 Tatsuya Daikoku
Tatsuya Daikoku- Department of Neuropsychology, Max Planck Institute for Human Cognitive and Brain Sciences, Leipzig, Germany
It has been suggested that musical creativity is mainly formed by implicit knowledge. However, the types of spectro-temporal features and depth of the implicit knowledge forming individualities of improvisation are unknown. This study, using various-order Markov models on implicit statistical learning, investigated spectro-temporal statistics among musicians. The results suggested that lower-order models on implicit knowledge represented general characteristics shared among musicians, whereas higher-order models detected specific characteristics unique to each musician. Second, individuality may essentially be formed by pitch but not rhythm, whereas the rhythms may allow the individuality of pitches to strengthen. Third, time-course variation of musical creativity formed by implicit knowledge and uncertainty (i.e., entropy) may occur in a musician's lifetime. Individuality of improvisational creativity may be formed by deeper but not superficial implicit knowledge of pitches, and that the rhythms may allow the individuality of pitches to strengthen. Individualities of the creativity may shift over a musician's lifetime via experience and training.
Introduction
Implicit Knowledge and Creativity in Brain
The brain models external phenomena as a hierarchy of statistical dynamical systems, which encode causal chain structure in the sensorium (Friston et al., 2006; Friston and Kiebel, 2009; Friston, 2010) to maintain low entropy and free energy in the brain (von Helmholtz, 1909), and predicts a future state based on the internalized stochastic model to minimize sensory reaction and optimize motor action regardless of consciousness (Friston, 2005). This prediction associates with the brain's implicit, domain-general, and innate system, called implicit learning or statistical learning (Reber, 1967; Saffran et al., 1996; Cleeremans et al., 1998; Perruchet and Pacton, 2006), in which our brain automatically calculates transitional probabilities (TPs) of sequential phenomena and grasps information dynamics. The terms implicit learning and statistical learning have been used interchangeably and are regarded as the same phenomenon (Perruchet and Pacton, 2006). Because of the implicitness of statistical learning and knowledge, humans are unaware of exactly what they learn (Daikoku et al., 2014). Nonetheless, neurophysiological and behavioral responses disclose implicit learning effects (Francois and Schön, 2011; François et al., 2013; Daikoku et al., 2015, 2016, 2017a,c,d; Koelsch et al., 2016; Yumoto and Daikoku, 2016, 2018; Daikoku and Yumoto, 2017). When the brain implicitly encodes TP distributions that are inherent in dynamical phenomena, several things are automatically expected, including a probable future state with a higher TP, facilitating optimisation of performance based on the encoded statistics despite being unable to describe the knowledge (Broadbent, 1977; Berry and Broadbent, 1984; Green and Hecht, 1992; Williams, 2005; Rebuschat and Williams, 2012), and inhibit neurophysiological response to predictable external stimuli for the efficiency and low entropy of neural processing based on predictive coding (Daikoku, 2018b). The implicit knowledge has been considered to contribute to many types of mental representation: the comprehension and production of complex structural information such as music and language (Rohrmeier and Rebuschat, 2012), intuitive decision-making (Berry and Dienes, 1993; Reber, 1993; Perkovic and Orquin, 2017), auditory-motor planning (Pearce et al., 2010a,b; Norgaard, 2014), and creativity (Wiggins, 2018) involved in musical composition (Pearce and Wiggins, 2012; Daikoku, 2018a) and musical improvisation (Norgaard, 2014). Additionally, compared to language (Chomsky, 1957; Jackendoff and Lerdahl, 2006), several studies suggest that musical representation including tonality is mainly formed by a tacit knowledge (Delie‘ge et al., 1996; Delie‘ge, 2001; Bigand and Poulin-Charronnat, 2006; Ettlinger et al., 2011; Koelsch, 2011; Huron, 2012). Thus, it is widely accepted that implicit knowledge causes a sense of intuition, spontaneous behavior, skill acquisition based on procedural learning, and is further closely tied to musical production such as intuitive creativity, composition, and playing.
Particularly in musical improvisation, musicians are forced to express intuitive creativity and immediately play their own music based on long-term training associated with procedural and implicit learning (Clark and Squire, 1998; Ullman, 2001; Paradis, 2004; De Jong, 2005; Ellis, 2009; Müller et al., 2016). Thus, compared to other types of musical composition in which a composer deliberates and refines a composition scheme for a long time based on musical theory, the performance of musical improvisation is intimately bound to implicit knowledge because of the necessity of intuitive decision-making (Berry and Dienes, 1993; Reber, 1993; Perkovic and Orquin, 2017) and auditory-motor planning based on procedural knowledge (Pearce et al., 2010a,b; Norgaard, 2014). This suggests that the stochastic distribution calculated from musical improvisation may represent the musicians' implicit and statistical knowledge and individual creativity in music that has been developed via implicit learning. Few studies have investigated the relationship between musical improvisation and implicit knowledge. Here, this study proposed the computational model of improvisational creativity based on the framework of implicit statistical learning.
Computational Model of Musical Creativity
The computational model is often used to understand general music acquisition (Cilibrasi et al., 2004; Backer and van Kranenburg, 2005; Albrecht and Huron, 2012; Ito, 2012; Prince and Schmuckler, 2012; Albrecht and Shanahan, 2013; London, 2013), entropy-based music prediction (Manzara et al., 1992; Ian et al., 1994; Reis, 1999; Pearce and Wiggins, 2006; Cox, 2010), implicit learning, and the metal representation of implicit knowledge (Dubnov, 2010; Wang, 2010; Rohrmeier and Rebuschat, 2012). Particularly, Competitive Chunker (Servan-Schreiber and Anderson, 1990), PARSER (Perruchet and Vinter, 1998), Information Dynamics of Music (IDyOM) (Pearce, 2005; Pearce and Wiggins, 2012), and n-gram models (Pearce and Wiggins, 2004) underpin the hypothesis that music is acquired by extracting and concatenating chunks, which is a main theory of implicit learning and statistical learning. Although experimental approaches are necessary for understanding the real-world brain's function in music acquisition, the modeling approaches partially outperform experimental results under conditions that are impossible to replicate in an experimental approach. For example, they can directly verify much of the real-world music and time-course variation over long time periods (Daikoku, 2018a). Most experimental approaches use the specific paradigms, which are ecologically unrealistic and focus on the specific type of short-term learning effects (e.g., chord perception, prediction, and timing). Additionally, some modeling approaches calculate statistics in music and device models, and also evaluate the validities of these models by neurophysiological and behavioral experiments and provide possibilities of novel tasks for neural and behavioral experiments (Potter et al., 2007; Pearce et al., 2010a,b; Pearce and Wiggins, 2012). A combination of the two approaches is better because each can complement the weak points of the other approach (Daikoku, 2018b).
The n-gram models, which correspond to various-order Markov model (Markov, 1971), calculate TPs of sequences by chopping them into short fragments (n-grams) up to a size of n, and are frequently used in both experimental and computational approaches (Pearce and Wiggins, 2004; Daikoku, 2018b). The online musical production, however, is not the mere chopping of one type of length of sequence, but it is a dynamical prediction to maintain an aesthetic melody with various length of sequence, temporal, and spectral features, and harmony that interact with each other (Lerdahl and Jackendoff, 1983; Hauser et al., 2002; Jackendoff and Lerdahl, 2006). That is, the musical production is not restricted to a single stream of events or a hierarchy but, rather, they interact with various hierarchical structures. Previous computational (Conklin and Witten, 1995; Pearce and Wiggins, 2012) and neural studies (Daikoku and Yumoto, 2017) expanded the n-gram method to modeling the interaction of parallel streams and enhanced the predictive power. However, the model that suffices to explain musical creativity cannot still be devised. Nonetheless, the nth-order Markov models could explain that the prediction continually occurs with each state of sequence and that the entropy in the brain (i.e., the average surprise of outcomes sampled from a probability distribution, Applebaum, 2008) gradually decreases by exposure to musical sequences. Thus, the TP distribution sampled from music based on nth-order Markov models may refer to the characteristics of a composer's superficial-to-deep implicit knowledge: a high-probability transition in music may be one that a composer is more likely to predict and choose based on the latest n states, compared to a low-probability transition. The notion has also been neurophysiologically demonstrated by our previous studies (Daikoku et al., 2017b). The model has also been applied to develop artificial intelligence that give computers learning and decision-making abilities similar to that of the human brain, such as an automatic composition system (Raphael and Stoddard, 2004; Eigenfeldt, 2010; Boenn et al., 2012) and natural language processing (Brent, 1999; Manning and Schütze, 1999). Thus, the Markov model is used in the interdisciplinary realms of neuroscience, behavioral science, engineering, and informatics.
Temporal and Spectral Feature in Musical Creativity
Temporal and spectral features are important pieces of information for which to configure characteristics of each type of music (e.g., individuality, genre, and culture). Additionally, two types of information are not independent of each other, but rather they closely interact. Thus, the relationships between temporal (i.e., rhythm) and spectral (i.e., melody) structures are a large question to understand music creativity. Some researchers indicated that humans cannot learn temporal structure independent of spectral structure (Buchner and Steffens, 2001; Shin and Ivry, 2002; O'Reilly et al., 2008), whereas other researchers demonstrated temporal implicit learning independent of pitch information (Salidis, 2001; Ullén and Bengtsson, 2003; Karabanov and Ulle'n, 2008; Brandon et al., 2012) and vice versa (Daikoku et al., 2017d). Additionally, neurophysiological and psychological studies suggested that humans can learn relative rather than absolute temporal and spectral (Daikoku et al., 2014, 2015) patterns. Thus, the relationships between temporal and spectral features on musical creativity and implicit learning remains controversial. To the best of my knowledge, there are no integrated models that cover temporal and spectral features in musical creativity. The present study first provides the implicit-learning models that unify temporal and spectral features in musical improvisation. Additionally, this study investigated which information (spectral and temporal) and hierarchy (1st to 6th orders) represent the individualities of creativity. To comprehensively understand how musical creativity occurs in the human brain and how temporal and spectral features are integrated to constitute musical individuality, it is necessary to investigate the relationships between spectral and temporal statistics inherent in music via various-order hierarchical models.
Study Purpose
The present study aimed to investigate the statistical differences and interactions between the temporal and spectral structure in improvisation among musicians using various-order Markov models, and to examine which information (spectral and temporal) and hierarchy represent the individualities of musical creativity. The statistical characteristics of the nth-order TP distribution of the spectral (pitch) and temporal sequences (pitch length and rest) in improvisational music were investigated. It was hypothesized that there were general statistical characteristics shared among musicians and specific statistical characteristics that were unique to each musician in both spectral and temporal sequences. Additionally, it was hypothesized that the detectability of the characteristics depends on hierarchy. If so, the individuality may depend on the depth of implicit knowledge. Furthermore, the chronological time-course variations of the entropies (uncertainly) and the predictability of each tone sequence were examined. It was hypothesized that implicit knowledge in music gradually shifts over a composer's lifetime. The present study first provided the findings on which information (spectral and temporal) and hierarchy (1st to 6th orders) represent the individualities of musical creativity.
Methods
Music Information Extraction
The music played by William John Evans (Autumn Leaves from Portrait in Jazz, 1959; Israel from Explorations, February 1961; I Love You Porgy from Waltz for Debby, June 1961; Stella by Starlight from Conversations with Myself, 1963; Who Can I Turn To? from Bill Evans at Town Hall, 1966; Someday My Prince Will Come from the Montreux Jazz Festival, 1968; A Time for Love from Alone, 1969), Herbert Jeffrey Hancock (Cantaloupe Island from Empyrean Isles, 1964; Maiden Voyage from Flood, 1975; Someday My Prince Will Come from The Piano, 1978; Dolphin Dance from Herbie Hancock Trio'81, 1981; Thieves in the Temple from The New Standard, 1996; Cottontail from Gershwin's World, 1998; The Sorcerer from Directions in Music, 2001), and McCoy Tyner (Man from Tanganyika from Tender Moments, 1967; Folks from Echoes of a Friend, 1972; You Stepped Out of a Dream from Fly with the Wind, 1976; For Tomorrow from Inner Voice; 1977; The Habana Sun from The Legend of the Hour, 1981; Autumn Leaves from Revelations, 1988; Just in Time from Dimensions, 1984) were used in the present study. The highest pitches including the length were chosen based on the following definitions: the highest pitches that can be played at a given point in time, pitches with slurs that can be counted as one, and grace notes were excluded. In addition, the rests that were related to highest-pitch sequences were also extracted. This spectral and temporal information were divided into four types of sequences: (1) a pitch sequence without length and rest information (i.e., pitch sequence without rhythms); (2) a rhythm sequence without pitch information (i.e., rhythm sequence without pitches); (3) a pitch sequence with length and rest information (i.e., pitch sequence with rhythms); and (4) a rhythm sequence with pitch information (i.e., rhythm sequence with pitches).
Stochastic Calculation
Pitch Sequence Without Rhythms
For each type of pitch sequence, all pitches were numbered so that the first pitch was 0 in each transition, and an increase or decrease in a semitone was 1 and −1 based on the first pitch, respectively. Representative examples were shown in Figure 1A. This revealed the relative pitch-interval patterns but not the absolute pitch patterns [30, 98]. This procedure was used to eliminate the effects of the change in key on transitional patterns. Interpretation of the key change depends on the musician, and it is difficult to define in an objective manner. Thus, the results in the present study may represent a variation in the statistics associated with relative pitch rather than absolute pitch. According to recent neurophysiological studies, human's implicit-learning system of auditory sequence capture relative rather than absolute transition patterns. In each piece of music for each musician, the TPs of the pitch sequences were calculated as a statistic based on multi-order Markov chains. The probability of a forthcoming pitch was statistically defined by the last pitch to six successive pitches (i.e., first- to six-order Markov chains). The nth-order Markov model is based on the conditional probability of an element en+1, given the preceding n elements:
Rhythm Sequence Without Pitches
The onset times of each note were used for analyses. Although note onsets ignore the length of notes and rests, this methodology can capture the most essential rhythmic features of the music [30,99]. To extract a temporal interval between adjacent notes, all onset times were subtracted from the onset of the preceding note. Then, for each type of rhythm sequence, the second to last temporal interval was divided by the first temporal interval. Representative examples are shown in Figure 1B. This revealed relative rhythm patterns but not absolute rhythm patterns; it is independent of the tempo of each piece of music. In each piece of music in each musician, the TPs of the rhythm sequences were calculated as a statistic based on multi-order Markov chains. The probability of a forthcoming temporal interval was statistically defined by the last temporal interval to six successive temporal intervals, respectively (i.e., first- to six-order Markov chains).
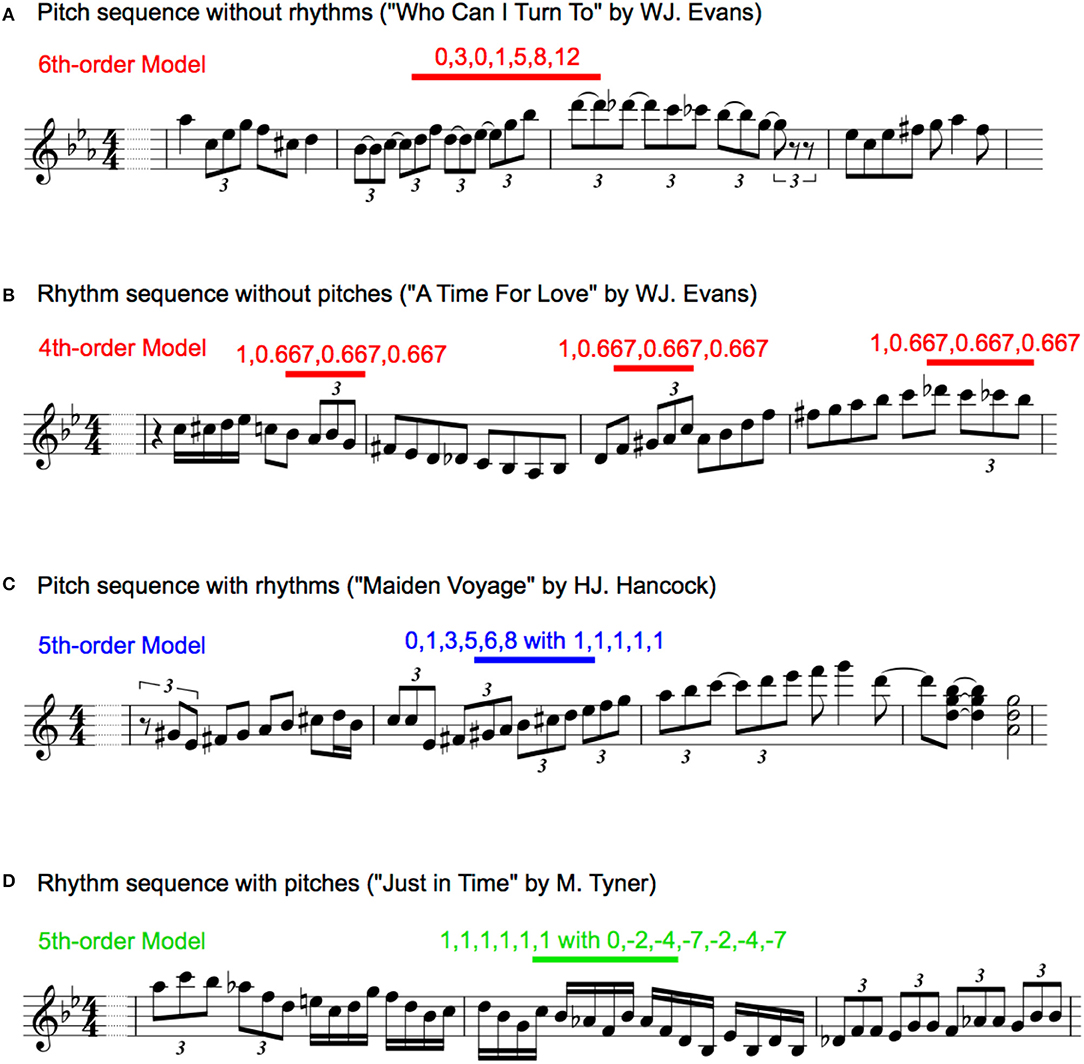
Figure 1. Representative phrases of transition patterns in pitch sequence without rhythms (A), rhythm sequences without pitches (B), pitch sequence with rhythms (C), and rhythm sequences with pitches (D). The musical information was extracted by listening music information recording media and originally written for the present study.
Pitch Sequence With Rhythms
The two methodologies of pitch and rhythm sequences were combined. For each type of sequence, all pitches were numbered so that the first pitch was 0 in each transition, and an increase or decrease in a semitone was 1 and −1 based on the first pitch, respectively. Additionally, for each type of pitch sequence, all onset times were subtracted from the onset of the preceding note, and the second to last temporal intervals were divided by the first temporal interval. The representative examples were shown in Figure 1C. For each piece of music for each musician, the TPs of the pitch sequences with rhythms were calculated as a statistic based on multi-order Markov chains. The probability of a forthcoming pitch with temporal information was statistically defined by the last pitch with temporal information to six successive pitches with temporal information, respectively (i.e., first- to six-order Markov chains). In the first-order hierarchical model of the pitch sequence with rhythms, a temporal interval was calculated as a ratio to the crotchet (i.e., quarter note), because only a temporal interval is included for each sequence and the note length cannot be calculated as a relative temporal interval. Thus, the patterns of pitch sequence (p) with rhythms (r) were represented as [p] with [r].
Rhythm Sequence With Pitches
The methodologies of sequence extraction were the same as those of the pitch sequence with rhythm (see Figure 1D), whereas the TPs of the rhythm, but not pitch, sequences were calculated as a statistic based on multi-order Markov chains. The probability of a forthcoming temporal interval with pitch was statistically defined by the last temporal interval with pitch to six successive temporal interval with pitch (i.e., first- to six-order Markov chains). Thus, the relative pattern of rhythm sequence (r) with pitches (p) were represented as [r] with [p].
Statistical Analysis
The TP distributions were analyzed by principal component analysis. The criteria of eigenvalue were set over 1. The first two components (i.e., the first and second highest cumulative contribution ratios) were adopted in the present study. Then, the information contents [I(en+1|en)] of TP were calculated based on information theory (Shannon, 1951). Furthermore, the conditional entropy [H(AB)] in n-order was calculated from information content:
where P(bj|ai) is a conditional probability of sequence “ai bj.” The entropy were chronologically ordered based on the time courses in which music is played in each musician. The time-course variations of the entropies were analyzed by multiple regression analyses using the stepwise method. The criteria of the variance inflation factor (VIF) and condition index (CI) were set at VIF < 2 and CI < 20 to confirm that there was no multi collinearity (Cohen et al., 2003).
Furthermore, in each musician, seven pieces of music were averaged in each type of sequence. The transitional patterns with first to fifth highest TPs in each musician, which show higher predictabilities in each musician, were used in the regression analyses. The transitional patterns were chronologically ordered based on the time courses in which music is played in each musician. The time-course variations of the TPs were analyzed by multiple regression analyses using the stepwise method. The criteria of the variance inflation factor (VIF) and condition index (CI) were set at VIF < 2 and CI < 20 to confirm that there was no multi collinearity.
The logit transformation was applied to normalize the TPs. Then, using the transitional patterns with first to fifth highest TPs in each musician, the repeated-measure analysis of variances (ANOVAs) with a between-factor player (WJ. Evans vs. HJ. Hancock vs. M. Tyner) and a within-factor sequences for each hierarchy of Markov model were conducted. When we detected significant effects, Bonferroni-corrected post-hoc tests were conducted for further analysis. Statistical significance levels were set at p = 0.05 for all analyses.
Results
PCA
Pitch Sequence Without Rhythms
The eigenvalue and percentages of variance, and the comulative variance and the eigenvectors for the principal components was shown in a Supplementary File. In the first-order hierarchical model (Figure 2A), the two components accounted for 91.445% of the total variance. All of the pieces of music loaded higher than.82 on component 1, suggesting that this explains the general component of jazz musical improvisation in three musicians. The eigenvectors of the pieces of music by W. J. Evans were higher than M. Tyner in component 2, suggesting that this explains a component of W. J. Evans or M. Tyner. The component of H. J. Hancock could not be detected. In the second-order hierarchical model, the two components accounted for 20.365% of the total variance. All of the pieces of music loaded higher than.18 on component 1, suggesting that this explains the general component of jazz musical improvisation in three musicians. In M. Tyner, the eigenvectors other than “The habana sun” were higher than W. J. Evans in component 2, suggesting that this explains a component of W. J. Evans or M. Tyner. The component of H. J. Hancock could not be detected. In the third-order hierarchical model, the two components accounted for 13.818% of the total variance. In H. J. Hancock and M. Tyner, the eigenvectors other than “Cotton tail” were lower than W. J. Evans in component 1, suggesting that this explains a component of W. J. Evans or a component combining H. J. Hancock and M. Tyner. No obvious difference among musicians could be detected in component 2. In the forth-, fifth-, and sixth-order hierarchical models, the two components accounted for 11.663, 10.968, and 10.586% of the total variance, respectively. The eigenvectors of the pieces of music by W. J. Evans were higher than H. J. Hancock and M. Tyner in component 1, suggesting that this explains a component of W. J. Evans or a component combining H. J. Hancock and M. Tyner. The eigenvectors of the pieces of music by H. J. Hancock were generally lower than W. J. Evans and M. Tyner in component 2, suggesting that this explains a weak component of H. J. Hancock or a component combining W. J. Evans and M. Tyner.
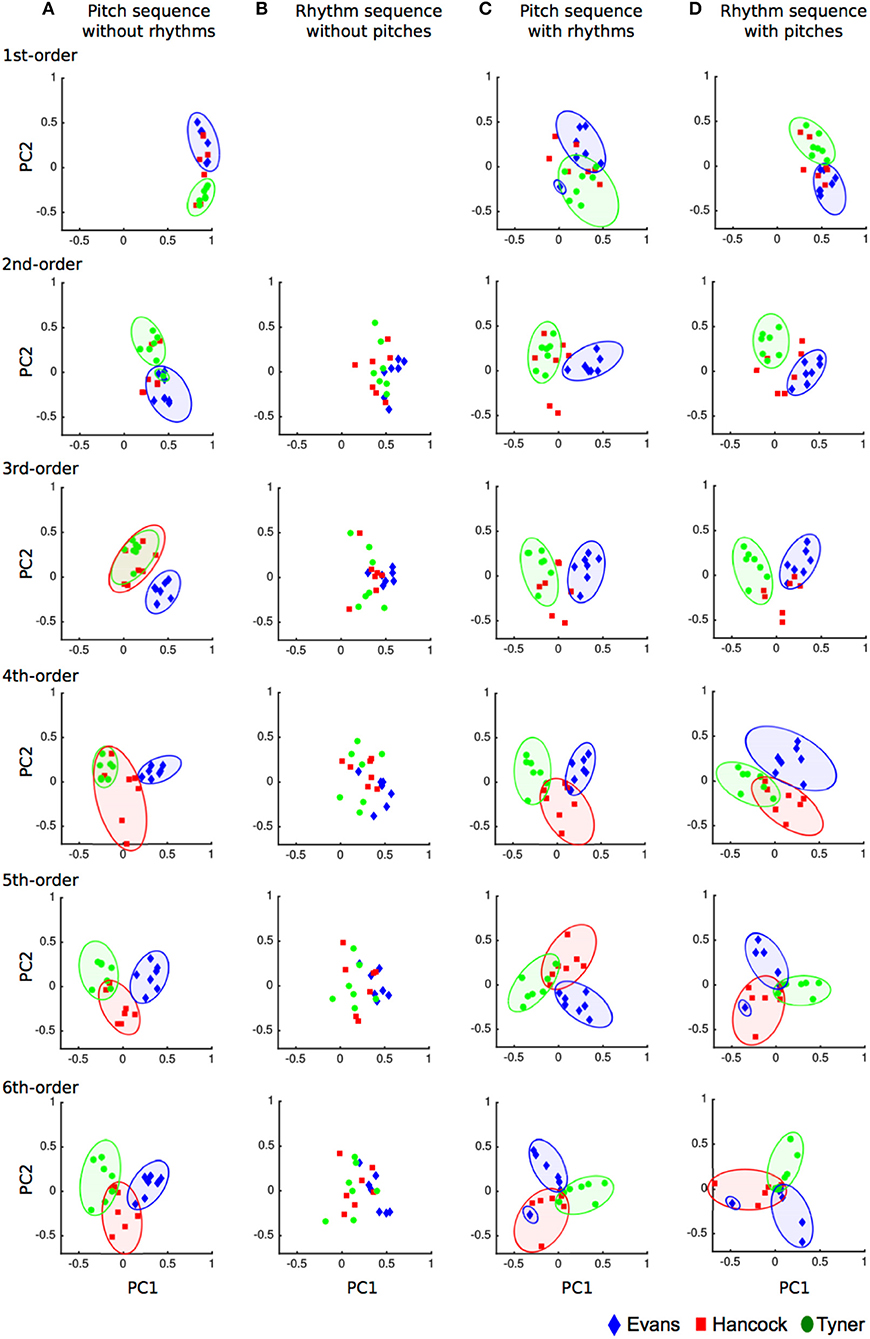
Figure 2. Principal component analysis scatter plots in pitch sequence without rhythms (A), rhythm sequences without pitches (B), pitch sequence with rhythms (C), and rhythm sequence with pitches (D). The horizontal and vertical axes represent principal component 1 and 2, respectively. The dots represent each piece of music.
Rhythm Sequence Without Pitches
In the first-order hierarchical model (Figure 2B), only one component, which accounted for 98.685% of the total variance, could be detected. The two components accounted for 91.445% of the total variance. All of the pieces of music loaded higher than.95 on the component, suggesting that this explains the general component of jazz musical improvisation in three musicians. In the second-, third-, forth, fifth-, and sixth-order hierarchical models, the two components accounted for 29.325, 20.985, 17.153, 14.780, and 13.376% of the total variance, respectively. No obvious difference among musicians could be detected in stochastic models of rhythms.
Pitch Sequence With Rhythms
In the first-order hierarchical models (Figure 2C), the two components accounted for 13.481% of the total variance. No obvious difference among musicians could be detected in component 1. In W. J. Evans, the eigenvectors other than “I love you porgy” were higher than M. Tyner in component 2, suggesting that this explains a component of W. J. Evans or M. Tyner. In the second-order hierarchical models, the two components accounted for 11.558% of the total variance. In W. J. Evans, the eigenvectors other than “I love you porgy” were higher than H. J. Hancock and M. Tyner in component 1, suggesting that this explains a component of W. J. Evans or a component combining H. J. Hancock and M. Tyner. No obvious difference among musicians could be detected in component 2. In the third-order hierarchical model, the two components accounted for 10.970% of the total variance. The eigenvectors of the pieces of music by W. J. Evans were higher than H. J. Hancock and M. Tyner in component 1, suggesting that this explains a component of W. J. Evans or a component combining H. J. Hancock and M. Tyner. No obvious difference among musicians could be detected in component 2. In the forth-order hierarchical model, the two components accounted for 10.774% of the total variance. In H. J. Hancock and M. Tyner, the eigenvectors other than “Dolphin dance” were lower than W. J. Evans in component 1, suggesting that this explains a component of W. J. Evans or a component combining H. J. Hancock and M. Tyner. The eigenvectors of the pieces of music by H. J. Hancock were generally lower than W. J. Evans and M. Tyner in component 2, suggesting that this explains a weak component of H. J. Hancock or a component combining W. J. Evans and M. Tyner. In the fifth-order hierarchical model, the two components accounted for 10.515% of the total variance. The eigenvectors of the pieces of music by W. J. Evans were higher than M. Tyner in component 1 and lower than H. J. Hancock in component 2, suggesting that these explain components of W. J. Evans, M. Tyner, and H. J. Hancock. In the sixth-order hierarchical model, the two components accounted for 10.344% of the total variance. In M. Tyner, the eigenvectors other than “For tomorrow” were higher than W. J. Evans and H. J. Hancock in component 1, suggesting that this explains a component of M. Tyner or a component combining W. J. Evans and H. J. Hancock. In W. J. Evans, the eigenvectors other than “Israel” were higher than H. J. Hancock in component 2, suggesting that these explain components of W. J. Evans or H. J. Hancock.
Rhythm Sequence With Pitches
In the first-order hierarchical model (Figure 2D), the two components accounted for 27.736% of the total variance. All of the pieces of music loaded higher than.25 on component 1, suggesting that this explains the general component of jazz musical improvisation in three musicians. The eigenvectors of the pieces of music by W. J. Evans were lower than M. Tyner in component 2, suggesting that this explains a component of W. J. Evans or M. Tyner. In the second-order hierarchical model, the two components accounted for 12.561% of the total variance. The eigenvectors of the pieces of music by W. J. Evans were higher than M. Tyner in component 1, suggesting that this explains a component of W. J. Evans or M. Tyner. No obvious difference among musicians could be detected in component 2. In the third- and forth-order hierarchical models, the two components accounted for 11.135 and 10.658% of the total variance, respectively. The eigenvectors of the pieces of music by W. J. Evans were higher than M. Tyner in component 1, suggesting that this explains a component of W. J. Evans or M. Tyner. In W. J. Evans, the eigenvectors other than “I love you porgy” in the third- and “Israel” in the forth-order hierarchical models were higher than H. J. Hancock in component 2, suggesting that this explains a component of W. J. Evans or H. J. Hancock. In the fifth-order hierarchical model, the two components accounted for 10.386% of the total variance. In M. Tyner, the eigenvectors other than “Autumn leaves” were higher than W. J. Evans in component 1, suggesting that this explains a component of W. J. Evans or M. Tyner. Tyner. The eigenvectors of the pieces of music by H. J. Hancock were generally lower than W. J. Evans and M. Tyner in component 2, suggesting that this explains a weak component of H. J. Hancock or a component combining W. J. Evans and M. Tyner. In the sixth-order hierarchical model, the two components accounted for 10.269% of the total variance. In H. J. Hancock, the eigenvectors other than “The sorcerer” were lower than M. Tyner in component 1, suggesting that this explains a weak component of H. J. Hancock or M. Tyner. In W. J. Evans, the eigenvectors other than “I love you porgy” were lower than M. Tyner in component 2, suggesting that this explains a weak component of W. J. Evans or M. Tyner.
Anova
Pitch Sequence Without Rhythms
In the first-order hierarchical models, the main sequence effect were significant [F(2.99, 53.84) = 7.51, p < 0.001, partial η2 = 0.29, Table 1A]. The main musician effect were significant [F(2, 18) = 4.29, p = 0.030, partial η2 = 0.32]. The TPs in W. J. Evans were significantly higher than those in M. Tyner (p = 0.046). The musician-sequence interactions were significant [F(12) = 6.54, p < 0.001, partial η2 = 0.42, Figure 3 and Tables 1B–D]. The TP of [0, −1] was significantly higher in W. J. Evans than M. Tyner (p = 0.008). The TP of [0, 0] was significantly lower in W. J. Evans than M. Tyner (p = 0.043). The TP of [0, 1] was significantly higher in W. J. Evans than H. J. Hancock (p = 0.003) and M. Tyner (p < 0.001). In the second-order hierarchical models, the main musician effect were significant [F(2, 18) = 7.11, p = 0.005, partial η2 = 0.44]. The TPs in M. Tyner were significantly lower than those in W. J. Evans (p = 0.006) and H. J. Hancock (p = 0.041). The musician-sequence interactions were significant [F(20) = 3.72, p < 0.001, partial η2 = 0.29, Figure 3 and Tables 1B–D]. The TP of [0, −1, −2] was significantly lower in M. Tyner than W. J. Evans (p = 0.006) and H. J. Hancock (p = 0.042). The TP of [0, −2, −3] was significantly higher in W. J. Evans than H. J. Hancock (p = 0.033) and M. Tyner (p < 0.001), and higher in H. J. Hancock than M. Tyner (p = 0.027). The TP of [0, −2, 0] was significantly higher in M. Tyner than W. J. Evans (p = 0.047). The TP of [0, 2, 3] was significantly higher in W. J. Evans than H. J. Hancock (p = 0.005) and M. Tyner (p < 0.001). In the third-order hierarchical models, the main sequence effect were significant [F(5.13, 10.26) = 5.00, p < 0.001, partial η2 = 0.22, Table 1A]. The musician-sequence interactions were significant [F(24) = 3.89, p < 0.001, partial η2 = 0.30, Figure 3 and Tables 1B–D]. The TP of [0, −1, −2, −3] was significantly lower in M. Tyner than W. J. Evans (p < 0.001) and H. J. Hancock (p = 0.008). The TP of [0, −1, −3, −4] was significantly lower in M. Tyner than W. J. Evans (p = 0.003). The TP of [0, −3, −7, −5] was significantly higher in M. Tyner than W. J. Evans (p = 0.040) and H. J. Hancock (p = 0.009). The TP of [0, 0, 0, 0] was significantly lower in W. J. Evans than H. J. Hancock (p = 0.037) and M. Tyner (p = 0.012). The TP of [0, 1, 3, 4] was significantly higher in W. J. Evans than H. J. Hancock (p < 0.001) and M. Tyner (p < 0.001). The TP of [0, 2, 4, 5] was significantly higher in W. J. Evans than H. J. Hancock (p = 0.034) and M. Tyner (p < 0.001), and higher in H. J. Hancock than M. Tyner (p = 0.021). In the forth-order hierarchical models, the main sequence effect were significant [F(4.65, 9.30) = 2.40, p = 0.048, partial η2 = 0.12, Table 1A]. The musician-sequence interactions were significant [F(26) = 5.92, p < 0.001, partial η2 = 0.40, Figure 3 and Tables 1B–D]. The TP of [0, −1, −2, −3, −4] was significantly higher in W. J. Evans than H. J. Hancock (p = 0.015) and M. Tyner (p < 0.001), and higher in H. J. Hancock than M. Tyner (p = 0.024). The TP of [0, −2, −4, 0, −2] was significantly higher in M. Tyner than W. J. Evans (p = 0.008) and H. J. Hancock (p = 0.042). The TP of [0, −3, −2, 2, 5] was significantly higher in W. J. Evans than H. J. Hancock (p < 0.001) and M. Tyner (p < 0.001). The TP of [0, 1, 5, 8, 12] was significantly higher in W. J. Evans than M. Tyner (p = 0.004). The TP of [0,2,3,5,6] was significantly higher in W. J. Evans than H. J. Hancock (p = 0.006) and M. Tyner (p < 0.001). The TP of [0, 5, 3, 0, −4] was significantly higher in M. Tyner than W. J. Evans (p = 0.004) and H. J. Hancock (p = 0.001). In W. J. Evans, the TPs of [0, −3, −2, 2, 5] was significantly higher than those of [0, −1, −2, −3, −4] (p < 0.001), [0, −2, −4,0, −2] (p < 0.001), [0, −2,2,0, −2] (p < 0.001), [0, −3,2,0, −3] (p = 0.021), [0, 0, 0, 0, 0] (p < 0.001), [0, 1, 3, 5, 6] (p < 0.001), [0, 2, 3, 5, 6] (p < 0.001), [0, 2, 3, 5, 7] (p = 0.002), [0, 2, 4, 6, 8] (p < 0.001), and [0,5,3,0, −4] (p < 0.001). The TPs of [0,0,0,0,0] was significantly lower than those of [0, −1, −2, −3, −4] (p = 0.002) and [0, 1, 5, 8, 12] (p = 0.045). The TPs of [0,2,4,6,8] was significantly lower than those of [0, −1, −2, −3, −4] (p < 0.001), [0, 1, 3, 4, 6] (p = 0.008), [0, 1, 5, 8, 12] (p = 0.003), and [0, 2, 3, 5, 6] (p = 0.008). In the fifth-order hierarchical models, the main musician effect were significant [F(2, 18) = 4.13, p = 0.033, partial η2 = 0.32]. The TPs in M. Tyner were significantly lower than those in W. J. Evans (p = 0.006) and H. J. Hancock (p = 0.041). The musician-sequence interactions were significant [F(28) = 7.07, p < 0.001, partial η2 = 0.44, Figure 3 and Tables 1B–D]. The TP of [0, −2, −4,−7, −2, −4] was significantly higher in M. Tyner than W. J. Evans (p = 0.008) and H. J. Hancock (p = 0.008). The TP of [0, −2, −4,0, −2, −4], [0, 1, 3, 4, 6, 7], and [0, 3, 0, 1, 5, 8] was significantly higher in M. Tyner than W. J. Evans (p = 0.022). The TP of [0, −3, −2, 2, 5, 9] was significantly higher in W. J. Evans than and H. J. Hancock and M. Tyner (all: p < 0.001). The TP of [0, 1, 3, 5, 6, 8] was significantly lower in H. J. Hancock than M. Tyner (p = 0.022). In the sixth-order hierarchical models, the musician-sequence interactions were significant [F(28) = 5.09, p < 0.001, partial η2 = 0.36, Figure 3 and Tables 1B–D]. The TP of [0, −1, −2, −3, −4, −5, −6] was significantly lower in M. Tyner than W. J. Evans (p = 0.037). The TP of [0, −2, −4, −7, −2, −4, −7] was significantly higher in M. Tyner than W. J. Evans (p = 0.014) and H. J. Hancock (p = 0.014). The TP of [0, 3, 0, 1, 5, 8, 12] and [0, 4, 7, 4, 5, 9, 12] was significantly higher in W. J. Evans than H. J. Hancock and M. Tyner (p < 0.001).

Table 1. The difference in TPs among pitch sequences without rhythms in each musician.
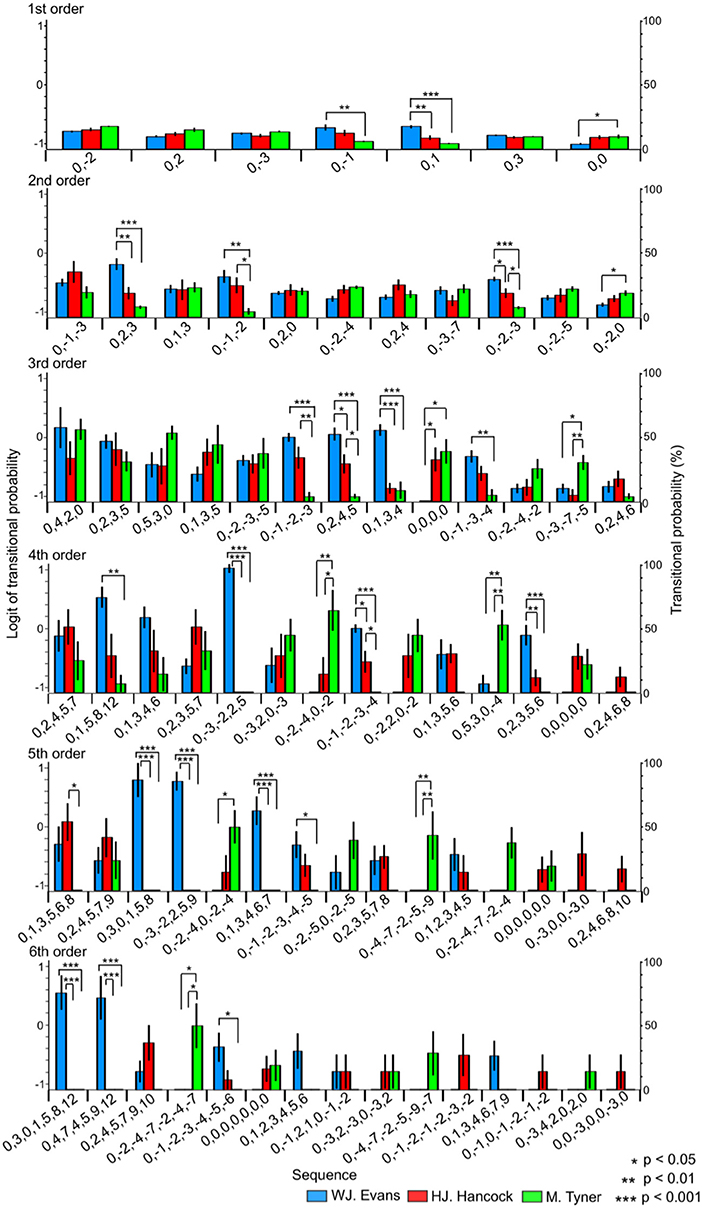
Figure 3. The difference in TPs among W.J. Evans (red), H.J. Hancock (blue), and M. Tyner (green) in pitch sequence without rhythms.
Rhythm Sequence Without Pitches
In the first-order hierarchical models, the main sequence effect were significant [F(1.24, 22.36) = 553.50, p < 0.001, partial η2 = 0.97, Table 2A]. The musician-sequence interactions were significant [F(12) = 2.03, p = 0.028, partial η2 = 0.18, Figure 4, Tables 2B–D]. The TP of [1, 3] was significantly higher in M. Tyner than W. J. Evans (p = 0.015) and H. J. Hancock (p = 0.023). The TP of [1, 0.333] was significantly higher in M. Tyner than W. J. Evans (p = 0.006) and H. J. Hancock (p = 0.002). In the second-order hierarchical models, the main sequence effect were significant [F(2.09, 37.68) = 74.54, p < 0.001, partial η2 = 0.81, Table 2A]. The musician-sequence interactions were significant [F(12) = 2.07, p = 0.025, partial η2 = 0.19, Figure 4, Tables 2B–D]. The TP of [1, 0.333] was significantly higher in H. J. Hancock than W. J. Evans (p = 0.015). In W. J. Evans, the TPs of [1, 1, 1] was significantly higher than those of [1, 0.5, 1], [1, 1, 1.5], [1, 1, 2], [1, 2, 1], and [1, 2, 2] (all: p < 0.001). The TPs of [1,0.5,0.5] was significantly higher than those of [1, 0.5, 1] (p = 0.013), [1,1,1.5] (p < 0.001), [1, 1, 2] (p < 0.001), and [1, 2, 2] (p = 0.003). The TPs of [1, 2, 1] was significantly higher than [1, 0.5, 1] (p = 0.034), [1, 1, 1.5] (p < 0.001), and [1, 1, 2] (p = 0.001). The TPs of [1, 2, 1] was significantly higher than [1, 1, 1.5] (p < 0.001) and [1, 1, 2] (p < 0.001). In H. J. Hancock, the TPs of [1, 1, 1] was significantly higher than those of [1, 0.5, 1], [1, 1, 1.5], [1, 1, 2], [1, 2, 1], and [1, 2, 2] (all: p < 0.001). The TPs of [1, 0.5, 0.5] was significantly higher than those of [1, 1, 1.5] (p < 0.001) and [1, 1, 2] (p = 0.001). The TPs of [1, 2, 1] was significantly higher than [1, 2, 2] (p = 0.027), [1, 0.5, 1] (p = 0.038), [1, 1, 1.5] (p < 0.001), and [1, 1, 2] (p < 0.001). The TPs of [1, 2, 2] was significantly higher than [1, 1, 1.5] (p < 0.001) and [1, 1, 2] (p = 0.037). The TPs of [1, 1, 1.5] was significantly lower than those of [1, 1, 2] (p = 0.006) and [1, 0.5, 1] (p = 0.015). In the third-order hierarchical models, the main sequence effect were significant [F(2.80, 50.41) = 45.17, p < 0.001, partial η2 = 0.72, Table 2A]. The musician-sequence interactions were significant [F(14) = 2.58, p = 0.03, partial η2 = 0.22, Figure 4, Tables 2B–D]. The TP of [1,0.667, 0.667, 0.667] was significantly higher in W. J. Evans than H. J. Hancock (p = 0.016). The TP of [1, 1, 1, 1.5] was significantly higher in W. J. Evans than H. J. Hancock (p = 0.002) and M. Tyner (p = 0.043). In the forth-order hierarchical models, the main sequence effect were significant [F(2.62, 47.21) = 22.03, p < 0.001, partial η2 = 0.55, Table 2A]. In the fifth-order hierarchical models, the main sequence effect were significant [F(3.02, 54.32) = 16.21, p < 0.001, partial η2 = 0.47, Table 2A]. The musician-sequence interactions were significant [F(16) = 2.11, p = 0.011, partial η2 = 0.19, Figure 4, Tables 2B–D]. In the sixth-order hierarchical models, the main sequence effect were significant [F(3.28, 59.06) = 17.89, p < 0.001, partial η2 = 0.50, Table 2A]. The musician-sequence interactions were significant [F(16) = 2.22, p = 0.007, partial η2 = 0.20, Figure 4 and Tables 2B–D].

Table 2. The difference in TPs among rhythm sequences without pitches in each musician.
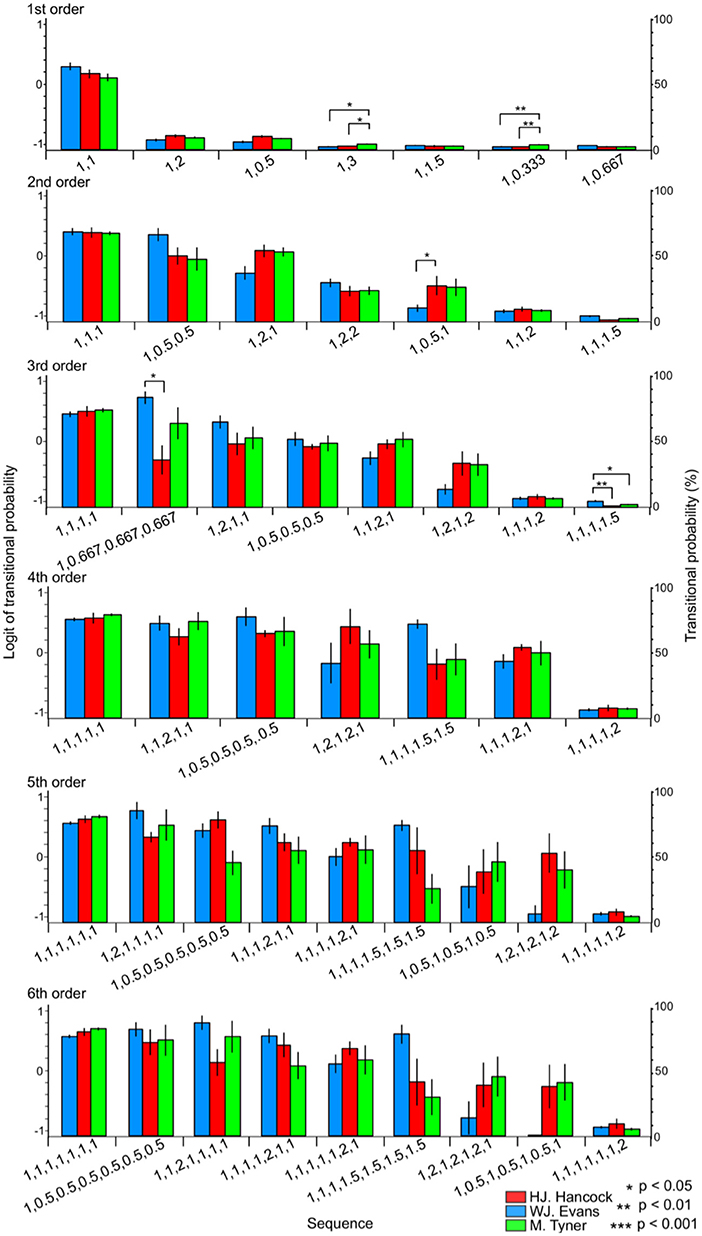
Figure 4. The difference in TPs among W.J. Evans (red), H.J. Hancock (blue), and M. Tyner (green) in rhythm sequences without pitches.
Pitch Sequence With Rhythms
The relative pattern of Pitch sequence (p) with rhythms (r) were represented as [p] with [r]. In the first-order hierarchical models, the musician-sequence interactions were significant [F(28) = 1.89, p = 0.006, partial η2 = 0.17, Figure 5]. The TP of [0, 1] with [0.5] was significantly higher in W. J. Evans than H. J. Hancock and M. Tyner (p < 0.001). In the second-order hierarchical models, the musician-sequence interactions were significant [F(28) = 3.58, p = 0.006, partial η2 = 0.28, Figure 5]. The TP of [0, −1, −2] with [1, 0.5], [0, 4,7] with [1, 0.5], and [0, −3, −2] with [1, 1.5] was significantly higher in W. J. Evans than M. Tyner (p = 0.031, p = 0.038, and p = 0.023, respectively). The TP of [0, 4, 7] with [1,1] was significantly higher in W. J. Evans than H. J. Hancock and M. Tyner (p < 0.001). The TP of [0, 7, 0] with [1, 1] was significantly higher in H. J. Hancock than M. Tyner (p = 0.029). The TP of [0, 4, 2] with [1, 2] was significantly higher in M. Tyner than W. J. Evans (p = 0.005) and H. J. Hancock (p = 0.007). The TP of [0, 2, 0] with [1, 3] was significantly higher in H. J. Hancock than W. J. Evans (p = 0.043). In the third-order hierarchical models, the musician-sequence interactions were significant [F(28) = 4.91, p < 0.001, partial η2 = 0.35, Tables 3A,B and Figure 5]. The TP of [0, −1, −2, −3] with [1,0.5,0.5] was significantly higher in W. J. Evans than H. J. Hancock (p = 0.036) and M. Tyner (p = 0.007). The TP of [0, −2, −5, −7] with [1, 1, 1] was significantly lower in W. J. Evans than H. J. Hancock (p = 0.042). The TP of [0, −2, 2, 0] with [1, 1, 1], and [0, 5, 3, 0] with [1, 1, 1] was significantly higher in M. Tyner than W. J. Evans (p = 0.039 and p = 0.004, respectively). The TP of [0, −4, 3, 0] with [1, 1, 1] was significantly higher in M. Tyner than W. J. Evans (p = 0.031) and H. J. Hancock (p = 0.013). The TP of [0, 1, 5, 8] with [1, 1, 1] was significantly higher in W. J. Evans than H. J. Hancock (p = 0.011) and M. Tyner (p < 0.001). The TP of [0, 2, 4, 5] with [1, 1, 1] was significantly lower in M. Tyner than W. J. Evans (p < 0.001) and H. J. Hancock (p = 0.041). The TP of [0, 3, 0, 1] with [1, 1, 1] was significantly higher in W. J. Evans than H. J. Hancock (p = 0.027) and M. Tyner (p = 0.001). The TP of [0, 7, 4, 5] with [1, 1, 1] was significantly higher in W. J. Evans than H. J. Hancock (p = 0.027) and M. Tyner (p = 0.001). In the forth-order hierarchical models, the musician-sequence interactions were significant [F(28) = 6.90, p < 0.001, partial η2 = 0.43, Tables 3A,B and Figure 5]. The TP of [0, −2, −3, −5, −6] with [1, 1, 1, 1], and [0, 1, 5, 8, 12] with [1, 1, 1, 1] was significantly lower in M. Tyner than W. J. Evans (all: p = 0.002). The TP of [0, −2, −4, 0, −2] with [1, 1, 1, 1], [0, −3, −7, −5, −3] with [1, 1, 1, 1], and [0, −3, 2, −1,−5] with [1, 1, 1, 1] was significantly higher in M. Tyner than W. J. Evans and H. J. Hancock (p = 0.008, p = 0.001, and p = 0.014, respectively). The TP of [0, −3, −2, 2, 5] with [1, 1, 1, 1] was significantly higher in W. J. Evans than H. J. Hancock (p = 0.009) and M. Tyner (p = 0.002). The TP of [0, −3, −2, 2, 5] with [1, 1, 1, 1] was significantly higher in W. J. Evans than H. J. Hancock and M. Tyner (all: p < 0.001). The TP of [0, −3, −5, −7, −5] with [1, 1, 1, 1] was significantly higher in M. Tyner than W. J. Evans (p = 0.017). The TP of [0, −3, −2, 2, 5] with [1, 1, 1, 1] was significantly higher in W. J. Evans than H. J. Hancock (p = 0.002) and M. Tyner (p < 0.001). The TP of [0, −3, −2, 2, 5] with [1, 1, 1, 1] was significantly higher in H. J. Hancock than M. Tyner (p = 0.035). In the fifth-order hierarchical models, the musician-sequence interactions were significant [F(28) = 6.38, p < 0.001, partial η2 = 0.42, Tables 3A,B and Figure 5]. The TP of [0, −2, −3, −4, −5, −6] with [1, 1, 1, 1, 1], and [0, 1, 3, 5, 6, 8] with [1, 1, 1, 1, 1] was significantly lower in M. Tyner than H. J. Hancock (p = 0.022 and p = 0.035, respectively). The TP of [0, −2, −4, 0, −2, −4] with [1, 1, 1, 1, 1], and [0, −2, −5, 0, −2, −5] with [1, 1, 1, 1, 1] was significantly higher in M. Tyner than W. J. Evans and H. J. Hancock (all: p = 0.014). The TP of [0, −3, −2, 2, 5, 9] with [1, 1, 1, 1, 1], [0, 1, 3, 4, 6, 7] with [1, 1, 1, 1, 1], and [0,3,0,1,5,8] with [1, 1, 1, 1, 1] was significantly higher in Evans than H. J. Hancock and M. Tyner (all: p < 0.001). In the sixth-order hierarchical models, the musician-sequence interactions were significant [F(28) = 4.20, p < 0.001, partial η2 = 0.32, Tables 3A,B and Figure 4]. The TP of [0, −2, −4, −7, −2, −4, −7] with [1, 1, 1, 1, 1, 1] was significantly higher in M. Tyner than W. J. Evans and H. J. Hancock (all: p = 0.014). The TP of [0, 3, 0, 1, 5, 8, 12] with [1, 1, 1, 1, 1, 1] was significantly higher in W. J. Evans than H. J. Hancock and M. Tyner (all: p = 0.001).
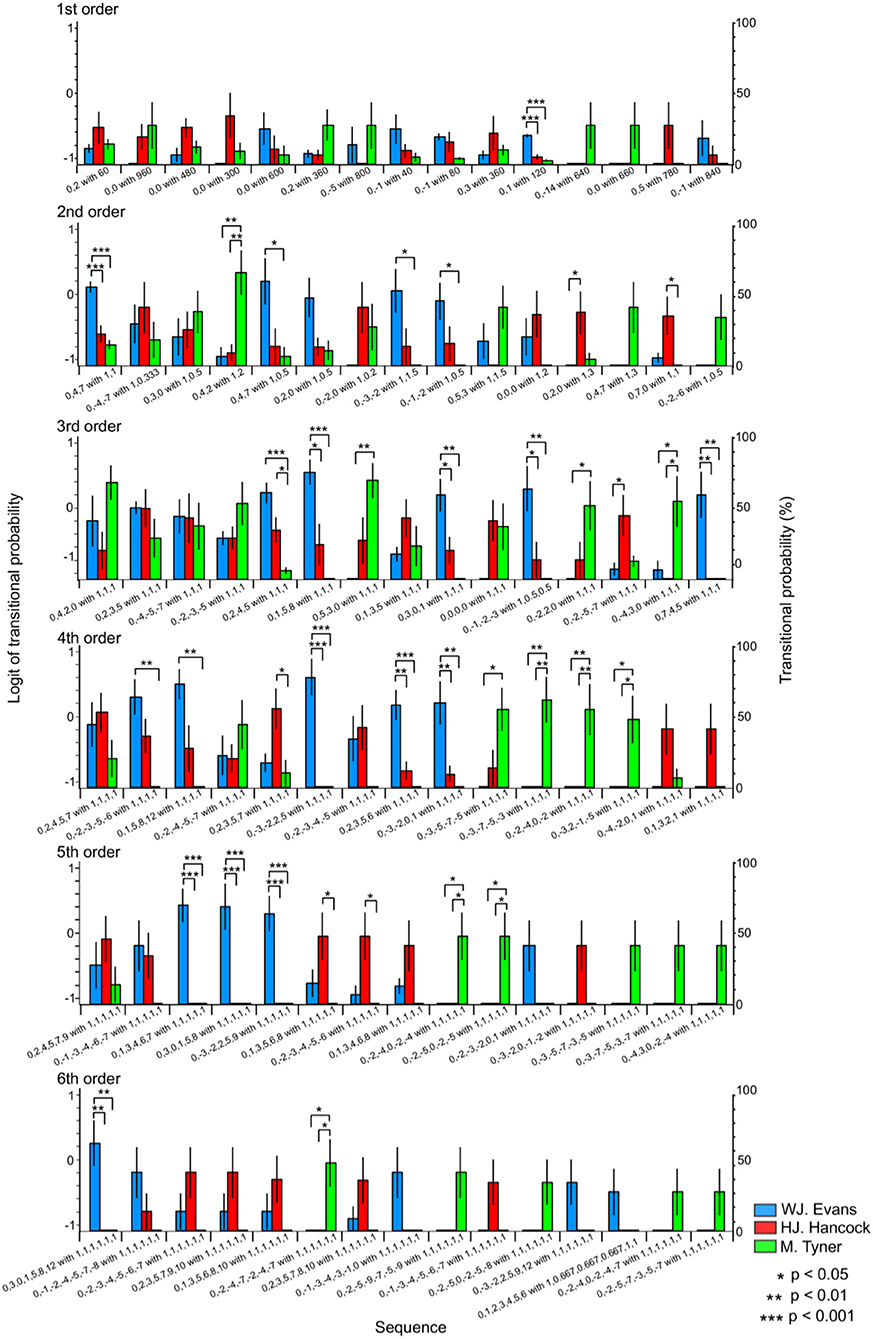
Figure 5. The difference in TPs among W.J. Evans (red), H.J. Hancock (blue), and M. Tyner (green) in pitch sequence with rhythms.

Table 3. The difference in TPs among pitch sequences with rhythms in each musician.
Rhythm Sequence With Pitches
In the first-order hierarchical models, the main sequence effect were significant [F(13, 234) = 4.45, p < 0.001, partial η2 = 0.20, Table 4]. The musician-sequence interactions were significant [F(26) = 3.54, p < 0.001, partial η2 = 0.28, Figure 6 and Table 4]. The TP of [1,1] with [0, −3, −6] was significantly lower in W. J. Evans than M. Tyner (p = 0.037). The TP of [1, 1] with [0, −4, −6], and [1,1] with [0, 3, 6] was significantly higher in W. J. Evans than M. Tyner (all: p = 0.025). The TP of [1, 1] with [0, 4, 6] was significantly higher in M. Tyner than W. J. Evans (p = 0.001) and H. J. Hancock (p = 0.004). In the second-order hierarchical models, the musician-sequence interactions were significant [F(24) = 5.53, p < 0.001, partial η2 = 0.42, Figure 6 and Table 4]. The TP of [1, 1, 1] with [0, −1, −3, −4] was significantly lower in M. Tyner than W. J. Evans (p < 0.001) and H. J. Hancock (p = 0.001). The TP of [1, 1, 1] with [0, −2, −4, −2], [1, 1, 1] with [0, −3, −7, −5] was significantly higher in M. Tyner than W. J. Evans and H. J. Hancock (p < 0.001). The TP of [1, 1, 1] with [0, −1, −3, −4] was significantly lower in H. J. Hancock than W. J. Evans (p = 0.007) and M. Tyner (p = 0.001). The TP of [1, 1, 1] with [0, −2, −4, −2], and [1, 1, 1] with [0, −3, −7, −5] was significantly higher in W. J. Evans than H. J. Hancock (p = 0.005) and M. Tyner (p < 0.001). The TP of [1, 1, 1] with [0, 2, 4, 5] was significantly lower in M. Tyner than W. J. Evans (p = 0.048). The TP of [1, 1, 1] with [0, 5, 3, 0] was significantly higher in M. Tyner than W. J. Evans (p = 0.002). In the third-order hierarchical models, the main sequence effect were significant [F(5.05, 90.90) = 2.91, p = 0.017, partial η2 = 0.14, Table 4]. The musician-sequence interactions were significant [F(26) = 5.88, p < 0.001, partial η2 = 0.40, Figure 6 and Table 4]. The TP of [1, 1, 1, 1] with [0, −1, −2, −3, −4] was significantly lower in M. Tyner than W. J. Evans (p = 0.040) and H. J. Hancock (p = 0.046). The TP of [1, 1, 1, 1] with [0, −2, −4, −7, −2], [1, 1, 1, 1] with [0, −2, 2, 0, −2] were significantly higher in M. Tyner than W. J. Evans (p = 0.008 and p = 0.015, respectively) and H. J. Hancock (p = 0.008 and p = 0.015, respectively). The TP of [1, 1, 1, 1] with [0, −3, −2, 2, 5] was significantly higher in W. J. Evans than H. J. Hancock and M. Tyner (all: p = 0.001). The TP of [1, 1, 1, 1] with [0, −3, 2, 0, −3] was significantly lower in W. J. Evans than M. Tyner (p = 0.038). The TP of [1, 1, 1, 1] with [0, 1, 3, 4, 6], and [1, 1, 1, 1] with [0, 2, 3, 5, 6] was significantly higher in W. J. Evans than M. Tyner (p = 0.046 and p = 0.002, respectively). The TP of [1, 1, 1, 1] with [0, 1, 5, 8, 12] was significantly higher in W. J. Evans than H. J. Hancock (p = 0.006) and M. Tyner (p < 0.001). In the forth-order hierarchical models, musician-sequence interactions were significant [F(28) = 5.58, p < 0.001, partial η2 = 0.38, Figure 6 and Table 4]. The TP of [1, 1, 1, 1, 1] with [0, −2, −4, −7, −2, −4], and [1, 1, 1, 1, 1] with [0, −2, −5, 0, −2, −5] were significantly higher in M. Tyner than W. J. Evans and H. J. Hancock (all: p = 0.008). The TP of [1, 1, 1, 1, 1] with [0, −3, −2, 2, 5, 9], [1, 1, 1, 1, 1] with [0, 1, 3, 4, 6, 7], and [1, 1, 1, 1, 1] with [0, 3, 0, 1, 5, 8], were significantly higher in W. J. Evans than H. J. Hancock and M. Tyner (all: p < 0.001). In the fifth-order hierarchical models, the musician-sequence interactions were significant [F(28) = 2.31, p < 0.001, partial η2 = 0.21, Figure 6 and Table 4]. The TP of [1, 1, 1, 1, 1, 1] with [0, −2, −4, −7, −2, −4, −7] was significantly higher in M. Tyner than W. J. Evans and H. J. Hancock (all: p = 0.008).

Table 4. The difference in TPs among rhythm sequences with pitches in each musician.
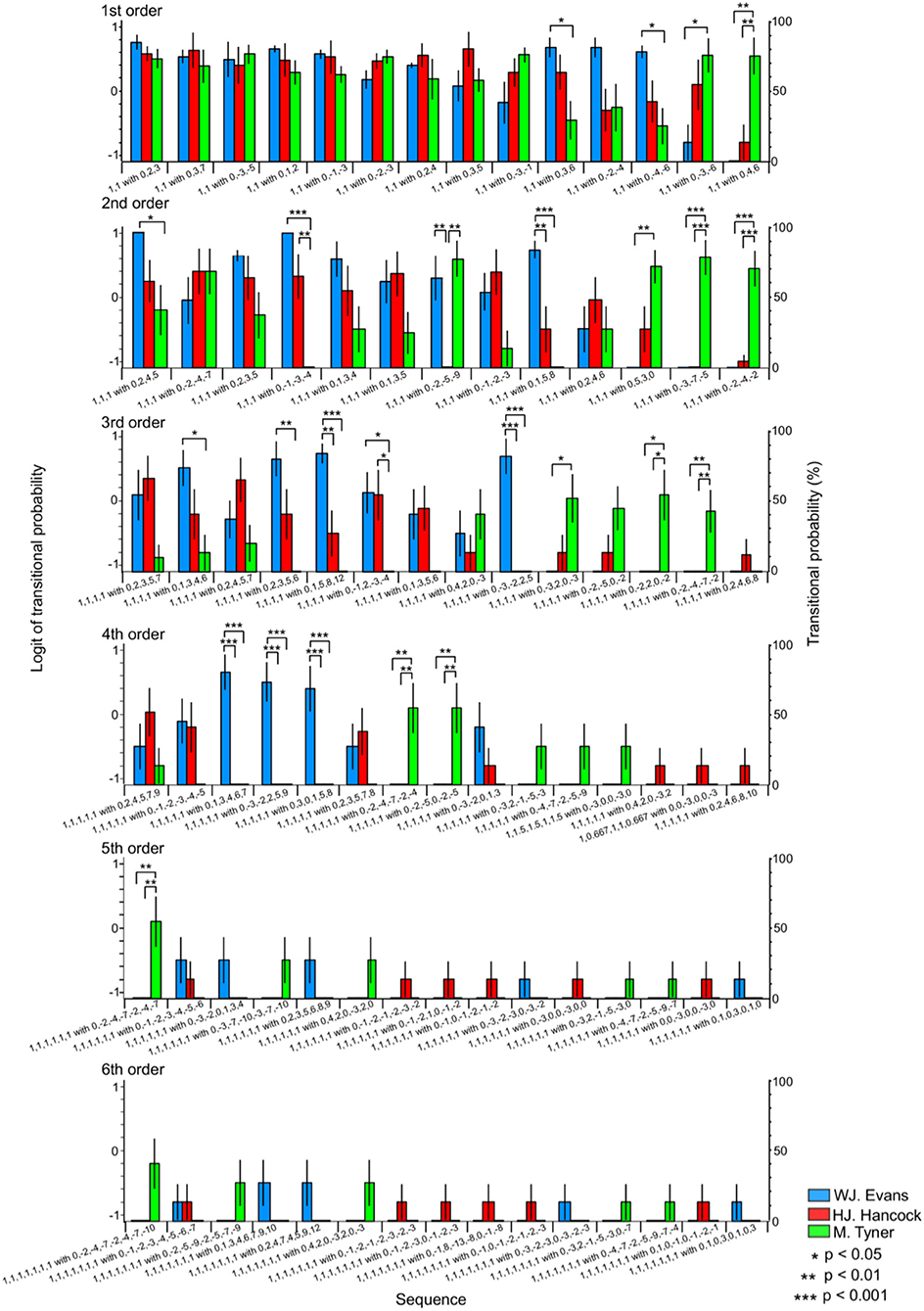
Figure 6. The difference in TPs among W.J. Evans (red), H.J. Hancock (blue), and M. Tyner (green) in rhythm sequence with pitches.
Regression Analysis
Pitch Sequence Without Rhythms
Results were shown in Table 5A. In W. J. Evans, no significant regression equation was detected in the first-, second-, forth-, and sixth-order hierarchical models. In the third-order hierarchical model, a significant regression equation was found [F(2, 4) = 16.19, p = 0.012], with an adjusted R2 of 0.84. The predicted chronological order is equal to 9.43–17.98 (transition of [0, −3, −7, −5]) −7.23 (transition of [0, 2, 4, 5]). The TPs of [0, 2, 4, 5] and [0, −3, −7, −5] gradually decreased consistently with the ascending chronological order ([0, −3, −7, −5] p = 0.007, [0, 2, 4, 5] p = 0.031). In the fifth-order hierarchical model, a significant regression equation was found [F(1, 5) = 14.74, p = 0.012], with an adjusted R2 of 0.70. The predicted chronological order is equal to 5.33–9.31 (transition of [0, 2, 3, 5, 7, 8]). The TPs of [0, 2, 3, 5, 7, 8] gradually decreased consistently with the ascending chronological order (p = 0.012). In H. J. Hancock, no significant regression equation was detected in all of the hierarchical models. In M. Tyner, no significant regression equation was detected in the first-, third-, forth-, fifth-, and sixth-order hierarchical models. Only in the second-order hierarchical model, a significant regression equation was found [F(2, 4) = 31.04, p = 0.004], with an adjusted R2 of 0.91. The predicted chronological order is equal to −3.68 + 28.30 (transition of [0, −2, −5]) + 10.59 (transition of [0, 2, 0]). The TPs of [0, −2, −5] and [0, 2, 0] gradually increased consistently with the ascending chronological order ([0, −2, −5] p = 0.003, [0, 2, 0] p = 0.038). These TPs were significant predictors of the chronological order.
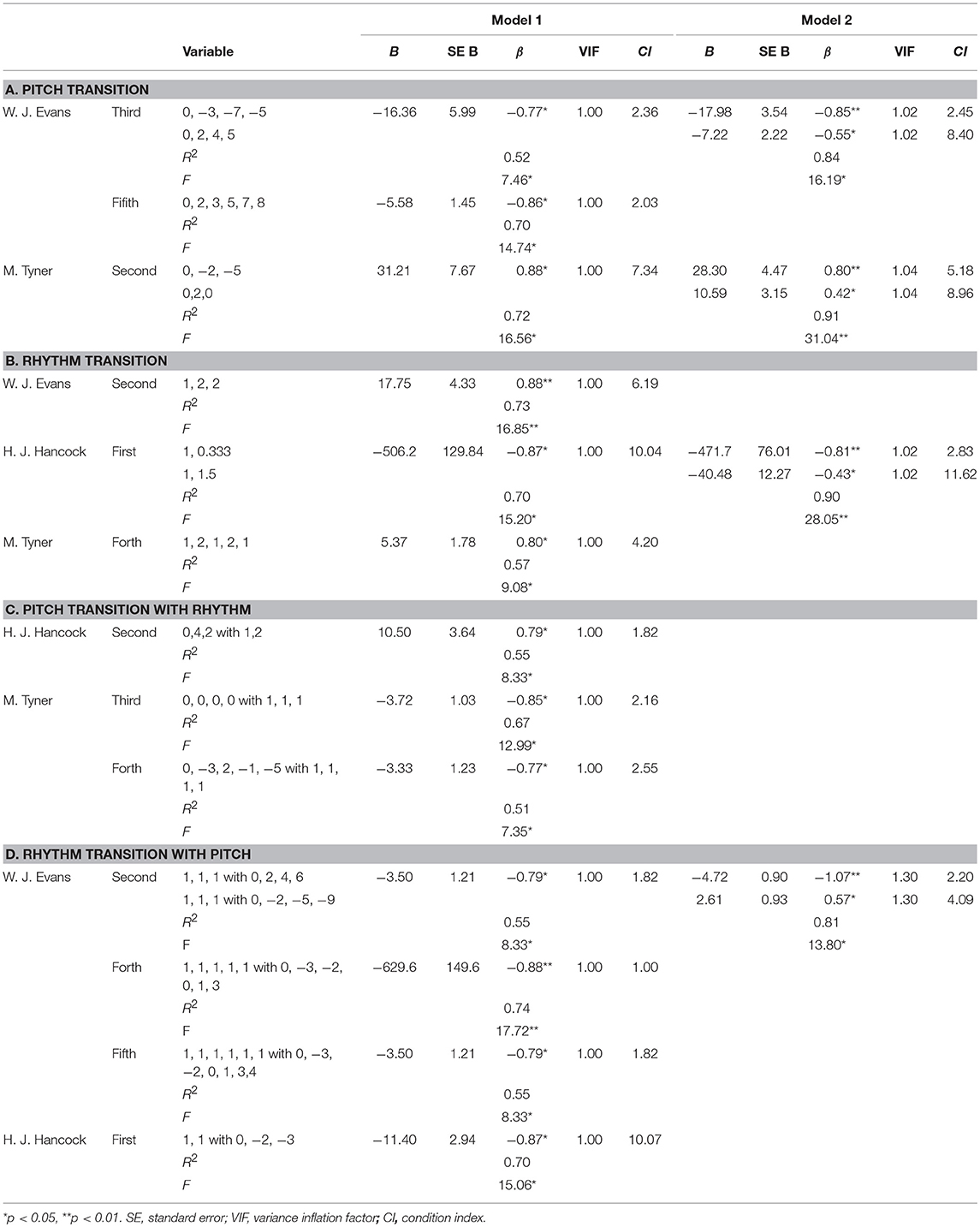
Table 5. Regression analyses based on the stepwise method.
Rhythm Sequence Without Pitches
Results were shown in Table 5B. In W. J. Evans, no significant regression equation was detected in the first-, third-, forth-, fifth-, and sixth-order hierarchical models. In the second-order hierarchical model, a significant regression equation was found [F(1, 5) = 16.85, p = 0.009], with an adjusted R2 of 0.73. The predicted chronological order is equal to −1.29 + 17.75 (transition of [1, 2, 2]). The TPs of [1, 2, 2] gradually increased consistently with the ascending chronological order (p = 0.009). In H. J. Hancock, no significant regression equation was detected in the second-, third-, forth-, fifth-, and sixth-order hierarchical models. In the first-order hierarchical model, a significant regression equation was found [F(3, 3) = 82.70, p = 0.002], with an adjusted R2 of 0.98. The predicted chronological order is equal to 12.73–583.67 (transition of [1, 0.333])−79.86 (transition of [1, 1.5]) + 33.53 (transition of [1, 2]). The TPs of [1, 0.333] and [1, 1.5] gradually decreased and those of [1, 2] gradually increased consistently with the ascending chronological order (p = 0.001, p = 0.007, and p = 0.034, respectively). In M. Tyner, no significant regression equation was detected in the first-, second-, third-, fifth-, and sixth-order hierarchical models. In the forth-order hierarchical model, a significant regression equation was found [F(1, 5) = 9.08, p = 0.030], with an adjusted R2 of 0.57. The predicted chronological order is equal to 0.82 + 5.37 (transition of [1, 2, 1, 2, 1]). The TPs of [1, 2, 1, 2, 1] gradually increased consistently with the ascending chronological order (p = 0.030). These TPs were significant predictors of the chronological order.
Pitch Sequence With Rhythms
Results were shown in Table 5C. In W. J. Evans, no significant regression equation was detected in all of the hierarchical models. In H. J. Hancock, no significant regression equation was detected in the first-, third-, forth-, fifth-, and sixth-order hierarchical models. In the second-order hierarchical model, a significant regression equation was found [F(1, 5) = 8.33, p = 0.034], with an adjusted R2 of 0.55. The predicted chronological order is equal to 3.0 + 10.50 (transition of [0, 4, 2] with [1, 2]). The TPs of [0, 4, 2] with [1, 2] gradually increased consistently with the ascending chronological order (p = 0.034). In M. Tyner, no significant regression equation was detected in the first-, second-, fifth-, and sixth-order hierarchical models. In the third-order hierarchical model, a significant regression equation was found [F(1, 5) = 12.99, p = 0.015], with an adjusted R2 of 0.67. The predicted chronological order is equal to 5.44–3.72 (transition of [0, 0, 0, 0] with [1, 1, 1]). The TPs of [0, 0, 0, 0] with [1, 1, 1] gradually decreased consistently with the ascending chronological order (p = 0.015). In the forth-order hierarchical model, a significant regression equation was found [F(1, 5) = 7.35, p = 0.042], with an adjusted R2 of 0.51. The predicted chronological order is equal to 5.67–3.33 (transition of [0, −3, 2, −1, −5] with [1, 1, 1, 1]). The TPs of [0, −3, 2, −1, −5] with [1, 1, 1, 1] gradually decreased consistently with the ascending chronological order (p = 0.042). These TPs were significant predictors of the chronological order.
Rhythm Sequence With Pitches
Results were shown in Table 5D. In W. J. Evans, no significant regression equation was detected in the first-, third-, and sixth-order hierarchical models. In the second-order hierarchical model, a significant regression equation was found [F(2, 4) = 13.80, p = 0.016], with an adjusted R2 of 0.81. The predicted chronological order is equal to 3.61–4.72 (transition of [1, 1, 1] with [0, 2, 4, 6]) + 2.61 (transition of [1, 1, 1] with [0, −2, −5, −9]). The TPs of [1, 1, 1] with [0, 2, 4, 6] gradually decreased (p = 0.006) and the TPs of [1, 1, 1] with [0, −2, −5, −9] gradually increased (p = 0.049) consistently with the ascending chronological order. In the forth-order hierarchical model, a significant regression equation was found [F(1, 5) = 17.72, p = 0.008], with an adjusted R2 of 0.74. The predicted chronological order is equal to 5.33–629.65 (transition of [1, 1, 1, 1, 1] with [0, −3, −2, 0, 1, 3]). The TPs of [1, 1, 1, 1, 1] with [0, −3, −2, 0, 1, 3] gradually decreased consistently with the ascending chronological order (p = 0.008). In the fifth-order hierarchical model, a significant regression equation was found [F(1, 5) = 8.33, p = 0.034], with an adjusted R2 of 0.55. The predicted chronological order is equal to 5.00–3.50 (transition of [1, 1, 1, 1, 1, 1] with [0, −3, −2, 0, 1, 3, 4]). The TPs of [1, 1, 1, 1, 1, 1] with [0, −3, −2, 0, 1, 3, 4] gradually decreased consistently with the ascending chronological order (p = 0.034). In H. J. Hancock, no significant regression equation was detected in the second-, third-, forth-, fifth-, and sixth-order hierarchical models. In the first-order hierarchical model, a significant regression equation was found [F(1, 5) = 15.06, p = 0.012], with an adjusted R2 of 0.70. The predicted chronological order is equal to 12.64–11.40 (transition of [1, 1] with [0, −2, −3]). The TPs of [1, 1] with [0, −2, −3] gradually decreased consistently with the ascending chronological order (p = 0.012). These TPs were significant predictors of the chronological order. In M. Tyner, no significant regression equation was detected in all of the hierarchical models.
Time-Course Variation of Entropy
Results were shown in Table 6. In the rhythm sequence with pitches in H. J. Hancock, significant regression equation was detected in the higher- but not lower-order hierarchical models. In the fifth-order hierarchical model, a significant regression equation was found [F(1, 5) = 10.58, p = 0.023], with an adjusted R2 of 0.62. The predicted chronological order is equal to 5.73–193.34. The entropies of rhythm sequence with pitches gradually decreased (p = 0.023) consistently with the ascending chronological order. In the sixth-order hierarchical model, a significant regression equation was found [F(1, 5) = 9.28, p = 0.029], with an adjusted R2 of 0.58. The predicted chronological order is equal to 5.67–272.31. The entropies of rhythm sequence with pitches gradually decreased (p = 0.029) consistently with the ascending chronological order. No significant regression equation was detected in W.J. Evans and M.Tyner.
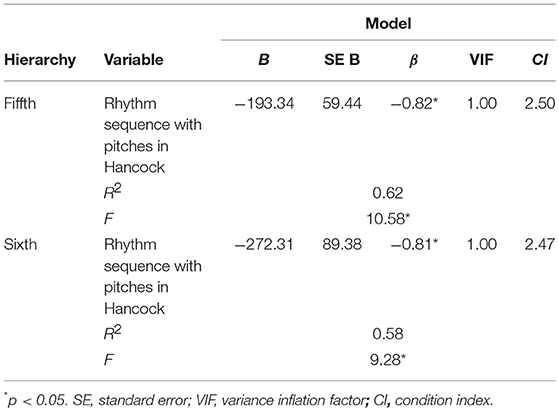
Table 6. Time–course variation of entropy (rhythm sequence with entropies).
Discussion
Interpretation of Multi-Order Hierarchical Models for Implicit Learning
In the context of implicit-learning models on information theory and predictive coding (Friston, 2005; Pearce and Wiggins, 2012; Rohrmeier and Rebuschat, 2012), the TP distribution sampled from musical improvisation based on n-order Markov models may refer to the characteristics of a composer's superficial-to-deep (i.e., n-order) implicit knowledge: a tone with high TP compared to a tone with a low TP may be one that a composer is more likely to predict and choose based on the latest n tones. The notion has been neurophysiologically demonstrated by our previous studies on predictive coding (Daikoku et al., 2017b). Using the various-order Markov stochastic models that unify temporal and spectral features in musical improvisation, the present study investigated the stochastic difference of temporal and spectral features among musicians, and clarified which information (pitch and rhythm) and depth (1st to 6th orders) represent the individualities of improvisational creativity and how they interact with each other.
Hierarchy
The results of principal component analysis (PCA) suggested that the lower-order models represented general statistical characteristics shared among musicians, whereas higher-order models represented specific statistical characteristics that were unique to each musician (Figure 1). In the 1st-order models of any type of temporal and spectral sequences, and 2nd-order models of sequences other than pitch sequence with rhythm, component 1 showed general characteristics in improvisation. These results suggest that the individuality of improvisational creativity depends on the depth of implicit knowledge. This hypothesis could also be underpinned by ANOVA results. To understand the differences between TPs in each sequence among musicians, only the transitional patterns with first to fifth highest TPs from each musician, which showed higher predictabilities in each musician, were analyzed using an ANOVA. In lower-order models, universal sequences that are common among musicians could be detected. For example, in a 1st-order model of pitch sequence without rhythm (Figure 3, top), the extracted sequences of [0, 0], [0, −1], [0, 1], [0, −2], [0, 2], [0, −3], and [0, 3] correspond to repetition of the same tone, and semi-tone, whole-tone, and minor-third transitions. These sequences are frequently exploited in many types of music (e.g., Classical, Jazz), are easier to immediately play because of the small pitch intervals, and lead to a smooth melody. However, in the 6th-order model (Figure 3, bottom), the TPs for the sequences of [0, 3, 0, 1, 5, 8, 12] and [0, −2, −4, −7, −2, −4, −7] were different among musicians. Although the difference could also be detected even in the 1st-order model, higher-order models showed a larger difference of TPs among musicians, suggesting that individuality of musical prediction and production is larger with a deeper implicit knowledge. In summary, the results of the present study suggest that the individuality of improvisational creativity may be formed by deeper implicit knowledge, whereas lower-order implicit knowledge may be shared among musicians.
Pitch and Rhythm
In the pitch sequences with and without rhythms and the rhythm sequence with pitches (Figures 1A,C,D), W. J. Evans' and M. Tyner's components could be detected in any-order model. In a rhythm sequence without pitch (Figure 1B), however, no obvious difference among musicians could be detected. These results suggest that individuality of musical creativity is shaped by spectral, rather than temporal, implicit knowledge. However, the results also suggest that temporal knowledge at least contributes to formation of individuality; TP distribution of pitch sequences “with” rhythms, compared to those “without” rhythms, showed clear individuality among three musicians from a lower-order model (i.e., 4th-order model). Additionally, in two types of rhythm sequences without and with pitches (Figures 2B,D, respectively), TP distribution with, but not without, pitches showed individuality of improvisation. This suggests that temporal and spectral implicit knowledge interact with each other. The ANOVA results support these PCA findings. In lower-order models, the extent of the difference in TPs among musicians is larger for pitch sequences with rhythms (Figure 7) than for those without rhythm (Figure 3). Additionally, in two types of rhythm sequences without and with pitches (Figures 5, 7, respectively), the extent of the TP difference among musicians is larger in rhythm sequences with, compared to without, pitches. Together, these results suggest that the individuality of improvisational creativity may essentially be formed by pitch, but not rhythm, implicit knowledge. However, implicit knowledge of rhythm may strengthen individuality.
Time-Course Variation of Implicit Knowledge
In all types of spectro-temporal sequences of each hierarchy, time-course variation of TPs in some sequences could be detected. There were two types of time-course variations: TPs that gradually decrease, and those that gradually increase, consistent with the chronological order. Thus, implicit knowledge of pitch and rhythm could be shifted over a musician's life. However, the findings suggested that the time-course variations in TPs do not depend on hierarchy and spectro-temporal features, while the individuality among musicians may depend on these features. This suggests that the shifts in implicit knowledge may occur in each musician's lifetime, regardless of spectro-temporal features and the depth of knowledge. It may be interesting to investigate if the findings of gradual shifts in TPs reflect those of implicit knowledge via experience and training. Learning to play the piano enhances auditory-motor skills based on procedural knowledge (Norgaard, 2014), which corresponds to implicit knowledge (Clark and Squire, 1998; Ullman, 2001; Paradis, 2004; De Jong, 2005; Ellis, 2009; Müller et al., 2016). Thus, through experience and long-term training over the player's life, implicit knowledge that is tied to musical expression may shift (Daikoku et al., 2012). On the other hand, the time-course variations of the entropies, which represent uncertainly in music (Pearce and Wiggins, 2006), could be detected in higher-order hierarchy in one musician. Future study is needed to investigate the relationships of time-course variation between specific phrase and general uncertainty. In addition, the results of the present study cannot completely support the hypothesis because time-course variations among only seven pieces of music for each musician were investigated. Further research is needed to verify a larger number of music pieces in a musician's lifetime, and to examine behavioral and neurophysiological results.
General Discussion: Informatics and Neural Aspects in Musical Creativity
In summary, the present study found three types of results on improvisational music and implicit knowledge: hierarchy, spectro-temporal features, and time-course variation. First, the lower-order TP distribution represented general characteristics shared among musicians, whereas higher-order TP distribution detected specific characteristics that were unique to each musician. Thus, the individuality of improvisational creativity might be formed by deeper (i.e., higher-order), but not superficial (i.e., lower-order), implicit knowledge. Second, the TP distribution with pitch information detected specific characteristics that were unique to each musician, whereas the TP distribution with only rhythm information could not detect differences among musicians. Thus, the individuality of improvisational creativity may essentially be formed by spectral (i.e., pitch), but not temporal (i.e., rhythm), implicit knowledge, whereas the rhythms may allow the individuality of pitches to strengthen. Third, TPs of some phrase were gradually decreased, and increased consistent with the chronological order for each musician, regardless of hierarchy and spectro-temporal feature in the TP distributions. Thus, time-course variation of implicit knowledge in pitches and rhythms may occur throughout a musician's lifetime regardless of the depth of knowledge. On the other hand, the time-course variations of the entropies, which represent uncertainly in music (Pearce and Wiggins, 2006), could be detected in higher-order hierarchy in one musician.
It is generally considered that musical expression in improvisation is mainly shaped by tacit knowledge (Delie‘ge et al., 1996; Koelsch et al., 2000; Delie‘ge, 2001; Bigand and Poulin-Charronnat, 2006; Ettlinger et al., 2011; Koelsch, 2011; Huron, 2012). Particularly, the expression of musical improvisation, compared to other types of musical composition in which a composer deliberates a composition scheme for a long time based on musical theory, forces musicians to continually predict each forthcoming tone, and immediately play the melody based on intuitive decision-making and auditory-motor planning, which are considered to tie in with procedural and implicit knowledge (Berry and Dienes, 1993; Reber, 1993; Clark and Squire, 1998; Ullman, 2001; Paradis, 2004; De Jong, 2005; Ellis, 2009; Norgaard, 2014; Müller et al., 2016; Perkovic and Orquin, 2017). Thus, the musical improvisation may be more strongly related to the implicit knowledge, compared to other types of music. Few studies have investigated the relationship between musical improvisation and implicit learning via computational model (Norgaard, 2014) and neural correlate (Adhikari et al., 2016; Lopata et al., 2017). In a series of my previous neurophysiological studies using Markov stochastic models and other studies on music, implicit learning of pitch, harmony, and dyad chord could be reflected in event-related responses (ERP/ERF) based on predictive coding (Daikoku et al., 2014, 2015, 2016, 2017a; Daikoku and Yumoto, 2017; Moldwin et al., 2017). Other studies also detected neural correlates to the motor control for auditory prediction and production when playing the piano (Bianco et al., 2016), and to improvisational creativity of music (Pinho et al., 2015; Adhikari et al., 2016; Lopata et al., 2017). These studies suggest that the mental representation of a musician's knowledge facilitates optimisation of motor actions (Daikoku et al., 2018) in the framework of information theory on brain function. The findings of the present study were based on relative but not absolute stochastic feature of music. Thus, the results in this study could support the previous neurophysiological and psychological studies that suggest that human's brain learn relative rather than absolute temporal and spectral (Daikoku et al., 2014, 2015) patterns.
The verification of computational models and the neural correlates have also been performed in previous studies (see review, Rohrmeier and Rebuschat, 2012). For example, the n-gram models calculate probability of sequential patterns by chopping them into short fragments (n-grams) up to a size of n. This model, which is frequently verified by neural approaches, is considered to correspond to chunking and word-segmentation processes in implicit learning (Saffran et al., 1996). The online perception and production of real-world dynamical music, however, is not the mere chopping of sequential patterns like word segmentation, but dynamical prediction to maintain an aesthetic melody with various temporal and spectral features, hierarchical structure, and harmony, which interact with each other (Lerdahl and Jackendoff, 1983; Hauser et al., 2002; Jackendoff and Lerdahl, 2006). Musical prediction and the representation constantly occurs with each state of sequences during learning and playing music. In addition, they are not restricted to a single stream of events or hierarchy but, rather, they interact with each parallel stream (Conklin and Witten, 1995; Pearce and Wiggins, 2012). Given the real-world phenomenon of music perception and prediction, various-order Markov models may be able to express dynamical and hierarchical creativity that occur in a musician's brain when they play music (Pearce and Wiggins, 2012), and to interdisciplinarily verify lower-to-deeper implicit knowledge and its representation using one experiment via neurophyisiological and informatics approaches. Using the models, however, future study is needed to also investigate other aspects of music such as harmony, non-adjacent dependency, and tree-structure nature of melody and harmony.
In conclusion, the present study suggested that the formation of individuality of musical creativity may depend on spectro-temporal features and hierarchy. The present study first provides the hierarchical implicit-learning model that unifies temporal and spectral features in musical improvisationa and creativity and that is interdisciplinarily verifiable using neurophysiological, behavioral, and information-thepretic approaches.
Data Availability
All relevant data are within the paper.
Author Contributions
The author confirms being the sole contributor of this work and has approved it for publication.
Conflict of Interest Statement
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This work was supported by Grant-in-Aid for Grant for Groundbreaking Young Researchers of Suntory foundation, and Nakayama Foundation for Human Science.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fncom.2018.00089/full#supplementary-material
References
Adhikari, B. M., Norgaard, M., Quinn, K. M., Ampudia, J., Squirek, J., and Dhamala, M. (2016). The brain network underpinning novel melody creation. Brain Connect 6, 772–785. doi: 10.1089/brain.2016.0453
Albrecht, J., and Huron, D. (2012). A statistical approach to tracing the historical development of major and minor pitch distributions, 1400-1750. Music Percept. 31, 223–243. doi: 10.1525/mp.2014.31.3.223
Albrecht, J., and Shanahan, D. (2013). The use of large corpora to train a new type of key-finding algorithm: an improved treatment of the minor mode. Music Percept. 31, 59–67. doi: 10.1525/mp.2013.31.1.59
Applebaum, D. (2008). Probability and Information: An Integrated Approach. Cambridge, UK: Cambridge University Press.
Backer, E., and van Kranenburg, P. (2005). On musical stylometry—a pattern recognition approach. Pattern Recogn. Lett. 26, 299–309. doi: 10.1016/j.patrec.2004.10.016
Berry, D. C., and Broadbent, D. (1984). On the relationship between task performance and associated verbalisable knowledge. Q. J. Exp. Psychol. 36, 209–231. doi: 10.1080/14640748408402156
Berry, D. C., and Dienes, Z. (1993). Implicit Learning: Theoretical and Empirical Issues. Hove: Lawrence Erlbaum.
Bianco, R., Novembre, G., Keller, P. E., Scharf, F., Friederici, A. D., Villringer, A., et al. (2016). Syntax in action has priority over movement selection in piano playing: an erp study. J. Cogn. Neurosci. 28, 41–54. doi: 10.1162/jocn_a_00873
Bigand, E., and Poulin-Charronnat, B. (2006). Are we “experienced listeners”? A review of the musical capacities that do not depend on formal musical training. Cognition 100, 100–130. doi: 10.1016/j.cognition.2005.11.007
Boenn, G., Brain, M., De Vos, M., and ffitch, J. (2012). “Automatic composition of melodic and harmonic music by answer set programming,” in Logic Programming. Proceedings of the 24th International Conference, ICLP 2008.5366 ed. eds M. Garcia de la Banda and E. Pontelli (Udine: Springer; Lecture Notes in Computer Science), 160–174.
Brandon, M., Terry, J., Stevens, C. J., and Tillmann, B. (2012). Incidental learning of temporal structures conforming to a metrical framework. Front. Psychol. 3:294. doi: 10.3389/fpsyg.2012.00294
Brent, M. R. (1999). Speech segmentation and word discovery: a computational perspective. Trends Cogn. Sci. 3, 294–301. doi: 10.1016/S1364-6613(99)01350-9
Broadbent, D. (1977). Levels, hierarchies and the locus of control. Q. J. Exp. Psychol. 29, 181–201. doi: 10.1080/14640747708400596
Buchner, A., and Steffens, M. C. (2001). Simultaneous learning of different regularities in sequence learning tasks: limits and characteristics. Psychol. Res. 65, 71–80. doi: 10.1007/s004260000052
Cilibrasi, R., Vitanyi, P., and Wolf, R. (2004). Algorithmic clustering of music based on string compression. Comput. Music J. 28, 49–67. doi: 10.1162/0148926042728449
Clark, R. E., and Squire, L. R. (1998). Classical conditioning and brain systems: the role of awareness. Science 280, 77–81. doi: 10.1126/science.280.5360.77
Cleeremans, A., Destrebecqz, A., and Boyer, M. (1998). Implicit learning: News from the front. Trends Cogn. Sci 2, 406–416. doi: 10.1016/S1364-6613(98)01232-7
Cohen, H., Cohen, O., West, S. G., and Aiken, L. S. (2003). Applied Multiple Regression/Correlation Analysis for the Behavioral Sciences, 3rd Edn. LEA.
Conklin, D., and Witten, I. (1995). Multiple viewpoint systems for music prediction. J. New Music Res. 24, 51–73. doi: 10.1080/09298219508570672
Cox, G. (2010). “On the relationship between entropy and meaning in music: An exploration with recurrent neural networks,” in Proceedings of the Cognitive Science Society, (Portland, OR) 32.
Daikoku, T. (2018a). Time-course variation of statistics embedded in music: Corpus study on implicit learning and knowledge. PLoS ONE 13:e0196493. doi: 10.1371/journal.pone.0196493
Daikoku, T. (2018b). Neurophysiological markers of statistical learning in music and language: hierarchy, entropy and uncertainty. Brain Sci. 8:114. doi: 10.3390/brainsci8060114
Daikoku, T., Ogura, H., and Watanabe, M. (2012). The variation of hemodynamics relative to listening to consonance or dissonance during chord progression. Neurol. Res. 34, 557–563.
Daikoku, T., Okano, T., and Yumoto, M. (2017b). “Relative difficulty of auditory statistical learning based on tone transition diversity modulates chunk length in the learning strategy,” in Biomagnetic Sendai 2017, Proceedings of the Biomagnetic, (Sendai), 22–24.
Daikoku, T., Takahashi, Y., Futagami, H., Tarumoto, N., and Yasuda, H. (2017c). Physical fitness modulates incidental but not intentional statistical learning of simultaneous auditory sequences during concurrent physical exercise. Neurol Res. 39, 107–116. doi: 10.1080/01616412.2016.1273571
Daikoku, T., Takahashi, Y., Tarumoto, N., and Yasuda, H. (2017d). Auditory statistical learning during concurrent physical exercise and the tolerance for pitch, tempo, and rhythm changes. Motor Control 5, 1–24. doi: 10.1123/mc.2017-0006
Daikoku, T., Takahashi, Y., Tarumoto, N., and Yasuda, H. (2018). Motor reproduction of time interval depends on internal temporal cues in the brain: sensorimotor imagery in rhythm. Front. Psychol. 9:1873. doi: 10.3389/fpsyg.2018.01873
Daikoku, T., Yatomi, Y., and Yumoto, M. (2014). Implicit and explicit statistical learning of tone sequences across spectral shifts. Neuropsychologia 63, 194–204. doi: 10.1016/j.neuropsychologia.2014.08.028
Daikoku, T., Yatomi, Y., and Yumoto, M. (2015). Statistical learning of music- and language-like sequences and tolerance for spectral shifts. Neurobiol. Learn Mem. 118, 8–19. doi: 10.1016/j.nlm.2014.11.001
Daikoku, T., Yatomi, Y., and Yumoto, M. (2016). Pitch-class distribution modulates the statistical learning of atonal chord sequences. Brain Cogn. 108, 1–10. doi: 10.1016/j.bandc.2016.06.008
Daikoku, T., Yatomi, Y., and Yumoto, M. (2017a). Statistical learning of an auditory sequence and reorganization of acquired knowledge: a time course of word segmentation and ordering. Neuropsychologia 95, 1–10. doi: 10.1016/j.neuropsychologia.2016.12.006
Daikoku, T., and Yumoto, M. (2017). Single, but not dual, attention facilitates statistical learning of two concurrent auditory sequences. Sci. Rep. 7:10108. doi: 10.1038/s41598-017-10476-x
De Jong, N. (2005). Learning Second Language Grammar by Listening, Unpublished Ph. D. thesis. Netherlands Graduate School of Linguistics.
Delie‘ge, I. (2001). Prototype effects in music listening: an empirical approach to the notion of imprint. Music Percept. 18, 371–407. doi: 10.1525/mp.2001.18.3.371
Delie‘ge, I., Me‘len, M., Stammers, D., and Cross, I. (1996). Musical schemata in real time listening to a piece of music. Music Percept. 14, 117–160. doi: 10.2307/40285715
Dubnov, S. (2010). “Musical information dynamics as models of auditory anticipation,” in Machine Audition: Principles, Algorithms and Systems, ed W. Wang (Hershey, PA: IGI Global Publication), 371–397.
Eigenfeldt, A. (2010). “Realtime generation of harmonic progressions using controlled markov selection,” in Proceedings of the First International Conference on Computational Creativity (Lisbon).
Ellis, R. (2009). “Implicit and explicit learning, knowledge and instruction,” in Implicit and Explicit Knowledge in Second Language Learning, Testing and Teaching, eds R. Ellis, S. Loewen, C.Elder, R.Erlam, J.Philip, and H.Reinders (Bristol: Multilingual Matters), 3–25.
Ettlinger, M., Margulis, E. H., and Wong, P. C. M. (2011). Implicit memory in music and language. Front. Psychol. 2:211. doi: 10.3389/fpsyg.2011.00211
François, C., Chobert, J., Besson, M., and Schön, D. (2013). Music training for the development of speech segmentation. Cereb. Cortex. 23, 2038–2043. doi: 10.1093/cercor/bhs180
Francois, C., and Schön, D. (2011). Musical expertise boosts implicit learning of both musical and linguistic structures. Cereb. Cortex 21, 2357–2365. doi: 10.1093/cercor/bhr022
Friston, K. (2005). A theory of cortical responses. Philos. Trans. R. Soc B 360, 815–836. doi: 10.1098/rstb.2005.1622
Friston, K. (2010). The free-energy principle: a unified brain theory? Nat. Rev. Neurosci. 11, 127–138. doi: 10.1038/nrn2787
Friston, K., and Kiebel, S. (2009). Predictive coding under the free-energy principle (1521). Philos. Trans. R. Soc. Lond. B Biol. Sci. 364, 1211–1221 doi: 10.1098/rstb.2008.0300
Friston, K., Kilner, J., and Harrison, L. (2006). A free energy principle for the brain. J. Physiol. Paris 100, 70–87. doi: 10.1016/j.jphysparis.2006.10.001
Green, P., and Hecht, K. (1992). Implicit and explicit grammar: An empirical study. Appl. Linguist. 13, 168–184. doi: 10.1093/applin/13.2.168
Hauser, M. D., Chomsky, N., and Fitch, W. T. (2002). The faculty of language: What is it, who has it, and how did it evolve? Science 298, 1569–1579. doi: 10.1126/science.298.5598.1569
Huron, D. (2012). Two challenges in cognitive musicology. Top. Cogn. Sci. 4, 678–684. doi: 10.1111/j.1756-8765.2012.01224.x
Ian, H. W., Leonard, C. M., and Darrell, C. (1994). Comparing human and computational models of music prediction. Comp. Music J. 18, 70–80. doi: 10.2307/3680523
Ito, J. P. (2012). Koch's metrical theory and mozart's music: a corpus study. Music Percept. 31, 205–222. doi: 10.1525/mp.2014.31.3.205
Jackendoff, R., and Lerdahl, F. (2006). The capacity for music: what is it, and what's special about it? Cognition 100, 33–72. doi: 10.1016/j.cognition.2005.11.005
Karabanov, A., and Ulle'n, F. (2008). Implicit and explicit learning of temporal sequences studied with the process dissociation procedure. J. Neurophysiol. 100, 733–739. doi: 10.1152/jn.01303.2007
Koelsch, S. (2011). Toward a neural basis of music perception—a review and updated model. Front Psychol. 2:110. doi: 10.3389/fpsyg.2011.00110
Koelsch, S., Busch, T., Jentschke, S., and Rohrmeier, M. (2016). Under the hood of statistical learning: a statistical MMN reflects the magnitude of TPs in auditory sequences. Sci. Rep. 6:19741. doi: 10.1038/srep19741
Koelsch, S., Gunter, T., and Friederici, A. (2000). Brain indices of music processing: “Nonmusicians” are musical. J. Cogn. Neurosci. 12, 520–541. doi: 10.1162/089892900562183
Lerdahl, F., and Jackendoff, R. (1983). A Generative Theory of Tonal Music, Cambridge, MA: MIT Press.
London, J. (2013). Building a representative corpus of classical music. Music Percept. 31, 68–90. doi: 10.1525/mp.2013.31.1.68
Lopata, J. A., Nowicki, E. A., and Joanisse, M. F. (2017). Creativity as a distinct trainable mental state: an EEG study of musical improvisation. Neuropsychologia 99, 246–258. doi: 10.1016/j.neuropsychologia.2017.03.020
Manning, C. D., and Schütze, H. (1999). Foundations of Statistical Natural Language Processing. Cambridge, MA: MIT Press.
Manzara, L. C., Witten, I. H., and James, M. (1992). On the entropy of music: an experiment with bach chorale melodies. Leonardo Music J. 2, 81–88. doi: 10.2307/1513213
Markov, A. A. (1971). “Extension of the limit theorems of probability theory to a sum of variables connected in a chain,” in Markov Chains (Vol. 1), Reprinted in Appendix B of: R. Howard D. Dynamic Probabilistic Systems, (New York, NY: John Wiley and Sons).
Moldwin, T., Schwartz, O., and Sussman, E. S. (2017). Statistical learning of melodic patterns influences the brain's response to wrong notes. J. Cogn. Neurosci. 29, 2114–2122. doi: 10.1162/jocn_a_01181
Müller, N. C., Genzel, L., Konrad, B. N., Pawlowski, M., Neville, D., Fernández, G., et al. (2016). Motor skills enhance procedural memory formation and protect against age-related decline. PLoS ONE 11:e0157770. doi: 10.1371/journal.pone.0157770
Norgaard, M. (2014). How jazz musicians improvise: e central role of auditory and motor pa erns. Music Percept. 31, 271–287. doi: 10.1525/mp.2014.31.3.271
O'Reilly, J. X., McCarthy, K. J., Capizzi, M., and Nobre, A. C. (2008). Acquisition of the temporal and ordinal structure of movement sequences in incidental learning. J. Neurophysiol. 99, 2731–2735. doi: 10.1152/jn.01141.2007
Pearce, M. (2005). The Construction and Evaluation of Statistical Models of Melodic Structure in Music Perception and Composition. Ph.D. thesis, School of Informatics, City University, London.
Pearce, M., Müllensiefen, D., and Wiggins, G. (2010b). The role of expectation and probabilistic learning in auditory boundary perception: a model comparison. Perception 39, 1365–1389. doi: 10.1068/p6507
Pearce, M., and Wiggins, G. (2006). Expectation in melody: the influence of context and learning. Music Percept. 23, 377–405. doi: 10.1525/mp.2006.23.5.377
Pearce, M., and Wiggins, G. (2012). Auditory expectation: The information dynamics of music perception and cognition. Topics Cogn. Sci. 4, 625–652. doi: 10.1111/j.1756-8765.2012.01214.x
Pearce, M. T., Ruiz, M. H., Kapasi, S., Wiggins, G. A., and Bhattacharya, J. (2010a). Unsupervised statistical learning underpins computational, behavioural and neural manifestations of musical expectation. NeuroImage 50, 302–313. doi: 10.1016/j.neuroimage.2009.12.019
Pearce, M. T., and Wiggins, G. A. (2004). Improved methods for statistical modelling of monophonic music. J. New Music Res.33, 367–385. doi: 10.1080/0929821052000343840
Perkovic, S., and Orquin, J. L. (2017). Implicit statistical learning in real-world environments leads to ecologically rational decision making. Psychol. Sci. 1:956797617733831. doi: 10.1177/0956797617733831
Perruchet, P., and Pacton, S. (2006). Implicit learning and statistical learning: one phenomenon, two approaches. Trends Cogn Sci 10, 233–238. doi: 10.1016/j.tics.2006.03.006
Perruchet, P., and Vinter, A. (1998). PARSER: a model of word segmentation. J. Memory Lang. 39, 246–263. doi: 10.1006/jmla.1998.2576
Pinho, A. L., Ulle'n, F., Castelo-Branco, M., Fransson, P., and de Manzano, O. (2015). Addressing a paradox: Dual strategies for creative performance in introspective and extrospective networks. Cereb. Cortex 26, 3052–3063. doi: 10.1093/cercor/bhv130
Potter, K., Wiggins, G. A., and Pearce, M. T. (2007). Towards greater objectivity in music theory: informationdynamic analysis of minimalist music. Musicae Sci. 11, 295–322. doi: 10.1177/102986490701100207
Prince, J. B., and Schmuckler, M. A. (2012). The tonal-metric hierarchy: a corpus analysis. Music Percept. 31, 254–270. doi: 10.1525/mp.2014.31.3.254
Raphael, C., and Stoddard, J. (2004). Functional harmonic analysis using probabilistic models. Comput. Music J. 28, 45–52. doi: 10.1162/0148926041790676
Reber, A. S. (1967). Implicit learning of artifical grammar. J. Verbal Learn. Verbal Behav. 6, 855–863. doi: 10.1016/S0022-5371(67)80149-X
Reber, A. S. (1993). Implicit Learning and Tacit Knowledge. An Essay on the Cognitive Unconscious. New York, NY: Oxford University Press.
Rebuschat, P., and Williams, J. N. (2012). Implicit and explicit knowledge in second language acquisition. Appl. Psychol. 33, 829–856. doi: 10.1017/S0142716411000580
Reis, B. Y. (1999). Simulating Music Learning With Autonomous Listening Agents: Entropy, Ambiguity and Context. Unpublished doctoral dissertation, Computer Laboratory, University of Cambridge, UK.
Rohrmeier, M., and Rebuschat, P. (2012). Implicit learning and acquisition of music. Top. Cogn. Sci. 4, 525–553. doi: 10.1111/j.1756-8765.2012.01223.x
Saffran, J. R., Aslin, R. N., and Newport, E. L. (1996). Statistical learning by 8-month-old infants. Science 274, 1926–1928. doi: 10.1126/science.274.5294.1926
Salidis, J. (2001). Nonconscious temporal cognition: learning rhythms implicitly. Mem. Cogn. 29, 1111–1119. doi: 10.3758/BF03206380
Servan-Schreiber, D., and Anderson, J. (1990). R. Learning artificial grammars with competitive chunking. J. Exp. Psychol. Learn. Mem. Cogn. 16, 592–608. doi: 10.1037/0278-7393.16.4.592
Shin, J. C., and Ivry, R. B. (2002). Concurrent learning of temporal and spatial sequences. J. Exp. Psychol. Learn. Mem. Cogn. 28, 445–457. doi: 10.1037/0278-7393.28.3.445
Ullén, F., and Bengtsson, S. L. (2003). Independent processing of the temporal and ordinal structure of movement sequences. J. Neurophysiol. 90, 3725–3735. doi: 10.1152/jn.00458.2003
Ullman, M. T. (2001). The declarative/procedural model of lexicon and grammar. J. Psychol. Res. 30, 37–69. doi: 10.1023/A:1005204207369
von Helmholtz, H. (1909). Treatise on Physiological Optics, Vol. III, 3rd Edn. Hamburg: verlag von Leopold Voss
Wang, W. (ed.). (2010). Machine Audition: Principles, Algorithms and Systems. Hershey, PA: IGI Global Publication.
Wiggins, G. A. (2018). Creativity, information, and consciousness: the information dynamics of thinking. Phys. Life Rev. doi: 10.1016/j.plrev.2018.05.001. [Epub ahead of print].
Williams, J. N. (2005). Learning without awareness. Stud. Second Lang. Acquisit. 27, 269–304. doi: 10.1017/S0272263105050138
Yumoto, M., and Daikoku, T. (2016). “IV Auditory system. 5 basic function,” in Clinical Applications of Magnetoencephalography, eds S. Tobimatsu and R. Kakigi (Berlin; Heidelberg: Springer), 97–112.
Keywords: Implicit learning, statistical learning, n-gram, Markov model, entropy, characteristics, uncertainty, hierarchy
Citation: Daikoku T (2018) Musical Creativity and Depth of Implicit Knowledge: Spectral and Temporal Individualities in Improvisation. Front. Comput. Neurosci. 12:89. doi: 10.3389/fncom.2018.00089
Received: 13 August 2018; Accepted: 18 October 2018;
Published: 13 November 2018.
Edited by:
Rong Chen, University of Maryland, Baltimore, United StatesReviewed by:
Evangelos Paraskevopoulos, Aristotle University of Thessaloniki, GreeceJan Lauwereyns, Kyushu University, Japan
Copyright © 2018 Daikoku. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Tatsuya Daikoku, ZGFpa29rdUBjYnMubXBnLmRl