Abstract
Theory of mind (ToM) is the ability to attribute mental states to oneself and others, and to understand that others have beliefs that are different from one's own. Although functional neuroimaging techniques have been widely used to establish the neural correlates implicated in ToM, the specific mechanisms are still not clear. We make our efforts to integrate and adopt existing biological findings of ToM, bridging the gap through computational modeling, to build a brain-inspired computational model for ToM. We propose a Brain-inspired Model of Theory of Mind (Brain-ToM model), and the model is applied to a humanoid robot to challenge the false belief tasks, two classical tasks designed to understand the mechanisms of ToM from Cognitive Psychology. With this model, the robot can learn to understand object permanence and visual access from self-experience, then uses these learned experience to reason about other's belief. We computationally validated that the self-experience, maturation of correlate brain areas (e.g., calculation capability) and their connections (e.g., inhibitory control) are essential for ToM, and they have shown their influences on the performance of the participant robot in false-belief task. The theoretic modeling and experimental validations indicate that the model is biologically plausible, and computationally feasible as a foundation for robot theory of mind.
1. Introduction
Theory of Mind (ToM) is the ability to infer and understand other people's mental states to predict their behavior (Premack and Woodruff, 1978). It is a fundamental cognitive ability for the social brain. One of the most critical milestones in the ToM development is gaining the ability to attribute false belief: that is, to recognize that others can have beliefs about the world that are diverging (Wimmer and Perner, 1983). There is a wide variety of false-belief task (Huang and Liu, 2017; Scott and Baillargeon, 2017), but most of them can be divided into unexpected transfer task (Wimmer and Perner, 1983), unexpected contents task (Perner et al., 1987), and appearance-reality distinction (Flavell et al., 1983). Flavell et al. (1983) present a classical unexpected transfer task, Sally-Anne Test: Sally first placed a marble into her basket; then, she left the scene, and the marble was transferred by Anne and hidden in her box. Then Sally returned, and children were asked a belief question “Where will Sally look for her marble?” If the children pointed to the previous location of the marble, it meant that the children could understand that Sally held a false belief about the marble's location. Most 4-year-olds could point to the correct location, but most 3-year-olds failed—they predict that Sally will find her marble in the box.
As indicated in Asakura and Inui (2016), although ToM research has made progress on empirical findings and theoretical advances, relatively few efforts have been made from the biological plausible computational models' perspective, especially for false belief understanding. Based on findings of neural correlates and mechanisms of the false-belief task, we propose and build a Brain-inspired model of Theory of Mind (Brain-ToM model). And we challenge the false-belief task by incorporating the proposed model to humanoid robots. In this paper, we only focus on non-verbal unexpected transfer tasks as described below, including how to learn to understand object permanence and visual access from self-experience and use them to infer other's belief and predict their behavior. The object permanence is the ability to understand that objects continue existence even it cannot be perceived (Piaget and Cook, 1952).
From our point of view, self-experience in autobiographical memory and its utilization to infer other's belief or predict other's action is fundamental and crucial to the ToM. It is also mentioned as self-projection in Buckner and Carroll (2007) or using memories to understand others (Moreau et al., 2013). It enables real understanding of the self and others as well as their relationships, and utilize them to infer others' mental states based on personal experience from the self point of view. This perspective seems somewhat missing in existing research about the computational model.
In our opinion, an agent who can infer other's belief and predict their behavior should have the capability of self-other distinction as the premise. So in Zeng et al. (2016, 2017), we proposed a brain-inspired robot bodily self-model with the neural mechanisms of bodily self-perception based on extensions to primate mirror neuron system, and apply it to the humanoid robot for self-recognition. In this paper, based on the related findings for neural correlates and mechanisms of the ToM, we propose a Brain-ToM model to make the humanoid robot learn from self-experience. With the Brain-ToM model, the robot can pass the non-verbal unexpected transfer tasks adapted from Senju et al. (2011) and Southgate et al. (2007). The efforts may also provide a possible computational model and hints on how infant infers and understands other people's beliefs. Compared to the previous model, the characteristics of our model are with relatively more solid details from the biological brain. It explores the effect of self-experience as a core and is with considerations on the maturation of correlated brain areas (e.g., calculation capability) and their connections (e.g., inhibitory control). Besides, the model is naturally a brain-inspired spiking neural network model and is fundamentally based on brain plasticity principles.
The rest of this paper is organized as follows: Section 2 reviews the related work of computational models, the false belief tasks, and the brain regions in the ToM. In section 3, the architecture of the Brain-ToM model, the concrete neural network architecture, the Voltage-driven Plasticity centric Spiking Neural Networks (VPSNN), and the inhibitory control mechanism are introduced. The experimental settings, the experimental results and analyses are given in section 4. Some discussions and conclusions are drawn in sections 5, 6, respectively.
2. Related Works
In this section, we briefly review several related works, including the computational models, the false belief tasks, and the related brain regions of ToM.
2.1. Computational Models
Berthiaume et al. (2013) presented a constructivist connectionist model to simulate the false-belief task. The model encoded the location of an object, whether an agent has observed the object's movement, and the location where the agent came back to search. With the increased hidden units to improve computational power, the model would predict the correct search in two different false belief tasks—the approach task and the avoidance task. Their model was the first computational model to autonomously construct and transit between structures and to cover the two major false-belief task transitions. They suggested the view that the source of the transition is not developed in the understanding of beliefs, but changes in auxiliary skills such as: executive function, understanding and using representations, working memory, or language. Goodman et al. (2006) built two Bayesian models named CT model (copy theorist) and PT model (perspective theorist). Beliefs were only correlated to the location of the toy in the former model, and in the later model, the belief was not only correlated to the toy's location but also Sally's visual access, i.e., could Sally saw the toy moved or not. With the increase of resources and complexity in the PT model, the model could pass the false-belief task. Asakura and Inui (2016) designed a Bayesian framework that integrates theory-theory and simulation theory for false belief reasoning in the unexpected-contents task. This framework predicted other's belief by the self model and others model which were responsible for simulation-based and theory-based reasoning, respectively. In their opinion, the multiplicative effect of the ability to understand diverse beliefs and knowledge access could predict children's false belief ability. Their model provided good fits to a variety of ToM scale data for preschool children. Rabinowitz et al. (2018) designed a ToM neural network to learn how to model other agents by meta-learning. They constructed an observer who could collect agent's behavioral traces, and its goal was to predict the agent's future behavior. They applied the proposed ToMnet model in simple grid world environments, showing that the observer could model agents effectively and passed Sally Anne Test. And the observer needed not to be able to execute the behaviors itself. O'Laughlin and Thagard (2000) built a connectionist network whose nodes represent the relevant event in the false-belief task, and passed the false-belief task by modifying the connection weight of excitatory links and inhibitory links. Milliez et al. (2014) presented a spatio-temporal reasoning system SPARK, which included a well-designed model of object position hypotheses and generated beliefs. They enabled the robot to passed the Sally-Anne test and performed well in dialog disambiguation. Patacchiola and Cangelosi (2020) proposed a developmental cognitive architecture for trust and ToM in humanoid robots. This architecture was inspired by psychological and biological observations. And it based on an actor-critic (AC) framework, an epigenetic robotic architecture (ERA), and a Bayesian network (BN). These modules represent the functions of the corresponding brain regions in ToM, and they could uncover the detailed mechanisms of trust-based learning in children and robots. Finally, they reproduced psychological experiments with the iCub humanoid robot, and the results are coherent with the real experimental data from children.
2.2. False Belief Tasks
There is a wide variety of false-belief tasks, here we introduce two non-verbal unexpected transfer tasks that will be adapted to verify the validity of the model.
Senju et al. (2011) investigated whether 18-month-olds infants would use their own past experience of visual access to attribute perception and consequent beliefs to other people. Infants are divided into two groups, one group wore opaque blindfolds, and another wore trick blindfolds which looked opaque but were actually transparent. The opaque blindfold and trick blindfold looked identical. The test stage is the same as Southgate's as described below. The puppet hid an object in the left box. After the actor wore the same blindfold, the puppet removed the object from the scene. The opaque blindfold group expected the actor to behave according to false belief, and the trick blindfolds did not. Their results show that 18-month-olds used self-experience with the blindfold to assess the actor's visual access and predict their behavior.
Southgate et al. (2007) used an anticipatory looking measure to test whether 2-year-olds infants have the ability of false belief understanding. In the familiarization trials, the puppet hid an object in the left or right box, then left the scene. The actor reached through the corresponding window after doors illuminated with the simultaneous chime. Note that “doors illuminated with simultaneous chime” indicated that the actor was going to reach the object. In one test trial, the puppet hid the object in the left box then move it to the right box. After the actor turned around, the puppet removed the object from the scene. In another test trial, the puppet hid the object in the left box, then the actor turned around. The puppet moved the object to the right box and hid it, then remove the object from the scene. For both test trails, the actor turned back and doors illuminated with simultaneous chime after the object was removed from the scene. Most infants could gaze toward the correct window. Their data demonstrated that 25-month-old infants had the ability of false belief understanding. The details of this experiment were illustrated in the figure of Southgate et al. (2007).
2.3. Brain Regions in Theory of Mind
Several brain regions, including the mPFC, bilateral TPJ, and precuneus, have been consistently found to be activated in various mentalizing tasks in healthy individuals (Green et al., 2015). Schurz et al. (2014) meta-analyzed 757 activation foci reported from 73 imaging studies of ToM that involved 1,241 participants, and their meta-analysis contained six different task groups—False belief vs. photo, Trait judgments, Strategic games, Social animations, Mind in the eyes, and rational actions. They found the mPFC and bilateral posterior TPJ were activated in all task groups. In false belief vs. photo stories task group, they found TPJp, IPL, precuneus, posterior cingulate gyrus, mPFC connectivity clusters 3 and 4, ventral parts of the mPFC, anterior cingulate gyrus, right anterior temporal lobe, and adjacent parts of the insula be activated. Molenberghs et al. (2016) conducted a series of activation likelihood estimation (ALE) meta-analyses on 144 datasets (involving 3,150 participants) to address the brain areas that implicated in specific types of ToM tasks. In terms of commonalities, consistent activation was identified in the medial prefrontal cortex and bilateral temporoparietal junction. Schurz and Perner (2015) reviewed nine current neurocognitive theories of how the ToM was implemented in the brain and evaluate them based on the results from a recent meta-analysis by Schurz et al. (2014). From theories about cognitive processes being associated with certain brain areas, they deduced predictions about which areas should be engaged by the different types of ToM tasks. These brain areas contain the mPFC, the pSTS, the TPJ, and the IPL.
3. Methods
3.1. Architecture of the Brain-ToM Model
The architecture of the Brain-ToM model is shown in Figure 1.
Figure 1
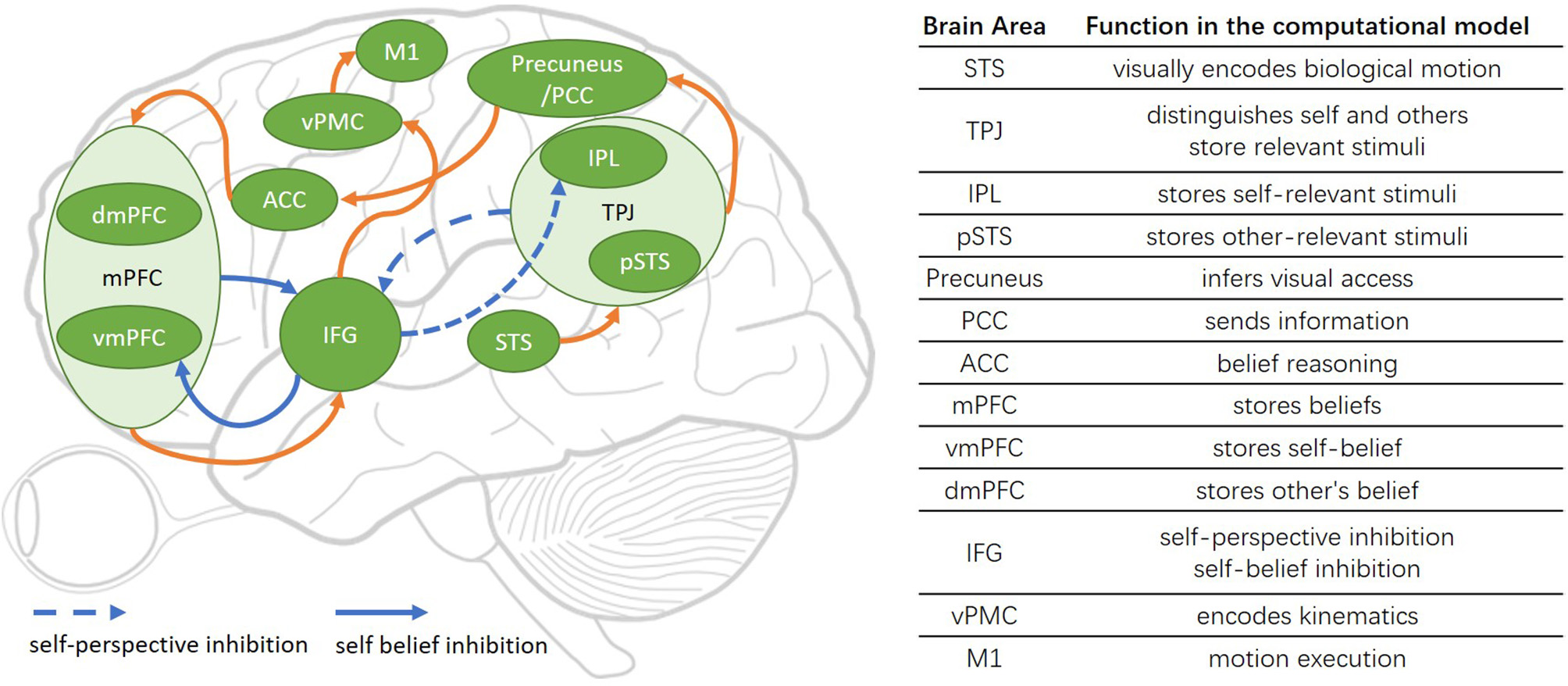
The Brain-ToM model (including major functional brain areas, pathways, and their interactions).
The STS is sensitive to biological motion, and in our computational model, its function is to visually encode biological motion (Grossman and Blake, 2002).
The TPJ is considered as a crucial area in self-other distinction (Eddy, 2016; Bardi et al., 2017), controls representations relating to the self and other (Eddy, 2016), and involvement in self perspective-taking as well as other perspective-taking (Vogeley et al., 2001; van der Meer et al., 2011). There is no consensus on the anatomical definition of the extent and precise location of the TPJ (Igelstrom and Graziano, 2017), but in general, the TPJ contains two anatomically distinct regions including the IPL and pSTS (Abu-Akel and Shamay-Tsoory, 2011; Schurz et al., 2014; Igelstrom and Graziano, 2017). In our computational model, the TPJ is used to distinguish self and others, store self and other-relevant stimuli, and decide the output sequence of self and other-relevant stimuli.
The IPL is considered as a critical area in distinguishing the self from others and identifying the body ownership in our robot bodily self-model in Zeng et al. (2016, 2017), and some studies have indicated that it will be activated during lower-order self-perception (Schurz and Perner, 2015; Igelstrom and Graziano, 2017). So in our computational model, the IPL is used to store self-relevant stimuli. The pSTS (Frith and Frith, 1999; Schurz and Perner, 2015) is concerned with representing the actions of others and perspective taking (Frith and Frith, 2006). In our computational model, the pSTS is used to store other-relevant stimuli.
The precuneus is often activated during visuo-spatial imagery, episodic memory retrieval, self- processing operations (Cavanna and Trimble, 2006), and retrieving previous experiences (Molenberghs et al., 2016). And a main function of the precuneus in ToM is mental imagery to represent the perspective of another person (Cavanna and Trimble, 2006; Schurz et al., 2013, 2014) or modeling other people's views (Vogeley et al., 2004). In our computational model, the precuneus is the critical area for a machine to learn visual access from its own experience and uses it to infer other people's visual access. The PCC is the caudal part of the cingulate cortex, and the precuneus lies posterior and superior to the PCC (Leech and Sharp, 2014). In our computational model, the PCC receives the information from precuneus and sends it to ACC.
The anterior paracingulate cortex is often considered to be a part of the ACC and is used for representing mental states “decoupled” from reality (Gallagher and Frith, 2003). In our computational model, the ACC is the critical area in acquiring the ability of object permanence and then used it for belief reasoning.
The mPFC contains vmPFC and dmPFC. The vmPFC has typically been associated with self-referential processing, and the dmPFC has typically been associated with others-referential processing (Abu-Akel and Shamay-Tsoory, 2011; Denny et al., 2012; Jiang et al., 2016; Molenberghs et al., 2016). In our computational model, the mPFC is used to store the result of belief reasoning from ACC: the vmPFC stores the result of self-belief reasoning, and the dmPFC stores the other's belief reasoning.
The IFG is a critical area for the inhibition process: self-perspective inhibition and self-belief inhibition. The IFG inhibits self-perspective when self perspective and other-perspective are conflictive (Hartwright et al., 2012, 2015), and is suggested to inhibit self-belief to obtain correct task performance in the false-belief task (Mossad et al., 2016). Another function of IFG is encoding action goals and responding to goal-driven motions (Hamzei et al., 2016). The vPMC encodes kinematics based on motion goals from IFG, the encoded information is sent to M1. M1 encodes the strength and orientation of motion and controls the concrete motion execution (Georgopoulos et al., 1986).
As indicated in Green et al. (2015) and Jiang et al. (2016), the specific roles that brain areas have in the mentalization processes is not clear. Based on the neuroimaging studies as described above, we propose four pathways for robots learning from self-experience and uses it in the false-belief task, they are self-experience learning pathway, motivation understanding pathway, reasoning about one's own belief pathway and reasoning about other people's belief pathway.
The self-experience learning pathways is consist of object permanence learning pathway [Precuneus/PCC → ACC] and the visual access learning pathway [STS → TPJ(IPL) → Precuneus/PCC].
The test pathways are consist of motivation understanding pathway, reasoning about one's own belief pathway, and reasoning about other people's belief pathway.
The motivation understanding pathway is STS → pSTS → TPJ(IPL) → IFG.
The reasoning about one's own belief pathway contains belief reasoning pathway [STS → TPJ(IPL) → Precuneus/PCC → ACC → MPFC(vMPFC)] and the motor response pathway [MPFC(vMPFC) → IFG → vPMC → M1].
The reasoning about other people's belief pathway contains the true belief reasoning pathway and the false belief reasoning pathway.
The true belief reasoning pathway contains belief reasoning pathway [STS → TPJ(pSTS) → Precuneus/PCC → ACC → MPFC(dMPFC)] and the motor response pathway [MPFC(dMPFC) → IFG → vPMC → M1].
The false belief reasoning pathway contains the belief reasoning pathway [STS → TPJ → IFG → TPJ(pSTS) → Precuneus/PCC → ACC → MPFC(dMPFC)] and the motor response pathway [MPFC → IFG → MPFC (dMPFC) → IFG → vPMC → M1].
In the reasoning about other people's belief pathway of false belief reasoning, the conflict between self-and-other perspective in TPJ will activate IFG, then IFG will inhibit self-relevant stimuli in IPL. So the others-relevant stimuli in pSTS will be the first output of TPJ, then it sends to Precuneus/PCC. In the motor response pathway of false belief reasoning, the conflict between self-belief and other's belief in mPFC will activate the IFG, then the IFG inhibits self-belief in vmPFC. So the other's belief in dmPFC will be the output of mPFC, then it will be sent to IFG for encoding action goals.
3.2. Concrete Neural Network Architecture
The concrete neural network architecture of the model is shown as Figure 2, and it uses the leaky integrate-and-fire model (LIF) neurons. This section describes (1) the input and output encoding information of different brain areas, (2) the Voltage-driven Plasticity-centric Spiking Neural Networks (VPSNN) used in Precuneus/PCC and ACC for visual access learning and object permanence learning respectively, and (3) the inhibitory control mechanism which was used to select correct output information of TPJ or mPFC.
Figure 2
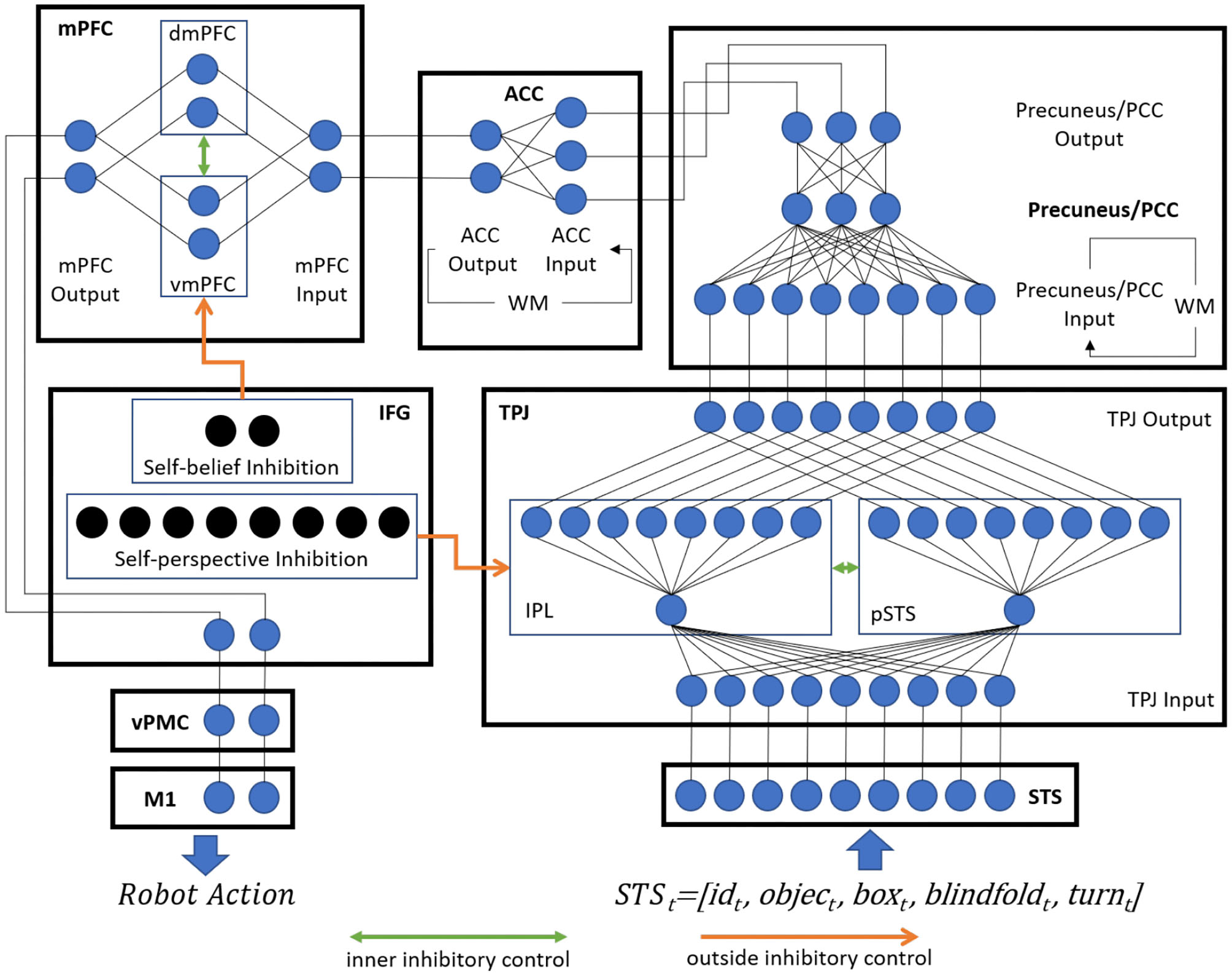
The concrete neural network architecture of Brain-ToM model (WM denotes working memory).
3.2.1. STS
The STS encodes the processed results of visual perception and body information of the self and others at time t.
We detect this information using traditional template matching methods and represent the result by neurons with an input synaptic current I of 1.0 or 0.0. The idt uses two neurons to represent the identification of self or others. For the identification of idt, we use the Fast R-CNN to recognize others at time t. More details could be found in our previous work (Zeng et al., 2017). The objectt and boxt are both tuples consist of object or box identification information and its location information respectively. For the identification of the objectt, boxt, blindfoldt, we first collect their image templates, and then use the traditional template matching method to identify them at time t. The location of objectt or boxt is calculated by the distance between the center of the black rectangles and the center of the object or box at time t. The blindfoldt uses two neurons to represent the wearing state of the blindfold (wear or not wear) and uses another two neurons to represent whether there is a blindfold at time t. Here we define the state of self as wearing a blindfold if the blindfold covers most areas of its visual field, and define the state of others as wearing a blindfold if the blindfold covers the other's face. The turnt uses two neurons to represent the state of turning. Here the turning-around state of the robot itself is detected by the degree to which its head is twisted, and the turning-around state of the other robot is detected by whether its face or back is recognized.
3.2.2. TPJ
The input information of the TPJ is directly from STS, as
and the information is divided into self-relevant stimuli and others-relevant stimuli by the idt, and then stored in IPL and pSTS, respectively. The information in IPL, pSTS, and the output of TPJ are encoded as.
3.2.3. Precuneus/PCC
The Precuneus/PCC is used for visual access learning. Here we use the VPSNN based on our previous work (Tielin et al., 2018) to train the robot to learn visual access.
The input information of Precuneus/PCC contains the current information from the output of TPJ and the previous information from working memory, and it could be represented as
where
The ζ is the forgetting factor. In the training stage, the target output of Precuneus/PCC is the perceived location of the object (active the unseen signal if no object is detected). The output of Precuneus/PCC is encoded by the input synaptic current I of either 1.0 or 0.0 in the perception neurons,
There are 160 trials in the training process. Each training trial contains two images collected from the robot as shown in Figure 4. The first image is collected when putting the various objects in one location as shown in Figure 4a. The second image is collected when the robot is asked “Where is the [object label]?” in three scenes: (1) when the blindfold is interposed (Figures 4b,c), (2) when the robot has turned around, (3) when the object is moved to another location. For example, the first image is collected at time t − 1, and the second image is collected at time t. The input of the VPSNN is Precuneus/PCCinputt, and the target output of the VPSNN is Precuneus/PCCoutputt. The Precuneus/PCCinputt receives two inputs: one is the raw TPJoutputt and the other is the Precuneus/PCCinputt−1 with a forgetting factor. In each training trial, there is no previous information from working memory when collecting the first image, so the Precuneus/PCCinputt−1 is equal to the TPJoutputt−1. The Precuneus/PCCoutputt is the perceived location of the object at time t. The robot trains the self-experience of visual access to the wearing of the blindfold or the turning around of the robot in the process of visual access learning, then uses it to infer itself and other robot's visual access in the Opaque-and-Transparent Blindfold Test and Turn Around Test.
3.2.4. ACC
The ACC is used for object permanence learning. Here we use the VPSNN to train the robot to learn object permanence. The input information of ACC contains the current information from the output of Precuneus/PCC and the previous information from working memory, and it could be represented as
where
The ζ is the forgetting factor. In the training stage, the target output of ACC is the location of the object. The output of ACC is encoded by the input synaptic current I of either 1.0 or 0.0 in the related neurons, i.e.,
There are 50 trials in the training process. Each training trial contains three images collected from the visual sensor, when (1) the various objects are put in one location (Figure 5b), (2) an object is hidden in the box (Figure 5c), and (3) the box is moved away (Figure 5d). For example, the first, second, third image is collected at time t − 1, t, t + 1, respectively. The input of the VPSNN is ACCinputt, and the target output of the VPSNN is ACCoutputt+1. The ACCinputt receives two inputs: one is the raw Precuneus/PCCoutputt and the other is the ACCoutputt−1 with a forgetting factor. The ACCoutputt−1 is the perceived location of the object at time t − 1. To train the ability of object permanence in the robot, we make the robot always perceive the location of the object at the end of each training trial. The ACCoutputt+1 is the perceived location of the object at time t + 1. The robot trains itself a belief that objects are still where it has last located them, even they are out of its field of visual perception, and then uses it to infer itself and other robot's belief in the Opaque-and-Transparent Blindfold Test and Turn Around Test.
We train the visual access learning in Precuneus/PCC first, then the object permanence learning in ACC.
3.2.5. mPFC
The input of mPFC is identical to the output of ACC and distinguishes between the self-belief and other-belief by the source of the information: IPL or pSTS. The vmPFC and dmPFC both use two neurons to store the self-belief and other-belief about the location of the object.
The output of mPFC depends on the questions, which are set as follows: if the question is “Where is the ladybird according to the blue robot?” the other-belief stored in dmPFC tries to be the output of mPFC; if the question is “Where is the ladybird according to yourself?” the self-belief stored in vmPFC tries to be the output of mPFC.
3.2.6. IFG
In the proposed model, IFG receives inputs from three sources: (1) the inhibit result neurons in TPJ that could stimulate IFG for self-perception inhibition, (2) the inhibit result neurons in mPFC that could stimulate IFG for self-belief inhibition, and (3) some other neurons in mPFC that could stimulate IFG to encode the action goal.
IFG uses the same number of neurons as IPL and as vmPFC to inhibit self-perception information and self-belief information, respectively, and uses another two neurons to encode the action goal, which is later sent to vPMC to control the robot's actions. The details of the inhibitory control mechanism of IFG could be found in section 3.4.
With the exception in the above mentioned evaluation, the synaptic plasticity only takes place in Precuneus/PCC and ACC in the process of training, while the weights of the other connections between various areas remain unchanged in the experiment.
3.3. VPSNN
For the mathematically modeling of brain regions such as Precuneus/PCC and ACC, here we select a standard VPSNN model (Tielin et al., 2018), which is a shallow feed-forward SNN and may well simulate input-output signals with the integration of supervised learning (with an additional teaching signal given directly to the output layer neurons) and unsupervised learning (tuned with biologically plasticity principles, e.g., STDP, and homeostatic membrane potential).
Two three-layer SNN architectures are designed for Precuneus/PCC (with 24 input neurons, three hidden neurons, and two output neurons) and ACC (with three input neurons, three hidden neurons, and two output neurons), respectively, as shown in Figure 2. The VPSNN includes four steps, namely: feed-forward information (including both membrane potential and spikes) propagation, unsupervised homeostatic state learning, supervised last layer learning, and passively updating synaptic weights based on STDP rules. In this paper, we take advantage of these four steps for the fast network tuning and update the methodologies of giving teaching signals from single SNN to two SNNs together for the better model integration.
3.3.1. The LIF Neuron Model
The basic neuron model in VPSNN is the LIF model, which describes the dynamics of the membrane potential of V and synaptic-weight-related gE, as shown in Equations (1) and (2). Once the pre-synaptic neurons fire, there is a non-linear increment of gE, which will then propagate into V. The gL is leaky conductance, VL is leaky potential, τm and τE are conductance decay, η is the learning rate, and VE is reversal potential.
3.3.2. The Feed Forward Propagation
The information propagation in the LIF neuron is slower compared with giving input directly into V. However, this is a specially designed procedure that will make the network-tuning focusing more on the homeostatic membrane potential adjustment and STDP learning. The information (especially the membrane potential) will be propagated from pre-synaptic neurons (e.g., Vj) into the post-synaptic neurons (e.g., Vi), and the whole feed-forward procedure is shown in Equation (3), in which the Vth is the firing threshold of the neurons.
3.3.3. Unsupervised Homeostatic Membrane Potential Learning
The basic homeostatic mechanism occurs in the input-output balance of the single neuron, described as the Equation (4).
The entire network homeostatic state can be represented as the addition of all of the neurons in each layer, i.e., . Moreover, after the calculation (the detailed methodologies are shown in paper Tielin et al., 2018), the homeostatic membrane potential can be updated according to Equation (5). The ηi is the learning rate.
With the integration of Equations (3) and (5), the update rule of each neuron state Vi is shown in Equation (6). The t is the training time slot and T is the total training time in SNN learning.
3.3.4. Supervised Last Layer Learning and STDP-Based Weights Consolidation
An additional teaching signal will be given to the network for guiding the proper network output. Here we add teaching signals into the last layer of SNN in the training procedure, as shown in Equation (7), in which VT is teacher signal state, ηc is the learning rate.
STDP rules (Bi and Poo, 2001; Dan and Poo, 2004; Bengio et al., 2015a,b) are further used for the knowledge consolidation from the membrane potential to synaptic weights, e.g., the synaptic weights could be passively updated by the changes of the pre- and post-synaptic neuron states. The function is as shown in Equation (8), in which the is the derivative value of Vi.
3.4. Inhibitory Control Mechanism
The inhibitory control is used to select correct output information of TPJ or mPFC, and it can be divide into inner and outside inhibitory control. The inner inhibitory control cannot inhibit predominant information from self when the related information of self and others is conflictive, so we use the outside inhibitory control from IFG to inhibit the predominant information. Inhibitory control of one single neuron is shown in Figure 3. The IPL neurons (or vmPFC neurons) and pSTS neurons (or dmPFC neurons) receive electrovital currents of self-relevant stimuli and other-relevant stimuli, respectively. The input of inhibit neurons and temporary neurons depend on reasoning about other's belief (contains self-perspective inhibition and self-belief inhibition) or self-belief (contains other-perspective inhibition and other-belief inhibition), and the former is used to inhibit stimuli, the later is used to temporarily store uninhibited stimuli. In the process of self-perspective inhibition or self-belief inhibition, the input electrovital currents of inhibit neuron are equal to other-relevant stimuli, and the temporary neuron is equal to self-relevant stimuli (only in TPJ). So other-relevant stimuli will be the first output, and self-relevant stimuli will be the second output in TPJ, and other's belief will be exported in mPFC. In the process of other-perspective inhibition and other-belief inhibition, the inhibit electrovital currents are very big that it can completely inhibit other-relevant stimuli, and the temporary neuron is equal to other-relevant stimuli (only in TPJ). Therefore, in TPJ, self-related stimulus will be output first, other-related stimulus will be output second, and then self-belief will be output in mPFC.
Figure 3
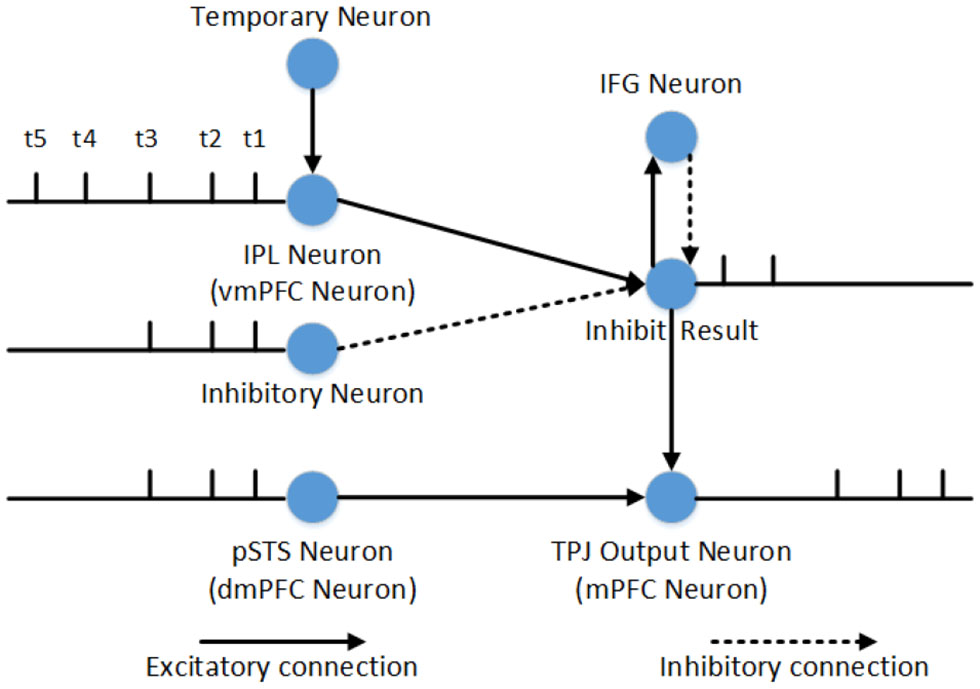
Inhibitory control of one single neuron in reasoning about other's belief. At time t1, t2, and t3, the firing pattern of pSTS and IPL are identical, which means that the other-relevant stimuli and self-relevant stimuli are identical. The inhibitory neurons can inhibit self-relevant stimuli successfully. But at time t4 and t5, the other-relevant stimuli and self-relevant stimuli are in conflict with each other, and the inhibitory neurons cannot inhibit self-relevant stimuli. The inhibit result neurons will fire and stimulate IFG activation, while IFG activation will inhibit the firing of inhibit result neuron. The inhibit result neurons will combine with neurons in pSTS to generate other-relevant stimuli output firstly. Then the temporary neuron stimulates IPL, because the electrovital currents in pSTS and the inhibitory neuron is zero at this moment, self-relevant stimuli will be the second output of TPJ. Compared to the process of self-perspective inhibition, the only difference is that the inhibitory control in TPJ is used to decide the sequence of information output, and the inhibitory control in mPFC is used to decide which belief to export. Therefore, the process of self-belief inhibition does not require the involvement of temporary neuron.
4. Experiments
In this section, we introduce the experimental settings and the result of our proposed model.
4.1. Experimental Settings
We deploy the computational model to humanoid robotics and use the Opaque-and-Transparent Blindfold Test and Turn Around Test to validate the Brain-ToM model. Furthermore, we test the effect of self-experience, maturation of correlate brain areas (e.g., calculation capability) and their connections (e.g., inhibitory control) on the performance of participant robot in Opaque-and-Transparent Blindfold Test.
4.1.1. Opaque-and-Transparent Blindfold Test
The Opaque-and-Transparent Blindfold Test is adapted from Senju et al. (2011).
We enable all the robots to learn the visual access of blindfold from self experiences, as the infants' experience in Senju's experiment. In the proposed model, this process takes place in Precuneus (Vogeley et al., 2004; Cavanna and Trimble, 2006; Schurz et al., 2013, 2014). The robots are divided into two groups—the opaque blindfold group and the transparent blindfold group. The opaque blindfold and transparent blindfold look identical, at least the robot cannot distinguish them from appearance, but the transparent blindfold can make the robot who wears it see through, and the opaque blindfold cannot. Figure 4 presents the visual inputs of the robot in the opaque blindfold group (with Movie S1) and the transparent blindfold group (with Movie S2). In this stage, the robots could not observe other robots wearing the blindfold, as the infants in Senju's experiment, so they have no opportunity to learn the property of the blindfold from the third-person point of view.
Figure 4

Visual access learning of blindfold from self-experience. (a) An object is put on either of the black rectangles. (b) Visual inputs of the opaque blindfold group (with Movie S1). We interpose blindfold between the eyes of the robot and the object, then ask it “Where is the [object label]?” The robot will reply with the location of the object or with the fact that it did not see it. (c) Visual inputs of the transparent blindfold group (with Movie S2). The process is the same as the opaque blindfold group.
We suggest that the ability of learning object permanence is the prerequisite for the ToM. As indicated in Piaget and Cook (1952) and Bruce and Muhammad (2009), Piaget defined six developmental stages of object permanence. During the early stages (Stage I, Stage II, Stage III), children failed to find a hidden object. During Stage IV (8–12 months) children can retrieve an object when its concealment is observed. But they cannot find the object when it is continuously moving. During Stage V (12–18 months), the children can retrieve an object when it is hidden several times within his or her view. In summary, when an object was hidden in location A and then hidden in location B, the children would try to find the object in location A during Stage IV and would try to find it in location B during Stage V. With similar principles, here we enable all of the robots in the experiment acquire the ability of learning object permanence from their own self experiences, and in our model, ACC acts as a central role to realize this cognitive function (Gallagher and Frith, 2003). Figure 5 shows the visual inputs of the robots in this process.
Figure 5

Object permanence learning from self-experience. (a) The black rectangles are used to indicate the candidate positions of the object. (b) An object is put on either of the black rectangles, the robot can detect the location of the object—left side or right side. (c) The yellow box and the green box are used to hide the object. The robot cannot perceive the object in its visual field, hence cannot find it. It is similar to the early stages in Piaget's Stages of Object Permanence. (d) The boxes are removed, and the robot can perceive the object's location in its visual field.
In the test stage, participant robots use the Brain-inspired Robot Bodily Self Model which we proposed in Zeng et al. (2016, 2017) to distinguish self and others. As in the experiment of Senju et al. (2011), the actor robot will try to find the hidden object in the box before the final test. By this way, the participant robot could understand that the actor has the same cognitive ability (e.g., visual ability) and the goal of the actor robot (Movie S3). In the final test, the opaque blindfold group and the transparent blindfold group are tested with the same process as shown in Figure 6. Then the participant robot be asked two questions: “Where is the ladybird according to the blue robot?” and “Where is the ladybird according to yourself?” We determine whether the robot can pass the task by detecting the direction of the finger which makes the results more intuitive.
Figure 6

Visual inputs of participant robot in the test stage. (a) The blue robot in the left is the actor, and the red robot in right is the participant who should infer the actor's belief. The middle screen in the (a), and the remaining figures are the visual inputs of the participant robot. (b) An object (ladybird) is put on the left black rectangle. (c) The ladybird is hidden in the yellow box. (d) The blindfold is interposed between the actor (the blue robot) and the object (ladybird), and the object is moved to the right side. (e) The ladybird is hidden in the green box. (f) Finally, the blindfold is removed.
4.1.2. Turn Around Test
The Turn Around Test is adapted from Southgate et al. (2007).
The robot learns the visual access of turning around from self-experience. The Turn Around Test is similar to the Opaque-and-Transparent Blindfold Test. The diversity of belief is caused by different blindfolds in the Opaque-and-Transparent Blindfold Test, and in Turn Around Test, it is caused by the behavior of turn around. The visual inputs of the participant robot are shown in Figure 7. As with the Opaque-and-Transparent Blindfold Test, the participant robot also be asked two questions: “Where is the ladybird according to the blue robot?” and “Where is the ladybird according to yourself?” And we determine whether the robot can pass the task by detecting the direction of the finger.
Figure 7

Turn Around Test. An object (ladybird) is put on the left black rectangle and hidden it in the yellow box firstly. In the false belief condition, the object was moved to the other box when the actor robot turned around (Movie S6). And in true belief task, the actor robot did not turn around when the object was moved to the other box (Movie S7).
4.1.3. Maturation Test
The ability for the ToM comes with individual development process (Grosse Wiesmann et al., 2017). Grosse Wiesmann et al. (2017) discussed the influence of white matter structure on ToM by tract-based spatial statistics analysis and probabilistic tractography. They found that “the developmental breakthrough in false belief understanding is associated with age-related changes in local white matter structure in temporoparietal regions, the precuneus, and medial prefrontal cortex, and with increased dorsal white matter connectivity between temporoparietal and inferior frontal regions.” And they thought “the emergence of mental state representation is related to the maturation of core belief processing regions and their connection to the prefrontal cortex” (Grosse Wiesmann et al., 2017). But their research focused on the 3- and 4-year-old children in the explicit false-belief tasks, and did not include younger infants who cannot pass the implicit false-belief task. They did not test whether this finding is also associated with an implicit task, because of the difficulties in performing MRI with toddlers.
Although the developmental neural basis for the implicit false-belief task is still not very clear, we hypothesize that the developmental process in implicit false belief understanding is relevant with explicit one, and will also be associated with the maturation of correlate brain areas and their connections. We aim to test this hypothesis by our computation model, and apply it to the Brain-ToM model that we developed for machine intelligence.
The maturation of correlate brain areas could be regarded as calculation capability in our model, and the calculation capability increases with the maturation of brain areas. The calculation capability in this model is proportional to the number of neurons in the hidden layer. We simulate immature Precuneus/PCC by reducing the number of the neurons in its own hidden layer, then verify the effect of this condition on the performance of the participant robot.
The maturation of the connection between brain areas is critical for information transmission and information integration, especially inhibitory connection and control. The inhibitory control is generally considered as a key mechanism in false-belief task (Leslie and Polizzi, 1998; Scott and Baillargeon, 2017), and we think that the maturation of connections between IFG and TPJ, IFG and vmPFC are the neural basis of self-perspective inhibition and self-belief inhibition, respectively. We simulate immature connections between IFG and TPJ, IFG and vmPFC by set the synaptic weights as 0, then verify the effect of this condition on the performance of the participant robot.
4.2. Experimental Results and Analyses
In this section, we present the results of our model. Besides, we analyze the temporal and spatial activation of different brain areas during different tasks, the effect of self-experience, maturation of correlate brain areas (e.g., calculation capability) and their connections (e.g., inhibitory control) on the performance of participant robot in Opaque-and-Transparent Blindfold Test.
4.2.1. Opaque-and-Transparent Blindfold Test
The opaque blindfold group can be regarded as the false belief condition, as the actor robot's belief is inconsistent with the representations of reality. When asking the participant robot “Where is the ladybird according to the blue robot?” the participant robot will point to the yellow box on the left side. And when asking the participant robot “Where is the ladybird according to yourself?” the participant robot will point to the green box on the right side (Movie S4).
The transparent blindfold group can be regarded as the true belief condition, as the actor robot's belief is consistent with the representations of reality. When asking the participant robot the upper two questions, for both of them, the participant robot will point to the green box on the right side (Movie S5).
We repeat this experiment 20 times, the robot could pass the task every time, and we calculate the mean value and standard deviation of time consumption in different brain areas. To make the results more visible and clear, the data from STS, Precuneus/PCC, ACC, vPMC/M1 are excluded, because their time consumption is similar in different tasks. We select the time consumption in TPJ, IFG, and mPFC as examples. The time consumption of false belief reasoning (87.7 ms) is longer than true belief reasoning (69.8 ms). And the time consumption of reasoning about other's belief (78.8 ms) is longer than self-belief (15.2 ms). In the process of reasoning about self-belief, the time consumption of false belief condition (15.4 ms) and true belief condition (15 ms) are similar. In traditional true belief task, the time consumption will be shorter. The perception in TPJ is identical, hence the IFG will not be activated in this task and the time consumption is reduced.
Here we provide the time consumption in different tasks. Based on the belief about the object location, the task can be divided into reasoning about actor robot's false-belief task (other-incongruent condition) and true belief task (other-congruent condition), reasoning about participant robot's own belief task which contains self-incongruent condition (self-belief is divergent from other's) and self-congruent condition (self-belief is corresponding with other's). Figure 8 shows the temporal and spatial activation of different brain areas during different tasks. This process only contains the perception conflict stage (as shown in Figure 6d) and motion response stage which have critical differences in different tasks. The time consumptions in STS and vPMC of different tasks are similar, about 448 and 500 ms, respectively. So we select 400-900 ms to show the process and the difference in different tasks. Reasoning about other's belief in the transparent group can be regarded as true belief task, but it must be noted that, the information from self-perspective and other-perspective are identical in tradition true belief task, while they conflict with each other in this task which is originally from Senju et al. (2011) based on human studies of 18-month-olds. For example, in the transparent blindfold task, the participant robot perceived from self-perspective that “I (participant robot) saw the object moved to the green box without blindfold” and the participant robot perceived from other-perspective that “the actor robot saw the object moved to the green box with blindfold,” so the information is conflictive in this task. And in traditional true belief task, the information is identified as “I (participant robot) saw the object was moved to the green box” and “the actor saw the object was moved to the green box” without the difference caused by the transparent blindfold.
Figure 8
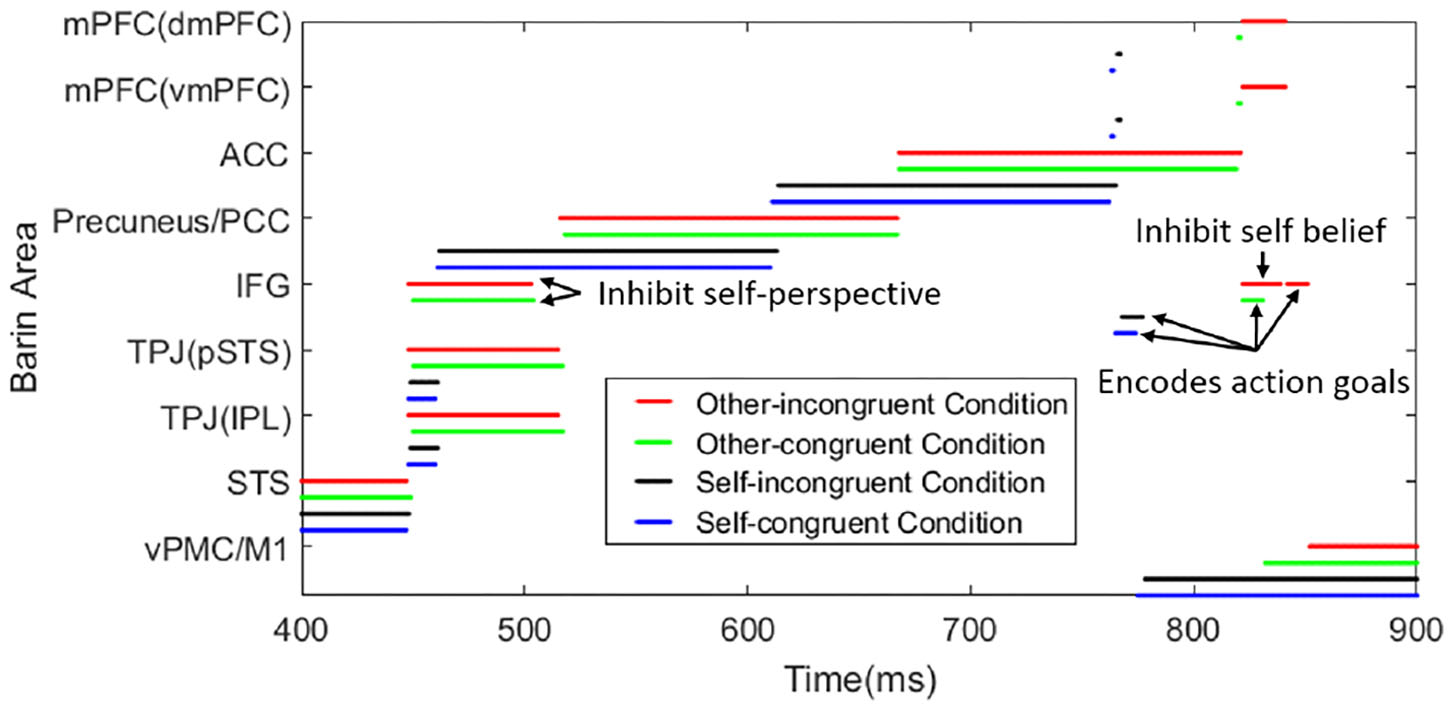
The temporal and spatial activation of different brain areas during different tasks. The time consumption in STS (visually encoding biological motion), Precuneus/PCC (inferring visual access), ACC (belief reasoning), IFG (encoding action goals), and vPMC/M1 (encoding kinematics/motion execution) are similar in different tasks. In the process of TPJ activation (deciding the output sequence of self and other-relevant stimuli) in other-incongruent condition (red line) and other-congruent condition (green line), IFG is activated to inhibit self-perspective. In the process of mPFC activation (deciding belief for motor response) in other-incongruent condition, IFG is activated to inhibit self-belief. In the tasks of self-incongruent condition (black line) and self-congruent condition (blue line), the IFG is only activated in the process of encoding action goals. The value of total time consumption is self-congruent condition < self-incongruent condition < other-congruent condition < other-incongruent condition. To show the function of IFG easily, we make the arrow mark in the figure.
Our focus is the activation sequence of brain areas and reaction time in the various task, such as the other-incongruent condition spends more time than self-congruent condition rather than the numerical value of time consumption, these result is consistent with the functional neuroimaging studies in Mossad et al. (2016) and Dohnel et al. (2012).
In the process of inferring visual access which corresponds to Figure 6d, even though the visual inputs in both groups are identical, the output is different when the participant robot infer other's visual access with different self-experience. In other words, when inferring visual access of another person by self-experience, the opaque blindfold group will know the actor cannot see the moving object, and the transparent blindfold group will know the actor can. When inferring self visual access, the perception of visual inputs and the result of precuneus are identical in both groups.
In the process of inferring other's visual access, the IFG will not be activated when self-perspective and other-perspective is identical, as shown in Figures 6b,c,f. If the self-perspective and other-perspective are in conflict with each other in the process of reasoning about other's belief, the IFG will be activated to inhibit the information of self-perspective, as shown in Figures 6d,e.
In the process of motor response in reasoning about other's belief, the IFG will inhibit self-belief if the beliefs are conflictive. So the other's belief in dmPFC will be the output of mPFC. Then IFG receives input from mPFC and encodes action goals to control vPMC to action.
In addition, we also test the effect of blindfold position in this task. In the visual access of blindfold learning stage, we add a new phase: we put the blindfold on the desk or interpose it at others position to make that both the blindfold and object can be perceived by the participant robot, and we also ask the question “Where is the [object label]?” In the test stage, we put the blindfold on the desk or interpose it at other positions where the actor's visual inputs are not blocked. Both of the groups can infer the visual access of actor robot correctly, and conclude that the actor robot could see the object move to the right side. And self-belief is corresponding to other's belief in both groups. This additional test could prove that the actor robot does not use low-level features such as whether the blindfold exists when inferring other's mental state, and it also proves the effect of the bodily model in this task.
4.2.2. Turn Around Test
In the false belief condition, the actor robot's belief is inconsistent with the representations of reality. When asking the participant robot “Where is the ladybird according to the blue robot?” the participant robot will point to the yellow box on the left side. And when asking the participant robot “Where is the ladybird according to yourself?” the participant robot will point to the green box on the right side (Movie S6).
In the true belief condition, the actor robot's belief is consistent with the representations of reality. When asking the participant robot the upper two questions, for both of them, the participant robot will point to the green box on the right side (Movie S7).
We repeat this experiment 20 times, the robot could pass the task every time. The mechanism of Turn Around Test is similar to the Opaque-and-Transparent Blindfold Test, the only difference is that the self-perspective and other-perspective are identical in true belief task of Turn Around Test. So IFG was not activated in this stage. We select the time consumption in TPJ, IFG, and mPFC as examples. The time consumption of false belief reasoning (87.3 ms) is longer than true belief reasoning (16.1 ms). And the time consumption of reasoning about other's belief (51.7 ms) is longer than self-belief (15.3 ms). In the process of reasoning about self-belief, the time consumption of false belief condition (15.4 ms) and true belief condition (15.2 ms) are similar.
4.2.3. Maturation Test
The maturation of correlate brain areas will be regarded as calculation capability in our model, and the calculation capability increases with the maturation of brain areas. The calculation capability in this model is proportional to the number of neurons in the hidden layer. For example, If the neuron number involved in the calculation of the hidden layer in Precuneus/PCC is two or fewer, even though participant robot can learn visual access of blindfold, it failed in inferring other's visual access. As indicated in Myowa-Yamakoshi et al. (2011), 8-month-old infants and 12-month-old infants had experienced being blindfolded, when they saw a blindfolded actor did a successful goal-directed action which normally could not succeed with a blindfold, 12-month-old infants will look longer, but 8-month-old infants will not. We think that with the maturation of correlate brain areas as well as their connections, more neurons and synaptic connections will be included in the task processing.
The maturation of the connection between brain areas is critical for information transmission and information integration, especially inhibitory connection and control. The inhibitory control is generally considered as a key mechanism in false-belief task (Leslie and Polizzi, 1998; Scott and Baillargeon, 2017), and we think that the maturation of connections between IFG and TPJ, IFG and vmPFC are the neural basis of self-perspective inhibition and self-belief inhibition respectively. As shown in Figure 9, the inhibitory control uses inhibitory neurons and temporary neurons which store information temporarily for the selection of correct output information of TPJ or mPFC. In the process of reasoning about other's belief, the inhibitory neurons in TPJ and mPFC receive other-relevant information from STS or ACC, respectively. The information of inhibitory neurons in TPJ is identical with the information of other-relevant stimuli in pSTS, and the information of inhibitory neurons in mPFC is identical with the information of other's belief in dmPFC. The temporary neurons in TPJ receive self-relevant information from STS, and the temporary neurons' information is identical with the information of self-relevant stimuli in IPL. The self-perspective inhibition takes place in TPJ and the self-belief inhibition takes place in mPFC. Then we test the effect of these connections in the false-belief task, and observe that the different maturation of connections leads to different permanence in the task. In this figure, the inhibitory neurons (In) are used to inhibit information in IPL or vmPFC, and the inhibitory result (InR) is the result of their interaction. If the connections between IFG and TPJ, IFG and vmPFC are mature, the activated neurons of InR will activate IFG to inhibit the information in InR neurons, and then make the correct information as the output of TPJ and mPFC. These connections will not influence the process of reasoning about self-belief.
Figure 9
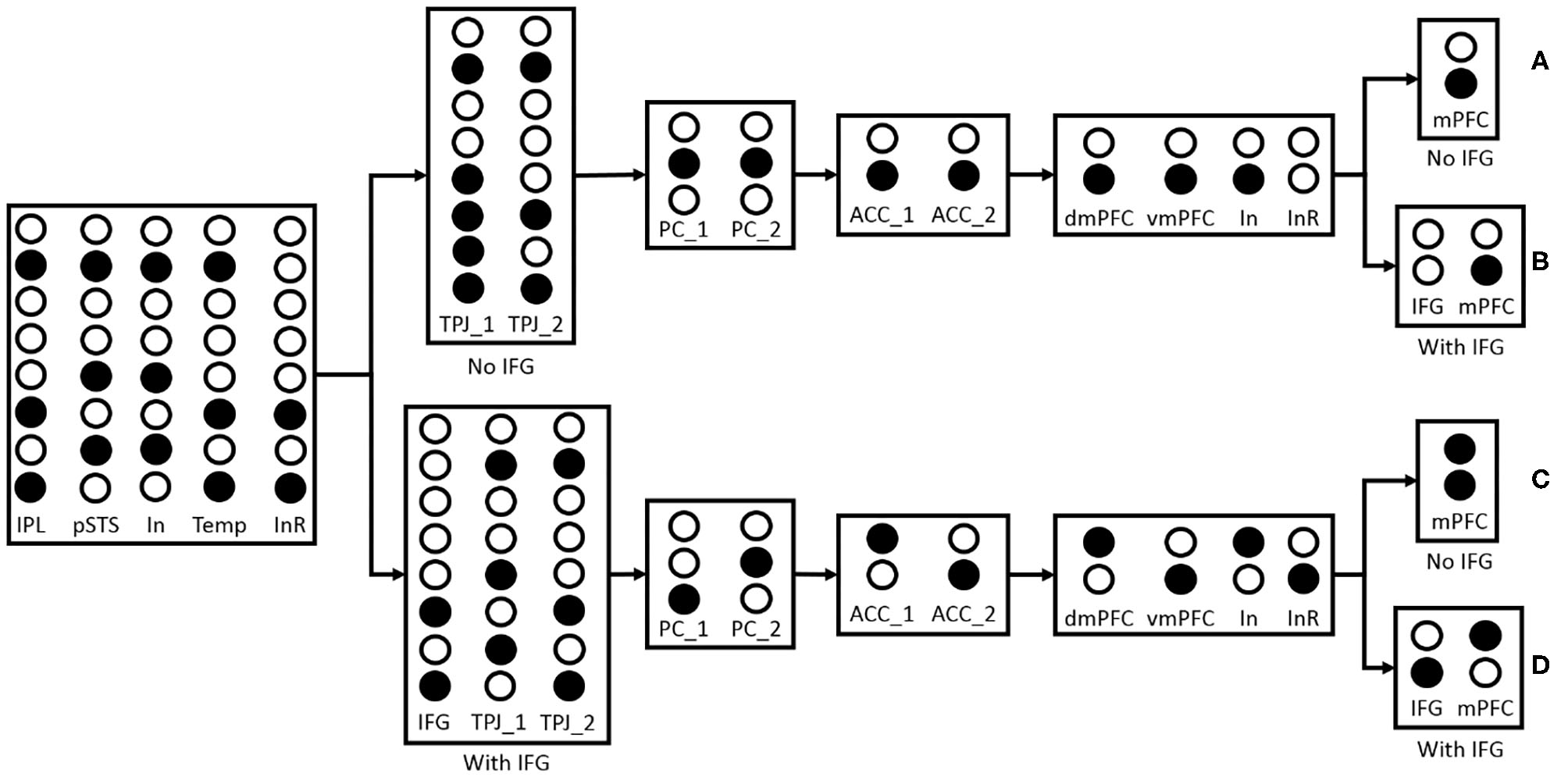
The effect of IFG connection in the false-belief task. The solid circles indicate that the neurons have been activated. “No IFG” means the connection between IFG and TPJ or IFG and vmPFC is immature, and ‘With IFG' means the connection between IFG and TPJ or IFG and vmPFC is mature. (A) Both of the connections between IFG and TPJ, IFG and vmPFC are immature. The first output of TPJ (TPJ_1) is different from IPL or pSTS because the self-perspective inhibition failed which caused by the immature connection between IFG and TPJ, and the second output (TPJ_2) is identical with IPL. The inferring visual access result of PC_1 and PC_2 in Precuneus/PCC are identical, and the belief reasoning result of ACC_1 and ACC_2 in ACC are identical. In the process of motor response, the InR neurons have not been activated because the belief in dmPFC and vmPFC are identical, so the output of mPFC is identical with dmPFC. The behavior of the participant robot to predict the actor robot's action is the same as the action caused by self-belief, so it failed in the false-belief task. (B) The connection between IFG and TPJ is immature, and the connection between IFG and vmPFC is mature. The participant robot also failed in this task because the result of inferring other's visual access is wrong which causes by the immature connection between IFG and TPJ. (C) The connection between IFG and TPJ is mature, and the connection between IFG and vmPFC is immature. The activated InR neurons activate IFG to inhibit self-perspective. The TPJ_1 and TPJ_2 could be output correctly. The participant robot could infer other's belief correctly, but it cannot inhibit the effect of self-belief without IFG. Both of the two candidate responses are activated when asked the question “Where is the ladybird according to the blue robot.” The participant robot will tend to select action directed by self-belief and failed in the false-belief task. (D) Both of the connections between IFG and TPJ, IFG, and vmPFC are mature. With the connection to IFG, the participant robot will inhibit self-perspective in TPJ and inhibit self-belief in mPFC, then succeed in this task.
5. Discussion
In this section, we will discuss the characteristics of the model, the reasons why robot experiments and cognitive experiments are not completely consistent, and the possible mechanisms of why toddlers fail in high inhibition tasks.
Compared to the previous models which we introduce in the related works, our model explores and is fundamentally based on the role of self-experience. In our model, robots learn to understand object permanence and visual access of blindfold or turn around from self-experience, then use it to infer other's belief and predict their actions. All of the participant robots learn the ability of understanding object permanence from the same experience. In the Opaque-and-Transparent Blindfold Test, they are divided into opaque blindfold group and transparent blindfold group. Even though the visual inputs of both groups in the test stage are identical, the different experience with an opaque blindfold or transparent blindfold leads to different performances. In Turn Around Test, the different behaviors of the actor robot in the test stage result in different performances. Compared with the recently published work from Patacchiola and Cangelosi (2020): (1) Our model is based on spiking neural networks, and just uses the STDP to successfully reproduce the complex cognitive function of ToM, hence more biological plausible. And their model is based on an actor-critic (AC) framework, an epigenetic robotic architecture (ERA) and a Bayesian network (BN). (2) Our model considered more brain regions that have been consistently found in many experimental paradigms of ToM, such as the TPJ that used for self-other distinction, the IFG that used for self-perspective inhibition and self-belief inhibition, etc. (3) Our model is used for the false belief task, which is one of the most classical and widely used experimental paradigms of ToM, and their model challenges a different task. The two studies have complementary contributions to the ToM models through bio-inspired mechanisms.
Through the integration of biological inspirations and computational modeling, we suggest that the self-experience, maturation of correlated brain areas (e.g., calculation capability) and connection between brain areas (e.g., inhibitory control) will have great influence on the participant's performance in the false-belief task.
As indicated in Scott and Baillargeon (2017), the false belief tasks contain spontaneous-response and elicited-response tasks that belong to the implicit task and explicit task, respectively. The difference in spontaneous-response and elicited-response tasks is that the former investigates the capacity of false belief understanding by spontaneous behavior such as anticipatory-looking, preferential-looking, etc with a non-verbal task, and the latter investigates this capacity by answering direct questions that predict agent's behavior who has a false belief with the verbal task. Children can pass the spontaneous-response task before 2 years old, but they can not pass the elicited-response tasks until about 4 years old. Our tasks on robots are not completely consisted with Senju et al. (2011) on 18-month-olds infants and Southgate et al. (2007) on 2-year-olds infants. Both of them used spontaneous-response to test the infants on whether they can pass the task. And in the test trial, they removed the object from the scene to make infants pass the task easier. In our task, we determine whether the robot can pass the task by detecting the direction of the finger which makes the results more intuitive. And in the test trial, we move the object to the other box. Setoh et al. (2016) found that 2.5-year-olds toddlers could succeeded in a traditional false-belief task with reduced processing demands. Toddlers could pass the elicited-intervention and low inhibition task (removing object from the scene) which is described by language and picture, but would fail in high inhibition task (moving the object to another box). They thought the reason why toddlers failed in high inhibition task is that toddlers cannot inhibit the response of the actual location of the object. We suppose that the core mechanism of belief reasoning is identical in both tasks, and the only difference should be in the process of motor response. In the motor response process of the elicited-intervention task, it may use the brain areas which control the hand movement. And in spontaneous-response task, it may use the brain areas which control the eye movement. The main reason why we use high inhibition task to replace low inhibition task is that the behavior of the robots in the true belief task is more intuitive to be understood (for the high inhibition task, the robot can point to the position of the object, while for the low inhibition task, the objects are removed outside the scene, and the robot cannot point to their positions).
And we suppose that the reason why toddlers failed in high inhibition task should be related to the lack of motor response ability rather than ToM (e.g., understanding that others have beliefs that are different from one's own). As shown in Figure 9, the connection between IFG and TPJ are matured but the connection between IFG and vmPFC are not, both of the two candidate responses are activated when the participant robot is asked “Where is the ladybird according to the blue robot.” The participant robot will tend to select action directed by self-belief rather than randomly, as the result of behavior data shown in Setoh et al. (2016) and Samson et al. (2005). In the low inhibition task, the participant has no idea about the object's location and one of the two candidate motor responses are activated, so the participant robot can succeed in this task. And in Samson et al. (2005), the participant who has a lesion of the right inferior and middle frontal gyri performed well in low-inhibition false-belief task but failed in the high-inhibition task.
Here we don't attempt to compare our model with the traditional Theories of ToM as Theory Theory (Gopnik and Wellman, 1994), Simulation Theory (Gallese, 1998), etc., because what we focus on in this paper is to build a computationally feasible model which could uncover the detailed mechanisms of ToM and enhance our understanding of how the self-experience, maturation of correlated brain areas and connection between brain areas affect the participant's performance in the false-belief task.
6. Conclusion
The computational model for the robotic ToM is regarded as one of the Grand Challenges for Artificial Intelligence and Robotics (Yang et al., 2018). Here we proposed a Brain-ToM model based on existing biological findings of ToM, and this model shows its relevance to ToM of human from the mechanism and behavior perspectives.
In summary, we propose a Brain-ToM model to enable machines to acquire the ability of ToM through learning and inferring based on self-experience. We validate the model by deploying it on humanoid robots. Our model successfully enabled the robot to pass the false-belief task, which is a classical task designed to understand the nature and mechanisms of ToM from Cognitive Psychology. The model and its application on robots show that current understanding on the mechanisms of the ToM can be computationally unified into a consistent framework and enable the robots to be equipped with the initial cognitive ability of ToM.
Statements
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author/s.
Author contributions
YZe conceived the initial idea. YZh and YZe designed the model, carried out, and analyzed the experiments. TZ, YZe, and DZ designed and implemented the SNN algorithm. FZ contributed to the inhibitory control mechanism. YZe, YZh, TZ, and EL wrote the manuscript.
Funding
This work was supported by the Strategic Priority Research Program of Chinese Academy of Sciences [Grant No. XDB32070100], the Beijing Municipality of Science and Technology [Grant No. Z181100001518006], the CETC Joint Fund [Grant No. 6141B08010103], the Major Research Program of Shandong Province [2018CXGC1503] and the Key Research Program of Frontier Sciences of Chinese Academy of Sciences [Grant No. ZDBS-LY-JSC013].
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnbot.2020.00060/full#supplementary-material
Movie S1Visual access learning of blindfold from self-experience (opaque blindfold group). This process enables the participant robot understand that other robots wearing a blindfold cannot see.
Movie S2Visual access learning of blindfold from self-experience (transparent blindfold group). This process enables the participant robot understand that other robots wearing a blindfold can see.
Movie S3Familiarization phase. This process enables the participant robot understand the goal of the actor robot.
Movie S4Opaque-and-transparent blindfold test (opaque blindfold group). The details in opaque blindfold group of blindfold test.
Movie S5Opaque-and-transparent blindfold test (transparent blindfold group). The details in transparent blindfold group of blindfold test.
Movie S6Turn around test (false-belief task). The details in false-belief task of turn around test.
Movie S7Turn around test (true belief task). The details in true belief task of turn around test.
- ToM
theory of mind
- STS
superior temporal sulcus
- TPJ
temporo-parietal junction
- IPL
inferior parietal lobule
- pSTS
posterior superior temporal sulcus
- PCC
posterior cingulate cortex
- ACC
anterior cingulate cortex
- mPFC
medial prefrontal cortex
- vmPFC
ventral medial prefrontal cortex
- dmPFC
dorsal medial prefrontal cortex
- IFG
inferior frontal gyrus
- vPMC
ventral premotor cortex
- M1
primary motor cortex.
Abbreviations
References
1
Abu-AkelA.Shamay-TsooryS. (2011). Neuroanatomical and neurochemical bases of theory of mind. Neuropsychologia49, 2971–2984. 10.1016/j.neuropsychologia.2011.07.012
2
AsakuraN.InuiT. (2016). A bayesian framework for false belief reasoning in children: A rational integration of theory-theory and simulation theory. Front. Psychol. 7:2019. 10.3389/fpsyg.2016.02019
3
BardiL.SixP.BrassM. (2017). Repetitive TMS of the temporo-parietal junction disrupts participant's expectations in a spontaneous theory of mind task. Soc. Cogn. Affect. Neurosci. 12, 1775–1782. 10.1093/scan/nsx109
4
BengioY.LeeD.-H.BornscheinJ.MesnardT.LinZ. (2015a). Towards biologically plausible deep learning. arXiv [Preprint]. arXiv:1502.04156.
5
BengioY.MesnardT.FischerA.ZhangS.WuY. (2015b). Stdp as presynaptic activity times rate of change of postsynaptic activity. arXiv [Preprint]. arXiv:1509.05936.
6
BerthiaumeV. G.ShultzT. R.OnishiK. H. (2013). A constructivist connectionist model of transitions on false-belief tasks. Cognition126, 441–458. 10.1016/j.cognition.2012.11.005
7
BiG.-Q.PooM.-M. (2001). Synaptic modification by correlated activity: Hebb's postulate revisited. Annu. Rev. Neurosci. 24, 139–166. 10.1146/annurev.neuro.24.1.139
8
BruceS.MuhammadZ. (2009). The development of object permanence in children with intellectual disability, physical disability, autism, and blindness. Int. J. Disabil. Dev. Educ. 56, 229–246. 10.1080/10349120903102213
9
BucknerR. L.CarrollD. C. (2007). Self-projection and the brain. Trends Cogn. Sci. 11, 49–57. 10.1016/j.tics.2006.11.004
10
CavannaA. E.TrimbleM. R. (2006). The precuneus: a review of its functional anatomy and behavioural correlates. Brain129(Pt 3), 564–583. 10.1093/brain/awl004
11
DanY.PooM.-M. (2004). Spike timing-dependent plasticity of neural circuits. Neuron44, 23–30. 10.1016/j.neuron.2004.09.007
12
DennyB. T.KoberH.WagerT. D.OchsnerK. N. (2012). A meta-analysis of functional neuroimaging studies of self- and other judgments reveals a spatial gradient for mentalizing in medial prefrontal cortex. J. Cogn. Neurosci. 24, 1742–1752. 10.1162/jocn_a_00233
13
DohnelK.SchuwerkT.MeinhardtJ.SodianB.HajakG.SommerM. (2012). Functional activity of the right temporo-parietal junction and of the medial prefrontal cortex associated with true and false belief reasoning. NeuroImage60, 1652–1661. 10.1016/j.neuroimage.2012.01.073
14
EddyC. M. (2016). The junction between self and other? Temporo-parietal dysfunction in neuropsychiatry. Neuropsychologia89, 465–477. 10.1016/j.neuropsychologia.2016.07.030
15
FlavellJ. H.FlavellE. R.GreenF. L. (1983). Development of the appearance-reality distinction. Cogn. Psychol. 15, 95–120. 10.1016/0010-0285(83)90005-1
16
FrithC. D.FrithU. (1999). Interacting minds-a biological basis. Science286, 1692–1695. 10.1126/science.286.5445.1692
17
FrithC. D.FrithU. (2006). The neural basis of mentalizing. Neuron50, 531–534. 10.1016/j.neuron.2006.05.001
18
GallagherH. L.FrithC. D. (2003). Functional imaging of “theory of mind”. Trends Cogn. Sci. 7, 77–83. 10.1016/S1364-6613(02)00025-6
19
GalleseV. (1998). Mirror neurons and the simulation theory of mind-reading. Trends Cogn. Sci. 2, 493–501. 10.1016/S1364-6613(98)01262-5
20
GeorgopoulosA.SchwartzA.KettnerR. (1986). Neuronal population coding of movement direction. Science233, 1416–1419. 10.1126/science.3749885
21
GoodmanN. D.BakerC. L.BonawitzE. B.MansinghkaV. K.GopnikA.WellmanH.et al. (2006). “Intuitive theories of mind: a rational approach to false belief,” in Proceedings of the Twenty-Eighth Annual Conference of the Cognitive Science Society (Vancouver, BC), 1382–1387.
22
GopnikA.WellmanH. M. (1994). “The theory theory,” in Mapping the Mind: Domain Specificity in Cognition and Culture, eds L. A. Hirschfeld and S. A. Gelman (Cambridge University Press) 257. 10.1017/CBO9780511752902.011
23
GreenM. F.HoranW. P.LeeJ. (2015). Social cognition in schizophrenia. Nat. Rev. Neurosci. 16, 620–631. 10.1038/nrn4005
24
Grosse WiesmannC.SchreiberJ.SingerT.SteinbeisN.FriedericiA. D. (2017). White matter maturation is associated with the emergence of theory of mind in early childhood. Nat. Commun. 8:14692. 10.1038/ncomms14692
25
GrossmanE. D.BlakeR. (2002). Brain areas active during visual perception of biological motion. Neuron35, 1167–1175. 10.1016/S0896-6273(02)00897-8
26
HamzeiF.VryM. S.SaurD.GlaucheV.HoerenM.MaderI.et al. (2016). The dual-loop model and the human mirror neuron system: an exploratory combined fMRI and DTI study of the inferior frontal gyrus. Cereb. Cortex26, 2215–2224. 10.1093/cercor/bhv066
27
HartwrightC. E.ApperlyI. A.HansenP. C. (2012). Multiple roles for executive control in belief-desire reasoning: distinct neural networks are recruited for self perspective inhibition and complexity of reasoning. NeuroImage61, 921–930. 10.1016/j.neuroimage.2012.03.012
28
HartwrightC. E.ApperlyI. A.HansenP. C. (2015). The special case of self-perspective inhibition in mental, but not non-mental, representation. Neuropsychologia67, 183–192. 10.1016/j.neuropsychologia.2014.12.015
29
HuangQ.LiuX. (2017). Do infants have an understanding of false belief?Adv. Psychol. Sci. 25, 431–442. 10.3724/SP.J.1042.2017.00431
30
IgelstromK. M.GrazianoM. S. A. (2017). The inferior parietal lobule and temporoparietal junction: a network perspective. Neuropsychologia105, 70–83. 10.1016/j.neuropsychologia.2017.01.001
31
JiangQ.WangQ.LiP.LiH. (2016). The neural correlates underlying belief reasoning for self and for others: evidence from ERPS. Front. Psychol. 7:1501. 10.3389/fpsyg.2016.01501
32
LeechR.SharpD. J. (2014). The role of the posterior cingulate cortex in cognition and disease. Brain137(Pt 1), 12–32. 10.1093/brain/awt162
33
LeslieA. M.PolizziP. (1998). Inhibitory processing in the false belief task: two conjectures. Dev. Sci. 1, 247–253. 10.1111/1467-7687.00038
34
MilliezG.WarnierM.ClodicA.AlamiR. (2014). “A framework for endowing an interactive robot with reasoning capabilities about perspective-taking and belief management,” in Ro-Man: the IEEE International Symposium on Robot and Human Interactive Communication (Edinburgh), 1103–1109. 10.1109/ROMAN.2014.6926399
35
MolenberghsP.JohnsonH.HenryJ. D.MattingleyJ. B. (2016). Understanding the minds of others: a neuroimaging meta-analysis. Neurosci. Biobehav. Rev. 65, 276–291. 10.1016/j.neubiorev.2016.03.020
36
MoreauN.VialletF.Champagne-LavauM. (2013). Using memories to understand others: the role of episodic memory in theory of mind impairment in Alzheimer disease. Ageing Res. Rev. 12, 833–839. 10.1016/j.arr.2013.06.005
37
MossadS. I.AuCoin-PowerM.UrbainC.SmithM. L.PangE. W.TaylorM. J. (2016). Thinking about the thoughts of others; temporal and spatial neural activation during false belief reasoning. NeuroImage134, 320–327. 10.1016/j.neuroimage.2016.03.053
38
Myowa-YamakoshiM.KawakitaY.OkandaM.TakeshitaH. (2011). Visual experience influences 12-month-old infants' perception of goal-directed actions of others. Dev. Psychol. 47, 1042–1049. 10.1037/a0023765
39
O'LaughlinC.ThagardP. (2000). Autism and coherence: a computational model. Mind Lang. 15, 375–392. 10.1111/1468-0017.00140
40
PatacchiolaM.CangelosiA. (2020). A developmental cognitive architecture for trust and theory of mind in humanoid robots. IEEE Trans. Cybern.1–13. 10.1109/TCYB.2020.3002892
41
PernerJ.LeekamS. R.WimmerH. (1987). Three-year-olds' difficulty with false belief: the case for a conceptual deficit. Br. J. Dev. Psychol. 5, 125–137. 10.1111/j.2044-835X.1987.tb01048.x
42
PiagetJ.CookM. (1952). The Origins of Intelligence in Children, Vol. 8. New York, NY: International Universities Press. 10.1037/11494-000
43
PremackD.WoodruffG. (1978). Does the chimpanzee have a theory of mind?Behav. Brain Sci. 1, 515–526. 10.1017/S0140525X00076512
44
RabinowitzN. C.PerbetF.SongH. F.ZhangC.EslamiS.BotvinickM. (2018). Machine theory of mind. arXiv [Preprint]. arXiv:1802.07740.
45
SamsonD.ApperlyI. A.KathirgamanathanU.HumphreysG. W. (2005). Seeing it my way: a case of a selective deficit in inhibiting self-perspective. Brain128(Pt 5), 1102–1111. 10.1093/brain/awh464
46
SchurzM.AichhornM.MartinA.PernerJ. (2013). Common brain areas engaged in false belief reasoning and visual perspective taking: a meta-analysis of functional brain imaging studies. Front. Hum. Neurosci. 7:712. 10.3389/fnhum.2013.00712
47
SchurzM.PernerJ. (2015). An evaluation of neurocognitive models of theory of mind. Front. Psychol. 6:1610. 10.3389/fpsyg.2015.01610
48
SchurzM.RaduaJ.AichhornM.RichlanF.PernerJ. (2014). Fractionating theory of mind: a meta-analysis of functional brain imaging studies. Neurosci. Biobehav. Rev. 42, 9–34. 10.1016/j.neubiorev.2014.01.009
49
ScottR. M.BaillargeonR. (2017). Early false-belief understanding. Trends Cogn. Sci. 21, 237–249. 10.1016/j.tics.2017.01.012
50
SenjuA.SouthgateV.SnapeC.LeonardM.CsibraG. (2011). Do 18-month-olds really attribute mental states to others? A critical test. Psychol. Sci. 22, 878–880. 10.1177/0956797611411584
51
SetohP.ScottR. M.BaillargeonR. (2016). Two-and-a-half-year-olds succeed at a traditional false-belief task with reduced processing demands. Proc. Natl. Acad. Sci. U.S.A. 113, 13360–13365. 10.1073/pnas.1609203113
52
SouthgateV.SenjuA.CsibraG. (2007). Action anticipation through attribution of false belief by 2-year-olds. Psychol. Sci. 18, 587–592. 10.1111/j.1467-9280.2007.01944.x
53
TielinZ.YiZ.DongchengZ.MengtingS. (2018). “A plasticity-centric approach to train the non-differential spiking neural networks,” in Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (New Orleans, LA), 1–8.
54
van der MeerL.GroenewoldN. A.NolenW. A.PijnenborgM.AlemanA. (2011). Inhibit yourself and understand the other: neural basis of distinct processes underlying theory of mind. NeuroImage56, 2364–2374. 10.1016/j.neuroimage.2011.03.053
55
VogeleyK.BussfeldP.NewenA.HerrmannS.HappeF.FalkaiP.et al. (2001). Mind reading: neural mechanisms of theory of mind and self-perspective. NeuroImage14(1 Pt 1), 170–181. 10.1006/nimg.2001.0789
56
VogeleyK.MayM.RitzlA.FalkaiP.ZillesK.FinkG. R. (2004). Neural correlates of first-person perspective as one constituent of human self-consciousness. J. Cogn. Neurosci. 16, 817–827. 10.1162/089892904970799
57
WimmerH.PernerJ. (1983). Beliefs about beliefs: representation and constraining function of wrong beliefs in young children's understanding of deception. Cognition13, 103–128. 10.1016/0010-0277(83)90004-5
58
YangG.-Z.BellinghamJ.DupontP. E.FischerP.FloridiL.FullR.et al. (2018). The grand challenges of science robotics. Sci. Robot. 3, 1–14. 10.1126/scirobotics.aar7650
59
ZengY.ZhaoY.BaiJ. (2016). “Towards robot self-consciousness (i): Brain-inspired robot mirror neuron system model and its application in mirror self-recognition,” in International Conference on Brain Inspired Cognitive Systems (Beijing), 11–21. 10.1007/978-3-319-49685-6_2
60
ZengY.ZhaoY.BaiJ.XuB. (2017). Toward robot self-consciousness (ii): Brain-inspired robot bodily self model for self-recognition. Cogn. Comput. 10, 307–320. 10.1007/s12559-017-9505-1
Summary
Keywords
theory of mind, false-belief task, brain inspired model, self-experience, connection maturation, inhibitory control
Citation
Zeng Y, Zhao Y, Zhang T, Zhao D, Zhao F and Lu E (2020) A Brain-Inspired Model of Theory of Mind. Front. Neurorobot. 14:60. doi: 10.3389/fnbot.2020.00060
Received
22 May 2020
Accepted
27 July 2020
Published
28 August 2020
Volume
14 - 2020
Edited by
Jun Tani, Okinawa Institute of Science and Technology Graduate University, Japan
Reviewed by
Jing Zhao, Yanshan University, China; Xiaoqian Mao, Qingdao University of Science and Technology, China
Updates
Copyright
© 2020 Zeng, Zhao, Zhang, Zhao, Zhao and Lu.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yi Zeng yi.zeng@ia.ac.cn
†These authors have contributed equally to this work
Disclaimer
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.