 Chirag Jitendra Chandnani
Chirag Jitendra Chandnani Shlok Chetan Kulkarni
Shlok Chetan Kulkarni Geraldine Bessie Amali D
Geraldine Bessie Amali D Rohini Selvaraj
Rohini Selvaraj- School of Computer Science and Engineering, Vellore Institute of Technology, Vellore, Tamil Nadu
Rigorous urbanization leads to unprecedented climate change. Pune area in India has witnessed recent flash floods and landslides due to unplanned rapid urbanization. It, therefore, becomes vital to manage and analyse man-made impact on the environment through effective land use land cover classification (LULC). Accurate LULC classification allows for better planning and effective allocation of resources in urban development. Remote sensing images provide surface reflectance data that are used for accurate mapping and monitoring of land cover. Convolution neural networks (CNN) trained with Relu are conventionally used in classifying different land types. However, every neuron has a single hyperplane decision boundary which restricts the model's capability to generalize. Oscillatory activation functions with their periodic nature have demonstrated that a single neuron can have multiple hyperplanes in the decision boundary which helps in better generalization and accuracy. This study proposes a novel framework with convoluted oscillatory neural networks (CONN) that synergistically combines the periodic, non-monotonic nature of oscillatory activation functions with the deep convoluted architecture of CNNs to accurately map LULC. Results carried out on LANDSAT-8 surface reflectance images for the Pune area indicate that CONN with Decaying Sine Unit achieved an overall train accuracy of 99.999%, test accuracy of 95.979% and outperforms conventional CNN models in precision, recall and User's Accuracy. A thorough ablation study was conducted with various subsets of the feature set to test the performance of the selected models in the absence of data.
1 Introduction
Remote sensing technologies provide valuable information for observing and analyzing the Earth's surface. More importantly, these data monitor environmental changes, including climate change, urbanization, and natural disasters, such as landslides (Kamusoko, 2017). Without remote sensing data, monitoring these environmental changes would be very difficult, and it requires extensive human resources. Land use land cover (LULC) classification provides detailed information regarding land cover and land usage patterns in specific regions (Attri et al., 2015). Accurate LULC classification is essential for urban planning, supporting urban development with environmental sustainability, thereby mitigating conflicts between the two. With rapid urbanization, cities such as Pune require accurate LULC data to address and minimize land degradation. Remote sensing involves gathering data through different approaches, including the use of satellites, aerial vehicles, and aircraft-mounted cameras. It helps to provide the necessary information for LULC classification in the Pune area (Fu et al., 2020). Among them, LANDSAT, MODIS, and Sentinel satellites are Earth observation satellites, which provide remote sensing data for periodic monitoring of LULC changes (Zhao et al., 2022). Sentinel-2 has a fast revisit time and high spatial resolution. Very high resolution (VHR) sensors like WorldView-3 and the Gaofen (GF) series provide complex urban detail, often at 0.8–1.2 m resolution (Pal et al., 2023) However, these VHR datasets pose major problems as they are commercial and expensive, which complicates large-area analysis (Wei et al., 2023). Furthermore, Sentinel-2 has been proven to be less accurate than Landsat-8 for certain LULC classifications (Kumari and Karthikeyan, 2023). Landsat's superiority over Sentinel-2 lies in its cost efficiency, and continuous long-term historical analysis. Researchers frequently rely on LANDSAT datasets for accurate observation and analysis, given their high spatial and temporal resolution. With its 30-m spatial resolution, it supports detailed monitoring of surface features and their variations over time. In addition, it supports the identification of subtle features, including urban development, agricultural patterns, and shifts in forest ecosystems (Hansen and Loveland, 2012). Substantial computational resources and specialized software are needed to process this high-resolution data. Google Earth Engine (GEE) provides a cloud-based platform with access to extensive datasets and computational power (Amani et al., 2020). The LULC classification process within GEE involves data pre-processing, feature extraction, and classification using machine learning algorithms. This process can be carried out using two main methods: pixel-based and object-based approaches. In the pixel-based method, individual pixels are treated as standalone entities, with features extracted solely from each pixel without considering any surrounding context. In contrast, the object-based method converts pixels into larger objects, allowing for feature extraction from these objects. This strategy utilizes spatial, spectral, and contextual inputs to achieve a comprehensive analysis of LULC patterns (Dingle Robertson and King, 2011). Some of the main object-based methods include simple linear iterative clustering (SLIC) and simple non-iterative clustering (SNIC) (Achanta et al., 2012; Achanta and S'́usstrunk, 2017). Using SNIC for image segmentation improves classification accuracy by grouping pixels with similar characteristics into clear segments. SNIC's non-iterative method can be faster because it skips the repeated steps found in SLIC, which may result in quicker processing times. This approach helps in creating more defined and accurate image classifications (Selvaraj and Amali, 2024). To effectively classify these extracted features, a variety of machine learning algorithms, including random forest, support vector machines, and Naive Bayes, are employed. However, issues including algorithm selection, parameter adjustment, and susceptibility to overfitting can influence the precision and robustness of the final LULC classification (Talukdar et al., 2020).
Several studies (Nigar et al., 2024) have highlighted the benefits of Deep Learning (DL) over traditional ML for LULC classification due to DL's automatic feature extraction and ability to handle complex and generalized, high-dimensional data. Among DL techniques, CNNs have proven highly effective, as they can extract features without manual intervention and enhance classification precision across multiple image datasets (Zhao et al., 2023; Teja et al., 2024).
The strength of DL lies in its ability to capture intricate feature representations, which has led to superior results across diverse classification applications such as LULC classification. Among DL models, CNNs in particular have emerged as the most effective for imagebased classification tasks. CNNs excel in image processing and analysis as they leverage their convolutional layers to detect spatial features which help the model learn patterns efficiently. In contrast to standard machine learning algorithms that rely on manual feature collection, CNNs automatically learn patterns such as edges, textures, and object shapes thus making them suitable for RS based use cases. However, despite their advantages, DL models face certain challenges. The vanishing gradient problem represents a significant drawback, as shrinking gradients during backpropagation can result in stalled or very slow learning in deep architectures. This issue is particularly pronounced in deep CNNs using traditional activation functions like Sigmoid and Tanh, which reduce the inputs to a narrow range thereby limiting the gradient flow. To address this, recent research has proposed alternative oscillatory activation functions that enhance gradient propagation and improve model performance. Oscillating activation functions offer a distinct advantage in deep learning tasks that involve complex, repetitive patterns by leveraging their periodic nature (Noel et al., 2025b). Unlike traditional functions like ReLU and sigmoid, which can suffer from saturation (where gradients vanish and learning stagnates), oscillating functions maintain consistent gradient flow, enabling faster convergence and better performance on nonlinear separable (Noel et al., 2025b). Bio-inspired oscillating activation functions functionally bridge the performance gap between biological and artificial neurons. With the recent discovery of special human neocortical pyramidal neurons that can individually learn the XOR function the fundamental performance gap is clear, as it is impossible for single artificial neurons using traditional activation functions to learn the XOR function (Noel et al., 2025a). The XOR function is significant because it requires the neuron to learn a non-linearly separable data. Traditionally, two hyperplanes are required for class separation, meaning activation functions must have a minimum of two zeros to solve this problem with a single neuron. However, popular activation functions like sigmoid, ReLU, Swish, and Mish are single-zero activation functions which means they have a single zero at origin and thus cannot solve the XOR function individually (Noel et al., 2025a). They are limited to only linear classification. The biological neurons in layers two and three of the human cortex have oscillating activation functions which first increase to a maximum with input and then decrease. Thus, being able to learn the XOR function individually. Biologically inspired Oscillating activations due to their multiple zero boundaries allow a single artificial neuron to divide its input space with multiple hyperplanes like a biological neuron, enabling it to make more complex, non-linear decisions (Noel et al., 2025a). A single neuron enhanced with oscillating activation functions can learn the XOR problem. Oscillating activation functions such as shifted sinc unit (SSU) and decaying sine unit (DSU) have a derivative of 1 at the origin. This helps learning quickly when weights are initialized to small values. Due to their higher representative power, classification problems can be solved with fewer neurons and fewer layers than required by networks using popular activation functions. Furthermore, they are non-saturating for all inputs thus they do not suffer from the vanishing gradient problem prevalent in the traditional activation functions. The XOR problem involves learning the following dataset (Figure 1):
The XOR problem was solved using a single neuron with oscillatory activation functions, mean-square loss, and simple Stochastic Gradient Descent (SGD). A learning rate of α = 0.1 and the SGD update rule
was used. The initial weight vector w was initialized with uniform random numbers in the interval [−1, 1]. The XOR function was successfully learned by a single neuron with activation function g(z) chosen as:
The target y for each input was taken as the class label, namely 1 or −1. After training, the output of the neuron is mapped to the class label in the usual manner. Positive outputs are mapped to +1 and negative outputs to −1. This is done by using a signum function defined as:
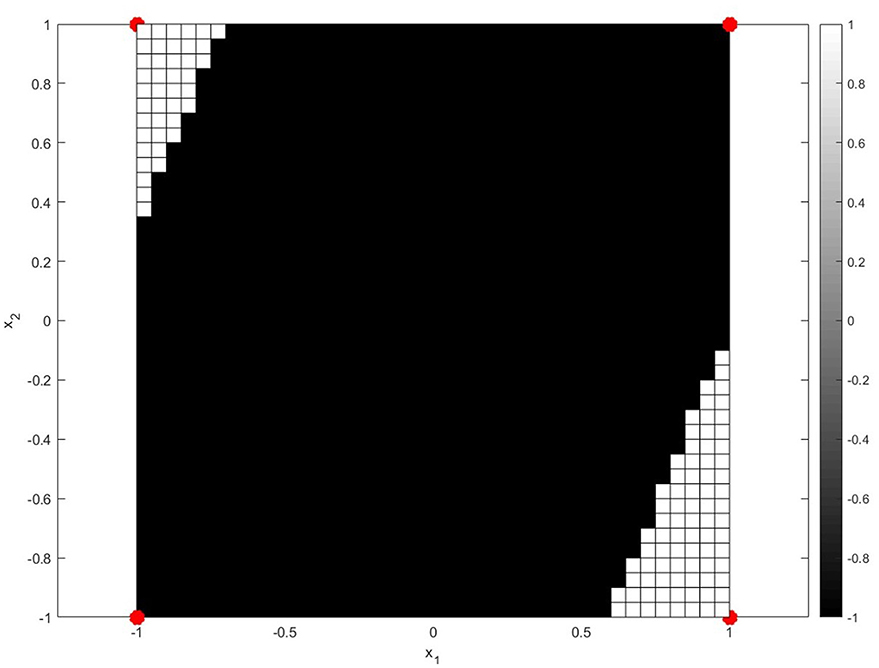
Figure 1. The XOR problem learnt by a single neuron using the DSU activation function.
The study explores the integration of oscillatory activation functions in deep convolutional architectures, along with SNIC and GLCM for LULC classification. Unlike traditional activation functions, oscillatory activation functions, are known to maintain a more consistent gradient flow attributed to their periodic nature, potentially addressing critical training limitations such as the vanishing gradient problem and slow convergence speed. The work proposes Convoluted Oscillatory Neural Networks (CONN), in which we aim to optimize feature extraction and model accuracy. Through the integration of SNIC and GLCM textural features, the framework is optimized to enhance both feature representation and classification accuracy. The main focus is to propose an efficient and reliable LULC classification technique for the city of Pune using publicly available remote sensing data, specifically LANDSAT-8 images, classifying the region into four classes: Water, Urbanized, Vegetation and Barren land (Xie et al., 2021; Digra et al., 2022) and emphasizing the Surface Reflectance imagery (Whiteside and Ahmad, 2005).
The Pune Metropolitan Region in western India covers around 5,052 km2, with a population of over 7.18 million (see Figures 2, 3). It presents a wide variety of features, such as forests, lakes, and farmland. Additionally, in recent years, it has showcased a high rate of urbanization (Census of India, 2024; Maharashtra Government, 2020). This high rate of urbanization is alarming as it poses a threat of environmental degradation, resource exhaustion, and even the breakdown of the natural ecosystems (Padigala, 2012). This rapid transition has already been shown to have a negative impact on the temperature, rainfall patterns, and even hydrological cycles in the region (Sandbhor et al., 2022). However, a lack of accurate and current land cover data makes it harder to manage and protect the region effectively (Samuel and Atobatele, 2019). The region, therefore, serves as an excellent candidate for the purposes of this study.
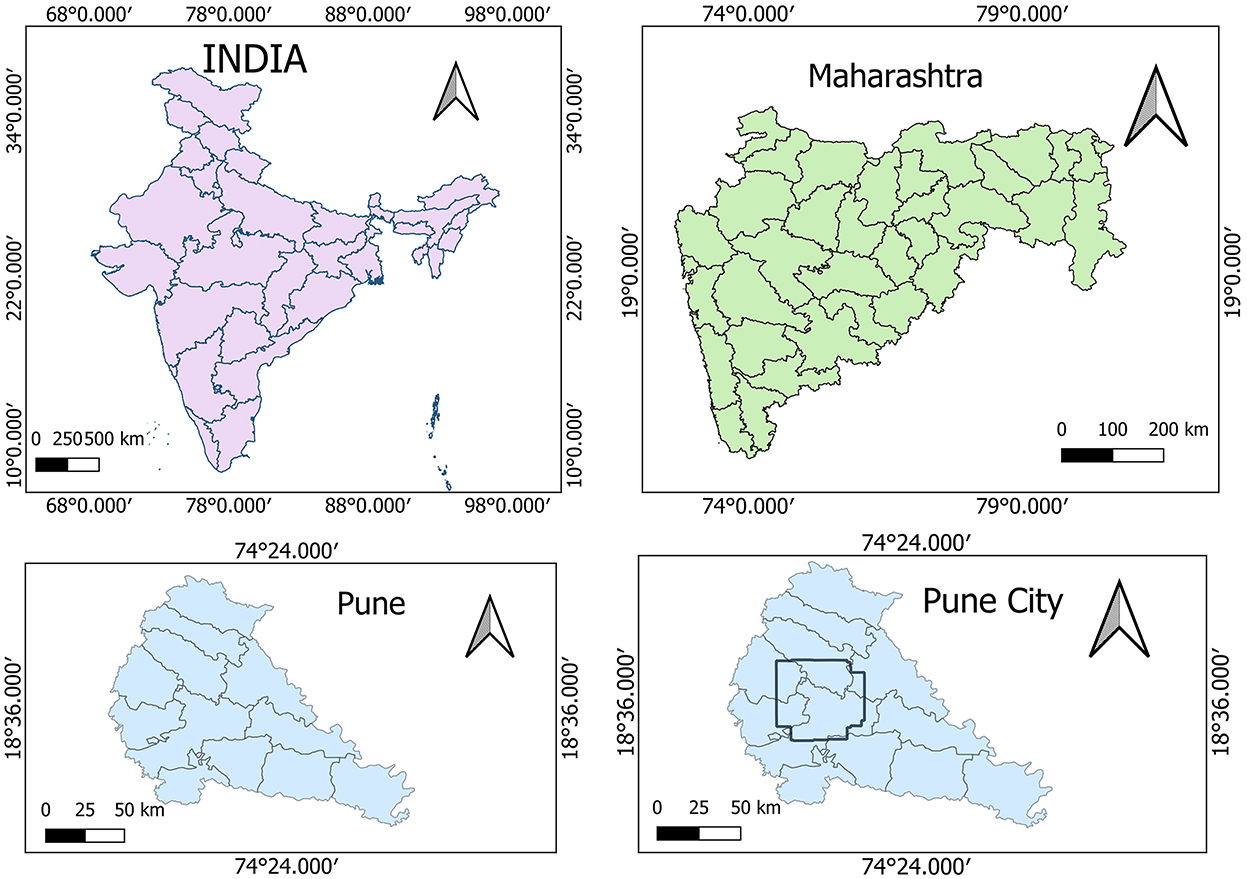
Figure 2. Study area—Pune.
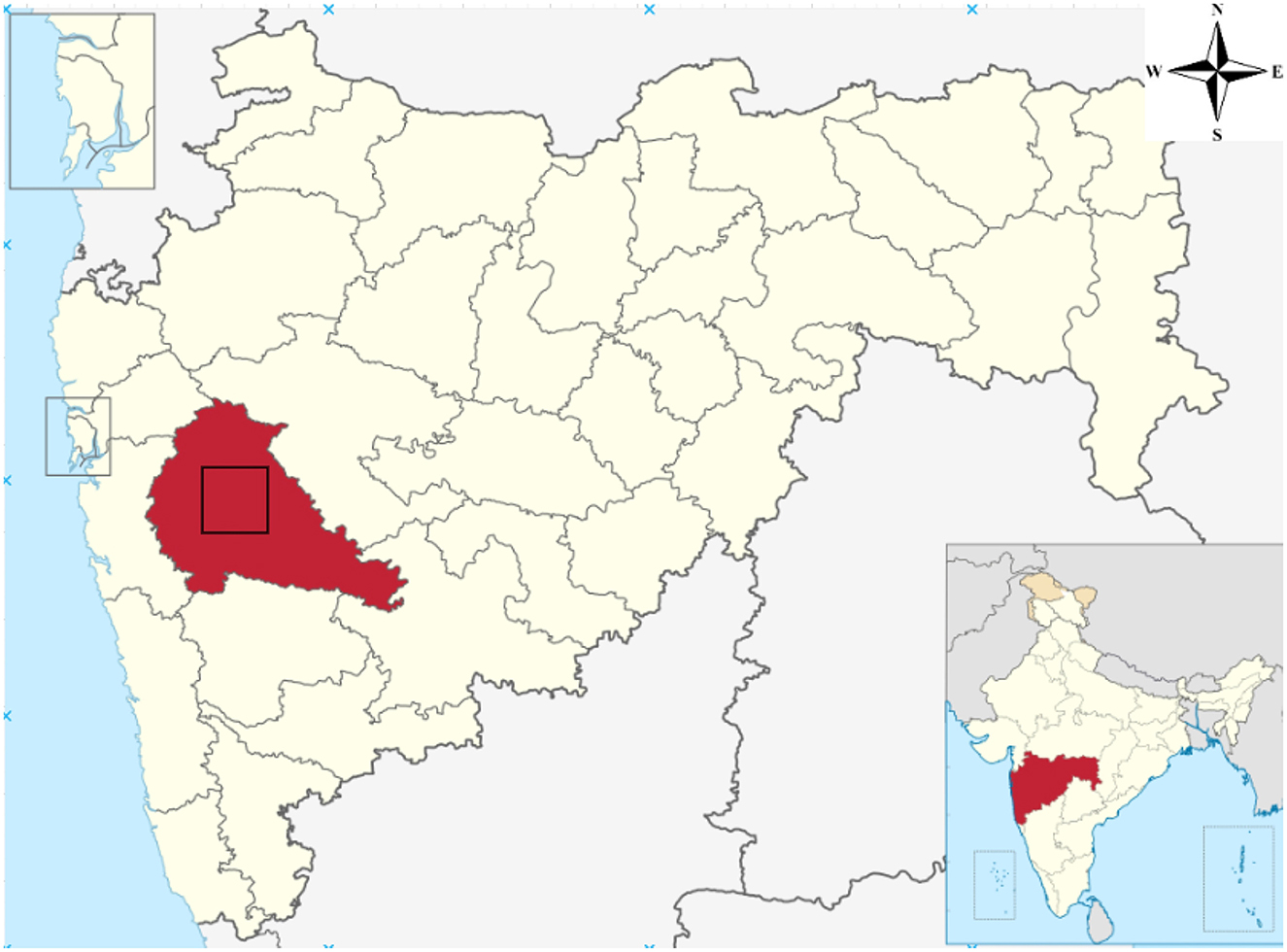
Figure 3. Pune region geometry.
The remainder of the study is organized as follows: Section 2 contains the proposed methodology which includes a detailed explanation of the proposed methodology, including the dataset, pre-processing techniques, and the models used. Results and Ablation Study section discusses the findings, compares them with previous works, and highlights key insights inferred from the model output. Finally, Conclusion and Future Works concludes the study by summarizing the contributions and outlining potential future research directions.
2 Materials and methods
This section, as shown in Figure 4, discusses the steps—data collection, SNIC segmentation, feature selection and engineering, data pre-processing, model training, and finally, the metrics and hardware and software setup utilized.
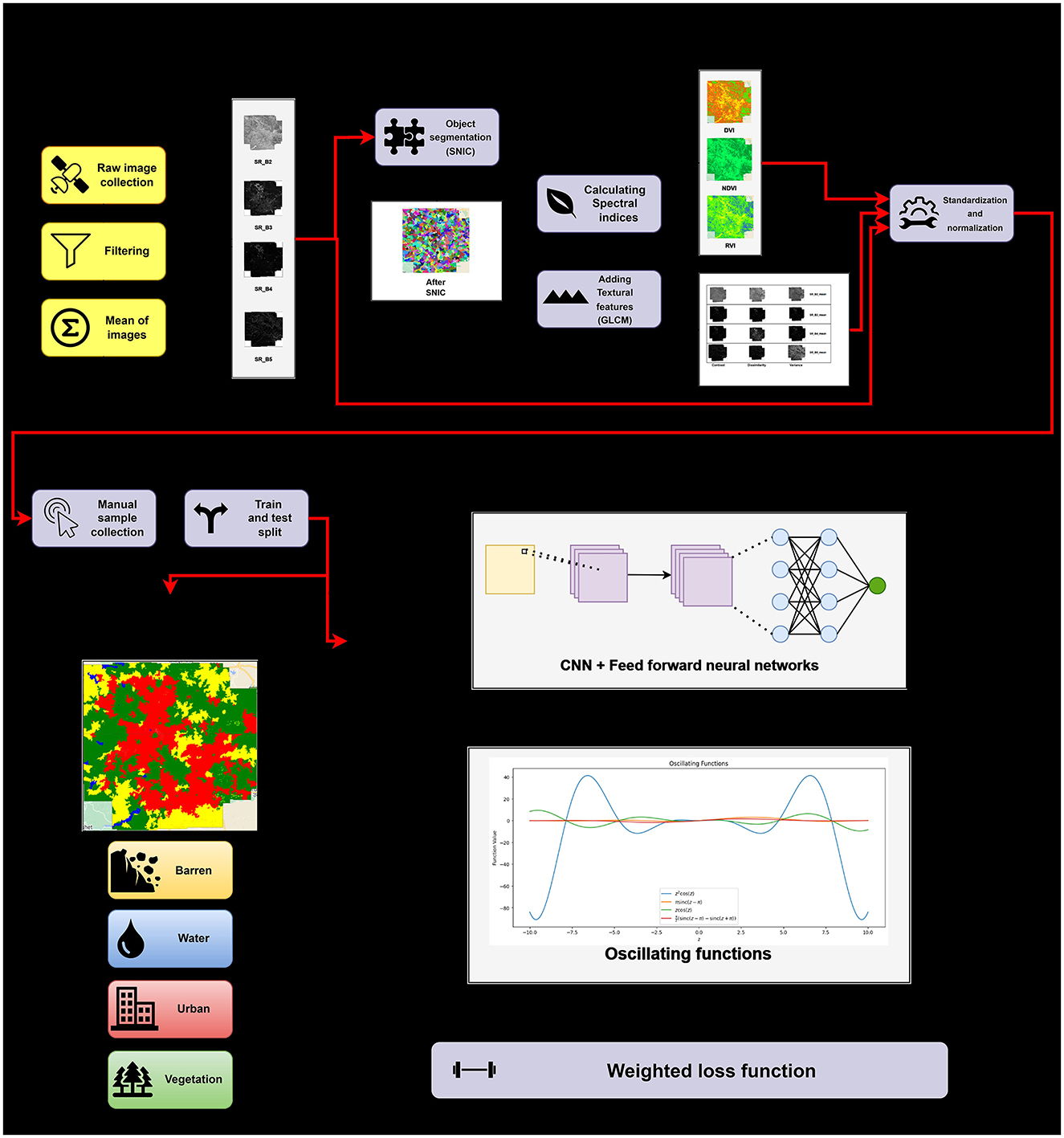
Figure 4. Workflow diagram for the proposed methodology.
2.1 Data collection
This study utilizes the “Landsat 8 Level 2 Tier 2 Collection 2” SR images that are already geometrically and atmospherically corrected (Markham and Barsi, 2017). Another major advantage of the dataset is the near-continuous availability of data. With Landsat-8 and 9 updating data once every 16 days, it is possible to have regular monitoring of land use patterns. Furthermore, while Landsat-9 data is of higher radiometric resolution, this study utilizes a Landsat-8 data collection to strike a balance between computational load and LULC classification accuracy.
The images in the aforementioned image collection consist of four visible bands, 1 Near-Infrared band (NIR), and two Short-Wave Infrared bands (SWIR). Additionally, the quality assessment (QA) band in the SR collection makes it easier to filter out cloud cover. From the aforementioned bands available in the image collection, this study utilizes bands SRB_5, SRB_4, SRB_3, and SRB_2. Each of these bands provides essential information that helps in distinguishing various land cover types, including urban areas, vegetation, and water bodies (U.S. Geological Survey, 2019). Their specific uses are provided in Table 1. Finally, a masked image of the study area for the selected features was obtained using the geometry as shown in Figure 5. Furthermore, a mean composite was calculated for all the images in the region over the selected time period. This was chosen to be from January 2024 to February 2024, as this time period was observed to have the lowest cloud cover, eliminating the need for complex image corrections. Table 2 summarizes the important input parameters required for data insertion in GEE. This image is then used to create objects using SNIC segmentation.
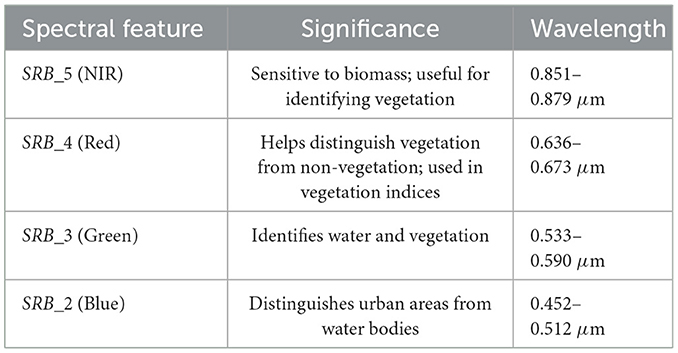
Table 1. Significance of selected spectral features with wavelength information.
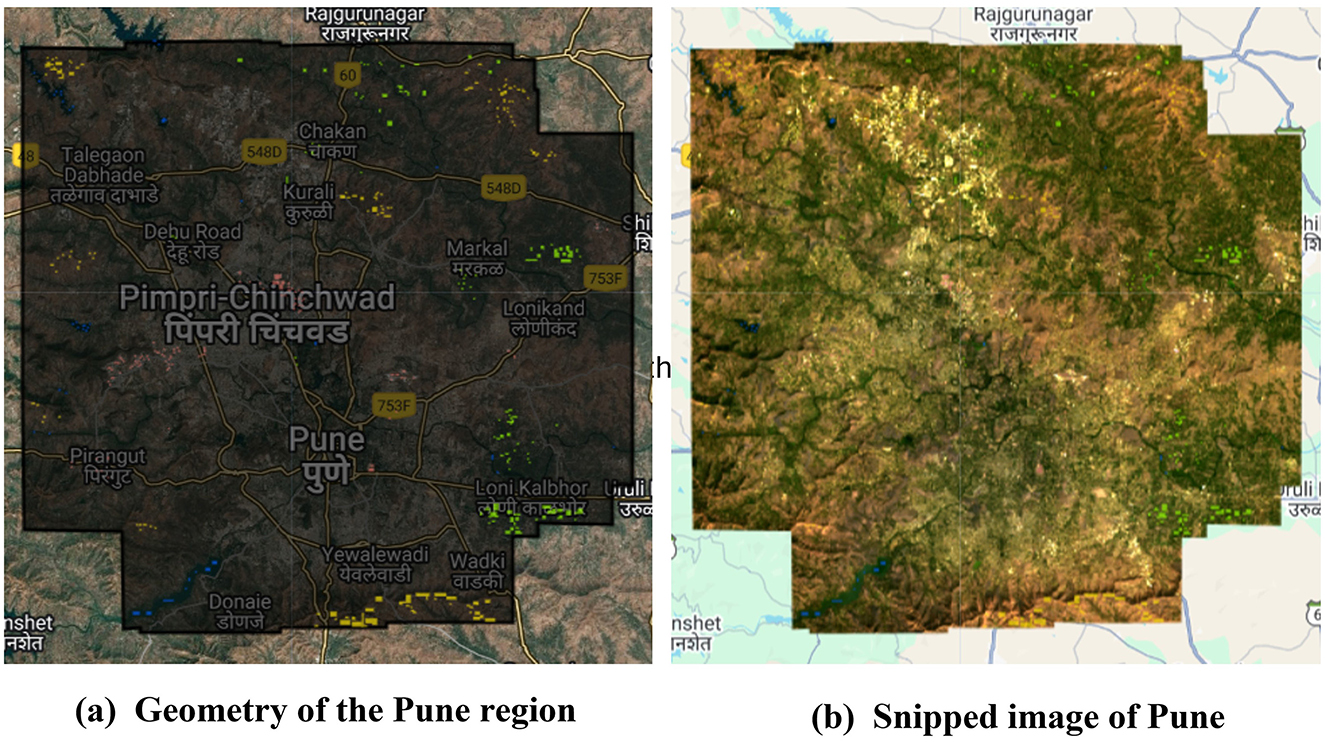
Figure 5. Process of extracting the image for Pune region from Landsat 8 imagery. (a) Geometry of the Pune region and (b) snipped image of Pune.
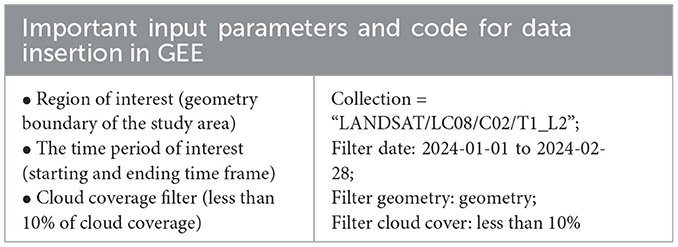
Table 2. Important input parameters for data insertion in GEE.
2.2 Object-based segmentation using simple non-iterative clustering (SNIC)
Object-based segmentation forms an integral part of this study. The inclusion of object-based segmentation ensures that the model is less susceptible to noise and avoids other issues associated with pixel-based segmentation techniques, like the “salt and pepper effect” (Ouchra et al., 2022). For the task of object-based segmentation, this study utilizes SNIC as it has shown to be effective in previous literature (Whiteside and Ahmad, 2005). Algorithm 1 depicts the SNIC algorithm. Firstly, the label map L is created with all zeros. Following that, the priority queue and seed elements are initialized. SNIC is initialized with k initial centroids which are spaced size pixels apart, where k is a user-defined parameter and size is calculated using k and the dimensions of the image. All these seed elements are then pushed into the priority queue Q, with each element containing values of position, color, label, and distance. In the second stage i.e. the propagation stage, the element in the priority queue with the smallest distance, ei, is popped. This distance is calculated using Equation 1. If the element is not yet assigned to a centroid in the label map, it is then assigned to centroid ki. After this update is done, the centroid ki itself is updated to incorporate the new element using online averaging. The algorithm then proceeds to check all connected neighbors of ei and assign them the label ki. If not already labeled on the label map, these elements are pushed onto Q. This is repeated until Q is empty, and the label map L will be returned as a result.
where:
• cj,ck: Color vectors in CIELAB/Lab* space
• xi,xj: Spatial coordinates
• m: compactness parameter
• s: initial grid spacing

Algorithm 1. SNIC Segmentation Algorithm
The parameters used for the SNIC algorithm and the codes are presented in Table 3. Similarly, the output of the SNIC segmented image can be observed in Figure 6. Post object-based segmentation on the image, feature engineering was performed to calculate additional features.

Table 3. SNIC segmentation parameters and code example.
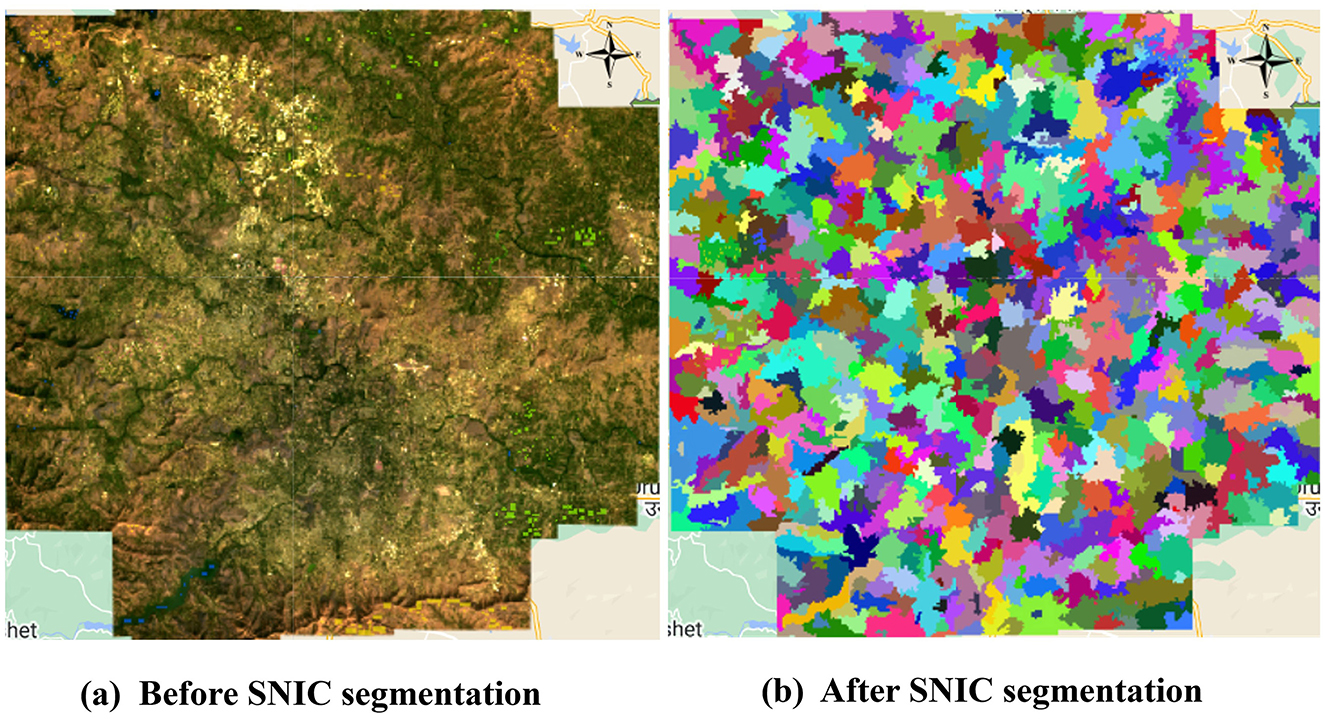
Figure 6. Comparison before and after applying SNIC segmentation. (a) Before SNIC segmentation and (b) after SNIC segmentation.
2.3 Feature selection and engineering
This study utilizes several features extracted from the aforementioned Landsat-8 image collection, each chosen for its relevance to the land cover classification task. This study makes use of textural features obtained using the Gray-Level Co-occurrence Matrix (GLCM) as they have been shown to enhance the classification accuracy for LULC tasks (Haralick et al., 1973). Additionally, this study also utilizes spectral indices like the Normalized Difference Vegetation Index (NDVI), Ratio Vegetation Index (RVI), and Difference Vegetation Index (DVI). The bands selected for this study, along with their descriptions, are provided in Table 4. Furthermore, the frequencies of these bands have been visualized in Figure 7.
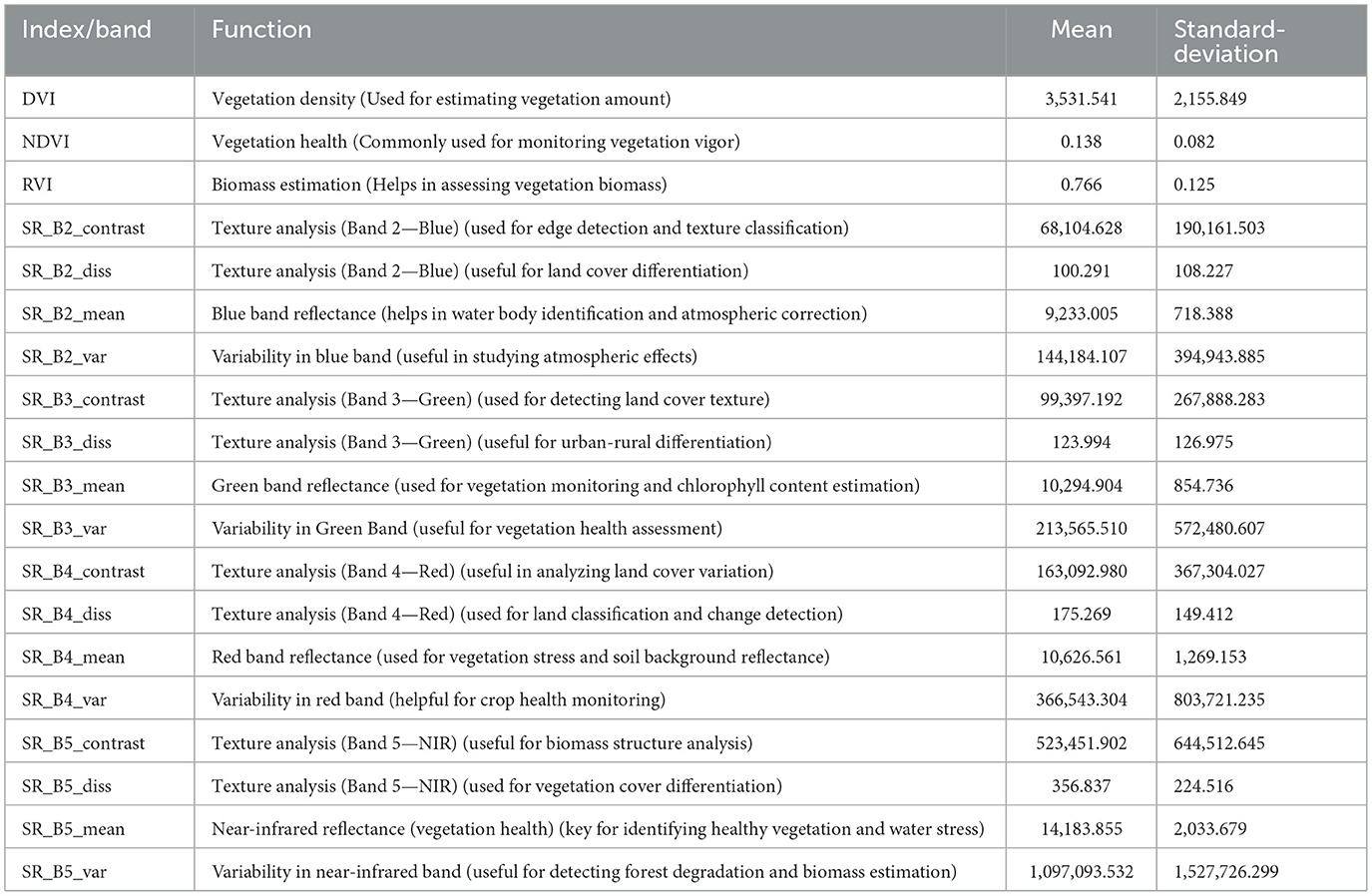
Table 4. Bands and their applications.
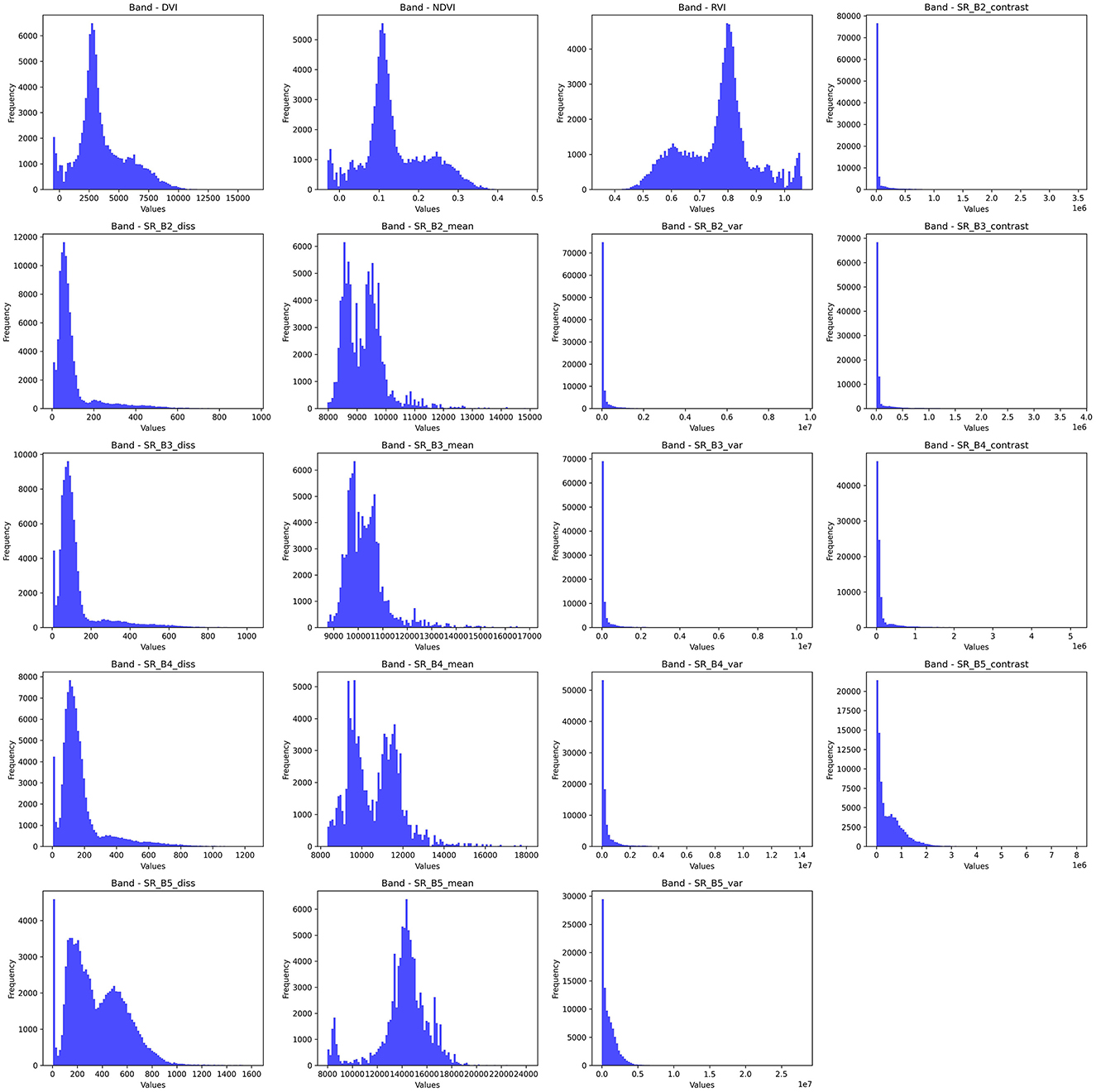
Figure 7. Band frequency visualization for selected bands.
2.3.1 Vegetation indices (spectral indices)
Vegetation indices refer to mathematical transformations of the spectral bands. They are used to better visualize and identify vegetation and can, therefore, be used to boost the efficacy of LULC tasks. This study utilizes NDVI, RVI, and DVI. Each of these indices uses different spectral bands for their calculation, offering distinct perspectives on vegetation properties and enabling targeted insights into land cover characteristics (as shown in Table 5).
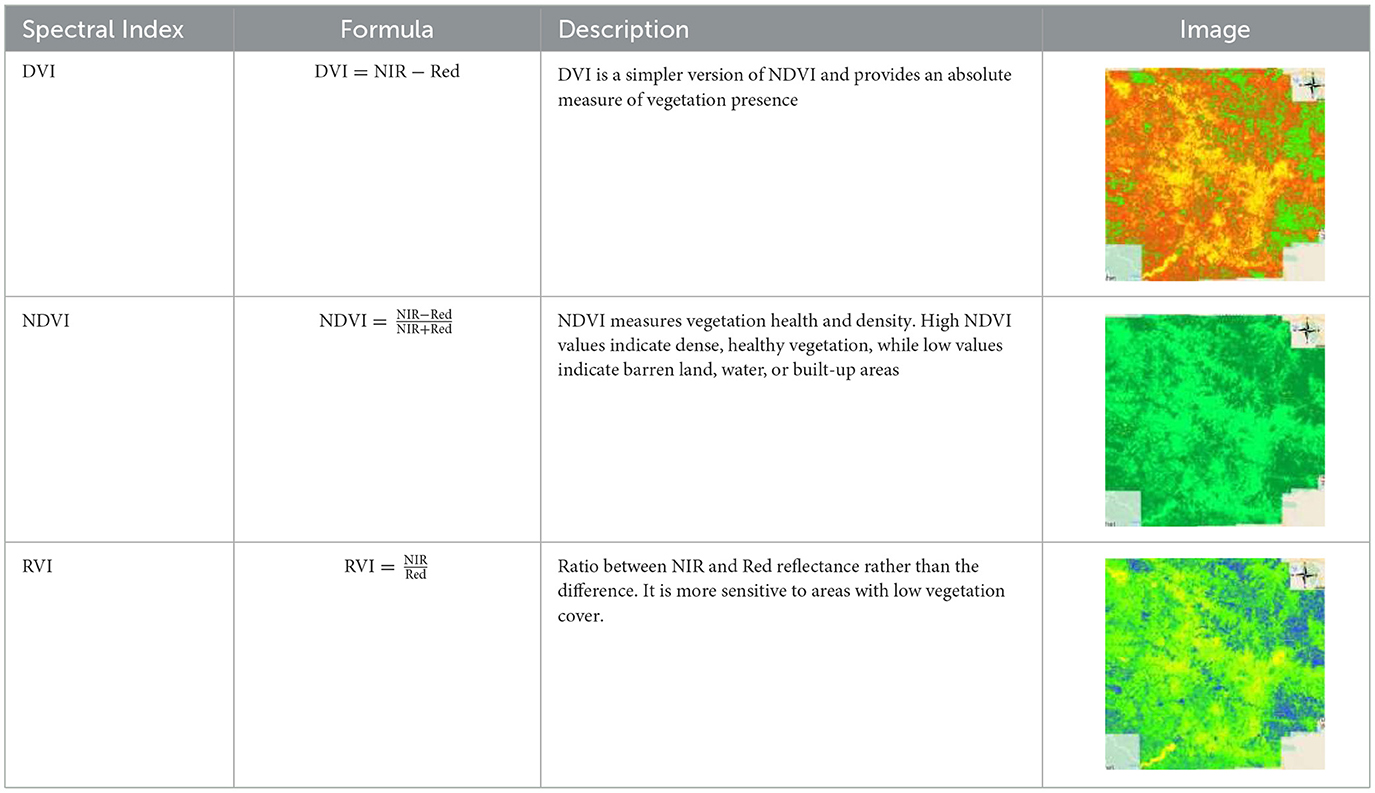
Table 5. Descriptions of vegetation indices used in this study.
2.3.2 Textural features
In addition to spectral features and spectral indices, this study also utilizes GLCM to generate textural features for the study area. GLCM produces a total of 18 features for each band present in the input image, however, due to computational constraints, this study has selected the following three features that were found to be the most relevant to the task at hand.
2.3.2.1 Contrast
The contrast feature of GLCM captures the difference between the intensities of neighboring pixels. This feature is especially useful for detecting similar materials with different surface textures. This ability is paramount for the LULC task, as high contrast values usually indicate important landscape features such as water, vegetation, urban, etc. The depiction of GLCM contrast features for each of the selected bands can be observed in Figure 8.

Figure 8. GLCM contrast, dissimilarity, variance bands.
2.3.2.2 Variance
The variance feature in GLCM represents the difference between the intensities of pixels in a spatial neighborhood. A high variance indicates a change in land cover, such as vegetation health or soil moisture. Moreover, variance is more resistant to noise in the data and hence is more suited for diverse regions. The depiction of GLCM variance features for each of the selected bands can be observed in Figure 8.
2.3.2.3 Dissimilarity
The dissimilarity feature in GLCM represents the dissimilarity or difference of a pixel as compared to its neighboring pixels. This feature lends itself to the detection of edges, which is essential in LULC classification. The depiction of GLCM dissimilarity features for each of the selected bands can be observed in Figure 8.
2.4 Data preprocessing–Using normalization
Pre-processing is a fundamental step for training machine and deep learning models. It boosts data quality by tending to issues like noise, lost values, and irregularities. This is essential for superior model performance and precision. Alongside irregular data patterns, one of the primary constraints in ML training is the disparity in feature scales. Since algorithms often prioritize attributes with larger values, proper feature scaling is necessary to ensure balanced learning. Feature scaling also helps machine learning and deep learning algorithms train and converge faster, which improves model performance. There are multiple methods for scaling data, but this study utilizes normalization as it is better suited for non-gaussian data distributions.
Normalization works by adjusting numerical values in a dataset to a consistent range, usually between 0 and 1 or sometimes –1 and 1, to maintain uniformity across features. This method is particularly helpful when features are on vastly different scales and lack extreme values. Normalization effectively scales data to a consistent range by using Equation 2
where:
• X is the original data value,
• Xmin and Xmax are the minimum and maximum values of the data feature, respectively.
This approach compresses data into an n-dimensional unit hypercube Scikit-Learn offers a transformer called MinMaxScaler for this process, which was utilized in this study.
2.5 The proposed CONN architecture
The proposed CONN model is designed to process nineteen raster-based input features, with representative samples shown in Figure 9 and the corresponding ground truth illustrated in Figure 10. These inputs are organized into batches of 32 during training to ensure efficient learning and optimization. The overall architecture of the model is illustrated in Figure 11.
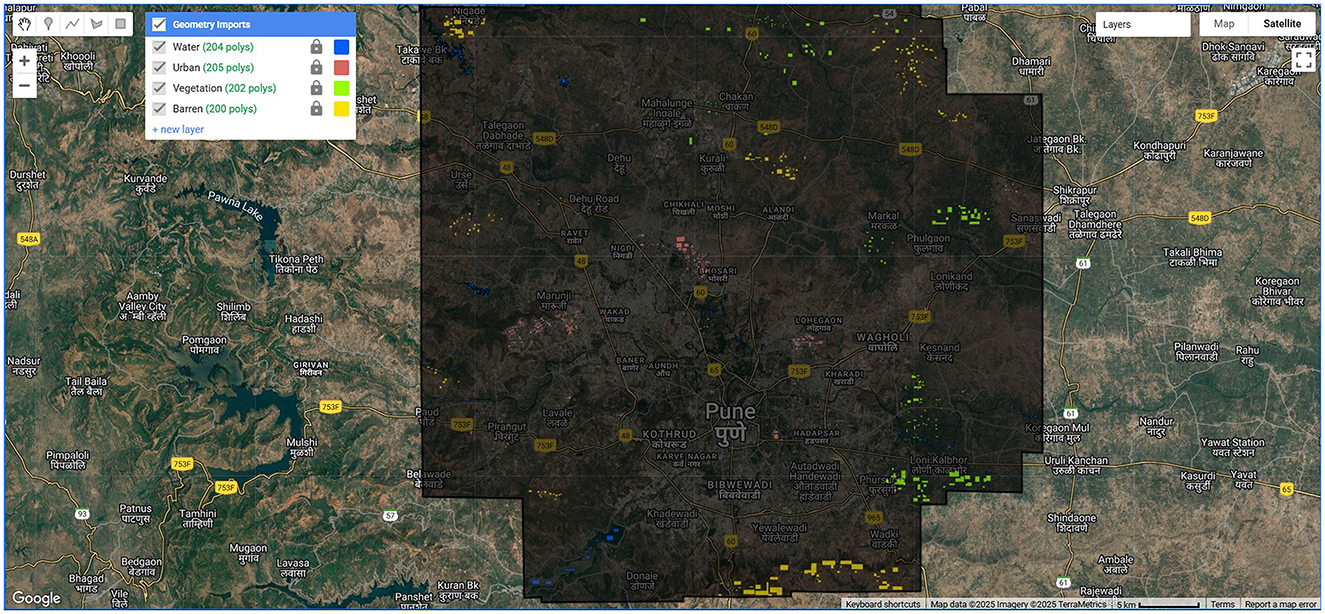
Figure 9. Training and test sample collection using polygon tool in GEE.

Figure 10. Ground truth sample.
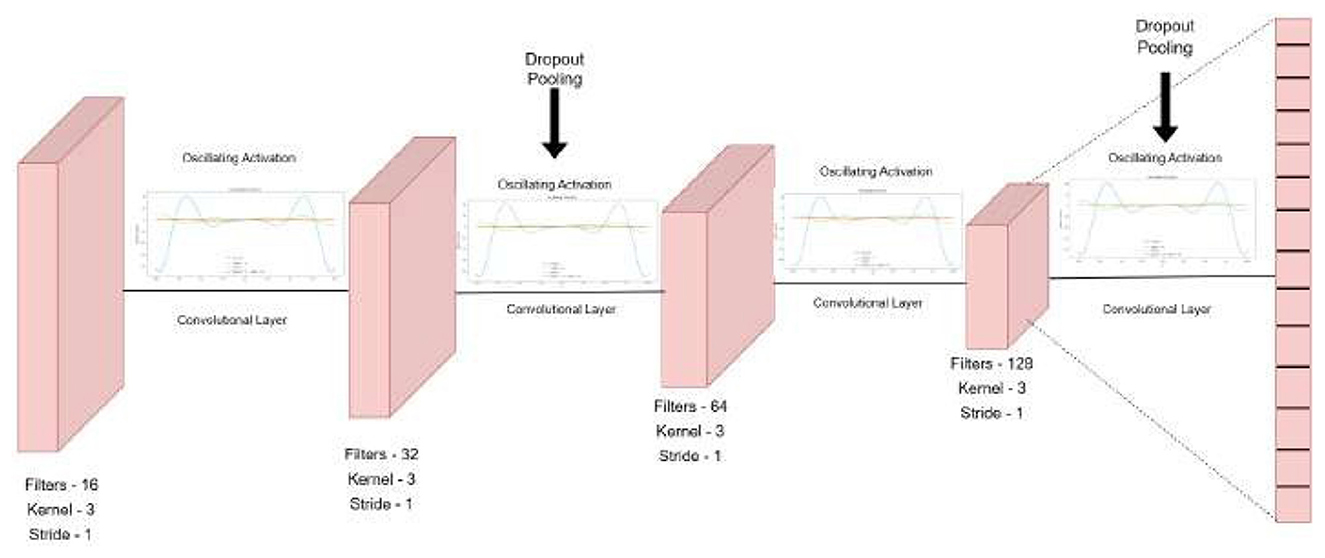
Figure 11. Oscillatory activated convolution layers.
It gives the output classification probabilities for each of the four classes and classifies the region based on the given output probabilities. The sampling steps and the data are split into train and test batches of 80–20 ratio. Table 6 presents the detailed number of training and testing samples. The model is trained in mini-batches, and each epoch consists of forward and backward propagation steps through the network using the specified loss function. Model parameters are iteratively updated to minimize the loss, with the training process monitored using a separate validation (test) set to ensure generalization and avoid overfitting. This protocol facilitates reliable learning of the textural and spectral features present in the raster input data. It consists of stacked one-dimensional convolutional layers, coupled with a one-dimensional Max-Pooling layer for reducing the feature map size and efficient raster data analysis while extracting vital textural and spectral features from the raster data. The stacked CNN model gradually increases the output channel of the data, expanding it to 128 channels, therefore capturing more complex patterns and features from the data. These 128 extracted features, serve as input to the fully connected layers, which reduce the dimensionality gradually, by a factor of two, ensuring that there is no information lost in the flow of representations from one layer to the other.

Table 6. Sample distribution by class.
To prevent overfitting and serve as a regularization parameter, every pooling and fully connected layer is followed by a Dropout layer (Huang et al., 2021) with a dropout rate of 20%. To ensure smooth gradient flow during backpropagation and to prevent saturation and stagnation during the training of the model, the architecture utilizes oscillating activation functions after each convolutional and feed-forward layer (Rumelhart et al., 1986). These functions and their advantages in the training process have been further discussed in Section 2.5.2
In this study, we have chosen specific kernel sizes, strides, and filter counts for the CNN model to enhance feature extraction after thorough experimentation with a number of variations. The current parameters strike a balance between computational efficiency and the model's ability to identify significant patterns in the data. The architecture increases the number of filters after each layer by a factor of two, yielding a map of 128 channels before feeding into the decision head, which consists of a feed-forward neural network with dropout and oscillating activation functions in the end. The model architecture is shown in Figure 12.
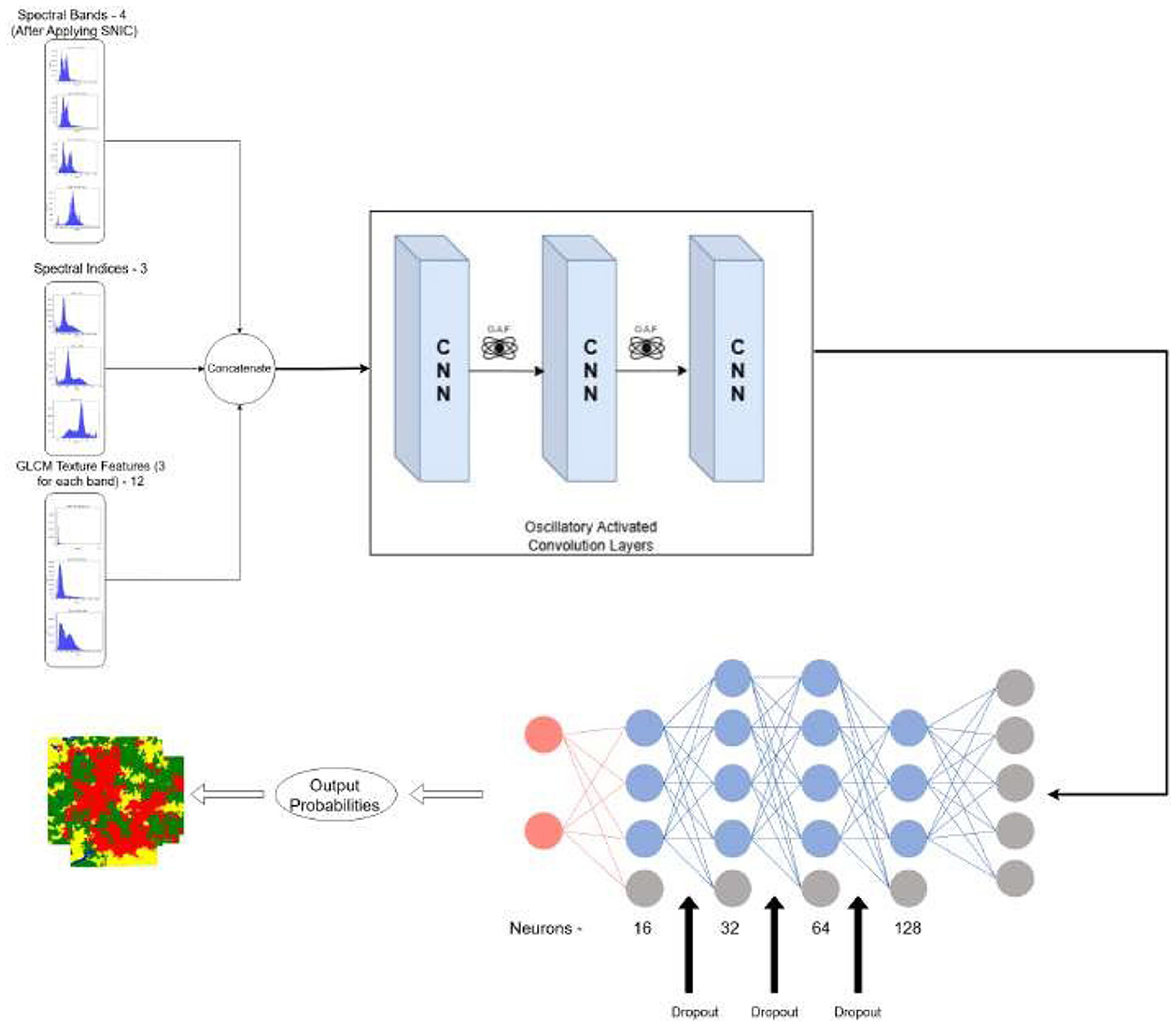
Figure 12. Oscillatory activated convolution layers.
2.5.1 Convolutional and feed forward neural network
CNN architectures serve as the backbone of many image-classification and feature-extraction tasks today (Taye, 2023). By stacking multiple CNN layers, they are capable of learning local patterns within data, thereby extracting high-level spatial and texture features through learnable filters and pooling operations. This allows the network to build a hierarchical feature representation in the model's stored parameters as it progresses through each layer. The feed-forward neural networks in these cases serve as the decision head by classifying the learned features into their respective classes. Commonly employed activation functions like ReLU, LeakyReLU, and Swish suffers from commonly known issues in Deep Neural Networks like vanishing gradient and saturation problems (Hu et al., 2021). Recently discovered oscillatory activation functions show promising results due to their periodic nature and also their ability of possessing multiple hyperplanes as compared to commonly used activation functions, which only have one (Noel et al., 2025b). This property allows a single neuron to solve the XOR problem, thus demonstrating higher information retention capability.
2.5.2 Oscillating activation functions
LULC classification using remote sensing data is highly non-linear due to the presence of overlapping spectral signatures, and the complex non-linear decision-making capability of oscillatory activation functions can be beneficial for providing accurate classification in such cases. These oscillatory activation functions, inspired by biological neurons from the neuro-cortex in a human brain, have a unique property of partitioning its input space with more than one hyperplane as compared to various state-of-the-art, non-linear activation functions like ReLU, LeakyReLU, and Swish as seen in Equations 3–5.
The ability to possess multiple decision boundaries significantly boosts the representative power of neurons incorporating these activation functions. Due to the enhanced ability of each neuron to hold complex representations, the overall ability of a neural network utilizing such neurons is also significantly increased. This, in turn, leads to an increase in training speed and efficiency. This can also be observed in the results of this study. It has also been observed that the proposed model performs and generalizes better with fewer neurons.
where α is a small constant (e.g., α = 0.01).
where σ(x) is the sigmoid function and β is a parameter (often set to 1).
Their property of being differentiable at all points ensures that the neuron doesn't saturate and gives derivative values close to 0, which leads to the underflow problem while calculating the derivative of the loss function with respect to the model parameters. This is termed as vanishing gradients (Tan and Lim, 2019), a common problem during training of deep neural nets, and can be an encumbrance to the model's ability to learn from the data collection and store its representation in the form of weights. Saturation (Kolbusz, Janusz et al., 2018), on the other hand, is a stage where the output values of a neuron are close to the activation function's boundary values. It negatively affects both the information capacity and the learning ability of a neural network. The proposed model architecture utilizes four oscillating activation functions and gives a comprehensive analysis and comparison between each activation function along with the existing state-of-the-art non-linear activation functions such as ReLU, LeakyReLU, and Swish. The activation functions used in the study are z2cos(z), Shifted Sin Unit (SSU), Growing Cosine Unit (GCU), and Decaying Sin Unit (DSU) and are defined in Equations 6–9. The behavior of these functions and their derivatives is shown in Figures 13, 14.
Equations 8, 9 can be written as:
![Graph displaying four oscillating functions labeled as \(z2 \cos(z)\), \(n \sin(x z - n)\), \(z \cos(z)\), and \(\frac{1}{2} [\sin(c(z - n)) - \sin(c(z + n))]\). The x-axis is labeled \(z\), ranging from \(-10\) to \(10\), and the y-axis represents function values, ranging from \(-80\) to \(40\). Each function is depicted with a different color and pattern, showing various oscillation amplitudes and frequencies.](https://www.frontiersin.org/files/Articles/1696859/frai-08-1696859-HTML/image_m/frai-08-1696859-g013.jpg)
Figure 13. Plot of the oscillating activation functions incorporated in the study in the limits [–10, 10].
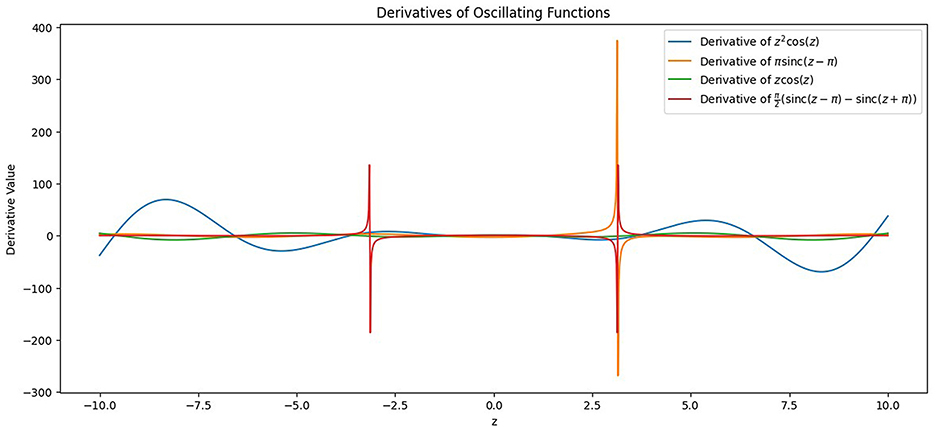
Figure 14. Plot of the derivatives of the oscillating activation functions incorporated in the study in the limits [–10, 10].
2.5.3 Loss functions
The model applies the weighted cross-entropy loss function on the outputs of the softmax layer. The usage of an additional parameter, weight wi in the function, proves to be vital while handling datasets with uneven class distributions, especially in the use-cases of LULC. In such instances, employing standard Cross-entropy loss can bias the model toward the majority class, often resulting in misclassifications and reduced performance on minority classes during test data inferencing (Ebrahimy et al., 2022). Weighted Cross-Entropy Loss (in Equation 12) addresses this issue by allocating distinct weights to each class, thereby equilibrating their impact throughout training. The class weights are determined according to the frequency with which each label appears in the dataset Equation 13 and depend inversely on it. For the optimization procedure for each epoch, utilize the state-of-the-art, adaptive optimization algorithm, the AMS-Grad variant of the Adam (Kingma and Ba, 2017) optimizer. This trains the model and updates the parameters during backpropagation. The AMSGrad version has been proven to be better than the base version of Adam in terms of convergence and also improving the generalizability of the model (Reddi et al., 2019).
where N denotes the total number of samples, ni represents the number of samples belonging to class i, C is the total number of classes, L refers to the weighted loss, wi indicates the weight assigned to class i, yi is the true label of class i, and ŷi denotes the predicted probability for class i. The end-to-end training of the model is done by backpropagation and weight updates as denoted in Equation 14. The model has been trained for a total of 100 epochs for each of the oscillating activation functions, in order to perform a thorough comparison between each of the activation functions. In addition to this, a comparison was also carried out among the various machine learning algorithms used for LULC.
where: θij represents the weight or parameter between neuron i and neuron j, η is the learning rate, E is the error (or loss) function, is the partial derivative of the error with respect to θij. This formula updates θij by moving it in the direction that reduces the error, with η controlling the step size of each update. The values of each of the hyper-parameters of the model have been listed in Table 7.
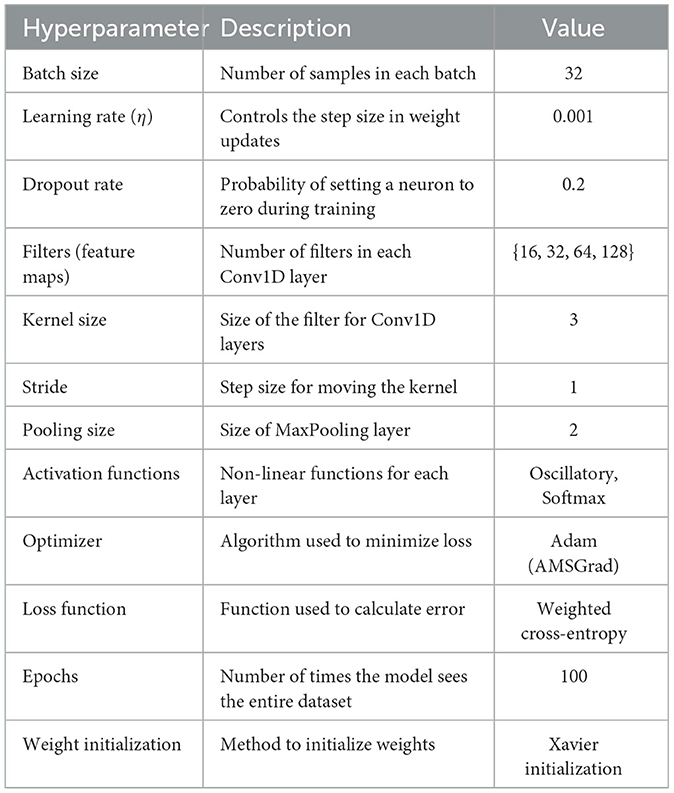
Table 7. Hyperparameters used for the proposed CONN model.
2.6 Performance metrics
The metrics used to evaluate the performance of the CONN include accuracy score, precision, recall, F1-score, confusion matrix, user's accuracy, producer's accuracy, and Kappa score. This subsection aims to discuss the efficacy of each of the selected metrics in gauging certain aspects of the performance of the models being compared. Those metrics are presented in Table 8. where TP is true positives, TN is true negatives, FP is false positives, FN is false negatives, Po is the observed agreement and Pe is the random agreemen. b and c are disagreeing cases where one model predicts positive and the other predicts negative in the McNemar test.
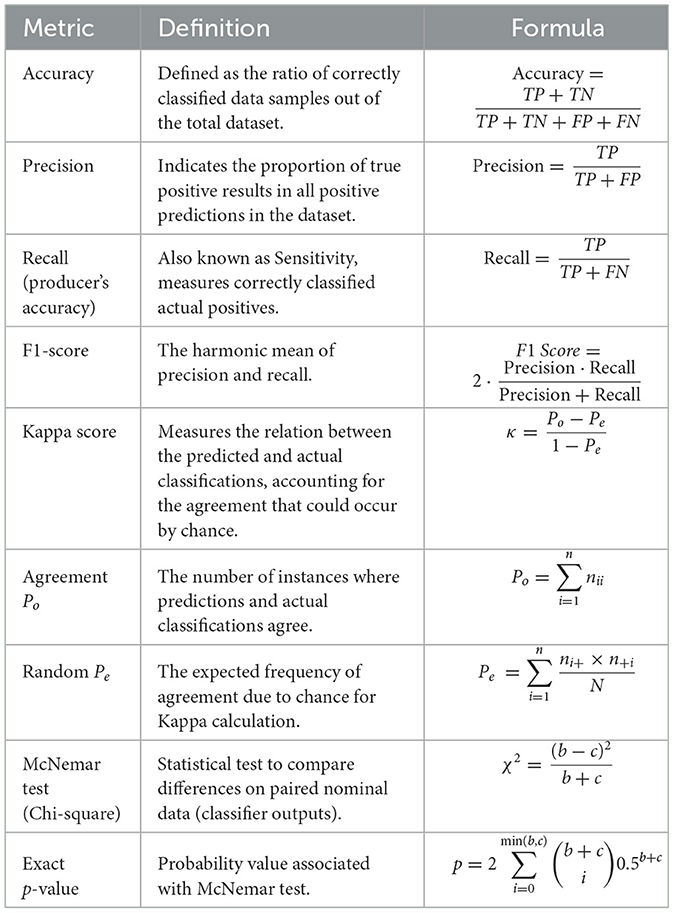
Table 8. Metrics and their formulas for classification evaluation.
2.7 Software and hardware specifications
The dataset for Landsat-8 SR was obtained from GEE utilizing the JavaScript API version 0.1.397, it was also utilized to implement algorithms such as SNIC and GLCM. For data preprocessing, model training and experimentation, Python version 3.10 was used, along with the PyTorch framework version 2.0. The hardware employed for training the model is an Intel Xeon CPU (2.3 GHz), 16GB of DDR4 RAM, and 12GB of VRAM.
3 Results
The experimental setup for the study is presented in Sections 2.5, 2.7 and Table 9. CONN comprises four layers of Convolutional Oscillatory activated layers with a kernel size of three and a stride of 1, along with two dropout and max pooling layers of kernel size 2. This architecture is then followed by Feed feed-forward oscillatory Neural Network of four hidden layers and each followed by a dropout layer.
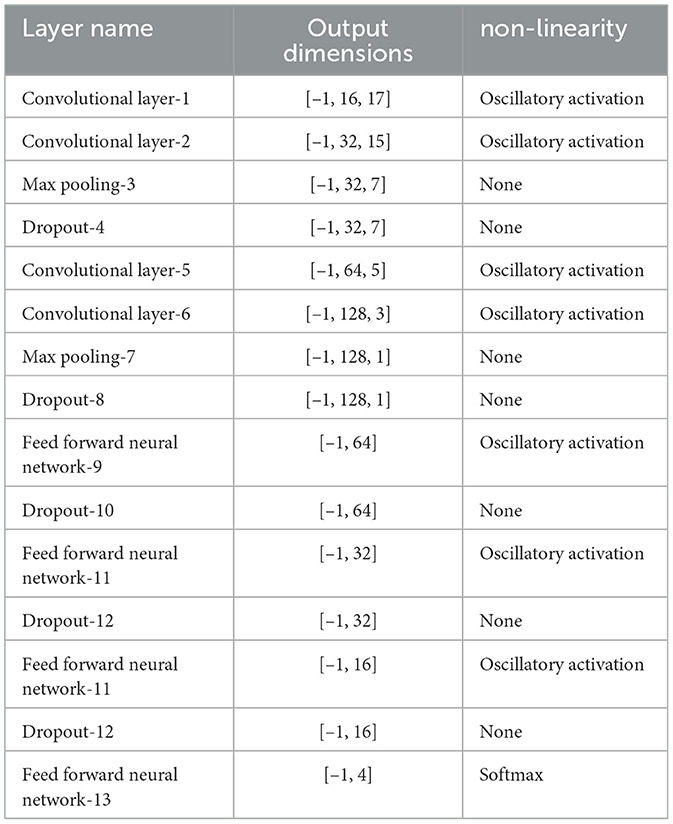
Table 9. Layer configuration details of the employed CONN architecture along with oscillatory activation functions.
The results presented in Table 10 indicate that the CONN model outperforms the conventionally activated functions across all the chosen metrics. There has been an especially large improvement when it comes to the Kappa score with DSU being nearly 0.4 higher than Swish. The confusion matrix for the proposed CONN-DSU is present in Table 11. This indicates the higher reliability of the CONN model over conventionally activated models when it comes to imbalanced datasets such as remote sensing data. Additionally, the CONN model improves greatly upon the precision for each class. This indicates that the CONN model makes significantly fewer misclassifications, even in cases where classes have very similar spectral characteristics, such as the barren and urban classes.
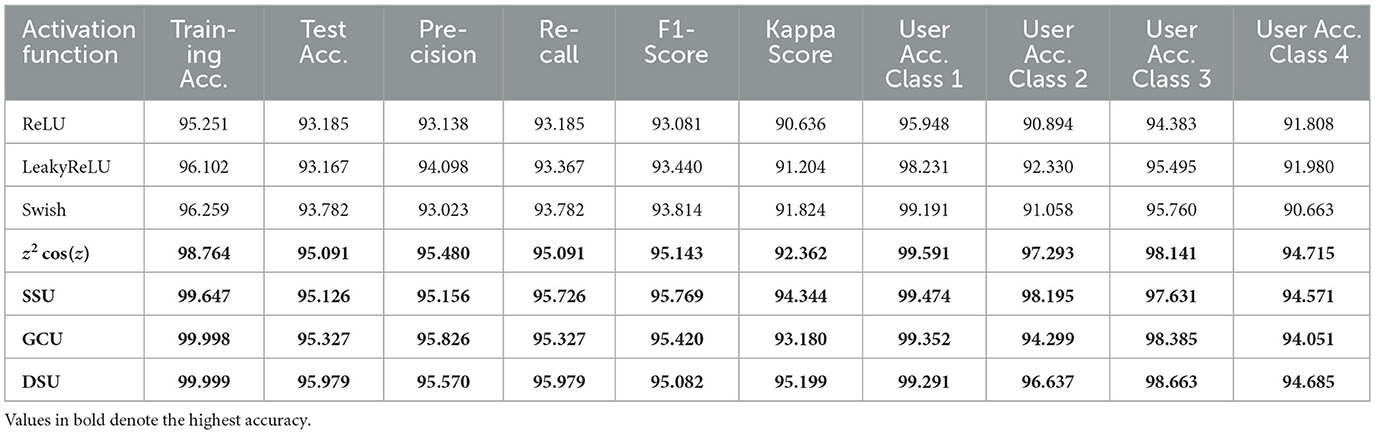
Table 10. Comparison of activation functions based on performance metrics.
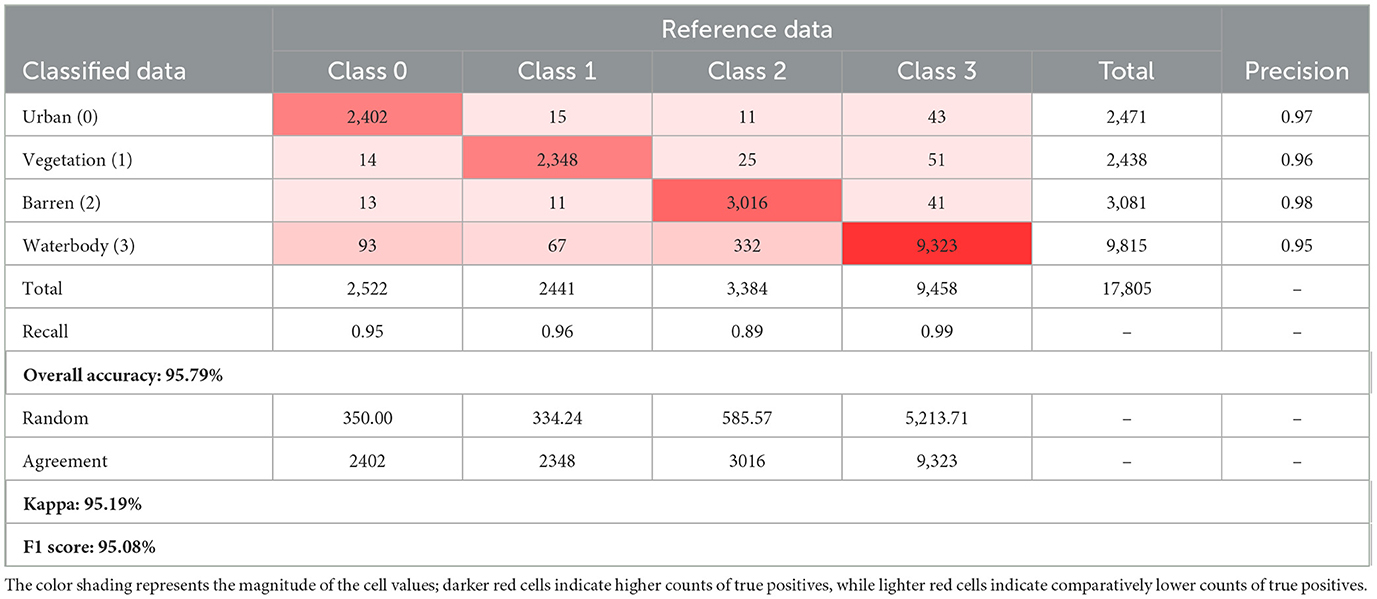
Table 11. Confusion matrix for proposed CONN-DSU.
The ability of the oscillatory functions to be able to represent more information with the same number of neurons allows the CONN model to build a more complex representation of the classes, deterring over-reliance on spectral features alone for classification. This ability of the CONN model is also showcased in Figure 15, with the CONN model being able to classify smaller objects of some classes more accurately as we can see with the water body and vegetation patch in Figure 16. The spatial classification output map of the current study area is presented Figure 17.
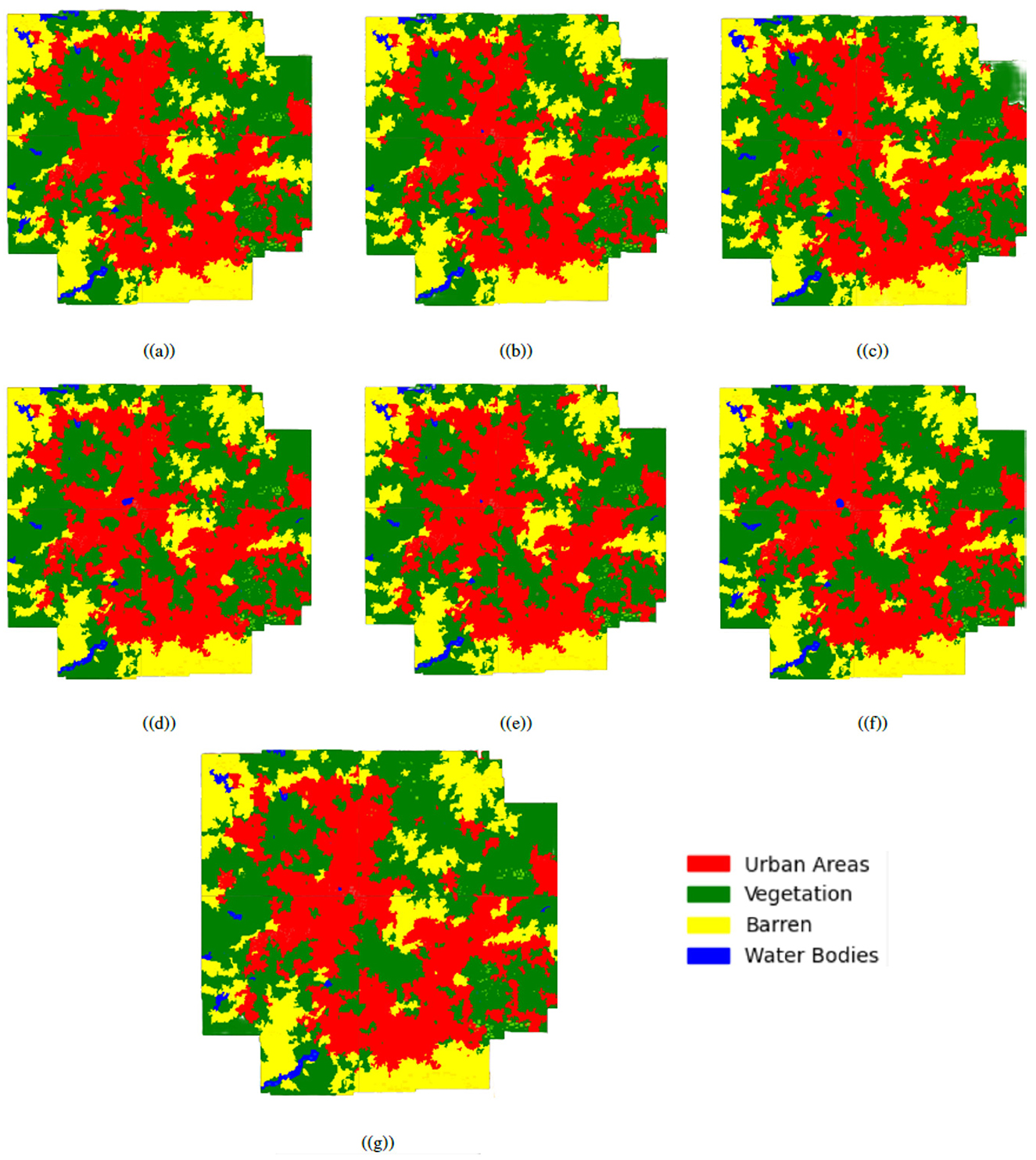
Figure 15. The classification results for the dataset using the following activation functions, (a) ReLU, (b) LeakyReLU, (c) Swish, (d) z2 cos(z), (e) DSU, (f) GCU, and (g) SSU, respectively.
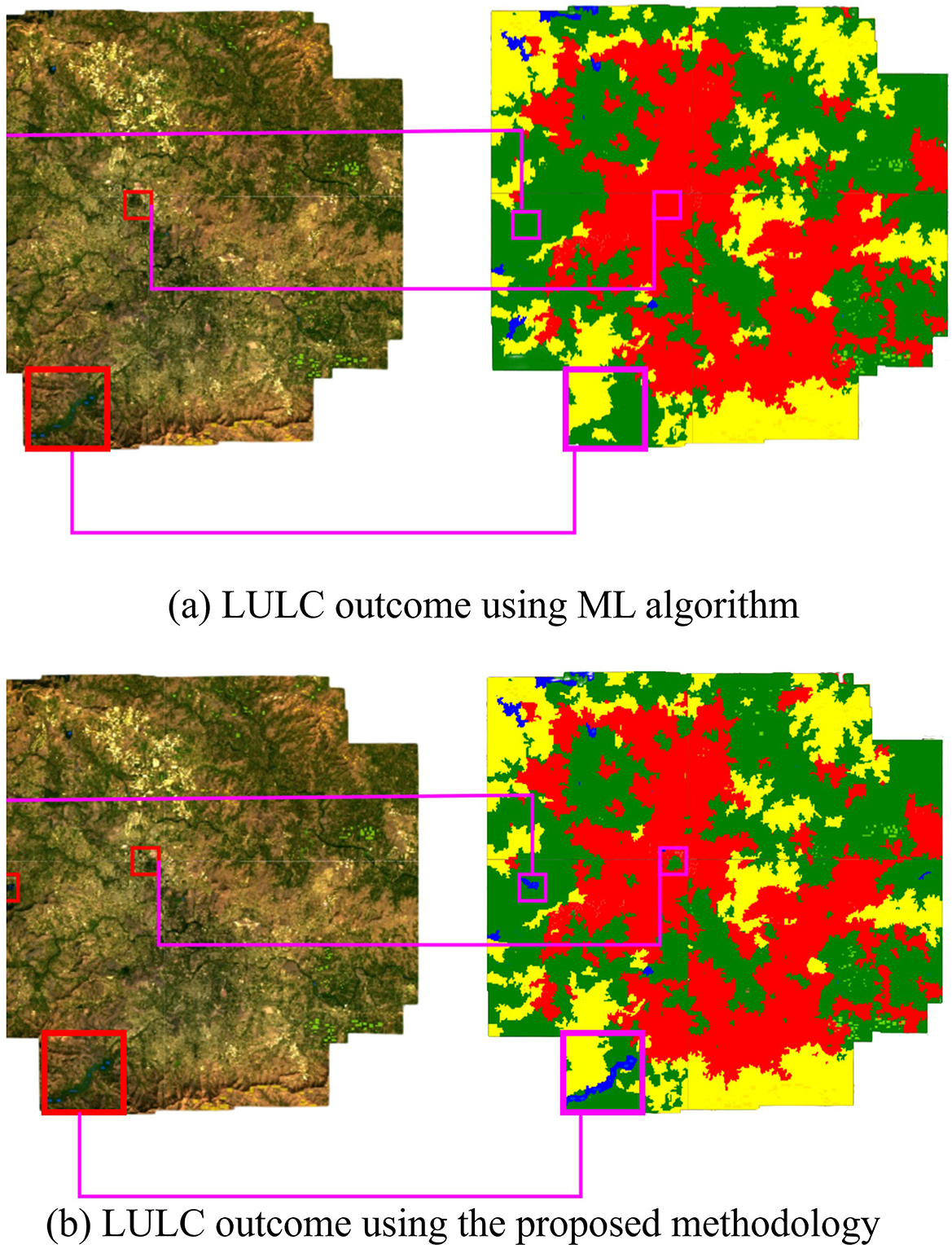
Figure 16. (a) LULC outcome using the proposed methodology and (b) LULC outcome of the ML Techniques.
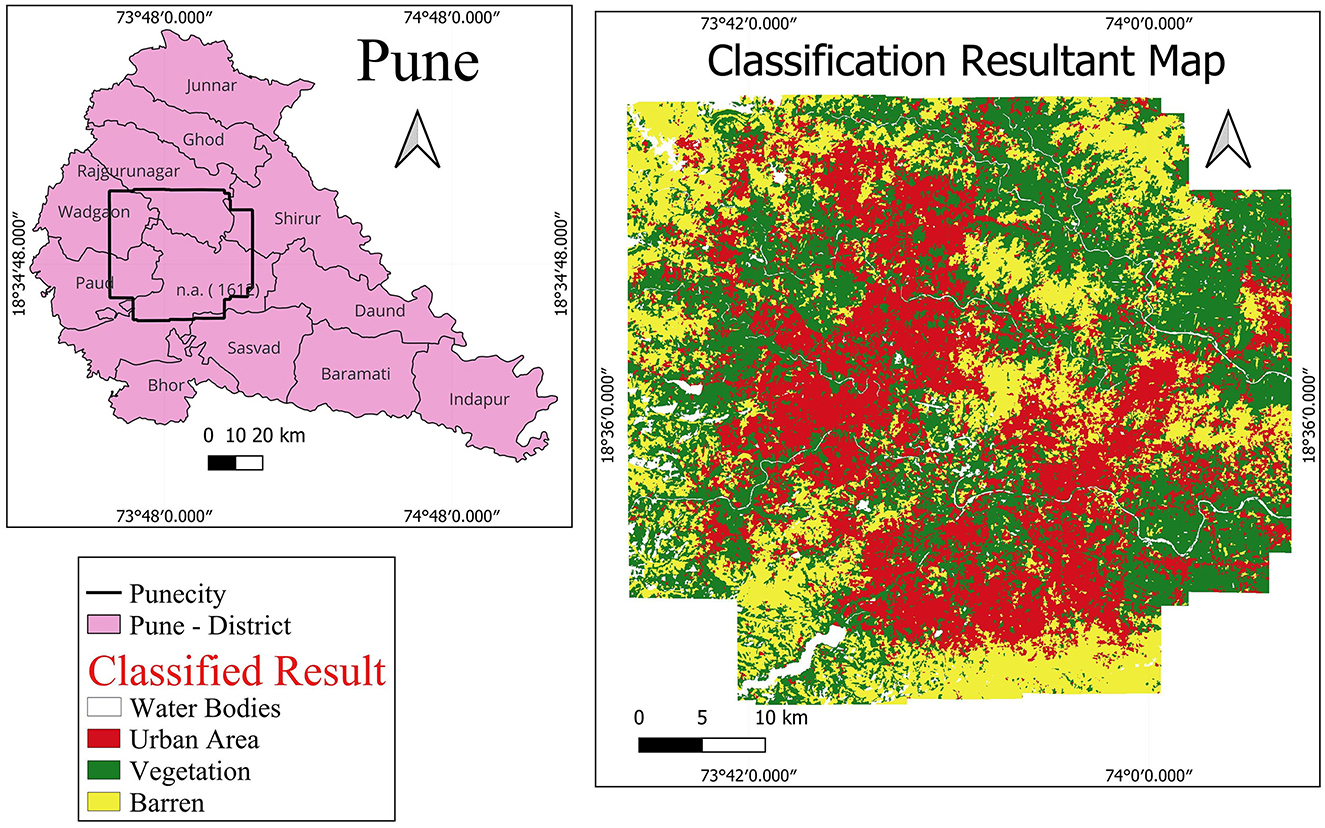
Figure 17. LULC maps of the study area using proposed CONN-DSU. Note that we use QGIS software(https://qgis.org/en/site/, version: 3.24.2) for plotting.
Furthermore, it can also be observed from Figures 18–21 that over a period of 50 epochs, the proposed CONN model equipped with oscillatory activation functions, such as SSU, converge much faster than conventional activation functions. In addition to the comparison of the activation functions over the entire dataset, this study also performs an ablation study which tests the robustness of the CONN model as compared to conventionally activated CNNs when some features are not present. The results of the ablation study are presented in the following section.
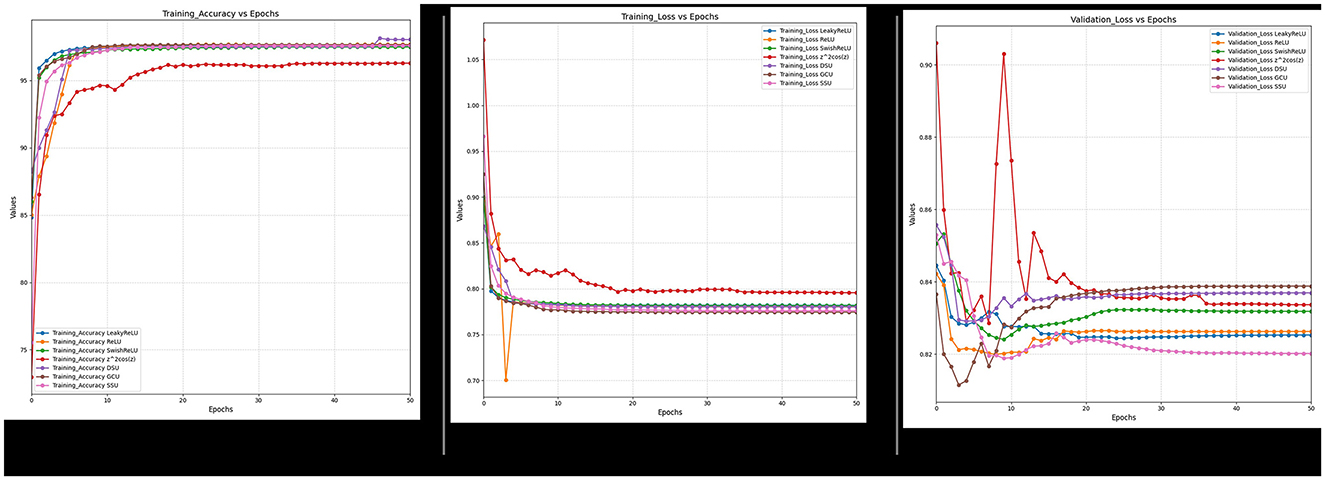
Figure 18. Ablated data training accuracy, loss, and validation loss for spectral feature.
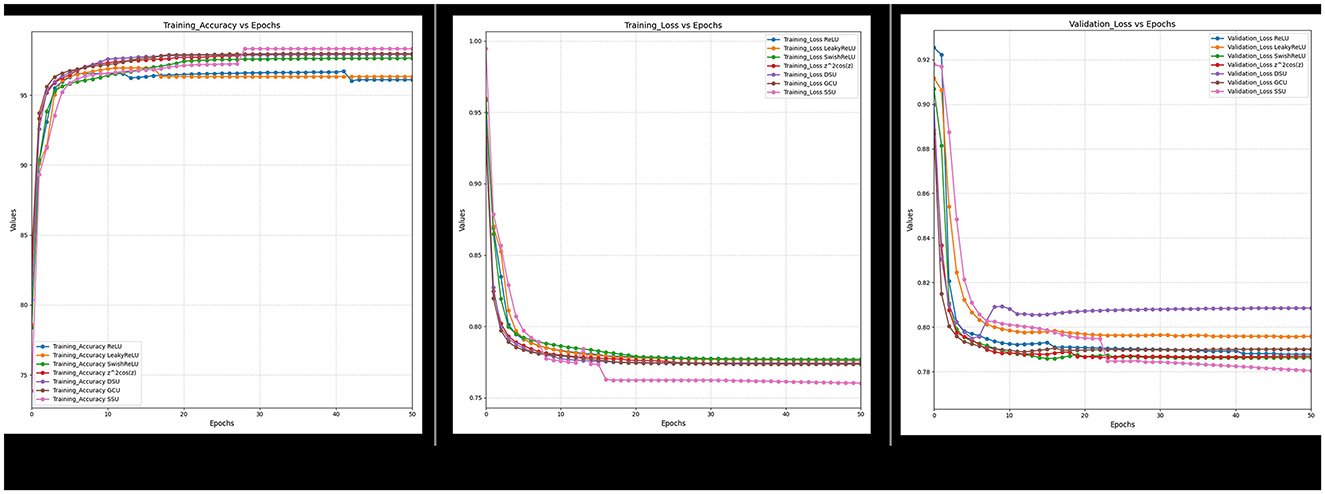
Figure 19. Ablated data training accuracy, loss, and validation loss for spectral and indices feature.
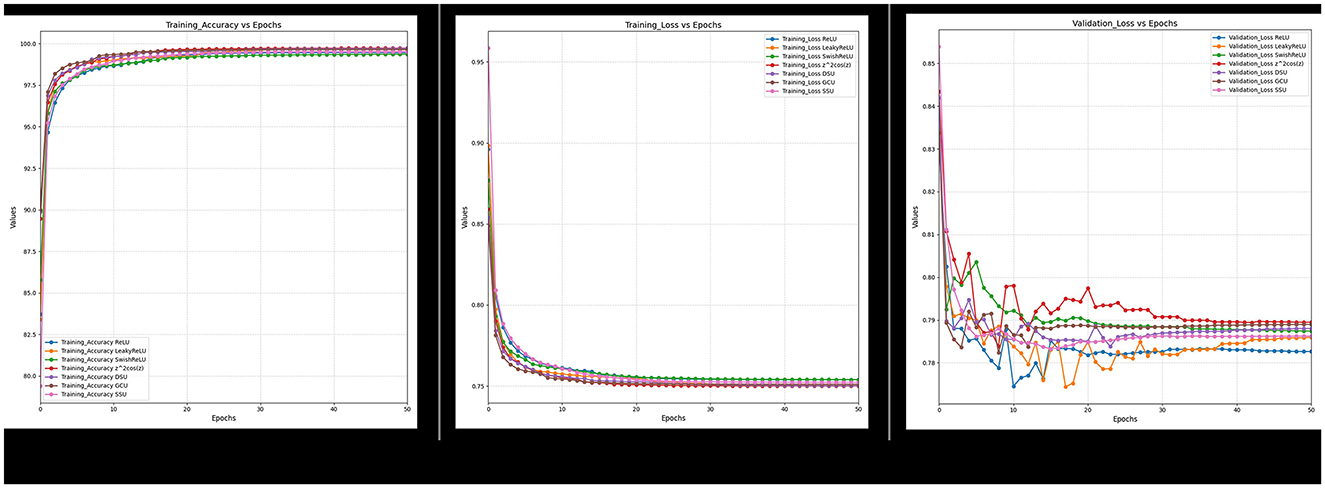
Figure 20. Ablated data training accuracy, loss, and validation loss for Spectral and texture feature.
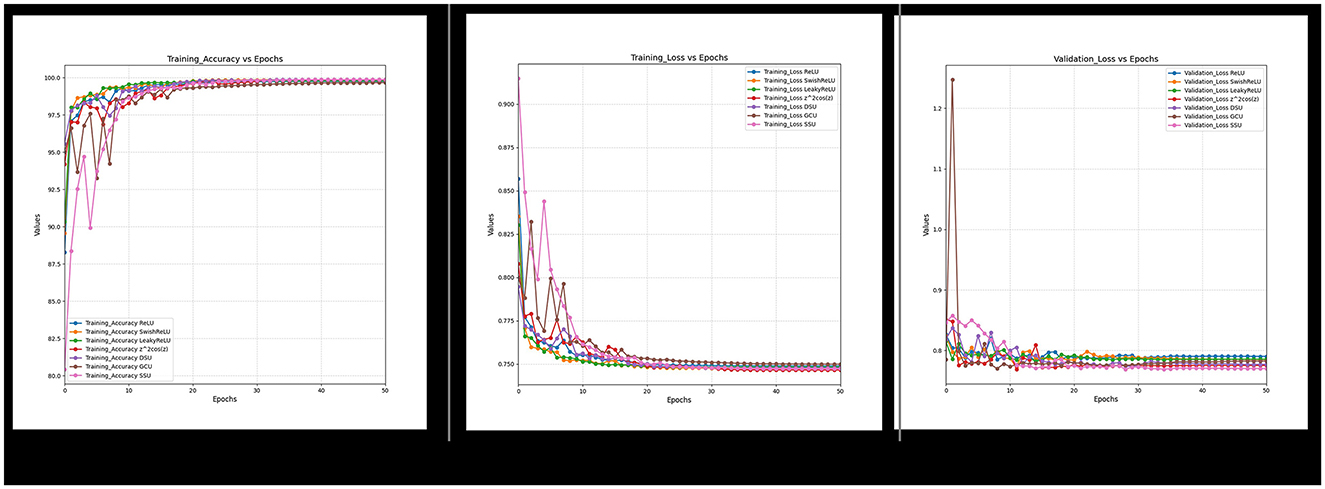
Figure 21. Training accuracy, loss and validation loss for non-ablated data.
4 Discussion
This paper performs an ablation study by removing parts of the feature set used in the original dataset and comparing the performance of both ML and DL models for these variations. The variations utilized are Spectral features, spectral and textural features, and Spectral features and spectral indices. The compared DL models include the proposed CONN model along with CNN models using ReLU, LeakyReLU, and Swish activation functions. The ML models chosen for this ablation study are Random Forest (RF), Support Vector Machine (SVM), Naive Bayes (NB), and AdaBoost. Additionally, the hyperparameters of these ML models were optimized using GridSearchCV, and the hyperparameters utilized for the test can be seen in Table 12. This test was performed in order to ascertain the importance of each feature, in addition to the CONN model's ability to work with fewer features. When utilizing remote sensing data, obtaining reliable data for all features may not be feasible. In such cases, the model should also possess the capability to train on suboptimal data and still provide serviceable results. Additionally, this test is also beneficial in identifying the importance of individual features.

Table 12. Hyperparameters utilized for the Listed ML models in the study.
The results of the study for all the DL models, as shown in Table 13, indicate that for all three variations of the dataset, the CONN model utilizing oscillatory activation functions outperforms all the conventionally activated DL models for all the chosen metrics. Furthermore, it can be observed in Figure 21 that despite the additional performance, the CONN model provides similar convergence speeds to conventional activation functions and, in some cases, shows sustained improvements till much higher epochs. Additionally, the results for ML models presented in Tables 14, 15 further establish the better performance of the CONN model over ML models on all three variations of the dataset.
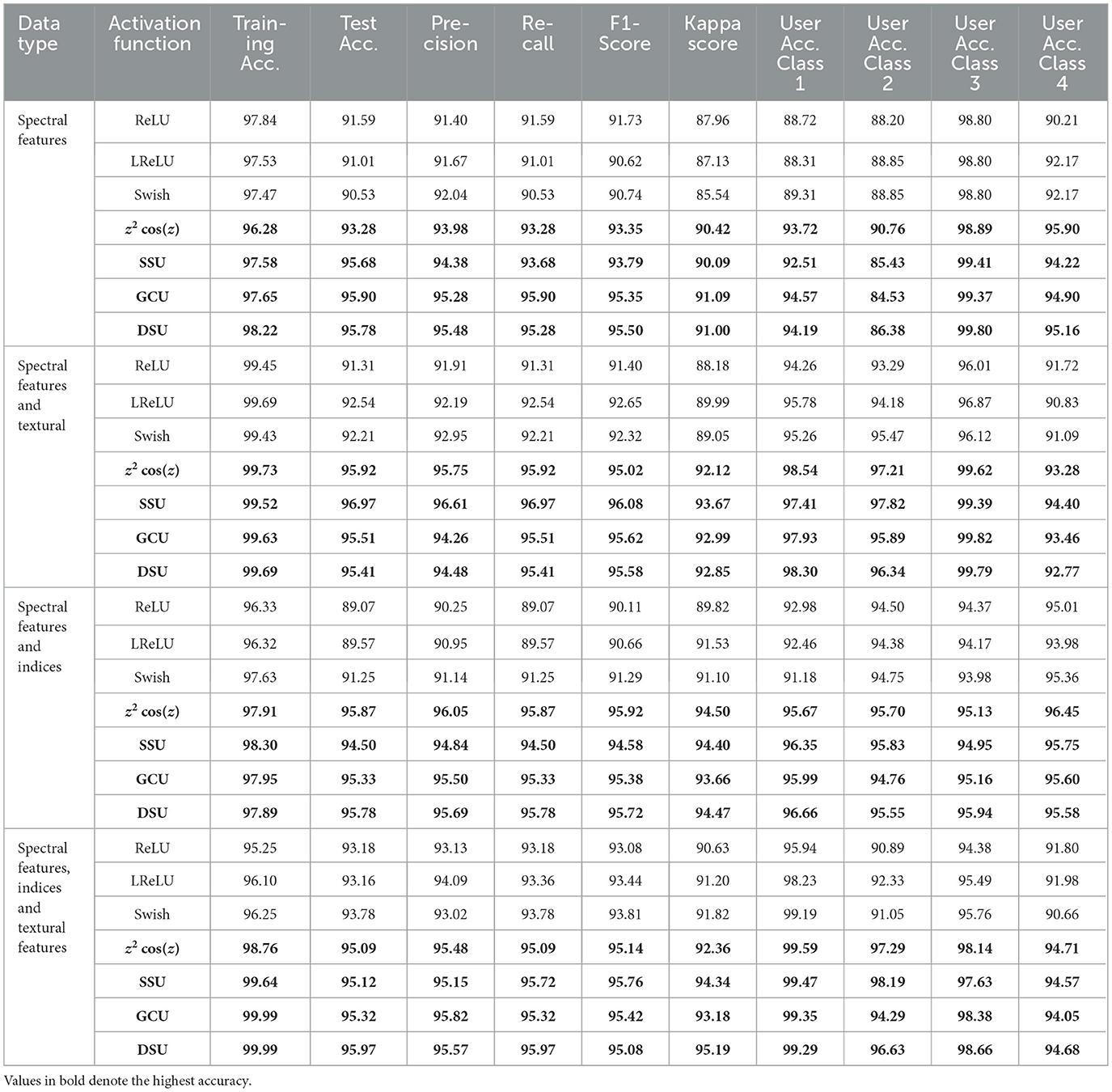
Table 13. Results with training accuracy and other metrics.
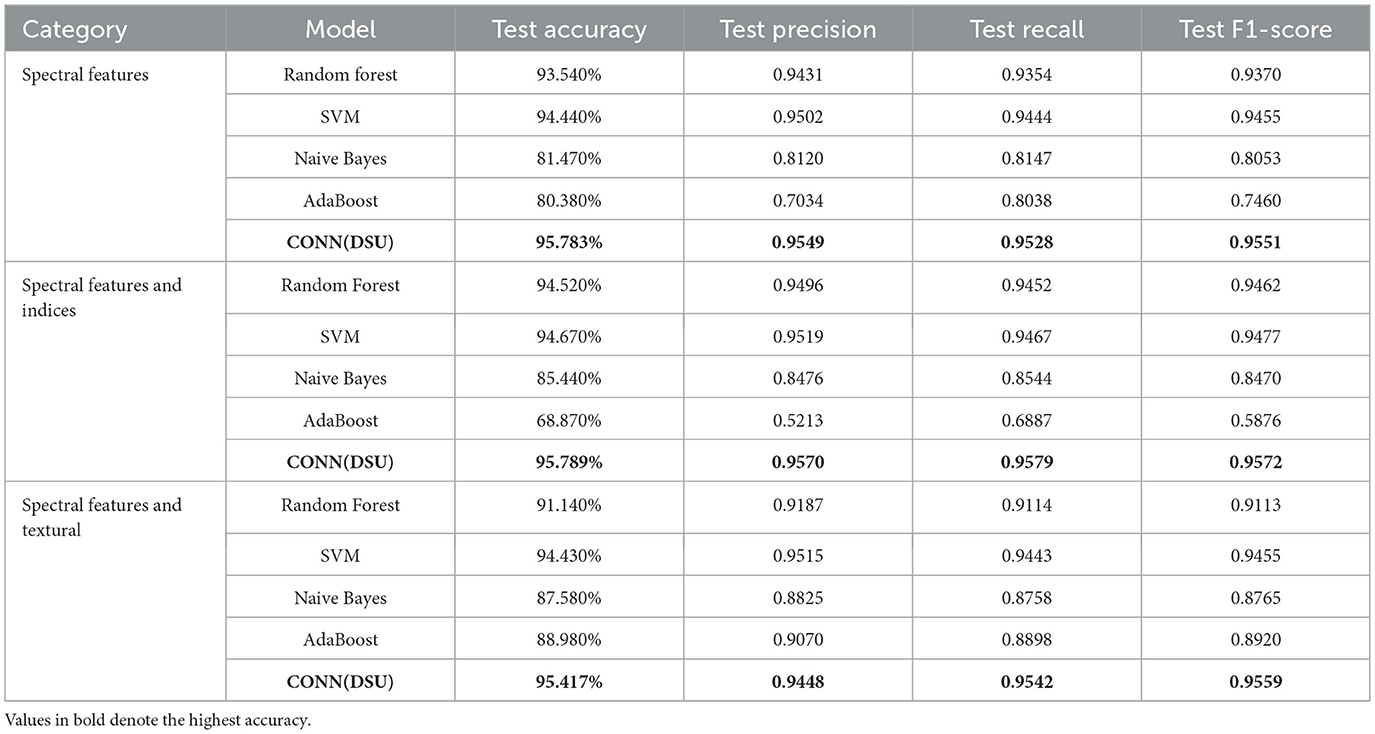
Table 14. Comparison of CONN (DSU) and ML models results on test data.
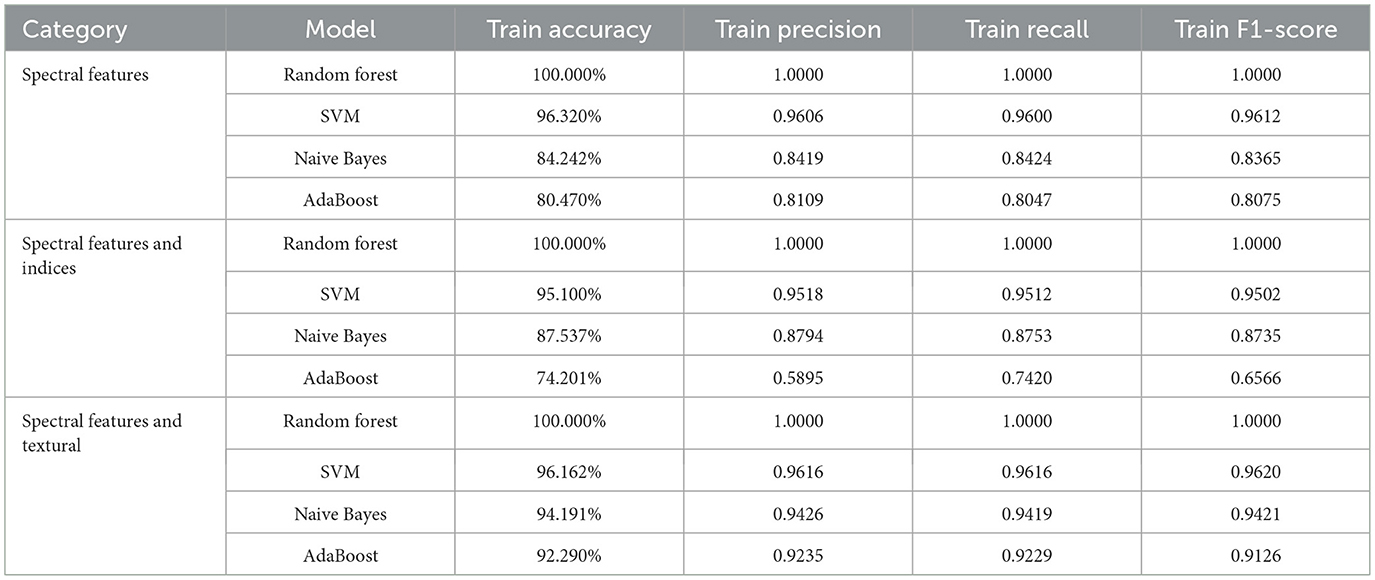
Table 15. Training results for ML models on the ablated datasets.
4.1 Statistical analysis of the performance
The McNemar test was conducted to determine whether there was a statistically significant difference in the classification errors (discordant cases) between the proposed and the existing models, based on the confusion matrices provided. Table 16 presents several key parameters to assess the statistical significance of differences between models. These include the contingency values (a, b, c, d), the actual p-value, the significance threshold (α = 0.05), the observed chi-square (χ2) value, and the 95% confidence interval for this difference. In contingency value, a represents positive predictions, and d represents negative predictions by both models respectively, while b and c represent disagreeing cases where one model predicts positive and the other predicts negative. The null hypothesis H0 was taken to be: “there is no significant difference in the number of discordant pairs between the models.” Alternative hypothesis H1 was taken to be: “there is a significant difference in the number of discordant pairs between the models.” The statistical McNemar test was applied to compare the proposed DSU classification model with other DL models namely DL with ReLu, Leaky ReLu, Swish, z2 cos, GCU and SSU and Random Forest, SVM, Na'́ıve Bayes, and Adaboost ML models. All comparisons resulted in extremely low p-values, consistently below the conventional threshold (α = 0.05), confirming that the observed differences are statistically significant and not due to random variation. The observed chi-square values for most models were above the critical value of 3.841, indicating a clear improvement in classification performance by the proposed DL model with DSU activation function. Confidence intervals for these differences were consistently narrow, supporting the reliability of the findings. Even in the case of Random Forest model, the smallest difference noted remained significant. Moreover, the extremely large difference with Adaboost model highlights not only statistical but also substantial practical improvement. The statistical McNemar test shows that the DSU model's improvements are reliable and consistent, clearly supporting its better performance compared to other models.
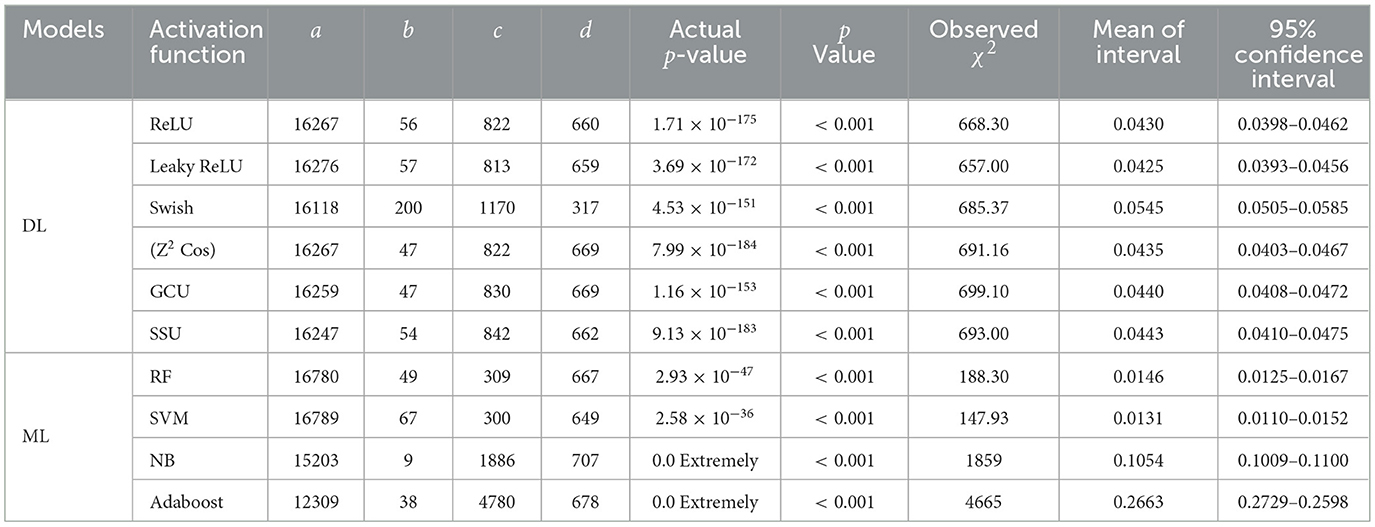
Table 16. Statistical comparison: proposed DSU vs. other models.
5 Conclusion and future works
This study proposes a convoluted oscillatory neural networks (CONN) architecture for accurate object based LULC classification. The proposed model utilizes the periodic, non-monotonic nature of the oscillatory activation functions with the deep, convoluted architecture of CNNs to accurately map and classify LULC. The study uses the surface reflectance images captured using Landsat 8 in the Pune area. GLCM textural features and spectral indices were then extracted from the objects segmented using the SNIC segmentation algorithm. According to experimental results, the proposed CONN with Decaying Sine Unit achieved an overall train accuracy of 99.999%, test accuracy of 95.979%, precision of 95.570%, recall of 95.979%, F1-score of 95.082%, and kappa score of 95.199%. The efficient gradient flow during Back propagation while training the proposed CONN allows the model to mitigate the vanishing gradient problem and to create a complex representation of data. The comparative analysis and comprehensive ablation study also highlight the superior performance of CONN over traditional ML approaches and conventional DL model-based architectures in the absence of critical features such as textures and spectral indices. It was also observed that although traditional ML models outperformed in training accuracy, they lack generalizing ability during testing, as showcased on the ablated test dataset. Since the neurons enhanced with oscillating activation functions have higher representation power, the number of neurons in the architecture has to be reduced in order to avoid overfitting. Future work can also explore transformer-based models, Quadratic Neural Networks (QNNs) (Noel and Muthiah-Nakarajan, 2024), along with time-series analysis. Transformer models have been proven to be better than traditional ANN-based architectures at capturing the correlation and difference in the time-series data (Nayak et al., 2024) and graph neural networks to further optimize classification performance and computational efficiency (Kavran et al., 2023).
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found at: https://www.usgs.gov/.
Author contributions
CC: Formal analysis, Writing – original draft, Methodology, Conceptualization, Data curation, Investigation. SK: Writing – original draft, Formal analysis, Conceptualization, Methodology, Investigation, Data curation. GA: Visualization, Methodology, Resources, Conceptualization, Investigation, Supervision, Writing – review & editing. RS: Visualization, Writing – review & editing, Investigation, Supervision.
Funding
The author(s) declare that no financial support was received for the research and/or publication of this article.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Gen AI was used in the creation of this manuscript.Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Achanta, R., Shaji, A., Smith, K., Lucchi, A., Fua, P., S'́usstrunk, S., et al. (2012). Slic superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 34, 2274–2282. doi: 10.1109/TPAMI.2012.120
Achanta, R., and S'́usstrunk, S. (2017). “Superpixels and polygons using simple non-iterative clustering,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Honolulu, HI: IEEE), 4895–4904. doi: 10.1109/CVPR.2017.520
Amani, M., Ghorbanian, A., Ahmadi, S. A., Kakooei, M., Moghimi, A., Mirmazloumi, S. M., et al. (2020). Google earth engine cloud computing platform for remote sensing big data applications: a comprehensive review. IEEE. J. Sel. Top. Appl. Earth Obs. Remote Sens. 13, 5326–5350. doi: 10.1109/JSTARS.2020.3021052
Attri, P., Chaudhry, S., and Sharma, S. (2015). Remote sensing &GIS based approaches for lulc change detection-a review. Int. J. Curr. Eng. Technol. 5, 3126–3137.
Census of India (2024). Population Data of Pune Metropolitan Region. Office of the Registrar General & Census Commissioner, New Delhi, India.
Digra, M., Dhir, R., and Sharma, N. (2022). Land use land cover classification of remote sensing images based on the deep learning approaches: a statistical analysis and review. Arab. J. Geosci. 15. doi: 10.1007/s12517-022-10246-8
Dingle Robertson, L., and King, D. J. (2011). Comparison of pixel-and object-based classification in land cover change mapping. Int. J. Remote Sens. 32, 1505–1529. doi: 10.1080/01431160903571791
Ebrahimy, H., Mirbagheri, B., Matkan, A. A., and Azadbakht, M. (2022). Effectiveness of the integration of data balancing techniques and tree-based ensemble machine learning algorithms for spatially-explicit land cover accuracy prediction. Remote Sens. Appl. Soc. Environ. 27, 100785. doi: 10.1016/j.rsase.2022.100785
Fu, W., Ma, J., Chen, P., and Chen, F. (2020). “Remote sensing satellites for digital earth,” in Manual of Digital Earth, eds. H. Guo, M. F. Goodchild, and A. Annoni (Cham: Springer), 55–123. doi: 10.1007/978-981-32-9915-3_3
Hansen, M. C., and Loveland, T. R. (2012). A review of large area monitoring of land cover change using landsat data. Remote Sens. Environ. 122, 66–74. doi: 10.1016/j.rse.2011.08.024
Haralick, R. M., Shanmugam, K., and Dinstein, I. (1973). Textural features for image classification. IEEE Trans. Syst. Man Cyberne. 3, 610–621. doi: 10.1109/TSMC.1973.4309314
Hu, Z., Zhang, J., and Ge, Y. (2021). Handling vanishing gradient problem using artificial derivative. IEEE Access 9, 22371–22377. doi: 10.1109/ACCESS.2021.3054915
Huang, S., Tang, L., Hupy, J. P., Wang, Y., and Shao, G. (2021). Commentary review on the use of normalized difference vegetation index (NDVI) in the era of popular remote sensing. J. For. Res. 32:2719. doi: 10.1007/s11676-020-01176-w
Kamusoko, C. (2017). “Importance of remote sensing and land change modeling for urbanization studies,” in Urban Development in Asia and Africa: Geospatial Analysis of Metropolises, eds. Y. Murayama, C. Kamusoko, A. Yamashita, and R. C. Estoque (Cham: Springer), 3–10. doi: 10.1007/978-981-10-3241-7_1
Kavran, D., Mongus, D., Žalik, B., and Lukač, N. (2023). Graph neural network-based method of spatiotemporal land cover mapping using satellite imagery. Sensors 23:6648. doi: 10.3390/s23146648
Kingma, D. P., and Ba, J. (2017). Adam: A Method for Stochastic Optimization. doi: 10.48550/arXiv.1412.6980
Kolbusz, J., Rozycki, P., Lysenko, O., and Wilamowski, B. M. (2018). “Neural networks saturation reduction,” in Artificial Intelligence and Soft Computing: 17th International Conference, ICAISC 2018, Zakopane, Poland, June 3-7, 2018, Proceedings, Part I 17 (Cham: Springer), 108–117. doi: 10.1007/978-3-319-91253-0_11
Kumari, A., and Karthikeyan, S. (2023). Sentinel-2 data for land use/land cover mapping: a meta-analysis and review. SN Comput. Sci. 4:815. doi: 10.1007/s42979-023-02214-0
Maharashtra Government (2020). Geographical Coordinates of Pune. Government of Maharashtra, Mumbai, India.
Markham, B. L., and Barsi, J. A. (2017). “Landsat-8 operational land imager on-orbit radiometric calibration,” in 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS) (Fort Worth, TX: IEEE), 4205–4207. doi: 10.1109/IGARSS.2017.8127929
Nayak, G. H., Alam, M. W., Avinash, G., Kumar, R. R., Ray, M., Barman, S., et al. (2024). Transformer-based deep learning architecture for time series forecasting. Softw. Impacts 22:100716. doi: 10.1016/j.simpa.2024.100716
Nigar, A., Li, Y., Jat Baloch, M. Y., Alrefaei, A. F., and Almutairi, M. H. (2024). Comparison of machine and deep learning algorithms using google earth engine and python for land classifications. Front. Environ. Sci. 12:1378443. doi: 10.3389/fenvs.2024.1378443
Noel, M. M., Arunkumar, L., Trivedi, A., and Dutta, P. (2025a). Oscillating activation functions can improve the performance of convolutional neural networks. Appl. Soft Comput. 175:113077. doi: 10.1016/j.asoc.2025.113077
Noel, M. M., Bharadwaj, S., Muthiah-Nakarajan, V., and Dutta, P. D.. (2025b). Biologically inspired oscillating activation functions can bridge the performance gap between biological and artificial neurons. Expert Syst. Appl. 266:126036. doi: 10.1016/j.eswa.2024.126036
Noel, M. M., and Muthiah-Nakarajan, V. (2024). Efficient Vectorized Backpropagation Algorithms for Training Feedforward Networks Composed of Quadratic Neurons. doi: 10.48550/arXiv.2310.0290
Ouchra, H., Belangour, A., and Erraissi, A. (2022). A comparative study on pixel-based classification and object-oriented classification of satellite image. Int. J. Eng. Trends Technol. 70, 206–215. doi: 10.14445/22315381/IJETT-V70I8P221
Padigala, B. (2012). Urbanization and changing green spaces in Indian cities (case study - city of Pune). Int. J. Geol. Earth Environ. Sci. 2, 148–156.
Pal, R., Mukhopadhyay, S., Chakraborty, D., and Suganthan, P. N. (2023). A hybrid algorithm for urban lulc change detection for building smart-city by using worldview images. IETE J. Res. 69, 5748–5754. doi: 10.1080/03772063.2022.2163928
Rumelhart, D. E., Hinton, G. E., and Williams, R. J. (1986). Learning representations by back-propagating errors. Nature 323, 533–536. doi: 10.1038/323533a0
Samuel, K., and Atobatele, R. (2019). Land use/cover change and urban sustainability in a medium-sized city. Int. J. Sustain. Soc. 11, 13. doi: 10.1504/IJSSOC.2019.101961
Sandbhor, P., Singh, T., and Kalshettey, M. (2022). Spatiotemporal change in urban landscape and its effect on behavior of diurnal temperature range: a case study of Pune district, India. Environ. Dev. Sustain. 24, 646–665. doi: 10.1007/s10668-021-01461-6
Selvaraj, R., and Amali, D. G. B. (2024). A new texture aware—seed demand enhanced simple non-iterative clustering (ESNIC) segmentation algorithm for efficient land use and land cover mapping on remote sensing images. IEEE Access 12, 121208–121222. doi: 10.1109/ACCESS.2024.3519612
Talukdar, S., Singha, P., Mahato, S., Pal, S., Liou, Y.-A., Rahman, A., et al. (2020). Land-use land-cover classification by machine learning classifiers for satellite observations—a review. Remote Sens. 12:1135. doi: 10.3390/rs12071135
Tan, H. H., and Lim, K. H. (2019). “Vanishing gradient mitigation with deep learning neural network optimization,” in 2019 7th International Conference on Smart Computing and Communications (ICSCC) (Sarawak: IEEE), 1–4. doi: 10.1109/ICSCC.2019.8843652
Taye, M. M. (2023). Theoretical understanding of convolutional neural network: Concepts, architectures, applications, future directions. Computation 11:52. doi: 10.3390/computation11030052
Teja, J., Vaddi, R., Lakshmika, K., and Nirupama, P. (2024). “Land use and land cover change detection using google earth engine,” in 2024 International Conference on Inventive Computation Technologies (ICICT) (Lalitpur: IEEE), 2034–2038. doi: 10.1109/ICICT60155.2024.10544386
U.S. Geological Survey (2019). Landsat 8 (L8) Data Users Handbook. Department of the Interior. Reston, VA: U.S. Geological Survey.
Wei, X., Zhang, W., Zhang, Z., Huang, H., and Meng, L. (2023). Urban land use land cover classification based on gf-6 satellite imagery and multi-feature optimization. Geocarto Int. 38:2236579. doi: 10.1080/10106049.2023.2236579
Whiteside, T., and Ahmad, W. (2005). “A comparison of object-oriented and pixel-based classification methods for mapping land cover in Northern Australia,” in Proceedings of SSC2005 Spatial Intelligence, innovation and Praxis: The National Biennial Conference of the Spatial Sciences Institute, 1225–1231.
Xie, C., Zhu, H., and Fei, Y. (2021). Deep coordinate attention network for single image super-resolution. IET Image Process. 16:12364. doi: 10.1049/ipr2.12364
Zhao, Q., Yu, L., Du, Z., Peng, D., Hao, P., Zhang, Y., et al. (2022). An overview of the applications of earth observation satellite data: impacts and future trends. Remote Sens. 14:1863. doi: 10.3390/rs14081863
Keywords: convolution neural network, LANDSAT-8, remote sensing, oscillatory functions, land use land cover (LULC)
Citation: Chandnani CJ, Kulkarni SC, Amali D GB and Selvaraj R (2025) A new framework with convoluted oscillatory neural network for efficient object-based land use and land cover classification on remote sensing images. Front. Artif. Intell. 8:1696859. doi: 10.3389/frai.2025.1696859
Received: 01 September 2025; Revised: 11 October 2025;
Accepted: 18 November 2025; Published: 17 December 2025.
Edited by:
Xinghua Li, Wuhan University, ChinaReviewed by:
Antonio Sarasa-Cabezuelo, Complutense University of Madrid, SpainWenyi Hu, The Engineering Technical College of Chengdu University of Technology, China
Copyright © 2025 Chandnani, Kulkarni, Amali D and Selvaraj. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Geraldine Bessie Amali D, Z2VyYWxkaW5lLmFtYWxpQHZpdC5hYy5pbg==