 Grzegorz Bokota1†
Grzegorz Bokota1† Marta Magnowska2†
Marta Magnowska2† Tomasz Kuśmierczyk3†Michał Łukasik4
Tomasz Kuśmierczyk3†Michał Łukasik4 Matylda Roszkowska2
Matylda Roszkowska2 Dariusz Plewczynski1,5*
Dariusz Plewczynski1,5*- 1Centre of New Technologies, University of Warsaw, Warsaw, Poland
- 2Nencki Institute of Experimental Biology, Polish Academy of Sciences, Warsaw, Poland
- 3Department of Computer and Information Science, Norwegian University of Science and Technology, Trondheim, Norway
- 4Department of Computer Science, University of Sheffield, Sheffield, UK
- 5Faculty of Pharmacy, Medical University of Warsaw, Warsaw, Poland
The common approach in morphological analysis of dendritic spines of mammalian neuronal cells is to categorize spines into subpopulations based on whether they are stubby, mushroom, thin, or filopodia shaped. The corresponding cellular models of synaptic plasticity, long-term potentiation, and long-term depression associate the synaptic strength with either spine enlargement or spine shrinkage. Although a variety of automatic spine segmentation and feature extraction methods were developed recently, no approaches allowing for an automatic and unbiased distinction between dendritic spine subpopulations and detailed computational models of spine behavior exist. We propose an automatic and statistically based method for the unsupervised construction of spine shape taxonomy based on arbitrary features. The taxonomy is then utilized in the newly introduced computational model of behavior, which relies on transitions between shapes. Models of different populations are compared using supplied bootstrap-based statistical tests. We compared two populations of spines at two time points. The first population was stimulated with long-term potentiation, and the other in the resting state was used as a control. The comparison of shape transition characteristics allowed us to identify the differences between population behaviors. Although some extreme changes were observed in the stimulated population, statistically significant differences were found only when whole models were compared. The source code of our software is freely available for non-commercial use1. Contact: ZC5wbGV3Y3p5bnNraUBjZW50LnV3LmVkdS5wbA==.
1. Introduction
Brain plasticity depends on the functional and structural reorganization of the synapses. The majority of the excitatory synapses are located on dendritic spines, which are small membranous protrusions localized on the surface of neuronal dendrites. The important feature of dendritic spines is their structural variability, which ranges from long, filopodia spines to short stubby and mushroom-shaped spines. Dendritic spines are typically composed of a head that is connected to the dendrite by a neck. The size of the spine head is proportional to the postsynaptic density area and correlates with the postsynaptic receptor content and synaptic strength (Nusser et al., 1998; Kharazia and Weinberg, 1999; Takumi et al., 1999). The length of the dendritic spine neck is correlated with the postsynaptic potential (Araya et al., 2006; Tønnesen et al., 2014). Thus, the dendritic spine shape has been accepted for determining the strength of the synaptic connections and is thought to underlie the processes of information coding and memory storage in the brain. Furthermore, alterations in dendritic spine shape, size, and density are associated with a number of brain disorders (DeKosky and Scheff, 1990; Irwin et al., 2001; Selemon et al., 2006; Knobloch and Mansuy, 2008; Sweet et al., 2008; Hutsler and Zhang, 2010; Penzes et al., 2011; Levenga and Willemsen, 2012).
The morphology of spines can change in an activity-dependent manner. The structural plasticity of dendritic spines is related to synaptic function, as the morphological modifications of pre-existing spines as well as the formation or loss of synapses accompany the learning and memory processes (Xu et al., 2009; Yang et al., 2009; for reviews see Holtmaat and Svoboda, 2009; Caroni et al., 2012). The cellular models of synaptic plasticity, long-term potentiation (LTP) and long-term depression (LTD) associate the synaptic strength with spine enlargement and spine shrinkage, respectively (Yuste and Bonhoeffer, 2001; Holtmaat and Svoboda, 2009; Kasai et al., 2010).
Understanding dendritic spine shape taxonomy and shape transitions upon synaptic potentiation is of great importance. The common approach in analysis of dendritic spine morphological changes is to categorize the spines into subpopulations based on whether they are stubby, mushroom, thin, or filopodia shaped (Su et al., 2014). Of importance, the existing categorization of dendritic spine shapes (Su et al., 2014) does not provide a clear definition of each group. Moreover, the literature lacks methods allowing an automated assigment between dendritic spine shapes. Additionally, a recent report suggests the existence of dendritic spine shapes continuum rather than specific spine subclasses (Loewenstein et al., 2015). Thus, the existing classifications have to be revisited and a new automatic classification method with clear mathematical rules should be derived. To address this issue, we employed a new methodological approach with potential applicability in the studies of dendritic spine shape taxonomy and transitions in time. Our clustering-based approach permits analysis of dendritic spine dynamics in multi-dimensional feature space by reducing the complexity subpopulations. To test this method, similarly to previous works, we potentiated the synapses with cLTP stimulation that produces a long-lasting increase in network activity and mimics several aspects of LTP, including synaptic receptor incorporation to the dendritic spine membrane. The morphology of single dendritic spines was assessed using time-lapse imaging of living neurons. In the rest of the paper, we refer to a population of spines stimulated by cLTP as ACTIVE, and the non-treated spines are denoted as CONTROL.
The paper is organized as follows. In Section 2, we describe the process of data gathering and data representation and the statistical approach to analysis of spine shapes. First, we analyze the basic characteristics of features in the populations named ACTIVE and CONTROL and conclude that before a meaningful comparison can be performed, the populations need to be normalized. In Section 3, we develop a simple but meaningful numerical representations of spines and we provide an approach to dendritic spine taxonomy construction and models of shape transitions together with statistical tests for model comparisons. For taxonomy development, we propose a clustering-based approach that does not depend on subjective decisions of experts and can accommodate arbitrary numerical features. Later, we introduce a corresponding probabilistic model of spine transitions between the clusters in time. We also propose a bootstrap-based approach and two statistical tests that are applied for the purpose of the comparison of models built for different populations of spines. Finally, in Section 4, we present an example of method application. We summarize our work in Section 5.
2. Data Preparation and Analysis
In this section, we describe the statistical analyses of mammalian dendritic cell populations ACTIVE and CONTROL. A comparison of the descriptor distributions showed that an initial data preprocessing was necessary, which we performed by carefully choosing subsets of the spines from both populations2. Finally, we introduce the algorithm for spine representation dimensionality reduction.
2.1. Data Acquisition
Dissociated hippocampal cultures were prepared as described previously in Nunez (2008). On the 10th day, in vitro cells were transfected using Effectene (Qiagen) according to the manufacturer's protocol with a plasmid carrying red fluorescence protein under β-actin promoter. All the experiments were performed over the course of 19–21 days in vitro. During the imaging session, the cells were kept in an acquisition chamber with controlled temperature (37°C) and stable CO2 (5%) concentration. Chosen dendritic segments decorated with dendritic spines were imaged at the two time points: at the time 0 (before the stimulation) and 10 min after the stimulation. In the ACTIVE group the chemical LTP (cLTP) was induced by bath application of a mixture of 50 μM forskolin, 50 μM picrotoxin and 0.1 μM rolipram (each dissolved in DMSO) in maintenance media. The CONTROL group received compound-free solvent (DMSO). Of note, the implemented way of stimulation (cLTP) mimics several LTP aspects such as enhanced network activity of the hippocampal neurons (Niedringhaus et al., 2012), delivery of the extrasynaptic AMPA-receptors (Oh et al., 2006), and changes in the dendritic spine structure (Szepesi et al., 2014).
Image acquisition was performed using the Leica TCS SP 5 confocal microscope with a PL Apo 40 × /1.25 NA oil immersion objective using a 561 nm line of diode pumped solid state laser with 10% transmission and collected date with a pixel size of 1024 × 1024. Captured cell images consisted of series of z-stacks taken at every 0.4μm step. On average, around 14–17 slices (depending on specimen thickness) were taken per stack. The final sampling density was 0.07μm per pixel.
The resolution of the confocal microscope along the optical axis (z axis) is three time worse than the resolution along the lateral direction. The majority of observed dendritic spines arise in the lateral direction. Thus, due to limitations of confocal microscopy, it is almost impossible to determine the three-dimensional dendritic spine features. The spines that could be easily distinguished and that protruded in the transverse direction were chosen for analysis. Because of the synaptic scaling, dendritic spine structure and density are modulated with respect to the position along the dendritic tree (Menon et al., 2013). To avoid this issue and following the approach by Michaluk et al. (2011), we chose spines that belonged to the secondary dendrites.
The next step of data preparation was to obtain the numerical features of the spines. Although many spine extraction methods exist (Fanti et al., 2011; Schmitz et al., 2011; Li and Deng, 2012), the methods do not prove to be useful in our approach. Therefore, we analyzed the images semi-automatically using custom written software (Ruszczycki et al., 2012). The recorded dendritic spine features (denoted as DESCRIPTORS) were length, head width (denote hw), max width location (denote mwl), max width (denote mw), neck width (denote nw), foot, circumference, area, width to length ratio (denote wlr), length to width ratio (denote lwr), and length to area ratio (denote lar). Since in this paper we focus on the two dimensional data, the direct dendritic spine volume analysis is not possible. However, the volume can be estimated based on the area. Moreover, the method per se can be used to analyze the three dimensional data. Although researches have not found a consensus yet on which features should be considered, this set covers parameters that are the most often used (Michaluk et al., 2011; Szepesi et al., 2014; Tønnesen et al., 2014). The spine length was determined by measuring the curvilinear length along the virtual skeleton of the spine, which was obtained by fitting the curve (using fourth-degree polynomial). The fitting procedure involved searching for a curve along which the integrated fluorescence was at a maximum level. Many spines were distinctly bent such that the distance along a straight line between the tip and the base of the spine underestimates the length of the spine. To define the head width, we used the diameter of the largest spine section that was perpendicular to the virtual skeleton, while the bottom part of the spine (third of the spine length adjacent to the dendrite) was excluded. To define the neck width, we used the thinnest part of the spine between the position of the head-width measurement and the point at which the spine is anchored into the dendrite. The details can be found at work done by Ruszczycki et al. (2012).
We ended up with two groups of spines, the stimulated ACTIVE type consisting of 433 samples and the control CONTROL type consisting of 490 samples. For each spine, all of the above 11 features were measured at two different timestamps: t0 (the time before stimulation) and t1 (10 min after t0). It has been shown that that after 10 min (Szepesi et al., 2014), modifications in the spine structure could already be observed and demonstrated that stimulation causes the cleavage of important adhesion molecules at the dendritic spines (Stawarski et al., 2014). Consequently, by ACTIVE (CONTROL), we denote all features at all timestamps and, by ACTIVEx, we denote all spines from the ACTIVE data set described only by features at time tx (similarly, CONTROLx).
2.2. Balanced Subset Selection
In Table 1, we report the mean values for descriptors from ACTIVE0 and CONTROL0 populations. We report p-values from two-tailed t-tests3 for the difference of means between both sets. We report significant differences for almost all descriptors (only for three features is the p-value above the threshold value p > 0.001).
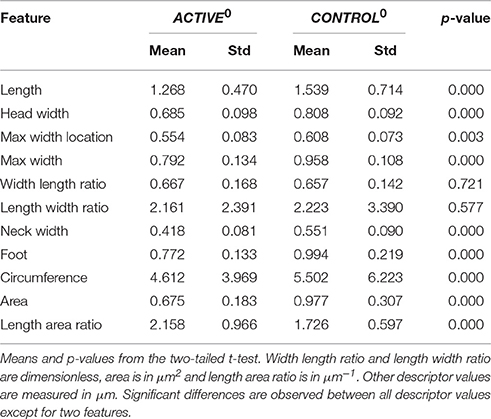
Table 1. Differences between ACTIVE and CONTROL at time t0.
Such large differences between both sets may influence the statistical analysis of their behavior. Therefore, we decided to preprocess the datasets by excluding some spines, such that the means in the new sets are similar with respect to the statistical test used. Namely, we drew a number of pairs of closest spines, each pair consisting of a spine from the ACTIVE set and a spine from the CONTROL. The measure of how close the spines are is based on the normalized Euclidean distance4 between the vectors of features at time t0. The pseudo-code for the algorithm is presented in Algorithm S1 in the Supplementary Material.
Such an approach can be justified by the fact that the two cultures were obtained from different animals (each culture consist of a mix of dissociated hippocampal neurons isolated from one litter of rat pups), thus a systematic differences might appear between in vitro cultures. Initially dendritic spines may exhibit a significant structural differences between cultures, yet here we focus on the direction of stimulation-induced structural changes. The implemented standardization allowed us to eliminate the changes unrelated to the treatment and highlight the stimulation-related modifications in dendritic spine structure between the analyzed groups5. One can not exclude a possibility that the change in the dendritic spines may be dependent on their initial morphological features (Kasai et al., 2003; Szepesi et al., 2014). Thus, the implemented normalization of the dendritic spine shape at the beginning of the analysis should not affect the obtained outcome.
In Table 2, we report new statistics on the differences between samples after the 300 closest pairs have been drawn6. The same statistical test that was performed before is used here as well. The p-values are significantly higher for all features, and no one feature is significantly different in the two compared groups. We are going to further investigate these new “normalized” sets, denoted as ACTIVE300 (the 300 closest spines drawn from ACTIVE) and CONTROL300 (the 300 closest spines drawn from CONTROL).
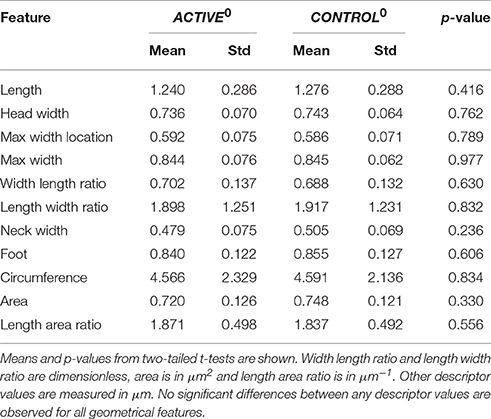
Table 2. Differences between ACTIVE3000 and CONTROL3000 at time t0.
3. Methods
In this section, we present PCA and apply two clustering methods to construct the spine shape taxonomy in an unsupervised way. Further, we build the probabilistic model of shape changes in time. Finally, the bootstrap analysis is presented to statistically evaluate the differences between both the resting and potentiated populations.
3.1. Simplification of Shape Representations
The Principal Component Analysis (PCA) (for details see Jolliffe, 2002) is used where the reduction of the data dimensionality is required. It has been used in order to provide the most significant information. The PCA method provides orthogonal basis, which is required for Euclidian metrics used for clustering. We applied PCA to spines from both populations CONTROL and ACTIVE and for both t0 and t1. For the first two features (components) in the reduced representation, we cover about 91% of the variance in the data (see Figure S1). The removal of other features does not reduce the available information by much (only 9% of the variance is lost). The new features are linear combinations of the initial features: Comp.1′ = −0.27 · length − 0.49 · lwr − 0.81 · circumference − 0.15 · area; Comp.2′ = − 0.17 · hw − 0.17 · mw − 0.11 · wlr + 0.71 · lwr − 0.12 · nw − 0.12 · foot − 0.41 · circumference − 0.21 · area + 0.44 · lar. We see that Comp.1′ is composed mostly of features related to size such as length, circumference, and area. Therefore, this feature can be treated as a generalized size descriptor. Similarly, we can interpret Comp.2′ as a generalized contour (shape slenderness) descriptor.
The interpretation of the above components as size and contour descriptors allows us to construct more meaningful features. The initial features can be directly divided into two sets: DESCRIPTORSSIZE ={length, circumference, area} (size related features) and DESCRIPTORSCONTOUR ={hw, foot, mwl, mw, wlr, lwr, lar, nw} (contour related features). Then, PCA is applied separately to each of the sets. Using the first feature from PCA on DESCRIPTORSSIZE and the first feature from PCA on DESCRIPTORSCONTOUR, 87% of the variance is explained (see Figure S2). The loss of the variance compared with PCA computed on all features merged together is equal to 4%. However, the new representation (denoted as DESCRIPTORSPCA) is easy to interpret. The new features provide a clear meaning of size and contour slenderness and reduce to a simple form:
Comparing the loadings (weights) against previous formulas for Comp.1′ and Comp.2′, we notice that the differences are small, i.e., below 15% in most cases. The most important feature of the size descriptor is the circumference (the highest loading), and the most important feature of the contour descriptor is lwr. Most of the initial features, i.e., hw, foot, mwl, mw, and nw, are not included (We used the Principal Component Analysis function (princomp) which is implemented in programming language R. Feature weights smaller than 10% were neglected.
Spine distributions in the new feature space Comp.1 × Comp.2 are shown in Figure 1. The whole space of features was partitioned into tiles of size 4 × 4, and for each tile, one representative spine (the closest to the tile center) was chosen. We can see how the spine size changes along Comp.1 from the smallest on the right side to the biggest one on the left side. Similarly, spine slenderness change along Comp.2, from the thinnest on the top to the thickest on the bottom.
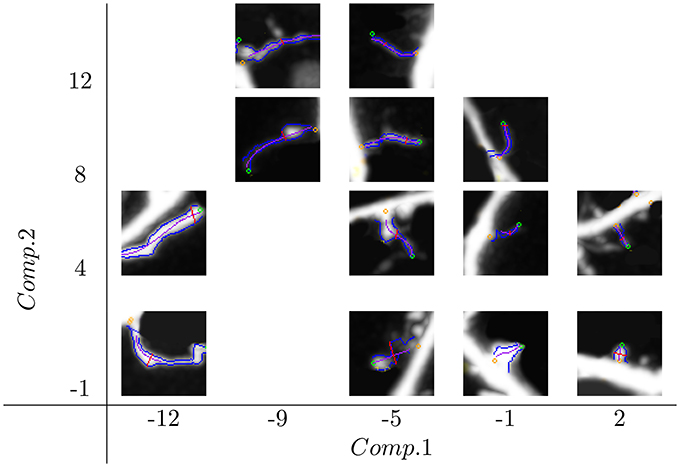
Figure 1. Distribution of spine shapes in space composed of the features Comp.1 and Comp.2. Comp.1 is a generalized size descriptor, and Comp.2 is a generalized spine slenderness. Spine sizes change along Comp.1 from the smallest on the right side to the biggest on the left side. The spine contour slenderness changes along Comp.2 from the thinnest on the top to the thickest on the bottom.
3.2. Clusters of Shapes
Initially, the spines are represented in some arbitrary multidimensional space of features, e.g., DESCRIPTORSPCA. Our goal is to obtain a high-level representation that would be both meaningful and simple. Therefore, we propose to apply clustering. Clustering allows for assigning similar objects in terms of their geometrical properties (for example, spines) to groups; i.e., subsets that we call clusters in our paper. In this study the clusters represent the possible shapes of spines. The underlying idea is that the spines in a cluster have greater similarity shapes (they are more similar in terms of derived features) among themselves than to spines outside the given cluster. We consider two well-established algorithms, cmeans (Bezdek, 1981) and average-linkage hierarchical (Murtagh, 1983), that represent the two main types of clustering: crisp and fuzzy.
In clustering, each spine s is assigned a vector w(s) = (w1(s), …, wk(s)) of k membership weights that are non-negative and sum up to 1. For example, wn(s) is a membership of the spine s against the n-th cluster. In crisp clustering, spines are assigned to exactly one cluster (wn(s) = 1⇔ s assigned to n-th cluster; 0 otherwise). In fuzzy clustering, weights can be arbitrary real numbers between 0 and 1. Additionally, weights can be interpreted as probabilities, e.g., wn(s) can be interpreted as the probability that spine s belongs to the n-th cluster.
To obtain a taxonomy of shapes that would describe the spines in both time points equally well, we applied clustering to data ACTIVE ∪ CONTROL from both time points t0 and t1. Consequently, each spine was included twice and assigned two vectors of weights. Spine s at time t0 is assigned the vector w0(s) and at time t1 the vector w1(s). We denote as the probability that spine s belongs to cluster n at time ti.
The above clustering algorithms have either one (hierarchical) or two (cmeans) parameters: k - number of clusters and m - fuzzifier (indicates cluster fuzziness). A large m results in smaller weights and more fuzzy clusters. For small m, e.g., m = 1, we obtain results close to crisp clustering. Consequently, low values of both k and m are preferred. Although these parameters can be selected in many ways, we decided to use the Within Cluster Sum of Squares (WSS) (Thorndike, 1953). The definition of WSS is as follows: where is the n-th cluster centroid and stands for the vector of features assigned to object s. WSS has several good properties; i.e., simple meaning, applicability to both crisp and fuzzy cases, and the same behavior no matter what data and what clustering algorithm are used (it decreases when k increases and when m decreases). For a balance between the number of clusters, data fitness values of k and m at the “knee point” (the point where WSS plot bends the most) should be selected.
3.3. Shape Transition Model
3.3.1. Assumptions and Brief Description
It has been showed that the initial dendritic spine morphology may influence how this structure will change upon specific treatment (Matsuzaki et al., 2004; Szepesi et al., 2014); i.e., the induction of long-term potentiation. Therefore, we assume that changes of spines depend on their initial shapes and that each spine follows patterns of behavior highly correlated with its initial shape. We introduce a novel probabilistic model of behavior that relies on these principles.
The shapes of dendritic spines are represented as weights of shape clusters wn(s). The changes of spines shapes are represented by the combinations of behavior patterns represented with probabilities P(Cn → Cm|Cn) or the probability that the shape represented by cluster Cn will change into the shape represented by cluster Cm when t0 → t1. Probabilities P can be stored in a k × k matrix called transition matrix, where rows are enumerated with n and columns with m. An even more convenient representation of the same information is a graph, where nodes represent shape clusters and edges are labeled with probabilities, denoted as a transition graph (i.e., Figures 3, 4).
3.3.2. Probability Estimation
In the crisp, e.g., hierarchical model of shapes, we can estimate the probability P as follows: . In the denominator, we have the number of spines that belong to cluster Cn in time t0 (normalizer). In the nominator, there is the number of spines that belong to cluster Cn in time t0 and to cluster Cm in time t1 (recall that only for one n in and for one m in a , the values are ones; elsewhere, they are zeros). With such a computation, we consider how many spines moved from shape cluster Cn to Cm and normalize it by the number of all spines in the initial cluster Cn.
There are arbitrarily many generalizations that are consistent with the above crisp derivation for the fuzzy model, (e.g., the cmeans model); i.e., can be reformulated in many ways without changing the values of Pcrisp, e.g., as . We suggest using the generalization for which the model minimizes the prediction error for the distribution of shapes at time t1. The probability that spine s in time t1 will be in cluster Cm for our linear model is given according to the law of total probability as follows:
The overall prediction error can be computed as a sum of squared differences between predicted () and derived probabilities (P1):
where for each spine s in the data, we compare the membership for cluster Cm at time t1 with the prediction of the model. The problem can be now formulated as an optimization task where we search for probabilities P(Cn → Cm|Cn) that minimize the overall prediction error E:
The above derivations can be easily represented in matrix form, and the above optimization problem is an example of a standard quadratic programming optimization task with constraints. The details are presented in Section S2 in Supplementary Material.
3.3.3. Prediction of the Weights at Time t1
To verify the model (for example, in the case of cross-validation procedure), or apply it to new datasets, we implemented the computational method to estimate structural changes (described here as 2D descriptors) of a spine in time. The estimation of weights in time t1 for a new spine s (not in the training data) is not always obvious. For hierarchical clustering, we used a first nearest neighbor classifier for parameters in time t0; i.e., we searched for the most similar sample vector (s′), in time t0, from the training data and assigned w(s) = w(s′), where w0(s) is the classification and w1(s) is the estimation of changes of s in time. For cmeans clustering, the prediction of weights of a new spine (s) is more straightforward. Each spine, whether from the training data or not, has weights (w0) assigned according to the same explicit formula: where where cn is the n-th cluster centroid. This calculates the probability that a given spine is in the n-th cluster based on the distance from the cluster centroid. Estimation of the weights w1(s) can be calculated as matrix-multiplication with transition matrix w1(s) = Pw0(s), where P = [pi, j] and pi, j = P(Cj → Ci|Cj).
3.3.4. Parameter Reliability
To derive information on the reliability of the obtained probabilities, we use the following bootstrap-based procedure. We generate R = 1000 new populations sampled with replacement from the original population. For each new population, we calculate all the probabilities again. The average squared differences between the probabilities for the new populations and the original populations are used as the estimates of parameter errors. Formally, the error of the probability P(Cn → Cm|Cn) is calculated as:
where P(Cn → Cm|Cn)|r denotes the probability calculated for the r-th bootstrap population.
3.4. Comparison of Models
Bootstrap Hypothesis Testing (Efron and Tibshirani, 1993) is a method of testing statistical hypotheses. To apply the method, one has to first modify the testing sample so that the null hypothesis is satisfied. Subsequently, a large number of bootstrap samples are drawn from such a modified sample. Finally, for the fixed statistic of interest, one must evaluate how extreme the value of the statistic is for the original sample compared with the values obtained for the drawn bootstrap samples.
This general rule in our case proceeds as follows. We take the two groups ACTIVE300 and CONTROL300 and join them into one group ACTIVE300 ∪ CONTROL300. This group contains information about changes between t0 and t1 time. At each iteration of bootstrap sampling, two new groups are drawn from the joint dataset. This way, the null hypothesis of a common distribution for both groups is satisfied. Next, for each bootstrap, the sample clusters and Shape Transition Model are constructed for both groups. Then, the test statistic is computed. Finally, the statistic are computed on models built from the original groups and compared with the bootstrap sampling results.
3.4.1. Comparison of Changes in Cluster Distributions
We cluster spines according to their shapes (see Section 3.2). As a result, for each spine s at t0 and t1, we obtain the set of weights representing a mixture of shapes. Then, we derive the overall distribution (total weights) of shapes (by shapes, we mean clusters of shapes) at both t0 and t1. The n-th cluster total weight (in the case of crisp; e.g., hierarchical clustering, it is equivalent to the number of spines) in t0 is equal to and in t1 is equal to . Consequently, the relative change in the n-th cluster weight between t0 and t1 for population G can be computed as follows: . The statistic that measures the difference between relative changes in distributions of shapes for populations G1, G2 can be now defined as:
3.4.2. Comparison of Transition Matrices
By applying the Shape Transition Model (see Section 3.3), we construct two Markov matrices (transition matrices) describing the transitions for both populations. To check how similar the matrices are, we also decided to apply bootstrap hypothesis testing. For comparing the matrices, we use the sum of squared differences between corresponding cells from the two matrices:
where G1, G2 are populations, e.g., ACTIVE300, CONTROL300, to be compared. Pnm|Gi ≡ P(Cn → Cm|Cn)|Gi stands for the value of a cell in the n-th row and in the m-th column of the transition matrix P built with data from population Gi.
4. Results
Here, we provide an example of an application of the method. To obtain the taxonomy of spine shapes, we applied cmeans and hierarchical clustering to DESCRIPTORSPCA for ACTIVE ∪ CONTROL for t0 and t1. To select the proper values of the parameters, we used WSS plots with “knee” shapes (see Figure S3). We obtained k = 10 for hierarchical and k = 8, m = 4 for cmeans clustering. According to WSS measures, these values ensure a good balance between the complexity of the results; i.e., the number of clusters and quality of cluster fitness.
Figure 2A presents the results of hierarchical clustering calculated for ACTIVE ∪ CONTROL according to the procedure described in Section 3.2. Each spine is represented with a single point, and the colors represent the cluster memberships. For each cluster, we identified three representative spines lying nearest to the cluster center. Representative spines are shown in Figure 2B. The obtained clusters express the universal taxonomy of shapes that will be later employed for the computation of Shape Transition Model for ACTIVE, CONTROL, ACTIVE300, and CONTROL300. Representative spines can be used for visual inspection and biological interpretation.
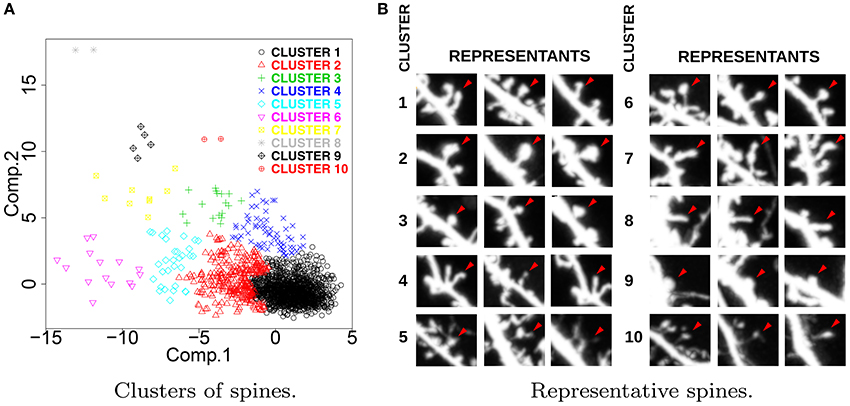
Figure 2. (A) Distribution of spine clusters obtained by hierarchical clustering. (B) Representative spines obtained for ACTIVE ∪ CONTROL. The presented clusters represent the universal taxonomy of spine shapes. For each cluster, we present three spines that are nearest to the cluster center. Representative spines facilitate visual aid for interpretation purposes.
Apart from hierarchical clustering, we also consider cmeans clustering. Table 3 presents the comparison of the prediction error E for both methods. Values were obtained using 10-fold cross-validation. For the purposes of cross-validation, the dataset was randomly separated into ten (10) subsets. Numbers from the same column but in different rows should not be compared. Different clustering methods result in different shape clusters that have different members and thus are incomparable. Although the errors E for different methods have different ranges and cannot be compared, different models with the same method can be compared.

Table 3. Prediction error E for various models and clustering methods.
The Shape Transition Model is compared with three baselines. The first baseline is the majority vote model, where all spines from a particular cluster move to a single destination cluster that is selected as the most popular choice. The second baseline is the model, where we assume that all spines remain in the initial clusters, i.e., weights in t1 are the same as in t0. Finally, the third baseline assumes random values for the probability P. For both clustering methods, the Shape Transition Model has the smallest error E and predicts spine behavior the best.
Transition graphs of the Shape Transition Model for ACTIVE and CONTROL are shown in Figures 3A,B. Each cluster of shapes is represented by an oval. Initial sizes, i.e., weights of clusters (for hierarchical clustering equivalent to number of spines), are listed. Edges representing transitions are labeled with probability P. They are filtered out, and only transitions (probabilities) greater than 20% of the initial weight are visible.
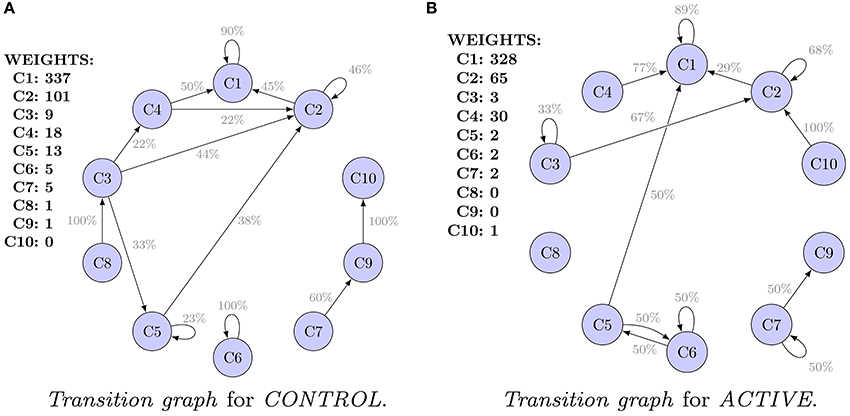
Figure 3. Transition graphs for hierarchical clustering. For each cluster, the initial weight (number of spines in the cluster) is presented. Only transitions (probabilities) of values higher than 20% are shown. Only clusters 1–5 are well represented in the data. Transitions for the remaining clusters are uncertain. (A) Transition graph for CONTROL. (B) Transition graph for ACTIVE.
Only five clusters (numbers 1–5) are well represented in the data. Clusters 1, 2, and 4 are the most dense. Clusters 3 and 5 are interpreted as peripheral. Finally, clusters 6–10 have only a few spines. For transitions from clusters 6–10, high errors were obtained. For example, SE for P(C9 → C10|C9) is equal to 66%. Conclusions concerning clusters 6–10 are not reliable. Analogous plots of clustering results and transition graphs for cmeans are presented in Figures S4, S5A,B.
Graphs presented in Figures 3A,B should not be compared because they are computed for populations of different characteristic at t0. Alternatively, Figure 4 presents a comparison of the transition graphs for CONTROL300 and ACTIVE300 for hierarchical clustering (the exact values of the probabilities can be found in Table S1). A similar analysis for cmeans is presented in Figure S6, and the values of the transitions in percent can be found in Table S2.
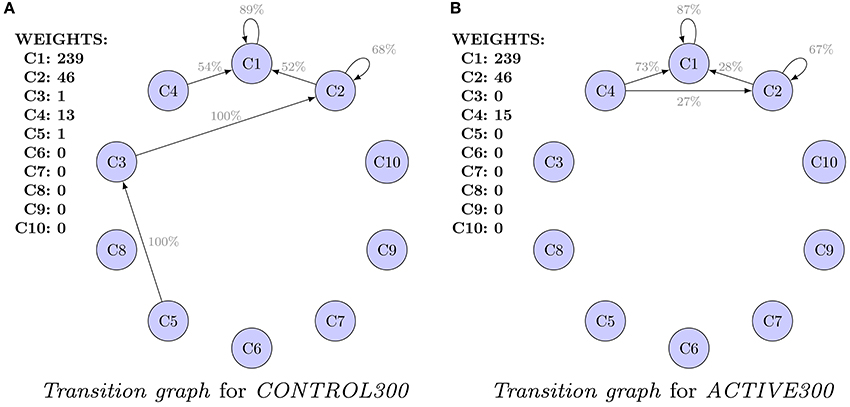
Figure 4. Comparison of the transition graphs for balanced subpopulations and hierarchical clustering. For each cluster, the initial weight (number of spines in the cluster) is presented. Values are given in percents. Only transitions (probabilities) of values higher than 20% are shown. Differences in transitions between graphs are observed, but because of high uncertainties, none of them is significant. (A) Transition graph for CONTROL300. (B) Transition graph for ACTIVE300.
In the case of the CONTROL300 and ACTIVE300 subsets (Figure 4), only clusters 1, 2, and 4 contain enough spines to produce credible conclusions. For CONTROL300, cluster 1 has a slightly stronger inertia than for ACTIVE300 (91 vs. 87% spines remained in the same cluster). For cluster 2, the situation is the opposite: 41% of spines from cluster 2 for CONTROL300 remain in cluster 2 compared with 67% for ACTIVE300. For both populations, a large transition of spines from cluster 2 to cluster 1 is observable. However, for CONTROL300, it is present for 52% of the spines, whereas for ACTIVE300, it is present only for 28%. Another difference is visible for transitions from cluster 4. For CONTROL300, 73% of spines move to cluster 1 and 27% to cluster 2. For ACTIVE300, only 54% of spines move to cluster 1, and the rest move to clusters 2–5. Unfortunately, none of the observed differences is significant when the errors are taken into consideration. Therefore, to identify such differences, the models must be compared as a whole.
Table 4 presents p-values of RDC and SMD statistics (Equations 5 and 6) used for a comparison of models for ACTIVE300 and CONTROL300. Results below 0.05 are marked in bold font. Detailed plots of the statistical distributions using kernel estimation are shown in Figures S7, S8. For hierarchical clustering, only SMD shows a significant difference between ACTIVE300 and CONTROL300. This statistic compares transitions of spines between shapes, which is well captured by hierarchical clustering. The RDC statistics depend only on changes of distributions, and hierarchical clustering enforces that each spine belongs to only one shape cluster at the particular time point, which may noticeably affect the overall distributions. In contrast, the distributions are well captured by cmeans clustering, where each spine is an arbitrary mixture of shapes and RDC shows a significant difference. Different clustering methods are sensitive to different properties of the data. The selection of the right clustering method and appropriate test depends on the characteristic of the data that is of interest to the researcher.
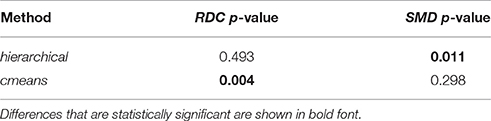
Table 4. P-values of RDC and SMD statistics with bootstrap tests used to compare balanced subpopulations ACTIVE300 and CONTROL300 for various clustering methods.
5. Discussion and Conclusions
The majority of excitatory synapses in the brain are located on dendritic spines. These highly dynamic and plastic structures undergo constant morphological changes in different physiological and pathological processes (Kasai et al., 2010). The structure of the dendritic spines is tightly correlated with their function and reflects the synapse properties. Synapse strengthening or weakening along with dendritic spine formation and elimination assure correct processing and storage of the incoming information in the neuronal network. This plastic nature of the dendritic spines allows them to undergo activity-dependent structural modifications, which are thought to underlie learning and memory formation. At the cellular level, the most extensively studied aspect of this phenomena is related to dendritic spine enlargement in response to stimulation.
In this study, we show a computational method that permits statistical analysis of the impact of an externally applied stimulation on the dendritic spine structural dynamics. We applied statistical tests and examined a population consisting of 923 dendritic spines. We used two dissociated neuronal cell cultures and compared the dendritic spine volume and shape changes between two populations at two different states, unstimulated (CONTROL) and LTP-stimulated (ACTIVE), and at two time points (with a 10-min time interval). We preprocessed the datasets and reduced the dendritic spine number to 300 for each analyzed group.
We provided a probabilistic model for dendritic spine population dynamics. First, the resting state model was constructed (Figure 3A). Then, the probabilistic null model for active neurons was built (Figure 3B). We showed that LTP treatment induced transition of filopodia-like spines (cluster 4) into mushroom-shaped spines (cluster 2). For the first time, we provided exact transition probabilities for this morphological transformation (from cluster 4 to cluster 2, the transition probability was found to be 0.27 ± 0.11). Our result show that in ACTIVE300 in comparision to CONTROL300 there is significant group of growing neurons which partially supports the previous studies (Szepesi et al., 2014) that report chemical LTP-induced spine enlargement in dissociated cultures.
Finally, we compared the models for balanced populations (Figure 4). We found differences between active and non-active neurons. Unfortunately, none of the observed differences between the models was significant when particular transitions between shape clusters were considered. Such absence of significant differences can be explained by too small number of spines in analyzed data. Large errors predominated the differences between values in cells of appropriate transition matrices. However, statistically significant differences were detected when models of populations were compared. Different clustering algorithms showed statistically significant differences between the two analyzed groups (ACTIVE300, CONTROL300). Crisp clustering captured the difference in shapes transitions well, whereas fuzzy clustering captured the difference in changes of shape cluster distributions.
Ethics Statement
All experimental procedures were carried out in accordance with the Ethical Committee on Animal Research of the Nencki Institute, based on the Polish Act on Animal Welfare and other national laws that are in full agreement with EU directive on animal experimentation.
Author Contributions
MM and MR performed biological experiments and did manually segmentation of spines from confocal microscope images. TK, MŁ, GB, and DP designed the computational method and performed statistical analysis. GB contributed in the data analysis and visualization. All authors read and approved the final manuscript.
Funding
TK and MŁ were partially supported by research fellowships within “Information technologies: research and their interdisciplinary applications” agreement POKL.04.01.01-00-051/10-00. MM and MR were supported by the grants no. 6651/B/P01/2011/40 and UMO-2015/17/B/NZ3/00557 from National Science Centre Poland. DP, GB, TK, and MŁ was supported by the Polish National Science Centre (Grant numbers 2013/09/B/NZ2/00121 and 2014/15/B/ST6/05082) and COST BM1405 and BM1408 EU actions.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors are grateful to Prof. Jakub Wlodarczyk, Prof. Grzegorz Wilczynski, and Prof. Subhadip Basu for extensive discussions on the information processing problem in neuronal systems and especially to Blazej Ruszczycki for preparation of the segmentation software used for acquiring the morphological descriptors. Some calculations were performed at the Interdisciplinary Centre for Mathematical and Computational Modelling, University of Warsaw, grant No. G49-19. The data used in the experimental part of the study were gathered in the Laboratory of Cell Biophysics at Nencki Institute of Experimental Biology under the supervision of Prof. Jakub Wlodarczyk. We would like to thank Wayne Dawson for help with editing the final version of the manuscript. The authors are grateful to reviewers for their remark.
Supplementary Material
The Supplementary Material for this article can be found online at: http://journal.frontiersin.org/article/10.3389/fncom.2016.00140/full#supplementary-material
Footnotes
1. ^https://bitbucket.org/3dome/spines
2. ^Even under ideal experimental conditions, variation among the spines is still present; thus, we choose to standardize them. This practice allows us to start with more homogeneous data and to reveal subtle differences.
3. ^The null hypothesis is that the means are equal, and the alternative is that the means are different.
4. ^Each feature is normalized by subtracting the mean and dividing by the standard deviation, both calculated based on the feature values from both the ACTIVE and CONTROL sets.
5. ^Systematic differences between the analyzed populations were observed and it is noted that the implemented statistical normalization could cause certain biases.
6. ^We tried various different numbers of spines (100, 200, 300, 400) and concluded that 300 is the largest which satisfies the desired condition for assessing similarity between different spines.
References
Araya, R., Jiang, J., Eisenthal, K. B., and Yuste, R. (2006). The spine neck filters membrane potentials. Proc. Natl. Acad. Sci. U.S.A. 103, 17961–17966. doi: 10.1073/pnas.0608755103
Bezdek, J. C. (1981).Pattern Recognition with Fuzzy Objective Function Algorithms. Norwell, MA: Kluwer Academic Publishers. doi: 10.1007/978-1-4757-0450-1
Caroni, P., Donato, F., and Muller, D. (2012). Structural plasticity upon learning: regulation and functions. Nat. Rev. Neurosci. 13, 478–490. doi: 10.1038/nrn3258
DeKosky, S. T., and Scheff, S. W. (1990). Synapse loss in frontal cortex biopsies in Alzheimer's disease: correlation with cognitive severity. Ann. Neurol. 27, 457–464. doi: 10.1002/ana.410270502
Efron, B., and Tibshirani, R. (1993). An Introduction to the Bootstrap. New York, NY: Macmillan Publishers Limited. doi: 10.1007/978-1-4899-4541-9
Fanti, Z., Elena Martinez-Perez, M., and De-Miguel, F. F. (2011). Neurongrowth, a software for automatic quantification of neurite and filopodial dynamics from time-lapse sequences of digital images. Dev. Neurobiol. 71, 870–881. doi: 10.1002/dneu.20866
Holtmaat, A., and Svoboda, K. (2009). Experience-dependent structural synaptic plasticity in the mammalian brain. Nat. Rev. Neurosci. 10, 647–658. doi: 10.1038/nrn2699
Hutsler, J. J., and Zhang, H. (2010). Increased dendritic spine densities on cortical projection neurons in autism spectrum disorders. Brain Res. 1309, 83–94. doi: 10.1016/j.brainres.2009.09.120
Irwin, S. A., Patel, B., Idupulapati, M., Harris, J. B., Crisostomo, R. A., Larsen, B. P., et al. (2001). Abnormal dendritic spine characteristics in the temporal and visual cortices of patients with fragile-X syndrome: a quantitative examination. Am. J. Med. Genet. 98, 161–167. doi: 10.1002/1096-8628(20010115)98:2<161::AID-AJMG1025>3.0.CO;2-B
Kasai, H., Fukuda, M., Watanabe, S., Hayashi-Takagi, A., and Noguchi, J. (2010). Structural dynamics of dendritic spines in memory and cognition. Trends Neurosci. 33, 121–129. doi: 10.1016/j.tins.2010.01.001
Kasai, H., Matsuzaki, M., Noguchi, J., Yasumatsu, N., and Nakahara, H. (2003). Structure stability function relationships of dendritic spines. Trends Neurosci. 26, 360–368. doi: 10.1016/S0166-2236(03)00162-0
Kharazia, V., and Weinberg, R. (1999). Immunogold localization of AMPA and NMDA receptors in somatic sensory cortex of albino rat. J. Comp. Neurol. 412, 292–302. doi: 10.1002/(SICI)1096-9861(19990920)412:2<292::AID-CNE8>3.0.CO;2-G
Knobloch, M., and Mansuy, I. M. (2008). Dendritic spine loss and synaptic alterations in Alzheimers disease. Mol. Neurobiol. 37, 73–82. doi: 10.1007/s12035-008-8018-z
Levenga, J., and Willemsen, R. (2012). “Chapter 8 - Perturbation of dendritic protrusions in intellectual disability,” in Down Syndrome: From Understanding the Neurobiology to Therapy, volume 197 of Progress in Brain Research, eds M. Dierssen and R. D. L. Torre (Oxford: Elsevier), 153–168.
Li, Q., and Deng, Z. (2012). A surface-based 3-d dendritic spine detection approach from confocal microscopy images. IEEE Trans. Image Process. 21, 1223–1230. doi: 10.1109/TIP.2011.2166973
Loewenstein, Y., Yanover, U., and Rumpel, S. (2015). Predicting the dynamics of network connectivity in the neocortex. J. Neurosci. 35, 12535–12544. doi: 10.1523/JNEUROSCI.2917-14.2015
Niedringhaus, M., Chen, X., Dzakpasu, R., and Conant, K. (2012). MMPs and soluble ICAM-5 increase neuronal excitability within in vitro networks of hippocampal neurons. PLoS ONE 7:e42631. doi: 10.1371/journal.pone.0042631
Matsuzaki, M., Honkura, N., Ellis-Davies, G. C., and Kasai, H. (2004). Structural basis of long-term potentiation in single dendritic spines. Nature 429, 761–766. doi: 10.1038/nature02617
Oh, M. C., Derkach, V. A., Guire, E. S., and Soderling, T. R. (2006). Extrasynaptic membrane trafficking regulated by glur1 serine 845 phosphorylation primes AMPA receptors for long-term potentiation. J. Biol. Chem. 281, 752–758. doi: 10.1074/jbc.M509677200
Menon, V., Musial, T. F., Liu, A., Katz, Y., Kath, W. L., Spruston, N., et al. (2013). Balanced synaptic impact via distance-dependent synapse distribution and complementary expression of AMPARs and NMDARs in hippocampal dendrites. Neuron 80, 1451–1463. doi: 10.1016/j.neuron.2013.09.027
Michaluk, P., Wawrzyniak, M., Alot, P., Szczot, M., Wyrembek, P., Mercik, K., et al. (2011). Influence of matrix metalloproteinase MMP-9 on dendritic spine morphology. J. Cell Sci. 124, 3369–3380. doi: 10.1242/jcs.090852
Murtagh, F. (1983). A survey of recent advances in hierarchical clustering algorithms. Comput. J. 26, 354–359. doi: 10.1093/comjnl/26.4.354
Nunez, J. (2008). Primary culture of hippocampal neurons from P0 newborn rats. J. Visual. Exp. 895. doi: 10.3791/895
Nusser, Z., Lujan, R., Laube, G., Roberts, J. D. B., Molnar, E., Somogyi, P., et al. (1998). Cell type and pathway dependence of synaptic AMPA receptor number and variability in the hippocampus. Neuron 21, 545–559. doi: 10.1016/S0896-6273(00)80565-6
Penzes, P., Cahill, M. E., Jones, K. A., VanLeeuwen, J.-E., and Woolfrey, K. M. (2011). Dendritic spine pathology in neuropsychiatric disorders. Nat. Neurosci. 14, 285–293. doi: 10.1038/nn.2741
Ruszczycki, B., Szepesi, Z., Wilczynski, G., Bijata, M., Kalita, K., Kaczmarek, L., et al. (2012). Sampling issues in quantitative analysis of dendritic spines morphology. BMC Bioinformatics 13:213. doi: 10.1186/1471-2105-13-213
Schmitz, S. K., Hjorth, J. J., Joemai, R. M., Wijntjes, R., Eijgenraam, S., de Bruijn, P., et al. (2011). Automated analysis of neuronal morphology, synapse number and synaptic recruitment. J. Neurosci. Methods 195, 185–193. doi: 10.1016/j.jneumeth.2010.12.011
Selemon, L. D., Begović, A., Goldman-Rakic, P. S., and Castner, S. A. (2006). Amphetamine sensitization alters dendritic morphology in prefrontal cortical pyramidal neurons in the non-human primate. Neuropsychopharmacology 32, 919–931. doi: 10.1038/sj.npp.1301179
Stawarski, M., Rutkowska-Wlodarczyk, I., Zeug, A., Bijata, M., Madej, H., Kaczmarek, L., et al. (2014). Genetically encoded FRET-based biosensor for imaging MMP-9 activity. Biomaterials 35, 1402–1410. doi: 10.1016/j.biomaterials.2013.11.033
Su, R., Sun, C., Zhang, C., and Pham, T. D. (2014). A novel method for dendritic spines detection based on directional morphological filter and shortest path. Comput. Med. Imaging Graph. 38, 793–802. doi: 10.1016/j.compmedimag.2014.07.006
Sweet, R. A., Henteleff, R. A., Zhang, W., Sampson, A. R., and Lewis, D. A. (2008). Reduced dendritic spine density in auditory cortex of subjects with schizophrenia. Neuropsychopharmacology 34, 374–389. doi: 10.1038/npp.2008.67
Szepesi, Z., Hosy, E., Ruszczycki, B., Bijata, M., Pyskaty, M., Bikbaev, A., et al. (2014). Synaptically released matrix metalloproteinase activity in control of structural plasticity and the cell surface distribution of GluA1-AMPA receptors. PLoS ONE 9:e98274. doi: 10.1371/journal.pone.0098274
Takumi, Y., Ramírez-León, V., Laake, P., Rinvik, E., and Ottersen, O. P. (1999). Different modes of expression of AMPA and NMDA receptors in hippocampal synapses. Nat. Neurosci. 2, 618–624. doi: 10.1038/10172
Thorndike, R. L. (1953). Who belongs in the family? Psychometrika 18, 267–276. doi: 10.1007/BF02289263
Tønnesen, J., Katona, G., Rózsa, B., and Nägerl, U. V. (2014). Spine neck plasticity regulates compartmentalization of synapses. Nat. Neurosci. 17, 678–685. doi: 10.1038/nn.3682
Xu, T., Yu, X., Perlik, A. J., Tobin, W. F., Zweig, J. A., Tennant, K., et al. (2009). Rapid formation and selective stabilization of synapses for enduring motor memories. Nature 462, 915–919. doi: 10.1038/nature08389
Yang, G., Pan, F., and Gan, W.-B. (2009). Stably maintained dendritic spines are associated with lifelong memories. Nature 462, 920–924. doi: 10.1038/nature08577
Keywords: dendritic spines, shape transitions, synaptic plasticity, image processing
Citation: Bokota G, Magnowska M, Kuśmierczyk T, Łukasik M, Roszkowska M and Plewczynski D (2016) Computational Approach to Dendritic Spine Taxonomy and Shape Transition Analysis. Front. Comput. Neurosci. 10:140. doi: 10.3389/fncom.2016.00140
Received: 06 May 2016; Accepted: 05 December 2016;
Published: 23 December 2016.
Edited by:
Concha Bielza, Technical University of Madrid, SpainReviewed by:
Florentin Wörgötter, University of Göttingen, GermanyRan Su, Tianjin University, Chile
Copyright © 2016 Bokota, Magnowska, Kuśmierczyk, Łukasik, Roszkowska and Plewczynski. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Dariusz Plewczynski, ZC5wbGV3Y3p5bnNraUBjZW50LnV3LmVkdS5wbA==
†shared first authorship.