 Ke Wang
Ke Wang Yong Liu
Yong Liu Chengwei Huang
Chengwei Huang- School of Computer Science and Engineering, Nanjing University of Science and Technology, Nanjing, China
This article presents a cross-domain robot (CDR) that experiences drive efficiency degradation when operating on water surfaces, similar to drive faults. Moreover, the CDR mathematical model has uncertain parameters and non-negligible water resistance. To solve these problems, a radial basis function neural network (RBFNN)-based active fault-tolerant control (AFTC) algorithm is proposed for the robot both on land and water surfaces. The proposed algorithm consists of a fast non-singular terminal sliding mode controller (NTSMC) and an RBFNN. The RBFNN is used to estimate the impact of drive faults, water resistance, and model parameter uncertainty on the robot and the output value compensates the controller. Additionally, an anti-input saturation control algorithm is designed to prevent driver saturation. To optimize the controller parameters, a human decision search algorithm (HDSA) is proposed, which mimics the decision-making process of a crowd. Simulation results demonstrate the effectiveness of the proposed control methods.
1. Introduction
In recent years, there has been a growing interest in multi-environment robots as single-environment robots are no longer sufficient to meet various practical needs (Cohen and Zarrouk, 2020). Researchers have proposed different designs to achieve this, such as bionic robots (Chen et al., 2021) and the legged amphibious robot (Xing et al., 2021). Furthermore, with the advancements in rotorcraft unmanned aerial vehicle (UAV) technology, researchers have started exploring the potential of integrating rotorcraft UAVs with wheeled mobile robots (WMRs) (Wang et al., 2019a). To enhance the capabilities of robots, cross-domain robots (CDRs) have been designed, which are capable of operating in multiple environments, including water, land, and air (Guo et al., 2019; Zhong et al., 2021). The robot presented in this paper is a CDR that combines a quadrotor UAV with a WMR equipped with webbed plates. These webbed plates on the wheels enable the robot to generate power at the water surface through their interaction with the water (Wang et al., 2022a,b).
The CDR presented in this study employs the same drive motors for ground and water surface operations. Assuming proper functionality during ground motion, a driver fault is considered to have occurred during the robot's operation on the water surface. Fault-tolerant controls (FTCs) are control algorithms that effectively deal with system faults (Najafi et al., 2022; Nan et al., 2022). Sliding-mode controllers (SMCs) are commonly employed in passive fault-tolerant algorithms due to their robustness in maintaining control performance when the maximum system fault is known. However, the use of non-singular terminal sliding mode control (NTSMC) and SMC results in jitter problems, and this robust control approach is considered too conservative (Ali et al., 2020; Hou and Ding, 2021; Guo et al., 2022). To address these issues, FTCs frequently employ adaptive sliding mode control (Wu et al., 2020) and integral sliding mode control (Yu et al., 2022). Additionally, observers are commonly used to detect drive faults. In Wang F. et al. (2022), a disturbance observer (DO) is used to quickly compensate and correct unknown actuator faults of unmanned surface vehicles (USVs). In the context of autonomous underwater vehicles (AUVs), a sliding mode observer-based fault-tolerant control algorithm has been proposed in the literature (Liu et al., 2018). However, the design of higher-order observers requires complex mathematical proofs and the adjustment of many parameters. Neural networks (NNs) are often used to estimate system model parameters and uncertainty terms due to their ability to approximate arbitrary non-linear functions. In Zhang et al. (2022), NNs are used to rectify the model parameters of a USV, and an NN-based adaptive observer is developed to estimate errors caused by drive faults. As demonstrated in Gao et al. (2022), NNs can directly estimate system faults by approximating the uncertainty terms in the system. Event-triggered fault-tolerant control is a type of AFTC algorithm that has the potential to reduce system hardware requirements. However, it requires the development of trigger thresholds and corresponding fault control algorithms, which increase the difficulty and complexity of controller design (Huang et al., 2019; Wu et al., 2021; Zhang et al., 2021). Another important consideration in the FTC algorithm is the control of input saturation. One efficient approach for solving this issue is to introduce virtual states in the controller. These virtual states regulate the input error of the controller, thereby suppressing control input saturation (Wang and Deng, 2019). Additionally, designing adaptive laws is an effective way to address control input saturation. In this approach, the adaptive control input decreases as the actual control input approaches the maximum physical constraint (Shen et al., 2018).
The controller design presented above does not involve any optimization of the controller parameters. To address this limitation, reinforcement learning techniques have been developed to optimize control parameters. In Gheisarnejad and Khooban (2020), a reinforcement learning algorithm is employed to optimize the PID controller parameters. Another study (Zhao et al., 2020) trains the optimal trajectory following controller using deep reinforcement learning. However, reinforcement learning algorithms typically require a significant amount of data and multiple iterations to achieve optimal results. Swarm intelligence (SI) optimization algorithms are a promising approach in practical applications, including data classification, path planning, and controller optimization (Xue and Shen, 2020, 2022). Among the various SI optimization algorithms, particle swarm optimization (PSO) is a classical algorithm known for fast convergence and few parameters (Song and Gu, 2004). However, traditional PSO algorithms tend to fall into local optima. Ant colony optimization (ACO) is another common SI optimization algorithm. ACO can jump out of local optima but has slower convergence (Dorigo et al., 1996). In addition, the gray wolf optimizer (GWO) simulates the predation process of wolves (Mirjalili et al., 2014) and the Harris hawk optimizer (HHO) simulates the predation process of hawks (Heidari et al., 2019). These algorithms have shown improvements in convergence speed and accuracy compared with other animal predation simulation algorithms. Other popular SI optimization algorithms include the firefly algorithm (Fister et al., 2013) and the sine/cosine search algorithm (Mirjalili, 2016). Each SI optimization algorithm has its own strengths and weaknesses and no single algorithm can effectively handle all optimization problems. The goal is to achieve satisfactory results in terms of convergence speed, accuracy, and robustness for a specific optimization problem.
Based on the previous discussion, an AFTC is proposed for the CDR on the ground and on the water surface. This control algorithm consists of three main parts:
a. To enhance the robustness of the robot control system, a fast NTSMC is designed based on the concept of passive FTC. Compared with traditional NTSMC and SMC, the proposed NTSMC has reduced control input chatter. Additionally, to reduce controller conservatism, an RBFNN is designed to detect and compensate for drive faults. The adaptive weight control law of the RBFNN is based on the Lyapunov function.
b. To prevent drive saturation, an anti-input saturation control algorithm based on the hyperbolic tangent (tanh) function is employed. An adaptive rate is designed to prevent singularities in this algorithm. This method does not require complex mathematical proofs and requires fewer tuning parameters.
c. A new SI optimization algorithm named HDSA is proposed for the optimization of the weight update rate parameter of RBFNNs. The proposed algorithm is compared with other SI optimization algorithms, and the test results demonstrate its faster convergence rate and higher accuracy.
2. Related work and mathematical models
2.1. HDSA's related work
To demonstrate the advantages of the proposed HDSA optimization algorithm, the results of the HDSA tests are shown in this section. The theory of HDSA is discussed in detail in the section entitled “RBFNN-Based Active Fault-Tolerant Control Algorithm”. The effectiveness of the proposed optimization algorithm was evaluated by comparing the test results of HDSA with other popular optimization algorithms, such as particle swarm optimization (PSO) (Song and Gu, 2004), the sine/cosine algorithm (SCA) (Mirjalili, 2016), the gray wolf optimizer (GWO) (Mirjalili et al., 2014), the firefly algorithm (FA) (Fister et al., 2013), and the Harris hawk optimizer (HHO) (Heidari et al., 2019). Twenty standard test functions were used for evaluation, which are presented in Tables 5–7 (included in the Simulation Results section).
The number of populations was pop = 100 and the maximum number of iterations was M = 100. The average fitness over 30 independent runs was considered as the optimization result. The convergence characteristics of the six algorithms in the single-peak function test are depicted in Figure 1, while Figure 2 illustrates the convergence characteristics in the multi-peak function test. Furthermore, Figure 3 demonstrates the convergence characteristics of the six algorithms on fixed-dimensional multi-peak functions. The test results of the six algorithms, based on 30 independent runs, are summarized in Tables 1, 2. In Tables 1, 2, purple indicates the optimal value of the test functions, pink indicates the mean value of the test functions, and white indicates the mean squared deviation of the test functions.
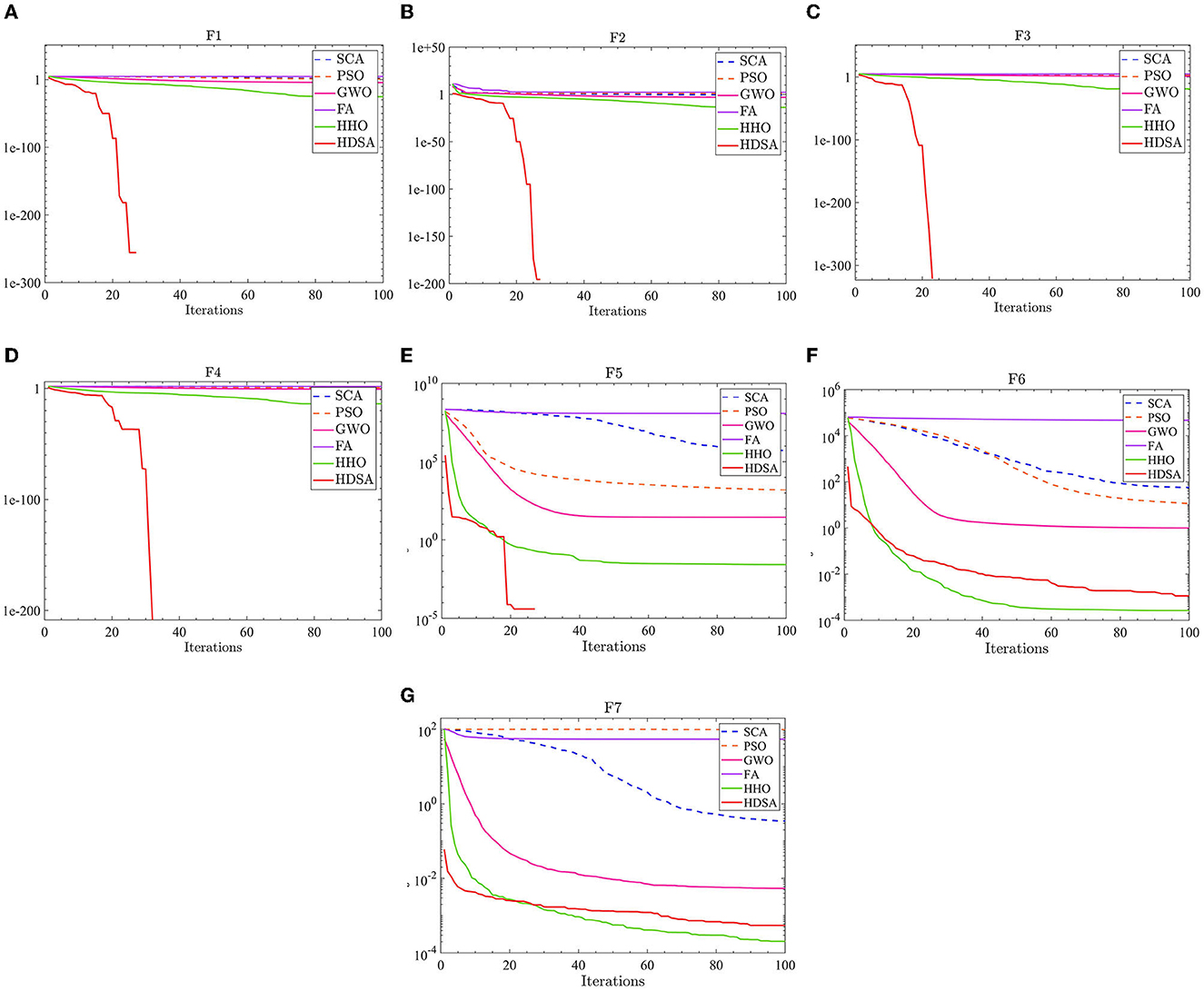
Figure 1. Single peak function test results. (A–G) represent the test results of the six algorithms in functions F1 to F7.
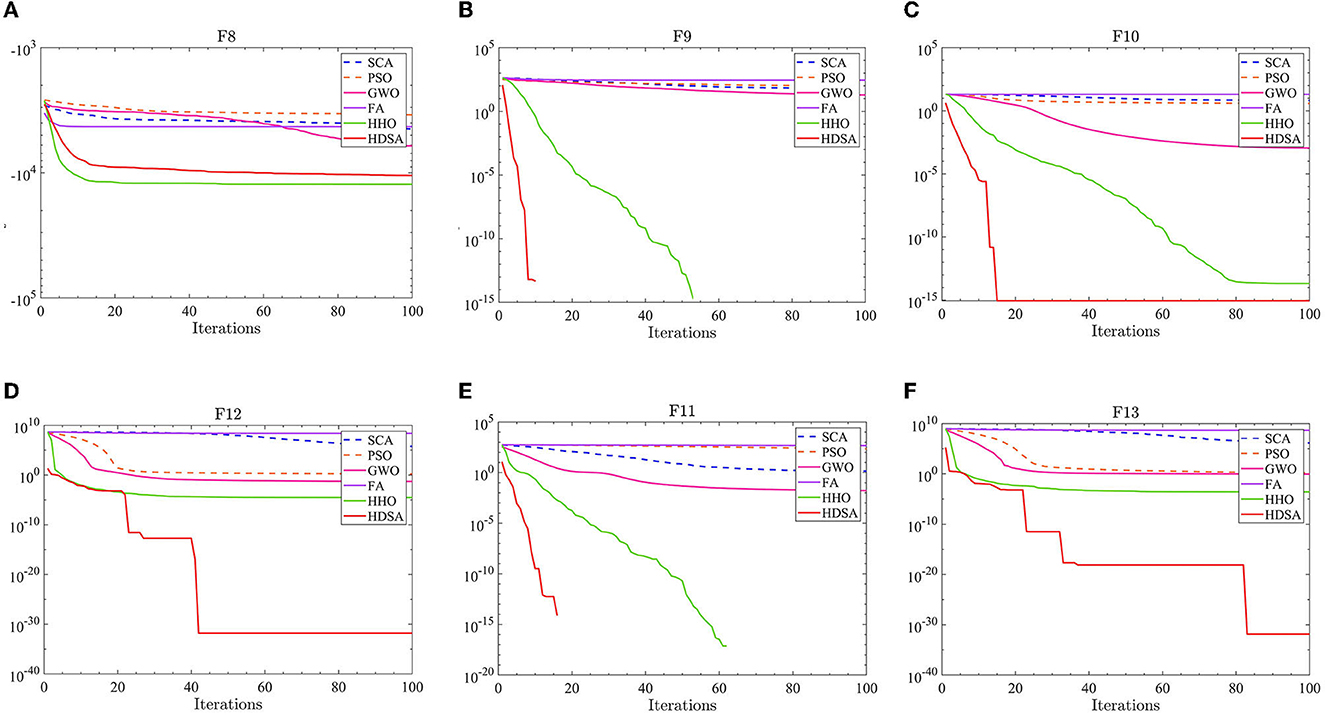
Figure 2. Multi-peak function test results. (A–F) represent the test results of the six algorithms in functions F8 to F13.
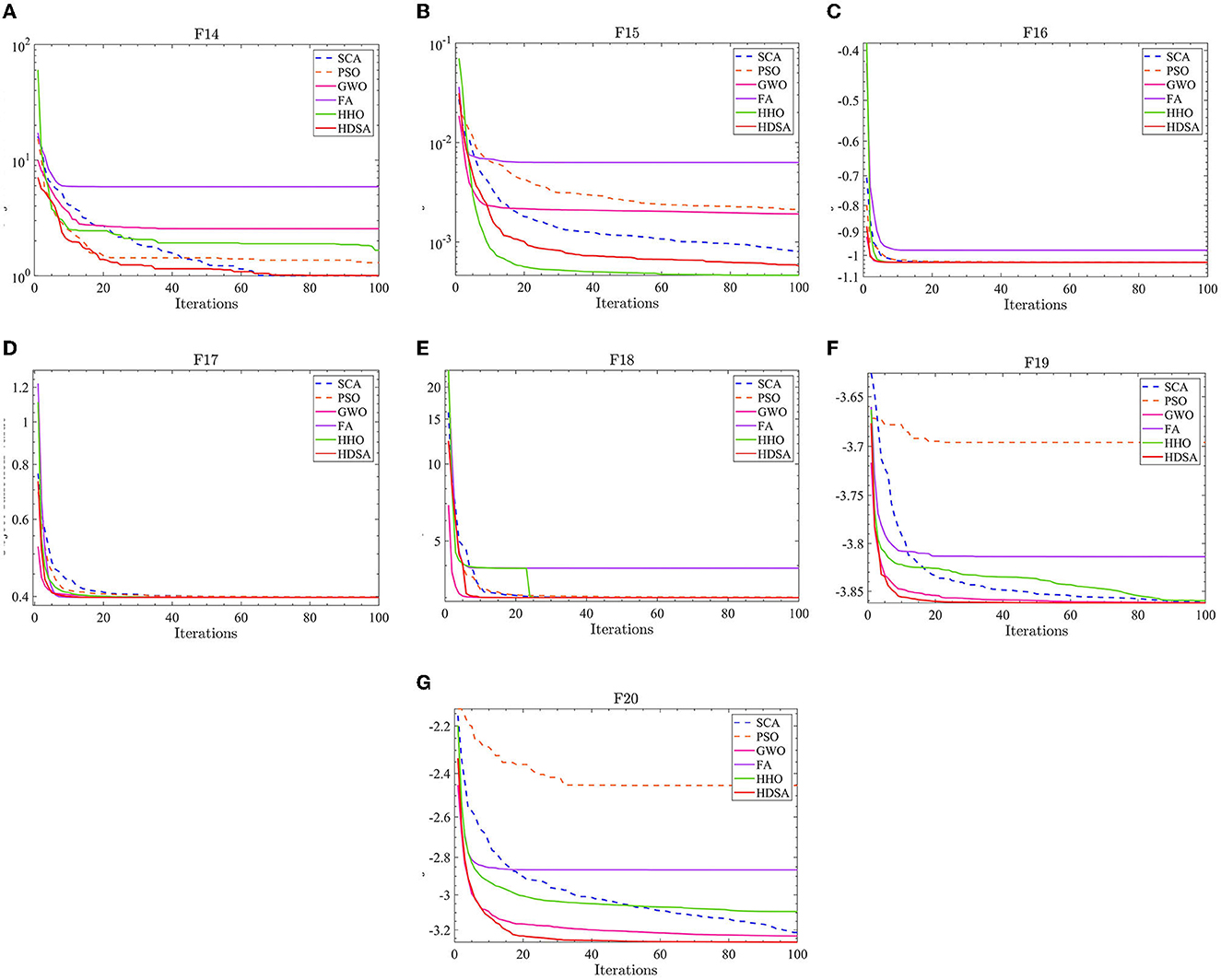
Figure 3. Fixed dimensional multi-peak function results. (A–G) represent the test results of the six algorithms in functions F14 to F20.
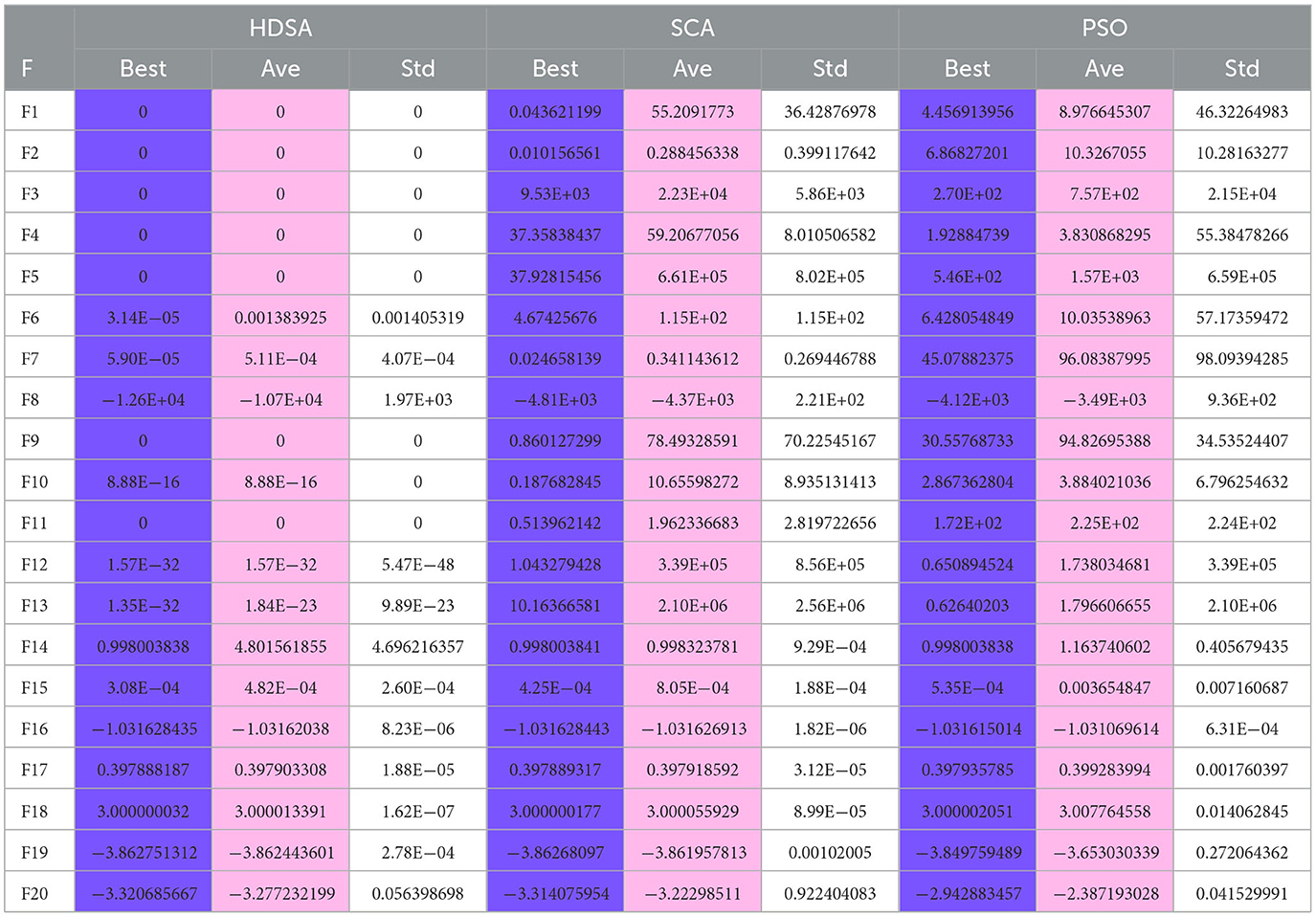
Table 1. Test results of HDSA SCA and PSO algorithms run independently 30 times.
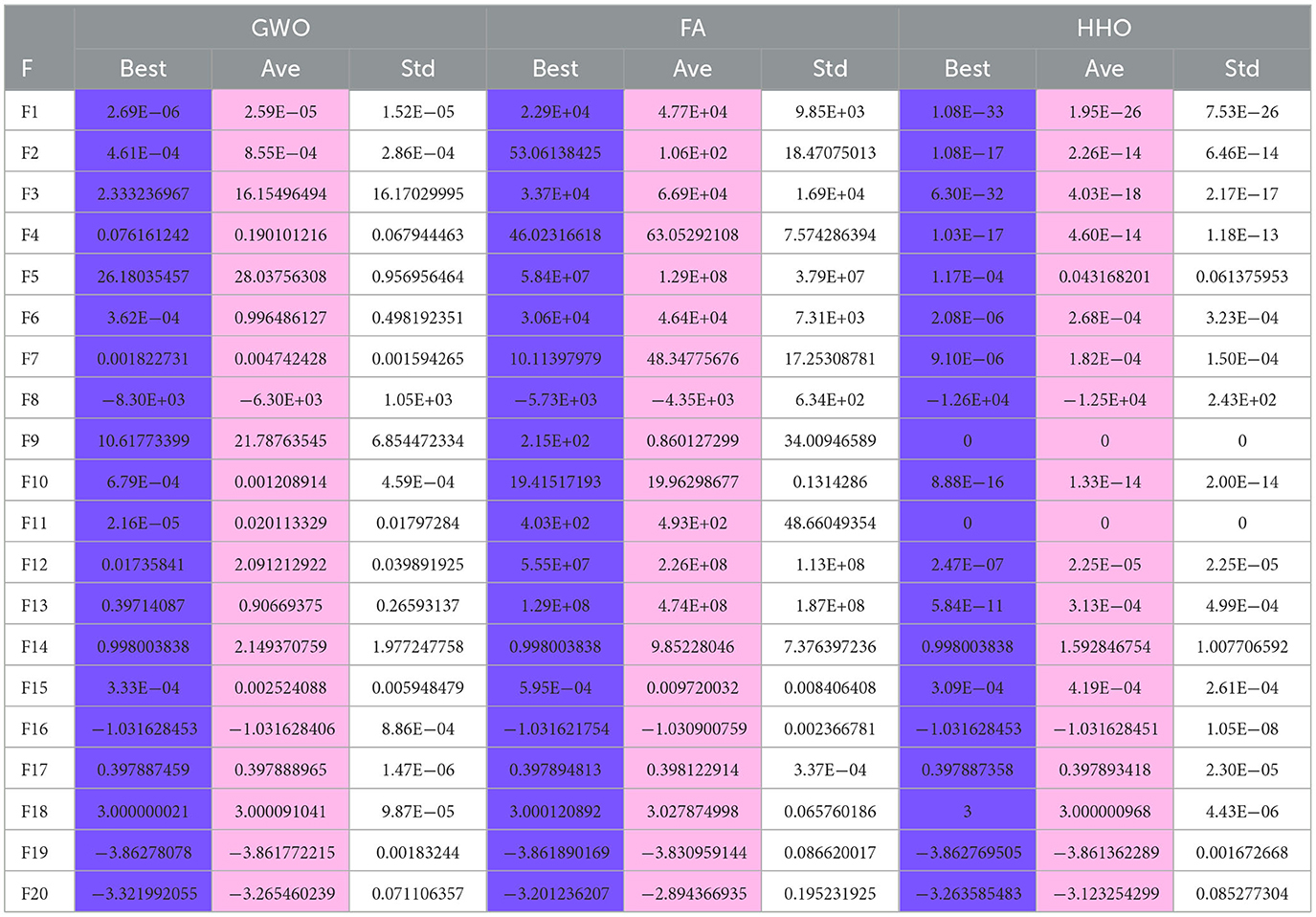
Table 2. Test results of GWO FA and HHO algorithms run independently 30 times.
The results of the single-peak functions F1–F7 test results are presented in Tables 1, 2. In these tests, the mean and optimal values obtained by HDSA in F1–F5 are both 0, indicating that HDSA achieves the highest accuracy among the six algorithms. Although the accuracy of HDSA is slightly inferior to HHO in the F6–F7 test functions, it still outshines SCA, PSO, GWO, and FA. HDSA has a standard deviation of 0 in tests F1–F5, suggesting that HDSA is the most stable algorithm. Although its stability is slightly lower than HHO in tests F6–F7, it still outperforms the other four methods. Convergence speed is depicted in Figure 2. HDSA has a significantly faster convergence speed compared with the other five algorithms, but its convergence accuracy in the F6–F7 tests is lower than that of HHO.
The test results for the multi-peak functions F8–F13 are presented in Tables 1, 2. In the tests from F9 to F13, HDSA exhibits significantly better stability and convergence accuracy compared with the other five algorithms. It achieves higher accuracy and the smallest standard deviation. As depicted in Figure 3, except for the F8 test function, HDSA showcases the fastest convergence speed and highest convergence accuracy among the algorithms.
The results of the fixed dimensional multi-peak functions F14–F20 test results are shown in Tables 1, 2. In the F14 test, SCA has the best optimal and average accuracy, while HDSA exhibits slightly lower average accuracy and stability compared with SCA, PSO, and HHO. However, HDSA still manages to find the optimal solution in 30 runs. In the F15–F18 test results, HDSA, SCA, GWO, and HHO perform closely, with good stability and accuracy. In the F19–F20 tests, HDSA outperforms the other five algorithms significantly in terms of accuracy and stability. As shown in Figure 3, HDSA exhibits the fastest convergence speed among the other test functions, except for F15, F17, and F18. In the F15 test, HDSA is only slightly slower than HHO, while in the F17 and F18 tests, HDSA converges slightly slower than FA.
2.2. Mathematical model of the CDR
Before discussing the mathematical model of the CDR, the following assumptions are made: Assumption 1: The center of gravity and the geometric center of the robot body coincide. Assumption 2: The motor output torque meets the actual performance requirements of the robot during ground and water motion. Assumption 3: The robot's vertical swing, horizontal rocking, and longitudinal rocking during its movement on the water surface are ignored. Assumption 4: The motion of the robot on the ground is purely rolling, without any sliding motion.
The CDR designed in this study can be seen as a combination of a quadrotor UAV and a WMR. Figure 4A shows the robot moves on the ground. Figure 4B shows the robot moves on the water surface by webbed plates. Figure 4C shows the robot moves on the water surface by propllers. The robot moves in the air in a similar way to the quadrotor UAV as shown in Figures 4D, E. Figure 4F shows the structure of the robot, where webbed plates are mounted on the wheels. These webbed plates generate traction and rotational torque on the water surface by interacting with the water. However, as this paper focuses primarily on the FTC algorithm of the robot on the ground and on the water surface, the discussion does not explore the robot's aerial motion in detail.

Figure 4. (A) The robot moves on the ground. (B) The robot moves on the water surface by webbed plates. (C) The robot moves on the water surface by propllers. (D) The robot takes off from water surface. (E) The robot flying in the air. (F) The structure of robot.
The robot in the inertial frame and in the body frame is shown in Figure 5.
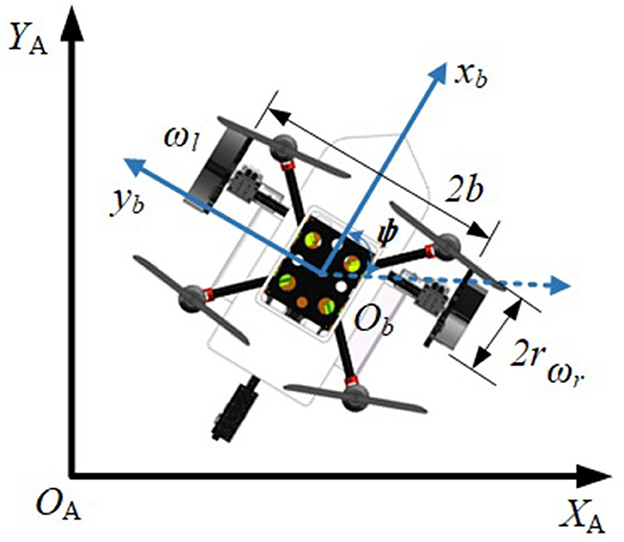
Figure 5. Robot in the inertial frame and the body frame.
In Figure 5, d is the distance from the geometric center of the robot Ob to the mass center of the robot. b is the axis radius and r is the wheel radius. ωl, ωr are the angular velocities of the left and right wheels. ψ is the angle between the robot body coordinate system b and the inertial coordinate system A, and ψ is the yaw angle of the robot. The kinematic model of the robot on the ground and water surface can be represented as (Liu et al., 2020):
where represents the position and orientation of the robot in the inertial frame, while is used to denote the longitudinal velocity, lateral velocity, and yaw angular velocity in the body frame. The coordinate conversion matrix is denoted by R, where . The dynamics model of the robot's motion on the ground can be expressed as
The matrices M are symmetric positive definite inertia matrices, while Cm represents the centripetal and Coriolis matrix. The term denotes mechanical friction, while τd is used to represent external disturbances. The input transformation matrices are denoted as B(q). Furthermore, the robot drive motors in the left and right wheel output torque are represented by .
The mass of the robot is represented by m. The I is a scalar quantity and represents the rotational inertia of the robot as it rotates in the X-Y plane. The angular velocity of the robot is assumed to vary smoothly, so that . According to assumption 1, the Coriolis matrix can be assumed to be negligible, resulting in Cm ≈ 0. According to assumption 1, d = 0, so the matrix . Based on these assumptions, the dynamics model of the robot on the ground can be rewritten as follows:
where , , . is the mechanical friction and is the external disturbance. Rewriting 3 into algebraic form can be expressed as:
The traction force is represented by Fu, while Tr represents the torque. To model the dynamics of the robot on the water surface, we can refer to the USV dynamics model (Chen et al., 2019), which can be expressed as follows
Mw is the inertia matrix. The traction force and torque of the robot at the water surface are . is the lumped disturbance and is the water resistance.
The disturbances are represented by τdw. On the other hand, Dw(η) represents the water resistance. The Coriolis force matrix can also be neglected according to Assumption 1 and Assumption 3, so Cw(q, η) ≈ 0. The elements of the non-diagonal matrix in matrix Dw(η) and matrix Mw are small and can be neglected. This model simplification approach is also more common (Liao et al., 2016; Wang et al., 2019b; Deng et al., 2020), where , , and m33 = Iz−Nṙ are the inertia parameters of the three axes and , , and Nṙ are the additional inertia parameters due to the wet water of the robot shell and the viscosity of the water. The dynamics model of the robot on the water surface can be expressed as:
Xu, X|u|u, Yu, Y|v|v, and Nω, N|ω|ω are the resistance coefficients. The resistance of the robot moving on the water surface can be approximated as a quadratic function of the velocity and angular velocity.
The mathematical model should be rewritten into a form that better suits the needs of the subsequent controller design. The dynamics model of the robot's motion on the ground is rewritten according to 4 as
Where dug is the lumped disturbance and , is the upper limit of the total disturbances. drg is the lumped disturbance and , is the upper limit of the total disturbances. The dynamics model of the robot on the water surface is
where Fuc is the desired tractive force and Fuc = Fu represents no force loss. is the force loss parameter. ΔF is the force disturbance due to mass change. duw is a lumped disturbance, . is the upper bound of duw. Duw is the uncertainty term when the robot moves on the water surface due to changes in system parameters, water resistance, and driver faults. Trc is the desired torque and Trc = Tr represents no force loss. is the power loss parameter. ΔT is the torque disturbance due to the change of inertia parameter. drw is a lumped disturbance, . is the upper bound of drw. Drw is the uncertainty term due to changes in system parameters, water resistance, and driver faults during robot rotation on the water surface.
3. Active fault tolerance control algorithm and human decision search algorithm
3.1. RBFNN-based active fault-tolerant control algorithm
Both the yaw control and the linear velocity control of the robot are essentially single-input single-output (SISO) second-order non-linear affine systems. Without loss of generality, a second-order non-linear affine SISO system with drive faults can be expressed as:
uc is unconstrained control input, ua is the drive bias, ξ is the power loss parameter, , 0 represents no power loss, and 1 represents a complete loss of efficiency. D = −g(x)ξuc + ua is the uncertainty term due to the driver fault. The disturbance d has a well-defined upper limit and . x1, x2 are system states. f(x) is the system function and g(x) is the input function. Owing to the physical constraints of the controlled object, the control input is subject to saturation:
umax is the physical constraint. To make the control input smoother, the cutoff function is usually replaced by a saturation function, such as tanh.
where ucon is the constrained control input and uf is a function of uc. Thus, the control objective is to design the constrained control law ucon so that it satisfies the control requirements even in the presence of drive faults and external disturbances in the controlled object. The steps for designing an AFT controller are the following:
Step 1: Define the state error e1 = x1d − x1. Establish the Lyapunov function . Taking the derivative of V1 with respect to the time t gives
Define the virtual state αx = k1e1 + ẋ1d as the desired input of the next step. If x2 can follow αx, . So, the next step of the control law must ensure that αx − x2 = 0. αx is the next desired state x2d.
Step 2: Define the state error e2 = x2d − x2, and the fast NTSMC is designed as
where α and β are positive adjustable parameters and λ is a positive odd number. The sliding mode convergence law is
where k1, k2, and γ1 are positive adjustable parameters. sgn is the symbolic function. The derivation of 13 yields:
where
The controller law can be designed as follows:
In 17, the uncertain term due to drive faults D is known. Establishing the Lyapunov function , the derivative of V2 yields
Bringing 17 into 18 yields
When , , ε > 0, thus:
where α1 = 2k2, .
LEMMA 1 [44] (Jiang and Lin, 2020): Consider a smooth positive definite V(x), x ∈ Rn. Suppose that real numbers p1 ∈ (0, 1), α > 0, and β > 0 exist such that . Then, an area U0 ∈ Rn exists, such that any V(x) starting from U0 can reach V(x) = 0 in finite time Tv, which is expressed as .
According to lemma 1, V2 can converge to 0 in finite time. In the above discussion, the uncertainty term D is assumed to be known, but the actual uncertain term D is unknown. As RBFNN can approximate arbitrary uncertain non-linear functions and does not depend on a mathematical model, it is more suitable for estimating stochastic uncertain terms. Therefore, optimal neural network weights w* must exist such that , ε0 is the estimated residual and h is the neuron. , ŵ is an estimate of w* and w* is a constant, so . Rewrite 9 as:
Step 3: Establish the Lyapunov function V3 as
The derivation of formula 22 yields
The control law is designed to
Bringing formula 24 into 23 yields
where ε1 = d + ε0, the upper limit of the estimation error of the neural network is . , , so that . The update law of the RBFNN weights is designed as
Bringing 26 into 25 yields
when , , where ε2 > 0, thus:
According to lemma 1, V2 can converge to 0 in finite time.
The control input uc in formula 24 is the unconstrained, to prevent the control input saturation, define ud = uc, where ud is the desired value in the next step, and the state error e3 = ud−ucon. ucon satisfies the constrained control input of the saturation function tanh; therefore, parameter uf must exist, such that ucon = umaxtanh(uf/umax), where umax is the maximum input.
Step 4: Establish the Lyapunov function and derive V3 and bring it into 29 to obtain:
is designed as
where δ = |uf|−2umax, Δ is a smaller normal value. γ2 ∈ (0, 1). The convergence of the controller is discussed in the following cases. When δ ≥ Δ, substituting 31 into 30 yields
where , 2k3 = β2. According to Lemma 1, V4 can converge to 0 in finite time. When δ < Δ, substituting 31 into 30 yields
where α3 = (γ2 + 1)/2, , and tanh(uc/umax) < 1, so c > 0. According to Lemma 2, V4 can converge in finite time.
LEMMA 2: Chu et al. (2022) Suppose that there is a positive definite continuous Lyapunov function V(x, t) defined on , where U1 ⊆ U ⊆ Rn. Rn is a neighborhood of the origin, and , where c > 0, 0 < α < 1. Then, the origin of the system is locally finite time stable. The settling time satisfies for a given initial condition x(t0) ∈ U1.
3.2. Human decision search algorithm
The human decision search algorithm (HDSA) is a swarm optimization technique that mimics the decision-making process of a human crowd. In many post-apocalyptic survival games or films, the strong group consciousness of humans is often portrayed, but the importance of individual consciousness is also emphasized. In human groups, a small group of individuals called decision-makers make the final decisions based on their experience and personal status. However, the decision of the decision-maker is not necessarily optimal. When the number of individuals in the group is small, it is important to involve more people in the decision-making process to guide the development of the group and to avoid the excessive impact of individual decisions on the group. However, when the number of individuals in the group is large, the proportion of decision-makers should be reduced and only a few elite individuals should be selected to determine the development of the group. This is because too many people involved in the decision-making process may take more time, and the experience of ordinary people may not be as good as that of elite individuals. Because people have emotions, they can think both rationally and emotionally when dealing with problems, and these two opposing ways of thinking must coexist.
Apart from the decision-makers, the rest of the human population is referred to as the executors, consisting of individuals who have no or less ability to make decisions. They carry out the optimal decisions made by the decision-makers. However, individuals among the executors who have some decision-making ability should be encouraged to seek more humane decisions based on the optimal decisions. These decisions should become more adapted to the current environment over time. The number of decision-makers is fixed, and elite individuals in the human population will always be selected as decision-makers. Over time, any individual has the potential to become a decision-maker, and the current decision-maker may become an executor.
In a human population, there are always individuals who question the current decision or believe they have a better one, including the decision-makers themselves. These individuals are known as adventurers, and their numbers and identities are random, making them a source of uncertainty within the population. Although adventurers can lead people to a better life, they can also lead them to disaster. Adventurers, on the other hand, inherit the current optimal choices of the human population and take them into account when making decisions. However, more adventurous individuals will also seek out possible optimal decisions based on their own state. To avoid harming the human population, adventurers must consider whether the decisions they make are more beneficial to their own survival. Additionally, there is a chance that an adventurer will become a decision-maker if they come up with a better or suboptimal decision. Based on the above analysis, the proposed algorithm for optimizing the human decision population consists of three main components: decision updating for decision-makers, decision updating for executors, and decision updating for adventurers.
3.2.1. Decision updates for decision makers
The number of decision-makers is fixed in proportion to the total number of people, and the number of decision-makers is 20–50% of the total number of people. The decision-makers make their decisions based on individual experience as well as individual characteristics. The sine and cosine functions are used to distinguish between rational and emotional decisions by people, and the individuals are randomly updated due to the random adoption of rational and emotional decisions by people.
where denotes the tth iteration of the ith human individual. r1 is a non-linear term, r1 = 2*(1 − i/(α1*dnum)). dnum is the number of decision-makers. α1 is a random number between (0, 1). r2 = α22π and α2 is the random number between (0, 1). r3 = 2α3, α3 is a random number between (0, 1). r is the random number between (0, 1). is the individual optimal solution for 1 to t iterations.
3.2.2. Decision updates for executors
Except for the decision-maker, the rest of the individuals are the executors. Among the executors, individuals with a fitness that is higher than the intermediate fitness are ordinary executors that must follow the optimal decision of the decision-maker. Individuals with a fitness below the intermediate fitness are considered as executors with some decision-making ability, and this group can continue to explore the next optimal decision that may exist based on the current optimal decision.
where is the current global best individual and is the current global worst individual. . is the fitness of the ith individual, , is the current best fitness, and is the current worst fitness. β1 is the random number of normal distribution with mean 0 and variance 1. The sgn function determines the direction of exploration of individuals. indicates that a more favorable decision result can be obtained over time.
3.2.3. Decision updates for adventurers
The adventurers are random individuals and the number of adventurers is also random. If the adventurer's fitness is less than the average fitness, the adventurer randomly explores based on the current optimal solution. If the adventurer's fitness is higher than the average fitness, the adventurer will continue to explore in the optimal direction according to the current state of the individual.
where c1 is a normally distributed random number with mean 0. c2 is a random number between (0, 1) with variance 1. is the Euclidean norm of and is the current mean fitness.
Based on the above discussion, the proposed HDSA has three steps. The first step performs a global random search using the formula 34. In the second step, a local search is performed based on the first step using the formula 35. The third step performs a second global random search using the formula 36 on the basis of the first and second steps. HDSA framework as Algorithm 1.

Algorithm 1. HDSA.
3.3. Yaw controller and linear velocity controller
According to the control algorithm in the “RBFNN-Based Active Fault-Tolerant Control Algorithm” section, the AFTC is used to design controllers in this section to follow the desired yaw angle ψd and desired linear velocity vd. The robot linear velocity sliding mode surface is: , where ev = vd−v. The sliding mode convergence law is .
The proof of convergence for the velocity controller is similar to that for the general-purpose controller in the “RBFNN-Based Active Fault-Tolerant Control Algorithm" section. The unconstrained control law is designed as
The anti-input saturation controller of linear velocity is designed as
Where eF = Fuc−Fucon.
The yaw angle controller is , where eψ = ψd − ψ. The yaw angle sliding mode surface is . The sliding mode convergence law is .
The unconstrained control law is designed as
The anti-input saturation controller of the yaw angle is designed as
where eT = Trc−Trcon. The controller parameters are not described in this section as they have been discussed in the “RBFNN-Based Active Fault-Tolerant Control Algorithm" section.
The input to the angular velocity neural network is both the yaw error and the angular velocity error, and the output is the uncertainty term in the angular velocity control. The coordinate vector matrix of the centroids of the Gaussian basis function neurons in the angular velocity neural network is
The width of the Gaussian basis function bψ = 0.1, i = 1⋯11.
The input to the linear velocity neural network is the velocity error and the output is the linear velocity control uncertainty term. The coordinate vector matrix of the centroids of the Gaussian basis function of the neurons in the linear velocity neural network is
. The width of the Gaussian basis function bv = 0.1, i = 1⋯11.
Based on the above discussion, the proposed framework for the AFTC is shown in Figure 6.
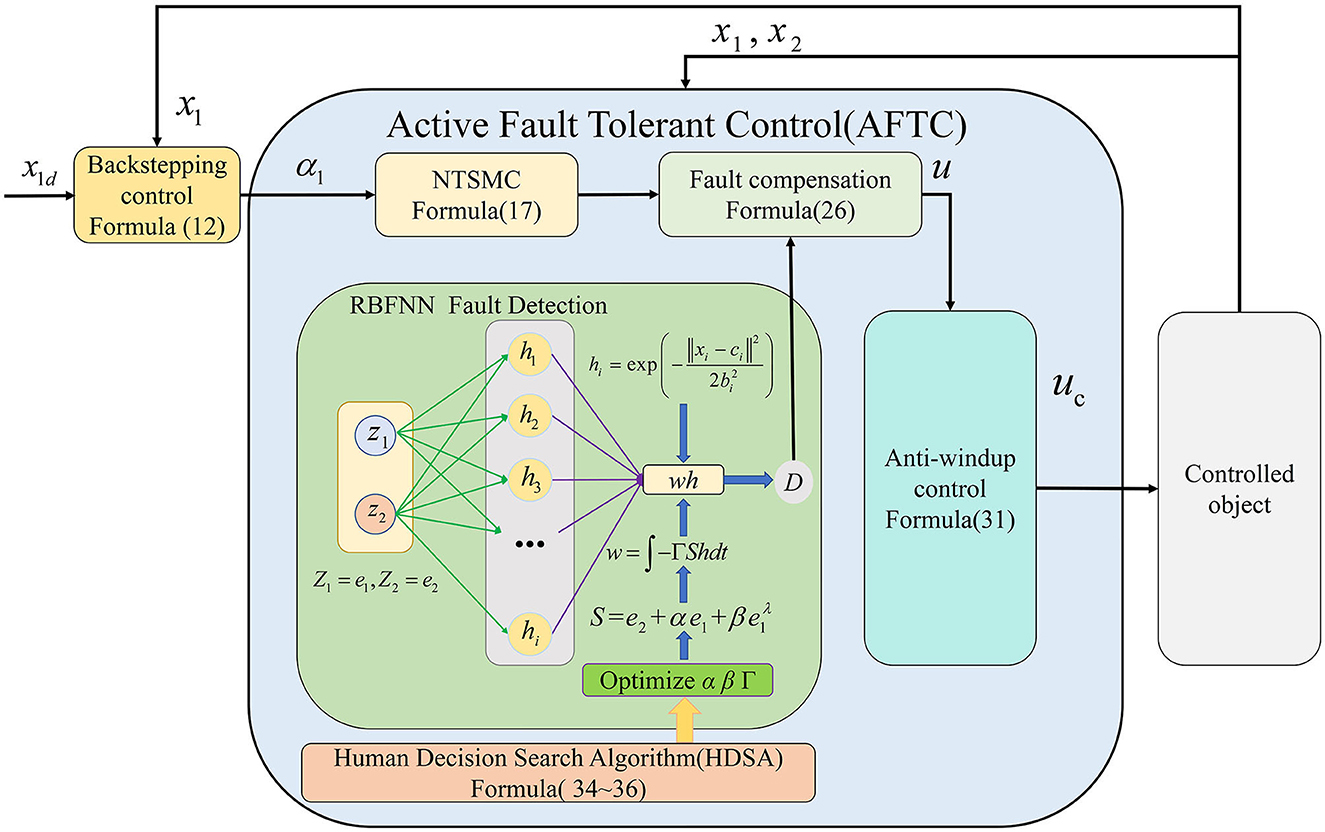
Figure 6. AFTC framework.
4. Simulation results
In the section entitled “HDSA's Related Work”, we have demonstrated the advantages of the proposed HDSA; therefore, in this section, the HDSA is used to optimize the sliding mode surface parameters of the yaw controller and the linear velocity controller. As the weight update parameters of the RBFNNs are related to the sliding mode parameters, this also indirectly optimizes the RBFNNs.
The parameters to be optimized for yaw angle control are the sliding mode surface coefficients αω, βω and the neural network update coefficient Γω. According to the idea of AFTC, the presence of −3N.m of disturbance torque in the robot model simulates the worst case. The initialized optimization algorithm parameters are as follows: dimension is 3, the number of populations is 20, the number of max iterations is 10, and the upper limit of parameters is 20 and the lower limit is −20.
The evaluation function of the yaw controller is designed as fobj = 0.8*|eψ| + 0.1*|eω| + 0.01*|Trc|. For yaw control, we want to reduce both the yaw error and the yaw velocity error with the smallest control input. As the control objective is to eliminate the yaw error, the yaw error is given the largest weight in the evaluation function. To keep the control input and yaw error in the same order, the control input weight is reduced. The optimization parameters for the yaw controller are shown in Figure 7.
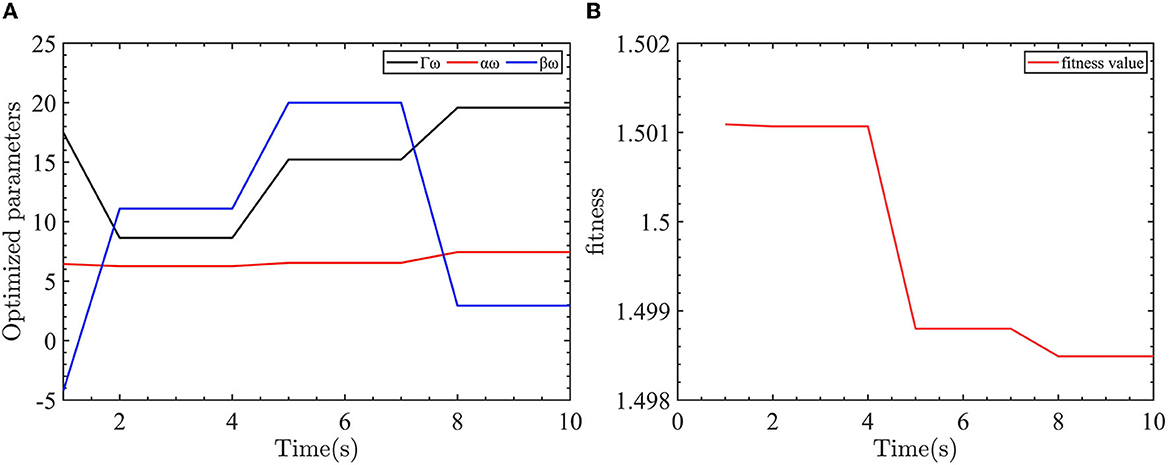
Figure 7. Yaw control parameter optimization and fitness of the yaw controller objective function. (A) The optimized parameters of yaw controller. (B) The objective function output value.
As shown in Figure 7, the optimized parameters converge after eight iterations. The values of Γω = 20, αω = 7.4407, and βω = 2.9369 are obtained through the optimization process.
The optimized parameters are substituted into the AFTC and the control results are compared with the unoptimized AFTC, NTSMC, and SMC. Before 10 s, the yaw angle is influenced by a torque with a mean value of −1N.m and a mean square error of 0.1. After 10 s, the yaw angle is influenced by a torque with a mean value of −3N.m and a mean square error of 0.1. The control parameters are given in Table 3.
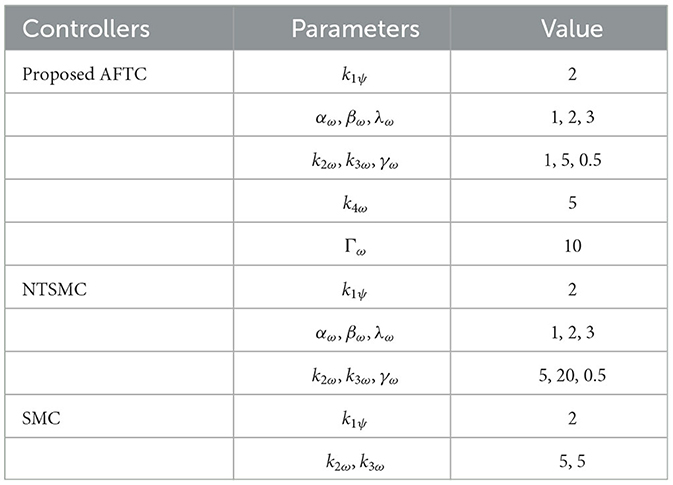
Table 3. Parameters of yaw angle controllers.
The results of the yaw angle controller are shown in Figure 8.
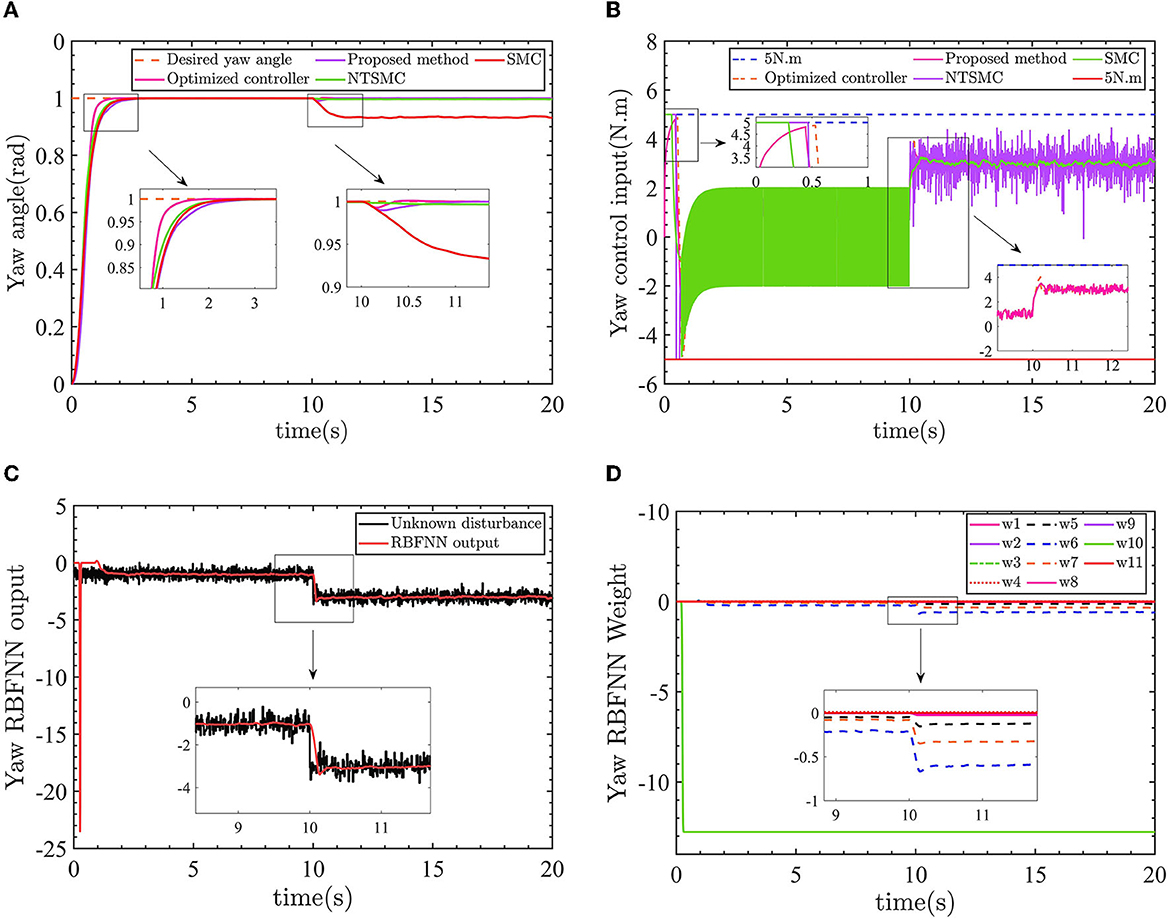
Figure 8. (A) The yaw angle control results. (B) Control input torque. (C) Yaw angle RBFNN output value. (D) Yaw angle RBFNN weight.
In Figure 8A, the optimized AFTC has a significantly faster response speed (pink line). Despite being influenced by a −1 N.m torque disturbance in the range of 0–10 s, the AFTC, NTSMC (green line), and SMC (red line) maintain their robustness and are not affected by the disturbance. After 10 s, the yaw angle is subjected to a torque of −3N.m, in which case reliance on the robustness of the controller can no longer guarantee yaw angle control performance, as shown in the 10–11 s enlargement in Figure 8A. The SMC is unable to follow the desired yaw angle with a static error of ~0.05 rad, and the NTSMC also has a small static difference.
As shown in Figure 8B, the proposed AFTC (pink line) and the optimized AFTC (orange line) do not enter the driver saturation state. The NTSMC (purple line) and the SMC (green line) enter the driver saturation state. Compared with the conventional SMC (green line) and NTSMC (purple line) control inputs, which have high-frequency input chatter, the control input of the proposed AFTC is more stable. This suggests that the robustness achieved by the conventional SMC comes at the expense of control input performance. In Figure 8C, the output of the radial basis function neural network (RBFNN) is displayed, showing a value of 1 before 10 s and 3 after 10 s. The RBFNN can estimate the unknown yaw disturbances online. The RBFNN weights are updated accordingly, as shown in Figure 8.
The parameters to be optimized for the velocity controller are the sliding mode surface coefficients αv and βv and the neural network update coefficients Γv. The presence of −5N force in the robot model simulates the worst case. The initialized optimization algorithm parameters are as follows: the dimension is 3, the number of populations is 20, the number of maximum iterations is 10, and the upper limit of parameters 20 and the lower limit is 20.
The evaluation function is designed as fobj = 0.8*|ev| + 0.02*|Fuc|. When controlling the linear velocity, we want to minimize the linear velocity error with the smallest control input. Therefore, the linear velocity error has the largest weight in the evaluation function. The weight of the control input is reduced to keep the control input and the linear velocity error at the same level. The linear velocity controller optimization parameters are shown in Figure 9.
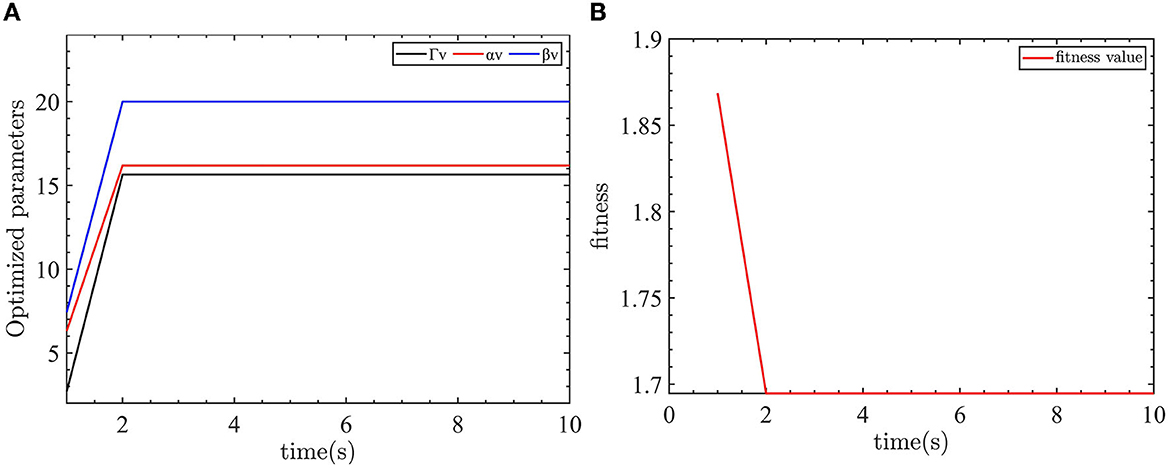
Figure 9. Velocity control parameter optimization and fitness of the velocity controller objective function. (A) The optimized parameters of velocity controller. (B) The objective function output value.
As shown in Figure 9, the optimization parameters converge after two iterations. The optimized parameters are Γv = 15.6467, αv = 16.1866, and βv = 20.
These parameters are used in the proposed AFTC, and the control results are compared and analyzed with the unoptimized AFTC, NTSMC, and SMC controllers. Before 10 s, the linear velocity is affected by a force with a mean value of −2N and a mean square error of 0.1. After 10 s, the velocity is influenced by a force with a mean value of −5N and a mean square error of 0.1. The velocity controller parameters are given in Table 4.
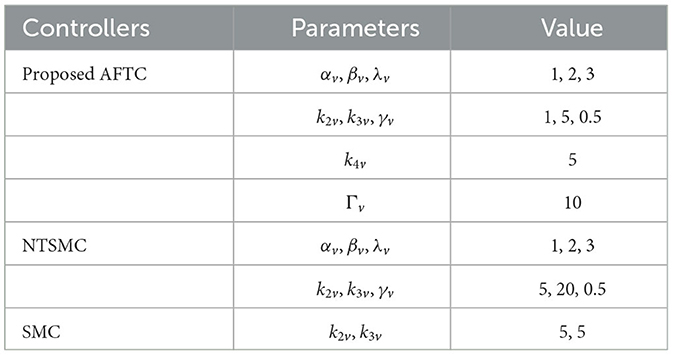
Table 4. The parameters of velocity controllers.
The control results of linear velocity controllers are shown in Figure 10.
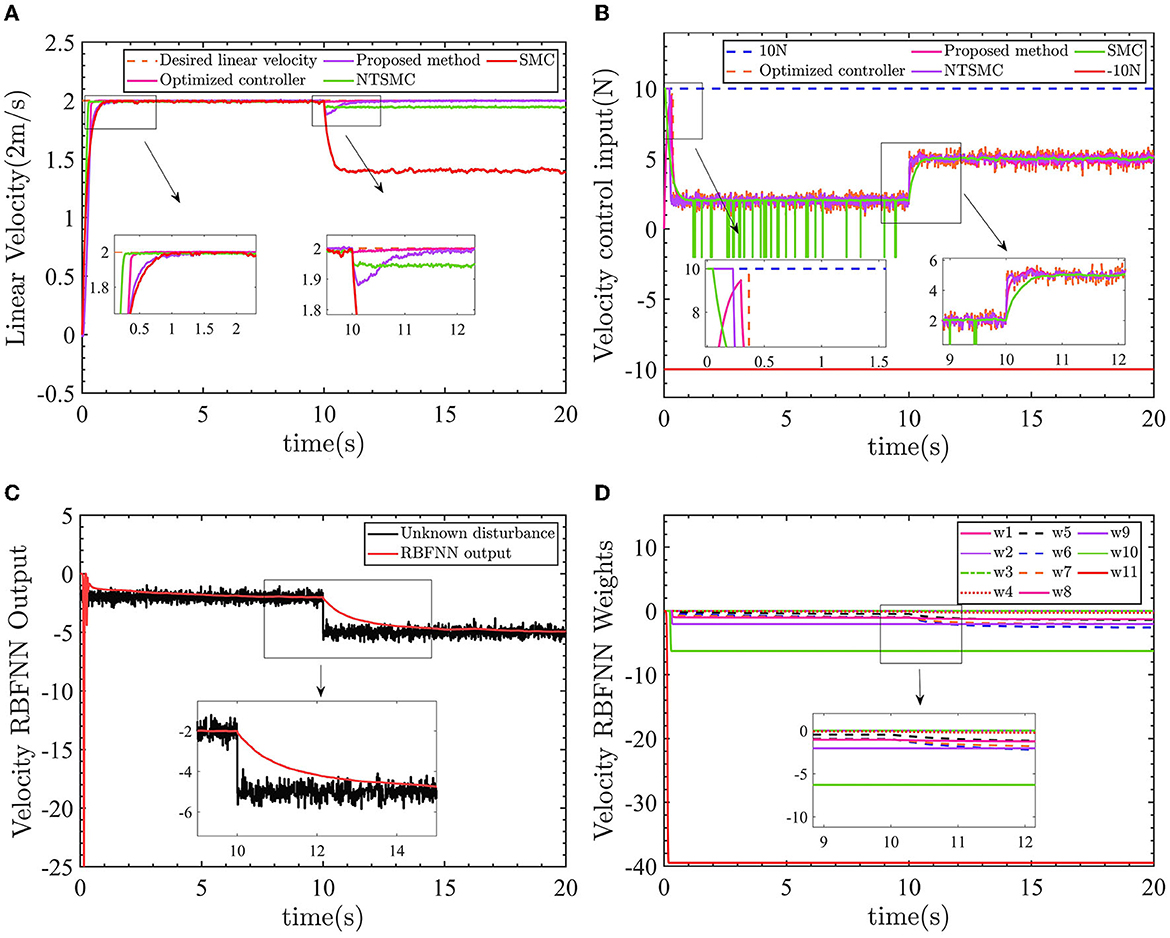
Figure 10. Linear velocity control results. (A) Velocity control results. (B) Control input force. (C) Velocity RBFNN output value. (D) Velocity RBFNN weight.
Similar to the performance of the yaw control, in Figure 10A, the optimized AFTC (pink line) responds faster compared with the proposed AFTC (purple line) and SMC (red line). Between 0 and 10 s, when the line speed is subjected to -2N force, AFTC (purple line), NTSMC (green line), and SMC (red line) are not affected by the disturbances. After 10 s, the linear velocity is subjected to a force of −5N and the velocity control performance cannot be guaranteed by the NTSMC and SMC. There is a static error of ~0.05m/s for the NTSMC and ~0.6m/s for the SMC, as shown in the 9–12 s enlargement in Figure 10A. Both the proposed AFTC and the optimized AFTC can follow the desired linear velocity, and the velocity controller is almost unaffected by the −5N force using the optimized parameters. The proposed AFTC and the optimized AFTC can effectively track the desired linear velocity, with minimal impact from the −5N force disturbance. The velocity controller of the AFTC is almost unaffected by the disturbance, indicating its robustness and ability to maintain precise control performance.
The previous discussion has highlighted the improved responsiveness and robustness of the optimized AFTC. To further emphasize the advantages of the optimized AFTC, the output value of the evaluation function is used as a criterion to evaluate the performance of the four controllers. A smaller output value of the evaluation function indicates better controller performance. The output values of the evaluation functions for the four controllers are depicted in Figure 11.
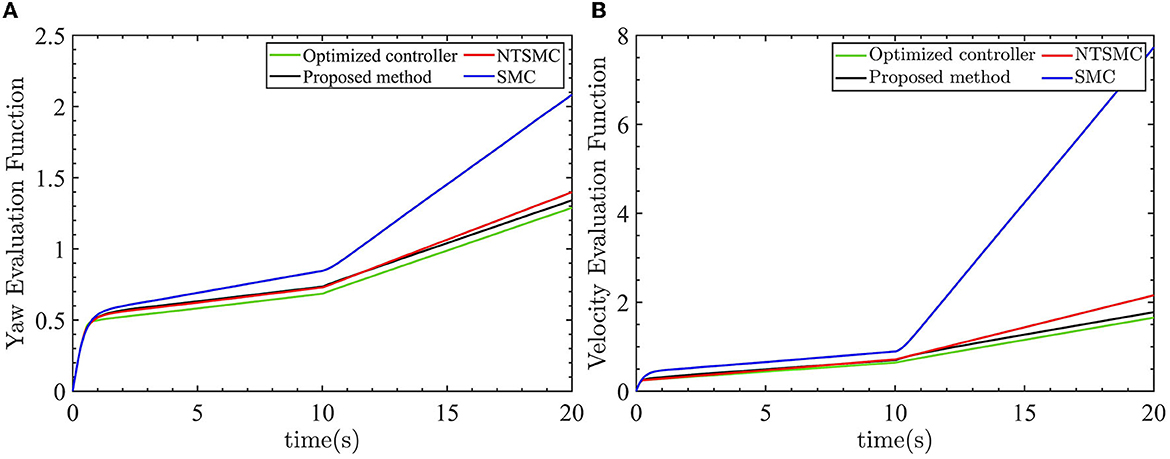
Figure 11. Four control evaluation function outputs. (A) Yaw angle evaluation function outputs. (B) Velocity evaluation function outputs.
As shown by the green lines in Figures 12A, B, the optimized AFTC controller exhibits the smallest value of the evaluation function. This signifies that the optimized AFTC achieves the best performance among the four controllers. As the linear velocity and yaw angle are consistently subjected to external disturbances, the output value of the evaluation function continually increases. This is because of the fact that the control inputs are not equal to zero. In the case of large external disturbances, the NTSMC and SMC controllers can no longer eliminate the yaw angle error and the linear velocity error. Consequently, the output value of the evaluation function rapidly increases, as indicated by the red and blue lines.
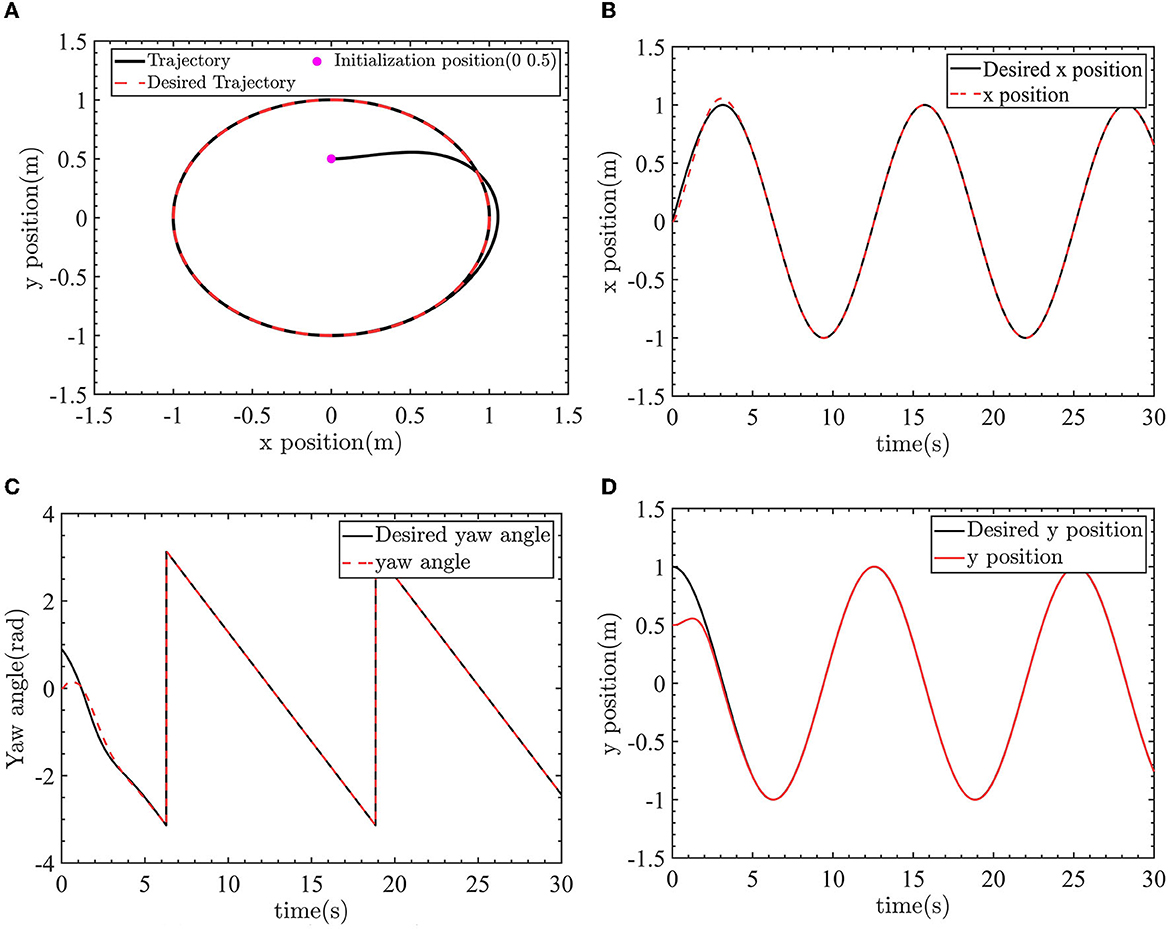
Figure 12. The robot tracks the desired trajectory. (A) Tracking the circle desired trajectory. (B) X-position control. (C) Yaw angle control. (D) Y-position control.
To further verify the effectiveness of the proposed algorithm, the AFTC is used to design the yaw angle controller and the velocity controller. The desired yaw angle and the desired linear velocity is planned by the LOS algorithm. The optimized parameters are selected as the controller's parameters. The LOS algorithm and the improved LOS algorithm can be found in the author's previous work (Wang et al., 2022b). The desired trajectory is a circular trajectory with radius R = 1m, angular velocity ωr = 0.5rad/s, and linear velocity vr = 0.5m/s. The initial position and pose of the robot is [0m, 0.5m, 0rad]. A drag force of −2N and a torque of −1N.m are applied to the robot. The LOS algorithm is
where ψL, vL are the desired yaw angle and desired linear velocity planned by the LOS algorithm. ex, ey is the position error in Frenet-Serret (F-S) frame. Δ and k are the positive adjustable parameters.
The control results of the robot tracking the desired circle trajectory are shown as Figures 12–14. The robot position control and yaw angle control are shown in Figure 12.
The robot can track the desired trajectory. The actual position pose of the robot is consistent with the desired position pose. The linear velocity control and angular velocity control are shown in Figure 13.
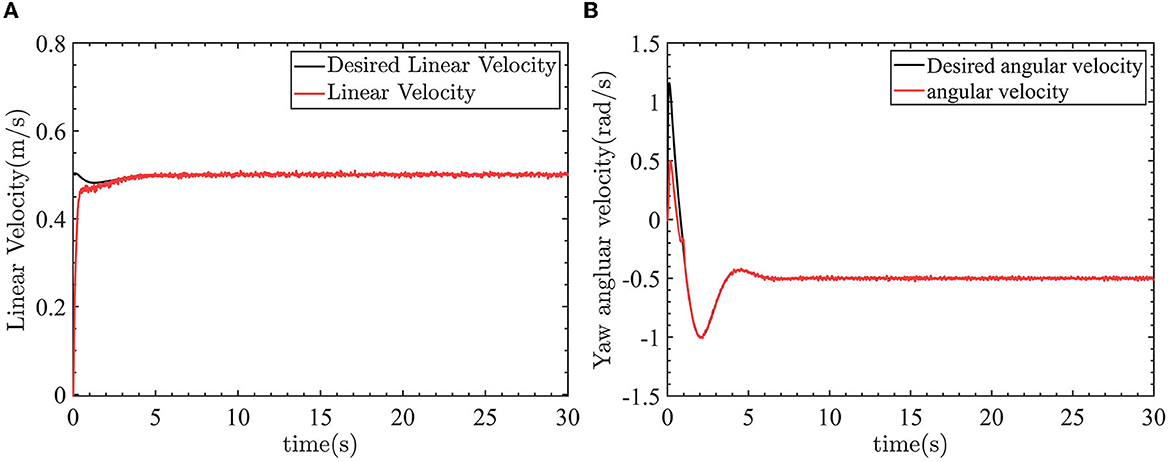
Figure 13. The control results of linear velocity and yaw angular velocity. (A) Linear velocity control. (B) Yaw angle velocity control.
In Figure 13A, the linear velocity can track the desired linear velocity of 0.5m/s. In Figure 13B, the angular velocity can track the desired angular velocity of −0.5rad/s. Figure 14 shows the linear velocity control input and yaw angle velocity control input.
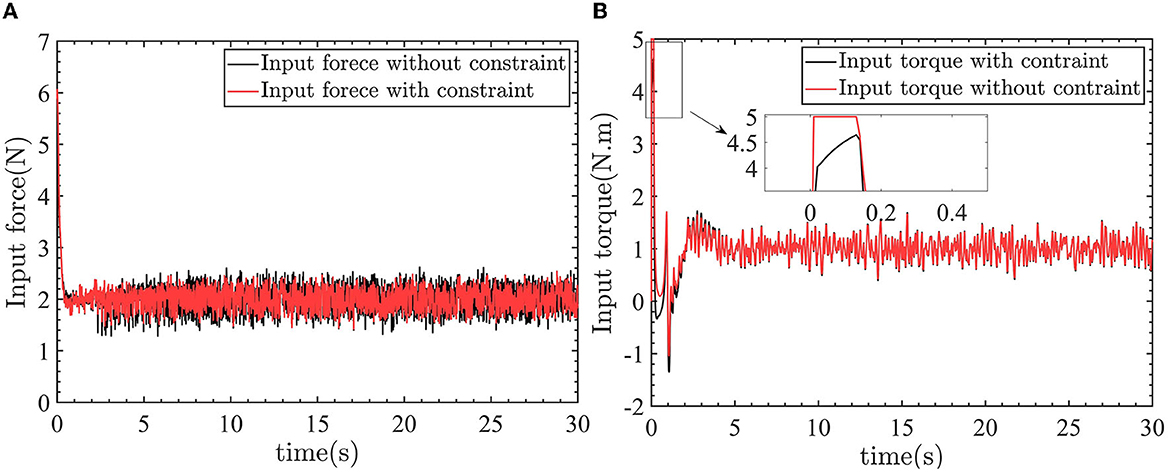
Figure 14. The linear velocity control input and yaw angular velocity control input. (A) Control input force. (B) Control input torque.
In Figures 14A, B, the −2N force and −1N.m torque are applied to the robot. So the control inputs are 2N and 1N.m to counteract the effect of the external force and torque on the robot.
The test functions for swarm intelligence optimization algorithms are shown in Tables 5–7.
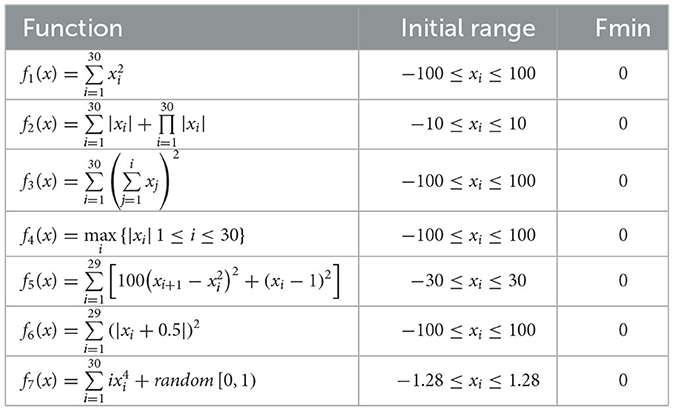
Table 5. The single-peak test functions.
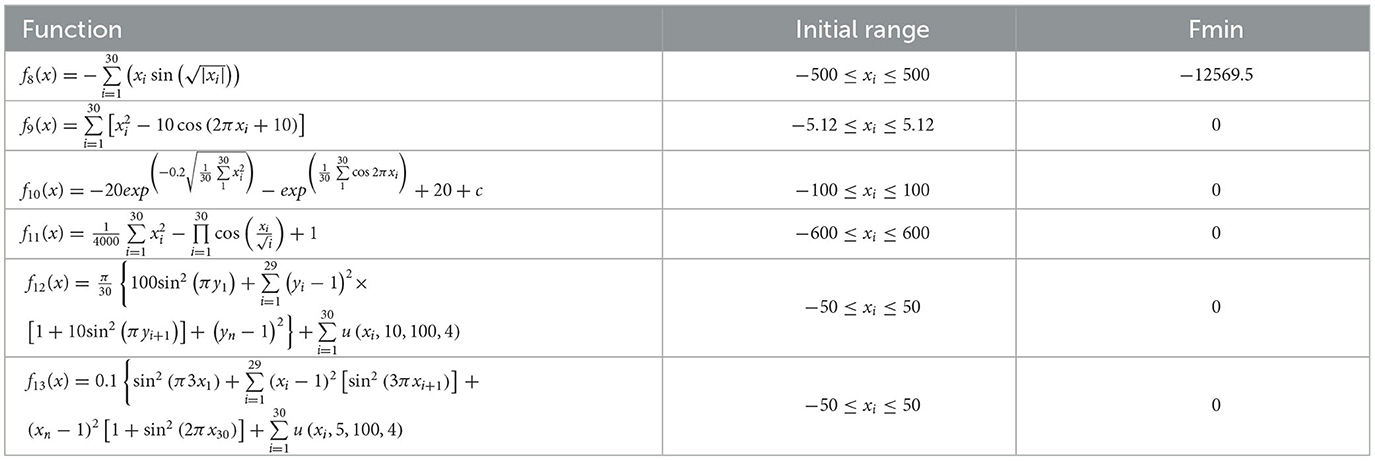
Table 6. The multi-peak test functions.
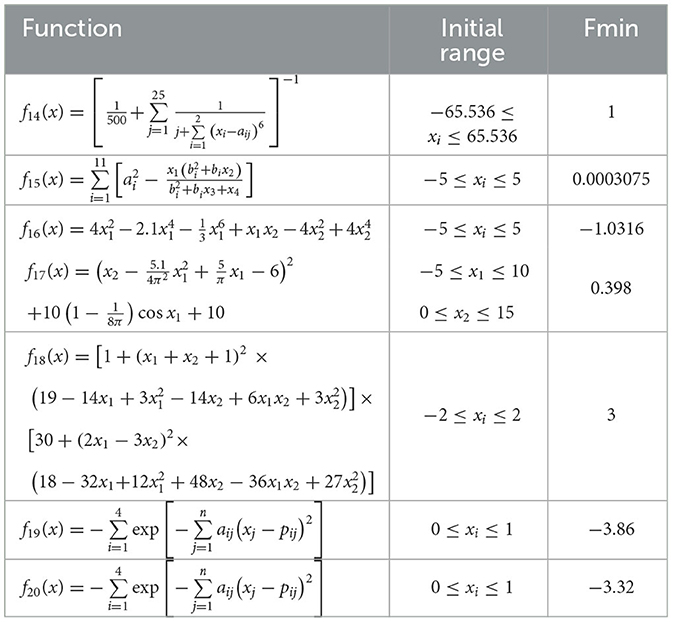
Table 7. The fixed-dimensional multi-peak test functions.
5. Conclusion
This paper proposes an RBFNN-based anti-input saturation AFTC to solve the problem of degraded control performance of the CDR during movement on the water surface caused by drive faults, uncertain water resistance, and uncertain model parameters. The AFTC incorporates a fast NTSMC, which ensures the robustness of the robot against external disturbances and the effects of uncertain model parameters. The RBFNN is used to estimate drive faults and compensate for the controller output. Additionally, an anti-input saturation control algorithm is introduced to prevent controller input saturation. Furthermore, the traditional approach of manually tuning controller parameters based on the designer's experience and iterative debugging is replaced with an optimization method called HDSA. The HDSA algorithm optimizes the controller parameters to ensure the optimal control performance of the robot.
In further work, adaptive algorithms are necessary for the adjustment of the upper limit of the maximum control input to the robot on the ground and on the water surface.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
KW implementation and execution of the theory research and experiment and writing of the manuscript. YL theoretical support on the idea and helped write the manuscript. CH preliminary work and revising the manuscript. All authors actively contributed to the preparation of the content of this paper.
Funding
This work was supported in part by the Sharing Technology Project (41412040102), the China National Science Foundation (61473155), the Jiangsu Technology Department under Modern Agriculture (BE2017301), and the Six Talent Peaks Project in Jiangsu Province (GDZB-039).
Acknowledgments
We thank the editors and reviewers of the journal.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Ali, N., Tawiah, I., and Zhang, W. (2020). Finite-time extended state observer based nonsingular fast terminal sliding mode control of autonomous underwater vehicles. Ocean Eng. 218, 108179. doi: 10.1016/j.oceaneng.2020.108179
Chen, G., Tu, J., Ti, X., Wang, Z., and Hu, H. (2021). Hydrodynamic model of the beaver-like bendable webbed foot and paddling characteristics under different flow velocities. Ocean Eng. 234, 109179. doi: 10.1016/j.oceaneng.2021.109179
Chen, L., Cui, R., Yang, C., and Yan, W. (2019). Adaptive neural network control of underactuated surface vessels with guaranteed transient performance: theory and experimental results. IEEE Transact. Ind. Electron. 67, 4024–4035. doi: 10.1109/TIE.2019.2914631
Chu, R., Liu, Z., and Chu, Z. (2022). Improved super-twisting sliding mode control for ship heading with sideslip angle compensation. Ocean Eng. 260, 111996. doi: 10.1016/j.oceaneng.2022.111996
Cohen, A., and Zarrouk, D. (2020). “The amphistar high speed amphibious sprawl tuned robot: design and experiments,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (Las Vegas, NV: IEEE), 6411–6418.
Deng, Y., Zhang, X., Im, N., Zhang, G., and Zhang, Q. (2020). Adaptive fuzzy tracking control for underactuated surface vessels with unmodeled dynamics and input saturation. ISA Trans. 103, 52–62. doi: 10.1016/j.isatra.2020.04.010
Dorigo, M., Maniezzo, V., and Colorni, A. (1996). Ant system: optimization by a colony of cooperating agents. IEEE Transact. Syst. Man Cybernet. Part B 26, 29–41. doi: 10.1109/3477.484436
Fister, I., Fister Jr, I., Yang, X.-S., and Brest, J. (2013). A comprehensive review of firefly algorithms. Swarm Evol. Comput. 13, 34–46. doi: 10.1016/j.swevo.2013.06.001
Gao, B., Liu, Y.-J., and Liu, L. (2022). Adaptive neural fault-tolerant control of a quadrotor uav via fast terminal sliding mode. Aerospace Sci. Technol. 129, 107818. doi: 10.1016/j.ast.2022.107818
Gheisarnejad, M., and Khooban, M. H. (2020). An intelligent non-integer pid controller-based deep reinforcement learning: Implementation and experimental results. IEEE Transact. Ind. Electron. 68, 3609–3618. doi: 10.1109/TIE.2020.2979561
Guo, J., Zhang, K., Guo, S., Li, C., and Yang, X. (2019). “Design of a new type of tri-habitat robot,” in 2019 IEEE International Conference on Mechatronics and Automation (ICMA) (Tianjin: IEEE), 1508–1513.
Guo, X., Huang, S., Lu, K., Peng, Y., Wang, H., and Yang, J. (2022). A fast sliding mode speed controller for PMSM based on new compound reaching law with improved sliding mode observer. IEEE Trans. Transp. Elect. 9, 2955–2968.
Heidari, A. A., Mirjalili, S., Faris, H., Aljarah, I., Mafarja, M., and Chen, H. (2019). Harris hawks optimization: Algorithm and applications. Fut. Gen. Comp. Syst. 97, 849–872. doi: 10.1016/j.future.2019.02.028
Hou, Q., and Ding, S. (2021). Finite-time extended state observer-based super-twisting sliding mode controller for pmsm drives with inertia identification. IEEE Transact. Transport. Electrif. 8, 1918–1929. doi: 10.1109/TTE.2021.3123646
Huang, J., Wang, W., Wen, C., and Li, G. (2019). Adaptive event-triggered control of nonlinear systems with controller and parameter estimator triggering. IEEE Trans. Automat. Contr. 65, 318–324. doi: 10.1109/TAC.2019.2912517
Jiang, T., and Lin, D. (2020). Fast finite-time backstepping for helicopters under input constraints and perturbations. Int. J. Syst. Sci. 51, 2868–2882. doi: 10.1080/00207721.2020.1803438
Liao, Y.-,l., Zhang, M.-,j., Wan, L., and Li, Y. (2016). Trajectory tracking control for underactuated unmanned surface vehicles with dynamic uncertainties. J. Cent. South Univ. 23, 370–378. doi: 10.1007/s11771-016-3082-4
Liu, K., Gao, H., Ji, H., and Hao, Z. (2020). Adaptive sliding mode based disturbance attenuation tracking control for wheeled mobile robots. Int. J. Control Automat. Syst. 18, 1288–1298. doi: 10.1007/s12555-019-0262-7
Liu, X., Zhang, M., and Yao, F. (2018). Adaptive fault tolerant control and thruster fault reconstruction for autonomous underwater vehicle. Ocean Eng. 155, 10–23. doi: 10.1016/j.oceaneng.2018.02.007
Mirjalili, S. (2016). Sca: a sine cosine algorithm for solving optimization problems. Knowl. Based Syst. 96, 120–133. doi: 10.1016/j.knosys.2015.12.022
Mirjalili, S., Mirjalili, S. M., and Lewis, A. (2014). Grey wolf optimizer. Adv. Eng. Softw. 69, 46–61. doi: 10.1016/j.advengsoft.2013.12.007
Najafi, A., Vu, M. T., Mobayen, S., Asad, J. H., and Fekih, A. (2022). Adaptive barrier fast terminal sliding mode actuator fault tolerant control approach for quadrotor uavs. Mathematics 10, 3009. doi: 10.3390/math10163009
Nan, F., Sun, S., Foehn, P., and Scaramuzza, D. (2022). Nonlinear mpc for quadrotor fault-tolerant control. IEEE Robot. Automat. Lett. 7, 5047–5054. doi: 10.1109/LRA.2022.3154033
Shen, Q., Yue, C., Goh, C. H., and Wang, D. (2018). Active fault-tolerant control system design for spacecraft attitude maneuvers with actuator saturation and faults. IEEE Transact. Ind. Electron. 66, 3763–3772. doi: 10.1109/TIE.2018.2854602
Song, M.-P., and Gu, G.-C. (2004). “Research on particle swarm optimization: a review,” in Proceedings of 2004 International Conference on Machine Learning and Cybernetics (IEEE Cat. No. 04EX826), (Shanghai: IEEE), 2236–2241.
Wang, F., Ma, Z., Gao, H., Zhou, C., and Hua, C. (2022). Disturbance observer-based nonsingular fast terminal sliding mode fault tolerant control of a quadrotor UAV with external disturbances and actuator faults. Int. J. Cont. Autom. Syst. 20, 1122–1130. doi: 10.1007/s12555-020-0773-2
Wang, H., Shi, J., Wang, J., Wang, H., Feng, Y., and You, Y. (2019a). Design and modeling of a novel transformable land/air robot. Int. J. Aero. Eng. doi: 10.1155/2019/2064131
Wang, K., Liu, Y., Huang, C., and Bao, W. (2022a). Water surface flight control of a cross domain robot based on an adaptive and robust sliding mode barrier control algorithm. Aerospace 9, 332. doi: 10.3390/aerospace9070332
Wang, K., Liu, Y., Huang, C., and Cheng, P. (2022b). Water surface and ground control of a small cross-domain robot based on fast line-of-sight algorithm and adaptive sliding mode integral barrier control. Appl. Sci. 12, 5935. doi: 10.3390/app12125935
Wang, N., and Deng, Z. (2019). Finite-time fault estimator based fault-tolerance control for a surface vehicle with input saturations. IEEE Trans. Ind. Informat. 16, 1172–1181. doi: 10.1109/TII.2019.2930471
Wang, N., Xie, G., Pan, X., and Su, S.-F. (2019b). Full-state regulation control of asymmetric underactuated surface vehicles. IEEE Trans. Ind. Informat. 66, 8741–8750. doi: 10.1109/TIE.2018.2890500
Wu, G., Chen, G., Zhang, H., and Huang, C. (2021). Fully distributed event-triggered vehicular platooning with actuator uncertainties. IEEE Transact. Vehic. Technol. 70, 6601–6612. doi: 10.1109/TVT.2021.3086824
Wu, L.-B., Park, J. H., Xie, X.-P., Gao, C., and Zhao, N.-N. (2020). Fuzzy adaptive event-triggered control for a class of uncertain nonaffine nonlinear systems with full state constraints. IEEE Transact. Fuzzy Syst. 29, 904–916. doi: 10.1109/TFUZZ.2020.2966185
Xing, H., Shi, L., Hou, X., Liu, Y., Hu, Y., Xia, D., et al. (2021). Design, modeling and control of a miniature bio-inspired amphibious spherical robot. Mechatronics 77, 102574. doi: 10.1016/j.mechatronics.2021.102574
Xue, J., and Shen, B. (2020). A novel swarm intelligence optimization approach: sparrow search algorithm. Syst. Sci. Control Eng. 8, 22–34. doi: 10.1080/21642583.2019.1708830
Xue, J., and Shen, B. (2022). Dung beetle optimizer: a new meta-heuristic algorithm for global optimization. J. Supercomput. 1–32. doi: 10.1007/s11227-022-04959-6
Yu, X.-N., Hao, L.-Y., and Wang, X.-L. (2022). Fault tolerant control for an unmanned surface vessel based on integral sliding mode state feedback control. Int. J. Control Automat. Syst. 20, 2514–2522. doi: 10.1007/s12555-021-0526-x
Zhang, G., Chu, S., Zhang, W., and Liu, C. (2022). Adaptive neural fault-tolerant control for usv with the output-based triggering approach. IEEE Transact. Vehic. Technol. 71, 6948–6957. doi: 10.1109/TVT.2022.3167038
Zhang, H., Xi, R., Wang, Y., Sun, S., and Sun, J. (2021). Event-triggered adaptive tracking control for random systems with coexisting parametric uncertainties and severe nonlinearities. IEEE Trans. Automat. Contr. 67, 2011–2018. doi: 10.1109/TAC.2021.3079279
Zhao, Y., Qi, X., Ma, Y., Li, Z., Malekian, R., and Sotelo, M. A. (2020). Path following optimization for an underactuated usv using smoothly-convergent deep reinforcement learning. IEEE Transact. Intell. Transport. Syst. 22, 6208–6220. doi: 10.1109/TITS.2020.2989352
Keywords: cross-domain robot (CDR), radial basis function neural network (RBFNN), active fault-tolerant control (AFTC), anti-input saturation, human decision search algorithm (HDSA)
Citation: Wang K, Liu Y and Huang C (2023) Active fault-tolerant anti-input saturation control of a cross-domain robot based on a human decision search algorithm and RBFNN. Front. Neurorobot. 17:1219170. doi: 10.3389/fnbot.2023.1219170
Received: 08 May 2023; Accepted: 26 June 2023;
Published: 14 July 2023.
Edited by:
Long Jin, Lanzhou University, ChinaReviewed by:
Ruoxi Qin, Henan Key Laboratory of Imaging and Intelligent Processing, ChinaHao Xu, Anhui University of Technology, China
Copyright © 2023 Wang, Liu and Huang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yong Liu, bGl1eTE2MDJAbmp1c3QuZWR1LmNu