 Kristin Passero
Kristin Passero Jennie G. Noll2
Jennie G. Noll2- 1Virginia Institute of Psychiatric and Behavioral Genetics, Virginia Commonwealth University, Richmond, VA, United States
- 2Department of Psychology, Mount Hope Family Center, University of Rochester, Rochester, NY, United States
- 3Department of Pathology and Laboratory Medicine, University of Pennsylvania, Philadelphia, PA, United States
- 4Center for Childhood Deafness, Language, and Learning, Boys Town National Research Hospital, Omaha, NE, United States
- 5Department of Genetics and Institute for Biomedical Informatics, University of Pennsylvania, Philadelphia, PA, United States
Cross-sectional data allow the investigation of how genetics influence health at a single time point, but to understand how the genome impacts phenotype development, one must use repeated measures data. Ignoring the dependency inherent in repeated measures can exacerbate false positives and requires the utilization of methods other than general or generalized linear models. Many methods can accommodate longitudinal data, including the commonly used linear mixed model and generalized estimating equation, as well as the less popular fixed-effects model, cluster-robust standard error adjustment, and aggregate regression. We simulated longitudinal data and applied these five methods alongside naïve linear regression, which ignored the dependency and served as a baseline, to compare their power, false positive rate, estimation accuracy, and precision. The results showed that the naïve linear regression and fixed-effects models incurred high false positive rates when analyzing a predictor that is fixed over time, making them unviable for studying time-invariant genetic effects. The linear mixed models maintained low false positive rates and unbiased estimation. The generalized estimating equation was similar to the former in terms of power and estimation, but it had increased false positives when the sample size was low, as did cluster-robust standard error adjustment. Aggregate regression produced biased estimates when predictor effects varied over time. To show how the method choice affects downstream results, we performed longitudinal analyses in an adolescent cohort of African and European ancestry. We examined how developing post-traumatic stress symptoms were predicted by polygenic risk, traumatic events, exposure to sexual abuse, and income using four approaches—linear mixed models, generalized estimating equations, cluster-robust standard error adjustment, and aggregate regression. While the directions of effect were generally consistent, coefficient magnitudes and statistical significance differed across methods. Our in-depth comparison of longitudinal methods showed that linear mixed models and generalized estimating equations were applicable in most scenarios requiring longitudinal modeling, but no approach produced identical results even if fit to the same data. Since result discrepancies can result from methodological choices, it is crucial that researchers determine their model a priori, refrain from testing multiple approaches to obtain favorable results, and utilize as similar as possible methods when seeking to replicate results.
1 Introduction
Cross-sectional studies have been the driving force behind developments in genome research, having given rise to the genome-wide association study (GWAS) and analogous methods, such as phenome-wide or environment-wide association studies (Hall et al., 2016). However, they have limited capability to evaluate genetic influences on the development of complex diseases as cross-sectional data lack the information necessary to model change (Singer and Willett, 2003). However, data with repeated phenotype measures over time not only allow the assessment of how the genome affects the phenotype at a given time point but can also describe how the trait progresses over time and how genetic risk alters this trajectory (Singer and Willett, 2003). Repeated measures, or longitudinal data, are clustered data, wherein a “cluster” is an individual with repeated measurements. It is expected that repeated measures within a sample will be correlated (dependent) (Gibbons et al., 2010), which violates the independence assumption of commonly used linear or logistic regression models. Ignoring this violation by analyzing clustered data without accommodating dependency could inflate the false positive rate (FPR). For instance, Musca et al. (2011) found that applying a t-test to dependent data produced an FPR of above 50% even if the dependency was low to moderate (Musca et al., 2011).
Many methods for analyzing longitudinal data exist, but the currently favored approaches are linear mixed models (LMMs) and generalized estimating equations (GEEs) (Gibbons et al., 2010; Garcia and Marder, 2017; Woodard, 2017). LMMs represent dependency by modeling “fixed” and “random” effects (i.e., the intercept or slope parameters defined in a regression equation) (McNeish et al., 2017). “Fixed” effects are shared by all clusters and can be thought as population-level effects (McNeish et al., 2017). A “random” effect is cluster-specific and allows each cluster to deviate uniquely from the fixed effects (McNeish et al., 2017), thereby accommodating the similarity from correlated repeated measures. LMMs are advantageous because they model time-invariant and time-variant predictors, treat time as a continuous variable, can represent two or more levels of clustering, and have less strict missingness assumptions (Gibbons et al., 2010; Garcia and Marder, 2017; Woodard, 2017). Nevertheless, they have many assumptions regarding the distribution of predictors, random effects, and residuals (McNeish et al., 2017), violations of which could negatively affect analytical performance (Dieleman and Templin, 2014). Generalized LMM extensions to analyze noncontinuous outcomes are also computationally expensive (Garcia and Marder, 2017; McNeish et al., 2017). Furthermore, they estimate additional parameters—the variance–covariance of random effects—that usually are not of interest to the researcher (McNeish et al., 2017). GEEs also model time-varying predictors and continuous time but have fewer assumptions than LMMs (Gibbons et al., 2010; Garcia and Marder, 2017; McNeish et al., 2017; Woodard, 2017). Instead, GEEs compute population-average coefficient estimates while separately estimating group dependency via a working correlation matrix that is used to correct parameter estimates (Gibbons et al., 2010; Garcia and Marder, 2017; McNeish et al., 2017; Woodard, 2017). Some limitations of GEEs are their decreased tolerance of missing data and use of quasi-likelihood, rather than maximum likelihood, estimation (Gibbons et al., 2010; Garcia and Marder, 2017; McNeish et al., 2017; Woodard, 2017). Popular likelihood-based measures or tests—the likelihood ratio test (LRT), Akaike information criterion, etc.—cannot be applied to GEEs because they are quasi-likelihood methods. Furthermore, open-access implementations of GEEs in R and Python also do not specify more than two levels of clustering (Halekoh et al., 2006; Seabold and Perktold, 2010; Carey et al., 2022).
Other approaches applicable to longitudinal data analysis are cluster-robust standard errors (CRSEs), fixed-effects (FE) models, and aggregate regression (AGG). CRSEs adjust coefficient standard errors to reflect dependency and make fewer assumptions than LMMs and GEEs (McNeish et al., 2017; Bauer et al., 2020). A linear or logistic regression model is fit to the dependent data, and then standard errors are re-calculated using the CRSE approach, which incorporates the dependency within clusters into the standard error estimation. CRSEs accommodate two levels of clustering and, as they only adjust the standard errors, they require that the regression model is correctly specified to ensure unbiased coefficient estimates (McNeish et al., 2017). The FE model accommodates group dependency by adding cluster membership to the regression model as a dummy-encoded covariate (Bauer et al., 2020). In FE models, inference cannot be done at the group level since all between-group differences are adjusted out of the model after including cluster membership as a covariate. However, FE models are conceptually simple, easy to implement, and outperform LMMs in situations with few groups (Dieleman and Templin, 2014; McNeish and Stapleton, 2016). AGG consolidates repeated measurements on an individual into a single value by averaging them over time (Aarts et al., 2014). This reduces clusters to single independent data points, and the new dataset can be analyzed with traditional methods that assume independence. However, the AGG approach necessarily precludes investigation into how a trait develops over time.
Previous GWASs have analyzed longitudinal traits with LMMs (Smith et al., 2010; Wendel et al., 2021) or GEEs (Honne et al., 2016). However, many GWASs opted to simplify the repeatedly measured phenotype into a single measure for analysis with methods assuming independence (Cousminer et al., 2013; Hoffmann et al., 2018; Alves et al., 2019; Tan et al., 2021). Longitudinal studies incorporating polygenic risk scores (PRSs) have been performed, using a wide variety of techniques. The most prevalent approaches are the LMM (Liu et al., 2021; Choe et al., 2022; Machlitt-Northen et al., 2022; Segura et al., 2022; Tomassen et al., 2022), GEE (Ihle et al., 2020; Tsapanou et al., 2021; Tomassen et al., 2022), and, for dichotomous outcomes, time-to-event analysis (Paul et al., 2018; Khera et al., 2019; Ihle et al., 2020; Liu et al., 2021; Ajnakina et al., 2022). Time-to-event analysis is used to investigate whether and when a change in phenotype status occurs, such as a switch from control to case status (Singer and Willett, 2003). However, time-to-event data have unique characteristics that require analysis by methods other than LMMs, GEEs, etc., and, as such, are not the focus of this study [for an overview, see Le-Rademacher and Wang, 2021; Schober and Vetter, 2018; Le-Rademacher and Wang, 2021; Schober and Vetter, 2018)]. Aggregate regression has also been used in longitudinal PRS studies, as by Waszczuk et al. (2022), who found various significant associations between various mental health PRSs and average post-traumatic stress disorder (PTSD) symptoms over time (Waszczuk et al., 2022). However, they complimented this approach with a latent trajectory analysis to show whether the PRSs also predicted the PTSD trajectory class (Waszczuk et al., 2022).
In this study, we investigated various longitudinal modeling approaches to determine how they compare when analyzing trajectory changes of a continuous, repeatedly measured phenotype. We evaluated the power, FPR, and estimation accuracy/precision of LMMs, GEEs, CRSEs, AGG, and FE models alongside naïve linear regression (NLR) with a simulation study. For this simulation study, not all methods explicitly modeled trait development over time. The AGG and NLR approaches always ignored changes in the dependent variable but were included to emphasize the differing results one may observe when discounting changes over time. NLR did not include any adjustments to account for modeling time or dependency and, as such, served as the baseline to which all other methods could be compared.
Using the simulation results, we applied the most accurate methods to a longitudinal cohort of African and European ancestry to examine the genetic and environmental influences on PTSD symptoms over time. The results showed that the analytical strategy and model design greatly influence results and interpretation. In our simulation, NLR and FE approaches had inflated false positive rates when analyzing a predictor that was fixed over time (e.g., genetics), whereas the viability of all other methods depended on the characteristics of the dataset being studied. In our longitudinal cohort, African-ancestry and European-ancestry participants showed different associations with PTSD symptoms over time. Researchers interested in genetic longitudinal studies need to consider the trade-offs between power, false positives, and estimation and accommodate potential time-varying effects in their analysis to procure accurate, reliable results.
2 Materials and methods
2.1 Simulation study comparing longitudinal data analysis methods
To compare the performance of longitudinal data analysis (LDA) methods, we designed a simulation study which generated longitudinal data and applied six methods in statistical hypothesis tests. The simulated longitudinal data consisted of repeated measures on individuals and disregarded higher levels of clustering. We simulated fixed effects and random effects in each longitudinal dataset to produce group dependency (fixed and random effects describe effects shared between groups and group-specific effects, respectively). The methods studied were NLR, CRSE, AGG, FE, LMM, and GEE.
To implement the simulations, we wrote R functions to generate data and apply the chosen analytical methods. These functions are stored in a custom package, LDA simulations, available on GitHub (https://github.com/HallLab/ldasimulations). We used base R functions to randomly generate variables. The fitting of models used various statistical R packages. The stats general linear model function was used to implement NLR and AGG models. For the CRSE approach, we first fit linear regression, and then the CRSE adjustment was applied to the output. CRSE calculations were provided by lmtest (Zeileis and Hothorn, 2002) and the cluster-robust variance estimator from the sandwich package (Zeileis, 2004; Zeileis, 2006; Zeileis et al., 2020); CRSEs utilized the default degrees of freedom and applied an HC1 sample-size correction. LMMs were implemented using lme4 (Bates et al., 2015) alongside lmerTest for the calculation of p-values (Kuznetsova et al., 2017). GEEs were implemented using geepack (Halekoh et al., 2006). All simulations were run in R version 4.1.
2.1.1 Simulation of longitudinal datasets and application of LDA methods to the simulated data
Phenotype trajectories can be described by their initial value and their change over time. The rate of change of the phenotype is necessarily a function of time but can also be altered by other variables, which is often of interest to the researcher (e.g., does greater polygenic risk increase the rate of change of body weight?). To examine situations where phenotype change over time is affected by a predictor
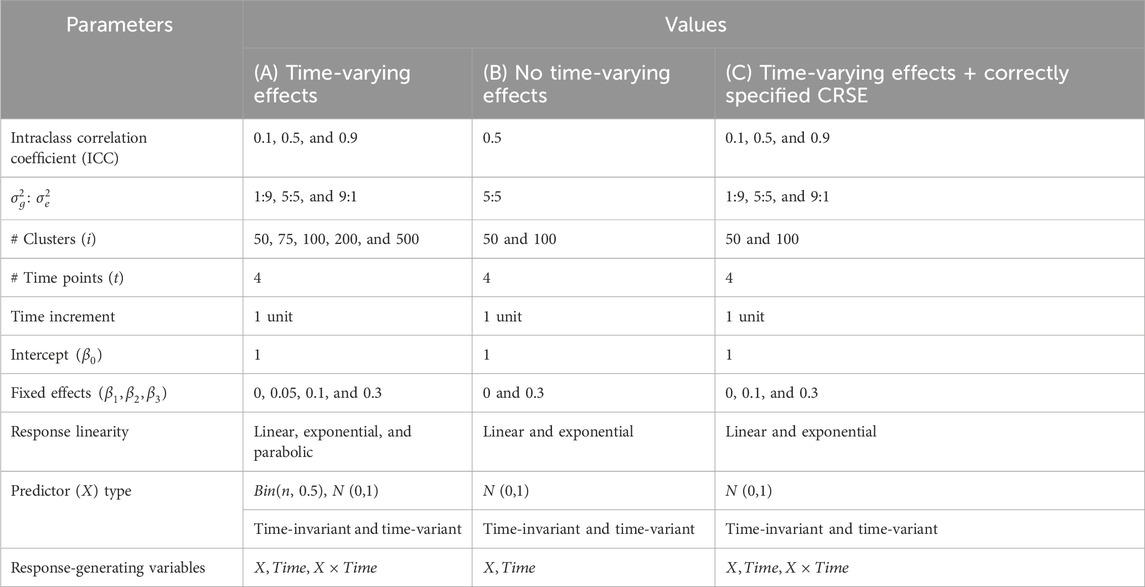
Table 1. Simulation parameters and values for (A) primary simulation, (B) limited simulation without time-varying effects, and (C) limited simulation with a correctly specified cluster-robust standard error (CRSE) model.
In total, there were 720 possible combinations of parameters (Table 1A); each was generated 1,000 times. After a dataset was generated, the six methods—NLR, CRSE, AGG, FE, LMM, and GEE—were applied. The resulting coefficient estimates and p-values were extracted for comparison. NLR was fit with the model
If the data contain true effects of
Data corresponding to each of these 16 possible parameter sets (Table 1B) were replicated 1,000 times. We applied NLR, AGG, CRSE, and two LMMs to these simulated datasets. The former three methods modeled
In the aforementioned simulations, the CRSE was implemented upon a regression that did not model
The output from each simulation is available at https://github.com/HallLab/ldasimulations.
2.1.2 Metrics compared in the simulation study
There were 1,000 unique datasets simulated for each possible combination of parameters (Table 1). All methods were applied to the dataset as described previously. Estimates and p-values were extracted for any non-intercept
To gauge the estimation accuracy and precision, we calculated the difference between the observed and expected effect sizes (
2.2 Motivated application to a real longitudinal dataset
2.2.1 Dataset and variable descriptions
To demonstrate how the choice of method affects the output, we applied a selection of the aforementioned methods to longitudinal data from a female adolescent cohort (n = 460) collected from the catchment area of a Midwest US hospital (Noll et al., 2022). A third of participants had cases of child sexual abuse (CSA) substantiated in the prior year; the remaining were demography- or census-matched controls (Noll et al., 2022). Participants were enrolled at ages 12–16 years and followed for 3 years to assess the health and development between CSA-exposed and -unexposed youths (Noll et al., 2022). Due to the high prevalence of CSA, PTSD was likely to develop among participants (Haag et al., 2022). We chose self-reported PTSD symptoms as our phenotype and examined how symptom development was affected by age, a PTSD-PRS, potentially traumatic events (PTEs), CSA, and income (Table 2). Noll et al. (2022) and Haag et al. (2022) described cohort design and variables in more detail (Haag et al., 2022; Noll et al., 2022).

Table 2. Variables from the longitudinal cohort examining post-traumatic stress disorder.
To compute a PTSD-PRS, meta-GWAS summary statistics from the study by Nievergelt et al. (2019) were extracted from stratified African- and European-ancestry analyses (Nievergelt et al., 2019). We kept SNPs (build GRCh37) with a minor allele frequency >1% and imputation quality ≥0.8. We removed SNPs with complementary A1 and A2 alleles and excluded duplicates. The African-ancestry summary statistic data retained 14,051,262 SNPs, while the European-ancestry summary statistic data retained 8,116,466 SNPs.
In our natural cohort, genome-wide SNP data were available for 408 samples genotyped on the Infinium Global Screening Array (build GRCh37). Using PLINK v1.9, we (1) applied a 99% sample call rate; (2) imposed a 99% variant call rate and 1% minor allele frequency; (3) deleted duplicate SNPs; and (4) calculated identity-by-descent to remove related pairs where
SNP coefficient estimates were adjusted in African-ancestry and European-ancestry participants using the PRS with continuous shrinkage (PRS-CS) method developed by Ge et al. (2019) and using the 1000 Genomes LD reference panel, respectively (Ge et al., 2019). The PRS-CS input parameters were as follows: phi was 1 × 10−2, the African-ancestry sample size was 15,339 participants, and the European-ancestry sample size was 174,659 participants [sample sizes were obtained from the study by Nievergelt et al. (2019)]. The PRS was computed using the score function in PLINK on the adjusted effect sizes from PRS-CS. We estimated ancestry-specific PCs using linkage disequilibrium-pruned (r2 < 0.2) data within each ancestral stratum. A total of 20 PCs per stratum were regressed out of their respective PTSD-PRS in R. Residuals from each regression were the final ancestry-specific PTSD-PRSs.
2.2.2 Analytical strategy applied to natural longitudinal data
This application was designed to show how different methods can produce varying results even if applied to the same natural dataset. From our cohort, we selected three waves of data on PTSD symptoms, PTSD-PRS, PTE, CSA, income, and age. We restricted the cohort to individuals of African or European ancestry and required that samples have complete data at all three time points. We excluded initially unexposed participants who experienced CSA during the study. There remained 124 participants in the African-ancestry subsample and 125 participants in the European-ancestry subsample with complete information. The following analyses were performed separately in each stratum defined by genetic ancestry.
We defined a longitudinal model wherein age, PTSD-PRS, PTE, CSA, and income were expected to influence PTSD symptoms over time. We also specified the interaction between age and all other predictors to allow the variables to show time-varying effects. PTE, PTSD-PRS, and income were z-scored before fitting the model. For individual i at time t, the model tested was
The LMM was fit using lme4 and lmerTest (Bates et al., 2015; Kuznetsova et al., 2017). Prior to fitting, we tested unconditional means and unconditional growth models to determine whether the LMM should contain random intercepts and/or slopes. The unconditional growth model failed to converge; this did not improve when the lme4 optimizer algorithm was changed. Thus, we only specified a random intercept. We fit the GEE using geepack and specified an “exchangeable” working correlation structure (Halekoh et al., 2006). CRSEs were applied with lmtest and the cluster-robust variance correction from the sandwich package (Zeileis and Hothorn, 2002; Zeileis, 2004; Zeileis, 2006; Zeileis et al., 2020). CRSEs used the default degrees of freedom and the HC1 correction.
Lastly, we averaged the select variables across all time points and fit an AGG model; as CSA, PRS, and income were constant over time, only PTSD symptoms and PTE had to be averaged. As the prior methods all fit models specifying development over time (age and its interactions), the AGG model served to compare how removing possible change-over-time from the data affects results. Likewise, we used complete data across all three time points. The average PTE, PTSD-PRS, and income were z-scored. The AGG model fit was
This application of LMMs, GEEs, CRSEs, and AGG to a natural dataset is intended to demonstrate how the method choice affects the interpretation of results and potentially any follow-up analyses based on the findings. We did not use a multiple test correction because the aim was to compare changes in output and because the models were inherently non-independent as they were fit using the same data and most or all of the same variables. We caution against using the results from this application to make strong claims about genetic/environmental influences on PTSD development, especially since models including CSA and PTE may need to include other potential environmental and psychosocial confounders (Keane et al., 2006; Qi et al., 2016; Shalev et al., 2017).
3 Results
3.1 NLR or CRSE had the highest power to detect the effect of
We simulated longitudinal datasets where the response trajectory was dependent on
Out of all the methods, the NLR usually had the highest power to detect the effect of
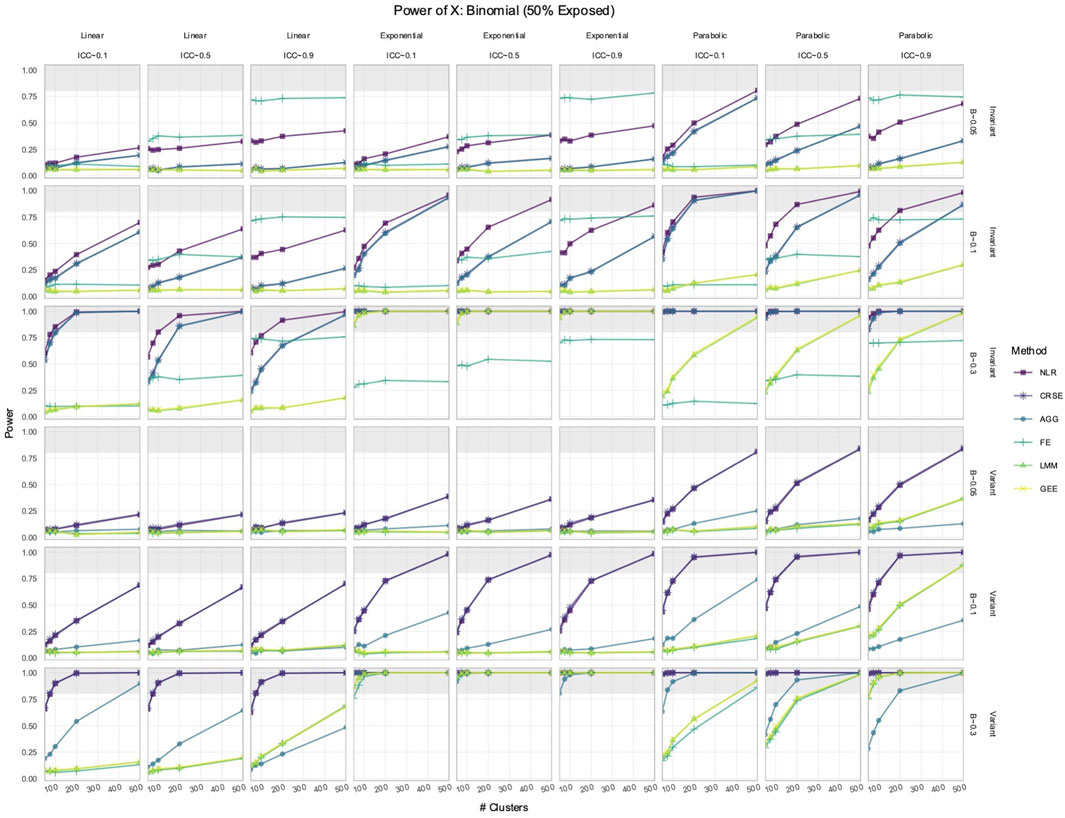
Figure 1. Power to detect the effect of the
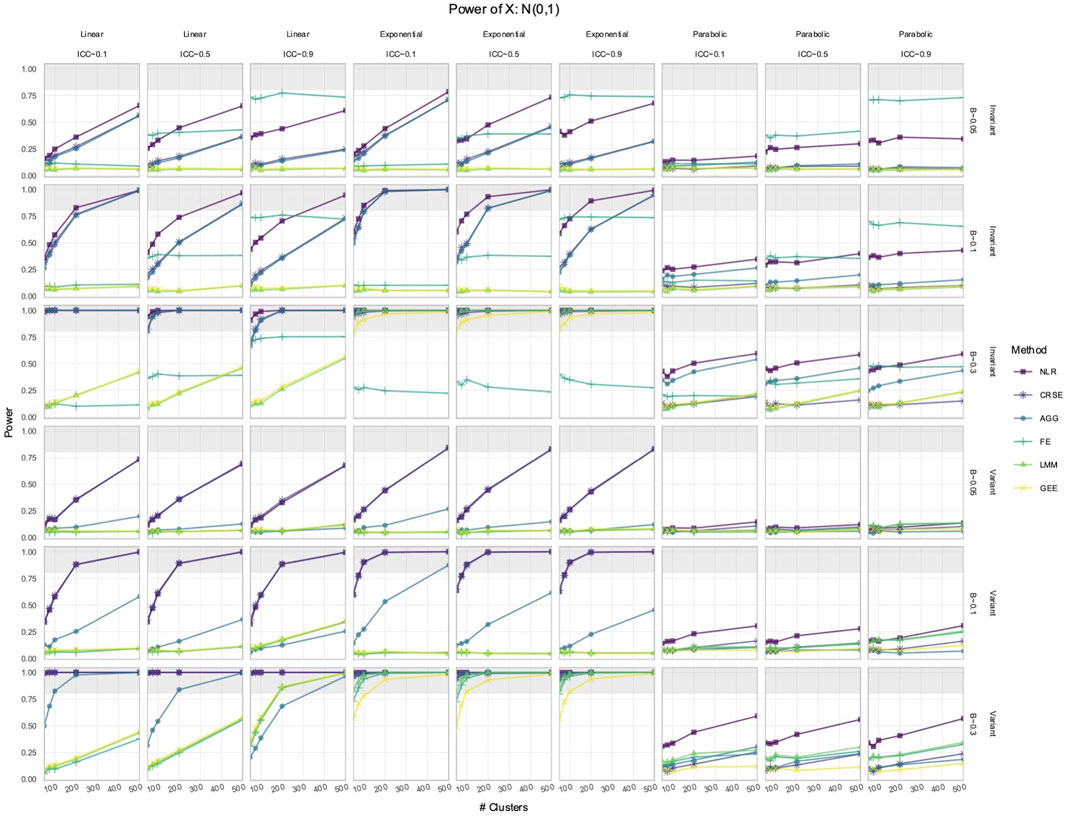
Figure 2. Power to detect the effect of an
3.2 FE, LMM, and GEE had comparable power to detect effects of Time and X × Time in simulated data with time-varying effects
In the simulated longitudinal datasets, where the response trajectory was dependent on
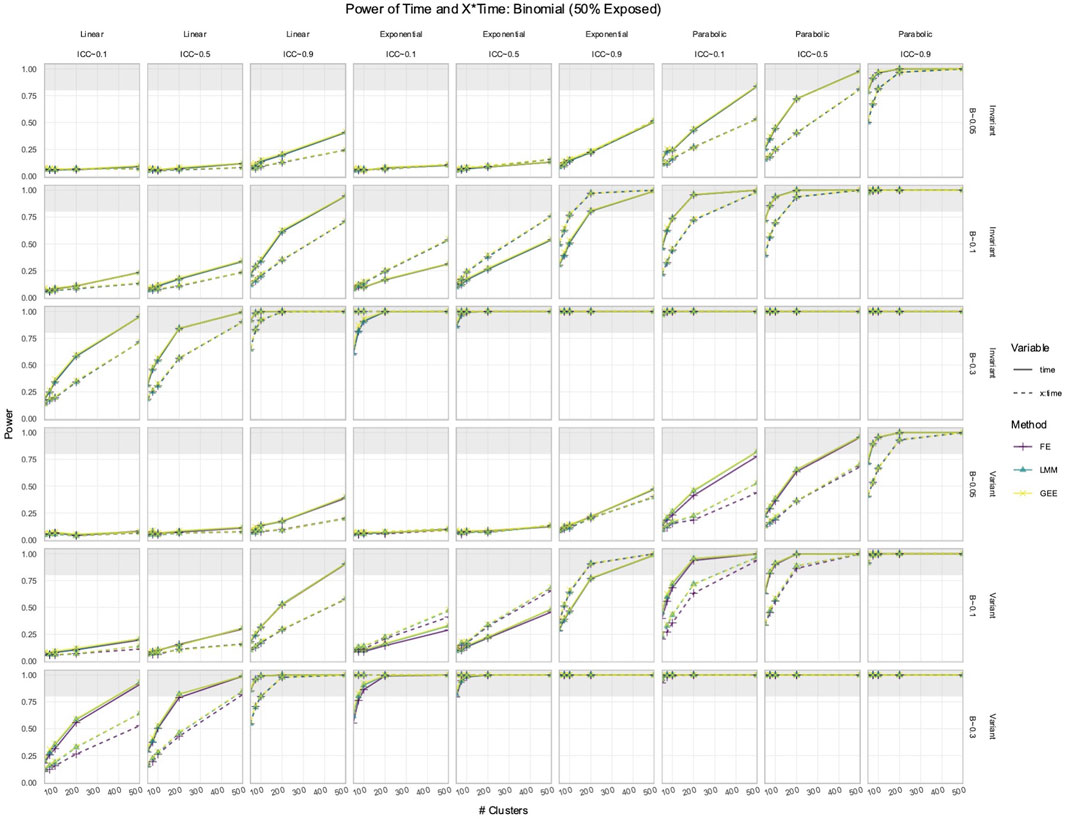
Figure 3. Power to detect the effect of
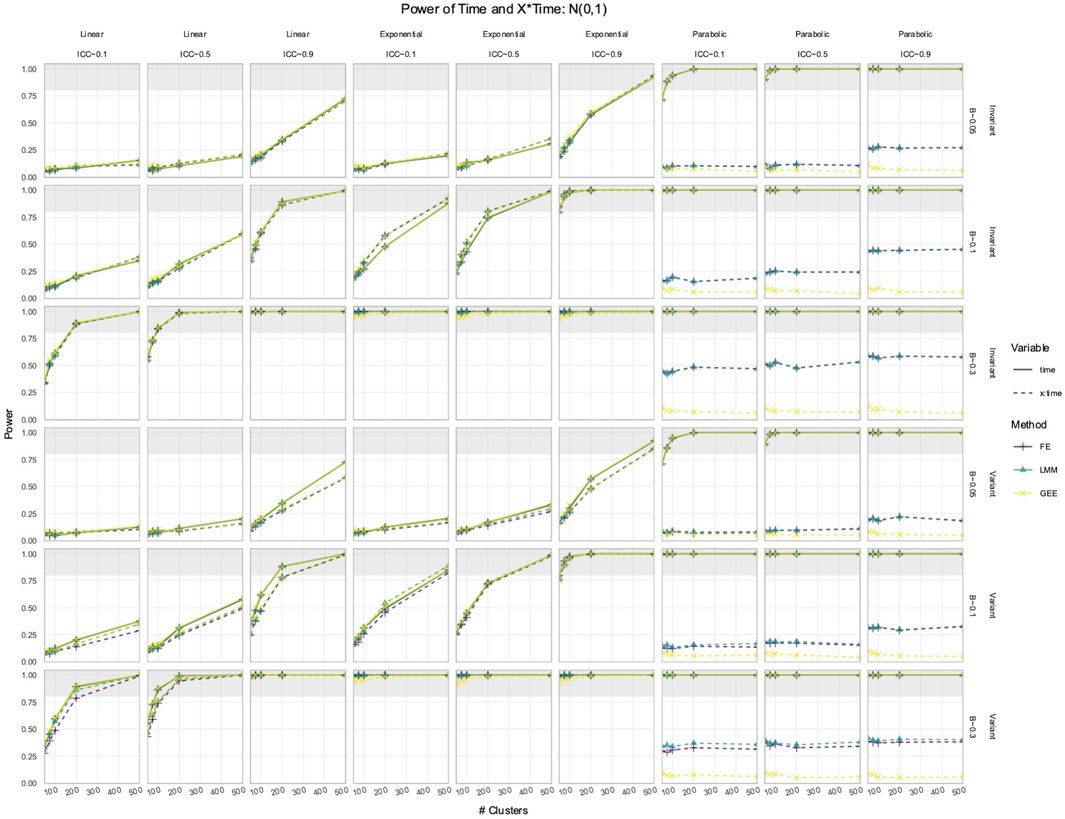
Figure 4. Power to detect the effect of
3.3 NLR and AGG always had a biased estimation of X in simulated data with time-varying effects
While power determines whether a true signal can be discovered by a method, estimation accuracy and precision reveal whether the reported magnitude of the signal is reliable. Overestimation or underestimation of an effect can portray an unrealistic relationship between the predictor and phenotype. We calculated the difference between each estimated and true effect. A positive difference indicated that the estimated
In data with time-varying effects, where the response trajectory is partly determined by the effect of
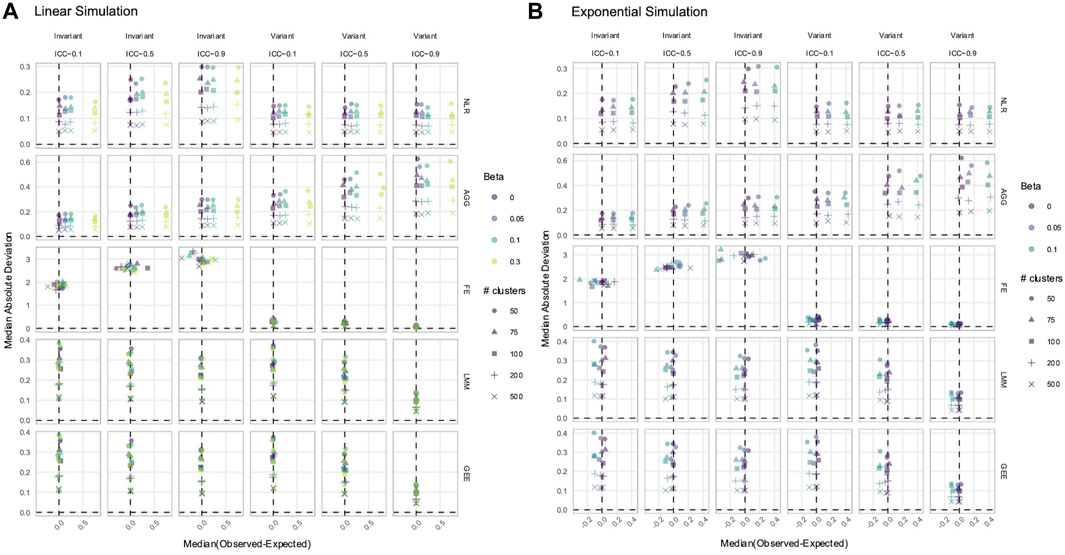
Figure 5. Estimation of the
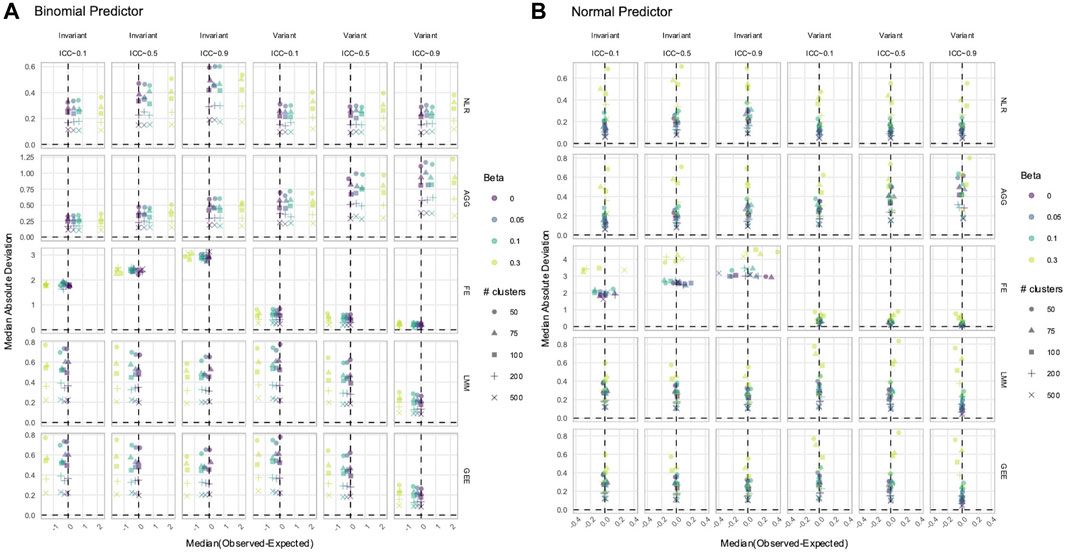
Figure 6. Estimation of the (A)
3.4 FE, LMM, and GEE only had a biased estimation of Time and X × Time in nonlinear simulated data with time-varying effects
To estimate true time-varying effects, the terms
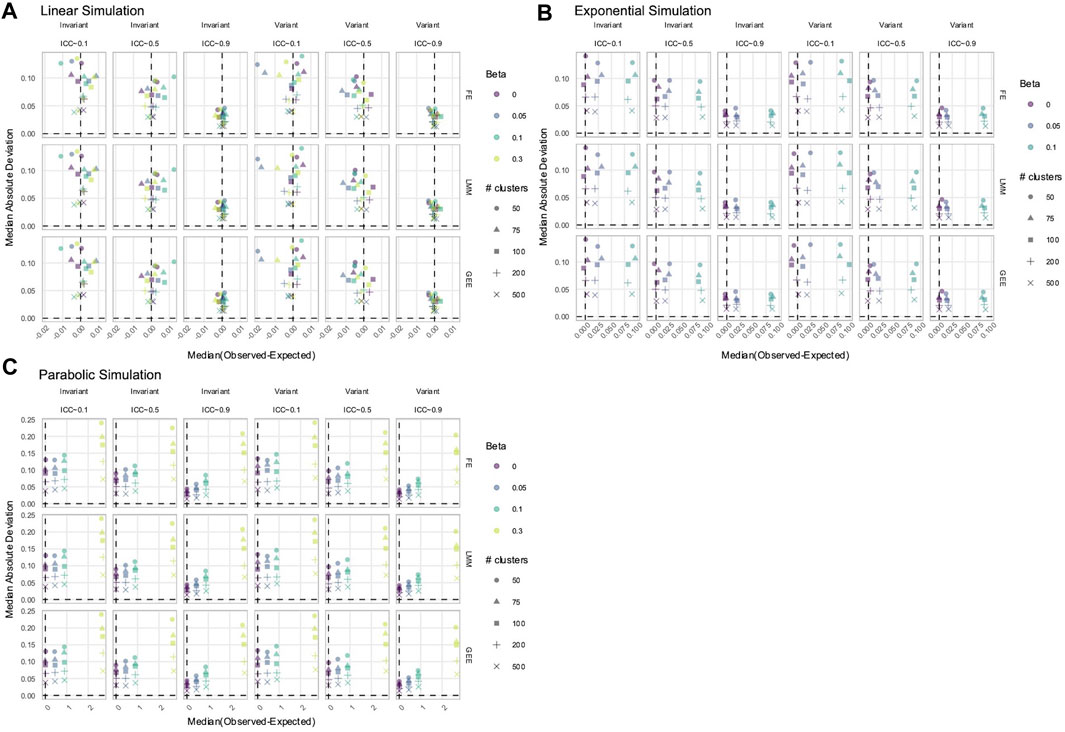
Figure 7. Estimation of
3.5 If X was time-invariant, NLR and FE had inflated FPRs in simulated data with time-varying effects
The FPR was considered maintained if it lay within Bradley’s liberal range of 2.5%–7.5% (Bradley, 1978). In time-invariant simulations, the NLR and FE models had inflated FPRs when detecting the effect of
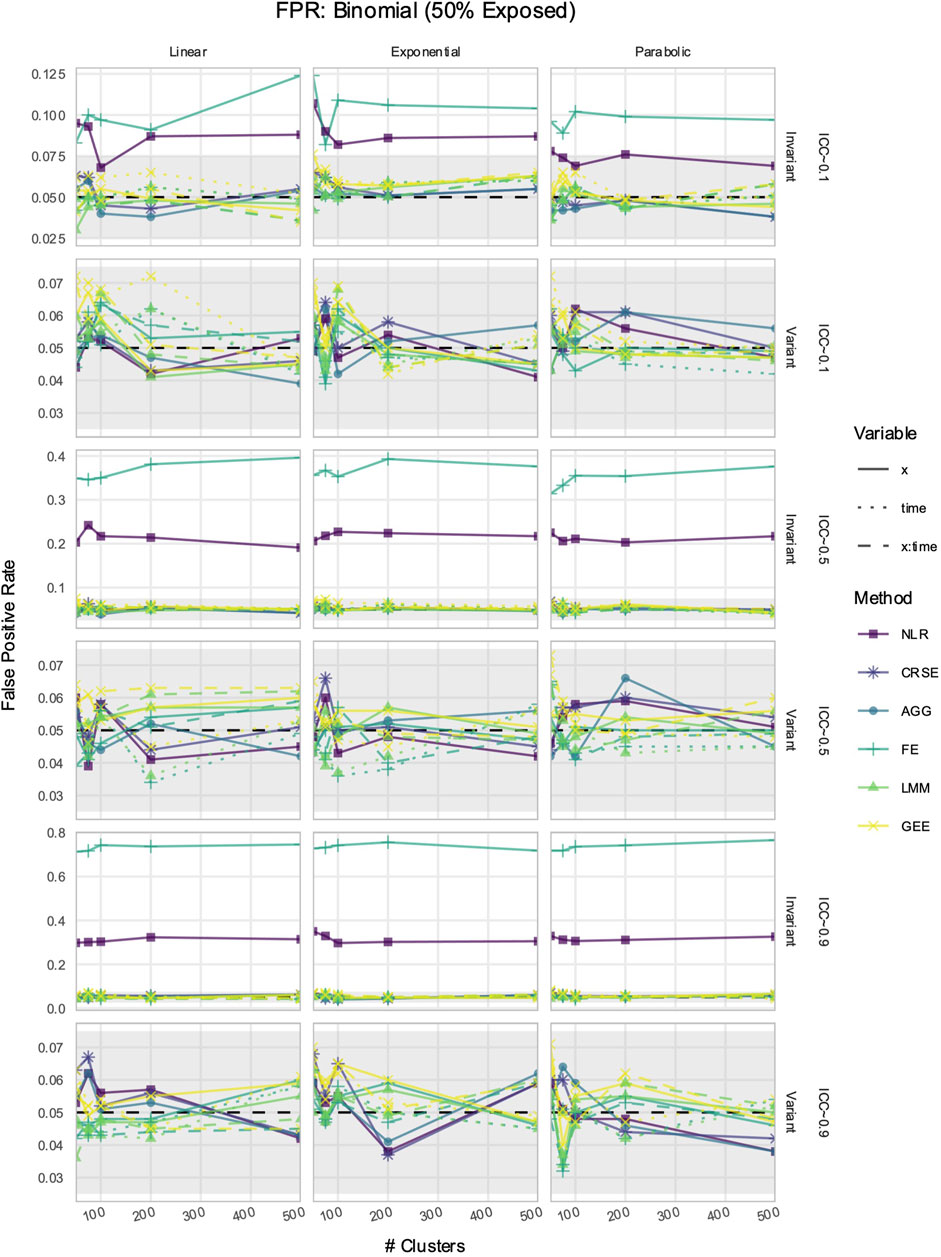
Figure 8. False positive rate (FPR) in simulations with a
3.6 All methods had unbiased estimation of
In some longitudinal data, the effect of a predictor
The power to detect the effect of the predictor
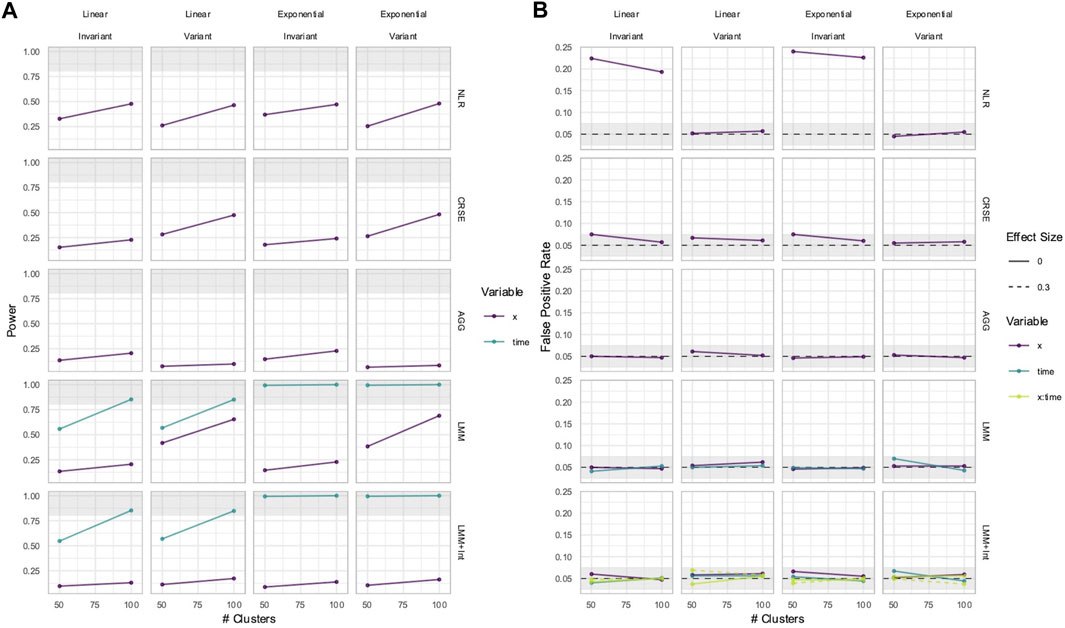
Figure 9. Power (A) and FPRs (B) in simulations without an
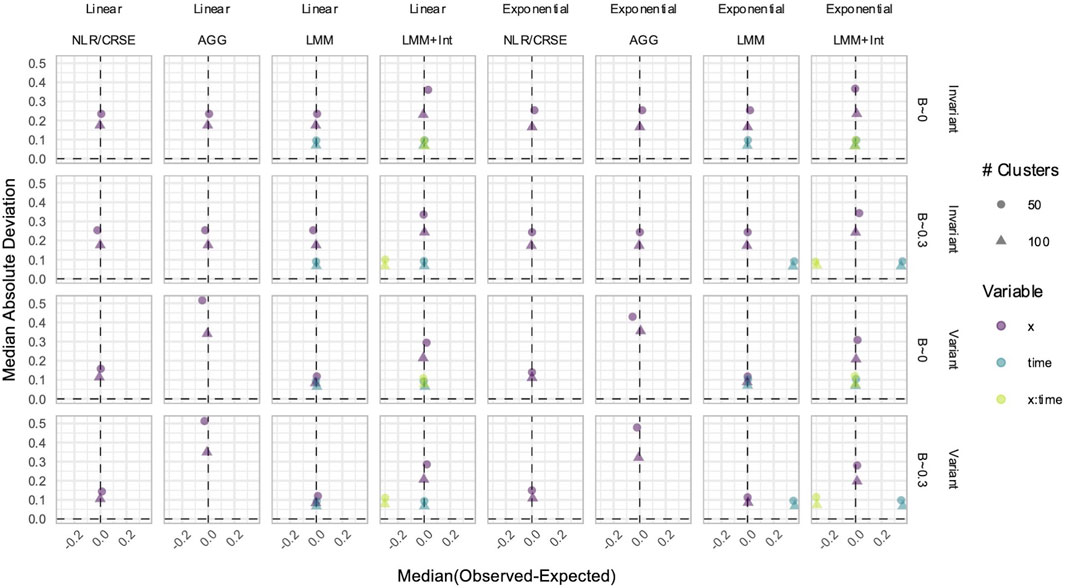
Figure 10. Estimation in simulations without an
3.7 CRSE had no estimate bias if all relevant predictors were included in the model
CRSEs can be applied atop any regression model as long as the clustering is two-level and group membership is known. Previously, our CRSE approach ignored time and was applied to a model with the form
NLR had higher power to detect
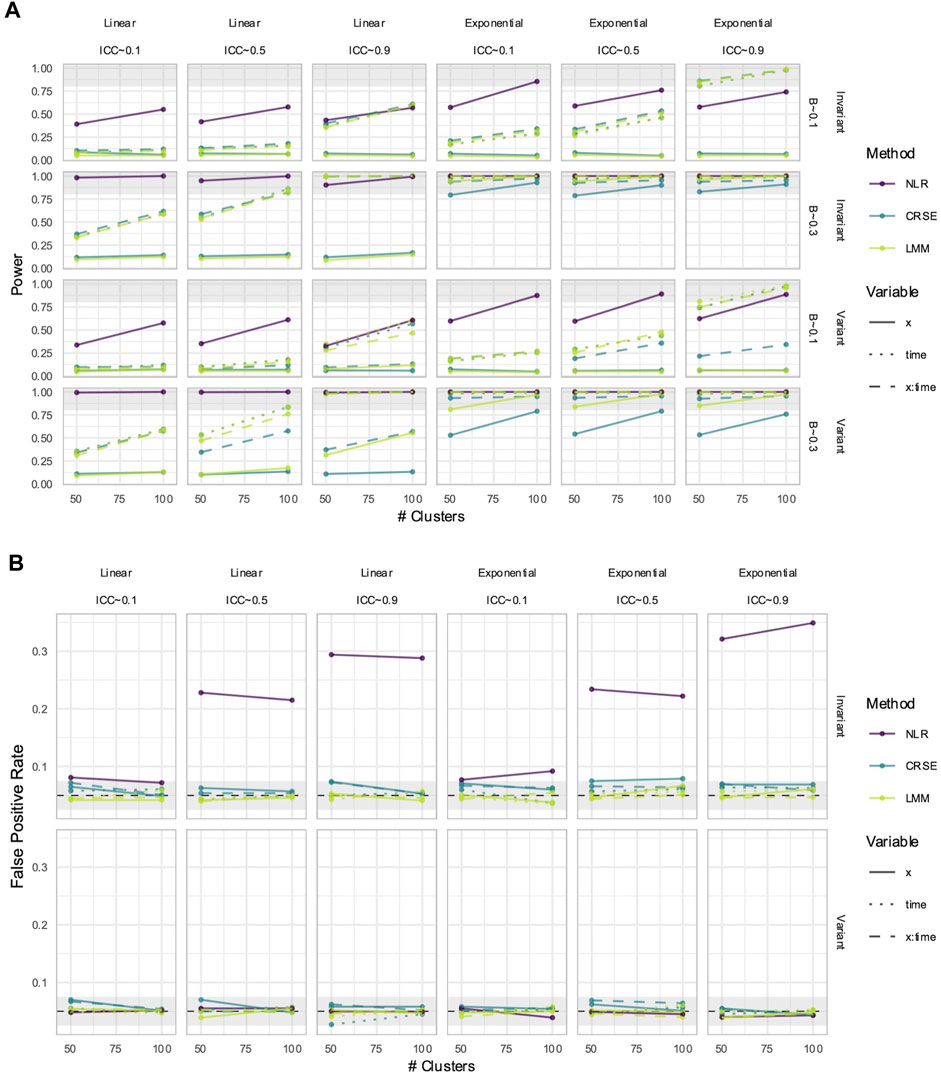
Figure 11. Power (A) and false positive rates (FPRs) (B) in simulations with correctly specified CRSE model. The x-axis number of clusters. The y-axis indicates (A) power or (B) FPR. On power plots, the shaded region is where power reaches or exceeds 80%. The shaded region on FPR plots is Bradley's liberal FPR region from 2.5% – 7.5%. The panel columns correspond to the simulation's linearity and the intraclass correlation coefficient (ICC). The panel rows correspond to the predictor's time-variance and, on power plots only, the effect size (β). Line color and type denote method and variable, respectively. NLR=naïve linear regression, CRSE=cluster-robust standard error, LMM= linear mixed model.
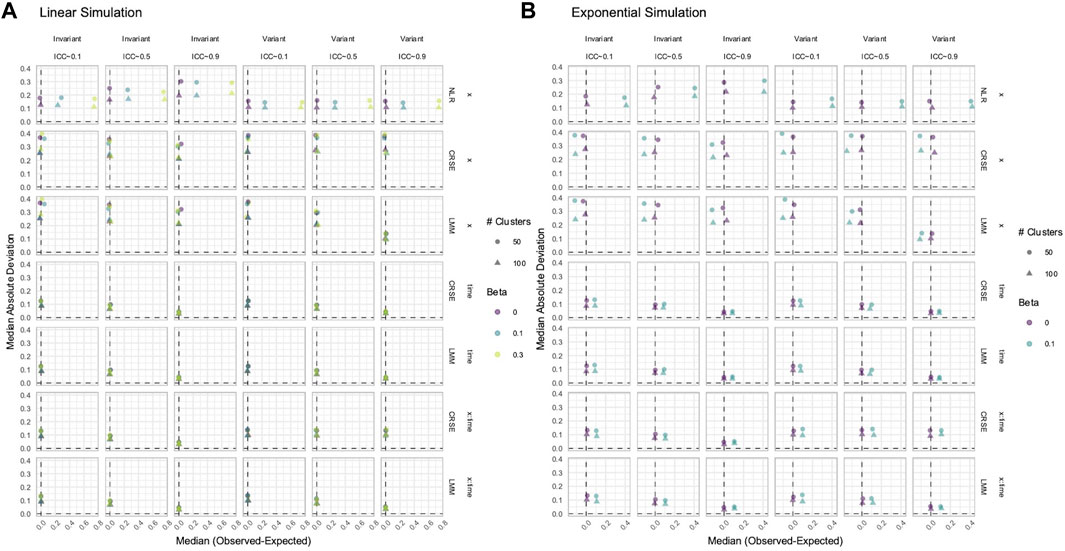
Figure 12. Estimation in (A) linear or (B) exponential simulations with a correctly specified CRSE model. The x-axis indicates median estimate difference. The y-axis indicates median absolute deviation (MAD); the y-axis range varies by panel. Point color and shape represent effect size (β) and the number of clusters, respectively. For the exponential simulation (B), the effect size of 0.3 is excluded. Point shape is the number of clusters. The dashed vertical and horizontal lines indicate a median or MAD of zero, respectively. Panel columns denote the simulation linearity and intraclass correlation coefficient (ICC). Panel rows correspond to the variable and method. NLR=naïve linear regression, CRSE=cluster-robust standard error, LMM= linear mixed model
3.8 Results varied among methods applied to natural data
Among African-ancestry participants, the directions of effects were consistent for all predictors across methods, but statistical significance differed (Table 3). The LMM and GEE had the most similar coefficients. The LMM and CRSE methods found positive associations between age and PTSD symptoms (
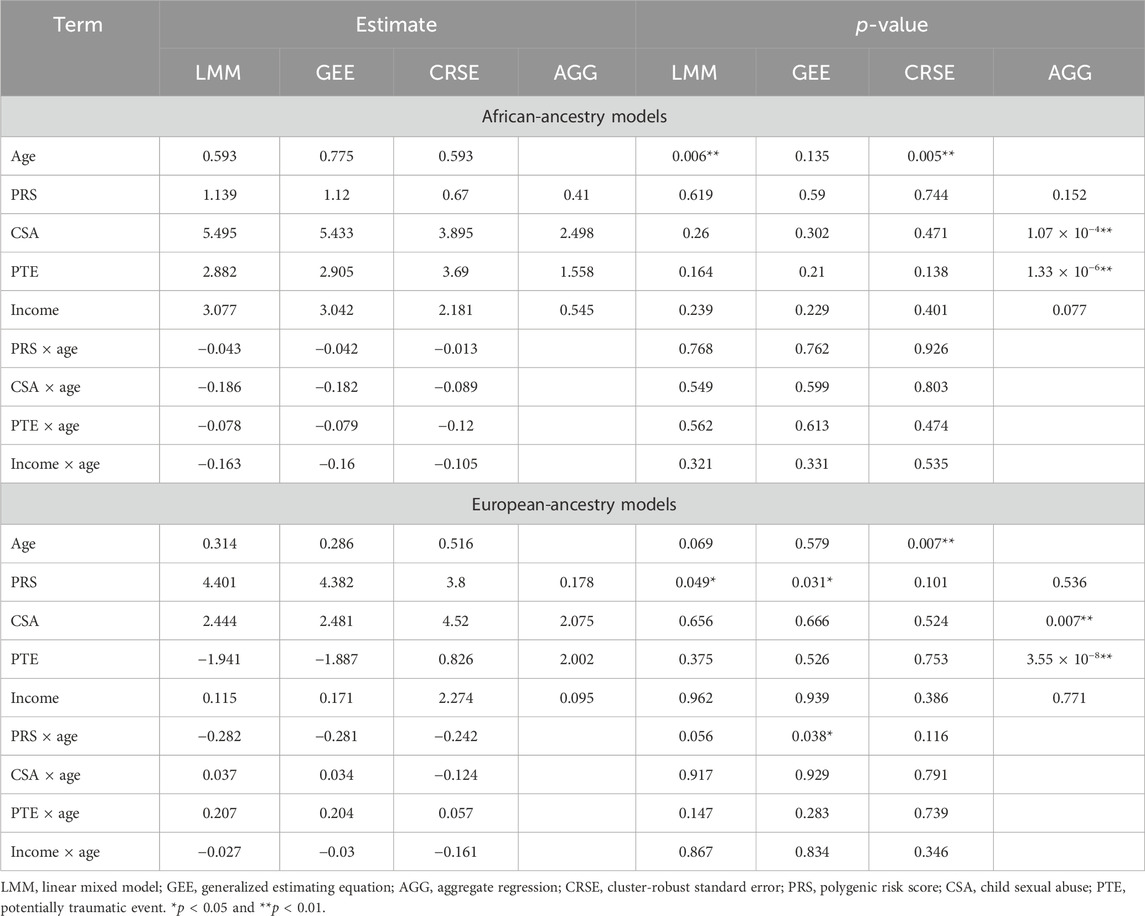
Table 3. Results of models applied to the African-ancestry or European-ancestry participants.
Differing directions of effect were observed when comparing the PTE and CSA × age results in European-ancestry samples, although the LMM and GEE estimates remained the most similar (Table 3). In the LMM and GEE, the coefficient for PTEs was negative, whereas for the CRSE and AGG, it was positive. For the CSA × age interaction, the LMM and GEE estimated a positive coefficient, implying that the effect of CSA increases with age, whereas the CRSE approach found a negative interaction. However, neither the PTE nor CSA × age was significant in any model. Rather, each approach found a different subset of statistically significant terms when applied in European-ancestry participants (Table 3). The LMM found a significant positive association of PRSs with PTSD symptoms (
4 Discussion
Longitudinal data provide researchers an avenue to investigate and understand how risks or buffers impact the development of disease. However, data with repeated measures on individual samples are implicitly dependent. This violates the independence assumption of linear or logistic regression models primarily used in GWASs or PRSs. Evaluating the effect of genetic and environmental risk factors on a repeatedly measured phenotype requires a statistical methodology that accommodates dependency. Many such methods exist, but not all may be suitable in a given analysis. Therefore, we examined five LDA methods and compared their performance among each other and to a naïve estimator. Of these methods, the LMM and GEE are often recommended for the analysis of dependent data (Gibbons et al., 2010; Garcia and Marder, 2017; McNeish et al., 2017; Woodard, 2017). We also considered AGG, CRSE, and FE approaches, which accommodate dependency, and NLR, which does not. Each method was applied to simulated longitudinal datasets to compare estimation, power, and FPR. Methods were further implemented in a cohort of African and European ancestry examining PTSD symptoms in maltreated adolescents to show how the method choice impacts the interpretation of polygenic and environmental risk effects on the symptom trajectory.
The results from the simulation suggest that three factors are most crucial to consider when selecting a model for LDA: whether (1) predictor(s) vary across time; (2) the effect of predictor(s) vary over time—i.e., interacts with
When the effect of the predictor varied over time, any method that did not explicitly model
The CRSE approach was initially implemented on a linear regression that did not model
In simulations with a nonlinear—exponential or parabolic—predictor–response relationship, all methods tended to have heightened power but consistent overestimation or underestimation of true effects. Uniquely, the power of GEE stagnated or even decreased in nonlinear simulations. Given its biased estimates, this power loss may counterintuitively benefit researchers as the inaccurate results of GEE are less likely to reach statistical significance. The overestimation of true effects did not bias the FPR upward in nonlinear simulations. However, researchers should investigate their data prior to analysis to check the linearity assumption. If nonlinearity is evident, then researchers should expect exaggerated coefficient estimates, which may overstate the relationship between risk factors and health outcomes.
We demonstrated how the choice of method impacts the obtained results by applying four longitudinal analysis methods to a natural cohort studying the risk of PTSD. We modeled four predictors and their time-varying effects with LMMs, GEEs, and CRSEs. In applying the AGG approach, we averaged all time-varying variables and fit a model that ignored potential PTSD development over time. Furthermore, our cohort was restricted to individuals with complete data on PTSD, CSA, PTE, PTSD-PRS, and income across all three time points. Thus, each method was applied to the exact same dataset. The LMM, GEE, and CRSE modeled the same fixed effects on the same data but had discrepancies in their results. Despite the LMM and GEE having the most similar estimates, each of these models called a different subset of terms significant across ancestry groups (Table 3). CRSE results had further estimates from those resulting from LMM and GEE models but more consistent statistical significance across ancestral strata. The AGG model, which regressed the average PTSD symptom count on the average predictor values, predictably had the most distinct results. Unlike the other approaches, it found strong significant effects of CSA and PTE on increased average PTSD symptoms (Table 3).
If different researchers had independently applied each of these approaches to our cohort, each would come away with a different interpretation of the role these risk factors play in PTSD. Had LMMs been applied, the results would have suggested that age increases PTSD symptoms among African-ancestry individuals, while the PRS is implicated among European-ancestry individuals. If GEEs were the chosen method, then the PRS and PRS × age would have been implicated in PTSD development only within the European-ancestry subsample. The application of CRSEs would have shown that both African-ancestry and European-ancestry participants showed increased PTSD symptoms with increased age. Lastly, if the researcher had chosen to average all time-varying variables prior to regression, they would have determined that more PTEs on average and CSA exposure led to an increased average PTSD symptom count in both ancestral groups. We are not in the position to state which model is the most appropriate as all methods applied to the cohort accommodated for the within-individual dependency of repeated measures data, and it is unknown whether the data truly meet the assumptions of each method. Nevertheless, we showed that the choice of method has downstream implications as different variables would be highlighted for follow-up investigations, dependent on the approach utilized. Discrepancies among results would be attenuated by acquiring a well-powered sample as our simulations imply that once the sample size, true effect size, and/or intraclass correlation are high enough, all methods will reach maximum power. We previously highlighted three issues researchers should consider when choosing methods: the variability of predictors across time, if the effects of predictors change over time, and whether the research question considers time an important factor. These considerations can guide methodological choices, as can other observations, such as the poorer FPR of GEEs, in small samples or the advantage both LMM and GEE show when within-individual dependency is very high.
Our simulation could not cover all possible data-generating scenarios. We adopted a simple two-level structure consisting of a cluster-level random intercept to simulate dependence and individual residual error. By doing so, our data-generating model met the assumptions of a random intercept LMM. Most of the LMMs we tested in the simulation study matched the data-generating model perfectly, and therefore, the good performance of the LMM across simulations was expected. The results from our simulation suggest that the LMM approach is the most robust method as it controlled the FPR and estimate bias across all samples sizes and had improved precision with increasing ICC values. However, we emphasize that our conclusions only pertain to situations where the data exhibit the random-effects structure assumed by the LMM. A major critique against LMM is that the assumptions it makes regarding random effects may not be met in natural data, which could bias results (McNeish et al., 2017). While we tested an LMM with incorrect fixed effects (Figures 9, 10), and the nonlinear simulations violated assumptions of linearity of all methods, we never looked at the performance of a LMM with incorrectly specified random effects. Furthermore, one expectation of longitudinal data is that measurements are more correlated with temporally close measurements than with those taken at distant time points (Gibbons et al., 2010; Garcia and Marder, 2017). Our simulated data did not reflect this as the data points were equally correlated across various time points (and our LMM and GEE models, implemented with a random intercept and “exchangeable” working correlation structure, reflected the dependence structure of the simulated data). However, it would be of benefit to researchers to understand how incorrectly specifying the within-group correlation structure biases results. Both the LMM and GEE can be implemented with various within-group correlation structures, and GEE is reportedly robust to misspecifications of its working correlation matrix (Garcia and Marder, 2017). The simulated data also did not reflect the attrition that occurs in longitudinal studies, which would result in unbalanced repeated measures. Future simulation studies could focus on simulating more “realistic” longitudinal data and examine how the misspecification of LMM and GEE models affects analysis.
A limitation of the application to our natural cohort is that the GWAS summary statistics used to compute the PRS in African-ancestry participants had a smaller sample size (∼15,000) than that used for the European-ancestry PRS (∼175,000). The African-ancestry PRS is underpowered relative to the European-ancestry PRS, so the lack of significant findings for the PTSD-PRS in any method applied to African-ancestry participants may be due to this technical limitation. We also reiterate that the results found in our cohort, relating the PRS, PTE, CSA, and income to PTSD symptoms, are intended to showcase the variability of results among longitudinal data analysis methods applied to non-simulated data. A more thorough investigation of the genetic and environmental risk factors associated with PTSD development would need to consider (1) more psychosocial confounders, (2) competing models of best fit with regards to time-varying effects, and (3) alternative summary statistics for the African-ancestry PRS. However, our findings do suggest that a failure to replicate results could be due to the fact that various approaches, despite being adequate methods for the data under study, produce minute differences in findings. Furthermore, researchers should not fit multiple methods to their data and then choose the one with the most significant results or which validates their hypotheses.
By demonstrating model behavior under different simulated scenarios, we showed where serious issues such as FPR inflation or inaccurate estimations are likely to occur. If researchers observe features in their data that cause such drawbacks, they can choose a method that alleviates them. Our simulations evaluated method performance in multiple situations, including the analysis of a time-invariant predictor, which is standard for genetics. Therefore, these results can be directly applied to studies investigating the longitudinal effects of PRSs. We also showed discrepancies between results in natural data to highlight the practical impacts of the method choice on result interpretation. Longitudinal analyses are an important tool for genetic epidemiology as they provide methods to investigate how genetics play a role in the development or prognosis of diseases and disorders. However, to take advantage of these methods requires a clear understanding of the available methodology. Our findings can be utilized to develop experimental designs and select the optimum model with regard to accuracy, precision, power, and FPR. With this article, we provide a tool to researchers to further the goal of determining the genetic and nongenetic underpinnings of how complex diseases develop. Applying the appropriate LDA approach will foster reliable analyses that identify the risk factors contributing to the progression of diseases and disorders.
Data availability statement
Original datasets simulated in this study are publicly available at https://github.com/HallLab/ldasimulations. Restrictions apply to the existing natural longitudinal cohort dataset used in this article. It is restricted from public access as it contains sensitive information that could compromise research participant privacy and confidentiality. Individual-level data cannot be provided due to the confidentiality agreement with participants. Requests for access should be directed to amVubmllX25vbGxAdXJtYy5yb2NoZXN0ZXIuZWR1.
Ethics statement
The studies involving humans were approved by the IRB #2012-0613; Federalwide Assurance #00002988; Federal Certificate of Confidentiality (CC-HG-12-83). The studies were conducted in accordance with the local legislation and institutional requirements. Written informed consent for participation was not required from the participants or the participants’ legal guardians/next of kin in accordance with the national legislation and institutional requirements.
Author contributions
KP: Conceptualization, Methodology, Formal analysis, Visualization, Writing–original draft. JGN: Data curation, Writing–review and editing. SSV: Methodology, Writing–review and editing. CS: Writing–review and editing. MAH: Writing–review and editing.
Funding
The collection and development of the application dataset was supported by the National Institutes of Health (PI: JGN, R01HD073130, P50HD096698, and T32HD101390). This work was additionally supported by the USDA National Institute of Food and Agriculture and Hatch Appropriations under Project #PEN04275 and Accession #1018544, start-up funds from the College of Agricultural Sciences, Pennsylvania State University (https://agsci.psu.edu/), the Dr. Frances Keesler Graham Early Career Professorship from the Social Science Research Institute, Pennsylvania State University (https://ssri.psu.edu/), and R01HL169458 to MAH.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fgene.2024.1203577/full#supplementary-material
References
Aarts, E., Verhage, M., Veenvliet, J. V., Dolan, C. V., and Van Der Sluis, S. (2014). A solution to dependency: using multilevel analysis to accommodate nested data. Nat. Neurosci. 17 (4), 491–496. doi:10.1038/nn.3648
Ajnakina, O., Shamsutdinova, D., Wimberley, T., Dalsgaard, S., and Steptoe, A. (2022). High polygenic predisposition for ADHD and a greater risk of all-cause mortality: a large population-based longitudinal study. BMC Med. 20 (1), 62. doi:10.1186/s12916-022-02279-3
Alves, A. C., De Silva, N. M. G., Karhunen, V., Sovio, U., Das, S., Rob Taal, H., et al. (2019). GWAS on longitudinal growth traits reveals different genetic factors influencing infant, child, and adult BMI. Sci. Adv. 5 (9), eaaw3095. doi:10.1126/sciadv.aaw3095
Bates, D., Mächler, M., Bolker, B. M., and Walker, S. C. (2015). Fitting linear mixed-effects models using lme4. J. Stat. Softw. 67 (1), 1–48. doi:10.18637/jss.v067.i01
Bauer, D. J., McNeish, D. M., Baldwin, S. A., and Curran, P. J. (2020). “Analyzing nested data multilevel modeling and alternative approaches,” in Cambridge handbook of research methods in clinical psychology. Editors A. Wright, and M. Hallquist (Cambridge: Cambridge University Press), 426–443.
Bradley, J. V. (1978). Robustness? Br. J. Math. Stat. Psychol. 31, 144–152. doi:10.1111/j.2044-8317.1978.tb00581.x
Carey, V. J., Lumley, T. S., Moler, C., and Ripley, B. (2022). Gee: generalized estimation equation solver.
Choe, E. K., Shivakumar, M., Lee, S. M., Verma, A., and Kim, D. (2022). Dissecting the clinical relevance of polygenic risk score for obesity—a cross-sectional, longitudinal analysis. Int. J. Obes. 46 (9), 1686–1693. doi:10.1038/s41366-022-01168-2
Cousminer, D. L., Berry, D. J., Timpson, N. J., Ang, W., Thiering, E., Byrne, E. M., et al. (2013). Genome-wide association and longitudinal analyses reveal genetic loci linking pubertal height growth, pubertal timing and childhood adiposity. Hum. Mol. Genet. 22 (13), 2735–2747. doi:10.1093/hmg/ddt104
Dieleman, J. L., and Templin, T. (2014). Random-effects, fixed-effects and the within-between specification for clustered data in observational health studies: a simulation study. PLoS ONE 9 (10), e110257. doi:10.1371/journal.pone.0110257
Fang, H., Hui, Q., Lynch, J., Honerlaw, J., Assimes, T. L., Huang, J., et al. (2019). Harmonizing genetic ancestry and self-identified race/ethnicity in genome-wide association studies. Am. J. Hum. Genet. 105 (4), 763–772. doi:10.1016/j.ajhg.2019.08.012
Garcia, T. P., and Marder, K. (2017). Statistical approaches to longitudinal data analysis in neurodegenerative diseases: huntington’s disease as a model. Curr. Neurol. Neurosci. Rep. 17 (2), 14. doi:10.1007/s11910-017-0723-4
Garnier, S., Ross, N., Rudis, B., Sciaini, M., Camargo, A. P., and Scherer, C. (2023). viridis(Lite) - colorblind-friendly color maps for R. doi:10.5281/zenodo.4679423
Ge, T., Chen, C.-Y., Ni, Y., Feng, Y.-C. A., and Smoller, J. W. (2019). Polygenic prediction via Bayesian regression and continuous shrinkage priors. Nat. Commun. 10 (1), 1776. doi:10.1038/s41467-019-09718-5
Genomes Project Consortium, T. G. P., Auton, A., Brooks, L. D., Durbin, R. M., Garrison, E. P., Kang, H. M., et al. (2015). A global reference for human genetic variation. Nature 526 (7571), 68–74. doi:10.1038/nature15393
Gibbons, R. D., Hedeker, D., and Dutoit, S. (2010). Advances in analysis of longitudinal data. Annu. Rev. Clin. Psychol. 6, 79–107. doi:10.1146/annurev.clinpsy.032408.153550
Haag, A.-C., Bonanno, G. A., Chen, S., Herd, T., Strong-Jones, S. S. S., Noll, J. G., et al. (2022). Understanding posttraumatic stress trajectories in adolescent females: a strength-based machine learning approach examining risk and protective factors including online behaviors. Dev. Psychopathol. 35, 1794–1807. doi:10.1017/S0954579422000475
Halekoh, U., Højsgaard, S., and Yan, J. (2006). The R package geepack for generalized estimating equations. J. Stat. Softw. 15 (2). doi:10.18637/jss.v015.i02
Hall, M. A., Moore, J. H., and Ritchie, M. D. (2016). Embracing complex associations in common traits: critical considerations for precision medicine. Trends Genet. 32 (8), 470–484. doi:10.1016/j.tig.2016.06.001
Hoffmann, T. J., Theusch, E., Haldar, T., Ranatunga, D. K., Jorgenson, E., Medina, M. W., et al. (2018). A large electronic health record-based genome-wide study of serum lipids. Nat. Genet. 50 (3), 401–413. doi:10.1038/s41588-018-0064-5
Honne, K., Hallgrímsdóttir, I., Wu, C., Sebro, R., Jewell, N. P., Sakurai, T., et al. (2016). A longitudinal genome-wide association study of anti-tumor necrosis factor response among Japanese patients with rheumatoid arthritis. Arthritis Res. Ther. 18 (1), 12. doi:10.1186/s13075-016-0920-6
Ihle, J., Artaud, F., Bekadar, S., Mangone, G., Sambin, S., Mariani, L., et al. (2020). Parkinson’s disease polygenic risk score is not associated with impulse control disorders: a longitudinal study. Park. Relat. Disord. 75, 30–33. doi:10.1016/j.parkreldis.2020.03.017
Keane, T. M., Marshall, A. D., and Taft, C. T. (2006). Posttraumatic stress disorder: etiology, epidemiology, and treatment outcome. Annu. Rev. Clin. Psychol. 2, 161–197. doi:10.1146/ANNUREV.CLINPSY.2.022305.095305
Khera, A. V., Chaffin, M., Wade, K. H., Zahid, S., Brancale, J., Xia, R., et al. (2019). Polygenic prediction of weight and obesity trajectories from birth to adulthood. Cell. 177 (3), 587–596. doi:10.1016/j.cell.2019.03.028
Kuznetsova, A., Brockhoff, P. B., and Christensen, R. H. B. (2017). lmerTest package: tests in linear mixed effects models. J. Stat. Softw. 82 (13). doi:10.18637/jss.v082.i13
Le-Rademacher, J., and Wang, X. (2021). Time-to-event data: an overview and analysis considerations. J. Thorac. Oncol. 16 (7), 1067–1074. doi:10.1016/j.jtho.2021.04.004
Liu, H., Lutz, M., and Luo, S., (2021). Association between polygenic risk score and the progression from mild cognitive impairment to alzheimer’s disease. J. Alzheimer’s Dis. 84 (3), 1323–1335. doi:10.3233/JAD-210700
Machlitt-Northen, S., Keers, R., Munroe, P., Howard, D., and Pluess, M. (2022). Gene–environment correlation over time: a longitudinal analysis of polygenic risk scores for schizophrenia and major depression in three British cohorts studies. Genes. 13 (7), 1136. doi:10.3390/genes13071136
McNeish, D., and Stapleton, L. M. (2016). Modeling clustered data with very few clusters. Multivar. Behav. Res. 51 (4), 495–518. doi:10.1080/00273171.2016.1167008
McNeish, D., Stapleton, L. M., and Silverman, R. D. (2017). On the unnecessary ubiquity of hierarchical linear modeling. Psychol. Methods 22 (1), 114–140. doi:10.1037/met0000078
Musca, S. C., Kamiejski, R., Nugier, A., Méot, A., Er-Rafiy, A., and Brauer, M. (2011). Data with hierarchical structure: impact of intraclass correlation and sample size on type-I error. Front. Psychol. 2, 74. doi:10.3389/fpsyg.2011.00074
Nievergelt, C. M., Maihofer, A. X., Klengel, T., Atkinson, E. G., Chen, C. Y., Choi, K. W., et al. (2019). International meta-analysis of PTSD genome-wide association studies identifies sex- and ancestry-specific genetic risk loci. Nat. Commun. 10 (1), 4558. doi:10.1038/S41467-019-12576-W
Noll, J. G., Haag, A., Shenk, C. E., Wright, M. F., Barnes, J. E., Kohram, M., et al. (2022). An observational study of Internet behaviours for adolescent females following sexual abuse. Nat. Hum. Behav. 6 (January), 74–87. doi:10.1038/s41562-021-01187-5
Paul, K. C., Schulz, J., Bronstein, J. M., Lill, C. M., and Ritz, B. R. (2018). Association of polygenic risk score with cognitive decline and motor progression in Parkinson disease. JAMA Neurol. 75 (3), 360–366. doi:10.1001/jamaneurol.2017.4206
Qi, W., Gevonden, M., and Shalev, A. (2016). Prevention of post-traumatic stress disorder after trauma: current evidence and future directions. Curr. Psychiatry Rep. 18 (2), 20. doi:10.1007/s11920-015-0655-0
Schober, P., and Vetter, T. R. (2018). Survival analysis and interpretation of time-to-event data: the tortoise and the hare. Anesth. Analgesia 127 (3), 792–798. doi:10.1213/ANE.0000000000003653
Seabold, S., and Perktold, J. (2010). Statsmodels: econometric and statistical modeling with Python. , 92–96. doi:10.25080/Majora-92bf1922-011
Segura, À. G., Martínez-Pinteño, A., Gassó, P., Rodríguez, N., Bioque, M., Cuesta, M. J., et al. (2022). Metabolic polygenic risk scores effect on antipsychotic-induced metabolic dysregulation: a longitudinal study in a first episode psychosis cohort. Schizophrenia Res. 244, 101–110. doi:10.1016/j.schres.2022.05.021
Shalev, A., Liberzon, I., and Marmar, C. (2017). Post-traumatic stress disorder. N. Engl. J. Med. 376 (25), 2459–2469. doi:10.1056/NEJMra1612499
Shenk, C. E., Noll, J. G., Griffin, A. M., Allen, E. K., Lee, S. E., Lewkovich, K. L., et al. (2016). Psychometric evaluation of the comprehensive trauma interview PTSD symptoms scale following exposure to child maltreatment. Child. Maltreatment 21 (4), 343–352. doi:10.1177/1077559516669253
Singer, J. D., and Willett, J. B. (2003). Applied longitudinal data analysis: modeling change and event occurrence. China: Oxford Academic.
Smith, E. N., Chen, W., Kähönen, M., Kettunen, J., Lehtimäki, T., Peltonen, L., et al. (2010). Longitudinal genome-wide association of cardiovascular disease risk factors in the bogalusa heart study. PLoS Genet. 6 (9), e1001094. doi:10.1371/journal.pgen.1001094
Tan, M. M. X., Lawton, M. A., Jabbari, E., Reynolds, R. H., Iwaki, H., Blauwendraat, C., et al. (2021). Genome-wide association studies of cognitive and motor progression in Parkinson’s disease. Mov. Disord. 36 (2), 424–433. doi:10.1002/mds.28342
Tomassen, J., den Braber, A., van der Lee, S. J., Reus, L. M., Konijnenberg, E., Carter, S. F., et al. (2022). Amyloid-β and APOE genotype predict memory decline in cognitively unimpaired older individuals independently of Alzheimer’s disease polygenic risk score. BMC Neurol. 22 (1), 484. doi:10.1186/s12883-022-02925-6
Tsapanou, A., Mourtzi, N., Charisis, S., Hatzimanolis, A., Ntanasi, E., Kosmidis, M. H., et al. (2021). Sleep polygenic risk score is associated with cognitive changes over time. Genes. 13 (1), 63. doi:10.3390/genes13010063
Waszczuk, M. A., Docherty, A. R., Shabalin, A. A., Miao, J., Yang, X., Kuan, P.-F., et al. (2022). Polygenic prediction of PTSD trajectories in 9/11 responders. Psychol. Med. 52 (10), 1981–1989. doi:10.1017/S0033291720003839
Wendel, B., Papiol, S., Andlauer, T. F. M., Zimmermann, J., Wiltfang, J., Spitzer, C., et al. (2021). A genome-wide association study of the longitudinal course of executive functions. Transl. Psychiatry 11 (1), 386. doi:10.1038/s41398-021-01510-8
Woodard, J. L. (2017). A quarter century of advances in the statistical analysis of longitudinal neuropsychological data. Neuropsychology 31 (8), 1020–1035. doi:10.1037/neu0000386
Zeileis, A. (2004). Econometric computing with HC and HAC covariance matrix estimators. J. Stat. Softw. 11 (10). doi:10.18637/jss.v011.i10
Zeileis, A. (2006). Object-oriented computation of sandwich estimators. J. Stat. Softw. 16 (9). doi:10.18637/jss.v016.i09
Zeileis, A., and Hothorn, T. (2002). Diagnostic checking in regression relationships. R. News 2 (3), 7–10. Available at: https://CRAN.R-project.org/doc/Rnews/.
Keywords: longitudinal analysis methods, repeated measures, simulation study, polygenic risk scores, post-traumatic stress disorder, longitudinal method comparison
Citation: Passero K, Noll JG, Verma SS, Selin C and Hall MA (2024) Longitudinal method comparison: modeling polygenic risk for post-traumatic stress disorder over time in individuals of African and European ancestry. Front. Genet. 15:1203577. doi: 10.3389/fgene.2024.1203577
Received: 11 April 2023; Accepted: 15 April 2024;
Published: 16 May 2024.
Edited by:
Zhana Kuncheva, Optima Partners, United KingdomReviewed by:
Sarah Wilker, Bielefeld University, GermanyDaniel Levey, Yale University, United States
Copyright © 2024 Passero, Noll, Verma, Selin and Hall. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Molly A. Hall, bW9sbHkuaGFsbEBwZW5ubWVkaWNpbmUudXBlbm4uZWR1