 Gabriele Chierchia
Gabriele Chierchia Giorgio Coricelli
Giorgio Coricelli- 1Department of Social Neuroscience, Max Planck Institute for Human Cognitive and Brain Science, Leipzig, Germany
- 2Center for Mind/Brain Science, University of Trento, Rovereto, Italy
- 3Economics Department, University of Southern California, Los Angeles, CA, USA
Homophily, or “love for similar others,” has been shown to play a fundamental role in the formation of interpersonal ties and social networks. Yet no study has investigated whether perceived similarities can affect tacit coordination. We had 68 participants attempt to maximize real monetary earnings by choosing between a safe but low paying option (that could be obtained with certainty) and a potentially higher paying but “risky” one, which depended on the choice of a matched counterpart. While making their choices participants were mutually informed of whether their counterparts similarly or dissimilarly identified with three person-descriptive words as themselves. We found that similarity increased the rate of “risky” choices only when the game required counterparts to match their choices (stag hunt games). Conversely, similarity led to decreased risk rates when they were to tacitly decouple their choices (entry games). Notably, though similarity increased coordination in the matching environment, it did not did not increase it in the decoupling game. In spite of this, similarity increased (expected) payoffs across both coordination environments. This could shed light on why homophily is so successful as a social attractor. Finally, this propensity for matching and aversion to decoupling choices was not observed when participants “liked” their counterparts but were dissimilar to them. We thus conclude that the impact of similarity of coordination should not be reduced to “liking” others (i.e., social preferences) but it is also about predicting them.
Introduction
“Any event in the history of the organism is, in a sense, unique. Consequently, recognition, learning, and judgment presuppose an ability to categorize stimuli and classify situations by similarity. As Quine (1969) puts it: “There is nothing more basic to thought and language than our sense of similarity; our sorting of things into kinds” (Tversky and Gati, 1978).
So many of our decisions are “social”: their outcomes depend on the decisions of others. This can generate “strategic uncertainty” (Van Huyck et al., 1990) and require agents to infer what others will do, while others do the same, in order to decide optimally.
Consider for instance the decision of joining a strike or a rebellion: all may know that if enough people join in the uprising, it will succeed, and everyone will benefit. However, rebelling in small numbers could be dangerous, so agents might hesitate to do so. Similarly, investing in a new technology might only worthwhile if enough others do the same, so it becomes the new standard and everyone profits. In such situations, two outcomes would do: “either all rebel/invest, or no one does,” but isolated actions are costly. Consequently, agents should attempt to match their choices.
Conversely, there are many situations in which choosing the same options can be disadvantageous, especially when resources cannot be shared. For instance, many markets can only provide revenue to a limited number of investors, because if too many do there will be a “price war,” and everyone loses (Camerer, 2003). Or more mundanely, driving space is limited, so a driver deciding whether to enter the freeway around rush hour might only do so if he convinces himself that not too many others will do the same, since if too many do, there will be a traffic jam1. In these situations, agents would prefer to decouple their choices, such that “either I take the free-way/enter the market and you don't, or vice versa; but we shouldn't enter together.”
In economics, the first class of situations are said to involve strategic complements, while the latter involve strategic substitutes (Bulow et al., 1985; Camerer and Fehr, 2006)2. In both cases however, when communication is impossible or inefficient3 (Morris and Shin, 2002; Heinemann et al., 2004), agents must find some “tacit agreement” on how to coordinate their choices.
Game theory is a standard approach to understanding interdependent decision problems (henceforth, “games”), and it is frequent practice in economics and political science to use it to provide strategic advice to investors, firms, or nations (Schelling, 1960; Gibbons, 1992). However, when it comes to a certain subset of interactions, namely “coordination problems” like the ones sketched above, game theory turns strikingly blind. This occurs because game theory fundamentally derives its predictions by applying deduction to the incentives and options of a given situation. Indeed, out of all the possible outcomes of an interaction, there is only a subset of them, called “Nash equilibria,” in which no agent has an incentive to “move further,” that is, to unilaterally deviate from his/her current choice. The fundamental problem with coordination games is that they have multiple Nash equilibria, and standard game theory provides no clear criteria for equilibrium selection4. Indeed, coordination has been said to constitute “the hardest problem of game theory” (Camerer, 2003).
Here, we investigated how coordination is affected by perceived interpersonal similarities. Indeed, homophily, or “love for similar others,” is one of the most strikingly ubiquitous predictors of interpersonal attraction and network formation in social species, as it has been observed across ages (i.e., Meltzoff, 2007; Over et al., 2013), cultures (Apicella et al., 2012) and species (i.e., Seyfarth and Cheney, 2012; Massen and Koski, 2014). Indeed, similarity along a wide variety of dimensions such as age, ethnicity, class, religion, personality and interests has been shown to shape friendship formation, partner selection and social networks in human adults (see McPherson et al., 2001 for a review)5. Correspondingly, a number of theoretical models have implicated similarity in the formation of friendship (Currarini et al., 2009) or the evolution of cooperation (Riolo et al., 2001); and simulations have shown how, in repeated cooperation dilemmas, agents that rely on a “perceived similarity index” can drive groups of stochastic or hostile “free-riders” to extinction, even if in minority (Fischer et al., 2013). Finally, studies have begun to emphasize the impact of similarity on coordination (Cole and Teboul, 2004; Fischer, 2009; Fu et al., 2012). Yet in spite of this mounting evidence, no study has empirically assessed whether coordination is actually affected by perceived interpersonal similarities.
Furthermore, no study has systematically compared the impact of similarity on the two opposite “declinations” of coordination illustrated above, namely matching (strategic compliments) and decoupling choices (strategic substitutes). In fact, common intuition suggests that similarity should generally decrease social uncertainty, plausibly because all else being equal, similar agents can use “their own minds” as a proxy to predict the choices of their counterpart. Indeed, this is in line with abundant experimental evidence showing that, even in the absence of similarity-related cues (and since childhood) social inferences are often contaminated by one's own thoughts and perspectives (i.e., Ross et al., 1977; Wimmer and Perner, 1983; Baron-Cohen et al., 1985; Keysar, 1994; Gilovich et al., 1998, 2000; Goldman, 2006)6, and that perceived interpersonal similarities accentuate the degree to which this occurs (Clement and Krueger, 2002; Ames, 2004; Epley et al., 2004; Robbins and Krueger, 2005)7.
The problem is that being more predictable might indeed help in environments that require agents to match their choices, but it might even be detrimental when agents are to somehow “outsmart” one another and decouple their choices. For instance, in competitive environments similar agents might find it harder to manipulate or lie to one another, thus similarity might deter them from attempting to do so. Or one could think of the paradigmatic form of interpersonal similarity, namely, monozygotic twins. In fact, twins have been shown to more frequently match their choices in cooperation dilemmas (Segal and Hershberger, 1999), however, what would happen if they were to play a game like “rock, paper, scissors”?8 The same similarity that helped them in the first scenario, might work against them in the latter, and Fischer (2009) nicely illustrates this problem with a mental experiment involving agents “playing” with their “mirror image.” Indeed, though it has been previously conjectured (Fischer, 2009; Fu et al., 2012; Krueger et al., 2012) that similarity could affect coordination in opposite ways, this has been never empirically demonstrated.
However, and importantly, similarity doesn't only alter social inferences. In fact, traditionally, it is mainly held to mediate interpersonal attraction (Byrne, 1971; McPherson et al., 2001; Montoya et al., 2008 for a review), thus moderating social attitudes and affect. In this sense, attraction for similar others could hinge on very basic and relatively “non-inferential” mechanisms (Zajonc, 1980; Mitchell et al., 2006) such as the “mere exposure” effect (see Zajonc, 2001 for review), which consists in the observation that simple repeated exposure to previously neutral stimuli increases their perceived attractiveness (Monahan et al., 2000)9.
Indeed, many effects of similarity on interactions could be potentially be explained by “social preference” theories (i.e., Fehr and Fischbacher, 2003; or Camerer, 2003 for a review), which are fundamentally different from the ones described above. In fact, proponents of a “similarity approach” (Ames, 2004; Fischer, 2009; Krueger et al., 2012; Fischer et al., 2013) usually refer to its impact on inferences and uncertainty, while social preferences, if taken rigorously, leave inferences untouched, and explain cooperation in terms, for instance, of “altruistic” motives (i.e., Van Lange, 1999). The difference is that in the latter case, subjects might be willing to incur more costs to benefit those they like rather than dislike (i.e., Jones and Rachlin, 2006), thus choosing the options that most benefit similar rather than dissimilar others.
Intriguingly, alternative evolutionary approaches to homophily seem to parallel this dichotomy (albeit naturally at a much more distal level). For instance, in line with a “preference” approach to similarity, a commonly quoted evolutionary basis for homophily is kinship selection (Hamilton, 1963), the notion that agents may have an incentive to benefit others proportionally to their genetic relatedness. Indeed, by helping relatives, agents promote the survival of the portion of genes they share with them. Similarity could then be involved in distinguishing kin from non-kin. For instance phenotypic matching (Porter, 1987)—that is, the implicit evaluation of relatedness based on phenotypic similarity—has been observed in ground squirrels (Holmes and Sherman, 1982), baboons (Alberts, 1999), rhesus monkeys, and a number of other species. In line with this, DeBruine (2002) showed that economic trust was increased when human agents played with a fictive player whose face had been morphed to physically resemble their own. Intriguingly, even genotypic homophily has been reported in humans (Fowler et al., 2011; Christakis and Fowler, 2014), such that friends are more likely to have similar genes, plausibly as a consequence of their seeking others with similar phenotypes. Importantly, kin-selection based explanations of homophily imply that individuals needn't directly benefit from similarity, if anything, their genes do.
On the other hand, different evolutionary approaches related to homophily seem to stress its predictive or strategic component, rather than its motivational one (Fu et al., 2012; Fischer et al., 2013). For instance, Vallortigara and Rogers (2005), were concerned by the fact that selection pressures on the individual cannot explain the fact that, at the population level, the great majority of vertebrates exhibit functional lateralization in proportions that are different from 1/2. For instance, there is no clear fitness advantage of being right or left-handed, yet humans are most frequently right-handed. The authors show how this might emerge as an evolutionary stable strategy when asymmetric organisms must coordinate their behavior with other asymmetric organisms of the same species (Ghirlanda and Vallortigara, 2004). Intriguingly, there is some evidence that species that are “less social” also exhibit less population-level lateralization (Vallortigara and Bisazza, 2002). In apparent contrast to kin-selection, homophily under this approach more clearly benefits both actors and counterparts, because it is the solution to a fundamental coordination problem (in this case, functional lateralization) stemming from the necessity to predict behavior Vallortigara and Rogers (2005).
However, similarity and liking seem deeply intertwined10, so we also asked what aspect of similarity may have an impact on coordinated behavior; or differently put, is similarity just one among the many mediators of social attraction, or is there some additional strategic/inferential benefit to interacting with similar others, that would be harder to obtain from social attitudes alone?
In synthesis, this study asks three questions. The main one is whether perceived similarities can have an impact on tacit coordination. The second is whether this impact is the same in coordination environments requiring players to either match or decouple their choices. The third asks what aspect of similarity might guide coordination: the fact that agents simply “like” similar others, or the fact that they are better at predicting them? To shed light on these questions, we varied similarity and liking independently and assessed their separate contributions to coordination problems involving strategic complements and substitutes.
Methods
The Games
We used two types of (two-player) coordination games: “Stag Hunts” (SHs) and “Entry Games” (EGs), which have been extensively studied, both in theory and experimental settings (reviewed in Camerer, 2003). In our versions—adapted from Heinemann et al. (2009)—we attempted to keep the superficial aspects of the two games as similar as possible, so that any behavioral difference would be due to their structural (incentive-related) differences. The two games were played in randomized order, and were as follows: in both, two agents had to choose between the same two options: (1) a potentially high paying but uncertain payoff (“UP”), always worth either $/€15.00 or 0; and (2) a lower paying but safe payoff (“SP”), worth a given $ amount (with SP ≤ 15.00). Both games capture a frequent situation, namely, that low gains can be obtained safely in isolation, while high paying outcomes involve coordination and uncertainty. Indeed, in both games, if the SP was chosen, it was obtained for sure, regardless the choice of one's counterpart. On the other hand, the outcome of choosing the UP depended on the choice of one's counterpart, and on the game: in SHs, $15.00 were obtained, by both players, if, and only if, both chose the uncertain option; thus, if only one chose the UP, he or she obtained 0. In EGs, on the other hand, the high gain could only be obtained in isolation, thus if both players chose the potentially high paying UP, both obtained 0. It follows that in SHs, the incentives induce players to attempt and match their choices (either both “risk” and choose the UP, or neither should, but mismatching is costly), while in EGs, players should try to decouple their choices (such that either one player “risks” and the other doesn't, or vice versa, but players should not risk together). Then, by progressively increasing the value of the SP and having participants choose at each (randomized) step we obtained a measure of their uncertainty in the two games; that is, of their willingness to choose the uncertain option, over the lower but certain one. Importantly, since initial coordination patterns usually determine the outcome of their repeated versions (Heinemann et al., 2004), and since we were here interested in the way social distance biases choices rather than how it may bias learning, no feedback on the outcomes of decisions was provided until the end of the experiment. Notably, this set up enabled to compare two very different games by visually altering only a minor detail. Indeed, both games presented (a list of) the SP magnitudes on one side of the screen and the fixed high payoff ($15.00) on the other. The games were thus only differentiated by what was written under the high payoff. The SH condition read, “$15.00 only if 2,” and the EG read, “$15.00 if at most 1” (see the instructions in the Supplementary Material for snapshots).
Similarity Induction
Similarity was manipulated by making participants play with counterparts that were either similar or dissimilar to them. The similarity between players and counterparts was based on the match (similarity condition) or mismatch (dissimilarity condition) of identification ratings (on a scale from 1 to 7) with a group of (three) adjectives describing personality traits. These groups of adjectives were obtained as follows: before participants knew about the games, they rated 100 adjectives describing personality traits. They did so twice: once, indicating how much they identified with a given trait (“ID”), and the second, how much they liked the same trait (“Like”) (in counterbalanced order). As soon as they finished, an algorithm (see Table 2 in the Supplementary Material for details) went through the identity and liking ratings of each of the 100 words and retrieved four groups of words (three words per group) for each participant: (1) the first group was composed of words that a given participant both strongly identified with and strongly liked (i.e., maximizing both liking and identity ratings) (“ID+_Like+”); (2) the second group consisted of words that were identified with but disliked (“ID+ Like−”); (3) the third group, of words that were liked but not identified with (“ID- Like+”); while (4) the fourth and last group was composed of words that were not identified with and were disliked (“ID- Like−”) (see Figure 1). Participants then were told that they would have interacted with several anonymous counterparts and that matched counterparts would have been mutually informed of how they identified with a same group of person-descriptive words. This was made known to participants by the use of rating bars (see Figure 1 below for the design; or Figure 4 in the instructions for a screenshot of the actual task—Supplementary Material).
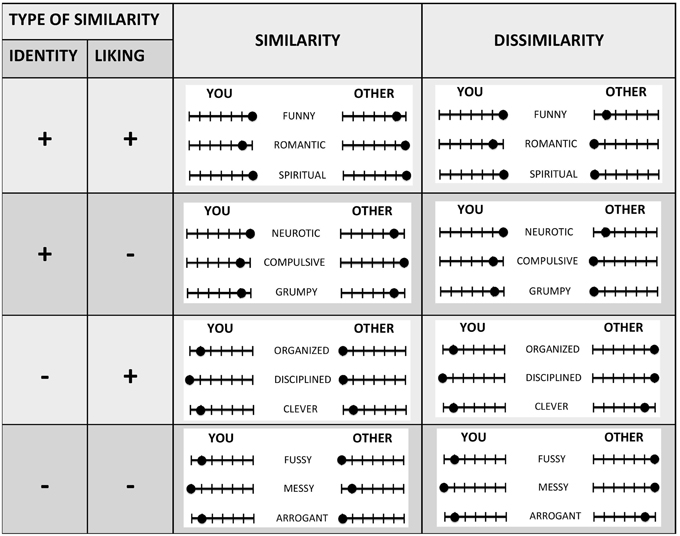
Figure 1. Experimental design. Before taking part in the interactions of interest, participants provided both “liking” and “identity” ratings of a set of 100 personality traits. Subsequently, they interacted with counterparts that were either similar or dissimilar to them with respect to a selected subset of the traits. While playing the games, matched counterparts were told that they mutually viewed rating bars indicating whether they identified or did not identify with the traits. “Liking+” and “Liking-” indicate that participants liked or disliked the selected traits.
Ideally, we would have preferred to not deceive participants, though our design made this difficult. The main problem was that there were relatively few words, for each participant, that satisfied the requirements of our design (i.e., that maximized identity and liking ratings etc.) and these rarely matched between participants. For instance, over the 100 person-descriptive words that participants rated, there were only few of them that each participant maximally (minimally) identified with and maximally (minimally) liked (on average, 4.3 for ID+Like+ condition—s.e. 1.7 -, and 5 for the ID-Like- condition). Furthermore, there were even less optimal words for the “incongruent” word conditions (on average, 1.8 and 1.6 for the ID+Like- and ID-Like+ conditions, respectively). Within the ~15–20 participant sessions we ran, it was thus difficult to find two players that actually rated the same words in similar ways. Perhaps this could have been achieved with a much larger sample size, which was unavailable to us. Alternatively, we could have chosen sub-optimal words (i.e., for the ID+Like+ condition, words that participants only weakly identified with but that were actually shared by multiple participants), though we were concerned that this would have reduced any effect of similarity. In sight of these tradeoffs, we resorted to generating the identity ratings of artificial counterparts, as this allowed us to probe for effects of similarity while effectively controlling for identity and liking. Finally, in order to minimize deception, before taking part in the task of interest, participants also took part in the same two games without knowing anything about their counterparts, and were paid for one of these randomly determined trials. Consequently, participants were in fact paid for their real choices and those of their matched counterparts, though they believed that any trial could be paid. In addition to this choice-dependent payment, participants earned a $5.00 show-up fee.
In synthesis, excluding the latter “trait-neutral” trials, this set-up yielded a 2 × 2 × 2 × 2 design, with factors: (1) game (SHs vs. EGs), (2) similarity (similar vs. dissimilar); (3) liking (liked vs. disliked traits); and (4) identity (high vs. low identification with traits). The instructions we used are available in the Supplementary Material. Within each of the resulting 16 experimental cells, SPs ranged from 1 to 15 in steps of 1, for a total of 240 decisions. Given this high number of decisions, we adopted a presentation method analogous to the strategy method (Selten, 1965), in which participants viewed all 15 SP options of a cell on a single page, rather than making each decision on a separate page. Each of the resulting 16 pages/cells (with 15 decisions for each page) was presented in randomized order.
Person-descriptive words were taken from Dumas et al. (2002), a list of 844 person related adjectives and had been rated on the basis of their likableness. Since we aimed to orthogonalize identity and liking scores as much as possible, while simultaneously inducing a sufficiently strong sense of identification and liking, we needed words that were valenced but not too clearly so, since traits with extreme (high or low) valences also had the lowest likableness variance. Thus, plausibly few people would have identified with words like “dishonest,” but some may have identified with words such as “disorganized” or “whiny.” Consequently, we sorted the traits on the basis of their likableness, and took 100 words from 2 clusters: 50 from a moderately positive cluster, and 50 from moderately negative one.
Lottery
To control for the potential impact of inter-individual differences in (non-strategic) risk attitudes, participants took part in a “lottery” condition, which took place after the strategic games. For the lottery task, participants were endowed with $5.00 additional dollars and were then allowed to make an investment on a lottery extraction with a winning probability of 2/3. Participants could invest any amount (0 included) of their $5.00 endowment. To implement the lottery, in clear sight of all, we placed two red balls and one blue ball (of equal dimension) into a hole on the top of an opaque box, and shook it. Participants were informed that, after placing their bets, a randomly designated participant would have blindly extracted a single ball from the box. If the ball was red the experimenters would have doubled participants' investments, while if the ball was blue, the investment would have been lost. We took the amount invested by each participant as a measure of their (non-strategic)-risk attitudes.
Participants
The experiment was carried out at the University of Southern California. In 5 sessions, 68 participants took part in the 2 coordination tasks, implemented in z-Tree (Fischbacher, 2007).
Procedures
Participants interacted in groups, from individually shielded computer cubicles. After assigning them to a random cubicle (via a bingo chip extraction), instructions were read out loud and followed on instruction sheets. Before starting, participants also took part in a questionnaire that probed their understanding of the games. The questionnaire could only be completed by correctly responding to all of its items. This enabled us to explicitly assure participants that they, and all their potential counterparts, had understood the rules of the games. All procedures were approved by local ethical committees. Our data is available upon request.
Statistical Analysis
Data was analyzed with generalized linear mixed effects models (“GLMMs”: Bolker et al., 2009), with a “bobyqa” optimization algorithm (Powell, 2009), as implemented in the lme4 package (Baayen et al., 2008), in the R environment (Venables and Smith, 2005).
Analysis of Choice
Since our principle dependent variable was the dichotomous choice “SP” or “UP” (i.e., “risk”) we used a GLMM with a logistic link function (as also done in Heinemann et al., 2009). Our main question of interest was whether similarity affected choices oppositely in coordination games that required participants to either match (SHs) or decouple their choices (EGs), and whether this depended on how much participants liked or identified with the personality characteristics that the similarity was based on. Correspondingly, our model included the four-way interaction between the following fixed-effect terms: game*similarity*liking*identity (which automatically included all lower-level interactions). Furthermore, as previous research (Nagel et al., in preparation) has shown that decreasing SPs affects the likelihood of “risking” differentially in SHs and EGs, we added an additional interaction term between these two factors as a covariate. Finally, since Heinemann et al. (2009) have shown that (non-strategic) risk attitudes (i.e., as established by lotteries with known probabilities) are related to “risk” in strategic games, we further introduced the (centered) investments participants had made in the lottery condition (“lottery”), and let this interact with the game factor. In synthesis, our model included the following fixed effect terms: sure payoff *game + game*similarity*liking*identity + lottery*game. At last, our model included a random intercept term to cluster choices by participant. We report the analysis of variance table of this model in the Supplementary Table 1. Then, to inspect the significant interaction constituents (when significant), we simply re-ran the model while resetting the reference point of the factor levels of interest (i.e., as also done in Kanngiesser et al., 2010).
Analysis of Expected Payoffs
As noted above, our participants were only allegedly paid for one randomly determined trial. However, to study the potential economic impact of similarity across SPs and conditions, we computed “expected payoffs” for all trials. To do so we did the following: in any condition, had a participant “i” chosen the SP, the specific value of the SP was attributed to i (since, in both games, if one chose the SP, this was obtained no matter what one's counterpart chose). If however, on a different trial, i had chosen the UP (i.e., to “risk”), then i's payoff was determined in expected value (“EV”), given the posterior probability of being matched to someone else that also chose the UP in the same game11. For instance, suppose that in a given trial participant i chose to risk and 70% of the other players ended up doing so as well. Then, had the trial been a SH, i's expected payoff, was computed as 0.7*15.00 [i.e., EVi = 0.7*15+0*(1 - 0.7)], while had the trial been an EG, it was simply computed as (1 - 0.7)*15.00. In this way, we were able to compute expected payoffs in all trials and explore how they varied as a function of similarity.
Analysis of Coordination Rates
We define “successful coordination” as the probability of “matching choices” (on either of the two options) in the matching environment, and of decoupling choices in the decoupling one. Notably, this notion of coordination ability needn't have a 1-to-1 relation with expected payoffs. For instance, if participants had always chosen the SP in the matching environment, they would have achieved a maximum coordination rate (according to the definition above). Moreover, they would have obtained the same (maximum) coordination rate by always choosing the “risky” option. However, they would have earned much more in the second case, coordination rates being equal. Consequently, in addition to expected payoffs, we aimed to assess how similarity affected the probability of successful coordination.
To compute the probability of successful coordination we did the following: if a given participant “i” had chosen the “risky” option in the matching environment, then his/her probability of successful coordination it coincided with the (posterior) likelihood of being matched to someone who had also chosen the risky option in the corresponding condition (and for the same SP-value)12. Conversely, in the decoupling environment, if a subject had chosen the “risky” option, likelihood of successful coordination was computed as the mean of potential counterparts who had not chosen the “risky” option. In a specular fashion, if a participant had chosen the “safe” option in the matching game, it coincided with the average amount of potential counterparts who had also chosen the safe option in the corresponding condition; while, if one chose the safe option in the decoupling environment it coincided with the mean “risk rates” of one's counterparts. In this manner we computed the probability of “successful coordination” for each choice participants made (given the actual choices of all the others), and we investigated how this was affected by similarity.
Results
Similarity Manipulation Validation
As was to be expected, we observed a positive correlation between identity and liking ratings of the 100 adjectives (r = 0.57, p < 0.001) (Figure 2, blue), suggesting that subjects usually like the traits they identify with or dislike the traits they don't identify with. In spite of this, all four groups of adjectives retrieved by our algorithm could be differentiated (Figure 2, black circles): averaged identity ratings within triplets were significantly higher for the ID+ group than the ID- group (p < 0.001), and liking ratings were higher in the Like+ group than the Like- group (p < 0.001). For the trait triplets meant to have coherent identification and liking scores (namely, ID+Like+ and ID-Like-), ratings between the two dimensions (identity and liking) were not differentiable (both ps > 0.08)13 While for “incoherent” triplets, in which liking and identity were pitted one against the other, the two scores strongly dissociated in the anticipated directions (both ps < 0.001)14. However, given the aforementioned correlation, liking and identity scores also slightly changed when passing from the coherent clusters (ID+Like+ and ID-Like-) to the incoherent ones (ID-Like+ and ID+Like-). For instance, liked adjectives that subjects didn't identify with (ID-Like+) were certainly liked more than disliked adjectives from either of the two “low-liking” clusters (both ps < 0.001)15, however they weren't liked as much as those that subjects also identified with16. To partially alleviate this residual multicollinearity of liking and identity, we checked that the results obtained in our statistical model held when using the centered identity and liking scores, rather than the corresponding (i.e., “high vs. low”) factors.
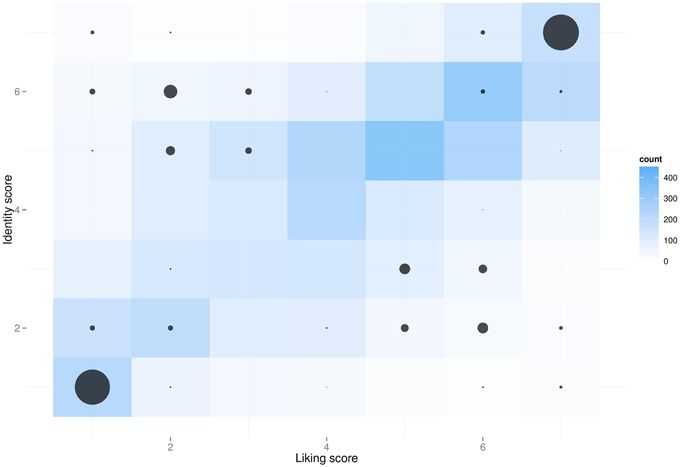
Figure 2. Identity and liking ratings of 100 personality traits by 68 participants (on a 1–7 Likert scale). Darker blue indicates more frequent observations, which can be clearly seen to fall on the diagonal, indicating that subjects usually identify with the traits they like, and vice versa. Of the 100 traits each subject rated, an algorithm selected four subject-specific triplets of adjectives that best fit into the four corners of this “identification-by-liking” space. Black circle sizes are proportional to the number of adjectives that were selected by the algorithm. During the subsequent games, subjects were matched with others that either identified or didn't identify with the triplet of traits selected by the algorithm.
Behavior in Games
A logistic generalized mixed effects model was fit to the data and no observations were excluded from the analysis. The model revealed a significant 4-way interaction between the factors game, similarity, identity, and liking (X2 = 5.046, p < 0.05) (see Table 1 in Supplementary Material). This suggests that similarity had a differential impact on choices depending on its characteristics and on whether choices had to be matched or decoupled. The direction of the interaction constituents was as anticipated: when traits were both liked and identified (ID+Like+) similarity significantly increased the probability of “risky” choices in SHs (p < 0.001)17 but decreased it in EGs (p < 0.05)18 (Figure 3, top left panel). Notably, neither of these effects was observed when similarity was based on traits that were liked but not identified with (i.e., “we're both not organized” vs. “I'm not organized, you are”) (ID-Like+) (p = 0.22)19, or when similarity was based on traits that were identified with but disliked (i.e., “we're both neurotic” vs. “I'm neurotic, you are not”) (ID+Like-) (p = 0.91)20 (see Figure 3, top right and bottom left panels).
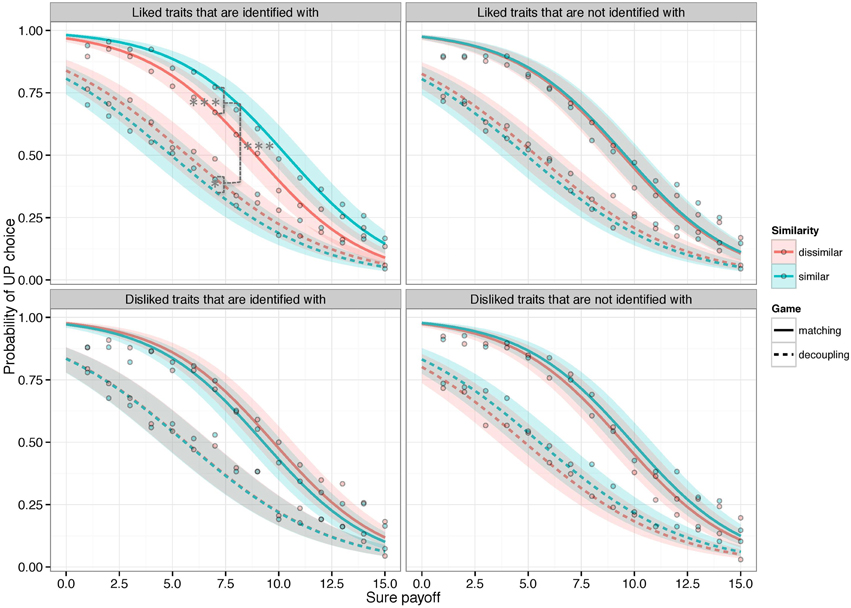
Figure 3. The impact of similarity on coordination games requiring players to either match their choices (“strategic complements” – “Stag hunt” games) or decouple them (“strategic substitutes” – “Entry” games) without communicating. Curves represent estimated probabilities of choosing a potentially higher paying, but uncertain payoff (y-axis) (“UP”), given increasing values of a safe alternative (x-axis), when interacting with either similar or dissimilar (anonymous) counterparts. Similarity was based solely on the fact that counterparts similarly identified (or did not identify) with three personality-descriptive words. Estimates were obtained with a generalized logistic mixed model. Error bands represent 95% confidence bands for the fixed effects. Points are the observed percentages of UP choices. Stars indicate significant effects of similarity on the estimated probability of making a risky choice *p < 0.05, ***p < 0.001.
Expected Payoff
Importantly, similarity not only affected choices, but it affected expected payoffs as well. Indeed, especially when personality traits were liked and identified with (liking*similarity*identity interaction: p < 0.05), we observed a positive effect of similarity on payoffs, in both the SHs ($0.50, s.e. = 0.14, p < 0.001) and the EGs ($0.14, s.e. = 0.05, p < 0.01).
Probability of Successful Coordination
Focusing on the condition in which we observed a significant effect of similarity on choice (the “ID+Like+” condition)21, we found that, in the matching environment participants in the similarity condition were indeed more likely to match their choices than in the dissimilarity condition (p < 0.001), especially when choosing the “risky” option. However, similarity did not increase coordination in the decoupling environment, that is, similar counterparts were not “better” at decoupling their choices than dissimilar ones (p = 0.23). More specifically, we found that this was due to the fact that, restricting the comparison of “coordination rates” to “safe choices” only, participants in the similarity condition were nearly worse at decoupling their choices than those in the dissimilarity condition (p = 0.07), that is, they “should have” entered more frequently. On the “flip side” of this, when restricting the same comparison to “risky choices,” participants in the similarity condition were more likely to successfully decouple their choices (p < 0.01).
Covariates: Game, Sure Payoff, and Risk Attitudes
As expected, our model estimated that the likelihood of making a “risky” decision was roughly 23% lower when choices had to be decoupled (EGs) rather than when they had to be matched (SHs) (p < 0.001), suggesting a relative propensity for matching choices, rather than decoupling them (regardless of similarity). In spite of this, uncertainty in SHs was far from absent. Indeed, while participants readily chose the uncertain option when the alternative safe payoffs were low, they gradually ceased to do so as safe payoffs increased (log odds of slope = −0.51, s.e. = 0.01, p < 0.001). Specifically, participants appeared indifferent between the two options when the sure payoff was roughly 2/3 of what they could have earned by choosing the uncertain option together (average indifference point = $9.98). Correspondingly, increasing SP values linearly decreased expected payoff as well (p < 0.001). Finally, risk attitudes as established from our lottery condition did explain some of this variance. Indeed, the more participants invested in the lotteries, the more likely they were to choose the uncertain option in the EG only (game*risk interaction: p < 0.001). However, the reported effects of similarity were net of the effect of all of these covariates.
Discussion
Across across ages (Meltzoff, 2007), cultures (Apicella et al., 2012), and species (Massen and Koski, 2014) similarity has been shown to play a fundamental role in the formation of social ties and networks (McPherson et al., 2001; Ames, 2004; Mitchell et al., 2006; Fischer, 2009; Krueger et al., 2012; Fischer et al., 2013). Coordination problems have also perplexed decision theorists for decades (Schelling, 1960; Cooper et al., 1990; Van Huyck et al., 1990; Camerer, 2003; Heinemann et al., 2009). Yet no study has investigated whether classic coordination problems are affected by perceived interpersonal similarities (Cole and Teboul, 2004).
In this study we investigated this by having participants decide whether to take a number of real financial risks (as opposed to a safe alternative), when tacitly coordinating their choices with counterparts who were either similar or dissimilar to them with regards to three person-descriptive words. We report three novel findings: (1) in coordination games with strategic compliments, in which participants had an incentive to match their choices (stag hunts), similar counterparts incurred higher financial “risks” than dissimilar counterparts; (2) however, in games with strategic substitutes, where participants were to decouple their choices (entry games), we observed the opposite pattern: similar counterparts were willing to incur less risk than dissimilar ones; (3) both of these effects were only observed when similarity was based on traits that participants also liked and identified with. We would like to comment on each of these findings in turn.
Similarity and “Complementarity”: Propensity for Matching Choices
Coordination games with strategic complementarities are not just a major theoretical problem for game theory (Camerer, 2003) they could also be a pragmatic one. The problem is that even in situations that present clear economic synergies to all players (i.e., typical “win-win” situations like stag hunts22), coordination still often fails (Cooper et al., 1990). Indeed, especially when the “risk” involved is high (Harsanyi and Selten, 1988)—that is, when the safe alternative to coordinating becomes large enough—coordination almost always fails (Cooper et al., 1992; Heinemann et al., 2009)23. Seemingly, this occurs because, even though all players would prefer to coordinate on the higher paying option24, they fear that their counterparts might not do the same25. Our results suggest that perceived interpersonal similarities could then provide the assurance26 players need in order to coordinate more efficiently: “I wish to choose the optimal option, and if my counterpart is like me he/she is more likely to do so as well.”
Notably, in our experimental design, similarity/dissimilarity was only based on self-reported identification with three trait-related words, and one could sensibly argue that this is no basis for a reliable estimate of similarity (or at least not enough to incur different financial risks for). In spite of this, even such a partial or occasional form of similarity proved sufficient to affect economic coordination. In fact, humans appear particularly sensitive to similarity-related cues, even to ones that are completely unrelated to the task at hand. For instance, notorious minimal-group paradigms have repeatedly shown how in-group favoritism and out-group discrimination in games can emerge even when the only thing that ingroups have in common is having preferred a painting of Kandinsky over Klee (Billig and Tajfel, 1973; or more recently, Chen and Li, 2009), rather than having over or under counted a number of dots on a screen (Gerard and Hoyt, 1974). In line with this, even non-social similarity (or “content free similarity”) has been shown to impact social inferences and perspective taking (Todd et al., 2010), as well as behavior in games (Mussweiler and Ockenfels, 2013)27. It thus appears that subjects can pick up on similarity-related cues rather easily and that they often then generalize them to unrelated domains28. Notably, a large meta-analysis on similarity (Montoya et al., 2008) suggests that, at least with respect to “relationship quality,” perceived similarities can even be more important than actual similarities, and this, in principle, could hold for coordination as well.
In line with this, we found that even our weak form of similarity not only decreased subjective uncertainty in stag hunts, but it also increased the expected payoff of the interactions. It follows that had the games been repeated, such similarity-related behaviors and cognitions could have been potentially been reinforced; and though this would be a matter for further experimentation, it opens the possibility that, regardless of whether generalizations of similarity are valid or invalid29, they could be adaptive in coordination environments with strategic complementarities.
Similarity and Substitutability: Aversion to Decoupling Choices
Our hypothesis that similarity would provide assurance in stag hunt games was based on the following paraphrased inference: “I wish to choose the optimal option, and if my counterpart is like me he/she is more likely to do so as well.” However, and critically, while such a line of inference would indeed generate assurance in stag hunts, it could even increase uncertainty in games involving strategic substitutes, such as entry games. Indeed, in such games, if both participants choose their own optimal outcomes, they both obtain nothing at all. Our findings are in line with this: while similar players took more “risk” than dissimilar players in stag hunts, the opposite was true for entry games: similar counterparts took less risk than dissimilar ones.
Even though the direct comparison has seldom been made in the literature, previous findings suggest that games with strategic substitutes elicit higher uncertainty than games with strategic compliments (Chark and Chew, 2013). For instance, Camerer and Karjalainen (1994) found that players exhibited an aversion to uncertainty when they were to decouple their choices (i.e., because their payoffs were anti-correlated), while Fox and Weber (2002) observed a relative propensity for uncertainty when players had to match them (in a coordination game involving correlated payoffs). This could be related to the notion that stag hunts and entry games differ in amount of required deliberation and recursive thinking (Nagel et al., in preparation). In line with this, we find that, regardless of similarity, players clearly choose the uncertain option less frequently in entry games than stag hunts (see Figure 330) and that they choose it even less when they play entry games with similar counterparts.
A second important difference between stag hunts and entry games is that the standard notion of mixed strategy equilibrium (“MSE”) works very poorly for stag hunts but very well for entry games (Camerer and Fehr, 2006)31. For example, in an entry game with SP = 1, (risk-neutral) players are in MSE, only if 93% of them are “entering” (i.e., choosing the UP). Indeed, if a given player “i” believed that 93% of (non-i) agents were entering in such a game (or, equivalently, that a single counterpart “j” entered with a probability of 0.93), his expected earning for entering as well would be equal to the high payoff ($15.00) multiplied by the probability of being matched to someone who did not enter; that is, (1 - 0.93)*15.00 = $1.00. As one can see, for this specific probability only (p = 0.93), the expected value of entering is equivalent to the amount player i would obtain for sure by choosing the SP option. Consequently, for this expected entry rate (of other players), an agent would be indifferent between the two options, thus in equilibrium.
Naturally, this reasoning would seem futile because players have little information on which to base their probability estimates in one-shot entry games, so how can they decide who should enter and who choose the certain option? Yet, without communication, or trial and error, groups of players are known to “split up” in proportions that are very similar to those predicted by MSE (Camerer and Fehr, 2006; reviewed in Erev and Rapoport, 1998). Indeed, we observed this in our data as well: aggregating choices across participants, we found that MSE-based probabilities (computed for each SP32) predicted very well the proportions in which participants “split up” between entering and non-entering (r = 0.97, p < 0.001) (“To a psychologist” Daniel Kahneman said, “it looks like magic”) (Kahneman, 1988).
To this we make one addition: since MSE outcomes are actually rather inefficient in terms of payoffs33, and similarity lowered entry rates, similarity can actually increase the expected payoffs in entry games. In other words, since similarity generally lowered entry rates (in the ID+Like+ condition), the relatively fewer participants that did enter had a sufficiently high probability of being matched to someone who had not entered; high enough to significantly grant a payoff advantage of similarity. Notably, this occurred in spite of the fact that similarity did not increase participants' general ability to decouple their choices (while it did favor matching in the matching environment). We thus suspect that similarity might have “indirectly” increased expected payoffs in decoupling environments, more as a result of increased uncertainty (i.e., lowered entry rates), rather than as a result of increased decoupling abilities.
At any rate, our findings show how similarity can potentially increase expected payoffs of interactions over the two opposite poles of coordination: matching and decoupling. This could shed light on why homophily is so successful as a social attractor.
The Impact of Similarity on Coordination: Not Just Social Preferences
As illustrated by Cooper et al. (1990), “a weakness of the Nash equilibrium concept is that it may not generate a unique equilibrium. In this case it must be augmented by a hypothesis refining the beliefs of players about the strategies selected by their opponents” [cursive our own]. So far, we have treated perceived similarities as affecting precisely the beliefs or inferences of players in coordination environments: if similarity leads players to believe they are more likely to make similar choices, this should decrease uncertainty when choices are to be matched (stag hunts), but increase it when they are to be decoupled (entry games).
However, this interpretation faces a potentially important confound. Indeed, as we illustrated in the introduction of this paper, similarity has primarily been considered to increase interpersonal attraction (Byrne, 1971; McPherson et al., 2001) and a social preferences approach (Van Lange, 1999; Fehr and Fischbacher, 2003) could in principle explain our findings without recurring to inferences or beliefs at all. In fact, under the latter view, participants would simply “prefer” similar to dissimilar others and consequently choose the options that benefit similar targets more than dissimilar ones. In line with this, it can be demonstrated for our two games that if payoff interdependencies are introduced—such that one's subjective utility is assumed to be proportional to the payoff of one's counterpart (in addition to his/her own)—then the expected value of “risking” (relative to the alternative sure payoff) increases in SHs, but decreases in EGs, which is in fact the behavioral pattern we observe34.
However, our design enabled to address this potential confound. Specifically we found that similarity only affected coordination when the traits on which it was based on were also liked and identified with (our ID+Like+ condition). Importantly, had this effect been due to “liking” alone, we should have observed the reversed pattern of similarity in the ID+Like- or ID-Like+ conditions. In fact, in these conditions, dissimilar others were characterized by traits that the participants liked, whereas similar others were not (ID-Like+); or dissimilar others did not identify with traits that participants disliked, while similar counterparts did (ID+Like-). Had the effect of similarity in the ID+Like+ condition been due to liking alone, we should have thus found that risk rates were higher when participants coordinated with dissimilar others in stag hunts, and higher for similar others in entry games. However, neither of these effects was observed. This suggests that our observed effect of similarity on coordination was not due to liking alone.
Conclusion
According to Quine (1969), “There is nothing more basic to thought and language than our sense of similarity”35 and psychologists have long insisted that, since early stages of development (Meltzoff, 2007), similarity could provide a fundamental window on to the minds of others (Ames, 2004; Robbins and Krueger, 2005; Goldman, 2006; Krueger et al., 2012). Indeed, the finding that similarity breeds attraction has been called “one of the most robust relationships in all of the behavioral sciences” (Berger, 1973). In spite of this, no study had investigated the impact of perceived similarities on tacit coordination.
Here, we demonstrated that agents are willing to incur higher financial risks when they are to coordinate their choices with similar others. However, we find that this effect is specific to coordination environments in which all agents would prefer to match their choices. In fact, when agents should decouple their choices, we observe the opposite effect; namely, similar others take less financial risks than dissimilar ones. On the basis of this, we suggest that perceived interpersonal similarities can indeed be used as a coordination device and that they can both decrease and increase strategic uncertainty, depending on the incentives at play. Furthermore, we find that when similarity is removed from interpersonal attraction, its impact on coordination is much decreased, if at all present. At last, our finding that perceived interpersonal similarities can increase the collected expected payoffs of agents might shed light on why homophily, or “love for similar others,” is so successful as a social attractor.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We thank Isabelle Brocas, Juan Carrillo and Aldo Rustichini for their insightful comments, as well as Anna Balatel, Dalton Combs, Elsa Fouragnan, Tommaso Furlanello, Mateus Joffily, Luca Polonio, Mariachiara Rummolino, and especially Silvia Caruso for their invaluable support. The study was funded by the European Research Council (ERC Consolidator Grant 617629) grant to GC.
Supplementary Material
The Supplementary Material for this article can be found online at: http://journal.frontiersin.org/article/10.3389/fnbeh.2015.00202
Footnotes
1. ^Analogously, in conceited arguments, everyone would like to get their message through first, though if everyone tries to do so at the same time, no one succeeds, because attentional resources are limited. Or, in emergencies, everyone would tend to rush through the fire exit, though overcrowding it would only make things worse.
2. ^Related measures have been proposed in terms of game “difficulty” (Rapoport, 1967), indexes of “correspondence” (Kelley and Thibaut, 1978), or game “harmony” (Zizzo and Tan, 2007).
3. ^Camerer (2003) provides a number of real-life examples in which coordination is required but communication isn't possible. Furthermore, even when communication is possible, it doesn't completely resolve “matching problems” (Cooper et al., 1992) and it has even been shown to potentially complicate “decoupling” ones (Cooper et al., 1989; Ellingsen and Östling, 2010). Notably, if words have slightly different meanings to different people (i.e., different cultures), communication can also lead to incomprehension and conflict (Weber and Camerer, 2003).
4. ^Though see Harsanyi and Selten (1988) or Carlsson and Van Damme (1993) for important game theoretic refinements on coordination.
5. ^Eric Fischer's city maps are a particularly compelling demonstration of ethnicity-based homophily (https://www.flickr.com/photos/walkingsf/4981444199/in/set-72157624812674967) (though distinguishing homophilic aggregation from segregation might not be straightforward).
6. ^One notorious instance of this is the “false-consensus effect” (see Marks and Miller, 1987 for a review); though see also Goldman (2006); Goldman (in particular Chapter 7) for a survey of all the (“high-level” mind-reading) domains in which subjects have been shown to attribute their own perspectives and knowledge to others.
7. ^Intriguingly, humans have even been shown to recruit the same neural structures when answering questions about themselves and similar, but not dissimilar others (Mitchell et al., 2006; Jenkins et al., 2008).
8. ^Notably, in notorious social dilemmas such as prisoner's dilemmas or public good games, cooperators aim to match their choices with their counterparts, while “free-riders” aim to decouple them. Indeed, many studies have stressed the strong link between cooperation and coordination (Dawes et al., 1977; Messé and Sivacek, 1979; Kollock, 1998a,b; Hayashi et al., 1999; Camerer, 2003). Consequently, if similarity has an effect on coordination, this could carry over to cooperation dilemmas (Fischer, 2009; Krueger et al., 2012; Fischer et al., 2013).
9. ^Even newly hatched chicks have been shown to move toward a tone they had prenatally been exposed to rather than novel tones (Rajecki, 1974).
10. ^Incidentally, in English, the same word can be used to express both concepts: “we like those who are like us.”
11. ^More specifically, the choices of one's “average counterpart” were taken from the same experimental cell only for the similarity conditions. In the dissimilarity condition this did not seem justified. For instance, when coordinating with a dissimilar other in the Like+ID+ condition (or the Like+ID-, Like-ID+, and Like-ID- conditions), participants were matched with someone with who did not identify in the same triplet of traits, thus of someone in the Like+ID- (“dissimilar”) condition (and respectively, the Like+ID-, Like-ID-, and Like-ID+ conditions), not of someone in the Like+ID+ (“dissimilar”) condition. Correspondingly, averaged counterpart choices in the dissimilarity condition only were re-mapped as just described.
12. ^In other words, the probability of successfully coordinating with others, when one chose the risky option, coincided with the “mean risk rate” of one's potential counterparts.
13. ^ID+Like+: mean difference (ID - Liking) = 0.04, p > 0.3; ID-Like- (ID - Liking) = 0.07, 95% CI [− 0.007 0.1], p = 0.08.
14. ^ID-Like+: mean difference (ID – Liking) = -3.4, p < 0.001; ID+Like- (ID – Liking): 3.7, p < 0.001.
15. ^Mean difference in liking (ID-Like+) – (ID+Like-) = 3.7, p < 0.001; mean difference in liking (ID-Like+) – (ID-Like-) = 4.4, p < 0.001.
16. ^Mean difference in liking (ID-Like+ - ID+Like+) = −1, p < 0.001.
17. ^Log-likelihood difference(sim−dissim) = 0.54, s.e. = 0.12.
18. ^Log-likelihood difference(sim−dissim) = −0.22, s.e. = 0.11.
19. ^SH(sim−dissim) = 0.05, s.e. = 0.11, p = 0.44; EG(sim−dissim) = −0.13, s.e. = −0.11, p = 0.22.
20. ^SH(sim−dissim): −0.17, s.e. = 0.11, p = 0.13; EG(sim−dissim): −0.01, s.e. = 0.11, p = 0.91.
21. ^In fact, a model including all the conditions revealed a significant 3-way interaction between similarity, liking, and identity (p < 0.05), in determining coordination rates.
22. ^Camerer (2003) calls the stag hunt game “the building block of economic situations with “strategic complementarities.”
23. ^A potential parallel observation in prisoner's dilemma games is Rapoport's “game difficulty index” (Rapoport, 1967), which predicts higher cooperation depending on the ratio between payoff magnitudes of the “cooperate” or “defect” outcomes. This was a curious and early finding because, according to game theory, subjects should always defect in (one-shot) prisoner's dilemmas, thus “risk” should have nothing to do with it.
24. ^In fact, when players can communicate their intentions to one another, they do coordinate on the higher paying option, even when they know that their “promises” are non-binding (Cooper et al., 1992).
25. ^Furthermore, players might not only be afraid that their counterparts will not coordinate on the payoff efficient outcome (i.e., a 1st order belief), but they might also think that their counterparts fear the same about them (i.e., a 2nd order belief), and so forth (for higher order beliefs). This can generate what Hofstadter calls “reverberating doubt” (Hofstadter, 1985).
26. ^Stag hunts are also called “assurance games” (Camerer, 2003).
27. ^For example, in one study (Todd et al., 2010), participants were divided into two groups, both of which were shown a pair of images of landscapes. One group had to list the similarities between the two images while the other group had to list the dissimilarities. The two groups then underwent a number of social tasks involving other agents. One of the tasks, for instance, required participants to neglect their own (privileged) knowledge, in order to correctly infer the false-beliefs of a naïve target. Surprisingly, participants in the similarity condition had more difficulties in doing so, thus systematically (over-) attributing their own thoughts and perspectives to others.
28. ^In spite of this, we don't expect similarity to always affect inferences, especially when it conflicts with other forms of relevant information. For instance, knowing that someone is very “risk-averse” would be arguably relevant to predicting his or her behavior in games involving some form of uncertainty. Consequently, we would expect similarity to no longer raise risk rates in stag hunts if it was, for instance, based on the fact that two players are similar in their “risk-aversion.” Similarities might also need to be salient enough, like group membership in related paradigms (Charness et al., 2006; Chen and Li, 2009).
29. ^The case has often been made (Dawes, 1989; Krueger, 2008; Krueger et al., 2012) that some egocentric biases may actually not be biases at all, but the result of correct Bayesian inferences that are based on a sample size of 1 (i.e. one's own opinion, preferences or attitude).
30. ^The two entry game curves are lower than the two stag hunt ones.
31. ^MSE assumes that players choose options with a given probability, rather than choosing each strategy with dichotomous probability (i.e., p = 1 or p = 0)—as in “pure strategy” equilibrium. For instance, in the game of “rock, paper scissors,” there is only one mixed-strategy equilibrium, which is for both players to choose each strategy with a probability of 1/3 (Cook et al., 2012). In fact, if a player adopted any other probability distribution over his/her choices this would be exploited by a rational counterpart, thus leading the first player to revert back to a uniform distribution.
32. ^We computed MSE solutions, for each SP value by solving for the “Pj (UP)” term in the following equation: SP = (1 - Pj (UP))*15.00; where Pj (UP) is the posterior probability of being matched with a counterpart who also chose the UP on the target trial.
33. ^For instance, in a hypothetical EG with SP = 0 MSE would predict all “rational” agents to enter, “collide” with one another and thus to all earn 0. Consequently, many deviations from this inefficient equilibrium can raise average expected payoffs.
34. ^Put differently, if one makes no inferences at all and simply wishes to choose the option that maximally benefits his/her counterpart, this option is the uncertain one in stag hunts, and the certain one in the entry game. Indeed, if one always made these respective choices in the two games, their counterparts would never lose.
35. ^Though see Sloman and Rips (1998) or Gilboa and Schmeidler (1995) for more recent reviews on similarity.
References
Alberts, S. C. (1999). Paternal kin discrimination in wild baboons. Proc. Biol. Sci. 266, 1501–1506. doi: 10.1098/rspb.1999.0807
Ames, D. R. (2004). Strategies for social inference: a similarity contingency model of projection and stereotyping in attribute prevalence estimates. J. Pers. Soc. Psychol. 87, 573. doi: 10.1037/0022-3514.87.5.573
Apicella, C. L., Marlowe, F. W., Fowler, J. H., and Christakis, N. A. (2012). Social networks and cooperation in hunter-gatherers. Nature 481, 497–501. doi: 10.1038/nature10736
Baron-Cohen, S., Leslie, A. M., and Frith, U. (1985). Does the autistic child have a “theory of mind”? Cognition 21, 37–46. doi: 10.1016/0010-0277(85)90022-8
Baayen, R. H., Davidson, D. J., and Bates, D. M. (2008). Mixed-effects modeling with crossed random effects for subjects and items. J. Mem. Lang. 59, 390–412.
Berger, C. R. (1973). Task performance and attributional communication as determinants of interpersonal attraction. Commun. Monogr. 40, 280–286. doi: 10.1080/03637757309375805
Billig, M., and Tajfel, H. (1973). Social categorization and similarity in intergroup behaviour. Eur. J. Soc. Psychol. 3, 27–52. doi: 10.1002/ejsp.2420030103
Bolker, B. M., Brooks, M. E., Clark, C. J., Geange, S. W., Poulsen, J. R., Stevens, M. H. H., et al. (2009). Generalized linear mixed models: a practical guide for ecology and evolution. Trends Ecol. Evol. 24, 127–135. doi: 10.1016/j.tree.2008.10.008
Bulow, J. I., Geanakoplos, J. D., and Klemperer, P. D. (1985). Multimarket oligopoly: strategic substitutes and complements. J. Polit. Econ. 95, 488–511. doi: 10.1086/261312
Camerer, C. (2003). Behavioral Game Theory: Experiments in Strategic Interaction. New York, NY: Princeton University Press.
Camerer, C. F., and Fehr, E. (2006). When does “economic man” dominate social behavior? Science 311, 47–52. doi: 10.1126/science.1110600
Camerer, C. F., and Karjalainen, R. (1994). “Ambiguity-aversion and non-additive beliefs in non-cooperative games: experimental evidence,” in Models and Experiments in Risk and Rationality (Boston, MA: Springer), 325–358. doi: 10.1007/978-94-017-2298-8_17
Carlsson, H., and Van Damme, E. (1993). Global games and equilibrium selection. Econometrica 95, 989–1018. doi: 10.2307/2951491
Chark, R., and Chew, S. H. (2013). A Neuroimaging Study of Preference for Strategic Uncertainty. Available online at: http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2016876
Charness, G., Rigotti, L., and Rustichini, A. (2006). Individual Behavior and Group Membership. Available online at: http://papers.ssrn.com/sol3/papers.cfm?abstract_id=894685. doi: 10.2139/ssrn.894685
Chen, Y., and Li, S. X. (2009). Group identity and social preferences. Am. Econ. Rev. 99, 431–457. doi: 10.1257/aer.99.1.431
Christakis, N. A., and Fowler, J. H. (2014). Friendship and natural selection. Proc. Natl. Acad. Sci.U.S.A. 111(Suppl. 3), 10796–10801. doi: 10.1073/pnas.1400825111
Clement, R. W., and Krueger, J. (2002). Social categorization moderates social projection. J. Exp. Soc. Psychol. 38, 219–231. doi: 10.1006/jesp.2001.1503
Cole, T., and Teboul, B. (2004). Non−zero−sum collaboration, reciprocity, and the preference for similarity: developing an adaptive model of close relational functioning. Pers. Relatsh. 11, 135–160. doi: 10.1111/j.1475-6811.2004.00075.x
Cook, R., Bird, G., Lünser, G., Huck, S., and Heyes, C. (2012). Automatic imitation in a strategic context: players of rock–paper–scissors imitate opponents' gestures. Proc. Biol. Sci. 279, 780–786. doi: 10.1098/rspb.2011.1024
Cooper, R., DeJong, D. V., Forsythe, R., and Ross, T. W. (1989). Communication in the battle of the sexes game: some experimental results. Rand J. Econ. 20, 568–587. doi: 10.2307/2555734
Cooper, R. W., DeJong, D. V., Forsythe, R., and Ross, T. W. (1990). Selection criteria in coordination games: some experimental results. Am. Econ. Rev. 80, 218–233.
Cooper, R., DeJong, D. V., Forsythe, R., and Ross, T. W. (1992). Communication in coordination games. Q. J. Econ. 107, 739–771.
Currarini, S., Jackson, M. O., and Pin, P. (2009). An economic model of friendship: homophily, minorities, and segregation. Econometrica 77, 1003–1045. doi: 10.3982/ECTA7528
Dawes, R. M. (1989). Statistical criteria for establishing a truly false consensus effect. J. Exp. Soc. Psychol. 25, 1–17. doi: 10.1016/0022-1031(89)90036-X
Dawes, R. M., McTavish, J., and Shaklee, H. (1977). Behavior, communication, and assumptions about other people's behavior in a commons dilemma situation. J. Pers. Soc. Psychol. 35, 1. doi: 10.1037/0022-3514.35.1.1
DeBruine, L. M. (2002). Facial resemblance enhances trust. Proc. Biol. Sci. 269, 1307–1312. doi: 10.1098/rspb.2002.2034
Dumas, J. E., Johnson, M., and Lynch, A. M. (2002). Likableness, familiarity, and frequency of 844 person-descriptive words. Pers. Individ. Dif. 32, 523–531. doi: 10.1016/S0191-8869(01)00054-X
Ellingsen, T., and Östling, R. (2010). When does communication improve coordination? Am. Econ. Rev. 100, 1695–1724. doi: 10.1257/aer.100.4.1695
Epley, N., Keysar, B., Van Boven, L., and Gilovich, T. (2004). Perspective taking as egocentric anchoring and adjustment. J. Pers. Soc. Psychol. 87, 327. doi: 10.1037/0022-3514.87.3.327
Erev, I., and Rapoport, A. (1998). Coordination,“magic,” and reinforcement learning in a market entry game. Games Econ. Behav. 23, 146–175. doi: 10.1006/game.1997.0619
Fehr, E., and Fischbacher, U. (2003). The nature of human altruism. Nature 425, 785–791. doi: 10.1038/nature02043
Fischbacher, U. (2007). z-Tree: Zurich toolbox for ready-made economic experiments. Exp. Econ. 10, 171–178. doi: 10.1007/s10683-006-9159-4
Fischer, I. (2009). Friend or foe: subjective expected relative similarity as a determinant of cooperation. J. Exp. Psychol. 138, 341. doi: 10.1037/a0016073
Fischer, I., Frid, A., Goerg, S. J., Levin, S. A., Rubenstein, D. I., and Selten, R. (2013). Fusing enacted and expected mimicry generates a winning strategy that promotes the evolution of cooperation. Proc. Natl. Acad. Sci. U.S.A. 110, 10229–10233. doi: 10.1073/pnas.1308221110
Fowler, J. H., Settle, J. E., and Christakis, N. A. (2011). Correlated genotypes in friendship networks. Proc. Natl. Acad. Sci. U.S.A. 108, 1993–1997. doi: 10.1073/pnas.1011687108
Fox, C. R., and Weber, M. (2002). Ambiguity aversion, comparative ignorance, and decision context. Organ. Behav. Hum. Decis. Process. 88, 476–498. doi: 10.1006/obhd.2001.2990
Fu, F., Nowak, M. A., Christakis, N. A., and Fowler, J. H. (2012). The evolution of homophily. Sci. Rep. 2:845. doi: 10.1038/srep00845
Gerard, H. B., and Hoyt, M. F. (1974). Distinctiveness of social categorization and attitude toward ingroup members. J. Pers. Soc. Psychol. 29, 836. doi: 10.1037/h0036204
Ghirlanda, S., and Vallortigara, G. (2004). The evolution of brain lateralization: a game-theoretical analysis of population structure. Proc. Biol. Sci. 271, 853–858. doi: 10.1098/rspb.2003.2669
Gilboa, I., and Schmeidler, D. (1995). Case-based decision theory. Q. J. Econ. 110, 605–639. doi: 10.2307/2946694
Gilovich, T., Medvec, V. H., and Savitsky, K. (2000). The spotlight effect in social judgment: an egocentric bias in estimates of the salience of one's own actions and appearance. J. Pers. Soc. Psychol. 78, 211. doi: 10.1037/0022-3514.78.2.211
Gilovich, T., Savitsky, K., and Medvec, V. H. (1998). The illusion of transparency: biased assessments of others' ability to read one's emotional states. J. Pers. Soc. Psychol. 75, 332. doi: 10.1037/0022-3514.75.2.332
Goldman, A. I. (2006). Simulating Minds: The Philosophy, Psychology, and Neuroscience of Mindreading. New York, NY: Oxford University Press. doi: 10.1093/0195138929.001.0001
Hamilton, W. D. (1963). The evolution of altruistic behavior. Am. Nat. 97, 354–356. doi: 10.1086/497114
Harsanyi, J. C., and Selten, R. (1988). A General Theory of Equilibrium Selection in Games, Vol. 1. Cambridge: MITPress Books.
Hayashi, N., Ostrom, E., Walker, J., and Yamagishi, T. (1999). Reciprocity, trust, and the sense of control a cross-societal study. Ration. Soc. 11, 27–46. doi: 10.1177/104346399011001002
Heinemann, F., Nagel, R., and Ockenfels, P. (2004). The theory of global games on test: experimental analysis of coordination games with public and private information. Econometrica 72, 1583–1599. doi: 10.1111/j.1468-0262.2004.00544.x
Heinemann, F., Nagel, R., and Ockenfels, P. (2009). Measuring strategic uncertainty in coordination games. Rev. Econ. Stud. 76, 181–221. doi: 10.1111/j.1467-937X.2008.00512.x
Hofstadter, D. (1985). Metamagical Themas: Questing for the Essence of Mind and Pattern. New York, NY: Basic Books.
Holmes, W. G., and Sherman, P. W. (1982). The ontogeny of kin recognition in two species of ground squirrels1. Am. Zool. 22, 491–517. doi: 10.1093/icb/22.3.491
Jenkins, A. C., Macrae, C. N., and Mitchell, J. P. (2008). Repetition suppression of ventromedial prefrontal activity during judgments of self and others. Proc. Natl. Acad. Sci.U.S.A. 105, 4507–4512. doi: 10.1073/pnas.0708785105
Jones, B., and Rachlin, H. (2006). Social discounting. Psychol. Sci. 17, 283–286. doi: 10.1111/j.1467-9280.2006.01699.x
Kahneman, D. (1988). “Experimental economics: a psychological perspective,” in Bounded Rational Behavior in Experimental Games and Markets, (Berlin; Heidelberg: Springer), 11–18. doi: 10.1007/978-3-642-48356-1_2
Kanngiesser, P., Gjersoe, N., and Hood, B. M. (2010). The effect of creative labor on property-ownership transfer by preschool children and adults. Psychol. Sci. 21, 1236–1241. doi: 10.1177/0956797610380701
Kelley, H. H., and Thibaut, J. W. (1978). Interpersonal Relations: A Theory of Interdependence. New York, NY: Wiley.
Keysar, B. (1994). The illusory transparency of intention: linguistic perspective taking in text. Cogn. Psychol. 26, 165–208. doi: 10.1006/cogp.1994.1006
Kollock, P. (1998a). Social dilemmas: the anatomy of cooperation. Annu. Rev. Sociol. 24, 183–214. doi: 10.1146/annurev.soc.24.1.183
Kollock, P. (1998b). “Transforming social dilemmas: group identity and cooperation,” in Modeling Rationality, Morality and Evolution, ed P. Danielson (Oxford, UK: Oxford University Press), 186–210.
Krueger, J. I. (2008). Methodological individualism in experimental games: not so easily dismissed. Acta Psychol. 128, 398–401. doi: 10.1016/j.actpsy.2007.12.011
Krueger, J. I., DiDonato, T. E., and Freestone, D. (2012). Social projection can solve social dilemmas. Psychol. Inq. 23, 1–27. doi: 10.1080/1047840X.2012.641167
Marks, G., and Miller, N. (1987). Ten years of research on the false-consensus effect: an empirical and theoretical review. Psychol. Bull. 102, 72. doi: 10.1037/0033-2909.102.1.72
Massen, J. J., and Koski, S. E. (2014). Chimps of a feather sit together: chimpanzee friendships are based on homophily in personality. Evol. Hum. Behav. 35, 1–8. doi: 10.1016/j.evolhumbehav.2013.08.008
McPherson, M., Smith-Lovin, L., and Cook, J. M. (2001). Birds of a feather: homophily in social networks. Annu. Rev. Sociol. 27, 415–444. doi: 10.1146/annurev.soc.27.1.415
Meltzoff, A. N. (2007). ‘Like me’: a foundation for social cognition. Dev. Sci. 10, 126–134. doi: 10.1111/j.1467-7687.2007.00574.x
Messé, L. A., and Sivacek, J. M. (1979). Predictions of others' responses in a mixed-motive game: self-justification or false consensus?. J. Pers. Soc. Psychol. 37, 602. doi: 10.1037/0022-3514.37.4.602
Mitchell, J. P. C., Neil Macrae, and Mahzarin, R., and Banaji. (2006). “Dissociable medial prefrontal contributions to judgments of similar and dissimilar others.” Neuron 50, 655–663. doi: 10.1016/j.neuron.2006.03.040
Monahan, J. L., Murphy, S. T., and Zajonc, R. B. (2000). Subliminal mere exposure: specific, general, and diffuse effects. Psychol. Sci. 11, 462–466. doi: 10.1111/1467-9280.00289
Montoya, R. M., Horton, R. S., and Kirchner, J. (2008). Is actual similarity necessary for attraction? A meta-analysis of actual and perceived similarity. J. Soc. Person. Relat. 25, 889–922. doi: 10.1177/0265407508096700
Morris, S., and Shin, H. S. (2002). Social value of public information. Am. Econ. Rev. 92, 1521–1534. doi: 10.1257/000282802762024610
Mussweiler, T., and Ockenfels, A. (2013). Similarity increases altruistic punishment in humans. Proc. Natl. Acad. Sci. U.S.A. 110, 19318–19323. doi: 10.1073/pnas.1215443110
Over, H., Carpenter, M., Spears, R., and Gattis, M. (2013). Children selectively trust individuals who have imitated them. Soc. Dev. 22, 215–224. doi: 10.1111/sode.12020
Porter, R. H. (1987). “Kin recognition: functions and mediating mechanisms,” in Sociobiology and Psychology: Ideas, Issues and Applications, eds C. Crawford, M. Smith, and D. Krebs (Hillsdale, NJ: Erlbaum Associates), 175–203.
Powell, M. J. (2009). The BOBYQA algorithm for bound constrained optimization without derivatives. Technical Report NA2009/06, Department of Applied Mathematics and Theoretical Physics, University of Cambridge.
Rajecki, D. W. (1974). Effects of prenatal exposure to auditory or visual stimulation on postnatal distress vocalizations in chicks. Behav. Biol. 11, 525–536. doi: 10.1016/S0091-6773(74)90845-1
Rapoport, A. (1967). A note on the “index of cooperation” for prisoner's dilemma. J. Conflict Resolut. 11, 100–103. doi: 10.1177/002200276701100108
Riolo, R. L., Cohen, M. D., and Axelrod, R. (2001). Evolution of cooperation without reciprocity. Nature 414, 441–443. doi: 10.1038/35106555
Robbins, J. M., and Krueger, J. I. (2005). Social projection to ingroups and outgroups: a review and meta-analysis. Person. Soc. Psychol. Rev. 9, 32–47. doi: 10.1207/s15327957pspr0901_3
Ross, L., Greene, D., and House, P. (1977). The “false consensus effect”: an egocentric bias in social perception and attribution processes. J. Exp. Soc. Psychol. 13, 279–301. doi: 10.1016/0022-1031(77)90049-X
Segal, N. L., and Hershberger, S. L. (1999). Cooperation and competition between twins: findings from a prisoner's dilemma game. Evol. Hum. Behav. 20, 29–51. doi: 10.1016/S1090-5138(98)00039-7
Selten, R. (1965). Die Strategiemethode zur Erforschung des Eingeschränkt Rationalen Verhaltens im Rahmen eines Oligopolexperimentes. Tübingen: Seminar für Mathemat, Wirtschaftsforschung u. Ökonometrie.
Seyfarth, R. M., and Cheney, D. L. (2012). The evolutionary origins of friendship. Annu. Rev. Psychol. 63, 153–177. doi: 10.1146/annurev-psych-120710-100337
Sloman, S. A., and Rips, L. J. (eds.). (1998). Similarity and Symbols in Human Thinking. Cambridge: Elsevier Health Sciences.
Todd, A. R., Hanko, K., Galinsky, A. D., and Mussweiler, T. (2010). When focusing on differences leads to similar perspectives. Psychol. Sci. 22, 134–141. doi: 10.1177/0956797610392929
Vallortigara, G., and Bisazza, A. (2002). How ancient is brain lateralization. Compar. Vertebrate Lateralization 28, 9–69. doi: 10.1017/CBO9780511546372.003
Vallortigara, G., and Rogers, L. J. (2005). Survival with an asymmetrical brain: advantages and disadvantages of cerebral lateralization. Behav. Brain Sci. 28, 575–588. doi: 10.1017/S0140525X05000105
Van Huyck, J. B., Battalio, R. C., and Beil, R. O. (1990). Tacit coordination games, strategic uncertainty, and coordination failure. Am. Econ. Rev. 80, 234–248.
Van Lange, P. A. (1999). The pursuit of joint outcomes and equality in outcomes: an integrative model of social value orientation. J. Pers. Soc. Psychol. 77, 337. doi: 10.1037/0022-3514.77.2.337
Venables, W. N., and Smith, D. M. (2005). “The R development core team,” in An Introduction to R. Notes on R: A Programming Environment for Data Analysis and Graphics.
Weber, R. A., and Camerer, C. F. (2003). Cultural conflict and merger failure: An experimental approach. Manage. Sci. 49, 400–415. doi: 10.1287/mnsc.49.4.400.14430
Wimmer, H., and Perner, J. (1983). Beliefs about beliefs: representation and constraining function of wrong beliefs in young children's understanding of deception. Cognition 13, 103–128. doi: 10.1016/0010-0277(83)90004-5
Zajonc, R. B. (1980). Feeling and thinking: preferences need no inferences. Am. Psychol. 35, 151. doi: 10.1037/0003-066X.35.2.151
Zajonc, R. B. (2001). Mere exposure: a gateway to the subliminal. Curr. Dir. Psychol. Sci. 10, 224–228. doi: 10.1111/1467-8721.00154
Keywords: coordination, similarity, homophily, economic games, social preferences, social cognition
Citation: Chierchia G and Coricelli G (2015) The impact of perceived similarity on tacit coordination: propensity for matching and aversion to decoupling choices. Front. Behav. Neurosci. 9:202. doi: 10.3389/fnbeh.2015.00202
Received: 10 November 2014; Accepted: 13 July 2015;
Published: 28 July 2015.
Edited by:
Pablo Brañas-Garza, Middlesex University London, UKReviewed by:
Jordi Brandts, Instituto de Analisis (CSIC), SpainAngela Sutan, LESSAC ESC Dijon, France
Copyright © 2015 Chierchia and Coricelli. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Gabriele Chierchia, Department of Social Neuroscience, Max Planck Institute for Human, Cognitive and Brain Science, Stephanstraße 1A, 04103 Leipzig, Germany,Y2hpZXJjaGlhQGNicy5tcGcuZGU=