 Ricardo Jorquera1
Ricardo Jorquera1 Guillermo Droppelmann2*Max Dollmann1Gonzalo Blanco1Ignacio Ahumada1
Guillermo Droppelmann2*Max Dollmann1Gonzalo Blanco1Ignacio Ahumada1 Alfonso Lira3
Alfonso Lira3 Felipe Feijoo3*
Felipe Feijoo3*- 1Workmed, Santiago, Chile
- 2Blackmind-AI, Santiago, Chile
- 3School of Industrial Engineering, Pontificia Universidad Católica de Valparaíso, Valparaíso, Chile
Background: Cardiovascular disease (CVD) is the leading cause of death worldwide. Although tools exist to assess individual cardiovascular risk (CVR), they often fall short in unique populations such as miners, who work under extreme conditions. To address these limitations, this study proposes the use of machine learning (ML) and longitudinal data to predict risk progression using accessible clinical markers. Body mass index (BMI) and blood glucose (BG) were chosen as key CVR proxies because they are affordable, measured routinely in occupational health checks, and responsive to metabolic stresses common in mining environments.
Methods: We conducted a retrospective longitudinal analysis of 89,045 Chilean mining workers (420,966 preemployment exams; 2021–2024). For each worker, we formed successive visit pairs to model transitions between clinically defined BMI and BG categories. Four binary outcomes based on the scenario per biomarker were specified (any upward transition; adjacent upward transition; obesity–morbid obesity/prediabetes–diabetes; any transition ending in morbid obesity/diabetes). Machine learning techniques were built to assess transitions for each scenario and biomarker. We applied a stratified 70/30 train–test split, repeated 7-fold cross-validation within training, random hyperparameter search (AUC objective), and downsampling of the majority classes within folds to address the imbalance. Performance in the original (imbalanced) test set was summarized by AUC, accuracy, sensitivity, and specificity with 95% CIs of the cross-validation process. The correlation between models was assessed using Pearson's correlations of predicted probabilities.
Results: Predicting BMI transitions (N = 18,035 pairs) was highly accurate between models. The best performance occurred for severe progression (Scenario 4, defined as any transition ending in morbid obesity): where XGB achieved AUC 0.95 and accuracy 0.91, with high sensitivity and strong specificity. For broader BMI transitions across scenarios 1–3, models remained reliable AUC 0.84–0.87. BG transitions (N = 16,161 pairs) were harder but still actionable. The strongest results were for progression to diabetes (Scenario 4), with RF reaching AUC 0.83 (95% CI: 0.82–0.90) and accuracy 0.76; other BG scenarios yielded AUC 0.71–0.77. Cross-validation closely matched test performance. Pairwise probability correlations were typically >0.90 for BMI and >0.80 for BG in severe scenarios, indicating good generalization and no evidence of overfitting.
Conclusion: ML models effectively predict clinically relevant BMI and BG risk transitions in the extraction of occupational health data. The use of longitudinal visit pairs and scenario-based evaluation improves the capacity of the models to achieve high AUC values and maintain accuracy and sensitivity, while ensuring generalization and consistency. These findings highlight the potential of this approach to improve the assessment of CVR and support preventive decision-making in high-risk working populations.
1 Introduction
Cardiovascular diseases (CVD) are responsible for more than 20.5 million deaths per year, accounting for more than a third of global mortality, currently representing the greatest mortality threat facing humanity (1). The impact is so significant that, in a single year, it exceeds all deaths recorded during the COVID-19 pandemic (2). CVD often begins silently and asymptomatically. However, it can rapidly progress to severe clinical manifestations such as ischemic heart disease, stroke, heart failure, and arrhythmias, leading to a substantial burden of morbidity and mortality. This underscores the critical need to implement effective early detection strategies (3, 4).
Current evidence suggests that an essential component of CVD prevention is the early identification of high-risk individuals, allowing timely interventions and reducing both the disease burden and its socioeconomic impact (5). Individual cardiovascular risk (CVR), reflects the probability of experiencing a major cardiovascular event over a given period of time, usually 5 or 10 years (6). This risk is determined by multiple factors, including body mass index (BMI) and blood glucose (BG), two widely available and routinely used clinical indicators, whose association with cardiovascular events is well established in the literature (7–9). Indeed, a BMI ≥ 35 is associated with a 43% increase in CVD risk in men and a 32% increase in women. Similarly, hyperglycemia in people with diabetes increases this risk by 75% in men and 87% in women, which contributes in particular to heart failure (10). Given the limitations in many occupational settings, there is a growing interest in simplifying CVR assessment by using routine low-cost biomarkers such as BMI and BG, especially in environments where traditional tools are impractical due to cost, logistics or lack of comprehensive clinical data (11, 12). Given their strong independent associations with cardiovascular events, BMI and BG are particularly well suited for longitudinal monitoring in occupational health programs (13). In fact, the Pan American Health Organization (PAHO) includes both BMI and BG as key elements for CVR evaluation and prevention strategies, particularly in resource-limited settings, as outlined in their guidelines for cardiovascular risk stratification (14).
The distribution, significance and evolution of these markers can differ significantly in populations exposed to demanding work conditions. In the mining population, this association was reported more than 30 years ago (15, 16). This group of workers is of particular interest in public and occupational health due to their prolonged exposure to harsh environments characterized by high physical workloads, long shifts, thermal stress, and, frequently, hypoxia from high-altitude work (17). These metabolic stress conditions contribute to an unfavorable CVR profile compared to the general population. This is strongly associated with high rates of hypertension, abdominal obesity, metabolic disorders, and sleep disturbances (18–20).
In Chile, mining is one of the main economic drivers of the country, employing more than 800,000 people in operations mainly located at high altitude in the northern and central regions (21, 22). Studies in the Chilean mining population have reported significant rates of metabolic syndrome and CVR, far exceeding those observed in the general population, reinforcing the need for targeted surveillance and predictive tools adapted to the occupational and individual context of these workers (17, 23). Despite this, there are several tools for CVR stratification, such as the Framingham equations and other scales proposed by the WHO or PREVENT, developed by the American Heart Association (10, 24, 25). The predictive power of these CVR models is well-established for estimating the 10-year risk of CVD events, with values of the area under the receiver operating characteristic curve (AUC-ROC) typically ranging from 0.70 to 0.82, depending on the model and population (26–28), although their predictive performance often varies depending on regional calibration and population-specific characteristics. The Framingham Risk Score, developed from a United States cohort, achieves AUC-ROC values of 0.75–0.78 for the prediction of coronary heart disease (26), while the SCORE model, designed for European populations, reports AUC-ROC values of 0.70–0.75, with performance varying by regional calibration (27). The PREVENT model, introduced by the American Heart Association, incorporates additional risk factors such as kidney function and social determinants, demonstrating an AUC-ROC of 0.82 for atherosclerotic CVD events, surpassing the 0.76 of the Pooled Cohort Equations in recent validations (10). However, these models may exhibit reduced capacity when applied to diverse populations due to variations in the prevalence of risk factors and event rates, often requiring recalibration to avoid over or underestimation of risk (29, 30). In addition, most risk scores do not incorporate the longitudinal evolution of clinical indicators such as BMI and BG, which are particularly relevant in occupational surveillance programs where periodic measurements are available. This underscores the need for population-specific validation to ensure robust risk stratification, particularly in unique settings like occupational health. In fact, these tools are widely used and were developed based on cohorts of the general population, with a limited representation of workers exposed to extreme conditions. This limits their external validity, reduces clinical applicability, and compromises their relevance in occupational health contexts. Furthermore, a systematic review of the Framingham rule reported that, among 40 studies that validated it in external populations, 67.5% found poor performance. However, the model was neither reconfigured nor updated in these cases (31).
For these reasons, there is an urgent need to develop alternative methods that optimize CVR assessment in mining workers, using easily available clinical indicators adapted to the unique characteristics of this population. In this study, rather than estimating CVR scores per se, we focus on predicting clinically relevant transitions in the BMI and BG categories over time as proxies of increasing CVR (11, 12). This transition-based approach has practical advantages: it facilitates interpretation by occupational physicians, enables early preventive actions, and aligns closely with regulatory thresholds used in worker health evaluations. This approach leverages routinely available and low-cost data while capturing meaningful changes in the risk profile of workers exposed to extreme occupational stressors (32). BMI and BG were selected as target variables because they are easy to obtain, inexpensive and are routinely measured in occupational health assessments. Both have been consistently associated with an increase in CVR and are sensitive to typical metabolic and environmental stressors of mining work, making them practical proxies to identify high-risk scenarios in this population (33).
In this context, machine learning (ML) has emerged as a promising tool to predict clinical events and improve diagnostic processes. ML models can identify complex patterns and nonlinear relationships between variables, often undetectable by traditional statistical methods (34). This ability is particularly relevant when analyzing large volumes of longitudinal data, such as those generated in periodic occupational health assessments, where subtle changes in indicators such as BMI and glucose over time may provide critical information to anticipate the progression of CVR (35). Additionally, ML models offer the potential to improve the consistency and reproducibility of evaluations, mitigating the intra- and inter-observer variability inherent to current methods and facilitating the implementation of personalized preventive strategies. In addition, ML models offer greater adaptability to local data structures and can be updated more efficiently than traditional models, improving long-term utility in occupational health systems.
Recent studies have demonstrated the usefulness of ML in the cardiovascular field (36, 37). For example, models based on regularized logistic regression (LR) and random forests (RF) have been used to predict the occurrence of acute coronary syndrome and cerebrovascular events with encouraging results (38–40). More recently, algorithms such as Extreme Gradient Boosting (XGB) have shown superior performance in multiple clinical classification tasks, due to their ability to handle heterogeneous data, robustness to outliers, and computational efficiency (41). Combining these algorithms with widely available low-cost clinical data, such as BMI and glucose, represents an attractive alternative to implement predictive models applicable in occupational settings such as mining.
However, applying ML models to the prediction of CVR still presents important challenges. Among them are the poor adaptation of existing models to populations exposed to extreme working conditions and the limited consideration of the longitudinal evolution of risk factors over time (42). In addition, most previous studies have focused on cohorts of the general population or hospital settings, limiting the generalizability of their results to the reality of mining workers (43). Added to this is the lack of consensus on the best way to operationalize clinically relevant transitions in indicators such as BMI and glucose, key elements for adequate risk stratification in occupational health.
For this reason, improving diagnostic accuracy and interpretative consistency in CVR assessment among mining workers has not only clinical implications, but also economic and social ones, both for workers and for the country. Implementing robust predictive models adapted to the specific needs of this population can optimize available health resources, reduce costs associated with work disability due to cardiovascular events, and ultimately improve quality of life and anticipate mortality among workers. The availability of longitudinal data from occupational health surveillance programs provides a unique opportunity to develop predictive models that integrate the temporal dynamics of risk, enabling more timely and effective preventive interventions (44).
To address these gaps, this study proposes a methodological framework based on ML and longitudinal data to predict clinically relevant transitions in the BMI and BG categories as proxies of increased CVR among high-altitude mining workers. Unlike previous studies that apply ML models to static risk estimation, our work uniquely focuses on predicting longitudinal transitions in risk categories using successive health evaluations. This allows for a more dynamic and proactive approach to risk surveillance. Furthermore, this study is the first to apply this strategy specifically to preemployment occupational surveillance, offering novel information on early metabolic risk changes even before job exposure begins.
This approach aligns with modern occupational health strategies that seek scalable, data-driven solutions to improve the early detection of CVR. The CVR is defined as transitions between the BMI and BG categories detectable on simple and periodic occupational examinations, thus reducing costs and complexity. The framework implements and compares three widely used artificial intelligence algorithms, LR, RF, and XGB, applied to an extensive longitudinal occupational health database. This approach aims to demonstrate that ML models can offer accurate, consistent, and customized predictions for high-risk occupational populations. We hypothesize that ML algorithms, trained in longitudinal occupational health records, can detect early transitions in the BMI and BG categories that signal a rise in CVR, thus supporting timely preventive interventions in high-risk mining workers. This hypothesis stems from the premise that traditional risk scores may not adequately capture dynamic physiological changes in workers facing extreme environments.
In summary, this study:
1. Demonstrates that ML models can accurately predict clinically significant changes in BMI and BG among mining workers using longitudinal occupational health records;
2. Compares the predictive performance of three ML algorithms (LR, RF, and XGB) to identify the most accurate and applicable approach to CVR stratification in this context;
3. Proposes a practical and scalable tool aligned with the Chilean occupational health system to improve early risk detection and preventive care in high-risk populations.
2 Materials and methods
2.1 Study design and data extraction
A retrospective observational study with an exploratory scope was conducted. The study followed the Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) recommendations (45). All pre-employment examinations of mining workers conducted by a private healthcare provider operating in different regions of the country were included. The sample included the entire population of available records within the study window of 36 months (from the second half of 2021 to the first half of 2024). No probabilistic sampling was performed, and exclusions were only applied to individuals with a single examination, and with missing values or outliers in the variables of interest.
2.2 Dataset characteristics
A total of 420,966 pre-employment examination records corresponding to 89,045 unique workers were accessed. This means that each worker often underwent more than one pre-employment examination during the study period and therefore multiple records were available per individual. These repeated evaluations allowed us to construct longitudinal pairs of visits, which were the basis for modeling transitions in the BMI and BG categories over time. In this context, the term “pair” specifically refers to two consecutive examinations by the same worker (for example, exam 1–exam 2, exam 2–exam 3), rather than only the first and last record. Each record was associated with a unique identifier and the date of the examination, allowing information to be grouped by individual and time point. The exam dates for each worker were then chronologically ordered to construct successive pairs of examinations with the aim of modeling individual clinical changes over time.
2.3 Data preparation
Data cleaning and preparation were performed to ensure consistency and analytical quality. Examination record without a follow up were excluded. To ensure comparability of features and facilitate model training, all continuous variables were standardized to follow a standard normal distribution. Any pair of records with missing values (NA) in any of the clinical variables of interest was excluded from further analysis. Although certain ensemble methods, such as Gradient Boosting and Random Forest, are capable of handling missing data internally, we deliberately opt for a complete case strategy. This decision was made to ensure a fair comparison across all model families, including logistic regression, which does not natively accommodate missing values. By applying a uniform approach, we avoided introducing differential sources of bias between architectures. It should be noted that the final sample size of the data set for BMI and BG differ due to data quality and filtering procedures (missing values, outliers, others) applied to each clinical indicator. To ensure fair modeling and avoid data leakage, predictor variables measured at the second visit of each pair were excluded because they could reflect the outcome itself. The only exception was the variable time between tests, which was retained because of its relevance in predicting clinical changes. Figure 1 provides an overview of the data selection process. It is important to note that the construction of longitudinal pairs inherently reduces the number of observations, since for each worker with N examination dates, only N−1 successive pairs can be formed. This reduction accounts for the transition in Figure 1 from 57,723 records to 34,684 pairs of successive records.
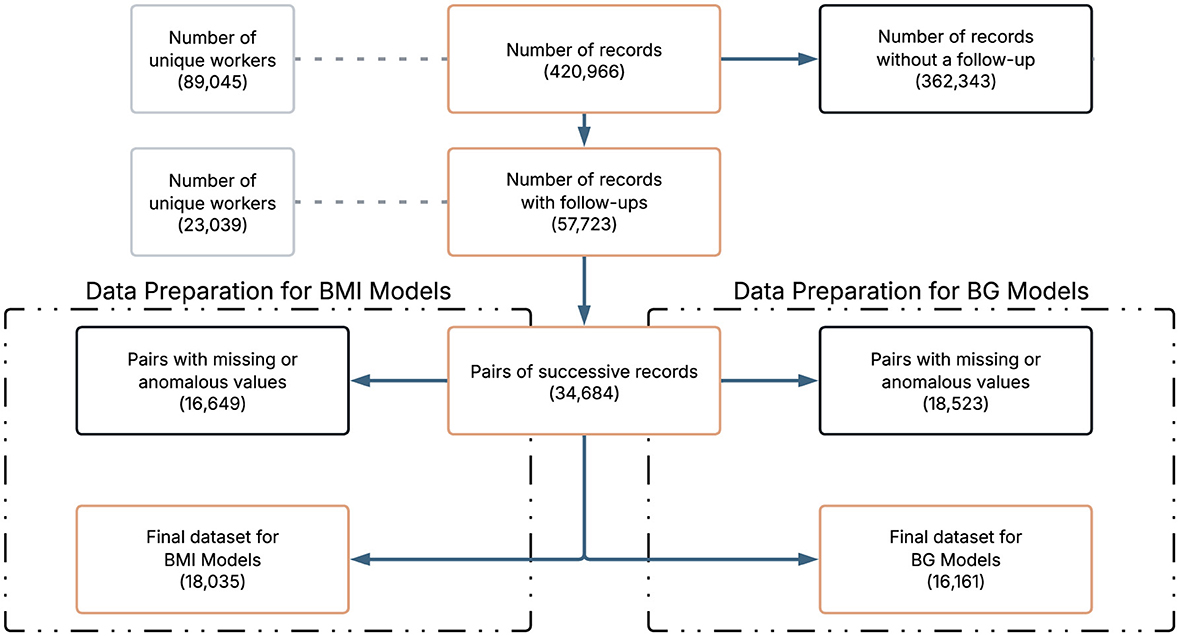
Figure 1. Flowchart for data selection.
2.4 Variables definitions and scenarios
To facilitate clinical interpretation, simplify classification, and align the predictive model with real-world occupational health decision making, the BMI and BG categories were defined based on clinically established thresholds from pre-employment examinations. These categories reflect the levels of health risk considered when assessing a worker's fitness for specific occupational tasks. See Tables 1, 2.
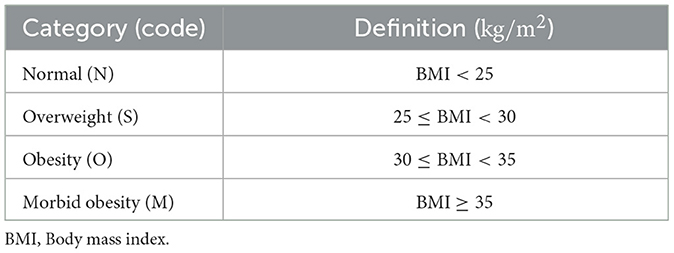
Table 1. BMI category definitions.

Table 2. BG category definitions.
Given the importance of early detection of health deterioration among workers, the scenarios analyzed were defined as transitions in the BMI and BG categories between two successive medical visits per worker. These scenarios were specifically designed to identify clinically relevant increases in risk, such as progression to obesity or diabetes, that could affect occupational fitness according to preemployment health standards.
For BMI, the following scenarios were defined: Scenario 1: A transition from a lower category to a higher category of BMI, such as normal to overweight or overweight to obesity, is labeled positive; otherwise, it is labeled negative (Figure 2A). Scenario 2: A transition to an adjacent higher category of BMI, such as normal to overweight but not normal to obesity, is labeled positive; otherwise, it is labeled negative (Figure 2B). Scenario 3: The transition from the obesity category to the morbid obesity category is labeled as positive; otherwise, it is labeled as negative (Figure 2C). Scenario 4: A transition that ends in the morbid obesity category, regardless of the starting category, is labeled as positive; otherwise, it is labeled as negative (Figure 2D).

Figure 2. BMI scenarios of category transitions. (A) Scenario 1: Any transition to a higher BMI category is labeled positive. (B) Scenario 2: Transition to an adjacent higher BMI category is labeled positive. (C) Scenario 3: Transition from obesity to morbid obesity is labeled positive. (D) Scenario 4: Any transition ending in morbid obesity, regardless of the starting category, is labeled positive. All other cases are labeled negative.
Scenario 1: A transition from a lower to a higher category of BG, such as from normal to prediabetic or from prediabetic to diabetic, is labeled as positive; otherwise, it is labeled as negative (Figure 3A). Scenario 2: A transition to a higher adjacent category of BG, such as normal to prediabetic, is labeled positive; otherwise, it is labeled negative (Figure 3B). Scenario 3: The transition from the prediabetic category to the diabetic category is labeled as positive; otherwise it is labeled as negative (Figure 3C). Scenario 4: A transition that ends in the diabetic category, regardless of the initial category, is labeled as positive; otherwise, it is labeled as negative (Figure 3D).

Figure 3. BG scenarios of category transitions. (A) Any transition to a higher BG category is labeled positive. (B) Transition to an adjacent higher BG category is labeled positive. (C) Transition from prediabetic to diabetic is labeled positive. (D) Any transition ending in the diabetic category, regardless of the starting category, is labeled positive. All other cases are labeled negative.
The case distribution is reported in Table 3 for all scenarios.
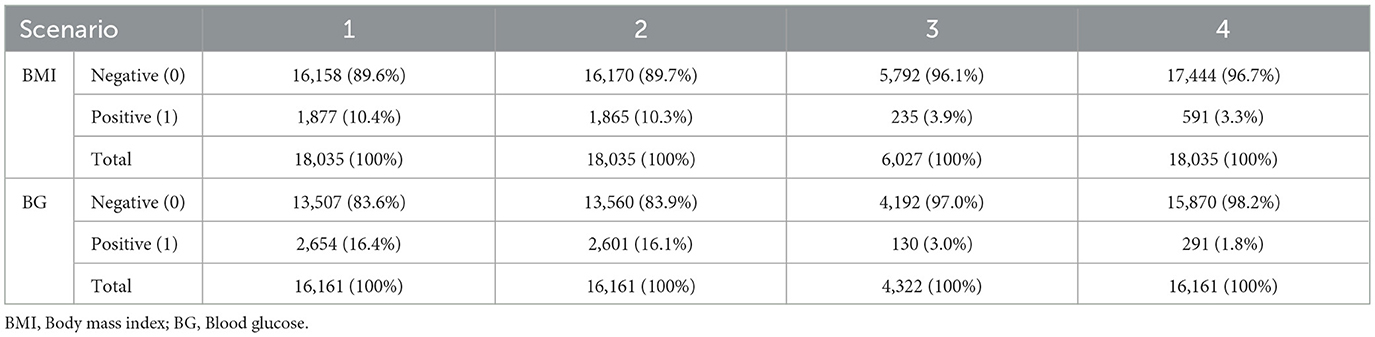
Table 3. Event distribution across scenarios for BMI and BG.
2.5 Model development and feature selection
To predict each of the defined scenarios, three ML models were implemented: LR, RF, and XGB, as justified below.
Logistic regression: The LR was used as a reference model due to its simplicity, interpretability, and widespread validation to predict clinical risk transitions. This parametric method assumes a linear relationship in the logarithmic odds between predictors and outcome probability, which is suitable for modeling the binary transitions targeted in this study, such as a shift to a higher-risk category in BMI or BG between successive visits. This approach enables direct quantification of how each predictor contributes to the probability of health deterioration, facilitating interpretation in a clinical and occupational context. Moreover, its well-established statistical properties make it a useful benchmark against more complex models (46, 47).
Random forest: The RF algorithm was selected as a robust nonparametric ensemble method capable of capturing complex, nonlinear interactions between predictors, which are expected when modeling BMI and BG category transitions in a heterogeneous occupational population. This approach identifies complex patterns in risk determinants without imposing strong assumptions on the functional form of variable relationships. In addition, its internal variable importance measure helps identify key factors associated with progression to higher clinical risk levels, helping to interpret and select characteristics in occupational settings. Although alternative models like SVM and deep learning were considered, they were excluded due to interpretability constraints and computational demands in large-scale, real-world applications. The method builds a set of decision trees, each trained on random samples of the dataset, and combines their predictions to minimize overall error (48).
Extreme gradient boosting: The XGB algorithm was included because of its ability to effectively model subtle and complex patterns in structured data, such as BMI and BG category transitions over time. This boosting method iteratively corrects previous prediction errors to optimize predictive accuracy, which is particularly useful for detecting gradual, but clinically significant changes that might go unnoticed with linear models. In general, XGB trains sequences of decision trees by minimizing a regularized loss function, enabling high accuracy without overfitting. Its efficient handling of missing and heterogeneous data, together with its competitive performance in clinical prediction tasks, makes it a suitable tool for modeling the individual dynamics of occupational health risk (49).
All variables considered in the initial step are presented in Table 4. The RF was used to rank the variables according to the importance of the characteristics and the most informative predictors were retained for each scenario. Confounders were systematically included in all models to ensure proper adjustment. Collinearity was evaluated at baseline, but was not used as an exclusion criterion, since tree-based algorithms, such as RF, are largely immune to biases caused by collinearity, as supported by previous research (50).
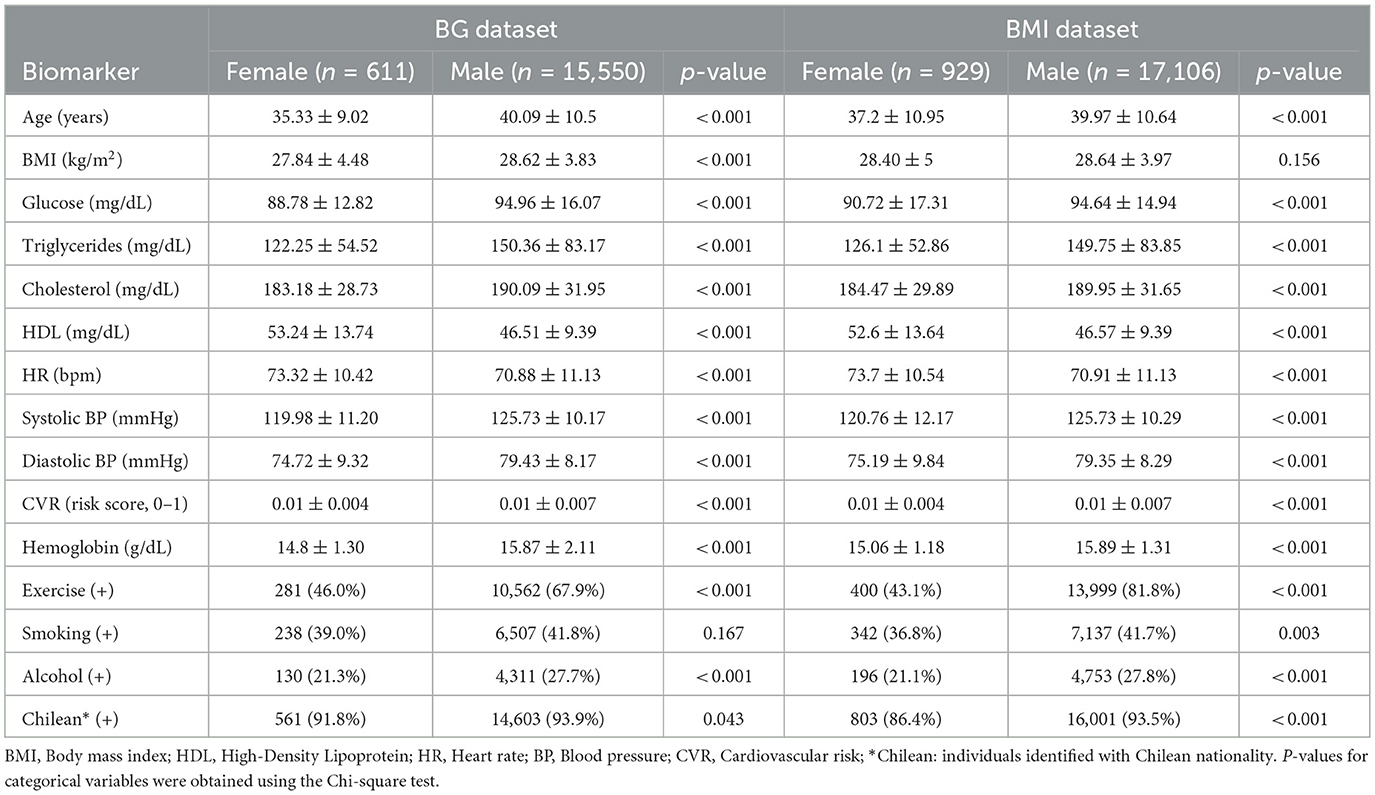
Table 4. Sex-based differences in sociodemographic and cardiovascular risk indicators.
2.6 Training procedure and hyperparameter tuning
To detect category transitions in BMI and BG levels, the data set was preprocessed to identify longitudinal changes that crossed clinically defined thresholds. Transition events were encoded as binary outcomes, enabling the use of classification algorithms to predict their occurrence. Special attention was paid to ensuring the temporal consistency of the input variables, aligning baseline and follow-up measurements for each individual. A K-fold repeated cross-validation was implemented to assess model robustness while preserving the longitudinal nature of the data. During cross-validation, feature scaling and encoding were performed within each fold to prevent data leakage. The hyperparameters of the RF and XGB models were optimized using a random grid search strategy, with the objective of maximizing the area under the receiver operating characteristic curve (AUC) while controlling for overfitting. The data set was divided into training subsets (70%) and testing subsets (30%), maintaining the distribution of transition events to reflect the original prevalence, and 95% confidence intervals were estimated for each performance metric. This pipeline enabled models to learn relevant patterns associated with changes in BMI and BG categories, improving predictive accuracy and generalizability (51).
RF relies on bootstrap aggregation, which generates multiple bootstrap samples of the dataset with replacement to train each decision tree. In contrast, the downsampling procedure used to correct the class imbalance during training was performed without replacement, ensuring that the majority class was reduced in a controlled and unbiased manner within each training fold. To address the class imbalance observed in the outcome distribution, several resampling strategies were evaluated, including oversampling, downsampling, and hybrid approaches. The downsampling technique was selected, as the minority class represented only 1.8%–16.4% (depending on the biomarker and scenario) of the observations and, hence, oversampling frequently resulted in severe overfitting. The procedure consisted of random sampling from the majority class within each training fold to match the minority distribution, combined with repeated K-fold cross-validation (K = 7 was used) to ensure robustness and mitigate variability introduced by the sampling process. To further guarantee consistency, we compared results across models using Pearson correlation coefficient. To classify predicted probabilities into binary outcomes, we applied the conventional 0.5 threshold. It is important to note that while the training process was balanced, the final model evaluation, including sensitivity, specificity, and related performance metrics, was conducted on the original imbalanced test set, which preserves the real prevalence of outcomes.
2.7 Model evaluation and statistical analysis
Descriptive statistics summarized the overall results of the pre-employment examinations, reporting categorical variables as frequencies and percentages, and quantitative variables as means and standard deviations. Data normality was assessed using the Shapiro-Wilk test. Categorical variables were compared using the Chi-square test, while quantitative variables were compared using Student's t test or the Mann–Whitney U test, depending on data distribution. Pearson correlation coefficient was used to compare the correlation among the outcomes of the different proposed models. Confusion matrices were calculated to derive true positives (TP), false positives (FP), false negatives (FN), and true negatives (TN), reflecting the ability of binary classifiers to correctly identify individuals transitioning to higher-risk BMI or BG categories. The primary evaluation metric was the area under the receiver operating characteristic curve (AUC-ROC), complemented by accuracy, sensitivity, and specificity to provide a comprehensive assessment of model performance.
The analysis provided a reliable estimate of the ability of the models to anticipate category transitions and inform early intervention strategies. All analyses and visualizations were performed using the R statistical software package (version 4.1.3). Sampling, model training, and cross-validation were performed using the caret package (version 7.0-1). Data visualization and performance evaluation were performed using pROC (version 1.18.5) and ggplot2 (version 3.5.1). Statistical significance was established at p < 0.05. Figure 4 presents an overview of the workflow and variable analysis.
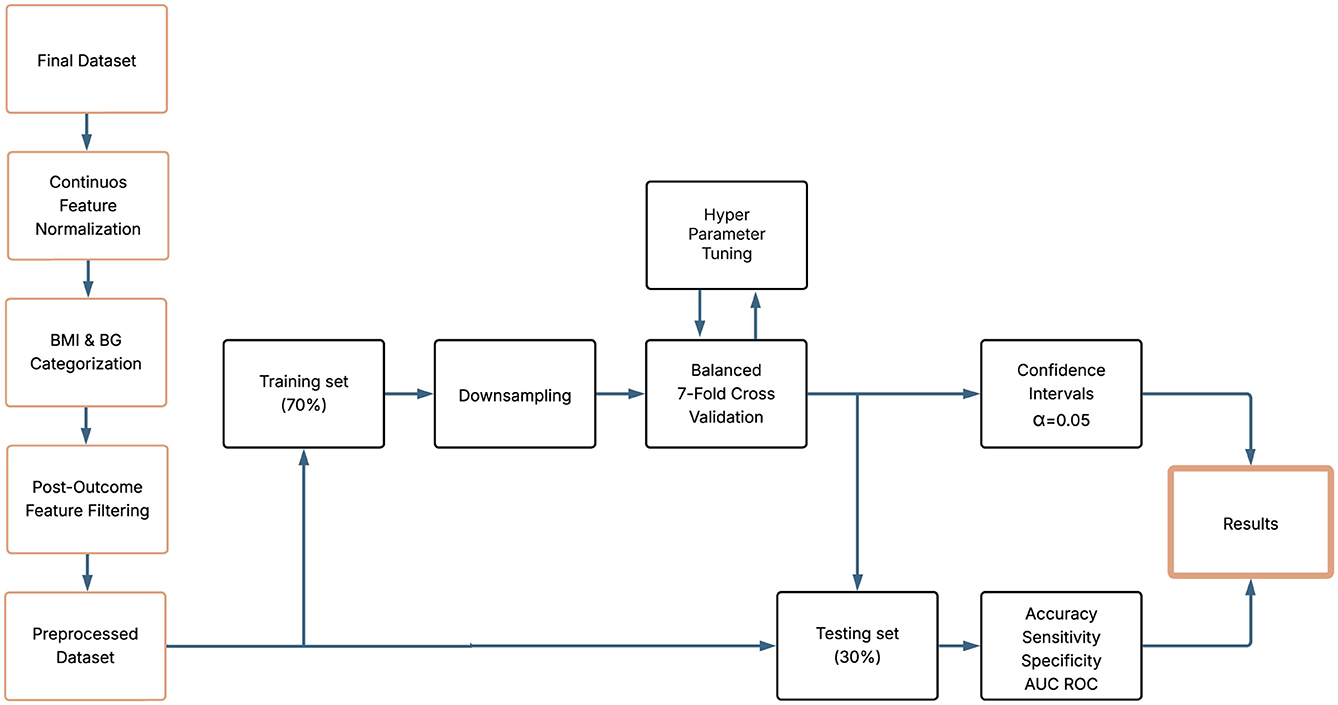
Figure 4. Workflow diagram.
3 Results
The study performed a detailed analysis of BMI and BG as primary proxies of CVR, given their critical role in evaluating metabolic health and glycemic control. Other biomarkers and lifestyle factors, such as age, lipid profiles, blood pressure, heart rate, hemoglobin, exercise habits, smoking, alcohol consumption, and nationality, were included solely for sociodemographic characterization and contextual purposes, without in-depth evaluation, to provide a comprehensive background for the primary analysis of BMI and BG. Table 4 shows the description of the data set for each of the biomarkers of interest, BMI and BG.
Tables 5, 6 report the performance of LR, RF, and XGB models in four classification tasks, for BMI and BG, respectively. For each task, the test results are presented alongside cross-validation metrics and their corresponding confidence intervals.
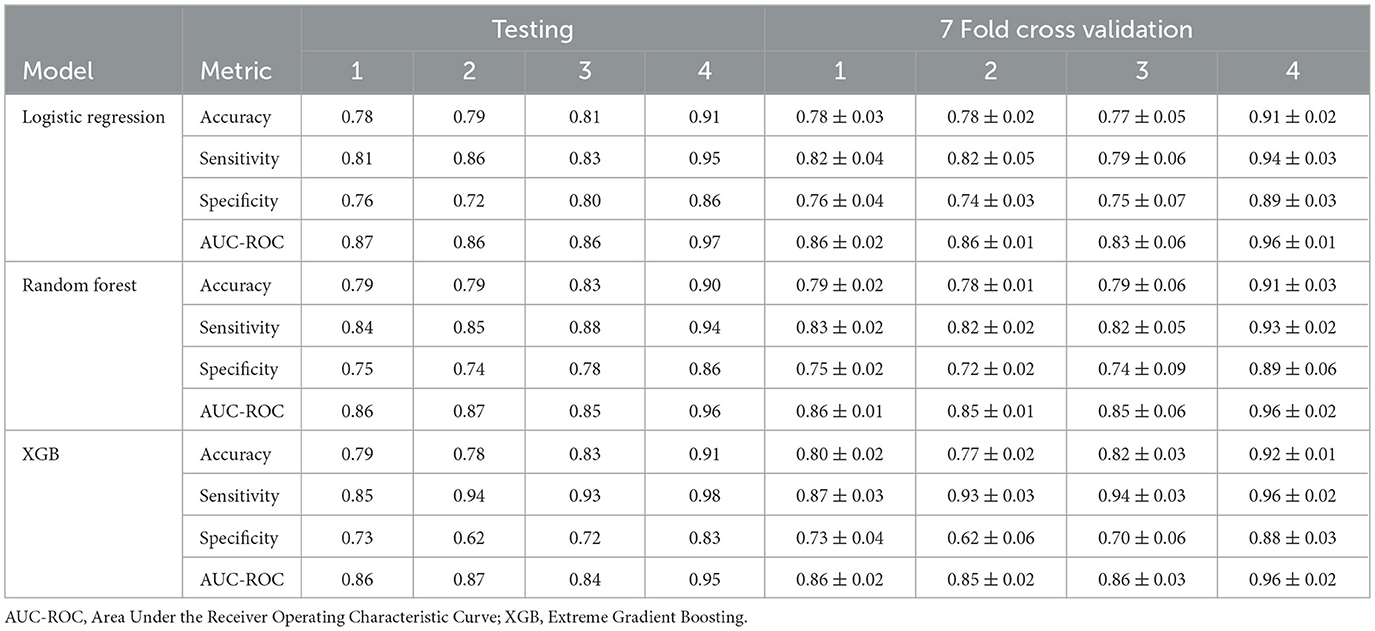
Table 5. Model performance metrics for BMI prediction (α = 0.05).
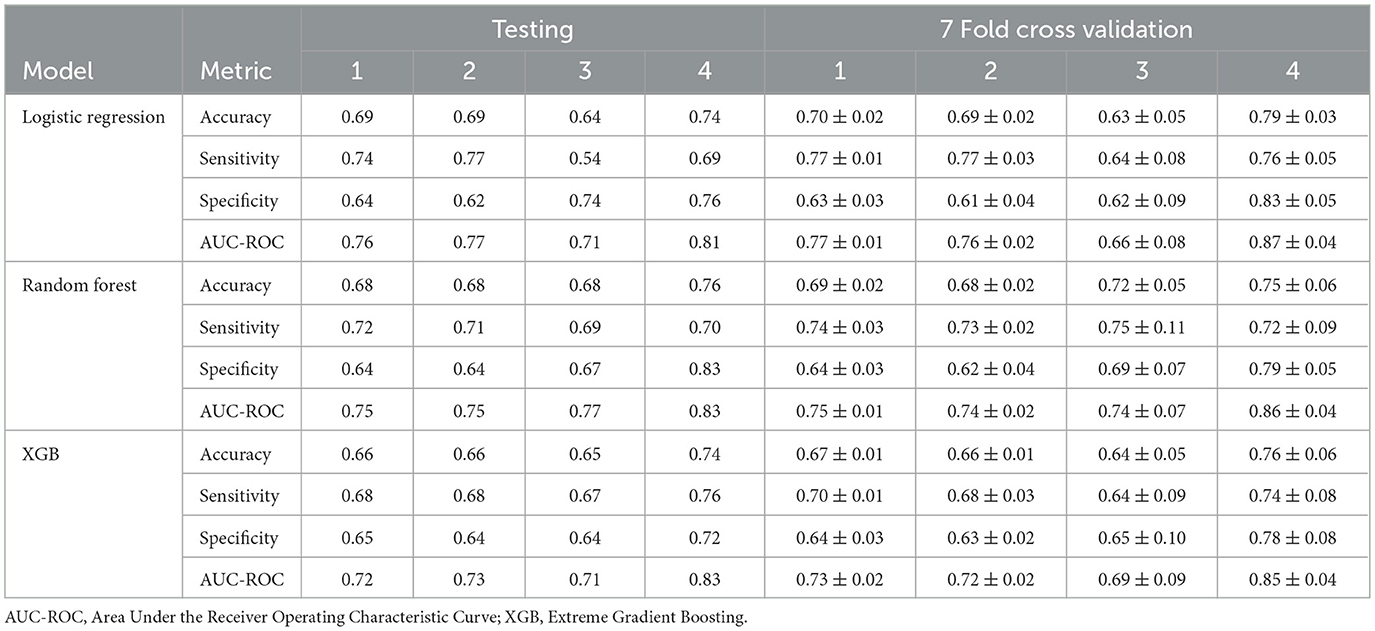
Table 6. Model performance metrics for BG prediction (α = 0.05).
Table 5 presents the performance of the LR, RF and XGB models in predicting transitions in the BMI categories in four scenarios. All models showed a strong predictive capacity, with XGB performing best in Scenario 4 (increase in morbid obesity, of any origin), achieving an AUC-ROC of 0.95 (95% CI 0.94–0.98) and accuracy of 0.91 (95% CI 0.91–0.93) in the test set. In this scenario, XGB also demonstrated high sensitivity (0.98) and specificity (0.83), indicating excellent detection of transitions to morbid obesity. For Scenarios 1 (any category increase), 2 (one-step category increase), and 3 (increase from obesity to morbid obesity), the models maintained good performance, with AUC-ROC values ranging from 0.84 to 0.87. Scenario 3 showed greater variability, likely due to fewer positive cases (235, Table 3), leading to wider confidence intervals (e.g., LR AUC-ROC: 0.83 ± 0.06). RF slightly outperformed in sensitivity for Scenarios 1 (0.84) and 3 (0.88), while XGB excelled in Scenarios 2 (sensitivity: 0.94). The cross-validation results closely matched the test set outcomes, suggesting minimal overfitting. The high correlation coefficients (0.9016–0.9724, Table 7) confirmed consistent predictions between models, particularly in Scenario 4. As shown in Figure 5, true positives in Scenario 4 were predominantly classified as high or very high risk, with few negative cases misclassified. These results demonstrate the reliability of the models in predicting BMI transitions, especially for severe risk increases, supporting their utility for early intervention in occupational health programs.
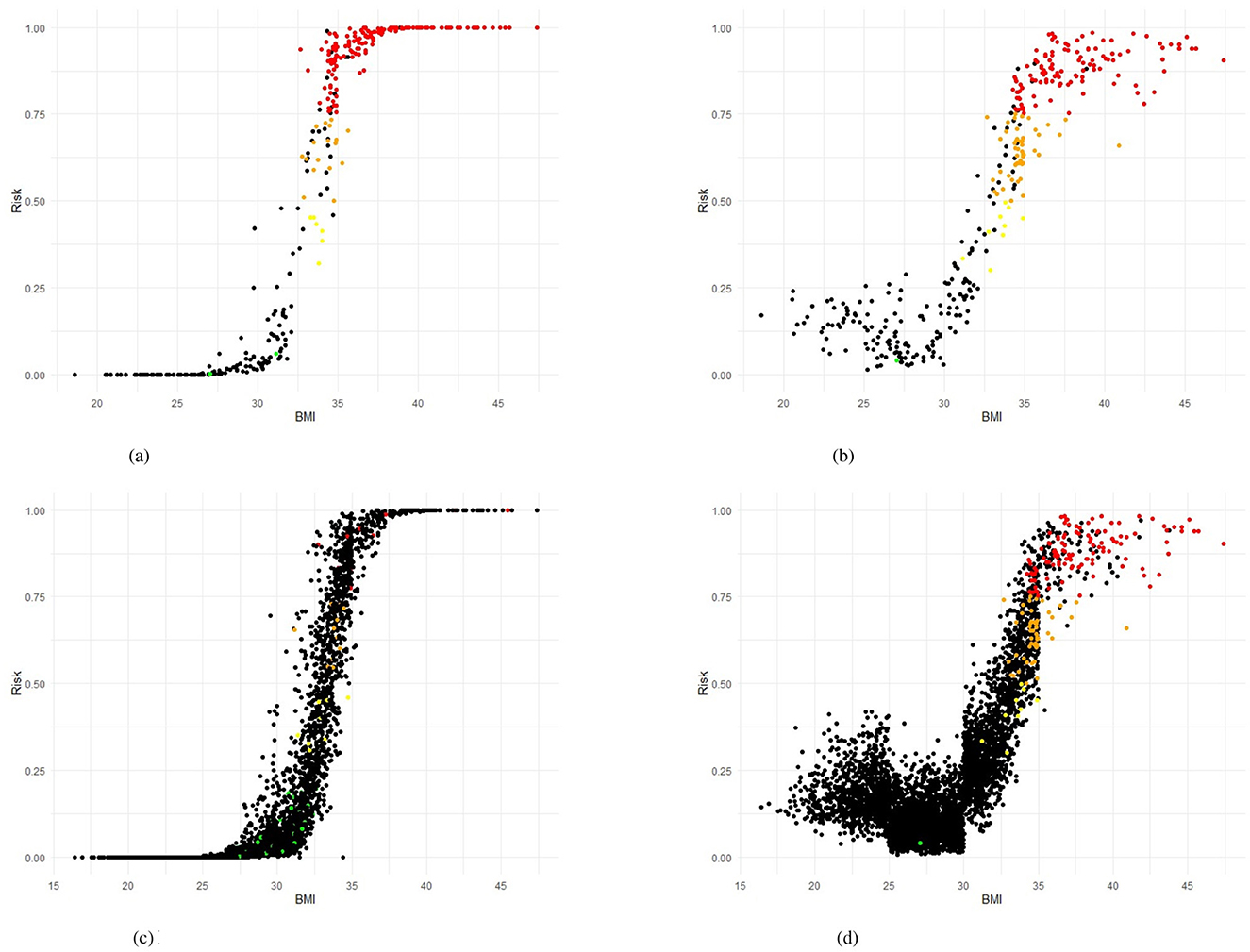
Figure 5. Training and testing sets in Scenario 4 showing Risk BMI for LR and RF models. (a) Logistic Regression (LR), training set. (b) Random Forest (RF), training set. (c) Logistic Regression (LR), testing set. (d) Random Forest (RF), testing set.
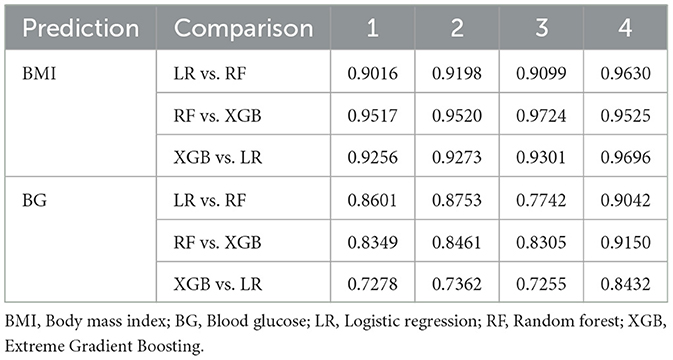
Table 7. Pearson's correlation coefficients between model predictions for BMI and BG.
Table 6 presents the performance of the LR, RF and XGB models in predicting the transitions of the category of BG in four scenarios. All models demonstrated robust predictive performance, with the strongest results in Scenario 4 (increase to diabetic, any origin). Here, RF achieved an AUC-ROC of 0.83 (95% CI: 0.82–0.90) and an accuracy of 0.76 (95% CI: 0.69–0.81) in the test set, with balanced sensitivity (0.70) and specificity (0.83), indicating a reliable detection of transitions to the diabetic category. For Scenarios 1 (any category increase), 2 (one-step category increase), and 3 (increase from prediabetic to diabetic), performance was slightly lower, with AUC-ROC values ranging from 0.71 to 0.77. Scenario 3 showed greater variability, likely due to fewer positive cases (130, Table 3), leading to wider confidence intervals (e.g., LR AUC-ROC: 0.66 ± 0.08 during training cross-validation). LR excelled in sensitivity for Scenario 1 (0.74) and Scenario 2 (0.77), while RF led in Scenario 3 (0.69). The cross-validation results were closely aligned with the results of the test set, confirming minimal overfitting. The correlation coefficients between the prediction of the model (Table 7), ranging from 0.7255 to 0.9150, indicated a strong agreement, particularly in Scenario 4. The models effectively predicted BG transitions, especially for severe risk escalations. Although slightly less robust than BMI predictions, probably due to glucose level variability and lower sample size, these results highlight the potential of the models to support targeted interventions in occupational health settings, even with limited event counts in some scenarios.
To further assess the consistency of the behavior of the model, Table 7 summarizes the pairwise correlations between the predicted probabilities of each model, providing insight into the degree of agreement between the modeling approaches. The correlation analysis revealed strong agreement between the models for the predictions of BMI and BG. These findings confirm that although all models performed well, XGB consistently provided the highest sensitivity and AUC, especially in severe transitions, making it more suitable for early alerts in occupational health. For example, RF and XGB had correlation coefficients greater than 0.95 in all scenarios of BMI. LR was also strongly aligned with both models. This consistency suggests that the choice of model has a limited impact on the predictions, reinforcing both the robustness of the modeling framework and the underlying correlations in the data. The variable importance identified by the RF, XGB, and LR models are shown in the Supplementary Tables 9, 10.
Figures 5a, b present the predicted risk levels vs. BMI for the LR and RF models in Scenario 4, offering a detailed assessment of their ability to classify the transitions to morbid obesity. The scatter plots display risk probabilities (risk identified by the corresponding model) on the y axis, ranging from 0 to 1, plotted against the BMI values on the x axis, with data points colored by predicted risk categories: low risk (< 0.25), yellow for low-mid risk (0.25– < 0.50), orange for mid-high risk (0.50– < 0.75) and high red risk (≥0.75). The black color code indicates individuals who actually did not have the event of interest. Individuals who had a positive event (true positive - TP) are coded by the corresponding risk identified by the model. For both models, the probability of risk demonstrates a consistent increase with higher BMI values, particularly exceeding the BMI of 30, where the majority of TP (red and orange points) are concentrated, indicating an effective identification of people who transition to morbid obesity. The LR plot exhibits a pronounced increase in risk probability around a BMI of 35, with most true positives clustered above a predicted risk of 0.9, suggesting high predictive confidence for severe transitions. Likewise, the RF plot shows a marked elevation beyond the BMI of 30, with a dense aggregation of TP in the high- and very-high-risk zones, corroborating its predictive accuracy. Figures 5c, d also display the predicted risk, but for the test set, as a function of the BMI measured at the most recent examination for the test set for Scenario 4. As noted in the Methods section, the test set is highly imbalanced, with only 3.3% positive cases. This imbalance explains the predominance of black dots in both figures. Similar to the training set plots (Figures 5a, b), an S-shaped distribution can be observed. The Random Forest model provides better discrimination of high-risk workers compared to the Logistic Regression model. This is consistent with Table 5, which shows that sensitivity exceeds specificity across all evaluated models. In the case, for the training set, misclassifications are limited, with few FN occurring in the high-risk range, and the majority of non-events (black points) remaining below a predicted risk of 0.25, reflecting strong discriminative power. This visual evidence aligns with the quantitative results, where the AUC-ROC values reach 0.97 (LR) and 0.96 (RF), Table 5, strengthening the reliability of the models in identifying at-risk individuals based on the previous BMI and supporting their application for early intervention in occupational health settings.
4 Discussion
The findings of this study confirm that ML models are accessible and robust tools to predict clinically relevant changes in CVR indicators, such as BMI and BG, among mining workers. Overall, the algorithms implemented demonstrated strong performance, particularly in predicting progression to more severe BMI categories. In particular, the results suggest that BMI changes can be accurately predicted using longitudinal occupational health data, allowing timely preventive interventions. These findings align with previous studies showing that ML models outperform traditional tools. In this research, although this study does not estimate CVR scores directly (e.g., Framingham), it evaluates two key clinical variables that directly relate to CVR. For example, the literature has identified that the presence of diabetes increases the risk of heart failure by 1.87 (1.71 to 2.05) in women and 1.75 (1.59 to 1.93) in men. Similarly, women with a BMI greater than 30, who increase their BMI by 5kg/m2, have a risk of heart failure of 1.32 (1.26–1.38), while men have a risk of 1.43 (1.36–1.51) (10).
Consistent with the literature, the high concordance observed between models in BMI predictions reinforces the stability and reliability of this approach, regardless of the algorithm used, and underscores the need for future research to employ larger, more comparable datasets and a broader range of ML models (52). In contrast, glucose predictions were less accurate and showed greater variability, likely due to the more unstable nature of this biomarker and the lower number of positive cases in certain categories, as previously reported in studies on diabetes in occupational settings (53, 54). However, the models performed better in scenarios with more balanced class distributions, and their generalization ability was adequate, as the test results aligned with the cross-validation estimates, indicating no evidence of overfitting (55). The better performance in the prediction of BMI can be explained by the more stable and cumulative nature of this indicator over time, compared to glucose, which tends to fluctuate due to the influence of dietary, metabolic and environmental factors on glycemic variability (56). Previous research has also highlighted the lower reproducibility of glucose as a CVR marker in populations exposed to adverse conditions, supporting our findings (57, 58).
Classical tools for estimating CVR, such as the Framingham and SCORE equations, have shown important limitations, especially when applied in contexts different from those in which they were developed. In particular, they tend to underestimate the actual risk by not taking into account the particularities of the environment and the longitudinal evolution of clinical indicators, as is the case for workers exposed to extreme environments, such as miners, where specific occupational factors are not considered, requiring recent adaptations (59). However, some scores lack validation in external cohorts and others have demonstrated a tendency to miscalculate risk when applied to populations different from their origin relying on classical risk factors, which limit their sensitivity and do not explain all observed cardiovascular events (30). Instead of creating entirely new models, future research should prioritize the adaptation and optimization of current frameworks, focusing on their alignment with occupational cohorts and real-time data acquisition (60). In contrast, the ML models presented in this study overcome these limitations by incorporating temporal data pairs and adapting to the specific characteristics of the population studied, consistent with recent research promoting the use of AI to improve risk stratification in special groups (61, 62).
Another relevant aspect concerns the trade-off between model interpretability and predictive performance. Although complex models such as XGB and RF offer high accuracy and flexibility, they often lack the transparency required for clinical interpretability and trust. Conversely, simpler models such as logistic regression facilitate understanding and decision-making but may fail to capture nonlinear interactions and temporal dynamics. This trade-off has been extensively discussed in occupational health modeling, where stakeholder participation and regulatory compliance often favor interpretable models (63). Therefore, the selection of models should align not only with predictive accuracy, but also with practical implementation constraints in workplace health systems.
However, this study has several limitations. First, using BMI and BG as a proxy of CVR might not be sufficient. However, there are no publicly available data on specific cardiovascular events in individuals belonging to the mining cohort. However, the literature shows that miners and other industrial workers are at increased risk of CVR (64). Another limitation relates to the lack of external validation in other populations. Furthermore, the low prevalence of events in some BG scenarios affected the stability of the model in those categories. Future studies should aim to include a broader range of clinical variables and prospectively validate these models to assess their real-world impact on the prevention of cardiovascular events.
Another methodological aspect concerns the handling of class imbalance. Several approaches were tested, including oversampling and hybrid techniques, but these frequently led to overfitting because of the small size of the minority class. In contrast, downsampling combined with repeated cross-validation yielded more stable and generalizable results, as confirmed by cross-model comparisons (Table 7). This supports the robustness of the chosen strategy, although future research should explore complementary approaches in external datasets. It is also important to note that a classifier may perform better on one class than the other, as sensitivity and specificity measure different aspects of performance, depending on its decision threshold, feature representation, or inherent model bias, even when trained on balanced data. In this context, model outcomes are reported using an unbalanced test dataset, replicating the actual data distribution. The proposed model achieved high AUC-ROC, sensitivity, and specificity. However, the consistently higher sensitivity compared to specificity indicates that the models are more effective at identifying true positive cases, namely workers who are actually at risk.
From a practical point of view, the findings of this study have direct implications for occupational health programs in mining populations. Implementing ML-based predictive models enables early identification of workers at risk of progressing to higher-risk categories, optimizing resources, and reducing the burden of disease and disability in this group. This approach aligns with current trends that promote more dynamic and personalized strategies in occupational health through the use of advanced technologies for the monitoring and follow-up of CVR (65, 66). Therefore, it is highly recommended that these predictive tools be used in conjunction with clinical follow-ups, nutritional interventions, physical activity programs, and periodic health checks to improve the health outcomes of workers.
Finally, this study not only supports the potential of ML as a complementary tool for healthcare teams, strengthening epidemiological surveillance in occupational populations, but also bridges the gap toward more precise, targeted and cost-effective interventions for high-risk workers. Integrating these models into occupational health systems represents a significant advance and a step forward toward more preventive, predictive, and personalized medicine. This reinforces the notion that ML, when contextualized and applied to dynamic occupational data, represents not just a predictive advance, but a paradigm shift in workplace CVR management.
5 Conclusion
This study demonstrates that ML models can effectively predict clinically significant changes in BMI and BG levels among mining workers, based on longitudinal occupational health data. Among the models tested, XGB showed particularly strong performance in predicting BMI transitions, with high accuracy and consistent results in different scenarios. These findings underscore the value of incorporating ML-based predictions into occupational health programs to support earlier and more targeted preventive strategies, ultimately improving CVR management in high-risk worker populations by enhancing accuracy and sensitivity as demonstrated in BMI predictions (AUC up to 0.97; sensitivity up to 0.98).
Future research should explore the integration of additional risk factors, such as sleep quality, stress levels, and genetic predispositions, to further refine risk stratification in occupational cohorts. In addition, health authorities could adopt ML-based alert systems to guide targeted preventive actions on a scale. Future studies should aim to externally validate these models in other high-risk occupational settings, such as construction or transportation, where periodic health evaluations and similar physiological stressors are common. Replicating this approach using datasets with longitudinal pre-employment or annual check-up data would provide robust evidence of their generalizability across diverse occupational contexts. Finally, this study provides a scalable evidence-based strategy to improve the early detection of CVR in vulnerable worker populations, aligning with global efforts to reduce the burden of noncommunicable diseases.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
The studies involving humans were approved by the Comité de Ética Científico Adultos del Servicio de Salud Metropolitano Oriente, located in Santiago, Chile. The studies were conducted in accordance with the local legislation and institutional requirements. The human samples used in this study were acquired from institutional clinical databases through retrospective review of patient records, with all data anonymized and analyzed in aggregate form. Ethical approval was obtained from the corresponding institutional review board, and informed consent was waived due to the retrospective nature of the study. Written informed consent for participation was not required from the participants or the participants' legal guardians/next of kin in accordance with the national legislation and institutional requirements.
Author contributions
RJ: Conceptualization, Investigation, Supervision, Writing – original draft, Writing – review & editing. GD: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Project administration, Resources, Software, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing. MD: Conceptualization, Investigation, Writing – review & editing. GB: Conceptualization, Investigation, Writing – review & editing. IA: Conceptualization, Writing – review & editing. AL: Conceptualization, Formal analysis, Visualization, Writing – review & editing. FF: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Project administration, Resources, Software, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing.
Funding
The author(s) declare that no financial support was received for the research and/or publication of this article.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Gen AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmed.2025.1678172/full#supplementary-material
References
1. Di Cesare M, Perel P, Taylor S, Kabudula C, Bixby H, Gaziano TA, et al. The heart of the world. Glob Heart. (2024) 19:11. doi: 10.5334/gh.1288
2. Wang H, Paulson KR, Pease SA, Watson S, Comfort H, Zheng P, et al. Estimating excess mortality due to the COVID-19 pandemic: a systematic analysis of COVID-19-related mortality, 2020-21. Lancet. (2022) 399:1513–36. doi: 10.1016/S0140-6736(21)02796-3
3. Olvera Lopez E, Ballard B, Jan A. Cardiovascular Disease. StatPearls Treasure Island (FL): StatPearls Publishing. (2024). Available online at: https://www.ncbi.nlm.nih.gov/books/NBK535419/ (accessed August 22, 2023).
4. Shams P, Gul Z, Makaryus AN. Silent myocardial ischemia. In: StatPearls. StatPearls Publishing. (2024).
5. Oude Wolcherink MJ, Behr CM, Pouwels XG, Doggen CJ, Koffijberg H. Health economic research assessing the value of early detection of cardiovascular disease: a systematic review. Pharmacoeconomics. (2023) 41:1183–203. doi: 10.1007/s40273-023-01287-2
6. Liang J, Wells S, Jackson R, Choi Y, Mehta S, Chung C, et al. Comparing 5-year and 10-year predicted cardiovascular disease risks in Aotearoa New Zealand: national data linkage study of 1.7 million adults. Eur J Prev Cardiol. (2025) 32:516–24. doi: 10.1093/eurjpc/zwae361
7. Belli M, Bellia A, Sergi D, Barone L, Lauro D, Barillà F. Glucose variability: a new risk factor for cardiovascular disease. Acta Diabetol. (2023) 60:1291–9. doi: 10.1007/s00592-023-02097-w
8. Asztalos BF, Russo G, He L, Diffenderfer MR. Body mass index and cardiovascular risk markers: a large population analysis. Nutrients. (2025) 17:740. doi: 10.3390/nu17050740
9. Cheng Y, Wu S, Chen S, Wu Y. Association of body mass index combined with triglyceride-glucose index in cardiovascular disease risk: a prospective cohort study. Sci Rep. (2025) 15:1–10. doi: 10.1038/s41598-025-02342-y
10. Khan SS, Matsushita K, Sang Y, Ballew SH, Grams ME, Surapaneni A, et al. Development and validation of the American Heart Association's PREVENT equations. Circulation. (2024) 149:430–49. doi: 10.1161/CIRCULATIONAHA.123.067626
11. Woo HG, Kim DH, Lee H, Kang MK, Song TJ. Association between changes in predicted body composition and occurrence of heart failure: a nationwide population study. Front Endocrinol. (2023) 14:1210371. doi: 10.3389/fendo.2023.1210371
12. Zhou Y, Chai X, Yang G, Sun X, Xing Z. Changes in body mass index and waist circumference and heart failure in type 2 diabetes mellitus. Front Endocrinol. (2023) 14:1305839. doi: 10.3389/fendo.2023.1305839
13. Alsaedi S, Skogstad M, Haugen F. GLU24/7 study: cardiometabolic health risk factors in night shift workers-protocol for a 2-year longitudinal study in an industrial setting in Norway. BMJ Open. (2025) 15:e098896. doi: 10.1136/bmjopen-2025-098896
14. de la Salud OP. Prevención de las enfermedades cardiovasculares. Directrices para la evaluación y el manejo del riesgo cardiovascular. OPS Washington, DC (2010). Available online at: https://www.paho.org/sites/default/files/2023-10/directrices-evaluacion-manejo-riesgo-cv-oms.pdf (Accessed November 19, 2025).
15. Mincheva L, Khadzhiolova I. An occupational physiology study at the Asarel mining and milling works-screening for risk factors of the cardiovascular system in workers in an open-pit mine. Problemi na khigienata. (1995) 20:47–59.
16. Arif AA, Adeyemi O. Mortality among workers employed in the mining industry in the United States: A 29-year analysis of the National Health Interview Survey–Linked Mortality File, 1986-2014. Am J Ind Med. (2020) 63:851–8. doi: 10.1002/ajim.23160
17. Pedreros-Lobos A, Calderón-Jofré R, Moraga D, Moraga FA. Cardiovascular risk is increased in miner's chronic intermittent hypobaric hypoxia exposure from 0 to 2,500 m? Front Physiol. (2021) 12:647976. doi: 10.3389/fphys.2021.647976
18. Esenamanova MK, Kochkorova FA, Tsivinskaya TA, Vinnikov D, Aikimbaev K. Chronic intermittent high altitude exposure, occupation, and body mass index in workers of mining industry. High Altit Med Biol. (2014) 15:412–7. doi: 10.1089/ham.2013.1150
19. Sarang VD, Subroto SN, Umesh LD. Metabolic syndrome in different sub occupations among mine workers. Indian J Occup Environ Med. (2015) 19:76–9. doi: 10.4103/0019-5278.165330
20. Casey ML, Fedan KB, Edwards N, Blackley DJ, Halldin CN, Wolfe AL, et al. Evaluation of high blood pressure and obesity among US coal miners participating in the Enhanced Coal Workers Health Surveillance Program. J Am Soc Hypert. (2017) 11:541–5. doi: 10.1016/j.jash.2017.06.007
21. Mining Skills Council, Eleva Program, Mining Council, Fundación Chile. The Workforce for 2021–2030 Large-Scale Mining in Chile: Diagnosis and Recommendations. Santiago, Chile: Mining Council and Fundacin Chile. (2021). All rights reserved. The contents of this document may be reproduced and distributed provided the sources are cited. Available online at: https://ccm-eleva.cl/wp-content/uploads/2024/01/Workforce-Study-of-Large-scale-Mining-in-Chile-2023-2032-english-version-v2.pdf (Accessed November 19, 2025).
22. Baussa AW, Kim SC. Chile-Country Commercial Guide. (2023). Available online at: https://www.trade.gov/country-commercial-guides/chile-mining (Accessed November 19, 2025).
23. Escuela de Salud Pública, Universidad de Chile. Estudio de los efectos de la exposición intermitente a gran altitud sobre la salud de trabajadores de faenas mineras. Santiago: Superintendencia de Seguridad Social (2018).
24. D'Agostino Sr RB, Vasan RS, Pencina MJ, Wolf PA, Cobain M, Massaro JM, et al. General cardiovascular risk profile for use in primary care: the Framingham Heart Study. Circulation. (2008) 117:743–53. doi: 10.1161/CIRCULATIONAHA.107.699579
25. Kaptoge S, Pennells L, De Bacquer D, Cooney MT, Kavousi M, Stevens G, et al. World Health Organization cardiovascular disease risk charts: revised models to estimate risk in 21 global regions. Lancet Global Health. (2019) 7:e1332–45. doi: 10.1016/S2214-109X(19)30318-3
26. Wilson PW, D'Agostino RB, Levy D, Belanger AM, Silbershatz H, Kannel WB. Prediction of coronary heart disease using risk factor categories. Circulation. (1998) 97:1837–47. doi: 10.1161/01.CIR.97.18.1837
27. Conroy RM, Pyörälä K, Fitzgerald Ae, Sans S, Menotti A, De Backer G, et al. Estimation of ten-year risk of fatal cardiovascular disease in Europe: the SCORE project. Eur Heart J. (2003) 24:987–1003. doi: 10.1016/S0195-668X(03)00114-3
28. Khan SS, Coresh J, Pencina MJ, Ndumele CE, Rangaswami J, Chow SL, et al. Novel prediction equations for absolute risk assessment of total cardiovascular disease incorporating cardiovascular-kidney-metabolic health: a scientific statement from the American Heart Association. Circulation. (2023) 148:1982–2004. doi: 10.1161/CIR.0000000000001191
29. Brindle P, Jonathan E, Lampe F, Walker M, Whincup P, Fahey T, et al. Predictive accuracy of the Framingham coronary risk score in British men: prospective cohort study. BMJ. (2003) 327:1267. doi: 10.1136/bmj.327.7426.1267
30. Talha I, Elkhoudri N, Hilali A. Major limitations of cardiovascular risk scores. Cardiovasc Ther. (2024) 2024:4133365. doi: 10.1155/2024/4133365
31. Ban JW, Abel L, Stevens R, Perera R. Research inefficiencies in external validation studies of the Framingham Wilson coronary heart disease risk rule: a systematic review. PLoS ONE. (2024) 19:e0310321. doi: 10.1371/journal.pone.0310321
32. Xu B, Lv L, Chen X, Li X, Zhao X, Yang H, et al. Temporal relationships between BMI and obesity-related predictors of cardiometabolic and breast cancer risk in a longitudinal cohort. Sci Rep. (2023) 13:12361. doi: 10.1038/s41598-023-39387-w
33. Liu C, Chiang Y, Hui Q, Zhou JJ, Wilson PW, Joseph J, et al. High variability of body mass index is independently associated with incident heart failure. J Am Heart Assoc. (2024) 13:e031861. doi: 10.1161/JAHA.123.031861
34. Mann J, Lyons M, O'Rourke J, Davies S. Machine learning or traditional statistical methods for predictive modelling in perioperative medicine: a narrative review. J Clin Anesth. (2025) 102:111782. doi: 10.1016/j.jclinane.2025.111782
35. Chinnasamy P, Kumar SA, Navya V, Priya KL, Boddu SS. Machine learning based cardiovascular disease prediction. Mater Today. (2022) 64:459–63. doi: 10.1016/j.matpr.2022.04.907
36. Xia B, Innab N, Kandasamy V, Ahmadian A, Ferrara M. Intelligent cardiovascular disease diagnosis using deep learning enhanced neural network with ant colony optimization. Sci Rep. (2024) 14:21777. doi: 10.1038/s41598-024-71932-z
37. Liu T, Krentz A, Lu L, Curcin V. Machine learning based prediction models for cardiovascular disease risk using electronic health records data: systematic review and meta-analysis. Eur Heart J-Digital Health. (2025) 6:7–22. doi: 10.1093/ehjdh/ztae080
38. Yang L, Wu H, Jin X, Zheng P, Hu S, Xu X, et al. Study of cardiovascular disease prediction model based on random forest in eastern China. Sci Rep. (2020) 10:5245. doi: 10.1038/s41598-020-62133-5
39. Ambrish G, Ganesh B, Ganesh A, Srinivas C, Mensinkal K, et al. Logistic regression technique for prediction of cardiovascular disease. Global Transit Proc. (2022) 3:127–30. doi: 10.1016/j.gltp.2022.04.008
40. Sumwiza K, Twizere C, Rushingabigwi G, Bakunzibake P, Bamurigire P. Enhanced cardiovascular disease prediction model using random forest algorithm. Inform Med Unlocked. (2023) 41:101316. doi: 10.1016/j.imu.2023.101316
41. Cao K, Liu C, Yang S, Zhang Y, Li L, Jung H, et al. Prediction of cardiovascular disease based on multiple feature selection and improved PSO-XGBoost model. Sci Rep. (2025) 15:12406. doi: 10.1038/s41598-025-96520-7
42. Shimizu GY, Romão EA, Da Costa JAC, de Azevedo-Marques JM, Scarpelini S, Suzuki KMF, et al. External validation and interpretability of machine learning-based risk prediction for major adverse cardiovascular events. In: 2024 IEEE 37th International Symposium on Computer-Based Medical Systems (CBMS). IEEE (2024). p. 140–145. doi: 10.1109/CBMS61543.2024.00031
43. Wang Y, Aivalioti E, Stamatelopoulos K, Zervas G, Mortensen MB, Zeller M, et al. Machine learning in cardiovascular risk assessment: towards a precision medicine approach. Eur J Clin Invest. (2025) 55:e70017. doi: 10.1111/eci.70017
44. Carrasco-Ribelles LA, Llanes-Jurado J, Gallego-Moll C, Cabrera-Bean M, Monteagudo-Zaragoza M, Violán C, et al. Prediction models using artificial intelligence and longitudinal data from electronic health records: a systematic methodological review. J Am Med Inf Assoc. (2023) 30:2072–82. doi: 10.1093/jamia/ocad168
45. Von Elm E, Altman DG, Egger M, Pocock SJ, Gótzsche PC, Vandenbroucke JP. The Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) statement: guidelines for reporting observational studies. Lancet. (2007) 370:1453–7. doi: 10.1016/S0140-6736(07)61602-X
46. Collins GS, de Groot JA, Dutton S, Omar O, Shanyinde M, Tajar A, et al. External validation of multivariable prediction models: a systematic review of methodological conduct and reporting. BMC Med Res Methodol. (2014) 14:1–11. doi: 10.1186/1471-2288-14-40
47. Hippisley-Cox J, Coupland C, Brindle P. Development and validation of QRISK3 risk prediction algorithms to estimate future risk of cardiovascular disease: prospective cohort study. BMJ. (2017) 357:j2099. doi: 10.1136/bmj.j2099
48. Ooka T, Johno H, Nakamoto K, Yoda Y, Yokomichi H, Yamagata Z. Random forest approach for determining risk prediction and predictive factors of type 2 diabetes: large-scale health check-up data in Japan. BMJ Nutr Prev Health. (2021) 4:140. doi: 10.1136/bmjnph-2020-000200
49. Lugner M, Rawshani A, Helleryd E, Eliasson B. Identifying top ten predictors of type 2 diabetes through machine learning analysis of UK Biobank data. Sci Rep. (2024) 14:2102. doi: 10.1038/s41598-024-52023-5
50. Lindner T, Puck J, Verbeke A. Beyond addressing multicollinearity: Robust quantitative analysis and machine learning in international business research. J Int Bus Stud. (2022) 53:1307–14. doi: 10.1057/s41267-022-00549-z
51. Bro R, Kjeldahl K, Smilde AK, Kiers H. Cross-validation of component models: a critical look at current methods. Anal Bioanal Chem. (2008) 390:1241–51. doi: 10.1007/s00216-007-1790-1
52. Delpino FM, Costa ÂK, do Nascimento MC, Moura HSD, Dos Santos HG, Wichmann RM, et al. Does machine learning have a high performance to predict obesity among adults and older adults? A systematic review and meta-analysis. Nutr Metabol Cardiov Dis. (2024) 34:2034–45. doi: 10.1016/j.numecd.2024.05.020
53. Lee Y, Seo E, Lee W. Long working hours and the risk of glucose intolerance: a cohort study. Int J Environ Res Public Health. (2022) 19:11831. doi: 10.3390/ijerph191811831
54. Kozinetz RM, Berikov VB, Semenova JF, Klimontov VV. Machine learning and deep learning models for nocturnal high-and low-glucose prediction in adults with type 1 diabetes. Diagnostics. (2024) 14:740. doi: 10.3390/diagnostics14070740
55. Santos MS, Soares JP, Abreu PH, Araujo H, Santos J. Cross-validation for imbalanced datasets: avoiding overoptimistic and overfitting approaches [research frontier]. IEEE Comput Intell Magaz. (2018) 13:59–76. doi: 10.1109/MCI.2018.2866730
56. Li J, Xu Z, Xu T, Lin S. Predicting Diabetes in patients with metabolic syndrome using machine-learning model based on multiple years data. Diab Metab Syndr Obes. (2022) 15:2951–2961. doi: 10.2147/DMSO.S381146
57. Zhou Z, Sun B, Huang S, Zhu C, Bian M. Glycemic variability: adverse clinical outcomes and how to improve it? Cardiovasc Diabetol. (2020) 19:1–14. doi: 10.1186/s12933-020-01085-6
58. Nahmias A, Stahel P, Xiao C, Lewis GF. Glycemia and atherosclerotic cardiovascular disease: exploring the gap between risk marker and risk factor. Front Cardiov Med. (2020) 7:100. doi: 10.3389/fcvm.2020.00100
59. de Menezes-Júnior LAA, de Moura SS, Carraro JCC, de Freitas SN, Pimenta FAP, Machado-Coelho GLL, et al. Framingham score adapted: a valid alternative for estimating cardiovascular risk in epidemiological studies. BMC Cardiov Disor. (2025) 25:187. doi: 10.1186/s12872-025-04579-x
60. Damen JA, Hooft L, Schuit E, Debray TP, Collins GS, Tzoulaki I, et al. Prediction models for cardiovascular disease risk in the general population: systematic review. BMJ. (2016) 353:i2416. doi: 10.1136/bmj.i2416
61. Lübeck F, Wildberger J, Träuble F, Mordig M, Gatidis S, Krause A, et al. Adaptable cardiovascular disease risk prediction from heterogeneous data using large language models. arXiv preprint arXiv:250524655. (2025).
62. Meder B, Asselbergs FW, Ashley E. Artificial intelligence to improve cardiovascular population health. Eur Heart J. (2025) 46:1907–16. doi: 10.1093/eurheartj/ehaf125
63. Mitrakas C, Xanthopoulos A, Koulouriotis D. Techniques and models for addressing occupational risk using fuzzy logic, neural networks, machine learning, and genetic algorithms: a review and meta-analysis. Appl Sci. (2025) 15:1909. doi: 10.3390/app15041909
64. Vearrier D, Greenberg MI. Occupational health of miners at altitude: adverse health effects, toxic exposures, pre-placement screening, acclimatization, and worker surveillance. Clin Toxicol. (2011) 49:629–40. doi: 10.3109/15563650.2011.607169
65. Lange M, Löwe A, Kayser I, Schaller A. Approaches for the use of AI in workplace health promotion and prevention: systematic scoping review. JMIR AI. (2024) 3:e53506. doi: 10.2196/53506
Keywords: blood glucose, body mass index, cardiovascular risk, machine learning, occupational health
Citation: Jorquera R, Droppelmann G, Dollmann M, Blanco G, Ahumada I, Lira A and Feijoo F (2025) Mining the risk: early cardiovascular detection in workers. Front. Med. 12:1678172. doi: 10.3389/fmed.2025.1678172
Received: 02 August 2025; Revised: 13 October 2025;
Accepted: 07 November 2025;
Published: 27 November 2025.
Edited by:
Takatoshi Kasai, Juntendo University, JapanReviewed by:
Kamran Mehrabani-Zeinabad, Isfahan University of Medical Sciences, IranAstrid Urbano, University of Santiago de Cali, Colombia
Copyright © 2025 Jorquera, Droppelmann, Dollmann, Blanco, Ahumada, Lira and Feijoo. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Guillermo Droppelmann, Z3VpbGxlcm1vLmRyb3BwZWxtYW5uQG1lZHMuY2w=; Felipe Feijoo, ZmVsaXBlLmZlaWpvb0BwdWN2LmNs