 Giovanni Nigita
Giovanni Nigita Dario Veneziano
Dario Veneziano Alfredo Ferro
Alfredo Ferro- 1Department of Molecular Virology, Immunology and Medical Genetics, Ohio State University, Columbus, OH, USA
- 2Department of Clinical and Molecular Biomedicine, University of Catania, Catania, Italy
RNA editing is a dynamic mechanism for gene regulation attained through the alteration of the sequence of primary RNA transcripts. A-to-I (adenosine-to-inosine) RNA editing, which is catalyzed by members of the adenosine deaminase acting on RNA (ADAR) family of enzymes, is the most common post-transcriptional modification in humans. The ADARs bind double-stranded regions and deaminate adenosine (A) into inosine (I), which in turn is interpreted by the translation and splicing machineries as guanosine (G). In recent years, this modification has been discovered to occur not only in coding RNAs but also in non-coding RNAs (ncRNA), such as microRNAs, small interfering RNAs, transfer RNAs, and long non-coding RNAs. This may have several consequences, such as the creation or disruption of microRNA/mRNA binding sites, and thus affect the biogenesis, stability, and target recognition properties of ncRNAs. The malfunction of the editing machinery is not surprisingly associated with various human diseases, such as neurodegenerative, cardiovascular, and carcinogenic diseases. Despite the enormous efforts made so far, the real biological function of this phenomenon, as well as the features of the ADAR substrate, in particular in non-coding RNAs, has still not been fully understood. In this work, we focus on the current knowledge of RNA editing on ncRNA molecules and provide a few examples of computational approaches to elucidate its biological function.
Background
While in the past researchers mainly focused on DNA mutations in order to further elucidate molecular pathways involved in numerous cancers, in the last decade focus has shifted to the analysis of post-transcriptional modification events, such as RNA editing. Concurrently, it has been estimated that only 1% of mammalian genome codes for protein, while the vast majority of the transcriptome is composed of non-coding RNAs crucially involved in gene expression pathways, such as transcription, translation, and gene regulation (Cech and Steitz, 2014). The editing machinery, occurring both in coding and non-coding RNAs, has been implicated in various human diseases (Galeano et al., 2012; Tomaselli et al., 2014). Strong interest is thus growing toward understanding how and why RNA editing can influence non-coding RNA function.
RNA editing is a type of post-transcriptional modification that takes place in eukaryotes. Several forms of RNA editing have been discovered, but nowadays A-to-I RNA editing is considered the predominant one in mammals (Nishikura, 2010). Adenosine (A) deamination produces its conversion into inosine (I), which in turn is interpreted as guanosine (G) by both the translation and splicing machineries (Rueter et al., 1999). Enzymes members of the adenosine deaminase acting on RNA (ADAR) family catalyze this biological phenomenon which occurs only on dsRNA structures (Bass, 2002; Jepson and Reenan, 2008; Nishikura, 2010). Double-stranded RNAs are imperfect duplexes formed by base-pairing between residues in the region proximate to the editing site (usually overlapping a neighboring intron) and the exonic sequence containing the A. Such proximate region is termed editing complementary sequence (ECS), potentially located several hundred to several thousand nucleotides upstream or downstream of the edited A. This requires experimental validation and represents one critical issue with the detection of editing sites.
Three members of the ADAR gene family can be distinguished in humans, in particular, two isoforms of ADAR1 (ADAR1p150 and ADAR1p110) (Kim et al., 1994), ADAR2 (Lai et al., 1997), and ADAR3 (Chen et al., 2000). While ADAR1 and ADAR2 are widely expressed in tissues, ADAR3 is limited to brain tissues (Melcher et al., 1996). Interestingly, unlike ADAR1 and ADAR2, ADAR3 possesses a catalytically inactive (Chen et al., 2000) arginine-rich R domain, which allows the enzyme to bind single strand structures.
An RNA edited site neighborhood profiling was established for ADAR1-2. While for ADAR1, no 3′ neighbor preference has been identified, a 5′ nearest neighboring preference consisting of U = A > C > G (Polson and Bass, 1994) can be observed. Like ADAR1, ADAR2 has a similar 5′nearest neighboring preference (U ≈ A > C = G) but, furthermore, it has a 3′nearest neighboring preference (U = G > C = A) as well, creating a particular trinucleotide sequence with the adenosine at the center (UAU, AAG, UAG, AAU) (Lehmann and Bass, 2000). In addition, the ADARs show selectivity based on both dsRNA length and the presence of mismatches, loops, and bulges that interrupt the base-pairing (Bass, 1997).
There are two kinds of A-to-I RNA editing: specific A-to-I editing occurs in short duplex regions interrupted by bulges and mismatches (Wahlstedt and Ohman, 2011); the promiscuous one occurs within longer stable duplexes of hundreds of nucleotides, mostly formed by repetitive elements, such as Alus, in which up to 50% of adenosines could be targeted by ADARs (Carmi et al., 2011; Bazak et al., 2014b).
Adenosine-to-inosine RNA editing has been discovered both in intronic and exonic regions, 5′ and 3′-UTRs as well. RNA editing events can take place in several cellular contexts: in the gene expression pathway (Bazak et al., 2014b), such as in translation (Nishikura, 2010) or in the creation and/or destruction of splicing sites (Rueter et al., 1999); during gene regulation through editing events in microRNA/mRNA binding regions (Nishikura, 2006; Borchert et al., 2009). Recent reports affirmed that RNA editing may occur in non-coding RNA molecules, particularly within precursor-tRNA (Su and Randau, 2011), pri-miRNA (Kawahara et al., 2008; Kawahara, 2012), and lncRNA (Mitra et al., 2012). It was estimated that 10–20% of miRNAs undergo A-to-I editing (Blow et al., 2006; Kawahara et al., 2008) at the pri-miRNA level (Yang et al., 2006). Editing can influence both the maturation process (Yang et al., 2006) and the recognition of binding sites on target mRNAs (Kawahara et al., 2007; Wu et al., 2011). Indeed, a single editing site in a miRNA seed region could drastically change its set of targets (Alon et al., 2012).
In the past decade, surprising results have been obtained in RNA editing site discovery, thanks initially to the application of bioinformatic approaches, subsequently fully replaced by RNAseq-based methods in recent years. The large amount of editing sites discovered by these methodologies has led to the creation of public databases (Kiran and Baranov, 2010; Kiran et al., 2013; Ramaswami and Li, 2014). As described below, all these resources containing very important information, such as editing level and genomic annotations, can help to functionally elucidate the RNA editing phenomenon.
This mini review summarizes both the current knowledge on RNA editing, as well as past and present approaches for discovery and analysis of editing sites, particularly emphasizing on RNA editing in non-coding RNA (ncRNA) molecules.
Computational Approaches to Discover and Analyze RNA Editing Events
The Origins of the Analysis and Detection of RNA Editing Sites – Computational and Biochemical Methods
In the early 2000s, the ADAR enzyme family was observed to play an important role during embryonic development (Higuchi et al., 2000; Wang et al., 2000), while also associating the alteration of the editing machinery to neurological diseases (Maas et al., 2001; Kawahara et al., 2004). At that time, only few RNA editing sites were discovered (Morse and Bass, 1999). Hoopengardner et al. (2003) using comparative genomics identified and experimentally validated 16 novel editing sites in fruit fly and one in human. Interestingly, they discovered that these editing sites are surrounded by highly conserved exonic regions which form a dsRNA structure as required for ADARs. Despite these efforts, most editing sites were detected by chance.
In 2004, unprecedented computational methods were designed in order to discover clustered A-to-I RNA editing sites in Alu repeats of the human transcriptome (Athanasiadis et al., 2004; Kim et al., 2004; Levanon et al., 2004), going from dozens to tens of thousands of editing sites. By aligning millions of publicly expressed sequence tags (EST) (Boguski et al., 1993) against a reference genome, it is indeed possible to identify A-to-G mismatches as putative candidates of A-to-I editing events. Unfortunately, without considering RNA editing, related features such as nearest neighbor preference sequence, this naïve approach produces a large amount of false positives due to sequencing errors originating from poor sequencing quality, somatic mutations, or single nucleotide polymorphisms (SNP). All of the above methods avoided this issue by taking into account cDNA-genome alignments along with clusters of mismatches in long and stable dsRNA structures and, finally, filtered known SNPs from the obtained candidates, reaching good accuracy.
A more quantitative and accurate analysis was later provided by Eggington et al. (2011) 1, who predicted editing sites in dsRNAs by assuming a multiplicative relationship between the coefficients (estimated by a non-linear regression model and dependent on the bases neighboring each site) used to determine the percentage of editing sites.
The bioinformatics methods for RNA editing detection comparing a cDNA sequence with a reference genome nevertheless present a significant problem: they are not able to distinguish a guanosine originating from an I-to-G replacement, from a guanosine as a product of noise, sequencing errors, or SNP. To overcome this limit, Sakurai et al. (2010) designed a biochemical method, called inosine chemical erasing (ICE), for the identification of inosine sites on RNA molecules by employing inosine-specific cyanoethylation with reverse transcription, PCR amplification, and direct sequencing. Without requiring changing profiles of cellular gene expression nor genomic DNA for reference, this method accurately and consistently identifies inosines in RNA strands. Recently, Sakurai et al. (2014) combined the ICE method with deep sequencing technology (ICE-seq) for an unbiased genome wide screening of novel A-to-I editing sites.
New era of RNA Editing Discovery – High-Throughput Sequencing Approaches
Despite the substantial results achieved with the approaches described above, some restrictions due to sequencing limitations remained. Before 2009, in fact, only a few dozen editing sites had been detected outside repetitive regions in humans due to the impossibility of designing a systematic method to discover editing events in ncRNA genes.
With the advent of high-throughput sequencing technology (HTS), things radically improved. In 2009, Li et al. (2009) developed the first HTS-based application which, through massively parallel target capture and DNA sequencing, identified 36,000 non-repetetive putative A-to-I editing events. Recently, several HTS-based approaches for editing discovery have been developed (see Table 1). It was latterly hypothesized that there are more than 100 million editing sites in human Alu repeats, located mainly in genic regions (Bazak et al., 2014a). Despite the increased accuracy, these methods have limitations in terms of false positives produced (Kleinman and Majewski, 2012; Lin et al., 2012; Pickrell et al., 2012).
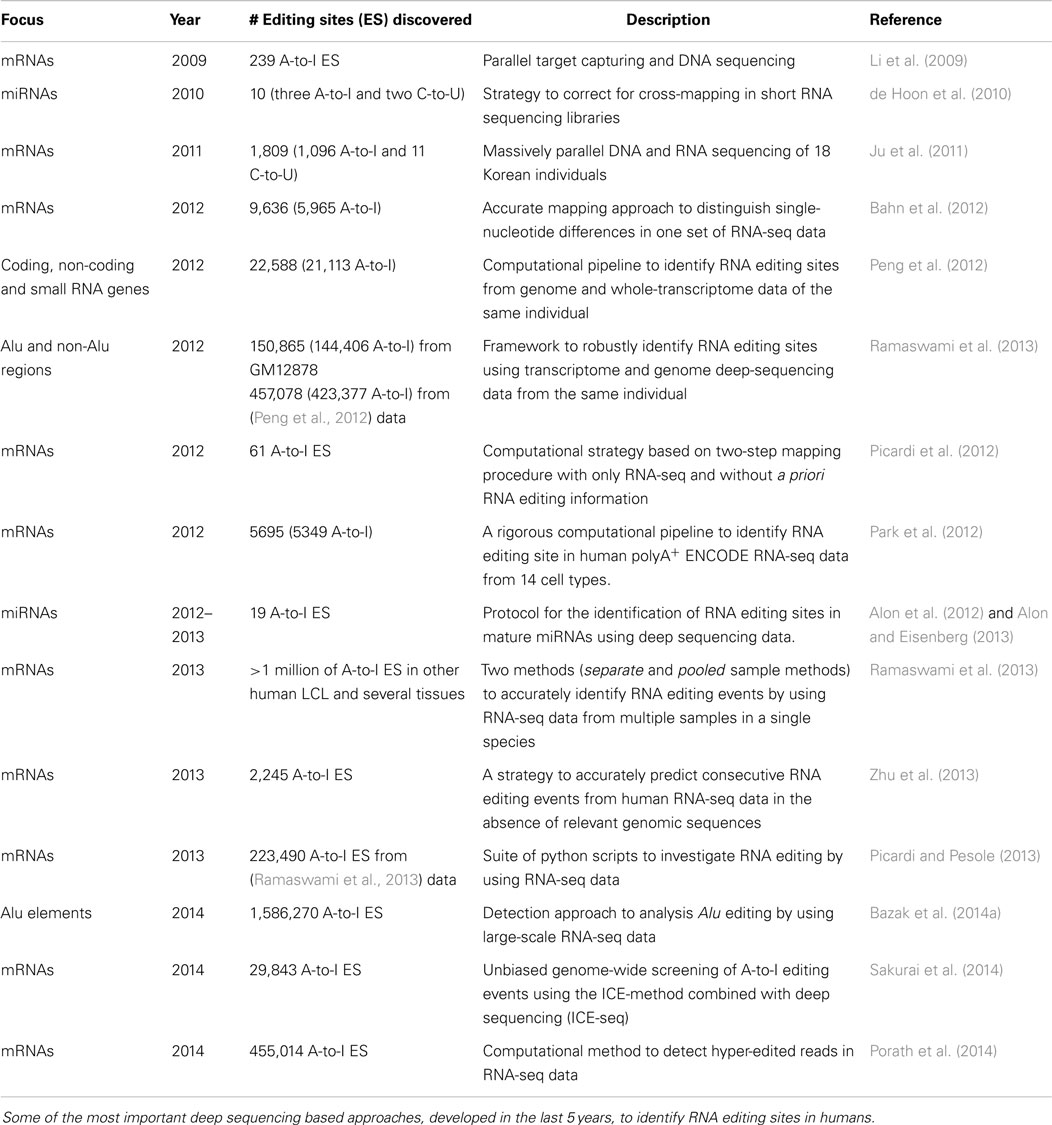
Table 1. Deep sequencing based approaches.
Table 1 depicts some of the most important studies on RNA editing detection by HTS. The majority was designed to identify RNA editing events in protein-coding RNA, while a few also focus on lncRNAs as well. In 2010, de Hoon et al. developed a strategy to correct cross-mapping of small RNA deep-sequencing libraries, applying it to analyze RNA editing in human mature miRNAs. They concluded that miRNA editing is rare in animals and addressed methodological problems in its analysis through RNAseq. Subsequently, Alon et al. (2012) systematically identified known editing events in mature miRNAs of human brain, in addition to 17 novel ones, 12 of which occur in the seed region (Alon and Eisenberg, 2013). They moreover identified sequence preference in the residues, both flanking and opposing the A-to-I editing site. As the authors suggested, this pipeline could identify editing sites in miRNAs from NGS data of different experimental set-ups. Currently, Alon’s method is the only one able to accurately detect and quantify A-to-I RNA editing events in mature miRNAs by NGS. Together with the latest pipeline published by Picardi et al. (2014) for RNA editing detection in human lncRNAs from deep sequencing experiments.
Current Knowledge of RNA Editing on ncRNA Molecules
Biological Databases: DARNED and RADAR
The birth of the first computational methods for the identification of RNA editing events (Athanasiadis et al., 2004; Kim et al., 2004; Levanon et al., 2004) caused a growing interest in the scientific community for RNA editing, as there was a strong need to collect in a centralized repository the tens of thousands of editing events discovered up to that point. For this reason, Kiran and Baranov designed DARNED2 (DAtabase of RNa EDiting), the first public database of known editing sites in human (Kiran and Baranov, 2010). The first release of DARNED contained more than 40,000 predicted human editing sites, of which a few were experimentally validated (Ramaswami et al., 2013). The usefulness of the repository rests in the ability to retrieve information on RNA regions where editing events can occur, such as genome coordinates, cell/tissue/organ sources, and the number of ESTs supporting referenced and edited bases. According to the first release of DARNED, Laganà et al. (2012) built miR-EdiTar3, a database of predicted miRNA binding sites that could be affected by A-to-I editing sites occurring in 3′UTRs.
In subsequent years, the advent of high-throughput RNA sequencing (RNAseq) and biochemically-based (Sakurai et al., 2010) techniques progressively led to the development of increasingly accurate transcriptome-wide methods for RNA editing detection. Furthermore, deep sequencing based approaches allowed to identify a large number of editing sites, up to two orders of magnitude higher than before. Two years later, a new release of DARNED recorded more than 330,000 editing sites in human (Kiran et al., 2013). This led to the design of tools to both visualize and annotate RNA-Seq data with known editing sites (Picardi et al., 2011; Distefano et al., 2013).
Although DARNED contains precious information regarding known editing sites, only a small portion of this have been later manually annotated, not providing any information about the spatiotemporal regulation of editing events through their editing level (Wahlstedt et al., 2009; Solomon et al., 2014). To improve this aspect, Ramaswami and Li built RADAR4, a rigorously annotated database of A-to-I editing sites. Particularly, they have enriched RNA editing knowledge by including detailed manually curated information for each editing site, such as genomic coordinates, type of genomic region (intergenic region, 3′-or-5′ UTR, intron, or coding sequence if the editing site occurs in genic region), type of repetitive element (when the editing event occurs in Alu or not-Alu element), the conservation in other species (chimpanzee, rhesus, mouse), and the tissue-specific editing level when known. Currently, RADAR contains about 1.4 million editing sites as detected in Homo Sapiens (Ramaswami and Li, 2014). Among them, the editing sites that occur in human ncRNAs are only a small fraction, consisting of about 21,000 events, with only 1,219 editing sites in microRNAs. Despite being a relatively small percentage, amounting to about 1.6% of the total number of human editing sites, these miRNA editing events may very well posses significant importance as far as the editing phenomenon is concerned.
Without a doubt, continuous updating of the RADAR database gradually will become a precious resource for researchers in this field, leading to a better understanding of the editing phenomenon in coming years.
Effect of RNA Editing in Non-Coding RNA Molecules
In the last decade, editing events have been discovered in ncRNA molecules, such as miRNAs, siRNAs, tRNAs, and lncRNAs. Although not fully demonstrated yet, these editing sites could alter the stability, the biogenesis, and target recognition of ncRNAs, as shown in Figure 1.
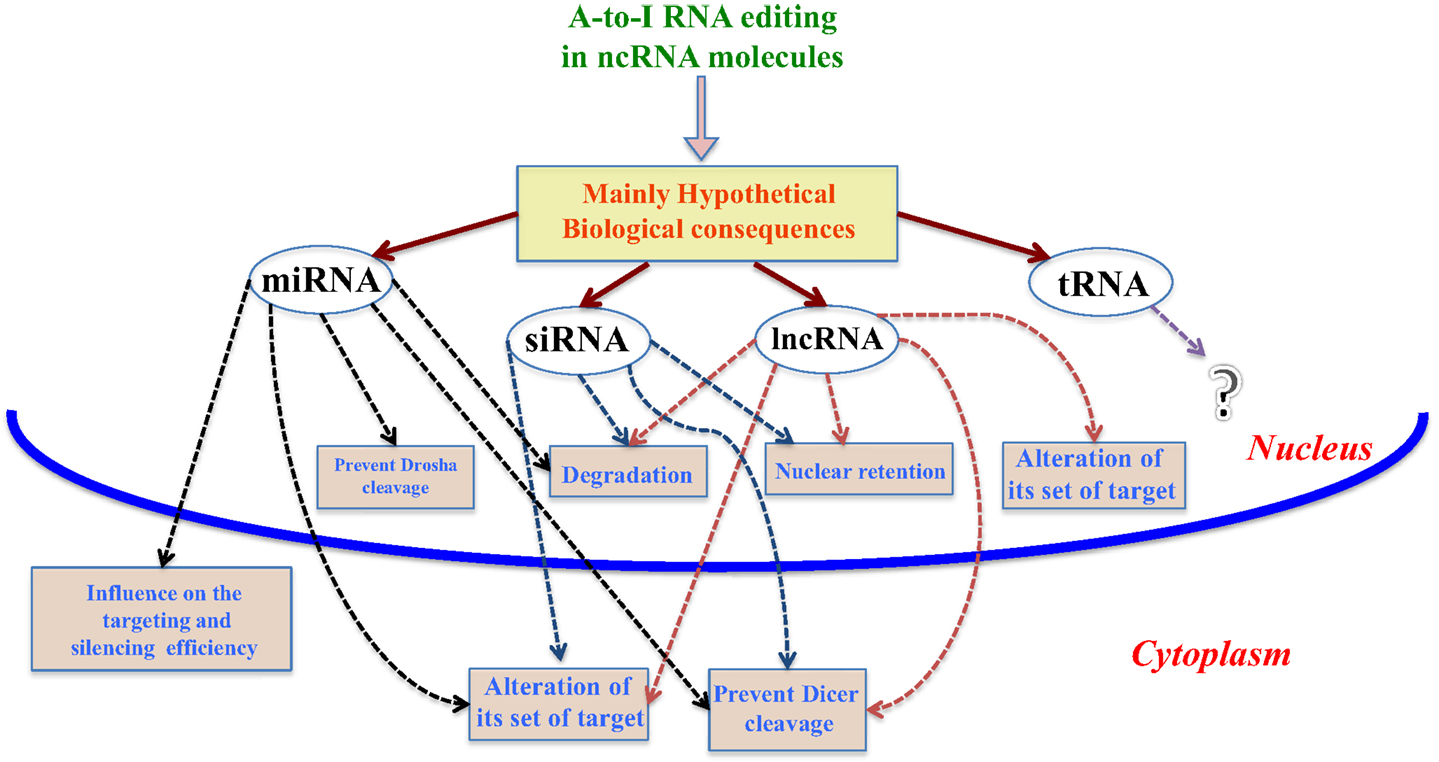
Figure 1. Mainly hypothetical biological consequences. In this figure, we show some of the main biological consequences of A-to-I RNA editing in ncRNA molecules, both in nucleus and cytoplasm.
RNA editing in miRNAs and siRNAs
As seen above, many A-to-I editing sites in miRNAs have been discovered (Luciano et al., 2004; Kawahara et al., 2007; Alon et al., 2012), and these could influence miRNA-mediated gene regulation in several ways (Nishikura, 2010), although in some cases low percentage editing of mature miRNAs could be a low level of genomewide editing noise rather than possessing biological relevance (de Hoon et al., 2010). First, editing sites occurring in pri-miRNAs can suppress cleavage processing by Drosha and/or Dicer due to the presence of inosines, while in addition, highly edited dsRNAs could be rapidly degraded by Tudor-SN (TSN) (Yang et al., 2006). Second, some editing events in pri-miRNAs can produce edited pre-miRNAs, for which different scenarios can occur based on the location of the editing site. In particular, studies have demonstrated that A-to-I editing sites in miRNA seed regions can drastically change their target set (Kawahara et al., 2008; Alon et al., 2012), causing a functional transformation, but also affect the mRNA target selection and silencing processes (Kume et al., 2014).
Small interfereing RNAs, differently from miRNAs, originate from long double-strand RNAs exported to the cytoplasm, where they are cleaved by the Dicer-TRBP complex and successively loaded inside the RISC complex. It has been observed that ADAR1-p150, which acts in the cytoplasm, can bind to siRNAs preventing and thus overall reducing the cleavage process of the Dicer-TRBP complex (Yang et al., 2005; Kawahara et al., 2007).
Lately, a new role for ADAR1-p150 not associated to RNA editing was discovered, in which the enzyme forms an heterodimer complex with Dicer by protein–protein interaction (PPI), increasing the rate of siRNA and miRNA processing and facilitating RISC loading and RNA silencing, instead of an antagonistic role in RNAi by an ADAR1–ADAR1 homodimer complex (Nishikura et al., 2013; Ota et al., 2013).
RNA editing in lncRNAs
Another category of ncRNAs is represented by long non-coding RNAs (lncRNAs). In recent years, HTS analyses have led to the identification of thousands of lncRNAs, many of which have revealed to be transcripts deriving from the antisense strand of protein coding genes. lncRNAs, due to their stable long double-strand regions, often originating from the presence of repetitive elements, such as Alus, can be affected by A-to-I RNA editing (Peng et al., 2012). The biological functions of A-to-I editing occurring in lncRNAs can be several.
Long non-coding RNAs can be retained in the nucleus as a consequence of the editing phenomenon until cleavage of the hyper-edited region takes place and the remaining lncRNA portion is exported to the cytoplasm (Prasanth et al., 2005). Nevertheless, as for miRNAs (Yang et al., 2006), edited lncRNAs could though be degraded through Tudor-SN. Considering the property lncRNAs possess to bind with RNA and DNA (Rinn and Chang, 2012; Mercer and Mattick, 2013), as well as RNA binding proteins (Hellwig and Bass, 2008), cases of editing sites in lncRNAs could clearly change their target set and RNP structures respectively, thus altering their intrinsic biological function (Geisler and Coller, 2013). Finally, a far more rare RNA editing phenomenon compared to the one caused by inverted repeat structures in mRNAs could occur for those transcripts which associate to antisense lncRNAs, providing a double strand RNA structure suitable for ADAR as suggested in (Geisler and Coller, 2013).
RNA editing in tRNAs
Differently from mRNAs and several categories of ncRNA molecules which undergo A-to-I editing primarily by ADARs, A-to-I editing events in mature transfer RNAs (tRNAs) in eukaryotes, can possibly be a result of adenosine deaminases acting on tRNA enzyme family (ADATs) (Su and Randau, 2011). A-to-I editing in these small ncRNAs is conserved in various species and occurs principally at positions 34, 37, and 57 of certain tRNAs (Torres et al., 2014). Despite this phenomenon being ubiquitously present in human tissues, the role of A-to-I tRNA editing remains still unknown.
Conclusion
As seen above, currently Alon’s pipeline is the only HTS-based method to systematically identify A-to-I editing sites in pre- and mature microRNAs. There is a current and urgent necessity for new HTS-based methodologies to emerge in order to not only accurately identify and analyze editing events in other categories of ncRNA molecules, such as tRNAs, lncRNAs, and so on, but also to investigate through functional enrichment analysis, the biological outcomes that a single editing event can generate. Concurrently, it could be interesting to analyze how the editing phenomenon can influence a biological pathway within a temporally changing cellular condition, such as starvation or hypoxia, considering that a single editing site in a ncRNA molecule could drastically modify its function.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This work was supported by Italian Foundation for Cancer Research (NG 15046).
Footnotes
References
Alon, S., and Eisenberg, E. (2013). Identifying RNA editing sites in miRNAs by deep sequencing. Methods Mol. Biol. 1038, 159–170. doi: 10.1007/978-1-62703-514-9_9
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Alon, S., Mor, E., Vigneault, F., Church, G. M., Locatelli, F., Galeano, F., et al. (2012). Systematic identification of edited microRNAs in the human brain. Genome Res. 22, 1533–1540. doi:10.1101/gr.131573.111
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Athanasiadis, A., Rich, A., and Maas, S. (2004). Widespread A-to-I RNA editing of Alu-containing mRNAs in the human transcriptome. PLoS Biol. 2:e391. doi:10.1371/journal.pbio.0020391
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Bahn, J. H., Lee, J.-H., Li, G., Greer, C., Peng, G., and Xiao, X. (2012). Accurate identification of A-to-I RNA editing in human by transcriptome sequencing. Genome Res. 22, 142–150. doi:10.1101/gr.124107.111
Bass, B. L. (1997). RNA editing and hypermutation by adenosine deamination. Trends Biochem. Sci. 22, 157–162. doi:10.1016/S0968-0004(97)01035-9
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Bass, B. L. (2002). RNA editing by adenosine deaminases that act on RNA. Annu. Rev. Biochem. 71, 817–846. doi:10.1146/annurev.biochem.71.110601.135501
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Bazak, L., Haviv, A., Barak, M., Jacob-Hirsch, J., Deng, P., Zhang, R., et al. (2014a). A-to-I RNA editing occurs at over a hundred million genomic sites, located in a majority of human genes. Genome Res. 24, 365–376. doi:10.1101/gr.164749.113
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Bazak, L., Levanon, E. Y., and Eisenberg, E. (2014b). Genome-wide analysis of Alu editability. Nucleic Acids Res. 42, 6876–6884. doi:10.1093/nar/gku414
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Blow, M. J., Grocock, R. J., Van Dongen, S., Enright, A. J., Dicks, E., Futreal, P. A., et al. (2006). RNA editing of human microRNAs. Genome Biol. 7, R27. doi:10.1186/gb-2006-7-4-r27
Boguski, M. S., Lowe, T., and Tolstoshev, C. M. (1993). dbEST – database for “expressed sequence tags.” Nat. Genet. 4, 332–333. doi:10.1038/ng0893-332
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Borchert, G. M., Gilmore, B. L., Spengler, R. M., Xing, Y., Lanier, W., Bhattacharya, D., et al. (2009). Adenosine deamination in human transcripts generates novel microRNA binding sites. Hum. Mol. Genet. 18, 4801–4807. doi:10.1093/hmg/ddp443
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Carmi, S., Borukhov, I., and Levanon, E. Y. (2011). Identification of widespread ultra-edited human RNAs. PLoS Genet. 7:e1002317. doi:10.1371/journal.pgen.1002317
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Cech, T. R., and Steitz, J. A. (2014). The noncoding RNA revolution-trashing old rules to forge new ones. Cell 157, 77–94. doi:10.1016/j.cell.2014.03.008
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Chen, C. X., Cho, D. S., Wang, Q., Lai, F., Carter, K. C., and Nishikura, K. (2000). A third member of the RNA-specific adenosine deaminase gene family, ADAR3, contains both single- and double-stranded RNA binding domains. RNA 6, 755–767. doi:10.1017/S1355838200000170
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
de Hoon, M. J. L., Taft, R. J., Hashimoto, T., Kanamori-Katayama, M., Kawaji, H., Kawano, M., et al. (2010). Cross-mapping and the identification of editing sites in mature microRNAs in high-throughput sequencing libraries. Genome Res. 20, 257–264. doi:10.1101/gr.095273.109
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Distefano, R., Nigita, G., Macca, V., Laganà, A., Giugno, R., Pulvirenti, A., et al. (2013). VIRGO: visualization of A-to-I RNA editing sites in genomic sequences. BMC Bioinformatics 14(Suppl. 7):S5. doi:10.1186/1471-2105-14-S7-S5
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Eggington, J. M., Greene, T., and Bass, B. L. (2011). Predicting sites of ADAR editing in double-stranded RNA. Nat. Commun. 2, 319. doi:10.1038/ncomms1324
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Galeano, F., Tomaselli, S., Locatelli, F., and Gallo, A. (2012). A-to-I RNA editing: the “ADAR” side of human cancer. Semin. Cell Dev. Biol. 23, 244–250. doi:10.1016/j.semcdb.2011.09.003
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Geisler, S., and Coller, J. (2013). RNA in unexpected places: long non-coding RNA functions in diverse cellular contexts. Nat. Rev. Mol. Cell Biol. 14, 699–712. doi:10.1038/nrm3679
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Hellwig, S., and Bass, B. L. (2008). A starvation-induced noncoding RNA modulates expression of dicer-regulated genes. Proc. Natl. Acad. Sci. U.S.A. 105, 12897–12902. doi:10.1073/pnas.0805118105
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Higuchi, M., Maas, S., Single, F. N., Hartner, J., and Rozov, A. (2000). Point mutation in an AMPA receptor gene rescues lethality in mice deficient in the RNA-editing enzyme ADAR2. Nature 406, 78–81. doi:10.1038/35017558
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Hoopengardner, B., Bhalla, T., Staber, C., and Reenan, R. (2003). Nervous system targets of RNA editing identified by comparative genomics. Science 301, 832–836. doi:10.1126/science.1086763
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Jepson, J. E. C., and Reenan, R. A. (2008). RNA editing in regulating gene expression in the brain. Biochim. Biophys. Acta 1779, 459–470. doi:10.1016/j.bbagrm.2007.11.009
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Ju, Y. S., Kim, J.-I., Kim, S., Hong, D., Park, H., Shin, J.-Y., et al. (2011). Extensive genomic and transcriptional diversity identified through massively parallel DNA and RNA sequencing of eighteen Korean individuals. Nat. Genet. 43, 745–752. doi:10.1038/ng.872
Kawahara, Y. (2012). Quantification of adenosine-to-inosine editing of microRNAs using a conventional method. Nat. Protoc. 7, 1426–1437. doi:10.1038/nprot.2012.073
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Kawahara, Y., Ito, K., Sun, H., Aizawa, H., Kanazawa, I., and Kwak, S. (2004). Glutamate receptors: RNA editing and death of motor neurons. Nature 427, 801–801. doi:10.1038/427801a
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Kawahara, Y., Megraw, M., Kreider, E., Iizasa, H., Valente, L., Hatzigeorgiou, A. G., et al. (2008). Frequency and fate of microRNA editing in human brain. Nucleic Acids Res. 36, 5270–5280. doi:10.1093/nar/gkn479
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Kawahara, Y., Zinshteyn, B., Sethupathy, P., Iizasa, H., Hatzigeorgiou, A. G., and Nishikura, K. (2007). Redirection of silencing targets by adenosine-to-inosine editing of miRNAs. Science 315, 1137–1140. doi:10.1126/science.1138050
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Kim, D. D. Y., Kim, T. T. Y., Walsh, T., Kobayashi, Y., Matise, T. C., Buyske, S., et al. (2004). Widespread RNA editing of embedded alu elements in the human transcriptome. Genome Res. 14, 1719–1725. doi:10.1101/gr.2855504
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Kim, U., Wang, Y., Sanford, T., Zeng, Y., and Nishikura, K. (1994). Molecular cloning of cDNA for double-stranded RNA adenosine deaminase, a candidate enzyme for nuclear RNA editing. Proc. Natl. Acad. Sci. U.S.A. 91, 11457–11461. doi:10.1073/pnas.91.24.11457
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Kiran, A., and Baranov, P. V. (2010). DARNED: a database of RNA editing in humans. Bioinformatics 26, 1772–1776. doi:10.1093/bioinformatics/btq285
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Kiran, A. M., O’Mahony, J. J., Sanjeev, K., and Baranov, P. V. (2013). Darned in 2013: inclusion of model organisms and linking with Wikipedia. Nucleic Acids Res. 41, D258–D261. doi:10.1093/nar/gks961
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Kleinman, C. L., and Majewski, J. (2012). Comment on “widespread RNA and DNA sequence differences in the human transcriptome”. Science 335, 1302. doi:10.1126/science.1209658
Kume, H., Hino, K., Galipon, J., and Ui-Tei, K. (2014). A-to-I editing in the miRNA seed region regulates target mRNA selection and silencing efficiency. Nucleic Acids Res. 42, 10050–10060. doi:10.1093/nar/gku662
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Laganà, A., Paone, A., Veneziano, D., Cascione, L., Gasparini, P., Carasi, S., et al. (2012). miR-EdiTar: a database of predicted A-to-I edited miRNA target sites. Bioinformatics 28, 3166–3168. doi:10.1093/bioinformatics/bts589
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Lai, F., Chen, C. X., Carter, K. C., and Nishikura, K. (1997). Editing of glutamate receptor B subunit ion channel RNAs by four alternatively spliced DRADA2 double-stranded RNA adenosine deaminases. Mol. Cell. Biol. 17, 2413–2424.
Lehmann, K. A., and Bass, B. L. (2000). Double-stranded RNA adenosine deaminases ADAR1 and ADAR2 have overlapping specificities. Biochemistry 39, 12875–12884. doi:10.1021/bi001383g
Levanon, E. Y., Eisenberg, E., Yelin, R., Nemzer, S., Hallegger, M., Shemesh, R., et al. (2004). Systematic identification of abundant A-to-I editing sites in the human transcriptome. Nat. Biotechnol. 22, 1001–1005. doi:10.1038/nbt996
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Li, J. B., Levanon, E. Y., Yoon, J.-K., Aach, J., Xie, B., Leproust, E., et al. (2009). Genome-wide identification of human RNA editing sites by parallel DNA capturing and sequencing. Science 324, 1210–1213. doi:10.1126/science.1170995
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Lin, W., Piskol, R., Tan, M. H., and Li, J. B. (2012). Comment on “widespread RNA and DNA sequence differences in the human transcriptome”. Science 335, 1302. doi:10.1126/science.1210624
Luciano, D. J., Mirsky, H., Vendetti, N. J., and Maas, S. (2004). RNA editing of a miRNA precursor. RNA 10, 1174–1177. doi:10.1261/rna.7350304
Maas, S., Patt, S., Schrey, M., and Rich, A. (2001). Underediting of glutamate receptor GluR-B mRNA in malignant gliomas. Proc. Natl. Acad. Sci. U.S.A. 98, 14687–14692. doi:10.1073/pnas.251531398
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Melcher, T., Maas, S., Herb, A., Sprengel, R., Higuchi, M., and Seeburg, P. H. (1996). RED2, a brain-specific member of the RNA-specific adenosine deaminase family. J. Biol. Chem. 271, 31795–31798. doi:10.1074/jbc.271.50.31795
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Mercer, T. R., and Mattick, J. S. (2013). Structure and function of long noncoding RNAs in epigenetic regulation. Nat. Struct. Mol. Biol. 20, 300–307. doi:10.1038/nsmb.2480
Mitra, S. A., Mitra, A. P., and Triche, T. J. (2012). A central role for long non-coding RNA in cancer. Front. Genet. 3:17. doi:10.3389/fgene.2012.00017
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Morse, D. P., and Bass, B. L. (1999). Long RNA hairpins that contain inosine are present in Caenorhabditis elegans poly(A)+ RNA. Proc. Natl. Acad. Sci. U.S.A. 96, 6048–6053. doi:10.1073/pnas.96.11.6048
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Nishikura, K. (2006). Editor meets silencer: crosstalk between RNA editing and RNA interference. Nat. Rev. Mol. Cell Biol. 7, 919–931. doi:10.1038/nrm2061
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Nishikura, K. (2010). Functions and regulation of RNA editing by ADAR deaminases. Annu. Rev. Biochem. 79, 321–349. doi:10.1146/annurev-biochem-060208-105251
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Nishikura, K., Sakurai, M., Ariyoshi, K., and Ota, H. (2013). Antagonistic and stimulative roles of ADAR1 in RNA silencing. RNA Biol. 10, 1240–1247. doi:10.4161/rna.25947
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Ota, H., Sakurai, M., Gupta, R., Valente, L., Wulff, B.-E. E., Ariyoshi, K., et al. (2013). ADAR1 forms a complex with Dicer to promote microRNA processing and RNA-induced gene silencing. Cell 153, 575–589. doi:10.1016/j.cell.2013.03.024
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Park, E., Williams, B., Wold, B. J., and Mortazavi, A. (2012). RNA editing in the human ENCODE RNA-seq data. Genome Res. 22, 1626–1633. doi:10.1101/gr.134957.111
Peng, Z., Cheng, Y., Tan, B. C.-M., Kang, L., Tian, Z., Zhu, Y., et al. (2012). Comprehensive analysis of RNA-Seq data reveals extensive RNA editing in a human transcriptome. Nat. Biotechnol. 30, 253–260. doi:10.1038/nbt.2122
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Picardi, E., D’Antonio, M., Carrabino, D., Castrignanò, T., and Pesole, G. (2011). ExpEdit: a webserver to explore human RNA editing in RNA-Seq experiments. Bioinformatics 27, 1311–1312. doi:10.1093/bioinformatics/btr117
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Picardi, E., D’Erchia, A. M., Gallo, A., Montalvo, A., and Pesole, G. (2014). Uncovering RNA editing sites in long non-coding RNAs. Front. Bioeng. Biotechnol. 2:64. doi:10.3389/fbioe.2014.00064
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Picardi, E., Gallo, A., Galeano, F., Tomaselli, S., and Pesole, G. (2012). A novel computational strategy to identify A-to-I RNA editing sites by RNA-Seq data: de novo detection in human spinal cord tissue. PLoS ONE 7:e44184. doi:10.1371/journal.pone.0044184
Picardi, E., and Pesole, G. (2013). REDItools: high-throughput RNA editing detection made easy. Bioinformatics 29, 1813–1814. doi:10.1093/bioinformatics/btt287
Pickrell, J. K., Gilad, Y., and Pritchard, J. K. (2012). Comment on “Widespread RNA and DNA sequence differences in the human transcriptome”. Science 335, 1302. doi:10.1126/science.1210484
Polson, A. G., and Bass, B. L. (1994). Preferential selection of adenosines for modification by double-stranded RNA adenosine deaminase. EMBO J. 13, 5701–5711.
Porath, H. T., Carmi, S., and Levanon, E. Y. (2014). A genome-wide map of hyper-edited RNA reveals numerous new sites. Nat. Commun. 5:4726. doi:10.1038/ncomms5726
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Prasanth, K. V., Prasanth, S. G., Xuan, Z., Hearn, S., Freier, S. M., Bennett, C. F., et al. (2005). Regulating gene expression through RNA nuclear retention. Cell 123, 249–263. doi:10.1016/j.cell.2005.08.033
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Ramaswami, G., and Li, J. B. (2014). RADAR: a rigorously annotated database of A-to-I RNA editing. Nucleic Acids Res. 42, D109–D113. doi:10.1093/nar/gkt996
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Ramaswami, G., Zhang, R., Piskol, R., Keegan, L. P., Deng, P., O’Connell, M. A. A., et al. (2013). Identifying RNA editing sites using RNA sequencing data alone. Nat. Methods 10, 128–132. doi:10.1038/nmeth.2330
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Rinn, J. L., and Chang, H. Y. (2012). Genome regulation by long noncoding RNAs. Annu. Rev. Biochem. 81, 145–166. doi:10.1146/annurev-biochem-051410-092902
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Rueter, S. M., Dawson, T. R., and Emeson, R. B. (1999). Regulation of alternative splicing by RNA editing. Nature 399, 75–80. doi:10.1038/19992
Sakurai, M., Ueda, H., Yano, T., Okada, S., Terajima, H., Mitsuyama, T., et al. (2014). A biochemical landscape of A-to-I RNA editing in the human brain transcriptome. Genome Res. 24, 522–534. doi:10.1101/gr.162537.113
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Sakurai, M., Yano, T., Kawabata, H., Ueda, H., and Suzuki, T. (2010). Inosine cyanoethylation identifies A-to-I RNA editing sites in the human transcriptome. Nat. Chem. Biol. 6, 733–740. doi:10.1038/nchembio.434
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Solomon, O., Bazak, L., Levanon, E. Y., Amariglio, N., Unger, R., Rechavi, G., et al. (2014). Characterizing of functional human coding RNA editing from evolutionary, structural, and dynamic perspectives. Proteins 82, 3117–3131. doi:10.1002/prot.24672
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Su, A. A. H., and Randau, L. (2011). A-to-I and C-to-U editing within transfer RNAs. Biochemistry (Mosc) 76, 932–937. doi:10.1134/S0006297911080098
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Tomaselli, S., Locatelli, F., and Gallo, A. (2014). The RNA editing enzymes ADARs: mechanism of action and human disease. Cell Tissue Res. 356, 527–532. doi:10.1007/s00441-014-1863-3
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Torres, A. G., Piñeyro, D., Filonava, L., Stracker, T. H., Batlle, E., and Ribas de Pouplana, L. (2014). A-to-I editing on tRNAs: biochemical, biological and evolutionary implications. FEBS Lett. 588, 4279–4286. doi:10.1016/j.febslet.2014.09.025
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Wahlstedt, H., Luciano, D. J., Enstero, M., and Ohman, M. (2009). Large-scale mRNA sequencing determines global regulation of RNA editing during brain development. Genome Res. 19, 978–986. doi:10.1101/gr.089409.108
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Wahlstedt, H., and Ohman, M. (2011). Site-selective versus promiscuous A-to-I editing. Wiley Interdiscip. Rev. RNA 2, 761–771. doi:10.1002/wrna.89
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Wang, Q., Khillan, J., Gadue, P., and Nishikura, K. (2000). Requirement of the RNA editing deaminase ADAR1 gene for embryonic erythropoiesis. Science 290, 1765–1768. doi:10.1126/science.290.5497.1765
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Wu, D., Lamm, A. T., and Fire, A. Z. (2011). Competition between ADAR and RNAi pathways for an extensive class of RNA targets. Nat. Struct. Mol. Biol. 18, 1094–1101. doi:10.1038/nsmb.2129
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Yang, W., Chendrimada, T. P., Wang, Q., Higuchi, M., Seeburg, P. H., Shiekhattar, R., et al. (2006). Modulation of microRNA processing and expression through RNA editing by ADAR deaminases. Nat. Struct. Mol. Biol. 13, 13–21. doi:10.1038/nsmb1041
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Yang, W., Wang, Q., Howell, K. L., Lee, J. T., Cho, D.-S. C., Murray, J. M., et al. (2005). ADAR1 RNA deaminase limits short interfering RNA efficacy in mammalian cells. J. Biol. Chem. 280, 3946–3953. doi:10.1074/jbc.M407876200
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Zhu, S., Xiang, J.-F., Chen, T., Chen, L.-L., and Yang, L. (2013). Prediction of constitutive A-to-I editing sites from human transcriptomes in the absence of genomic sequences. BMC Genomics 14:206. doi:10.1186/1471-2164-14-206
Pubmed Abstract | Pubmed Full Text | CrossRef Full Text | Google Scholar
Keywords: A-to-I RNA editing, ncRNA, microRNA, RNA-seq, ADARs, HTS
Citation: Nigita G, Veneziano D and Ferro A (2015) A-to-I RNA editing: current knowledge sources and computational approaches with special emphasis on non-coding RNA molecules. Front. Bioeng. Biotechnol. 3:37. doi: 10.3389/fbioe.2015.00037
Received: 31 October 2014; Accepted: 09 March 2015;
Published online: 25 March 2015.
Edited by:
Christian M. Zmasek, Sanford-Burnham Medical Research Institute, USAReviewed by:
Subrata H. Mishra, Johns Hopkins University School of Medicine, USAYingqun Huang, Yale University School of Medicine, USA
Copyright: © 2015 Nigita, Veneziano and Ferro. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Giovanni Nigita, Department of Molecular Virology, Immunology and Medical Genetics, Ohio State University, 460 W 12th Avenue, Columbus, OH 43210, USA e-mail:Z2lhbm5pLm5pZ2l0YUBnbWFpbC5jb20=