 Jonathan Omara
Jonathan Omara Estefania Talavera
Estefania Talavera Daniel Otim1
Daniel Otim1 Godliver Owomugisha
Godliver Owomugisha- 1Faculty of Engineering, Busitema University, Tororo, Uganda
- 2Faculty of Electrical Engineering, Data Management & Biometrics, University of Twente, Enschede, Netherlands
- 3Google, AI for Social Good, Mountain View, CA, United States
- 4Papoli Community Development Foundation, Tororo, Uganda
This study investigates crop disease monitoring with real-time information feedback to smallholder farmers. Proper crop disease diagnosis tools and information about agricultural practices are key to growth and development in the agricultural sector. The research was piloted in a rural community of smallholder farmers having 100 farmers participating in a system that performs diagnosis on cassava diseases and provides advisory recommendation services with real-time information. Here, we present a field-based recommendation system that provides real-time feedback on crop disease diagnosis. Our recommender system is based on question–answer pairs, and it is built using machine learning and natural language processing techniques. We study and experiment with various algorithms that are considered state-of-the-art in the field. The best performance is achieved with the sentence BERT model (RetBERT), which obtains a BLEU score of 50.8%, which we think is limited by the limited amount of available data. The application tool integrates both online and offline services since farmers come from remote areas where internet is limited. Success in this study will result in a large trial to validate its applicability for use in alleviating the food security problem in sub-Saharan Africa.
1. Introduction
Agriculture employs 70% of the population in eastern Africa (FAO, 2010). The farming community in the sub-Saharan region can be divided into two major groups. On one side, most of smallholder farmers (over 70%) grow subsistence crops, such as cassava, sweet potatoes, plantains, beans, and maize. On the other side, there are large-scale farmers who produce mainly cash crops and livestock. The challenge of crop pests and diseases remains a big threat and over 35–40% of yield is lost annually in the sub-Saharan region (Economics, 2018). Current methods of disease detection involve agricultural experts. However, a great shift has been observed from the use of experts to the use of machine learning and computer vision techniques to inspect crops by use of a mobile device (Barbosa et al., 2020; Kakani et al., 2020). Among the rural and smallholder farmers, a mobile phone connects individuals and provides information, market, and services. Therefore, this research is driven on the basis that an extension worker or smallholder farmer can use a mobile phone application for early detection and diagnosis of crop diseases and pest manifestations in the field (Danso-Abbeam et al., 2018; Michael et al., 2019). This study leverages techniques from machine learning to analyze crop images and diagnose crop diseases as well as their severity. This study also builds on initial studies, e.g., the study by Aduwo et al. (2010) and Owomugisha and Mwebaze (2016) that investigated cassava disease from leaf imagery.
The information needs of farmers are always changing and can be seen as an agricultural cycle in different sessions (Mendes et al., 2020). Farmers are always seeking information about their farms or gardens, and usually, they depend on agricultural expert information (Suvedi and Kaplowitz, 2016). In scenarios where this process has been automated, the feedback is not instant (Patel and Patel, 2016). For example, it is explained that it takes approximately 5–7 days before a farmer can get feedback from a diagnostic application (Monitor Uganda, 2019). Lack of real-time information to farmers has contributed to poor farming practices among smallholder farmers, hence high yield losses.
This study proposes a novel approach that relies on natural language processing (NLP) techniques for the support of diagnosis and assessment in real time of in-field crop disease by non-experts. The research aimed at integrating a smartphone-based disease diagnostic application with a real-time feedback tool that farmers can use at any time in their gardens. Computer vision and machine learning (ML) have been used to diagnose crop diseases in crops, e.g., study by Sambasivam and Opiyo (2021) that investigated cassava diseases, crop yield estimation, crop weed identification, and severity estimation among other areas (Kumar et al., 2015; Tripathi and Maktedar, 2020; Mafukidze et al., 2022). Transfer learning and convolutional neural network approach are used on a cassava dataset of 2,756 images comprising three cassava diseases and two types of pest damage (Ramcharan et al., 2017). The studies by Mwebaze and Biehl (2016) and Owomugisha et al. (2021) proposed to rely on prototype-based classification approaches for the detection of cassava diseases from images. Similar approaches exist in the literature, e.g., work by PlantVillage1 on crop disease diagnosis. However, the existing mobile diagnostic system with a Q&A component involves an expert in the loop where the questions are answered by farmers or experts in the community. The challenge with such an approach is that different people may have different opinions about a topic, thus applying machine learning will minimize the chances of giving wrong information.
This study makes two primary contributions. First, it demonstrates a mobile field-based recommendation system for crop disease detection. This system is based on a RetBERT sentence embedding approach that works by measuring similarity between text. The developed approach leads to a recommendation system based on the analysis of written text for early warning interventions. Second, it provides a new dataset composed of 3,939 question–answer pairs crowd-sourced from 100 farmers in Uganda. This dataset is publicly available.2
The rest of this study is organized as follows. Section 2 gives an overview of the related studies on agricultural systems on Q&A and the use of NLP in real-time feedback systems. Section 3 presents the material and methods that are used in the experiments. Section 4 presents the experiments that were implemented to assess our proposed approach. Results and discussion of the methods are presented in Section 5. Finally, Section 6 presents the conclusion and future work.
2. Related works
In this section, related studies in the field of recommendation systems for agriculture and crop disease diagnosis are discussed.
2.1. Agricultural systems on question and answer feedback
Real-time feedback systems using natural language are increasingly attracting attention from the machine learning community given the fast development of the field of human–robot interaction. AgriBot (Jain et al., 2019) presents an Agriculture-Specific Question Answer System that answers questions related to weather, market rates, plant protection and government schemes in India. The system is based on sentence embedding and entity extraction. Several studies have been introduced with the aim of helping farmers in rural areas in India. For example, FarmChat was introduced by Jain et al. (2018). The conversational agent system answers farmers' information needs by picking a question in form of audio and converting it to text in order to provide the most appropriate answer to the farmer. Similarly, TalkBot (Vijayalakshmi and Pandimeena, 2019) uses a speech synthesis web API to provide voice-based responses to farmers in India. A region-specialized system for India was proposed by Yashaswini et al. (2019). The Smart Chatbot agriculture tool uses a K-nearest neighbor algorithm to analyze new patterns in markets, rainfall, seasons, and soil types. E-AGRO (Ekanayake and Saputhanthri, 2020) uses Artificial Intelligence Markup Language (AIML) implemented in a cloud platform to provide responses to farmers. Even though the obtained results by the above-mentioned methods are promising, the existing applications cannot work for some local communities due to the fact that the datasets used to train the models were extracted from specific countries, that is to say, India and farmers need different types of information based on the type of crops grown in their regions.
2.2. Works on NLP and real-time feedback
Conversational AI systems are commonly known as chat-bots (Lokman and Ameedeen, 2019; Peng and Ma, 2019). They are intelligent models that can be further categorized into either retrieval-based (Wu et al., 2016; Yan et al., 2016; Tao et al., 2019) or generative models (Sheikh et al., 2019; Kapočiūtė-Dzikienė, 2020; Kim et al., 2020), or even as a combination of both (Yang et al., 2019). The retrieval-based models pick a response from a collection of responses based on the query. The generative models work by generating a response, word-by-word based on the query given, hence the models are prone to grammatical errors. One of the known challenges of generative models is that they are hard to train since they require to learn the proper sentence structure. However, once trained, the generative models tend to outperform the retrieval-based models in terms of handling previously unseen queries and creating an impression of talking with a human (Sojasingarayar, 2020).
In the study presented by Su et al. (2017), the authors introduced an LSTM-based multi-layer embedding for elderly care. The system involved collecting chitchat dataset from daily conversations with the elderly, converting it into patterns, then an LSTM-based multi-layer embedding model was used to extract the semantic information between words and sentences in a single turn with multiple sentences when chatting with the elderly. Finally, the Euclidean distance was employed to select a proper question pattern, which is further used to select the corresponding answer to respond to the elderly.
The study by Singh et al. (2018) presented a chat-bot for small businesses. The system was built on TensorFlow and included machine learning at its core. The process uses TensorFlow to make a neural network and train it with intent file to generate a response model. The response model is, then, used to predict the response from the query of the user. This system consists of three main parts as follows: 1) user interface, 2) neural network model and NLP unit, and 3) feedback system. The study by Mathew et al. (2019) proposed a chat-bot for disease prediction and treatment recommendation. The engine consists of the well-known machine learning algorithm K-nearest neighbor algorithm (KNN). This study indicated that a medical chat-bot can diagnose patients through the analysis of simple symptoms.
The chat-bot for e-learning introduced by Colace et al. (2018) presents the realization of a chat-bot prototype for supporting students during their learning activities. The study introduced two frameworks as follows: 1) the automatic identification of the students' needs due to the adoption of Natural Language Processing Techniques and 2) the selection of the best answer due to the use of the ontological representation of the knowledge domain. Qiu et al. (2017) proposed an AliMe Chat as a sequence to-sequence and Re-rank-based chat-bot engine. The hybrid system combines both generative and retrieval models to provide feedback and uses an attentive Seq2Seq model to optimize the joint results of information retrieval(IR) and generation models. The described techniques show that most of the existing systems either suffer from a generative model problem or a retrieval model problem.
3. Materials and methods
3.1. The question and answer dataset
Due to the non-existence of a database containing agronomic questions and answers on staple food crops such as cassava, maize, and beans in sub-Saharan Africa, the current approach contributed to the collection of data from farmers. The mobile-based diagnostic application with real-time information was tested in a community with 100 farmers participating in the pilot. Farmers participated by performing diagnostics on cassava (Manihot esculenta Cranz) affected by four major conditions as follows: cassava brown streak disease (CBSD), cassava mosaic disease (CMD), cassava bacterial blight (CBB), and cassava green mite (CGM), as well as healthy plants. Through the diagnostic tool, they also asked questions that surround three main crops (cassava, maize, and beans). Furthermore, the study carried out interviews with the farmers who had no smartphones to acquire more information and the challenges they faced with their crops. The interviews were conducted over 5 days. Each day, 10 farmers were interviewed, and a minimum of 10 questions were generated from each farmer. The areas surveyed included villages in the Kole district in northern Uganda and by the end of the exercise, a total of over 500 questions had been obtained. Of the 50 farmers who contributed to the Kole district, 26 farmers were male while 24 were female, and their ages ranged between 22 and 70 years. However, one of the biggest challenges was that some of the farmers were not comfortable sharing their information, and it was difficult to elicit questions from them. Therefore, the study implemented the first version of the application with the proposed method in Section 3.2, gave it to farmers to interact with it, as much as possible and their questions were stored in a database. Thus, the approach of farmers sending questions via their smartphones became flexible and convenient to both farmers and the receiving team. The data collected were then assigned to the agricultural experts for annotation and answers. The data collected from farmers through the application and the one collected from farmers through interviews were concatenated as a single dataset. Table 1 shows a sample of questions and answers extracted from this dataset.
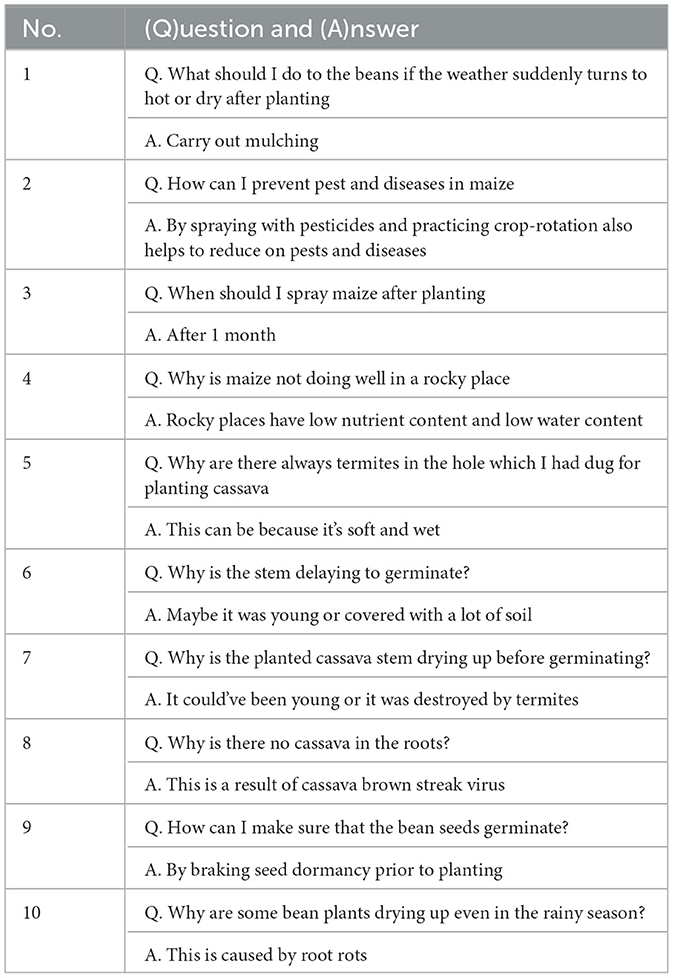
Table 1. A sample of 10 questions (Q) and their corresponding answers (A) from experts are extracted from the training dataset.
Figure 1 presents data coming from districts of Tororo and Busia (the most participating regions) and neighboring districts: Sironko, Butaleja Bugweri, Bugiri, and Iganga in the eastern region of Uganda. Other data coming in from the city centers: Kampala and Mukono. The green spots represent the areas of data collection within the district. The distribution of questions for the three crops with the majority of the questions asked on cassava crop (56%) while maize (16%) and beans (28%) had the least representation.
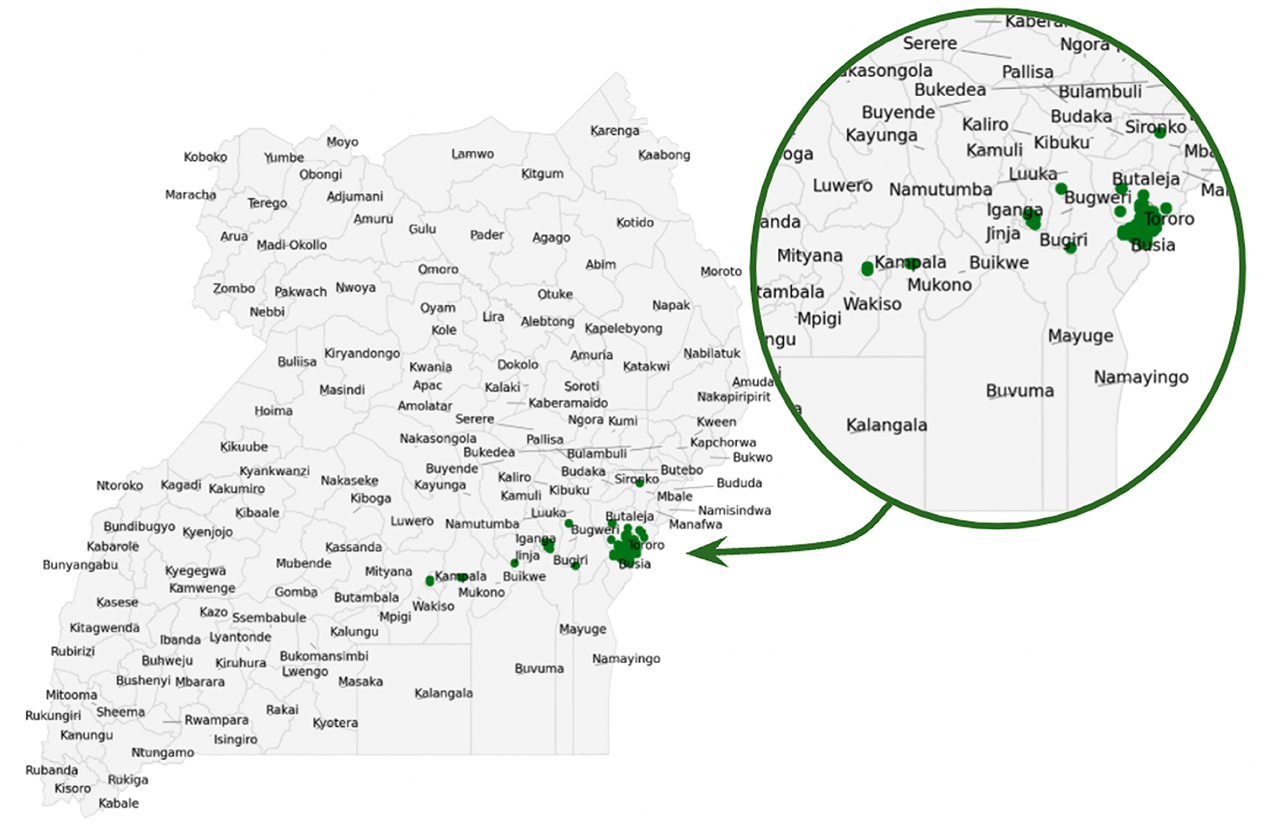
Figure 1. Data collection in eastern Uganda. Zoom-in highlights the districts represented by green spots. Green spots indicate the regions that participated in the data collection.
3.1.1. Data pre-processing
The data pre-processing stage was carried out to prepare the dataset for model training. The following steps were involved.
1. Spelling correction, white space, and punctuation removal: This involves reading through the sentences and correcting the miss-spelled English words. Grammatical errors both on the questions collected and the answers provided by the experts were checked as well as ensuring answers addressed the question appropriately. Punctuation and white space removal processes were automated.
2. Rephrasing answers and changing to lowercase: The process aimed at shortening the answers, also rephrasing the answers by checking grammatical errors. Spelling correction was performed manually by reading through each sentence. In addition, all letters were lowercased, and this task was automated.
3. Removing unanswered questions: Some questions could not be answered by the experts since they were not clear and understood due to misspelled words. To have a clean dataset for training model, the rows with missing answers were dropped.
3.2. The RetBERT framework training
Here, we briefly describe the machine learning framework employed, Sentence-BERT (SBERT) (Reimers and Gurevych, 2019). SBERT is a modification of the pre-trained BERT network (Devlin et al., 2018). To fine-tune the BERT, siamese and triplet networks were created to update the weights such that the produced sentence embeddings are semantically meaningful and can be compared with cosine similarity.
Model Architecture: The SBERT technique outputs sentence embeddings that are semantically meaningful and are later used to perform similarity search and ranking. SBERT works by adding a pooling operation to the output of BERT to derive a fixed-sized sentence embedding. A three pooling strategies are described in the literature. In this study, we used a default configuration (MEAN strategy) which computes the mean of all output vectors.
Objective function: The original SBERT network structure by Reimers and Gurevych (2019) proposes three objective functions, such as classification, regression, and triplet objective function. As mentioned, the proposed SBERT architecture uses a fine-tuned BERT in a siamese/triplet network. Given an anchor sentence a, a positive sentence b, and a negative sentence c, triplet loss tunes the network such that the distance between a and b is smaller than the distance between a and c. This loss function is mathematically described in Equation (1) as follows:
where sx the sentence embedding for a/c/b, ||·|| a distance metric, and margin ϵ. Margin ϵ ensures that sb is at least ϵ closer to sa than sc, where the Euclidean distance is set to ϵ = 1 in the default setting.
Training details: The data obtained were pre-processed following steps presented in Section 3.1.1, and subsequently trained on three techniques, such as RetBERT, Seq2seq, and Haystack. The proposed model techniques were chosen for their simplicity in solving semantic search problems than hungry top-performing models that require huge datasets. The following steps describe the proposed RetBERT model architecture from the data capture to the final output. This process is also presented in Figure 2.
1. Question as input: A question is taken in the form of text with no more than 256 characters. It, then, goes through a text pre-processor stage by converting it to lowercase, removing the punctuation as well as whitespace in the sentence if present. The text pre-processing stage showed a 5% increase in the model performance.
2. Sentence Embedding (SBERT): The SBERT model described above is then applied. The model encodes the pre-processed question into a dimensional vector of shape (384) and passes it to the similarity search function.
3. Similarity search and Ranking: A cosine similarity was applied to measure the similarity between vectors. This process returns a sorted array of values ranked by how similar the input question is to the existing questions in the training dataset. The model uses the k values to rank the question-answer pairs at index n as 1, 2, and 3 as the top three answers. Finally, the answer to the question at rank 1 is returned as the answer to the input question. For training and testing, a total of 3,939 question–answer pairs were used. Of this data, 90% of the data were used for training and 10% for testing. The batch size was 64 and the epoch size was 100.
4. Deployment—Integration into a mobile App: The retrieval model with a sentence BERT model was converted into an API and deployed into Google Cloud App Engine using Python (Flask). In addition, an Android app was built to access the model API. With this approach, farmers were required to have an internet connection. However, since farmers live in remote areas where internet connectivity is limited, an offline version of the Q&A system was deployed and built from PyTorch Mobile and TorchScript. The answers are still similar semantically, and typically, the selected answer from one model is in the top three responses in the other model. Given the highly similar performance of the two models, the tool was set to use only the offline model as default rather than switching between the two based on internet connectivity, which is error-prone and could lead to a frustrating and inconsistent user experience. Thus, the models will be periodically updated when there is a large influx of new questions from farmers and answers from experts.
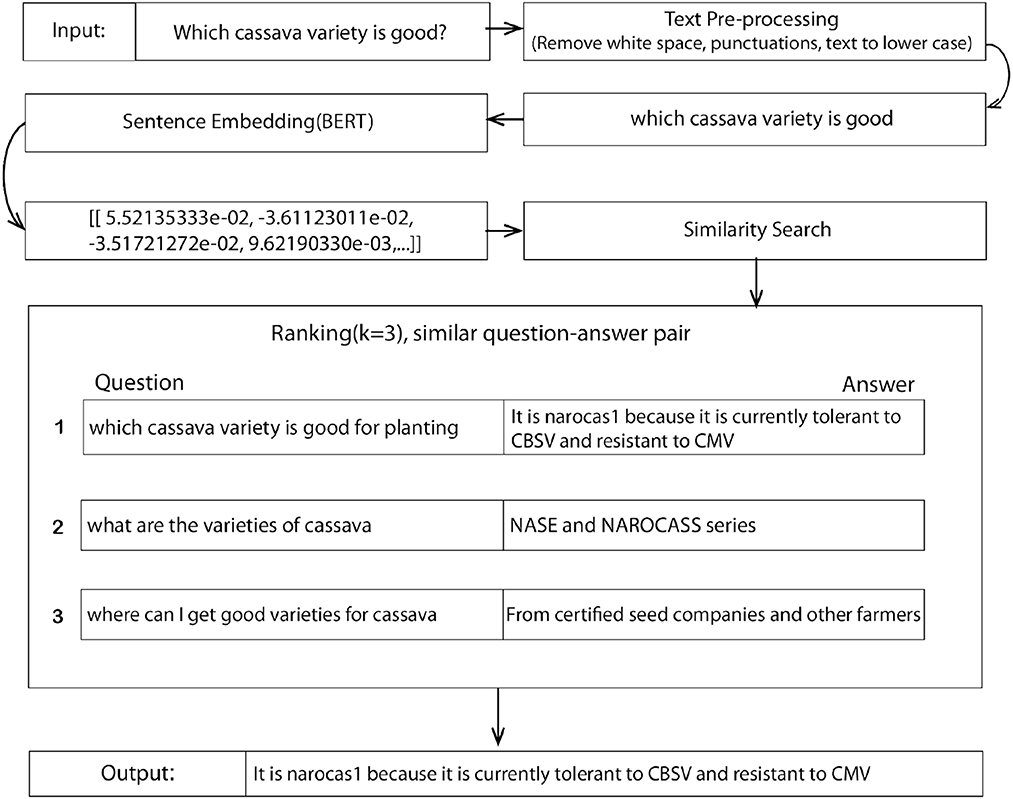
Figure 2. The proposed retrieval-based architecture (RetBERT) with a sentence embedding and ranking given an example input and the resulting output.
3.3. Crop disease diagnosis
The task of crop disease diagnosis has been previously addressed. The authors in Mwebaze et al. (2019) presented the iCassava 2019 Fine-Grained Visual Categorization Challenge. Thus, the disease diagnosis component of this study builds on iCassava 2019 dataset3 and follows the implementation at: https://tfhub.dev/google/cropnet/classifier/cassava_disease_V1/2 (accessed on 31 December 2022) with less modification. The open-source code model uses TensorFlow Lite, an efficient model format that can easily be deployed in embedded systems with limited hardware resources. The model is trained on 9,430 cassava leaf images under five categories, such as Healthy, Cassava Mosaic Disease (CMD), Cassava Bacterial Blight (CBB), Cassava Greem Mite (CGM), and Cassava Brown Streak Disease (CBSD). Figure 3 shows examples of cassava leaf images from the dataset for the above classes. The model uses MobileNetV3 architecture (Yang et al., 2018; Howard et al., 2019) and attains a classification accuracy of 88% for cassava disease detection. The model was deployed as a mobile application on an android smartphone. This uses android ML Kit4 that exposes the model as an on-device API. When a leaf image is taken by the phone camera, it is processed and passed to the model predict function as a bitmap image. The model processes the image and returns the predicted probabilities and their class names, as shown in Figure 4.

Figure 3. Sample images associated with the cassava disease classes that trained the diagnostic component. (A) Healthy, (B) CBB, (C) CGM, (D) CBSD, and (E) CMD.
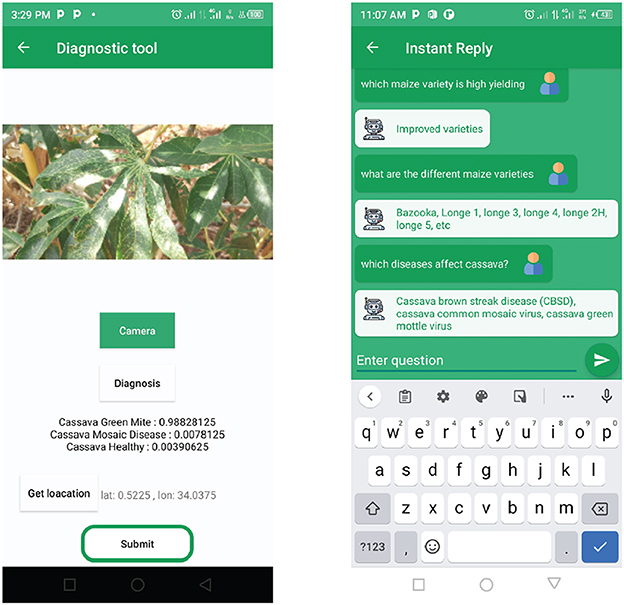
Figure 4. The user interfaces that a farmer uses to diagnose cassava crop disease and ask agronomic questions.
4. Experiments
This section describes the experimental setup that was used to assess the performance of the proposed recommendation framework.
4.1. Evaluation metrics
This study applied a BLEU score metric by Papineni et al. (2002) to evaluate the performance of the models. The metric has been applied in related studies in translation models, e.g., Vijayalakshmi and Pandimeena (2019), Yashaswini et al. (2019), Qiu et al. (2017), and Yan (2018). BLEU score metric is given by the formula as follows:
where Mmax represents the maximum clip count of the number of times a word (uni-gram) in the model answer appears in the reference answer (expert answer), and Wt is the count of words (uni-grams) in the model answer. For example, given the question “What caterpillars are affecting maize in the garden?,“ the expert answer is as follows: “They are fall army worms and stem borers.“ If the model gives the following answer, “Fall army worms or larvae,“ the BLUE score can be computed as follows:
The BLEU score is a value that ranges between 0 and 1, measuring the similarity of a model answer to an expert answer. The higher the BLEU score, the better the model. In python programming, the BLEU score can be accessed through the NLTK package by importing sentence_bleu, and the BLEU score can be calculated as follows:
where x is the model answer, y is the expert (reference) answer, and weights = (1, 0, 0, 0) for a uni-gram which compares word by word in each of the two sentences. The BLEU score is later treated as a percentage. Moreover, we also evaluate the computational cost for a system that needs to be deployed on a mobile device.
4.2. Baseline methods
To assess the performance of the proposed approach, two state-of-the-art models for conversational AI were implemented as follows:
• Seq2seq model (Qiu et al., 2017). This is implemented using an encoder with a Bi-directional Long Short Term Memory (LSTM) layer with 256 cells, an attention layer, dropout (rate = 0.3), and a Long Short Term Memory decoder layer with 512 cells. Both the encoder layer and decoder layer have an embedding layer connected to them with an output dimension of 1,024, a return sequence set to true given that the states of the cells are required. These layers are connected as follows: the decoder layer is connected to the attention layer, which is followed by a dropout layer. Finally, an output dense layer is added to it.
• Haystack (Landsberg and Michałek, 2019). Here, the study implemented a FAISSDocumentStore document store with parameters vector_dim = 128 and faiss_index_factory_str = “Flat” to output text vector embeddings of dimension = 128. The file conversion preprocessor was set as PreProcessor(clean_empty_lines = True, clean_whitespace = True, clean_header_footer = True, split_by = “word”, split_length = 200, split_respect_sentence_boundary = True) and used to add the processed file data as a list of json text data to the document store. All these were put in a pipeline with a sequence generator that was responsible for generating full sentences as feedback. In addition, Haystack was initially used to retrieve information from text documents5 that hold information on cassava, maize, and beans. This dataset is part of the pipeline for Section 3.1.1.
4.3. Implementation details
Training details: The proposed RetBERT Section 3.2 and baseline models Section 4.2 were trained on 3,939 question–answer pairs. The machine learning procedure started with data shuffling, a step that was performed prior to model training in order to create more representative training and testing sets. The model uses 90% and 10% for training and test sets, respectively.
This study was implemented using Python 3.7 with an Intel(R) Xeon(R) CPU @ 2.20GHz and RAM of 12.68 GB. We used TensorFlow version 2.8.2.
5. Results and discussion
This section presents results obtained from a recommendation system based on the RetBERT model and the other two baseline models on the same dataset.
The results in Table 2 present the quantitative performance of these three models in terms of the average BLEU score accuracy achieved. The results show that RetBERT had the highest average performance of 50.8%, Seq2seq had 46.9% while HayStack had the lowest of 31.9%. The standard deviations of the responses of the models were 29.6%, 19.9%, and 28.8% for RetBERT, HayStack, and Seq2Seq, respectively (Table 2). The presented the RetBERT model obtained an accuracy that represents an improvement of 3.9% and 18.9% with respect to the Seq2Seq and HayStack models, respectively. The RetBERT model performs better when retrieving answers from an existing dataset as compared with the baseline methods. Thus, standard deviations of 29.6%, 19.9%, and 28.8% applied to RetBERT, HayStack, and Seq2seq models, respectively. This results in low performance when it comes to predicting answers to questions that have no similar entries in the training dataset. For the Seq2Seq model to perform well, it should have seen something similar to the question being asked. HayStack also has the lowest average performance; however, the model scored more similarly across all questions as shown by a lower standard deviation of 19.9%.
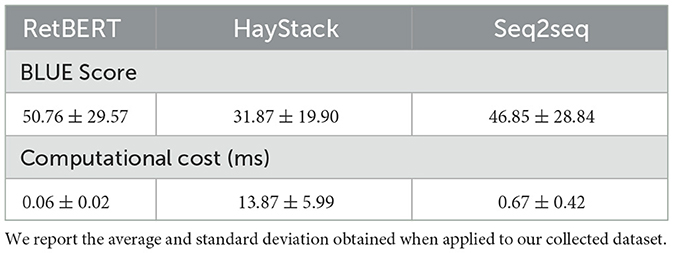
Table 2. Quantitative performance of the evaluated retrieval models RetBERT, HayStack, and Seq2seq.
To assess the performance of the models on hardware resources, the time taken during inference was calculated in milliseconds for each of these three models. This was performed using the test dataset, and the results are presented as computational costs in Table 2. For the HayStack model, more time was taken during inference, and more outliers were observed as compared the RetBERT and Seq2seq models. The result is obtained from querying a large text document during inference. The RetBERT model has a lower computational cost and can easily be deployed to run even on low-resource hardware devices. HayStack is the most computationally expensive model; thus, it would require more time and memory. Finally, the models were deployed on a mobile device with a user-friendly interface (Figure 4) to enable users to interact with these models on a mobile phone. A sample of five Q&A pairs from the test dataset was used to compare the model outputs with the original answers. These results are presented in Table 3, with a column containing the questions (Q) and original answers (A) and a column containing the answers returned by each of these models during inference. A total of two things were observed as follows: 1. Some answers had short sentences and others had lengthy sentences; and 2. Some answers were correct and others were not. In this set of samples, the RetBERT model got three out of five answers correct that were very similar to the original answers, and the HayStack model had the worst performance, getting only two out of five answers correct that were close to the original answers. However, its answers were also lengthy, which could have resulted from the fact that the HayStack (Landsberg and Michałek, 2019) model is querying a large text document for answers and has a sequence generator that does not perform well when it comes to generating short sentences.
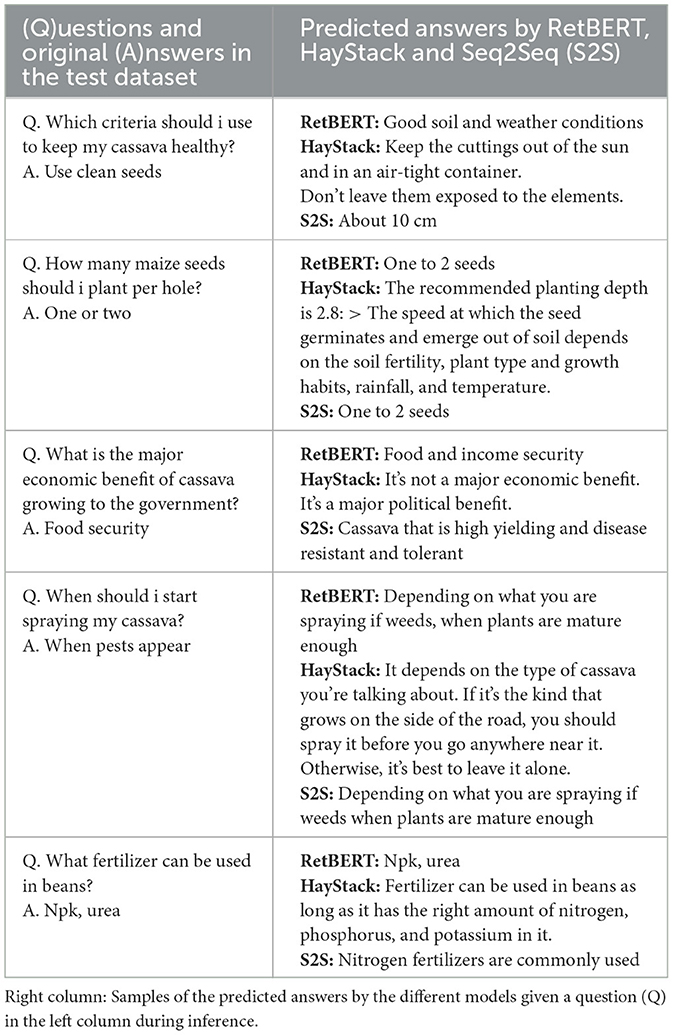
Table 3. Left column: Sets of sample questions (Q) and their original answers (A) extracted from the test dataset.
Overall, the performance of recommender-based applications is dependent on the size of the dataset. Initially, the recommender tool was built on 500 question–answer pairs with BLEU score accuracy below 40%. The performance gradually improved, as more questions were crowd-sourced from farmers over the period of 10 months obtaining 3,939 question–answer pairs at 50.8% accuracy. Although the performance accuracy of the system is not so high, this research creates a path for a recommendation system in agriculture where data are not available, and expert knowledge has been limited.
6. Conclusion
This research presents a recommendation system based on the analysis of written text information. The system was used by smallholder farmers in a rural community in eastern Uganda. The ultimate goal of this study was to equip farmers with a diagnostic tool on their smartphones that they can diagnose without waiting for expert visits. The flexibility of the tool allows farmers to move with their phones anywhere and can still access the application. The deployed application had both online and offline (on-device) options considering that most farmers live in remote areas where internet connectivity is limited, with similar performance between the two models.
The study contribution is two-fold; a new dataset that describes the interaction between farmers and an intelligent system presented, and a recommendation system based on text retrieval. Several methods are compared, including Seq2Seq, HayStack, and RetBERT. The BLEU score is used to assess performance, indicating the robustness of RetBERT, which achieves a score of 50.8%. The study concluded that the RetBERT model was sufficient for the field-based trial model. The key motivation for our approach is that it can work in low-resource environments or on low-computational power systems, but most importantly, it can perform recommendations, thus substituting the physical presence of experts. More study in this field will demand a higher amount of data given the current data hungry top-performing model.
Our future study will go in the following directions; (i) Validating our diagnostic model with another group of farmers and experts. This process will increase the diversity in terms of crop data and farmers, information, and it will, in turn, improve our question-and-answer model. (ii) Exploring the source of the differences between the models, e.g., converting the model to fundamental differences in precision in Python vs. Java computation. (iii) Combining different datasets in the Q/A model, e.g., text, visuals, and audio. The approach is motivated by the fact that most farmers use mobile phones that can collect images, videos, and audio, which we hypothesize can support the final recommendation.
In conclusion, the smartphone mobile diagnostic tool with real-time feedback comes with various benefits as follows: (i) Farmers do not have to wait for experts, as they can get instant advice on their gardens on three major crops, such as cassava, maize, and beans. (ii) The findings from this study paves way for the agricultural recommender systems in developing worlds by improving the livelihoods of smallholder farmers through early intervention measures, thus alleviating the food security problem in sub-Saharan Africa.
Data availability statement
The original contributions presented in the study are publicly available. This data can be found here: https://github.com/JonaOmara/AgroQA-Dataset/blob/main/AgroQA%20Dataset.csv.
Ethics statement
Written informed consent from the farmers was required to participate in this study in accordance with the national legislation and the institutional requirements.
Author contributions
JO and DT: analysis and interpretation of results. ET, DO, and GO: study conception, design, and manuscript preparation. EO: data collection. All authors reviewed the results and approved the final version of the manuscript.
Funding
This work was done with funding from: Google AI For Social Good (AI4SG) and ATPS, IDRC and AI4D Africa: AI4AFS/GA/AFS-0163245214.
Acknowledgments
The authors are grateful to the Papoli Community for accepting to participate in this study. The authors are also thankful to EO and the team at Papoli Community Development Foundation for supporting this study. We would also like to thank other partners: Makerere AI Lab and the Uganda National Crop Resources Research Institute (NaCRRI) with the expert team that supported the data annotation process.
Conflict of interest
DT was employed by Google.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1. ^https://play.google.com/store/apps/details?id=plantvillage.nuru&hl=en
2. ^https://github.com/JonaOmara/AgroQA-Dataset/blob/main/AgroQA%20Dataset.csv
3. ^https://www.kaggle.com/competitions/cassava-disease/data
4. ^https://developers.google.com/ml-kit
5. ^https://www.agriculture.go.ug/crop-sub-sector-publications/
References
Aduwo, J. R., Mwebaze, E., and Quinn, J. A. (2010). “Automated vision-based diagnosis of cassava mosaic disease,” in Advances in Data Mining. 10th Industrial Conference, ICDM 2010, July 2010, Workshop Proceedings (Berlin). 114–122.
Barbosa, J. Z., Prior, S. A., Pedreira, G. Q., Motta, A. C. V., Poggere, G. C., and Goularte, G. D. (2020). Global trends in apps for agriculture. Multi Sci. J. 3, 16–20. doi: 10.33837/msj.v3i1.1095
Colace, F., Santo, M. D., Lombardi, M., Pascale, F., and Pietrosanto, A. (2018). Chatbot for e-learning: a case of study. Int. J. Mech. Eng. Rob. Res. 7, 528–533. doi: 10.18178/ijmerr.7.5.528-533
Danso-Abbeam, G., Ehiakpor, D. S., and Aidoo, R. (2018). Agricultural extension and its effects on farm productivity and income: insight from northern ghana. Agric. Food Security 7, 74. doi: 10.1186/s40066-018-0225-x
Devlin, J., Chang, M., Lee, K., and Toutanova, K. (2018). BERT: pre-training of deep bidirectional transformers for language understanding. CoRR, abs/1810.04805. doi: 10.48550/arXiv.1810.04805
Economics (2018). Policy Paper on Transforming Smallholder Farming to Modern Agriculture in Uganda. National Planning Authority. Available online at: https://www.semanticscholar.org/paper/Policy-Paper-On-TRANSFORMING-SMALLHOLDER-FARMING-TO/a3cf6b6ec1942857bf124d9a2da14614cddcc356
Ekanayake, J., and Saputhanthri, L. (2020). E-AGRO: intelligent chat-bot. IoT and artificial intelligence to enhance farming industry. Agris On-line Pap. Econ. Inf. 12, 15–21. doi: 10.7160/aol.2020.120102
FAO (2010). Smallholder agriculture in East Africa. Available online at: https://www.fao.org/family-farming/detail/en/c/335952
Howard, A., Sandler, M., Chu, G., Chen, L.-C., Chen, B., Tan, M., et al. (2019). “Searching for mobilenetv3,” in 2019 IEEE/CVF International Conference on Computer Vision (ICCV) (Seoul: IEEE).
Jain, M., Kumar, P., Bhansali, I., Liao, Q. V., Truong, K., and Patel, S. (2018). FarmChat: a conversational agent to answer farmer queries. ACM Interact. Mobile Wearable Ubiquit. Technol. 2, 1–22. doi: 10.1145/3287048
Jain, N., Jain, P., Kayal, P., Sahit, J., Pachpande, S., Choudhari, J., et al. (2019). Agribot: Agriculture-Specific Question Answer System. Department of Science and Technology Government of Gujarat, IndiaRxiv. doi: 10.35543/osf.io/3qp98
Kakani, V., Nguyen, V. H., Kumar, B. P., Kim, H., and Pasupuleti, V. R. (2020). A critical review on computer vision and artificial intelligence in food industry. J. Agric. Food Res. 2, 100033. doi: 10.1016/j.jafr.2020.100033
Kapočiūtė-Dzikienė, J. (2020). A domain-specific generative chatbot trained from little data. Appl. Sci. 10, 2221. doi: 10.3390/app10072221
Kim, S., Kwon, O.-W., and Kim, H. (2020). Knowledge-grounded chatbot based on dual wasserstein generative adversarial networks with effective attention mechanisms. Appl. Sci. 10, 3335. doi: 10.3390/app10093335
Kumar, R., Singh, M. P., Kumar, P., and Singh, J. P. (2015). “Crop Selection Method to maximize crop yield rate using machine learning technique,” in International Conference on Smart Technologies and Management for Computing, Communication, Controls, Energy and Materials (Avadi), 138–145.
Landsberg, J. M., and Michałek, M. (2019). Towards finding hay in a haystack: explicit tensors of border rank greater than 2.02m in cm ⊗ cm ⊗ cm. ArXiv abs/1912.11927. doi: 10.48550/ARXIV.1912.11927
Lokman, A. S., and Ameedeen, M. A. (2019). “Modern chatbot systems: a technical review,” in Proceedings of the Future Technologies Conference (FTC) 2018, eds K. Arai, R, Bhatia, and S. Kapoor (Cham: Springer International Publishing), 1012–1023.
Mafukidze, H. D., Owomugisha, G., Otim, D., Nechibvute, A., Nyamhere, C., and Mazunga, F. (2022). Adaptive thresholding of cnn features for maize leaf disease classification and severity estimation. Appl. Sci. 12, 8412. doi: 10.3390/app12178412
Mathew, R. B., Varghese, S., Joy, S. E., and Alex, S. S. (2019). “Chatbot for disease prediction and treatment recommendation using machine learning,” in 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI) (Tirunelveli), 851–856. doi: 10.1109/ICOEI.2019.8862707
Mendes, J., Pinho, T. M., Neves Dos Santos, F., Sousa, J., Peres, E., Cunha, J., et al. (2020). Smartphone applications targeting precision agriculture practices–a systematic review. Agronomy 10, 855. doi: 10.3390/agronomy10060855
Michael, G.omez, S., Alejandro, V., Henry, R., Nancy, S., Sivalingam, E., Walter, O., et al. (2019). Ai-powered banana diseases and pest detection. Plant Methods 15. doi: 10.1186/s13007-019-0475-z
Monitor Uganda (2019). New App Diagnoses Crop Diseases. Available online at: https://www.monitor.co.ug/uganda/magazines/farming/new-app-diagnoses-crop-diseases-1847530
Mwebaze, E., and Biehl, M. (2016). “Prototype-based classification for image analysis and its application to crop disease diagnosis,” in Advances in Self-Organizing Maps and Learning Vector Quantization (Springer International Publishing), 329–339.
Mwebaze, E., Gebru, T., Frome, A., Nsumba, S., and Tusubira, J. (2019). Icassava Fine-Grained Visual Categorization Challenge [Dataset]. Available online at: https://arxiv.org/abs/1908.02900
Owomugisha, G., Melchert, F., Mwebaze, E., Quinn, J. A., and Biehl, M. (2021). Matrix relevance learning from spectral data for diagnosing cassava diseases. IEEE Access 9, 83355–83363. doi: 10.1109/ACCESS.2021.3087231
Owomugisha, G., and Mwebaze, E. (2016). “Machine learning for plant disease incidence and severity measurements from leaf images,” in IEEE International Conference on Machine Learning and Applications (Anaheim, CA: IEEE), 158–163.
Papineni, K., Roukos, S., Ward, T., and Zhu, W.-J. (2002). “Bleu: a method for automatic evaluation of machine translation,” in Annual Meeting of the Association for Computational Linguistics (Philadelphia, PA), 311–318.
Patel, H., and Patel, D. (2016). Survey of android apps for agriculture sector. Int. J. Inf. Sci. Techn. 6, 61–67. doi: 10.5121/ijist.2016.6207
Peng, Z., and Ma, X. (2019). A survey on construction and enhancement methods in service chatbots design. CCF Trans. Pervasive Comput. Interact. 1, 204–223. doi: 10.1007/s42486-019-00012-3
Qiu, M., Li, F.-L., Wang, S., Gao, X., Chen, Y., Zhao, W., et al. (2017). “AliMe chat: a sequence to sequence and rerank based chatbot engine,” in Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) (Vancouver, BC: Association for Computational Linguistics), 498–503.
Ramcharan, A., Baranowski, K., McCloskey, P., Ahmed, B., Legg, J., and Hughes, D. P. (2017). Deep learning for image-based cassava disease detection. Front. Plant Sci. 8, 1852. doi: 10.3389/fpls.2017.01852
Reimers, N., and Gurevych, I. (2019). “Sentence-bert: sentence embeddings using siamese bert-networks,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) (Hong Kong: Association for Computational Linguistics), 3982–3992
Sambasivam, G., and Opiyo, G. D. (2021). A predictive machine learning application in agriculture: Cassava disease detection and classification with imbalanced dataset using convolutional neural networks. Egyptian Inform. J. 22, 27–34. doi: 10.1016/j.eij.2020.02.007
Sheikh, S. A., Tiwari, V., and Singhal, S. (2019). “Generative model chatbot for human resource using deep learning,” in International Conference on Data Science and Engineering (Patna: IEEE), 126–132.
Singh, R., Paste, M., Shinde, N., Patel, H., and Mishra, N. (2018). “Chatbot using tensorflow for small businesses,” in 2018 Second International Conference on Inventive Communication and Computational Technologies (ICICCT) (Coimbatore), 1614–1619. doi: 10.1109/ICICCT.2018.8472998
Su, M.-H., Wu, C.-H., Huang, K.-Y., Hong, Q.-B., and Wang, H.-M. (2017). “A chatbot using lstm-based multi-layer embedding for elderly care,” in 2017 International Conference on Orange Technologies (ICOT), 70–74. doi: 10.1109/ICOT.2017.8336091
Suvedi, M., and Kaplowitz, M. (2016). What Every Extension Worker Should Know: Core Competency Handbook. Michigan State University. p. 7.
Tao, C., Wu, W., Xu, C., Hu, W., Zhao, D., and Yan, R. (2019). “Multi-representation fusion network for multi-turn response selection in retrieval-based chatbots,” in Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, WSDM '19 (New York, NY: Association for Computing Machinery), 267–275.
Tripathi, M. K., and Maktedar, D. D. (2020). A role of computer vision in fruits and vegetables among various horticulture products of agriculture fields: a survey. Inf. Process. Agric. 7, 183–203. doi: 10.1016/j.inpa.2019.07.003
Vijayalakshmi, J., and Pandimeena, K. (2019). Agriculture talkbot using AI. Int. J. Recent Technol. Eng. 8, 186–190. doi: 10.35940/ijrte.B1037.0782S519
Wu, Y., Wu, W., Xing, C., Zhou, M., and Li, Z. (2016). Sequential matching network: a new architecture for multi-turn response selection in retrieval-based chatbots. arXiv preprint arXiv:1612.01627. doi: 10.18653/v1/P17-1046
Yan, R. (2018). “chitty-chitty-chat bot”: Deep learning for conversational AI,” in Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI-18 (Stockholm: International Joint Conferences on Artificial Intelligence Organization), 5520–5526. doi: 10.24963/ijcai.2018/456778
Yan, Z., Duan, N., Bao, J., Chen, P., Zhou, M., Li, Z., et al. (2016). “Docchat: An information retrieval approach for chatbot engines using unstructured documents,” in Annual Meeting of the Association for Computational Linguistics (Berlin), 516–525.
Yang, L., Hu, J., Qiu, M., Qu, C., Gao, J., Croft, W. B., et al. (2019). “A hybrid retrieval-generation neural conversation model,” in ACM International Conference on Information and Knowledge Management (Beijing), 1341–1350.
Keywords: crop disease monitoring, recommendation systems, natural language processing, smart farming, question-answer pairs, food security
Citation: Omara J, Talavera E, Otim D, Turcza D, Ofumbi E and Owomugisha G (2023) A field-based recommender system for crop disease detection using machine learning. Front. Artif. Intell. 6:1010804. doi: 10.3389/frai.2023.1010804
Received: 03 August 2022; Accepted: 21 March 2023;
Published: 26 April 2023.
Edited by:
Lyndon Estes, Clark University, United StatesReviewed by:
Annalyse Kehs, The Pennsylvania State University (PSU), United StatesOmar A. Alzubi, Al-Balqa Applied University, Jordan
Copyright © 2023 Omara, Talavera, Otim, Turcza, Ofumbi and Owomugisha. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Godliver Owomugisha, b2dvZGxpdmVyQGVuZy5idXNpdGVtYS5hYy51Zw==