 Gero Szepannek
Gero Szepannek Karsten Lübke
Karsten Lübke- 1Institute of Applied Computer Science, Stralsund University of Applied Sciences, Stralsund, Germany
- 2Institute for Empirical Research and Statistics, FOM University of Applied Sciences, Dortmund, Germany
Algorithmic scoring methods are widely used in the finance industry for several decades in order to prevent risk and to automate and optimize decisions. Regulatory requirements as given by the Basel Committee on Banking Supervision (BCBS) or the EU data protection regulations have led to an increasing interest and research activity on understanding black box machine learning models by means of explainable machine learning. Even though this is a step into a right direction, such methods are not able to guarantee for a fair scoring as machine learning models are not necessarily unbiased and may discriminate with respect to certain subpopulations such as a particular race, gender, or sexual orientation—even if the variable itself is not used for modeling. This is also true for white box methods like logistic regression. In this study, a framework is presented that allows analyzing and developing models with regard to fairness. The proposed methodology is based on techniques of causal inference and some of the methods can be linked to methods from explainable machine learning. A definition of counterfactual fairness is given together with an algorithm that results in a fair scoring model. The concepts are illustrated by means of a transparent simulation and a popular real-world example, the German Credit data using traditional scorecard models based on logistic regression and weight of evidence variable pre-transform. In contrast to previous studies in the field for our study, a corrected version of the data is presented and used. With the help of the simulation, the trade-off between fairness and predictive accuracy is analyzed. The results indicate that it is possible to remove unfairness without a strong performance decrease unless the correlation of the discriminative attributes on the other predictor variables in the model is not too strong. In addition, the challenge in explaining the resulting scoring model and the associated fairness implications to users is discussed.
1 Introduction
The use of algorithmic scoring methods is very common in the finance industry for several decades in order to prevent risk and to automate and optimize decisions (Crook et al., 2007). Regulatory requirements as given by the Basel Committee on Banking Supervision (BCBS) (European Banking Authority, 2017) or the EU data protection regulations (Goodman and Flaxman, 2017) have led to an increasing interest and research activity on understanding black box machine learning models by means of explainable machine learning (cf. e.g., Bücker et al., 2021). Even though this is a step into a right direction, such methods are not able to guarantee for a fair scoring as machine learning models are not necessarily unbiased and may discriminate with respect to certain subpopulations such as a particular race, gender, or sexual orientation—even if the variable itself is not used for modeling. This is also true for white box methods like logistic regression.
In the study by O’Neil (2016), several popular examples are listed as to how algorithmic decisions enter and potentially negatively impact everyday lives. An expert group on the AI setup by the European Commission has worked out an assessment list for trustworthy artificial intelligence (ALTAI), where one requirement consists in diversity, non-discrimination, and fairness (EU Expert Group on AI, 2019).
There are different definitions of algorithm fairness. An overview is given by Verma and Rubin (2018) and will be summarized in Section 2. In the remainder of the section, the framework of counterfactual fairness is introduced as well as an algorithm that allows developing fair models based on techniques of causal inference (Pearl et al., 2016). In the study by Kusner and Loftus (2020), three tests on algorithmic fairness are presented.
Subsequently, in Section 3, fairness is discussed from the usage context of risk scoring models: as opposed to existing crisp fairness definitions a group unfairness index is introduced to quantify the degree of fairness of a given model. This allows for a fairness comparison of different models. Furthermore, it is shown how partial dependence profiles (Friedman, 2001) as they are popular in the field of explainable AI can be adapted in order to enable a visual fairness analysis of a model.
With the scope of the financial application context the aforementioned algorithm is applied to real-world data of credit risk scoring: the German Credit data which is publicly available by the UCI machine learning data repository (Dua and Graff, 2017). The data are very popular and have been used in numerous studies (cf. e.g., Louzada et al., 2016). In contrast to past publications, we used a corrected version of the data in our study as it has turned out that the original data were erroneous (Groemping, 2019). The latter observation has to be highlighted as the data from the UCI repository have been frequently used in credit scoring research during the last decades and thus have strongly influenced research results during the last years. The data and its correction are described in Section 4.1. In Section 4.2, the design of a simulation study based on the corrected German credit data is set up and its results are presented in Section 5: both a traditional scorecard model using weights of evidence and logistic regression as well as a fairness-corrected version of it are compared on the simulated data with regard to the trade-off between fairness and predictive accuracy. Finally, a summary of our results is presented in Section 6.
2 Fairness Definitions
2.1 Overview
In the literature, different attempts have been made in order to define fairness. An overview together with a discussion is given in Verma and Rubin (2018). In this section, a brief summary of important concepts is given using the following notation:
• Y is the observed outcome of an individual. Credit risk scoring typically consists in binary classification, that is, Y = 1 denotes a good and Y = 0 denotes a bad performance of a credit.
• P is a set of one or more protected attributes. With regard to these attributes fairness should be ensured.
• X are the remaining attributes used for the model (X ∩ P = ∅).
• S is the risk score, typically a strictly monotonic function in the posterior probability Pr(Y = y|X = x, P = p). Without loss in generality, in the context of this study both are chosen to be identical.
•
Typical examples of protected attributes are gender, race, or sexual orientation. An intuitive requirement of fairness is as follows: 1) to use only variables of X but no variables of P for the risk score model (unawareness). Note that while it is unrealistic that an attribute like sexual orientation directly enters the credit application process it has been demonstrated that this information is indirectly available from our digital footprint such as our Facebook profile (Youyou et al., 2015) and recent research in credit risk modeling proposes to extend credit risk modeling by including such alternative data sources (De Cnudde et al., 2019). From this it is easy to see the fairness definition of unawareness is not sufficient.
Many fairness definitions are based on the confusion matrix as it is given in Table 1: Confusion matrices are computed depending on P and resulting measures are compared.

TABLE 1. Confusion matrix and measures derived from it.
Fairness definitions related to the acceptance rate
Fairness definitions based on the predicted posterior probability Pr (Y) are as follows: 8) Predictive parity
An alternative yet intuitive fairness definition is given by 11) individual fairness: similar individuals i and j should be assigned similar scores, independently of the protected attributes: d1 (S(xi), S (xj)) ≤ d2 (xi, xj) where d1 (.,.) and d2 (.,.) are distance metrics in the space of the scores and the predictor variables, respectively. 12) Causal discrimination requires a credit decision
It should be noted that all these criteria can be incompatible so that it can be impossible to create a model that is fair with respect to all criteria simultaneously (Chouldechova, 2016).
2.2 Causal Inference
Pearl (2019) distinguishes three levels of causal inference as follows:
1) Association: Pr (y|x): Seeing: “What is?,” that is, the probability of Y = y given that we observe X = x.
2) Intervention: Pr (y|do(x)): Manipulation: “What if?,” that is, the probability of Y = y given that we intervene and set the value of X to x.
3) Counterfactuals: Pr (yx|x′, y′): Imagining: “What if I had acted differently?,” that is, the probability of Y = y if X had been x given that we actually observed x′, y′.
For levels 2 and 3, subject matter knowledge about the causal mechanism that generates the data is needed. This structural causal model can be encoded in a directed acyclic graph (DAG). The basic elements of such a graph reveal if adjustment for variable C may introduce or remove bias in the causal effect of X on Y (see e.g., Pearl et al., 2016):
• Chain: X → C → Y, where C is a mediator between X and Y and adjusting for C would mask the causal effect of X on Y.
• Fork: X ← C → Y, where C is a common cause of X and Y and adjusting for C would block the noncausal path between X and Y.
• Collider: X → C ← Y, where C is a common effect of X and Y and adjusting for C would open a biasing path between X and Y.
Luebke et al. (2020) provide easy to follow examples to illustrate these. In order to calculate the counterfactual (level 3) the assumed structural causal model and observed data is used in a three-step process as follows:
1) Abduction: Use the evidence, that is, data to determine the exogeneous variables, for example, error term, in a given structual causal model. For example assume a causal model with additive exogeneous Y = f(X) + U and calculate u for a given observation x′, y′.
2) Action: Substitute in the causal model the values for X with the counterfactual x (instead of x′).
3) Prediction: Calculate Y based on the previous steps.
For a more detailed introduction the reader is referred to Pearl et al. (2016).
2.3 Counterfactual Fairness
Causal counterfactual thinking enables the notion of counterfactual fairness as follows:
“Would the credit decision have been the same if the protected attribute had taken a different value (e.g. if the applicant had been male instead of female)?”
Kusner et al. (2017) present a FairLearning algorithm which can be considered as a preprocessing debiaser in the context of Agrawal et al. (2020), that is, a transformation of the attributes before the modeling by means of the subsequent machine learning algorithm. It consists of three levels as follows:
1) Prediction of Y is only based on non-descendants of P.
2) Use of postulated background variables.
3) Fully deterministic model with latent variables where the error term can be used as an input for the prediction of Y.
It should be noted that in general causal modeling is non-parametric and therefore any machine learning method may be employed. In order to illustrate the concept we utilize a (simple) linear model with a least squares regression of the attributes X (e.g., status in the example below) on the protected attributes P (e.g., gender) assuming an independent error. The resulting residuals (E) are subsequently used to model the Y (e.g., default) instead of the original attributes X which may depend on the protected attributes P. Our algorithm can be summarized as follows:
1) Regress X on P.
2) Calculate residuals
3) Model Y by E.
3 Analyzing Fairness of Credit Risk Scoring Models
3.1 Quantifying Fairness
The definitions as presented in the previous subsection are crisp in the sense that a model can be either fair or not. It might be desirable to quantify the degree of fairness of a model. In Section 2 different competing definitions of fairness are presented. It can be shown that sometimes they are even mutually exclusive, for example, in Chouldechova (2016) it is shown that for a calibrated model (i.e., Pr(Y = 1|S = s, P) = Pr(Y = 1|S = s), cf. above) not both equal opportunity (i.e.,
Analogously a similar index can be defined for other fairness definitions based on the acceptance rate
3.2 Visual Analysis of Fairness
A risk score S≔Pr(Y = y|X = x, P = p) that is independent of P necessarily results in group fairness as
that is, average prediction given the protected attributes P take the value p. For our purpose, for a data set with n observations (xi, pi) a protected attribute dependence profile can be estimated by the conditional average
In case of a fair model the protected attribute dependence profile should be constant.
4 Simulation Experiment
4.1 From German Credit Data to South German Credit Data
Traditionally, credit scoring research has suffered from a lack of available real-world data for a long time as credit institutes are typically not willing to share their internal data. The German credit data have been collected by the StatLog project (Henery and Taylor, 1992) and go back to Hoffmann (1990). They are freely available from the UCI machine learning repository (Dua and Graff, 2017) and consist of 21 variables: 7 numeric as well as 13 categorical predictors and a binary target variable where the predicted event denotes the default of a loan. The default rate on the data is has been oversampled to 0.3 on the available UCI data while the original sources report a prevalence of bad credits around 0.05.
In the recent past, a few data sets have been made publicly available, for example, by the peer-to-peer lending company LendingClub1 or FICO2 but a still a huge number of studies rely on the German credit data (Louzada et al., 2016). This is even more notable as in Groemping (2019) it has been figured out that the data available in the UCI machine learning repository are erroneous, for example, the percentage of foreign workers in the UCI data is 0.963 (instead of 0.037) because the labels have been swapped. In total, eleven of the 20 predictor variables had to be corrected. For seven of them (A1: Status of existing checking account, A3: Credit history, A6: Savings account/bonds, A12: Property, A15: Housing, and A20: Foreign worker) the label assignments were wrong and for one of them (A9: Personal status and sex) even two of the levels (female non-singles and male singles) had to be merged as they can’t be distinguished anymore. In addition, four other variables (A8: Installment rate in percentage of disposable income, A11: Present residence since, A16: Number of existing credits at this bank, and A18: Number of people being liable to provide maintenance for) which originally represent numeric attributes that are only available after binning such that their numeric values represent nothing but group indexes. For this reason the values of these variables are replaced by the corresponding bin labels. A table of all the changes can be found in the Supplementary Table S1. The corrected data set has been made publicly available on the UCI machine learning repository under the name south German credit data3 (Groemping, 2019).
For further modeling in this study the data have been randomly split into 70% training and 30% test data. Note that the size of the data is pretty small but as traditional scorecard development requires a manual plausibility check of the binning cross validation is not an option here (cf. also Szepannek, 2020).
4.2 Simulation of the Protected Attribute
A simulation study is conducted in order to compare both a traditional and a fair scoring model under different degrees of influence of the protected attributes. Note that the original variable personal status and sex (A9) does not allow for a unique distinction between men and women (cf. previous subsection) and cannot be used for this purpose. For this reason this variable has been removed from the data.
In traditional scorecard modeling information values (IVs, Siddiqi, 2006) are often considered to assess the ability of single variables to discriminate good and bad customers. Table 2 shows the IVs for the scorecard variables. In order to analyze the impact of building fair scoring models the data have been extended by an artificial protected variable Gender to mimic A9. For this purpose the variable Status with largest IV has been selected to construct the new protected variable. As it is shown in Table 3, in the first step two of the status-levels are assigned to women and the other two variables are assigned to men, respectively. In consequence, women take the lower risk compared to men from their corresponding status levels in the artificial data. The resulting graph is

TABLE 2. Information values of the scorecard variables and the removed variable personal status and sex.

TABLE 3. Construction of the variable gender for the training data.
As Lemma 1 of Kusner et al. (2017) states
In a second step the strength effect of gender on the status is varied by randomly switching between 0% and 50% of the males into females and vice versa. As a result, the designed effect of gender on status is disturbed to some extent and only holds for the remaining observations. The degree of dependence between both categorical variables is measured using Cramer’s V (Cramér, 1946, 282).
5 Results and Discussion
Logistic regression still represents the gold standard for credit risk scorecard modeling (Crook et al., 2007; Szepannek, 2020) even if in the recent past many studies have demonstrated potential benefits from using modern machine learning algorithms (cf. e.g., Lessmann et al., 2015; Bischl et al., 2016; Louzada et al., 2016). For this reason, a traditional scorecard using logistic regression is created as a baseline model for the simulation study. The model is built using preliminary automatic binning (based on the χ2 statistic and a maximum set to six bins per variable) with subsequent assignment of weights of evidence (
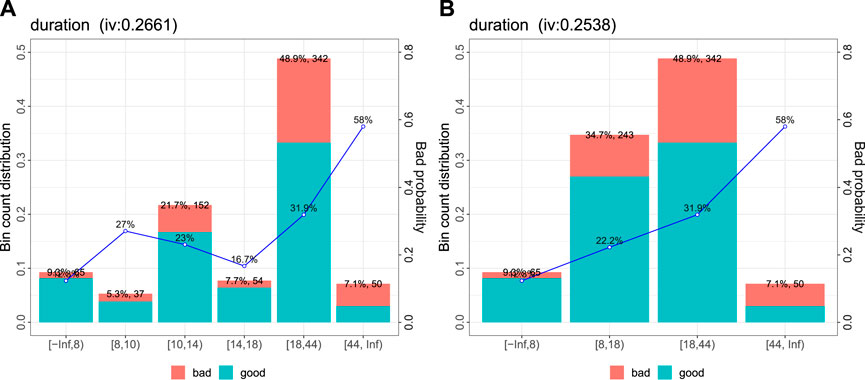
FIGURE 1. Automatically created bins (A) for the variable duration and manual update (B): a plausible trend of increasing risk with increading duration.
For plausibility reasons (i.e., the observed default rates for the different levels) the variable property has been removed from the data as from a business point of view there is no plausible reason for the observed increase in risk for owners of cars, life insurance or real estate (cf. Table 4). After forward variable selection using BIC on the training data the resulting scorecard model uses five input variables as they are listed in Table 2. The equation of the resulting logistic regression model is given in Table 5. The corresponding scorecard model with frequencies and default rates for all classes can be found in Table 6.

TABLE 4. Default rates of the variable property on the training data.

TABLE 5. Coefficients of the logistic regression model.
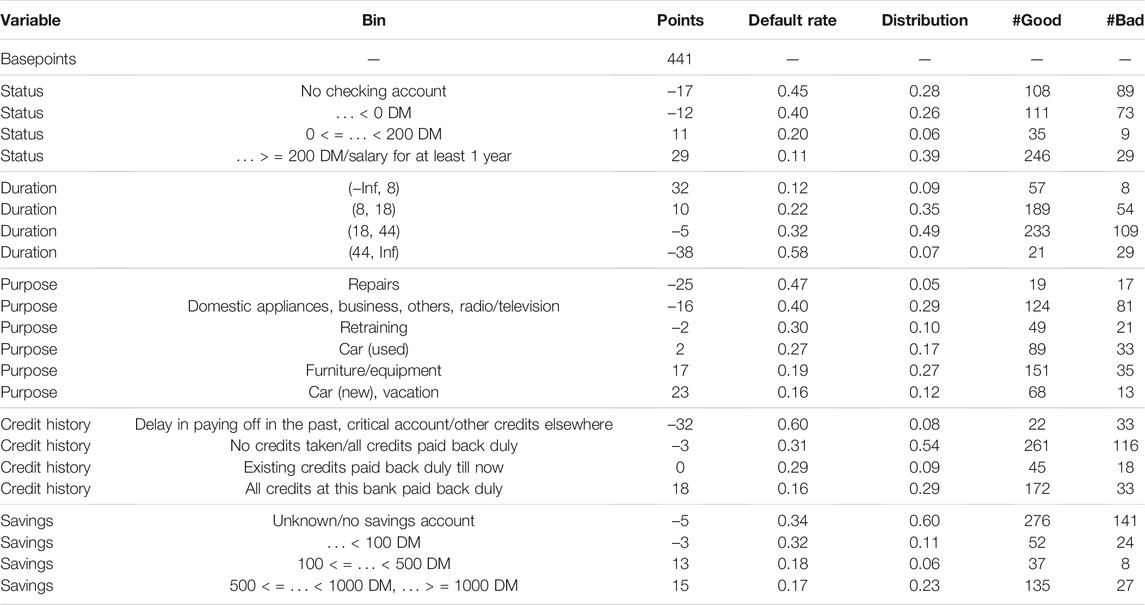
TABLE 6. Resulting scorecard model. In practice it is usual to assign scorecard points to the posterior probabilities as given by the score. Here, a calibration with 500 points at odds of 1/19 and 20 points to double the odds is used.
In addition to the traditional scorecard baseline model fair models are developed according to the algorithm presented in Section 2.3 by regressing WOE (Status) on the protected attribute Gender and using the residuals instead of the original variable Status as a new input variable, a level 3 assumption for a causal model in Kusner et al. (2017).
Figure 2 shows the results of the simulation study for different levels of dependence (measured by Cramer’s V) between protected variable Gender and Status in terms of both: performance of the model (in terms of the Gini coefficient) as well as the group unfairness index calculated on the training data. Note that for companies depending on the business strategy and corresponding acceptance rates it can be more suitable to put more emphasis on other performance measures such as the partial AUC (Robin et al., 2011) or the expected maximum profit (Verbraken et al., 2014). Nonetheless, for the purpose of this study we decided to use the Gini coefficient
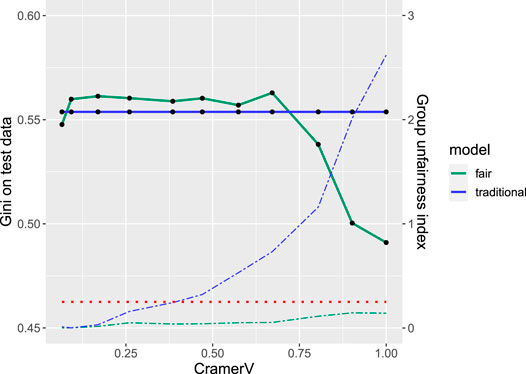
FIGURE 2. Fairness-performance trade-off: performance (solid) and unfairness (dashed) for traditional (blue) and fairness-corrected (green) model for different levels of correlation between the protected variable gender and the prediction variable status. The red dotted line indicates the thumb rule for unfairness.
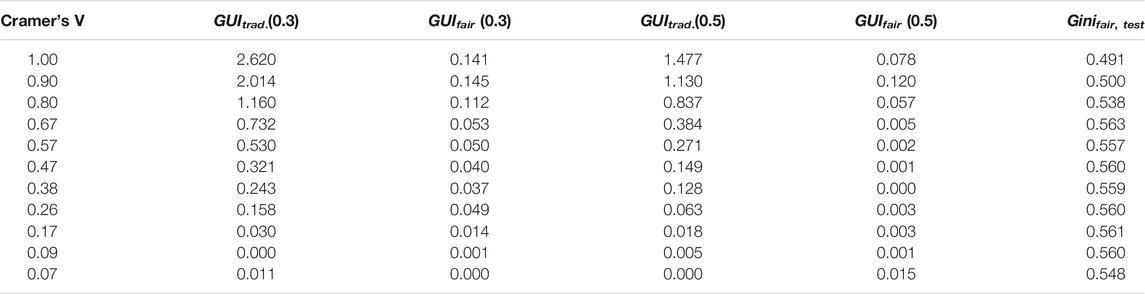
TABLE 7. Results of the simulation study: Group unfairness index (GUI) of both the traditional as well as the fair model and performance on the test data of the fair model for different levels of dependence (Cramer’s V) between the protected attribute and the variable status.
The solid lines indicate performance on the test data for the traditional (blue) and the fair model (green). The traditional model is unaffected by the protected variable and thus of constant performance with a Gini coefficient of 0.554. Remarkably, for some of the simulated data sets the fair model even slightly outperforms the traditional one which might be explained by the small number of observations in the data resulting in a large 95% (bootstrap) confidence interval (Robin et al., 2011) of (0.437,0.667) and only small performance decrease due to the fairness correction. The corresponding dashed lines show the group unfairness index of both models where the additional dotted red line represents the thumb rule threshold of 0.25 indicating unfairness. For the traditional model the threshold is already exceeded for dependencies as small as Cramer’s V = 0.3 while for the fair model it always stays below the threshold. Even more interesting for small and moderate levels of dependence (Cramer’s V ≤ 0.6) there is no performance decrease observed while at the same time fairness can be increased.
Figure 3 shows an example of the partial dependence profiles (cf. Section 3.2) for the traditional and the fairness-corrected model on one of the simulated data sets (Cramer’s V = 0.47, cf. Table 7). For these data no strong differences in performance are observed (0.554 vs. 0.560) but the GUI of 0.321 of the traditional model indicates unfairness. This is also reflected by the profile plots where a shift in the score point distributions can be noticed for the traditional model (
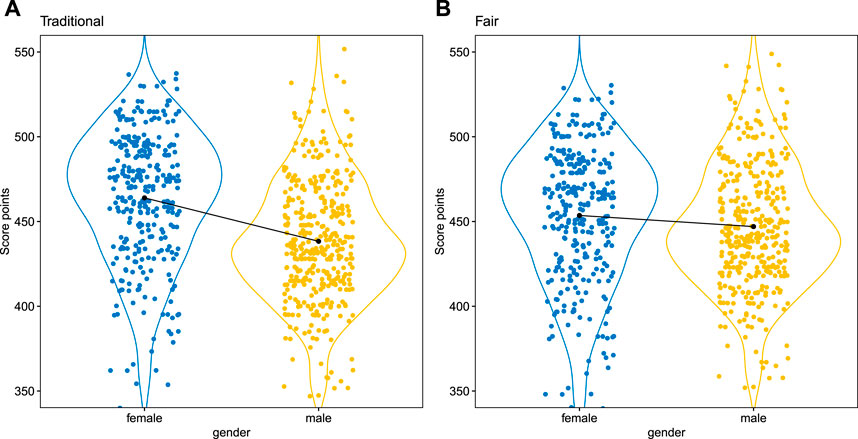
FIGURE 3. Protected attribute dependence plot of the traditional scorecard (A) vs. the fairness-corrected scorecard (B). Note that the calibrated versions of the scores are used with 500 points at odds of 1/19 and 20 points to double the odds.
Along with these promising results another side effect can be noticed: As a consequence of gender-wise fairness correction there are different WOEs for both genders in all bins and consequently also different scorecard points for each gender as it can be seen in Table 8. Thus, the price of having a fair scoring model is different points with respect to the protected attributes (here: Gender). This can be difficult to explain to technically less familiar users or moreover, this can be even critical under the regulation constraints of the customers’ right to explanation of algorithmic decisions (Goodman and Flaxman, 2017). Not enough, a traditional plausibility check during the scorecard modeling process concerns monotonicity of the WOEs with respect to the default rates (Szepannek, 2020) which now has to be done for all levels of the protected attribute and is not necessarily given anymore after fairness correction. Note that also in our example the order of the default rates of the two bins with the highest risk of the variable Status has changed for the female customers.

TABLE 8. Comparison of the variable Status for the traditional model (left) and female (center) and male (right) gender in the fair model.
Although in general the presented methodology can be applied to arbitrary machine learning models the changes in the data as induced by the fairness correction put even more emphasis on a deep understanding of the resulting model and corresponding methodology of interpretable machine learning to achieve this goal (cf. e.g., Bücker et al., 2021 for an overview in the credit risk scoring context). Further note that as it is demonstrated in Szepannek (2019) the obtained interpretations bear the risk to be misleading. For this reason other authors such as Rudin (2019) suggest restricting interpretable models and in summary a proper analysis of the benefits of using more complex models should be done in any specific situation (Szepannek, 2017).
For the simulations in this study only one protected attribute has been created which impacts only one of the predictor variables in a comparatively simple graph structure (Gender → Status → Y). For more complex data situations causal search algorithms can be used to identify potential causal relationships between the variables that are in line with the observed data (Hauser and Bühlmann, 2012; Kalisch et al., 2012). Then all descendants of the protected attributes must be corrected accordingly.
6 Summary
In this study, different definitions of fairness are presented from the credit risk scoring point of view as well as a fairness correction algorithm based on the concept of counterfactual fairness. Furthermore, the idea of population stability is transferred into a new group unfairness index which allows quantifying and comparing the degree of group fairness of different scoring models. In addition, partial dependence plots are proposed to visualize the fairness of a model with respect to some protected attribute. Based on these measures, a simulation study has been set up which makes use of a corrected version of the well-known German credit data. The results of the study are quite promising: Up to some degree fairness corrections are possible without strong loss in predictive accuracy as measured by the Gini coefficient on independent test data. Nonetheless, as inherent consequence traditional scores of fairness corrected models will typically differ with respect to protected attributes which may result in a new kind of problem under the perspective of the customer’s regulatory right for an explanation of algorithmic decisions. The explanation of algorithmic decisions gets even more complicated and future work has to be done in order to investigate the observed effects of our study for other classes of machine learning models such as random forests, gradient boosting, support vector machines, or neural networks.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material; further inquiries can be directed to the corresponding author.
Author Contributions
GS: summary of fairness definitions, methodology for quantifying and visualizing fairness of credit risk scoring models, south German credit data, and simulation study. KL: causal inference and couterfactual fairness.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
The authors would like to thank the reviewers for their valuable feedback and acknowledge the support of the Institute of Applied Computer Science at Stralsund University of Applied Sciences for funding open access publication.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frai.2021.681915/full#supplementary-material
Supplementary Table S1 | Summary of the differences between the German credit data and the South German credit data.
Footnotes
1https://www.lendingclub.com/.
2https://community.fico.com/s/explainable-machine-learning-challenge.
3https://archive.ics.uci.edu/ml/datasets/South+German+Credit+%28UPDATE%29
References
Agrawal, A., Pfisterer, F., Bischl, B., Chen, J., Sood, S., Shah, S., et al. (2020). Debiasing Classifiers: Is Reality at Variance with Expectation? Available at: aHR0cDovL2FyeGl2Lm9yZy9hYnMvMjAxMS4wMjQwNw==.
Bischl, B., Kühn, T., and Szepannek, G. (2016). “On Class Imbalance Correction for Classification Algorithms in Credit Scoring,” in Operations Research Proceedings 2014, Selected Papers of the Annual International Conference of the German Operations Research Society (GOR). Editors M. Lübbecke, A. Koster, P. Letmathe, R. Madlener, B. Peis, and G. Walther, 37–43. doi:10.1007/978-3-319-28697-6∖_610.1007/978-3-319-28697-6_6
Bücker, M., Szepannek, G., Gosiewska, A., and Biecek, P. (2021). Transparency, Auditability and eXplainability of Machine Learning Models in Credit Scoring. J. Oper. Res. Soc. in print. doi:10.1080/01605682.2021.1922098
Chouldechova, A. (2016). Fair Prediction with Disparate Impact: A Study of Bias in Recidivism Prediction Instruments. Available at: http://arxiv.org/abs/1610.07524.
Crook, J. N., Edelman, D. B., and Thomas, L. C. (2007). Recent Developments in Consumer Credit Risk Assessment. Eur. J. Oper. Res. 183, 1447–1465. doi:10.1016/j.ejor.2006.09.100
De Cnudde, S., Moeyersoms, J., Stankova, M., Tobback, E., Javaly, V., and Martens, D. (2019). What Does Your Facebook Profile Reveal about Your Creditworthiness? Using Alternative Data for Microfinance. J. Oper. Res. Soc. 70, 353–363. doi:10.1080/01605682.2018.1434402
Dua, D., and Graff, C. (2017). UCI Machine Learning Repository. Available at: https://archive.ics.uci.edu/ml/index.php.
European Banking Authority (2017). Guidelines on PD Estimation, LGD Estimation and the Treatment of Defaulted Exposures.
Friedman, J. (2001). Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 29, 1189–1232. doi:10.1214/aos/1013203451
Goodman, B., and Flaxman, S. (2017). European Union Regulations on Algorithmic Decision-Making and a "Right to Explanation". AIMag 38, 50–57. doi:10.1609/aimag.v38i3.2741
Groemping, U. (2019). South German Credit Data: Correcting a Widely Used Data Set. Department II, Beuth University of Applied Sciences Berlin. Available at: http://www1.beuth-hochschule.de/FB/UnderScore/II/reports/Report-2019-004.pdf.
Hauser, A., and Bühlmann, P. (2012). Characterization and Greedy Learning of Interventional Markov Equivalence Classes of Directed Acyclic Graphs. J. Machine Learn. Res. 13, 2409–2464. Available at: https://jmlr.org/papers/v13/hauser12a.html.
Henery, R. J., and Taylor, C. C. (1992). “StatLog: An Evaluation of Machine Learning and Statistical Algorithms,” in Computational Statistic. Editors Y. Dodge, and J. Whittaker (Heidelberg: Physica), 157–162. doi:10.1007/978-3-662-26811-7_23
Hoffmann, H. (1990). Die Anwendung des CART-Verfahren zur statistischen Bonitätsanalyse. Z. für Betriebswirtschaft 60, 941–962.
Kalisch, M., Mächler, M., Colombo, D., Maathuis, M. H., and Bühlmann, P. (2012). Causal Inference Using Graphical Models with the R Package Pcalg. J. Stat. Softw. 47, 1–26. doi:10.18637/jss.v047.i11
Kusner, M. J., and Loftus, J. R. (2020). The Long Road to Fairer Algorithms. Nature 578, 34–36. doi:10.1038/d41586-020-00274-3
Kusner, M., Loftus, J., Russell, C., and Silva, R. (2017). “Counterfactual Fairness,” in Proc. 31st int. Conf. Neural Information Processing Systems NIPS’17, Red Hook, NY, USA (Curran Associates Inc.), 4069–4079.
Lessmann, S., Baesens, B., Seow, H.-V., and Thomas, L. C. (2015). Benchmarking State-Of-The-Art Classification Algorithms for Credit Scoring: An Update of Research. Eur. J. Oper. Res. 247, 124–136. doi:10.1016/j.ejor.2015.05.030
Louzada, F., Ara, A., and Fernandes, G. B. (2016). Classification Methods Applied to Credit Scoring: Systematic Review and Overall Comparison. Surv. Operations Res. Manage. Sci. 21, 117–134. doi:10.1016/j.sorms.2016.10.001
Lübke, K., Gehrke, M., Horst, J., and Szepannek, G. (2020). Why We Should Teach Causal Inference: Examples in Linear Regression with Simulated Data. J. Stat. Educ. 28, 133–139. doi:10.1080/10691898.2020.1752859
O’Neil, C. (2016). Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy. New York, NY, USA: Crown Publishing Group.
Pearl, J., Glymour, M., and Jewell, N. (2016). Causal Inference in Statistics – a Primer. Chichester, UK: Wiley.
Pearl, J. (2019). The Seven Tools of Causal Inference, with Reflections on Machine Learning. Commun. ACM 62, 54–60. doi:10.1145/3241036
Robin, X., Turck, N., Hainard, A., Tiberti, N., Lisacek, F., Sanchez, J.-C., et al. (2011). pROC: An Open-Source Package for R and S+ to Analyze and Compare ROC Curves. BMC Bioinformatics 12, 77. doi:10.1186/1471-2105-12-77
Rudin, C. (2019). Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead. Nat. Mach Intell. 1, 206–215. doi:10.1038/s42256-019-0048-x
Siddiqi, N. (2006). Credit Risk Scorecards: Developing and Implementing Intelligent Credit Scoring. Second edition. Wiley.
Szepannek, G. (2020). An Overview on the Landscape of R Packages for Credit Scoring. Available at: http://arxiv.org/abs/2006.11835.
Szepannek, G. (2019). How Much Can We See? A Note on Quantifying Explainability of Machine Learning Models. Available at: http://arxiv.org/abs/1910.13376.
Szepannek, G. (2017). On the Practical Relevance of Modern Machine Learning Algorithms for Credit Scoring Applications. WIAS Rep. Ser. 29, 88–96. doi:10.20347/wias.report.29
Verbraken, T., Bravo, C., Weber, R., and Baesens, B. (2014). Development and Application of Consumer Credit Scoring Models Using Profit-Based Classification Measures. Eur. J. Oper. Res. 238, 505–513. doi:10.1016/j.ejor.2014.04.001
Verma, S., and Rubin, J. (2018). “Fairness Definitions Explained,” in Proc. Int. Workshop on software fairness FairWare ’18, New York, NY, USA. (ACM), 1–7. doi:10.1145/3194770.3194776
Xie, S. (2020). Scorecard: Credit Risk Scorecard – R Package. version 0.3.1. Available at: https://CRAN.R-project.org/package=scorecard.
Keywords: scoring, machine learning, causal inference, German credit data, algorithm fairness, explainable machine learning
Citation: Szepannek G and Lübke K (2021) Facing the Challenges of Developing Fair Risk Scoring Models. Front. Artif. Intell. 4:681915. doi: 10.3389/frai.2021.681915
Received: 17 March 2021; Accepted: 02 August 2021;
Published: 14 October 2021.
Edited by:
Jochen Papenbrock, NVIDIA GmbH, GermanyReviewed by:
Laura Vana, Vienna University of Economics and Business, AustriaHenry Penikas, National Research University Higher School of Economics, Russia
Copyright © 2021 Szepannek and Lübke. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Gero Szepannek, Z2Vyby5zemVwYW5uZWtAaG9jaHNjaHVsZS1zdHJhbHN1bmQuZGU=