 Jimmy Gammell
Jimmy Gammell Sonia Buckley
Sonia Buckley Sae Woo Nam1
Sae Woo Nam1 Adam N. McCaughan
Adam N. McCaughan- 1National Institute of Standards and Technology, Boulder, CO, United States
- 2Department of Electrical, Computer and Energy Engineering, University of Colorado Boulder, Boulder, CO, United States
Equilibrium propagation is a learning framework that marks a step forward in the search for a biologically-plausible implementation of deep learning, and could be implemented efficiently in neuromorphic hardware. Previous applications of this framework to layered networks encountered a vanishing gradient problem that has not yet been solved in a simple, biologically-plausible way. In this paper, we demonstrate that the vanishing gradient problem can be mitigated by replacing some of a layered network's connections with random layer-skipping connections in a manner inspired by small-world networks. This approach would be convenient to implement in neuromorphic hardware, and is biologically-plausible.
1. Introduction
As research into neural networks grows, there has been increased interest in designing biologically-inspired training algorithms, as they may offer insight into biological learning processes and also offer clues toward developing energy-efficient neuromorphic systems (Lillicrap et al., 2014; Bengio et al., 2015; Bartunov et al., 2018; Wozniak et al., 2018; Crafton et al., 2019; Ernoult et al., 2020). The equilibrium propagation learning framework introduced in Scellier and Bengio (2016) is one such algorithm. It is a method for training a class of energy-based networks, the prototype for which is the continuous Hopfield network (Hopfield, 1984). In particular, it addresses one of the major issues that prevent other training algorithms (such as backpropagation) from being biologically-plausible, which is the requirement for separate computation pathways for different phases of training. This also makes the algorithm appealing for practical implementation into neuromorphic hardware, because only a single computation circuit is required within each (non-output) neuron, rather than multiple distinct circuits. However, current implementations of the algorithm still have a defect that diminishes its biological plausibility: they require hand-tuned per-layer hyperparameters to account for a vanishing gradient through the network. In addition to not being biologically plausible, these multiplicative hyperparameters would be difficult to implement in a neuromorphic hardware system with limited bit depth. In this work, we demonstrate that the vanishing gradient problem can instead be addressed through topological means: by randomly replacing some of a layered network's connections with layer-skipping connections, we can generate a network that trains each layer more evenly and does not need per-layer hyperparameters. This solution is biologically-plausible and would be easier to implement in a neuromorphic system; additionally, it entails hand-tuning only two new hyperparameters (the number of layer-skipping connections and their initial weights), whereas the original solution adds a new hyperparameter for each pair of layers in a network.
Implementation of equilibrium propagation in Scellier and Bengio (2016) was hindered by a vanishing gradient problem whereby networks with as few as three hidden layers trained slowly on MNIST (LeCun and Cortes, 1998)—a serious issue given that network depth is critical to performance on difficult datasets (Simonyan and Zisserman, 2014; Srivastava et al., 2015b) and that convergence to a low error rate on MNIST is a low bar to meet. The problem was overcome in Scellier and Bengio (2016) by independently tuning a unique learning rate for each layer in the network. These learning rates were multiplicative factors that proportionally scaled the signals communicated between layers.
In our work, we have modified the strictly-layered topology of the original implementation by adding and removing connections to create a small-world-like network (Watts and Strogatz, 1998). Through this modification we have eliminated the per-layer hyperparameters without substantially degrading the algorithm's performance—after 250 epochs the modified network produces 0.0117% training error (out of 50,000 examples) and 2.55% test error (out of 10,000 examples) on MNIST using a network with three hidden layers and no regularization term in its cost function. These error rates are comparable to those of other biologically-motivated networks (Bartunov et al., 2018) and are approximately the same as those of the layered network with unique, manually-tuned learning rates in Scellier and Bengio (2016). Our method could be implemented with relative ease in any system with configurable connectivity, such as those already described in several neuromorphic hardware platforms (Schemmel et al., 2010; Davies et al., 2018; Shainline et al., 2019). Layer-skipping connections have been observed in biological brains (Bullmore and Sporns, 2009), so the approach is biologically-plausible. Similar techniques have seen success in convolutional (He et al., 2015; Srivastava et al., 2015a) and multilayer feedforward (Xiaohu et al., 2011; Krishnan et al., 2019) networks. Our findings outlined in this paper suggest that layer-skipping connections are effective-enough to be appealing in contexts where simplicity and biological plausibility are important. While small-world networks are not a novel concept, to our knowledge our work is the first to train small-world-like networks using the Equilibrium Propagation learning framework.
2. Background
2.1. Equilibrium Propagation
Similarly to backpropagation, the equilibrium propagation algorithm (Scellier and Bengio, 2016) trains networks by approximating gradient descent on a cost function. Equilibrium propagation is applicable to any network with dynamics characterized by evolution to a fixed point of an associated energy function; our implementation is a recreation of that in Scellier and Bengio (2016), which applies it to a continuous Hopfield network (Hopfield, 1984). The mathematical formulation of the framework can be found in Scellier and Bengio (2016). We discuss its appeal over backpropagation in section 4.2.
2.1.1. Implementation in a Continuous Hopfield Network
Here we summarize the equations through which a continuous Hopfield network is trained using equilibrium propagation; this summary is based on the more-thorough and more-general treatment in Scellier and Bengio (2016).
Consider a network with n neurons organized into an input layer with p neurons, hidden layers with q neurons and an output layer with r neurons. Let the activations of these neurons be denoted, respectively by vectors x ∈ ℝp, h ∈ ℝq and y ∈ ℝr, and let s = (hT, yT)T ∈ ℝq+r and u = (xT, sT)T ∈ ℝn be vectors of, respectively, the activations of non-fixed (non-input) neurons and of all neurons in the network. Let W ∈ ℝn×n and b ∈ ℝn denote the network's weights and biases where wij is the connection weight between neurons i and j and bi is the bias for neuron i (∀i wii = 0 to prevent self-connections), and let ρ denote its activation function; here and in Scellier and Bengio (2016),
is a hard sigmoid function where ρ′(0) = ρ′(1) is defined to be 1 to avoid neuron saturation. Let .
The behavior of the network is to perform gradient descent on a total energy function F that is modified by a training example (xd, yd). Consider energy function E:ℝn → ℝ,
and arbitrary cost function ; here and in Scellier and Bengio (2016) it is a quadratic cost function given by
though the framework still works for cost functions incorporating a regularization term dependent on W and b. The total energy function F:ℝn → ℝ is given by
where the clamping factor β is a small constant. s evolves over time t as
Equilibrium has been reached when . This can be viewed as solving the optimization problem
by using gradient descent to find a local minimum of F. Parameters θ can then be updated using the rule
The procedure for training on a single input-output pair (xd, yd) is as follows:
1. Clamp x to xd and perform the free-phase evolution: evolve to equilibrium on the energy function F(u; 0, W, b) in a manner dictated by Equation (5). Record the equilibrium state u0.
2. Perform the weakly-clamped evolution: evolve to equilibrium on the energy function F(u; β, W, b) using u0 as a starting point. Record the equilibrium state uβ.
3. Compute the correction to each weight in the network:
Adjust the weights using Wij ← Wij + αΔWij where the learning rate α is a positive constant.
4. Compute the correction to each bias in the network:
and adjust the biases using bi ← bi + αΔbi.
This can be repeated on as many training examples as desired. Training can be done on batches by computing ΔWij and Δbi for each input-output pair in the batch, and correcting using the averages of these values. Note that the correction to a weight is computed using only the activations of neurons it directly affects, and the correction to a bias is computed using only the activation of the neuron it directly affects. This contrasts with backpropagation, where to correct a weight or bias l layers from the output it is necessary to know the activations, derivatives, and weights of all neurons between 0 and l − 1 layers from the output.
2.2. Vanishing Gradient Problem
Vanishing gradients are problematic because they reduce a network's rate of training and could be difficult to represent in neuromorphic analog hardware due to limited bit depth. For instance, in a neuromorphic hardware system with 8-bit communications and weight storage, weight corrections near the input layer of the network may be smaller than the least significant bit (due to gradient attenuation) causing those small weight changes to be lost entirely.
The vanishing gradient problem is familiar in the context of conventional feedforward networks, where techniques, such as the weight initialization scheme in Glorot and Bengio (2010), the use of activation functions with derivatives that do not lead to output saturation (Schmidhuber, 2015), and batch normalization (Ioffe and Szegedy, 2015) have been effective at overcoming it. However, in the context of the networks trained in Scellier and Bengio (2016), the vanishing gradient problem persists even when the former two techniques are used. To our knowledge batch normalization has not been used in the context of equilibrium propagation; however, it seems unlikely to be biologically-plausible.
2.3. Small-World Networks
The topology presented in this paper is inspired by small-world networks described in Watts and Strogatz (1998). In that paper the authors consider ring lattice networks which are highly-cliquish in the sense that the neighbors of a vertex, defined as the set of vertices with which the vertex shares an edge, are very likely to share edges with one-another. The typical distance between a pair of vertices in such a network, defined as the minimum number of edges that must be traversed in order to move between them, tends to be large as well. The authors demonstrate that when each edge in the network is randomly re-wired with some probability p, the typical distance is reduced at a much higher rate than the cliquishness as p increases, and one can thereby create a network with a high degree of cliquishness yet a short typical path length between vertices. They call such a network a small-world network.
Since in our context networks with multilayer feedforward topology have gradients that attenuate by a multiplicative factor of distance from the output layer, it seems reasonable to expect attenuation to be reduced when the typical number of connections between a given neuron and the output layer is reduced. Based on this we were motivated to explore the small-world-inspired topology described in subsequent sections as a way to reduce the typical number of connections between a pair of neurons and therefore between a neuron and the output layer, while largely preserving the layered structure of a network. It is worth noting that multilayer feedforward topology is not a perfect analogy for a circular lattice network because it lacks connections within layers and is therefore not cliquish based on the definition used in Watts and Strogatz (1998); nonetheless, we have seen empirically that our small-world-inspired topology does mitigate the vanishing gradient problem and generally improve network performance.
2.4. Related Work
There is a variety of work exploring layer-skipping connections in the context of deep neural networks. He et al. (2015) uses layer-skipping identity mappings to train deep convolutional neural networks through backpropagation and demonstrates that this leads to substantial performance improvements. Srivastava et al. (2015a) proposes a similar method where the transformation applied by each layer is a superposition of a nonlinear activation function and an identity mapping where the relative weights of the two components can change based on how saturated a layer's activation functions are, and demonstrates that with this method deep networks can be trained more-effectively using stochastic gradient descent with momentum. These approaches differ from ours in that they are not random and have not been applied in the context of Equilibrium Propagation, but might be effective for similar reasons as our approach. Xiaohu et al. (2011) uses an approach similar to ours to convert a multilayer feedforward network into one with a small-world-like topology and finds that doing so improves performance on a function approximation task using backpropagation. Krishnan et al. (2019) demonstrates that deep neural networks can be pruned by starting with a small-world-style network rather than a network with an excessive number of parameters without significant compromises to final model accuracy or sparsity, thereby reducing the memory requirements of doing so. The successes seen in these other works suggest that layer-skipping connections can make neural networks train more-effectively. To our knowledge our work is the first that applies layer-skipping connections to mitigate the vanishing gradient problem in networks trained using Equilibrium Propagation.
There are various approaches to mitigating the vanishing gradient problem that do not use layer-skipping connections. Ioffe and Szegedy (2015) presents a practical method for normalizing inputs to each layer of a network throughout training so that the distribution of activation values from layers is roughly uniform throughout the network, and finds that this increases performance, providing regularization and makes the weight initialization less-important. We do not use this method in our experiments because it seems unlikely to be biologically-plausible. Glorot and Bengio (2010) presents a weight initialization scheme for deep neural networks which makes train faster and more-uniformly across layers; we use this initialization scheme in our experiments.
Bartunov et al. (2018) explores the present state of biologically-motivated deep learning. This describes attempts at biologically-plausible deep learning other than Equilibrium Propagation, and contextualizes the classification error on MNIST that we see with networks trained using Equilibrium Propagation and the small-world-inspired topology we introduce in this paper. Bengio et al. (2015) discusses the criteria a biologically-plausible network would need to satisfy, and provides context to our attempt to solve the vanishing gradient problem in a biologically-plausible way.
Pedroni et al. (2019) discusses various means of storing weights in memory in the context of neuromorphic implementations of spike timing dependent plasticity, which is similar to equilibrium propagation in that it is a biologically-inspired learning algorithm that performs weight updates using local information.
3. Implementation
We implemented1 the Equilibrium Propagation framework described in Scellier and Bengio (2016) using Pytorch (Paszke et al., 2019). Like the networks in Scellier and Bengio (2016), our networks are continuous Hopfield networks with a hard sigmoid activation function
and squared-error cost function with no regularization term
where y is the network's output and yd is the target output. As described in section 5.1 of Scellier and Bengio (2016), we numerically approximate the dynamics described by Equation (5) using a forward Euler approximation with step size ϵ, Nfree iterations of the free phase of training and Nweakly−clamped iterations of the weakly-clamped phase of training.
We use two performance-enhancing techniques that were used in Scellier and Bengio (2016): we randomize the sign of β before training on each batch, which was found in the original paper to have a regularization effect, and we use persistent particles, where the state of the network after training on a given batch during epoch n is used as the initial state for that batch during epoch n + 1. Persistent particles are useful when simulating equilibrium propagation on a digital computer because they allow the network to start an epoch closer to the equilibrium state, thereby reducing the number of iterations of the forward Euler approximation that are necessary to get sufficiently close to equilibrium. Note that this technique leads to higher error rates early in training than would be present with a more-thorough approximation of the differential equation. For purposes of computational efficiency we compute training error throughout training by recording the classification error on each training batch prior to correcting the network's parameters, and we compute the test error by evolving to equilibrium and evaluating classification error for each batch in the test dataset after each full epoch of training. In some of our trials (e.g., Figure 4) this approach causes the training error to exceed the test error early on in training because the network has undergone only part of an epoch of training prior to evaluating error on each training batch, but a full epoch prior to evaluating error on each test batch.
In all networks we use the weight initialization scheme in Glorot and Bengio (2010) for the weights of interlayer connections; weights connecting a pair of layers with n1 and n2 neurons are taken from the uniform distribution . We have found empirically that for new connections added in our topology, for a network with N layers it works reasonably well to draw all initial weights from U[−a, a] where and ni denotes the number of neurons in layer i.
3.1. Multilayer Feedforward (MLFF) Topology
The purpose of this paper is to address the vanishing gradient problem that is present in networks with a multilayer feedforward (MLFF) topology in Scellier and Bengio (2016). Therefore, we have done a variety of trials on networks with MLFF topology to provide points of reference. The MLFF topology is illustrated to the left in Figure 1; it consists of layers of neurons with connections between every pair of neurons in adjacent layers, no connections within layers, and no connections between neurons in non-adjacent layers.
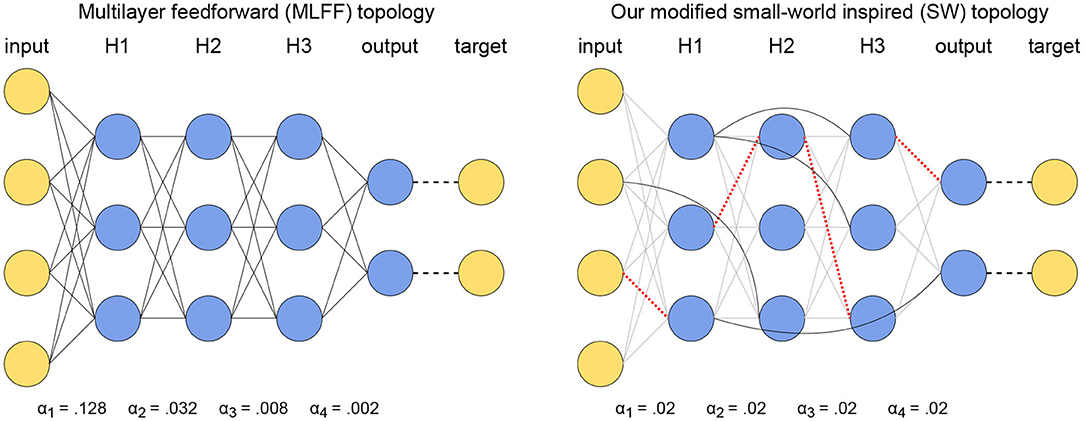
Figure 1. Illustration of our topological modifications to mitigate the vanishing gradient problem while using a global learning rate. (Left) A network with MLFF topology as tested in Scellier and Bengio (2016). Observe that the learning rate increases by a factor of 4 each time the distance from the output increases by one layer. (Right) A network with SW topology, where a subset of connections have been replaced by random layer-skipping connections and per-layer learning rates have been replaced by a single global learning rate. Red dotted lines denote removed connections and solid black lines denote the layer-skipping connections replacing them.
In some trials we use a single global learning rate α, and in other trials we use per-layer rates individually tuned to counter the vanishing gradient problem. The latter case entails N + 1 unique learning rates αi, i = 1, …, N + 1 for a network with N hidden layers, where the weights connecting layers i and i + 1 and the biases in layer i have learning rate αi.
3.2. Small-World Inspired (SW) Topology
We generate a network with small-world inspired (SW) topology by first starting with a MLFF topology as described above in section 3.1, then applying an algorithm similar to the one described in Watts and Strogatz (1998) to randomly replace2 existing connections by random layer-skipping connections with some probability p. This is done using Algorithm 1, and the resulting SW topology is illustrated to the right in Figure 1. In all of our trials networks with SW topology are trained using a single global learning rate α.

Algorithm 1: Algorithm to generate SW topology starting with a network with MLFF topology.
4. Results
4.1. Evaluation on MNIST Dataset
Here we compare the behavior of networks with the SW topology presented here to those with the MLFF topology used in Scellier and Bengio (2016) when training on the MNIST dataset. We are using this dataset because it allows us to reproduce and extend the trials in Scellier and Bengio (2016), and because it is non-trivial to effectively train on yet small enough to allow trials to complete in a reasonably-short amount of time.
4.1.1. Classification Error
Figure 2 shows the results of comparing the classification error on MNIST of a network with SW topology to that of a MLFF network with individually-tuned per-layer learning rates, as in Scellier and Bengio (2016), and to that of a MLFF network with a single global learning rate. For all networks we use 3 500-neuron hidden layers, ϵ = 0.5, β = 1.0, 500 free-phase iterations, eight weakly-clamped-phase iterations, and train for 250 epochs. For the SW network we use p = 10% and a global learning rate α = 0.02. For the MLFF network with per-layer rates we use learning rates α1 = 0.128, α2 = 0.032, α3 = 0.008, and α4 = 0.002. For the MLFF network with a single global learning rate, we use learning rate α = 0.02.
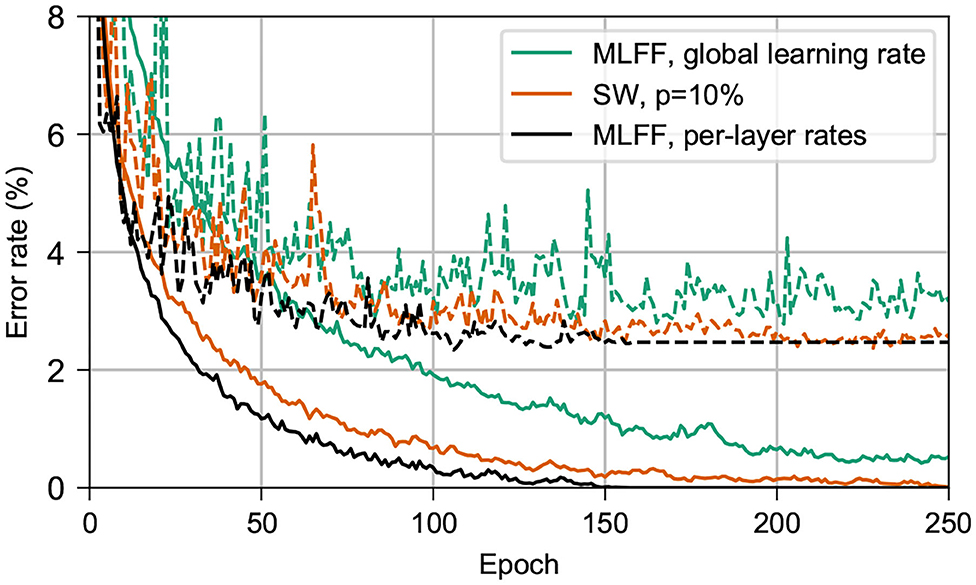
Figure 2. Performance on MNIST of networks with 3 500-neuron hidden layers. Dashed lines show the test error and solid lines show the training error. In black is a MLFF network with per-layer rates individually tuned to counter the vanishing gradient problem. In green is the same MLFF network but with a single global learning rate. In orange is a network with SW topology, p = 10%. Observe that the network with our topology trains almost as quickly as a network with per-layer rates, and significantly more-quickly than a network with a single learning rate.
We find that both the SW network and the MLFF network with per-layer rates significantly outperform the MLFF network with a single global learning rate during the first 250 epochs of training. The SW network achieves training and test error rates similar to those of the MLFF network with per-layer rates, albeit after around 100 additional epochs of training.
4.1.2. Training Rates of Individual Pairs of Layers
Here we consider the first 100 epochs of the trials described in section 4.1.1 above and track the root-mean-square correction to weights connecting each pair of adjacent layers. Figure 3 shows these values for the three network topologies, recorded after each batch and averaged over each epoch.
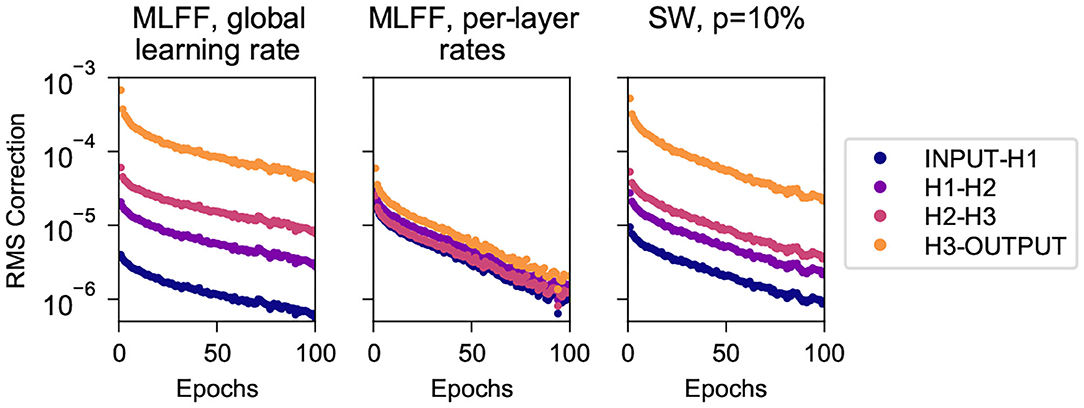
Figure 3. Root mean square corrections to weights in different layers while training on MNIST, for networks with 3 500-neuron hidden layers. (Left) A MLFF network with a single global learning rate. (Center) A MLFF network with per-layer rates individually tuned to counter the vanishing gradient problem. (Right) A network with SW topology, p = 10%. Observe that the correction magnitudes attenuate significantly with depth in the MLFF network with a single global learning rate, and that a network with SW topology reduces the severity of the issue, albeit less-effectively than individually tuning a learning rate for each layer. It can be seen that the RMS correction of H3-OUTPUT differs significantly from that of deeper weights; we have observed more-generally that when we transition to a SW topology the weights closest to the output train significantly faster than other weights while the training rates of deeper weights cluster together (this can also be seen in Figure 4).
We can clearly see the vanishing gradient problem for the MLFF network with a single global learning rate (left), manifesting as attenuation with depth of the root-mean-square corrections to weights. The problem is addressed very-effectively by the use of manually-tuned per-layer learning rates (center), and is mitigated to a more-modest extent when we use SW topology with a global learning rate. It is noteworthy that the speed of training of these networks as shown in Figure 2 is commensurate with the uniformity with which their layers train as shown in Figure 3.
It can be seen that in the network with SW topology the weights connecting to the output layer train significantly faster than deeper weights, which cluster together; we have observed similar behavior in a variety of datasets and network dimensions. We suspect it has to do with the fact that output neurons connect directly to the target output, whereas because layer-skipping connections are not attached to the target output the other layers must connect indirectly through at least two connections.
4.1.3. Behavior for Varying p
Figure 4 shows the behavior during the first 10 epochs of training on MNIST for a network with SW topology as p is increased from 0 to 0.727. The network being tested has 5 100-neuron hidden layers and is trained with α = 0.015, ϵ = 0.5, β = 1.0, 1,000 free-phase iterations and 12 weakly-clamped-phase iterations.
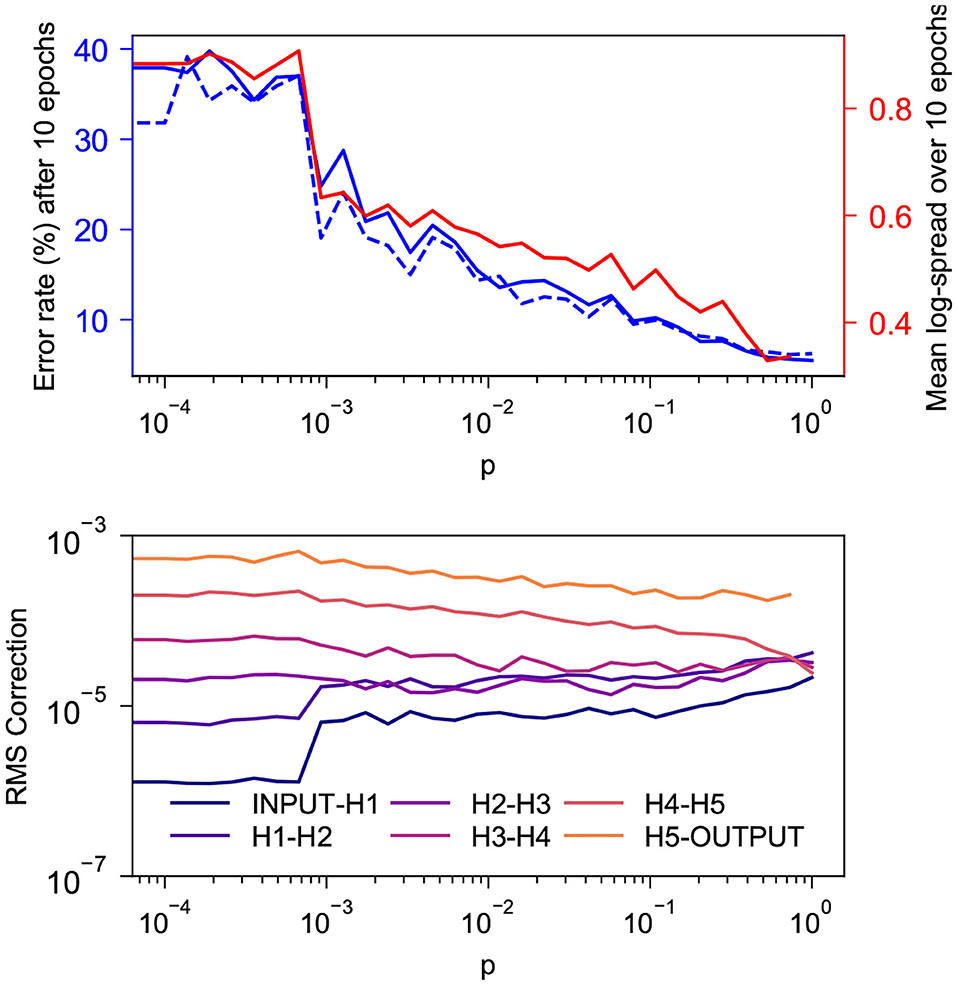
Figure 4. Behavior during the first 10 epochs of training on MNIST for a SW network with 5 100-neuron hidden layers for various values of p. (Top) In solid and dashed blue are the training and test error rates after 10 epochs and in red is the log-spread (Equation 10) averaged over the 10 epochs. As expected, both values decrease as p increases. There appears to be a strong linear correlation between the two, with coefficient of determination r2 = 0.970. This is consistent with our suspicion that mitigation of the vanishing gradient problem is the reason our topology tends to increase the rate at which layered networks train. (Bottom) Root mean square corrections to weights in different layers, averaged over the 10 epochs. As expected, the spread of these values decreases as p increases.
We see in the top graph that the training and test error rates after 10 epochs decay exponentially as p increases. The bottom graph indicates that the RMS corrections to weights become more-uniform with depth as p increases. Corrections to layers that do not connect directly to the output layer cluster closer together as p increases, but it appears that the corrections to weights connecting directly to the output layer train faster than deeper weights with a gap that does not appear to decrease with p; this is similar to the behavior seen in section 4.1.2.
To quantify the spread of the RMS corrections as a single scalar, we introduce the statistic
where N denotes the number of hidden layers in a network and wl denotes the root mean square magnitude of corrections to weights connecting the lth and l + 1th layers from the input, averaged over all epochs of training. In an ideal scenario, the values of wl would tend to be approximately the same, leading to log-spread close to 0. Large disparities in values of wl, leading to a large log-spread, indicate that some layers in the network are being trained much more thoroughly than others. The log-spread is plotted in the top graph alongside the error rate, and these values can be seen to have a strong linear correlation. The training error and the log-spread have a coefficient of determination r2 = 0.970.
4.1.4. Weight Correction Matrix
In Figure 5 we visualize the mean weight correction matrices resulting from training a MLFF network and a SW network with 5 100-neuron hidden layers as described in section 4.1.3. Training on a batch yields a correction matrix dW where element dWij denotes the change to the connection weight between neurons i and j; here we have recorded a matrix with element (i, j) containing the average of |dWij| over 100 epochs of training and displayed it as an image with the color of a pixel at position (i, j) encoding the magnitude of |dWij| as indicated by the legend.
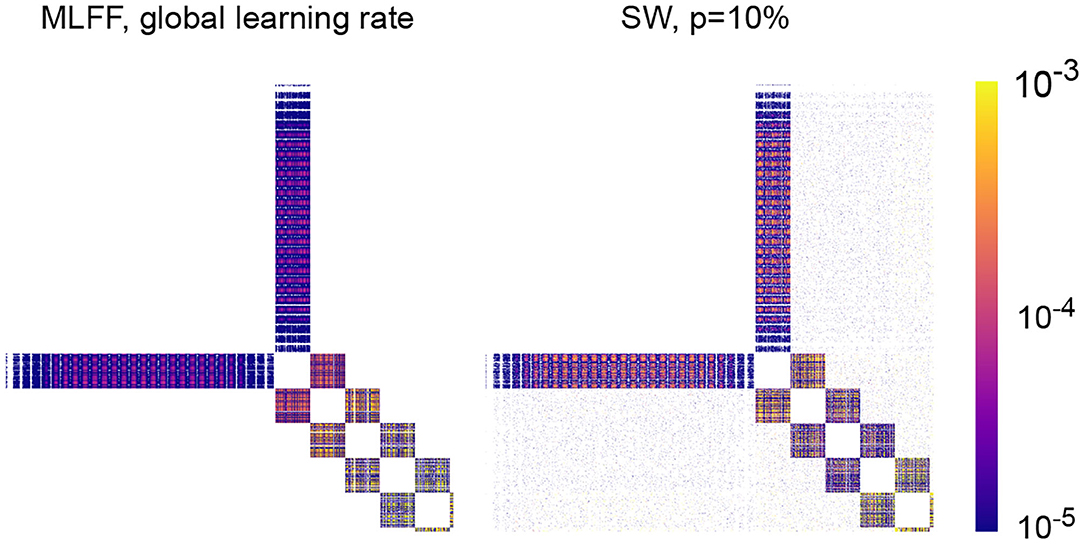
Figure 5. Mean absolute value correction matrix over 100 epochs for networks with 5 100-neuron hidden layers. A pixel at position (i, j) corresponds to the magnitude of the correction to the connection weight between neurons i and j. (Left) A network with MLFF topology and a single global learning rate. (Right) A network with SW topology, p = 10%. Observe that attenuation of these values with depth is less-significant in the latter than in the former.
As expected, there is attenuation with depth to weight correction magnitudes in a MLFF network with a single global learning rate, and transitioning to a network with SW topology reduces the severity of the problem. An interesting feature of the SW matrix that is visible upon close inspection is that layer-skipping connections tend to receive larger correction magnitudes when they are closer to the output of the network. Striations can be seen in correction magnitudes, which we believe correspond to sections of images in the MNIST dataset that contain varying amounts of information; for example, for corrections connecting to the input layer, there are 28 striations which likely correspond to the 28 rows of pixels in an image of a digit, with pixels closer to the edges of the images typically blank and pixels closer to the centers of the images typically containing most of the variation that encodes a digit.
4.2. Evaluation on Various Datasets and Topologies
Here we evaluate the presence of the vanishing gradient problem and the effectiveness of our topology at addressing it on MNIST (LeCun and Cortes, 1998), Fashion MNIST (FMNIST) (Xiao et al., 2017), and the diabetes and wine toy datasets distributed in scikit-learn (Pedregosa et al., 2011) with various network architectures. Our results are shown in Table 1. For all of these trials we use β = 1.0 and ϵ = 0.5. While hyperparameters in these trials have not been thoroughly optimized, the trials serve to illustrate that the trends we saw on the MNIST dataset in section 4.1 hold for deeper networks and for networks training on 4 different datasets.
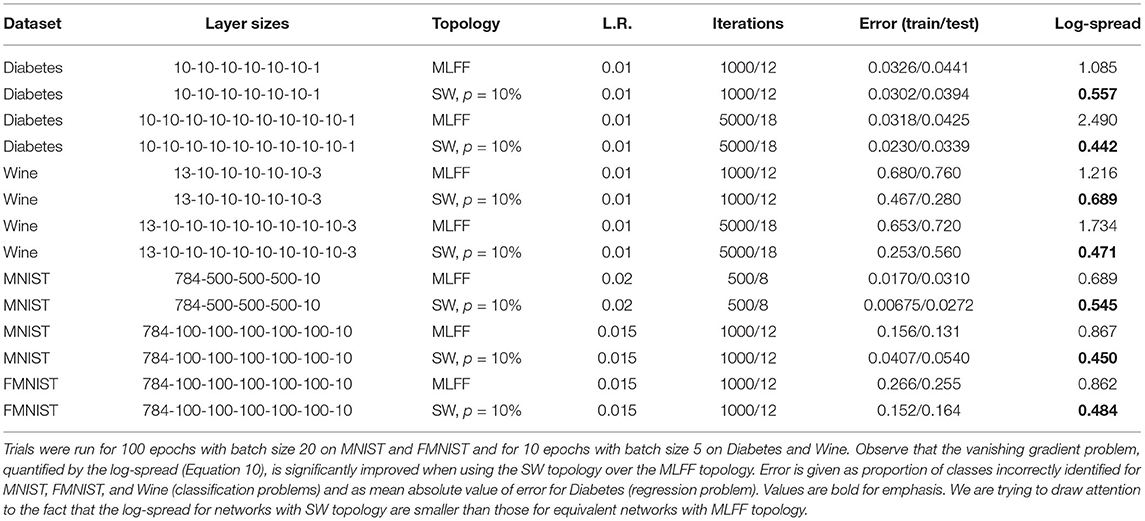
Table 1. Comparison of MLFF and SW topologies with various datasets and network architectures.
We report the training and test error after 100 epochs, as well as the log-spread (Equation 10). We see that networks with SW topology, p = 10%, have a consistently smaller log-spread than networks with a MLFF topology and a single global learning rate. Here this associated with smaller training and test error rates, though we have seen for some less-optimized combinations of hyperparameters that the error rates do not significantly change. We have observed that all of these networks behave in ways that are qualitatively similar to the networks explored in section 4.1.
5. Directions for Future Research
There are several directions in which future research could be taken:
• Evaluating the effectiveness of this approach on hard datasets, such as CIFAR and ImageNet.
• Evaluating the effect of p on a network's test error in the long term.
• Exploring the effectiveness of a network when layer-skipping connections are used during training and removed afterwards.
• Devise and mathematically justify a weight initialization scheme for layer-skipping connections.
• Mathematically justify the empirical results we have seen when using SW topology.
Data Availability Statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found at: Data and code used to generate figures: https://github.com/jgammell/eqp_paper_data; Code used to run experiments: https://github.com/jgammell/equilibrium_propagation.
Author Contributions
JG wrote the code and ran the experiments to determine the effects of layer-skipping connections. SB analyzed the differences between equilibrium propagation and backpropagation. SN provided the guidance. AM wrote the code and assisted with layer-skipping analysis. All authors contributed to the article and approved the submitted version.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fncom.2021.627357/full#supplementary-material
Footnotes
1. ^https://github.com/jgammell/equilibrium_propagation.
2. ^We have done a small number of trials in which layer skipping connections are added without removing an equal number of preexisting connections, and have observed behavior similar to that resulting from using Algorithm 1.
References
Bartunov, S., Santoro, A., Richards, B. A., Hinton, G. E., and Lillicrap, T. P. (2018). Assessing the scalability of biologically-motivated deep learning algorithms and architectures. CoRR abs/1807.04587. Available online at: https://proceedings.neurips.cc/paper/2018/file/63c3ddcc7b23daa1e42dc41f9a44a873-Paper.pdf
Bengio, Y., Lee, D., Bornschein, J., and Lin, Z. (2015). Towards biologically plausible deep learning. CoRR abs/1502.04156. Available online at: http://arxiv.org/abs/1502.04156
Bullmore, E., and Sporns, O. (2009). Complex brain networks: graph theoretical analysis of structural and functional systems. Nat. Rev. Neurosci. 10, 186–198. doi: 10.1038/nrn2618
Crafton, B., Parihar, A., Gebhardt, E., and Raychowdhury, A. (2019). Direct feedback alignment with sparse connections for local learning. CoRR abs/1903.02083. doi: 10.3389/fnins.2019.00525
Davies, M., Srinivasa, N., Lin, T. H., Chinya, G., Joshi, P., Lines, A., et al. (2018). Loihi: a neuromorphic manycore processor with on-chip learning. IEEE Micro 38, 82–99. doi: 10.1109/MM.2018.112130359
Ernoult, M., Grollier, J., Querlioz, D., Bengio, Y., and Scellier, B. (2020). Equilibrium Propagation With Continual Weight Updates.
Glorot, X., and Bengio, Y. (2010). “Understanding the difficulty of training deep feedforward neural networks,” in Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Volume 9 of Proceedings of Machine Learning Research (PMLR), eds Y. W. Teh and M. Titterington (Sardinia: Chia Laguna Resort), 249–256.
He, K., Zhang, X., Ren, S., and Sun, J. (2015). Deep residual learning for image recognition. CoRR abs/1512.03385. doi: 10.1109/CVPR.2016.90
Hopfield, J. (1984). Neurons with graded response have collective computational properties like those of two-state neurons. Proc. Natl. Acad. Sci. U.S.A. 81, 3088–3092. doi: 10.1073/pnas.81.10.3088
Ioffe, S., and Szegedy, C. (2015). Batch normalization: accelerating deep network training by reducing internal covariate shift. CoRR abs/1502.03167.
Krishnan, G., Du, X., and Cao, Y. (2019). Structural Pruning in Deep Neural Networks: A Small-World Approach.
LeCun, Y., and Cortes, C. (1998). The MNIST Database of Handwritten Digits. Available online at: http://yann.lecun.com/exdb/mnist/
Lillicrap, T. P., Cownden, D., Tweed, D. B., and Akerman, C. J. (2014). Random Feedback Weights Support Learning in Deep Neural Networks. Available online at: https://www.nature.com/articles/ncomms13276#citeas
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., et al. (2019). “Pytorch: an imperative style, high-performance deep learning library,” in Advances in Neural Information Processing Systems 32, eds H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett (Curran Associates, Inc.), 8024–8035.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., et al. (2011). Scikit-learn: machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830. Available online at: http://jmlr.org/papers/v12/pedregosa11a.html
Pedroni, B. U., Joshi, S., Deiss, S. R., Sheik, S., Detorakis, G., Paul, S., et al. (2019). Memory-efficient synaptic connectivity for spike-timing-dependent plasticity. Front. Neurosci. 13:357. doi: 10.3389/fnins.2019.00357
Scellier, B., and Bengio, Y. (2016). Equilibrium Propagation: Bridging the Gap Between Energy-Based Models and Backpropagation. doi: 10.3389/fncom.2017.00024
Schemmel, J., Brüderle, D., Grübl, A., Hock, M., Meier, K., and Millner, S. (2010). “A wafer-scale neuromorphic hardware system for large-scale neural modeling,” in Proceedings of 2010 IEEE International Symposium on Circuits and Systems, Paris, 1947–1950. doi: 10.1109/ISCAS.2010.5536970
Schmidhuber, J. (2015). Deep learning in neural networks: an overview. Neural Netw. 61, 85–117. doi: 10.1016/j.neunet.2014.09.003
Shainline, J. M., Buckley, S. M., McCaughan, A. N., Chiles, J. T., Jafari Salim, A., Castellanos-Beltran, M., et al. (2019). Superconducting optoelectronic loop neurons. J. Appl. Phys. 126:044902. doi: 10.1063/1.5096403
Simonyan, K., and Zisserman, A. (2014). Very Deep Convolutional Networks for Large-Scale Image Recognition.
Watts, D., and Strogatz, S. (1998). Collective dynamics of ‘small-world’ networks. Nature 393, 440–442. doi: 10.1038/30918
Wozniak, S., Pantazi, A., and Eleftheriou, E. (2018). Deep networks incorporating spiking neural dynamics. CoRR abs/1812.07040.
Xiao, H., Rasul, K., and Vollgraf, R. (2017). Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms.
Keywords: equilibrium propagation, deep learning, small-world, layer-skipping connections, neuromorphic computing, biologically-motivated
Citation: Gammell J, Buckley S, Nam SW and McCaughan AN (2021) Layer-Skipping Connections Improve the Effectiveness of Equilibrium Propagation on Layered Networks. Front. Comput. Neurosci. 15:627357. doi: 10.3389/fncom.2021.627357
Received: 09 November 2020; Accepted: 30 March 2021;
Published: 17 May 2021.
Edited by:
Petia D. Koprinkova-Hristova, Institute of Information and Communication Technologies (BAS), BulgariaReviewed by:
Wenrui Zhang, University of California, Santa Barbara, United StatesBruno Umbria Pedroni, University of California, San Diego, United States
Antoine Dupret, CEA LETI, France
Copyright © 2021 Gammell, Buckley, Nam and McCaughan. The U.S. Government is authorized to reproduce and distribute reprints for governmental purpose notwithstanding any copyright annotation thereon. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jimmy Gammell, amdhbW1lbGxAcHVyZHVlLmVkdQ==