 Charalambos Themistocleous
Charalambos Themistocleous Marie Eckerström
Marie Eckerström Dimitrios Kokkinakis
Dimitrios Kokkinakis- 1The Swedish Language Bank, Department of Swedish, University of Gothenburg, Gothenburg, Sweden
- 2Department of Neurology, Johns Hopkins University, School of Medicine, Baltimore, MD, United States
- 3Department of Psychiatry and Neurochemistry, Institute of Neuroscience and Physiology, University of Gothenburg, Gothenburg, Sweden
While people with mild cognitive impairment (MCI) portray noticeably incipient memory difficulty in remembering events and situations along with problems in decision making, planning, and finding their way in familiar environments, detailed neuropsychological assessments also indicate deficits in language performance. To this day, there is no cure for dementia but early-stage treatment can delay the progression of MCI; thus, the development of valid tools for identifying early cognitive changes is of great importance. In this study, we provide an automated machine learning method, using Deep Neural Network Architectures, that aims to identify MCI. Speech materials were obtained using a reading task during evaluation sessions, as part of the Gothenburg MCI research study. Measures of vowel duration, vowel formants (F1 to F5), and fundamental frequency were calculated from speech signals. To learn the acoustic characteristics associated with MCI vs. healthy controls, we have trained and evaluated ten Deep Neural Network Architectures and measured how accurately they can diagnose participants that are unknown to the model. We evaluated the models using two evaluation tasks: a 5-fold crossvalidation and by splitting the data into 90% training and 10% evaluation set. The findings suggest first, that the acoustic features provide significant information for the identification of MCI; second, the best Deep Neural Network Architectures can classify MCI and healthy controls with high classification accuracy (M = 83%); and third, the model has the potential to offer higher accuracy than 84% if trained with more data (cf., SD≈15%). The Deep Neural Network Architecture proposed here constitutes a method that contributes to the early diagnosis of cognitive decline, quantify the progression of the condition, and enable suitable therapeutics.
1. Introduction
Individuals with mild cognitive impairment (MCI) portray a noticeable memory difficulty in remembering events and situations along with problems in decision making, planning, interpreting instructions, and orientation (1–5). These cognitive problems become frequent and more severe compared to the cognitive decline in normal aging (see also 6, 7). As the MCI progresses, MCI individuals face a higher risk of developing Alzheimer's Disease (AD).
In search of less strenuous and non-invasive techniques for assessing MCI, currently, there has been substantial interest on the role of speech and language and its potentials as markers of MCI. Language impairment in AD is well established (e.g., 8–10) and can be evaluated by using assessments, such as naming tests (11), discourse (12–14), verbal fluency tests (e.g., 15), complexity measures, such as phonemes per word, phone entropy, verbal fluency, and word recall (8–10, 13, 16–22). Findings with respect to syntax and phonology have been inconsistent though (for a discussion on the role of syntax in MCI, see 23). Also, many studies explored the interactions of language and other predictors from imaging, biomarkers etc., in dementia (24–30). The fact that language impairment occurs early and commonly in the progression of AD, motivated many researchers to identify markers of language impairment in MCI. For example, Manouilidou et al. (31) showed that while MCI individuals preserve morphological rule knowledge, they face processing difficulties of pseudo-words (for a discussion and review of current studies, see 32, 33). As there is only a handful of studies on the acoustic properties of MCI speech (e.g., 30, 34), more research on speech acoustics is required to gain a better understanding of how MCI speech differs from that of healthy controls.
The development of automated machine learning models that can learn the characteristics of MCI and provide an early and accurate identification of MCI is of utmost importance for two main reasons: First, an early identification can enable multidomain life style interventions and/or pharmacological treatments at the MCI stage, or even earlier, which can potentially delay or might even prevent the development of AD and other types of dementia (5, 35). Second, the early identification, will provide time to patients and their families to make decisions about their care, family issues, and legal concerns (5).
The aim of this study is to provide an automated method that can identify MCI individuals and distinguish them from healthy controls using acoustic information. Specifically, in this study, we provide an automated machine learning method using Deep Neural Network Architectures that identifies individuals with MCI from healthy controls. We demonstrate its performance by using data from Swedish. Specifically, 55 Swedish participants, 30 healthy controls and 25 MCI, were instructed by a clinician to read a short passage, consisting of 144 words, as part of their evaluation. Reading tasks are being employed extensively in research because they provide rich linguistic data without straining the participants (36). Also, they have the advantage that they are restrictive with respect to the segmental environment of vowels and consonants, which is the same for all participants. Next, the speech material was transcribed and segmented into vowels and consonants. From the segmented material, we measured vowel F1−F5 formant frequencies, F0, and duration. Vowel formants are a range of vowel frequency peaks in the sound spectrum. Formant frequencies are the primary acoustic correlates for the production of vowels. F1 and F2 usually suffice for the identification of vowels in most languages but higher order formant frequencies can provide information about the social—such as the age, gender, and dialect—and physiological properties of speakers (37–39). In Swedish, F3 also contributes to the distinction of rounded and unrounded vowels (40). F0 is the acoustic correlate of intonation. Speakers vary the F0 of their utterances to produce various melodic patterns, such as when emphasizing parts of the utterance, asking questions, giving commands, etc. F0 (e.g., mean F0, F0 minimum and maximum) is found to be lower in individuals with depression (41, 42). In addition to frequency measurements, we measured vowel duration.
For the classification task, we have evaluated several Deep Neural Network Architectures based on Multilayer Perceptrons (MLP). MLPs are a type of sequential, Feed-Forward Neural Network, which when trained on a dataset, can learn a non-linear function approximator for the classification of MCI and healthy participant:
where m is the number of dimensions for input and o is the number of dimensions for output. Given a set of vowel features X = x1, x2, …, xm and a target y; namely, an array of values determining the condition of the participant (healthy controls vs. MCI), the neural network can learn the classification function. The advantage of this type of network for our data is that it can learn non-linear structures.
2. Methodology
In this section, we describe the development of the dataset and the structure of the predictors.
2.1. Speech Materials
Participants for this study were recruited from the Gothenburg MCI study, which is a large clinically based longitudinal study on mild cognitive impairment (5). This study aims to increase the nosological knowledge that will enable rational trials in AD and other types of dementia. It also includes longitudinal in-depth phenotyping of patients with different forms and degrees of cognitive impairment using neuropsychological, neuroimaging, and neurochemical tools (5). Speech recordings were conducted as part of the additional assessment tests that conduced for the purposes of the Riksbankens Jubileumsfond – The Swedish Foundation for Humanities & Social Sciences “Linguistic and extra-linguistic parameters for early detection of cognitive impairment” research grant (NHS 14-1761:1).
2.2. Participants
The recordings were conducted in an isolated environment at the University of Gothenburg. Thirty healthy controls and 25 MCI—between 55 and 79 years old (M = 69, SD = 6.4) participated in the study (see Table 1). The two groups did not differ with respect to age [t(52.72) = −1.8178, p = n.s.] and gender (W = 1567.5, p = n.s.), as is evident by the non-significant results from a t test and an independent 2-group Mann-Whitney U-test, respectively. Participants were selected based on specific inclusion and exclusion criteria: (i) participants should not have suffered from dyslexia and other reading difficulties; (ii) they should not have suffered from major depression, ongoing substance abuse, poor vision that cannot be corrected with glasses or contact lenses; (iii) they should not have been diagnosed with other serious psychiatric, neurological or brain-related conditions, such as Parkinson's disease; (iv) they had to be native Swedish speakers; (v) they had to be able to read and understand information about the study; and (vi) they had to be able to give written consent.
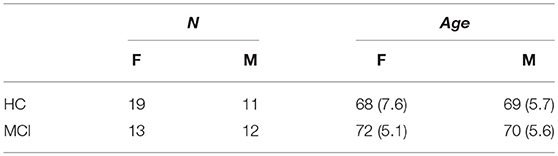
Table 1. Age and gender of healthy controls (HC) and participants with Mild Cognitive Impairment (MCI).
Healthy controls had a significantly higher Mini-Mental State Exam (MMSE) score. (The MMSE score is a scale of 0–30 and represents the cognitive status of an individual). Mean MMSE score for the MCI participants was 28.2, which is close to normal (43). Ethic approvals for the study were obtained by the local ethical committee review board (reference number: L091-99, 1999; T479-11, 2011); while the currently described study was approved by the local ethical committee decision 206-16, 2016.
2.3. Acoustic Features
2.3.1. Segmentation
Each vowel was segmented in the acoustic signal; that is, we located the right and left boundary of vowels and consonants. A segmentation example is shown in Figure 1. Specifically, the figure shows the waveform (upper panel) and spectogram of the word havsbottnen ‘seabed' taken here as an example from a larger sentence: öar kan uppstå när vulkaner höjer sig från havsbottnen eller när vattennivån i havet stiger eller faller “islands can occur when volcanoes rise from the seabed or when water levels in the ocean rise or fall” (see the Appendix for the whole passage). There are also three different tiers with the transcriptions, the top tier defines the boundaries of sentences; the second tier in the middle shows the word boundaries; and the lower tier shows the segmental boundaries, namely the boundaries of consonants and vowels (see also the thin lines extending from the lower tier to the middle of the spectogram and demarcate vowels and consonants). For the segmentation, we have employed an automatic module for Swedish developed by the first author (44). As measurements and processes rely on accurate segmentation this step is crucial; therefore, all segmentation decisions were evaluated twice based on the following segmentation criteria: vowel onsets and offsets were demarcated by the beginning and end of the first two formant frequencies; the rise of the intensity contour at the beginning of the vowel and its fall at the end of the vowel served as additional criteria for vowel segmentation. Then, we measured the acoustic properties of using Praat (45). Overall, there were 4396 HC and 4273 MCI productions, which is a relatively balanced data set.
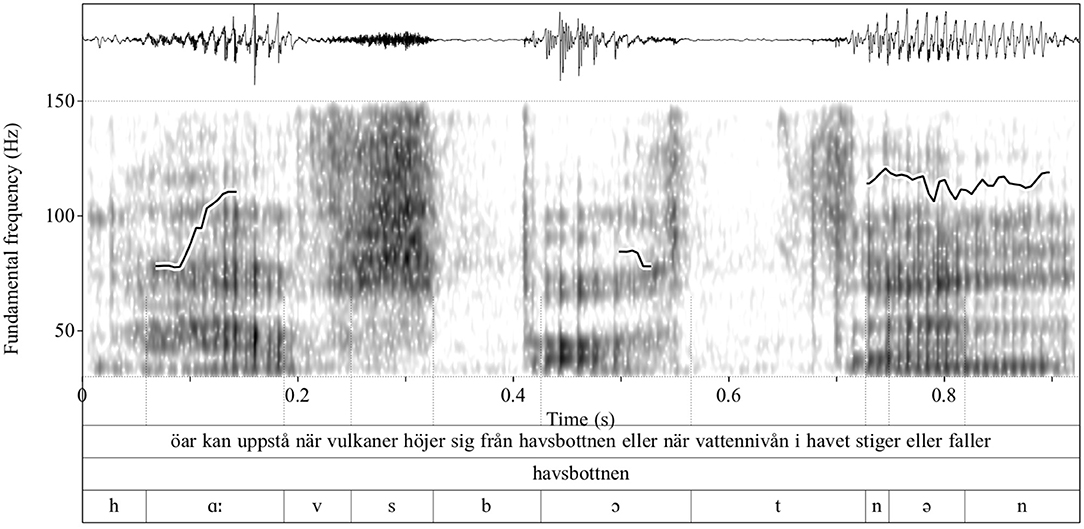
Figure 1. Waveform, spectrogram, and F0 contour—superimposed on the spectrogram—of an example utterance (upper tier). Shown in the plot is the segmentation of the word havsbottnen “seabed” (middle tier); the individual sounds are shown in the lowest tier. Sound boundaries are indicated with thin vertical lines. The ordinate shows the F0 values whereas the abscissa shows the time in second.
2.3.2. Acoustic Measurements
Vowel formants were measured at multiple positions. Traditionally vowel formants are measured using a single measurement at the middle of the vowel, which is supposedly the vowel target. Nevertheless, the shape of the formant contour can also convey information about participants' sociophonetic properties (see for a discussion 37). To this end, we conducted three measurements of formants at the 15, 50, 75% of vowels' duration. Vowel formants were calculated using standard Linear Predictive Coding (LPC-analysis) (46). We also measured vowel duration and fundamental frequency (F0) (47). The latter is the lowest frequency of speech; and it constitutes the main acoustic correlate of speech melody (a.k.a., intonation) (48). We calculated the minimum, maximum, and mean F0 for each vowel. F0 and formant frequencies were measured in Hertz.
2.3.3. Sociophonetic Features
In addition to the acoustic features, the model included as predictors information about participants' age and gender. Overall, the classification tasks included the following 24 acoustic and sociophonetic predictors:
1. Vowel Formants: We measured the first five formant frequencies of vowels (i.e., F1, F2, F3, F4, F5) at the 15%, 50%, and 75% of the vowels' total duration: i.e., F1 15%, F1 50%, F1 75%…F5 15%, F5 50%, and F5 75%; We also provided the log-transformed values of F1, F2, F3.
2. Fundamental frequency (F0): We measured the F0 across the duration of the vowel and calculated the mean F0, min F0, and max F0.
3. Vowel duration: Vowel duration measured in seconds from vowel onset to vowel offset.
4. Gender: Participants' gender.
5. Age: Participants' age.
2.4. Models and Experiments
In this section, we describe the neural network architectures employed in this work. Ten neural network architectures that differed in the total number of hidden layers from h1…h10 were evaluated twice using validation split and cross-validation (the other parameters were the same across models). We present all ten models and not the best model only because (i) we want to demonstrate the whole methodological process that led to the selection of the best model and stress out that the final model is the result of a dynamic process of model comparison; (ii) different randomization of the data may provide different output; thus, a rigorous evaluation can demonstrate whether the output is consistent across models. For example, by demonstrating that the output is not random and that there is a pattern between the different models; and (iii) the evaluation process is being part of the model and not external to the model as it can explain the final architecture of the model, such as the number of hidden layers in the model. An overview of the architectures is shown in Figure 2 and in Table 2. The neural architectures were implemented in Keras, a high-level neural networks API (49) running on top of TensorFlow (50) in Python 3.6.1. For the normalization and scaling of predictors, we employed modules from SCIKIT-LEARN, which is a machine learning library implemented in Python (51, 52).
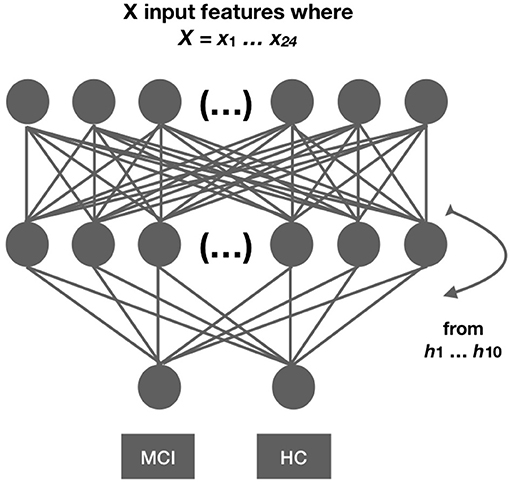
Figure 2. Network architecture. We developed 10 different networks with 21 predictors each. The networks differed in the number of hidden layers ranging from 1…10. Each network architecture was evaluated twice using cross-validation and evaluation split. Model comparison measures are reported for each evaluation separately.

Table 2. Deep neural network architectures with 1 to 10 hidden layers.
2.4.1. Model Design
1. Transformation. All predictors were centered and scaled, using standard scaling, which standardizes the features by removing the mean and by scaling to unit variance (for the scikit-learn implementation of a Standard Scaler, see 52). The mean and standard deviation are estimated on the training set. Then these estimated measures are used to transform the training and test sets separately. So, data in training and test sets are not transformed simultaneously. The reason for conducting different transformations is to avoid a bias from the test features when the mean and the standard deviation are estimated during standard scaling.
2. Layers. We tested ten different network architectures that differed in the number of hidden layers from h1…h10; the input and output layers are excluded. The number of layers in the network can affect its accuracy. Most layers except from the output layer were trained with a ReLU activation function (53, 54). The last layer had a sigmoid activation.
3. Optimization. We employed a Nesterov stochastic gradient descent (SGD) optimization algorithm. The learning rate was set to 0.1 and the momentum was set to 0.9.
4. Epochs and Batch Size. (a) In cross-validation: network architectures were trained for 80 epochs with 35 as a batch size. (b) In 90%-10% validation split: networks were trained for 100 epochs with 35 as a batch size.
2.4.2. Model Comparison and Evaluation Measures
During the training phase, the neural network learns the acoustic properties that characterize MCI and HC. During the evaluation phase, the network evaluates unknown data vectors from the test set; this time the corresponding label (i.e., MCI or HC) is not available to the model and makes a prediction whether these unknown data vectors correspond to MCI or HC productions. To estimate the performance of the neural network, we compare the predictions of the neural network with the classification made by clinicians using combined imaging and neurological, neuropsychological examination.
A confusion matrix represents the relationship between predicted values and actual values (see Table 3). The columns of Table 3 represent the actual condition (MCI or HC) and the rows represent the positive and negative predictions. A true positive (TP) indicates how many times the condition was MCI and the neural network actually predicted MCI; the false positive (FP) indicates when the condition was HC but the network predicted MCI; the false negative (FN) indicates when the condition was MCI and the network predicted HC; and lastly, the true negative indicates when the condition was HC and the neural network made the correct prediction, namely HC. The different neural network models were compared with each other based on the following evaluation measures: (i) accuracy, (ii) precision, (iii) recall, (iv) F1 score, and (v) ROC/AUC.
1. Accuracy: The accuracy is the most commonly employed evaluation measure in classification studies. It refers to the number of correct predictions made by the model divided by the total number of all estimations: Accuracy = (TP+TN)/(TP+TN+FP+FN). However, the accuracy is not always the best evaluation measure when the design is unbalanced and corrections are often required. To this end, the precision, recall, F1score, and ROC/AUC curve provide more balanced estimates.
2. Precision: The precision is the number of true positives divided by the sum of true positives and false positives, i.e., Precision = TP/(TP+FP). So, when there are many FPs, the precision measure will be low.
3. Recall: Recall (a.k.a. sensitivity) is the number of true positives divided by the sum of true positives and false negatives, i.e., Recall = TP/(TP+FN). This suggests that a low recall will indicate that there are many FNs.
4. F1 score: The F1score is the weighted average of Precision and Recall: F1 score = 2 × [(Precision×Recall)/(Precision+Recall)]. The F1 score captures the performance of the models better than the accuracy, especially when the design is unbalanced. A value of 1 indicates a perfect precision and recall, whereas a value of 0 designates the worst precision and recall. Because the F1 score can be less intuitive than the accuracy, most machine learning studies usually report the accuracy of the model.
5. ROC/AUC curve: The receiver operating characteristic (ROC) and the area under the curve (AUC) are two evaluation measures that display the performance of a model. The ROC is a curve that is created by plotting the true positive rate (i.e., the precision) against the false positive rate (i.e., 1-Recall). An optimal model has an ROC closer to 1 whereas a bad model has an ROC closer to 0.

Table 3. Confusion matrix.
2.4.3. Model Evaluation
1. 5-fold group cross-validation. In a “5-fold group cross-validation,” the data are randomized and split into five different folds and the network is trained five times. In each training setting, a different part of the available data is hold out as a test set. The “5 fold group crossvalidation” also ensures that there are no measurements from the same participants in the training and test sets as all data from a given participant will be either in the test set or in the training set but not in both sets (In a simple “5-fold cross-validation” measurements from a given participant might be in both the training and test set after randomization which creates a bias, because the network will be trained on properties from given participants and then asked to provide predictions with respect to these participants). To evaluate the cross-validation, we provide the mean and standard deviation of the accuracy we get from each evaluation. We also provide the ROC curve and the AUC scores that provide a corrected measure of the accuracy.
2. 90–10% Evaluation split. We also provide the findings from the validation split and discuss in detail validation measures, namely the accuracy of the model, the precision, recall, and F1 score. To this end, we split the data into two parts. The first part consists of the 90% of the data and functions as a training corpus whereas the second part, the remaining 10% functions as an evaluation set. Just like in the cross-validation, the speakers in the evaluation and test sets are different.
3. Results
First, we present the results from the evaluation task and then, we present the results from the validation split.
3.1. 5-Fold Group Crossvalidation
We conducted a 5-fold group cross-validation. Within each fold the model is validated 80 times, which is the number of epochs of the model and the mean accuracy, mean validation accuracy, and the corresponding standard deviation are calculated. Table 4 provides the mean accuracy and the mean validation accuracy along with the corresponding standard deviation that results from the 5-fold crossvalidation. As seen by Table 4 models six to ten are consistent with respect to their classification accuracy. These models have six to ten hidden layers and all resulted in 83% mean cross-validated accuracy. Figure 3 displays the mean ROC curve and AUC of the 10 neural network models. The shaded area indicates the SD for the final model: M10. The results from the cross-validation clearly show that when trained using a Sequential Neural Network, speech features can be employed for the identification of MCI. To establish this finding, we provide a second evaluation by training the same networks on the 90% of the data and evaluating on the remaining 10%.
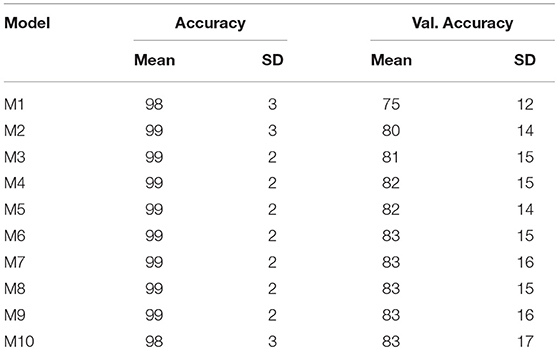
Table 4. Model M1…M10 mean classification accuracy and mean validation accuracy and the corresponding SD from the 5-fold crossvalidation.
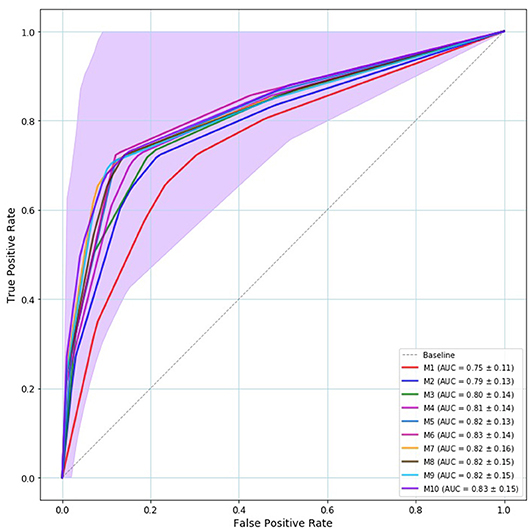
Figure 3. Mean ROC curve and AUC of the 5-fold crossvalidation. Model—M1…M10— are represented by solid line with a different color. The baseline is represented by a dashed gray line. All models provided ROC curves that were over the baseline. The best model is the model whose ROC curve approaches the left upper corner. The shaded area indicates the M10's SD that is the outperforming model both in terms of ROC/AUC (83%) and validation accuracy (83%).
3.2. 90–10% Evaluation Split
Table 5 shows a comparison of the accuracy scores on the training set. The highest accuracy was provided by Model 7 that resulted in 75% classification accuracy and the second best model was Model 5 with 71% classification accuracy at the validation set.
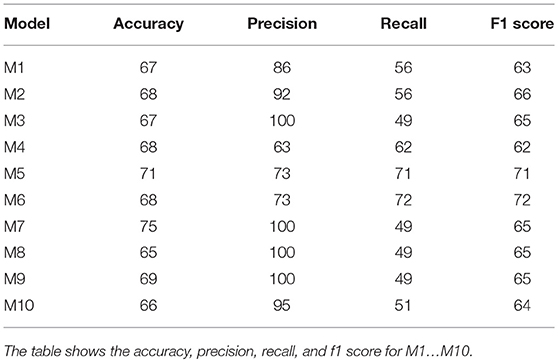
Table 5. 90%/10% validation split results.
4. Discussion
The number of people that are developing dementia is increasing worldwide. Identifying MCI early is of utmost importance as it can enable a timely treatment that can delay its progression. A number of studies have shown that speech and language, which are ubiquitous in everyday communication, can provide early signs of MCI and other prodromal stages of Alzheimer's disease (e.g., 22). The aim of this study has been to provide a classification model for the quick and fast identification of MCI individuals, using data from speech productions.
To this end, we have automatically transcribed, segmented, and acoustically analyzed Swedish vowel productions. The acoustic properties of vowels, namely their formants (F1−F5), duration, fundamental frequency, age, and gender of participants were employed as predictors. Specifically, ten Deep Neural Networks Architectures were trained on the acoustic productions and evaluated on how well they can identify MCI and healthy individuals, by comparing model predictions (i.e., MCI or HC), with the evaluations conducted by clinicians using combined imaging and neuropsychological examination. We have trained ten models each with a different number of hidden layers. Models 6 to 10 resulted in 83% mean classification accuracy (see Table 4).
One important contribution of this study is that it provides a model that can identify MCI individuals automatically and with high accuracy, providing a quick and early assessment of MCI, by using only a simple acoustic recording, without other neuropsychological or neurophysiological information. Also, it demonstrates that speech acoustic properties play a central role in MCI identification and points to the necessity for more acoustic studies with respect to MCI. Nevertheless, 83% accuracy might still be low for clinical use, if it is going to be employed as the only assessment. Two aspects can account for these accuracy results. First, there is a significant symptom variability among individuals with MCI, which has been stressed out by a number of papers including consensus papers for the diagnosis of MCI (e.g., 2, 4). Some of these symptoms are not related to speech, thus additional phonemic, moprhosytactic, etc., predictors might increase the accuracy. Also, by increasing the data and retraining the model, it is possible to improve model accuracy as it is evidenced by the fact that some of the crossvalidation folds resulted in considerably higher accuracy (cf., the SD is between 14 and 17%).
Moreover, this study presents the methodological process that can lead to the selection of the classification model of MCI vs. HC and the evaluation techniques that enable the selection of the final model from a set of ten different models. We have discussed two methods: i. validation split, and ii. crossvalidation. In the validation split, model 7 resulted in the highest accuracy, namely 75%. Nevertheless, the validation split is a weak evaluation method as it depends on the data selected as a training set and as a test set; different randomization of the data may provide a different output. It also depends on the split size (e.g., 75–25%, 80–20%, 90–10%). To avoid these confounds, we conducted a 5-fold crossvalidation, which performs multiple splits of the data, depending on the number of validation folds (cf. 55, 56). Most importantly, the significance of the proposed machine learning model formulation is not that it provides a specific model only but also because it offers a process for continuous evaluation and improvement of the model. Therefore, model evaluation and model comparison constitute indispensable parts of machine learning.
Future research is required (i) to evaluate multivariable acoustic predictors, e.g., predictors from consonants and non-acoustic predictors, i.e., linguistic features, such as parts of speech, syntactic and semantic predictors, sociolinguistic predictors like the education of the speaker; (ii) to establish whether these acoustic variables could be useful in predicting conversion from MCI to dementia; and (iii) to create an automated differential diagnostic tools, which will enable the classification of unknown MCI individuals from conditions with similar symptoms (cf., 57). A system of this form, will require more data from a larger population, yet our current findings do provide a promising step toward this purpose.
In conclusion, this study has showed that a Deep Neural Network architecture can identify MCI speakers and can potentially enable the development of valid tools for identifying cognitive changes early and enable multidomain life style interventions and/or pharmacological treatments at the MCI stage, which can potentially delay or even prevent the development of AD and other types of dementia.
Author Contributions
CT conducted the acoustic analysis of the materials, designed and run the Deep Neural Networks architectures and wrote the first draft of the paper. DK supervised the data collection. Subsequently all authors worked on refining and revising the text. All authors approved the final version.
Funding
This research has been funded by Riksbankens Jubileumsfond – The Swedish Foundation for Humanities and Social Sciences, through the grant agreement no: NHS 14-1761:1.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
1. Petersen R, Smith G, Waring S, Ivnik R, G Tangalos E, Kokmen E. Mild cognitive impairment: clinical characterization and outcome. Arch Neurol. (1999) 56:303–8. doi: 10.1001/archneur.56.3.303
2. Winblad B, Palmer K, Kivipelto M, Jelic V, Fratiglioni L, Wahlund LO, et al. Mild cognitive impairment – beyond controversies, towards a consensus: report of the International Working Group on Mild Cognitive Impairment. J Int Med. (2004) 256:240–6. doi: 10.1111/j.1365-2796.2004.01380.x
3. Dubois B, Feldman HH, Jacova C, Dekosky ST, Barberger-Gateau P, Cummings J, et al. Research criteria for the diagnosis of Alzheimer“s disease: revising the NINCDS-ADRDA criteria. Lancet Neurol. (2007) 6:734–46. doi: 10.1016/S1474-4422(07)70178-3
4. Petersen RC, Caracciolo B, Brayne C, Gauthier S, Jelic V, Fratiglioni L. Mild cognitive impairment: a concept in evolution. J Int Med. (2014) 275:214–28. doi: 10.1111/joim.12190
5. Wallin A, Nordlund A, Jonsson M, Lind K, Edman Å, Göthlin M, et al. The Gothenburg MCI study: design and distribution of Alzheimer's disease and subcortical vascular disease diagnoses from baseline to 6-year follow-up. J Cereb Blood Flow Metab. (2016) 36:114–31. doi: 10.1038/jcbfm.2015.147
6. Crook T, Bartus RT, Ferris SH, Whitehouse P, Cohen GD, Gershon S. Age-associated memory impairment: proposed diagnostic criteria and measures of clinical change—report of a national institute of mental health work group. Dev Psychol. (1986) 2:261–76. doi: 10.1080/87565648609540348
7. Levy R. Aging-associated cognitive decline. Int Psychogeriatr. (1994) 6:63–8. doi: 10.1017/S1041610294001626
8. Bayles KA, Tomoeda CK, Trosset MW. Relation of linguistic communication abilities of Alzheimer's patients to stage of disease. Brain Lang. (1992) 42:454–72. doi: 10.1016/0093-934X(92)90079-T
9. Powell JA, Hale MA, Bayer AJ. Symptoms of communication breakdown in dementia: carers' perceptions. Eur J Disord Commun. (1995) 30:65–75. doi: 10.3109/13682829509031323
10. Weiner MF, Neubecker KE, Bret ME, Hynan LS. Language in Alzheimer's disease. J Clin Psychiatry (2008) 69:1223. doi: 10.4088/JCP.v69n0804
11. Bowles N, Obler L, Albert M. Naming errors in healthy aging and dementia of the Alzheimer type. Cortex (1987) 23:519–24. doi: 10.1016/S0010-9452(87)80012-6
12. Caramelli P, Mansur LL, Nitrini R. Language and communication disorders in dementia of the Alzheimer type. In: Handbook of Neurolinguistics. London; New York, NY: Elsevier (1998). p. 463–473. doi: 10.1016/B978-012666055-5/50036-8
13. de Lira JO, Ortiz KZ, Campanha AC, Bertolucci PHF, Minett TSC. Microlinguistic aspects of the oral narrative in patients with Alzheimer's disease. Int Psychogeriatr. (2011) 23:404–12. doi: 10.1017/S1041610210001092
14. Luz S, la Fuente SD. A method for analysis of patient speech in dialogue for dementia detection. In: Kokkinakis D, editor. Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018). Paris: European Language Resources Association (2018). p. 7–12.
15. Henry JD, Crawford JR, Phillips LH. Verbal fluency performance in dementia of the Alzheimer's type: a meta-analysis. Neuropsychologia (2004) 42:1212–22. doi: 10.1016/j.neuropsychologia.2004.02.001
16. Griffiths JD, Marslen-Wilson WD, Stamatakis EA, Tyler LK. Functional organization of the neural language system: dorsal and ventral pathways are critical for syntax. Cereb Cortex (2013) 23:139–47. doi: 10.1093/cercor/bhr386
17. Thomas C, Keselj V, Cercone N, Rockwood K, Asp E. Automatic detection and rating of dementia of Alzheimer type through lexical analysis of spontaneous speech. In: IEEE International Conference Mechatronics and Automation, Vol. 3 (Ontario) (2005). p. 1569–74.
18. Kemper S, Thompson M, Marquis J. Longitudinal change in language production: effects of aging and dementia on grammatical complexity and propositional content. Psychol Aging (2001) 16:600–14. doi: 10.1037/0882-7974.16.4.600
19. Snowdon DA, Kemper SJ, Mortimer JA, Greiner LH, Wekstein DR, Markesbery WR. Linguistic ability in early life and cognitive function and Alzheimer's disease in late life: findings from the Nun Study. JAMA (1996) 275:528–32. doi: 10.1001/jama.1996.03530310034029
20. Bayles KA, Kaszniak AW, Tomoeda CK. Communication and Cognition in Normal Aging and Dementia. Boston, MA: College-Hill Press (1987).
21. Appell J, Kertesz A, Fisman M. A study of language functioning in Alzheimer patients. Brain Lang. (1982) 17:73–91. doi: 10.1016/0093-934X(82)90006-2
22. Ahmed S, Haigh AMF, de Jager CA, Garrard P. Connected speech as a marker of disease progression in autopsy-proven Alzheimer's disease. Brain (2013) 136:3727–37. doi: 10.1093/brain/awt269
23. Kemper S, LaBarge E, Ferraro R, Cheung H, Cheung H, Storandt M. On the preservation of syntax in Alzheimer's disease: evidence from written sentences. Arch Neurol. (1993) 50:81–6. doi: 10.1001/archneur.1993.00540010075021
24. Bayles KA. Language function in senile dementia. Brain Lang. (1982) 16:265–80. doi: 10.1016/0093-934X(82)90086-4
25. Fleisher AS, Sowell BB, Taylor C, Gamst AC, Petersen RC, Thal LJ. Alzheimer's disease cooperative study. Clinical predictors of progression to Alzheimer disease in amnestic mild cognitive impairment. Neurology (2007) 68:1588–95. doi: 10.1212/01.wnl.0000258542.58725.4c
26. Sarazin M, Berr C, De Rotrou J, Fabrigoule C, Pasquier F, Legrain S, et al. Amnestic syndrome of the medial temporal type identifies prodromal AD - A longitudinal study. Neurology (2007) 69:1859–67. doi: 10.1212/01.wnl.0000279336.36610.f7
27. Lehmann C, Koenig T, Jelic V, Prichep L, John RE, Wahlund LO, et al. Application and comparison of classification algorithms for recognition of Alzheimer's Disease in electrical brain activity (EEG). J Neurosci Methods (2007) 161:342–50. doi: 10.1016/j.jneumeth.2006.10.023
28. Khodabakhsh A, Kuşxuoğlu S, Demiroğlu C. Natural language features for detection of Alzheimer's disease in conversational speech. In: IEEE-EMBS International Conference on Biomedical and Health Informatics (BHI) (Valencia) (2014). p. 581–4. doi: 10.1109/BHI.2014.6864431
29. König A, Satt A, Sorin A, Hoory R, Toledo-Ronen O, Derreumaux A, et al. Automatic speech analysis for the assessment of patients with predementia and Alzheimer's disease. Alzheimer's Dement. (2015) 1:112–24. doi: 10.1016/j.dadm.2014.11.012
30. Fraser KC, Meltzer JA, Rudzicz F. Linguistic features identify Alzheimer's disease in narrative speech. J Alzheimer's Dis. (2016) 49:407–22. doi: 10.3233/JAD-150520
31. Manouilidou C, Dolenc B, Marvin T, Pirtošek Z. Processing complex pseudo-words in mild cognitive impairment: the interaction of preserved morphological rule knowledge with compromised cognitive ability. Clin Linguist Phonet. (2016) 30:49–67. doi: 10.3109/02699206.2015.1102970
32. Taler V, Phillips NA. Language performance in Alzheimer's disease and mild cognitive impairment: a comparative review. J Clin Exp Neuropsychol. (2008) 30:501–56. doi: 10.1080/13803390701550128
33. Mueller KD, Hermann B, Mecollari J, Turkstra LS. Connected speech and language in mild cognitive impairment and Alzheimer's disease: a review of picture description tasks. J Clin Exp Neuropsychol. (2018) 40:917–39. doi: 10.1080/13803395.2018.1446513
34. Roark B, Mitchell M, Hosom JP, Hollingshead K, Kaye J. Spoken Language Derived Measures for Detecting Mild Cognitive Impairment. IEEE Trans Audio Speech Lang Process. (2011) 19:2081–90. doi: 10.1109/TASL.2011.2112351
35. Korytkowska M, Obler LK. Speech-language pathologists (SLP) treatment methods and approaches for Alzheimer's dementia. Perspect ASHA Special Int Groups (2016) 1:122–8. doi: 10.1044/persp1.SIG2.122
36. Graves WW, Desai R, Humphries C, Seidenberg MS, Binder JR. Neural systems for reading aloud: a multiparametric approach. Cereb Cortex (2010) 20:1799–815. doi: 10.1093/cercor/bhp245
37. Themistocleous C. Dialect classification using vowel acoustic parameters [Journal Article]. Speech Commun. (2017) 92:13–22. doi: 10.1016/j.specom.2017.05.003
38. Themistocleous C. The nature of phonetic gradience across a dialect continuum: evidence from modern greek vowels. Phonetica (2017) 74:157–72. doi: 10.1159/000450554
39. Themistocleous C. Effects of two linguistically proximal varieties on the spectral and coarticulatory properties of fricatives: evidence from Athenian Greek and Cypriot Greek. Front Psychol. (2017) 8:1945. doi: 10.3389/fpsyg.2017.01945
40. Fujimura O. On the second spectral peak of front vowels: a perceptual study of the role of the second and third formants. Lang Speech (1967) 10:181–93. doi: 10.1177/002383096701000304
41. Nilsonne Å, Sundberg J, Ternström S, Askenfelt A. Measuring the rate of change of voice fundamental frequency in fluent speech during mental depression. J Acoust Soc Am. (1988) 83:716–28. doi: 10.1121/1.396114
42. Cummins N, Sethu V, Epps J, Schnieder S, Krajewski J. Analysis of acoustic space variability in speech affected by depression. Speech Commun. (2015) 75:27–49. doi: 10.1016/j.specom.2015.09.003
43. Grut M, Fratiglioni L, Viitanen M, Winblad B. Accuracy of the Mini-Mental Status Examination as a screening test for dementia in a Swedish elderly population. Acta Neurol Scand. (1993) 87:312–7. doi: 10.1111/j.1600-0404.1993.tb05514.x
44. Themistocleous C, Kokkinakis D. THEMIS-SV: automatic classification of language disorders from speech signals. In: Proceedings of the 4th European Stroke Organisation Conference. Gothenburg (2018).
45. Boersma P, Weenink D. Praat: Doing Phonetics by Computer (Version 6.0.32). (2017). Available online at: http://www.praat.org
47. Themistocleous C. Seeking an anchorage. Stability and variability in tonal alignment of rising prenuclear pitch accents in cypriot greek. Lang Speech (2016) 59:433–61. doi: 10.1177/0023830915614602
48. Leung JH, Purdy SC, Tippett LJ, Leão SHS. Affective speech prosody perception and production in stroke patients with left-hemispheric damage and healthy controls. Brain Lang. (2017) 166:19–28. doi: 10.1016/j.bandl.2016.12.001
49. Chollet F. Keras. (2015). Available online at: https://github.com/keras-team/keras
50. Abadi M, Agarwal, A, Barham, P, Brevdo, E, Chen, Z, Citro, C, et, al,. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. (2015). Available online at: https://www.tensorflow.org/
51. Jones E, Oliphant T, Peterson P. SciPy: Open Source Scientific Tools for Python (2001). Available online at: http://www.scipy.org/
52. Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, et al. Scikit-learn: machine learning in Python. J Mach Learn Res. (2011) 12:2825–30. Available online at: http://www.jmlr.org/papers/v12/pedregosa11a.html
53. Maas AL, Hannun AY, Ng AY. Rectifier nonlinearities improve neural network acoustic models. In: Proceedings of the 30th International Conference on Machine Learning. Atlanta, GE (2013). p. 1–6.
54. He K, Zhang X, Ren S, Sun J. Delving deep into rectifiers: surpassing human-level performance on ImageNet classification. CoRR 2015;abs/1502.01852. Available online at: http://arxiv.org/abs/1502.01852
55. Tharwat A. Classification assessment methods. Appl Comput Inform. (in press). doi: 10.1016/j.aci.2018.08.003
56. Sokolova M, Lapalme G. A systematic analysis of performance measures for classification tasks. Inform Process Manage. (2009) 45:427–37. doi: 10.1016/j.ipm.2009.03.002
57. Themistocleous C, Ficek B, Webster KT, Wendt H, Hillis AE, Den Ouden DB, et al. Acoustic markers of PPA variants using machine learning. Front Hum Neurosci. Conference Abstract: Academy of Aphasia 56th Annual Meeting. (2018). doi: 10.3389/conf.fnhum.2018.228.00092
Appendix
• Text in Swedish: Ordet ö beskriver ett område som är helt avskuret från land och som är omgivet av vatten på alla sidor. Öar kan uppstå när vulkaner höjer sig från havsbottnen eller när vattennivån i havet stiger eller faller. Ett flertal öar uppstod mot slutet av den förra istiden. När isen smälte och vattnet rann ut i havet höjdes vattennivån så mycket att de låga landområdena översvämmades. Idag ser man bara de högsta topparna sticka upp över vattenytan som öar. Djur och växter som på något sätt lyckas ta sig till en avlägsen ö kan sedan vanligtvis inte komma därifrån igen. För att överleva är de därför tvungna att mycket snabbt anpassa sig till den nya omgivningen. De levande arter som finns på öar löper en ständig risk att bli utrotade. Detta kan inträffa när nya djur dyker upp eller när människor kommer dit och börjar störa dem.
• Translated text in English: The word island describes an area that is completely cut off from the land and is surrounded by water on all sides. Islands can occur when volcanoes rise from the seabed or when water levels in the ocean rise or fall. A number of islands occurred at the end of the last ice age. When the ice melted and the water ran out into the sea, the water level was raised so much that the low lands were flooded. Today, only the highest peaks can be seen across the water surface as islands. Animals and plants that somehow manage to get to a distant island usually do not leave the place again. Therefore, in order to survive, they are forced to adapt very quickly to the new environment. The living species on islands run a constant risk of being extinct. This can happen when new animals appear or when people get there and start to disturb them.
Keywords: speech production, vowels, prosody, neural network, machine learning, dementia, MCI
Citation: Themistocleous C, Eckerström M and Kokkinakis D (2018) Identification of Mild Cognitive Impairment From Speech in Swedish Using Deep Sequential Neural Networks. Front. Neurol. 9:975. doi: 10.3389/fneur.2018.00975
Received: 05 July 2018; Accepted: 29 October 2018;
Published: 15 November 2018.
Edited by:
Stefano L. Sensi, Università degli Studi G. d'Annunzio Chieti e Pescara, ItalyReviewed by:
Noemi Massetti, Università degli Studi G. d'Annunzio Chieti e Pescara, ItalyReinhold Scherer, Graz University of Technology, Austria
Copyright © 2018 Themistocleous, Eckerström and Kokkinakis. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Charalambos Themistocleous, Y2hhcmFsYW1ib3MudGhlbWlzdG9jbGVvdXNAZ3Uuc2U=