 Shixiao Liang1*
Shixiao Liang1* Aaron Higuera1Christina Peters2
Aaron Higuera1Christina Peters2 Venkat Roy3Waheed U. Bajwa3Hagit Shatkay2Christopher D. Tunnell1
Venkat Roy3Waheed U. Bajwa3Hagit Shatkay2Christopher D. Tunnell1- 1Department of Physics and Astronomy, Rice University, Houston, TX, United States
- 2Department of Computer and Information Sciences, University of Delaware, Newark, DE, United States
- 3Department of Electrical and Computer Engineering, Rutgers University, Piscataway, NJ, United States
This work proposes a domain-informed neural network architecture for experimental particle physics, using particle interaction localization with the time-projection chamber (TPC) technology for dark matter research as an example application. A key feature of the signals generated within the TPC is that they allow localization of particle interactions through a process called reconstruction (i.e., inverse-problem regression). While multilayer perceptrons (MLPs) have emerged as a leading contender for reconstruction in TPCs, such a black-box approach does not reflect prior knowledge of the underlying scientific processes. This paper looks anew at neural network-based interaction localization and encodes prior detector knowledge, in terms of both signal characteristics and detector geometry, into the feature encoding and the output layers of a multilayer (deep) neural network. The resulting neural network, termed Domain-informed Neural Network (DiNN), limits the receptive fields of the neurons in the initial feature encoding layers in order to account for the spatially localized nature of the signals produced within the TPC. This aspect of the DiNN, which has similarities with the emerging area of graph neural networks in that the neurons in the initial layers only connect to a handful of neurons in their succeeding layer, significantly reduces the number of parameters in the network in comparison to an MLP. In addition, in order to account for the detector geometry, the output layers of the network are modified using two geometric transformations to ensure the DiNN produces localizations within the interior of the detector. The end result is a neural network architecture that has 60% fewer parameters than an MLP, but that still achieves similar localization performance and provides a path to future architectural developments with improved performance because of their ability to encode additional domain knowledge into the architecture.
1. Introduction
Astroparticle physics has experienced a renaissance during the last decade. For instance, experiments searching for exotic phenomena related to neutrinos and dark matter particles have made significant advances in answering fundamental questions in both cosmology and particle physics (Giuliani et al., 2019; Billard et al., 2021). Often these experiments conduct extreme rare-event searches for signals that are challenging to measure, thereby imposing new requirements on the detector technology and the accompanying data-analysis methods. The focus of this paper is developing new data-analysis methods to better understand these signals and meet the scientific requirements.
Machine Learning (ML), particularly in the form of deep neural networks (LeCun et al., 2015; Goodfellow et al., 2016), has also thrived in the last decade and enabled innovations in many fields, including experimental particle physics (Albertsson et al., 2018; Radovic et al., 2018). Recent advances in deep learning concentrate on “daily life” tasks such as computer vision and natural language processing (LeCun et al., 2015; Shrestha and Mahmood, 2019). Methodologically, neural networks have proven adept at such problems, with numerous neural network architectures appearing that are optimized for data sets in those fields, usually inspired by the properties of the data in these fields. Research into physics-specific approaches have focused on problems closely related to theoretical physics where the measurement process is abstracted away (Cranmer et al., 2019; Komiske et al., 2019). For instance, recent research in physics-informed neural networks (PINNs) focuses on solving differential equations by introducing additional terms to the loss function (Raissi et al., 2017). Similar work related to climate modeling shows that neural networks can emulate non-linear dynamical systems with increased precision by introducing analytical constraints into the network architecture (Beucler et al., 2021). This paper complements and extends these prior works by developing Domain-informed Neural Networks (DiNNs) that contain architectural constraints to encode prior knowledge of signal characteristics and detector geometry.
Our main contributions in the paper include description, implementation, and evaluation of a DiNN incorporating physics-detector domain knowledge for localization of particle interactions within a leading particle-detector technology. Section 2 describes the detector technology and the domain problem. Section 3 describes the generation process of the samples used for training a machine learning model. Section 4 explains the physics-informed neural network and describes the hard architectural constraints on its hidden and output layers. Sections 5 and 6 discuss, respectively, the performance of the prototype DiNN and the impact of the new architecture in comparison to the state-of-the-art methodology. Finally, Section 7 concludes the paper.
2. Problem of Particle Localization in Astroparticle Detectors
The physical properties of an interaction within a particle-physics experiment, such as the type of interaction, the amount of energy deposited, and the interaction position, are inferred using measurements from sensor arrays. The procedure for this so-called “reconstruction” (a.k.a, inverse problem) depends on the working principle of the particle detector, while the choice of detector technology depends upon which science is being pursued. For dark-matter direct detection, which attempt to terrestrially measure the Milky Way's dark matter wind, the most sensitive experiments use dual-phase liquid xenon time projection chambers (DP-LXeTPCs), e.g., XENON (Aprile et al., 2017), LUX (Akerib et al., 2013), and PandaX (Cui et al., 2017).
2.1. Detection Principle of a Time-Projection Chamber
Time-projection chambers (TPCs) are among the most versatile particle detectors. The essential feature of TPCs is the ability to accurately measure the positions of particle interactions inside the detector. There are many successful applications of TPCs in collider experiments (Anderson et al., 2003; Alme et al., 2010), neutrino experiments (Acciarri et al., 2017b; Abi et al., 2020), as well as in the study of dark matter. DP-LXeTPCs are the world-leading detectors for dark matter direct detection (Schumann, 2019) and are proven to be able to find extremely rare events (Aprile et al., 2019a). Additionally, LXeTPCs are a compelling technology for future neutrinoless double-β decay experiments (Albert et al., 2017).
The signal characteristics from a DP-LXeTPC have been extensively studied and are well-understood. A DP-LXeTPC consists of a liquid-xenon target observed from above and below by arrays of photosensors, where there is a buffer layer of xenon gas between the liquid and the top photosensor array as shown in Figure 1. Electrodes create strong electric fields throughout the detector to drift the electrons from the target into the gaseous xenon region. When energetic particles scatter with xenon atoms in the target, the resulting recoil excites and ionizes the medium (This results in scintillation light, often called S1 signal, that is almost immediately observed by the photosensors.). More importantly for this study, the ionization process results in unbound electrons. These free electrons are within an electric field, so they drift toward the top of the TPC. Once the electrons reach the top of liquid xenon volume, they are extracted into the gaseous xenon by the strong electric field, causing an electron cascade that also produces scintillation light (often called S2 signal). This S2 signal is observed by the same sensor arrays that observe the S1 signal. The 2D position, in the plane of the photosensors, of the interaction is inferred from the S2 signal illumination pattern , where nt is the number of photosensors in the top array. In practice, only the top array is used as it is the closest to the S2.
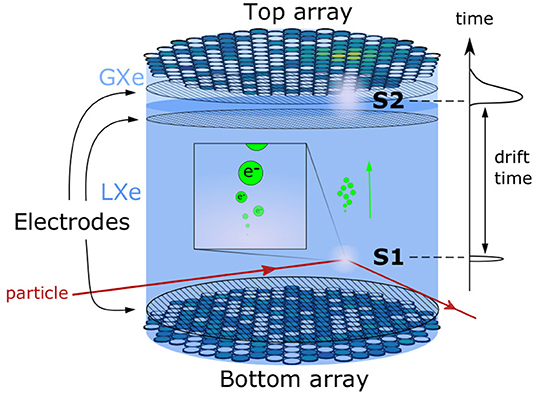
Figure 1. A schematic of the working principle of a DP-LXe TPC detector. Particles interact and deposit energy in liquid xenon target. An S1 signal is produced at the interaction location. Ionization electrons are released from the interaction point and drift toward the top of the TPC, where an S2 signal is produced and observed.
Without loss of generality, we consider a “generation two” (G2) TPC for direct-detection dark matter as an example application for this DiNN work. In our example, we consider nt = 253 photosensors in the top array and a detector cylinder of 67 cm in radius. The diameter of each photosensor is assumed to be 7.6 cm. More details on the simulation of S2 signals used for training and evaluation can be found in Section 3.
We focus on the challenge of interaction localization as this problem is difficult and representative of most reconstruction challenges in (astro)particle physics. In our case of DP-LXeTPCs, the required uncertainty for the inferred S2 position is less than 1 cm, one order of magnitude smaller than the length scale of the photosensors. We are considering a rare-event search where any misreconstructed S2 positions negatively impacts the sensitivity to dark matter. Challenges for this task include Poisson fluctuations in S2 pattern as the S2 signals are small, sometimes with only 40 photons detected across the entire array resulting from a single electron (Edwards et al., 2008; Aprile et al., 2014), and detector effects such as reflection of the S2 photons off of the wall of the TPC. Figure 2 visually illustrates the fluctuation in the S2 pattern of a relatively small S2 signal.
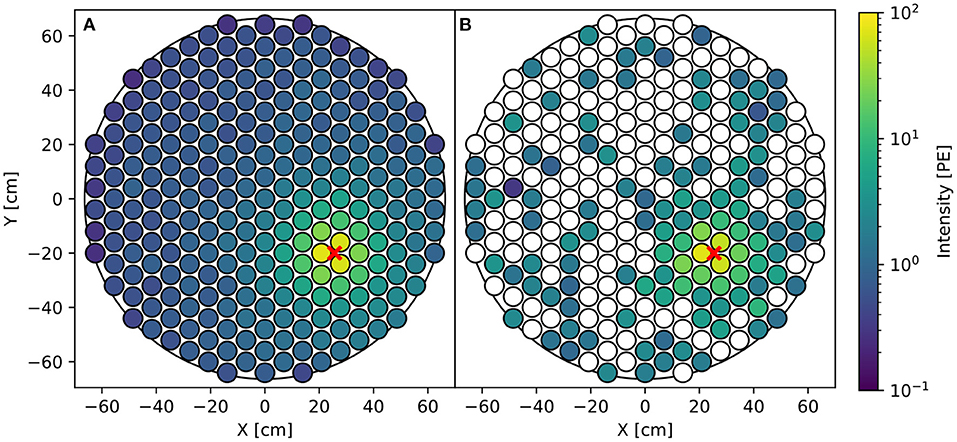
Figure 2. (A) Average simulated S2 pattern. (B) A single simulated S2 pattern. S2s are simulated assuming 20 electrons are extracted into the gaseous xenon at the location of the red marker. The averaged S2 pattern is ideal which allows us to infer the position perfectly, while the actual S2 pattern contains fluctuations, noises and detector effects that make accurate position reconstruction difficult.
2.2. Existing Techniques and Limitations
We summarize S2 localization methods developed for previous DP-LXeTPC experiments and their limitations. These methods are either used in the analyses of previous experiments or are candidates for upcoming experiments.
Likelihood fitters are used for S2 localization for DP-LXeTPCs (Solovov et al., 2012; Akerib et al., 2018; Simola et al., 2019; Pelssers, 2020; Zang et al., 2021). While this is the most robust and accurate method in theory, it is only true if the likelihood is tractable. The likelihood is often difficult to estimate due to various detector systematics, such as the difficulty in modeling the reflectivity of the materials in the detector (Levy, 2014) at the level required by the science. The reflectivity of materials also affects other methods, especially within the area close to the detector wall. Most importantly, likelihood fitters are slow compared to other methods as they often require computing the likelihood function multiple times, which makes it more difficult to be applied within a data analysis pipeline of experiments that take data at high rate.
The common method for S2 localization relies upon classical neural networks consisting of a fully-connected network, also known as multilayer perceptron (MLP) model. Typically, such networks consist of one or two hidden layers mapping with exponential linear unit (ELU) and LINEAR activation functions (Aprile et al., 2019b; de Vries, 2020). MLP models are able to learn a simple mapping from integrated light intensity seen by a photosensor to 2D coordinates. In practice, MLP methods are significantly faster than likelihood based methods, which is important as these algorithms may operate on petabytes of experimental data with real-time rates of more than 100 MB/s. However, MLP models are the most general form of neural networks and are therefore sub-optimal for this problem. There are two major challenges in particular related to the use of MLP models for our purposes. First, since the number of trainable parameters in fully connected networks increases rather quickly as the networks get deeper (Lecun et al., 1998), this increases the risk of overfitting due to the larger capacity of the networks (Lecun et al., 1998; Vapnik, 2000). Second, and perhaps most importantly, fully connected networks completely ignore the topology of the input data samples; the ordering of individual dimensions of data samples into the input layer can be changed without any effects on the training (Lecun et al., 1998). Both the density of connections in MLP models and their indifference to the data topology limit our ability to interpret their outcomes.
Convolutional neural networks (CNNs) (LeCun and Bengio, 1995) are an example of a neural network architecture in computer vision that uses assumptions about the data topology to reduce the computational complexity of deep learning. Specifically, convolutional layers encode the concept of “feature locality” in the data through learning a kernel that is translational invariant (i.e., weight sharing) and can therefore e.g., detect edges and other textures. These CNN models have successful applications in astroparticle physics experiments (Aurisano et al., 2016; Baldi et al., 2019), including both liquid-argon TPC (Acciarri et al., 2017a; Grobov and Ilyasov, 2020; Abratenko et al., 2021) and a liquid-xenon TPC (Delaquis et al., 2018). However, the nature of DP-LXeTPC experimental data—and particle-physics detectors more generally—does not often lend itself to CNN techniques as the nature of this data is not image based. Specifically, the photosensors typically are not arranged on a grid, or square lattice. It is possible to construct a contrived mapping of the photosensors array onto a square lattice for some certain arrangements (Hoogeboom et al., 2018; Abbasi et al., 2021), but this geometrically distorts features in the data while also affecting the performance due to artificial empty pixels from the transformation. In addition, CNN models built with plain convolutional layers are not ideal for coordinate transform problems including localization problems (Liu et al., 2018).
3. Simulation of S2-Signal Samples for Training and Evaluation
Here we describe how we simulate S2 patterns based on the generation mechanism of S2 signals in DP-LXeTPC for training and evaluating the algorithms for S2 localization. The photons of one S2 signal are considered to be released from a point source at where the electrons enter the gaseous xenon and the number of photons in a S2 signal is proportional to the number of electrons entering the gaseous xenon. The number of photons recorded by photosensors obey Poisson distributions Pois(μ), where the expectation value μ is calculated by multiplying the light collection efficiency LCE(x, y) of each photosensor and the number of photons in the S2 signal. The number of photons can be calculated by multiplying the number of electrons that generate the S2 signal Ne by the scintillation gain SG(x, y) which is the conversion factor between the number of S2 photons and the number of electrons. The recorded S2 signal intensity of each photosensor fluctuates due to the resolution of photosensors, which is considered to obey a normal distribution Norm(1, σ) with σ being the resolution of photosensors. Thus, the S2 intensity recorded by photosensor i can be expressed as a product of a Poisson random variable and a normal random variable:
where (x, y) is the coordinate of the true position of the S2 signal. The light collection efficiency function LCEi(x, y) heavily depends on the location of the photosensor and could change dramatically between photosensors.
We use a model that assumes the same light collection efficiency for all the photosensors as well as uniform scintillation gain. The light collection efficiency is modeled using an empirical function of the distance between the S2 position and the photosensor position similar to the one used in Akerib et al. (2018):
where ρ is the distance between the S2 position and the photosensor position. E0, a, b, p and d are parameters that determine the shape of this function with values shown in Table 1 used in this work.

Table 1. The model parameters used for this work for the intensity seen by an individual photosensor (Equation 2) with ρ in the unit of cm.
This light collection efficiency model does not take into account the optical effects of reflection from certain detector components. For example, the reflection from the detector wall which could largely change the light collection efficiency of photosensors placed close to the detector wall. When implementing any S2 localization algorithm trained on samples generated using the above model for an actual DP-LXeTPC detector, it is necessary to compare the model to both a data-driven and a simulation-based light collection efficiency model to ensure the appropriateness of the above approximations.
4. Method: Domain-Informed Neural Network Architecture for Interaction Localization
4.1. Encoding Signal Characteristics Using Graph-Constrained Hidden Layers
We encode our knowledge of the S2 signal characteristics into the network architecture through connectivity constraints. The photosensors closer to the S2 position have more photons incident upon them than those farther away, and thus provide more localization information. Moreover, photosensors outside the S2's field-of-view might record other signals uncorrelated to the S2 signal, such as position-uncorrelated single-electron S2s (Aprile et al., 2014), which may bias the inference of the S2 location. Therefore, we expect that encoding this intrinsic “locality” will be more efficient—and potentially more effective—at localizing S2s. Our motivation is the success of CNN models in computer vision, which rely on local connections and locality as discussed above.
This is achieved by limiting the receptive field of neurons in the hidden layers. The input vector to the network corresponds to an S2 pattern on the top sensor array, which means that there is a one-to-one relationship between photosensor positions and neurons in the input layer to the neural network model. We introduce an architectural constraint by assigning each neuron in the following layer a 2D position, and only making edges to neurons in the following layer if they are within some distance threshold d within (x, y) from neurons in the input layer. In this way, every neuron only receives information from a small cluster of nearby photosensors in the receptive field of a circular disk with radius d centered at the neuron's position and ignores others, as shown in Figure 3. This differs from the standard fully-connected technique where each neuron is connected to all neurons in the input layer. However, if the distance threshold is sufficiently large to include all neurons, the two techniques are equivalent. This technique contrasts CNNs as each neuron has its own receptive field without weight sharing as translational invariance is not guaranteed, and is similar to the idea of locally connected layers which is used in an other work in particle physics (de Oliveira et al., 2017).
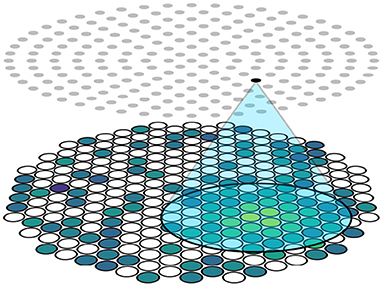
Figure 3. Schematic of the locality constraint. The distance between the highlighted neuron and photosensors in the blue area is smaller than a threshold. Photosensors inside the blue area are connected to the highlighted neuron while photosensors outside the blue area are not, limiting the receptive field of the highlighted neuron to be the blue area.
In practice, the network is constructed by placing the neurons and the photosensors on the same 2D plane and constructing a graph using the rule described above, where part of the adjacency matrix of this graph is used to mask the weight matrix of the neural network layer. With the input to this layer represented by , the operation of this layer can be represented as
where Wl and are the trainable weight matrix and the bias vector, respectively, f(·) is an activation function, and Al is the adjacency matrix that represents the connection between the input layer and the proceeding layer. We refer to this layer as graph constrained layer in the following sections.
The graph constrained layer requires neurons in its input layers to have 2D positions. With neurons being interpreted as points in a 2D plane, we can extend a neural network model by adding another graph constrained layer after one.
4.2. Encoding Detector Geometry Using a Geometry-Constrained Output Layer
We describe the design of a hard detector-inspired constraint on the output space for the neural network model. This constraint enforces the model to produce physically meaningful predictions located only within the detector.
We must modify the output layer of the network to incorporate this constraint. Historically, the localization regression is performed using two neurons with linear activation functions at the output layer since we are predicting a 2D position. The possible output space for these models is ℝ2. Meanwhile, S2s can only be produced inside the detector, which means the physically meaningful output space is a circular disk . It is important to require that the predicted positions are within the detector D(RTPC) as there are position-dependent corrections for each interaction that otherwise are ill-defined. Furthermore, due to the self-shielding properties of liquid xenon, most S2 signals are near the edge of the detector and are at higher risk of being localized outside the detector. This effect is also more significant for smaller S2s as they are harder to localize.
The first part of this hard constraint is constraining the output space to be the limited space instead of the infinite ℝ2 space. We use the TANH activation function in the output layer to make a temporary output in a 2D square . The second part is analytically mapping the temporary square T into a unit circle D(1) using Fernandez Guasti squircle (FG-squircle) mapping, as shown in Figure 4. Gausti (1992), Fong (2015), and Lambers (2016) and scale it to the radius of the TPC RTPC. The square to disk mapping is shown in Equation (4).
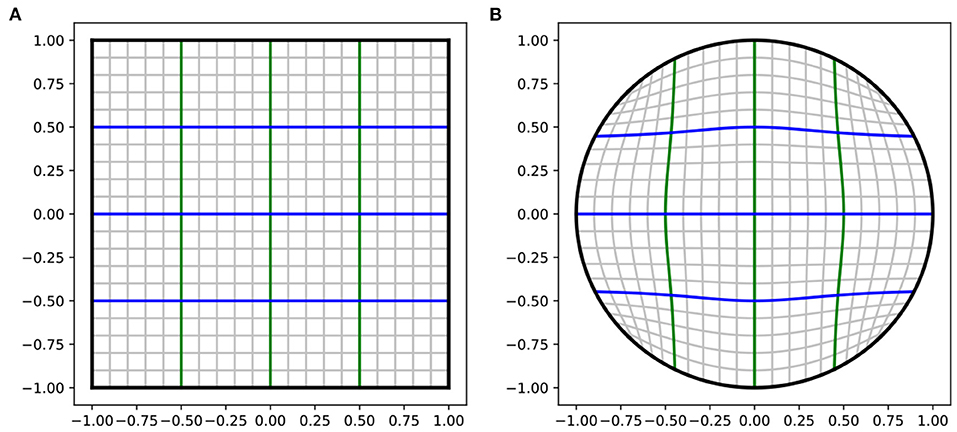
Figure 4. The analytical mapping from square to circle. (A) A square in 2D space . (B) Unit circle, mapped from the square using Equation (4). The lines in the square are mapped onto the curves in the circle.
4.3. Implementation
We implemented a prototype neural network model using the graph-constrained layer and the constraint on the output space. The architecture of this neural network model is shown in Figure 5. The input vector is embedded into an input layer with dimension 253 alone with the positions of photosensors. After the input layer there are 6 graph-constrained layers, with dimension [217, 169, 127, 91, 61, 37] respectively. In each layer, the assigned positions for the neurons are arranged in rings and distributed roughly uniformly in a circle that is approximately the same area as the TPC cross section. The threshold for connection used for this model is 30 cm and justification for this choice is discussed in Section 6. There are two fully connected layers after the graph-constrained layers, with the last one using TANH squashing function to produce a temporary output constrained to a filled square. The FG-squircle mapping is implemented to map the temporary square output onto the desired disk output space. The number of trainable parameters in this model is 22,921, less than 0.2 times the number of parameters in a fully connected network of the same architecture as this model.
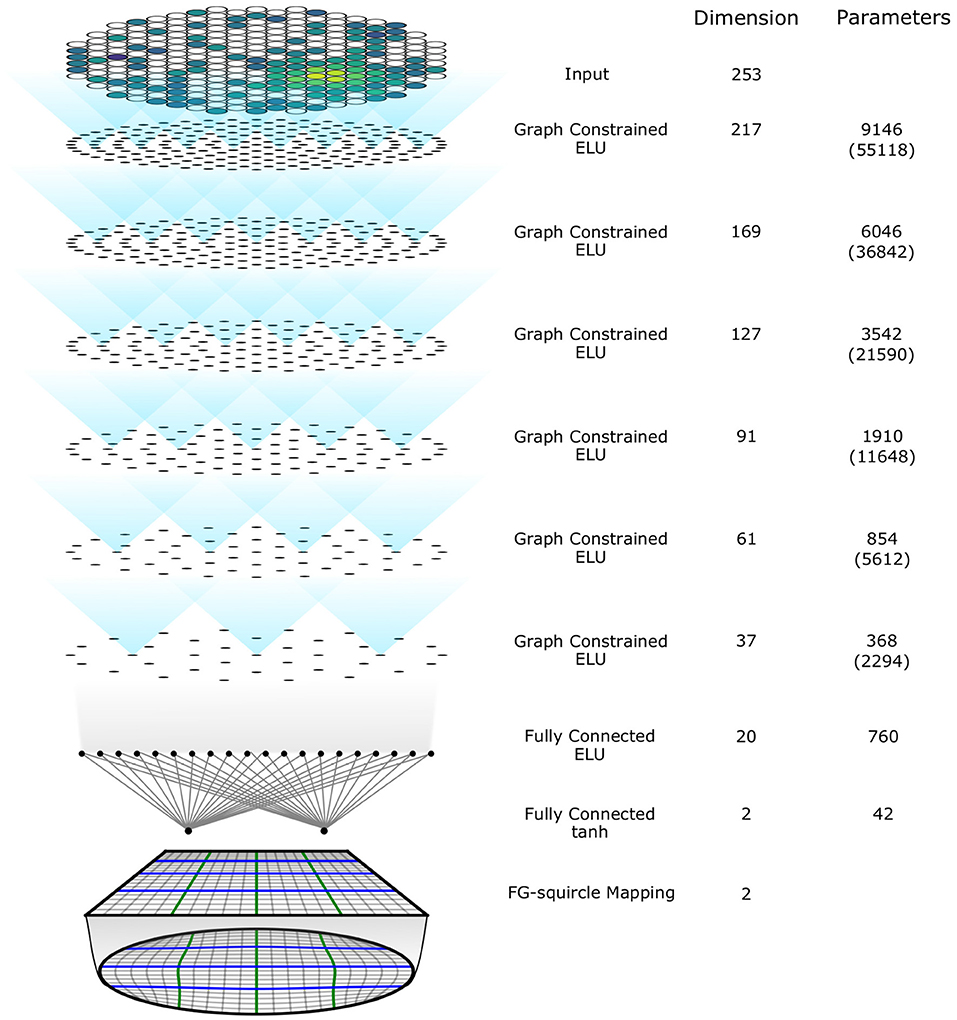
Figure 5. The architecture of the implemented prototype model. The dots in graph constrained layers represents the assigned positions of the neurons. The numbers in brackets are the number of parameters if the neurons are fully connected for graph constrained layers.
The model is implemented with TensorFlow (Abadi et al., 2015). We train the model on 5 × 105 simulated S2 patterns for 250 epochs with Adam optimizer (Kingma and Ba, 2014) using mean squared error as loss function. A adaptive learning rate scheduler is applied to lower the learning rate when the validation loss hits a plateau for more than 10 epochs. This model is referred to as a DiNN model in the following sections.
5. Evaluating Performance of Interaction Localization
Here, we define the metrics used to evaluate the performance of methods developed for S2 localization. The models are tested on simulated S2 signals with known true positions, which is needed for the calculation of these metrics. We then compare the performance of the DiNN model and a 4-layer MLP model trained on the same data set with the same optimizer and training configuration using these metrics. The MLP model, which is very similar to the one used in Aprile et al. (2019b), has 57,842 trainable parameters.
We use to denote the true S2 position used in simulation and to denote the prediction based on the model for a given S2 pattern. is the distance of the true S2 position from the center of the detector, commonly called the radius of S2. The difference between the true and predicted S2 positions, , is the localization error. As mentioned in Section 3, the S2 pattern is dependent on the number of electrons that generate the S2 signal. We mainly use simulated S2s generated by 100 electrons, referred to as 100 electron S2s, because this is approximately the intensity of S2 signals caused by dark matter particle interactions.
When searching for rare events, such as dark matter particle interactions, the radius of an interaction is more commonly used than the (x, y) coordinate in statistical inference (Aprile et al., 2019b). Figure 6 shows the distribution of the difference between the true and predicted S2 radii, , on simulated 100 electron S2s as a function of the true radius, R, for the MLP and DiNN model. Notice in the R < 60 cm region, the S2s are localized with radius error less than 1 cm, and has no dependence on true radius, which is compatible with the goal of setting the uncertainty of S2 localization to be one order of magnitude lower than the scale of the photosensors. In the R > 60 cm region, both the GCN and MLP models cannot maintain the same performance as they do in R < 60 cm region. The deteriorated performance could result from incomplete sampling of S2 signals in this region since there are no photosensors outside the detector. The large difference in the behavior in the R < 60 cm and R > 60 cm regions by both the DiNN and MLP models motivates a comparison of the two regions using other metrics.
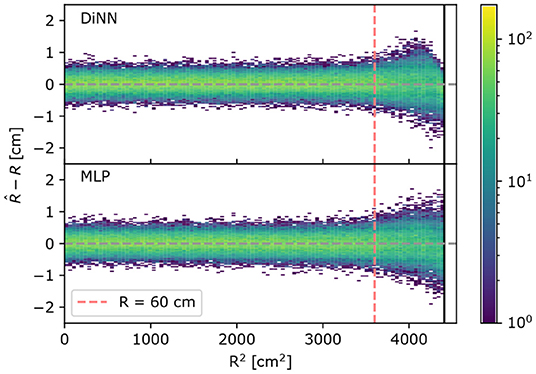
Figure 6. Radial error on 100 electrons simulated S2s. A positive radial error means the S2 is localized further away from the center of the detector than the true position and vice versa. Both the DiNN and MLP model cannot localize S2s in R > 60 cm region as accurate as S2s in R < 60 cm region, resulting in a wider spread in R > 60 cm region and the positive radial error is suppressed by the constrained output in the region extremely close to the detector wall for the DiNN.
While the (x, y) coordinate is not directly used for physical analysis, it is useful for diagnostic analysis for the detector. A high position resolution is crucial for identifying the topology of interactions (Wittweg et al., 2020). Thus, the distribution of localization error, , is useful for evaluating the performance of the models. The distribution of localization errors is shown in Figure 7. We calculate the mean value and the root mean squared (RMS) of the localization error for quantitative comparison. A small mean value in both the x and y direction indicates that the localization is not biased toward any direction, which appears to be the case for both the DiNN and MLP model in both R < 60 cm region and R > 60 cm region. A smaller RMS indicates more accurate localization. The DiNN model has similar RMS in both regions to the MLP model.
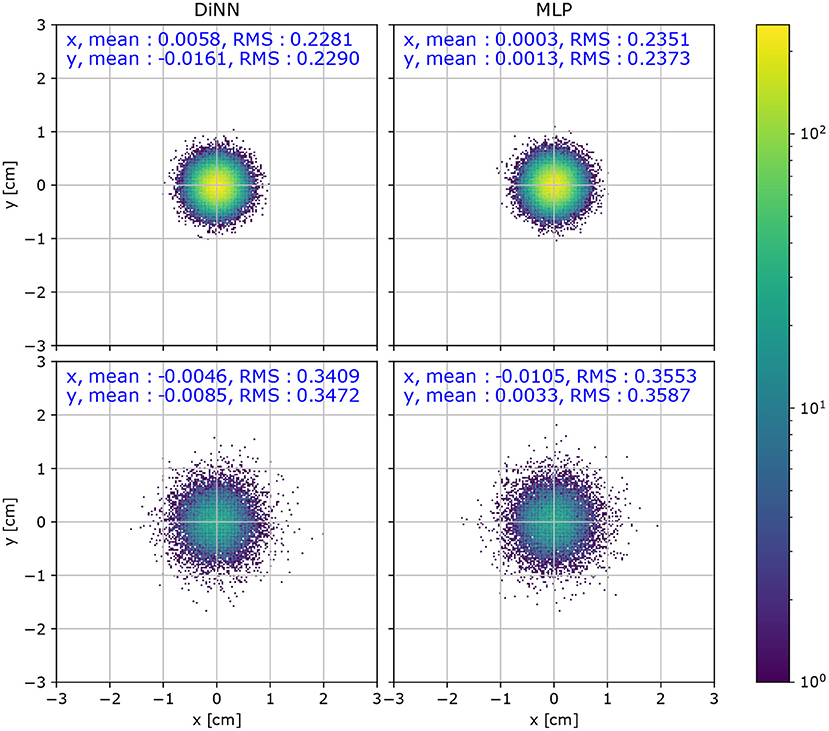
Figure 7. Distribution of localization error, , for a test set of simulated 100 electron S2 signals. S2 signals with R < 60 cm (top) have a smaller RMS than interactions with R < 60 cm (bottom).
The difficulty of localizing S2s varies with the intensity of S2. The 90th percentile of localization error can provide us an intuitive understanding of the resolution of localization as a function of S2 intensity level. As shown in Figure 8, the 90th percentile of localization error drops for both the DiNN and MLP model as S2 intensity increases. Again the 90th percentile of localization error is much larger in R > 60 cm region. In both regions the DiNN model has marginally smaller 90th percentile of localization error than the MLP model, which is consistent with the result from 100 electrons S2s shown in Figure 7.
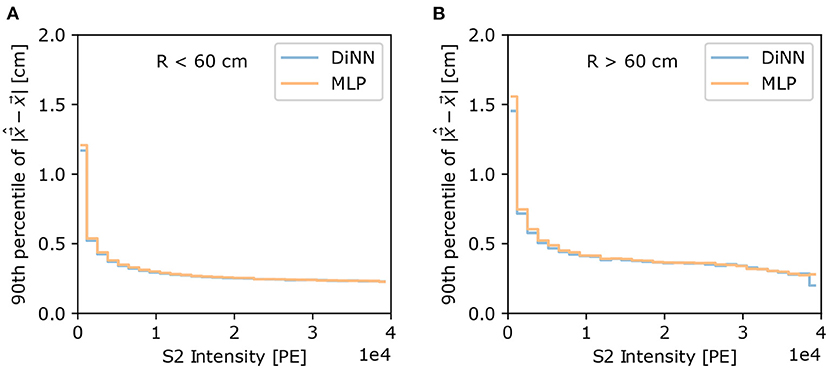
Figure 8. The 90th percentile of localization error as a function of S2 intensity, for (A) R < 60 cm and (B) R > 60 cm. S2s with higher intensities are localized with smaller error by both models, and S2s at R > 60 cm region are localized with larger error than S2s at R < 60 cm region, both as expected.
As stated in Section 4, smaller S2s are more sensitive to being localized outside the detector by the MLP model. We tested both the GCN and MLP model on simulated single electron S2s, which are the smallest possible S2s in the DP-LXeTPC detectors, to demonstrate the effect and determine how it is changed by the constrained output. Figure 9 shows the result of this test. The MLP model localizes a considerable amount of single electron S2s outside the detector, while the DiNN model localizes all the S2s inside the detector.
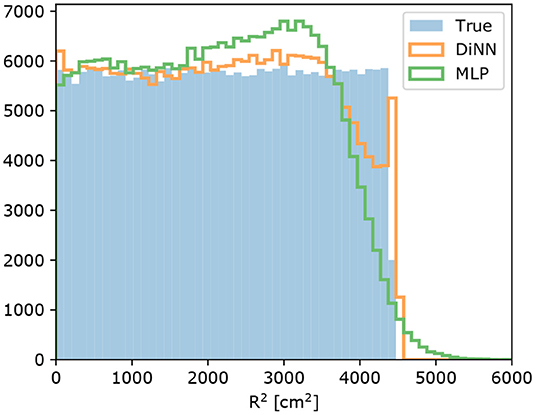
Figure 9. Radial distribution of simulated single electron S2 signals. The MLP model localizes 2,346 of 250,000 S2s outside the detector, while the DiNN model localizes all of them inside the detector with the output constraint.
6. Optimizing the Tunable Parameters in the Method
We introduced a parameter (distance threshold) in the graph constrained layer to determine its connections to the input layer. A smaller threshold means sparser connections and weaker representation power. A larger threshold means denser connections and stronger representation power, but also more parameters in the layer. When the threshold is large enough, the layer becomes fully connected, which is identical to the basic building block of MLP models. Intuitively, a threshold roughly equal to the scale of the region where a photosensor can receive light is the most meaningful and thus should work well. A well-selected threshold is essential for models built with graph constrained layers to achieve maximum performance with the least parameters.
To find the optimal threshold for the DiNN model, we trained a series of models of the same architecture, but with different distance thresholds. We also trained a DiNN model with a sufficiently large threshold so that all the graph constrained layers are fully connected. The purpose of this model is to set the limit for the performance that can be reached by the DiNN model. The total number of trainable parameters in the fully connected DiNN model is 133,906. All the models are evaluated on a test set of simulated 100 electrons S2s and the result is shown in Figure 10. When the threshold is small, the network does not have enough parameters to represent the mapping from S2 patterns to S2 positions. Increasing the threshold lowers the RMS of the distribution of localization errors. However, when the threshold is larger than 30 cm, the RMS reaches the same level as that using the fully connected DiNN model. Further increasing threshold does not lower the RMS of the distribution, but still increases the number of parameter in the DiNN model. In conclusion, a threshold of 30 cm appears to be optimal and thus is used for building the prototype DiNN model.
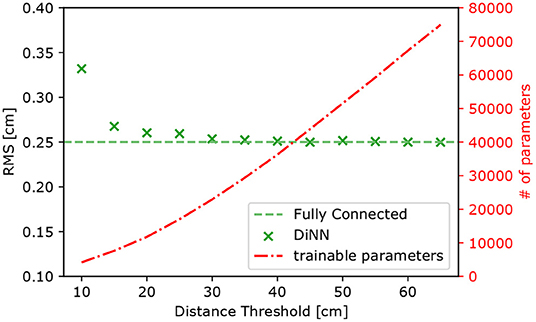
Figure 10. The RMS of localization error (left axis) and the number of trainable parameters in the DiNN model (right axis) as functions of threshold used for the graph constrained layers in the model. The RMS decreases as the threshold increases until the threshold reaches 30 cm, but the number of parameter still increases as the threshold increases. The RMS is calculated on models' prediction of simulated 100 electron S2s and averaged over x,y dimension.
The two components of the DiNN model, the main body built with graph constrained layer and the geometry-constrained output layer are not closely related and could be applied to models separately. Particularly, the TANH activation function and the FG-squircle mapping used for the constrained output layer introduces nonlinearity into the model, which might create difficulty for the model to learn the mapping from S2 patterns to S2 positions, especially at the regions close to the detector wall. To evaluate the effect of the main body built with graph constrained layer and the geometry-constrained output layer, we build and train MLP models and DiNN models with both linear output and geometry-constrained output and compare the RMS of the distribution of the localization errors on 100 electrons simulated S2s. The results are shown in Table 2. The models with constrained output have similar RMS in both R < 60 cm region and R > 60 cm region, which indicates that the nonlinearity introduced by the constrained output is not too complex for neural network models to learn and is not making localization at the region close to the detector wall difficult.
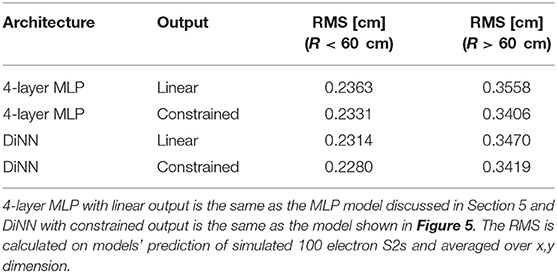
Table 2. Results for different combinations of neural network architectures and output layers.
7. Conclusion and Future Work
We introduce the concept of Domain-informed Neural Networks (DiNNs) for the application of the localization of S2 signals in experimental astroparticle physics. Using our prior knowledge of the S2 signal characteristics, we introduce an architectural constraint that limits the receptive field of the hidden layers. Using our prior knowledge of the detector geometry, we additionally introduce a constraint and geometrical transformation on the output layer.
A prototype DiNN model built with these two constraints is trained and tested on S2s simulated from a generic G2 dark matter search. This prototype model reached the same level of performance as a multilayer perceptron (MLP) model while containing 60% fewer trainable parameters. Therefore, with a careful selection of the distance threshold related to how far a sensor ‘sees', the graph-constrained layers within the DiNN can greatly reduce the number of trainable parameters without degrading the performance of the prototype DiNN model. Additionally, the network is more interpretable in the sense that the output constraint puts meaningful and practical limit on the outputs of this regression problem for the first time. Such a constraint can also be used for other neural network models for regression problems that predict positions within a detector using sensors with a limited field of view. The physics-informed locality constraint can further be applied to other astroparticle detectors such as liquid argon TPCs. Additionally, the method used for constructing this constraint can be transferred to other problems with irregular sensor arrangements.
The idea behind graph-constrained layers has some similarities with attention-based methods, which have proven successful in many tasks including localization-related computer vision task (Carion et al., 2020) as they focus on parts of the inputs. The attention mechanism allows neural networks to focus on parts of the input in a way that is learnt from data, but requires more computational resources. We are interested in efficiently combining our method with features that are learned in a data-driven manner by attention-based methods. Our future work is aimed at using these models on the spatiotemporal data, with a focus on calorimetry or signal detection.
Data Availability Statement
The code to reproduce this study can be found in Liang and Tunnell (2021) or https://github.com/DidactsOrg/DiNN.
Author Contributions
SL implemented, trained, and evaluated the models. All authors are members of the DIDACTS collaboration and were involved in developing, reviewing, and refining these results. All authors contributed to the article and approved the submitted version.
Funding
We acknowledge support from the National Science Foundation through awards 1940074, 1940209, and 1940080. We thank NVIDIA for their support by providing GPUs.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
We thank Luis Sanchez and Alejandro Oranday for helpful discussions at the early stage of this work.
References
Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., et al. (2015). TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. Available online at: https://www.tensorflow.org/
Abbasi, R., Ackermann, M., Adams, J., Aguilar, J. A., Ahlers, M., Ahrens, M., et al. (2021). A convolutional neural network based cascade reconstruction for the icecube neutrino observatory. arXiv [Preprint]. arXiv: 2101.11589. doi: 10.1088/1748-0221/16/07/P07041
Abi, B., Acciarri, R., Acero, M. A., Adamov, G., Adams, D., Adinolfi, M., et al. (2020). Deep underground neutrino experiment (DUNE), far detector technical design report, Volume IV: Far detector single-phase technology. arXiv [Preprint]. arXiv: 2002.03010. doi: 10.1088/1748-0221/15/08/T08010
Abratenko, P., Alrashed, M., An, R., Anthony, J., Asaadi, J., Ashkenazi, A., et al. (2021). Semantic segmentation with a sparse convolutional neural network for event reconstruction in MicroBooNE. arXiv [Preprint]. arXiv: 2012.08513. doi: 10.1103/PhysRevD.103.052012
Acciarri, R., Adams, C., An, R., Aparicio, A., Aponte, S., Asaadi, J., et al. (2017b). Design and construction of the MicroBooNE detector. arXiv [Preprint]. arXiv: 1612.05824. doi: 10.1088/1748-0221/12/02/P02017
Acciarri, R., Adams, C., An, R., Asaadi, J., Auger, M., Bagby, L., et al. (2017a). Convolutional neural networks applied to neutrino events in a liquid argon time projection chamber. arXiv [Preprint]. arXiv: 1611.05531. doi: 10.1088/1748-0221/12/03/P03011
Akerib, D. S., Bai, X., Bedikian, S., Bernard, E., Bernstein, A., Bolozdynya, A., et al. (2013). The large underground xenon (LUX) experiment. Nucl. Instrum. Meth. A. 704, 111–126. doi: 10.1016/j.nima.2012.11.135
Albert, J. B., Anton, G., Arnquist, I. J., Badhrees, I., Barbeau, P., Beck, D., et al. (2017). Sensitivity and discovery potential of nexo to neutrinoless double beta decay. arXiv [Preprint]. arXiv: 1710.05075. doi: 10.1103/PhysRevC.97.065503
Albertsson, K., Altoe, P., Anderson, D., Anderson, J., Andrews, M., Espnosa, J. P. A., et al. (2018). Machine learning in high energy physics community white paper. arXiv [Preprint]. arXiv: 1807.02876. doi: 10.1088/1742-6596/1085/2/022008
Alme, J., Andres, Y., Appelshauser, H., Bablok, S., Bialas, N., Bolgen, R., et al. (2010). The ALICE TPC, a large 3-dimensional tracking device with fast readout for ultra-high multiplicity events. Nucl. Instrum. Meth. A. 622, 316–367. doi: 10.1016/j.nima.2010.04.042
Anderson, M., Berkovitz, J., Betts, W., Bossingham, R., Bieser, F., Brown, R., et al. (2003). The Star time projection chamber: A Unique tool for studying high multiplicity events at RHIC. Nucl. Instrum. Meth. A. 499, 659–678. doi: 10.1016/S0168-9002(02)01964-2
Aprile, E., Aalbers, J., Agostini, F., Alfonsi, M., Althueser, L., Amaro, F. D., et al. (2019a). Observation of two-neutrino double electron capture in 124Xe with XENON1T. Nature 568, 532–535. doi: 10.1038/s41586-019-1124-4
Aprile, E., Aalbers, J., Agostini, F., Alfonsi, M., Althueser, L., Amaro, F. D., et al. (2019b). XENON1T dark matter data analysis: signal reconstruction, calibration and event selection. arXiv [Preprint]. arXiv: 1906.04717. doi: 10.1103/PhysRevD.100.052014
Aprile, E., Aalbers, J., Agostini, F., Alfonsi, M., Amaro, F. D., Anthony, M., et al. (2017). The XENON1T dark matter experiment. Eur. Phys. J. C. 77, 881. doi: 10.1140/epjc/s10052-017-5326-3
Aprile, E., Alfonsi, M., Arisaka, K., Arneodo, F., Balan, C., Baudis, L., et al. (2014). Observation and applications of single-electron charge signals in the XENON100 experiment. arXiv [Preprint]. arXiv: 1311.1088. doi: 10.1088/0954-3899/41/3/035201
Aurisano, A., Radovic, A., Rocco, D., Himmel, A., Messier, M. D., Niner, E., et al. (2016). A convolutional neural network neutrino event classifier. arXiv [Preprint]. arXiv: 1604.01444. doi: 10.1088/1748-0221/11/09/P09001
Baldi, P., Bian, J., Hertel, L., and Li, L. (2019). Improved energy reconstruction in nova with regression convolutional neural networks. Phys. Rev. D. 99, 012011. doi: 10.1103/PhysRevD.99.012011
Beucler, T., Pritchard, M., Rasp, S., Ott, J., Baldi, P., and Gentine, P. (2021). Enforcing analytic constraints in neural networks emulating physical systems. Phys. Rev. Lett. 126, 098302. doi: 10.1103/PhysRevLett.126.098302
Billard, J., Boulay, M., Cebrian, S., Covi, L., Fiorillo, G., Green, A., et al. (2021). Direct detection of dark matter APPEC committee report. arXiv [Preprint]. arXiv: 2104.07634. doi: 10.1088/1361-6633/ac5754
Bronstein, M. M, Bruna, J, Cohen, T, and Velickovic, P. (2008). BWorld Robot Control Software. Available online at: https://geometricdeeplearning.com/ (accessed July 19, 2008).
Bronstein, M. M., Bruna, J., LeCun, Y., Szlam, A., and Vandergheynst, P. (2017). Geometric Deep Learning: Going beyond Euclidean data. IEEE Sign. Process. Magn. 34, 18–42. doi: 10.1109/MSP.2017.2693418
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., and Zagoruyko, S. (2020). “End-to-end object detection with transformers,” in European Conference on Computer Vision (Springer), 213–229.
Cranmer, K., Brehmer, J., and Louppe, G. (2019). The frontier of simulation-based inference. Proc. Nat. Acad. Sci. 117, 30055–30062. doi: 10.1073/pnas.1912789117
Cui, X., Abdukerim, A., Chen, W., Chen, X., Chen, Y., Dong, B., et al. (2017). Dark matter results from 54-ton-day exposure of PandaX-II experiment. arXiv [Preprint]. arXiv: 1708.06917. doi: 10.1103/PhysRevLett.119.181302
de Oliveria, L., Paganini, M., and Nachman, B. (2017). Learning particle physics by example: location-aware generative adversarial networks for physics synthesis. arXiv [Preprint]. arXiv: 1701.05927. doi: 10.1007/s41781-017-0004-6
de Vries, L. (2020). Deep neural networks for position reconstruction in XENON1T (Master Thesis). University of Amsterdam, Amsterdam, Netherlands.
Delaquis, S., Jewell, M. J., Ostrovskiy, I., Weber, M., Ziegler, T., Dalmasson, J., et al. (2018). Deep neural networks for energy and position reconstruction in EXO-200. arXiv [Preprint]. arXiv: 1804.09641. doi: 10.1088/1748-0221/13/08/P08023
Edwards, B., Araujo, H. M., Chepel, V., Cline, D., Durkin, T., Gao, J., et al. (2008). Measurement of single electron emission in two-phase xenon. Astropart. Part. 30, 54–57. doi: 10.1016/j.astropartphys.2008.06.006
Fong, C. (2015). Analytical methods for squaring the disc. arXiv [Preprint]. arXiv: 1509.06344. doi: 10.48550/ARXIV.1509.06344
Gausti, M. F. (1992). Classroom notes. Int. J. Math. Educ. Sci. Tech. 23, 895–913. doi: 10.1080/0020739920230607
Giuliani, A., Cadenas, J. J. G., Pascoli, S., Previtali, E., Saakyan, R., Schaeffner, K., et al. (2019). Double beta decay APPEC committee report. arXiv [Preprint]. arXiv: 1910.04688. doi: 10.48550/ARXIV.1910.04688
Grobov, A., and Ilyasov, A. (2020). Convolutional neural network approach to event position reconstruction in DarkSide-50 experiment. J. Phys. Conf. Ser. 1690, 012013. doi: 10.1088/1742-6596/1690/1/012013
Hamilton, W. L., Ying, R., and Lesovec, J. (2017). Representation learning on graphs: Methods and applications. arXiv [Preprint]. arXiv: 1709.05584.
Hoogeboom, E., Peters, J. W. T., Cohen, T. S., and Welling, M. (2018). Hexaconv. arXiv [Preprint]. arXiv: 1803.02108. doi: 10.48550/ARXIV.1803.02108
Kingma, D. P., and Ba, J. (2014). Adam: A method for stochastic optimization. arXiv [Preprint]. arXiv: 1412.6980.
Komiske, P. T., Metodiev, E. M., and Thaler, J. (2019). Energy flow networks: Deep sets for particle jets. arXiv [Preprint]. arXiv: 1810.05165. doi: 10.1007/JHEP01(2019)121
Lambers, M. (2016). Mappings between sphere, disc, and square. J. Comp. Graph. Tech. 5, 1–21. Available online at: http://jcgt.org/published/0005/02/01/
LeCun, Y., and Bengio, Y. (1995). “Convolutional networks for images, speech, and time-series,” in The Handbook of Brain Theory and Neural Networks, ed M. A. arbib (Cambridge, MA: MIT Press).
Lecun, Y., Bottou, L., Bengio, Y., and Haffner, P. (1998). Gradient-based learning applied to document recognition. Proc. IEEE. 86, 2278–2324. doi: 10.1109/5.726791
Levy, C. (2014). Light propagation and reflection off teflon in liquid xenon detectors for the XENON100 and XENON1T dark matter experiments (Ph.D. thesis). University of Muenster, Munenster, Germany.
Li, Y., Tarlow, D., Brockschmidt, M., and Zemel, R. (2015). Gated graph sequence neural networks. arXiv [Preprint]. arXiv: 1511.05493.
Liang, S., and Tunnell, C. (2021). Domain-informed neural networks. Zenodo. doi: 10.5281/zenodo.5771868
Liu, R., Lehman, J., Molino, P., Such, F. P., Frank, E., Sergeev, A., and Yosinski, J. (2018). “An intriguing failing of convolutional neural networks and the CoordConv solution,” in Advances in Neural Information Processing Systems, eds S. Bengio, H. Wallch, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (Red Hook, NY: Curran Associates, Inc), 9628–9639. Available online at: https://proceedings.neurips.cc/paper/2018/file/60106888f8977b71e1f15db7bc9a88d1-Paper.pdf
Ortega, A., Frossard, P., Kovavevic, J., Moura, J. M., and Vandergheynst, P. (2018). Graph signal processing: Overview, challenges, and applications. Proc. IEEE. 106, 808–828.
Pelssers, B. E. J. (2020). Enhancing direct searches for dark matter: spatial-temporal modeling and explicit likelihoods (Ph.D. thesis). Department of Physics, Stockholm University, Stockholm, Sweden.
Radovic, A., Williams, M., Rousseau, D., Kagan, M., Bonacorsi, D., Himmel, A., et al. (2018). Machine learning at the energy and intensity frontiers of particle physics. Nature 560, 41–48. doi: 10.1038/s41586-018-0361-2
Raissi, M., Perdikaris, P., and Karniadakis, G. E. (2017). Physics informed deep learning (Part I): Data-driven solutions of nonlinear partial differential equations. arXiv [Preprint]. arXiv: 1711.10561.
Schumann, M. (2019). Direct detection of WIMP dark matter: Concepts and status. arXiv [Preprint]. arXiv: 1903.03026. doi: 10.1088/1361-6471/ab2ea5
Shrestha, A., and Mahmood, A. (2019). Review of deep learning algorithms and architectures. IEEE Access. 7, 53040–53065. doi: 10.1109/ACCESS.2019.2912200
Simola, U., Pelssers, B., Barge, D., Conrad, J., and Corander, J. (2019). Machine learning accelerated likelihood-free event reconstruction in dark matter direct detection. arXiv [Preprint]. arXiv: 1810.09930. doi: 10.1088/1748-0221/14/03/P03004
Solovov, V. N., Belov, V. A., Akimov, D. Y., Araujo, H. M., Barnes, E. J., Burenkov, A. A., et al. (2012). Position reconstruction in a dual phase xenon scintillation detector. IEEE Trans. Nucl. Sci. 59, 3286–3293. doi: 10.1109/TNS.2012.2221742
Vapnok, V. (2000). The nature of statistical learning theory. Statist. Eng. Infm. Sci. 8, 1–15. doi: 10.1007/978-1-4757-3264-1_1
Wittweg, C., Lenardo, B., Fieguth, A., and Weinheimer, C. (2020). Detection prospects for the second-order weak decays of 124Xe in multi-tonne xenon time projection chambers. arXiv [Preprint]. arXiv: 2002.04239. doi: 10.1140/epjc/s10052-020-08726-w
Wu, Z., Pan, S., Chen, F., Long, G., Zhang, C., and Philip, S. Y. (2020). A comprehensive survey on graph neural networks. IEEE Trans. Neur. Netw. Learn. Syst. 32, 4–24.
Xu, K., Hu, W., Leskovec, J., and Jegelka, S. (2018). How powerful are graph neural networks?. arXiv [Preprint]. arXiv: 1810.00826.
Keywords: astroparticle physics, direct-detection dark matter, machine learning, neural network, reconstruction, time-projection chamber
Citation: Liang S, Higuera A, Peters C, Roy V, Bajwa W, Shatkay H and Tunnell CD (2022) Domain-Informed Neural Networks for Interaction Localization Within Astroparticle Experiments. Front. Artif. Intell. 5:832909. doi: 10.3389/frai.2022.832909
Received: 10 December 2021; Accepted: 12 May 2022;
Published: 09 June 2022.
Edited by:
Jan Kieseler, European Organization for Nuclear Research (CERN), SwitzerlandReviewed by:
Alexander Radovic, Borealis AI, CanadaGeorgia Karagiorgi, Columbia University, United States
Copyright © 2022 Liang, Higuera, Peters, Roy, Bajwa, Shatkay and Tunnell. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Shixiao Liang, bGlhbmdzeEByaWNlLmVkdQ==