade neural network is implemented to act as a non-linear compensation whose task is to improve upon the performance of the nominal controller. The main contributions of this work are neural compensation based on a cascade neural networks and the function to update the weights of neural network used. The algorithm is implemented using radial basis function neural networks and a recompense function that leads longer traces for an identification problem. A two-degree-of-freedom robot manipulator is proposed to validate the proposed scheme and compare it with conventional PD control compensation.
1. Introduction
An industrial robot manipulator frequently works at high velocities to reach its desired position. Common tasks performed by robot manipulators include trajectory tracking, reaching positions, and picking and dropping objects. These tasks need the robot controllers to maintain satisfactory dynamic behavior in spite of possible external perturbations, unknown dynamic parameters, and sensor information loss (Armendariz et al., 2014). Several controllers that are often implemented to manage these features are also mentioned (Luo and Kuo, 2016; Makarov et al., 2016; Nicolis et al., 2016; Pan et al., 2018; Hwang and Yu, 2020). Over time, the Proportional Integral Derivative (PID) control has been used to design industrial robots due to their simple structure and simple hardware implementation. However, during operation, the PID integral gain provokes the controller to reduce its bandwidth and stability (Rahimi Nohooji, 2020). PD control with uncertainty compensation has been proposed to manage the increase of integral gain due to the steady-state error. The PD controllers are also limited without gravity compensation, which requires a dynamic model (Wen Yu and Rosen, 2013). In practice, the non-linearities of a dynamic robot system are generally unknown.
To solve this issue, different approaches have been developed in order to compensate for unmodeled uncertainties (i.e., noise, gravity, and friction). Intelligent compensation is a model free and it has been applied to well-known algorithms such as the neural networks (NNs) and fuzzy logic (FL) (Krishna and Vasu, 2018; Wang et al., 2019b). In Liu et al. (2020), the authors propose an adaptive NN backstepping control design for fractional-order non-linear systems with actuator faults whose parameters and patterns are fully unknown. Baek et al. (2016) present an adaptive sliding mode control scheme that implements the time-delay estimation. In Xu et al. (2018), a fuzzy NN sliding mode control is designed to improve controller performance against system uncertainty and external disturbances. Kumar et al. (2012) proposed a hybrid trajectory tracking controller for redundant robot manipulators. The adaptive controller is implemented to estimate unstructured uncertainties and error reconstruction. In He et al. (2018), one Radial Basis Function Neural Network (RBFNN) is used to estimate the unknown dynamics robotic manipulator. Jung and Hsia (2000) proposed two NN control schemes for a non-model-based robot manipulator, which show advantages over feedback error learning. In Zhang et al. (2018), the authors proposed a gravity compensation based on an RBFNN and robustness analysis, and the results were compared with a classic PID and PD with fixed gravity compensation. Gandolfo et al. (2019) propose a control scheme that combines a classical PD and a robust adaptive compensator based on NNs.
Although adaptive controllers are addressed for systems with non-linear and uncertainties dynamics, thus their slow convergence can lead to performance degradation or even affect operational safety. In Liu et al. (2019), an adaptive NN control with optimal number of hidden nodes and less computation is formulated for approximating the trajectory of robot manipulator. Similarly, Yang et al. (2018) develop a control and identification scheme in order to identify the unknown robot parameters with an enhanced convergence rate. Another approach is to relax the linear parameterized assumption and the requirements of system knowledge, thus, NNs have been used as function approximators. In time series modeling, RBFNN is commonly used for function approximation, since its value is different from zero in infinite space, and its approximation can avoid the local minimum (Wang et al., 2019a). An RBFNN uses a Gauss function as its activation function. In general, RBFNN controllers waste less computational resources in comparison to other NN controllers (He et al., 2018). In Wang et al. (2012), the authors proposed an RBFNN to compensate for non-linear dynamics of the robotic manipulator and a robust control designed to suppress the modeling error of NN.
However, update laws commonly increase the weight magnitudes until the output error has been mitigated, without a robust design continued training can lead to excessive control effort. In order to avoid this, adaptive controls frequently update the neural weights according to robust adaptive laws, which are computed with Lyapunov methods (Razmi and Macnab, 2020). In this work, a robust adaptive control design to compensate a nominal controller for robot manipulator with uncertainties and external perturbations is formulated. Moreover, a scheme based on two RBFNN in cascade is proposed in order to improve the response of the nominal controller. In the scheme aforementioned, the first NN is used to estimate the error and the second uses the estimation error value to improve the output of the nominal controller. NN weights are online updated by developing new adaptive laws. The adaptive law based on the gradient is modified by introducing a recompense function of the online error in order to improve the convergence of the NN weights.
In this work, a PD control with a scheme based on NNs in cascade is designed to manage the compensation of uncertainties in a robot manipulator. The main contributions of this paper are summarized as follows:
-
In order to improve the robustness of the system against external disturbance, and unknown system parameters, a scheme of cascade NNs is proposed.
-
A recompense function for neural weights updates is proposed in order to improve the NNs' weights convergence.
-
The response of the nominal controller is improved.
To validate the proposed scheme and compare it with conventional neural compensation, a two-degree-of-freedom robot manipulator (TDOFRM) is proposed. This paper is organized as follows: Section 2 presents the preliminary mathematical model of the TDOFRM, the conventional PD compensation with RBFNN. Section 3 describes the controller design based on NNs in cascade. Section 4 presents simulation experiments and compared with the conventional compensation, and finally, section 5 presents the conclusions.
2. Adaptive Control to Robotic Manipulator
2.1. Dynamic Model of Robotic Manipulator
The dynamic model of an n degree of freedom robot manipulator can be described as follows (Spong and Vidyasagar, 1989):
M(q) is a n × n inertia matrix, is a n × n is a centrifugal and Coriolis matrix, and g(q) is a n × 1 vector of gravity. are the position, velocity, and acceleration of each link, respectively. τ ∈ Rn is the control input and d denotes disturbances.
2.2. Proportional Derivative Control Scheme
In industrial application, the exact model is difficult to obtain and external disturbances are always present in practice. According to Liu (2013), a nominal model of robot manipulator can be computed as M0(q), , and g0(q). Considering ΔM = M0 − M, ΔC = C0 − C, and Δg = g0 − g, Equation (1) is reordered as follows:
Thus,
Defining and if f (·) is known, the control law is designed as
Submitting Equation (4) into Equation (3), the close loop system can be expressed as follows:
where e = q − qd, , and . Frequently, f (·) in industrial applications is unknown, hence, f (·) requires to be estimated and compensated.
2.3. Radial Basis Function Neural Network Approximation
The NNs approximates M(q), C(q), and g(q) when they are unknown. The Radial Basis Function (RBF) algorithm can approximate a continuous function and it is defined as
where x is the input vector, ϕ = [ϕ1, ϕ2, …, ϕn] is the output of the Gaussian function, y is the output of the NN, W is the weight values matrix, and ci is the center and bi is the width of the Gaussian function. In Gandolfo et al. (2019); Liu et al. (2019), it has been shown that an RBFNN can approximate a non-linear function f (·) under the following assumptions
-
The output is a continuous function.
-
Given a small positive constant ϵ0 and a continuous function f (·), a weight vector W* exists so that satisfies.
and , where W* is n × n matrix that denotes the optimal weigh values for f (·) approximation.
2.4. Adaptive Law to Compensation Control
In the controller scheme proposed (Feng, 1995), the close loop system is given by the following equation:
where and is an estimation of W*. Equations (1) and (9) have the same term, and the substitution result is shown in the following equation:
Then, the equation is subtracted with Equation (10) in both sides as follows:
The result is given as follows:
Equation (12) can be rewritten as follows:
Select to x = (e)T. Equation (13) turns into
where
Setting and , where ζ denotes the modeling error due to the use of the NN. The modeling error ζ is bounded by a finite constant ζ0, where . Finally,
The Lyapunov function is given by the following equation:
where is a definition that describes the estimation error. In Equation (17), P is a positive definite matrix that satisfies the Lyapunov equation
Equation (17) can be rewritten in terms of the next definition
Thus, the derivative of V is given as follows:
Substituting Equation (16) for (20), the results is given by
Considering that xTPBζ = ζTBTPx, and in Equation (21), this results in
2.5. Adaptive Control Based on Cascade Neural Network
The PD control has been widely implemented in robot control to deal with the drawbacks presented by the integer gain in PID control. However, the PD control can have similar deficiencies if the derivative gain has high values (Wen Yu and Rosen, 2013). The PD control with compensation presents positive results to avoid high derivative gains and identify uncertainties that occur in the real operation of robot manipulators. In this work, a compensation of the nominal controller is proposed. The adaptive control scheme is shown in Figure 1. Two RBFNN in cascade are proposed to deal with the tracking error and the NN weight estimation error.
Figure 1
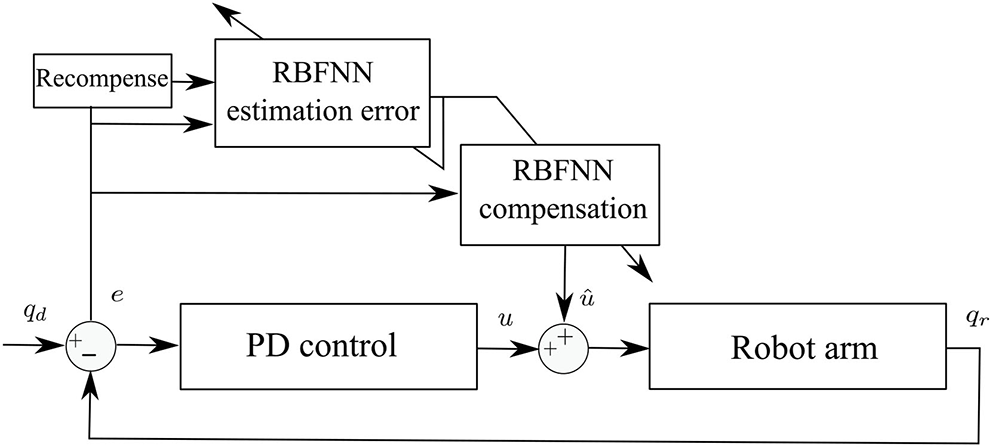
Proposed adaptive control scheme.
2.5.1. NN Weight Estimation Error
The input of NN is an error vector defined as follows:
where i and ϑ denote the real and desired position and velocity of the n-link of the robot. The NN estimation error anticipates which action to take in order to improve the output of the nominal control. Thus, the prediction of estimation error is also given as the output of RBFNN as follows:
where ϕe is the Gaussian function given by Equation (6). The criterion for the weight update is proposed in the following equation:
where is a function that represents the recompense signal. The goal of the recompense function is to lead longer traces for an identification problem.
2.5.2. Adaptive Law to Compensate the Nominal Controller
A novel adaptive control scheme is proposed to ensure that the output of the nominal controller for the system defined in Equation (1) reaches the position desired, and the estimated NN can converge an ideal weight. An RBFNN is selected to approximate the system dynamics and deals with uncertainties and external disturbances, which is given as follows:
where ϕc is a Gaussian function given by the equation form 6. The NN actor provides compensation to the PD controller to, that is, . The weigh update of the NN actor is proposed according to the following equation:
If we select the parameter update law as , we assume that the value . Substituting Equation (27) into Equation (22), the result is given as
As it is well-known, and from Equation (15), , and Equation (28) can be written as follows:
where λmin denotes the minimum eigenvalues of matrix Q and λmax denotes the maximum eigenvalues of matrix P. In order to satisfy , the value of ∥x∥ should be satisfied as follows:
According to Equation (28), is negative semidefinite, that is L(x, W, t) ≤ L(x, W, 0). It implies that x, and W are bounded. Let function and integrate Ω with respect to time as follows:
Due to L(x, W, 0) is bounded, and L(x, W, t) is non-increasing and bounded, the following result can be computed:
Since is bounded, by Barbalat's lemma (Slotine and Li, 1991), , that is x → 0 as t → ∞.
3. Results
In order to validate the proposed scheme of control, a set of simulations was carried out. Two simulations are proposed, the first considers an adaptive control using an RBFNN, and the second is based on the proposed scheme using two RBFNNs in cascade. The controllers were also implemented in a TDOFRM, which is shown in Figure 2. The main objective of controllers is the position tracking in the presence of external disturbances.
where:
The parameters came from Kelly and Santibáñez (2003) and presented in Table 1.
Figure 2
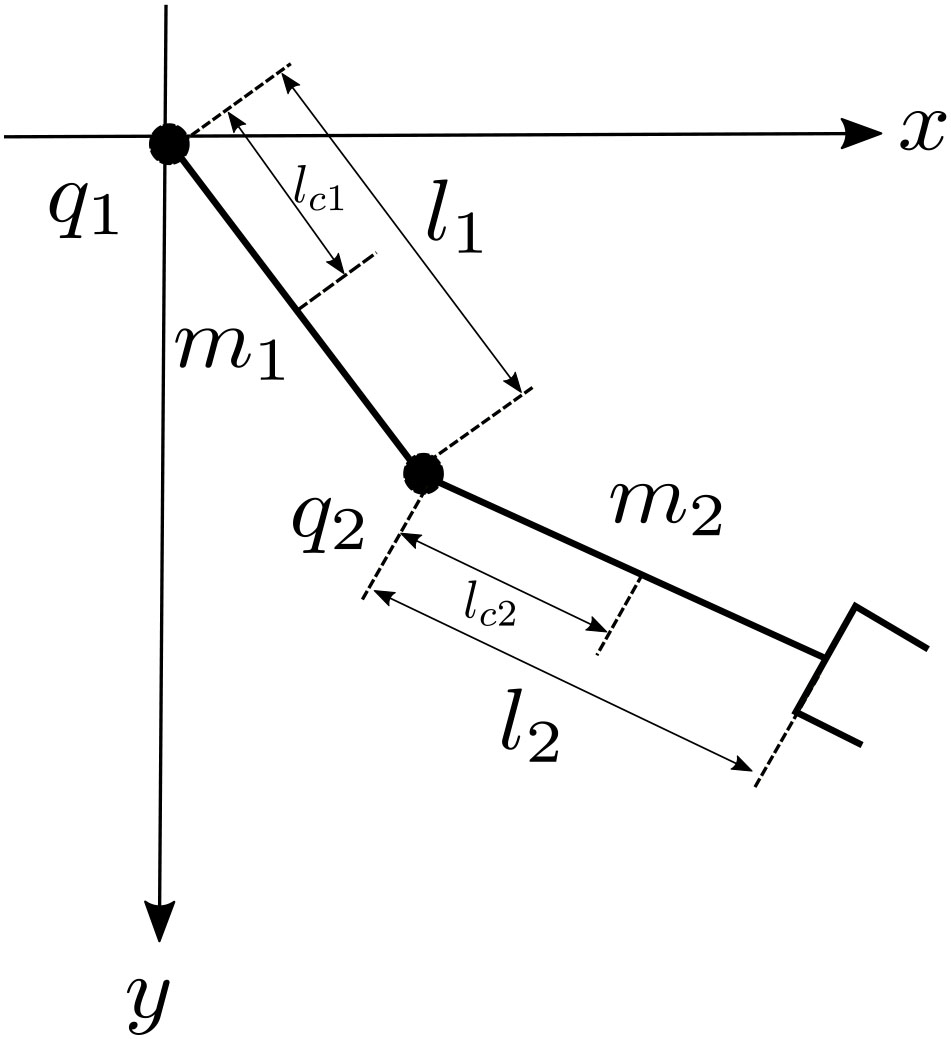
Model of two degree-of-freedom (DOF) robot manipulator.
Table 1
| Parameter | Value | Units |
|---|---|---|
| l 1 | 0.45 | m |
| l 2 | 0.45 | m |
| l c1 | 0.091 | m |
| l c2 | 0.048 | m |
| m 1 | 23.902 | kg |
| m 2 | 3.880 | kg |
| I 1 | 1.266 | kgm 2 |
| I 1 | 0.093 | kgm 2 |
| g | 9.81 |
Robot manipulator parameters.
The desired position vector is defined as follows:
The initial positions are given by . The uncertainties and unknown disturbances are defined as follows:
The matrix Q, A, and B are
Two RBFNNs are proposed for critic and actor agents. Here, γe is the learning rate of the RBFNN estimation error and γc is the learning rate of the RBFNN tracking error; ci is the center vector of neural net i and b is the width value of Gaussian function for neural net i. The next values are proposed due to the optimal weight for the actor NN and critic NN could take arbitrary large values, but in order to avoid any numerical problems, this work considers γe = 0.5, γc = 0.4, ci = , bi = 0.5, and i = 4.
Figure 3 shows the tracking position of links 1 and 2, where NN and NNc indicate an RBFNN compensation and a compensation based on two RBFNN in cascade, respectively. The green lines show the desired tracking position. The red lines indicate the tracking position of NN compensation. The blue lines show the tracking position of the proposed controller. The uncertainties and disturbances were added to the controller. According to the RBFNN in cascade, an RBFNN predicts the NN estimation error, and this value is included in adaptive laws to update the RBFNN compensation in order to take adequate action for the disturbances and guarantee the convergence of tracking error. The proposed recompense function helps to maintain longer traces for the identification task over time.
Figure 3
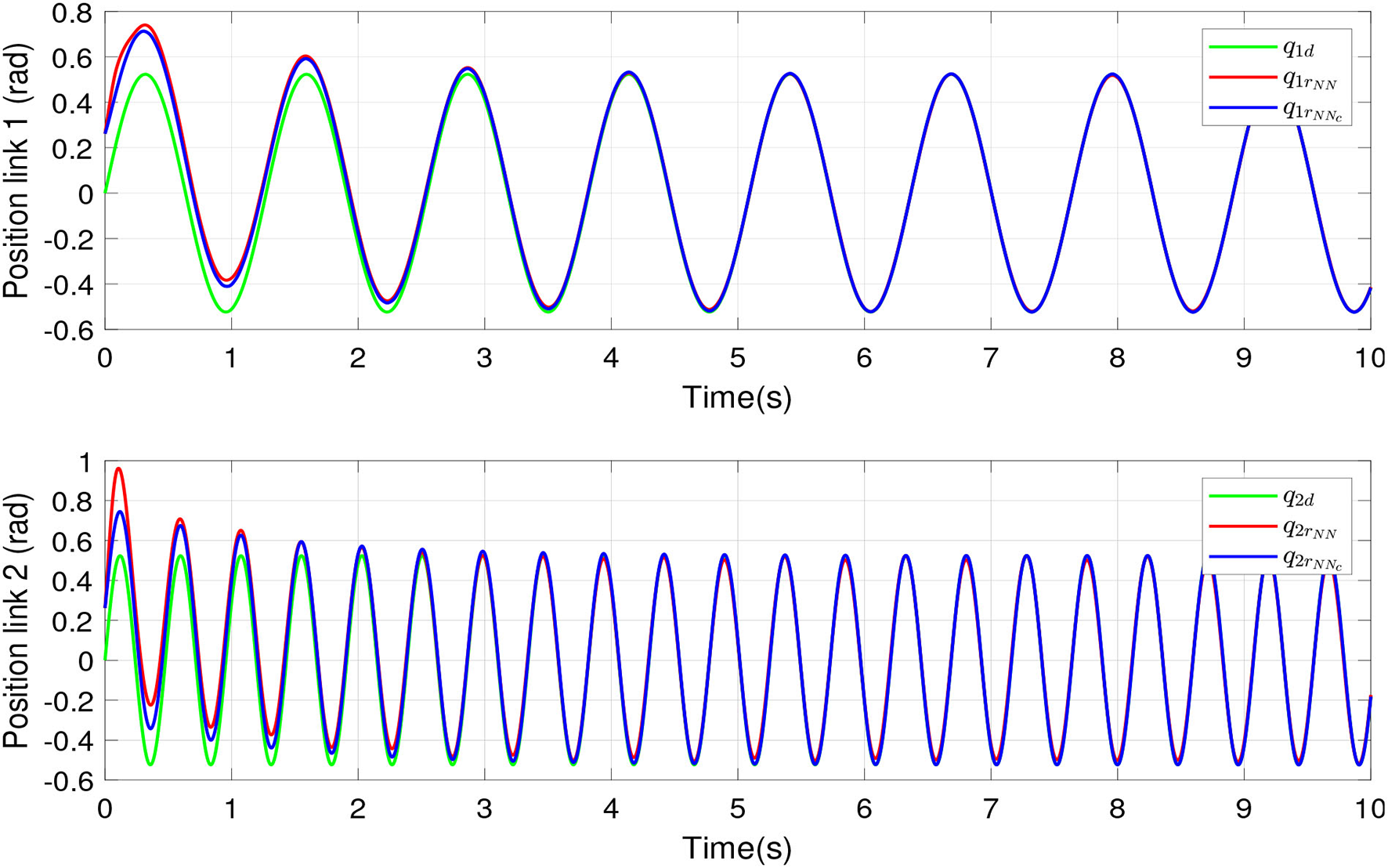
Real and desired links positions of the robot manipulator.
The compensation of proposed algorithm is compared with an RBFNN compensation. Figure 4 shows tracking errors for links 1 and 2. The red line represents the tracking error of an RBFNN for compensation, which presents overshoot to reach the desired positions and oscillations in steady state. The blue line indicates the tracking error of the proposed algorithm, which present robustness against uncertainties and disturbances. The green line indicates the desired tracking positions for links 1 and 2.
Figure 4
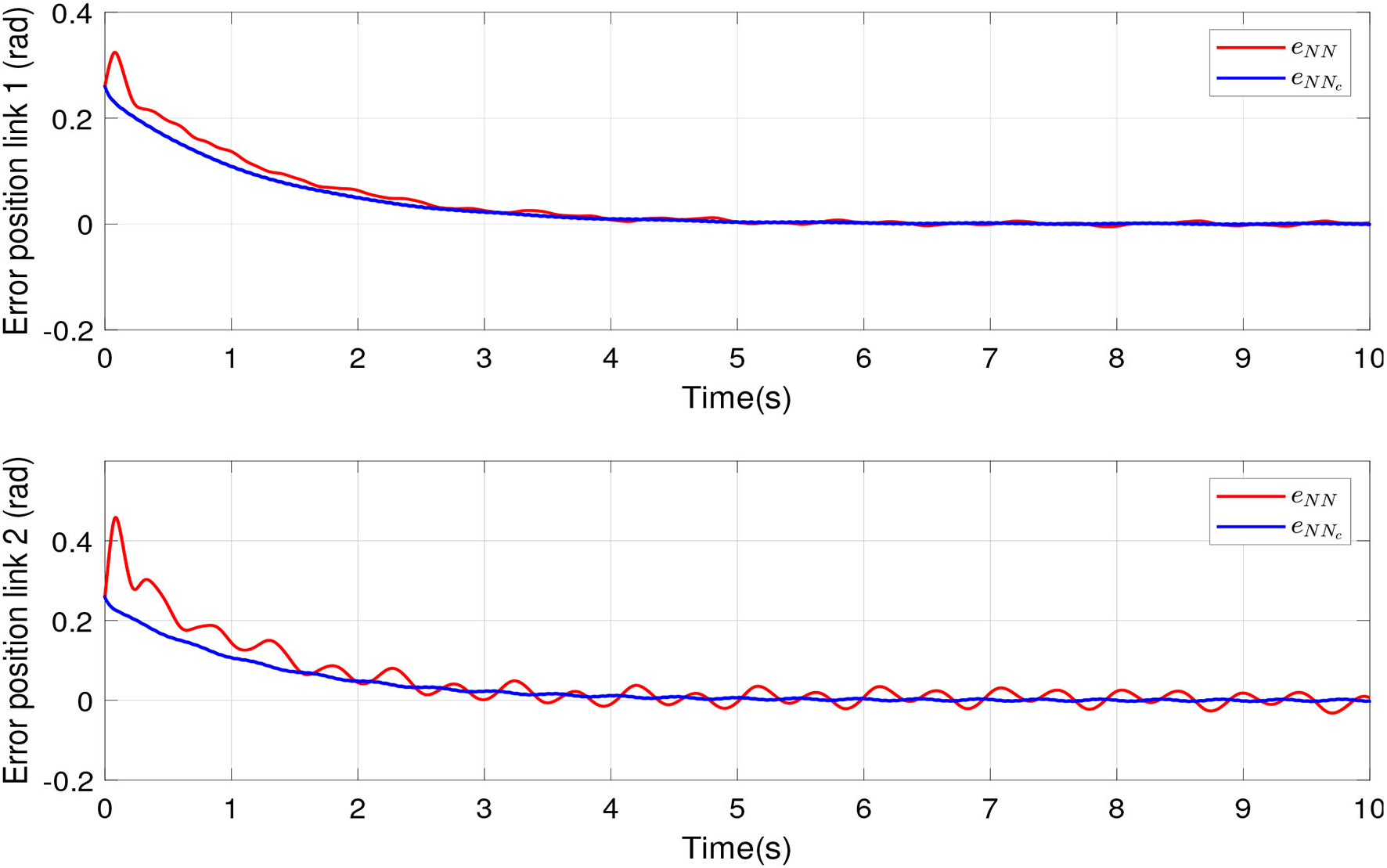
Tracking error of the robot manipulator joints by scheme proposed and conventional compensation.
The simulations were proposed in order to show the difference between adaptive conventional control and the proposed scheme. In this sense, two desired tracking signal was proposed that goes at different velocities, and link 1 follows a slow signal and link 2 follows a fast signal. Figure 5 shows the control inputs to links 1 and 2, and it also exhibits the improvement of the nominal controller under our scheme proposed in comparison with adaptive conventional control.
Figure 5
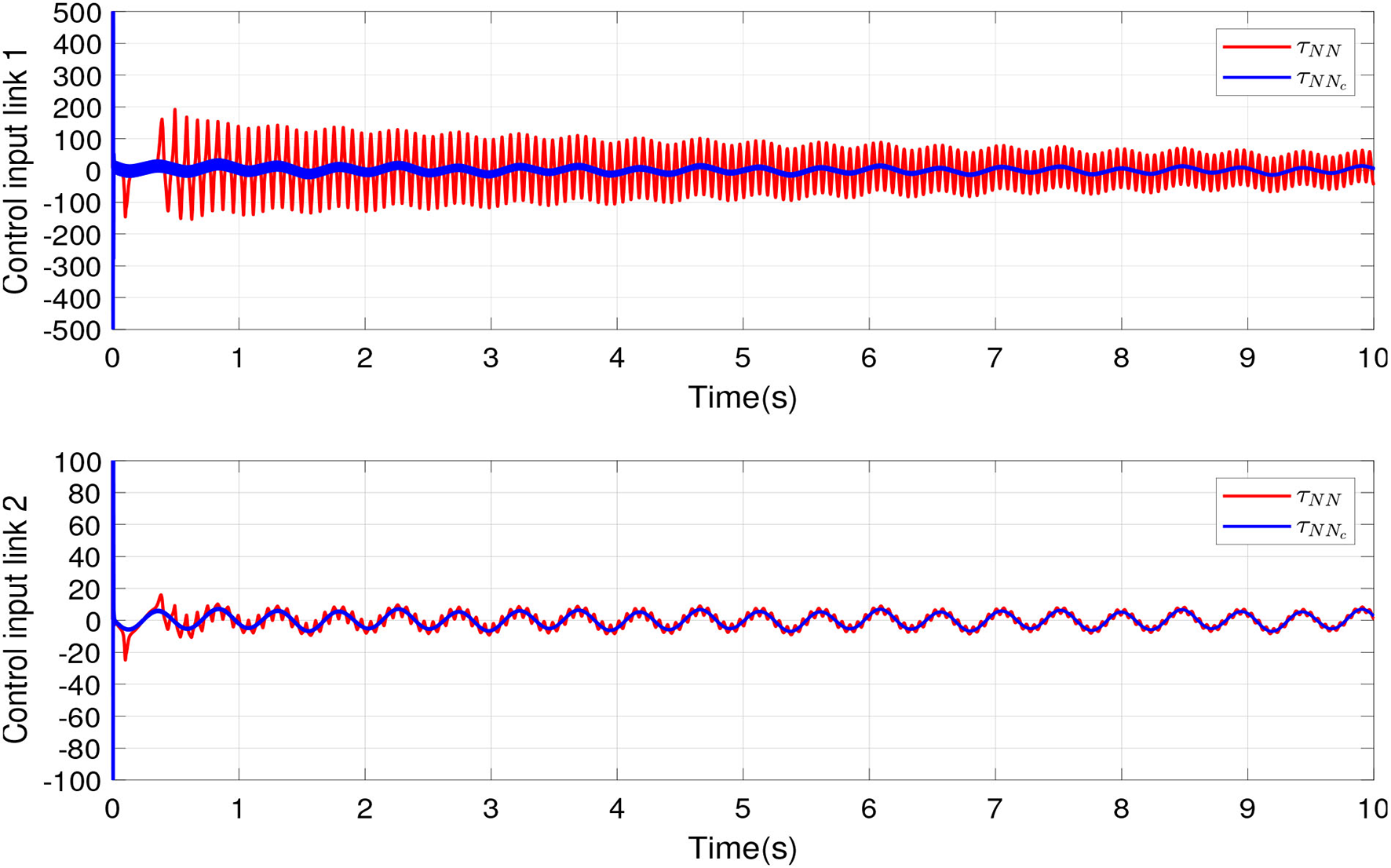
Control inputs of links 1 and 2.
In Figure 6, the NN weights convergence process of the two RBFNN in cascade are shown. Figure 6 also denoted as the identification process in order to deal with the uncertainties and external disturbances is reached.
Figure 6
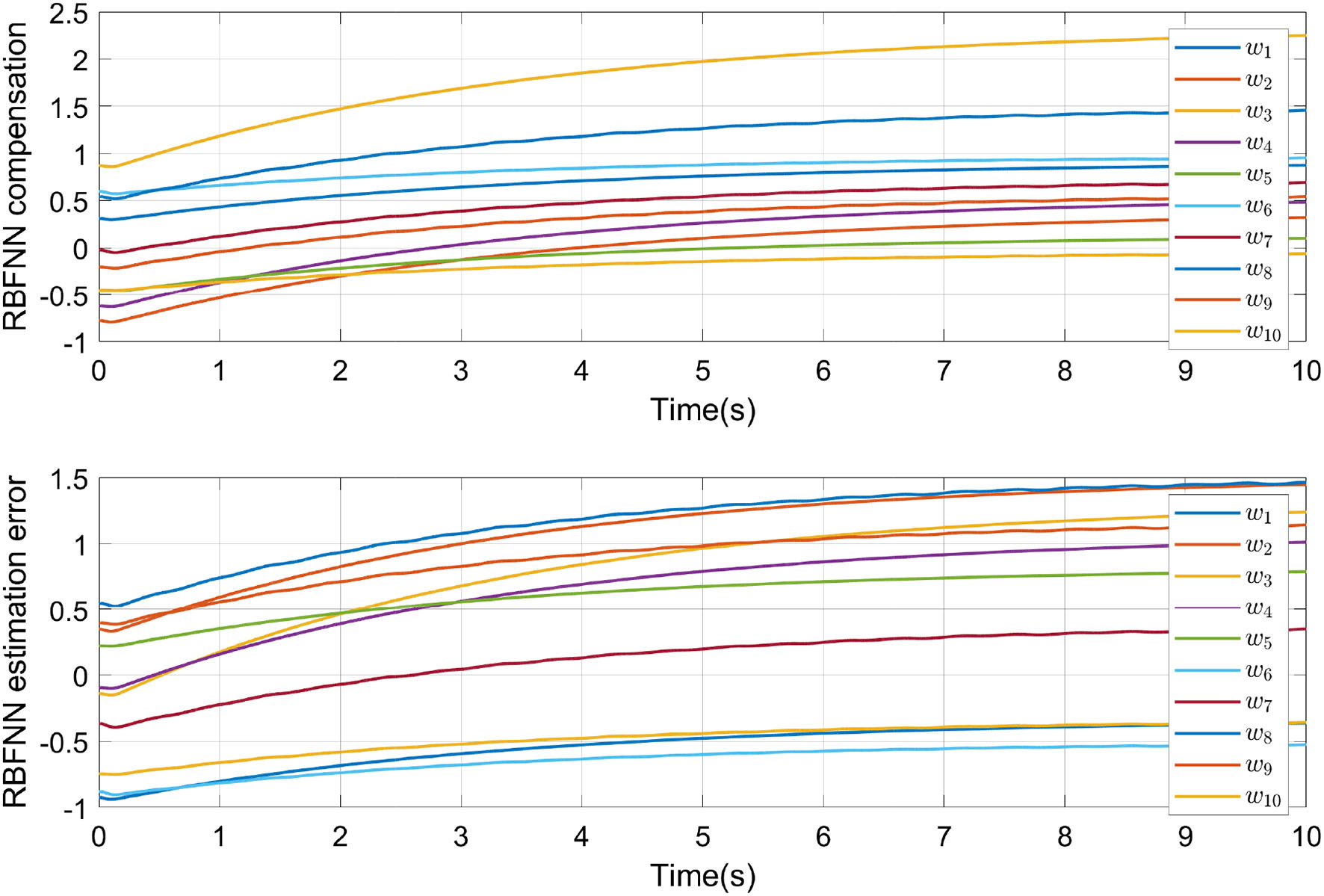
Convergence of neural networks parameters.
The important factors that usually must be considered together are time and error. A performance index is a measure that indicates those features of the response that are regarded to be important. In order to evaluate the performance of the proposed controller, a comparison of different performance indices is shown in Table 2. Hence, Table 2 is based on the next four equations, integral absolute error (IAE), integral square error (ISE), integral time absolute error (ITAE), and integral time square error (ITSE).
Table 2 shows that the proposed controller presents a better response than the conventional PD control compensation based on an RBFNN. According to the performance indices of links 1 and 2, the proposed scheme presents an adequate response against external disturbance. Moreover, it presents less oscillation in steady state and less time in the transient response than the conventional compensation based on an RBFNN.
Table 2
| Controller | Indices | Link 1 | Link 2 |
|---|---|---|---|
| PD+NN | IAE | 0.3758 | 0.4992 |
| ISE | 0.0554 | 0.0869 | |
| ITAE | 0.5162 | 1.0030 | |
| ITSE | 0.0340 | 0.0578 | |
| PD+NNC | IAE | 0.3057 | 0.3077 |
| ISE | 0.0373 | 0.0370 | |
| ITAE | 0.3898 | 0.4148 | |
| ITSE | 0.0232 | 0.0231 |
Comparison of different errors, ITAE, ITSE, IAE, and ISE as performance indices.
4. Conclusions
The algorithm proposed has been implemented to compensate for the PD control of a TDOFRM. A PD control was selected because the common knowledge that if designed with gravity compensation, it can reach asymptotic stability. The cascade scheme was implemented by two RBFNN in cascade, which compensates for the control input in order to deal with the estimation error, uncertainties, and external disturbances. The proposed algorithm was validated using a simulation of a TDOFRM. Two adaptive algorithms for compensating for the controller of robot manipulators were implemented. The first was based on a conventional RBFNN, and the second is the proposed algorithm that uses two RBFNN. An adaptive law is proposed to deal with the simultaneous convergence of both NNs, which are used to estimate for tracking error and estimation error. The results showed that the proposed compensation scheme based on RBFNN presents robustness against external uncertainties and disturbances, also an adequate convergence for the NN weights. Position tracking has been reached without overshoots and oscillations in steady state in comparison to compensations with a conventional RBFNN scheme.
Statements
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author contributions
JB and GH proposed a two-degree-of freedom robot manipulator to validate the scheme proposed and they also design the robot manipulator simulation. JV-N and DB contributed to the analysis and discussion of results. LS and EZ contributed with the theoretical analysis, simulations, and also written the main text. All authors participated and contributed to the final version manuscript.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
1
Armendariz J. Parra-Vega V. Garcia-Rodriguez R. Rosales S. (2014). Neuro-fuzzy self-tuning of PID control for semiglobal exponential tracking of robot arms. Appl. Soft Comput. 25, 139–148. 10.1016/j.asoc.2014.08.037
2
Baek J. Jin M. Han S. (2016). A new adaptive sliding-mode control scheme for application to robot manipulators. IEEE Trans. Indus. Electron. 63, 3628–3637. 10.1109/TIE.2016.2522386
3
Feng G. (1995). A compensating scheme for robot tracking based on neural networks. Robot. Auton. Syst. 15, 199–206. 10.1016/0921-8890(95)00023-9
4
Gandolfo D. C. Rossomando F. G. Soria C. M. Carelli R. O. (2019). Adaptive neural compensator for robotic systems control. IEEE Latin Am. Trans. 17, 670–676. 10.1109/TLA.2019.8891932
5
He W. Huang B. Dong Y. Li Z. Su C.-Y. (2018). Adaptive neural network control for robotic manipulators with unknown deadzone. IEEE Trans. Cybernet. 48, 2670–2682. 10.1109/TCYB.2017.2748418
6
Hwang C.-L. Yu W.-S. (2020). Tracking and cooperative designs of robot manipulators using adaptive fixed-time fault-tolerant constraint control. IEEE Access8, 56415–56428. 10.1109/ACCESS.2020.2979795
7
Jung S. Hsia T. (2000). Neural network inverse control techniques for PD controlled robot manipulator. Robotica18, 305–314. 10.1017/S0263574799002064
8
Kelly R. Santibáñez V. (2003). Control de Movimiento de Robots Manipuladores. Madrid: Pearson Educación; Prentice Hall.
9
Krishna S. Vasu S. (2018). Fuzzy PID based adaptive control on industrial robot system. Mater. Tdy Proc. 5(5 Pt 2), 13055–13060. 10.1016/j.matpr.2018.02.292
10
Kumar N. Borm J.-H. Panwar V. Chai J. (2012). Tracking control of redundant robot manipulators using RBF neural network and an adaptive bound on disturbances. Int. J. Precis. Eng. Manufactur. 13, 1377–1386. 10.1007/s12541-012-0181-5
11
Liu C. Zhao Z. Wen G. (2019). Adaptive neural network control with optimal number of hidden nodes for trajectory tracking of robot manipulators. Neurocomputing350, 136–145. 10.1016/j.neucom.2019.03.043
12
Liu H. Pan Y. Cao J. Wang H. Zhou Y. (2020). Adaptive neural network backstepping control of fractional-order nonlinear systems with actuator faults. IEEE Trans. Neural Netw. Learn. Syst. 10.1109/TNNLS.2020.3027335. [Epub ahead of print].
13
Liu J. (2013). Radial Basis Function (RBF) Neural Network Control for Mechanical Systems. Berlin; Heidelberg: Springer. 10.1007/978-3-642-34816-7
14
Luo R. C. Kuo C.-W. (2016). Intelligent seven-DoF robot with dynamic obstacle avoidance and 3-D object recognition for industrial cyber-physical systems in manufacturing automation. Proc. IEEE104, 1102–1113. 10.1109/JPROC.2015.2508598
15
Makarov M. Grossard M. Rodriguez-Ayerbe P. Dumur D. (2016). Modeling and preview $H_\infty$ control design for motion control of elastic-joint robots with uncertainties. IEEE Trans. Indus. Electron. 63, 6429–6438. 10.1109/TIE.2016.2583406
16
Nicolis D. Zanchettin A. M. Rocco P. (2016). Constraint-based and sensorless force control with an application to a lightweight dual-arm robot. IEEE Robot. Automat. Lett. 1, 340–347. 10.1109/LRA.2016.2517206
17
Pan Y. Wang H. Li X. Yu H. (2018). Adaptive command-filtered backstepping control of robot arms with compliant actuators. IEEE Trans. Control Syst. Technol. 26, 1149–1156. 10.1109/TCST.2017.2695600
18
Rahimi Nohooji H. (2020). Constrained neural adaptive PID control for robot manipulators. J. Franklin Instit. 357, 3907–3923. 10.1016/j.jfranklin.2019.12.042
19
Razmi M. Macnab C. (2020). Near-optimal neural-network robot control with adaptive gravity compensation. Neurocomputing389, 83–92. 10.1016/j.neucom.2020.01.026
20
Slotine J.-J. E. Li W. (1991). Applied Nonlinear Control. Englewood Cliffs, NJ: Prentice Hall.
21
Spong M. W. Vidyasagar M. (1989). Robot Dynamics and Control. New York, NY: Wiley.
22
Wang F. Chao Z.-Q. Huang L.-B. Li H.-Y. Zhang C.-Q. (2019a). Trajectory tracking control of robot manipulator based on RBF neural network and fuzzy sliding mode. Cluster Comput. 22, 5799–5809. 10.1007/s10586-017-1538-4
23
Wang H. Lei Z. Zhang X. Zhou B. Peng J. (2019b). A review of deep learning for renewable energy forecasting. Energy Convers. Manage. 198, 1–16. 10.1016/j.enconman.2019.111799
24
Wang L. Chai T. Yang C. (2012). Neural-network-based contouring control for robotic manipulators in operational space. IEEE Trans. Control Syst. Technol. 20, 1073–1080. 10.1109/TCST.2011.2147316
25
Xu J. Wang Q. Lin Q. (2018). Parallel robot with fuzzy neural network sliding mode control. Adv. Mech. Eng. 10, 1–8. 10.1177/1687814018801261
26
Yang C. Jiang Y. He W. Na J. Li Z. Xu B. (2018). Adaptive parameter estimation and control design for robot manipulators with finite-time convergence. IEEE Trans. Indus. Electron. 65, 8112–8123. 10.1109/TIE.2018.2803773
27
Yu W. Rosen J. (2013). Neural PID control of robot manipulators with application to an upper limb exoskeleton. IEEE Trans. Cybernet. 43, 673–684. 10.1109/TSMCB.2012.2214381
28
Zhang H. Du M. Wu G. Bu W. (2018). PD control with RBF neural network gravity compensation for manipulator. Eng. Lett. 26, 236–244.
Summary
Keywords
cascade neural networks, robot manipulator, PD control, radial basis function, control compensation
Citation
Soriano LA, Zamora E, Vazquez-Nicolas JM, Hernández G, Barraza Madrigal JA and Balderas D (2020) PD Control Compensation Based on a Cascade Neural Network Applied to a Robot Manipulator. Front. Neurorobot. 14:577749. doi: 10.3389/fnbot.2020.577749
Received
29 June 2020
Accepted
14 September 2020
Published
03 December 2020
Volume
14 - 2020
Edited by
Yongping Pan, National University of Singapore, Singapore
Reviewed by
Heng Liu, Guangxi University for Nationalities, China; Huiming Wang, Chongqing University of Posts and Telecommunications, China
Updates
Copyright
© 2020 Soriano, Zamora, Vazquez-Nicolas, Hernández, Barraza Madrigal and Balderas.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Luis Arturo Soriano lsorianoa@chapingo.mx
Disclaimer
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.