 Thijs Veugen
Thijs Veugen Vincent Dunning
Vincent Dunning Michiel Marcus
Michiel Marcus Bart Kamphorst
Bart Kamphorst- 1Unit ICT, Strategy and Policy, TNO, The Hague, Netherlands
- 2Department of Semantics, Cybersecurity and Services, University of Twente, Enschede, Netherlands
Topic modelling refers to a popular set of techniques used to discover hidden topics that occur in a collection of documents. These topics can, for example, be used to categorize documents or label text for further processing. One popular topic modelling technique is Latent Dirichlet Allocation (LDA). In topic modelling scenarios, the documents are often assumed to be in one, centralized dataset. However, sometimes documents are held by different parties, and contain privacy- or commercially-sensitive information that cannot be shared. We present a novel, decentralized approach to train an LDA model securely without having to share any information about the content of the documents. We preserve the privacy of the individual parties using a combination of privacy enhancing technologies. Next to the secure LDA protocol, we introduce two new cryptographic building blocks that are of independent interest; a way to efficiently convert between secret-shared- and homomorphic-encrypted data as well as a method to efficiently draw a random number from a finite set with secret weights. We show that our decentralized, privacy preserving LDA solution has a similar accuracy compared to an (insecure) centralised approach. With 1024-bit Paillier keys, a topic model with 5 topics and 3000 words can be trained in around 16 h. Furthermore, we show that the solution scales linearly in the total number of words and the number of topics.
1 Introduction
Topic modelling is a set of techniques that can discover abstract topics over a large set of textual documents. This is useful when there is a lot of textual data that needs to be analyzed and manual analysis is infeasible. Topic modelling can help to categorize and filter the data or to find related documents. Research until now has focused on centralized datasets, where the training data is available in one database. It is possible that certain private databases contain valuable textual data for a topic model that data holders are unwilling to share. There are two main reasons why data can be too sensitive to share: either commercially sensitive, or personal information that is privacy sensitive.
An example of the latter motivation occurs in the medical domain, where information on patients is generated by doctors in various different hospitals or other medical institutions. Combining the textual data from these different entities is valuable for two reasons: firstly, they often contain different types of information, which makes the input to the topic model more diverse and the resulting topic model richer. Secondly, topic models generally need a large amount of input, so combining inputs to train one larger topic model would result in a better topic model. The topic model can for example be used to categorize the textual data to enrich the structured patient data with new information and predict inpatient violence (1), detect virus outbreaks at an early stage (2), or get more insight into symptoms of certain diseases.
Privacy-Enhancing Technologies (PETs) provide a solution that retains the advantages of big data analytics of textual data and ensures privacy (or protects other kinds of sensitivity) of the analyzed documents. In the context of the GDPR, PETs contribute to data minimization—and therefore to proportionality—and to data control. In our work, we specifically focus on a PET called Secure Multi-Party Computation (MPC). In a nutshell, MPC allows to perform computations on data of multiple parties while keeping the inputs secret and only revealing the outcome.
Our work proposes an algorithm that enables topic modelling on distributed textual documents in a privacy-preserving way, using two MPC techniques called homomorphic encryption and secret sharing. This opens the door to new business cases that require topic models over textual personal data distributed over different entities, such as the ones previously mentioned.
1.1 Latent Dirichlet allocation
We focus on an existing algorithm called Latent Dirichlet Allocation to train a topic model for a set of documents. Intuitively, a topic model categorizes documents into different topics, where each document is assigned a combination of one or more topics. Furthermore, this gives insights into what words are often associated with these topics. Latent Dirichlet Allocation (LDA) is one of many topic modelling techniques. Among the most common topic modelling techniques, LDA is the most consistent performer over several comparison metrics, making it the most suitable algorithm for most applications (3). In particular, we consider LDA and use a technique called Gibbs sampling to train the model. Gibbs sampling is an iterative method to estimate latent distributions of a dataset based on observations from that dataset.
This means that we iterate over all the words in all the documents and observe what topic it most likely belongs to. With this topic, we then update the parameters of the topic model. This is done until the parameters converge to a stable representation of the topic model. There are also other methods to train latent parameters, but Gibbs sampling was chosen because it often yields relatively simple algorithms for approximate inference in high-dimensional models such as LDA (4, Figure 8).
1.2 Related work
Some research has already been done on privacy-preserving Latent Dirichlet Allocation. We can distinguish two lines of research: work that enables privacy-preserving LDA on centralized textual data, such that the final model does not leak information about the inputs (5), and work that enables LDA on distributed textual data, such that the information sent throughout the protocol does not leak information about the inputs (6–8).
Our work falls into the latter category and therefore distinguishes itself from the work in the former category by enabling LDA on decentralized data instead of centralized data. We present several new secure protocols to perform each step of the LDA algorithm in a privacy-preserving way. We now provide more explanation of the other works in the latter category. A comparison between our work and related work can be found in Table 1.
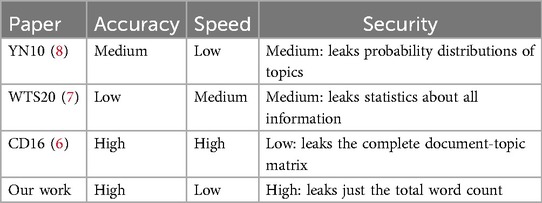
Table 1. Comparison with related work.
The first work on privacy-preserving LDA on distributed data was published in 2010 by Yang and Nakagawa (8). Similar to us, they use homomorphic encryption. They use a custom protocol to draw the topics, which reveals the distributions to all parties. Additionally, they use a slightly altered version of the LDA algorithm, as do we. Whereas they argue the validity of their alteration with a notion of convergence based on the number of changes the algorithm makes, we use a more robust analysis using the perplexity score, showing that our alteration retains the quality and convergence rate of regular LDA.
Wang, Tong and Shi (7) propose a privacy-preserving LDA solution using federated learning and differential privacy. Their solution makes it possible to do local sampling, as the intermediate values are perturbed using differential privacy techniques. As their experiments show, this comes at a quality cost, as the perplexity score is higher for their solution than for regular LDA. Instead, we use homomorphic encryption to keep all information hidden, including intermediate values.
Colin and Dupuy (6) propose a solution to decentralized LDA with varying network topologies. They claim that their solution attains privacy of the textual documents, but no privacy arguments are given. In each iteration, two nodes, each holding a number of documents, exchange (and average) their local statistics. This is similar to sharing the matrix , which we avoid in our solution for privacy reasons.
1.3 Our contributions
We present a novel solution for decentralized topic modelling in a privacy-preserving manner using latent Dirichlet allocation. This is the first solution that does not leak anything about the content of the documents while at the same time maintaining the accuracy of non-private versions of LDA. This way, we bridge the gap between accuracy and security in distributed LDA training by presenting a solution that is both highly accurate as well as secure. Furthermore, we present two generic, cryptographic building blocks of independent interest:
– Securely drawing a random number from a finite set without revealing the drawing probabilities, as described in Sections 3.4, 3.5.
– A generic solution to efficiently convert (multiple) additively homomorphic encrypted values to secret sharings, as described in Sections 3.6, 4.2.
1.4 Problem setting
In this work, we consider the scenario where the documents are not stored in a single database, but are distributed among multiple parties that want to train a joint topic model, but do not wish to simply share these documents with each other. Concretely, our goal is to mimic the existing LDA algorithm in a privacy-preserving manner while maintaining the same accuracy as the non-private version of the algorithm.
Suppose we have documents, document , , containing words. We consider the setting where we have multiple parties, each having one or more (sensitive) documents. Let be the number of topics, and the number of terms1 in our vocabulary. Let be the Dirichlet hyperparameters for the topics in the topics-document distribution, and the Dirichlet hyperparameters for the terms in the terms-topic distribution. All these parameters are public.
During the distributed algorithm, we need to manage the secret matrix elements , representing the number of words in document that have topic , and , representing the number of words with term that have topic . Note that is a matrix, which will be referred to as the document-topic matrix. Furthermore, will be referred to as the topic-term matrix. The document-topic matrix can be split into vectors, such that each party can manage and store only the vectors corresponding to its own documents. For the second matrix we need a different solution to avoid sharing sensitive data, see Section 3.
The purpose of the algorithm is to train the latent variable , denoting the topic of the word of document . In each iteration, for each document, and for each word within that document, a new topic is sampled for that word from a dynamic multinomial distribution. Given the word with index and term , this distribution is proportional to:
where indicates the count , excluding the current word with index , and similarly (4). The first ratio can be roughly interpreted as the empirical probability that a word (not the current word) with topic has term . The second ratio can be roughly interpreted as the empirical weight of topic in document . The hyperparameters and are often called pseudo-counts (from prior belief) and contribute too.
2 Preliminaries
Our work leverages cryptographic techniques to ensure secrecy of the documents’ contents, while still enabling us to learn from them. There are different technologies that can be applied to enable privacy-preserving computations. In this work we use additively homomorphic encryption (AHE) (9, 10) and secret-sharing (11, 12). In its basic form, both techniques represent the messages they encrypt as integers, which is also what we follow in this work. The key difference is that AHE can be computed by a single party knowing the required information, while with secret sharing all operations need to be performed by all the parties holding the secrets. Parties can perform the linear operations on the shares individually, but for more complex operations such as multiplication and division, interaction is required between the parties. Nevertheless, for non-linear operations, secret sharing often yields more efficient solutions than AHE.
2.1 Additively homomorphic encryption
We denote the encryption of a message or plaintext by . We use the Paillier encryption scheme (9), which gives us the operations and such that:
for any public constant , and secret messages and . That is, given encryptions and of and , we can obtain an encryption of the sum without decrypting the ciphertexts. The resulting ciphertext can be decrypted to yield the result, or be input for further encrypted operations.
2.2 Secret sharing
Secret Sharing has similar properties but works in a fundamentally different, key-less way. Suppose we have a secret and wish to use this in a computation with a set of parties . The party holding the secret can split this secret up into a number of shares and send each to party . We denote the sharing of by .
Each party can then compute operations for a public constant and secret sharings for secrets and such that:
In this work, we use the Shamir secret sharing scheme (12), which is a linear secret sharing scheme. This means we can compute the linear additions and multiplications with a public constant without interaction between the parties. Multiplication of two secrets is additionally possible with communication between the parties.
3 Secure distributed LDA
In this section, we present the building blocks and algorithms required for securely performing the distributed LDA algorithm. To this end, we start in Section 3.1 with the required security assumptions. After that, in Section 3.2 we explain our solution for securely keeping track of the document-topic and topic-term matrices. Next we describe the main algorithm for securely performing Gibbs sampling in Section 3.3. Finally, in Sections 3.4–3.6 we respectively introduce separate building blocks for securely drawing a new topic from secret weights, computing encrypted integer weights and converting Paillier ciphertexts into Shamir secret sharings.
3.1 Security model
For both techniques, we assume the semi-honest setting, where each entity tries to learn as much information about the other entities’ data as possible, but does follow the steps of the protocol. For most use cases, this security model will suffice, as it is likely that honest participation will be agreed upon within a contractual agreement between the entities. Furthermore, since LDA already has some inherent privacy properties (5), it is unlikely that during execution a dishonest entity can retrieve a significant amount of information about other entities’ documents. However, we acknowledge this security model might not be appropriate for large-scale deployments with many potentially dishonest entities.
3.2 Tracking the matrices
As highlighted in Section 1.4, LDA essentially manages and updates two matrices: a document-topic matrix and a topic-term matrix. The document-topic matrix keeps track of the topic distribution of each document and consists of elements , representing the portion of document belonging to topic . The topic-term matrix keeps track of the topic distribution of each term in the vocabulary and consists of elements , representing the portion of term belonging to topic over all documents.
However, these matrices are precisely the sensitive information that completely leaks the content of the documents of a party when simply giving it away. Therefore, we need to find a secure way to store these matrices without (significantly) decreasing the accuracy of the algorithm.
A crucial observation is that during the LDA algorithm, the matrix elements of the document-topic matrix are only needed by the party actually holding document . Therefore, it is not needed to maintain a complete, joint matrix of all the documents, but it suffices to let each party locally maintain a part of that matrix corresponding to only its own documents.
On the other hand, the topic-term matrix depends on the distribution over all the documents and should therefore be available to all the parties in an oblivious way. Maintaining this matrix comes down to adding to, and subtracting from, the elements in the matrix, which suggests the use of additively homomorphic encryption for this. To avoid individual parties from decrypting and learning the entries, we furthermore need threshold decryption (10). This ensures that a decryption can only be done if all the parties participate. Note that if we were to do this with secret sharing, each party would need to keep track of the entire matrix, which would introduce a lot of computational overhead.
3.3 Performing the algorithm
A formal description of our Secure LDA solution for securely computing the topic-term matrix and the document-topic matrix can be found in Algorithm 1. In Figure 1, we present an intuitive overview of how our algorithm works. Roughly speaking, our Secure LDA solution consists of three phases: initialisation (blue), sampling (green) and updating (orange). Finally, the results are decrypted in a joint decryption phase (red).

Algorithm 1. Protocol for performing the distributed LDA algorithm.
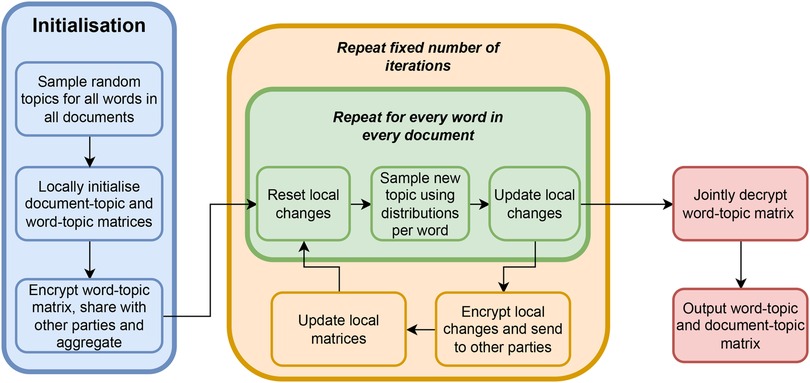
Figure 1. Intuitive sketch of our algorithm.
In the initialisation phase, the goal is to initialise the two matrices with a random distribution that will be refined. To this end, all the parties sample random topics for each word in each document, and use these to fill in an initial (local) view on the document-topic matrix and the topic-term matrix. Next, the parties need to build a global view of the complete topic-term matrix. To achieve this, the parties encrypt all the elements in their local topic-term matrix and combine these by sending the encrypted elements to each other and aggregate them into a global matrix by adding the (encrypted) matrices of all the parties element-wise.
After the initialisation, for a fixed number of iterations, the parties perform a sampling and an updating phase. During the sampling phase, the parties use the (secret) matrices as they are at the start of the iteration, to compute, for each word in each document, a probability distribution over the topics. The secure sampling procedure ensures that the distributions remain hidden from the parties and is outlined in Sections 3.4, 3.5. For each party, the secure sampling procedure yields a new topic for each word in each document. A party uses this information to update her local version of the encrypted topic-term matrix and local document-topic matrix.
The distribution that is drawn from is proportional to Equation 1. Note that these distributions are in an encrypted form and the actual probabilities can thus not be seen by the parties. First, we compute the encrypted weights for all the topics using the procedure presented in Section 3.5. After that, we can perform a secure draw from the encrypted weights using our novel algorithm to draw from a secret probability distribution as presented in Section 3.4. This way, the parties obtain for each word in each document a newly sampled topic. During this sampling, the parties locally keep track of the matrix updates, which means that they decrease their local counters corresponding to the matrix elements of the old word topic by one, and increase the counters for the new topic by one.
The second part of each iteration then consists of each party updating its local document-topic matrix and the parties together updating the global topic-term matrix using the locally tracked changes. To this end, each party encrypts their local changes to the topic-term matrix and sends this to all the other parties. Then the parties can simply add these encrypted counters to their encrypted topic-term matrix to get the new, consistent, topic-term matrix. The document-topic matrix can be updated locally by each party without any communication.
We observe that the LDA algorithm requires linear computations, except for the computation of the probability and the secure draw that uses these probabilities in the sampling step. Therefore, we perform most of the operations for tracking the topic-term matrix using AHE, and introduce a novel mechanism to switch between AHE and secret sharing in Sections 3.6, 4.2 to obtain the best performance. Concretely, we use AHE for the linear operations and only switch to (Shamir) secret sharings for securely drawing the new topics.
Typically, convergence of an LDA algorithm is checked by monitoring the changes in the model parameters, or monitoring how well the model fits a separate set of documents. In the encrypted domain, this can be quite costly to check after each iteration. Therefore, we simply iterate a sufficiently large, fixed number of times.
3.4 Random draw with secret probabilities
An important building block of secure LDA is a method of drawing a new topic , given secret weights , such that
The new, randomly chosen topic will be revealed to party , the holder of the current document. The intuition behind our solution is to compute cummulative weights , such that . For notational convenience, we define an “extra” weight . Next, the parties sample a random value in the range and find between which two cumulative weights this value lies, which then corresponds to the sampled topic. Since is sampled uniformly at random in the total range, the probability of precisely ending up between cumulative weights and is exactly . This can be implemented with only secure comparisons between and thresholds (with varying ) by traversing a binary tree from the root to the leaf representing the new topic. Note that our solution assumes that the weights are integers. In Section 3.5, we explain how we securely transform fractional weights into integer weights.
Formally, the parties do the following for every word in each document:
1. The parties generate a secret random number , :
(a) They generate a secret random number , for sufficiently large .
(b) They securely multiply with , and compute the secure truncation , where
2. They find , such that , by repeating times:
(a) Party determines the next secret threshold (see below).
(b) The parties compute the secure comparison , and reveal the outcome to .
To see that indeed a uniformly random variable is generated, we count the number of that lead to , for . We need , i.e. . The number of that satisfy this is , or . Therefore, we need , where is the statistical security parameter, to assure that is statistically indistinguishable from a uniformly random variable.
The first threshold choice will be , each iteration adapting the threshold following the binary search principle. This means that if , we go to the left and otherwise to the right. As the numbers are secret-shared, party needs to generate a secret-shared binary indicator vector , such that the threshold can be computed by . Party is the only party that can determine the binary indicator vector, because it is the only party that is allowed to learn .
3.5 Computing the integer weights
A key element of Algorithm 1 is the secure, random sampling of new topics for all of the words. As explained in Section 3.3, this is done in two steps: computing the integer weights and performing the secure draw. This subsection will introduce the steps required to compute the integer weights for Equation 1 given the matrices.
We assume we are given matrices and , the first one encrypted and the second one privately known to party , the holder of document . We omit the index for convenience.
To sample a new topic, first the weights have to be computed that determine the probabilities according to Equation 1, which we denote as for simplicity. The weights consist of numerators
and denominators
The encrypted numerators and denominators can easily be computed by party due to the additively homomorphic property of our encryption scheme.
The only problem is that the hyperparameters and are not integers, while the secret sharing scheme requires the plaintexts to be integers. For this work, we chose symmetric priors, meaning , , and , (see Section 5.3). We then approximate the fractions and , where , , and are integers. Then the numerators and denominators are converted to integers and by multiplying both with .
Eventually, we want to obtain integer weights for the secure draw (see Section 3.4). To avoid costly secure integer divisions , we multiply these fractions with to obtain as follows:
1. Party computes the encryptions and , which are converted to secret sharings (see Section 3.6) for efficiency reasons.
2. With one fan-in multiplication (13) the parties compute .
3. For each , , they jointly compute the multiplicative inverse (14, Prot.4.11).
4. The parties compute , .
3.6 Converting encryptions to secret-sharings
During the execution of Algorithm 1, we need to transform the encrypted weights to Shamir secret sharings to randomly draw new topics more efficiently. Suppose we have precomputed pairs , such that contains more bits than , and , where , , is the modulus of the Shamir secret sharing scheme. Then a conversion from to is relatively straightforward:
1. Compute , and (jointly) decrypt it.
2. Jointly compute .
Note that is different from the used earlier in Section 3.4. The pairs could be precomputed as follows:
1. Each party generates random number that has more bits than , and encrypts it.
2. Each party computes , and generates a secret sharing for it.
3. Each party sends each other party a share of , together with .
4. The parties compute , and .
We have , because , and . It is not necessary that all parties generate a random number; it is sufficient that at least parties do.
4 Optimisations
During the development of the protocol, we came up with several optimisations to improve the performance. The optimisations that we implemented are described below. Additional optimisations, that were not implemented due to time constraints, can be found in the Appendix A.
4.1 Parallelisation of secure samplings
We combine the sampling of all new topics of one party [step 2(a)iiB], such that we can parallelise each step of the binary search (see Section 3.4), and drastically reduce the number of communication rounds. This means that the probabilities from Equation 1 are not recomputed after each single topic sampling, but only when during one iteration all words of all documents of a certain party have been assigned a new topic. This version, which we will refer to as batched LDA, enables us to execute all secure comparisons at the same level of the binary tree (see Section 3.4) in parallel, and significantly reduce the total number of communication rounds. The disadvantage is that the drawing probabilities are not constantly adjusted, which might lead to accuracy loss, see Section 5.4.1.
4.2 Multiple conversions
We have multiple conversions that can be efficiently combined into one protocol. Suppose we have weights , and corresponding pairs , , such that , where is an upper bound on the bit size of the weights, is the bit size of number of parties and the bit size of the encryption modulus. Then the conversions can be combined as follows.
1.
2. For to do
3. The parties jointly decrypt and split it into , each component consisting of bits.
4. For each , , the parties compute .
This reduces the number of decryptions by a factor , at the cost of some extra multiplications that combined are comparable to one decryption effort. To further reduce the number of secure additions each party could pack random numbers before encrypting them when precomputing pairs [see Section 3.6], which also reduces the communication effort.
5 Evaluation
5.1 Security
Because topic sampling is performed in a secure, but joint way, the parties learn the total number of words in all documents of a single party. However, nobody learns the sampling probabilities, and only the document holder learns the new topics (of the words in his documents). Our solution is secure in the semi-honest model, i.e., parties are expected to exactly follow the protocol steps, but are allowed to compute with any data that is received during execution in an attempt to gain additional insights in other parties’ data.
As we use standard building blocks, such as secure comparison and random number generation, of the MPyC platform, which is known to be secure in the semi-honest model, our computations with secret-sharings are secure too. Similarly, Paillier is known to be semantically secure, and since we use threshold decryption, encrypted information will never fall in strange hands.
Therefore, we only need to investigate the conversions from encryptions to secret-sharings, as described in Section 3.6. Because the numbers contain more bits than the weights, where is the statistical security parameter, we know that the sum is statistically indistinguishable from a large random number, and can be safely revealed. Furthermore, as each party generates its own and , the sums and can be considered as secret random numbers.
5.2 Implementation
We have implemented our secure LDA approach in Python 3.8. For the homomorphic encryption functionalities, we have used the Paillier implementation available in the TNO MPC Lab (15). This implementation is based on the distributed Paillier solution presented in (10). For the functionalities based on secret sharing, we have used the MPyC framework (16). This framework implements a number of functionalities based on Shamir secret sharing. We performed all of our experiments with three parties, but stress that our implementation also works for more parties.
5.3 Experimental setup
For our experiments, we used the Amazon reviews dataset presented by Ni, Li and McAuley (17). In total, this dataset consists of over 200 million reviews. However, we only used the first 150 entries. Furthermore, we split these 150 entries into three separate datasets of 50 documents for the three different parties. In total, this results in a vocabulary length of terms and a total number of 2,965 words in the distributed corpus. For the experiments, we used 5, 10, 20, 30, 40 and 50 documents per party. As the number of words is not the same for every document, we compared the number of words over all documents for the actual experiments, which is 16, 406, 873, 1549, 2,197 and 2,965 respectively. Furthermore, we chose the symmetric priors . This corresponds to the default parameter choices in the scikit-learn implementation of LDA.
All experiments have been run on a single server running an Intel Broadwell CPU at 2.1 GHz with 4 cores and 32 GB RAM. The parties communicated via (local) HTTPS connections.
5.4 Performance
We evaluate the performance of our solution in terms of accuracy and runtime.
5.4.1 Accuracy
In order to evaluate the accuracy of our secure LDA solution, we compare its results to the results obtained when performing a regular LDA implementation without any encryption or secret sharing. We compare both using the perplexity metric. This metric is standard in language modelling and is defined as . Here, is the total number of words, and is the predictive likelihood of all words in document (4). Perplexity is an objective metric that essentially computes the geometric mean of the log-likelihood per word in a set of observed documents. Lower perplexity scores imply a model that describes the dataset better. We have implemented and compared three versions of LDA:
– Standard LDA: this is a standard implementation of LDA without the use of encryption and updating the matrices after each word topic generation.
– Batching LDA: this version also does not use encryption, but implements a batched version of LDA, updating the matrices only once at the end of each pass through the entire corpus.
– Secure LDA: this is the solution presented in this work. It implements a privacy-preserving batched version of the LDA algorithm.
By comparing the standard- and batching versions of LDA, we can measure the impact of the adaptation we made to the algorithm. By then comparing the batching- and the secure variants, we can furthermore measure the accuracy of our privacy-preserving solution.
We let all three variants run for 100 iterations with two topics and 50 documents per party, which results in a total of 2965 words distributed over the parties. The results of this experiment can be found in Figure 2. We ran all versions for five times and present the average results.
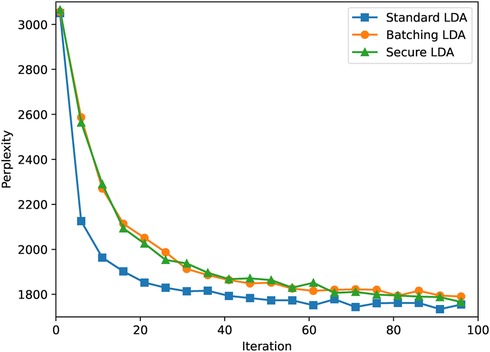
Figure 2. Perplexity traces of three LDA variants.
As can be seen, the standard version of LDA converges faster than the batching- and secure variants. Furthermore, we see that by updating the weights after every word, the standard version generates a slightly better model. However, the differences do not seem to be significant. Finally, we observe that the secure variant shows behaviour similar to the batched plaintext variant, which strongly suggests that the use of encryption and secret sharing does not reduce the accuracy of the algorithm.
5.4.2 Runtime
To see the influence of the input size and the desired complexity of the model to train, we ran benchmarks varying both the total number of words in all the documents, and the number of topics to model. We separately measured the runtime of the pre-processing step for the ciphertext conversions and performing one iteration of the secure LDA algorithm. For all benchmarks, we used a 1024-bit Paillier key2 for the homomorphic encryptions and a 64-bit field size for the Shamir secret shares. All parameter combinations have been tested five times and averaged.
First, we present the results for a varying number of topics for the preprocessing phase and the iteration phase in Figures 3a,b respectively. As can be seen, the amount of work for the preprocessing phase is linear in both the number of words and the number of topics, which is as expected as the number of tuples required per iteration is . For the iterations, the general trend for an increasing number of topics is also linear with slightly steeper increases from 2 to 3, 4 to 5 and 8 to 9. This is explained by the fact that for the secure drawing, the number of intervals is extended by dummies to reach a power of two (either , , , or in these experiments), which incurs an extra step in the binary search (see Appendix A.3 to avoid this). Other than that, the amount of work scales linearly in the number of topics.
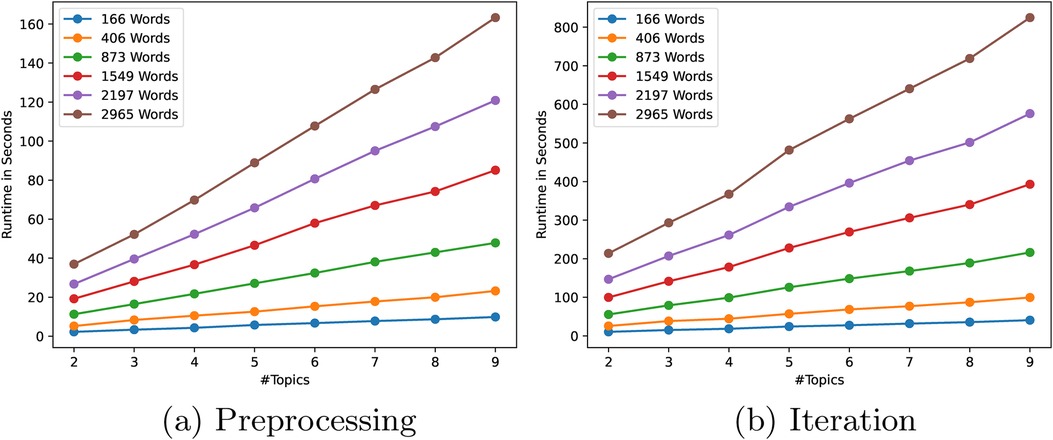
Figure 3. Benchmark of secure LDA in the number of topics. (a) Preprocessing. (b) Iteration.
Second, to see the influence of the input size, we also plotted the runtimes in Figure 4 against an increasing number of words over all parties. As expected, the preprocessing phase again shows a linear increase in the number of words. However, the runtime of one iteration seems to grow slightly faster than linear which might seem surprising at first as the algorithm description does not suggest exponential increase as the number of words grows. This behaviour is explained by the way we batch conversions in Section 4.2. Namely, a fixed number of weights can be converted at once, depending on the size of the Paillier modulus. As long as the number of conversions that need to be performed fits in the same number of decryptions, the runtime of an iteration grows linearly. However, if more decryptions are required in this step, the increase in runtime grows faster.
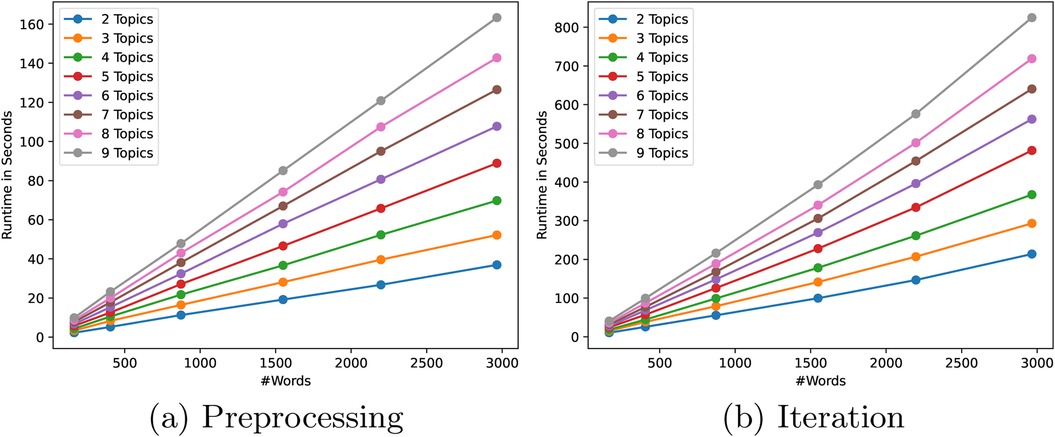
Figure 4. Benchmark results of secure LDA in the number of words. (a) Preprocessing. (b) Iteration.
5.5 Comparison to prior work
As explained in Section 1.2, there are three works that also consider decentralized, privacy-preserving LDA. In Table 1, we highlight the most important differences between our works and these related works. Due to the lack of comparable runtime measurements in these works it is hard to compare our work in that regard. Instead, we turn to a conceptual comparison.
In terms of accuracy, it is unclear how the altered algorithm of (8) impacts the accuracy exactly since they do not provide metrics such as perplexity. We do know that their convergence notion influences the resulting model accuracy to some extend. Furthermore, they leak the probability distributions for the topics in every round, which is a privacy risk as this reveals information about other parties’ data. Our solution keeps secret throughout the entire protocol. Furthermore, they do not provide a security argument for their solution, which we do.
Due to the use of differential privacy, (7) is not able to match the accuracy of non-private LDA like we are able to do using MPC. Furthermore, this is a weaker security guarantee and might still leak some (statistical) information about the data of the other parties. This solution is, however, faster than our solution.
Finally, in (6) an approach is used where statistical information about the documents of the parties is shared in every round. This way, they are able to learn models with high accuracy and obtain a high performance at the cost of very low security guarantees as this essentially comes down to sharing your document-topic matrix.
All in all, our solution is very secure and accurate, at the cost of a lower performance. However, our solution scales linearly in both the number of words and the number of topics, which makes it scalable in practice.
6 Conclusions
In this work, we have presented and evaluated a fundamentally new approach to securely perform an LDA algorithm on a set of documents distributed amongst several, untrusting parties. Compared to earlier solutions, our solution provides stronger secrecy as we keep almost everything secret, including the topic weights. The only thing leaked in our solution is the total number of words over all documents of a party. Furthermore, we minimize the risk of leakage as the data is protected using cryptographic assumptions instead of statistical techniques like differential privacy, which might accidentally still leak some information. Furthermore, we show that the accuracy of our approach is similar to non-secure variants of the LDA algorithm.
Finally, we show that our solution scales nearly linear in the number of topics and the number of words. All in all, this makes it an attractive solution in practice, even for larger datasets.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding authors.
Author contributions
TV: Writing – review & editing, Writing – original draft. VD: Writing – original draft, Writing – review & editing. MM: Writing – review & editing, Writing – original draft. BK: Writing – review & editing, Writing – original draft.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. The research was performed within TNO’s Appl.AI program.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1. ^Term refers to the element of a vocabulary, and word refers to the element of a document. A term has a particular meaning and can be instantiated by several words.
2. ^From a security perspective, a 2048-bit key would have been preferable, but our primal goal was to investigate input scalability.
References
1. Rijcken E, Kaymak U, Scheepers F, Mosteiro P, Zervanou K, Spruit M. Topic modeling for interpretable text classification from EHRs. Front Big Data. (2022) 5:846930. doi: 10.3389/fdata.2022.846930
2. Noble PJM, Appleton C, Radford AD, Nenadic G. Using topic modelling for unsupervised annotation of electronic health records to identify an outbreak of disease in UK dogs. PLoS One. (2021) 16(12):e0260402. doi: 10.1371/journal.pone.0260402
3. Harrando I, Lisena P, Troncy R. Apples to apples: a systematic evaluation of topic models. In: RANLP. INCOMA Ltd. (2021). p. 483–93.
5. Zhao F, Ren X, Yang S, Han Q, Zhao P, Yang X. Latent dirichlet allocation model training with differential privacy. IEEE Trans Inf Forensics Secur. (2021) 16:1290–305. doi: 10.1109/TIFS.2020.3032021
6. Colin I, Dupuy C. Decentralized topic modelling with latent dirichlet allocation. CoRR [Preprint]. abs/1610.01417 (2016).
7. Wang Y, Tong Y, Shi D. Federated latent dirichlet allocation: a local differential privacy based framework. In: AAAI. AAAI Press (2020). p. 6283–90.
8. Yang B, Nakagawa H. Computation of ratios of secure summations in multi-party privacy-preserving latent dirichlet allocation. In: PAKDD (1). Springer (2010). p. 189–97. Lecture Notes in Computer Science; vol. 6118.
9. Paillier P. Public-key cryptosystems based on composite degree residuosity classes. In: EUROCRYPT. Springer (1999). p. 223–38. Lecture Notes in Computer Science; vol. 1592.
10. Veugen T, Attema T, Spini G. An implementation of the paillier crypto system with threshold decryption without a trusted dealer. IACR Cryptol. ePrint Arch. [Preprint]. (2019). p. 1136.
11. Chaum D, Crépeau C, Damgård I. Multiparty unconditionally secure protocols (extended abstract). In: STOC. ACM (1988). p. 11–9.
13. Bar-Ilan J, Beaver D. Non-cryptographic fault-tolerant computing in constant number of rounds of interaction. In: PODC. ACM (1989). p. 201–9.
14. de Hoogh S, van Tilborg H. Design of large scale applications of secure multiparty computation: secure linear programming (Ph.D dissertation). Eindhoven, Netherlands: Department of Mathematics and Computer Science, Technische Universiteit Eindhoven (2012).
15. TNO MPC Lab. Paillier encryption scheme implementation. Available online at: https://github.com/TNO-MPC/encryption_schemes.paillier (Accessed July 15, 2025).
16. Schoenmakers B. Secure multiparty computation in python. Available online at: https://www.win.tue.nl/ berry/mpyc/ (Accessed May 2018).
17. Ni J, Li J, McAuley JJ. Justifying recommendations using distantly-labeled reviews and fine-grained aspects. In: EMNLP/IJCNLP (1). Association for Computational Linguistics (2019). p. 188–97.
18. Damgård I, Meldgaard S, Nielsen JB. Perfectly secure oblivious RAM without random oracles. In: TCC. Springer (2011). p. 144–63. Lecture Notes in Computer Science; vol. 6597.
19. Ostrovsky R, Shoup V. Private information storage (extended abstract). In: STOC. ACM (1997). p. 294–303.
Appendix A. Optimizations
We describe a few optional optimisations that were not implemented due to time constraints.
A.1 Use of oblivious RAM
Another promising solution for securely storing and accessing the topic-term matrix is by oblivious RAM (18, 19). In the semi-honest model, a more efficient solution is to store the matrix entries somewhere, e.g. in the cloud, in an homomorphically encrypted way. Each party can query and modify entries, without the other parties noticing it.
A.2 Avoid indicator vectors
To avoid generating indicator vectors and computing a secure inner product for each new threshold, we could decide to postpone the conversions. Given the encrypted weights, party can first add the proper weights to determine the next threshold. Only then the encrypted threshold is converted to a secret-sharing. This does not increase the number of conversions. The transforming of fractional to integer weights might become more intensive though.
Given our parallel approach of combining all drawings of one party, we could compute all weights as follows:
1.
2. {secure product}
3. {secure product and secure inverse}
Given , where , the weights for each term can be computed as with one secure product. Using the local matrix , these weights can be adjusted locally to document , to cope with the factor . This adjustment comes down to the exponentiation , where .
To generate a secret random number , given term and document , the encryption needs to be converted to a secret-sharing. During each iteration step of the binary search, the proper weights can be accumulated by party to obtain the new threshold, which can then be converted to a secret-sharing for the secure comparison.
A.3 Number of topics not a power of two
If the number of topics is a power of two, the binary search can be easily performed. If , then the number of iterations ( or ) of the binary search would disturb the uniform distribution of the randomly chosen topic. An easy way to fix this is to add dummy values, such that the number of iterations is always . However, this takes more secure comparisons than strictly necessary. We describe a way to avoid these additional secure comparisons without leaking information.
1. Party randomly chooses different dummy indices , , such that . See argumentation below how this should be done.
2. ; {Initialise counters}
3. For to do: {Compute new weights }If then ; else ;
4. The parties perform a binary search with weights , :
– If there is only one non-dummy index remaining, party ends the binary search.
– In each iteration, party constructs an indicator vector of length (ignoring the dummy weights).
We need to be even to avoid information leakage. E.g., for the index will never be selected after one iteration, irrespective of the chosen dummy index. This means that party has to first choose one special dummy in case is odd that should not lead to skipping iterations (in Step 4). The question remains how the random dummy indices (in Step 1) should be chosen, assuming is even.
We order the indices in pairs of consecutive numbers. We choose random positions out of these pairs. We add two dummies to each chosen pair, just before each element of the pair. In this way, each of the indices will have an identical probability of being chosen after (no dummies in the pair) or (dummies in the pair) rounds.
Keywords: latent Dirichlet allocation, secure multi-party computation, Shamir secret sharing, Paillier crypto system, topic modelling
Citation: Veugen T, Dunning V, Marcus M and Kamphorst B (2025) Secure latent Dirichlet allocation. Front. Digit. Health 7:1610228. doi: 10.3389/fdgth.2025.1610228
Received: 11 April 2025; Accepted: 3 July 2025;
Published: 24 July 2025.
Edited by:
Stefano Dalmiani, Monasterio Foundation, ItalyEdited by:
Maria Pisani, Toscana Gabriele Monasterio Foundation, ItalyDamodaran, Vel Tech Rangarajan Dr. Sagunthala R&D Institute of Science and Technology, India
Copyright: © 2025 Veugen, Dunning, Marcus and Kamphorst. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Thijs Veugen, dGhpanMudmV1Z2VuQHRuby5ubA==
†ORCID:
Thijs Veugen
orcid.org/0000-0002-9898-4698
Vincent Dunning
orcid.org/0009-0004-1148-3017
Michiel Marcus
orcid.org/0000-0003-0936-2289
Bart Kamphorst
orcid.org/0000-0002-9490-5841