 Helya Goharbavang
Helya Goharbavang Artem T. Ashitkov1
Artem T. Ashitkov1 David Mayerich
David Mayerich- 1Department of Electrical Engineering, University of Houston, Houston, TX, United States
- 2Department of Cell and Developmental Biology, University of Virginia School of Medicine, Charlottesville, VA, United States
- 3Department of Computer Science, University of Houston, Houston, TX, United States
Recent advances in three-dimensional microscopy enable imaging of whole-organ microvascular networks in small animals. Since microvasculature plays a crucial role in tissue development and function, its structure may provide diagnostic biomarkers and insight into disease progression. However, the microscopy community currently lacks benchmarks for scalable algorithms to measure these potential biomarkers. While many algorithms exist for segmenting vessel-like structures and extracting their surface features and connectivity, they have not been thoroughly evaluated on modern gigavoxel-scale images. In this paper, we propose a comprehensive yet compact survey of available algorithms. We focus on essential features for microvascular analysis, including extracting vessel surfaces and the network’s associated connectivity. We select a series of algorithms based on popularity and availability and provide a thorough quantitative analysis of their performance on datasets acquired using light sheet fluorescence microscopy (LSFM), knife-edge scanning microscopy (KESM), and X-ray microtomography (µ-CT).
1 Introduction
Microvasculature plays an important role in tissue development and function. While its role is often complex, the shape and structure of microvascular networks are studied in conjunction with disease. Due to imaging constraints, these studies largely focus on the local network structure constrained to a limited field of view or tissue section. Recent advances in three-dimensional microscopy, including light sheet fluorescence microscopy (LSFM) (Kirst et al., 2020), knife-edge scanning microscopy (KESM) (Mayerich et al., 2008), and X-ray microtomography (µ-CT) (Hong et al., 2020; Quintana et al., 2019), overcome this limitation by enabling whole-organ imaging in small animals. However, the microscopy community currently lacks scalable algorithms and benchmarks to quantify microvascular structure at such a large scale.
While many algorithms exist for segmenting vessel-like structures, their scalability on modern whole-organ three-dimensional images has not been rigorously assessed. In addition, segmentation errors can increase disproportionately with volume coverage because acquiring larger volumes introduces trade-offs in SNR, resolution, and sampling anisotropy. This requires more complex algorithms - including pre-processing and machine learning - that are not as scalable as traditional thresholding or segmentation based on localized features (Daetwyler et al., 2019).
In this paper, we propose a comprehensive yet compact survey of available algorithms. We focus on essential features for microvascular analysis, including extracting vessel surfaces and the network’s associated connectivity. Algorithms were selected based on popularity and availability and provide a thorough quantitative analysis of their performance on datasets acquired using emerging techniques.
2 Microvascular models
Microvasculature is a meshwork of capillaries that penetrate tissue to provide nutrients and remove cellular waste. The structure of this mesh changes over time and plays a critical role in tissue function and disease progression. Most current studies are limited to small volumes, primarily characterizing vascular density, along with morphological metrics such as capillary length, radius, and tortuosity (Cassot et al., 2006). These metrics provide fundamental information about the network’s geometric properties and spatial organization. They also serve as the foundation for more advanced analyses, such as quantifying flow dynamics, assessing tissue perfusion, and understanding function. Moreover, downstream pipelines such as computational flow modeling and perfusion simulations can incorporate the segmentations and skeletons to enable quantitative studies of hemodynamics and tissue function (Vidotto et al., 2019).
As image sizes increase, researchers attempt to apply existing metrics at larger scales using software packages like VesselVio (Kirst et al., 2020) or multi-step pipelines such as TubeMap. We expect new metrics and biomarkers to develop over time as larger models are explored. For now, we focus on methods that convert large-scale microvascular images into explicit models that support existing analyses. This leads to two key representations: the microvascular geometry and its skeleton (Figure 1).
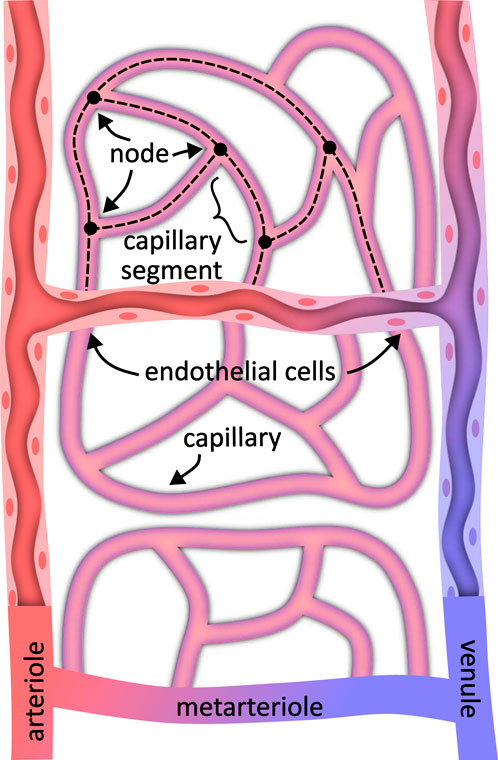
Figure 1. A microvascular model specifies both the geometry representing the surface structure and connectivity in the form of a spatial graph. Depending on the labeling method, the vascular geometry may represent the vessel interior or include endothelial cells lining the vessel and capillary walls. The vessel connectivity generally consists of a graph of vessel centerlines joined at nodes where vessels interconnect.
The geometry of the network represents the vascular surface that separates the region inside from the surrounding tissue. This representation enables the calculation of metrics such as vessel radii, surface area, and volume. The geometry is frequently extracted by identifying these inside/outside regions and then calculating the surface that separates them. Binarization is the first step for resolving the microvascular geometry (Figures 2b,e). These methods rely on separating pixels within the network from the surrounding tissue, providing an implicit representation of the geometry that can be readily converted to an explicit surface mesh.
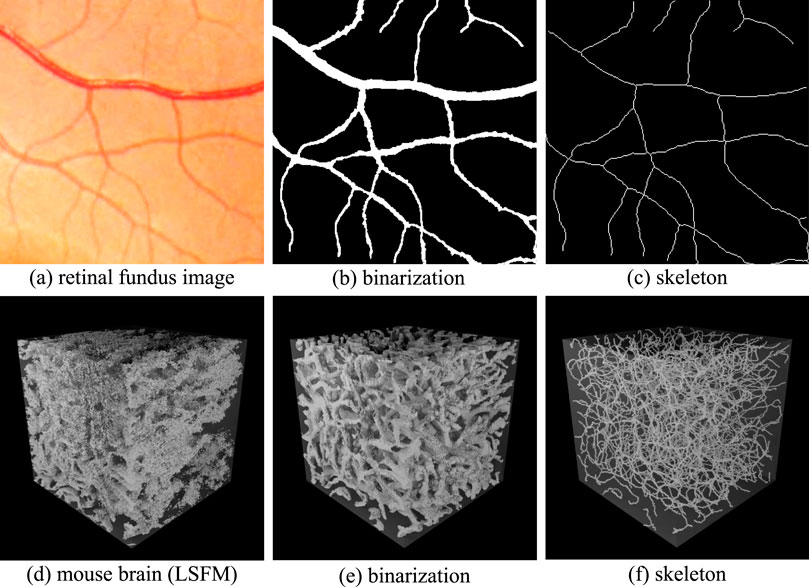
Figure 2. Implicit representations of binarization and skeletonization in 2D and 3D images. Retinal fundus images are shown in 2D (a). The associated binarization (b) indicates pixels that lie inside (white) and outside (black) of the vascular network. The skeletonization (c) shows the vessel paths and points where they connect. The 3D case shows a volumetric visualization of an LSFM image (d) with the associated binarization (e) and centerlines (f).
The network skeleton represents its topology, combining a connectivity graph with vessel centerlines. This representation enables the calculation of metrics such as tortuosity, vessel length, and branching statistics. The skeleton is usually extracted from the geometry using specialized thinning algorithms. Skeletonization is used to extract vessel centerlines (Figures 2c,f) and calculate a connectivity graph. Skeletonization methods frequently rely on an initial binarized volume or surface mesh. However, some techniques, such as tracing, can compute the skeleton directly (Govyadinov et al., 2019).
2.1 Geometry
Vessel geometry can be represented using implicit (voxel-based) or explicit (mesh-based) data structures. In the implicit representation, the vascular network is segmented from surrounding tissue using a three-dimensional voxel grid similar to the original image, with individual voxels labeled as inside or outside vessels. Voxels are convenient for calculating volumes or performing voxel-wise statistical analyses.
Explicit representations, such as polygonal meshes, define vessel surfaces through interconnected vertices and edges. Meshes facilitate calculations of surface area and enable simulations requiring surface geometry. In this survey, all segmentation algorithms produce voxel-based results. We tested two skeletonization algorithms (tagliasacchi and antiga) that require triangular meshes as input, which we produce from segmentation results using the marching cubes algorithm.
This implicit representation can optionally be converted to a surface mesh using algorithms such as marching cubes (Lorensen and Cline, 1998). Measurements are taken across either structure as convenient. For example, surface area can be measured by integrating across a surface mesh, while volume can be measured by adding up the pixels within the network.
2.2 Skeleton
The vascular skeleton is almost always represented explicitly for analysis using connected curves. This explicit representation is fundamentally a connectivity graph, where each node represents a bifurcation and each edge represents a single non-branching vessel segment (Figure 1). The vessel centerlines are curves that can be integrated to calculate features such as length and tortuosity. Algorithms such as depth- and breadth-first searches can also be applied to calculate path lengths and branching characteristics.
In this paper, we evaluate the performance of algorithms for extracting the geometry and connectivity of a microvascular network in large images on imaging methods applicable to whole organs. Most algorithms first binarize the original image using semantic segmentation, using the result as the foundation for medial axis transforms that provide the skeleton (Figure 3).
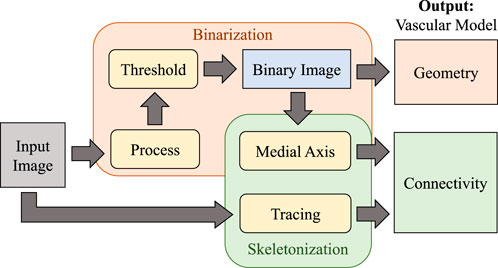
Figure 3. Overview of the vascular modeling pipeline. The input image is first processed (using various filtering or machine learning approaches) and binarized to extract geometry. The medial axis is then calculated to determine network connectivity. Tracing may also be applied directly to the raw image as an alternative approach for skeletonization.
3 Microvascular imaging
Microvascular imaging faces two competing challenges. First, imaging systems must be capable of collecting
3.1 Imaging methods
Meeting the criteria for resolution and volume coverage is challenging because microscopes are diffraction-limited and tissue samples are highly scattering. However, recent advances are starting to enable sufficient resolution and volume coverage. This paper considers the following broadly-accessible imaging methods:
X-ray microtomography (µ-CT) is nondestructive and measures the absorbance of X-rays incident on a sample to create three-dimensional images (Ritman, 2004). While µ-CT enables large-volume imaging of whole mouse brains (Hong et al., 2020), its low contrast limits spatial resolution. Recent advances in vascular perfusion compounds such as Vascupaint 2 (MediLumine, Montreal, Quebec, Canada) improve µ-CT resolution to
Light sheet fluorescence microscopy (LSFM) is characterized by separating illumination and detection. A thin sheet of light illuminates the sample (Hsu et al., 2022), and an orthogonally oriented objective (Figure 4) collects the emitted two-dimensional image using a CCD or CMOS camera. While the penetration depth is traditionally limited by tissue scattering, recent developments in clearing protocols (ex. CUBIC or iDISCO+) (Susaki et al., 2015; Renier et al., 2014) enable large-scale imaging of whole rodent brains. Recent cleared-tissue implementations span a broad range of resolutions. For example, hybrid open-top light sheet systems can achieve lateral resolution of 0.45 µm and axial resolution of 2.9 µm across millimeter-scale volumes (Glaser et al., 2022). When combined with
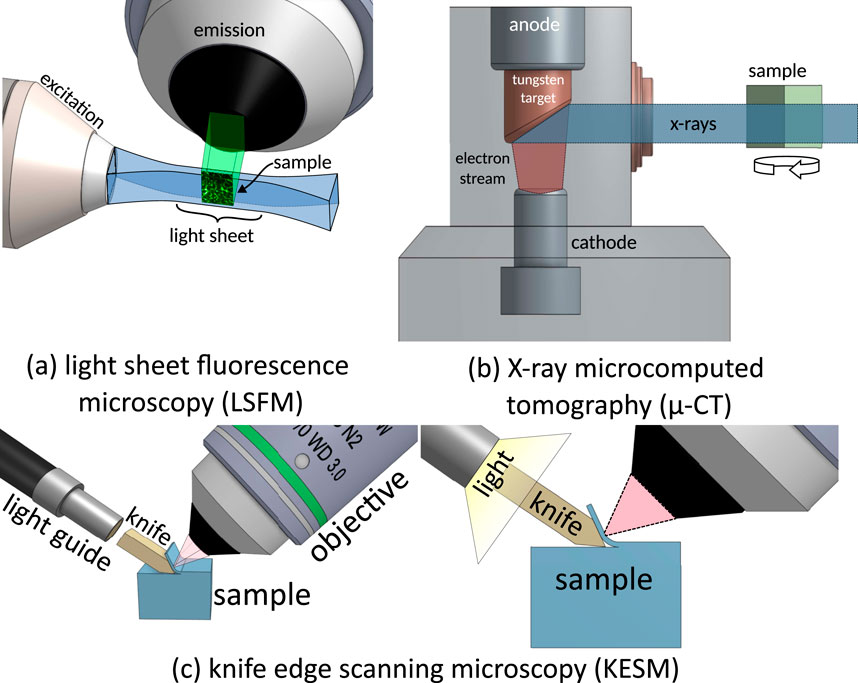
Figure 4. Imaging techniques tested for microvascular reconstruction. (a) Light sheet fluorescence microscopy uses a laser-scanned light sheet to excite fluorophores within a sample plane that are imaged through a high-NA objective. (b) X-ray micro-CT images the sample by rotating it within a transmission X-ray beam. (c) Knife-edge scanning microscopy is a milling-based imaging system that images tissue slices as they are sequentially ablated from a sample.
Milling microscopy removes layers of a sample during the imaging process to expose deeper tissue volumes. Initial experiments used on two-photon microscopy followed by photo-ablation (Tsai et al., 2003), demonstrating that volume constraints could be eliminated by systematically removing tissue. More recent techniques separate tissue sections using physical cutting. Knife-edge scanning microscopy (KESM) (Mayerich et al., 2008; Mayerich et al., 2011) separates a tissue slice from the rest of the block during imaging, while milling with ultraviolet surface excitation (MUSE) performs block-face imaging followed by ablation (Guo et al., 2019).
3.2 Datasets
We evaluated our binarization and skeletonization methods on three datasets representing the modalities described in Section 3.1.
X-ray microtomography (µ-CT) scans of mouse brain (Tg(Slco1c1-BAC-CreER); R26-lsl-TdTom/+) vascular networks were acquired using a Skyscan 1276 (Bruker, Billerica, MA, United States) at an isotropic sampling rate of 10 µm per voxel. Mice were prepared based on previously published protocols (Suarez et al., 2024). Briefly, the vasculature was perfused with Vascupaint (MediLumine, Product number: MDL-121; Montreal, Quebec, Canada) to provide vascular and microvascular X-ray contrast (Figure 5a).
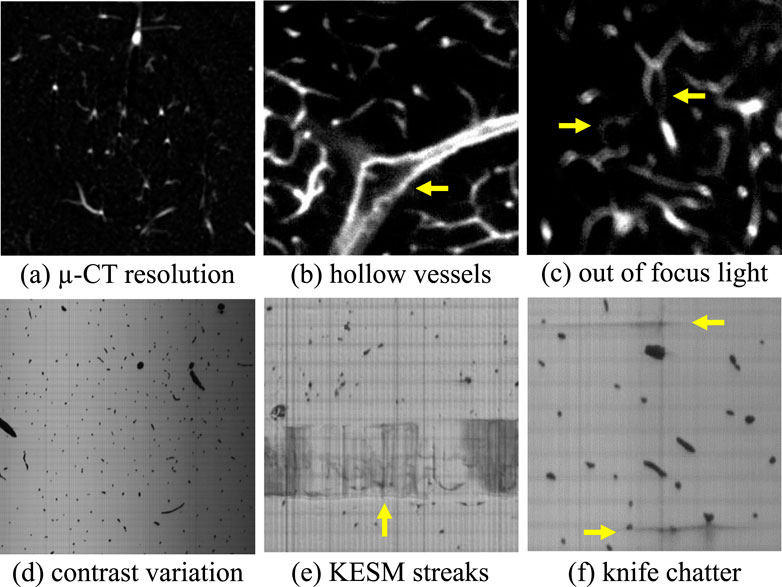
Figure 5. Noise and systematic artifacts that occur in high-throughput imaging techniques. Limitations in resolution (a) reduced the ability to detect small vessels that form connections in the network. Large vessels in LSFM are often hollow (b) because contrast is provided by labeling the vessel wall. Misalignments during imaging can also produce blurry sections (c) that can confound segmentation algorithms. KESM introduces physical artifacts such as variations in illumination across a slice (d) and physical streaks caused by the interaction between the sample and cutting tool (e,f).
Light sheet fluorescence microscopy (LSFM) images of mouse brain microvasculature were acquired using a Cleared Tissue LightSheet (CTLS) Microscopy Workstation XL (3i, Intelligent Imaging Innovations, Denver, CO), equipped with a 30 fps Fusion BT sCMOS camera (
Milling microscopy images were acquired using a knife edge scanning microscope KESM at a voxel resolution of
Ground truth volumes for training and validation were manually annotated in Slicer (Kikinis et al., 2013). Binarization and skeletonization methods were evaluated on a
3.3 Noise and artifacts
Each of these imaging modalities introduces sources of noise and other artifacts that challenge segmentation, including:
Resolution limitations are introduced due to both the signal strength and diffraction limit. Standard LSFM is typically anisotropic, with poorer axial than lateral resolution. Recent implementations (Glaser et al., 2022; Lin et al., 2025) can achieve sub-micron isotropic resolution, with trade-offs in speed or volume coverage. µ-CT is primarily limited by SNR to
Staining and labeling used in LSFM relies on targeting cells in the vessel wall, producing hollow vessels when their diameter is significantly larger than the diffraction limit (Figure 5b). In practice, vascular perfusion with fluorescent compounds like dextran can overcome these artifacts while improving contrast (at the expense of molecular specificity). In that case we would expect images that are more comparable to KESM.
Blurred vessels can occur in LSFM images due to temporary misalignment during long imaging periods (Figure 5c).
Contrast variations are introduced by non-uniform illumination and/or staining in both LSFM and KESM. Contrast is also reduced in LSFM as a function of depth due to scattering.
Machining artifacts introduced by cutting tools in milling microscopy can cause lines (Figure 5e) and streaks (Figure 5f) in individual z-axis slices.
4 Evaluation methodology
We characterize each algorithm’s performance using established metrics and perform an evaluation of adjustable parameters. All algorithms were tested on
4.1 Selection criteria
We evaluate a subset of available algorithms based on multiple criteria, prioritizing algorithms used in popular, domain-specific vessel analysis software. This includes Slicer (Kikinis et al., 2013), the Vascular Modeling Toolkit (VMTK) (Izzo et al., 2018), and VesselVio (Bumgarner and Nelson, 2022). Second, we prioritized algorithms with an established open-source implementation that was preferably provided by the authors. We selected representative algorithms from three classes of methods, including: (1) classical thresholding methods, (2) Hessian-based and gradient-based enhancement filters, and (3) deep learning-based semantic segmentation models. We selected skeletonization methods for a range of input data types, including: (1) binarized images, (2) meshes, and (3) point clouds. Our goal is to reflect diverse methodological approaches used for microvascular modeling. This selection process ensures that our evaluation adequately represents current best practices and popular trends in the field, providing a robust benchmark for future developments. Table 1 provides the dates and citations of the proposed algorithms.
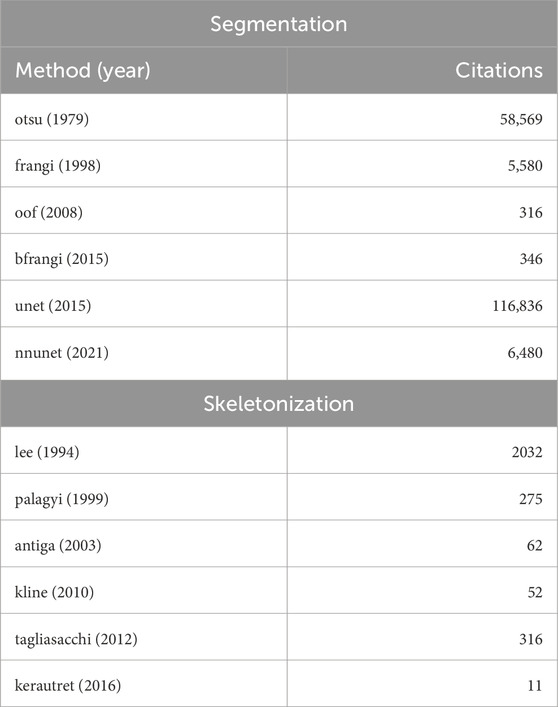
Table 1. Algorithms assessed in this paper for performing binarization (left) and skeletonization (right). The publication date is shown along with their citation count as of this writing.
Otsu’s method was evaluated as a baseline binarization algorithm (otsu3d), and used as the final binarization step as required for other algorithms. Vesselness filters, including both Frangi (frangi) and Beyond Frangi (bfrangi), were included due to their overwhelming popularity for vessel enhancement. Optimally oriented flux (oof) filters were included as a more recent innovation with the open-source implementations provided by the authors. U-Net architectures are extensively used for semantic segmentation in biomedical imaging, so we elected to test a baseline U-Net architecture (unet) while including recent work on self-configured U-Nets (nnunet).
We selected the thinning algorithms by Lee (lee) and Palágyi (palagyi) because of their popularity in skeletonization literature. While the level-set method by Kline (kline) and the confidence accumulation method by Kerautret (kerautret) are not used in existing modeling packages, the authors provide open-source implementations that were tested. We also selected the most recent skeletonization methods available for meshes (tagliasacchi). The selected methods and keywords are provided in Table 2.
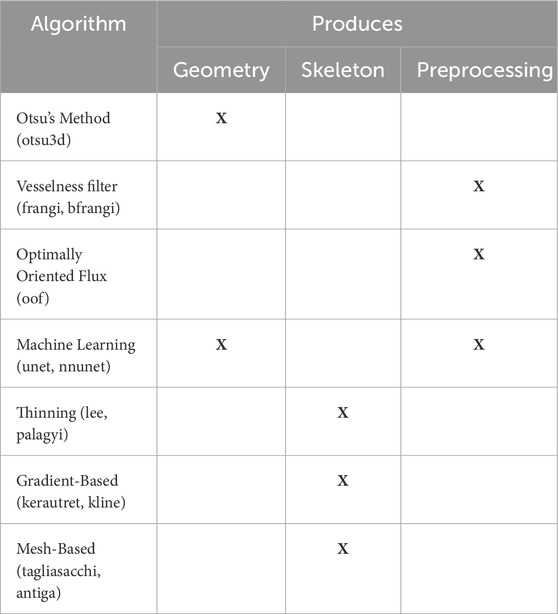
Table 2. Algorithms evaluated in this paper, along with their classes and output data types. Algorithm types are shown in the first column alongside names used to reference the associated results. Remaining columns show the algorithm output (geometry or skeleton). Preprocessing methods such as “vesselness” filters and OOF are used to enhance vessels prior to thresholding with Otsu’s method.
4.2 Geometry metric
Since microvasculature accounts for
The Jaccard index is in the range
We also calculate the precision, emphasizing the accuracy of the positive predictions, and recall, which quantifies the model’s ability to identify true positives. The precision (p) and recall (r) are often combined using the F-score (F), which is both equal to the Dice coefficient and a function of the Jaccard index in the case of binarization:
4.3 Skeleton metric
We adopt the definition of the skeleton as: a set of curves that have identical topology to the geometric surface and are equidistant to the boundary (Wei et al., 2018). We enforce these conditions by manually generating ground truth skeletons based on this definition.
Skeletonization is evaluated using NetMets (Mayerich et al., 2012), which calculates the similarity between two sets of curves
where
The precision is the percentage of the test skeleton that correctly corresponds to the ground truth, and the recall is the percentage of the ground truth skeleton that is correctly detected in the test case. The sensitivity parameter
5 Segmentation algorithms and evaluation
The selected segmentation algorithms largely fall into three groups that largely build on each other: (1) basic thresholding, (2) vessel enhancement and preprocessing, (3) convolutional neural networks.
Thresholding is the most basic approach to binarization, and in many cases an optimal threshold can be calculated automatically. Minimum cross entropy (Li and Tam, 1998), IsoData (Ridler and Calvard, 1978), and Fuzzy thresholding (Huang and Wang, 1995) are popular approaches (Kramer et al., 2022; Huang et al., 2019) that exist in several software packages (Fedorov et al., 2012). The most established algorithm is Otsu’s method, which determines the optimal threshold to separate foreground and background components.
Modern approaches rely on some form of image enhancement that is applied prior to thresholding. This includes filters designed to enhance the contrast of tube-like structures, as well as machine learning to perform semantic segmentation. The methods tested here include vesselness filters (Frangi et al., 1998; Jerman et al., 2016) and optimally oriented flux (OOF) (Law and Chung, 2008).
Convolutional neural networks (CNNs) have taken a prominent role in image segmentation. The U-Net architecture (Ronneberger et al., 2015) and its self-configuring extension, nnU-Net (Isensee et al., 2021), represent the current state-of-the-art in semantic (pixel-level) segmentation. These architectures use a symmetric U-shaped encoder-decoder design (Figure 10) to capture details at multiple scales by processing progressively larger image patches. While machine learning approaches tend to outperform deterministic methods, a significant amount of effort must be applied to annotation and training. As a result, the deterministic approaches are still extensively used in popular software packages.
All methods that require thresholding use Otsu’s method (Otsu, 1979), which computes a threshold
Several preprocessing methods use scale-space filtering (Witkin, 1987) to account for variations in vessel diameter. Scale-space approaches add a discrete dimension to a field (ex.
5.1 Hessian-based vessel enhancement
The most popular method for enhancing vessels is the Hessian-based approach described by Frangi et al. (1998), originally designed for 2D retinal fundus images. The Hessian matrix is calculated at each point in the image
The original “vesselness” algorithm (frangi) is outlined in Algorithm 1 and relies on four parameters: tuning parameters
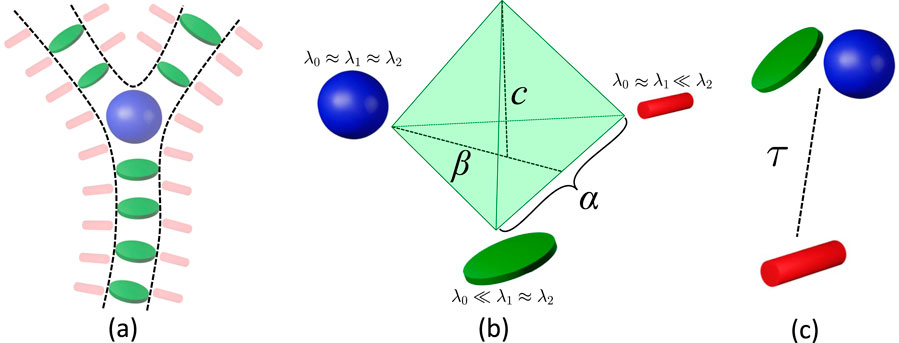
Figure 6. Hessian-based filters emphasize (a) plate-like (green) and blob-like (blue) tensors as vessels and bifurcations, while stick-like (red) tensors emphasize surfaces (including vessel surfaces). (b) The vesselness filter proposed (frangi, ofrangi) uses parameters
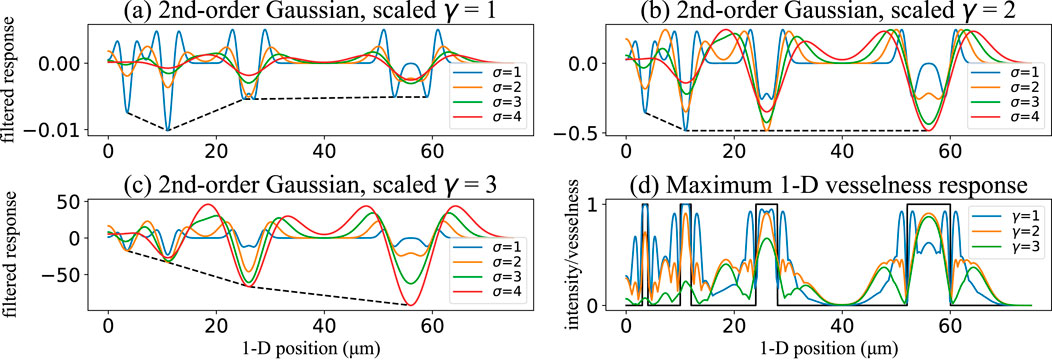
Figure 7. Effect of the scale-normalization exponent
Since the parameters in the original algorithm can be challenging to select, we provide two comparisons. First, we examine binarization results based on parameters used in the original paper (frangi), and after parameter optimization (ofrangi) for each dataset using training data. A parallel implementation was used to create sensitivity maps for each parameter (Figure 8). The relationship between parameters for frangi is shown in Figure 6a.
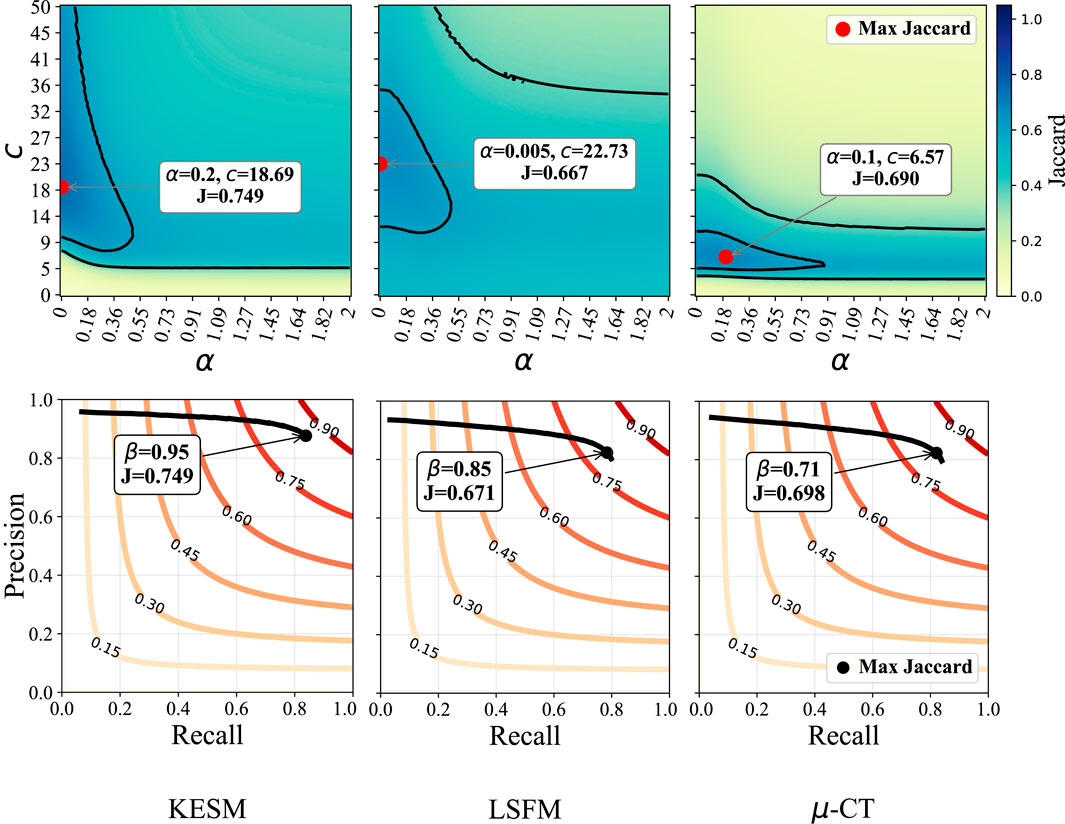
Figure 8. Sensitivity to
A modified implementation of the vesselness framework replaces the parameters with a single normalization term
Figure 9. Sensitivity to
5.2 Optimally oriented flux
The second derivatives within the Hessian are numerically calculated using finite-difference methods, introducing artifacts when features are adjacent. An alternative approach proposes optimally oriented flux (OOF) (Law and Chung, 2010), which relies on first derivatives and integrating gradient information over a spherical region. This applies a hard cut-off that localizes the gradient information used.
Given a point
where
Our tests used the OOF method available in MATLAB (oof), where the only tunable parameters are the sphere radii
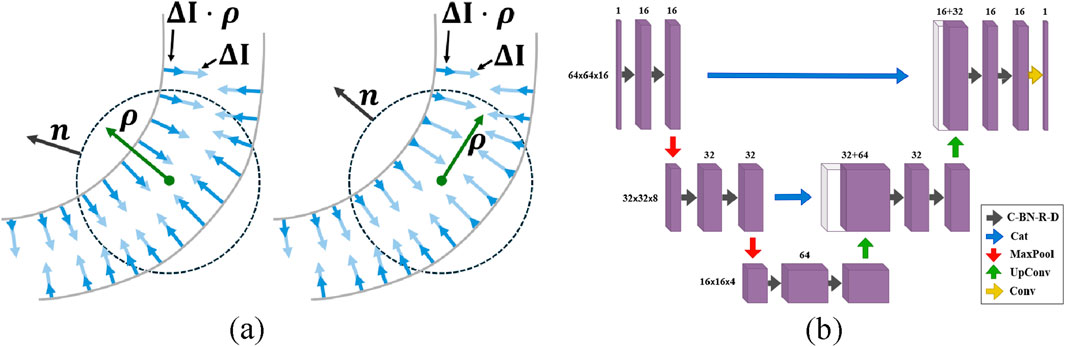
Figure 10. In Optimally Oriented Flux (a), the vessel orientation is determined by maximizing the outward-oriented gradient flux over a spherical region. Diagram of the U-Net architecture (b). The network consists of convolutional layers with batch normalization, ReLU activation, and dropout (C-BN-R-D), concatenation layers (Cat), max-pooling layers (MaxPool), up-convolutional layers (UpConv), and convolutional layers (Conv).
5.3 Convolutional neural networks
The U-Net (unet) architecture uses parallel encoder/decoder paths bridged by skip connections that merge high-resolution features from the encoder into the decoder. The network meta-parameters were determined through iterative trial and error based on validation performance. This U-Net uses 3 × 3 × 3 convolutional layers, ReLU activation, and 2 × 2 × 2 max-pooling layers (Figure 10). The data is divided into smaller volumes, selecting only those with intensities above the global mean to avoid empty or near-empty voxels that reduce training quality (Çiçek et al., 2016). The unet model tested here is trained and tested on these selected volumes using the Focal Tversky loss function (Abraham and Khan, 2019).
The nnU-Net (nnunet) architecture builds on U-Net by overcoming the need for manual meta-parameter tuning. nnU-Net maintains the encoder-decoder structure with skip connections while automatically adapting its architecture and hyperparameters. Like U-Net, it employs 3 × 3 × 3 convolutional layers, ReLU activation, and pooling layers but integrates additional strategies, such as ensemble modeling and deep learning-based boundary enhancement to improve segmentation accuracy (Schott et al., 2023). During training, nnU-Net uses standard loss functions and ensemble modeling, where multiple models are trained and combined. We used the source code provided by the authors1 for these experiments.
5.4 Geometry results
Our binarization results are shown in Table 3, providing the Jaccard Index, precision, and recall. Otsu’s method (otsu) was tested on raw data and used to select the final threshold for all preprocessing algorithms. The vesselness filter was tested using published parameters in the original paper (frangi) and after optimization of all parameters (ofrangi), while Beyond Frangi (bfrangi) was tested after optimization of
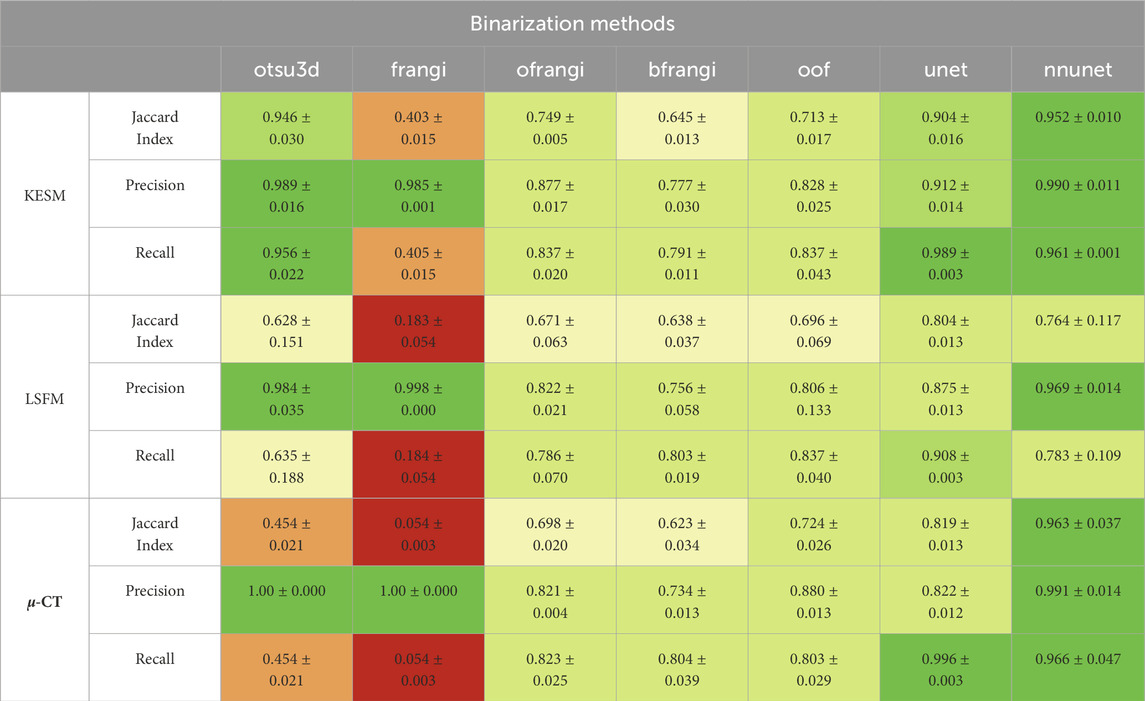
Table 3. Segmentation results showing the Jaccard index, precision, and recall for each binarization algorithm (red = bad, green = good). The original vesselness paper (frangi) recommends 0.5, 0.5, and half of the maximum value of the Hessian norm for
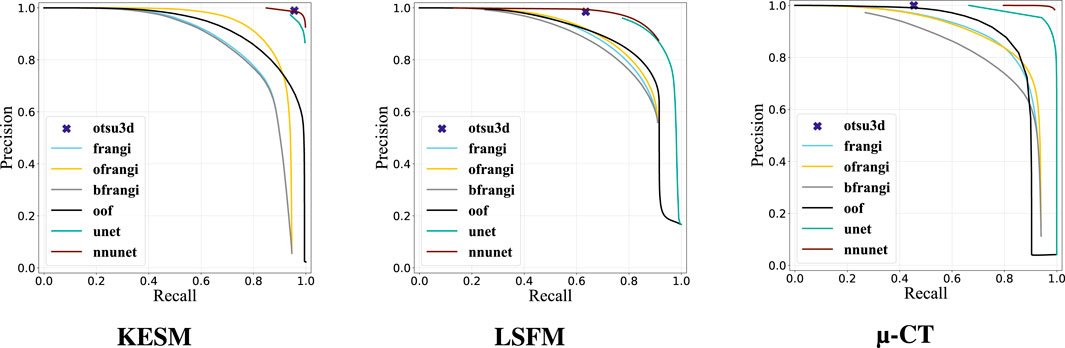
Figure 11. Precision-Recall curve of evaluated segmentation methods.
Raw image sections are provided from each dataset, along with the best corresponding binarization result for each algorithm (Figure 12). Further discussion is provided in Section 7.
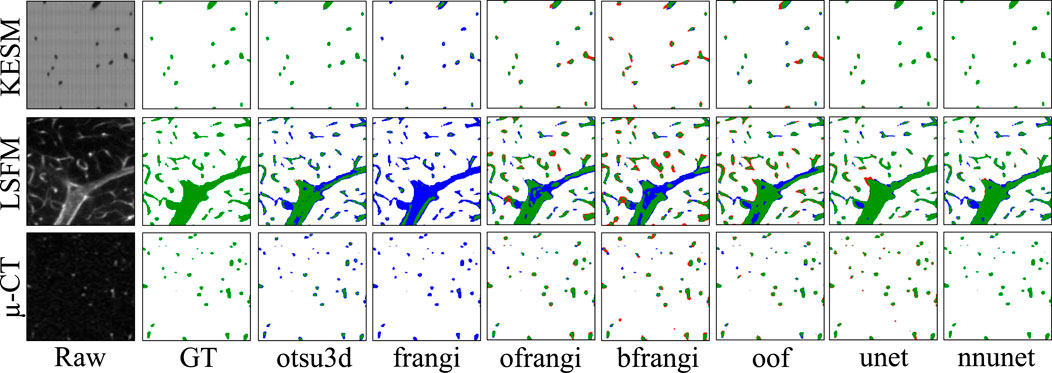
Figure 12. Cross-sections of three-dimensional volumes showing segmentation results for each modality. Green pixels indicate correctly labeled vessels, while white pixels show correctly detected background. Blue indicates undetected vessels (false negatives), while red indicates background pixels that are incorrectly labeled as vessels (false positives). GT indicates the manually annotated ground truth.
6 Skeletonization algorithms and evaluation
The presented skeletonization algorithms require either an initial binary image or a geometric surface. Whenever the vascular surface is required, it is extracted using the marching cubes algorithm from the binarized output.
6.1 Skeletonization
Skeletonization is the method of determining the connected vessel centerlines, usually based on the extracted geometry. A binarized image is used as an input to thinning algorithms, while other approaches calculate the skeleton (or medial axis) from an explicit geometry.
Thinning uses morphological erosion to calculate an implicit representation of the skeleton from a binarized image. Voxels are iteratively removed until a thin single-voxel skeleton remains. The concept was originally proposed in Blum’s grassfire propagation (Blum, 1967), while Tsao and Fu (1981) were the first to introduce a three-dimensional algorithm based on formalized topological and geometric rules. The main concept in erosion-based methods is determining the “simple points” that can be removed without changing the model topology. Thinning algorithms usually differ in how they detect and remove simple points. The most popular method used in current software packages (Fedorov et al., 2012; Bumgarner and Nelson, 2022) is Lee et al. (1994) approach.
Mesh-based medial axis transforms approximate the skeleton from a geometric surface. These include point-sampling methods that leverage ray casting Kerautret et al. (2016) to localize the skeleton. While these methods face challenges when differentiating the “inside” and “outside” of complex shapes (Wei et al., 2018), statistical methods can overcome these problems using vector accumulation maps to probabilistically approximate the skeleton (Kerautret et al., 2016). This can be overcome by directly evolving the geometry towards its centerline using an active contour model (Tagliasacchi et al., 2012).
Another subcategory of mesh-based transforms leverages a Voronoi diagram of the surface (Antiga et al., 2003). The boundaries of the Voronoi cells within vessels can be tracked to extract the medial axis. Despite their precise results, Voronoi-based techniques require careful handling of boundary conditions and specifying seed points to avoid generating spurious branches.
6.2 Thinning
Thinning algorithms reduce an object to a single-voxel-thick centerline while maintaining topology (ex. connectivity, cavities, tunnels). This is accomplished by examining the local neighborhood of each voxel to identify simple points whose deletion preserves topology. These points are iteratively removed until a thinned skeleton remains.
The lee algorithm (Lee et al., 1994) identifies simple points using an octree to recursively subdivide the local neighborhood (Supplementary Algorithm S3). A later approach (Palágyi and Kuba, 1999) uses predefined templates to detect and flag simple points, which is easier to parallelize. Both the sequential lee and parallel palagyi algorithms are parameter-free and take a binarized image as input.
6.3 Gradient-based skeletonization
The Kerautret et al. (2015) algorithm extracts a centerline from a surface mesh by casting rays from each surface point along its normal. The rays are accumulated in a voxel grid where the maximal ridges represent centerlines. The most recent modification (Kerautret et al., 2016) determines an accumulation confidence value for each voxel, where points with higher confidence are more likely to be located on the centerline.
The only required parameter is the accumulation distance
The kline algorithm (Kline et al., 2010) calculates a distance field using the fast marching method (FMM), and then internal ridges (maxima) are followed from user-specified seed points. This algorithm assumes that the geometry is a connected tree of tubular structures branching from a single root point. Since microvascular networks do not have a unique root, a large number of seed points are required to comprehensively trace the network.
6.4 Mesh-based skeletonization
The tagliasacchi algorithm (Tagliasacchi et al., 2012) calculates the skeleton from a closed mesh using mean curvature flow (MCF). The medial axis is extracted by moving the mesh along its surface normal proportional to the surface curvature. This iteratively collapses the mesh into a one-dimensional curve (Figure 13). We tested the tagliasacchi method using an implementation provided by StarLab2, which requires a watertight manifold mesh and is highly sensitive to mesh boundaries. We forced a watertight mesh at all boundaries and applied the algorithm to each closed mesh component separately.
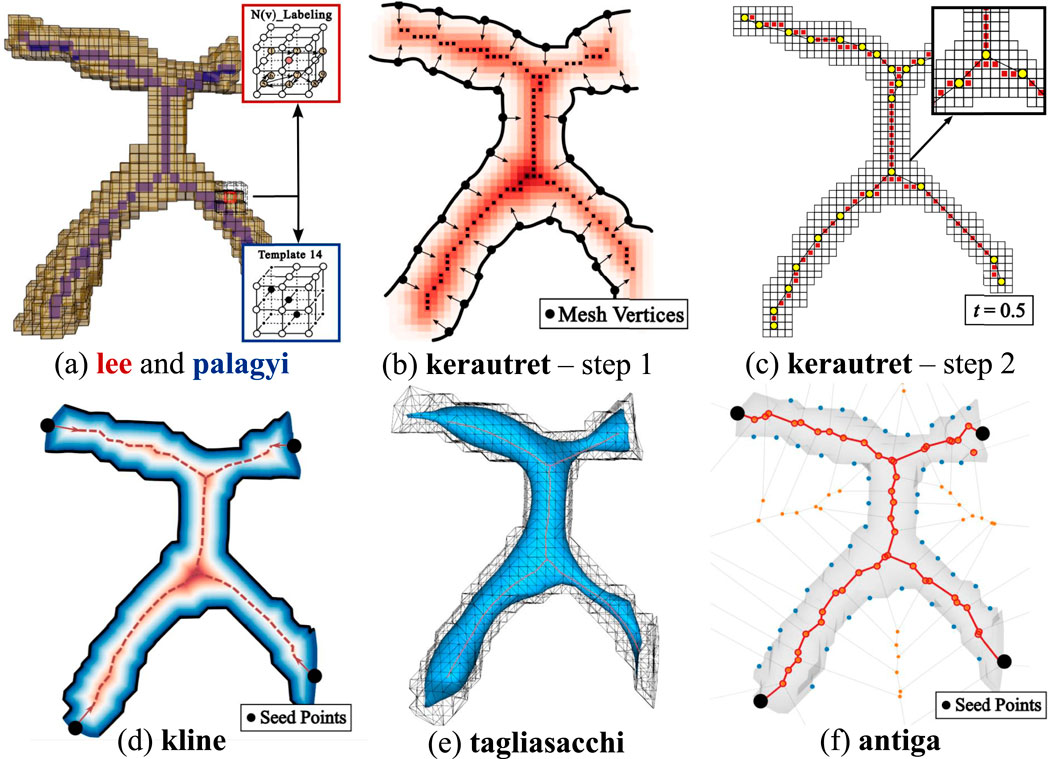
Figure 13. Overview of skeletonization methods. (a) Thinning-based methods: lee applies
The antiga algorithm (Antiga et al., 2003) builds a Voronoi diagram from point samples of the vascular surface. The intersections of each Voronoi region lie equidistant to the sampled surface, such that medial axis curves can be traced between user-specified seed points. The Delaunay tessellation is calculated from a set of points
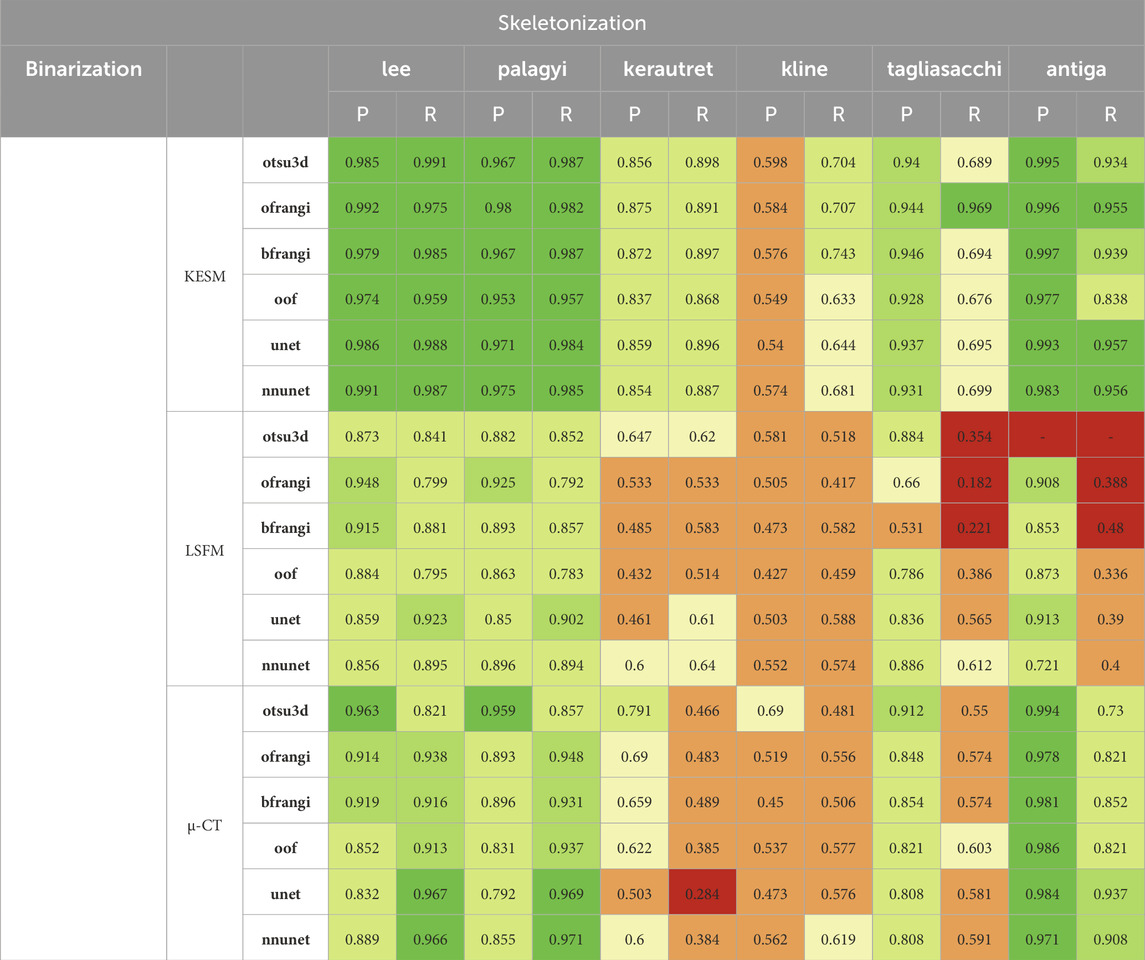
Table 4. Results of centerline extraction on binarization results (left columns: precision, right columns: recall). Thinning was performed using all binarized data for each dataset (see Table 3).
6.5 Skeletonization results
The precision and recall for the proposed skeletonization methods are shown in Table 4. The NetMets algorithm is used to quantify performance using
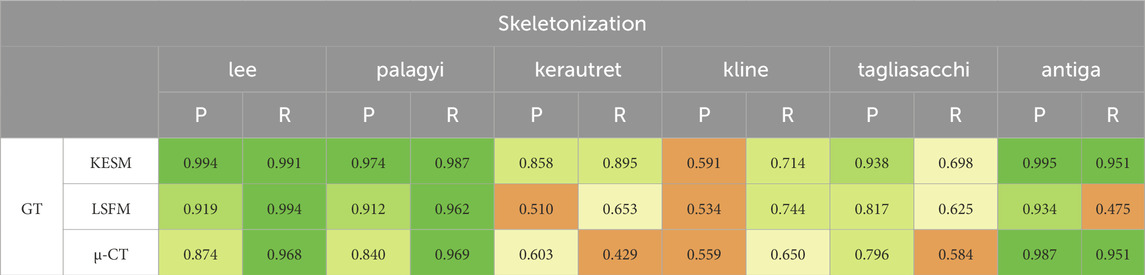
Table 5. Results for skeletonization on the ground truth segmentations.
The lee and palagyi methods achieved the highest F-score across all images, capturing vessel continuity at the cost of adding spurious branches to larger vessels. The antiga method provided the highest precision, however, it identified fewer vessels. The method failed to extract skeletons from binarized results using Otsu’s method due to the excessive number of vertices and edges. Gradient-based methods (kerautret and kline) performed poorly across most images. While kline was designed for vessels, it is poorly suited to microvascular networks since they are not tree-like. The difference in the performance of the kerautret for KESM data also stands out, likely due to the higher resolution of KESM data. This provides (1) a more completely connected mesh and (2) larger distances between adjacent unconnected vessels.
7 Discussion
Machine learning (unet, nnunet) achieved the best consistent performance across all images. This is expected given their established performance on semantic segmentation (Wang et al., 2022). While U-Nets have been extensively explored in two-dimensional images, recent advances that mitigate parameter explosion (Saadatifard et al., 2020) make them more practical in 3D. In our experiments, nnU-Net was run in its 3d_fullres mode, which includes isotropic resampling and intensity normalization. Although effective for KESM and µ-CT, this normalization likely suppressed subtle variations unique to LSFM data, reducing the recall and Jaccard index. It is possible that significantly larger training sets could mitigate these issues.
KESM was generally easier to segment due to its high contrast and spatial resolution. In fact, Otsu’s method (otsu3d) performed similarly to CNNs on KESM data. KESM also exhibits noise and imaging artifacts that are localized to individual slices, potentially making them easier to ignore. The Vesselness algorithms proposed by Frangi et al. (frangi), and later modified by Jerman et al. (bfrangi), are the most popular for enhancing tubular structures. While “out-of-the-box” parameters did not perform well, systematic optimization of these parameters (ofrangi) provided reasonable performance. However, this requires some form of optimization or training that may not provide a benefit over U-Net. If training data is unavailable, optimally oriented flux (oof) provides the best performance.
For skeletonization (Table 4), both lee and palagyi provided consistently good performance. The implementation that we tested for lee4 was significantly faster. The antiga algorithm provided the best precision for both KESM and µ-CT data. However, this came at a cost to recall since antiga tended to miss vessel centerlines (Figure 14). It also performed poorly on LSFM data, likely due to the surface complexity. In fact, the algorithm was unable to skeletonize the LSFM data segmented using otsu3d, which exceeded memory limits during the skeletonization process.
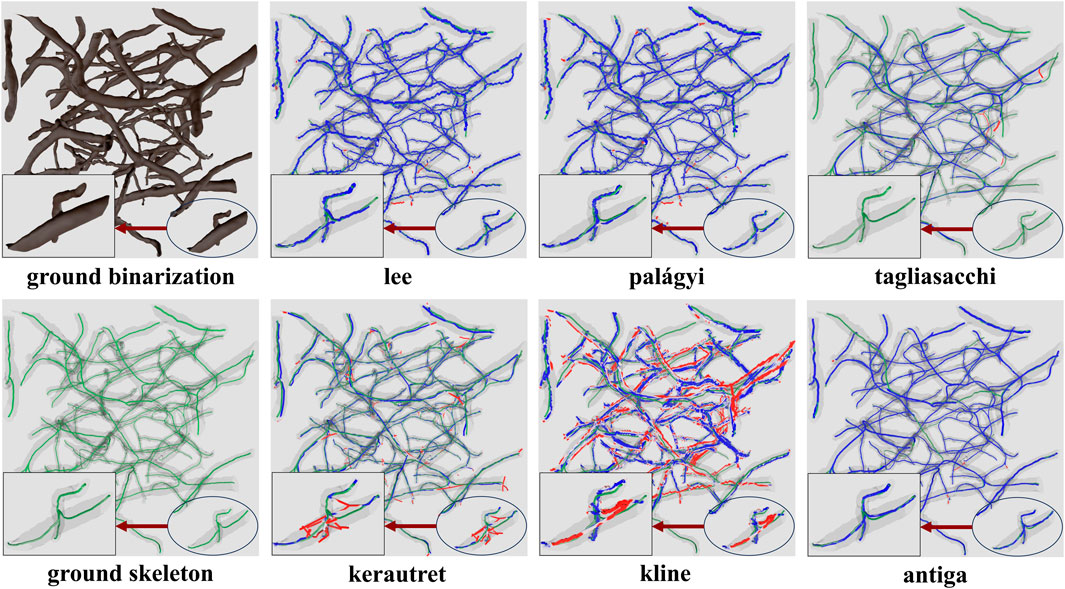
Figure 14. Skeletonization results on the ground truth segmentation of KESM dataset. The ground truth skeleton is colored green in each figure. The skeleton obtained by each method is shown in blue, with false positives marked in red.
One of the more interesting findings was that the most accurate binarization (generally a CNN) did not necessarily provide the best input for skeletonization. For example, otsu3d µ-CT provided better precision than nnunet when used as an input for LSFM and µ-CT. The reduced precision is likely due to consistent mislabeling of internal vessels (Figure 15). All skeletonization algorithms were also tested on ground truth data (Table 5) to demonstrate potential performance given a highly accurate segmentation.
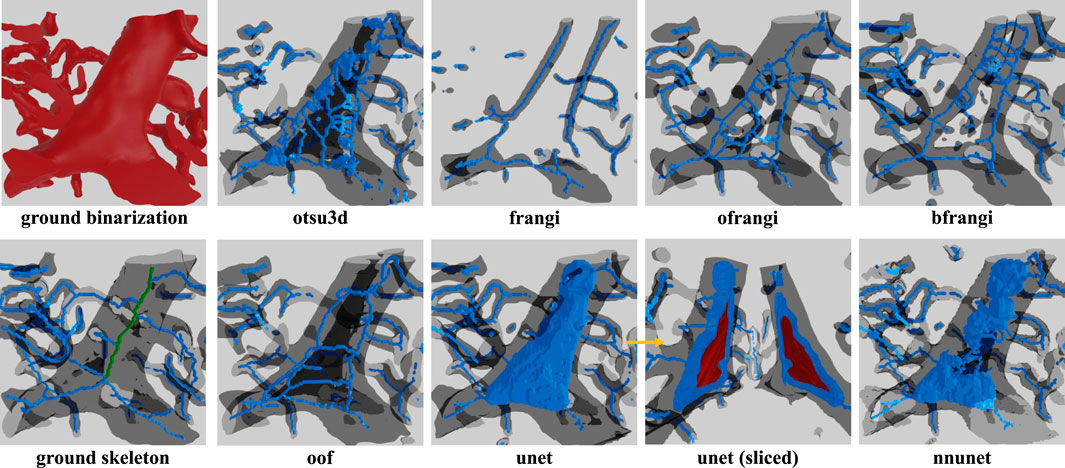
Figure 15. Skeleton extracted using lee using different binarizations. One problem frequently encountered in LSFM is hollow vessels that lead to poor recall in the resulting skeletonization. This is due to regions inside large vessels that are misinterpreted as background. This is most commonly encountered in LSFM because the endothelial cells at the vessel surface are common targets for fluorescent labels. This leads to a variety of incorrect “shells” or “networks” that surround the internal gap. The correct medial axis of the hollow vessel is green in the ground truth image.
8 Conclusion
This work aims to quantify the performance of algorithms for building large-scale microvascular networks. We focus on data from microscopes with the potential for organ-scale vascular imaging (LSFM, KESM, and µ-CT). We tested two classes of algorithms: binarization and skeletonization. These results can be used to reconstruct microvascular surfaces and study network properties. Importantly, the resulting models can feed directly into post-processing frameworks (e.g., CFD-based flow simulations or perfusion analysis) to facilitate functional interpretation and disease modeling (Celaya-Alcala et al., 2021; Zhang et al., 2022). All of the data, annotations, and links to algorithms are available in a public Git repository.5
Although KESM and µ-CT images share high contrast and SNR, their disparate voxel resolutions yield very different results: a global threshold such as otsu performs reliably in KESM, yet degrades in µ-CT where learning-based models like nnunet can incorporate local intensity variations to recover performance. It is important to note that this accuracy is quantified with respect to the ground truth and does not account for the reduced resolution of µ-CT: the accuracy of the segmentation does not necessarily reflect the accuracy of the final model. Modality-specific features, such as pixel sizes, ultimately bound the fidelity of the reconstructed vascular model, even when segmentation metrics appear equivalent across algorithms.
If the user can provide annotated training data, they will likely see the best performance using nnunet (Isensee et al., 2021) for binarization, followed by skeletonization with lee (Lee et al., 1994). Users may see an improvement in skeletonization results using antiga, provided the vasculature has a lower total surface area.
If a significant amount of training data is unavailable, the authors recommend oof (Law and Chung, 2008) for binarization, followed by lee for skeletonization. The user may be able to achieve better performance using frangi after significant optimization (ofrangi) (Frangi et al., 1998).
Author contributions
HG: Writing – review and editing, Investigation, Validation, Conceptualization, Software, Methodology, Writing – original draft, Formal Analysis, Visualization, Data curation. AA: Software, Writing – review and editing, Validation. AP: Writing – review and editing, Data curation, Validation. JW: Funding acquisition, Resources, Project administration, Writing – review and editing, Methodology, Data curation. GC: Conceptualization, Methodology, Project administration, Funding acquisition, Writing – original draft, Visualization, Writing – review and editing, Supervision. DM: Writing – review and editing, Formal Analysis, Project administration, Methodology, Supervision, Software, Funding acquisition, Writing – original draft, Conceptualization, Resources, Investigation.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This work was supported in part by the University of Virginia Comprehensive Cancer Center (JDW); the National Institutes of Health R01 HL146745 (JDW and DM), R01 HL159159 (JDW), R01 HL173597-01 (DM), and R01DK135870 (DM) and UC2 AR082200 (JDW); and by the National Science Foundation CAREER Award #1943455.
Conflict of interest
DM is a stakeholder in SwiftFront, LLC.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fbinf.2025.1645520/full#supplementary-material
Footnotes
1https://github.com/MIC-DKFZ/nnUNet
2https://github.com/taiya/starlab-mcfskel
4skimage.morphology.skeletonize function in the scikit-image Python library.
5https://github.com/helia77/MicroVasc-Review
References
Abraham, N., and Khan, N. M. (2019). “A novel focal tversky loss function with improved attention U-Net for lesion segmentation,” in 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 08-11 April 2019, 683–687.
Ahn, T., Largoza, G. E., Younis, J., Dickinson, M. E., Hsu, C.-W., Wythe, J. D., et al. (2024). Protocol for optical, aqueous-based clearing of murine tissues using ez clear. Star. Protoc. 5, 103053. doi:10.1016/j.xpro.2024.103053
Antiga, L., Ene-Iordache, B., and Remuzzi, A. (2003). “Centerline computation and geometric analysis of branching tubular surfaces with application to blood vessel modeling,” in Proceedings of the world society for computer graphics (WSCG).
Blum, H. (1967). “A transformation for extracting new descriptions of shape,” in Models for the perception of speech and visual form, 362–380.
Bumgarner, J. R., and Nelson, R. J. (2022). Open-source analysis and visualization of segmented vasculature datasets with VesselVio. Cell Rep. Methods 2, 100189. doi:10.1016/j.crmeth.2022.100189
Cassot, F., Lauwers, F., Fouard, C., Prohaska, S., and Lauwers-Cances, V. (2006). A novel three-dimensional computer-assisted method for a quantitative study of microvascular networks of the human cerebral cortex. Microcirculation 13, 1–18. doi:10.1080/10739680500383407
Celaya-Alcala, J. T., Lee, G. V., Smith, A. F., Li, B., Sakadžić, S., Boas, D. A., et al. (2021). Simulation of oxygen transport and estimation of tissue perfusion in extensive microvascular networks: application to cerebral cortex. J. Cereb. Blood Flow and Metabolism 41, 656–669. doi:10.1177/0271678x20927100
Chung, J. R., Sung, C., Mayerich, D., Kwon, J., Miller, D. E., Huffman, T., et al. (2011). Multiscale exploration of mouse brain microstructures using the knife-edge scanning microscope brain atlas. Front. neuroinformatics 5, 29. doi:10.3389/fninf.2011.00029
Çiçek, Ö., Abdulkadir, A., Lienkamp, S. S., Brox, T., and Ronneberger, O. (2016). “3d u-net: learning dense volumetric segmentation from sparse annotation,” in Medical Image Computing and Computer-Assisted Intervention–MICCAI 2016: 19th International Conference, Athens, Greece, October 17-21, 2016 (Springer), 424–432.
Daetwyler, S., Günther, U., Modes, C. D., Harrington, K., and Huisken, J. (2019). Multi-sample spim image acquisition, processing and analysis of vascular growth in zebrafish. Development 146, dev173757. doi:10.1242/dev.173757
Fedorov, A., Beichel, R., Kalpathy-Cramer, J., Finet, J., Fillion-Robin, J.-C., Pujol, S., et al. (2012). 3D slicer as an image computing platform for the quantitative imaging network. Magn. Reson. imaging 30, 1323–1341. doi:10.1016/j.mri.2012.05.001
Frangi, A. F., Niessen, W. J., Vincken, K. L., and Viergever, M. A. (1998). “Multiscale vessel enhancement filtering,” in Medical image computing and computer-assisted intervention — MICCAI’98. Editors W. M. Wells, A. Colchester, and S. Delp (Berlin, Heidelberg: Springer: Lecture Notes in Computer Science), 130–137. doi:10.1007/BFb0056195
Glaser, A. K., Bishop, K. W., Barner, L. A., Susaki, E. A., Kubota, S. I., Gao, G., et al. (2022). A hybrid open-top light-sheet microscope for versatile multi-scale imaging of cleared tissues. Nat. methods 19, 613–619. doi:10.1038/s41592-022-01468-5
Glaser, A., Chandrashekar, J., Vasquez, S., Arshadi, C., Javeri, R., Ouellette, N., et al. (2025). Expansion-assisted selective plane illumination microscopy for nanoscale imaging of centimeter-scale tissues. Elife 12, RP91979. doi:10.7554/elife.91979.4
Govyadinov, P. A., Womack, T., Eriksen, J. L., Chen, G., and Mayerich, D. (2019). Robust tracing and visualization of heterogeneous microvascular networks. IEEE Trans. Vis. Comput. Graph. 25, 1760–1773. doi:10.1109/TVCG.2018.2818701
Guo, J., Artur, C., Eriksen, J. L., and Mayerich, D. (2019). Three-dimensional microscopy by milling with ultraviolet excitation. Sci. Rep. 9, 14578. doi:10.1038/s41598-019-50870-1
Hong, S.-H., Herman, A. M., Stephenson, J. M., Wu, T., Bahadur, A. N., Burns, A. R., et al. (2020). Development of barium-based low viscosity contrast agents for micro CT vascular casting: application to 3D visualization of the adult mouse cerebrovasculature. Tech. Rep. 98, 312–324. doi:10.1002/jnr.24539
Hsu, C.-W., Cerda III, J., Kirk, J. M., Turner, W. D., Rasmussen, T. L., Suarez, C. P. F., et al. (2022). Ez clear for simple, rapid, and robust mouse whole organ clearing. Elife 11, e77419. doi:10.7554/elife.77419
Huang, L.-K., and Wang, M.-J. J. (1995). Image thresholding by minimizing the measures of fuzziness. Pattern Recognit. 28, 41–51. doi:10.1016/0031-3203(94)E0043-K
Huang, C., Lowerison, M. R., Lucien, F., Gong, P., Wang, D., Song, P., et al. (2019). Noninvasive contrast-free 3D evaluation of tumor angiogenesis with ultrasensitive ultrasound microvessel imaging. Sci. Rep. 9, 4907. doi:10.1038/s41598-019-41373-0
Isensee, F., Jaeger, P. F., Kohl, S. A. A., Petersen, J., and Maier-Hein, K. H. (2021). nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 18, 203–211. doi:10.1038/s41592-020-01008-z
Izzo, R., Steinman, D., Manini, S., and Antiga, L. (2018). The vascular modeling toolkit: a python library for the analysis of tubular structures in medical images. J. Open Source Softw. 3, 745. doi:10.21105/joss.00745
Jerman, T., Pernus, F., Likar, B., and Spiclin, Z. (2015). Beyond frangi: an improved multiscale vesselness filter. Orlando, Florida, United States, 94132A. doi:10.1117/12.2081147
Jerman, T., Pernuš, F., Likar, B., and Špiclin, Ž. (2016). Enhancement of vascular structures in 3d and 2d angiographic images. IEEE Trans. Med. Imaging 35, 2107–2118. doi:10.1109/TMI.2016.2550102
Kerautret, B., Krähenbühl, A., Debled-Rennesson, I., and Lachaud, J.-O. (2015). “3d geometric analysis of tubular objects based on surface normal accumulation,” in Image Analysis and Processing—ICIAP 2015: 18th International Conference, Genoa, Italy, September 7-11, 2015 (Springer), 319–331.
Kerautret, B., Krähenbühl, A., Debled-Rennesson, I., and Lachaud, J.-O. (2016). “Centerline detection on partial mesh scans by confidence vote in accumulation map,” in 2016 23rd International Conference on Pattern Recognition (ICPR), 1376–1381.
Kikinis, R., Pieper, S. D., and Vosburgh, K. G. (2013). “3d slicer: a platform for subject-specific image analysis, visualization, and clinical support,” in Intraoperative imaging and image-guided therapy (Springer), 277–289.
Kirst, C., Skriabine, S., Vieites-Prado, A., Topilko, T., Bertin, P., Gerschenfeld, G., et al. (2020). Mapping the fine-scale organization and plasticity of the brain vasculature. Cell180 (04), 780–795. doi:10.1016/j.cell.2020.01.028
Kline, T. L., Zamir, M., and Ritman, E. L. (2010). Accuracy of microvascular measurements obtained from Micro-CT images. Ann. Biomed. Eng. 38, 2851–2864. doi:10.1007/s10439-010-0058-7
Kramer, B., Corallo, C., van den Heuvel, A., Crawford, J., Olivier, T., Elstak, E., et al. (2022). High-throughput 3D microvessel-on-a-chip model to study defective angiogenesis in systemic sclerosis. Sci. Rep. 12, 16930. doi:10.1038/s41598-022-21468-x
Law, M. W. K., and Chung, A. C. S. (2008). “Three dimensional curvilinear structure detection using optimally oriented flux,” in Computer vision – ECCV 2008. Editors D. Forsyth, P. Torr, and A. Zisserman (Berlin, Heidelberg: Springer), 368–382. doi:10.1007/978-3-540-88693-8_27
Law, M. W. K., and Chung, A. C. S. (2010). “An oriented flux symmetry based active contour model for three dimensional vessel segmentation,” in Computer vision – ECCV 2010. Editors K. Daniilidis, P. Maragos, and N. Paragios (Berlin, Heidelberg: Springer), 720–734. doi:10.1007/978-3-642-15558-1_52
Lee, T. C., Kashyap, R. L., and Chu, C. N. (1994). Building skeleton models via 3-D medial surface axis thinning algorithms. CVGIP Graph. Models Image Process. 56, 462–478. doi:10.1006/cgip.1994.1042
Li, C., and Tam, P. (1998). An iterative algorithm for minimum cross entropy thresholding. Pattern Recognit. Lett. 19, 771–776. doi:10.1016/S0167-8655(98)00057-9
Lin, J., Marin, Z., Wang, X., Borges, H. M., N’Guetta, P.-E. Y., Luo, X., et al. (2025). Feature-driven whole-tissue imaging with subcellular resolution. bioRxiv. doi:10.1101/2025.01.23.634600
Lindeberg, T. (1998). Edge detection and ridge detection with automatic scale selection. Int. J. Comput. Vis. 30, 117–156. doi:10.1023/A:1008097225773
Lorensen, W. E., and Cline, H. E. (1998). “Marching cubes: a high resolution 3d surface construction algorithm,” in Seminal graphics: pioneering efforts that shaped the field, 347–353.
Margolis, R., Merlo, B., Chanthavisay, D., Chavez, C., Trinh, B., and Li, J. (2024). Comparison of micro-CT image enhancement after use of different vascular casting agents. Quantitative Imaging Med. Surg. 14, 2568–2579. doi:10.21037/qims-23-901
Mayerich, D., Abbott, L., and McCORMICK, B. (2008). Knife-edge scanning microscopy for imaging and reconstruction of three-dimensional anatomical structures of the mouse brain. J. Microsc. 231, 134–143. doi:10.1111/j.1365-2818.2008.02024.x
Mayerich, D., Kwon, J., Sung, C., Abbott, L., Keyser, J., and Choe, Y. (2011). Fast macro-scale transmission imaging of microvascular networks using KESM. Biomed. Opt. Express 2, 2888–2896. doi:10.1364/BOE.2.002888
Mayerich, D., Bjornsson, C., Taylor, J., and Roysam, B. (2012). NetMets: software for quantifying and visualizing errors in biological network segmentation. BMC Bioinforma. 13 (Suppl. 8), S7. doi:10.1186/1471-2105-13-S8-S7
Otsu, N. (1979). A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man, Cybern. 9, 62–66. doi:10.1109/TSMC.1979.4310076
Palágyi, K., and Kuba, A. (1999). A parallel 3D 12-Subiteration thinning algorithm. Graph. Models Image Process. 61, 199–221. doi:10.1006/gmip.1999.0498
Quintana, D. D., Lewis, S. E., Anantula, Y., Garcia, J. A., Sarkar, S. N., Cavendish, J. Z., et al. (2019). The cerebral angiome: high resolution microct imaging of the whole brain cerebrovasculature in female and male mice. Neuroimage 202, 116109. doi:10.1016/j.neuroimage.2019.116109
Renier, N., Wu, Z., Simon, D. J., Yang, J., Ariel, P., and Tessier-Lavigne, M. (2014). Idisco: a simple, rapid method to immunolabel large tissue samples for volume imaging. Cell 159, 896–910. doi:10.1016/j.cell.2014.10.010
Ridler, T. W., and Calvard, S. (1978). Picture thresholding using an iterative selection method. IEEE Trans. Syst. Man, Cybern. 8, 630–632. doi:10.1109/TSMC.1978.4310039
Ritman, E. L. (2004). Micro-computed tomography—current status and developments. Annu. Rev. Biomed. Eng. 6, 185–208. doi:10.1146/annurev.bioeng.6.040803.140130
Ronneberger, O., Fischer, P., and Brox, T. (2015). U-Net: Convolutional networks for biomedical image segmentation. ArXiv:1505.04597, 234–241. doi:10.1007/978-3-319-24574-4_28
Saadatifard, L., Mobiny, A., Govyadinov, P., Van Nguyen, H., and Mayerich, D. (2020). “Cellular/vascular reconstruction using a deep CNN for semantic image preprocessing and explicit segmentation,” in Machine learning for medical image reconstruction. Editors F. Deeba, P. Johnson, T. Würfl, and J. C. Ye (Cham: Springer International Publishing), 134–144. doi:10.1007/978-3-030-61598-7_13
Schott, B., Weisman, A. J., Perk, T. G., Roth, A. R., Liu, G., and Jeraj, R. (2023). Comparison of automated full-body bone metastases delineation methods and their corresponding prognostic power. Phys. Med. and Biol. 68, 035011. doi:10.1088/1361-6560/acaf22
Suarez, C. P. F., Harb, O. A., Robledo, A., Largoza, G., Ahn, J. J., Alley, E. K., et al. (2024). Mek signaling represents a viable therapeutic vulnerability of kras-driven somatic brain arteriovenous malformations. bioRxiv. doi:10.1101/2024.05.15.594335
Susaki, E. A., Tainaka, K., Perrin, D., Yukinaga, H., Kuno, A., and Ueda, H. R. (2015). Advanced cubic protocols for whole-brain and whole-body clearing and imaging. Nat. Protoc. 10, 1709–1727. doi:10.1038/nprot.2015.085
Tagliasacchi, A., Alhashim, I., Olson, M., and Zhang, H. (2012). Mean curvature skeletons. Comput. Graph. Forum 31, 1735–1744. doi:10.1111/j.1467-8659.2012.03178.x
Tsai, P. S., Friedman, B., Ifarraguerri, A. I., Thompson, B. D., Lev-Ram, V., Schaffer, C. B., et al. (2003). All-optical histology using ultrashort laser pulses. Neuron 39, 27–41. doi:10.1016/S0896-6273(03)00370-2
Tsao, Y., and Fu, K. (1981). A parallel thinning algorithm for 3-D pictures. Comput. Graph. Image Process. 17, 315–331. doi:10.1016/0146-664X(81)90011-3
Vidotto, E., Koch, T., Koppl, T., Helmig, R., and Wohlmuth, B. (2019). Hybrid models for simulating blood flow in microvascular networks. Multiscale Model. and Simul. 17, 1076–1102. doi:10.1137/18m1228712
Wang, R., Lei, T., Cui, R., Zhang, B., Meng, H., and Nandi, A. K. (2022). Medical image segmentation using deep learning: a survey. IET image Process. 16, 1243–1267. doi:10.1049/ipr2.12419
Wei, M., Wang, Q., Li, Y., Pang, W.-M., Liang, L., Wang, J., et al. (2018). Centerline extraction of vasculature mesh. IEEE Access 6, 10257–10268. doi:10.1109/ACCESS.2018.2802478
Yang, S.-F., and Cheng, C.-H. (2014). Fast computation of Hessian-based enhancement filters for medical images. Comput. Methods Programs Biomed. 116, 215–225. doi:10.1016/j.cmpb.2014.05.002
Zhang, Q., Luo, X., Zhou, L., Nguyen, T. D., Prince, M. R., Spincemaille, P., et al. (2022). Fluid mechanics approach to perfusion quantification: vasculature computational fluid dynamics simulation, quantitative transport mapping (qtm) analysis of dynamics contrast enhanced mri, and application in nonalcoholic fatty liver disease classification. IEEE Trans. Biomed. Eng. 70, 980–990. doi:10.1109/tbme.2022.3207057
Keywords: segmentation, skeletonization, vascular, microvascular, network
Citation: Goharbavang H, Ashitkov AT, Pillai A, Wythe JD, Chen G and Mayerich D (2025) Segmentation and modeling of large-scale microvascular networks: a survey. Front. Bioinform. 5:1645520. doi: 10.3389/fbinf.2025.1645520
Received: 11 June 2025; Accepted: 22 August 2025;
Published: 31 October 2025.
Edited by:
Thomas Boudier, Centrale Marseille, FranceReviewed by:
Stephan Daetwyler, University of Texas Southwestern Medical Center, United StatesDhiyanesh B, SRM Institute of Science and Technology, Vadapalani Campus, India
Copyright © 2025 Goharbavang, Ashitkov, Pillai, Wythe, Chen and Mayerich. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: David Mayerich, bWF5ZXJpY2hAdWguZWR1