 Yan Du
Yan Du Kaisen Huang1
Kaisen Huang1 Xiaojian Deng
Xiaojian Deng Ning Wang
Ning Wang- 1Department of Cardiology, Deyang People's Hospital, Deyang, Sichuan, China
- 2Department of Clinical Medicine, School of Clinical Medicine, Southwest Medical University, Luzhou, Sichuan, China
- 3School of Medical Information and Engineering, Southwest Medical University, Luzhou, Sichuan, China
Accurate segmentation of cardiac structures in magnetic resonance imaging (MRI) is essential for reliable diagnosis and quantitative analysis of cardiovascular diseases. However, conventional convolutional neural networks often struggle to maintain both semantic consistency and geometric smoothness, particularly in challenging slices with high anatomical variability. In this work, we propose CASNet, a novel U-Net-based architecture that integrates three key enhancements to address these limitations. First, we introduce a Multi-Scale Context Block (MSCB) at the network bottleneck to enrich encoder features with diverse receptive fields, enabling robust representation of cardiac structures across varying spatial scales. Second, we replace standard skip connections with Cross-Attentive Skip Connections (CASC), allowing the decoder to selectively aggregate spatial features from encoder layers via attention-weighted fusion. This mitigates semantic mismatch and promotes more effective feature reuse. Third, we incorporate a Curvature-Aware Loss that penalizes second-order spatial discontinuities in the predicted segmentation, thereby improving the smoothness and anatomical plausibility of the boundaries. Extensive experiments on the ACDC dataset demonstrate that CASNet outperforms baseline U-Net models and recent attention-based architectures, achieving superior performance in both region overlap and boundary accuracy metrics. The proposed approach provides a robust and generalizable solution for high-precision cardiac MRI segmentation, which may serve as a foundation for future downstream clinical applications in AI-assisted cardiac analysis.
1 Introduction
Cardiovascular diseases (CVDs) remain the leading cause of morbidity and mortality worldwide (1–3). Accurate segmentation of cardiac structures in magnetic resonance imaging (MRI) is crucial for the assessment of cardiac function and disease progression (4, 5). Reliable delineation of regions such as the left ventricle (LV), right ventricle (RV), and myocardium (MYO) enables quantitative evaluation of ventricular volumes, ejection fraction, and myocardial mass, which are essential clinical indicators (6). However, automated cardiac segmentation remains a challenging task due to several factors: the large anatomical variability between patients, poor contrast at boundaries, the presence of pathological changes, and the variability across different slices from apex to base.
In recent years, deep convolutional neural networks (CNNs), particularly encoder—decoder architectures like U-Net, have shown remarkable success in medical image segmentation (7, 8). These networks extract hierarchical features through a series of downsampling and upsampling layers, enabling both low-level spatial detail preservation and high-level semantic abstraction. Nevertheless, traditional U-Net suffers from two critical limitations that hinder its segmentation performance in cardiac MRI (9, 10).
First, standard U-Net applies a fixed-size convolution kernel at each layer, limiting its receptive field and capacity to model multi-scale anatomical structures (11). This becomes problematic in cardiac MRI, where structural patterns vary significantly across slices. Various studies have attempted to address this issue by introducing pyramid pooling modules, atrous convolutions, or hybrid multi-branch networks (12, 13). While these approaches improve scale-awareness, they are often placed in the decoder or final prediction layers, leaving the encoder bottleneck underutilized in terms of contextual modeling.
Second, the skip connections in U-Net directly concatenate encoder and decoder features at corresponding resolutions without any feature selection or semantic alignment (14, 15). This naive fusion assumes that encoder features, which are often dominated by low-level edge and texture cues, are compatible with the semantically richer decoder features. In practice, this assumption frequently leads to semantic inconsistencies and noisy feature propagation, especially in regions with weak contrast or ambiguous boundaries (16). Attention mechanisms have been introduced to re-weight channel or spatial features, but many methods focus on self-attention within single feature maps rather than cross-level interaction (17, 18).
In addition to representation issues, most existing methods use pixel-wise loss functions such as Dice or binary cross-entropy (BCE), which optimize for region-level overlap but do not explicitly enforce geometric regularity. As a result, predicted boundaries can appear jagged or fragmented, particularly in small or thin structures such as the myocardium. This raises concerns about the anatomical plausibility and clinical utility of the segmentation outputs (19, 20).
To address these challenges, we propose a novel architecture named CASNet, which incorporates three key innovations. Motivated by the need for robust multi-scale representation, we introduce a multi-scale context block at the bottleneck layer of the encoder. This module captures fine-to-coarse features using parallel convolutions of varying kernel sizes and fuses them to enrich semantic information before decoding. To bridge the semantic gap between encoder and decoder features, we design cross-attentive skip connections, allowing the decoder to selectively query and aggregate spatially relevant encoder features via a learned attention mechanism. Finally, to enhance the geometric consistency of the predicted contours, we introduce a curvature-aware loss term that penalizes high-frequency changes in the segmentation boundary by regularizing second-order spatial derivatives.
These modules are carefully integrated into a U-Net backbone, forming a unified framework capable of learning discriminative and structure-preserving representations for cardiac MRI segmentation. Our method is evaluated on the public ACDC dataset and demonstrates superior performance over existing baselines in terms of both region-based and boundary-aware metrics.
The main contributions of this work are as follows:
• We propose a multi-scale context block (MSCB) placed at the bottleneck layer, which enriches the encoder output with multi-receptive field features to improve the robustness of semantic representation.
• We design cross-attentive skip connections (CASC) that replace naive feature concatenation with attention-guided feature selection, enhancing the semantic compatibility between encoder and decoder layers.
• We introduce a curvature-aware loss function that regularizes boundary smoothness by penalizing second-order curvature changes, leading to anatomically plausible segmentation with better boundary quality.
2 Related work
Deep learning has substantially advanced medical image segmentation, particularly through the use of convolutional neural networks (CNNs), which offer strong capabilities in hierarchical feature learning (21, 22). U-Net (23) and its numerous variants have become the backbone for a wide range of tasks, including cardiac MRI segmentation, due to their encoder–decoder symmetry and skip connections that balance semantic abstraction and spatial precision (24, 25). Nonetheless, challenges persist in capturing multi-scale anatomical structures, preserving boundary smoothness, and mitigating semantic gaps between encoder and decoder features.
One major research direction focuses on multi-scale context modeling. This is especially important in cardiac segmentation due to substantial inter-slice anatomical variation. To enhance scale sensitivity, UNet++ (26) employed dense nested pathways, while methods such as DeepLabV3 (27), CE-Net (28), and other studies (29) introduced atrous spatial pyramid pooling, pyramid pooling, or dilated convolutions. However, most of these designs apply multi-scale modules at the decoder or output stages, which may limit their impact on early semantic feature encoding. In contrast, the Multi-Scale Context Block (MSCB) in our framework is embedded in the encoder bottleneck, enriching deep features with varied receptive fields to improve upstream contextual representation.
Another research line involves the use of attention mechanisms to enhance feature selection and fusion. AG-UNet (30), SE-Net (31), and CBAM (32) introduced channel-wise or spatial attention in different parts of the encoder-decoder pipeline. More recent models have employed self-attention for long-range dependency modeling (33, 34). Most of these approaches focus on internal attention within feature maps. In contrast, our Cross-Attentive Skip Connections (CASC) introduce cross-attention between decoder queries and encoder keys/values, enabling the decoder to selectively retrieve spatially relevant encoder features. This approach is inspired by transformer designs and aligns with recent efforts to bridge encoder–decoder gaps via attention.
Boundary and shape-aware supervision is another critical direction. While pixel-wise losses such as Dice and binary cross-entropy remain standard, they do not penalize geometric irregularities in segmentation masks (35). Prior work has introduced contour-aware losses, distance transform penalties, and active contour formulations to enforce structural plausibility. Our proposed curvature-aware loss takes a different approach by regularizing second-order derivatives through the Hessian matrix. This penalizes local curvature inconsistency and promotes smooth, anatomically realistic boundaries.
Transformer-based models such as Swin-Unet (36) and MedT (37) have also demonstrated strong performance in medical segmentation tasks by modeling non-local dependencies. However, these models often require extensive training data and high computational cost. Recent efforts to integrate transformers into CNN backbones (38–40) have led to hybrid designs that aim to balance global modeling and efficiency. Notably, recent work has explored anatomical structure-aware transformers for cardiac MRI segmentation (41), demonstrating the value of incorporating prior anatomical knowledge into transformer architectures. Block-partitioned transformer designs with global-local information integration have also shown promise in cardiac segmentation tasks (42). Additionally, transformer-based models have been assessed for detecting cardiac systolic abnormalities in catheterization imaging (43), highlighting their growing adoption in diverse cardiac imaging modalities. While these transformer-based approaches are promising, they may introduce architectural complexity or computational overhead that limits clinical applicability. CASNet instead retains a CNN-compatible design, incorporating lightweight cross-attention mechanisms while maintaining practical feasibility and efficiency.
Finally, there is growing interest in the integration of segmentation with downstream diagnostic tasks. (44) combined deep features and radiomics to improve brain tumor grading, highlighting the relevance of segmentation quality to subsequent clinical decision-making. Although our work focuses on methodological contributions to segmentation, improvements in anatomical accuracy may benefit future downstream applications in AI-assisted cardiology and risk stratification.
3 Methodology
3.1 Model overview
Our proposed architecture, named CASNet, is based on the U-Net framework and integrates three key innovations: a Multi-Scale Context Block (MSCB), Cross-Attentive Skip Connections (CASC), and a Curvature-Aware Loss. The overall structure of the network is illustrated in Figure 1.
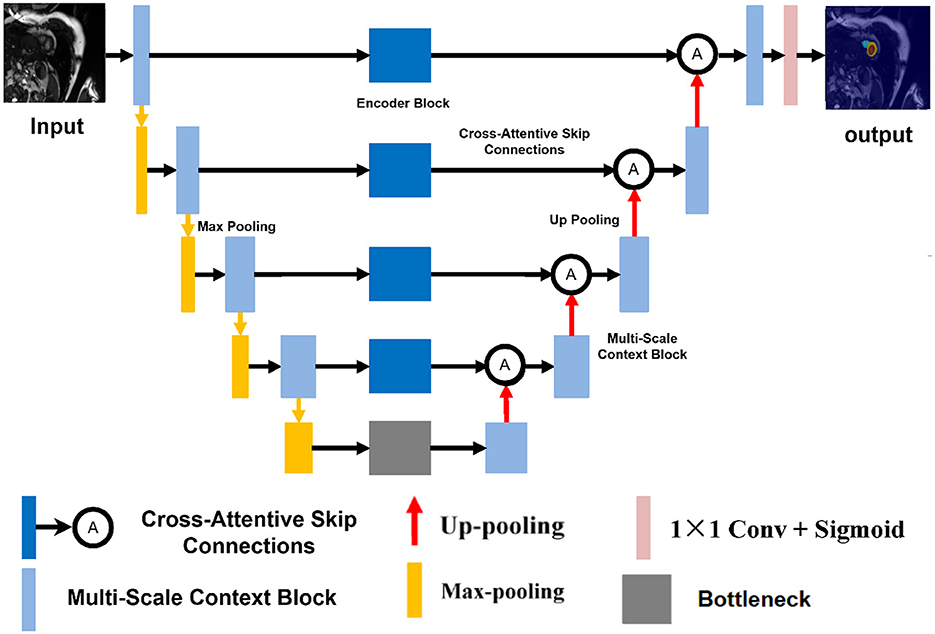
Figure 1. Overview of the proposed CASNet architecture. It consists of a U-Net backbone enhanced with a Multi-Scale Context Block (yellow), Cross-Attentive Skip Connections (orange), and optimized using a Curvature-Aware Loss.
As shown in Figure 1, the backbone of CASNet follows a standard encoder–decoder topology. The encoder path captures hierarchical semantic features through repeated downsampling and convolutional layers. In the bottleneck region, we incorporate a Multi-Scale Context Block (MSCB) that processes the deepest encoder features using multiple convolution branches with different kernel sizes (e.g., 1 × 1, 3 × 3, and 5 × 5) to enhance receptive field diversity and contextual understanding.
To bridge the semantic gap between encoder and decoder features, we replace the standard skip connections with Cross-Attentive Skip Connections (CASC). Instead of naïvely concatenating feature maps, CASC leverages cross-attention to allow the decoder to selectively query relevant encoder features. This mitigates the mismatch between low-level spatial details and high-level semantic cues. Finally, the entire network is supervised using a composite loss that includes a Curvature-Aware Loss term. This term encourages the predicted contours to be structurally consistent and smooth, which is especially beneficial for cardiac MR segmentation where boundary accuracy is critical.
3.2 Multi-scale context block
Convolutional neural networks typically rely on fixed-size kernels, which limits their ability to capture object structures at different spatial scales. This limitation is particularly problematic in medical image segmentation tasks, such as cardiac MRI, where anatomical structures (e.g., the left ventricle, right ventricle, and myocardium) can exhibit significant variation in shape and size across different axial slices. To address this issue, we propose the Multi-Scale Context Block (MSCB), which aims to enrich the semantic representation of the encoder output by aggregating contextual information from multiple receptive fields.
Let denote the feature map produced by the deepest encoder layer. We process Fin through multiple parallel convolutional branches with different kernel sizes to capture multi-scale features. Specifically, we define three branches using 1 × 1, 3 × 3, and 5 × 5 convolutions:
where σ(·) denotes a non-linear activation function, such as ReLU. Each branch is padded appropriately to maintain the spatial size of the input feature map. The outputs of the three branches are concatenated along the channel dimension:
To fuse the multi-scale information and reduce the channel dimension back to C, a 1 × 1 convolution is applied:
The resulting feature map Fout contains a rich mixture of fine and coarse contextual cues, enabling the decoder to better resolve ambiguities in anatomical boundaries. This is particularly important in basal and apical slices, where structure shapes are less prominent and harder to distinguish with single-scale representations.
The MSCB is placed at the bottleneck of the network, right after the final encoder layer and before the decoder begins. This ensures that multi-scale contextual information is fully propagated to the upsampling path, enhancing semantic decoding while incurring minimal computational overhead due to the small spatial resolution at this depth. From a functional perspective, the MSCB can be interpreted as a selective enhancement operator:
where ⊕ denotes channel-wise concatenation and ϕ(·) represents the final 1 × 1 convolution used for fusion. This formulation allows the MSCB to act as a multi-scale feature extractor with minimal parameter and memory overhead, while significantly improving the network's ability to handle scale variation and ambiguous regions.
3.3 Cross-attentive skip connections
In the standard U-Net architecture, skip connections directly concatenate encoder feature maps with decoder feature maps at corresponding resolution levels. While effective at preserving low-level spatial details, this design assumes that encoder and decoder features are semantically compatible. In practice, this assumption often fails—early encoder layers primarily capture low-level gradients, edges, and textures, while decoder layers operate in a high-level semantic space, refining task-specific predictions. Consequently, naive concatenation may lead to feature misalignment, semantic noise injection, and ultimately degrade segmentation performance.
To address these limitations, we propose Cross-Attentive Skip Connections (CASC) illustrated in Figure 2, a more flexible and adaptive mechanism that replaces direct concatenation with a cross-attention interaction. The intuition is to allow the decoder to act as a semantic query source, dynamically selecting informative spatial regions from the encoder based on their relevance to the current decoding stage. This enables the network to learn what to skip and what to suppress, promoting more coherent feature fusion.
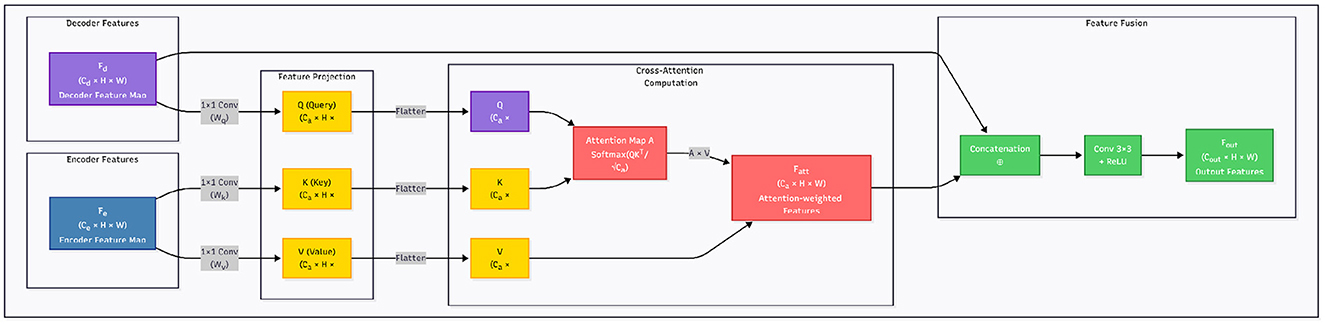
Figure 2. Overview of the Cross-Attentive Skip Connection (CASC) mechanism. Unlike standard skip connections that directly concatenate encoder and decoder features, CASC employs decoder features as queries to extract context-aware features from encoder maps using attention.
Formally, let denote the encoder feature map and denote the decoder feature map at the same spatial resolution. We first project them into a shared embedding space using learnable 1 × 1 convolutions:
Here, denote the query, key, and value tensors, respectively. The attention map is computed via scaled dot-product similarity across spatial positions:
The attended feature for each location i is given by:
This process can be interpreted as the decoder asking: “Which spatial encoder features should I incorporate to reconstruct this region?” Unlike naive skip fusion, the attention map A is data-dependent and spatially adaptive, enabling precise alignment between semantic concepts and fine-grained textures.
We then fuse the attention-enhanced encoder features with the decoder features via channel-wise concatenation, followed by a 3 × 3 convolution for feature re-calibration:
This architecture is applied at each resolution level where skip connections are traditionally used. By doing so, the decoder benefits from scale-specific guidance from the encoder while avoiding the semantic conflicts of direct fusion.
From a training perspective, CASC introduces additional non-linearity and information selection pathways that improve gradient flow and regularization. During backpropagation, gradients are weighted by attention relevance, which implicitly suppresses noise in irrelevant regions and encourages the network to focus on informative features. This leads to improved generalization, especially in medical imaging tasks where class imbalance, low contrast, and structural ambiguity are common. CASC transforms skip connections from a rigid structural shortcut into a learnable semantic alignment mechanism. It facilitates fine-to-coarse and coarse-to-fine interactions in a principled manner, improving both the expressiveness and robustness of the segmentation network.
3.4 Curvature-aware loss
Standard loss functions for medical image segmentation, such as Dice loss and binary cross-entropy (BCE), primarily focus on per-pixel accuracy and region-level overlap. While effective at aligning global shape, these losses are typically agnostic to the structural continuity and geometric plausibility of predicted contours. In cardiac MRI, where anatomical boundaries like the myocardial wall or endocardium are expected to form smooth, closed curves, traditional pixel-wise supervision often results in jagged or fragmented predictions.
To address this limitation, we incorporate a Curvature-Aware Loss that explicitly penalizes local curvature inconsistencies in the predicted segmentation mask. The key idea is to regularize the second-order spatial derivatives of the predicted probability map, encouraging smoothness and continuity along predicted boundaries.
Let denote the predicted probability map, and Y∈{0, 1}H×W the corresponding ground truth mask. The overall loss function is defined as a weighted combination of three components:
where λ1, λ2, λ3 are balancing coefficients, and denotes the curvature-aware term.
We define the curvature-aware loss as the squared Frobenius norm of the image Hessian, capturing local changes in curvature:
Here, denotes the 2 × 2 Hessian matrix of the prediction at pixel (i, j), computed via second-order partial derivatives:
This formulation penalizes high-frequency changes along the predicted boundary and promotes smoother transitions. Operationally, the second-order derivatives can be approximated using discrete Laplacian or finite difference kernels, making the implementation efficient and fully differentiable.
Intuitively, acts as a geometric regularizer, enforcing that the predicted boundary forms a smooth, natural-looking curve. When combined with region-based losses like Dice and BCE, this loss function ensures both accurate segmentation and anatomically plausible contour shapes.
Empirically, we observe that curvature-aware regularization significantly improves boundary quality, especially in challenging slices with weak edges or low contrast. In addition, this loss term improves robustness to noise and enhances generalization across patients with varying cardiac morphologies.
4 Experimental analysis
4.1 Datasets
Two publicly available cardiac MRI datasets were utilized to train and evaluate our method. The first dataset is the ACDC-17 dataset, provided by the MICCAI 2017 Automated Cardiac Diagnosis Challenge. It consists of short-axis cardiac cine MRI images acquired from patients with five cardiac conditions: dilated cardiomyopathy (DCM), hypertrophic cardiomyopathy (HCM), myocardial infarction (MI), abnormal right ventricle (ARV), and healthy controls (N). Each case includes end-diastolic (ED) and end-systolic (ES) frames with corresponding manual annotations for the left ventricle (LV), right ventricle (RV), and myocardium (MYO).
The second dataset is M&Ms-2 (Multi-Disease, Multi-View, and Multi-Center), a large-scale cardiac MRI dataset collected from multiple clinical centers using scanners from different vendors. It contains both short-axis (SA) and long-axis (LA) cine sequences, offering higher diversity in imaging protocols and patient pathologies. Similar to ACDC, it provides annotated masks for LV, RV, and MYO in both ED and ES phases.
An overview of the datasets is presented in Table 1.

Table 1. Summary of the datasets used in this study.
4.2 Experimental setup
All experiments were implemented using PyTorch 1.12 and conducted on an NVIDIA RTX 3090 GPU with 24 GB of memory. The training process used the Adam optimizer with an initial learning rate of 1 × 10−4, (β1, β2) = (0.9, 0.999). The learning rate was halved if the validation loss plateaued for more than 10 epochs. Models were trained for 150 epochs with a batch size of 8. Input images were resized to 256 × 256 and normalized to the range [0, 1]. To improve generalization, we applied standard data augmentation techniques during training, including random horizontal and vertical flipping, 0°–15° rotations, scaling within [0.9, 1.1], and elastic deformations. All models, including CASNet and the baseline variants, were trained from scratch under identical conditions. The checkpoint with the best validation performance was used for final evaluation. We employed five-fold cross-validation on both ACDC-17 and M&Ms-2 datasets to ensure robustness. For each fold, 80% of the data was used for training and 20% for testing. All results were averaged across folds. For CASNet, the total loss function combined three components: binary cross-entropy (BCE), Dice loss, and the proposed curvature-aware loss. The weighting coefficients were set to 0.5 for BCE, 0.4 for Dice, and 0.1 for the curvature-aware loss.
4.3 Evaluation metrics
To evaluate segmentation performance comprehensively, we adopt several standard metrics: Dice Similarity Coefficient (DSC), Recall, Accuracy (ACC), Precision, Jaccard Index (JC), Hausdorff Distance (HD), and Mean Absolute Distance (MAD). These metrics collectively reflect both region-based overlap and boundary alignment quality.
The Dice Similarity Coefficient (DSC) measures the overlap between the predicted segmentation Ŷ and the ground truth Y, and is defined as:
where TP, FP, and FN represent the number of true positives, false positives, and false negatives, respectively.
Recall (sensitivity) and Precision evaluate the completeness and exactness of the segmentation:
Accuracy (ACC) computes the proportion of correctly classified pixels over the entire image:
The Jaccard Index (JC) or Intersection over Union (IoU), quantifies the ratio of the intersection over the union of prediction and ground truth:
Hausdorff Distance (HD) measures the maximum surface distance between the boundary points of the predicted and ground truth masks. Formally, it is defined as:
where A and B are sets of contour points from the predicted and ground truth masks.
Mean Absolute Distance (MAD) captures the average distance between corresponding points on the predicted and ground truth boundaries, given by:
This metric is more robust to outliers than HD and provides a reliable estimate of average boundary deviation.
4.4 Compared models
To validate the effectiveness of the proposed CASNet, we conducted a comprehensive comparative analysis against both traditional CNN-based architectures and recent Transformer-based models for medical image segmentation. All baseline models were trained under identical settings, including data splits, augmentation strategies, loss functions, and training schedules, to ensure a fair and rigorous evaluation.
The following models were selected as benchmarks:
• U-Net (23): A classical encoder–decoder architecture with skip connections, which serves as a foundational baseline in medical image segmentation. It is widely adopted due to its simplicity and effectiveness in capturing both low-level spatial details and high-level semantic features.
• U-Net++ (26): An enhanced version of U-Net that introduces nested and dense skip pathways between encoder and decoder layers, aiming to reduce the semantic gap and improve gradient flow through deep supervision.
• DeepLabV3 (27): A model that employs atrous spatial pyramid pooling (ASPP) to capture multi-scale contextual information. Although originally designed for natural image segmentation, it has been successfully adapted to various medical imaging tasks.
• CE-Net (28): A context encoder network that augments U-Net with a context extraction module based on dilated convolutions and a residual encoder–decoder framework. It is particularly effective at balancing spatial detail preservation and semantic representation.
• Swin-Unet (36): A pure Transformer-based architecture that employs shifted window multi-head self-attention for hierarchical representation learning. It represents the state-of-the-art in Transformer-based medical image segmentation.
• TransUNet (45): A hybrid CNN-Transformer model that integrates Transformer encoders with U-Net decoders to capture both local texture patterns and global semantic dependencies, demonstrating strong performance on various medical segmentation benchmarks.
All models were re-implemented or adapted using the PyTorch 1.12 framework and trained on the same hardware configuration (NVIDIA RTX 3090 GPU). This controlled experimental setup ensures that any performance differences can be attributed to architectural innovations rather than implementation details or training inconsistencies.
4.5 Quantitative results
In this section, we present a comprehensive quantitative evaluation of the proposed CASNet model on two benchmark cardiac MRI datasets: ACDC and M&Ms-2. The results are compared against six baseline methods spanning both traditional CNN architectures (U-Net, U-Net++, DeepLabV3, and CE-Net) and recent Transformer-based models (Swin-Unet, TransUNet). All models were trained under identical experimental conditions to ensure fair comparison.
Performance is reported using seven widely adopted metrics: Dice Similarity Coefficient (DSC), Recall (sensitivity), Accuracy (ACC), Precision, Jaccard Coefficient (JC), Hausdorff Distance (HD), and Mean Absolute Distance (MAD). To assess statistical significance, we conducted paired t-tests comparing CASNet with each baseline method for each metric, with significance levels indicated as: * (p < 0.05), ** (p < 0.01), and *** (p < 0.001). For distance-based metrics (HD and MAD), lower values are better, so significance indicates CASNet achieved significantly lower (better) values.
4.5.1 Results on ACDC dataset
Table 2 presents the quantitative results on the ACDC dataset. Our proposed CASNet achieves the highest DSC of 96.3%, surpassing TransUNet (95.9%) by 0.4 percentage points, CE-Net (95.6%) by 0.7 percentage points, and substantially outperforming earlier architectures such as Swin-Unet (94.8%), DeepLabV3 (93.5%), U-Net++ (86.8%), and U-Net (85.1%).
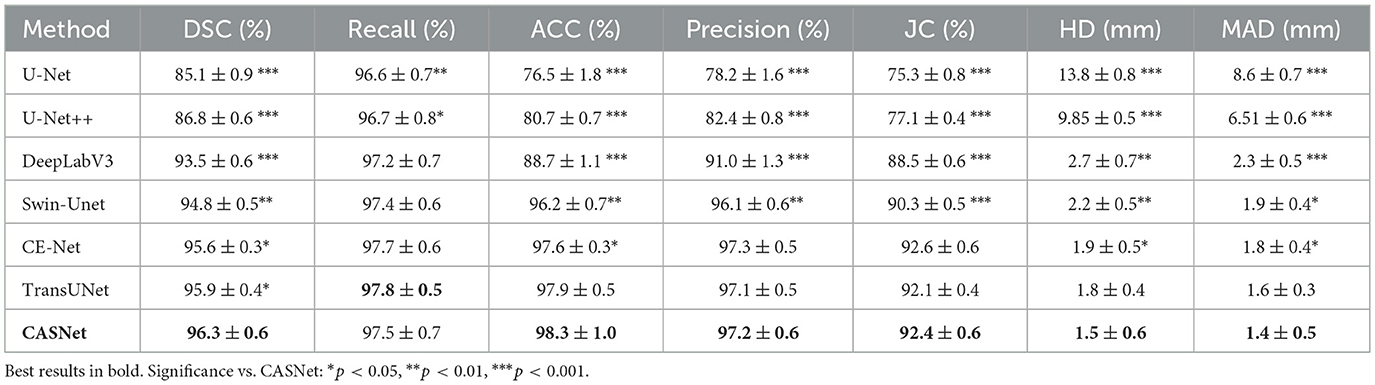
Table 2. Quantitative comparison on the ACDC dataset.
Statistical analysis confirms that CASNet achieves significant improvements across nearly all metrics and baseline comparisons. Notably, while TransUNet demonstrates competitive performance with the highest recall (97.8%), benefiting from its hybrid CNN-Transformer design, CASNet achieves the best overall performance with superior accuracy (98.3%) and significantly better boundary delineation (HD: 1.5 mm, MAD: 1.4 mm). The comprehensive statistical significance across multiple evaluation dimensions validates the robustness of our methodological contributions.
4.5.2 Results on M&Ms-2 dataset
Table 3 summarizes the segmentation results on the M&Ms-2 dataset, which poses additional challenges due to its multi-center, multi-vendor acquisition protocols and greater anatomical diversity. Despite these challenges, CASNet maintains robust generalization performance, achieving a DSC of 95.7%—the highest among all compared methods, with statistically significant improvements across all metrics for most baseline comparisons.
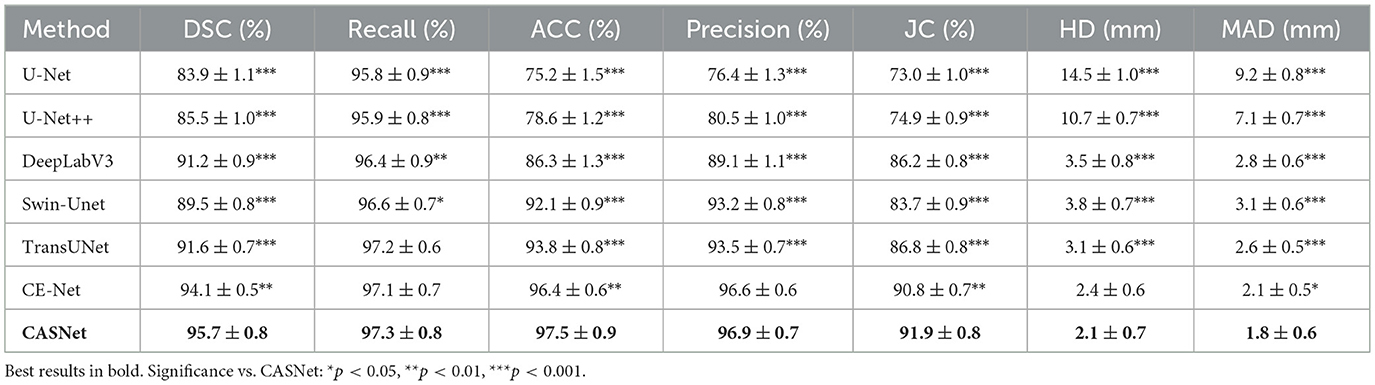
Table 3. Quantitative comparison on the M&Ms-2 dataset.
The performance gap is more pronounced on this challenging dataset. CASNet surpasses CE-Net by 1.6 percentage points in DSC and TransUNet by 4.1 percentage points, with highly significant differences (** or ***) observed for nearly all metrics. The consistent statistical significance across both overlap-based metrics (DSC, JC, and Precision) and distance-based metrics (HD, MAD) on this diverse dataset validates the superior generalization capability and clinical applicability of our approach.
4.6 Computational cost analysis
Although the proposed CASNet introduces additional modules such as cross-attentive skip connections and a multi-scale context block, it remains computationally efficient. To assess the practical feasibility of our approach, we compare the computational cost of CASNet against several widely used baseline models under the same hardware and input settings.
All models were evaluated on an NVIDIA RTX 3090 GPU using 2D cardiac MR images resized to 256 × 256. Table 4 reports the number of trainable parameters, FLOPs per inference, training time per epoch, and inference latency.
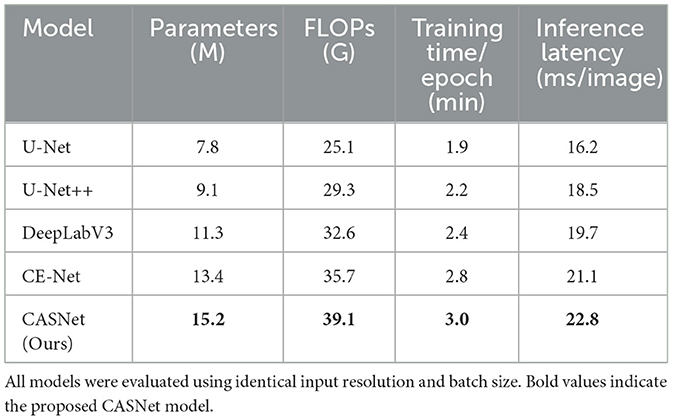
Table 4. Comparative analysis of computational cost.
As shown in Table 4 CASNet exhibits a moderate increase in computational demand compared to CE-Net and DeepLabV3, which is expected due to the attention operations. However, the overhead remains within acceptable limits for offline training and inference workflows. The performance gains in segmentation accuracy and boundary quality justify this additional cost in most practical applications.
4.7 Ablation study
To assess the individual contributions of each proposed component in CASNet, we conducted a series of ablation experiments. Specifically, we evaluated the effect of the Multi-Scale Context Block (MSCB), Cross-Attentive Skip Connections (CASC), and Curvature-Aware Loss by selectively enabling or disabling them in different variants of the network.
The baseline is a standard U-Net architecture without any of the proposed modules. We then sequentially introduced MSCB, CASC, and the curvature-aware loss, both individually and in combination, while keeping all other training settings constant. This controlled setup enables a clear assessment of each module's impact on segmentation performance. Statistical significance was assessed using paired t-tests comparing each variant against the baseline, with n = 100 test cases for ACDC and n = 160 test cases for M&Ms-2. Significance levels are denoted as *: p < 0.05, **: p < 0.01, ***: p < 0.001. The results are reported on both the ACDC and M&Ms-2 datasets.
To evaluate the contribution of each proposed component, we conduct an ablation study on the ACDC dataset. The experimental results are summarized in Table 5. Starting from the vanilla U-Net baseline, we incrementally add the Multi-Scale Context Block (MSCB), Cross-Attentive Skip Connections (CASC), and Curvature-Aware Loss to analyze their individual and combined effects.
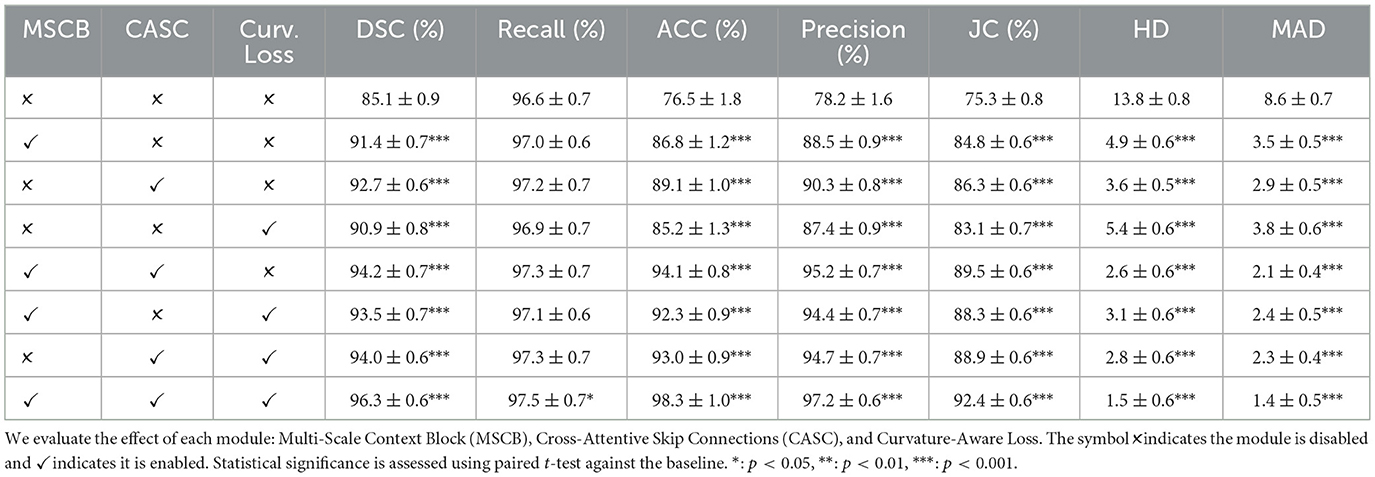
Table 5. Ablation study on the ACDC dataset.
Introducing MSCB alone significantly improves the Dice score from 85.1% to 91.4% (p < 0.001), indicating its effectiveness in capturing contextual features at different scales. Similarly, CASC independently boosts the Dice score to 92.7% (p < 0.001), showcasing the importance of semantically aligned skip connections. The Curvature-Aware Loss also contributes positively, increasing the Dice score to 90.9% (p < 0.001) and reducing Hausdorff Distance (HD) and Mean Absolute Distance (MAD), particularly enhancing contour smoothness.
Combinations of any two modules yield further improvements, all statistically significant (p < 0.001). Notably, combining MSCB and CASC (without the loss term) achieves a Dice of 94.2%, while adding Curvature Loss to either of the blocks provides similar gains in both accuracy and boundary consistency. Incorporating all three modules leads to the best performance across all metrics, with a Dice score of 96.3%, Accuracy of 98.3%, and HD/MAD reduced to 1.5 and 1.4, respectively (all p < 0.001 compared to baseline). This clearly demonstrates the complementary nature of the three components in enhancing both region-wise segmentation and structural fidelity.
From Table 6, we observe that all three modules contribute positively to segmentation performance with statistical significance (p < 0.001 for all individual modules). Introducing the MSCB improves DSC by over 5% compared to the baseline, indicating its ability to capture multi-scale contextual features. The CASC also offers significant gains in both DSC and boundary accuracy (HD/MAD), demonstrating the importance of semantically guided feature fusion. The Curvature-Aware Loss alone improves contour regularity, evident in the reduction of HD and MAD.
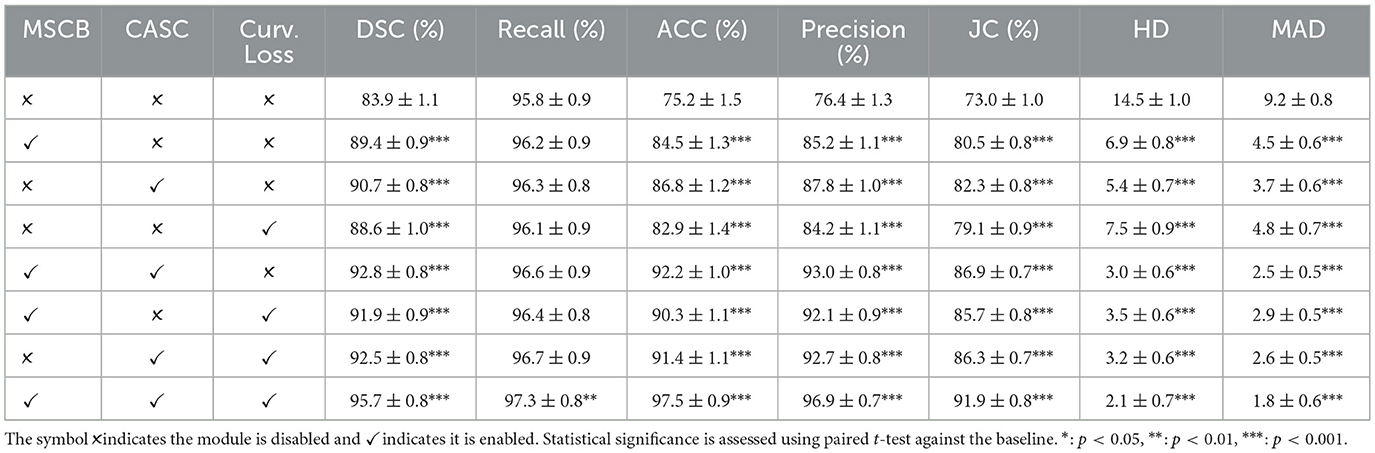
Table 6. Ablation study on the M&Ms-2 dataset.
Combining MSCB and CASC yields a DSC of 92.8% (p < 0.001), while pairwise combinations with the curvature loss achieve similar performance levels (all p < 0.001). The full model incorporating all three modules achieves the highest performance with a DSC of 95.7%, Accuracy of 97.5%, and substantial reductions in HD and MAD to 2.1 and 1.8, respectively (all p < 0.001 compared to baseline). These results confirm the robustness and generalizability of the proposed components across different datasets with varying imaging characteristics.
4.8 Qualitative visualization and analysis
To further validate the effectiveness of the proposed method, we present qualitative visual comparisons of segmentation results on both datasets. Figures 3, 4 illustrate sample outputs from multiple baseline models and the proposed CASNet.
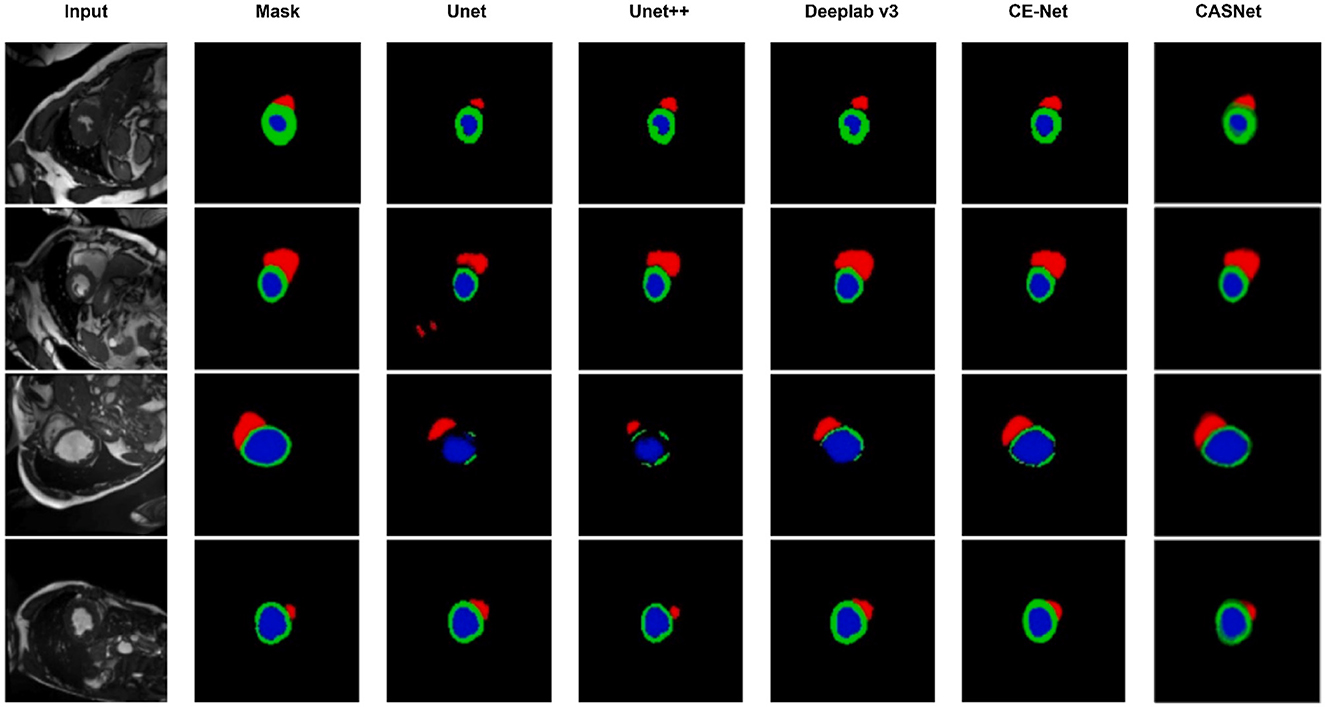
Figure 3. Visual comparison of segmentation results on the ACDC dataset. From left to right: Input, Ground Truth, U-Net, U-Net++, DeepLabv3, CE-Net, and our proposed CASNet. CASNet clearly produces more accurate and smooth contours, especially around boundaries and small regions.
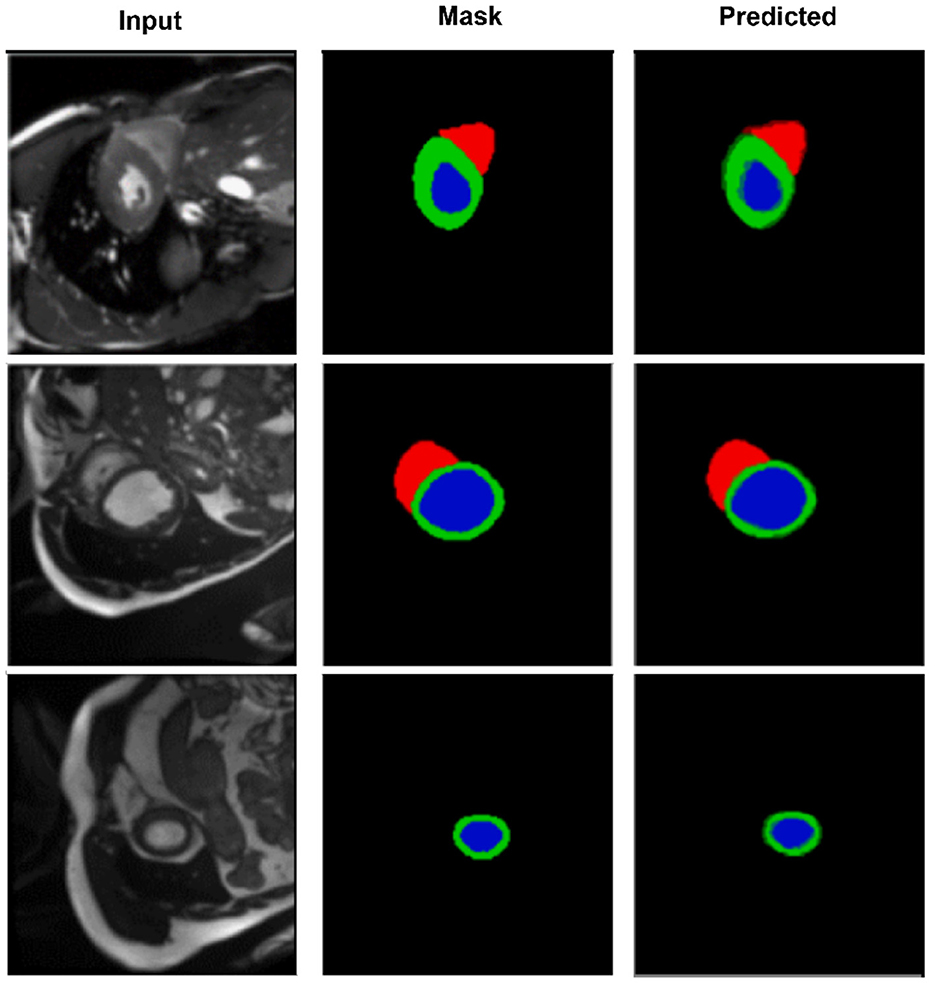
Figure 4. Segmentation results on the M&Ms-2 dataset. Columns represent the input image, ground truth, and output from CASNet. CASNet shows robust generalization and maintains precise delineation across varying patient cases.
As shown in Figure 3, CASNet yields segmentations that are more spatially coherent and closer to the ground truth compared to other methods. For instance, in cases where DeepLabv3 and CE-Net introduce irregular boundaries or miss parts of the myocardium, CASNet successfully preserves anatomical shape with sharper and more consistent predictions. This demonstrates the benefit of the proposed cross-attentive and curvature-aware designs in learning structured features.
Figure 4 further highlights CASNet's robustness under domain variability. Despite differences in contrast and shape, the model consistently segments the left ventricle (blue), myocardium (green), and right ventricle (red) accurately. The smooth contours and structural continuity across frames confirm the model's generalization ability on heterogeneous data.
To gain a deeper understanding of spatial alignment between predicted segmentations and the input anatomy, Figure 5 presents a qualitative overlay of CASNet's predictions on the ACDC dataset. This visualization allows us to evaluate not only the shape fidelity but also the spatial consistency of segment boundaries relative to the original MR images. The overlay columns demonstrate that CASNet is capable of producing highly aligned and anatomically plausible contours. In all three examples, the boundaries between the myocardium, left ventricle, and right ventricle closely follow the true anatomical structures visible in the grayscale input. Notably, regions with tight curvature or close class adjacency are well captured without excessive bleeding or class mixing.
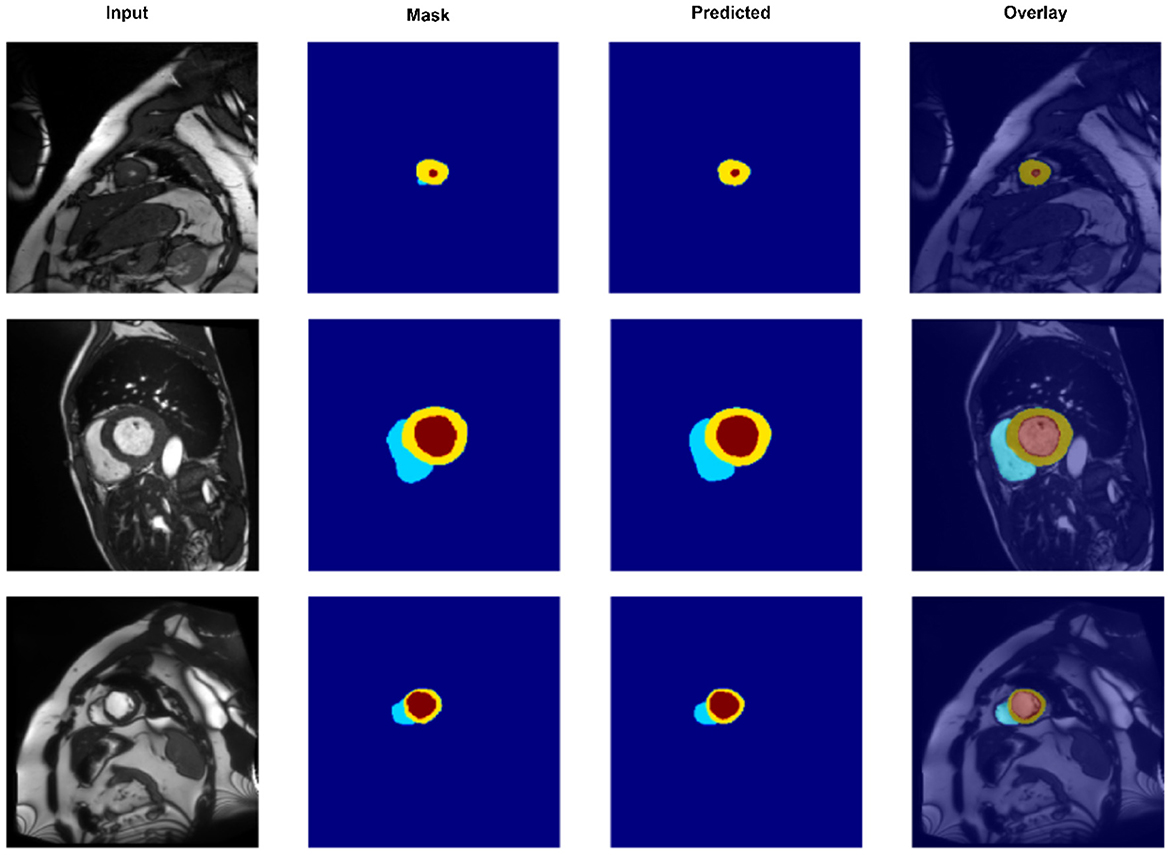
Figure 5. Overlay visualization of segmentation predictions on the ACDC dataset using CASNet. From left to right: Input image, ground truth mask, predicted mask, and overlay of prediction on the original input. The color-coded regions represent the right ventricle (cyan), myocardium (yellow), and left ventricle (red).
4.9 External validation on Sunnybrook dataset
To further assess the generalization capability of CASNet to unseen clinical centers and acquisition protocols, we conducted external validation on the Sunnybrook Cardiac Dataset. This dataset comprises 45 cardiac MRI cases acquired at an independent institution with different imaging parameters and patient demographics. We applied the models trained on the ACDC training set directly to all Sunnybrook subjects without any fine-tuning, domain adaptation, or hyperparameter modification. This zero-shot cross-domain evaluation protocol rigorously assesses the intrinsic robustness of learned representations when transferred to a completely unseen imaging domain.
Table 7 presents an ablation analysis on the Sunnybrook dataset using models trained on ACDC, revealing the contribution of each component to cross-domain generalization. The baseline U-Net trained on ACDC achieves 74.3% DSC when directly applied to Sunnybrook, establishing a lower bound for zero-shot performance. Incorporating standard skip connections improves DSC to 76.8%, demonstrating the benefit of multi-level feature fusion for domain transfer. The model with Cross-Attentive Skip Connections (CASC) further boosts performance to 78.5%, indicating that adaptive feature recalibration enhances robustness to domain variations. Adding the Multi-Scale Context Block (MSCB) yields 80.2% DSC, showing that multi-scale contextual modeling improves generalization across different imaging protocols. The full CASNet with Curvature-Aware Loss (CAL) achieves 82.4% DSC and 70.2% JC, representing an 8.1 percentage point improvement in DSC over the baseline and demonstrating that explicit boundary regularization contributes to cross-domain robustness.
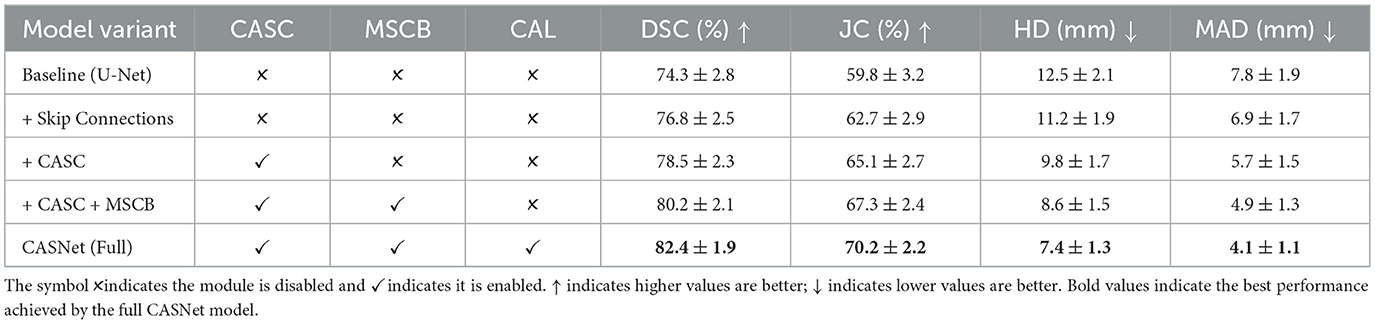
Table 7. Ablation study on Sunnybrook dataset using models trained on ACDC (zero-shot cross-domain evaluation).
Comparing the zero-shot performance on Sunnybrook (82.4% DSC) with the in-distribution performance on ACDC test set (96.3% DSC), CASNet exhibits a 13.9 percentage point degradation, which is expected given the substantial domain shift between the two datasets. Notably, the incremental contributions of CASC, MSCB, and CAL remain relatively consistent across domains, validating that our architectural innovations promote learning of domain-invariant features rather than dataset-specific patterns. The Hausdorff Distance and Mean Absolute Distance metrics show pronounced improvements with each component addition, with the full CASNet achieving 7.4 mm HD and 4.1 mm MAD. The Curvature-Aware Loss yields substantial improvement in boundary metrics even under domain shift, confirming its effectiveness in maintaining edge quality across different imaging conditions. These results demonstrate that CASNet's design choices collectively contribute to robust cross-domain generalization, supporting its potential for clinical deployment across diverse imaging centers without requiring site-specific retraining.
5 Conclusion
In this work, we proposed CASNet, a novel deep learning architecture for accurate and anatomically consistent cardiac MRI segmentation. CASNet integrates three key innovations into a U-Net backbone: a Multi-Scale Context Block (MSCB) to enhance contextual representation at the encoder bottleneck, Cross-Attentive Skip Connections (CASC) to bridge semantic gaps between encoder and decoder layers, and a Curvature-Aware Loss to regularize boundary smoothness and structural fidelity. Extensive experiments conducted on two benchmark datasets, ACDC and M&Ms-2, demonstrate that CASNet consistently outperforms established baselines. Ablation studies further confirm the complementary roles of each proposed component, with each module contributing independently and synergistically to the final performance. Qualitative visualizations also highlight CASNet's ability to preserve anatomical integrity and generate smooth, precise segmentation masks even in complex or low-contrast regions.
Despite its strong performance, CASNet has several limitations. First, the cross-attention mechanism introduces additional computational overhead, which may limit its real-time applicability on resource-constrained devices. Second, while our curvature-aware loss improves boundary quality, it relies on accurate second-order derivative approximations, which may be sensitive to image noise or aliasing. Third, CASNet was trained and evaluated on 2D slices, which may limit its ability to fully capture 3D anatomical continuity across frames in cine-MRI sequences. Furthermore, although the model generalized well across two datasets, broader validation on additional centers and imaging protocols is needed to confirm clinical robustness.
Future work will pursue several promising directions to address these limitations and extend the capabilities of CASNet. To leverage volumetric information, we plan to develop a 3D variant of CASNet by replacing 2D convolutions with 3D counterparts in the encoder and decoder, enabling the model to capture inter-slice dependencies and improve spatial coherence across cardiac volumes. For temporal consistency in cine-MRI sequences, we will explore integrating recurrent modules such as ConvLSTM or temporal attention mechanisms into the decoder to model cardiac motion dynamics across consecutive frames. To reduce computational cost for clinical deployment, we will investigate model compression techniques including knowledge distillation, where a compact student network learns from the full CASNet teacher, and neural architecture search to identify efficient architectures that balance accuracy and inference speed. Additionally, we will explore hybrid architectures that combine lightweight convolutional backbones with selective attention modules to maintain performance while reducing parameter count. To improve cross-domain generalization, we plan to incorporate unsupervised domain adaptation methods such as adversarial training or style transfer, enabling the model to adapt to new imaging protocols without requiring labeled data from each site. Finally, integrating anatomical shape priors through learned shape embeddings or atlas-based regularization may further enhance structural consistency and robustness to pathological variations. Preliminary experiments suggest that these directions are both feasible and promising for advancing CASNet toward broader clinical applicability.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
YD: Formal analysis, Investigation, Methodology, Validation, Visualization, Writing – original draft, Writing – review & editing. KH: Conceptualization, Methodology, Project administration, Funding acquisition, Writing – original draft. MY: Investigation, Methodology, Validation, Writing – review & editing. CC: Conceptualization, Investigation, Methodology, Writing – review & editing. XD: Formal analysis, Investigation, Methodology, Validation, Writing – review & editing. NW: Formal analysis, Investigation, Methodology, Validation, Writing – review & editing.
Funding
The author(s) declared that financial support was received for this work and/or its publication. This study was supported by grants from the China Medical Foundation (Grant No. 2025CMFC2) and the Sichuan Provincial Administration of Traditional Chinese Medicine (Grant No. 25MSZX285).
Conflict of interest
The author(s) declared that this work was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declared that generative AI was used in the creation of this manuscript. The author(s) verify and take full responsibility for the use of generative AI in the preparation of this manuscript. Generative AI was used to assist in the refinement of academic writing, including improving grammar, clarity, and coherence of the text. All content, scientific claims, data interpretation, and conclusions were reviewed and validated by the author(s) to ensure accuracy and originality. No generative AI tools were used to fabricate data, generate experimental results, or create figures.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Gaziano TA. Cardiovascular diseases worldwide. Public Health Approach Cardiovasc Dis Prev Manag. (2022) 1:8–18. doi: 10.1201/b23266-2
2. Jagannathan R, Patel SA, Ali MK, Narayan KV. Global updates on cardiovascular disease mortality trends and attribution of traditional risk factors. Curr Diab Rep. (2019) 19:44. doi: 10.1007/s11892-019-1161-2
3. Gaidai O, Cao Y, Loginov S. Global cardiovascular diseases death rate prediction. Curr Probl Cardiol. (2023) 48:101622. doi: 10.1016/j.cpcardiol.2023.101622
4. Davies RH, Augusto JB, Bhuva A, Xue H, Treibel TA, Ye Y, et al. Precision measurement of cardiac structure and function in cardiovascular magnetic resonance using machine learning. J Cardiov Magn Reson. (2022) 24:16. doi: 10.1186/s12968-022-00846-4
5. Peng P, Lekadir K, Gooya A, Shao L, Petersen SE, Frangi AF, et al. A review of heart chamber segmentation for structural and functional analysis using cardiac magnetic resonance imaging. Magn Reson Mater Phys Biol Med. (2016) 29:155–95. doi: 10.1007/s10334-015-0521-4
6. Qin JX, Shiota T, Thomas JD. Determination of left ventricular volume, ejection fraction, and myocardial mass by real-time three-dimensional echocardiography. Echocardiography. (2000) 17:781–6. doi: 10.1111/j.1540-8175.2000.tb01237.x
7. Yao W, Bai J, Liao W, Chen Y, Liu M, Xie Y. From CNN to transformer: a review of medical image segmentation models. J Imag Inform Med. (2024) 37:1529–47. doi: 10.1007/s10278-024-00981-7
8. Kayalibay B, Jensen G, Van Der Smagt P. CNN-based segmentation of medical imaging data. arXiv preprint arXiv:1701.03056. (2017).
9. Wu B, Fang Y, Lai X. Left ventricle automatic segmentation in cardiac MRI using a combined CNN and U-net approach. Computer Med Imag Graph. (2020) 82:101719. doi: 10.1016/j.compmedimag.2020.101719
10. Simantiris G, Tziritas G. Cardiac MRI segmentation with a dilated CNN incorporating domain-specific constraints. IEEE J Sel Top Signal Process. (2020) 14:1235–43. doi: 10.1109/JSTSP.2020.3013351
11. Neha F, Bhati D, Shukla DK, Dalvi SM, Mantzou N, Shubbar S. U-net in medical image segmentation: a review of its applications across modalities. arXiv preprint arXiv:2412.02242. (2024).
12. Duggento A, Conti A, Guerrisi M, Toschi N. A novel multi-branch architecture for state of the art robust detection of pathological phonocardiograms. Philos Trans R Soc A. (2021) 379:20200264. doi: 10.1098/rsta.2020.0264
13. Xiong P, Yang L, Zhang J, Xu J, Yang J, Wang H, et al. Detection of inferior myocardial infarction based on multi branch hybrid network. Biomed Signal Process Control. (2023) 84:104725. doi: 10.1016/j.bspc.2023.104725
14. Li S, Li X, Wang P, Liu K, Wei B, Cong J. An enhanced visual state space model for myocardial pathology segmentation in multi-sequence cardiac MRI. Med Phys. (2025) 52:4355–70. doi: 10.1002/mp.17761
15. El-Rewaidy H, Fahmy AS, Pashakhanloo F, Cai X, Kucukseymen S, Csecs I, et al. Multi-domain convolutional neural network (MD-CNN) for radial reconstruction of dynamic cardiac MRI. Magn Reson Med. (2021) 85:1195–208. doi: 10.1002/mrm.28485
16. Xiao Y, Chen C, Fu X, Wang L, Yu J, Zou Y, et al. A novel multi-task semi-supervised medical image segmentation method based on multi-branch cross pseudo supervision. Appl Intell. (2023) 53:30343–58. doi: 10.1007/s10489-023-05158-3
17. Hashmi A, Dietlmeier J, Curran KM, O'Connor NE. Cardiac MRI reconstruction with CMRatt: an attention-driven approach. In: 2024 32nd European Signal Processing Conference (EUSIPCO). IEEE (2024). p. 1666–1670. doi: 10.23919/EUSIPCO63174.2024.10715046
18. Bernard O, Lalande A, Zotti C, Cervenansky F, Yang X, Heng PA, et al. Deep learning techniques for automatic MRI cardiac multi-structures segmentation and diagnosis: is the problem solved? IEEE Trans Med Imaging. (2018) 37:2514–25. doi: 10.1109/TMI.2018.2837502
19. Bijnens B, Cikes M, Butakoff C, Sitges M, Crispi F. Myocardial motion and deformation: what does it tell us and how does it relate to function? Fetal Diagn Ther. (2012) 32:5–16. doi: 10.1159/000335649
20. Josephson ME, Anter E. Substrate mapping for ventricular tachycardia: assumptions and misconceptions. JACC. (2015) 1:341–52. doi: 10.1016/j.jacep.2015.09.001
21. Bilal A, Jourabloo A, Ye M, Liu X, Ren L. Do convolutional neural networks learn class hierarchy? IEEE Trans Vis Comput Graph. (2017) 24:152–62. doi: 10.1109/TVCG.2017.2744683
22. Yan Z, Zhang H, Piramuthu R, Jagadeesh V, DeCoste D, Di W, et al. HD-CNN: hierarchical deep convolutional neural networks for large scale visual recognition. In: Proceedings of the IEEE International Conference on Computer Vision (2015). p. 2740–2748. doi: 10.1109/ICCV.2015.314
23. Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer (2015). p. 234–241. doi: 10.1007/978-3-319-24574-4_28
24. Fuin N, Bustin A, Küstner T, Oksuz I, Clough J, King AP, et al. A multi-scale variational neural network for accelerating motion-compensated whole-heart 3D coronary MR angiography. Magn Reson Imag. (2020) 70:155–67. doi: 10.1016/j.mri.2020.04.007
25. Qi L, Zhang H, Tan W, Qi S, Xu L, Yao Y, et al. Cascaded conditional generative adversarial networks with multi-scale attention fusion for automated bi-ventricle segmentation in cardiac MRI. IEEE Access. (2019) 7:172305–20. doi: 10.1109/ACCESS.2019.2956210
26. Zhou Z, Rahman Siddiquee MM, Tajbakhsh N, Liang J. Unet++: a nested u-net architecture for medical image segmentation. In: International Workshop on Deep Learning in Medical Image Analysis. Springer (2018). p. 3–11. doi: 10.1007/978-3-030-00889-5_1
27. Chen LC, Papandreou G, Schroff F, Adam H. Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587. (2017).
28. Gu Z, Cheng J, Fu H, Zhou K, Hao H, Zhao Y, et al. CE-Net: context encoder network for 2D medical image segmentation. IEEE Trans Med Imaging. (2019) 38:2281–92. doi: 10.1109/TMI.2019.2903562
29. Ekiz S, Acar U. Improving building extraction from high-resolution aerial images: Error correction and performance enhancement using deep learning on the Inria dataset. Sci Prog. (2025) 108:00368504251318202. doi: 10.1177/00368504251318202
30. Oktay O, Schlemper J, Folgoc LL, Lee M, Heinrich M, Misawa K, et al. Attention u-net: Learning where to look for the pancreas. arXiv preprint arXiv:1804.03999. (2018).
31. Hu J, Shen L, Sun G. Squeeze-and-excitation networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018). p. 7132–7141. doi: 10.1109/CVPR.2018.00745
32. Woo S, Park J, Lee JY, Kweon IS. Cbam: convolutional block attention module. In: Proceedings of the European Conference on Computer Vision (ECCV) (2018). p. 3–19. doi: 10.1007/978-3-030-01234-2_1
33. Pang S, Du A, Orgun MA, Wang Y, Yu Z. Tumor attention networks: better feature selection, better tumor segmentation. Neural Netw. (2021) 140:203–22. doi: 10.1016/j.neunet.2021.03.006
34. Huang Z, Ling Z, Gou F, Wu J. Medical assisted-segmentation system based on global feature and stepwise feature integration for feature loss problem. Biomed Signal Process Control. (2024) 89:105814. doi: 10.1016/j.bspc.2023.105814
35. Yeung M, Sala E, Schönlieb CB, Rundo L. Unified focal loss: generalising dice and cross entropy-based losses to handle class imbalanced medical image segmentation. Computer Med Imag Graph. (2022) 95:102026. doi: 10.1016/j.compmedimag.2021.102026
36. Cao H, Wang Y, Chen J, Jiang D, Zhang X, Tian Q, et al. Swin-unet: Unet-like pure transformer for medical image segmentation. In: European Conference on Computer Vision. Springer (2022). p. 205–218. doi: 10.1007/978-3-031-25066-8_9
37. Qi Q, Lin L, Zhang R, Xue C. MEDT using multimodal encoding-decoding network as in transformer for multimodal sentiment analysis. IEEE Access. (2022) 10:28750–9. doi: 10.1109/ACCESS.2022.3157712
38. Zhang Z, Wu H, Zhao H, Shi Y, Wang J, Bai H, et al. A novel deep learning model for medical image segmentation with convolutional neural network and transformer. Interdiscipl Sci. (2023) 15:663–77. doi: 10.1007/s12539-023-00585-9
39. Ji Z, Sun H, Yuan N, Zhang H, Sheng J, Zhang X, et al. BGRD-TransUNet: a novel TransUNet-based model for ultrasound breast lesion segmentation. IEEE Access. (2024) 12:31182–96. doi: 10.1109/ACCESS.2024.3368170
40. Yu J, Qin J, Xiang J, He X, Zhang W, Zhao W. Trans-UNeter: a new decoder of TransUNet for medical image segmentation. In: 2023 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). IEEE (2023). p. 2338–2341. doi: 10.1109/BIBM58861.2023.10385407
41. Wang H, Wang Z, Wang X, Wu Z, Yuan Y, Li Q. AnatSwin: an anatomical structure-aware transformer network for cardiac MRI segmentation utilizing label images. Neurocomputing. (2024) 577:127379. doi: 10.1016/j.neucom.2024.127379
42. Abouei E, Pan S, Hu M, Kesarwala AH, Zhou J, Roper J, et al. Cardiac MRI segmentation using block-partitioned transformer with global-local information integration. In: Medical Imaging 2024: Clinical and Biomedical Imaging. SPIE (2024). p. 510–514. doi: 10.1117/12.3006929
43. Noroozi M, Arabi H, Karimian AR. Assessment of transformer-based models for cardiac systolic abnormality segmentation in cardiac catheterization X-ray images. In: 2024 31st National and 9th International Iranian Conference on Biomedical Engineering (ICBME). IEEE (2024). p. 129–134. doi: 10.1109/ICBME64381.2024.10895718
44. Zhang Z, Miao Y, Wu J, Zhang X, Ma Q, Bai H, et al. Deep learning and radiomics-based approach to meningioma grading: exploring the potential value of peritumoral edema regions. Phys Med Biol. (2024) 69:105002. doi: 10.1088/1361-6560/ad3cb1
Keywords: cardiac MRI segmentation, curvature-aware loss, deep learning, medical image analysis, multi-scale context
Citation: Du Y, Huang K, Yue M, Chen C, Deng X and Wang N (2026) CASNet: curvature-aware cardiac MRI segmentation with multi-scale and attention-driven encoding for enhanced risk-oriented structural analysis. Front. Med. 12:1688872. doi: 10.3389/fmed.2025.1688872
Received: 19 August 2025; Revised: 06 December 2025; Accepted: 10 December 2025;
Published: 21 January 2026.
Edited by:
Ling Sun, Nanjing Medical University, ChinaReviewed by:
Yafei Li, Nanjing Medical University, ChinaQuanfeng Ma, Tianjin Medical University, China
Copyright © 2026 Du, Huang, Yue, Chen, Deng and Wang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xiaojian Deng, ZGVuZ3hpYW9qaWFuMjAyNUAxNjMuY29t; Ning Wang, MTgxMTExOTY2MTVAMTYzLmNvbQ==