 Khashayar Namdar
Khashayar Namdar Masoom A. Haider
Masoom A. Haider Farzad Khalvati
Farzad Khalvati- 1Department of Medical Imaging, University of Toronto, Toronto, ON, Canada
- 2The Hospital for Sick Children (SickKids), Toronto, ON, Canada
- 3Lunenfeld-Tanenbaum Research Institute, Sinai Health System, Toronto, ON, Canada
- 4Sunnybrook Research Institute, Toronto, ON, Canada
Receiver operating characteristic (ROC) curve is an informative tool in binary classification and Area Under ROC Curve (AUC) is a popular metric for reporting performance of binary classifiers. In this paper, first we present a comprehensive review of ROC curve and AUC metric. Next, we propose a modified version of AUC that takes confidence of the model into account and at the same time, incorporates AUC into Binary Cross Entropy (BCE) loss used for training a Convolutional neural Network for classification tasks. We demonstrate this on three datasets: MNIST, prostate MRI, and brain MRI. Furthermore, we have published GenuineAI, a new python library, which provides the functions for conventional AUC and the proposed modified AUC along with metrics including sensitivity, specificity, recall, precision, and F1 for each point of the ROC curve.
Introduction
Classification is an important task in different fields, including Engineering, Social Science, and Medical Science. To evaluate quality of classification, a metric is needed. Accuracy, precision, and F1 score are three popular examples. However, there are other metrics that are more accepted in specific fields. For example, sensitivity and specificity are widely used in Medical Science.
For binary classification, Receiver Operating Characteristic (ROC) curve incorporates different evaluation metrics. The Area Under ROC Curve (AUC) is a widespread metric, especially in Medical Science (Sulam et al., 2017). In engineering, AUC has been used to evaluate the classification models since the early 1990s (Burke et al., 1992), and AUC research has continued ever since. Kottas et al. proposed a method to report confidence intervals for AUC (Kottas et al., 2014). Yu et al. proposed a modified AUC which is customized for gene ranking (Yu et al., 2018). Yu also proposed another version of AUC for penalizing regression models used for gene selection with high dimensional data (Yu and Park, 2014). Rosenfeld et al. used AUC as a loss function and demonstrated AUC-based training lead to better generalization (Rosenfeld et al., 2014). Their research, however, is not in the context of Neural Networks (NN); instead, they use Support Vector Machines (SVM). Therefore, their method does not address the challenges we address in this paper, including taking confidence of the model into account in calculating AUC and thus, making it a better metric for training neural networks. Zhao et al. proposed an algorithm for AUC maximization in online learning (Zhao et al., 2011). A stochastic approach for the same task was introduced by Ying et al. (2016). Cortes and Mohri studied correlation of AUC, as it is optimized, and error rate (Cortes and Mohri, 2004). Their research showed that minimizing the error rate may not result in maximizing AUC. Ghanbari and Scheinberg directly optimized error rate and AUC of the classifiers; however, their approach only applies to linear classifiers (Ghanbari and Scheinberg, 2018).
This paper explains in detail the meaning of AUC, how reliable it is, under which circumstances it should be used, and its limitations. It also proposes a novel approach to eliminate these limitations. Our primary focus is on deep learning and Convolutional Neural Networks (CNNs), which differentiates our work from the previous work in the literature. We propose confidence-incorporated AUC (cAUC) as a modified AUC which directly correlates to Cross-Entropy Loss function and thus, helps to stop CNN training at a more optimum point in terms of confidence. This is not possible with conventional AUC, as not only the minimum of Binary Cross-Entropy loss function may not correlate with the maximum of AUC, but also AUC does not take the confidence of the model into account. We have also published a new library called GeuineAI1, which contains our modified AUC and conventional AUC with more features in comparison to the existing standard python libraries.
Revisiting the Concept of AUC
In supervised binary classification, each datapoint has a label. Conformed with standards of Machine Learning, labels are either 0/1 or 01/10 or sometimes +1/-1 and the model’s (classifier’s) outputs are usually probabilities. In the case of cancer detection, for example, input data may be CT or MRI images. Cancerous cases will be images labeled with 1 (positive) and normal (healthy) images will have 0 (negative) as their labels. The model returns a probability for each image. In the ideal scenario, the model’s output will be 1 for cancerous images and 0 for normal ones.
Four possible outcomes of binary classification are True Positive (TP), True Negative (TN), False Positive (FP), and False Negative (FN). From Table 1, it can be inferred that TX means Truly predicted as X and FX means Falsely predicted as X.
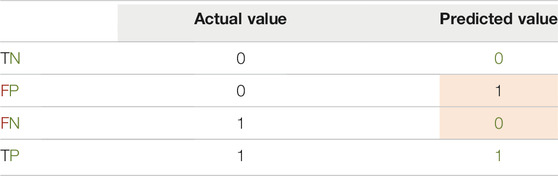
TABLE 1. Possible outcomes of binary classification.
Defined as the total number of correct predictions out of total cases, Accuracy is calculated by Equation (1).
As it can be seen, accuracy is only concerned about correct versus wrong predictions. In many situations, especially in Medical Science, this is not enough. The consequences of misclassifying a normal case as cancerous and considering a cancerous case as normal are way different. The first one is referred to FP, also known as Type I error, whereas the second one is a FN or Type II error. True Positive Rate (TPR) and False Positive Rate (FPR) are two criterions which distinguish the error types.
TPR is also known as sensitivity and refers to the ratio of correct predictions to total within actual positives. FPR is the ratio of wrong predictions within actual negatives. FPR is related to specificity by Eq. 4, which is used frequently in Medical Science.
As mentioned before, predicted value should be binary, but output of the model is probability. Thresholding is how probabilities are converted to predicted values. As an example, if the output is 0.6 and the threshold is 0.5, predicted value is 1.
y in Eq. 5 is the predicted value, p is the output of the model, which is a probability, and t is the threshold. Depending on t, TPR and FPR will be different. ROC is the curve formed by plotting TPR versus FPR for all possible thresholds and AUC is the area under that curve.
In the following, we take an example-based approach to highlight the fundamentals of AUC.
Example 1: Table 2 contains the simplest possible example. It should be followed from left to right.

TABLE 2. Example 1.
It can be seen from Table 2 that actual positives and actual negatives are necessary to draw an ROC curve. Although it may seem trivial, lack of one category in one batch leads to NaN in training of Machine Learning (ML) models. Furthermore, if the batch size is equal to one, the batch AUC is always NaN. Consequently, for any NN to be directly trained with a modified AUC, or for any code where AUC is calculated within each batch, batch size of one cannot be used. Furthermore, the sampler should be customized in a way to return samples from both classes in each batch.
Example 2: Table 3 contains an example of classifying one positive and one negative cases and Figure 1 shows the corresponding ROC curve. There are important points in this example. ROC curves always start from (0,0) and always end at (1,1). The reason is that if threshold is 0, all predicted values are 1. They will be either TP or FP. Therefore, both TPR and FPR are 1. On the other hand, if threshold is 1, everything is predicted as negative. In this case, predictions are all TN or FN. Consequently, TPR and FPR will be both zero. Two things must be taken into account when writing a ML code: t = 0, and t = 1 should be treated separately and t should be iterated backward if going from (0, 0) to (1, 1) is desired. Backward iteration necessity comes from the fact that the highest t corresponds to the lowest TPR and FPR. Exceptions of t = 0 and t = 1 are needed for rare cases when the output of the model is exactly 0 or 1.Example 3: Our third example is complement of Example 2. As it is indicated in Table 4, output probability for the positive case (

TABLE 3. Example 2.
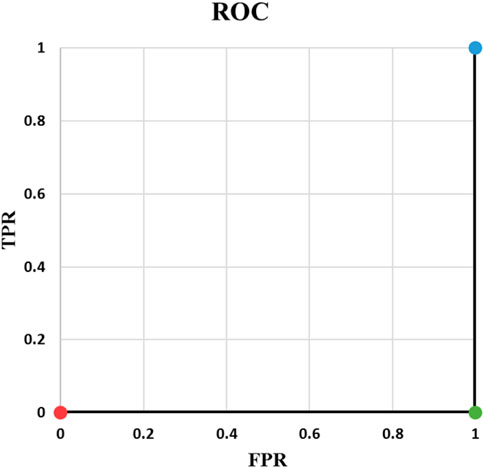
FIGURE 1. ROC of Example 2.

TABLE 4. Example 3.
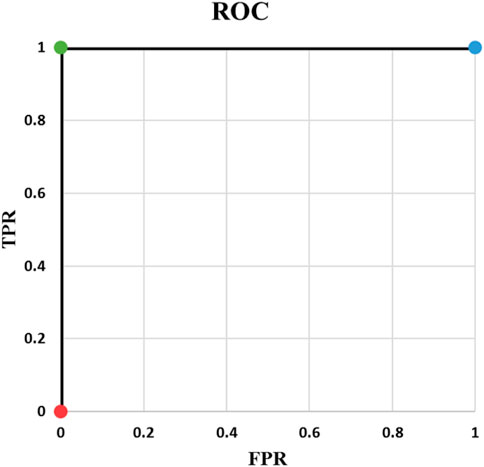
FIGURE 2. ROC of Example 3.
Example 4: In the fourth example (Table 5), the output probabilities are the same for the two samples. This leads to AUC of 0.50. This example shows that whenever all output probabilities are equal, AUC is 0.50 and ROC is a straight line from (0, 0) to (1, 1) (Figure 3). This is true for all different values of N where N is batch size or number of samples.

TABLE 5. Example 4.
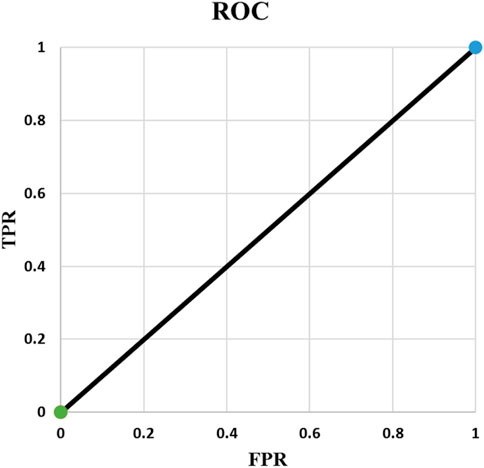
FIGURE 3. ROC of Example 4.
Example 5: In example 5, N is equal to 3 and there are 4 points in the ROC curve (Figures 4, 5). The reason for this phenomenon is effective threshold boundaries. As it can be seen in Table 6, up to t = 0.4, no value of t changes the model’s predictions. It turns out that those effective boundaries are defined by predicted probabilities. It should now be highlighted, in Examples 2 and 3, N was 2 and there were 3 points on the ROC curve. In the general form, for N predictions, there will be N+1 points on the ROC curve. For each pair of predictions with equal probabilities, one point is omitted. The extreme case is when all output probabilities are equal. In this case, there will be two points on the ROC curve and AUC is 0.5 (Example 4).
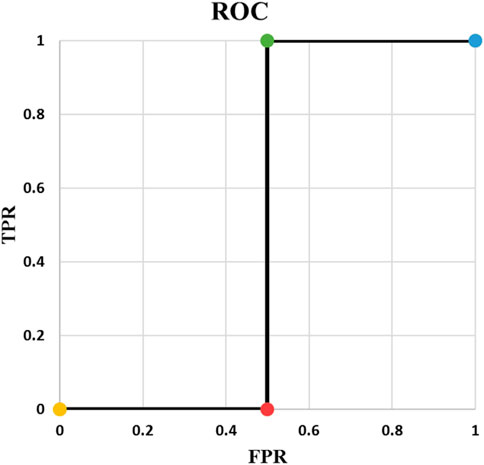
FIGURE 4. ROC of Example 5.
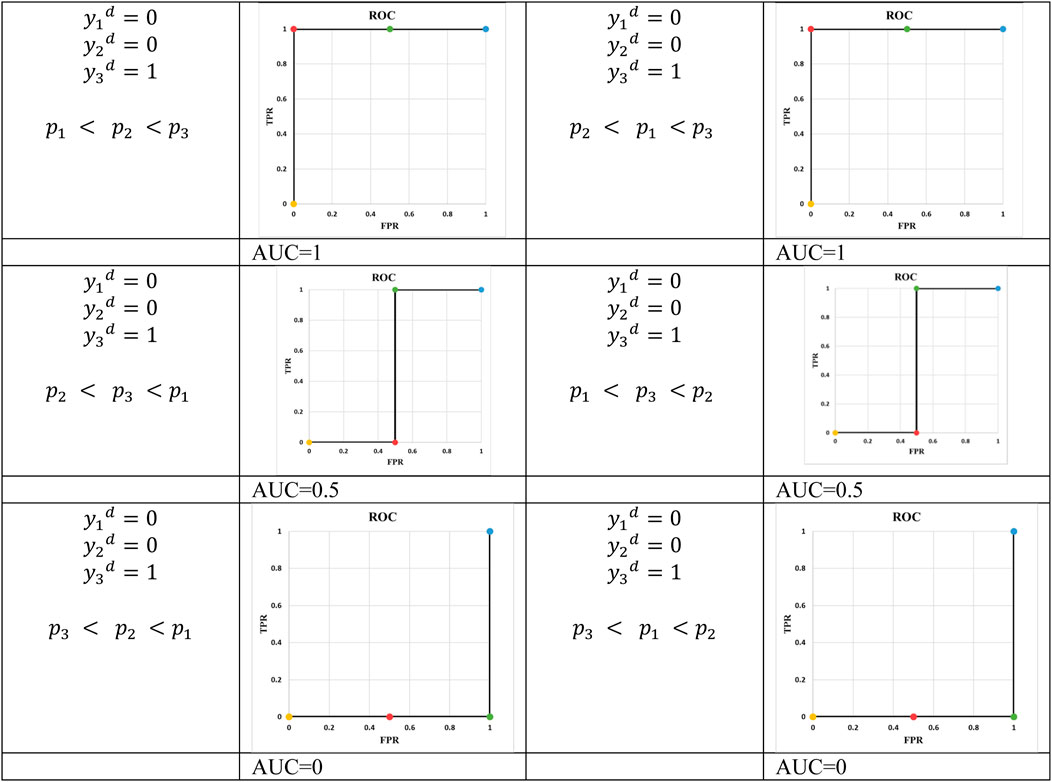
FIGURE 5. ROC curves for N = 3, two actual negative and an actual positive.

TABLE 6. Example 5.
Methods
Inspired by the previous examples, we will now investigate some characteristics of ROC and AUC. We will demonstrate how misclassification of a single data point can decrease AUC, and what extreme scenarios of misclassification look like. We will then provide an example to show a higher AUC does not necessarily correspond to better classification. The section is concluded with introducing cAUC, our proposed modified AUC, and mathematical support for its correlation to Binary Cross Entropy (BCE).
A result of having N+1 points on the ROC curve is that N+1 different effective values can be assigned to threshold t. In other words, while infinite values for t can be selected, selecting more than N+1 values for t would not help to achieve more accurate AUC or “smoother” ROC curve. Even if calculations are precise, the efficiency will be degraded because if t values are not selected from different effective intervals, they will result in the same point on ROC. In Example 3, t = 0, 0.1, 0.2, 0.3, or any other value below 0.4 will result in (1, 1) on ROC. Furthermore, because continuous variables have to be discretized, selecting fixed step size to increase t may result in inaccuracy. It happens almost certainly if two probabilities are highly close to each other and the fixed step is not small enough to land between them. Usually high values of N create such circumstances. Therefore, having a method for selecting optimal threshold is crucial. Changing value of t is effective if and only if it affects predictions. Assuming probabilities are sorted, any value of t between
Figure 5 depicts all possible outcomes (except special cases of equal probabilities). It seems ROC is always staircase looking, except for the situations where a pair of predicted probabilities are equal. Thus, using trapezoid integration is the best and most accurate technique to calculate AUC. Furthermore, Figure 5 demonstrates order of predicted probabilities plays a key role in amount of AUC. If there is at least one threshold t where the probabilities of all actual positives and negatives are above and below it, respectively, then the AUC is equal to 1. Although the mathematical proof needs more fundamentals, there is one key support: selecting t at the boundary of positive and negative data points results in a perfect classification corresponding to (0, 1) on ROC.
Where AP and AN are actual positives and actual negatives, respectively.
To be able to separate positive and negative datapoints in a way that probabilities of positive cases are higher, we introduce ε. In Table 7, ε is a positive real number which is less than or equal to p. This ensures p-ε is zero or positive and implies that p-ε is less than p. For example, if p is 0.8, ε can be in the range of 0–0.8. It also explains why (7) is true. For any
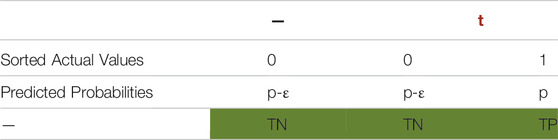
TABLE 7. A group of realizations with N = 3, AN = 2, and AP = 1.
In Table 7, probabilities of all actual negatives are equal (p-ε). To be able to sort probabilities within each class of datapoints,

TABLE 8. A group of realizations with N = 8, AN = 4, AP = 4, and AUC = 1.
Table 9 shows the other extreme. When there is threshold t such that probabilities of all actual positives and negatives are below and above it, respectively, then the AUC is zero.

TABLE 9. A group of realizations with N = 8, AN = 4, AP = 4, and AUC = 0.
Table 10 depicts all remaining possible scenarios where AUC is greater than zero (0 < AUC). Table 10 gives the big picture. For
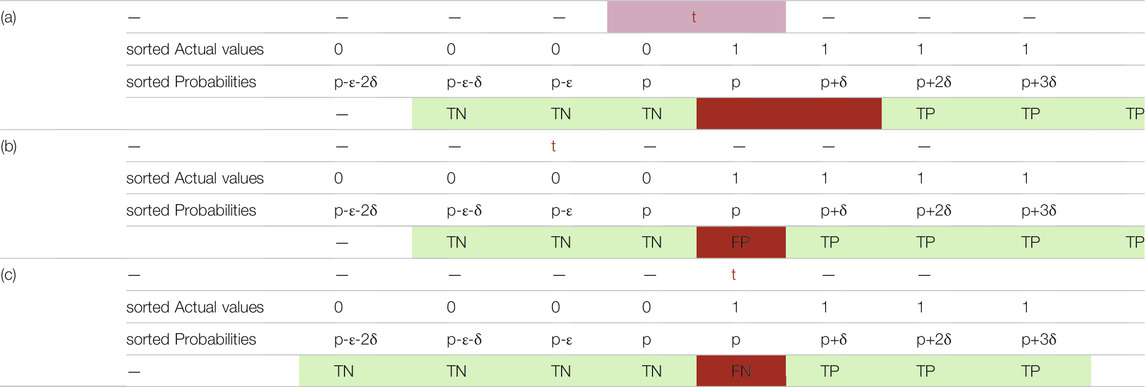
TABLE 10. A group of realizations with N = 8, AN = 4, AP = 4, and 0 < AUC<1.
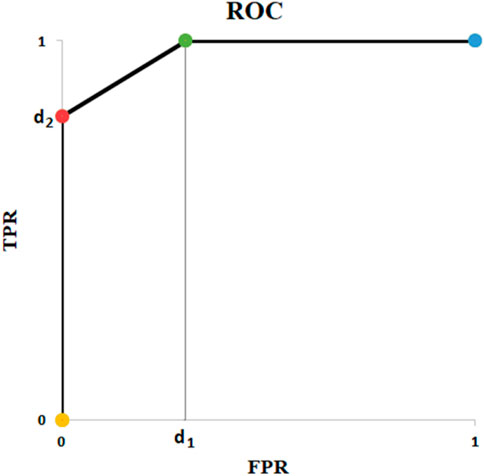
FIGURE 6. ROC of Example of Table 10.
The fact that the AUC does not discriminate between FP and FN implies that what should be used as a criterion when training a model is ROC curve itself and not the AUC. Hence, in order to translate probabilities to predictions, one specific t
In medical science (e.g., cancer detection), instead of AUC value, the clinical value of a classification method is usually studied in terms of TPR or FPR. For example, for a desired TPR, using the ROC curve, the point with lowest FPR is selected. From there, the desired threshold is derived, and the classification is performed. Thus, to evaluate the performance, confusion matrix is the most informative way of reporting where a model with a lower AUC may be preferred when the specific TPR/FPR are considered. One possible example is illustrated in Figure 7.
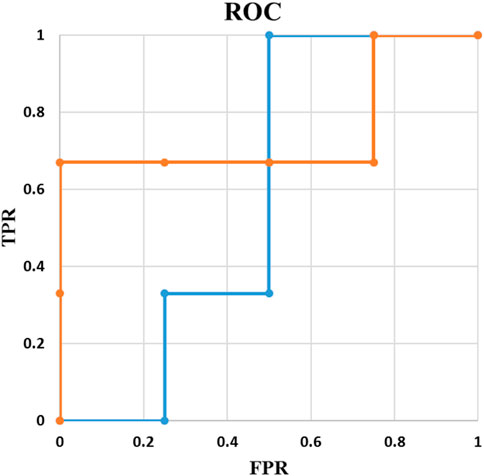
FIGURE 7. ROC curves for two different models with N = 7.
In Figure 7, AUC of the orange line and the blue line are 0.75 and 0.58, respectively. Although the orange line has a higher AUC, if the acceptable sensitivity is set at 1, the blue line corresponds to the best model. In other words, to be able to identify every single positive example, with the orange line we will misclassify 75% of our negative examples compared with 50% of misclassification by the blue one.
Proposed AUC With Confidence
We call a model confident if it returns probabilities near 1 for all positive cases and probabilities near 0 for all negative examples. In previous section, it was demonstrated that AUC does not provide the confidence of the classification model under study. In other words, whether the predicted probabilities are close to each other or not does not affect the AUC value. As a result, a classification model that is able to separate the positive and negative cases by a small margin (e.g., 5%), has the same AUC as the one that separates the positive and negative cases by a large margin (e.g., 25%). Risk assessment in Medical Science and regression in Statistics are cases where having large margins may not be the target. However, in the context of classification, the margin is a key point. The whole idea of Support Vector Machines (SVM) is formed around large margin classification (Parikh and Shah, 2016). The ultimate effect of Cross Entropy (CE) loss function on NNs is imposing separation between predicted probability of positive and negative examples (Zhang and Sabuncu, 2018).
To address this issue, we propose a modified AUC (cAUC), which provides a confidence measure for the classification model. To do so, we introduce two coefficients,
The idea behind Eq. 11 is the smaller the range between the probabilities of the two classes, the lower the AUC will be and vice versa. If the range is the maximum possible value (which is 1), the AUC remains unchanged. Otherwise, it is decreased.
In the following, we show that our cAUC local maximums correspond to BCE local minimums. Intuitively, BCE is minimized when the probabilities created by the model are close to 1 for APs and near 0 for ANs. This translates to the concept of confidence we discussed above. Mathematically, BCE is explained through Eq. 12. Using the same separation approach, we have used so far, BCE can be rewritten for APs and ANs as Eq. 13. From Eq. 13, it can be concluded ideal BCE loss is resulted under conditions of Eq. 14.
If conditions of Eq. 14 are met, from Eq. 7 it can be inferred AUC is equal to 1 because for any threshold between 0 and 1, all datapoints are correctly classified. In this case Eq. 9, 10 result in
We proved that if AUC is equal to 1, the probability of positive and negative examples can be close to each other and thus, leading to high BCE. Therefore, a high AUC does not necessarily mean low BCE. Thus, instead of AUC, we propose monitoring cAUC, which in global optimums is guaranteed to result in ideal BCE and AUC, and in local optimums has higher potential for stopping the training when the model is confident, not overfit, and achieves a high AUC.
Results
We will evaluate our confidence-incorporated AUC (cAUC) on 4 different scenarios: random predictions, a customized dataset based on MNIST (LeCun and Cortes, 2010), our proprietary Prostate Cancer (PCa) dataset, and a dataset based on BraTS19 (Menze et al., 2015; Bakas et al., 2017; Bakas, 2018). Our PCa dataset of Diffusion-weighted MRI is described in our previous research (Yoo et al., 2019). The CNN architectures and the utilized settings are similar to our shallow models used in other research projects (Hao et al., 2020). Nonetheless, the details are provided in Supplementary Appendix A. Given the fact that AUC is not differentiable, to train the network we used BCE. The only essential point which should be covered is input channels of our CNN for MNIST classification. Because MNIST is a single channel dataset, we revised the network to be compatible with it.
cAUC vs AUC on Random Data
To test the proposed AUC, in an N = 10 simulation, real values and predicted probabilities were generated randomly using U [0, 1] as Table 11. In case of arbitrary classification, expected value of AUC is 0.5. The goal here is to calculate expected values of cAUC for such conditions. Another point for the presented values in Table 11 is to highlight importance of sample size. With the widespread use of AI in Medical Science, researchers must care about sample sizes. Our experiment shows AUC = 0.66 is not hard to achieve through chance when N is not high enough.
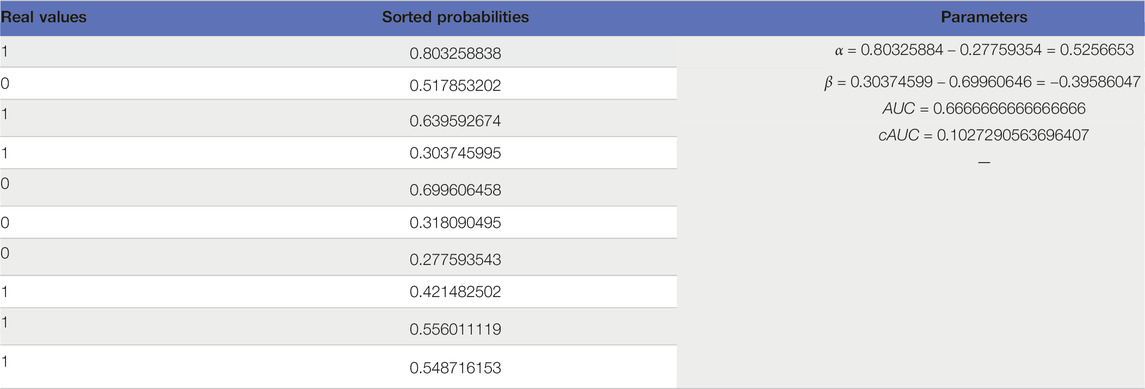
TABLE 11. Comparison of AUC and the proposed AUC for a random case.
Simulations with N = 100 and 10,000 trials show expected value of AUC is 0.50 and expected value of the revised AUC is 0.07. Intuitively, AUC = 0.5 happens when everything is by chance. We showed one example is when output of the model is constant. In other words, when variance of the output vector is zero. In this case, coefficients
cAUC vs. AUC on an MNIST-Based Dataset
MNIST is a well-known dataset of handwritten digits, including 60,000 train and 10,000 test images (LeCun and Cortes, 2010). It includes single channel, 28 × 28 pixel, normalized images. The 10 different digits form classes of data in MNIST, by default. Because our ultimate goal was Medical applications, we marked examples of 7 as positive and all other digits as negative to create our imbalanced binary MNIST-based dataset. Our train set included the first 5,000 examples of training cohort of MNIST and our validation set was 1,500 examples (indices: 45,000–46,500) of it. Our test set was built from the first 1,000 examples of MNIST test. This was done to ensure our dataset size is reasonable in comparison to Medical ones. To make our data noisy, as it is always seen in Medical datasets, we added uniform random noise to each pixel. For that end, we first scaled MNIST examples in order to have each pixel values in the range of [0, 1]. Then we added 5 times of a random image to it and scaled the result back to [0, 1] as stated in Eq. 15
Figure 8 shows results of the classification over 50 epochs of training. In each epoch, average BCE loss, AUC, and cAUC for training, validation, and test cohorts are calculated. This procedure is maintained until the last epoch and then the monitored values are plotted.
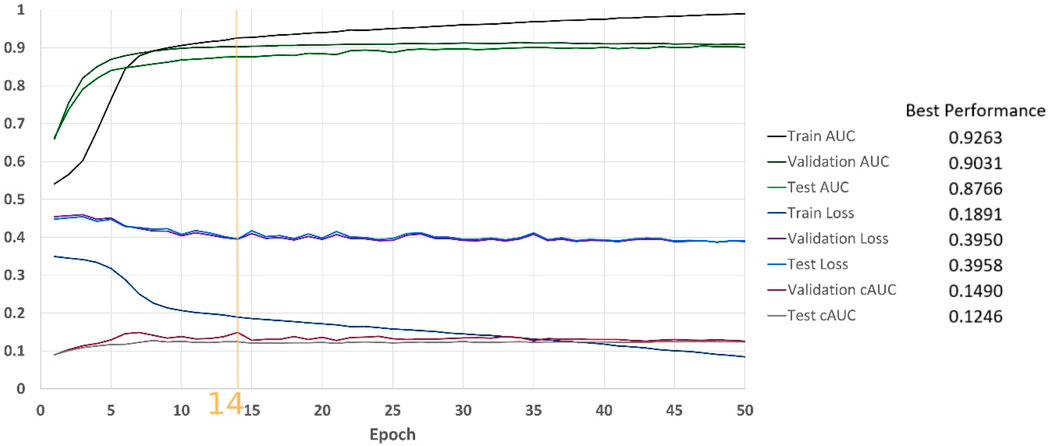
FIGURE 8. Classification results on the MINIST-based dataset.
cAUC vs. AUC on a Proprietary PCa Dataset
Figure 9 depicts the results of classification over our institutional review board approved PCa dataset, which included Diffusion-weighted MRI images of 414 prostate cancer patients (5,706 2D slices). The dataset was divided into training (217 patients, 2,955 slices), validation (102 patients, 1,417 slices), and test sets (95 patients, 1,334 slices). Label for each slice was generated based on the targeted biopsy results where a clinically significant prostate cancer (Gleason score>6) was considered a positive label. The golden vertical line is where cAUC guides us to stop and the grey vertical line is where we would stop if AUC was used.
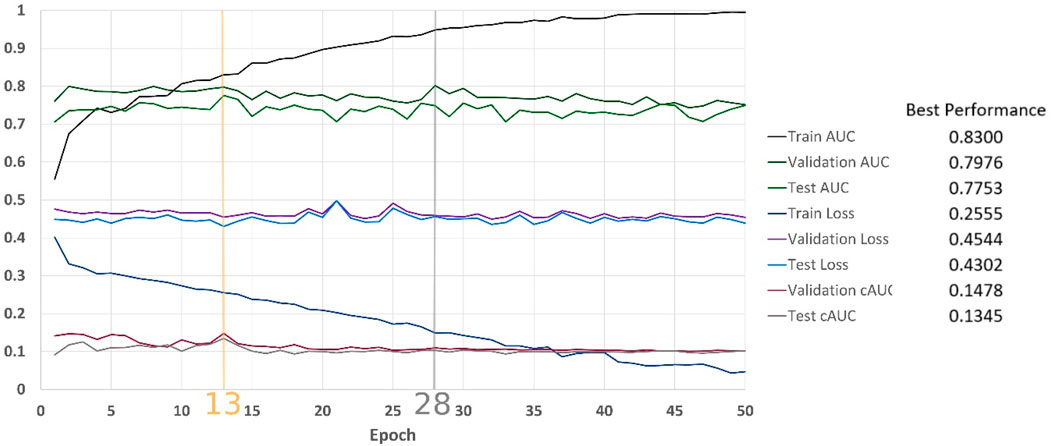
FIGURE 9. Classification results on the PCa dataset.
cAUC vs. AUC on a BraTS-Based Dataset
We used the BraTS19 dataset, with the same setting as our previous research (Hao et al., 2021). The dataset contains 335 patients of which 259 patients were diagnosed with high-grade glioma (HGG) and 76 patients had low-grade glioma (LGG). For each patient, we stacked three MRI sequences, which are T1-weighted, post–contrast-enhanced T1-weighted (T1C), and T2-weighted (T2) volumes. With the help of BraTS segmentations, we randomly extracted 20 slices per patient with the tumor region in axial plane. Our training dataset contained 203 patients, which corresponds to 2,927 slices (1,377 LGG and 1,550 HGG examples). 66 patients were included in the validation set (970 slices, 450 LGG and 520 HGG examples). Another 66 patients formed our test set (970 slices, 450 LGG and 520 HGG examples). LGG slices were labeled as 0 and HGGs were assigned to be 1. The images were resized to 224 × 224 pixels. Figure 10 illustrates the results of classification over the dataset. cAUC directs the model to stop at epoch number 4 whereas both AUC and BCE would lead to the seventh epoch.
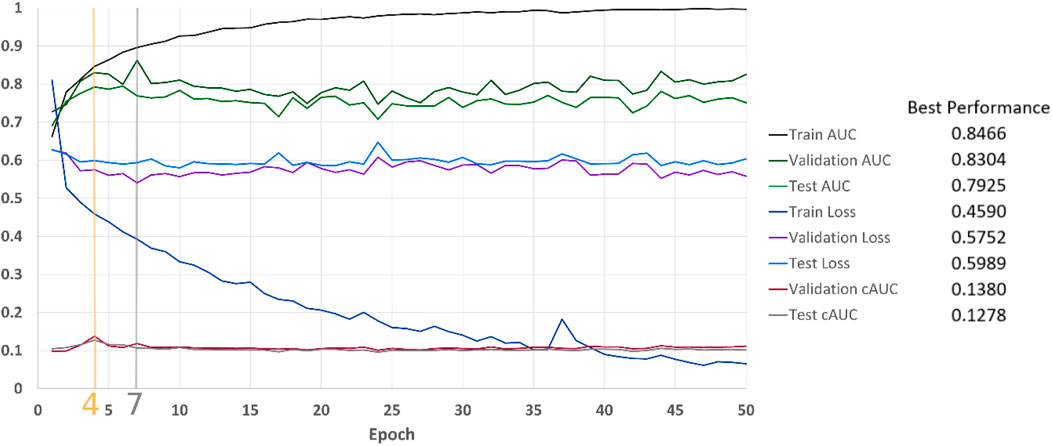
FIGURE 10. Classification results on our BraTS-based dataset.
Discussion
In this research, we first highlighted several important ROC and AUC characteristics. We demonstrated that to draw ROC curve, both actual positives and actual negatives are needed. Threshold equal to 1 corresponds to (0,0) in the ROC curve and t = 0 appears as (1,1). If a function is to calculate TPR, FPR or other metrics, it should iterate backward on the t values. The AUC is not concerned about confidence of the model. Regardless of N, if all the predictions are the same (
The core of our research was the amendment of AUC in terms of margins. To add confidence to the optimized model, AUC needs to be refined. Using two coefficients, a revised AUC was proposed. Through simulations and mathematics, we showed the revised AUC reflects confidence of the model.
Unlike AUC, through experiments on MNIST, our PCa, and BraTS dataset, we demonstrated that local maximums in the proposed modified AUC correspond to local minimums of cross-entropy loss function. It was shown that selecting the best model based on cAUC is computationally efficient, mathematically reasonable, and it results in avoiding overfitting.
The conventional approach for when to stop training a CNN to achieve the highest AUC is to monitor the AUC while the model is being trained with a loss function such as BCE, and save the model whenever AUC breaks the previous highest score. However, when BCE is set to be used as the loss function, the hypothesis is that the best model has the lowest loss and therefore, the minimum loss is what the model is trained for. Hence, choosing the best model based on the highest AUC is not well rationalized and may not lead to the optimum point.
Our proposed metric inherits several limitations of the standard AUC and ROC but does not add any additional restrictions. Similar to AUC, cAUC is not differentiable and cannot be directly used as a loss function for training any NN. Additionally, calculating cAUC for a batch of data, especially if the batch size is small, will not help because it will be a measure of ranking in a small sample of the dataset. Similar to the standard AUC, cAUC does not give more importance to the positive examples.
Conclusion
Our results demonstrate the proposed cAUC is a better metric to choose the best performing model. On our MNIST-based dataset, when training a CNN, it results in stopping earlier which is computationally desirable. Moreover, it has landed in a less overfitting-prone area. Our results on the prostate MRI dataset are particularly interesting. With standard AUC we would stop training the CNN model at a suboptimal point with regards to BCE. With our proposed cAUC, we are able to stop at an optimal point where the training model gives the highest AUC. Our BraTS dataset experiments demonstrate cAUC can indicate optimum points that neither AUC nor BCE would direct the model towards them.
Data Availability Statement
The data analyzed in this study is subject to the following licenses/restrictions: Three datasets have been used for the research. The MNIST and the BraTS datasets are publicly available. The prostate dataset analyzed in this research is available from the corresponding author on reasonable request pending the approval of the institution(s) and trial/study investigators who contributed to the dataset. Requests to access these datasets should be directed to bWFoYWlkZXJAcmFkZmlsZXIuY29t.
Author Contributions
KN and FK contributed to the design of the concept and implementation of the algorithms. MH contributed in collecting and reviewing the data. All authors contributed to the writing and reviewing of the manuscript. All authors read and approved the final manuscript.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frai.2021.582928/full#supplementary-material
Footnotes
1https://pypi.org/project/GenuineAI/
References
Bakas, S., Akbari, H., Sotiras, A., Bilello, M., Rozycki, M., Kirby, J. S., et al. (2017). Advancing the Cancer Genome Atlas Glioma MRI Collections with Expert Segmentation Labels and Radiomic Features. Sci. Data 4, 170117. doi:10.1038/sdata.2017.117
Bakas, S., Reyes, M., Jakab, A., Bauer, S., Rempfler, M., Crimi, A., et al. (2018). Identifying the Best Machine Learning Algorithms for Brain Tumor Segmentation, Progression Assessment, and Overall Survival Prediction in the BRATS Challenge.
Bottou, L., Curtis, F. E., and Nocedal, J. (2016). Optimization Methods for Large-Scale Machine Learning. SIAM Review 60 (2), 223–311. doi:10.1137/16M1080173
Burke, H. B., Ph, D., Rosen, D. B., Ph, D., and Goodman, P. H. (1992). Comparing Artificial Neural Nrworks to Other Statistical Memods for Medical Outcome Prediction, 2213–2216.
Cortes, C., and Mohri, M. (2004). AUC Optimization vs. Error Rate Minimization. Adv. Neural Inf. Process. Syst.
Ghanbari, H., and Scheinberg, K. (2018). Directly and Efficiently Optimizing Prediction Error and AUC of Linear Classifiers. [Online]. Available: http://arxiv.org/abs/1802.02535.
Hao, R., Namdar, K., Liu, L., Haider, M. A., and Khalvati, F. A. (2020). A Comprehensive Study of Data Augmentation Strategies for Prostate Cancer Detection in Diffusion-Weighted MRI Using Convolutional Neural Networks. J. Digit Imaging 34 (4), 862–876. doi:10.1007/s10278-021-00478-7
Hao, R., Namdar, K., Liu, L., and Khalvati, F. (2021). A Transfer Learning-Based Active Learning Framework for Brain Tumor Classification. Front. Artif. Intell. 4, 61. doi:10.3389/frai.2021.635766
Kottas, M., Kuss, O., and Zapf, A. (2014). A Modified Wald Interval for the Area under the ROC Curve (AUC) in Diagnostic Case-Control Studies. BMC Med. Res. Methodol. 14 (1), 1–9. doi:10.1186/1471-2288-14-26
LeCun, Y., and Cortes, C. (2010). {MNIST} Handwritten Digit Database. [Online]. Available: http://yann.lecun.com/exdb/mnist/.
Menze, B. H., Jakab, A., Bauer, S., Kalpathy-Cramer, J., Farahani, K., Kirby, J., et al. (2015). The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS). IEEE Trans. Med. Imaging 34 (10), 1993–2024. doi:10.1109/TMI.2014.2377694
Parikh, K. S., and Shah, T. P. (2016). Support Vector Machine - A Large Margin Classifier to Diagnose Skin Illnesses. Proced. Tech. 23, 369–375. doi:10.1016/j.protcy.2016.03.039
Rosenfeld, N., Meshi, O., Tarlow, D., and Globerson, A. (2014). Learning Structured Models with the AUC Loss and its Generalizations. J. Mach. Learn. Res. 33, 841–849.
Sulam, J., Ben-Ari, R., and Kisilev, P. (2017). “Maximizing AUC with Deep Learning for Classification of Imbalanced Mammogram Datasets,” Eurographics Work. Bremen, Germany: Vis. Comput. Biol. Med.. [Online]. Available: https://www.cs.bgu.ac.il/∼rba/Papers/MaximizingAUC_MG.pdf.
Ying, Y., Wen, L., and Lyu, S. (2016). Stochastic Online AUC Maximization. Adv. Neural Inf. Process. Syst. No. Nips, 451–459.
Yoo, S., Gujrathi, I., Haider, M., and Khalvati, F. (2019). Prostate Cancer Detection Using Deep Convolutional Neural Networks. Nat. Sci. Rep. doi:10.1038/s41598-019-55972-4
Yu, W., Chang, Y.-C. I., and Park, E. (2018). Applying a Modified AUC to Gene Ranking. Csam 25 (3), 307–319. doi:10.29220/CSAM.2018.25.3.307
Yu, W., and Park, T. (2014). AucPR: AucPR: An AUC-Based Approach Using Penalized Regression for Disease Prediction with High-Dimensional Omics Data. BMC Genomics 15 (Suppl. 10), 1–12. doi:10.1186/1471-2164-15-S10-S1
Zhang, Z., and Sabuncu, M. R. (2018).Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels. Adv. Neural Inf. Process. Syst., 8778–8788.
Keywords: AUC, ROC, CNN, binary classification, loss function
Citation: Namdar K, Haider MA and Khalvati F (2021) A Modified AUC for Training Convolutional Neural Networks: Taking Confidence Into Account. Front. Artif. Intell. 4:582928. doi: 10.3389/frai.2021.582928
Received: 13 July 2020; Accepted: 30 September 2021;
Published: 30 November 2021.
Edited by:
Jake Y. Chen, University of Alabama at Birmingham, United StatesReviewed by:
Akram Mohammed, University of Tennessee Health Science Center (UTHSC), United StatesRubul Kumar Bania, North-Eastern Hill Uiveristy, Tura Campus, India
Copyright © 2021 Namdar, Haider and Khalvati. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Khashayar Namdar, ZXJuZXN0Lm5hbWRhckB1dG9yb250by5jYQ==