 Katharina J. Morik1*
Katharina J. Morik1* Helena Kotthaus1
Helena Kotthaus1 Raphael Fischer1Sascha Mücke1Matthias Jakobs1Nico Piatkowski2Andreas Pauly1Lukas Heppe1Danny Heinrich1
Raphael Fischer1Sascha Mücke1Matthias Jakobs1Nico Piatkowski2Andreas Pauly1Lukas Heppe1Danny Heinrich1- 1Faculty of Computer Science, TU Dortmund University, Dortmund, Germany
- 2Fraunhofer Institute for Intelligent Analysis and Information Systems, Sankt Augustin, Germany
Machine learning applications have become ubiquitous. Their applications range from embedded control in production machines over process optimization in diverse areas (e.g., traffic, finance, sciences) to direct user interactions like advertising and recommendations. This has led to an increased effort of making machine learning trustworthy. Explainable and fair AI have already matured. They address the knowledgeable user and the application engineer. However, there are users that want to deploy a learned model in a similar way as their washing machine. These stakeholders do not want to spend time in understanding the model, but want to rely on guaranteed properties. What are the relevant properties? How can they be expressed to the stake- holder without presupposing machine learning knowledge? How can they be guaranteed for a certain implementation of a machine learning model? These questions move far beyond the current state of the art and we want to address them here. We propose a unified framework that certifies learning methods via care labels. They are easy to understand and draw inspiration from well-known certificates like textile labels or property cards of electronic devices. Our framework considers both, the machine learning theory and a given implementation. We test the implementation's compliance with theoretical properties and bounds.
1. Introduction
Machine learning (ML) has become the driving force pushing diverse computational services like search engines, robotics, traffic forecasting, natural language processing, and medical diagnosis, to only mention a few. This has led to a more diverse group of people affected by ML.
Placing the human in the center of ML investigates the needs of the user and the interaction between developer and user. Many approaches refer—possibly indirectly—to a pairing of a developer and a deployer, interacting for a certain application. Typical examples are from ML in sciences, where the physicist, biologist, or drug developer interacts with the ML expert to establish a reliable data analysis process. In the long run, others may benefit from this without ever accessing the ML process. Patients, for instance, take for granted that diagnosis methods or drugs are approved by a valid procedure.
Other applications involve further parties. A vendor company, its online shop, the company that optimizes the click rate, a recommendation engine, and the customers buying the products are all playing their part in modern sales ecosystems. Modern financial business processes, like money laundry detection, involve a network of stakeholders who need to know the reliability of the ML classifications. Companies apply diverse ML methods, and some have employees who know ML well. For them, to inspect a learned model is important and explainable AI is serving them. In contrast, the customers are affected by the process but do not face the ML system directly nor do they interact with its developers. They rely on tech companies to have done their job in a trustworthy manner.
In an even broader context, societies establish regulations that protect individual rights, e.g., regarding privacy of data and fair business processes. Moreover, the goals of sustainability and the fight against climate change demand regulations on energy consumption of ML processes. Now the regulating agencies need valid information about ML processes.
We see the diversity of stakeholders who need valid information in order to accept or not accept a certain ML process. Some of them know the ML theory and are experienced in evaluating models. Some of them will interpret the models directly if they are nicely visualized. Some of them will find the time for an interactive inspection of models. All these needs have raised considerable attention in the AI community and paved the way for explainable AI (XAI). However, methods that inform users who do not want to spend time in learning about ML method are missing — this is the type of user we want to address.
We consider this user type a customer of ML who wants the product to fulfill some requirements. Whether a method meets the expectation is partially given by theoretical properties. However, such statements are scattered across decades of scientific publications, and finding and understanding them requires years of studies. Of course, our ‘customers' who do not want to invest time into considering a particular model will have even less interest in visiting courses. The necessity of communicating theoretical insights more easily has led to the concept of care labels (Morik et al., 2021), which we adopt here. This concept moves beyond individual man-machine interaction toward a public declaration of a method's properties. It is closer to certification than to XAI and would allow for specific regulations, for instance, regarding energy consumption.
The design of ML care labels requires defining the set of relevant properties. Robustness in the sense that small changes to data should not deteriorate the model too much is a property that is studied intensively. Runtime and memory bounds are straightforward. Communication needs are important for applications in the area of the Internet of Things. Energy consumption is important due to the potentially high impact on our environment (Strubell et al., 2020). As an example, the state-of-the-art NLP model “BERT” has an average power consumption of 12 kW, with training alone consuming 1 MWh (as much as a single-person household consumes in 8 months1).
Most classes of ML methods, like exponential families, offer a range of algorithms for training and inference. Consider the choice of algorithm for performing inference on probabilistic graphical models, which leads to totally different theoretical properties, runtimes, and CO2 footprints. The marginal probabilities are often under- or overestimated by using the approximative loopy belief propagation (LBP) algorithm instead of the exact junction tree (JT) algorithm, which on the downside has high asymptotic runtime complexity. If the implications of choosing among both algorithms is indicated clearly by a care label, even an inexperienced user can decide whether the particular application requires exact JT or resource-friendly LBP inference. In general, different ML methods may need different categories, and even the same category may need different criteria to be tested. Hence, if we take a more detailed look at the overall ML field, there is not one single set of categories with test criteria for all. Instead, an expert database should store the specific instances of the categories for ML methods.
Moreover, considering static characteristics of a method does not suffice. Worst-case asymptotic time and memory bounds are given by theory, but can vary by orders of magnitude across compute platforms, even if they implement the same abstract method. A convolutional neural network (CNN), for example, may be trained on a resource-hungry GPU system consuming several hundred Watt, or on a microcontroller which usually consume less than W (e.g., Arduino or field programmable gate array (FPGA)). The latter, on the other hand, may be severely constrained with respect to the number of layers, or input data types: An FPGA may work best using only integer arithmetic, or the Arduino may only have 256 kB of RAM, which limits the model's number of parameters. In general, the same method can be implemented on different hardware architectures and particular implementations might vary. Hence, the more dynamic behavior of ML execution environments must be covered by the labels, as well.
For each property, ranges of values need to be defined that will then be expressed by symbols similar to those on the paper slips found in clothes and textiles. Since we want to validate the properties, we need criteria which classify a certain instance of a method into the appropriate value range. Where static properties may be listed based on theoretical results, the dynamic properties of a particular implementation on particular hardware demand tests on specific data sets. Overall, for the set of properties with their value ranges, a certification process needs to be implemented.
In this work, we propose a novel means of communication between ML scientists and stakeholders that goes beyond logical, visual or natural language descriptions of single models. We instead aim at providing a framework for certifying ML methods in general, as schematically displayed in Figure 1. Our contribution comprises the following points:
1. We present an easy-to-understand care label design, serving as a single graphical certificate (Figure 2) for ML methods and their implementations.
2. We devise a rating system, drawing from an expert knowledge database created, maintained and continually expanded by the research community.
3. We introduce categories under which we bundle criteria, which represent important properties of ML methods. They are stored in the expert knowledge base.
4. We suggest to certify a given implementation against its underlying theory with the help of reliability and performance bound checks on profiling data sets, and reporting resource consumption.
5. We define badges that are awarded to ML methods that fulfill certain noteworthy criteria.
6. We present a concept for a Certification Suite that accesses the expert knowledge database and certifies a method together with its implementation.
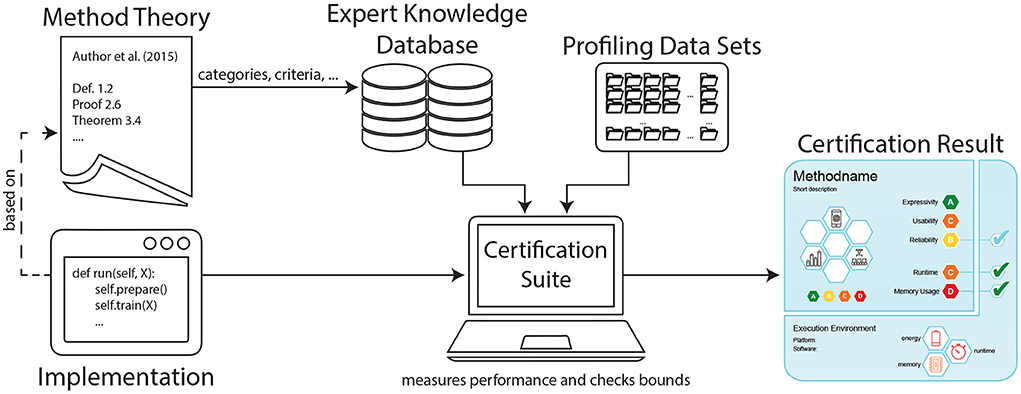
Figure 1. Proposed framework for certifying machine learning methods with care labels. For a given implementation, the certification suite generates a label that informs both on aspects of underlying theory (fetched from the expert knowledge database) as well as practical performance implications (based on profiling data sets).
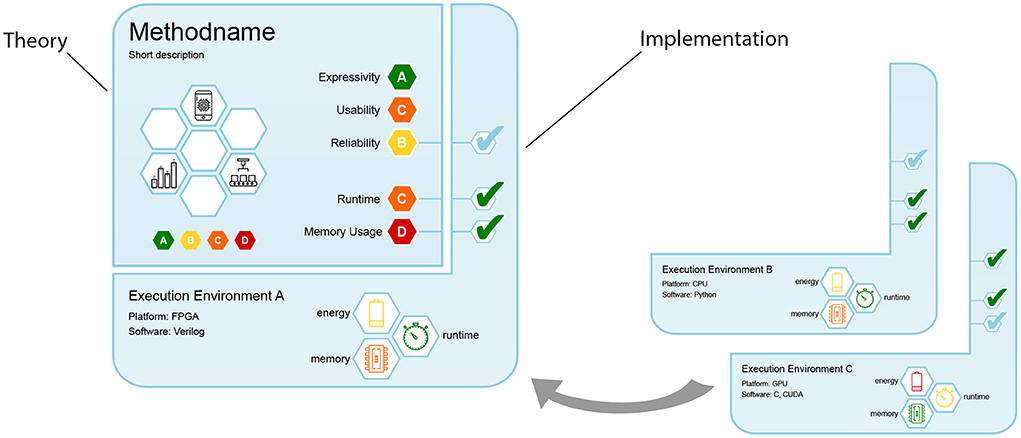
Figure 2. Design of machine learning care labels, consisting of theory and implementation segments.
We start by giving an overview of good standards that have already been achieved for ML certification, and identifying their shortcomings. Next up, we introduce our novel care label concept and its constituting parts in Section 3. In Section 4 we put our concept into practice for Markov random fields (MRFs), a class of probabilistic graphical models with a wide range of applications. MRFs constitute a powerful probabilistic tool with a rich theoretical background, serving to illuminate all aspects of our care label concept. We conclude our work with a summary of our investigations, and outline future work in Section 5.
2. Related work
The importance of trustworthy AI methods is increasing, especially because decision-making takes data-based models more and more into account (Bellotti and Edwards, 2001; Floridi et al., 2018; Lepri et al., 2018; Houben et al., 2021). In her comprehensive book, Virginia Dignum addresses AI's ethical implications of interest to researchers, technologists, and policymakers (Dignum, 2019). Another recent book brings together many perspectives of AI for humanity and justifies the urgency of reflecting on AI with respect to reliability, accountability, societal impact, and juridical regulations (Braunschweig and Ghallab, 2021). Brundage et al. (2020) and Langer et al. (2021) summarized important aspects of developing trustworthy learning systems. Their reports emphasize that institutional mechanisms (e.g., auditing, red team exercises, etc.), software mechanisms (e.g., audit trails, interpretability, etc.) and hardware mechanisms (assessing secure hardware, high precision compute management, etc.) are required for obtaining trusted systems, and that the diversity of stakeholders needs to be taken into account. This brings the issue of certification and testing to the foreground (Cremers et al., 2019). Miles Brundage and colleagues argue that descriptions must be verifiable claims (Brundage et al., 2020). Verification methods have been applied for trustworthy deep neural networks (Huang et al., 2020) and for investigate verification of probabilistic real-time systems (Kwiatkowska et al., 2011).
Where privacy-preserving data mining (e.g., Atzori et al., 2008) on the side of data analysis methods and the European General Data Protection Regulation (GDPR) on the side of political regulation successfully went together toward citizen's rights, a similar strategy for ML models and regulations in concert is missing.
2.1. Inherent trustworthiness
From its beginning, the machine learning community aimed at offering users understandable machine learning processes and results. Interpretability guided the development of methods, their combination and transformation enabling users to inspect a learned model (Rüping, 2006). Recently, Chen et al. (2018) investigated interpretability of probabilistic models. Inductive logic programming (ILP) assumed that relational logic, and description logic in particular, is easily understandable (Morik and Kietz, 1991; Muggleton, 1991). Particular methods for interactive inspection and structuring of learned knowledge and given data offered a workbench for cooperative modeling of an expert with the ILP system (Morik, 1989). This close man-machine interaction in building a model creates common understanding of system developers and users. However, it does not scale to larger groups of affected stakeholders.
Decision trees were promoted as inherently understandable. However, feature selection and very deep trees quickly outgrow human intuition, and subtleties are only recognized by experts. For instance, the weights of redundant features are not appropriately computed in decision trees, whereas in support vector machines, they are (Mierswa and Wurst, 2005). Statistics, even if expressed in natural language, is not easy to understand correctly, as has been shown empirically (Wintle et al., 2019).
2.2. Explainable AI
Explainable AI aims at offering an easy understanding of complex models for inspection by stakeholders. They investigate particular tasks, e.g., recommender systems (Nunes and Jannach, 2017), or particular ML families, e.g. Deep Neural Networks (Samek et al., 2019; Huang et al., 2020), or survey the needs of diverse stakeholders (Langer et al., 2021). Agnostic explanation routines are to explain a variety of learned models (Ribeiro et al., 2016; Guidotti et al., 2018). Given the large amount of research in this field, it has become a necessity in its own right to describe explanation methods along a proposed schema (Sokol and Flach, 2018). For model inspection by a domain expert or application developer, these methods are of significant importance.
2.3. Resource-aware machine learning
The approaches mentioned so far also do not consider resource usage (e.g., power consumption), even though it is crucial information for users (Henderson et al., 2020) and allows for discussing the environmental ethical impact of ML methods. Often, there is a trade-off between two important properties, such as higher runtime in exchange for lower energy consumption, which might influence the customer's decision on which model to choose. As an example, FPGAs offer unique performance and energy-saving advantages, but the software engineering part is challenging (Omondi and Rajapakse, 2006; Teubner et al., 2013). The challenges faced when deploying machine learning on diverse hardware in different application contexts (Hazelwood et al., 2018) even gave rise to a new conference, bridging the gap between machine learning and systems researchers (Ratner et al., 2019). The current increase in awareness regarding CO2 emissions foregrounds these properties even more for users who want to design ML systems responsibly. Indeed, the amount of CO2 emitted during training and deployment of state-of-the-art machine learning models has increased drastically in recent years (Schwartz et al., 2019; Strubell et al., 2020). To give more insight into this issue, Schwartz et al. (2019) urge researchers to provide a price tag for model training alongside the results, intending to increase visibility and making machine learning efficiency a more prominent point of evaluation. In Henderson et al. (2020), the authors provide a framework to measure energy consumption of ML models. However, they only measure specific model implementations, mostly disregarding theoretical properties and guarantees. We argue that a proper framework also needs to consider known theory, ideally stored as a database.
2.4. Description of methods and models
Modern machine learning toolboxes like RapidMiner, KNIME, or OpenML (Mierswa et al., 2006; van Rijn et al., 2013) are oriented toward knowledgeable users of ML or application developers. They and others (Brazdil et al., 2003; Falkner et al., 2018) use meta-data which offer a descriptive taxonomy of machine learning. In this sense, the ML processes are carefully described and documented. The user may click on any operator to receive its description and requirements. RapidMiner, in addition, recognizes problems of ML pipelines and recommends or automatically performs fixes. It enhances understandability by structuring ML pipelines and offering processes in terms of application classes.
Moving beyond the direct interaction between system and application developer aims at accountable descriptions of models and data. The approaches for FactSheets from IBM (Arnold et al., 2019) and Model cards from Google (Mitchell et al., 2019) are closely related to our approach. They give impetus to document particular models for specific use cases in the form of natural language and tabular descriptions, and even suggest to include them with ML publications.
In a recent user study, most interviewees found the idea of model-specific FactSheets helpful in understanding the methodology behind the model creation process (Hind et al., 2020). Another line of work aims at automatically tracking and visualizing the training process, including computed metrics as well as model architecture (Vartak et al., 2016; Schelter et al., 2017).
While these approaches are an important and necessary call for participation in the endeavor of describing learned models, we argue that natural language descriptions and empirical results alone are not enough to enhance trust in the model. They do not account for whether or not the theoretical properties of the model are fulfilled in the specific implementation at hand. This was stunningly shown by Dacrema et al. (2019), where baseline heuristics were able to beat top-tier methods, and many results could not be reproduced at all.
A summary of related work is shown in Table 1, highlighting which aspects of ML certification the authors cover, and where they fall short. What we find missing in the current state-of-the-art is a unifying concept to certify ML methods and their implementation on diverse hardware in terms of adherence to known theoretical properties and resulting resource demands. We argue that a method's properties need to be classified independently from a specific use case or data set. Additionally, this information needs to be accessible for non-experts, thus complicated theory has to be concealed through appropriate levels of abstraction. This is where our proposed care labels come into play, offering a comprehensive and easy to interpret overview of methodological properties, both theoretical and given the particular implementation at hand.

Table 1. Our proposed care label approach in comparison to other methods trying to certify certain aspects of the machine learning process.
3. Machine learning care labels
We now introduce our care label concept for certifying ML methods, addressing all aforementioned issues. With “method,” we refer to a combination of “components” for performing a specific machine learning task, such as training or applying a model. Most components are customizable, resulting in wildly varying properties. We later show this in practice for different probabilistic inference algorithms. Implementation and choice of hardware add yet another layer of complexity. Our care labels produce relief by hiding all underlying complexity behind a user-friendly façade. In the following sections, we discuss the details of our concept, following the structure of our contribution list from Section 1.
3.1. Care label design
Evidently, our proposed care labels need to take manifold theoretical and practical insights about ML methods into account, and compile them into a single short comprehensive document, similar to an index card. Our design is shown in Figure 2 and consists of two segments: The upper-left segment contains information about the method's theoretical properties, while the bottom-right segment also considers the given execution environment. As methods can be implemented in various ways and on various compute architectures, we designed this segment to “attach” to its theory. This is analogous to different brands of refrigerators: While the abstract task stays the same (keeping food and beverages cool), manufacturers use different components and circuits, and their specifics (e.g., lowest possible temperature, noise level, energy consumption) vary. In the same way, different ML implementations perform the same abstract task, but have their specific strengths and weaknesses.
Both segments contain a name and short description in their upper left corner. The theoretical segment displays the method's rating for five important categories (cf. Section 3.3) on the right, represented as colored hexagons. By restricting the care label to simple color-based ratings introduced in Section 3.2, we allow for a high-level assessment without the need for deeper understanding of the underlying theory. On the left, white hexagonal fields provide space for badges, which we describe in Section 3.5.
The segment contains three checkbox fields on the right that connect to three theoretical categories, indicating whether the theoretical properties are verified for the implementation. For a refrigerator, this could be a test whether the temperature reliably stays below the point where bacteria grow quickly. For ML methods, we can check if theoretical bounds about result quality, runtime or memory consumption hold.
Additionally, three white hexagonal fields with colored symbols at the bottom show measurement results for runtime, memory, and energy consumption (for more details see Section 3.4). In short, our design accomplishes the following:
• Provides general information about the ML method at a glance.
• Shows simple ratings for important categories, trading complexity and detail for simplicity and user-friendliness.
• Clearly highlights the interplay of theory and implementation by showing whether the implementation fulfills all theoretical properties.
• Is understandable for users without scientific background, allowing for easy comparison between ML methods.
• Highlights noteworthy properties that stakeholders may need for their particular application.
3.2. Expert knowledge database for method ratings
The theory behind machine learning methods is manifold, with different model classes having their own intricacies that can only be fully understood by experts. Consequently, they are required to assess important properties, identify to what extent a method exhibits them, and convey that knowledge to less informed users.
We propose to assemble a database with criteria that describe theoretical properties of ML methods, independent of their implementation. By bundling criteria into few concise categories, we allow for easier comparability between methods. We further propose to assign a rating to each category, consisting of four levels A—D, each represented by a color from a gradient ranging from green (A, best rating) to red (D, worst rating). This is inspired by similar certification concepts, e.g., the EU energy labeling framework (Council of European Union, 2017), which rates energy efficiency of electronic devices, or Nutri-Score for nutrient content in food (Julia et al., 2018). The ratings represent an expert assessment of how strongly the method at hand fulfills the respective criteria, as listed in Table 2.

Table 2. Rating scale assigned to categories, depending on expert assessment, aided by proportion of fulfilled criteria.
As mentioned before, customizable components of a method can lead to quite different properties: While a basic model class may fulfill most criteria and consequently be rated A, a specific component may override the rating to B, e.g., due to much slower asymptotic runtime, or simplifying assumptions resulting in weaker theoretical guarantees. To address this issue, we propose a “building block” approach, by storing separate ratings for methods and their components in the database and combining them for a user-specified method. Where ratings for certain categories are not affected by configuring the component, we allow neutral ratings. Generally, ratings should be combined pessimistically, i.e. good ratings get overridden by worse ratings, this is depicted in Figure 3. This complexity is hidden from users, as they only receive a single label.
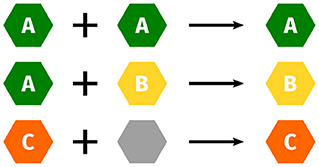
Figure 3. Ratings of individual components are combined. Neutral ratings (gray) get overridden.
3.3. Categories and criteria
In an attempt to untangle all aspects that ML users should consider when choosing a method and implementation, we propose a set of categories that summarize desirable properties.
For each category, we compile a list of yes-no type criteria: A high number of fulfilled criteria supports a method's aptitude w.r.t. the category, resulting in a higher rating. In this section we give only a few examples of criteria for each category, hoping that through practical insights and input from fellow researchers the list will grow.
While the categories we propose are designed to be more or less universal across model families, the constituting criteria may not apply to certain types of models or algorithms, e.g., because they belong to completely different paradigms. A solution to this problem would be to differentiate between model families, such as generative and discriminative models, providing alternative criteria for each separately.
We want to point out that we purposefully do not include categories or criteria concerning quality metrics like accuracy or convergence speed. These are highly dependent on specific input data and give no reliable impression of how well a method performs in an arbitrary, unknown use case. Giving simple ratings for these criteria would strongly contradict the “no free lunch” theorem—the fact that no single method performs universally well on all problems (Wolpert and Macready, 1997). We do however propose to investigate selected performance properties of method implementations, as described in Section 3.4.
3.3.1. Expressivity
• Example criterion: The method provides at least one human-interpretable measure of uncertainty along with its output.
We call a model expressive if it produces a variety of useful outputs for different input formats. This simple definition implies multiple properties: On the one hand, an expressive model should be able to handle arbitrarily complex functions, e.g., a classifier splitting every labeled data set, or a generative model approximating any probability distribution. On the other hand, highly expressive models provide additional outputs (e.g. measures of uncertainty or justification) to make them more interpretable. For users with certain safety-critical application contexts, such information may even be a strict requirement.
3.3.2. Usability
• Example criterion: The model is free of hyperparameters.
This category is concerned with the method's ease of use for end users. A main aspect is the number and complexity of hyperparameters: A hyperparameter-free method can be directly applied to a problem, while a method with many parameters needs fine-tuning to produce good results, which requires considerable effort and experience. Even more experience is required for choosing parameter values that are difficult to interpret: Choosing k for a k-Means Clustering is conceptually much easier than choosing the weight decay in stochastic gradient descent. The difficulty of choosing optimal hyperparameters can be alleviated by theoretical knowledge of optimal parameter settings. We consider a method to be more easily usable if there are algorithms or formulas for deriving good or even optimal parameter values for given inputs.
3.3.3. Reliability
• Example criterion: The method produces theoretically exact results.
We require reliable models to be firmly grounded in theory, i.e. when there is evidence of mathematical error bounds, and if there are insights about the model's fairness or bias. As an example, uncertainty given by neuron activations in ANNs alone was found to not necessarily be a reliable measure (Guo et al., 2017). Such models are highly untrustworthy when they are used in safety-critical fields such as autonomous driving. Contrary, MRFs were proven to recover the correct marginal probabilities with increasing number of data points, given the underlying independence structure (Piatkowski, 2019). It is important to comprehensible visualize these fundamental differences.
Importantly, if there are theoretical bounds for the method at hand, they should also be verifiable by software tests, which we call bound checks. The particular tests need to be defined separately for all methods eligible for certification—we discuss details in Section 3.4.
3.3.4. Theoretical time and memory consumption
• Example criterion: The method's runtime scales (at worst) quadratically with the input dimensionality, i.e. in (n2).
Runtime and memory usage are factors of utmost importance for stakeholders, especially when facing resource constraints. ML theory provides insights on (worst-case) time and memory consumption of algorithms in the form of big notation. Based on this theoretical tool, we propose a ranking of asymptotic time and memory complexity classes, with the rank being displayed in the care label's theory segment. In cases where big notation depends on different factors (e.g., number of features or data points), we propose to classify the method according to the factor with the highest complexity class.
Energy is another important factor to consider when deploying ML, but it results directly from runtime, memory consumption and hardware. As such, theory does not provide any additional information here.
3.4. Certifying the implementation
So far we only considered static theoretical properties of ML methods, and how corresponding information can be summarized via simple care label ratings. However, looking at theory alone is not enough, as practically rolled out ML can diverge from it. Consider runtime as a practical example: In theory, an algorithm may be very efficient, but its implementation may still be very slow, due to slow periphery or inefficient code. Many popular ML implementations even suffer from severe bugs (Thung et al., 2012; Islam et al., 2019), let alone aligning with respective theoretical properties. We therefore propose to also certify the implementation's compliance with its underlying theory via test procedures that we call bound checks, which either investigate the dynamic aspects of reliability or performance.
The former intend to verify method-specific theoretical guarantees for reliability (cf. Section 3.3), as provided by the expert knowledge database. We propose to check those guarantees programmatically via software tests. This requires synthetic data with known properties, which is fed into the implementation. Its output is then checked against the known expected results.
Our performance checks investigate runtime and memory usage in the given execution environment. We here draw from the previously introduced asymptotic complexity classes, that the implementation is expected to comply with. We check this compliance by running experiments on synthetic data with varying input sizes. Measuring the corresponding runtime and memory usage in a software profiling fashion (cf. Section 4.2.2) allows for checking whether the theoretical complexity holds. Checkmark symbols on the right hand segment of our care label denote whether the implementation satisfies the reliability and performance checks.
Information about the available hardware allows to also assess the energy consumption, and thus, carbon footprint. As motivated earlier, this is of high interest for aspects of environmental ethics (Henderson et al., 2020). By drawing inspiration from electronic household devices and informing about energy consumption, our care label rewards energy-efficient implementations and ultra-low-power devices such as FPGAs and ASICs, even if they are limited in expressivity or have a higher runtime. For providing specific information, we assess the practical runtime (in seconds) and memory demand (in megabytes), along with energy consumption (in Watt-seconds) for a medium-sized data set. Those measurements are displayed in the implementation segment. For comprehensibility we also display them as colored badges, based on their position on a scale for different orders of magnitudes.
3.5. Badges for noteworthy criteria
We argue that there are certain properties, which are particularly noteworthy, because they are rare among comparable methods and have great impact on the method's overall rating. Examples of such noteworthy properties include uncertainty measures, whether the method can be tested for robustness, and whether the model can be used with streaming data. In order to highlight these properties, we introduce badges in form of pictograms that get printed on the care labels. Some examples of badges, along with short explanations, are given in Figure 4.
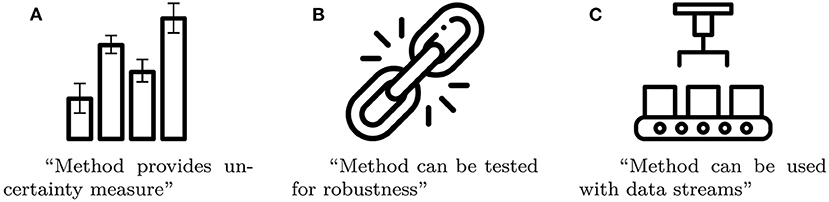
Figure 4. Three examples of badges as a compact way to summarize a method's noteworthy properties (Images taken from Flaticon.com). (A) Method provides un-certainty measure. (B) Method can be tested for robustness. (C) Method can be used with data streams.
3.6. Certification suite concept
We propose to develop a certification suite software that enables a less informed user to enquire comprehensible information on ML methods and their implementations, in the form of care labels. Most importantly, it allows to configure a specific method from its available constituting components. For the chosen configuration, the software queries the ranking information, asymptotic performance bounds, and reliability bounds from the knowledge database, and combines them into the theoretical label segment. After configuring the method's backend implementation according to the user input, the suite then profiles and runs bound checks. We also propose to implement an interactive, high-level interface, that hides all complicated ML logic from users who are not very experienced in the field of ML. In terms of our work we have already implemented a simple prototype, see Section 4.2.2 for more information.
4. Applying the care label concept to graphical models
We now implement our concept for selected members of the probabilistic graphical model (PGM) family. Having a long history in statistics and computer science, theoretical properties of graphical models have been studied rigorously in literature (Koller and Friedman, 2009). Thus, they are well-suited to demonstrate our care label concept as a means to aid the user in their decision making process. Firstly, we briefly discuss the theoretical background of Markov random fields (MRFs), a specific subtype of probabilistic graphical models (PGMs). Secondly, we present the care label generation procedure for two different MRF variants (Section 4.2). We discuss the static, theoretical properties and corresponding rating, as stored in the expert knowledge database, determining the theory segment of our label (Section 4.2.1). In addition, we present results of our testing procedures, which certify a given MRF implementation against the underlying theory, both in terms of reliability and resource demand, while also assessing the energy consumption of the execution environment at hand (Section 4.2.2).
4.1. Background on Markov random fields
MRFs belong to the family of PGMs and are used in many different applications like satellite image gap filling (Fischer et al., 2020), medical diagnosis (Schmidt, 2017), and security-critical systems (Lin et al., 2018). Moreover, MRFs can be used for constrained learning scenarios, like distributed environments (Heppe et al., 2020) or platforms under strict resource requirements (Piatkowski et al., 2016). We now shortly discuss the underlying theory of MRFs, as it provides guarantees and static properties that determine their care label ratings.
MRFs combine aspects from graph and probability theory in order to model complex probability distributions ℙ(X) over some d-dimensional random vector efficiently. Conditional independences between elements of X are exploited and modeled through a graph G = (V, E), where each vertex v ∈ G is associated with one random variable of X. If two vertices i and j are not connected by an edge, Xi and Xj are conditionally independent given the remaining variables. In this work we focus on discrete MRFs, allowing for an intuitive parametrization, therefore each element Xi can take values in its discrete finite state space i. By introducing the so-called potential functions ψC:C ↦ ℝ+ for each of the cliques in G, mapping variable assignments to positive values, the joint density factorizes according to Hammersley and Clifford (1971) as follows:
where Z, which is called partition function, acts as normalization,
The potential functions ψ are parametrized by weights, which allows to define a loss function. By minimizing it during the training process the model adapts to a given data set. Typically, the weights are learned via maximum-likelihood-estimation with first order optimization methods.
Having access to the joint density clears the path for many further ML tasks, such as generating data via Gibbs sampling, answering marginal ℙ(Xi = x) or conditional ℙ(Xi = xi|Xj = xj) probability queries, or providing maximum a-posteriori (MAP) estimates. However, solving such tasks requires probabilistic inference. Algorithms for such computations can be divided into two variants, namely exact and approximate algorithms (see upper part of Figure 5). On the one hand, the junction tree (JT) algorithm (Wainwright and Jordan, 2008) is a well-known method to perform exact inference on arbitrary graph structures, while having a very slow asymptotic runtime. On the other hand, the loopy belief propagation (LBP) algorithm (Kim and Pearl, 1983) performs approximate inference, sacrificing theoretical guarantees for considerably faster performance. Further approximation algorithms include the variational (Wainwright et al., 2003) and sampling-based approaches (Andrieu et al., 2003). Keep in mind that exact probabilistic inference is a #P-complete task (Piatkowski, 2018).
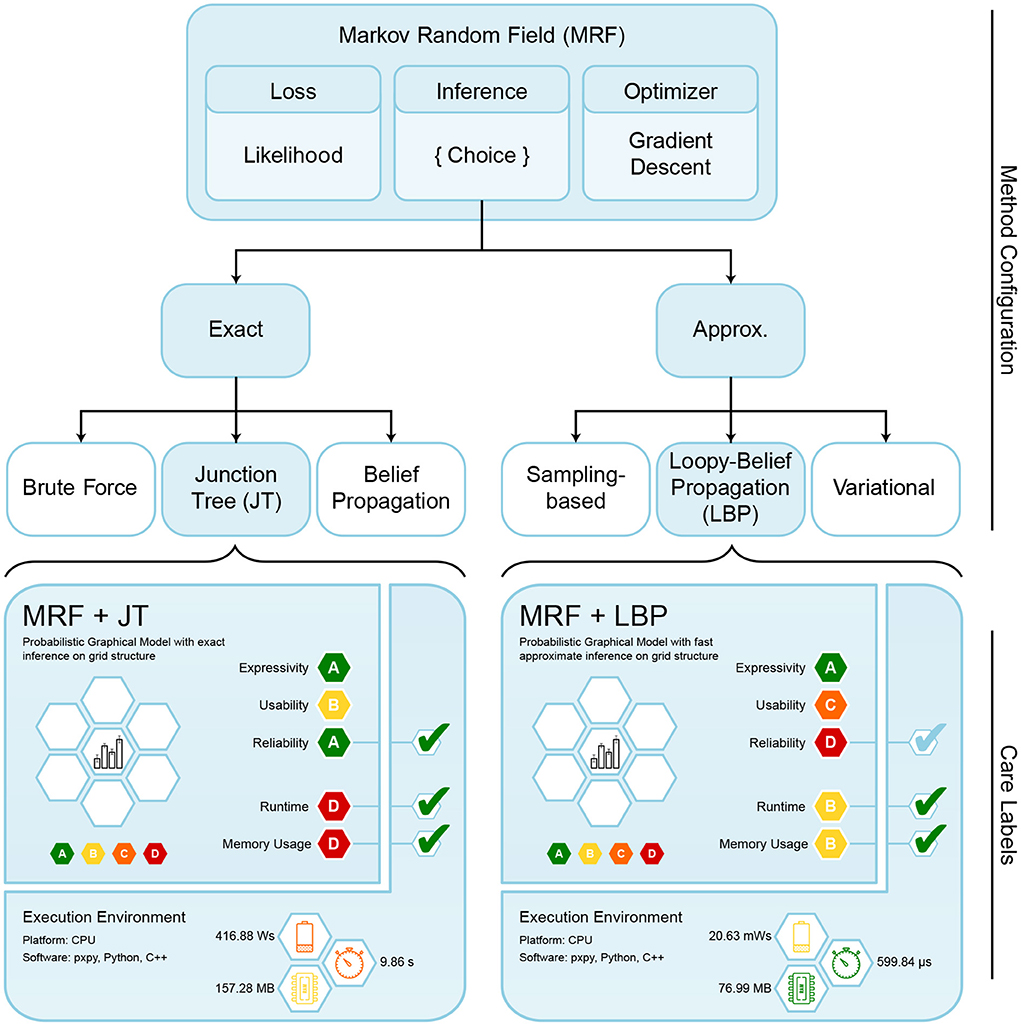
Figure 5. Overview of configurable components for MRFs. Each instanced model requires choosing the loss, an optimizer and an inference algorithm. For our experiments we chose likelihood as loss function, gradient descent for optimization, and evaluated two different inference algorithms. The respectively instantiated care labels are shown below, with resulting theoretical and practical ratings.
4.2. Deriving care labels for Markov random fields
We generate care labels for different MRFs, based on combinations of chosen components. In the context of MRFs, there are three major configurable components: an optimizer, a loss function, and an inference algorithm. We restrict ourselves to investigating gradient descent optimization with a likelihood loss function, using either the LBP or the JT algorithm for performing inference. These combinations are depicted in Figure 5, along with their corresponding final care labels.
4.2.1. Expert knowledge-based ratings
MRFs already exhibit certain static properties and receive corresponding ratings for our categories. The ratings in the theoretical segment of the care label are stored in the expert knowledge database (cf. Section 3.2) and were agreed upon by 10 experts using a majority vote. In case of a tie, we decided in favor of the method. As combining the individual components can greatly influence the rating, we also have to identify their individual ratings. Combining the component ratings should be based on a fixed set of rules. Here, we stick to the already proposed way of taking the infimum overall ratings (cf. Figure 3). We display the respective ratings for the MRF components and variants in Table 3, and now explain their expert-knowledge-based justification and corresponding implications for the user, following the columns from left to right.
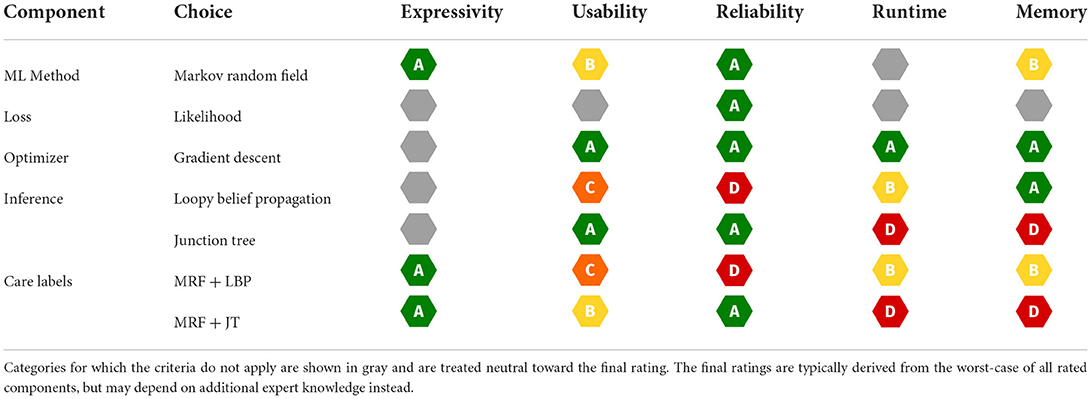
Table 3. Ratings for individual components based on theoretical properties and expert knowledge rated from A to D alongside the final combined ratings for two concrete configurations.
4.2.1.1. Expressivity
Looking at Table 3, it stands out that the general ML method choice is the only component affecting the expressivity rating. We reason that the expressive power of MRFs is determined only by its inherent properties, while the customizable components are neutral. MRFs are very expressive, because they can perform all generative model tasks: they can be queried for conditional or joint probabilities and they allow to sample data from the distribution. In addition, their probability output is a natural uncertainty measure. Therefore, we argue that MRFs should be rated A.
4.2.1.2. Usability
In terms of usability, MRFs receive the grade B, since the independence graph is usually unknown for real-world use cases, and thus has to be defined manually. For this, the user must either incorporate expert knowledge or use procedures for structure estimation (Yang et al., 2014). The loss function does not impact the usability and is rated neutral. Gradient descent only requires choosing a step size, which is well-documented with reasonable defaults, therefore we rate it A. The LBP inference requires careful tuning of the stopping criterion by specifying the convergence threshold or number of iterations. However, more iterations do not necessarily improve performance, which makes the choice quite unintuitive, resulting in a C rating for usability. JT inference does not require additional hyperparameter tuning, which yields an A rating. The usability rating shows the user that LBP makes MRFs a bit harder to use.
4.2.1.3. Reliability
When provided with an exact inference algorithm and a convex optimization problem, MRFs are guaranteed to recover the correct distribution, with the error being bounded by the number of training instances (Bradley and Guestrin, 2012). This bound, which we call distribution recovery check, can be verified through software, resulting in an A rating. Since the likelihood as a loss function exhibits strong statistical guarantees, like consistency, unbiasedness and efficiency, we also award it with A. Given a density, which is convex w.r.t. parameters, a gradient descent optimizer is able to recover the global optimum, resulting in an A rating. This is also verifiable for the dynamic properties of a specific implementation via software, the so-called convergence check. However, all this reliability is only given if the chosen inference algorithm provides exact results for the gradient update. We reflect this restriction by assigning D and A ratings to LBP and JT respectively, as the former does not even provide a bound on the approximation error2. Our ratings clearly show the user that LBP makes MRFs a lot less reliable.
4.2.1.4. Runtime and memory
The theoretical runtime and memory complexity classes depend mostly on the chosen inference algorithm component, while the MRFs type's general runtime is unspecified. Their memory demand for parametrization depends on the data complexity in two ways: It grows linearly with the number of features and quadratically with the number of discrete states, resulting in a B rating. Due to only requiring a plain mathematical function evaluation, the likelihood loss acts neutrally on both categories. The gradient descent optimizer itself is resource efficient, assuming we are given the gradients of our loss function. Both memory and runtime complexity scale linearly with the model dimension, resulting in an A rating for both categories.
The resource requirements of our inference algorithms are shown in Table 4 (Piatkowski, 2018). We rated the runtime of JT inference with D due to scaling exponentially with the junction tree's width3 w. Memory receives the same rating, because the underlying data structures also grow exponentially with tree width. Thus, users might find JT inference feasible for sparse independence structures, while for dense graphs its runtime and memory demand may exceed available resources. LBP on the other hand works efficiently on general graphs and even provides exact solutions for trees and polytrees. It is rated B due to scaling quadratically in number of states of the largest state space max, and linearly in the number of edges |E| in the graph, the number of iterations I and the size of the largest neighborhood max in G. The memory consumption for LBP is rated A as we only have to store intermediate results, whose memory demands scale linearly in the number of states per clique. Choosing between JT and LBP inference, the user can trade exactness and strong guarantees for better runtime and memory. This is illustrated in Figure 7, showing runtime and memory consumption for MRFs with increasing number of vertices.
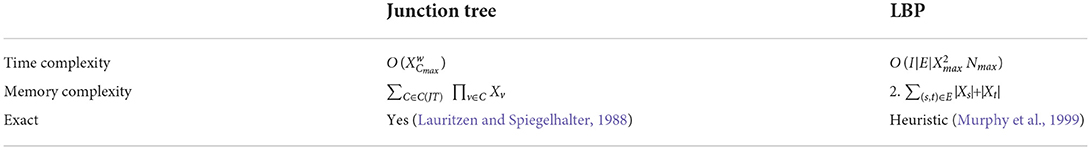
Table 4. Guarantees and resource consumption of different inference algorithms.
4.2.2. Testing the implementation
To test the dynamic properties of specific MRF implementations and derive the care label's implementation segments, we implemented a certification suite, as described in Section 3.6. It draws the theory-based static bounds and ratings from the expert knowledge database, performs reliability bound checks, investigates the implementation's behavior in terms of runtime, memory and energy consumption, and outputs the complete care label.
4.2.2.1. Experimental setup
In order to run our bound checks (cf. Section 3.4) we generated synthetic data sets by defining specific distributions and sampling from them. Having access to both the sampled data and their underlying distribution parameters allows for assessing whether reliability checks pass. As graph structure we chose a grid graph, with binary state space and increasing grid size from 2 × 2 up to 15 × 15. This resulted in data sets of different sizes, which have been utilized to perform the resource bound checks.
For running the MRFs logic, we utilized the pxpy4 library, which implements JT and LBP.
Our certification suite measures runtime, memory demand5, and CPU energy consumption6 via established tools, similar to Henderson et al. (2020). All experiments were performed on a workstation equipped with an Intel(R) Xeon(R) W-2155 CPU, 64 GB RAM and Ubuntu 20.04.1 LTS as operating system.
4.2.2.2. Reliability bound checks
To verify the reliability of the implementation against the static characteristics described in Section 4.2.1, which are especially important for safety-critical applications, we perform two exemplary bound checks: The distribution recovery check (Hoeffding, 1963) and the likelihood convergence check. The first check is performed by comparing the true marginal probabilities μ* to the marginals computed by the provided implementation for the true parameters θ*. Therefore, clique-wise KL-divergences are computed and reduced to the max value. If this value falls below a given threshold, the check passes. The second check verifies if the given implementation fits the data. To this end, we run an optimization procedure with the true structure and our samples, checking convergence based on the gradient norm. If the norm falls below a given threshold, the check passes. The investigated JT implementation was able to pass both checks. Recall that LBP inference is not exact as depicted in Figure 6 and received a D for reliability. Even though the LBP algorithm does not exhibit theoretical guarantees, it was able to pass the reliability tests for some data sets. Still, it failed for most, therefore the implementation did not receive the reliability checkmark.
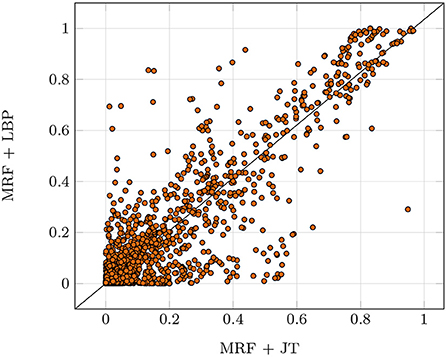
Figure 6. Deviations of LBP marginals compared to the true marginals computed with the exact JT algorithm over five runs. We used a random Erdos-Renyi-Graph with 20 nodes and an edge probability of 0.25. Each dot represents a single marginal probability, with all marginals ideally being located on the diagonal (LBP marginal equal to JT marginal).
4.2.2.3. Runtime and memory bound checks
Next, we evaluate whether the performance in the given execution environment complies with the identified complexity classes. We depict the measured resource consumption for both JT and LBP configurations in Figure 7. As expected, it shows that both memory usage and runtime increase with the number of vertices for JT. For our automatic checks, we fit different linear regression models with the resource measurements (i.e. one model for linear, quadratic, cubic, etc. complexity). We also cross-validated this assessment by subdividing the measurements into several independent sets, and fitting the regression for each group. In our experiments, those results corresponded to the identified theoretical complexity of the tested MRF configurations, thus all methods receive memory and runtime checkmarks.
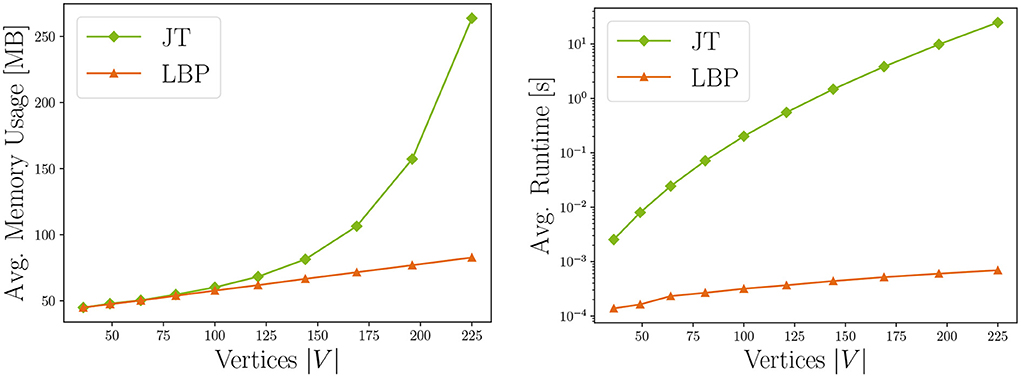
Figure 7. Comparison of running JT and LBP inference in terms of memory consumption and runtime for increasing number of vertices, i.e. model complexity. Results are averaged over ten experiment repetitions (standard deviation σ < 0.5).
4.2.2.4. Resource consumption testing
For specific resource measurements, we chose a medium-sized data set stemming from a grid-structured graph with 14 × 14 vertices and binary state space. The results are displayed in Table 5. They confirm that the JT configuration requires much more runtime and energy than LBP. The hardware platform was internally measured to consume an average of 20 − 43 Watt per experiment. To obtain the complete energy consumption, we multiplied the power with runtime. The badge colors in the implementation part of the care labels are directly derived from those measurements.

Table 5. Comparison of the two methods on a data set with a grid independence structure sized 14 × 14.
Our experimental findings show the usefulness of our care label concept, compacting the extensive theory of PGMs, while still providing useful information that is otherwise not accessible for users.
5. Conclusion and further work
With state-of-the-art systems, ML user requirements can differ vastly. Certain users might know the theory or have an intuitive understanding of properties and guarantees. Often, however, users are not aware of the intricacies of different methods. There are approaches that discuss how trust in ML can be increased, but they often fail to connect theory and practice, or are too abstract and inaccessible to non-experts who do not want to understand system in the same manner that they do not want to understand their washing machine.
We address these issues via our care labels to inform a broad range of users and ML customers. Our labels identify theoretical properties that are highly relevant for safety-critical or resource-constrained use cases. We test implementations against theory by performing bound checks for reliability and measuring resource consumption. All this information is neatly displayed in our care label design, which is easy-to-understand for both experts and customers without a scientific background. If demanded, more intricate details could be provided to users.
We demonstrated that our concept is practical for MRFs as an example for undirected generative models. For the experimental evaluation, we implemented a verification suite, expert knowledge database, and care label design (cf. Figure 1). Looking at their inference, we have inspected the exact JT and the approximate LBP algorithms. The generated labels allow users to assess implications of using MRF variants with different components where the extensive amount of theory behind PGMs remains invisible to the user.
Subsequent to this work, we intend to refine and finally publish a verification suite for ML practitioners. Here, we contributed the general framework concept and proof-of-concept results for MRFs. Future work could investigate other probabilistic inference methods, i.e. variational inference and the MCMC method. Tests for discriminative methods like Conditional Random Fields or directed PGMss like Latent Dirichlet Allocation or Hidden Markov Models are yet to be generated in order to assign care labels to these.
Other ML methods like deep neural networks might also bring attention to totally different properties like robustness. A wide range of tools for testing robustness or measuring resource consumption is already available, e.g., cleverhans https://github.com/cleverhans-lab/, carbon tracker https://github.com/lfwa/carbontracker and many more. In order to integrate those tools into our framework, the tests become related to a particular architecture with a particular parameter setting. This is more complex, but preliminary studies already show that it is possible.
The question of scalability is indeed a pressing one, because the expert knowledge database and criteria checks need to be assembled and implemented manually. The ultimate goal would be to automatically generate tests from the proofs and experiments that are published in scientific papers. The collection of https://paperswithcode.com is a first step into that direction. Turning this into generating calls of executing experiments whose results can be framed as care labels is the very long-term perspective of our approach.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
KM had the idea with the care labes and KM and HK designed the study. DH, RF, and AP performed the statistical analysis. LH, DH, RF, SM, AP, and MJ wrote the first draft of the manuscript. KM, HK, and NP wrote sections of the manuscript. All authors contributed to manuscript revision, read, and approved the submitted version.
Funding
This research has been funded by the Federal Ministry of Education and Research of Germany and the state of North-Rhine Westphalia as part of the Lamarr-Institute for Machine Learning and Artificial Intelligence, LAMARR22B. Parts of the work on this paper has been supported by Deutsche Forschungsgemeinschaft (DFG)—project number 124020371—within the Collaborative Research Center SFB 876 ‘Providing Information by Resource-Constrained Analysis', DFG project number 124020371, SFB project A1.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1. ^Based on the average power consumption per capita in Europe https://ec.europa.eu/eurostat/statistics-explained/index.php/Electricity_and_heat_statistics.
2. ^Under certain, special conditions LBP may have guarantees, but this is generally not the case (Ihler et al., 2005).
3. ^The junction tree (Huang and Darwiche, 1996) is an auxiliary graph which needs to be derived in order to run the complete inference algorithm.
4. ^https://pypi.org/project/pxpy/
References
Andrieu, C., de Freitas, N., Doucet, A., and Jordan, M. I. (2003). An introduction to mcmc for machine learning. Mach. Learn. 50, 5–43. doi: 10.1023/A:1020281327116
Arnold, M., Bellamy, R. K. E., Hind, M., Houde, S., Mehta, S., Mojsilovic, A., et al. (2019). Factsheets: Increasing trust in ai services through supplier's declarations of conformity. IBM J. Res. Dev. 63, 6:1–6:13. doi: 10.1147/JRD.2019.2942288
Atzori, M., Bonchi, F., Giannotti, F., and Pedreschi, D. (2008). Anonymity preserving pattern discovery. Int. J. Very Large Data Bases 17, 703–727. doi: 10.1007/s00778-006-0034-x
Bellotti, V., and Edwards, K. (2001). Intelligibility and accountability: Human considerations in context-aware systems. Hum. Comput. Interact. 16, 193–212. doi: 10.1207/S15327051HCI16234_05
Bradley, J. K., and Guestrin, C. (2012). “Sample complexity of composite likelihood,” in Proceedings of the Fifteenth International Conference on Artificial Intelligence and Statistics, AISTATS 2012 (La Palma), 136–160.
Braunschweig, B., and Ghallab, M. (2021). “Reflections on artificial intelligence for humanity,” in Lecture Notes in Artificial Intelligence (Springer International Publishing).
Brazdil, P., Soares, C., and da Costa, J. P. (2003). Ranking learning algorithms: using IBL and meta-learning on accuracy and time results. Mach. Learn. 50, 251–277. doi: 10.1023/A:1021713901879
Brundage, M., Avin, S., Wang, J., Belfield, H., Krueger, G., Hadfield, G., et al (2020). Toward trustworthy AI development: Mechanisms for supporting verifiable claims. ArXiv. Available online at: https://arxiv.org/abs/2004.07213
Chen, J.-J., von der Brueggen, G., Shi, J., and Ueter, N. (2018). “Dependency graph approach for multiprocessor real-time synchronization,” in Real-Time Systems Symposium (RTSS).
Council of European Union. (2017). Regulation (EU) 2017/1369 of the European Parliament and of the Council of 4 July 2017 setting a framework for energy labelling and repealing directive 2010/30/EU. Available online at: https://eur-lex.europa.eu/eli/reg/2017/1369/
Cremers, A., Englander, A., Gabriel, M., Hecker, D., Mock, M., Poretschkin, M., et al. (2019). “Trustworthy use of artificial intelligence-priorities from a philosophical, ethical, legal, and technological viewpoint as a basis for certification of artificial intelligence,” in Fraunhofer Institute for Intelligent Analysis and Information Systems (IAIS).
Dacrema, M. F., Cremonesi, P., and Jannach, D. (2019). “Are we really making much progress? a worrying analysis of recent neural recommendation approaches,” in Proceedings of 13th ACM Conference on Recommender Systems-RecSys?19 (ACM Press).
Dignum, V. (2019). Responsible Artificial Intelligence: How to Develop and Use AI in a Responsible Way. Springer.
Falkner, S., Klein, A., and Hutter, F. (2018). “BOHB: robust and efficient hyperparameter optimization at scale,” in Proceedings of the 35th ICML, 1436–1445.
Fischer, R., Piatkowski, N., Pelletier, C., Webb, G., Petitjean, F., and Morik, K. (2020). “No cloud on the horizon: Probabilistic gap filling in satellite image series,” in Proceedings of the IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA), Environmental and Geo-spatial Data Analytics, eds G. Webb, L. Cao, Z. Zhang, V. S. Tseng, G. Williams, and M. Vlachos (Sydney, NSW: The Institute of Electrical and Electronics Engineers, Inc.), 546–555.
Floridi, L., Cowls, J., Beltrametti, M., Chatila, R., Chazerand, P., Dignum, V., et al. (2018). AI4people?an ethical framework for a good ai society: opportunities, risks, principles, and recommendations. Minds Mach. 28, 689–707. doi: 10.1007/s11023-018-9482-5
Guidotti, R., Monreale, A., Ruggieri, S., Turini, F., Giannotti, F., and Pedreschi, D. (2018). A survey of methods for explaining black box models. ACM Comput. Surv. 51, 3236009. doi: 10.1145/3236009
Guo, C., Pleiss, G., Sun, Y., and Weinberger, K. Q. (2017). “On calibration of modern neural networks,” in Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, eds D. Precup and Y. W. Teh (Sydney, NSW: International Convention Centre), 1321–1330.
Hammersley, J. M., and Clifford, P. (1971). Markov fields on finite graphs and lattices. Available online at: https://ora.ox.ac.uk/objects/uuid:4ea849da-1511-4578-bb88-6a8d02f457a6
Hazelwood, K., Bird, S., Brooks, D., Chintala, S., Diril, U., Dzhulgakov, D., et al. (2018). “Applied machine learning at facebook: a datacenter infrastructure perspective,” in 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA) (Vienna: IEEE), 620–629.
Henderson, P., Hu, J., Romoff, J., Brunskill, E., Jurafsky, D., and Pineau, J. (2020). Towards the systematic reporting of the energy and carbon footprints of machine learning. J. Mach. Learn. Res. 21, 1–43. doi: 10.48550/arXiv.2002.05651
Heppe, L., Kamp, M., Adilova, L., Piatkowski, N., Heinrich, D., and Morik, K. (2020). “Resource-constrained on-device learning by dynamic averaging,” in ECML PKDD 2020 Workshops, eds I. Koprinska, M. Kamp, A. Appice, C. Loglisci, L. Antonie, A. Zimmermann, R. Guidotti, Ö. Özgöbek, R. P. Ribeiro, R. Gavaldà, J. Gama, L. Adilova, Y. Krishnamurthy, P. M. Ferreira, D. Malerba, I. Medeiros, M. Ceci, G. Manco, E. Masciari, Z. W. Ras, P. Christen, E. Ntoutsi, E. Schubert, A. Zimek, A. Monreale, P. Biecek, S. Rinzivillo, B. Kille, A. Lommatzsch, and J. A. Gulla (Cham: Springer International Publishing), 129–144.
Hind, M., Houde, S., Martino, J., Mojsilovic, A., Piorkowski, D., Richards, J., et al. (2020). “Experiences with improving the transparency of ai models and services,” in Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems, CHI EA '20 (New York, NY: Association for Computing Machinery), 1–8.
Hoeffding, W. (1963). Probability inequalities for sums of bounded random variables. J. Am. Stat. Assoc. 58, 13–30. doi: 10.1080/01621459.1963.10500830
Houben, S., Abrecht, S., Akila, M., Bär, A., Brockherde, F., Feifel, P., et al. (2021). Inspect, understand, overcome: A survey of practical methods for ai safety. Technical Report.
Huang, C., and Darwiche, A. (1996). Inference in belief networks: a procedural guide. Int. J. Approx. Reason. 15, 225–263. doi: 10.1016/S0888-613X(96)00069-2
Huang, X., Groening, D., Ruan, W., Sharp, J., Su, Y., Thamo Emese ad Wu, M., et al. (2020). A survey of safety and trustworthinesse of deep neural networks: verification, testing, adversarial attack and defence, and interpretability. arXiv:1812.08342v08345. doi: 10.1016/j.cosrev.2020.100270
Ihler, A. T., Fischer, J. W III, and Willsky, A. S. (2005). Loopy belief propagation: convergence and effects of message errors. J. Mach. Learn. Res. 6, 905–936. Available online at: http://jmlr.org/papers/v6/ihler05a.html
Islam, M. J., Nguyen, G., Pan, R., and Rajan, H. (2019). “A comprehensive study on deep learning bug characteristics,” in Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 510–520.
Julia, C., Etilé, F., and Hercberg, S. (2018). Front-of-pack nutri-score labelling in france: an evidence-based policy. Lancet Public Health 3, e164. doi: 10.1016/S2468-2667(18)30009-4
Kim, J. H., and Pearl, J. (1983). “A computational model for causal and diagnostic reasoning in inference systems,” in IJCAI'83 (San Francisco, CA: Morgan Kaufmann Publishers Inc.), 190–193.
Koller, D., and Friedman, N. (2009). Probabilistic Graphical Models-Principles and Techniques. MIT Press.
Kwiatkowska, M., Norman, G., and Parker, D. (2011). “Prism 4.0: verification of probabilistic real-time systems,” in Computer Aided Verification, eds G. Gopalakrishnan and S. Qadeer (Berlin; Heidelberg: Springer Berlin Heidelberg), 585–591.
Langer, M., Oster, D., Kästner, L., Speith, T., Baum, K., Hermanns, H., et al. (2021). What do we want from explainable artificial intelligence (xai)? a stakeholder perspective on xai and a conceptual model guiding interdisciplinary xai research. Artif. Intell. 296, 103473. doi: 10.1016/j.artint.2021.103473
Lauritzen, S. L., and Spiegelhalter, D. J. (1988). Local computations with probabilities on graphical structures and their application to expert systems. J. R. Stat. Soc. Ser. B 50, 157–224.
Lepri, B., Oliver, N., Letouze, E., Pentland, A., and Vinck, P. (2018). Fair, transparent, and accountable algorithmic decision-making processes. Philos. Technol. 31, 611–627. doi: 10.1007/s13347-017-0279-x
Lin, Q., Adepu, S., Verwer, S., and Mathur, A. (2018). “Tabor: a graphical model-based approach for anomaly detection in industrial control systems,” in Proceedings of the 2018 on Asia Conference on Computer and Communications Security, 525–536.
Mierswa, I., and Wurst, M. (2005). “Efficient feature construction by meta learning-guiding the search in meta hypothesis space,” in Proceedings of the International Conference on Machine Learning, Workshop on Meta Learning.
Mierswa, I., Wurst, M., Klinkenberg, R., Scholz, M., and Euler, T. (2006). “YALE: rapid prototyping for complex data mining tasks,” in ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2006) (New York, NY: ACM Press), 935–940.
Mitchell, M., Wu, S., Zaldivar, A., Barnes, P., Vasserman, L., Hutchinson, B., et al. (2019). “Model cards for model reporting,” in Proceedings of the Conference on Fairness, Accountability, and Transparency, FAT* 2019, Atlanta, GA, USA, January 29-31, 2019 (New York, NY: Association for Computing Machinery), 220–229.
Morik, K., Chatila, R., Dignum, V., Fisher, M., Giannotti, F., Russell, S., et al. (2021). Trustworthy AI, Chapter 2. Springer International Publishing.
Morik, K., and Kietz, J.-U. (1991). “Constructive induction of background knowledge,” in Proceedings of the IJCAI-Workshop on Evaluating and Changing Representations in Machine Learning.
Muggleton, S. (1991). Inductive logic programming. New Generat. Comput. 8, 295–318. doi: 10.1007/BF03037089
Murphy, K. P., Weiss, Y., and Jordan, M. I. (1999). “Loopy belief propagation for approximate inference: an empirical study,” in Proceedings of the Fifteenth conference on Uncertainty in artificial intelligence (Morgan Kaufmann Publishers Inc.), 467–475
Nunes, I., and Jannach, D. (2017). A systematic review and taxonomy of explanations in decision support and recommender systems. User Model Useradapt Interact. 27, 393–444. doi: 10.1007/s11257-017-9195-0
Piatkowski, N. (2018). Exponential Families on Resource-Constrained Systems (Ph.D. thesis). TU Dortmund University, Dortmund.
Piatkowski, N. (2019). “Distributed generative modelling with sub-linear communication overhead,” in Decentralized Machine Learning at the Edge, eds M. Kamp, D. Paurat, and Y. Krishnamurthy (Springer).
Piatkowski, N., Lee, S., and Morik, K. (2016). Integer undirected graphical models for resource-constrained systems. Neurocomputing 173, 9–23. doi: 10.1016/j.neucom.2015.01.091
Ratner, A., Alistarh, D., Alonso, G., Andersen, D. G., Bailis, P., Bird, S., et al (2019). Mlsys: The new frontier of machine learning systems. Available online at: https://repository.upenn.edu/cgi/viewcontent.cgi?article=1011&context=cps_machine_programming
Ribeiro, M. T., Singh, S., and Guestrin, C. (2016). “"why should i trust you?": explaining the predictions of any classifier,” in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD '16 (New York, NY: ACM), 1135–1144.
Samek, W., Montavon, G., Vedaldi, A., Hansen, L. K., and Müller, K.-R. (Eds.). (2019). Explainable AI: Interpreting, Explaining and Visualizing Deep Learning. Lecture Notes in Computer Science. Springer International Publishing.
Schelter, S., Böse, J.-H., Kirschnick, J., Klein, T., and Seufert, S. (2017). “Automatically tracking metadata and provenance of machine learning experiments,” in Machine Learning Systems Workshop at NIPS 2017.
Schmidt, M. (2017). Datenzusammenfassungen auf Datenströmen (Master's thesis). TU Dortmund University.
Schwartz, R., Dodge, J., Smith, N. A., and Etzioni, O. (2019). Green AI. arXiv preprint arXiv:1907.10597. doi: 10.48550/arXiv.1907.10597
Sokol, K., and Flach, P. (2018). “Conversational explanations of machine learning predictions through class-contrastive counterfactual statements,” in Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-18), 5785–5786.
Strubell, E., Ganesh, A., and McCallum, A. (2020). “Energy and policy considerations for modern deep learning research,” in The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, February 7-12, 2020 (New York, NY: AAAI Press), 13693–13696.
Teubner, J., Woods, L., and Nie, C. (2013). XLynx–an FPGA-based XML filter for hybrid XQuery processing. ACM Trans. Database Syst. 38, 23. doi: 10.1145/2536800
Thung, F., Wang, S., Lo, D., and Jiang, L. (2012). “An empirical study of bugs in machine learning systems,” in 2012 IEEE 23rd International Symposium on Software Reliability Engineering (Dallas, TX: IEEE), 271–280.
van Rijn, J. N., Bischl, B., Torgo, L., Gao, B., Umaashankar, V., Fischer, F., et al. (2013). “OpenML: a collaborative science platform,” in Machine Learning and Knowledge Discovery in Databases, number 8190 in Lecture Notes in Computer Science, eds H. Blockeel, K. Kersting, S. Nijssen, and F. Železný (Berlin; Heidelberg: Springer Berlin Heidelberg), 645–649.
Vartak, M., Subramanyam, H., Lee, W.-E., Viswanathan, S., Husnoo, S., Madden, S., et al. (2016). “Modeldb: a system for machine learning model management,” in Proceedings of the Workshop on Human-In-the-Loop Data Analytics, HILDA '16 (New York, NY: Association for Computing Machinery).
Wainwright, M. J., Jaakkola, T. S., and Willsky, A. S. (2003). “Tree-reweighted belief propagation algorithms and approximate ml estimation by pseudo-moment matching,” in International Conference on Artificial Intelligence and Statistics.
Wainwright, M. J., and Jordan, M. I. (2008). Graphical models, exponential families, and variational inference. Foundat. Trends Mach. Learn. 1, 1–305. doi: 10.1561/2200000001
Wintle, B., Fraser, H., Wills, B., Nicholson, A., and Fidler, F. (2019). Verbal probabilities: very likely to be somewhat more confusing than numbers. PLoS ONE 14, e0213522. doi: 10.1371/journal.pone.0213522
Wolpert, D., and Macready, W. (1997). No free lunch theorems for optimisation. IEEE Trans. Evolut. Comput. 1, 67–82. doi: 10.1109/4235.585893
Keywords: trustworthy AI, testing machine learning, certification, probabilistic graphical models, care labels
Citation: Morik KJ, Kotthaus H, Fischer R, Mücke S, Jakobs M, Piatkowski N, Pauly A, Heppe L and Heinrich D (2022) Yes we care!-Certification for machine learning methods through the care label framework. Front. Artif. Intell. 5:975029. doi: 10.3389/frai.2022.975029
Received: 21 June 2022; Accepted: 24 August 2022;
Published: 21 September 2022.
Edited by:
Elisa Fromont, University of Rennes 1, FranceReviewed by:
Marie-Christine Rousset, Université Grenoble Alpes, FranceFrancesca Pratesi, Pisa Research Area, National Research Council (CNR), Italy
Copyright © 2022 Morik, Kotthaus, Fischer, Mücke, Jakobs, Piatkowski, Pauly, Heppe and Heinrich. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Katharina J. Morik, a2F0aGFyaW5hLm1vcmlrQHR1LWRvcnRtdW5kLmRl