 Cuong Ly
Cuong Ly Cody Nizinski
Cody Nizinski Alex Hagen
Alex Hagen Luther W McDonald IV
Luther W McDonald IV Tolga Tasdizen
Tolga Tasdizen- 1Department of Electrical and Computer Engineering, College of Engineering, University of Utah, Salt Lake City, UT, United States
- 2Pacific Northwest National Laboratory (DOE), Richland, UT, United States
- 3Scientific Computing and Imaging Institute, College of Engineering, University of Utah, Salt Lake City, UT, United States
- 4Department of Civil and Environmental Engineering, College of Engineering, University of Utah, Salt Lake City, UT, United States
The quantitative characterization of surface structures captured in scanning electron microscopy (SEM) images has proven to be effective for discerning provenance of an unknown nuclear material. Recently, many works have taken advantage of the powerful performance of convolutional neural networks (CNNs) to provide faster and more consistent characterization of surface structures. However, one inherent limitation of CNNs is their degradation in performance when encountering discrepancy between training and test datasets, which limits their use widely. The common discrepancy in an SEM image dataset occurs at low-level image information due to user-bias in selecting acquisition parameters and microscopes from different manufacturers. Therefore, in this study, we present a domain adaptation framework to improve robustness of CNNs against the discrepancy in low-level image information. Furthermore, our proposed approach makes use of only unlabeled test samples to adapt a pretrained model, which is more suitable for nuclear forensics application for which obtaining both training and test datasets simultaneously is a challenge due to data sensitivity. Through extensive experiments, we demonstrate that our proposed approach effectively improves the performance of a model by at least 18% when encountering domain discrepancy, and can be deployed in many CNN architectures.
1 Introduction
In a nuclear forensics investigation, the inherent characteristics, or signatures, are determined to provide insights into the provenance and processing history of an unknown intercepted nuclear material. Discovering the processing history of an unknown nuclear material reveals crucial information about how and where it was made; consequently, this allows the authority to mitigate the illicit trafficking and prevents future recurrence of the same incident. During this process, various analytical tools are available to the investigators. For instance, Keegan et al. utilized tools, such as scanning electron microscope (SEM), X-ray diffraction (XRD), X-ray fluorescene (XRF), inductively coupled plasma-mass spectrometry (ICP-MS), and others to examine an unknown material seized in a raid in Australia (Keegan et al., 2014).
Keegan et al. (2014) used SEM only for qualitative characterization of surface structures of an unknown sample. Recently, many works (Olsen et al., 2017; Hanson et al., 2019; Hanson et al., 2021; Heffernan et al., 2019; Schwerdt et al., 2019) have demonstrated that quantitative characterization of surface structures captured in SEM images can be used as meaningful signatures for determining the processing history of an unknown nuclear material. The quantitative characterization of surface structures has been used to discern calcination conditions (Olsen et al., 2017), impurities (Hanson et al., 2019), mixtures of uranium ore concentrates (UOCs) (Heffernan et al., 2019), and storage conditions (Hanson et al., 2021). Moreover, in recent years, convolutional neural networks (CNNs) have been the main workhorse behind many image analysis applications due to their powerful, fast, and consistent performance. Similarly, we have witnessed a vast amount of works, (Abbott et al., 2019; Hanson et al., 2019; Schwerdt et al., 2019; Ly et al., 2020; Nizinski et al., 2020; Girard et al., 2021), incorporating CNNs to provide better quantitative characterization of surface structures, in turn improving processing history discernment.
Despite a remarkable performance, one major inherent limitation of CNNs is their performance degradation when encountering discrepancy between training and test data (also referred to as source domain, SD, and target domain data, TD, respectively), which limits their use in practice. Nizinski et al. (2022) demonstrated that CNNs performed poorly on a classification task when encountering SEM images captured with microscopes from different manufacturers. Thus, the overarching goal of this research study is to address the robustness of CNNs against different microscopes or acquisition parameters between SD and TD. The proposed solution strengthens the practicality of CNNs for large scale deployment.
Improving the robustness of CNNs against domain discrepancy is formally known as domain adaptation. Previous works on domain adaptation have proposed to learn domain-invariant features through adversarial learning (Ganin and Lempitsky, 2015; Tzeng et al., 2017), maximum mean discrepancy (Motiian et al., 2017; Li et al., 2018), and multidomain reconstruction (Ghifary et al., 2015). One shortcoming in these studies is the requirement of access to both SD and TD data concurrently, which proves to be difficult in many applications, including nuclear forensics, due to data sensitivity. A domain adaptation framework, called source-free domain adaptation (SFDA), has recently been proposed to overcome the difficulty in data sharing. The SFDA framework consists of two phases: initial training and model adaptation. In the initial training phase, a model of interest is trained on the SD dataset. Then, the unlabeled TD dataset is used to update the pretrained model using various strategies, such as updating only the last few layers of the model (Liang et al., 2020), normalizing the appearance of the TD dataset (Karani et al., 2021; Valvano et al., 2021), updating using the TD dataset pseudo-labels generated from the pretrained model (Chen et al., 2021), developing a multitask model (Bateson et al., 2020), or updating only batch normalization (BN) layers (Wang et al., 2021).
The domain-dependent characteristics of BN drive the decision to update only BN layers. Specifically, in a CNN, each BN layer normalizes a given input by the mean and variance, and rescales using the corresponding scaling parameters. During the training process, the mean and variance are computed based on the current input, whereas the scaling parameters are trainable parameters. Then, the estimated population mean, variance, and optimized scaling parameters are used during inference. Therefore, BN layers need to be updated to better reflect the statistics of the test dataset when they are different from the training dataset.
Despite the effectiveness of updating only BN layers, a large discrepancy between the SD and TD datasets can pose a challenge to adequately update a pretrained model. Specifically, the variation in acquisition parameters or microscopes from different manufacturers commonly causes the discrepancy in low-level image information or the appearance (both terms will be used interchangeably), e.g., brightness, contrast, and texture. Hence, in the present study, we propose an SFDA framework in which the adaptation phase involves transforming the appearance of the TD dataset before using it for updating BN layers. The motivation for this proposed approach is that the domain discrepancy problem in this work occurs in low-level image information. Mapping the low-level image information of test samples to be similar to those of the SD dataset alleviates the discrepancy gap between training and test samples. Thus, using the transformed TD dataset to update BN layers allows for better convergence. Through extensive experiments, we show that our proposed SFDA effectively improves the robustness of CNNs when encountering data from a domain with discrepant low-level image information. In addition, we validate our proposed SFDA on two CNNs in two learning paradigms, supervised and unsupervised, to further demonstrate the generalization of the proposed approach.
2 Materials and methods
2.1 Uranium oxides SEM dataset
We used a dataset comprised of SEM images collected with three scanning electron microscopes: an FEI Teneo with Trinity Detection System, an FEI Helios Nanolab 650, and an FEI Nova NanoSEM 630. We refer to them as Teneo, Helios, and Nova for brevity for the rest of this work. Three experimenters collected images on the Nova with Immersion Mode using the secondary electron (SE) signal and the through-lens detector (TLD). Two experimenters were allocated to use the Helios for imaging the backscattered electron (BSE) signal with TLD. Two experimenters were assigned to use T1 and T2 detectors of the Teneo for collecting images with BSE and SE, respectively.
These SEM images characterize the surface structures of uranium oxides, triuranium octoxide (U3O8) and uranium dioxide (UO2), synthesized via eight processing routes. Specifically, four processing routes from the precipitation of ammonium diuranate (ADU), ammonium uranyl carbonate (AUC), uranyl hydroxide (UO2(OH)2), and sodium diuranate (SDU) were synthesized to U3O8 and UO2. The details of these synthesis processes can be found in Schwerdt et al. (2019). Meanwhile, two other precipitation routes, washed and unwashed uranyl peroxide (UO4-2H2O), were used only to make UO2, which were previously described in Abbott et al. (2019). The last two processing routes in this study were synthesized to U3O8 by calcinating UO4-2H2O precipitated from either uranyl nitrate (UO2(NO3)2) or uranyl chloride (UO2Cl2) aqueous starting solutions; the process is reported in detail in Abbott et al. (2022). We refer to the processing route in this study by the precipitation process or by the uranyl solution if the processing routes have the same precipitation process.
2.2 Source-free domain adaptation
Figure 1 illustrates an overview of the proposed approach with the top and bottom portions showing the initial training phase and the adaptation phase, respectively. The initial training phase involves training a downstream task model,
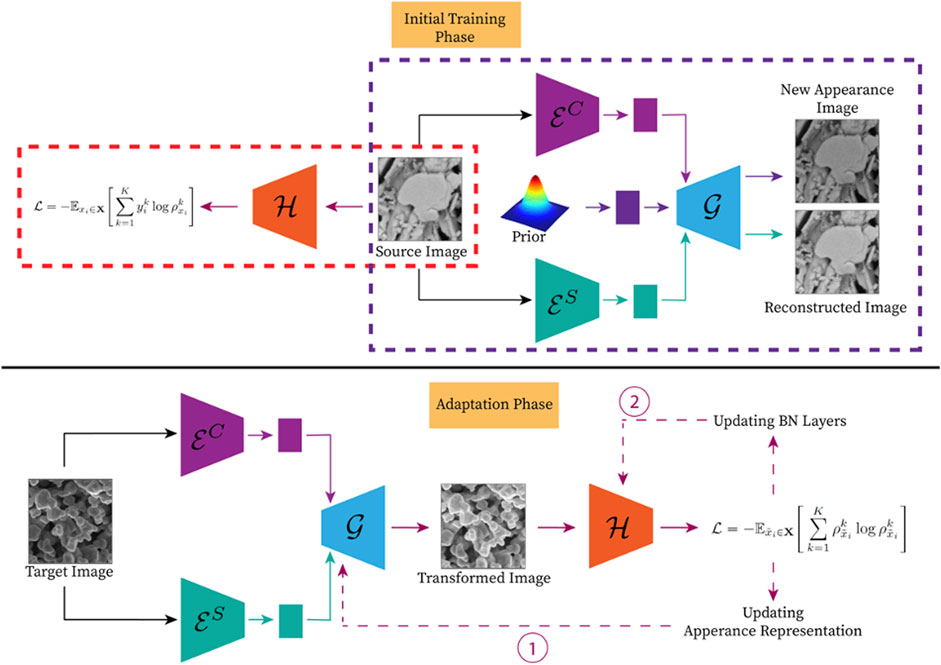
FIGURE 1. An overview of the proposed SFDA framework. The top portion details the training process, which involves training a downstream task model (highlighted by the orange dashed rectangle) and the appearance transformation model (highlighted by the purple dashed rectangle) using a SD dataset. Meanwhile, the bottom portion demonstrates the adaption phase in which the appearance representation is updated accordingly, and then used to update BN layers to adapt the pretrained downstream task model for the TD dataset. (Please refer to the web version for the interpretation of the references to color).
2.2.1 The appearance transformation model
We exploited an image-to-image (I2I) translation model for transforming the appearance of the TD dataset. An I2I translation model is employed to transform the appearance characteristic of a domain to another while retaining the semantic content information. For example, an I2I translation model is used to transform a given image captured during the daytime to look as if it was captured in the nighttime or vice versa.
In this study, we utilized an I2I translation framework used in Huang et al. (2018). This I2I translation framework is comprised of two modules in which each module is for a domain, and contains two encoders and a decoder. The encoders are tasked with encoding the content and appearance representations separately. Meanwhile, the decoder is assigned with generating the corresponding image from the given content and appearance representations. Thus, transforming the appearance of a domain to another can be done by combining the corresponding content representation with the appearance representation from the other domain as input to the decoder. Formally, to transform the appearance of a given image
In the SFDA setting, we have access to only a single domain. Thus, we considered only a single module from the I2I translation framework in Huang et al. (2018). The translation problem in I2I is now reduced to modulating the appearance of a given input with a new appearance representation sampled from a prior. Formally, for a given input xi, the appearance transformation model learns to reconstruct that image,
2.2.2 Updating BN layers
The BN layer is found in many modern CNNs architectures. The BN layer is designed to improve the stability and speed of convergence during the training process in a large CNN. In each BN layer, the input is normalized by its mean and variance, and rescaled by two learnable parameters, γ and β. During the training process, the mean and variance are the statistics from the current input batch. Then, the exponential moving mean and variance estimated throughout the training process along with the learned γ and β are used during inference. Thus, updating BN layers allows the model to adequately adjust to the different statistics of the TD dataset. Wang et al. (2021) were the first group to propose updating BN layers via minimizing the entropy of model prediction because the entropy generally correlates with prediction error and can be used as supervision signal when the label is unavailable. Concretely, the BN layers are updated proportionally to the gradient of the entropy of the last layer in the network, which represents the probability of a class a given input belongs to.
We adopted the updating BN layers from Wang et al. (2021) in this study. Different from Wang et al. (2021), we used the transformed TD dataset as input for updating BN layers instead of the original TD dataset. By using the transformed TD dataset that is similar to the SD dataset, the statistics of the TD dataset is much closer to that of the SD dataset, thereby allowing better convergence. Eq. 1 depicts the objective function used to update BN layers.
where
2.2.3 Model adaptation and inference
Here, we detail the process of combining the TD dataset transformation with updating BN layers to adapt a pretrained downstream task model, which is exhibited in the bottom portion of Figure 1. At the start of this process, we utilized the appearance transformation model to iteratively transform the appearance of the TD dataset to be similar to the SD dataset. Concisely, we first encoded an input image into the appearance and content representations, and used the decoder to reconstruct that image from the given representations. Next, the reconstructed image was used as input to the pretrained downstream task model. We made use of Eq. 1 to iteratively alter the appearance representation to generate an image with the low-level image information similar to that of the SD dataset. After the appearance transformation, we updated the BN layers as described in the previous section with the transformed TD dataset. This adaptation phase needs to be carried out only once for each new TD dataset. After the adaptation phase, only the appearance transformation of test samples is performed to obtain the final result in the inference.
3 Results
3.1 Discrepancy between imaging modes
In the present study, we investigated the effectiveness of the proposed SFDA approach against the discrepancy in low-level image information induced by acquisition parameters and microscopes from different manufacturers. We separated the uranium oxides dataset into groups defined by the acquisition parameters and microscope used to collect the images, and referred to a group as an imaging mode. The acquisition signal is the acquisition parameter that differentiates these groups. Hence, we named these groups: Teneo-BSE, Teneo-SE, Helios-BSE, and Nova-SE. Figure 2 demonstrates the discrepancy between these imaging modes in this dataset with a few representative samples. As seen in the figure, the discrepancy between the imaging modes is apparent. Moreover, this dataset also contains the discrepancy induced by user-bias in other acquisition parameters. This discrepancy can be clearly seen in the Helios-BSE imaging mode. The assigned experimenters for that imaging mode did not select the optimal contrast setting; hence, the images in that imaging mode contain a haze-like artifact.

FIGURE 2. A few representative samples of SEM images captured in four imaging modes. Each imaging mode in this study is defined by the acquisition signal and the manufacturer of the microscope used to acquire the images. To clearly show the discrepancy between imaging modes, we selected these images from the same processing route, i.e., U3O8 synthesized via UO4-2H2O precipitated from uranyl nitrate aqueous starting solution.
To further explore the discrepancy in low-level image information between imaging modes in this dataset we first present the difference in the distribution of the mean image intensity between imaging modes across all the processing routes in Figure 3. Each violin plot in that figure represents the distribution of the mean image intensity of SEM images in an imaging mode with the corresponding marker indicating the median value. As seen in Figure 3, the distributions between imaging modes vary significantly in each processing routes. Generally, the micrographs in Teneo-SE imaging mode had the lowest intensities and the micrographs in Teneo-BSE imaging mode had the highest intensities.
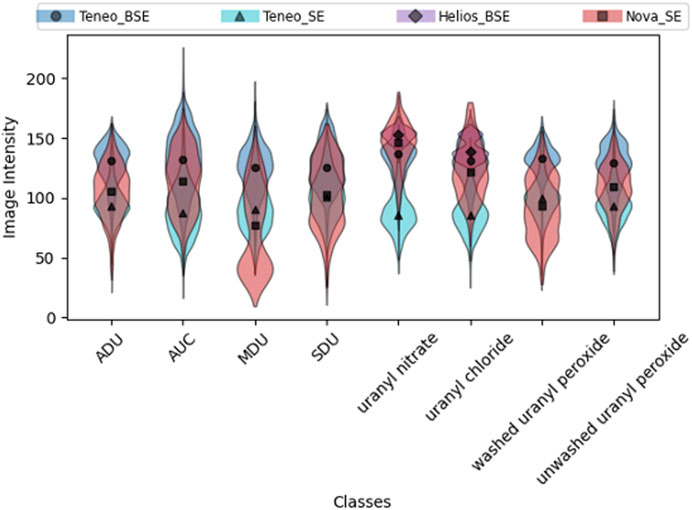
FIGURE 3. A side-by-side comparison between four acquisition modes used in this study across different processing routes. Each violin plot represents the distribution of the mean image intensity of the corresponding imaging mode. (Please refer to the web version for the interpretation of the references to color).
We also show the discrepancy in low-level image information between imaging modes with feature maps from a CNN model trained on object recognition task. The feature maps in a trained CNN model contain expressive representations. The first few layers in a model associate with the low-level information whereas the deeper layers in the network contain abstract and semantic information of an input image. Thus, we examined the discrepancy between imaging modes using the early layers of a pretrained CNN model. We made use of UMAP (McInnes and Healy, 2018), which is a dimension reduction technique, to show the ad hoc relationship in feature space between imaging modes. Concretely, we used UMAP (McInnes and Healy, 2018) to reduce the dimension of the first convolutional layer in the VGG-16 (Simonyan and Zisserman, 2015) model trained on ImageNet (Russakovsky et al., 2015) dataset and visualized the relationship between imaging modes in the reduced embedding space.
We chose the first convolutional layer in the network to illustrate the low-level image information discrepancy beyond the image intensity level. Figure 4 shows the UMAP embedding space of a few processing routes. The embedding space of the samples from the same imaging mode is labeled with the same color, and the opacity represents the density of samples in a region. From that figure, we see that the samples from the same imaging mode cluster together, and different imaging modes distinguishably separate themselves from the others. For instance, in the AUC processing routes, we can easily distinguish different clusters formed by the Teneo-BSE, Teneo-SE, and Nova-SE imaging modes. A fairly similar pattern can also be observed in the uranyl chloride processing route. Moreover, the Helios-BSE imaging mode contains artifact induced by user-bias in selecting acquisition parameters; hence, that cluster is more separated than the other clusters.
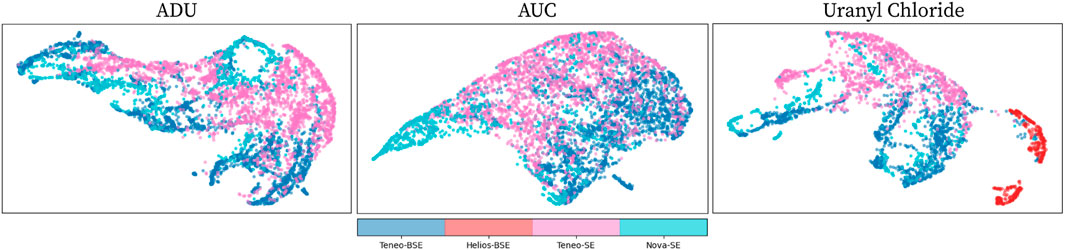
FIGURE 4. The visualization of the UMAP embedding space for different imaging modes of the uranium oxides SEM dataset used in the present study. Different colors represent different imaging modes whereas the opacity represents the density of samples in a region. Each subplot in the figure represents a processing route, which is indicated at the top of the subplot. (Please refer to the web version for the interpretation of the references to color).
3.2 The effectiveness of the proposed SFDA
For the experiments shown in this section and the subsequent section, we alternated each imaging mode as the SD dataset and the others as the TD dataset. We performed experiments using only Teneo-BSE, Teneo-SE, or Nova-SE as the SD dataset. We did not run the experiments with Helios-BSE as the SD dataset because the data for that imaging mode do not capture the complete label set of eight processing routes.
Since the dataset used in this study is designed for determining the processing routes of uranium oxides, we utilized two CNNs proposed in Ly et al. (2020) and Girard et al. (2021) as the downstream task model. Ly et al. (2020) proposed a multi-input single-output (MISO) supervised learning model that takes input captured at multiple magnifications to provide a more accurate prediction by leveraging the complementary information captured at different magnifications. On the other hand, Girard et al. (2021) designed an unsupervised learning framework that leverages the latent representation of an auto-encoder for discerning the processing routes. We modified the framework proposed in Girard et al. (2021) slightly to make it compatible with the proposed approach, and referred to as MLP-VQVAE for the rest of this study. We refer the readers to the Supplementary Material for more details on this modification.
Table 1 presents the performance comparison across different SFDA frameworks: only updating BN layers (BN), which corresponds to the method proposed in Wang et al. (2021), and ours, i.e., combining the appearance transformation model and updating BN layers (App.+BN). Each value in the table represents the mean of 10 repetitions in which each repetition has a different subset of images in an imaging mode used for training and testing. We also included the Baseline and Benchmark performances in both classification models. The Baseline performance is the result when a classification model was trained and tested with SD dataset whereas Benchmark denotes the result when using an imaging mode in the TD set for both training and testing. As seen in the table, the performance of both classification models is drastically lower when encountering a test imaging mode that is different from the training imaging mode. This result shows the importance of providing robustness to CNNs against domain discrepancy.
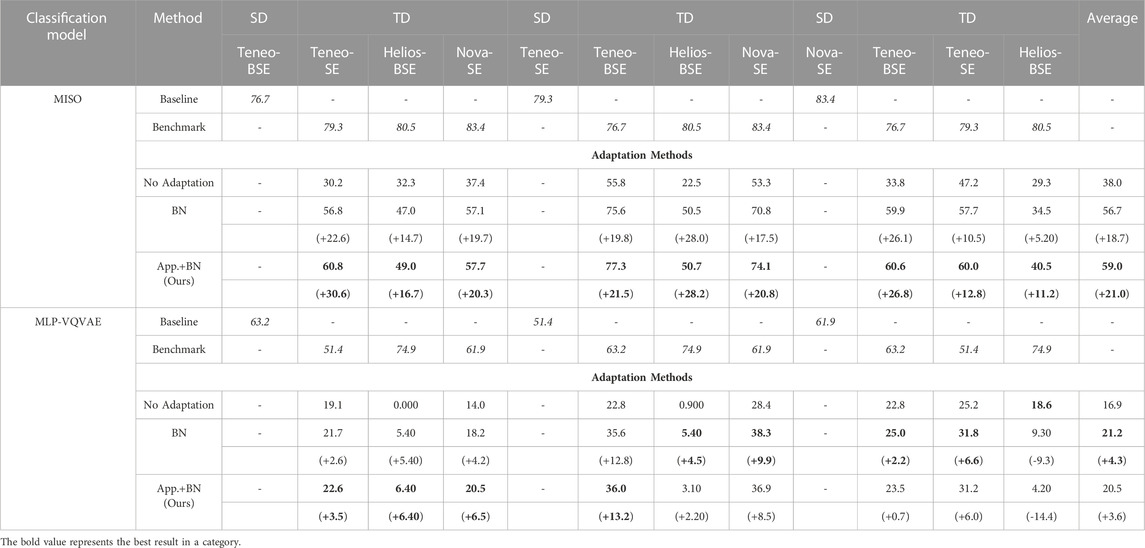
TABLE 1. The performance of MISO and MLP-VQVAE when applying different adaption methods: only updating BN layers (BN) and combining both appearance transformation and updating BN layers (App.+BN). Each row shows the performance of a specific adaptation method when it was trained on a specified SD dataset and tested on images from the other imaging modes, and the improvement over the No Adaptation in parentheses.
We see that employing different SFDA approaches improve the overall performance over the baseline, i.e., No Adaptation, in both MISO and MLP-VQVAE. More importantly, our proposed approach achieved a better performance across the majority of the scenarios. The MISO model benefits more from our proposed approach compared to the MLP-VQVAE model. We hypothesize the slightly worse performance of App.+BN compared to BN in MLP-VQVAE case is caused by poorly transformed images. In other words, the appearance transformation model relies on Eq. 1 to iteratively update the appearance representation of an input image. The MLP-VQVAE model might not provide adequate information using Eq. 1 for the appearance transformation. We illustrate this hypothesis in the next section. Overall, the experiments in this section show the effectiveness of our proposed approach in improving the robustness of CNNs against domain discrepancy in low-level image information, and the benefit of using the transformed TD dataset to update BN layers to achieve a better performance.
4 Discussion
In this section, we explore the significant of using the proposed appearance transformation model to achieve better results compared to other appearance transformation methods. Specifically, we compared the proposed appearance transformation model to histogram matching (HM) and whitening and color transformation (WCT). The WCT is a data transformation technique that normalizes a given input to have an identity covariance matrix and then rescales it to a new space. Eq. 2 formally defines the WCT transformation for changing a desired image’s appearance to be similar to a reference image r:
Since we do not have access to the SD dataset in the SFDA setting, we computed the average cumulative distribution function (CDF) of the image intensity of the SD dataset and used it during the adaptation for the HM approach. Similarly, we replaced μr and σr with the μ and σ of the entire SD dataset for the WCT approach.
Figure 5 shows the qualitative comparison between different appearance transformation approaches. In this figure, the original test images (top row) were images captured in the Helios-BSE imaging mode, whereas the SD dataset used to train the classification models and the appearance transformation model consists of images from the Teneo-BSE imaging mode (bottom row). The left and right portions represent the transformation with MISO and MLP-VQVAE as the classification model, respectively. For the MISO model, we show four different images since the MISO model takes multiple images simultaneously at different magnifications as input. As seen in Figure 5, the HM approach creates unwanted artifacts. Meanwhile, the WCT approach provides a slightly better transformation. However, the WCT did not completely remove the haze-like artifact observed in the Helios-BSE dataset. On the other hand, the appearance transformation model produced more perceptually realistic images and was much more similar to the SD dataset (bottom row).

FIGURE 5. The qualitative assessment of various appearance transformation approaches. The left portion represents the result using the MISO model, and the right most column shows the transformation when using the MLP-VQVAE as the classification model.
We further examined the advantage of using the appearance transformation model compared to others by visualizing the UMAP embedding space of an imaging mode before and after appearance transformation. We followed the same process mentioned above to visualize the UMAP embedding space. Figure 6 maps the embedding space of the SD dataset and TD dataset, which correspond to Teneo-BSE and Helios-BSE respectively, as well as the embedding space of the transformed TD dataset using HM, WCT, and the proposed appearance transformation model. The result from the proposed appearance transformation model is obtained by using the MISO model as the classification model in this experiment. As clearly seen from the figure, the transformed TD dataset using the proposed appearance transformation model are positioned much closer to the SD dataset clusters compared to the original TD dataset or other appearance transformation approaches. This result again shows the effectiveness of the proposed appearance transformation model to adequately transform complex appearance between imaging modes.
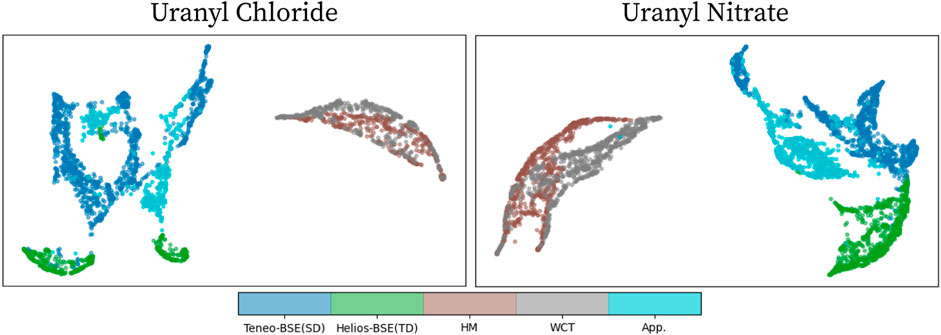
FIGURE 6. The visualization of UMAP embedding space before and after appearance transformation using HM, WCT, and the proposed appearance transformation model. In this example, the Teneo-BSE imaging mode is the SD dataset whereas the Helios-BSE is the TD dataset. The HM, WCT, and App. Labels represent the transformed Helios-BSE samples using the corresponding appearance transformation approach. (Please refer to the web version for the interpretation of the references to color).
Lastly, we show the quantitative comparison of these appearance transformation approaches when combining with updating BN layers in Table 2. From Table 2, we see that the proposed appearance transformation model provides the largest improvement across many settings. The proposed appearance transformation model does not achieve the best overall performance when using MLP-VQVAE as the classification model; the WCT transformation achieved a slightly better overall performance when MLP-VQVAE was used as the classification model. Furthermore, the performance of combining WCT transformation and updating BN layers exceeds that of updating only BN. This provides additional evidence that using the transformed TD dataset to update BN layers achieves a better performance.
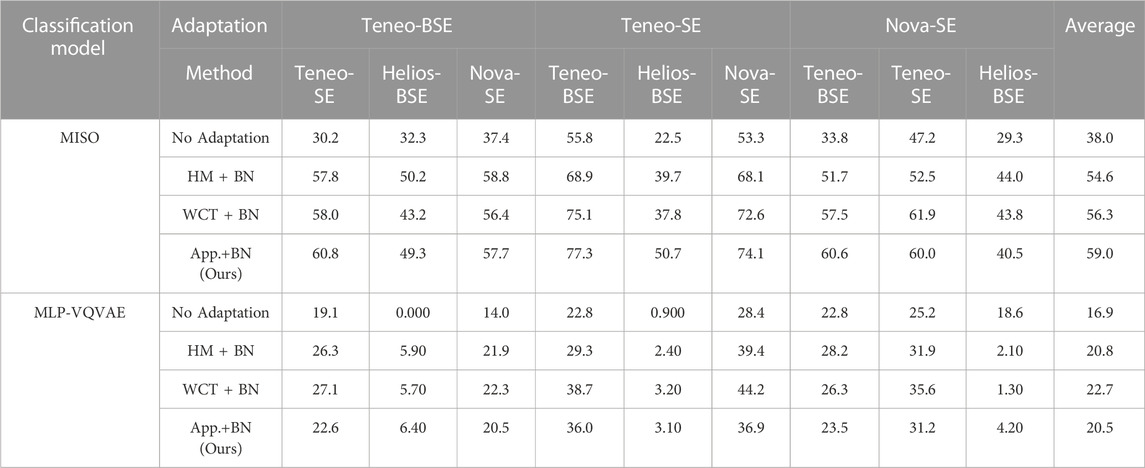
TABLE 2. The performance of MISO and MLP-VQVAE when applying different appearance transformation methods. The best performance across different adaptation methods is highlighted in bold.
5 Conclusion
In this work, we witnessed the susceptibility of CNNs to domain discrepancy in low-level image information induced by microscopes from different manufacturers and user-bias in selecting acquisition parameters. We then presented an SFDA framework to improve the robustness of CNNs against domain discrepancy in low-level image information. Through extensive experiments, we demonstrated that our proposed framework successfully improves the overall performance. Moreover, our proposed approach is model-agnostic, which makes it easily adoptable for many other applications with minimal modifications.
Despite the effectiveness of the proposed SFDA framework, there are a few shortcomings that should be addressed in future work. Specifically, from the experiments in this study, we saw that the proposed approach did not provide much improvement when using MLP-VQVAE model as the downstream task model. Thus, for the intermediate future work, we would like to explore alternative SFDA approaches that can provide a consistent improvement across many models. In addition, we also want to explore an approach that can lessen the additional overhead cost of training the appearance transformation model. Improving robustness of CNNs when encountering misrepresented and poor quality micrographs caused by uncalibrated microscope, the drift of the stage during an acquisition, electron beam-induced contamination, and others (Postek et al., 2013; Postek and Vladár, 2013; Postek et al., 2014; Postek and Vladár, 2015) is another directly related follow-up work that also needs to be addressed. These pitfalls present a much more challenging problem, and are also commonly encountered in real-world scenarios.
Data availability statement
The code and a few representative samples of the dataset used in this study can be found at https://github.com/pnnl/UDASS.
Author contributions
CL, Conceptualization, Methodology, Validation, Formal analysis, Software Investigation, Writing–Original Draft. CN, Methodology, Resources, Data Curation, Writing–Review Editing; AH, Software, Methodology, Writing–Review Editing, Supervision, Funding Acquisition. LM, Resources, Methodology, Data curation, Writing–Review Editing, Supervision, Funding Acquisition. TT, Conceptualization, Methodology, Writing–Review Editing, Supervision, Funding Acquisition. All authors contributed to the article and approved the submitted version.
Funding
This work is supported by the Department of Homeland Security, Domestic Nuclear Detection Office, under Grant Number 2015-DN-077-ARI092 and the Department of Energy’s National Nuclear Security Administration, Office of Defense Nuclear Non-proliferation Research and Development, under project number LA21-ML-MorphologySignatures-FRD1Bb. The images used for this study were collected by work supported by the Department of Energy’s National Nuclear Security Administration, Office of Defense Nuclear Non-proliferation Research and Development, under project number LA21-ML-MorphologySignature-P86-NTNF1b.
Acknowledgments
This work appeared as a chapter in an academic thesis—Ly, NH 2022, Characterizing Surface Structures Captured in Scanning Electron Microscopy Images with Convolutional Neural Networks, PhD thesis, University of Utah, Salt Lake City.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author TT declared that they were an editorial board member of Frontiers at the time of submission. This had no impact on the peer review process and the final decision.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnuen.2023.1230052/full#supplementary-material
References
Abbott, E. C., Brenkmann, A., Galbraith, C., Ong, J., Schwerdt, I. J., Albrecht, B. D., et al. (2019). Dependence of uo2 surface morphology on processing history within a single synthetic route. Radiochim. Acta 107, 1121–1131. doi:10.1515/ract-2018-3065
Abbott, E. C., O’Connor, H. E., Nizinski, C. A., Gibb, L. D., Allen, E. W., and McDonald, L. W. (2022). Thermodynamic evaluation of the uranyl peroxide synthetic route on morphology. J. Nucl. Mater. 561, 153533. doi:10.1016/j.jnucmat.2022.153533
Bateson, M., Kervadec, H., Dolz, J., Lombaert, H., and Ayed, I. B. (2020). “Source-relaxed domain adaptation for image segmentation,” in Medical image computing and computer assisted intervention (Springer), 490–499.
Chen, C., Liu, Q., Jin, Y., Dou, Q., and Heng, P. (2021). “Source-free domain adaptive fundus image segmentation with denoised pseudo-labeling,” in Medical image computing and computer assisted intervention (Springer), 225–235.
Ganin, Y., and Lempitsky, V. S. (2015). “Unsupervised domain adaptation by backpropagation,” in Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6-11 July 2015, 1180–1189.
Ghifary, M., Kleijn, W. B., Zhang, M., and Balduzzi, D. (2015). “Domain generalization for object recognition with multi-task autoencoders,” in 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, December 7-13, 2015, 2551–2559. doi:10.1109/ICCV.2015.293
Girard, M., Hagen, A., Schwerdt, I., Gaumer, M., McDonald, L., Hodas, N., et al. (2021). Uranium oxide synthetic pathway discernment through unsupervised morphological analysis. J. Nucl. Mater. 552, 152983. doi:10.1016/j.jnucmat.2021.152983
Hanson, A. B., Lee, R. N., Vachet, C., Schwerdt, I. J., Tasdizen, T., and McDonald, L. W. (2019). Quantifying impurity effects on the surface morphology of α-U3O8α-U3O8. Anal. Chem. 91, 10081–10087. doi:10.1021/acs.analchem.9b02013
Hanson, A. B., Schwerdt, I. J., Nizinski, C. A., Lee, R. N., Mecham, N. J., Abbott, E. C., et al. (2021). Impact of controlled storage conditions on the hydrolysis and surface morphology of amorphous-UO3. ACS Omega 6, 8605–8615. doi:10.1021/acsomega.1c00435
Heffernan, S. T., Ly, C., Mower, B. J., Vachet, C., Schwerdt, I. J., Tasdizen, T., et al. (2019). Identifying surface morphological characteristics to differentiate between mixtures of U3O8 synthesized from ammonium diuranate and uranyl peroxide3O8 synthesized from ammonium diuranate and uranyl peroxide. Radiochim. Acta 108, 29–36. doi:10.1515/ract-2019-3140
Huang, X., Liu, M., Belongie, S. J., and Kautz, J. (2018). “Multimodal unsupervised image-to-image translation,” in Computer Vision - ECCV 2018-15th European Conference, Munich, Germany, September 8-14, 2018, 179–196. doi:10.1007/978-3-030-01219-9_11
Karani, N., Erdil, E., Chaitanya, K., and Konukoglu, E. (2021). Test-time adaptable neural networks for robust medical image segmentation. Med. Image Anal. 68, 101907. doi:10.1016/j.media.2020.101907
Keegan, E., Kristo, M. J., Colella, M., Robel, M., Williams, R., Lindvall, R., et al. (2014). Nuclear forensic analysis of an unknown uranium ore concentrate sample seized in a criminal investigation in Australia. Forensic Sci. Int. 240, 111–121. doi:10.1016/j.forsciint.2014.04.004
Li, H., Pan, S. J., Wang, S., and Kot, A. C. (2018). “Domain generalization with adversarial feature learning,” in 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018, 5400–5409. doi:10.1109/CVPR.2018.00566
Liang, J., Hu, D., and Feng, J. (2020). “Do we really need to access the source data? source hypothesis transfer for unsupervised domain adaptation,” in Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, 6028–6039.
Ly, C., Vachet, C., Schwerdt, I., Abbott, E., Brenkmann, A., McDonald, L. W., et al. (2020). Determining uranium ore concentrates and their calcination products via image classification of multiple magnifications. J. Nucl. Mater. 533, 152082. doi:10.1016/j.jnucmat.2020.152082
McInnes, L., and Healy, J. (2018). UMAP: uniform manifold approximation and projection for dimension reduction. CoRR abs/1802.03426.
Motiian, S., Piccirilli, M., Adjeroh, D. A., and Doretto, G. (2017). “Unified deep supervised domain adaptation and generalization,” in IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017 5716–5726. doi:10.1109/ICCV.2017.609
Nizinski, C. A., Hanson, A. B., Fullmer, B. C., Mecham, N. J., Tasdizen, T., and McDonald, L. W. (2020). Effects of process history on the surface morphology of uranium ore concentrates extracted from ore. Miner. Eng. 156, 106457. doi:10.1016/j.mineng.2020.106457
Nizinski, C. A., Ly, C., Vachet, C., Hagen, A., Tasdizen, T., and McDonald, L. W. (2022). Characterization of uncertainties and model generalizability for convolutional neural network predictions of uranium ore concentrate morphology. Chemom. Intelligent Laboratory Syst. 225, 104556. doi:10.1016/j.chemolab.2022.104556
Olsen, A. M., Richards, B., Schwerdt, I., Heffernan, S., Lusk, R., Smith, B., et al. (2017). Quantifying morphological features of α-U3O8 with image analysis for nuclear forensicsα-U3O8 with image analysis for nuclear forensics. Anal. Chem. 89, 3177–3183. doi:10.1021/acs.analchem.6b05020
Postek, M. T., and Vladár, A. E. (2015). Does your sem really tell the truth? how would you know? part 4: charging and its mitigation. Proc. SPIE Int. Soc. Opt. Eng. 9636, 963605. doi:10.1117/12.2195344
Postek, M. T., and Vladár, A. E. (2013). Does your sem really tell the truth? how would you know? part 1. Scanning 35, 355–361. doi:10.1002/sca.21075
Postek, M. T., Vladár, A. E., and Cizmar, P. (2014). Does your sem really tell the truth? how would you know? part 3: vibration and drift. SPIE Proc. 9236, 923605. doi:10.1117/12.2065235
Postek, M. T., Vladár, A. E., and Purushotham, K. P. (2013). Does your sem really tell the truth? how would you know? part 2. Scanning 36, 347–355. doi:10.1002/sca.21124
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., et al. (2015). Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 115, 211–252. doi:10.1007/s11263-015-0816-y
Schwerdt, I. J., Hawkins, C. G., Taylor, B., Brenkmann, A., Martinson, S., and McDonald, L. W. (2019). Uranium oxide synthetic pathway discernment through thermal decomposition and morphological analysis. Radiochim. Acta 107, 193–205. doi:10.1515/ract-2018-3033
Simonyan, K., and Zisserman, A. (2015). “Very deep convolutional networks for large-scale image recognition,” in 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015.
Tzeng, E., Hoffman, J., Saenko, K., and Darrell, T. (2017). “Adversarial discriminative domain adaptation,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017 2962–2971. doi:10.1109/CVPR.2017.316
Valvano, G., Leo, A., and Tsaftaris, S. A. (2021). “Stop throwing away discriminators! re-using adversaries for test-time training,” in Domain Adaptation and Representation Transfer, and Affordable Healthcare and AI for Resource Diverse Global Health - Third MICCAI Workshop, DART 2021, and First MICCAI Workshop, FAIR 2021, Held in Conjunction with MICCAI 2021, Strasbourg, France, September 27 and October 1, 2021 (Springer), 68–78. doi:10.1007/978-3-030-87722-4_7
Keywords: nuclear forensics, machine learning, convolutional neural networks, domain adaptation, scanning electron microscopy
Citation: Ly C, Nizinski C, Hagen A, McDonald LW IV and Tasdizen T (2023) Improving robustness for model discerning synthesis process of uranium oxide with unsupervised domain adaptation. Front. Nucl. Eng. 2:1230052. doi: 10.3389/fnuen.2023.1230052
Received: 27 May 2023; Accepted: 21 September 2023;
Published: 25 October 2023.
Edited by:
Robert Lascola, Savannah River National Laboratory (DOE), United StatesReviewed by:
Shingo Tamaki, Osaka University, JapanNirmal Mazumder, Manipal Academy of Higher Education, India
Copyright © 2023 Ly, Nizinski, Hagen, McDonald and Tasdizen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Cuong Ly, bmhhdGN1b25nLmx5QHBubmwuZ292