 Tim Breitenbach
Tim Breitenbach Thomas Dandekar
Thomas Dandekar- Lehrstuhl für Bioinformatik, Biozentrum, Julius-Maximilians-Universität Würzburg, Würzburg, Germany
How can we be sure that there is sufficient data for our model, such that the predictions remain reliable on unseen data and the conclusions drawn from the fitted model would not vary significantly when using a different sample of the same size? We answer these and related questions through a systematic approach that examines the data size and the corresponding gains in accuracy. Assuming the sample data are drawn from a data pool with no data drift, the law of large numbers ensures that a model converges to its ground truth accuracy. Our approach provides a heuristic method for investigating the speed of convergence with respect to the size of the data sample. This relationship is estimated using sampling methods, which introduces a variation in the convergence speed results across different runs. To stabilize results—so that conclusions do not depend on the run—and extract the most reliable information encoded in the available data regarding convergence speed, the presented method automatically determines a sufficient number of repetitions to reduce sampling deviations below a predefined threshold, thereby ensuring the reliability of conclusions about the required amount of data.
Highlights
• We analyze the convergence speed of accuracies and uncertainties over data sample sizes for ML and mechanistic models.
• We develope an algorithm that stabilized statistic properties of distributions determined by repeated sampling.
• The approach is also applicable for estimating the data size at which test statistics exhibit sufficiently low variability, enabling the formulation of reliable hypotheses that do not depend on the concrete sampling.
1 Introduction
Assuming that measuring data is equivalent to randomly drawing samples from a data pool, a key aspect is determining the size of a sample dataset that sufficiently represents the properties of the data pool. According to the law of large numbers, model accuracy—or any other quantity, such as a test statistic—computed on a sample dataset converges to its ground truth value as the size of the data sample, which is used for model generation or calculating a test statistic, increases.
In related work, an optimal model size is investigated for a given dataset (Friedland et al., 2018). Moreover, how model size and data size are supposed to scale for a given compute budget is also analyzed (Hoffmann et al., 2022). Our investigation focuses on the analysis of how the accuracy of a model increases when the sample dataset increases while assuming a well-suited model for each sample set size. Mapping the model accuracy against the size of the dataset to estimate the dataset size at which a desired accuracy is achieved is called the learning curve approach and has already been explained in the following publications. One can increase the sample data size and monitor the accuracy of a trained model, and additionally monitor the spread of the accuracy given several randomly chosen samples from a pool for each sample size (Cortes et al., 1993; Morgan et al., 2003; Mukherjee et al., 2003; Figueroa et al., 2012). The presented work extends these works by introducing a mechanism that adaptively chooses the number of randomly chosen samples automatically for each sample size, thus stabilizing the statistical properties of the accuracy distributions on training and test sets. If the numbers for repetition are manually set too high, it might waste computational resources. If they are set too low, the results of the algorithm, such as the convergence speed and uncertainties, might change across different runs. By providing tolerances for the properties of the distributions, we directly control the allowable uncertainty based on the use case and avoid manually performing several runs to meet those tolerances. This approach is also computationally efficient as we perform only as many repetitions as needed to fulfill the required tolerances. The convergence of the presented procedure is grounded in mathematical theorems from probability theory. The convergence speed, which cannot be directly derived from such theory, might be influenced by the complexity of the dynamics generating the data, inherent noise (including that introduced by the measurement process and its inaccuracies), and model-specific factors such as the architecture and the training/fitting method. The purpose of our work is to provide a heuristic method, analogous to that of Mukherjee et al. (2003), for analyzing the convergence speed of the model with respect to accuracy as a function of sample size, its uncertainty decay, and for enabling predictions of these quantities for larger datasets; this method is extended with stabilized random sampling to produce reliable estimations of additional data in an automated and computationally cost-efficient manner. The overall benefit of using learning curve analysis, particularly in a production environment, is to obtain a model that meets certain quality and reliability requirements in terms of accuracy. This approach allows the prediction of expected accuracy and its associated uncertainty on unseen data, providing an important tool for ensuring quality.
A useful application of the presented framework arises in scenarios where data annotation in machine learning (ML) or data measurement in life sciences is expensive, and thus, the estimation of an optimal cost-to-reliability gain of a model is of importance, along with balancing its ratio when necessary.
We emphasize that the presented approach is not limited to ML models but works for any model, such as a mechanistic model (Mendoza and Xenarios, 2006; Breitenbach et al., 2021; Breitenbach et al., 2022), which can be represented by a function
A concept related to estimating the amount of data is the power estimation of a statistical test. The power of a statistical test is the probability of rejecting the null hypothesis if the alternative hypothesis is true. In the case of model fitting, the null hypothesis is that the model fits the data; thus, the model deviations from the data are only caused by random fluctuations, and a corresponding chi-square test of goodness-of-fit is used to test this hypothesis. The alternative hypothesis is that the model does not fit the data, and a non-central chi-square distribution can be used to calculate the probabilities of the observed chi-square values under the assumption that the alternative hypothesis is true. However, we need to know the expected deviation of the test statistic (how non-central the chi-square distribution should be) in advance. This estimation is carried out based on the available data and could vary depending on the specific data sample. Consequently, our proposed framework can also be used in a general manner to estimate required data size at which the estimated parameters of a statistical method, such as those used in power analysis or in determining the non-centrality parameter of a non-central chi-square test, vary sufficiently little; this allows for the formulation of a quantified alternative hypothesis with reliable parameter values, indicating that these values are sufficiently close to the ground truth values.
2 Methods
In this section, we present our method in Algorithm 1, which is based on Mukherjee et al. (2003), and explain it. A Python implementation of Algorithm 1 is provided in Supplementary Material.
In the following paragraphs, we explain Algorithm 1. In the first step, we set certain parameters. The parameter

Algorithm 1. This algorithm identifies stable statistical properties of samples of different sizes to identify sufficiently large datasets on which a model has reliable properties.
The main idea of Step 2 is that we consider the dataset
The optional part of Step 2 is from Mukherjee et al. (2003) and is used to find the minimum sample size where the relations in the training data also hold mainly true on the test data. The core concept is to train a model on the training data, where the output is shuffled, and then to compare its prediction capability on a non-shuffled test set with a model trained on a non-shuffled training dataset. The aim of this procedure is to identify the minimum sample size at which relationships observed in the training set are also present in the test dataset, thereby ensuring a basic level of comparability in the statistical properties of the training and test data samples. We make sure that all distributions of accuracies are sufficiently stable before we compare the accuracies from the model trained on shuffled data with those of the model trained on non-shuffled data. In our implementation, we use the Mann–Whitney U test (scipy.stats.mannwhitneyu) to investigate the null hypothesis that both samples are drawn from the same distribution, where the p-value is calculated with regard to the alternative hypothesis that the model trained on the non-shuffled data has better accuracies on test data than the model trained on shuffled data. If the model cannot achieve better performance for larger sample sizes than the model based on shuffled data, it might be worth checking if the target is predictable at all given the input data (Zadeh et al., 2025).
In Step 3, for each
where
In step 4, we use the inverse of the fitted functions to extrapolate the amount of data that results in the desired accuracy and uncertainty requirements.
As already mentioned in the introduction, we can use Algorithm 1 to estimate the data size to obtain test statistics with a sufficiently small uncertainty, such as the non-centrality of the chi-square test or the effect of a therapy on shifting a distribution of a parameter in contrast to untreated patients. In case no model needs to be trained or parameters need to be fitted, such as the shift of a certain parameter under treatment, we modify Step 2.(b) in such a way that we split the randomly drawn data into
3 Results—showcasing the application of Algorithm 1
In this section, we showcase the application of Algorithm 1 based on the diabetes dataset from sklearn. The models are linear regression and the KNeighbors model from sklearn. To evaluate the success of the models, the
Figure 1 shows the fitted curves for the mean, median, and 25th and 75th percentiles for a tolerance of 0.001 for the absolute value of the difference between two means, medians, and 25th and 75th percentiles that we use to test similarity in Step 2.(d) of Algorithm 1 and the optional part of Step 2. The corresponding figures appear identical, demonstrating the function of the adaptive sampling mechanism. The limit accuracies are provided in Table 1.
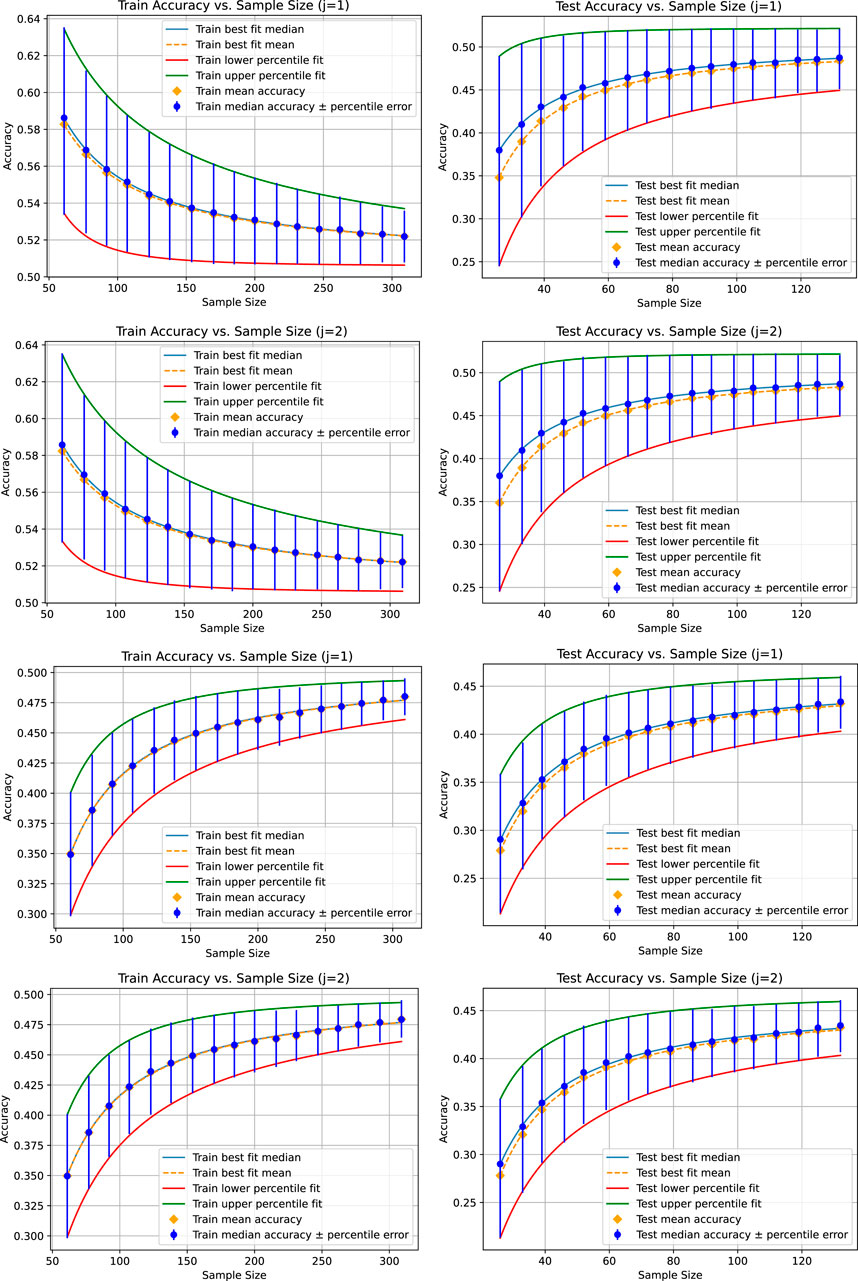
Figure 1. Results for the liner regression (top two figure rows) and the KNeighborsRegressor (bottom two figure rows) based on a tolerance of 0.001 for the absolute value of the difference between the mean, median, 25th percentile, and 75th percentile of each pair of accuracy distributions for each sample size. In this case, there are two instances of each accuracy distribution whose statistical characteristics are compared with respect to the tolerance, numbered by
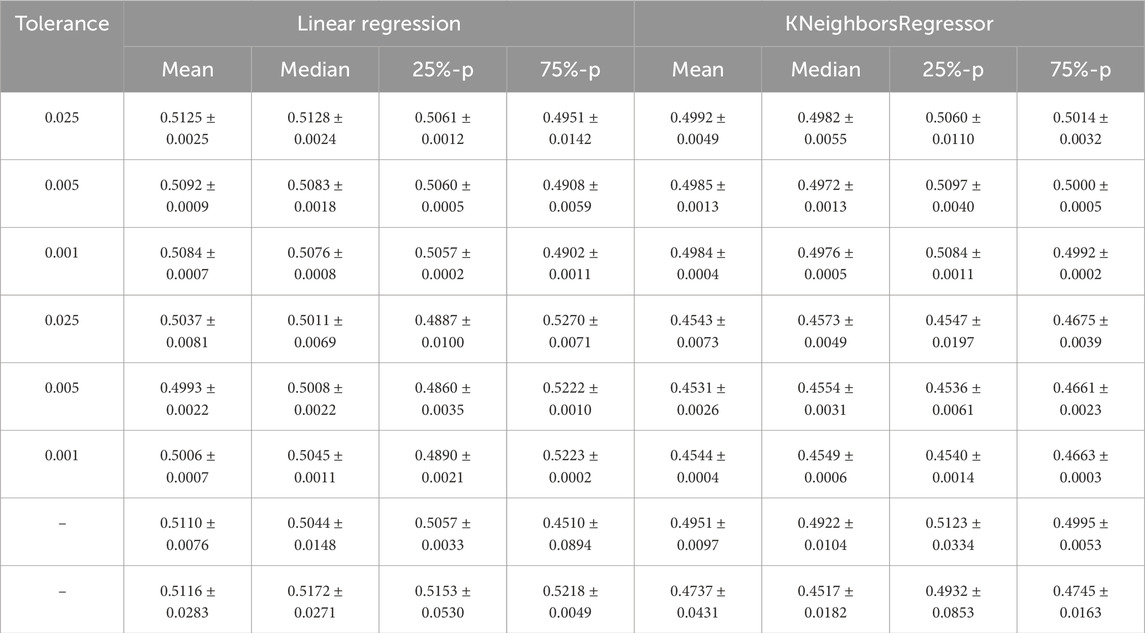
Table 1. Mean value and standard deviation of the limit accuracy of the curves fitted to the means, medians, 25th percentile (25%-p), and 75th percentile (75%-p) of the accuracy distributions for all sub-sampling sizes. The first three rows are based on the training set, and the next three rows are based on the test set. The tolerance is the maximum number for the absolute value of the difference between two means, medians, and 25th and 75th percentiles. To calculate the mean and standard deviation for the limit accuracies, the results of three runs of Algorithm 1 are considered with
The accuracy distributions underlying the graphs of Figure 2 are calculated according to the method described by Mukherjee et al. (2003) with a sampling number of 50 data points per distribution. We observe a higher variation in the statistical characteristics of the distributions for each sampling size compared to Figure 1. A larger number of data points will provide less variation; however, it is challenging to estimate a fitting number a priori. Our method automatically finds a suitable number of data points such that the variation is below a certain tolerance, which is even adaptive to each sampling size.

Figure 2. Results similar to Figure 2; however, the accuracy distributions for each sample size are generated according to Mukherjee et al. (2003) with a sampling number of 50 per distribution. In the first row, we see the result for the linear regression model, and in the second row, we see the result for the KNeighborsRegressor model.
In Table 1, we compare the limit accuracy of the curves fitted to the four statistical characteristics of the accuracy distributions over the sample size with respect to their variation across different runs of our algorithm. To illustrate this, we choose to calculate the mean and standard deviation (square root of the standard variance) based on three runs of Algorithm 1 to observe how this variation decreases if tolerances for the differences of statistical characteristics decrease. Since
Since the model with its architecture and hyperparameter setting is a part of the convergence process and thus influences the amount of data needed for stable and reliable results, we demonstrate in Table 2 how our proposed method can reveal that overfitting might be due to an unfortunate hyperparameter setting (
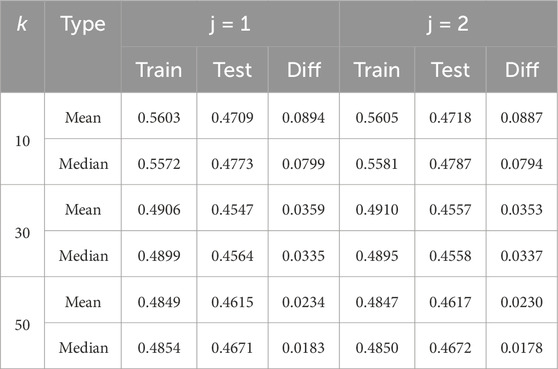
Table 2. Limit accuracy on the training (Train) and test (Test) sets of the curves, each fitted for the mean and median. The difference between the training and test limit accuracy is provided in the column named “Diff” for different
In the next experiment, we fit the curves only to the first seven data points and compare how the model predicts the ones not fitted to. Figure 3 shows the results. The points not used for fitting the power law can be used as a measure of goodness-of-fit and can also be used for model selection, helping identify which model best predicts the limit convergence behavior. This experiment is intended to show that the power law might only be an approximation for the convergence behavior. For example, the fitted parameters might only be valid up to a certain sample size. When using the curve to estimate the additional amount of data to reach certain accuracy gains or levels of uncertainty, we can use sanity checks to determine whether the model might still be valid for the sample size we predict. For example, if the curves for the 25th and 75th percentiles already intersect before the estimated data size. An intersection occurs for the example shown in Table 1 because the limit accuracy for the 25th percentile is higher than that for the 75th percentile on the training set. However, on the test set, the limit accuracies are in the right order. At the latest, after the intersection of the two curves, we would know that we are outside the area where such fitted curves might reliably be used. If our data requirements are not fulfilled before that point and other models do not fit better, meaning that they do not exhibit the same issue, this would be a strong indication that more data must be collected before repeating the analysis. With our proposed method, we can ensure that the identified area where the model is no longer reliable is not due to an unfortunate sampling but is a stable pattern from which we can draw corresponding conclusions.
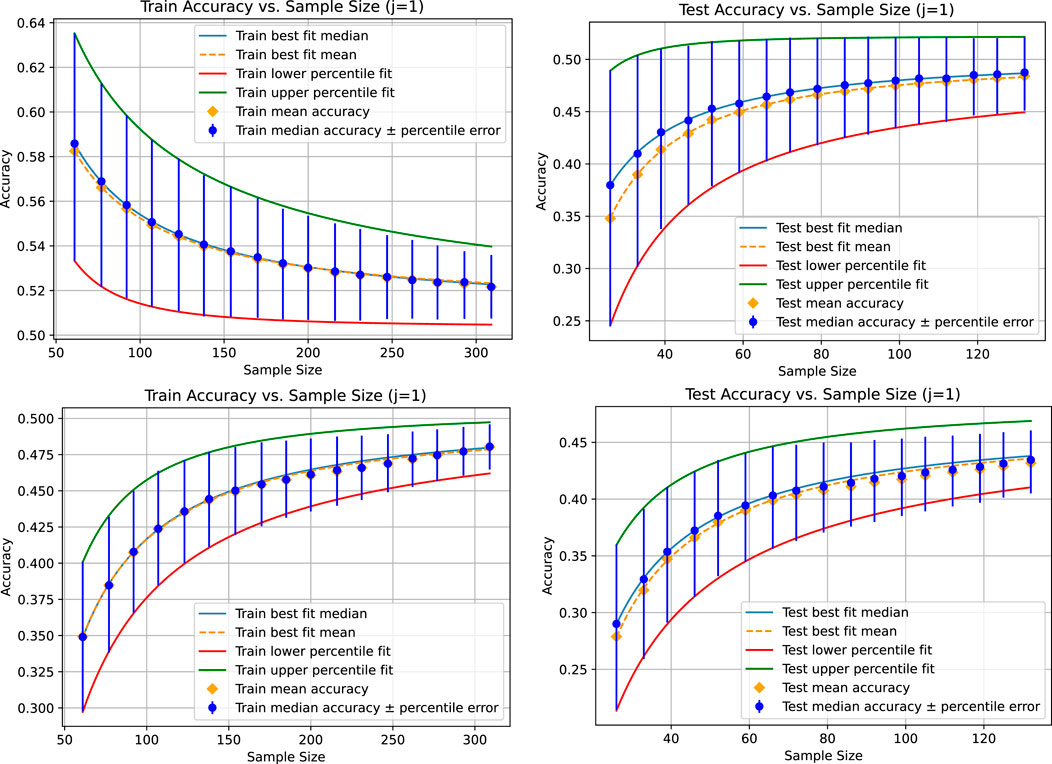
Figure 3. Results for the linear regression (top) and the KNeighborsRegressor (bottom) based on a tolerance of 0.001 for the absolute value of the difference between the mean, median, and 25th and 75th percentiles of the accuracy distribution for each sampling size compared pairwise. In this case, there are two accuracy distributions for each sampling size, each denoted with
4 Discussion
This work aims to provide a heuristic method to analyze the convergence speed of a model to the achievable ground truth accuracy when increasing the size of the data, reducing the effects of sampling variations by introducing tolerances for the corresponding distribution differences. By repeatedly sampling from the available data pool—starting with small amounts of data and gradually increasing the sample size, where each set represents one realization of a potential measurement of that size—we can observe the convergence behavior. Furthermore, we can observe how the uncertainty of the accuracy decreases to a certain range. This is particularly relevant when the reliability of a model in production is important as we can estimate how the accuracy might vary on the unseen data and, thus, whether the model is applicable at all or what amount of training data might still be needed. An example might be personalized medicine. The presented method is general and applicable to all types of models, whether ML or mechanistic.
Increasing the size of the dataset captures more of the underlying dynamics involved in data generation. If the dataset is large enough, there is a high probability that it contains a sufficient number of instances to learn all relevant aspects of these dynamics, regardless of the sampling. By providing broad information about the process to be modeled, we ensure that modeling is not overly specific to a dataset and that the model captures the ground truth dynamics, allowing it to perform reliably in real-world use cases. To apply the presented framework and deal with the many model trainings/fittings that are needed, the total process of model training/fitting needs to be automated to lower the costs of this procedure, e.g., for manual work. We need to run our presented method initially from a data pool
Estimating when reaching a certain degree of reliability in the accuracy is particularly important when data acquisition involves high costs. Examples are in life sciences when working with samples from patients or other samples whose preparation needs a lot of manual work or when there are costly annotation processes such as in ML scenarios, e.g., in natural language processing. With the suggested framework, realistic budgets for data acquisition can be estimated to bring a project to production. Having a clear view of the required data after a proof-of-concept might be crucial to estimating the remaining costs to bring a model to the desired reliability and quality required for production.
One limitation of the framework is that a model needs to be trained several times, which can become an issue in terms of computational costs for large models, such as language models. However, we note that training from scratch might not always be needed as a trained/fitted model from previous data samplings can be used, and the parameters can just be fine-tuned on other datasets to the corresponding parameters optimal for the specific sampled dataset. We note that an implementation of Algorithm 1 can be highly parallelized, e.g., for each
Furthermore, in the case of estimating whether the collection of new data for an existing dataset is required to provide greater model reliability, we assume that the data quality stays the same over time. In particular, we assume that there is no drift in the data as the achievable ground truth accuracy might change because of more noise or data drift. In such a case where the ground truth dynamic changes rapidly compared to the data collection speed, an overall convergence is not guaranteed. An example of changing dynamics can be found in time-series prediction, particularly in predicting pandemic evolution (Vianna et al., 2024), where abrupt and unpredictable changes—such as new rules established by governments—can significantly impact outcomes. For time-series prediction, due to the issue that we cannot interchange data between the training and test sets (it would represent bringing information from the future to the present and thus obscure an ongoing dynamic change), we cannot directly apply our proposed method. As proposed by Vianna et al. (2024) (Figure 1), we can extend the time horizon defining the present to simulate obtaining more historical data for training while keeping the future data regarding the current present (or only a fixed period into the future) for validation to monitor the convergence of the model. However, if we assume that there is no dynamic change, such as in data from a periodic process (like the orbits of planets), then our method can be applied to estimate the convergence of the model with respect to the data sampling size. Although it is a time-series prediction, as there is no dynamic change, the system is closed without absolute time, and the temporal order is only important within the features of a model but not between different data points.
Our framework can be applied in cases where studies claim that an insufficient amount of data is a limiting factor (Hwang et al., 2024; Rodrigues, 2019; Sapoval et al., 2022; Ching et al., 2018). It can be used to estimate the approximate amount of additional data needed, allowing for more accurate planning of the costs of further studies, particularly the costs for data acquisition. This is similar to the approach of Valeri et al. (2023), where it was tested a posteriori whether less amount of data generation would be sufficient in subsequent experiments. Another application of our framework is where models are used to approximate computationally costly functions, such as mutual information between many random variables (Franzese et al., 2024). Mutual information describes how much knowing the value of one random variable reduces the uncertainty about another, i.e., how dependent the variables are on each other in their value distributions. Although such functions might be approximations themselves, which might cause a deviation from the ground truth mutual information, our method deals with estimating the amount of data needed to avoid additional variation in accuracy caused by an insufficiently small data sample. In this case, the approximated value does not depend on the size of the data but only on the mechanism of the approximation. However, in the case of convergence of the approximation to the ground truth mutual information for increasing data, our framework also includes an estimation of the speed of this convergence as our framework considers all components involved in the modeling of the data. Furthermore, with our presented framework, we can study models differing in the hyperparameter setting and test which model converges to a better limit accuracy or which is faster in convergence, similar to Valeri et al. (2023) (Supplementary Figure S1), where different models perform differently well for small datasets. One example can be a model with more layers or free parameters, which tests whether the smaller model is too small, and the other bigger model can store more of the information, which might be the case if the model with more free parameters leads to better limit accuracies on the training and test sets. In case both models converge to the same limiting accuracy, the smaller model is preferable and seems sufficient to represent the data and underlying dynamic.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found here: sklearn diabetes.
Author contributions
TB: conceptualization, data curation, formal analysis, investigation, methodology, project administration, software, supervision, validation, visualization, writing – original draft, and writing – review and editing. TD: writing – review and editing.
Funding
The author(s) declare that no financial support was received for the research and/or publication of this article.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fbinf.2025.1528515/full#supplementary-material
References
Billingsley, P. (2013). Convergence of probability measures. Hoboken, New Jersey: John Wiley and Sons.
Breitenbach, T., Englert, N., Osmanoglu, Ö., Rukoyatkina, N., Wangorsch, G., Heinze, K., et al. (2022). A modular systems biological modelling framework studies cyclic nucleotide signaling in platelets. J. Theor. Biol. 550, 111222. doi:10.1016/j.jtbi.2022.111222
Breitenbach, T., Helfrich-Förster, C., and Dandekar, T. (2021). An effective model of endogenous clocks and external stimuli determining circadian rhythms. Sci. Rep. 11 (1), 16165. doi:10.1038/s41598-021-95391-y
Breitenbach, T., Liang, C., Beyersdorf, N., and Dandekar, T. (2019). Analyzing pharmacological intervention points: a method to calculate external stimuli to switch between steady states in regulatory networks. PLoS Comput. Biol. 15 (7), e1007075. doi:10.1371/journal.pcbi.1007075
Ching, T., Himmelstein, D. S., Beaulieu-Jones, B. K., Kalinin, A. A., Do, B. T., Way, G. P., et al. (2018). Opportunities and obstacles for deep learning in biology and medicine. J. R. Soc. interface 15 (141), 20170387. doi:10.1098/rsif.2017.0387
Cho, J., Lee, K., Shin, E., Choy, G., and Do, S. (2015). How much data is needed to train a medical image deep learning system to achieve necessary high accuracy? arXiv preprint arXiv:151106348.
Cortes, C., Jackel, L. D., Solla, S., Vapnik, V., and Denker, J. (1993). Learning curves: asymptotic values and rate of convergence. Adv. neural Inf. Process. Syst. 6.
Crouch, S. A., Krause, J., Dandekar, T., and Breitenbach, T. (2024). DataXflow: synergizing data-driven modeling with best parameter fit and optimal control–An efficient data analysis for cancer research. Comput. Struct. Biotechnol. J. 23, 1755–1772. doi:10.1016/j.csbj.2024.04.010
Durrett, R. (2019). Probability: theory and examples. Cambridge, UK: Cambridge University Press, Vol. 49.
Figueroa, R. L., Zeng-Treitler, Q., Kandula, S., and Ngo, L. H. (2012). Predicting sample size required for classification performance. BMC Med. Inf. Decis. Mak. 12, 8–10. doi:10.1186/1472-6947-12-8
Franzese, G., Bounoua, M., and Michiardi, P. (2024). MINDE: mutual information neural diffusion estimation. In: The twelfth international conference on learning representations. Singapore: ICLR. Available online at: https://openreview.net/forum?id=0kWd8SJq8d.
Friedland, G., Krell, M. M., and Metere, A. (2018). A practical approach to sizing neural networks. Livermore, CA, United States: Lawrence Livermore National Lab.
Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., et al. (2022). Training compute-optimal large language models. arXiv preprint arXiv:220315556.
Hwang, H., Jeon, H., Yeo, N., and Baek, D. (2024). Big data and deep learning for RNA biology. Exp. and Mol. Med. 56, 1293–1321. doi:10.1038/s12276-024-01243-w
Mendoza, L., and Xenarios, I. (2006). A method for the generation of standardized qualitative dynamical systems of regulatory networks. Theor. Biol. Med. Model. 3, 13–18. doi:10.1186/1742-4682-3-13
Morgan, J., Daugherty, R., Hilchie, A., and Carey, B. (2003). Sample size and modeling accuracy of decision tree based data mining tools. Acad. Inf. Manag. Sci. J. 6 (2), 77–91.
Mukherjee, S., Tamayo, P., Rogers, S., Rifkin, R., Engle, A., Campbell, C., et al. (2003). Estimating dataset size requirements for classifying DNA microarray data. J. Comput. Biol. 10 (2), 119–142. doi:10.1089/106652703321825928
Raue, A., Schilling, M., Bachmann, J., Matteson, A., Schelke, M., Kaschek, D., et al. (2013). Lessons learned from quantitative dynamical modeling in systems biology. PloS one 8 (9), e74335. doi:10.1371/journal.pone.0074335
Raue, A., Steiert, B., Schelker, M., Kreutz, C., Maiwald, T., Hass, H., et al. (2015). Data2Dynamics: a modeling environment tailored to parameter estimation in dynamical systems. Bioinformatics 31 (21), 3558–3560. doi:10.1093/bioinformatics/btv405
Rodrigues, T. (2019). The good, the bad, and the ugly in chemical and biological data for machine learning. Drug Discov. Today Technol. 32, 3–8. doi:10.1016/j.ddtec.2020.07.001
Sapoval, N., Aghazadeh, A., Nute, M. G., Antunes, D. A., Balaji, A., Baraniuk, R., et al. (2022). Current progress and open challenges for applying deep learning across the biosciences. Nat. Commun. 13 (1), 1728. doi:10.1038/s41467-022-29268-7
Valeri, J. A., Soenksen, L. R., Collins, K. M., Ramesh, P., Cai, G., Powers, R., et al. (2023). BioAutoMATED: an end-to-end automated machine learning tool for explanation and design of biological sequences. Cell. Syst. 14 (6), 525–542.e9. doi:10.1016/j.cels.2023.05.007
Van der Vaart, A. W. (2000). Asymptotic statisticsCambridge, UK: Cambridge University Press, Vol. 3.
Vianna, L. S., Gonçalves, A. L., and Souza, J. A. (2024). Analysis of learning curves in predictive modeling using exponential curve fitting with an asymptotic approach. Plos one 19 (4), e0299811. doi:10.1371/journal.pone.0299811
Zadeh, S. G., Shaj, V., Jahnke, P., Neumann, G., and Breitenbach, T. (2025). Towards measuring predictability: to which extent data-driven approaches can extract deterministic relations from data exemplified with time series prediction and classification. Trans. Mach. Learn. Res. Available online at: https://openreview.net/forum?id=jZBAVFGUUo.
Keywords: model reliability, data size estimation, stochastic convergence to ground truth properties, stability of sampling properties, reliable alternative hypothesis formulation
Citation: Breitenbach T and Dandekar T (2025) Adaptive sampling methods facilitate the determination of reliable dataset sizes for evidence-based modeling. Front. Bioinform. 5:1528515. doi: 10.3389/fbinf.2025.1528515
Received: 14 November 2024; Accepted: 08 July 2025;
Published: 04 September 2025.
Edited by:
William C. Ray, Nationwide Children’s Hospital, United StatesReviewed by:
Wolfgang Rumpf, University of Maryland Global Campus (UMGC), United StatesDarren Wethington, Nationwide Children’s Hospital, United States
Copyright © 2025 Breitenbach and Dandekar. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Tim Breitenbach, dGltLmJyZWl0ZW5iYWNoQHVuaS13dWVyemJ1cmcuZGU=