 Lichun Guo1*
Lichun Guo1* Shuang Liang
Shuang Liang Wenlong Hang
Wenlong Hang- 1College of Art and Design, Nanjing Audit University Jinshen College, Nanjing, China
- 2College of Computer and Information Engineering, Nanjing Tech University, Nanjing, China
- 3School of Internet of Things, Nanjing University of Posts and Telecommunications, Nanjing, China
Automatic classification of interior decoration styles has great potential to guide and streamline the design process. Despite recent advancements, it remains challenging to construct an accurate interior decoration style recognition model due to the scarcity of expert annotations. In this article, we develop a new weight-aware semi-supervised self-ensembling framework for interior decoration style recognition, which selectively leverages the abundant unlabeled data to address the aforementioned challenge. Specifically, we devise a weight module that utilizes a truncated Gaussian function to automatically assess the reliability of unlabeled data. This enables more reliable unlabeled samples to be adaptively assigned higher weights during the training process. By incorporating adaptive weights, we devise a weighted consistency regularization to enforce consistent predictions for reliable unlabeled data under different perturbations. Furthermore, we devise a weighted relation consistency regularization to preserve the semantic relationships of reliable unlabeled data across various perturbations. Additionally, we introduce a weighted class-aware contrastive learning regularization to improve the model's discriminative feature learning capability using reliable unlabeled data. The synergistic learning of weighted consistency regularization, weighted relation consistency, and weighted class-aware contrastive learning significantly enhances the model's generalizability. Extensive experiments conducted on interior decoration style image datasets demonstrate the superior performance of our framework compared to existing semi-supervised learning methods.
1 Introduction
Automatic classification of interior decoration styles has great potential in guiding and streamlining the design process. By using artificial intelligence techniques, it is possible to analyze various design elements (e.g., color schemes, furniture types, materials, and layouts) to categorize a given interior decoration into predefined categories, including Country, Chinese, European, Simple, and others. This can help designers make informed decisions, provide clients with more personalized recommendations, and speed up the design process (Shan et al., 2022; Guo et al., 2024; Liu et al., 2021). At present, deep learning methods play a pivotal role in interior design practice and are extensively applied across various domains, including interior decoration style classification (Kim and Lee, 2020), style colorization (Tong et al., 2019), style design (Wu et al., 2024), and other related aspects.
Although deep learning methods have achieved remarkable success in various visual recognition tasks, their performance heavily relies on large-scale, high-quality labeled datasets. In the context of interior decoration style classification, obtaining such labeled data is both labor-intensive and time-consuming. In contrast, unlabeled images are easier to collect in real-world scenarios. Semi-supervised learning methods have demonstrated significant potential by effectively exploiting unlabeled data to enhance model performance. Consequently, semi-supervised learning is progressively emerging as the predominant method for interior decoration style classification. Most existing semi-supervised learning methods mainly rely on the smoothness assumption, which posits that nearby samples tend to belong to the same class. Based on this principle, the consistency learning strategy (Tarvainen, 2017) leverages unlabeled data by enforcing consistent outputs from the network when subjected to input or model perturbations. Another strategy is pseudo-labeling (Iscen et al., 2019), where the pseudo-labels are generated for the unlabeled data and then combined with labeled samples to train the model. A prevailing trend is to integrate the consistency learning and pseudo-labeling techniques to enhance the effectiveness of semi-supervised learning (Chen et al., 2021; Liu et al., 2022). To date, semi-supervised learning methods have achieved notable success in various real-world applications, including image recognition (Wu et al., 2022; Hang et al., 2022), image segmentation (Hang et al., 2025, 2020), and text classification (Duarte and Berton, 2023; Han et al., 2023).
Despite promising progress, existing semi-supervised learning methods still encounter major difficulties when the pseudo-labels of unlabeled data are unreliable. For consistency learning-based methods, perturbations applied to inaccurate predictions may result in potentially erroneous training signals, thereby degrading the effectiveness of consistency learning (Liu et al., 2022). Besides, for pseudo-labeling-based semi-supervised learning methods, incorporating inaccurate unlabeled data into training process introduces confirmation bias, which significantly deteriorates model performance (Hang et al., 2024). In light of this, various strategies have been proposed to mitigate the adverse effects of unreliable pseudo-labels, yielding promising results across multiple applications. For pseudo-labeling-based methods, a commonly adopted strategy involves setting a high confidence threshold to filter out low-confidence pseudo-labeled samples (Berthelot et al., 2019; Sohn et al., 2020; Yu et al., 2019). Although effective, the quality of pseudo-labels still heavily depend on the predefined confidence threshold, making the confirmation bias problem caused by unreliable pseudo-labels unresolved. For example, FixMatch (Sohn et al., 2020) adopted a confidence threshold 0.95 to retain some unlabeled data. Other approaches utilized the self-generated probability predictions to reweight the out-of-distribution unlabeled data. For instance, CCSSL (Wu et al., 2022) utilized probability outputs to reweight unlabeled samples. The higher the probability, the more reliable the data, and vice versa.
For consistency learning-based methods, the self-EMA (Tarvainen, 2017; Tang et al., 2021; Zhou et al., 2021) framework was designed to produce pseudo-labels under the assumption that a weighted average model can yield the reliable predictions. Some other semi-supervised learning methods allow one subnetwork to learn from another if the latter exhibits higher prediction confidence. This confidence is typically estimated based on the model's predictions (Wu et al., 2022; Hang et al., 2025), with higher confidence values indicating more reliable pseudo-labels. In this manner, the subnetworks can perform selective cross-supervision and mutually refine each other. Despite these advancements, most existing methods access the reliability of unlabeled data based on either predefined confidence thresholds or the model's prediction confidence, which limits their effectiveness in identifying truly reliable samples and makes them prone to confirmation bias.
To address above challenges, we propose WSSL, a weight-aware semi-supervised learning framework for interior decoration style classification that selectively utilizes the reliable unlabeled data. Specifically, WSSL introduces a weighting module that employs a truncated Gaussian function to automatically assess the reliability of unlabeled data. This weight module is capable of assigning higher weights to more reliable unlabeled samples during the training process. By incorporating these weights, WSSL introduces a weighted consistency (WCS) regularization that enforces prediction consistency for reliable unlabeled data under different perturbations. Besides, WSSL further introduces a weighted relation consistency (WRCS) regularization to preserve the semantic relationship consistency of reliable unlabeled samples under various perturbations. Additionally, WSSL introduces a weighted class-aware contrastive learning (WCCL) scheme to enhance the discriminative feature learning ability of model. Most importantly, experimental results show that the synergistic learning of WCS regularization, WRCS regularization, and WCCL regularization can significantly improve the model's generalizability.
Above all, the main contributions of this work are summarized as follows:
(1) We present WSSL, a novel semi-supervised framework to selectively leverage reliable unlabeled data through an adaptive weighting module to enhance interior decoration style classification.
(2) WSSL integrates three novel components: WCS regularization to enforce prediction consistency for reliable unlabeled data under different perturbations, WRCS regularization to encourage the consistency of semantic relationships among these data, and WCCL regularization to enhance the discriminative capability of the model through the use of reliable unlabeled data.
(3) The synergistic learning of WCS, WRCS, and WCCL effectively mitigates confirmation bias caused by unreliable pseudo-labels. Experimental results on interior decoration style image datasets confirm the superior performance of WSSL.
2 Related works
2.1 Deep semi-supervised learning
Semi-supervised learning methods effectively utilize the combination of limited labeled data and abundant unlabeled data to improve model performance. At present, consistency regularization and pseudo-labeling are two dominant paradigms for exploiting unlabeled data. As previously discussed, consistency learning-based methods (Tarvainen, 2017; Liu et al., 2022; Hang et al., 2025; Liu et al., 2020; Yu et al., 2019; Chen et al., 2021; Ouali et al., 2020; Miyato et al., 2018) were designed to guide the model toward producing consistent predictions for the same input under slight perturbations. These perturbations can be applied at different levels, including the input (Tarvainen, 2017), feature representations (Miyato et al., 2018), network parameters (Hang et al., 2025) or combinations of these (Liu et al., 2022). The Mean Teacher (MT) model (Tarvainen, 2017) enforces consistency by using two models with identical architectures. It employs the predictions of one model under stochastic perturbations as training targets for the other model. The parameters of the teacher network are updated through an exponential moving average (EMA) of the student network's parameters. In Hang et al. (2025), a pseudo-label-based selective mutual learning framework introduces network perturbations by utilizing two subnetworks with different architectures. Additionally, Liu et al. (2022) explores a combination of diverse perturbations to boost the generalization ability of consistency learning. Nevertheless, inaccurate predictions on unlabeled data remain a major challenge for semi-supervised learning methods, as potential mispredictions can negatively impact the consistency learning performance.
Self-training (Grandvalet and Bengio, 2004) is one of the most widely adopted strategies in pseudo-labeling-based semi-supervised learning methods, wherein pseudo-labels are assigned to unlabeled data and subsequently used together with labeled data to retrain the model. To mitigate confirmation bias induced by unreliable pseudo-labels, most semi-supervised learning methods apply a high-confidence threshold to filter out pseudo-labels with low confidence, thereby avoiding the use of potentially erroneous labels. For instance, many semi-supervised learning methods (Berthelot et al., 2019; Sohn et al., 2020; Li et al., 2020, 2023; Lee, 2013) typically use a threshold of 0.95 retain only high-confidence pseudo-labels. However, defining an optimal confidence threshold that can filter out all unreliable pseudo-labels while preserving all reliable ones remains highly challenging. A high threshold may eliminate some reliable pseudo-labels, while a low threshold increases the risk of incorporating noisy labels, potentially limiting the generalization capacity of the model.
Recently, several semi-supervised learning methods (Berthelot et al., 2019; Yu et al., 2019; Li et al., 2023; Su et al., 2024; Wu et al., 2021; Wang et al., 2023) aim to effectively utilize unlabeled data through integrating consistency learning and pseudo-labeling strategies to improve model performance. For instance, in Li et al. (2023), a diverse co-training method was devised to choose partially reliable pseudo-labels for cross-supervision between different models. Besides, Su et al. (2024) developed a mutual learning framework that utilized two subnetworks, in which the pseudo-labels with higher prediction confidence were used to guide the training of the other subnetwork. Although effective, these methods also face challenges from confirmation bias induced by potentially incorrect pseudo-labels, which can adversely impact model performance.
2.2 Reliable unlabeled data learning
The main challenge of semi-supervised learning methods lies in effectively identifying reliable unlabeled data, as unreliable unlabeled data adversely affect model performance. In practice, unreliable unlabeled data typically originate from two main sources: (1) out-of-distribution unlabeled data; and (2) unlabeled data associated with incorrect self-generated pseudo-labels. Current semi-supervised learning methods suffer from these unreliable unlabeled data, leading to worse performance than supervised baselines (Su et al., 2021). As models inherently produce inaccurate pseudo-labels for OOD samples, several approaches have been proposed to assess pseudo-label reliability for selecting trustworthy unlabeled data. For instance, Yao et al. (2022) proposed a confidence-aware cross pseudo supervision network that measures the confidence of pseudo-labels using KL-divergence, and then directs model focus on learning from more confident pseudo-labels. In Guo et al. (2020), pseudo-labeled unlabeled data were combined with labeled data to train the model, while performance of the supervised model was continuously monitored to prevent performance degradation. Furthermore, Hang et al. (2022) extended this strategy to construct a reliability-aware self-ensembling framework for semi-supervised classification. Following this line, this paper further explores the selective utilization of reliable unlabeled data, aiming to bridge the gap between research and practical deployment, particularly in the context of interior decoration style classification.
3 Weighted-aware semi-supervised self-ensembling framework
In this section, we first introduce our weight-aware module based on a truncated Gaussian function. Subsequently, we describe the proposed weighted consistency (WCS) regularization, weighted relation consistency (WRCS) regularization, and weighted class-aware contrastive learning (WCCL) regularization, respectively.
3.1 Problem statement
For the interior decoration style image dataset, suppose we have a small labeled training set , where represents the i-th training image and is its corresponding ground-truth label. The total number of classes is denoted as C. We have an unlabeled training set , with N≪M. The goal is to develop a semi-supervised learning model that can perform well on the test interior decoration style images.
To address the confirmation bias induced by unreliable pseudo-labels, we devise a weight-aware semi-supervised self-ensembling (WSSL) framework, as illustrated in Figure 1. WSSL first introduces a weight module that employs a truncated Gaussian function to automatically assign higher weights to more reliable unlabeled samples during training. Based on these weights, WSSL introduces a WCS regularization to enforce consistent predictions for reliable unlabeled data under different perturbations. Besides, WSSL further introduces a WRCS regularization to ensure that the semantic relations among reliable unlabeled data remain consistent under different perturbation scenarios. Additionally, WSSL introduces a WCCL regularization to enhance the model's discriminative feature learning ability. The following sections provide detailed descriptions of the core components of WSSL, including adaptive weight learning, WCS regularization, WRCS regularization, and WCCL regularization.
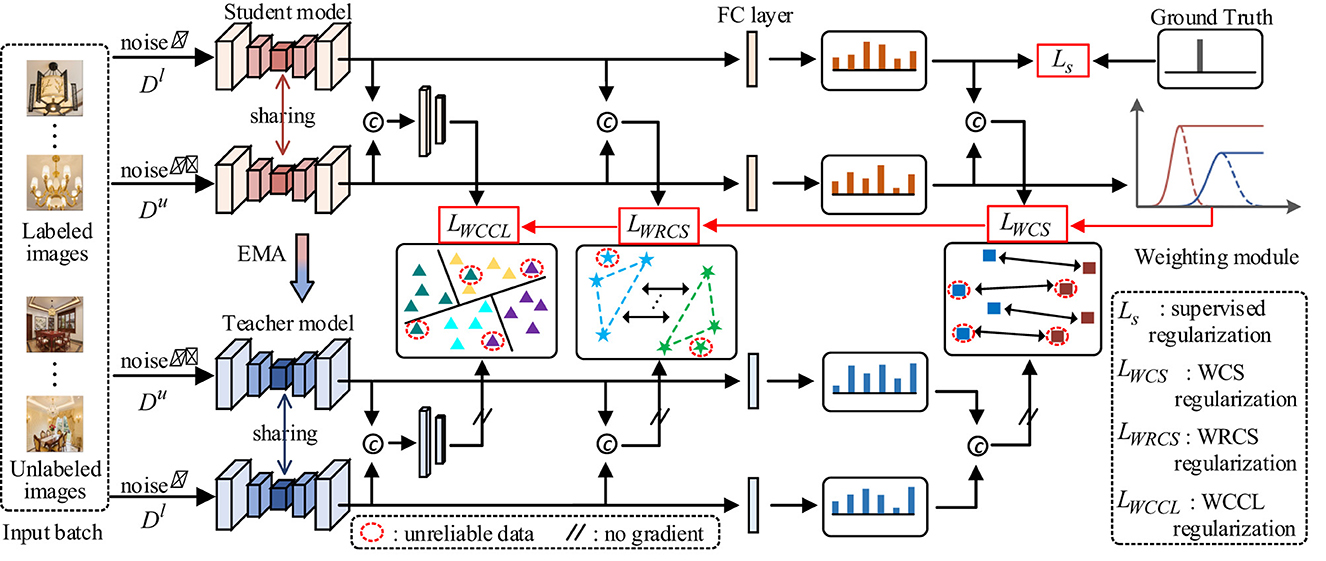
Figure 1. Diagram of a machine learning framework with student and teacher models, showing the flow of labeled and unlabeled images through added noise. It illustrates data sharing between models, application of regularization techniques, and a weighting module. Key components include feature extraction, comparison with ground truth, and error minimization. Annotations describe processes like EMA, unreliable data handling, and the role of various regularizations such as supervised, WCS, WRCS, and WCCL. Visuals include charts and network representations, explaining how input data is processed. The architecture of WSSL for interior decoration style classification. An input batch containing labeled and unlabeled data were fed into student and teacher network, respectively. The weighting module employs a truncated Gaussian function to automatically calculate the weights for unlabeled data. These weights were then used in WCS regularization LWCS, WRCS regularization LWRCS, and WCCL regularization LWCCL. Finally, the supervised loss Ls was combined with LWCS, LWRCS and LWCCL to optimize the model.
3.2 Adaptive weight learning
To exploit the reliable unlabelled interior decoration style images, we first introduce an adaptive weight learning module that assigns weights to unlabeled data by estimating the quality of their corresponding pseudo-labels. Without loss of generality, we denote the network's prediction of an unlabeled image x as p(y|x), which is abbreviated as p. Thus, the adaptive weight function is presented as g(p):ℝC → ℝ, which maps model's output on unlabeled data to their corresponding weights. As mentioned above, relying on a fixed confidence threshold to effectively distinguish unreliable pseudo-labels from reliable ones is inherently limited, thereby constraining the model's generalization capability.
To address above issue, we assume the max value of network predictions max(p) follows a Gaussian distribution when max(p) < μ, and a uniform distribution when max(p)≥μ. Here, we consider the deviation of max(p) from the mean μ of Gaussian as a proxy measure of the correctness of pseudo-labels when max(p) < μ. Hence, the adaptive weight function g(p) can be formulated as a truncated Gaussian function within the range [0, λmax]:
where μc(t) and σc(t), ∀c = 1, 2, ⋯ , C denote the mean and variance of the Gaussian function for the c-th class at the t-th iteration, respectively. Referring to Chen et al. (2023), the parameters λmax is set to 1. Besides, we estimate μc(t) and σc(t) using the historical predictions of model stored in a queue list M. Therefore, we can obtain:
Here, and denote the empirical mean and the variance of confidence of c-th images in M. Parameter α is used to balance the contributions of historical mean and the variance. In the training procedure, the queue list is iteratively update by using the images in the current batch to replace the oldest ones.
3.3 Weighted consistency (WCS) regularization
The proposed WSSL framework is built upon the self-ensembling paradigm, which usually takes consistency learning as regularization to exploit unlabeled data. The objective function is expressed as:
Here, Ls is the supervised loss, whileLu represents the unsupervised consistency loss (e.g., mean squared error), which is utilized for exploiting the unlabeled data. θ and θ′ refer to the student and teacher network parameters, respectively. Besides, η and η′ denote the different input perturbations, such as random rotations, translations, and horizontal flips. According to the self-ensembling principle (Tarvainen, 2017), the parameters of the teacher network are updated through EMA of the student network's parameters.
It can be observed from Equation 4 that all unlabeled data are treated equally during model training, without considering the potential negative impact of unreliable unlabeled data on model performance. To address this limitation, we incorporate the adaptive weight learning module to assign differentiated weights to unlabeled data. We then propose a weighted consistency (WCS) regularization LWCS, which selectively enforces consistency on reliable unlabeled data, which can be formulated as:
where the weights wi = g(pi), i = N+1, N+2, ⋯ , N+M can be automatically estimated from Equation 1. It can be seen from Equation 5, the proposed WCS regularization enforces consistency among ensemble predictions for reliable unlabeled samples under different input perturbations.
3.4 Weighted relation consistency (WRCS) regularization
The above WCS regularization only focuses on individual reliable data points, we argue that the relationships between reliable data should also remain consistent under different perturbations. In view of this, we design a weighted sample relation consistency (WRCS) regularization to model the intrinsic relationships among reliable data. The proposed WRCS encourages the network to keep consistent semantic relationships between samples under different perturbations, enabling the model extract inherent semantic information from reliable unlabeled data.
Assuming the input min-batch xB contains B samples, the feature representations are expressed as F∈ℝB×C×H×W. H, W and C denote height, width and number of channels. We reshape F to E∈ℝB×CHW, and compute the sample relation matrix G as the Gram Matrix of E:
Here, the (i, j)-th term Gi, j denotes the inner product of vectorized features Ei and Ej. Equation 6 can thus be interpreted as a similarity measure between the feature maps of the i-th and j-th samples. We then use L2 normalization to each row of sample relation matrix G:
Finally, the WRCS regularization used to preserve the semantic relationships under different perturbations can be formulated as:
Here, W = [w1, w2, ⋯ , wN+M] subsumes and . Besides, the weights Wu is automatically computed by using Equation 1. LWRCS can help maintain the intrinsic relationships among samples across various perturbations, thereby facilitating the extraction of additional semantic information within unlabeled data.
3.5 Weighted class-aware contrastive learning (WCCL) regularization
Supervised contrastive learning (Zhang et al., 2022; Li et al., 2021) has been commonly employed in semi-supervised learning framework to capture pairwise relationships among unlabeled samples based on their pseudo-labels. However, the incorrect pseudo-labels may degrade the effectiveness of contrastive learning. To address this issue, we devise a weighted class-aware contrastive learning (WCCL) regularization, which selectively emphasizes reliable unlabeled samples to promote the discriminative feature learning capability of model.
Formally, the classical supervised contrastive learning scheme is expressed as:
In this context, zi and , ∀i = 1, 2, ⋯M are the normalized embeddings produced by the projection networks h and ĥ, denoted as zi = h(f(xi, η; θ)) and . τ is a hyper-parameter. Q is a dynamic queue list. P(i) refers to the set of indices for all positive samples based on their pseudo-labels.
Although above supervised contrastive learning strategy is effective, the unreliable unlabeled data may impair the classification performance of model. Hence, we devise a weighted contrastive learning (WCCL) regularization, which can be expressed as:
Notably, LWCCL will degenerate to LCCL when wi of each unlabeled data tends to 1. It can be seen that LWCCL selectively leverages the reliable unlabeled data, thereby enhancing the effectiveness of contrastive learning.
3.6 Objective function
Overall, the objective of our weight-aware semi-supervised self-ensembling (WSSL) framework can be formulated as:
Here, Ls denotes the supervised cross-entropy loss. λ1, λ2, and λ3 are hyper-parameters that are used to balance the regularizations. The optimization procedure of our WSSL is given in Algorithm 1 in detail.

Algorithm 1. Optimization of WSSL framework.
4 Experiments
This section presents the evaluation of WSSL on five distinct interior decoration style image datasets, including: (1) TV background wall, (2) chandelier, (3) living room, (4) dining room, and (5) bedroom. Initially, we provided a detailed description of these datasets. Then, we introduce the comparative semi-supervised learning methods and outline the corresponding implementation details. Finally, we report and analyze the experimental results.
4.1 Datasets
4.1.1 TV background wall
The dataset comprises 1,643 images, categorized into four types: 250 for Country style, 270 for Chinese style, 322 for European style, and 801 for Simple style.
4.1.2 Chandelier
The dataset includes 969 images, distributed across four style categories: 295 for Country style, 169 for Chinese style, 351 for European style, and 154 for Simple style.
4.1.3 Living room
The dataset comprises 1,489 images: 138 for Country style, 248 for Chinese style, 523 for European style, and 580 for Simple style.
4.1.4 Dining room
The dataset contains 520 images: 91 for Country style, 98 for Chinese style, 178 for European style, and 153 for Simple style.
4.1.5 Bedroom
The dataset includes 643 images: 149 for Country style, 119 for Chinese style, 191 for European style, and 184 for Simple style.
All images were resized to a resolution of 900 × 700 pixels. Besides, each of the five datasets used in this study was individually partitioned at random into training (70%), validation (10%), and testing (20%) sets.
4.2 Experimental setup
To assess the performance of WSSL for interior decoration style classification, we compared WSSL with several semi-supervised learning methods. The comparison methods include: (1) DenseNet121 (Huang et al., 2017); (2) MT model (Tarvainen, 2017); (3) MixMatch (Berthelot et al., 2019); (4) UDA (Xie et al., 2020); (5) FlexMatch (Zhang et al., 2021); (6) SimMatch (Zheng et al., 2022); (7) SRC-MT (Liu et al., 2020); (8) the proposed weight-aware semi-supervised learning framework (WSSL).
In the experiment, DenseNet121 was employed as the backbone for all the comparison methods. For pseudo-labeling-based semi-supervised learning methods MixMatch, FlexMatch and SimMatch, we refer to the original work to apply the weak and strong augmentations on the input images. Besides, the confidence value was set to 0.95. In consistency learning-based semi-supervised learning methods MT, SRC-MT and our WSSL, a series of random transformations were used as the perturbations for the input images, including rotation, translation, and horizontal/vertical flips. Specifically, the random rotation angle was configured to span from −10 degrees to 10 degrees Hang et al., (2024). For image translation, the number of pixels for both horizontal and vertical displacements was defined within ±2% of the image width. Moreover, input images were subjected to random horizontal and vertical flips with a probability of 50%. Besides, parameter of EMA was set to 0.99. For our WSSL, the hyper-parameters λ1, λ2, and λ3 assigned values of 0.7, 0.7 and 0.1, respectively. Model training was conducted using the Adam optimizer for 10K iterations, with a fixed learning rate of 0.0001. Each training batch comprised 24 samples, equally divided into 12 labeled and 12 unlabeled images. Other experimental settings for the comparison methods followed their original implementations. Our WSSL was implemented using two RTX 3090 GPUs.
In the experiments, AUC, accuracy (ACC), sensitivity (SEN), precision (PREC), and F1 score (F1) were utilized as the evaluation metrics to assess the classification performance of compared methods.
4.3 Comparison with state-of-the-art methods
Tables 1–5 present the classification results of comparison methods trained with 20% labeled and 80% unlabeled training images across five interior decoration style image datasets. The results obtained by DenseNet121 trained with 100% labeled data are considered as the upper-bound performance, while the performance of DenseNet121 trained solely on 20% labeled data is regarded as the baseline. Among all classification results, we highlighted the best results in bold, as shown in Tables 1–5. For clarity, the performance improvements relative to the baseline are indicated in parentheses. According to the classification results presented in Tables 1–5, we can make the following observations.
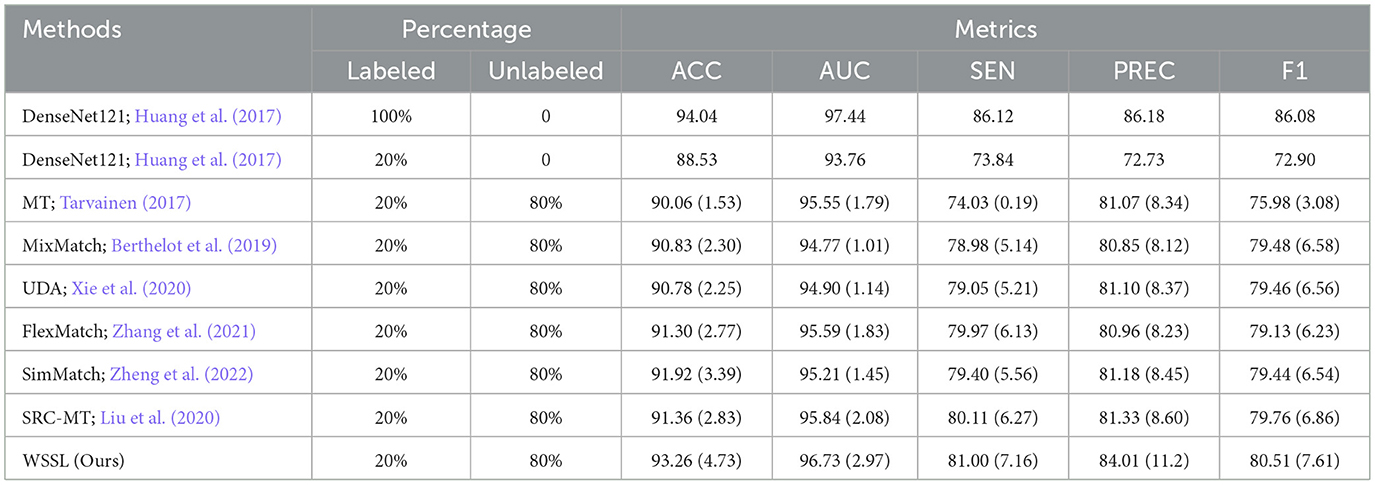
Table 1. Performance (%) comparison with different semi-supervised learning methods on TV background wall dataset.
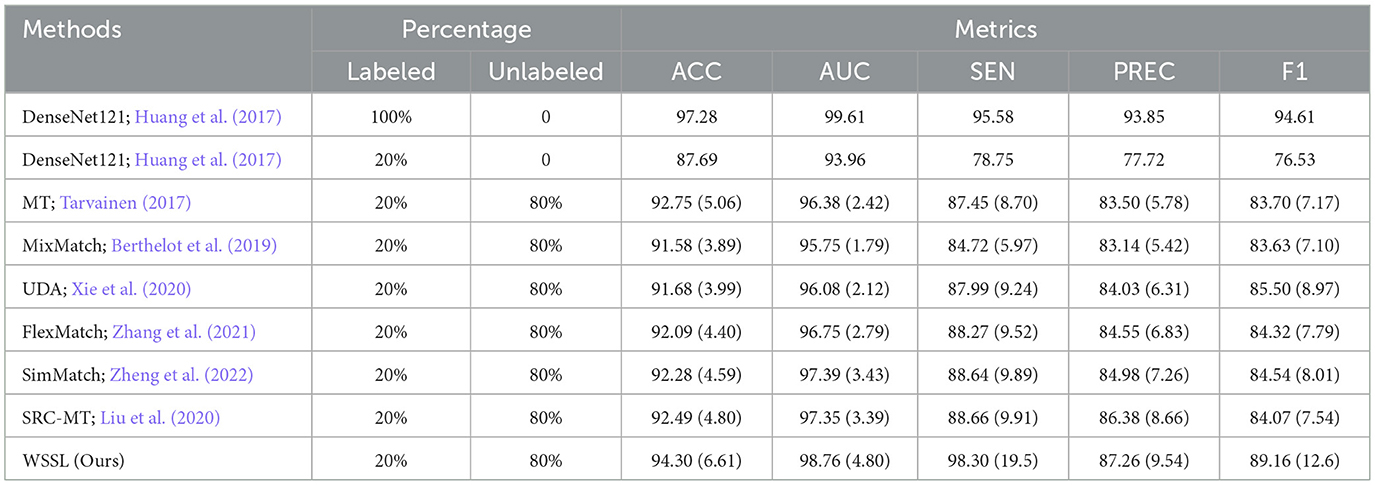
Table 2. Performance (%) comparison with different semi-supervised learning methods on chandelier dataset.
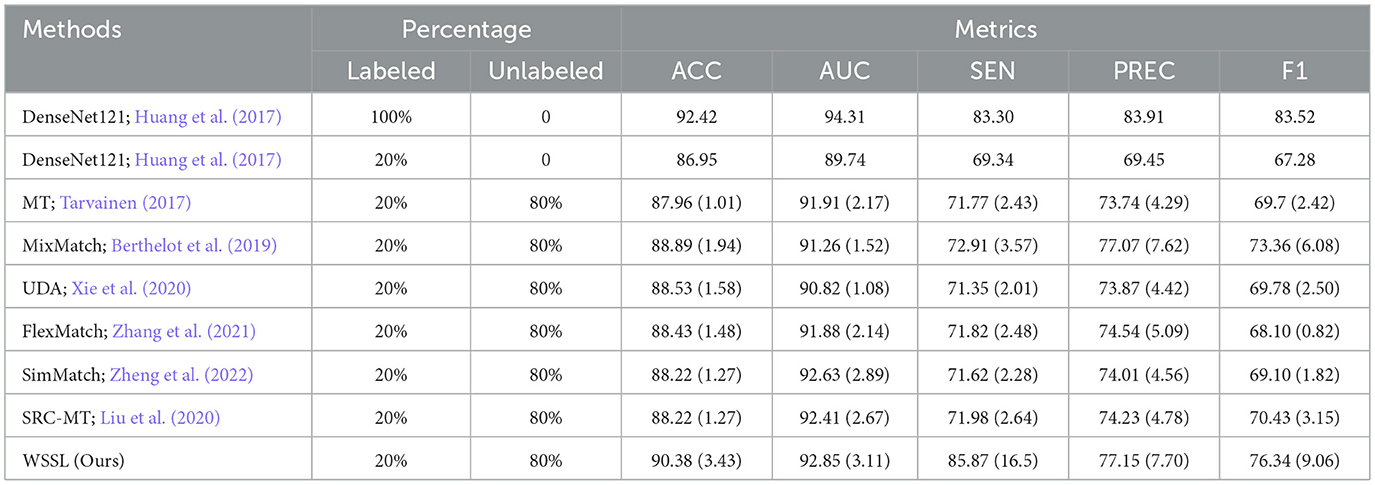
Table 3. Performance (%) comparison with different semi-supervised learning methods on living room dataset.
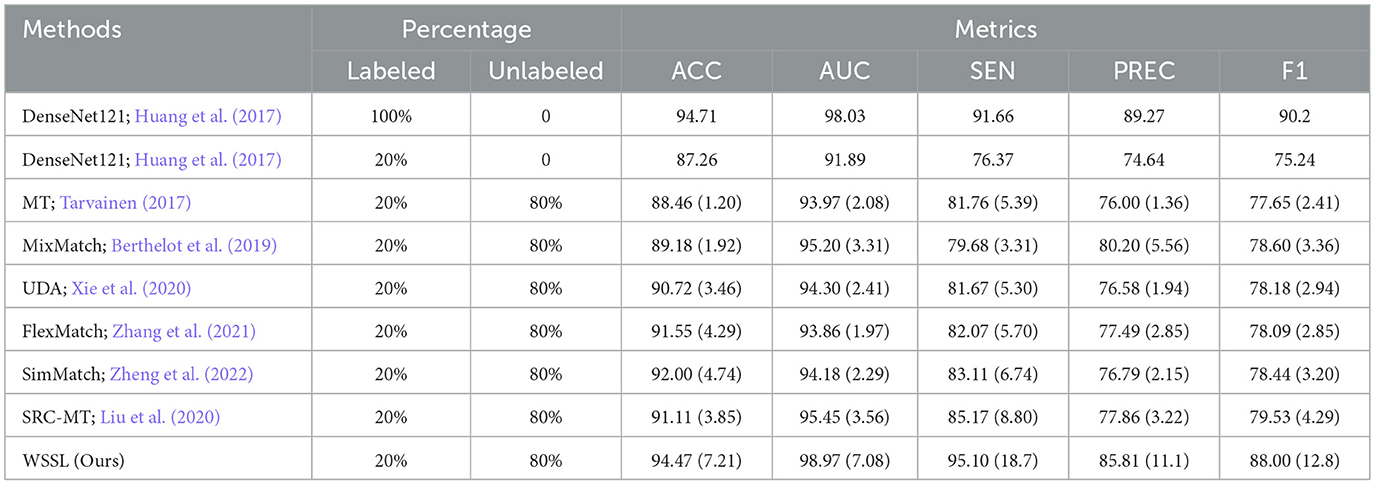
Table 4. Performance (%) comparison with different semi-supervised learning methods on dining room dataset.
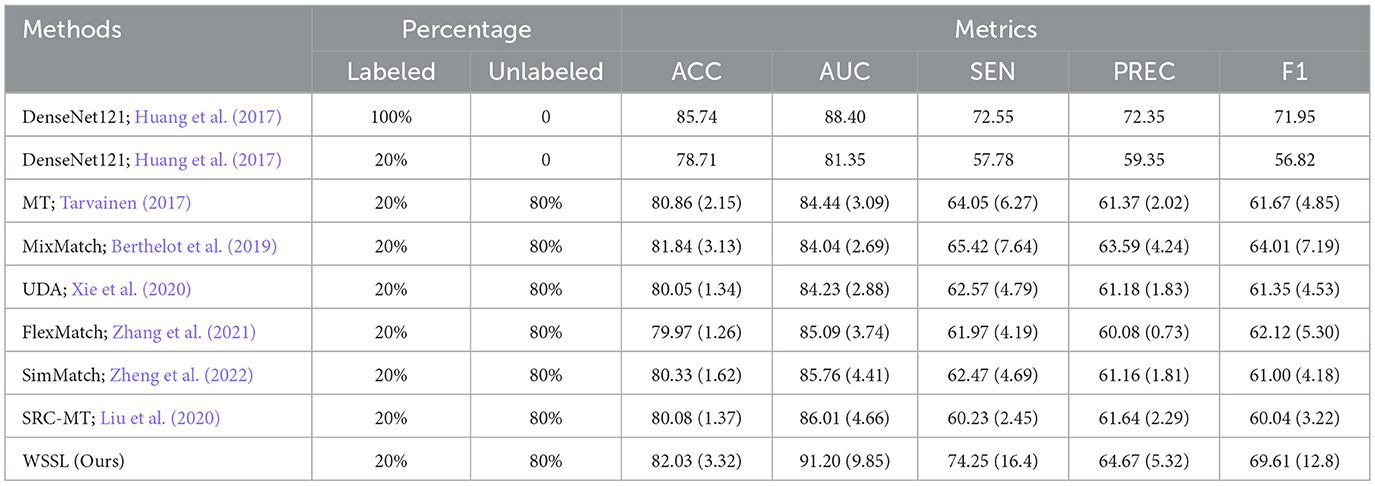
Table 5. Performance (%) comparison with different semi-supervised learning methods on bedroom dataset.
Overall, the semi-supervised learning methods consistently outperform baseline model by leveraging both labeled and unlabeled data during training. Besides, almost all semi-supervised learning methods fail to surpass the upper-bound classification results obtained by DenseNet 121 trained on 100% labeled data. This performance gap is primarily attributed to the adverse impact of inaccurate self-generated pseudo-labels on model training. WSSL exhibits superior classification performance compared to other semi-supervised methods, confirming the efficacy of our weight-aware semi-supervised learning framework. Most importantly, WSSL even exceeds the upper-bound performance on certain evaluation metrics, demonstrating its effectiveness in selectively exploiting reliable unlabeled data through the proposed adaptive weighting module. For example, our WSSL consistently achieves higher SEN and AUC scores than DenseNet121 trained on 100% labeled data across the majority of datasets. Besides, WSSL closely approaches the upper-bound classification results across multiple evaluation metrics. These results further underscore the benefits of selectively leveraging reliable unlabeled data, which also explains the performance gains achieved by our method.
Specifically, our WSSL achieves notable performance gains over the baseline across five image datasets, with average improvements of 5.06%, 5.56%, 15.65%, 8.97%, and 10.97% in terms of ACC, AUC, SEN, PREC, and F1, respectively. When compared to the most competitive consistency learning-based semi-supervised learning method SRC-MT, WSSL obtained the classification improvements of 2.24%, 2.29%, 9.64%, 3.46%, and 5.96%, respectively. Similarly, compared to the most competitive pseudo-labeling-based semi-supervised learning method SimMatch, WSSL demonstrates respective gains of 1.94%, 2.67%, 9.82%, 4.13%, and 6.22%, respectively. The encouraging classification results highlight the efficacy of the synergistic integration of the proposed weighted consistency regularization, weighted relation consistency regularization, and weighted class-aware contrastive learning regularization. In addition, for each interior decoration style image dataset, our WSSL consistently outperforms other comparative methods on all evaluation metrics. For instance, WSSL outperforms the strongest competing method, SRC-MT, on the TV background wall dataset, with improvements of 1.9%, 0.89%, 0.89%, 2.6%, and 0.75% in terms of ACC, AUC, SEN, PREC, and F1, respectively. On the Bedroom dataset, WSSL outperformed the most competitive method, MixMatch, with improvements of 0.19%, 7.16%, 8.76%, 1.08%, and 5.61% across various evaluation metrics. To analyze the classification performance across individual categories, we present the confusion matrices of the proposed WSSL on two class-imbalanced datasets, i.e., TV Background Wall dataset and Living Room dataset, as shown in Figure 2. It can be observed that the diagonal elements in both confusion matrices remain relatively balanced, indicating that WSSL achieves stable performance across different classes. Although WSSL primarily focuses on selecting reliable unlabeled samples rather than explicitly handling class imbalance, it still demonstrates promising classification performance on these imbalanced datasets. These enhancements further demonstrate the benefits of incorporating the weight-aware strategy into semi-supervised learning framework.
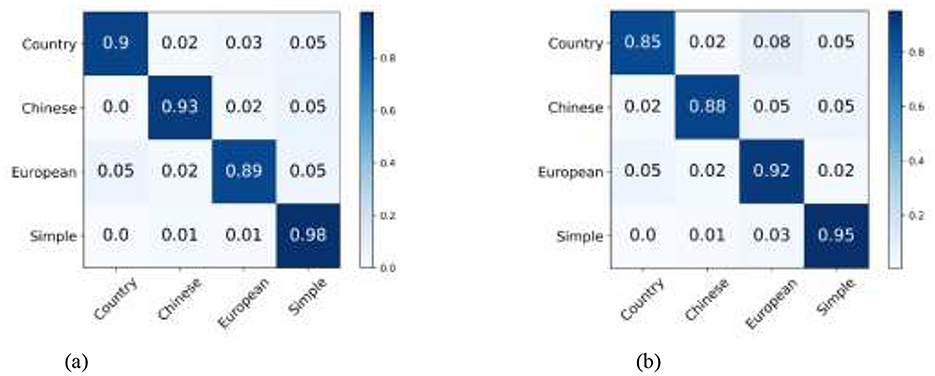
Figure 2. Two confusion matrices compare datasets. (a) TV Background Wall dataset shows high accuracy with values on the diagonal: Country 0.9, Chinese 0.93, European 0.89, Simple 0.98. (b) Living Room dataset shows similar accuracy: Country 0.85, Chinese 0.88, European 0.92, Simple 0.95. Non-diagonal values are lower, indicating classification errors. Color intensity represents value magnitude. Confusion matrix of WSSL for interior decoration style classification: (a) TV background wall dataset, and (b) Living room dataset.
To further evaluate the statistical significance of classification results, we conducted pairwise two-tailed t-tests to determine whether the performance of WSSL is significantly superior to that of other semi-supervised methods in interior decoration style image classification. The statistical outcomes across five datasets are summarized in Table 6, where p-values less than 0.05 are highlighted. As observed, in most cases, the null hypothesis can be rejected at a 95% confidence level, which means the observed performance gains of WSSL over comparison methods are statistically significant.
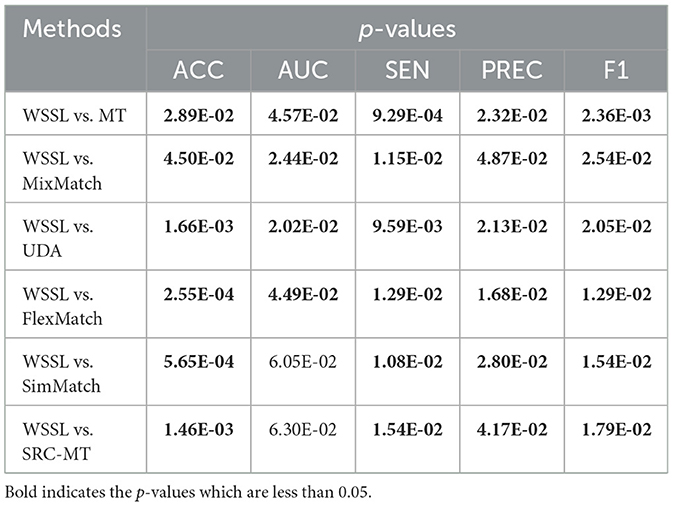
Table 6. Statistical significance comparisons of different metrics of WSSL and other methods on five datasets.
4.4 Evaluation of the proposed WSSL framework
4.4.1 Efficacy of different components
To further access the classification efficacy of the proposed WSSL, we conducted the ablation study for evaluating the individual contributions of its components. Without loss of generality, the classification performance obtained using different components on the Chandelier and Dining Room datasets were presented in Tables 7, 8. In the experiment, we utilized the following models: (a) DenseNet121 (Scenario 1); (b) MT framework with DenseNet121 as the backbone network (Scenario 2); (c) MT framework with WCS regularization (Scenario 3); (d) MT framework with WCS regularization and WRCS regularization (Scenario 4); (e) MT framework with WCS regularization and WCCL regularization (Scenario 5); (f) MT framework with WCS regularization, WRCS regularization, and WCCL regularization (Scenario 6, WSSL).

Table 7. Ablation study of different components on the classification performance of chandelier dataset.
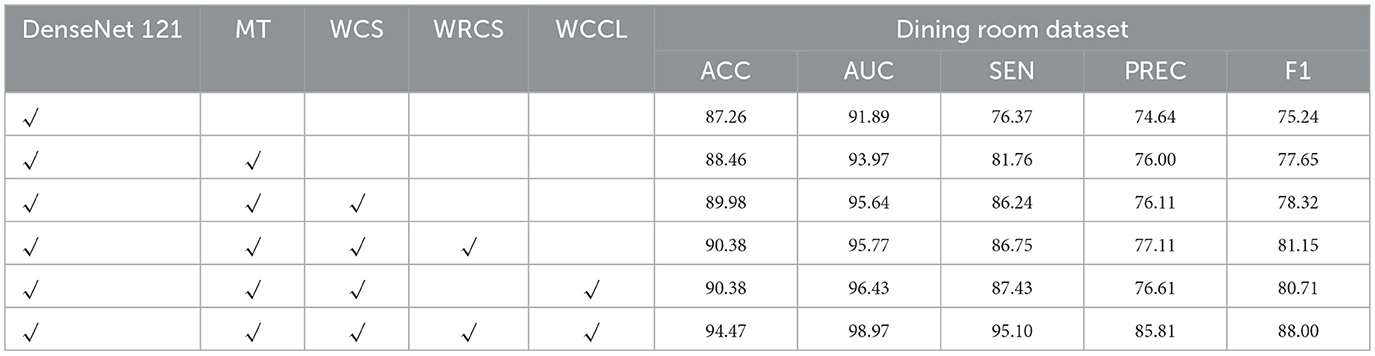
Table 8. Ablation study of different components on the classification performance of dining room dataset.
As demonstrated in Tables 7, 8, the classification performance in Scenario 2 outperforms Scenario 1, confirming MT can effectively leverage unlabeled data. The classification results of Scenario 3 surpass those of Scenario 2, providing empirical evidence for the efficacy of the proposed WCS. Besides, the classification results of Scenario 4 and Scenario 5 surpass Scenario 3, further verifying the effectiveness of the proposed WRCS and WCCL regularizations. We then integrated WCS, WRCS, and WCCL regularizations into the MT framework, i.e., Scenario 6, leading to further enhancements of classification performance. These results confirm the effectiveness of weight-aware mechanism to use the reliable unlabeled data.
Furthermore, we adopted Gradient Weighted Class Activation Mapping (Grad-CAM) Selvaraju et al., (2020) to visualize the salient regions in the image that significantly impact the model's prediction for specific classes. To further examine the effectiveness of different components, we presented the Grad-CAMs of Scenarios 3–6, as illustrated in Figures 3, 4. As observed, the first and second row displays images in Chinese and the European styles, respectively. Notably, the chandelier serves as a representative style attribute that reflects the overall interior decoration category. The salient regions in Figures 3b, 4b indicate only partial stylistic cues (i.e., chandelier) identified under the MT framework with WCS regularization. Moreover, the highlighted regions in Figures 3c, 4c and Figures 3d, 4d are more accurately localized than those in Figures 3b, 4b, confirming the effectiveness of WRCS regularization and WCCL regularization, respectively. Notably, Figures 3e, 4e demonstrate that WSSL can accurately localize multiple chandeliers that correspond to distinct style attributes. These visualizations suggest that WSSL not only captures stylistic variation more effectively but also emphasizes the discriminative characteristics inherent to each style category. For a human design perspective, designers often use lighting elements (e.g., chandelier) to define and differentiate interior styles, indicating that the model's attention aligns well with human design logic. Overall, this attention maps from Grad-CAM visualizations not only demonstrate the model's ability to capture discriminative, style-specific features but also provide valuable interpretability and guidance for downstream applications in real-world interior design.
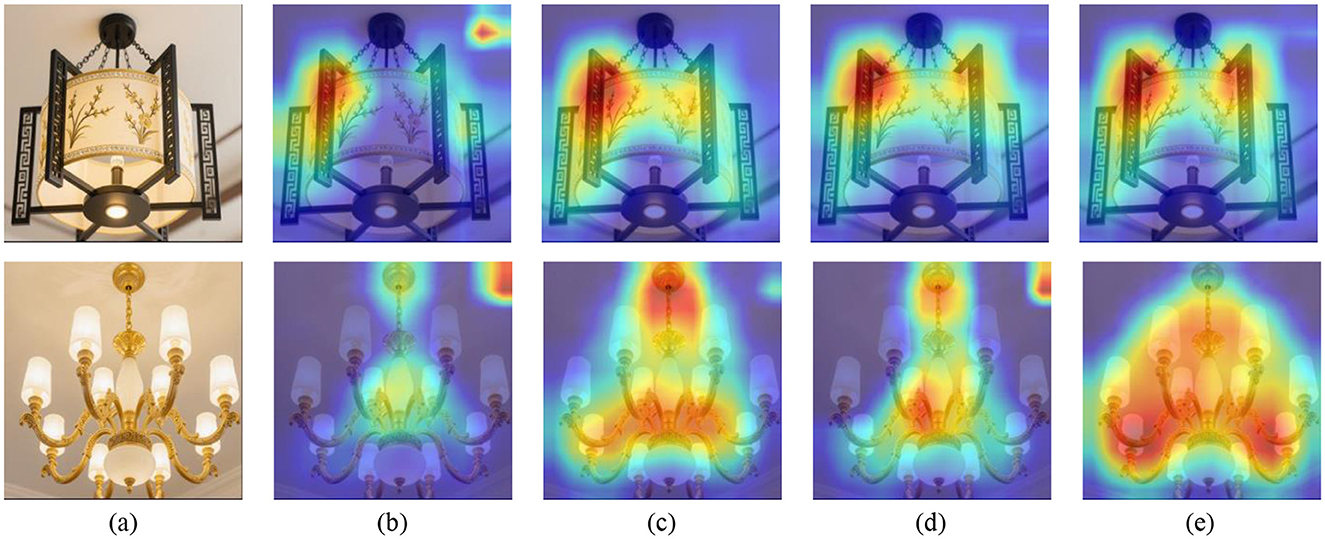
Figure 3. Top row shows five images of a hanging lantern, with the first being a clear photo and the next four displaying heat maps indicating areas of interest. Bottom row features similar sequence with chandeliers, beginning with a clear image followed by four heat maps highlighting different focal points. Grad-CAM visualizations of attention regions for interior decoration style image from the Chandelier dataset. (a) Original images, (b) Scenario 3, (c) Scenario 4, (d) Scenario 5, and (e) Scenario 6. The first and the second row denote Chinese style and European style, respectively.

Figure 4. Two rows of images compare original photographs and heatmaps. The top row shows an interior dining room with the original image (a) followed by heatmaps (b-e) indicating areas of interest in varying colors from blue to red. The bottom row features another dining room with the original image (a), followed by similar heatmaps (b-e), highlighting different focal points. Grad-CAM visualizations of attention regions for interior decoration style image from the dining room dataset. (a) Original images, (b) Scenario 3, (c) Scenario 4, (d) Scenario 5, and (e) Scenario 6. The first and the second row denote Chinese style and European style, respectively.
4.4.2 Impact of different percentage of labeled data
To investigate the classification performance of WSSL under varying proportions of annotated images, we conducted experiments using 5%, 10%, and 20% of annotated training images. We compared WSSL with three representative approaches, i.e., the baseline method DenseNet 121, the most competitive pseudo-labeling-based method SimMatch, and the most competitive consistency learning-based method RAC-MT. The classification results using different percentage of annotated images were listed in Table 9. Overall, the classification performance of all methods continues to improve as the proportion of annotated images increases. Moreover, the classification performance of the proposed WSSL consistently outperforms other comparison methods across different proportion of annotated images, further validating the scalability of weight-aware self-ensembling framework. The results verify the efficacy of the weighting mechanism and highlight the critical role of using reliable unlabeled images in both semantic learning and semantic relationship modeling.
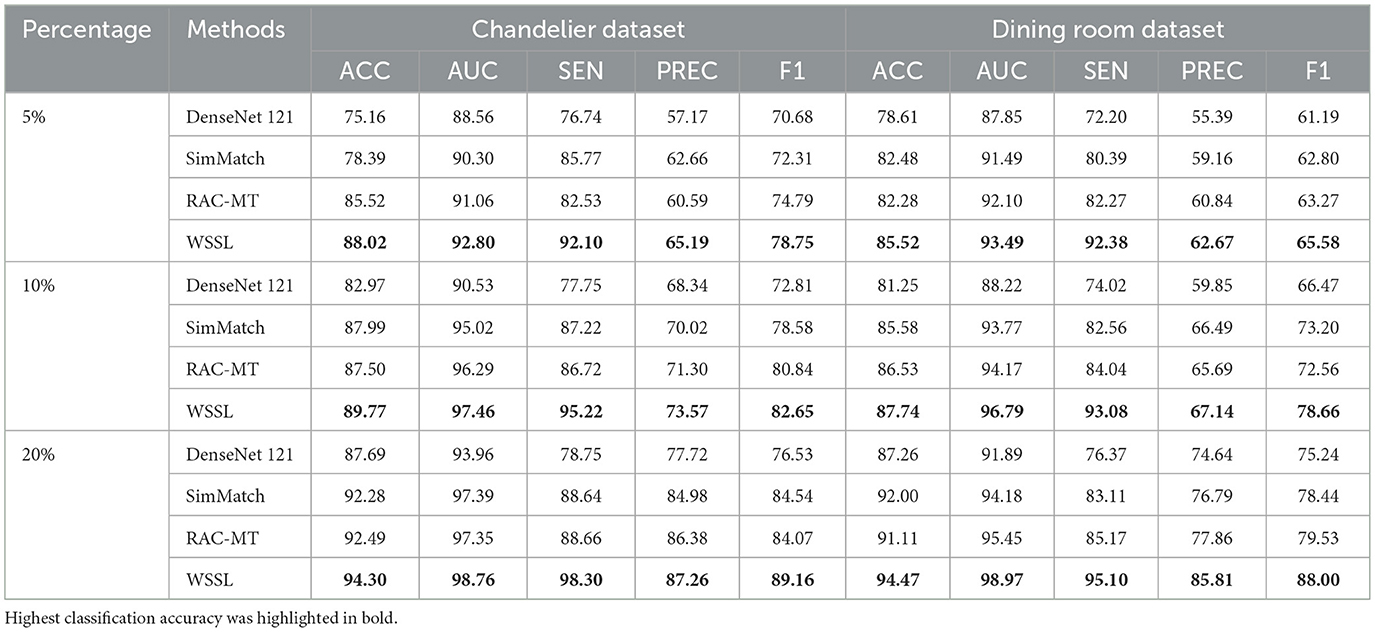
Table 9. Performance (%) of comparison methods using different percentage of labeled data on two datasets.
4.4.3 Impact of hyper-parameters
The impact of hyper-parameters on the classification performance of WSSL were also investigated. WSSL has three hyper-parameters, i.e., λ1, λ2, andλ3, where λ1 is the weight for WCS regularization, λ2 is the weight for WRCS regularization, and λ3 is the weight for WCCL regularization. The two parameters were held constant while the third was adjusted to evaluate its impact on the classification performance of WSSL, as shown in Table 10. When λ1 = λ2 = 0.7, the classification performance improves as the hyper-parameter λ3 increases, indicating that assigning greater emphasis to the WCCL regularization can effectively enhance the classification results. However, as λ3 continues to increase, the classification performance degrades, indicating that neglecting the other two regularizations may negatively impact classification performance. For hyper-parameters λ2 andλ3, the similar results can be found, as shown in Table 10. These results demonstrate the robustness of the proposed weight-aware semi-supervised self-ensembling framework.
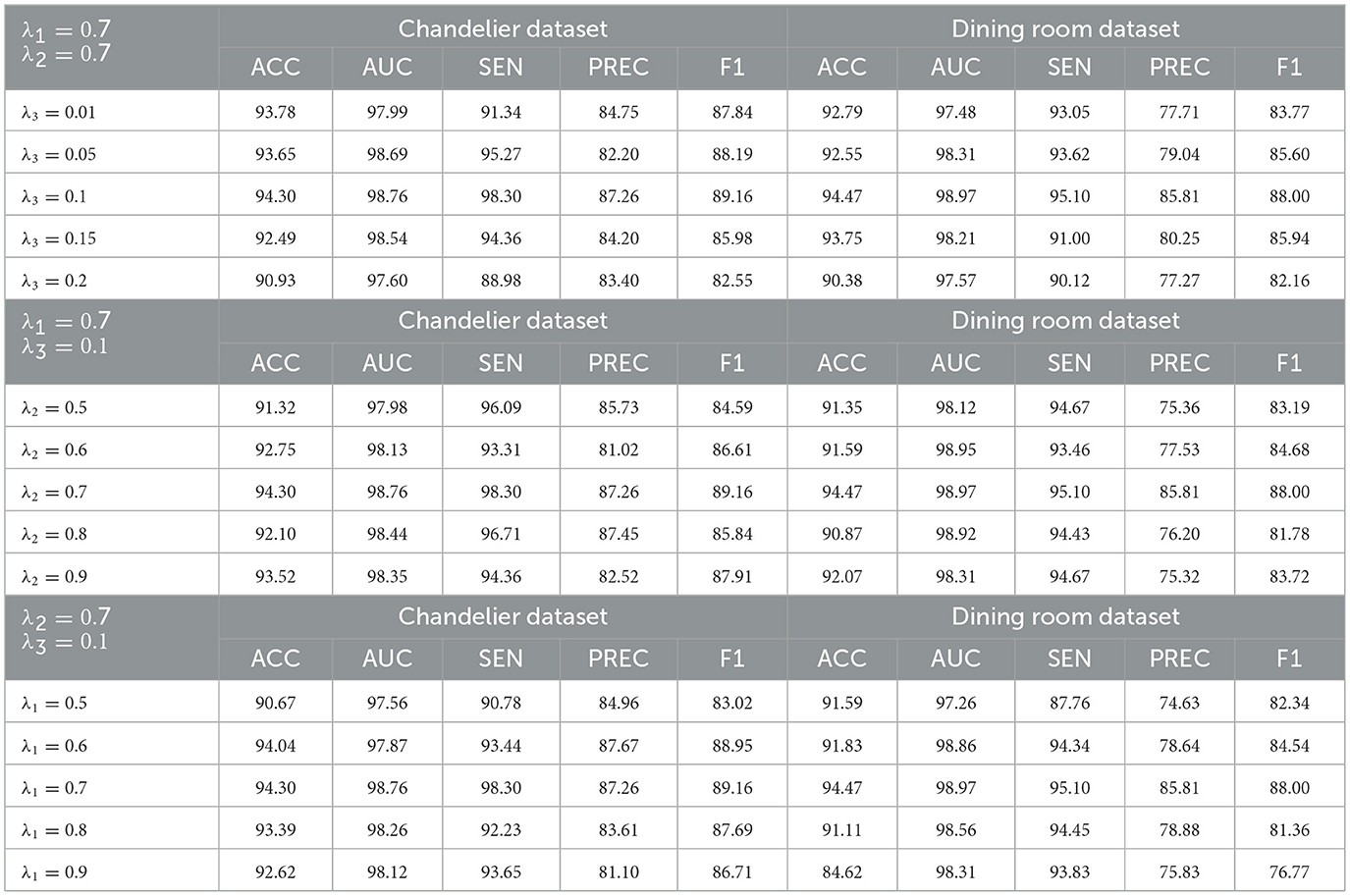
Table 10. Sensitivity of trade-off coefficients on the classification performance (%) on two datasets.
5 Conclusions
We develop a weight-aware semi-supervised self-ensembling framework, termed WSSL, to enhance interior decoration style classification by selectively leveraging reliable unlabeled data through an adaptive weighting mechanism. WSSL follows the Mean Teacher paradigm and identifies reliable unlabeled data using a truncated Gaussian function during training. Additionally, WSSL incorporates three novel regularization modules: weighted consistency regularization to enforce consistent predictions for reliable unlabeled data under different perturbations, weighted relation consistency regularization to encourage the consistency of semantic relationships among reliable unlabeled data under different perturbations, and weighted class-aware contrastive learning regularization to enhance the model's discriminative feature learning ability. The synergistic learning of the proposed three regularizations effectively mitigates confirmation bias induced by unreliable pseudo-labels. Extensive experiments on multiple interior decoration style image datasets demonstrate that WSSL consistently outperforms state-of-the-art semi-supervised methods.
Despite the promising performance of WSSL, three is still room for further improvement. For instance, WSSL does not explicitly address domain shifts across different interior decoration style image datasets, which may reduce its generalization ability on unseen styles. In addition, the adaptive weighting function assumes that the maximum values of network predictions follow a Gaussian distribution, which may not always hold and could impact model performance if violated. Furthermore, the current WSSL does not explicitly count for class imbalance, which could be addressed in future work by incorporating imbalance-aware strategies. In future work, we plan to further investigate the generalizability and effectiveness of WSSL in more complex real-world classification tasks, including medical imaging, autonomous driving, and remote sensing.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author contributions
LG: Data curation, Project administration, Writing – review & editing. HZ: Data curation, Writing – review & editing. JW: Software, Validation, Visualization, Writing – original draft. SL: Conceptualization, Investigation, Writing – review & editing. WH: Conceptualization, Funding acquisition, Project administration, Writing – original draft.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This work was supported by Natural Science Foundation of the Higher Education Institutions of Jiangsu Province under Grant (23KJB520012).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Gen AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Berthelot, D., Carlini, N., Goodfellow, I., Papernot, N., Oliver, A., Raffel, C., et al. (2019). Mixmatch: A holistic approach to semi-supervised learning. Advances in neural information processing systems. arXiv [preprint] arXiv:1905.02240. doi: 10.48550/arXiv.1905.02249
Chen, H., Tao, R., Fan, Y., Wang, J., Wang, Y., Schiele, B., et al. (2023). Softmatch: Addressing the quantity-quality trade-off in semi-supervised learning. arXiv [preprint] arXiv:2301.10921. doi: 10.48550/arXiv.2301.10921
Chen, X., Yuan, Y., Zeng, G., and Wang, J. (2021). “Semi-supervised semantic segmentation with cross pseudo supervision,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (Nashville, TN: IEEE), 2613–2622.
Duarte, J. M., and Berton, L. A. (2023). review of semi-supervised learning for text classification. Artif. Intellig. Rev. 56, 9401–9469. doi: 10.1007/s10462-023-10393-8
Grandvalet, Y., and Bengio, Y. (2004). “Semi-supervised learning by entropy minimization,” in Advances in Neural Information Processing Systems. Vancouver, BC, Canada: Neural information processing systems foundation.
Guo, L., Zeng, H., Shi, X., Xu, Q., Shi, J., Bai, K., et al. (2024). Semi-Supervised Interior Decoration Style Classification with Contrastive Mutual Learning. Mathematics 12:2980. doi: 10.3390/math12192980
Guo, L. Z., Zhang, Z. Y., Jiang, Y., Li, Y., and Zhou, Z. (2020). “Safe deep semi-supervised learning for unseen-class unlabeled data,” in International Conference on Machine Learning, 3897–3906.
Han, M., Wu, H., Chen, Z., Li, M., and Zhang, X. (2023). A survey of multi-label classification based on supervised and semi-supervised learning. Int. J. Mach. Learn. Cybernet. 14, 697–724. doi: 10.1007/s13042-022-01658-9
Hang, W., Dai, P., Pan, C., Liang, S., Zhang, Q., Wu, Q., et al. (2025). Pseudo-label guided selective mutual learning for semi-supervised 3D medical image segmentation. Biomed. Signal Process. Control 100:107144. doi: 10.1016/j.bspc.2024.107144
Hang, W., Feng, W., Liang, S., Yu, L., Wang, Q., Choi, K. S., et al. (2020). “Local and global structure-aware entropy regularized mean teacher model for 3D left atrium segmentation,” in Medical Image Computing and Computer Assisted Intervention–MICCAI 2020:23rd International Conference (Lima: Springer International Publishing), 562–571.
Hang, W., Huang, Y., Liang, S., Lei, B., Choi, K. S., and Qin, J. (2022). “Reliability-aware contrastive self-ensembling for semi-supervised medical image classification,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (Cham: Springer Nature Switzerland), 754–763.
Hang, W., Huang, Y., Wu, Y., Liu, H., Liang, S., Wang, Q., et al. (2024). RSSL: a unified reliability-aware semi-supervised learning framework for medical image classification. IEEE Trans. Emerg. Topics Comp. Intellig. 9, 2690–2702. doi: 10.1109/TETCI.2024.3444694
Huang, G., Liu, Z., Maaten, L., and Weinberger, K. Q. (2017). “Densely connected convolutional networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Honolulu, HI: IEEE), 4700–4708. doi: 10.1109/CVPR.2017.243
Iscen, A., Tolias, G., Avrithis, Y., and Chum, O. (2019). “Label propagation for deep semi-supervised learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (Long Beach, CA: IEEE), 5070–5079.
Kim, J., and Lee, J. K. (2020). Stochastic detection of interior design styles using a deep-learning model for reference images. Appl. Sci. 10:7299. doi: 10.3390/app10207299
Lee, D. (2013). “Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks,” in International Conference on Machine Learning Workshops (ICMLW). Atlanta, GA: ACM.
Li, J., Xiong, C., and Hoi, S. C. H. (2021). “CoMatch: Semi-supervised learning with contrastive graph regularization,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (Montreal, QC: IEEE), 9475–9484.
Li, Y., Chen, J., Xie, X., Ma, K., and Zheng, Y. (2020). “Self-loop uncertainty: A novel pseudo-label for semi-supervised medical image segmentation,” in International Conference on Medical Image Computing and Computer-Assisted Intervention, 614–623, doi: 10.1007/978-3-030-59710-8_60
Li, Y., Wang, X., Feng, L., Zhang, W., Yang, L., and Gao, Y. (2023). Diverse cotraining makes strong semi-supervised segmentor. arXiv [preprint] arXiv:2308.09281. doi: 10.1109/ICCV51070.2023.01471
Liu, Q., Yu, L., Luo, L., Dou, Q., and Heng, P. A. (2020). Semi-supervised medical image classification with relation-driven self-ensembling model. IEEE Trans. Med. Imaging 39, 3429–3440. doi: 10.1109/TMI.2020.2995518
Liu, S., Bo, Y., and Huang, L. (2021). Application of image style transfer technology in interior decoration design based on ecological environment. J. Sensors 2021:9699110. doi: 10.1155/2021/9699110
Liu, Y., Tian, Y., Chen, Y., Liu, F., Carneiro, G., and Belagiannis, V. (2022). “Perturbed and strict mean teachers for semi-supervised semantic segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (New Orleans, LA: IEEE), 4258–4267. doi: 10.1109/CVPR52688.2022.00422
Miyato, T., Maeda, S.-i., Koyama, M., and Ishii, S. (2018). Virtual adversarial training: a regularization method for supervised and semi-supervised learning. IEEE Trans. Pattern Anal. Mach. Intell. 41, 1979–1993. doi: 10.1109/TPAMI.2018.2858821
Ouali, Y., Hudelot, C., and Tami, M. (2020). “Semi-supervised semantic segmentation with cross-consistency training,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (Seattle, WA: IEEE), 12674–12684.
Selvaraju, R. R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., and Batra, D. (2020). Grad-CAM: visual explanations from deep networks via gradient-based localization. Int. J. Comput. Vis. 128, 336–359. doi: 10.1007/s11263-019-01228-7
Shan, W. L., Jin, R. M., and Ding, X. Y. (2022). Chinese decorative color based on improved alexnet in interior decoration design. Mathem. Prob. Eng. 2022:2358905. doi: 10.1155/2022/2358905
Sohn, K., Berthelot, D., Carlini, N., Zhang, Z., Carlini, N., Cubuk, E. D., et al. (2020). “Fixmatch: Simplifying semi-supervised learning with consistency and confidence” in Advances in Neural Information Processing Systems, 596–608. (Vancouver, BC, Canada: Neural information processing systems foundation).
Su, J., Luo, Z., Lian, S., Lin, D., and Li, S. (2024). Mutual learning with reliable pseudo label for semi-supervised medical image segmentation. Med. Image Anal. 94:103111. doi: 10.1016/j.media.2024.103111
Su, J. C., Cheng, Z., and Maji, S. (2021). “A realistic evaluation of semi-supervised learning for fine-grained classification,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 12966–12975.
Tang, Y., Chen, W., Luo, Y., and Zhang, Y. (2021). “Humble teachers teach better students for semi-supervised object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (Nashville, TN: IEEE), 3132–3141.
Tarvainen, V. H. (2017). “Mean teachers are better role models: Weight averaged consistency targets improve semi-supervised deep learning results,” in Advances in Neural Information Processing Systems.
Tong, H., Wan, Q., Panetta, K., Kaszowska, A., Taylor, H. A., and Agaian, S. (2019). ARFurniture: augmented reality interior decoration style colorization. Elect. Imag. 31, 1–9. doi: 10.2352/ISSN.2470-1173.2019.2.ERVR-175
Wang, Y., Xiao, B., Bi, X., Li, W., and Gao, X. (2023). “MCF: mutual correction framework for semi-supervised medical image segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (Vancouver, BC: IEEE), 15651–15660.
Wu, K., Zhang, S., Liu, Y., Wang, C., Yang, F., Zeng, L., et al. (2022). “Class-aware contrastive semi-supervised learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 14421–14430.
Wu, Y., Xu, M., Zhang, L., Cai, J., and Ge, Z. (2021). “Semi-supervised left atrium segmentation with mutual consistency training,” in Medical Image Computing and Computer Assisted Intervention–MICCAI 2021:24th International Conference (Strasbourg: Springer International Publishing), 297–306.
Wu, Z., Jia, X., Jiang, R., Ye, Y., Qi, H., and Xu, C. (2024). CSID-GAN: a customized style interior floor plan design framework based on generative adversarial network. IEEE Trans. Consumer Elect. 70, 2353–2364. doi: 10.1109/TCE.2024.3376956
Xie, Q., Dai, Z., Hovy, E., Luong, M., and Le, Q. (2020). “Unsupervised data augmentation for consistency training,” in Advances in Neural Information Processing Systems (Vancouver, BC, Canada: Neural information processing systems foundation), 6256–6268.
Yao, H., Hu, X., and Li, X. (2022). Enhancing pseudo label quality for semi-supervised domain-generalized medical image segmentation. Proc. AAAI Conf. Artif. Intellig. 36, 3099–3107. doi: 10.1609/aaai.v36i3.20217
Yu, H., Wang, S., Li, X., Fu, C.-W., and Heng, P.-A. (2019). “Uncertainty-aware self-ensembling model for semi-supervised 3D left atrium segmentation,” in Medical Image Computing and Computer Assisted Intervention–MICCAI 2019:22nd International Conference (Shenzhen: Springer International Publishing), 605–613.
Zhang, B., Wang, Y., Hou, W., Wu, H., Wang, J., Okumura, M., et al. (2021). Flexmatch: Boosting semi-supervised learning with curriculum pseudo labeling. Adv. Neural Inf. Process. Syst. 34, 18408–18419.
Zhang, Y., Li, J., Qiu, R. C., Zhang, X., Tian, Q., and Xu, H. (2022). Semi-supervised contrastive learning with similarity co-calibration. IEEE Trans. Multimedia 25, 1749–1759. doi: 10.1109/TMM.2022.3158069
Zheng, M., Xu, C., You, S., Qian, C., Huang, L., and Wang, F. (2022). “Simmatch: Semi-supervised learning with similarity matching,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (New Orleans, LA: IEEE), 14471–14481. doi: 10.1109/CVPR52688.2022.01407
Keywords: self-ensembling, consistency regularization, contrastive learning, interior decoration style, semi-supervised learning
Citation: Guo L, Zeng H, Wang J, Liang S and Hang W (2025) Weight-aware semi-supervised self-ensembling framework for interior decoration style classification. Front. Artif. Intell. 8:1645877. doi: 10.3389/frai.2025.1645877
Received: 12 June 2025; Accepted: 11 August 2025;
Published: 09 September 2025.
Edited by:
Qiao Liu, Chongqing Normal University, ChinaReviewed by:
Surapati Pramanik, Nandalal Ghosh B.T. College, IndiaAmir Ali Shahmansouri, Washington State University, United States
Copyright © 2025 Guo, Zeng, Wang, Liang and Hang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Lichun Guo, Z3VvbGljaHVuQG5hdWpzYy5lZHUuY24=