 Xiaofei Han1,2*
Xiaofei Han1,2* Xin Dou2
Xin Dou2- 1Business College, California State University, Long Beach, CA, United States
- 2School of Business and Management, Shanghai International Studies University, Shanghai, China
In common graph neural network (GNN), although incorporating social network information effectively utilizes interactions between users, it often overlooks the deeper semantic relationships between items and fails to integrate visual and textual feature information. This limitation can restrict the diversity and accuracy of recommendation results. To address this, the present study combines knowledge graph, GNN, and multimodal information to enhance feature representations of both users and items. The inclusion of knowledge graph not only provides a better understanding of the underlying logic behind user interests and preferences but also aids in addressing the cold-start problem for new users and items. Moreover, in improving recommendation accuracy, visual and textual features of items are incorporated as supplementary information. Therefore, a user recommendation model is proposed that integrates hierarchical graph attention network with multimodal knowledge graph. The model consists of four key components: a collaborative knowledge graph neural layer, an image feature extraction layer, a text feature extraction layer, and a prediction layer. The first three layers extract user and item features, and the recommendation is completed in the prediction layer. Experimental results based on two public datasets demonstrate that the proposed model significantly outperforms existing recommendation methods in terms of recommendation performance.
1 Introduction
In the era of rapid information expansion, users are increasingly overwhelmed by vast amounts of digital content, leading to issues such as information overload and difficulty in efficiently locating relevant content. This challenge is particularly pronounced on emerging short video, social media, and e-commerce platforms, where the volume and diversity of data far exceed users’ cognitive and processing capacities. Consequently, intelligent recommendation systems have become essential tools for filtering massive datasets and delivering personalized content to users ((Liu et al., 2024; Wu et al., 2024; Yamada, 2021) and limited representation capacity, all of which hinder their performance in dynamic and complex environments (Zhang et al., 2019; Gao et al., 2022). With the rise of deep learning, the landscape of recommendation systems has evolved significantly. Techniques such as convolutional neural network (CNN) and recurrent neural networks (RNN) have shown strong capabilities in feature extraction and modeling temporal user preferences (Han et al., 2024; Wang et al., 2024, 2025, Yan et al., 2025).
Traditional recommendation approaches—such as content-based filtering (CBF), collaborative filtering (CF), and hybrid recommendation (HR)—primarily rely on users’ historical interactions (e.g., purchases or browsing records) and similarity computations to provide recommendations (Javed et al., 2021; Wu et al., 2023). While these methods have achieved moderate success, they struggle with key issues such as the cold start problem, data sparsity, and limited representation capacity, all of which hinder their performance in dynamic and complex environments (Zhang et al., 2019).
With the rise of deep learning, the landscape of recommendation systems has evolved significantly. Techniques such as convolutional neural network (CNN) and recurrent neural networks (RNN) have shown strong capabilities in feature extraction and modeling temporal user preferences (Steck et al., 2021; Bandyopadhyay et al., 2024). For example, Visa et al. proposed a CNN-based feature extraction method, which uses matrix multiplication between users and items to uncover latent relationships, effectively solving the sparsity issue of similarity matrices and optimizing recommendation results (Visa and Patel, 2021). Cho et al. designed an RNN-based recommendation system that analyzes temporal data to precisely capture dynamically changing user needs, providing more accurate recommendations (Cho et al., 2014). More recently, graph neural networks (GNNs) have demonstrated remarkable effectiveness in capturing intricate relationships between users and items by modeling them as graph structures (Jiang et al., 2023). For instance, the GraphRec model proposed by Fan et al. constructs a user information model that combines social network data with user characteristics and uses a multilayer perceptron to extract features of target items, improving recommendation accuracy (Fan et al., 2019). Chen et al. improved the recommendation system’s efficiency by leveraging social neighbor network information and using heterogeneous GNN methods (Chen and Wong, 2021).
Parallel to these advances, knowledge graphs (KG) have emerged as a promising auxiliary resource for enhancing recommendation performance. By formally encoding entities and their semantic relationships, KGs enable richer user-item interaction modeling. Existing KG-enhanced recommendation strategies include embedding-based, path-based, and joint learning approaches. These techniques have demonstrated improved interpretability and accuracy by incorporating external structured knowledge into recommendation pipelines (Guo et al., 2020; Zhang et al., 2024). Oramas et al. (2016) proposed a recommendation system that combines semantic and collaborative characteristics by extracting information from KG using both entity-and path-based strategies, transforming it into linear features. Path-based recommendations involve establishing user-item relation graph to uncover connections between entities, measure node similarity, and recommend content. Path analysis in KG reveals complex relationships between entities, allowing for precise exploration of user preferences through specific meta-paths, enhancing the interpretability of the recommendation system (Sun et al., 2020). Ma et al. (2019) developed the RuleRec algorithm, which extracts rules from an item-centric KG to identify various associations and provides recommendations using these inferred rules. Joint recommendation methods integrate path analysis and knowledge graph embedding approaches, where user interests are first captured via a propagation mechanism across the entire knowledge graph and then extracted through graph embedding techniques, ultimately completing the recommendation process (Yang et al., 2022). Wang X. et al. (2019) proposed the model, which combines user-item bipartite graph with knowledge graph and performs iterative diffusion in shared knowledge graph via GNN, enriching entity embeddings. Shi et al. (2021) introduced the method, modeling a heterogeneous information network, extracting multi-dimensional similarity matrices using different meta-paths, and integrating this information through deep learning network to complete the recommendation process.
Furthermore, multimodal recommendation systems—which integrate visual, textual, and sometimes audio data—have received growing attention for their ability to address the limitations of single-modal systems and further refine personalization (Li et al., 2019). By leveraging the complementary nature of different data types, multimodal methods can offer more comprehensive user representations and deeper insights into user preferences.
Motivated by the limitations of traditional and single-modal recommendation methods, this study proposes a novel recommendation framework that integrates hierarchical graph attention networks with a multimodal knowledge graph (HGAN-MKG). The model consists of four major components: a collaborative knowledge graph neural layer, an image feature extraction layer, a text feature extraction layer, and a prediction layer. Specifically, the collaborative KG layer captures deep user-item interactions via attention mechanisms and gated recurrent unit (GRU); the image layer applies a multi-path attention structure to analyze visual user behavior; the text layer uses multi-head self-attention and CNN to extract contextual features; and the prediction layer fuses all modalities to generate accurate recommendations. Experiments conducted on two benchmark datasets confirm the effectiveness of the proposed model, which outperforms several state-of-the-art baselines.
The remainder of this study is organized as follows: Section 2 introduces the underlying theory, Section 3 describes the design details of the algorithm, Section 4 presents experimental validation, and Section 5 concludes the research work.
2 Theoretical foundations
2.1 K-means clustering algorithm
The K-Means algorithm is an effective data clustering method that partitions a dataset into K clusters, with each cluster associated with its nearest center (Bock, 2007). This iterative algorithm continuously updates cluster centers and reassigns points to clusters until a predefined stopping criterion is met. The algorithm’s principle is determined by solving an optimization function, with the sum of squared errors serving as the evaluation metric. The objective is to minimize the total cost function, as defined in Equation 1.
In the context of recommendation systems, K-Means is applied to group users based on behavior, converting user activity data into vector form, and clustering users into 𝐾 groups. This method identifies similarities between users, enabling personalized recommendations for items that users within the same group are likely to find interesting.
2.2 Attention mechanism technologies
2.2.1 Attention mechanism
The attention mechanism allocates different weights to various inputs based on their importance, prioritizing more relevant information while ignoring less significant details. As depicted in Figure 1, each input’s Key, Value, and Query are processed as vectors, and the weight for each Key is determined by calculating its similarity to the Query. This results in a weighted sum of all Values, generating the final output. The calculation of similarity can be approached through four distinct strategies which is presented in Equation 2.
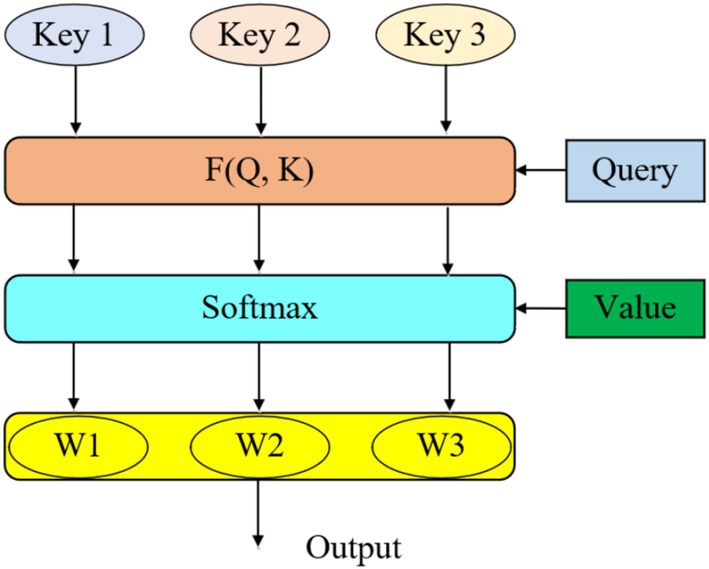
Figure 1. Allocation of attention mechanism weight.
2.2.2 Graph attention mechanism
With the expansion of research in this field, GAN and their variants have emerged, becoming integral to GNN These mechanisms typically form the core of complex deep learning architectures involving multiple convolutional or pooling layers designed to handle graph-structured data. Each layer participates in the propagation and aggregation of features between nodes and their neighbors, updating node representations and performing classification tasks. The graph attention mechanism emphasizes the dynamic evaluation of relative importance between nodes, calculating weights accordingly. As a critical component of GNN, it plays a pivotal role in computing node weights and handling diverse graph structures and tasks.
This mechanism assigns weights based on input features, allowing for weighted aggregation of data for more precise and effective representation. By assessing similarities between nodes and their neighbors, attention coefficients are computed to allocate weights. This strategy enhances the significance of key nodes while mitigating noise interference. Typically, a trainable network model is used to determine attention coefficients, considering the unique features of nodes and their relative positions with neighboring nodes, ultimately generating attention weights. Once these weights are obtained, node feature vectors are combined with their corresponding weights, resulting in a weighted feature vector that represents either a node or the entire graph.
2.2.3 Multi-head self-attention mechanism
The multi-head self-attention mechanism, a critical component of the Transformer model, has been widely adopted across various domains. Within the Transformer architecture, the attention mechanism consists of two key parts: scaled dot-product attention and multi-head attention, which together form the foundation of the model. The computation of scaled dot-product attention is as follows, as defined in Equation 3:
Both single-head and multi-head self-attention are considered derivative forms of the attention mechanism, with multi-head attention enhancing the model’s ability to manage long sequences and their complexity. Given an input sequence [𝑤1, 𝑤2, 𝑤3, …, 𝑤𝑇], where each 𝑤𝑖 represents the vector form of the word in the sequence.
The final representation 𝑏=[𝑏1, 𝑏2, 𝑏3, …, 𝑏𝑟] is derived from the weighted aggregation of attention heads. In a single-head attention mechanism, 𝑞1, 𝑘1, and 𝑣1 constitute one “head.” The multi-head self-attention mechanism multiplies specific 𝑤1 values with multiple 𝑊𝑄, 𝑊𝐾, and 𝑊𝑉 matrices to generate multiple sets of 𝑞1, 𝑘1, and 𝑣1, which is presented in Figure 2.
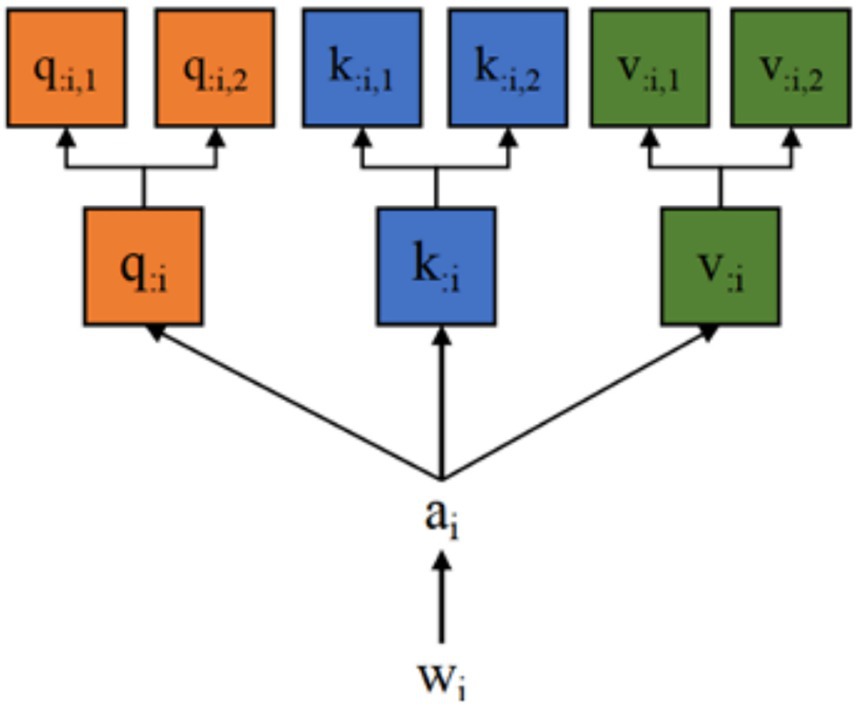
Figure 2. Multi-head self-attention.
After obtaining the outputs from all heads, these feature vectors are concatenated and linearly transformed to generate the final representation as defined in Equation 4:
2.3 Knowledge graph
A knowledge graph is essentially a semantic structure represented in the form of a graph, containing multiple categories of entities and offering a more intuitive and transparent visualization of complex relationships. It effectively encodes semantic information between entities and provides a highly structured means of representation. Mapping the entities and their relations into a low-dimensional continuous vector space is a critical step toward knowledge modeling and enhancing recommendation systems. During this process, it is essential to preserve both the structural properties of the graph and the semantic consistency of the nodes, in order to minimize information loss or distortion.
Various techniques have been proposed for feature extraction in knowledge base construction, including distance-based embedding models, similarity-based conceptual models, and path-based relational learning methods. Among them, translational models have gained widespread adoption due to their simplicity and scalability. Representative distance-based translational models include TransE, TransR, and TransD. For instance, TransR models entities as collections of multi-attribute information and achieves triple-level embedding by projecting entities into relation-specific spaces.
In TransR, each relation r is associated with a distinct relation space, and a projection matrix is defined to map entity vectors from the entity space to the corresponding relation space. Given a head entity h, a tail entity t, and a relation r, their representations in the relation space are represented in Equation 5:
Figure 3 illustrates the core concept of TransR. For each triple (ℎ+𝑟), the entities ℎ and 𝑡 are mapped to the relationship space r through a projection matrix , resulting in representations ℎ𝑟 and 𝑡𝑟. The goal is to ensure that (ℎ𝑟+𝑟) closely approximates 𝑡r. The transformation of entities in the space is represented by the following Equation 6:
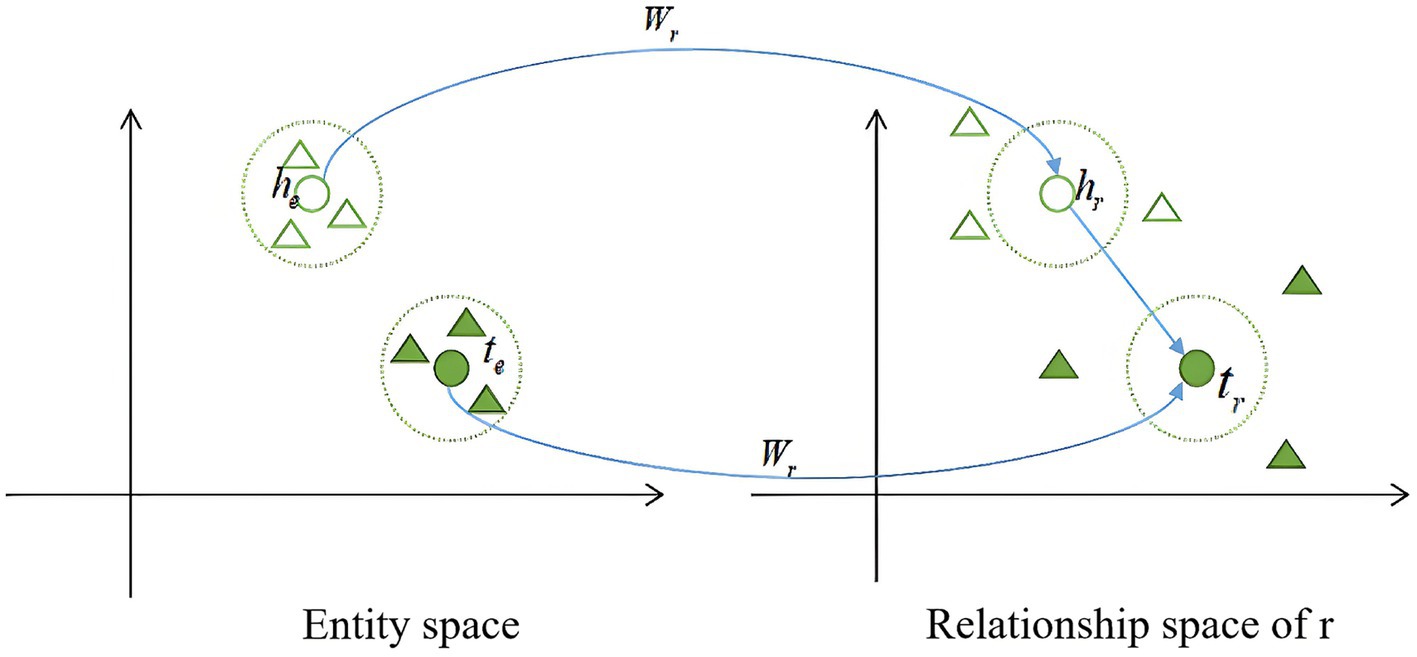
Figure 3. Graphical description of TransR.
The score function for determining the proximity between head and tail entities is given by Equation 7:
According to Equation 7, the lower the score of the triple, the closer the head and tail entities are in the relationship space 𝑟, which increases the probability of the triple being correct.
3 Methodology
The proposed recommended model HGAN-MKG, first extracts knowledge graph information. It then utilizes the VGG19 network to extract image features of items and combines multi-head self-attention mechanisms with CNN to extract text features. Finally, the model fuses these three types of information for recommendation purposes. The proposed model consists of four key components: the collaborative knowledge graph neural layer, the image feature extraction layer, the text feature extraction layer, and the prediction network layer. The model architecture is illustrated in Figure 4.

Figure 4. User recommendation method integrating hierarchical graph attention network with multimodal knowledge graph.
3.1 Collaborative knowledge graph neural layer
In the collaborative knowledge graph neural layer, the bipartite graph between users and items in the knowledge graph is integrated to connect item features, thereby forming a knowledge graph. Let 𝑉={𝑣1, 𝑣2, …, 𝑣𝑚} represent the set of items and 𝑈={𝑢1, 𝑢2, …, 𝑢𝑛} represent the users. The set 𝐸={𝑒1, 𝑒2, …, 𝑒𝑜} corresponds to the set of entities, where 𝑜, 𝑛, and 𝑚 denote the total number of entities, users, and items, respectively. The matrix 𝑌𝑖𝑗 indicates the interactions between users and items, defined as 𝑌𝑖𝑗 =1 if an interaction exists, and 𝑌𝑖𝑗=0 otherwise. A knowledge graph 𝐺={(ℎ, 𝑟, 𝑡)|ℎ, 𝑟=𝜀, 𝑟∈𝑅} is defined, where each triple consists of a head entity ℎ, a relationship 𝑟, and a tail entity 𝑡. If there is an association between ℎ and 𝑡, the elements in GGG represent entities and their associations.
In practice, the representation of entities and their relationships within a KG is typically approached using translation-based learning methods. These methods perform logical reasoning and mapping of entities and their relationships in a low-dimensional space for knowledge representation. In the TransE model, the triple (ℎ, 𝑟, 𝑡) is expressed in vectorized form, where the relationship 𝑟 is understood as a translation from ℎ to 𝑡. By fine-tuning the vector representations of the triples, the equation ℎ+𝑟 ≈𝑡 is satisfied. As technology has advanced, derivative techniques have emerged, such as the TransR model, where each entity is viewed as having multiple facets. Different relationships correspond to different aspects of an entity, and each semantic space corresponds to a specific relationship.
Through embedding techniques, item vector representations are obtained, and the attention mechanism is applied to explore the interactions between entities within the knowledge graph. This method not only integrates user data but also incorporates the internal relationships and complex hierarchical structures between entities in the knowledge graph. The training process based on the attention mechanism involves random sampling of nodes and the calculation of weight scores to capture direct relationships between entities. Subsequently, the attention mechanism analyzes these weights to identify and understand first-order entity relationships, which can be further extended to 𝐿-order entity relationships.
This paper delves into the training methods for the initial stages and extends the analysis to multi-layer 𝐿-structures. In this network layer, Equation 8 reveals the interactions between two entities, while Equation 9 measures the degree to which a user prefers specific relationships and entity information. For a specific item 𝑣0, its neighboring nodes in the set are described by the formula, where (𝑟, 𝑖, 𝑗) defines the connections between entities, and the attention mechanism is used to compute and evaluate the weights.
To explore deeper entity information, this layer is extended from a single level to multiple layers, resulting in 𝐿-order vectorized descriptions of entities. This 𝐿 -order vector representation aggregates data from neighboring entities up to (𝐿−1)-order. The final vector representation of the item 𝑣𝐿 is obtained, where 𝑊𝐿 represents the weight parameters and 𝑏𝐿 denotes the bias. This is calculated precisely using Equation 11.
Ultimately, a summary analysis is conducted to derive a representation 𝑢A, reflecting the user’s short-term interests, which is illustrated in Equation 12:
To more accurately capture the user’s final interests, vectors generated by the embedding layer are used to represent the user’s long-term interests. At the same time, aggregated vectors processed by the attention mechanism reflect the user’s short-term interests. A GRU model is then applied to integrate both long-term and short-term interests, forming a comprehensive representation of the user’s interest preferences. GRU is adopted due to its efficient gating mechanism and relatively lower computational complexity compared to LSTM, while maintaining comparable performance in modeling sequential dependencies. Unlike Transformer-based models, which typically require large-scale training data and extensive tuning, GRU provides a lightweight and effective solution for learning user preferences in data-constrained or latency-sensitive scenarios. The initial set of items interacting with the user is denoted as 𝑣𝑜.
User long-term preference representations 𝑢𝐿 are trained using historical interaction data. These are then combined with short-term preferences 𝑢𝐴 and trained through the GRU model. After training, the selected hidden layer undergoes normalization to produce the final representation of the user’s preference 𝑢𝐺. Ultimately, the long-term preferences 𝑢𝐿 are fused with the short-term preferences 𝑢𝐴, and a deep GRU model is used for training. The resulting hidden layers are normalized to generate the final user preference expression 𝑢𝐺 as shown in Equation 14:
3.2 Image feature extraction layer
In the image feature extraction layer, K-Means clustering is first applied to the image features corresponding to the user’s interaction history, aiming to uncover latent user preference patterns. Specifically, image features are extracted using a pretrained VGG19 model (employing its static components from Conv1 to FC7 layers), and uniformly transformed into 4,096-dimensional vector representations. These feature vectors are then input into a K-Means clustering algorithm to generate a set of representative cluster centroids, each corresponding to a latent category of visual preference. The resulting clusters are utilized not only for modeling user interests in visual content but also as input for subsequent dynamic feature learning. To further capture semantic representations of these clustered features at the individual user level, a trainable feature modeling module composed of three fully connected layers is constructed. This module is designed to generate high-level semantic representations of images. The computational process is defined as follows, as shown in Equation 15:
In this section, the first 18 layers of the VGG19 network are fixed as output 𝑝𝑜, which is used to extract the visual features 𝑝𝑣 of items. The images representing user-item interactions capture the user’s visual preferences. Since the contribution of these historical interaction images to capturing user preferences varies, an image aggregation network is employed to integrate these images differentially. The specific structure of the aggregation network is shown in Figure 5. The network utilizes a multi-channel attention mechanism, where the item’s image features and the initial representation of the target item serve as query vectors. These vectors are then passed through various fully connected networks to form individual weights and weighted vectors. The weighted vectors from the two channels are then aggregated to obtain a visual representation of the user’s historical behavior, calculated as shown in Equation 16:

Figure 5. Structure of image feature aggregation.
This represents the set 𝑝𝑖 of images from items previously interacted with by the user. The image of the item is transformed into a vector through embedding technology, which also includes the embedded representation of the target item image 𝑝𝑣. The training parameters are denoted by 𝜑, and the formulas for and are as shown in Equation 17:
3.3 Text feature extraction layer
This layer is responsible for extracting textual features. K-Means clustering is first applied to the user data before proceeding with further operations. For text feature extraction, consider a movie as an example. A movie’s textual features include its title, genre, and description, all of which are logically related. In this network layer, multi-head self-attention is employed to extract features from each component (movie title, genre, and description), which are then fused to form the final textual feature representation.
Regarding item categories, using movies as an example, when a user selects a movie for viewing in an app, they generally choose a broad genre, such as comedy, romance, or drama. If the user selects a comedy, they may further choose from sub-genres like slapstick, satirical, dark humor, or martial arts comedy. Similar patterns apply to other genres. Therefore, for category features, both broad and fine-grained categories are considered for feature extraction. During embedding, the ID is input and transformed into low-dimensional representations 𝑒𝑠 and 𝑒𝑑𝑠. The hidden category representation is then learned as shown in Equation 18:
Next, the item title is used to obtain its feature representation. This part involves three steps. First, the word sequence of the item title is transformed into a low-dimensional semantic vector sequence, converting the sequence of title words into a vector . The CNN component then extracts short-range contextual features from the words in the movie title. Using CNN, the context representation of the word is derived as , calculated as shown in Equation 19:
The final step uses multi-head self-attention to model the relationships between components, enabling better capture of distant textual features. The attention head’s representation of the word is calculated as shown in Equation 20:
Since the same word carries varying amounts of critical information across different item components, attention is used to assign weight proportions. The calculation for this is as shown in Equation 21:
The final representation of each component is obtained by aggregating the weighted expressions of the words. The calculation is as shown in Equation 22:
Given that different components contain varying amounts of information—titles and descriptions may carry more relevant details, while categories more accurately represent the item’s attributes—attention is employed to balance the weights, reflecting the amount of information each component carries. The calculation is as shown in Equation 23:
Similarly, the attention weights for categories and sub-categories are denoted as 𝑎𝑠 and 𝑎𝑑𝑠. The final representation is the weighted sum of the component representations, as presented in Equation 24:
Structure of text feature extraction is presented in Figure 6. Lastly, since user preferences may be related and users tend to browse items with similar categories, a multi-head self-attention mechanism is used to capture interactions between similar items, enhancing the representation of the user. The attention head’s representation of the item is calculated as presented in Equation 25:
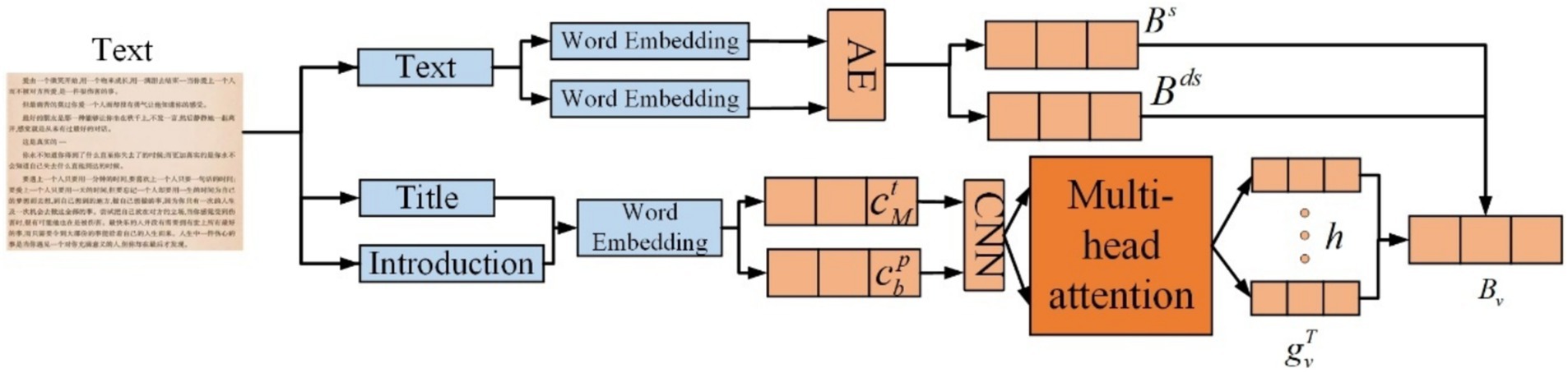
Figure 6. Structure of text feature extraction.
The user feature extraction part is shown in Figure 7. For user representation, the amount of user feature information carried by different items varies. Therefore, an attention mechanism is employed to better learn the user representation. The attention weight for the item is calculated as presented in Equation 26:
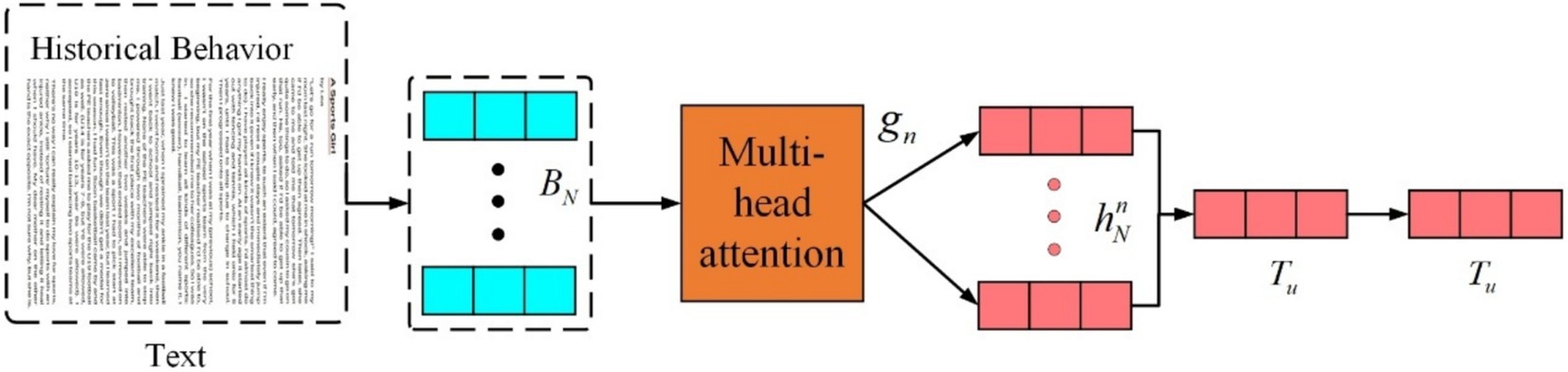
Figure 7. Structure of user feature extraction.
3.4 Prediction layer
After processing through the collaborative knowledge graph neural layer, the image feature extraction layer, and the text feature extraction layer, user and item features are obtained. Let 𝑄𝑢 and 𝑄𝑣 represent the sets of user and item features, respectively. The calculation process is presented in Equation 27:
These feature vectors are concatenated to form the final vector representation of the user and item, as expressed by Equation 28:
The final step involves applying the dot product of the user and item vectors to estimate the target user’s preference score for a specific item. The calculation is presented in Equation 29:
4 Experimental results and analysis
4.1 Dataset description
Two publicly available cross-domain recommendation datasets were employed in this study, covering the domains of movies and books: MovieLens-1M and Amazon-Book. The MovieLens-1M dataset, provided by the GroupLens research group, has been widely used in movie recommendation research and contains user rating records for movies (Harper and Konstan, 2015). The Amazon-Book dataset, extracted from the book subset of the Amazon Review Corpus, captures user rating behaviors toward book products (He and McAuley, 2016). To ensure experimental consistency, interaction records in each dataset were partitioned into a training set (80%), a test set (10%), and a validation set (10%, sampled from the training set) for model tuning. Table 1 summarizes the key statistics of the two datasets, including the number of users, items, and interactions, as well as data sparsity. Additionally, it presents the corresponding KG statistics, including the number of entities, relations, and total triples.

Table 1. Statistics of the datasets and corresponding knowledge graphs.
From Table 1, it is observed that the Movielens-1M dataset has 836,478 interactions and a sparsity of 96.18%, with 385,923 triples in its knowledge graph. The Amazon-Book dataset contains 8,477,733 interactions, with a sparsity of 99.95% and 2,557,746 triples in its knowledge graph.
4.2 Performance metrics
The evaluation metrics used in this experiment are Recall and NDCG, both of which accurately describe recommendation performance.
4.2.1 Recall
This metric measures how many relevant items are correctly predicted within the top-X recommendations. It is computed as Equation 30:
4.2.2 NDCG
NDCG gives more weight to higher-ranked results, reflecting the diminishing relevance of items further down the ranking. It is defined as Equation 31:
4.3 Baseline models and experimental setup
The following five baseline models were used in the experiments:
CKE (Zhang et al., 2016): A model based on collaborative filtering, which integrates text, image, and structural features within a single framework and uses TransR to enhance matrix factorization.
RippleNet (Wang et al., 2018): A model that continuously explores user preferences by incorporating a knowledge graph into the recommendation system, mitigating the cold-start problem.
KGNN-LS (Wang H. W. et al., 2019): This model constructs personalized graph representations for users using knowledge graphs, considering users’ unique preferences for different relations within the knowledge graph. It introduces label smoothing to improve generalization.
KGAT (Wang X. et al., 2019): A model that uses attention mechanisms to aggregate higher-order information between entities, addressing sparsity issues and improving recommendation accuracy.
KGECF (Zhang et al., 2021): A knowledge graph-based recommendation system that extracts latent features related to items, creating a personalized knowledge subgraph. It employs an end-to-end collaborative learning framework to merge knowledge graph and user behavior data for higher accuracy.
In light of current trends in KG-based recommendation research, although several emerging models have been proposed, the aforementioned five baseline methods remain representative in key aspects such as multimodal fusion, graph-based modeling, and user preference construction. These methods have also been extensively validated across various datasets, providing a solid foundation for comparative analysis. To further enhance readability, Table 2 summarizes the modalities utilized and feature fusion strategies adopted by each model. This comparison highlights the superiority of the proposed method in terms of its multimodal fusion capabilities.
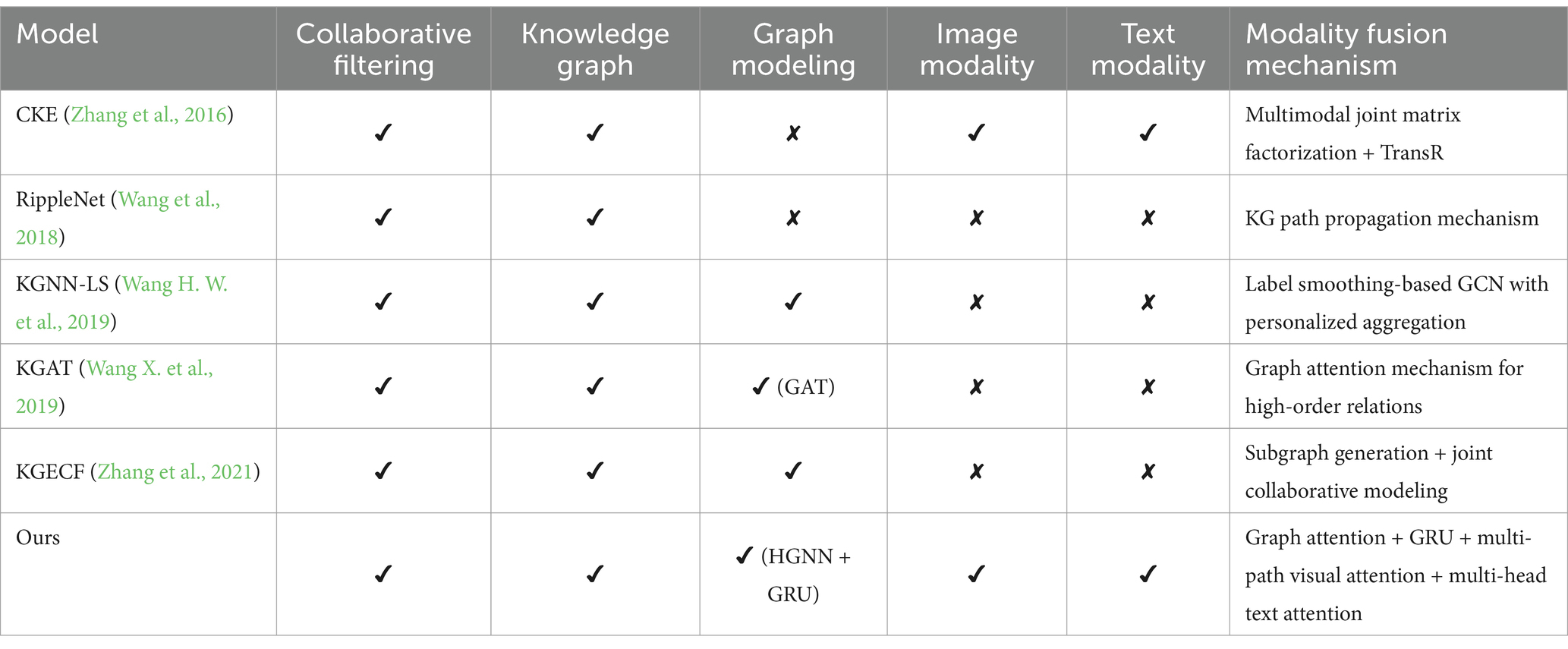
Table 2. Comparison of modality usage and feature fusion mechanisms across different recommendation models.
As shown in the table, the proposed model not only maintains strong collaborative modeling capabilities but also systematically integrates knowledge graph, image, and text modalities. By incorporating a more fine-grained multi-path attention mechanism and a hierarchical structure, the model enables a more comprehensive representation of user preferences, thereby enhancing both recommendation accuracy and generalization performance.
The experiments were conducted on a Microsoft Windows 10 system, with an Nvidia 3,070 GPU, 32 GB of memory, and an AMD R7-6800H processor. The programming language used is Python 3.8.6, and PyTorch is utilized to implement the models. Item and user embedding sizes were set to 64, with a batch size of 256. The Adam optimizer is used with a learning rate of 0.002, and model parameters were initialized using the Glorot method. The training, validation, and test sets were split in an 80:10:10 ratio based on recommendation evaluation metrics.
4.4 Comparison of model performance
In this experiment, the proposed model is compared with the four baseline models across two datasets. Since recommendation accuracy is influenced by the number of recommendations, X is set to {5, 10, 15, 20, 25}. The performance results on the Movielens and Amazon-Book datasets are shown in Tables 3, 4, respectively.
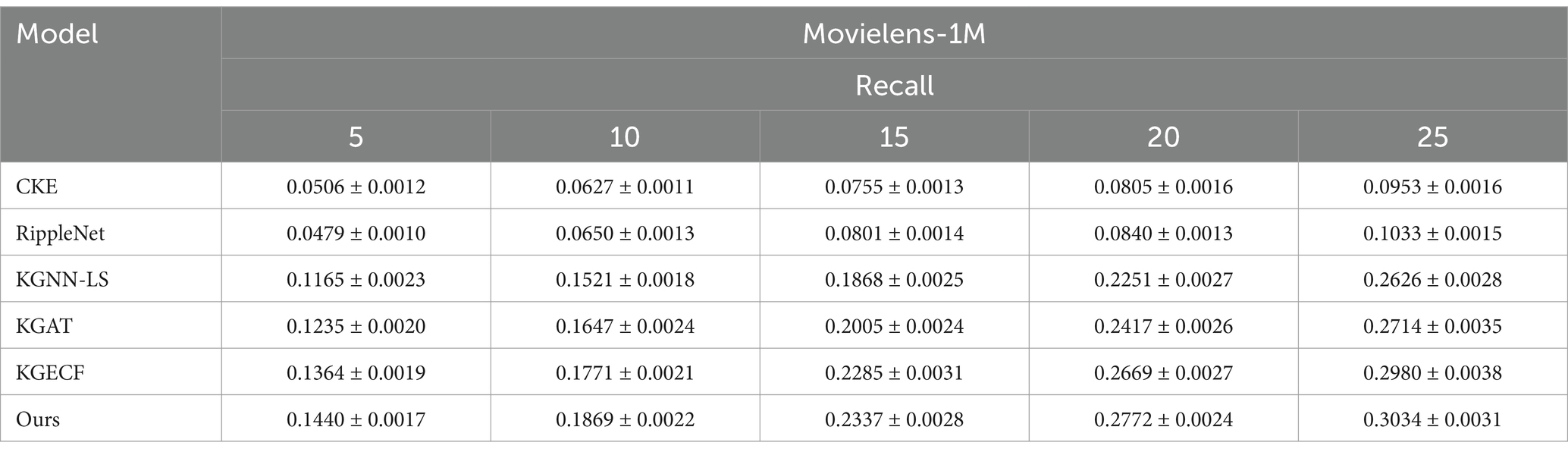
Table 3. Performance comparison on Movielens-1M dataset.
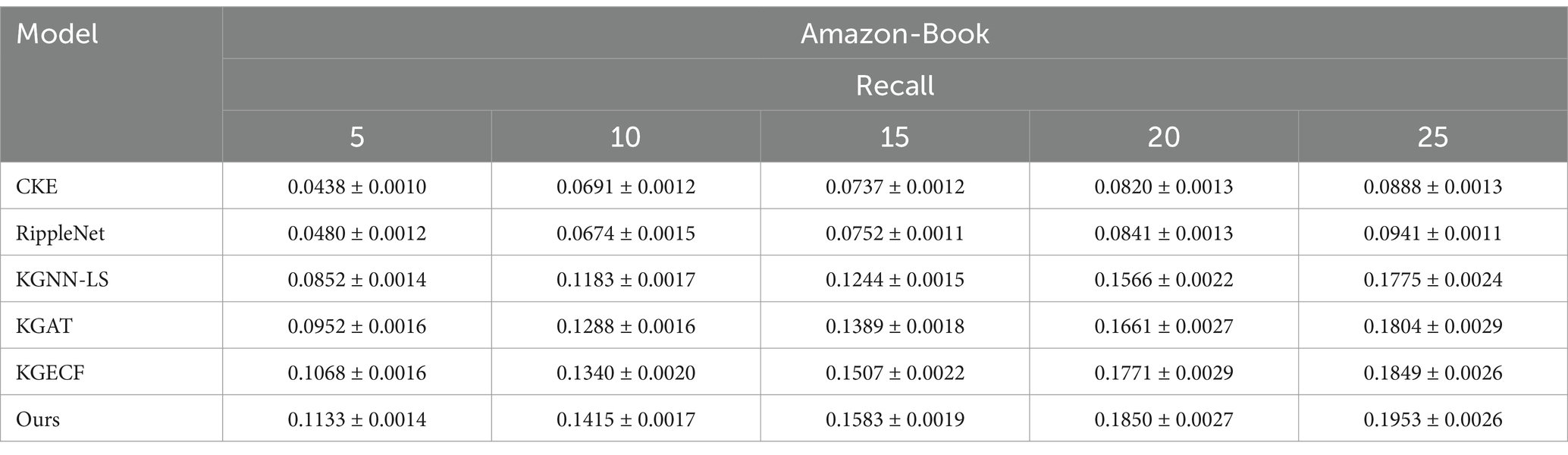
Table 4. Performance comparison on Amazon-Book dataset.
The baseline comparison analysis for the two datasets shows that the recall rate (Recall) of all models increases with the number of recommendations (X). In this trend, the MKGAR model proposed in this study demonstrates the highest recall rate, significantly outperforming other models. This result confirms that the MKGAR model substantially improves the performance of recommendation systems.
Upon analyzing the experimental results, it is observed that the CKE and RippleNet models performed relatively poorly, while KGNN-LS, KGAT, and KGECF performed better. Specifically, the CKE model did not incorporate the TransR method, which led to an inability to fully capture the complex structure of the knowledge graph. This confirms the superiority of the TransR method in handling knowledge graph information. In contrast, RippleNet showed slight improvements over CKE by utilizing a knowledge graph, but it failed to fully explore higher-order connectivity and collaborative signals from users.
For the Recall metric, CKE and RippleNet exhibited similar performance across both datasets, while the proposed model showed a significant improvement over both. On the other hand, KGNN-LS, KGAT, and KGECF demonstrated clear advantages. KGNN-LS, which combines knowledge graphs and label smoothing regularization, improves recommendation accuracy and interpretability but focuses primarily on learning local structural features, potentially overlooking the impact of global information. The KGAT model, despite aggregating information by calculating spatial relationships between head and tail entities, did not adequately account for interactions between users. The KGECF model utilizes an attention mechanism to efficiently extract higher-order relational information from the knowledge graph, and integrates users’ long-term and short-term preferences through gated neural networks, significantly improving recommendation accuracy. However, these models do not account for the potential influence of text and image features on the recommendations, resulting in lower performance compared to the proposed model. The proposed model leverages multi-perspective features—particularly textual and visual modalities—which play a crucial role in enhancing recommendation accuracy. This effectiveness has been empirically validated. For instance, in terms of Recall, the proposed model demonstrates significant improvements over KGNN-LS, KGAT, and KGECF on both the MovieLens-1M and Amazon-Book datasets. These results indicate that by effectively mining latent information from multiple modalities, the proposed approach exhibits strong recommendation capabilities.
Based on the results of hypothesis testing (two-sample t-test, n = 5, two-tailed test assuming equal variances), the p-values for the proposed method compared with each baseline across different recall positions on the two datasets are presented in Tables 5, 6. Significance levels are denoted as follows: p < 0.05 (*), p < 0.01 (**). The detailed results of the significance tests are shown below.
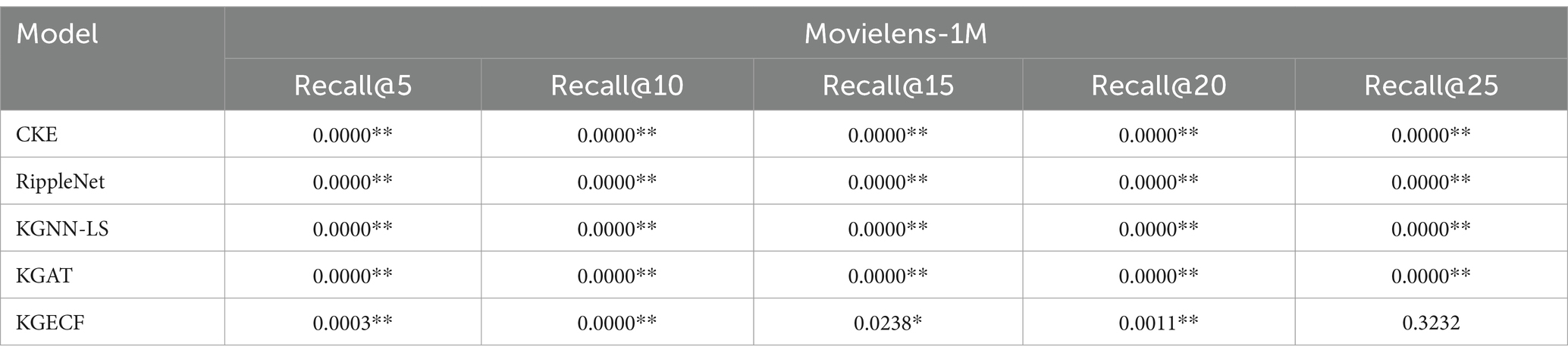
Table 5. p-values on the MovieLens-1M dataset.
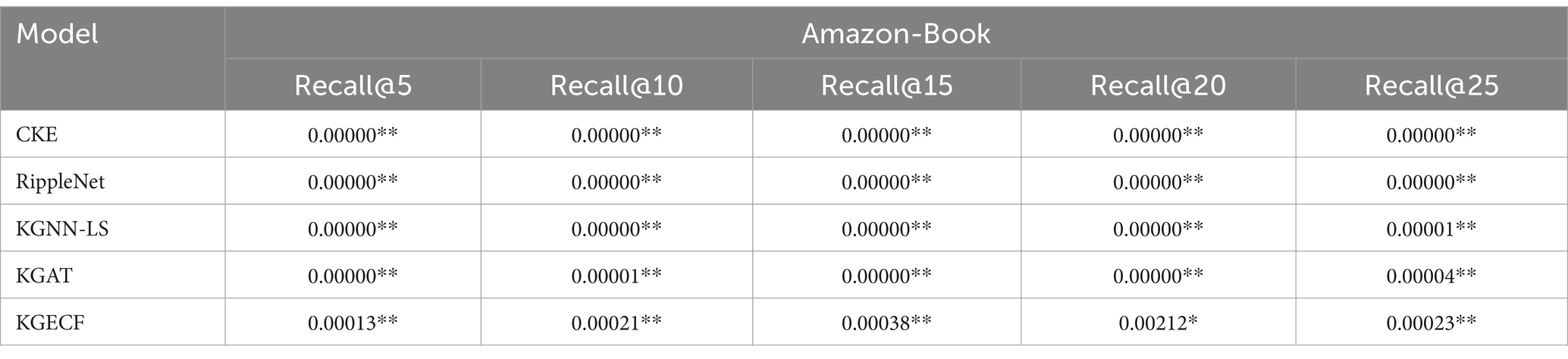
Table 6. p-values on the Amazon-Book dataset.
As observed from Tables 5, 6, the proposed method demonstrates statistically significant improvements over all baseline models under most settings, with p < 0.01 in the majority of comparisons. In particular, the comparison with KGECF at Recall@15 on MovieLens-1M and Recall@20 on Amazon-Book yields p-values slightly above the 0.01 threshold but still below 0.05, indicating moderate significance. The only non-significant result occurs at Recall@25 on MovieLens-1M when compared with KGECF (p = 0.3232). These significance testing results further verify the robustness and consistent performance improvements of the proposed model across different recall levels and datasets.
4.5 Ablation study
This section explores how user preferences related to visual and semantic features, derived from item images and text, can be integrated into item embeddings. To assess the specific impact of image and text features on the performance of the recommendation system, experiments were designed by modifying the user and item feature components in Equation 28. The models were then evaluated by removing either the image features (model labeled HGAN-MKG1) or the text features (model labeled HGAN-MKG2). By comparing these ablated models with the full model (MKGAR) across different top-K values (5, 10, 20, 25), we can gain detailed insights into the contribution of each modality to the recommendation results. The detailed metrics including NDCG and Recall are reported in Table 7.
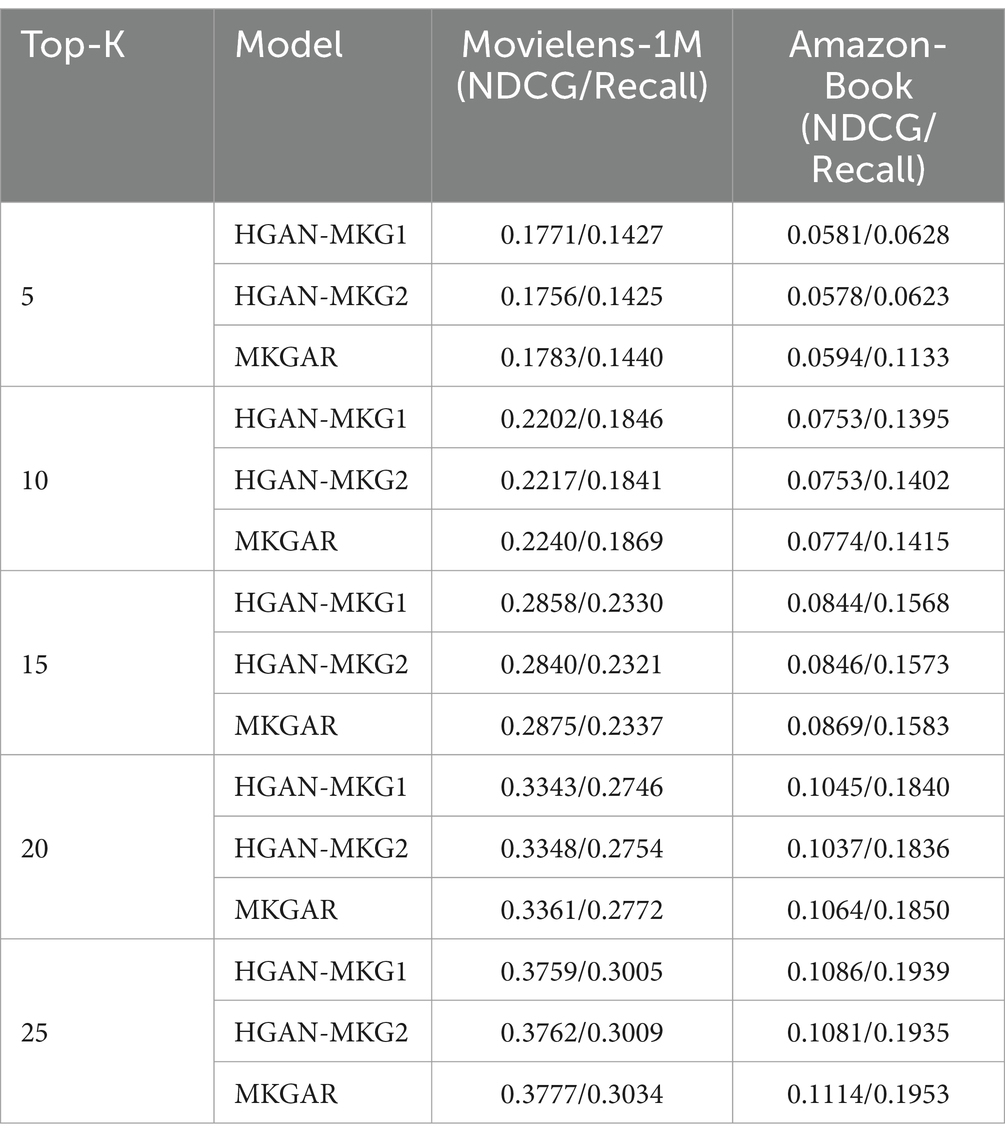
Table 7. Comparative experimental results of ablation study.
As seen from the above results, both image and text features contribute positively to model performance across all top-K values. However, the magnitude of their impact is relatively modest. This is attributed to the redundancy and strong expressive power of the knowledge graph-based structural features, which may already encode rich item semantics and relationships. Thus, the additional visual and textual modalities, though helpful, offer only incremental improvements. These results highlight the robustness of the knowledge-aware representation while also confirming that multi-modal auxiliary features can enhance performance, especially under sparse or cold-start conditions.
4.6 Hyperparameter experiment
In the collaborative knowledge graph neural layer, the attention coefficient 𝛼𝑖 plays a crucial role, as the attention score depends on the spatial relationship between entities in the knowledge graph. To evaluate the impact of the attention coefficient on the model performance, we varied the value of 𝛼 within the range [0, 1] and compared the results with those obtained from the original model using 𝛼𝑖. The performance is evaluated using NDCG on the Amazon-Book dataset with the number of recommendations set to 20. The changes in NDCG with different values of α\alphaα are shown in Figure 8, illustrating the impact of different attention coefficients on model performance.
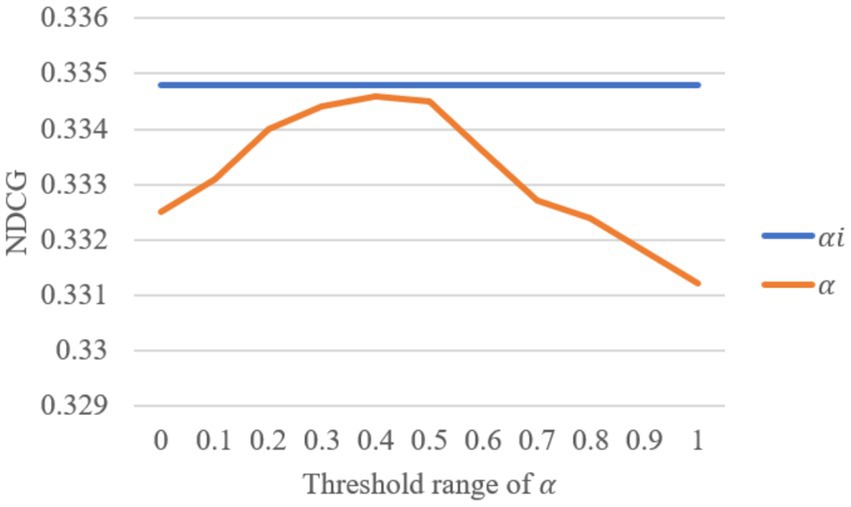
Figure 8. Impact of the attention coefficient α in the knowledge graph attention network layer on model performance.
The analysis of the data in Figure 8 shows that when the attention coefficient 𝛼 is set to the value of 𝛼𝑖, the NDCG reaches its peak at 0.3348. No value of 𝛼 within the range [0, 1] exceeded this performance. Specifically, as 𝛼 increases, the performance initially rises to a peak and then begins to decline. The highest NDCG is observed at 𝛼=0.4 with a value of 0.3346, while at 𝛼=1, the performance dropped to 0.3312. Notably, when 𝛼=1, the performance improved by 1.09% compared to the original 𝛼𝑖 value. This result indicates that dynamically adjusting the attention coefficient based on the spatial relationship between entities, rather than using a static threshold, can more effectively enhance model performance. This is because a smaller threshold may introduce noise from irrelevant entities, while a higher threshold may excessively filter out nodes, reducing the amount of information. Therefore, dynamically adjusting the attention coefficient to align with the spatial relationships of entities is an effective strategy for optimizing recommendation system performance.
5 Conclusion
This paper introduces a recommendation method that combines hierarchical graph attention networks and multimodal knowledge graphs. The core components of the approach include the integration of knowledge graphs with graph neural attention mechanisms and multimodal feature fusion. In the collaborative knowledge graph neural layer, the knowledge graph serves as a structured representation, encompassing a wealth of entities, relationships, and attributes, while graph neural networks help uncover deeper collaborative relationships. Additionally, by incorporating image and text features (such as movie posters, book covers, names, descriptions, and categories), the model enhances its understanding of users’ visual and semantic preferences. This approach not only effectively models user interests but also provides more accurate recommendations. Extensive experiments on the MovieLens and Amazon-Book datasets demonstrate that the proposed model significantly outperforms other knowledge graph-based recommendation models in terms of performance.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found at: https://grouplens.org/datasets/movielens/.
Author contributions
XH: Conceptualization, Writing – original draft. XD: Software, Writing – review & editing.
Funding
The author(s) declare that no financial support was received for the research and/or publication of this article.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The authors declare that no Gen AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Bandyopadhyay, S., Thakur, S. S., and Mandal, J. K. (2024). Emotion detection for online recommender system using deep learning: a proposed method. Innov. Syst. Softw. Eng. 20, 719–726. doi: 10.1007/s11334-022-00437-7
Bock, H. H. (2007). Clustering methods: a history of k-means algorithms. In P. Brito, P. Bertrand, G. Cucumel, F. Carvalho, and Y. Escoufier, eds., Selected contributions in data analysis and classification, 34: 161–172, Springer, Cham
Chen, T., and Wong, R. C. W. (2021). An efficient and effective framework for session-based social recommendation. Proceedings of the 14th ACM International Conference on Web Search and Data Mining. Virtual Event, Israel: ACM, 400–408.
Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., et al. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv [Preprint]. arXiv:1406.1078.
Fan, W., Ma, Y., Li, Q., He, Y., Zhao, E., Tang, J., et al. (2019). Graph neural networks for social recommendation. The World Wide Web Conference, 417–426.
Gao, C., Cai, G., Jiang, X., Zheng, F., Zhang, J., Gong, Y., et al. (2022). Conditional feature learning based transformer for text-based person search. IEEE Transactions on Image Processing, 31, 6097–6108.
Guo, Q., Zhuang, F., Qin, C., Zhu, H., Xie, X., Xiong, H., et al. (2020). A survey on knowledge graph-based recommender systems. IEEE Trans. Knowl. Data Eng. 34, 3549–3568. doi: 10.1109/TKDE.2020.3028705
Han, D., Qi, H., Wang, S., Hou, D., and Wang, C. (2024). Adaptive stepsize forward–backward pursuit and acoustic emission-based health state assessment of high-speed train bearings. Struct. Health Monit. 14759217241271036.
Harper, F. M., and Konstan, J. A. (2015). The movielens datasets: history and context. ACM Trans. Intell. Syst. Technol. 5, 1–19.
He, R., and McAuley, J. (2016). Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. Proceedings of the 25th international conference on world wide web, 507–517.
Javed, U., Shaukat, K., Hameed, I. A., Iqbal, F., Mahboob Alam, T., and Luo, S. (2021). A review of content-based and context-based recommendation systems. Int. J. Emerg. Technol. Learn. 16, 274–306. doi: 10.3991/ijet.v16i03.18851
Jiang, J., Zhao, H., He, M., Wu, L., Zhang, K., Fan, J., et al. (2023). Knowledge-aware cross-semantic alignment for domain-level zero-shot recommendation. Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, 965–975.
Li, C., Niu, X., Luo, X., Chen, Z., and Quan, C. (2019). A review-driven neural model for sequential recommendation [A], the 28th International Joint Conference on Artificial Intelligence, 2866–2872.
Liu, Y., Zhou, X., Kou, H., Zhao, Y., Xu, X., Zhang, X., et al. (2024). Privacy-preserving point-of-interest recommendation based on simplified graph convolutional network for geological traveling. ACM Trans. Intell. Syst. Technol. 15, 1–17. doi: 10.1145/3620677
Ma, W., Zhang, M., Cao, Y., Jin, W., Wang, C., Liu, Y., et al. (2019). Jointly learning explainable rules for recommendation with knowledge graph. The World Wide Web Conference, 1210–1221.
Oramas, S., Ostuni, V. C., Noia, T. D., Serra, X., and Di Sciascio, E. (2016). Sound and music recommendation with knowledge graphs. ACM Trans. Intell. Syst. Technol. 8, 1–21. doi: 10.1145/2926718
Shi, C., Han, X. T., Song, L., Wang, X., Wang, S., Du, J., et al. (2021). Deep collaborative filtering with multi-aspect information in heterogeneous networks. IEEE Trans. Knowl. Data Eng. 33, 1413–1425. doi: 10.1109/TKDE.2019.2941938
Steck, H., Baltrunas, L., Elahi, E., Liang, D., Raimond, Y., and Basilico, J. (2021). Deep learning for recommender systems: a Netflix case study. AI Mag. 42, 7–18. doi: 10.1609/aimag.v42i3.18140
Sun, R., Cao, X., Zhao, Y., Zhou, K., Zhang, F., Wang, Z., et al. (2020). Multi-modal knowledge graphs for recommender systems. Proceedings of the 29th ACM international conference on information & knowledge management, 1405–1414.
Visa, M. R., and Patel, D. B. (2021). A deep learning approach of collaborative filtering to recommender system with opinion mining. Rising threats in expert applications and solutions: proceedings of FICR-TEAS 2020. Springer, Singapore, 119–131
Wang, X., He, X. N., Cao, Y. X., Liu, M., and Chua, T. S. (2019). KGAT: knowledge graph attention network for recommendation [C], Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2019, 950–958.
Wang, X., Jiang, H., Mu, M., and Dong, Y. (2025). A dynamic collaborative adversarial domain adaptation network for unsupervised rotating machinery fault diagnosis. Reliab. Eng. Syst. Safety. 255:110662.
Wang, H., Liu, Z., and Han, Z. (2024). HO2RL: A novel hybrid offline-and-online reinforcement learning method for active pantograph control. IEEE Transactions on Industrial Electronics. doi: 10.1109/TIE.2024.3477002
Wang, H., Zhang, F., Wang, J., Zhao, M., Li, W., Xie, X., et al. (2018). RippleNet: Propagating user preferences on the knowledge graph for recommender systems. International Conference on Information and Knowledge Management, Proceedings, 417–426.
Wang, H. W., Zhang, F. Z., Zhang, M. D., Leskovec, J., Zhao, M., Li, W. J., et al. (2019). Knowledge-aware graph neural networks with label smoothness regularization for recommender systems [C], Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ser. KDD’19, 968–977.
Wu, L., Li, Z., Zhao, H., Huang, Z., Han, Y., Jiang, J., et al. (2024). Supporting your idea reasonably: a knowledge-aware topic reasoning strategy for citation recommendation. IEEE Trans. Knowl. Data Eng. 36, 4275–4289. doi: 10.1109/TKDE.2024.3365508
Wu, L., Li, Z., Zhao, H., Wang, Z., Liu, Q., Huai, B., et al. (2023). Recognizing unseen objects via multimodal intensive knowledge graph propagation. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2618–2628.
Yamada, K. D., Lin, F., and Nakamura, T. (2021). Developing a novel recurrent neural network architecture with fewer parameters and good learning performance. Interdiscip. Inf. Sci. 27, 25–40.
Yan, J., Cheng, Y., Zhang, F., Zhou, N., Wang, H., Jin, B., et al. (2025). Multi-modal imitation learning for arc detection in complex railway environments. IEEE Transactions on Instrumentation and Measurement. doi: 10.1109/TIM.2025.3556896
Yang, Y., Huang, C., Xia, L., and Li, C. (2022). Knowledge graph contrastive learning for recommendation. Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval, 1434–1443.
Zhang, Y. H., Wang, W., Liu, H. Z., Gu, R., and Hao, Y. (2021). Collaborative filtering recommendation algorithm based on knowledge graph embedding. Appl. Res. Comput. 38, 3590–3596.
Zhang, S., Yao, L., Sun, A., and Tay, Y. (2019). Deep learning based recommender system: a survey and new perspectives. ACM Comput. Surv. 51, 1–49. doi: 10.1145/3158369
Zhang, F., Yuan, N. J., Lian, D., Xie, X., and Ma, W. Y. (2016). Collaborative knowledge base embedding for recommender systems, Processing of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 353–362.
Keywords: user recommendation, hierarchical graph attention network, knowledge graph, multimodal, visual features, textual features
Citation: Han X and Dou X (2025) User recommendation method integrating hierarchical graph attention network with multimodal knowledge graph. Front. Neurorobot. 19:1587973. doi: 10.3389/fnbot.2025.1587973
Edited by:
Xianmin Wang, Guangzhou University, ChinaReviewed by:
Likang Wu, Tianjin University, ChinaHaimonti Dutta, University at Buffalo, United States
Lars Wagner, Technical University of Munich, Germany
Copyright © 2025 Han and Dou. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xiaofei Han, ZmVuZHloYW54aWFvZmVpQHNoaXN1LmVkdS5jbg==