 Henrique Oyama
Henrique Oyama Takazumi Matsumoto
Takazumi Matsumoto Jun Tani
Jun Tani- Cognitive Neurorobotics Research Unit, Okinawa Institute of Science and Technology Graduate University, Okinawa, Onna, Japan
Mind-wandering reflects a dynamic interplay between focused attention and off-task mental states. Despite its relevance in understanding fundamental cognitive processes, such as attention regulation, decision-making, and creativity, previous models have not yet provided an account of the neural mechanisms for autonomous shifts between focus state (FS) and mind-wandering (MW). To address this, we conduct model simulation experiments employing predictive coding as a theoretical framework of perception to investigate possible neural mechanisms underlying these autonomous shifts between the two states. In particular, we modeled perception processes of continuous sensory sequences using our previously proposed variational RNN model under free energy minimization. The current study extends this model by introducing an online adaptation mechanism of a meta-level parameter, referred to as the meta-prior w, which regulates the complexity term in the free energy minimization. Our simulation experiments demonstrated that autonomous shifts between FS and MW take place when w switches between low and high values responding to a decrease and increase of the average reconstruction error over a past time window. Particularly, high w prioritized top-down predictions while low w emphasized bottom-up sensations. In this work, we speculate that self-awareness of MW may occur when the error signal accumulated over time exceeds a certain threshold. Finally, this paper explores how our experiment results align with existing studies and highlights their potential for future research.
1 Introduction
During mindfulness practice, such as focusing on sensations like breathing, our attention sometimes spontaneously deviates to mental imagery or thoughts about the past and future, a phenomenon known as mind-wandering (Smallwood and Schooler, 2015; Christoff et al., 2016; Seli et al., 2016). This shift from a focused state to mind-wandering can occur not only during meditation but also in everyday activities, such as driving, listening to music, or tasting food. Mind-wandering tends to occur more frequently during tasks that are either too easy or too difficult. When tasks are less demanding, such as simply attending to breathing, instances of mind-wandering increase. Conversely, during more challenging tasks, such as reading complex material, our minds are more prone to wander because maintaining focus becomes difficult over long periods (Seli et al., 2018; Peral-Fuster et al., 2023).
An interesting aspect is that the transition from the focused state (FS) to the mind-wandering state (MW) often happens without conscious awareness, whereas the shift from MW back to FS involves recognizing the mind-wandering episode consciously (Smallwood and Andrews-Hanna, 2013). Various studies have investigated the psychological and systematic mechanisms underlying these shifts. For example, Henŕıquez et al. (2016) argued that the transition from FS to MW is gradual, as evidenced by increasing response times during focused tasks. In contrast, Vago and Zeidan (2016) suggested that the shift is abrupt, triggered by sudden internal or external stimuli.
Voss et al. (2018) proposed a model where mental states alternate between FS and MW, with MW episodes ending when individuals consciously recognize their mind-wandering and return to the task. This “two-stage model” assumes that the probability of being in FS is higher at the beginning of an episode and decreases over time. However, contrary to this prediction, Zukosky and Wang (2021) found that the probability of FS does not decline within an FS-MW episode in a subject study introducing a probe at a random time during the episode. To address this discrepancy, the authors proposed the “multiple sub-event model,” which hypothesizes that unconscious alternations between FS and MW occur multiple times before an individual becomes aware of being in MW. Their simulation study suggested that as the number of sub-sequences increases, the decline in the probability of FS becomes less pronounced.
Although the studies mentioned above clarified some phenomena in the shift from FS to MW from psychological observation, they have not provided sufficient accounts for the underlying neuronal mechanisms. Recently, some studies (Sandved-Smith et al., 2021; Idei et al., 2024) suggested system level neuroscience models incorporated with the concept of the free energy principle (FEP) (Friston, 2005). Here, FEP is briefly explained for better understanding of the readers. The FEP is a neuroscience theory that has attracted large attention. The FEP posits that humans and animals execute various functions such as learning, perception, and action generation to maximize their chances of survival by minimizing surprises they encounter during interaction with the environment. According to the FEP, these functions are achieved by optimizing generative models for predicting the sensation, whereby a common statistical quantity called free energy is minimized. The FEP supports two frameworks, one is predictive coding and the other is active inference. Predictive coding provides a formalism accounting for how agents perceive sensations. It suggests that the brain predicts sensory observations in the top-down pathway, while at the same time updating posterior beliefs about those sensations in the bottom-up pathway whenever errors arise between predictions and observations (Rao and Ballard, 1999; Friston, 2005; Clark, 2015). By updating posterior beliefs in the direction of minimizing errors, perceptual inference for the observed sensation can be achieved. On the other hand, active inference (AIF) provides a theory for action generation by assuming that the brain is embodied deeply and embedded in the environment, such that acting on it changes future sensory observation. Then, AIF considers that actions should be selected such that the error between the desired and predicted sensations can be minimized (Friston et al., 2010, 2011).
Sandved-Smith et al. (2021) postures the underlying mechanism of the shift from FS to MW using active inference of “mental action” in terms of attention changes. The proposed model assumes a hierarchical probabilistic generative model wherein the hidden meta-awareness states in the higher level account for “how aware am I of where my attention is?,” the hidden mental states in the middle level dealing with focus of attention account for “what am I paying attention to?,” and the sensorimotor hidden states in the lowest level do for “what am I perceiving or trying to do?” according to the authors. The states at each level condition the ones in the next lower level by controlling their precisions or beliefs. Agent's perceptual and attentional states are inferred at each time step by means of active inference in minimizing the expected free energy. The results of simulation experiments show that when the meta-awareness state is manually shifted from high to low, distracted or MW state is developed more frequently. Under this condition, redirection back to FS by consciously being aware of the current MW state tends to take more time because of less precision in the attention toward distracted state.
Idei et al. (2024) investigated mind-wandering mechanism by conducting a model simulation study on allostasis using a hierarchically organized variational recurrent neural network, so-called the PV-RNN (Ahmadi and Tani, 2019). Dynamic behavior of PV-RNN can be characterized by a meta-level parameter, referred to as meta-prior w, that regulates the complexity term against the accuracy term in free energy which is minimized in the inference of the posterior probability distribution of the latent variables. It was shown that a high setting of meta-prior w enhances the generation of the top-down imagery while a low setting of it enhances the bottom-up sensory perception (Ohata and Tani, 2020; Chame et al., 2020; Wirkuttis et al., 2023). Analogous to this, Idei et al. (2024) showed that a low setting of w generates stronger sensory bottom-up which leads to FS wherein less change in movement as well as neural activity are observed. On the other hand, high setting of w generates weak attention to sensation and stronger top-down processing which leads to MW wherein more movement as well as neural activity.
The aforementioned FEP-based studies provide valuable insights into macroscopic neural mechanisms, such as redirecting attention to focused states by inferring one's attentional state, or generating mind-wandering by balancing top-down and bottom-up information flows. However, these studies do not provide systematic explanations for how the shifts between FS and MW could be autonomously generated, since the shift from FS to MW in Sandved-Smith et al. (2021) is caused by manual change of the meta-aware state from high to low and the one in Idei et al. (2024) does this by resetting meta-prior w from low to high value.
In this regard, the current study speculates that autonomous transition between FS and MW could be generated by introducing an online adaptation mechanism of meta-prior w to PV-RNN in which w is modulated with response to some macroscopic variables such as an average reconstruction error. In our study, PV-RNN learns to predict a target sequence of continuously changing sensory patterns which is generated by means of predetermined probabilistic transitions among a set of cyclic patterns. In the test phase after the training, given one of the pre-trained cyclic patterns as the target inputs, the PV-RNN predicts encountering sensory inputs by simultaneously inferring the approximated posterior of the latent state at each time step by minimizing the free energy while adapting w. Analogous to studies (Ohata and Tani, 2020; Chame et al., 2020; Wirkuttis et al., 2023; Idei et al., 2024), when w modulates to a lower value by reflecting the surge of the average reconstruction error, the inference process may improve by placing greater emphasis on bottom-up sensations. This situation may correspond to FS. On the other hand, when w modulates to a higher value by responding to the decline of the average reconstruction error, the PV-RNN may generate top-down imagery by following the learned probabilistic transitions of the patterns while ignoring the target sensory inputs. This may correspond to MW. Our simulation study with PV-RNN under various parameter settings will evaluate this hypothesis. The following section introduces the proposed model, followed by a detailed description of the simulation experiment setup, the presentation of the results, and a discussion that includes proposals for extensions to future research work.
2 Materials and methods
2.1 Overview
This study investigates autonomous shifts between the focused state (FS) and mind-wandering (MW) during a perception task using sequential sensory input patterns. The predictive coding framework is employed to model this perception process. Predictive coding assumes a generative model that predicts sensory sequences by learning both the latent state transition function and the likelihood mapping from latent states to sensory observations. Additionally, this generative model infers the current latent state through continuous sensory sequence observations.
Both learning and inference processes are achieved by minimizing reconstruction error, or more specifically, free energy. We hypothesize that FS is enhanced by strengthening bottom-up inference, while MW becomes more likely by emphasizing top-down sensory pattern generation. It is also hypothesized that shifts between FS and MW take place autonomously by incorporating an online adaptation of meta-level states in response to particular system variables. To test this, we propose an extended version of a variational recurrent neural network model, referred to as the Predictive Coding Inspired Variational RNN (PV-RNN) (Ahmadi and Tani, 2019). Details of the original PV-RNN and its extensions are provided in the following sections.
2.2 Predictive coding inspired variational RNN model
The PV-RNN is based on the free energy principle (Friston, 2005), where learning and inference are achieved by minimizing free energy (Equation 1) in accordance with Bayes' theorem:
Here, pθ(X) is the marginal likelihood of the sensory observation X, given the generative model pθ parameterized by θ. The latent variables z and inference model qϕ, parameterized by ϕ, allow for posterior inference through minimization of free energy. Free energy consists of two terms: the complexity term (a measure of divergence between prior and posterior distributions) and the accuracy term (log-likelihood of sensory observations) (Friston, 2010). PV-RNN serves as both a generative model and an inference model. The generative model predicts future sensory inputs via top-down processes, while the inference model estimates the approximate posterior from observed sensory sequences through free energy minimization as bottom-up processes.
The following subsections describe the PV-RNN implementation and the use of the meta-prior w.
2.2.1 Model implementation
The free energy ℱ for PV-RNN predicting a time series of T steps is given by:
PV-RNN introduces two types of latent variables: probabilistic latent variables (z) governed by Gaussian distributions, and deterministic latent variables (d). Their relationships are shown in Figure 1. In Equation 2, a meta-level parameter, named meta-prior w, is introduced to balance the complexity and accuracy terms during this process. This regulation is particularly important when the limited amount of training data prevents reliable estimation of latent variable distributions. Also, dynamic behavior of PV-RNN is largely affected by the setting of the meta-prior. It was shown that high setting of meta-prior w enhances generation of the top-down imagery while low setting of it enhances the bottom-up sensory perception (Ohata and Tani, 2020; Chame et al., 2020; Wirkuttis et al., 2023; Idei et al., 2024).
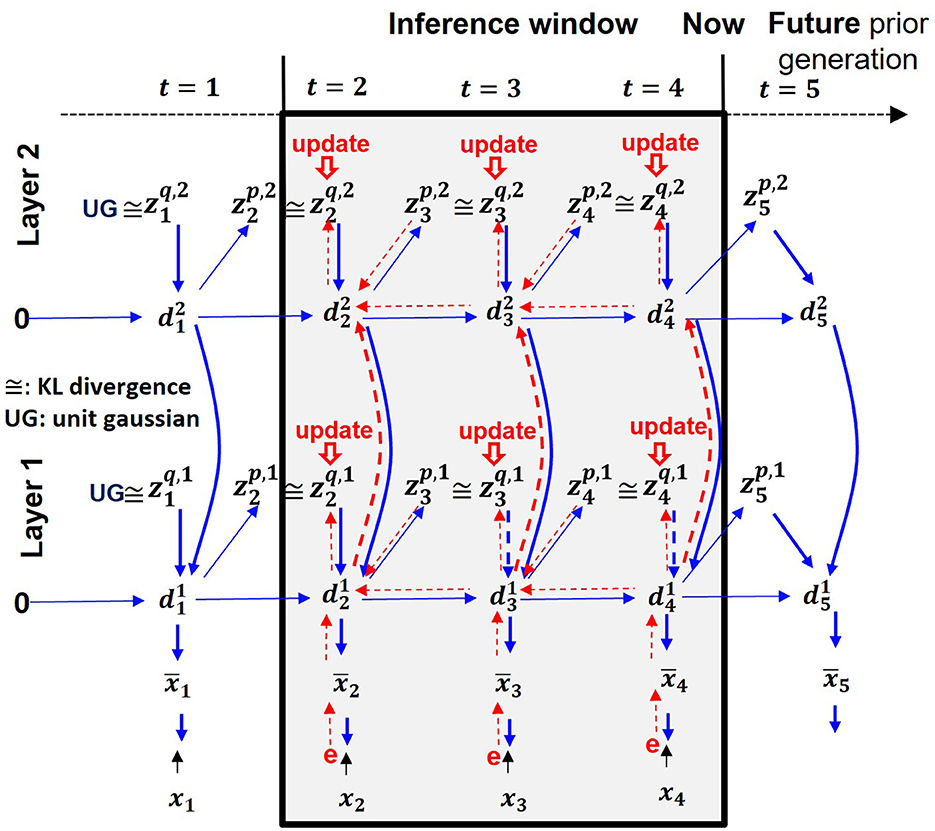
Figure 1. A hierarchical two-layer PV-RNN architecture. Solid blue lines represent the generative process, while dotted red lines indicate the inference process. The shaded area shows an inference window of length 3.
Next, the forward computation of each variable used in PVRNN is described. At each time step t, the internal states of the l-th layer () are recursively computed:
The PV-RNN structure supports hierarchical information processing using time constants τl, enabling the differentiation of temporal dynamics across layers (Yamashita and Tani, 2008; Schillaci et al., 2020).
The generative model computes prior distributions () as Gaussian variables parameterized by mean () and standard deviation ():
and are bias terms for and , respectively. ϵ represents a noise sampled from a standard normal distribution for usage of the reparameterization trick (Kingma and Welling, 2014). Analogous to the computation of the prior distribution, the inference model qϕ approximates the posterior as a Gaussian distribution with mean and standard deviation .
where and are bias terms for computing and , respectively. and are adaptive variables to be optimized for inferring the posterior distribution which is parameterized by and .
Intuitively, the random variable zp can be regarded as a time-dependent prior/top-down expectation about the encountering sensation. The adaptive vector A (i.e., zq) can be regarded as the approximate posterior distribution that may or may not be close to the prior distribution, depending on the setting of meta-prior. zp and zq are used by the generative and inference model, respectively to compute the latent variable d.
2.2.2 Learning and inference
The free energy ℱ of PV-RNN can be computed as follows by adapting the original (Equation 2). Given a PV-RNN with L layers, predicting a T time series sensory inputs, ℱ can be written as
where wl is meta-prior specific to l-th layer, and denotes the prediction output of the PV-RNN. In Equation 6, we approximate the expectation with respect to the approximate posterior by iterative sampling. Also, the accuracy term is replaced by the squared error, which can be regarded a special case of computation of log-likelihood wherein each dimension of X and is independent and follows a Gaussian distribution with standard deviation 1. Since the Kullback-Leibler (KL) divergence between two one-dimensional Gaussian distributions takes a simple expression, Equation 6 is reduced to
where
represents rth element of of the prior, and the same notation is applied to , , and . denotes the dimension of . Given that the complexity term is summed over all the dimension of z, which is arbitrary to the network design, and the accuracy term is to all the data dimension, which varies among data, the free energy is normalized with respect to the dimension of z and the data dimension. Therefore, introducing such normalization, the free energy of PV-RNN in the study is computed by
where RX is the data dimension, is the number of z variables in each layer, and . These normalization constants ensure scale-invariant learning across layers and datasets. Dividing the KL divergence by the z dimensionality prevents layers with more z units from disproportionately affecting the free energy. Likewise, dividing the prediction error by the data dimension RX accounts for variability in sensory data size, which helps avoid overfitting to high-dimensional outputs. This practice aligns with stability improvements shown in variational inference literature, including our prior work (Ohata and Tani, 2020).
In our implementation, the meta-prior w initially introduced as a global parameter (Equation 2) is extended to layer-specific versions wl for flexibility (Equation 9). This allows for layer-wise precision modulation, which mirrors the hierarchical structure of cortical processing. While all wl can be set equal to a global w, we allow them to vary to reflect biologically inspired architectures (e.g., Idei et al., 2024), where layers may exhibit different time constants and confidence levels.
By minimizing Equation 9, the posterior inference is performed during network learning and during the perception task. Figure 1 shows a schematic illustration of the posterior inference process of a two-layer PV-RNN model used in the current simulation with an optimization window of three time steps. At every sensory step, an adaptive variable A in the window is optimized through multiple epochs of stochastic gradient descent. In the network learning phase, weights and bias parameters θ and ϕ of the generative and inference models, including an adaptive variable A for the approximate posterior zq are jointly optimized. In the perception task phase, network parameters θ and ϕ are fixed, and free energy is minimized at each time step within a dedicated inference window by optimizing only A parameterizing the approximate posterior.
2.2.3 Adaptation of meta-prior
The meta-prior w is dynamically adapted based on the average prediction error (ersum) over a fixed length time window in the past. When the error decreases below a predefined threshold (ThrL), w transitions to a high value (wH), prioritizing top-down generation, which leads to generating MW. This can be intuitively understood from analogy that continuing easy or predictable tasks tends to initiate MW (Peral-Fuster et al., 2023; Seli et al., 2018). Conversely, when the average prediction error exceeds an upper threshold (ThrH), w transitions to a low value (wL), enhancing bottom-up inference. The implementation strategy for autonomous meta-prior switching between FS and MW is described in Algorithm 1. Specifically, the probabilistic shifting between the two modes is given by Equations 10, 11, where Temp is the temperature, a tunable parameter that can reflect how stochastic or deterministic the system is (see Section 3.2). This probabilistic switching mechanism is inspired by neurobiological models of policy selection under uncertainty. Similar mechanisms, such as the softmax function, are widely used in computational neuroscience and reinforcement learning to simulate probabilistic neural state transitions and action selection (Friston et al., 2014). While the specific threshold values (ThrL, ThrH) are hyperparameters, they are interpreted functionally as reflectors of a minimal or excessive prediction error context, consistent with meta-awareness-triggering mechanisms proposed in prior models (Sandved-Smith et al., 2021). It is highly speculated that this dynamic adaptation should enable autonomous transitions between FS and MW, as will be validated in the simulation experiments detailed in subsequent sections.

Algorithm 1. Autonomous meta-prior switching between focus state (FS) and mind-wandering (MW).
3 Experiments and results
3.1 Model training
First, we trained a PV-RNN with 2-dimensional sensory sequence data. The training data comprised 200 sequences, each containing 3,000 time steps. For preparing those trajectories, we designed 4 different 2-dimensional cyclic patterns, each with a periodicity of 30 time steps. Each trajectory was made of probabilistic switching among these 4 cyclic patterns wherein after one cycle of a particular pattern the same pattern repeats with a probability of 27.27% and the pattern transits to any other pattern with a probability of 72.73% equally. Noise has been added to individual points at randomly spaced intervals. The intervals between noise points are determined by drawing from a normal distribution (mean of 1, standard deviation of 10), providing a variable time step size. At each noise interval, Gaussian noise (mean of 0, standard deviation of 0.003) is added to the current data point, slightly perturbing its coordinates to simulate natural fluctuations without disrupting the cyclic structure. A part of the training trajectory is shown in Figure 2.
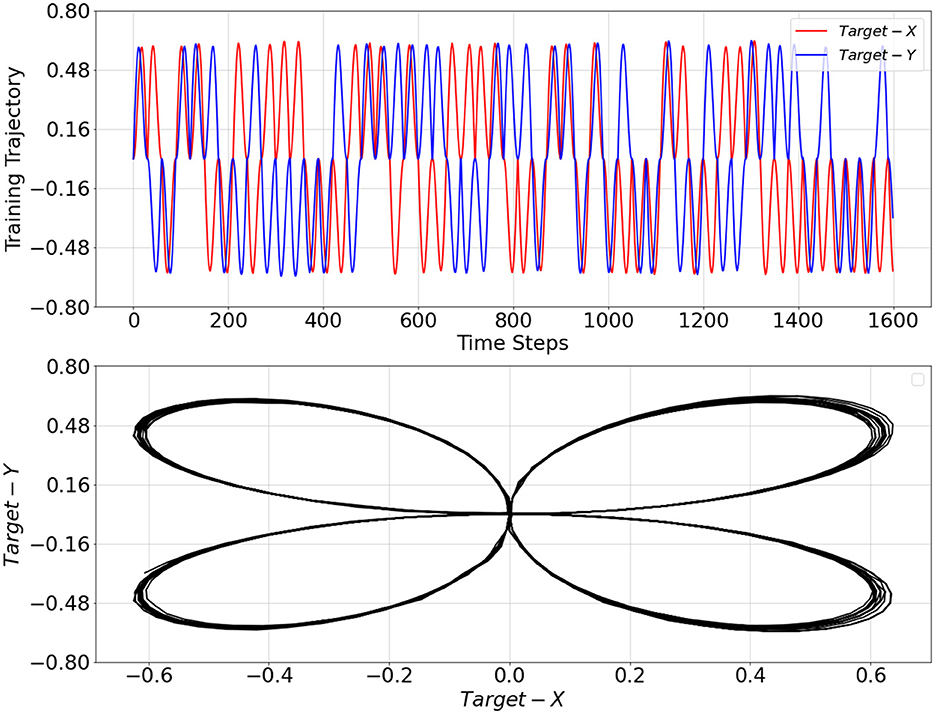
Figure 2. Training trajectory over 1,600 time steps (top plot) and its representation in X−Y space (bottom plot). Target−X and Target−Y correspond to the first and second dimensions of the training trajectory, respectively.
The network parameters used for training PV-RNN are listed in Table 1. #d, #z, τ, wtr indicates the number of d neurons, number of z neurons, time constant, and meta-prior during the training phase, respectively.
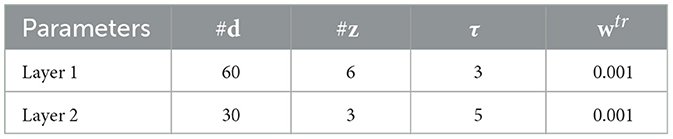
Table 1. PV-RNN training parameters.
The PV-RNN was trained over 150, 000 epochs minimizing free energy in Equation 9 using the Adam optimizer (Kingma and Ba, 2014) and back-propagation through time (BPTT) (Rumelhart et al., 1985) with learning rate 0.001 to optimize all network parameters of θ and ϕ of the generative and inference model, and the adaptive variable A corresponding to each training trajectory.
The trained network was evaluated on the basis of how well probabilistic transitions in the training data were reflected in the PV-RNN generative process, the so-called prior generation of the PV-RNN, which is conducted without performing the inference of the latent variables with sensory observation. In prior generation, the prior distribution was initialized with a unit Gaussian (Equation 4) and then latent states were recursively computed to generate network output sequences. Figure 3 shows an example of the prior generation outputs over 1,600 time steps. We can see that the patterns shift from one to another, where the two patterns used for training appear randomly. In addition, using a categorizer to discriminate between the two patterns, different prior generation outputs over 10,000 time steps have shown a probability of 28.92% of switching to a different pattern and a probability of 71.08% of staying in the same pattern, which are close to the training dataset.
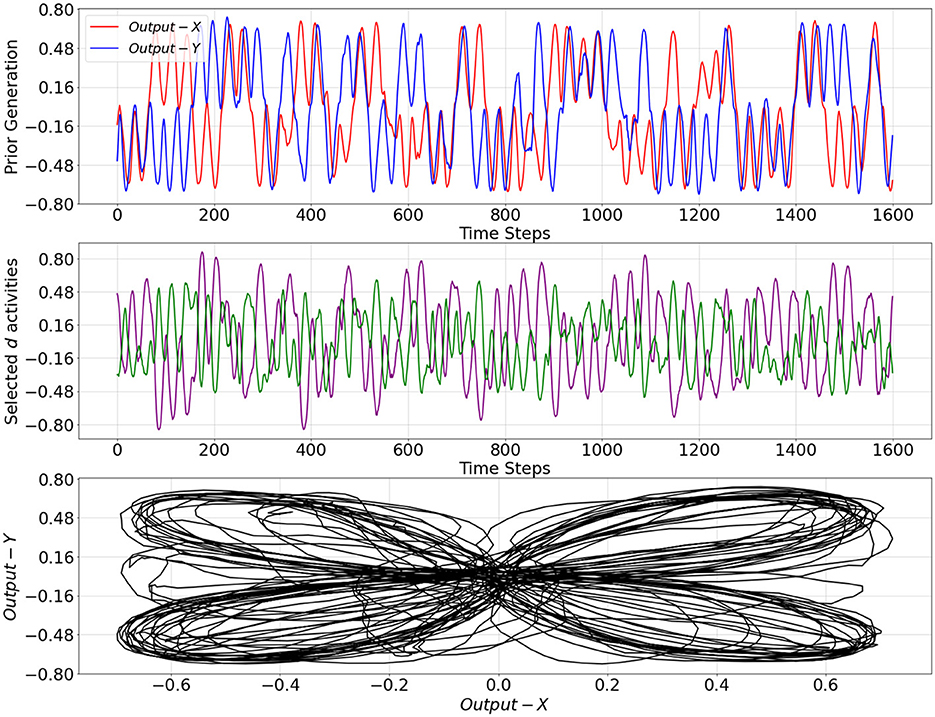
Figure 3. Prior generation over 1,600 time steps under trained model with meta-prior wtr from Table 1 (top plot), selected activities of the d neurons in the bottom layer of the PV-RNN (middle plot), and a representation in X−Y space (bottom plot). Output−X and Output−Y correspond to the first and second dimensions of the prior generation output trajectory, respectively.
3.2 Testing of perception task
The trained PV-RNN was tested by performing the perception task. In the test, the inference process was performed within the inference window, while one of the trained patterns was used as the target sensory sequence for the inference of the latent variables. The length of the inference window was set to 400 time steps. The adaptation of meta-prior, w, during inference with the monitoring of the average reconstruction error over 300 time steps1 was carried out using the parameters listed in Table 2.
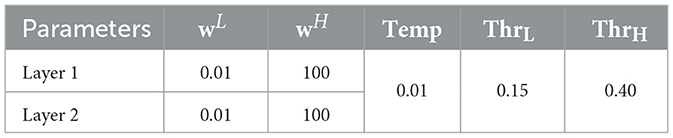
Table 2. PV-RNN testing parameters.
The mechanistic behavior when w adapted to low and high values are shown in Figures 4, 5, respectively. The plots show the output trajectory, the target sensory sequence, the average reconstruction error, and KL divergence at the PV-RNN bottom layer for each case. Importantly, no external triggers are used to impose state transitions. Instead, the model is trained on probabilistically switching sequences, allowing it to internalize the statistical structure. During inference, the switching behavior is driven solely by the internal dynamics of the average reconstruction error. Here, the autonomous modulation of meta-prior based on learned internal signals ensures that transitions reflect endogenous state changes, not artificially induced behavior.
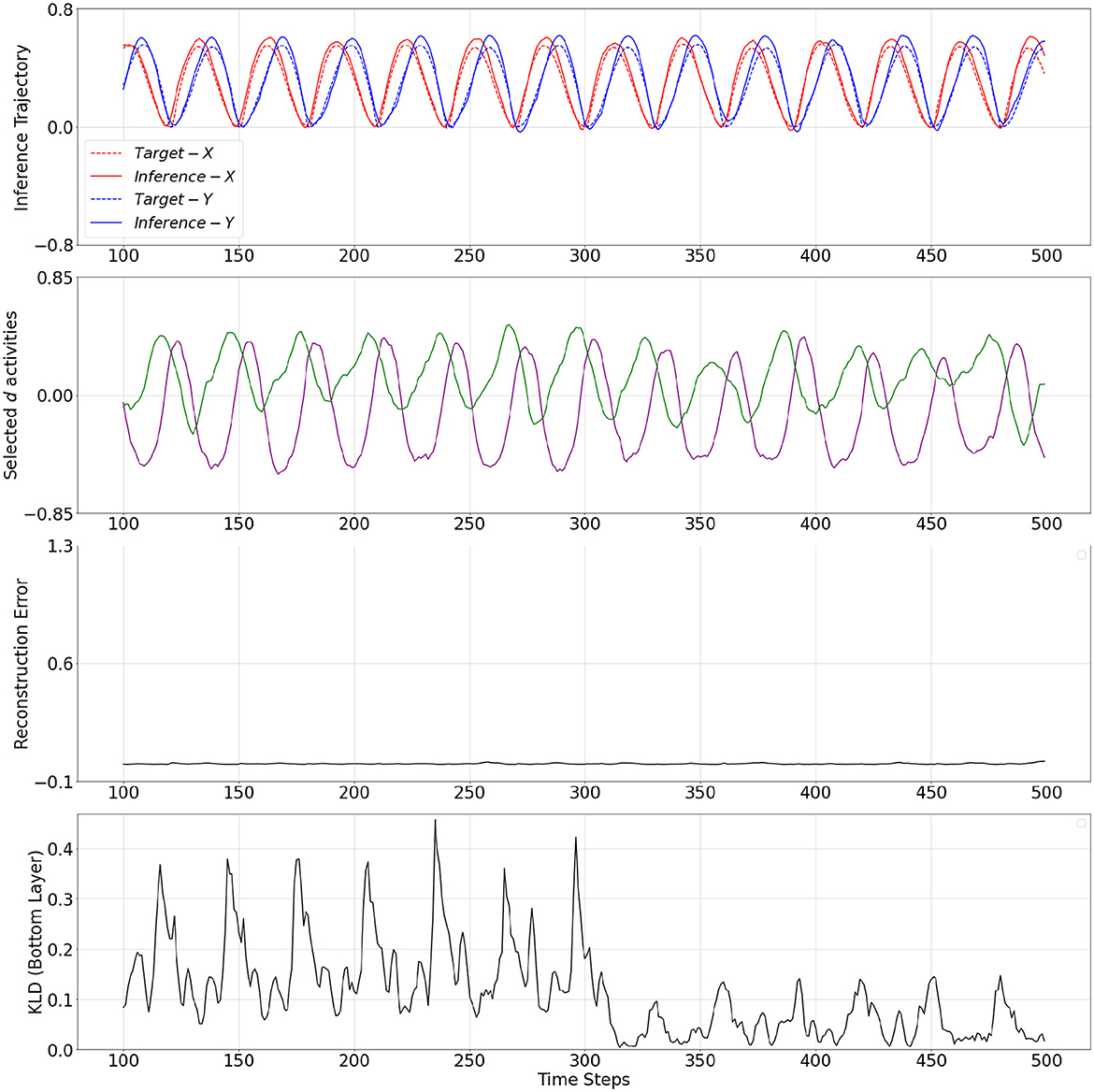
Figure 4. From top to bottom: inference output trajectory with meta-prior wL from Table 2, selected activities of the d neurons in the bottom layer of the PV-RNN, average reconstructions error over the inference window at time step 100, and KL divergence at the PV-RNN bottom layer. Inference−X and Inference−Y correspond to the first and second dimensions of the inference output trajectory, respectively.
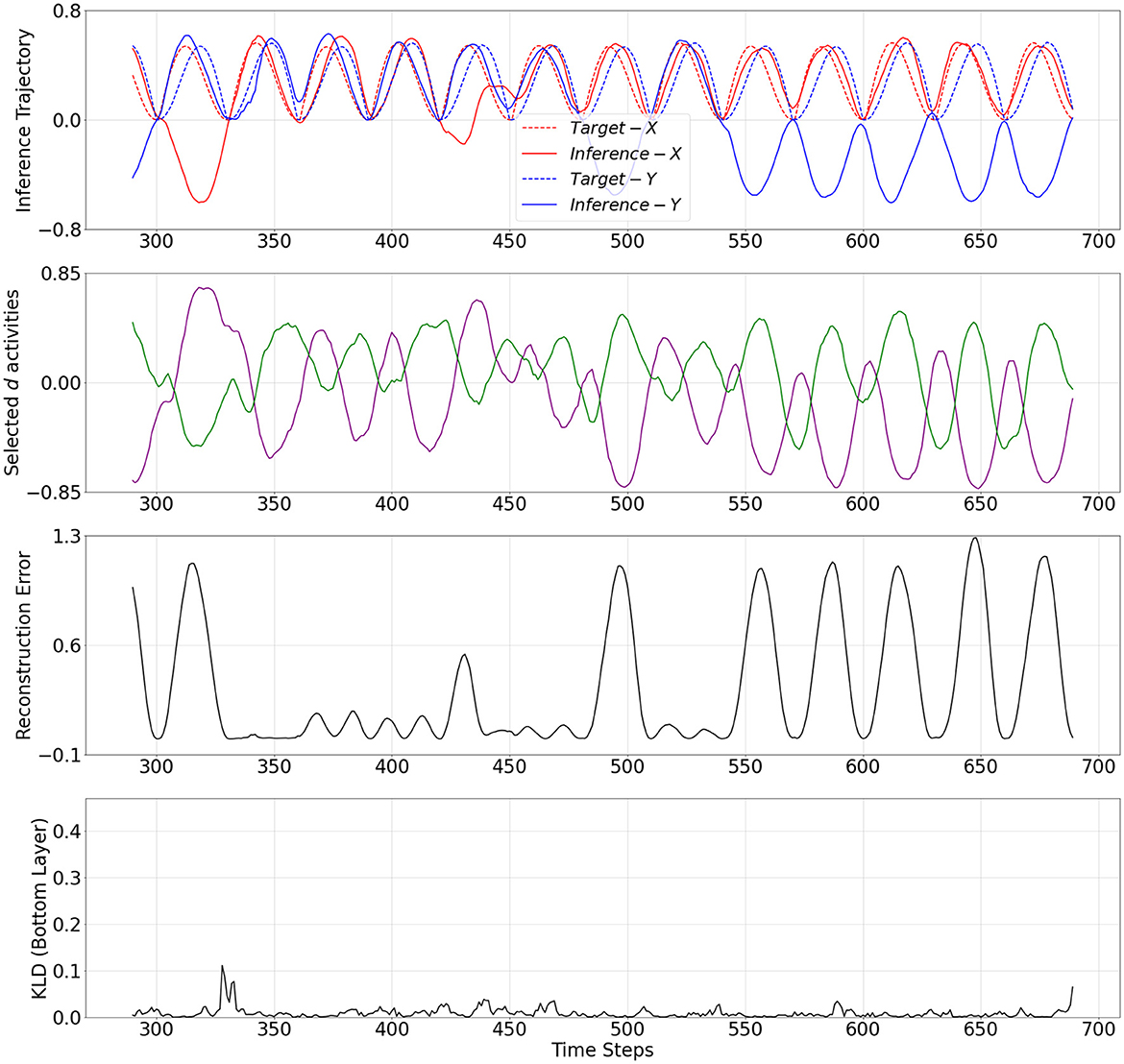
Figure 5. From top to bottom: inference output trajectory with meta-prior wH from Table 2, selected activities of the d neurons in the bottom layer of the PV-RNN, average reconstructions error over the inference window at time step 290, and KL divergence at the PV-RNN bottom layer. Inference−X and Inference−Y correspond to the first and second dimensions of the inference output trajectory, respectively.
In fact, it can be seen in Figure 4 that when w adapted to wL, a pattern used for the target sensory sequence is generated well during inference while the average reconstruction error remains low (below 0.05) over the entire inference window. This indicates that adaptation of w to wL enabled the output to accurately reconstruct the target sensory sequence. This period is analogous to a situation of FS.
On the other hand, Figure 5 demonstrates a period when w adapted to wH. In this period, the inference trajectory is generated similarly to the prior generation shown in Figure 3. In particular, we can observe in Figure 5 that after a few cycles of one pattern, the inference trajectory generates one of the other patterns in the inference window. Specifically, when w changed to wH, KL divergence between prior and inference is more heavily weighted in Equation 9 and, thus, it becomes smaller compared to the KL divergence observed in Figure 4. At the same time, to minimize the free energy, this increase in the meta-prior value allows the prediction error signal to become larger compared to the prediction error computed in Figure 4. As a result, the average reconstruction error increases once the inference trajectory starts to deviate from the target sensory sequence. This observation is analogous to a situation of MW.
Selected d activities of the PV-RNN bottom layer during prior generation after training, as well as during inference with adaptation of w to low and high values, are shown in Figures 3–5. In both cases of the inference, the correspondence between d activity patterns and the output patterns is analogous to that observed during prior generation after training. Specifically, the d activities follow a single pattern when w adapted to the low value, while the d activities alternate between different patterns, closely reflecting the dynamics of the d activities seen in the prior generation when w adapted to the high value.
Figure 6 shows the overall behavior of autonomous shifts between two distinct states obtained in the experiments. The plots show the average reconstruction error during inference and meta-prior values of the PV-RNN bottom layer over time. It can be observed that when PV-RNN is under wH, the average reconstruction error increases as close to the high threshold value, which makes the probability of switching from wH to wL larger according to Equation 11. Then, w is switched to the low value (wL). After this shift, the average reconstruction error continues to decline until it becomes close to the low threshold value, which increases the probability of switching from wL to wH. w is then switched back to the high value. The former case corresponds to the shift from MW to FS and the latter case corresponds to the shift from FS to MW.
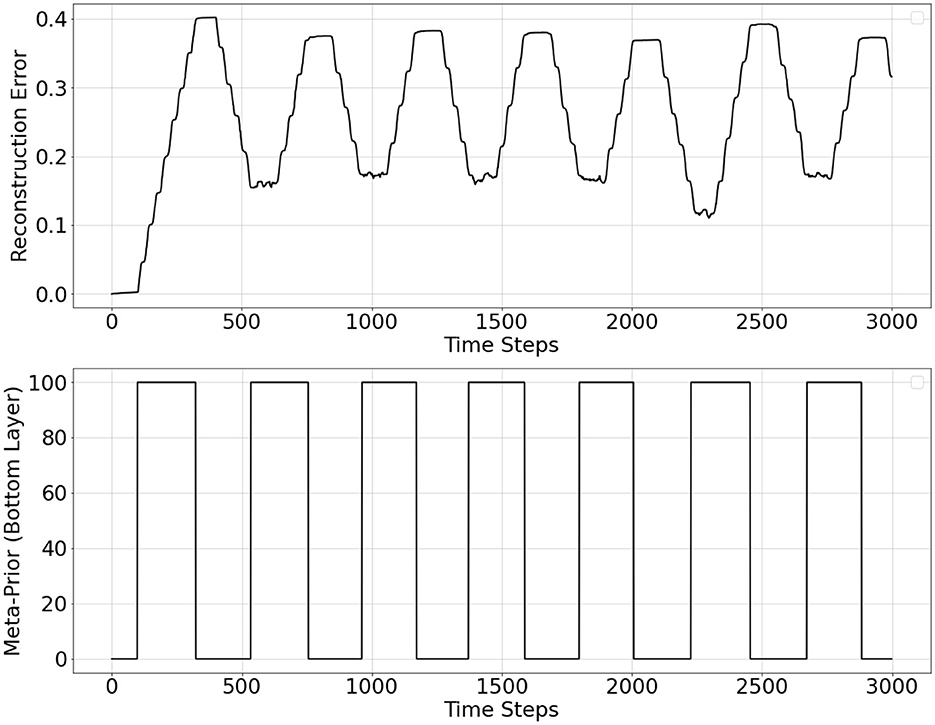
Figure 6. Reconstruction error over inference window computed at each time step (top plot) and adaptive meta-prior value (w) of the PV-RNN bottom layer over time (bottom plot).
Finally, we investigated the effect of changing temperature values on the characteristics of the shifts between FS and MW. For this purpose, we counted the number of transitions that occurred from FS to MW during 1000 steps in the perception test. The results are shown in Figure 7. It can be seen that the transition frequency from FS to MW increases as the temperature increases. In particular, for larger temperature values, the transitions from FS to MW become more frequent (i.e., the system becomes more random) since the probability of switching from FS to MW becomes closer to 50% due to the argument inside the sigmoid function being closer to zero in Equation 10. In contrast, when the temperature is smaller, the transitions from FS to MW become less frequent (i.e., the system becomes more deterministic), which primarily happens when the average reconstruction error reaches the low threshold. For the case study in Figure 6, 0.01 was chosen to be the temperature with a mean of 1.78 transitions from FS to MW per 1,000 time steps.
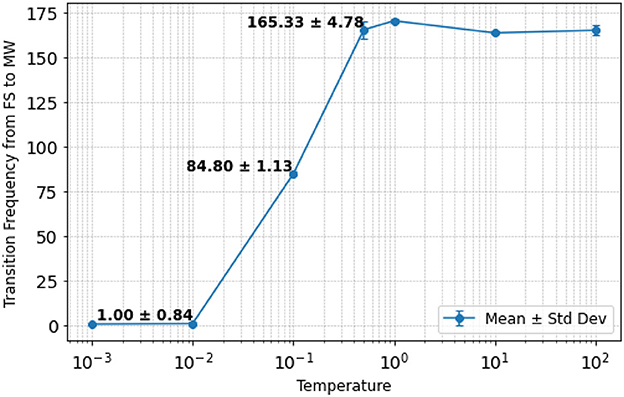
Figure 7. Transition frequency from FS to MW per 1,000 time steps under different temperature values. The mean and standard deviation are displayed for three intermediate cases when temperature is 0.01, 0.10, and 0.50.
4 Discussion
This study explored the neural mechanisms underlying autonomous shifts between the focused state and mind-wandering through simulation experiments using a newly proposed model based on the free energy principle. The proposed model, an extension of PV-RNN, introduces an online adaptation mechanism for a meta-level parameter, the meta-prior w, which is modulated based on the average reconstruction error over a fixed-size past window. Specifically, w probabilistically switches to a high value when the average reconstruction error decreases close to a minimal threshold and to a low value when the average reconstruction error increases near a maximal threshold.
In the simulation experiments, the PV-RNN was first trained to generate probabilistic transitions between four distinct cyclic patterns. In the perception task phase, latent variables within the inference window were inferred to minimize the reconstruction error for a given target sensory sequence while adapting w. Here, one of the trained cyclic patterns was used as the target sequence.
When w shifted to a low value, stronger bottom-up sensory perception dominated, regenerating the observed sensory sequence in the outputs with minimal reconstruction error while allowing larger Kullback-Leibler divergence between the prior and the approximate posterior. This process leads to a state closely aligned with focused attention. In contrast, when w shifted to a high value, the approximate posterior is attracted toward the prior by a stronger mean of minimizing the Kullback-Leibler divergence between the prior and the approximate posterior. This allowed stronger top-down processing with less emphasis on sensation, generating relatively large reconstruction error in the inference window. This results in a state resembling mind-wandering.
One may argue that a limitation of the current study is that the proposed model may not account for the phenomenon of becoming consciously aware of MW, which enables redirection of attention back to FS. Previous work in our group (Tani and White, 2022; Tani, 1998) hypothesized that self-consciousness arises from the interplay of top-down predictions and bottom-up sensory inputs, specifically during moments of incoherence between internal predictions and external sensory feedback. In particular, when the system operates smoothly with minimal prediction error, the processes of action and perception may remain unconscious and seamlessly synchronized. However, a large prediction error may disrupt this synchrony, forcing the system to adjust its internal states and expectations to re-establish the system's coherence. This moment of error-driven model recalibration may be accompanied by the emergence of conscious awareness, as the system actively attempts to reconcile conflicting information and restore its predictive model. In the current study, we could consider that self-awareness may be triggered by a prediction error signal accumulated during MW. We, however, speculate that such a hypothetical idea could be improved further by incorporating possible meta-cognitive mechanisms in consciousness.
In this regard, Sandved-Smith et al. (2021) proposes an inference of meta-states from higher levels to lower levels in terms of attention. Particularly, this framework integrates a three-level generative model to simulate how meta-awareness emerges and modulates attention. At the first level, the model represents sensory or perceptual states, encoding external stimuli. The second level captures attentional states, such as “focused” or “distracted,” which condition the precision of sensory observations at the first level. The third level introduces meta-awareness states, which monitor and regulate attentional states by dynamically adjusting their precision and transitions. In Sandved-Smith et al. (2021), although the meta-awareness state is shifted manually by manipulating a meta-parameter, by formalizing the hierarchical relationship between meta-awareness and attention, meta-awareness states can modulate confidence in attentional states, which, in turn, influence the precision of sensory observations. This structure allows for inference and control of attentional processes, enabling the agent to recognize transitions in attention, detect MW, and refocus.
Drawing from Sandved-Smith et al. (2021), we describe in the following how the hypothesis proposed by Tani and White (2022) and Tani (1998) based on prediction error could be extended by including the process of inference of a meta-state associated with self-awareness during MW. In particular, a generative model may be included on top of the highest layer of the proposed PV-RNN architecture that receives the average reconstruction error (ersum) as the target signal from the output layer of PV-RNN. This meta-level generative model predicts the average reconstruction error over a time window to minimize free energy. In this internal closed-loop computation, the probabilistic shift between FS and MW is now controlled by the predicted ersum of the meta-level generative model using Equations 10, 11. A meta-level state may be included in this PV-RNN model that is inferred when the mismatch between the predicted ersum and the actual ersum exceeds a certain meta-level threshold at which self-awareness of MW occurs.
In the current proposed work, due to the probabilistic nature of the threshold mechanism for the average reconstruction error, the effective threshold for switching from MW to FS varies dynamically between a lower and higher range. Here, we speculate that consciousness arises specifically when this switching occurs at an effective threshold exceeding a certain “consciousness threshold” (which may be different from the threshold ThrH defined for Equation 11). This perspective explains both the two-stage model (Voss et al., 2018) or the multiple sub-event model (Zukosky and Wang, 2021). In the two-stage model, MW persists until a single transition back to FS occurs at a relatively low “consciousness threshold.” In contrast, the multiple sub-event model allows for repeated, unconscious FS-MW shifts before reaching a higher “consciousness threshold” that triggers conscious awareness. By incorporating this into our proposed PV-RNN framework, we provide a meta-cognitive perspective on how conscious awareness of MW emerges probabilistically, linking predictive coding with varying thresholds of self-awareness based on average reconstruction error.
To enhance the empirical relevance of our model, we now provide a qualitative comparison between its behavioral signatures and well-established findings from experimental studies of mind-wandering (MW). Although our current simulations do not directly incorporate or validate against human neurophysiological data, the model successfully captures several key behavioral characteristics observed in MW literature. These alignments support the potential of our predictive-coding-inspired framework to serve as a mechanistic model of spontaneous attentional dynamics. One robust behavioral marker of MW is increased response time variability during cognitive tasks, as demonstrated by both Smallwood et al. (2008) and Henŕıquez et al. (2016). In our simulations, this phenomenon emerges naturally during periods when the meta-prior shifts to a high value. In this state, the model prioritizes top-down processing, and its output trajectory becomes less constrained by incoming sensory information. This internal mode leads to divergence from the task-aligned trajectory, which would manifest as variability in response behavior if implemented in a real-time embodied system. Thus, the dynamic increase in prediction error and loss of sensory fidelity in the MW state qualitatively parallels the behavioral variability observed in human studies.
The model also accounts for spontaneous alternation between task-focused and mind-wandering states, which has been described as a core feature of the human attentional stream (Zukosky and Wang, 2021; Smallwood and Schooler, 2015). In our framework, transitions between low w (FS) and high w (MW) modes arise autonomously through probabilistic switching driven by fluctuations in the average reconstruction error. Crucially, these shifts are not externally triggered but emerge from the internal dynamics of prediction error accumulation, reflecting a self-organizing process akin to that observed in subjective reports of spontaneous MW episodes.
In addition, our model can reproduce temporal dynamics associated with MW frequency over extended task performance. Empirical studies such as Zanesco et al. (2024) have shown that MW tends to increase with time-on-task, often attributed to reduced cognitive engagement or habituation. In our simulations, prolonged accurate predictions lead to a steady decrease in the average reconstruction error, which in turn increases the probability of transitioning into the MW state. This behavior provides a computational account for the time-dependent drift toward MW observed in attentional tasks, as the internal model becomes overconfident and sensory information is deprioritized.
Furthermore, the model can reflect the empirically observed nonlinear dependence of MW on task difficulty (Robison et al., 2020; Xu and Metcalfe, 2016). When the task is too easy, prediction error remains low and the model is prone to transition into the high w mode, corresponding to disengagement or MW. Under moderately challenging conditions, the model sustains engagement as prediction error fluctuates within a manageable range. When the task becomes highly difficult, persistent prediction error may trigger frequent or prolonged re-entries into MW-like states, reflecting cognitive overload or motivational disengagement. These qualitative dynamics are consistent with behavioral studies showing that MW is minimized at intermediate levels of task challenge and increases under both underload and overload conditions.
Notably, Shinagawa and Yamada (2025) recently proposed a homeostatic reinforcement learning (HRL) framework to model mind-wandering under structured task conditions, particularly the Sustained Attention to Response Task (SART). Although our model differs architecturally (i.e., being grounded in predictive coding and variational inference), it shares the key objective of capturing autonomous cognitive state transitions without external supervision. Both models simulate internal modulation mechanisms (e.g., prediction error and homeostatic drives) that regulate attentional shifts between task-focused and internally guided states.
Although we have not explicitly implemented a SART-like structure in our simulation setup, our model's probabilistic state switching and its sensitivity to internal error dynamics mirror the mechanisms used in HRL-SART simulations. We believe that adapting the extended PV-RNN to directly simulate or align with task-based paradigms like SART represents a valuable direction for future work. Such an extension would enable quantitative comparison with behavioral and physiological data, helping bridge synthetic modeling with empirical paradigms in attention and mind-wandering research.
Taken together, these qualitative comparisons suggest that our extended PV-RNN model captures essential properties of MW dynamics reported in behavioral studies. The internal modulation of the meta-prior based on reconstruction error not only supports autonomous shifts between attentional states but also aligns with empirical observations in timing, variability, and task-context sensitivity of mind-wandering.
As for neurophysiological validation, we acknowledge that such comparison remains an open and important direction for future work. The current study is intended as a principle-level computational investigation that explores the feasibility of autonomous attentional modulation via predictive coding mechanisms. Nevertheless, future extensions of the model could examine whether its internal state transitions, particularly changes in the meta-prior, correspond to physiological markers of MW such as fluctuations in EEG alpha-band activity, pupil diameter, or large-scale fMRI network reconfigurations involving the default mode and salience networks. Such investigations would provide stronger links between the model's theoretical mechanisms and observed neural phenomena.
Moreover, numerous studies have indicated that MW during the resting state is intricately linked to the functional organization and dynamics of brain networks, particularly the default network (DN), central executive network (CEN), and salience network (SN) (Mason et al., 2007; Godwin et al., 2017; Denkova et al., 2019). However, the current study does not model interactions between such distinct networks. Reservoir computing may also be utilized as a component of the brain network, which has been proposed to be a neural basis in the cortex (Yonemura and Katori, 2024). Extending the model to incorporate dynamic interactions among these networks would provide a tighter connection to established neuroscientific findings on resting-state phenomena and offer deeper insights into mind-wandering.
Finally, beyond theoretical modeling, our approach may hold potential for practical applications. For instance, adaptive learning systems could use internal signals such as prediction error or meta-prior shifts to detect mind-wandering episodes and adjust content delivery in real time. Similarly, our model could be a mental health or mindfulness support tool to inform computational accounts of attentional fluctuations, and guide human-AI systems toward more flexible attentional control. We view these applications as promising but preliminary, and future work will be needed to integrate the model into real-world tasks and evaluate its practical effectiveness.
Data availability statement
The proposed PV-RNN and dataset generated for this study can be found in the following GitHub repository: https://github.com/oist-cnru/tiny/tree/mw_develop. Further inquiries can be directed to the corresponding author.
Author contributions
HO: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Project administration, Resources, Software, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing. TM: Conceptualization, Resources, Software, Writing – review & editing. JT: Conceptualization, Data curation, Formal analysis, Funding acquisition, Investigation, Methodology, Project administration, Resources, Supervision, Validation, Writing – original draft, Writing – review & editing.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This study was funded by the Japan Society for the Promotion of Science (JSPS) KAKENHI Early-Career Scientists Grant [25K21307] and JSPS KAKENHI Transformative Research Area (A): unified theory of prediction and action [24H02175].
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Gen AI was used in the creation of this manuscript.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1. ^For the implementation strategy described in Algorithm 1, the length of the inference window and time window for computing the average reconstruction error can be considered design decisions and do not need to be the same length. This choice may depend on how the high and low thresholds are defined, which impact the probability of transition from FS to MW (and vice-versa) and, thus, the expected probabilistic behavior of the system. For instance, an average reconstruction error computed over a small time window may not reach or may be too far from a desired threshold. In this scenario, the probability of staying in the current state (FS or MW) would remain large over the entire simulation time.
References
Ahmadi, A., and Tani, J. (2019). A novel predictive-coding-inspired variational rnn model for online prediction and recognition. Neural Comput. 31, 2025–2074. doi: 10.1162/neco_a_01228
Chame, H. F., Ahmadi, A., and Tani, J. (2020). A hybrid human-neurorobotics approach to primary intersubjectivity via active inference. Front. Psychol. 11:3207. doi: 10.3389/fpsyg.2020.584869
Christoff, K., Irving, Z. C., Fox, K. C., Spreng, R. N., and Andrews-Hanna, J. R. (2016). Mind-wandering as spontaneous thought: a dynamic framework. Nat. Rev. Neurosci. 17, 718–731. doi: 10.1038/nrn.2016.113
Clark, A. (2015). Surfing Uncertainty: Prediction, Action, and the Embodied Mind. Oxford: Oxford University Press. doi: 10.1093/acprof:oso/9780190217013.001.0001
Denkova, E., Nomi, J. S., Uddin, L. Q., and Jha, A. P. (2019). Dynamic brain network configurations during rest and an attention task with frequent occurrence of mind wandering. Hum. Brain Mapp. 40, 4564–4576. doi: 10.1002/hbm.24721
Friston, K. (2005). A theory of cortical responses. Philosop. Trans. R. Soc. B 360, 815–836. doi: 10.1098/rstb.2005.1622
Friston, K. (2010). The free-energy principle: a unified brain theory? Nat. Rev. Neurosci. 11, 127–138. doi: 10.1038/nrn2787
Friston, K., Mattout, J., and Kilner, J. (2011). Action understanding and active inference. Biol. Cybern. 104, 137–160. doi: 10.1007/s00422-011-0424-z
Friston, K., Schwartenbeck, P., FitzGerald, T., Moutoussis, M., Behrens, T., and Dolan, R. J. (2014). The anatomy of choice: dopamine and decision-making. Philosop. Trans. R. Soc. B 369:20130481. doi: 10.1098/rstb.2013.0481
Friston, K. J., Daunizeau, J., Kilner, J., and Kiebel, S. J. (2010). Action and behavior: a free-energy formulation. Biol. Cybern. 102, 227–260. doi: 10.1007/s00422-010-0364-z
Godwin, C. A., Hunter, M. A., Bezdek, M. A., Lieberman, G., Elkin-Frankston, S., Romero, V. L., et al. (2017). Functional connectivity within and between intrinsic brain networks correlates with trait mind wandering. Neuropsychologia 103, 140–153. doi: 10.1016/j.neuropsychologia.2017.07.006
Henríquez, R. A., Chica, A. B., Billeke, P., and Bartolomeo, P. (2016). Fluctuating minds: spontaneous psychophysical variability during mind-wandering. PLoS ONE 11:e0147174. doi: 10.1371/journal.pone.0147174
Idei, H., Suzuki, K., and Yamashita, Y. (2024). Awareness of being: a computational neurophenomenological model of mindfulness, mind-wandering, and meta-attentional control. PsyArXiv. doi: 10.31234/osf.io/stxu6
Kingma, D. P., and Ba, J. (2014). Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980.
Mason, M. F., Norton, M. I., Van Horn, J. D., Wegner, D. M., Grafton, S. T., and Macrae, C. N. (2007). Wandering minds: the default network and stimulus-independent thought. Science 315, 393–395. doi: 10.1126/science.1131295
Ohata, W., and Tani, J. (2020). Investigation of the sense of agency in social cognition, based on frameworks of predictive coding and active inference: a simulation study on multimodal imitative interaction. Front. Neurorobot. 14:61. doi: 10.3389/fnbot.2020.00061
Peral-Fuster, C. I., Herold, R. S., Alder, O. J., Elkelani, O., Ribeiro-Ali, S. I., Deane, E. M., et al. (2023). “Intentional mind wandering is objectively linked to low effort and tasks with high predictability,” in Proceedings of the European Conference on Cognitive Ergonomics, 1–8. doi: 10.1145/3605655.3605672
Rao, R. P., and Ballard, D. H. (1999). Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects. Nat. Neurosci. 2:79. doi: 10.1038/4580
Robison, M. K., Miller, A. L., and Unsworth, N. (2020). A multi-faceted approach to understanding individual differences in mind-wandering. Cognition 198:104078. doi: 10.1016/j.cognition.2019.104078
Rumelhart, D. E., Hinton, G. E., and Williams, R. J. (1985). Learning internal representations by error propagation. Technical report, California Univ San Diego La Jolla Inst for Cognitive Science. doi: 10.21236/ADA164453
Sandved-Smith, L., Hesp, C., Mattout, J., Friston, K., Lutz, A., and Ramstead, M. J. (2021). Towards a computational phenomenology of mental action: modelling meta-awareness and attentional control with deep parametric active inference. Neurosci. Consc. 2021:niab018. doi: 10.1093/nc/niab018
Schillaci, G., Ciria, A., and Lara, B. (2020). “Tracking emotions: intrinsic motivation grounded on multi-level prediction error dynamics,” in 10th Joint IEEE ICDL-EPIROB, 1–8. doi: 10.1109/ICDL-EpiRob48136.2020.9278106
Seli, P., Konishi, M., Risko, E. F., and Smilek, D. (2018). The role of task difficulty in theoretical accounts of mind wandering. Conscious. Cogn. 65, 255–262. doi: 10.1016/j.concog.2018.08.005
Seli, P., Risko, E. F., Smilek, D., and Schacter, D. L. (2016). Mind-wandering with and without intention. Trends Cogn. Sci. 20, 605–617. doi: 10.1016/j.tics.2016.05.010
Shinagawa, K., and Yamada, K. (2025). Extending homeostasis to thought dynamics for a comprehensive explanation of mind-wandering. Sci. Rep. 15:8677. doi: 10.1038/s41598-025-92561-0
Smallwood, J., and Andrews-Hanna, J. (2013). Not all minds that wander are lost: the importance of a balanced perspective on the mind-wandering state. Front. Psychol. 4:441. doi: 10.3389/fpsyg.2013.00441
Smallwood, J., Beach, E., Schooler, J. W., and Handy, T. C. (2008). Going awol in the brain: Mind wandering reduces cortical analysis of external events. J. Cogn. Neurosci. 20, 458–469. doi: 10.1162/jocn.2008.20037
Smallwood, J., and Schooler, J. W. (2015). The science of mind wandering: Empirically navigating the stream of consciousness. Annu. Rev. Psychol. 66, 487–518. doi: 10.1146/annurev-psych-010814-015331
Tani, J. (1998). An interpretation of the ‘self' from the dynamical systems perspective: a constructivist approach. J. Consc. Stud. 5, 516–542.
Tani, J., and White, J. (2022). Cognitive neurorobotics and self in the shared world, a focused review of ongoing research. Adapt. Behav. 30, 81–100. doi: 10.1177/1059712320962158
Vago, D. R., and Zeidan, F. (2016). The brain on silent: mind wandering, mindful awareness, and states of mental tranquility. Ann. N. Y. Acad. Sci. 1373, 96–113. doi: 10.1111/nyas.13171
Voss, M. J., Zukosky, M., and Wang, R. F. (2018). A new approach to differentiate states of mind wandering: effects of working memory capacity. Cognition 179, 202–212. doi: 10.1016/j.cognition.2018.05.013
Wirkuttis, N., Ohata, W., and Tani, J. (2023). Turn-taking mechanisms in imitative interaction: Robotic social interaction based on the free energy principle. Entropy 25:263. doi: 10.3390/e25020263
Xu, J., and Metcalfe, J. (2016). Studying in the region of proximal learning reduces mind wandering. Memory Cogn. 44, 681–695. doi: 10.3758/s13421-016-0589-8
Yamashita, Y., and Tani, J. (2008). Emergence of functional hierarchy in a multiple timescale neural network model: a humanoid robot experiment. PLoS Comput. Biol. 4:e1000220. doi: 10.1371/journal.pcbi.1000220
Yonemura, Y., and Katori, Y. (2024). Dynamical predictive coding with reservoir computing performs noise-robust multi-sensory speech recognition. Front. Comput. Neurosci. 18:1464603. doi: 10.3389/fncom.2024.1464603
Zanesco, A. P., Denkova, E., and Jha, A. P. (2024). Mind-wandering increases in frequency over time during task performance: an individual-participant meta-analytic review. Psychol. Bull. 151, 217–239. doi: 10.1037/bul0000424
Keywords: mind-wandering, predictive coding, free energy principle, variational RNN, brain-inspired modeling
Citation: Oyama H, Matsumoto T and Tani J (2025) Modeling autonomous shifts between focus state and mind-wandering using a predictive-coding-inspired variational recurrent neural network. Front. Comput. Neurosci. 19:1578135. doi: 10.3389/fncom.2025.1578135
Received: 17 February 2025; Accepted: 26 May 2025;
Published: 02 July 2025.
Edited by:
Zardad Khan, United Arab Emirates University, United Arab EmiratesReviewed by:
Vivek Parmar, Indian Institute of Technology Delhi, IndiaRupesh Kumar Chillale, University of Maryland, College Park, United States
Copyright © 2025 Oyama, Matsumoto and Tani. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jun Tani, anVuLnRhbmlAb2lzdC5qcA==