 Evanthia Kaimaklioti Samota
Evanthia Kaimaklioti Samota Robert P. Davey
Robert P. Davey- 1Earlham Institute, Norwich, United Kingdom
- 2School of Biological Sciences, University of East Anglia, Norwich, United Kingdom
We constructed a survey to understand how authors and scientists view the issues around reproducibility, focusing on interactive elements such as interactive figures embedded within online publications, as a solution for enabling the reproducibility of experiments. We report the views of 251 researchers, comprising authors who have published in eLIFE Sciences, and those who work at the Norwich Biosciences Institutes (NBI). The survey also outlines to what extent researchers are occupied with reproducing experiments themselves. Currently, there is an increasing range of tools that attempt to address the production of reproducible research by making code, data, and analyses available to the community for reuse. We wanted to collect information about attitudes around the consumer end of the spectrum, where life scientists interact with research outputs to interpret scientific results. Static plots and figures within articles are a central part of this interpretation, and therefore we asked respondents to consider various features for an interactive figure within a research article that would allow them to better understand and reproduce a published analysis. The majority (91%) of respondents reported that when authors describe their research methodology (methods and analyses) in detail, published research can become more reproducible. The respondents believe that having interactive figures in published papers is a beneficial element to themselves, the papers they read as well as to their readers. Whilst interactive figures are one potential solution for consuming the results of research more effectively to enable reproducibility, we also review the equally pressing technical and cultural demands on researchers that need to be addressed to achieve greater success in reproducibility in the life sciences.
Introduction
Reproducibility is a defining principle of scientific research, and broadly refers to the ability of researchers, other than the original researchers, to achieve the same findings using the same data and analysis (Claerbout and Karrenbach, 1992). However, irreproducible experiments are common across all disciplines of life sciences (Begley and Ellis, 2012) and many other disciplines (Ioannidis, 2005), such as psychology (Open Science Collaboration, 2015), computer science (Crick et al., 2017), economics (Ioannidis et al., 2017; Christensen and Miguel, 2018) and ecology (Fraser et al., 2018). A 2012 study showed that 88% of drug-discovery experiments could not be reproduced even by the original authors, in some cases forcing retraction of the original work (Begley and Ellis, 2012). Irreproducible genetic experiments with weak or wrong evidence can have negative implications for our healthcare (Yong, 2015). For example, 27% of mutations linked to childhood genetic diseases cited in literature have later been discovered to be common polymorphisms or misannotations (Bell et al., 2011). While irreproducibility is not confined to biology and medical sciences (Ioannidis and Doucouliagos, 2013), irreproducible biomedical experiments pose a strong financial burden on society; an estimated $28 billion was spent on irreproducible biomedical science in 2015 in the United States alone (Freedman et al., 2015).
Reproducibility should inevitably lead to robust science, relating to the way in which conclusions rely on specific analyses or procedures undertaken on experimental systems. Unfortunately, the community has yet to reach consensus on how we traverse the space of re-use, re-analysis and re-interpretation of scientific research to try to define suitable overarching definitions for reproducibility. Thus, there are different definitions of reproducibility used in the literature (Drummond, 2009; Plesser, 2018), some of which contradict one another. A recent exhaustive review has also documented this problem (Leipzig et al., 2020), so our survey and results do need to be contextualised somewhat by this lack of consensus. The terms repeatability, replicability and reproducibility are also occasionally confused (Peng et al., 2006; Liberman, 2015), therefore it is important to differentiate these terms from each other.
1. Repeatability The original researchers using the same data, running precisely the same analysis and getting the same results, on multiple runs (Drummond, 2009).
2. Replicability Different teams performing different experimental setups and using independent data, achieving the same result as the original researchers, on multiple trials (Peng et al., 2006; Peng, 2011; Stodden et al., 2013a).
3. Reproducibility Different teams re-running the same analysis with the same data and getting the same result (Claerbout and Karrenbach, 1992; Peng et al., 2006; Peng, 2011; Stodden et al., 2013a).
It is argued that in many science disciplines replicability is more desirable than reproducibility because a result needs to be corroborated independently before it can be generally accepted by the scientific community (Peng, 2011; Nuijten et al., 2018). However, reproducibility can serve as a cost-effective way of verifying results prior to replicating results (Nuijten et al., 2018).
Computational reproducibility, or reproducible computational research, refers to the reproducibility of computational experiments, where an independent team can produce the same result utilising the data and computational methods (code and workflow) provided by the original authors (Donoho, 2010; Stodden et al., 2013a; Stodden and Miguez, 2013; Stodden et al., 2018; Leipzig et al., 2020). Computational reproducibility is influenced by both technical and cultural (social) factors (LeVeque et al., 2012; Stodden et al., 2013a; Stodden et al., 2018). Technical challenges to computational reproducibility include poorly written, incorrect, or unmaintained software, changes in software libraries on which tools are dependent, or incompatibility between older software and newer operating systems (Cataldo et al., 2009). Cultural factors that challenge computational reproducibility include the attitudes and behaviors of authors when performing and reporting research. Examples include authors not providing sufficient descriptions of methods and being reluctant to publish original data and code under FAIR (Findable, Accessible, Interoperable, and Reusable) principles (Stodden et al., 2013b; Baker, 2016; Munafo et al., 2017). Other cultural factors include favoring of high prestige or high impact scientific publications over performing rigorous and reproducible science (which tends to be improved by open access policies) (Eisner, 2018; Hardwicke et al., 2018). We refer to the cultural factors affecting computational reproducibility as the culture of reproducibility (Peng, 2011).
Several projects have attempted to address some of the technical aspects of reproducibility by making it easier for authors to disseminate fully reproducible workflows and data, and for readers to perform computations. For example F1000 Living Figure (Colomb and Brembs, 2014) and re-executable publications (Ingraham, 2017; Perkel, 2017; Ingraham, 2017) using Plotly (plot.ly) and Code Ocean widgets (codeocean.com); Whole Tale Project (Brinckman et al., 2018); ReproZip project (Chirigati et al., 2016); Python-compatible tools and widgets (interactive widgets for Jupyter Notebooks with Binder); Zenodo (zenodo.org) and FigShare (figshare.com) as examples of open access repositories for scientific content (including datasets, code, figures, reports); Galaxy (Afgan et al., 2018); CyVerse (formerly iPlant Collaborative) (Goff et al., 2011); myExperiment (Goble et al., 2010); UTOPIA (Pettifer et al., 2009; Pettifer et al., 2004); GigaDB (Sneddon et al., 2012); Taverna (Hull et al., 2006; Oinn et al., 2004; Wolstencroft et al., 2013); workflow description efforts such as the Common Workflow Language (Amstutz et al., 2016); and Docker (docker.com), Singularity (sylabs.io) (Kurtzer et al., 2017) and other container systems. Even though these tools are widely available and seem to address many of the issues of technical reproducibility and the culture of reproducibility, they have not yet become a core part of the life sciences experimental and publication lifecycle. There is an apparent disconnection between the development of tools addressing reproducibility and their use by the wider scientific and publishing communities who might benefit from them.
This raises the question of “how do researchers view their role in the production and consumption of scientific outputs?” A common way for researchers to quickly provide information about their data, analysis and results is through a figure or graph. Scientific figures in publications are commonly presented as static images. Access to the data (including the raw, processed and/or aggregated data), analysis, code or description of how the software was used that produced the figure are not available within the static images (Barnes and Fluke, 2008; Barnes et al., 2013; Grossman et al., 2016; Newe, 2016; Weissgerber et al., 2016; Rao et al., 2017; Perkel, 2018). This can be especially pertinent to figures that have thousands or millions of points of data to convey (Perkel, 2018). In order for readers to interrogate published results in more detail, examine the transparency and reproducibility of the data and research, they would need to download a complete copy of the data, code, and any associated analysis methodology (data pre-processing, filtering, cleaning, etc) and reproduce this locally, provided all those elements are available and accessible (Stodden et al., 2016). Computational analyses often require running particular software which might require configuration and parameterisation, as well as library dependencies and operating system prerequisites. This is a time-consuming task and achieving reproducibility of computational experiments is not always possible (Stodden et al., 2016; Kim et al., 2018). Thus, solutions that automatically reproduce computational analyses and allow the investigation of the data and code presented in the figure in detail would be advantageous (Peng, 2011; Perkel, 2017; Perkel, 2018).
Many solutions now exist that allow for the reproducibility of computational analyses outside the research paper and are typically supplied as links within the research paper or journal website redirecting to many different types of computational systems, such as Galaxy workflows, Binder interactive workspaces converted by GitHub repositories with Jupyter notebooks (Jupyter et al., 2018), and myExperiment links (Goble et al., 2010). The endpoint of these analyses are often graphical figures or plots, and these may well be interactive, thus allowing modification of plot type, axes, data filtering, regression lines, etc. Whilst these figures may well be interactive in that a user can modify some part of the visualisation, this does not implicitly make the data or code that produced that figure more available, and hence more reproducible.
Technologies that can expose code, data and interactive figures are now mature. For example, Jupyter notebooks are built up of executable “cells” of code which can encapsulate a link to a data file hosted on a cloud service, code to get and analyze this data file, and then produce an interactive figure to interpret the dataset. Again, this is somewhat disconnected from the actual research publication. However, as technology has progressed in terms of available storage for data, computational power on the web through cloud services, and the ability of these services to run research code, we are now coming to the point where the production of interactive figures within publications themselves is achievable. These interactive figures which would inherently have access to the underlying data and analytical process can provide users with unique functionality that can help increase the reproducible nature of the research. This combination of code, data, analysis, visualisation and paper are examples of “executable documents” (Ghosh et al., 2017; Maciocci et al., 2019).
Interactive figures within executable documents, therefore, have incorporated data, code and graphics so that when the user interacts with the figure, perhaps by selecting a cluster of data points within a graph, the user could then be presented with the data that underlies those data points. Similarly, a user could make changes to the underlying parameters of the analysis, for example modifying a filter threshold, which would ultimately make changes to the visualisation of the figure or the document itself (Barnes and Fluke, 2008; Barnes et al., 2013; Grossman et al., 2016; Newe, 2016; Weissgerber et al., 2016; Rao et al., 2017; Perkel, 2018). By means of an example, an executable document could represent an interactive figure showing a heat map of gene expression under different stress conditions. In a traditional article, the user would be tasked with finding references to the datasets and downloading them, and subsequently finding the code or methodology used to analyze the data and retrace the original authors’ steps (if the code and data were available at all). Within an interactive figure in an executable document, a user could select a particular gene of interest by clicking on the heatmap and viewing the gene expression information within a pop-up browser window. Whilst this is useful for general interpretation, to achieve reproducibility this pop-up window would provide a button that allows the user to pull the sequencing read data that was the basis for the results into a computational system in order to re-run the differential expression analysis. This raises many questions around how this infrastructure is provided, what technologies would be used to package up all elements needed for reproducibility, the subsequent costs of running the analysis, and so on.
These caveats aside, interactive figures within executable documents can benefit the reader for the consumption of the research outputs in an interactive way, with easy access to the data and removing the need for installing and configuring code and parameters for reproducing the computational experiments presented in the figure within the publication (Perkel, 2017). The aforementioned solutions would not only be helpful to the readers of papers (Tang et al., 2018) but benefit the peer review process (Perkel, 2018).
There have been efforts to make the connection between production and consumption of research outputs within online publications. One of the first interactive figures to have been published in a scholarly life sciences journal is the Living Figure by Björn Brembs and Julien Colomb which allowed readers to change parameters of a statistical computation underlying a figure (Ghosh et al., 2017). F1000Research has now published more papers that include Plotly graphs and Code Ocean widgets in order to provide interactivity and data and code reproducibility from within the article figures (Ghosh et al., 2017; Ingraham, 2017). The first prototype of eLIFE’s computationally reproducible article aims to convert manuscripts created in a specific format (using the Stencila Desktop, stenci.la, and saved as a Document Archive file) into interactive documents allowing the reader to “play” with the article and its figures when viewed in a web browser (Maciocci et al., 2019). The Manifold platform (manifoldapp.org) allows researchers to show their research objects alongside their publication in an electronic reader, whilst including some dynamic elements. The Cell journal included interactive figures in a paper using Juicebox js for 3D visualisation of Hi-C data (http://aidenlab.org/juicebox/) (Rao et al., 2017; Robinson et al., 2018). Whilst there are few incentives to promote the culture of reproducibility (Pusztai et al., 2013; Higginson and Munafò, 2016), efforts in most science domains are being made to establish a culture where there is an expectation to share data for all publications according to the FAIR principles. The implementation of these principles is grounded in the assumption that better reproducibility will benefit the scientific community and the general public (National Institutes of Health, 2015; Wilkinson et al., 2016). Studies have suggested that reproducibility in science is a serious issue with costly repercussions to science and the public (Stodden et al., 2013b; Pulverer, 2015). Whilst there have been survey studies canvassing the attitudes of researchers around reproducibility in other disciplines to some extent (Baker, 2016; Feger et al., 2019; Stodden, 2010), fewer studies have investigated the attitudes and knowledge of researchers around reproducibility in the life sciences (Baker, 2016). In particular, minimal research has been conducted into the frequency of difficulties experienced with reproducibility, the perception of its importance, and preferences with respect to potential solutions among the life sciences community.
This paper presents a survey that was designed to assess researchers’ understanding of the concepts of reproducibility and to inform future efforts in one specific area: to help researchers be able to reproduce research outputs in publications. The development of tools, one example of which are interactive figures within journal publications, may better meet the needs of producers and consumers of life science research. Our survey is limited in that we do not assess how open-access tools for the production of reproducible research outputs compare, but how the consumption of research information through interactive means is regarded. We constructed the survey in order to understand how the following are experienced by the respondents:
• Technical factors affecting computational reproducibility: issues with accessing data, code and methodology parameters, and how solutions such as interactive figures could promote reproducibility from within an article.
• Culture of reproducibility: attitudes toward reproducibility, the social factors hindering reproducibility, and interest in how research outputs can be consumed via interactive figures and their feature preferences.
Methods
Population and Sample
The data were analyzed anonymously, nonetheless, we sought ethical approval. The University of East Anglia Computing Sciences Research Ethics Committee approved this study (CMPREC/1819/R/13). Our sample populations were selected to include all life sciences communities across levels of seniority, discipline and level of experience with the issues we wished to survey. The first survey was conducted in November 2016 and sent out to 750 researchers working in the Norwich Biosciences Institutes (NBI) at a post-doctoral level or above. We chose to survey scientists of post-doctoral level or above, as these scientists are more likely to have had at least one interaction with publishing in scientific journals. The NBI is a partnership of four United Kingdom research institutions: the Earlham Institute (formerly known as The Genome Analysis Center), the John Innes Center, the Sainsbury Center, and the Institute of Food Research (now Quadram Institute Bioscience). Invitations to participate were distributed via email, with a link to the survey. The second survey, similar to the first but with amendments and additions, was distributed in February 2017 to a random sample of 1,651 researchers who had published papers in the eLIFE journal. Further information about the eLIFE sample is found in Supplementary section 3. Invitations to participate were sent using email by eLIFE staff. We achieved a 15% (n = 112) response rate from the NBI researchers and an 8% response rate from the eLIFE survey (n = 139). Table 1 shows the survey questions. Questions were designed to give qualitative and quantitative answers on technical and cultural aspects of reproducibility. Questions assessed the frequency of difficulties encountered in accessing data, the reasons for these difficulties, and how respondents currently obtain data underlying published articles. They measured understanding of what constitutes reproducibility of experiments, interactive figures, and computationally reproducible data. Finally, we evaluated the perceived benefit of interactive figures and of reproducing computational experiments, and which features of interactive figures would be most desirable.

TABLE 1. Questions used to survey the knowledge of respondents about research reproducibility.
Validation of the Survey Design
We undertook a two-step survey: firstly NBI, then eLIFE interactions leading to additional questions. We tested the initial survey on a small cohort of researchers local to the authors to determine question suitability and flow. We reported the qualitative results of the surveys in accordance with the Standards for Reporting Qualitative Research (SRQR) (O’Brien et al., 2014).
The survey questions were not designed based on specific culture theory, but rather on our understanding of the field of reproducibility, that is the human factors and researcher attitudes toward reproducibility, as well as the mode of conducting science. We assume that these factors affect how reproducible and robust the science, and therefore the published work, will be. Therefore, we adopt the term “culture of reproducibility” to encompass the attitudes of life scientists toward science and reproducibility directly related to research articles, and not referring to human demographics. The rationale behind evaluating the culture of reproducibility was to examine how the attitudes or means by which researchers present their work in research papers can affect reproducibility.
It is important to state that not any one survey question was assessing solely the technical factors affecting reproducibility or solely the culture of reproducibility. For example, accessing data for the reader is both a cultural and technical factor, i.e., data available from public repositories via persistent identifiers and APIs vs. “data available on request”. For the author of the paper, not publishing the data is solely a cultural/social factor as it could be seen that they are not conducting and presenting their research in an open reproducible manner, or they do not have the support or knowledge around the best practice for reproducible data publishing in their domain.
We also evaluated the sentiment around interactive figures in our research. In themselves, they are a technical factor that we suggest can promote reproducibility. However, the interest of the readers in finding interactive figures desirable, including what features they think are favourable, can be a variable factor depending on the social background or demographic of the respondent (for example, training received, data they work with, discipline they work in).
We understand that there are a lot of human factors in the way reproducibility is achieved, which are mainly centered around the attitude of life scientists toward reproducibility. How robust, open-source, open-access they conduct and share their research affects the reproducibility of their work. In this way we wanted to evaluate, assess and see the extent of the issue in quantifying and qualifying how difficult it is to access data and code presented in papers, and how difficult it is to understand the methods presented in a paper. Our work adds to existing surveys that also highlight reproducibility as an issue.
We received consistent responses where all or most respondents interpreted the questions in a similar manner suitable for cross-comparison. The NRP study results produced consistent results with the eLIFE study results, which were sent out at different times and to the different survey cohorts. We primarily took surveys and conclusions raised in the existing literature and the results of discussions with various researchers who are looking into reproducibility in our local institutions to form our construct validity. The questions we asked indicated they fit our requirements to better understand the qualitative nature of the respondents' answers and perform empirical analyses (Chi-squared) to show relationships. We used the same process to determine content validity, where we tried to provide questions that would cover the breadth of the domain we were assessing as we “cast a wide net” over potential respondents that would comprise people from a wide variety of domains, expertise, and other demographics. Finally, our theory of how researchers view reproducibility fed into our questions to provide translation validity where we formed two practical surveys based on our theory assessments from previous literature.
Statistical Analysis
Results are typically presented as proportions of those responding, stratified by the respondent’s area of work, training received, and version of the survey as appropriate. Chi-square tests for independence were used to test for relationships between responses to specific questions, or whether responses varied between samples. The analysis was conducted using R (version 3.5.2; R Core Team, 2018) and Microsoft Excel. All supplementary figures and data are available on Figshare (see Data Availability).
We assessed if there was a significant difference in the ability and willingness to reproduce published results between the cohort of eLIFE respondents who understand the term “computationally reproducible data” and those who do not and whether training received (bioinformatics, computer science, statistics, or no training) had an effect. Given the free-text responses within the “unsure” group as to the understanding of the term “computationally reproducible data”, where many understood the term, we did not include in our analysis the data from those who replied, “unsure” (see Section “Understanding of reproducibility, training and successful replication” below). The respondents who chose “yes tried reproducing results, but unsuccessfully”, “have not tried to reproduce results” and “it is not important to reproduce results” were grouped under “unsuccessfully”.
Results
Characteristics of the Sample
Figure 1 shows the distribution of areas of work of our respondents, stratified by survey sample. Genomics (proportion in the whole sample = 22%), biochemistry (17%), and computational biology (15%) were the most common subject areas endorsed in both NBI and eLIFE samples. With regard to how often respondents use bioinformatics tools, 25% replied “never”, 39% “rarely”, and 36% “often”. Many (43%) received statistical training, (31%) bioinformatic training, (20%) computer science training.
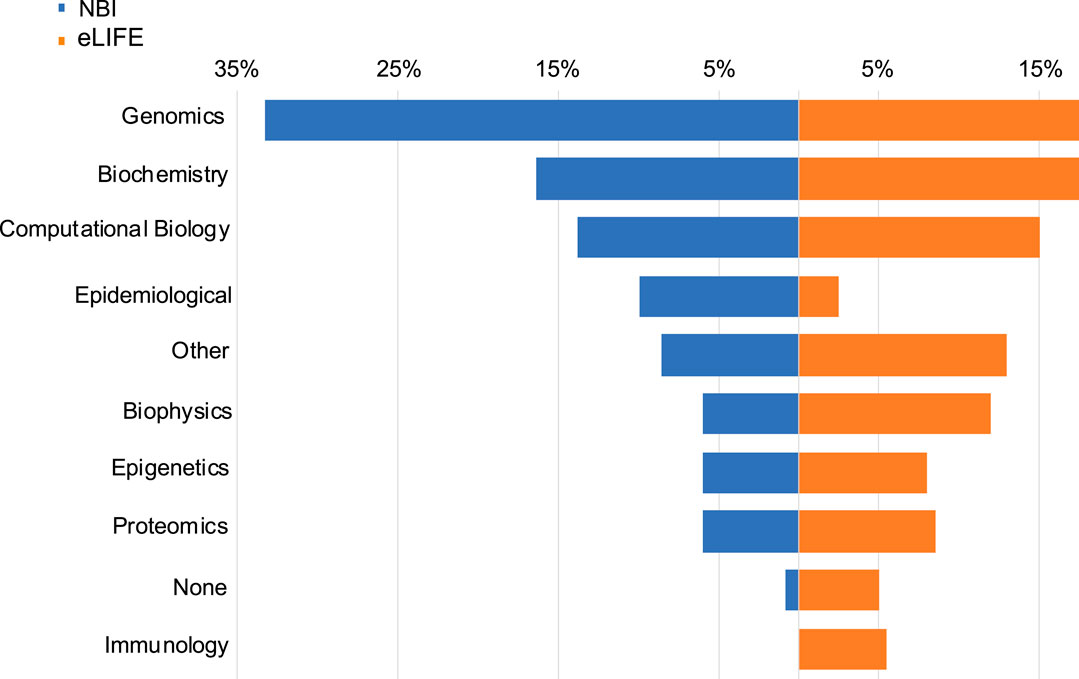
FIGURE 1. Data types used by NBI and eLIFE respondents. Responses were not mutually exclusive. Data type choices were the same as the article data types available in the eLIFE article categorisation system.
Access to Data and Bioinformatics Tools
In both samples, 90% of those who responded, reported having tried to access data underlying a published research article (Figure 2). Of those who had tried, few had found this “easy” (14%) or “very easy” (2%) with 41% reporting that the process was “difficult” and 5% “very difficult”. Reasons for difficulty were chiefly cultural (Figure 2), in that the data was not made available alongside the publication (found by 75% of those who had tried to access data), or authors could not be contacted or did not respond to data requests (52%). Relatively few found data unavailable for technical reasons of data size (21%), commercial sensitivity (13%) or confidentiality (12%). With respect to data sources, 57% of the total sample have used open public databases, 48% reported data was available with a link in the paper, and 47% had needed to contact authors.
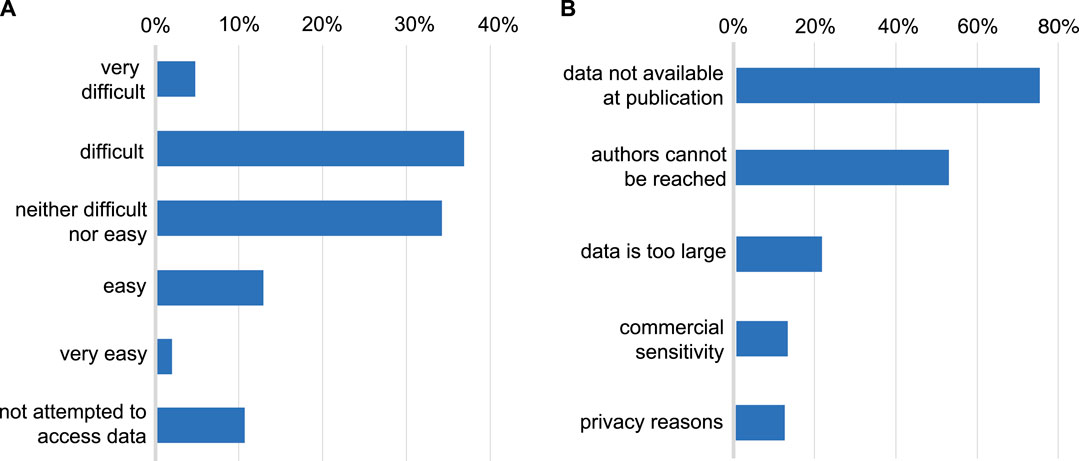
FIGURE 2. (A): Difficulty encountered accessing data underlying published research. Whether respondents have attempted to access data underlying previous publications and the level of difficulty typically encountered in doing so. (B): Reasons given for difficulty accessing data. The reasons given by respondents for being unable to access data (restricted to those who have attempted to access data).
Very few of the respondents either “never” (2%) or “rarely” (8%) had problems with running, installing, configuring bioinformatics software. Problems with software were encountered “often” (29%) or “very often” (15%) suggesting that nearly half of respondents regularly encountered technical barriers to computational reproducibility.
Understanding of Reproducibility, Training and Successful Replication
Most respondents reported that they understood the term “reproducibility of experiments” and selected the explanation for the term as defined in the introduction above, which corresponds to the most established definitions of reproducibility (Peng et al., 2006; Peng, 2011; Stodden et al., 2013b). It is important to state that for this question, we allowed for respondents to choose more than one answer, as we recognise the limitation that there is no standard and accepted definition for reproducibility, as well as the familiarity of the term between scientists from different backgrounds, can differ. The first three definitions are plausible definitions for reproducibility. Given the results, we can assume that some of the respondents chose both correct and wrong definitions. The majority of the answers (77%) included the definition of reproducibility as we define it in the manuscript. However, by looking into the individual responses (n = 54), 11.1% (n = 6) of respondents chose only option A thus appeared to understand that this matched the definition of reproducibility, as we state in the manuscript. 5.5% (n = 3) chose only option D, which is incorrect. The majority of people (57%, n = 23) picked any of A, B, or C and did not pick D, which seems to suggest that they understand that replicability is not reproducibility, but they are still not clear on exact definitions, which matches the general lack of consensus (Drummond, 2009; Liberman, 2015; Plesser, 2018). Just over a third (37%, n = 20) picked one or all of A, B and C, and picked D, which seems to suggest that they didn't understand the difference between reproducibility and replicability at all and considered any form of repeating a process could be classed as reproducibility of experiments (see Supplementary Table 4).
Most (52%) participants provided a different interpretation of the term “computationally reproducible data” to our interpretation, while 26% did know and 22% were unsure. We received several explanations (free text responses) of the term of which the majority were accurate (Supplementary section 2, free responses to question 13). We assign meaning to the term as data as an output (result) in a computational context, which was generated when reproducing computational experiments. Although the term “computationally reproducible data” is not officially defined, other sources and studies have referred to the concept of data that contributes to computational reproducibility (Baranyi and Greilhuber, 1999; Weinländer et al., 2009; de Ruiter, 2017; Perkel, 2017; Tait, 2017; Pawlik et al., 2019). From the unsure responses (n = 30), we categorised those that gave free-text responses (70%, n = 21, see Supplementary section 2, free responses) into whether they did actually understand the term, those that did not understand the term, and those that did not give any free text. The majority of respondents that chose “unsure” and gave a free text response (71%, n = 15) did understand the term “computationally reproducible data”. The remaining 29% (n = 6) did not understand the term correctly.
Some (18%) reported not attempting to reproduce published research. Very few (n = 5; 6%) of the sample endorsed the option that “it is not important to reproduce other people’s published results” (Supplementary figure 1). Even though the majority (60%) reported successfully reproducing published results, almost a quarter of the respondents found that their efforts to reproduce any results were unsuccessful (23%). Table 2 shows respondents’ ability to reproduce experiments, stratified by their understanding of the term “computationally reproducible data” and the training received (bioinformatics, computer science, statistics). A chi-square test of independence was performed to examine the relationship between the ability to reproduce published experiments and knowing the meaning of the term “computationally reproducible data”. The relationship between these variables was significant, χ2(1, n = 75) = 3.90, p = .048. Those who knew the meaning of the term “computationally reproducible data” were more likely to be able to reproduce published experiments. Taking their training background into account did not show any significant difference. However, when testing with the responses “yes tried reproducing results, but unsuccessfully”, “have not tried to reproduce results” and “it is not important to reproduce results” (not grouped under “unsuccessfully” in order to get an indication of how willingness and success together differed between the training groups), we found a significant difference (see Supplementary Table 1). The distribution of the training variable with those who received computer science training and those without was significantly different (Fisher exact test for independence, p = 0.018). It appears that respondents with computer science training are less likely to have tried to reproduce an experiment but be more likely to succeed when they did try.
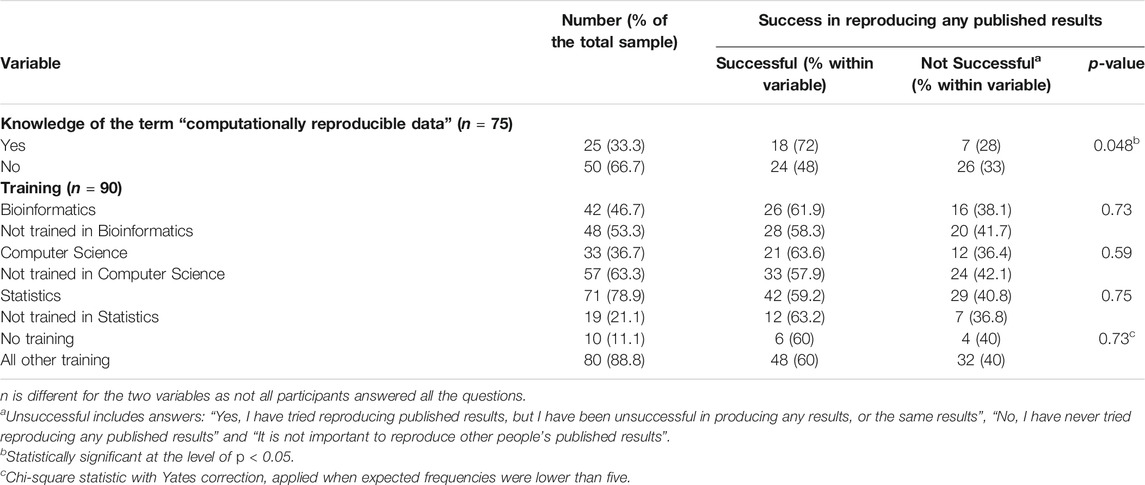
TABLE 2. Success in reproducing any published results stratified by their knowledge of the term “computationally reproducible data” and training received.
There was no evidence for a difference in the ability and willingness to reproduce published results between the respondents who use bioinformatics tools often, and those who use them rarely or never, χ2(3, n = 90) = 0.53, p = 0.91 (Supplementary Table 2). The majority of the respondents who use bioinformatics tools often were coming from the scientific backgrounds of Biophysics, Biochemistry, Computational Biology and Genomics. Most of the respondents who answered “reproducibility is not important” and “haven’t tried reproducing experiments” were scientists coming from disciplines using computational or bioinformatics tools “rarely” or “never” (Supplementary Table 3).
Improving Reproducibility of Published Research
The majority (91%) of respondents stated that authors describing all methodology steps in detail, including any formulae analysing the data can make published science more reproducible. Around half (53%) endorsed the view that “authors should provide the source code of any custom software used to analyze the data and that the software code is well documented”, and that authors provide a link to the raw data (49%) (Supplementary figure 2). Two respondents suggested that achieving better science reproducibility would be easier if funding was more readily available for reproducing the results of others and if there were opportunities to publish the reproduced results (Supplementary section, free responses). Within the same context, some respondents recognised the current culture in science that there are not sufficient incentives in publishing reproducible (or indeed negative findings) papers, but rather being rewarded in publishing as many papers as possible in high impact factor journals (Supplementary section, free responses).
Interactive Figures
Participants ranked their preferences for interactive figure features within a research article. The most preferred interactive figure feature was “easy to manipulate”, followed by “easy to define parameters” (Figure 3). Generally, the answers from both the eLIFE and NBI surveys followed similar trends. Furthermore, free-text responses were collected, and most respondents stated that mechanisms to allow them to better understand the data presented in the figure would be beneficial, e.g., by zooming in on data (Supplementary section, free responses).
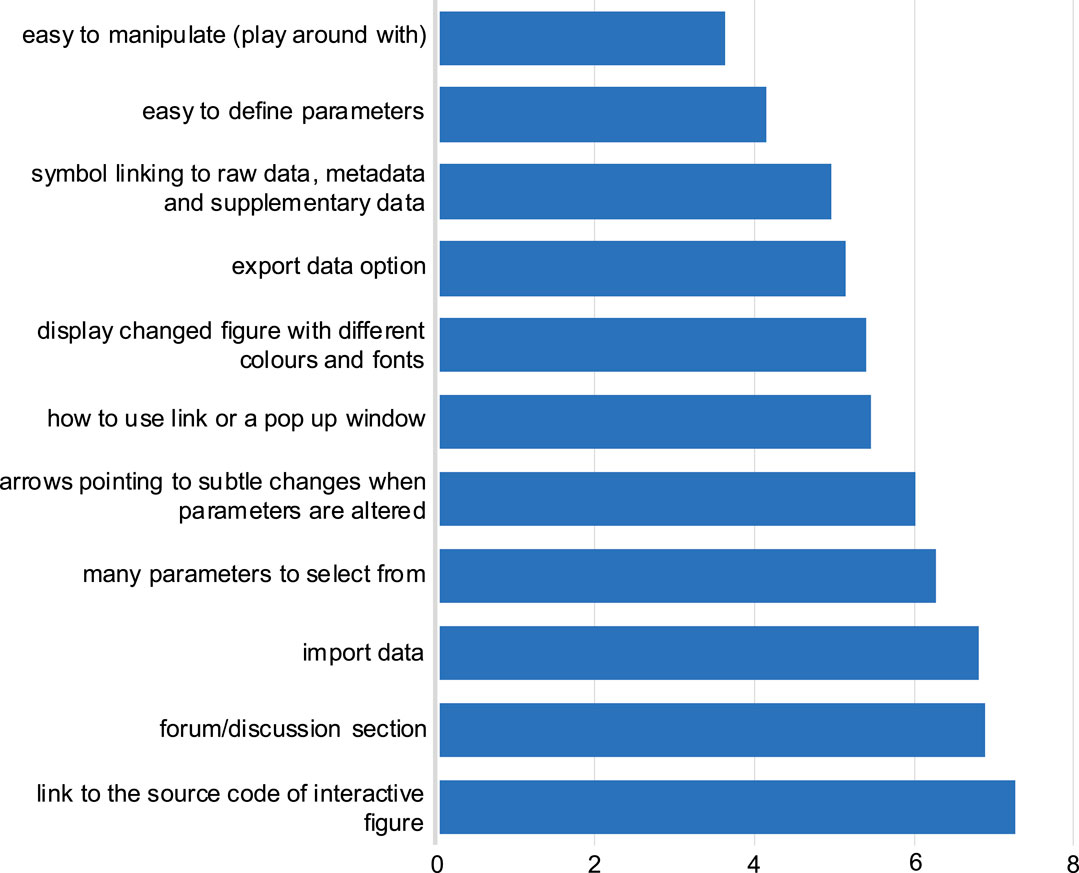
FIGURE 3. Preferred features for the interactive figure. Responses to question 9: Respondents were asked to rank in order of preference the above features, with one most preferred feature, to 11 the least preferred feature. The average score for each feature was calculated in order of preference as selected by the respondents from both NBI and eLIFE surveys. The lower the average score value (x-axis), the more preferred the feature (y-axis).
The majority of the respondents perceive a benefit in having interactive figures in published papers for both readers and authors (Figure 4). Examples of insights included: the interactive figure would allow visualising further points on the plot from data in the supplementary section, as well as be able to alter the data that is presented in the figure; having an interactive figure like a movie or to display protein 3D structures, would be beneficial to readers. The remaining responses we categorised as software related, which included suggestions of software that could be used to produce a figure that can be interactive, such as R Shiny (shiny.studio.com). We received a total of 114 free-text responses about the respondents’ opinions on what interactive figures are and a proportion of those (25%) suggested that they had never seen or interacted with such a figure before, and no indication was given that an interactive figure would help their work (see Supplementary section, free responses).
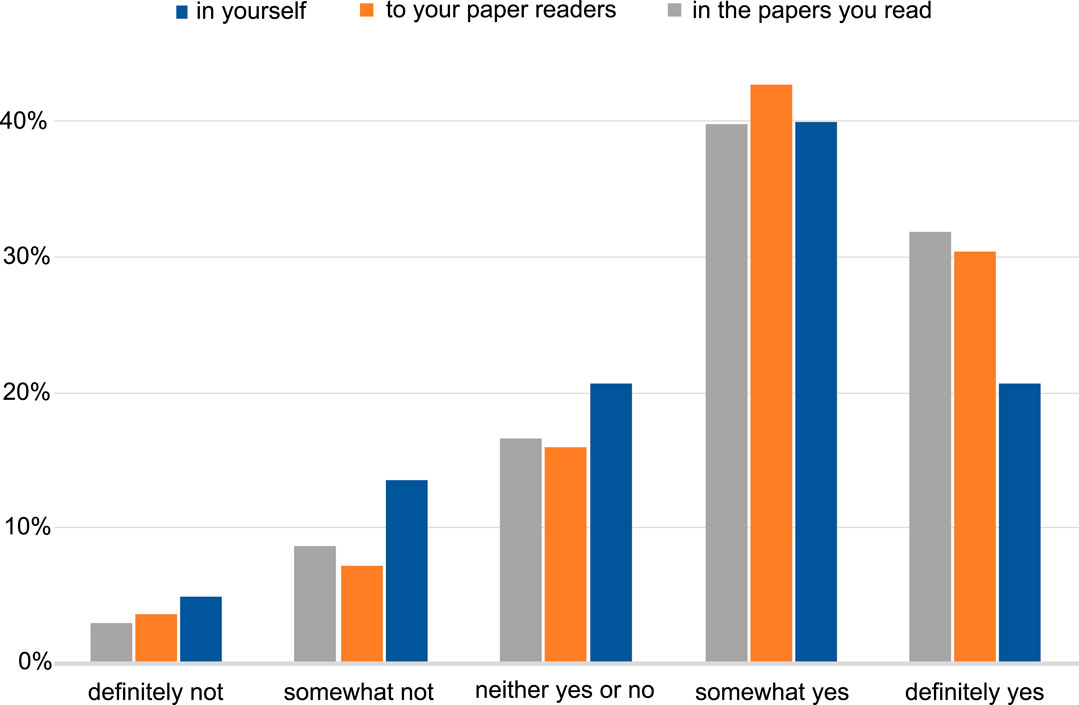
FIGURE 4. The level of perception of benefit to having the ability to publish papers with interactive figures. The benefit to the author, to the readers of the author’s papers and to the papers the author reads. Answers include the responses from both NBI and eLIFE surveys for question 11.
The majority of the respondents also said that they see a benefit in automatically reproducing computational experiments and manipulating and interacting with parameters in computational analysis workflows. Equally favourable was to be able to computationally reproduce statistical analyses (Figure 5). Despite this perceived benefit, most respondents (61%) indicated that the ability to include an interactive figure would not affect their choice of a journal when seeking to publish their research.
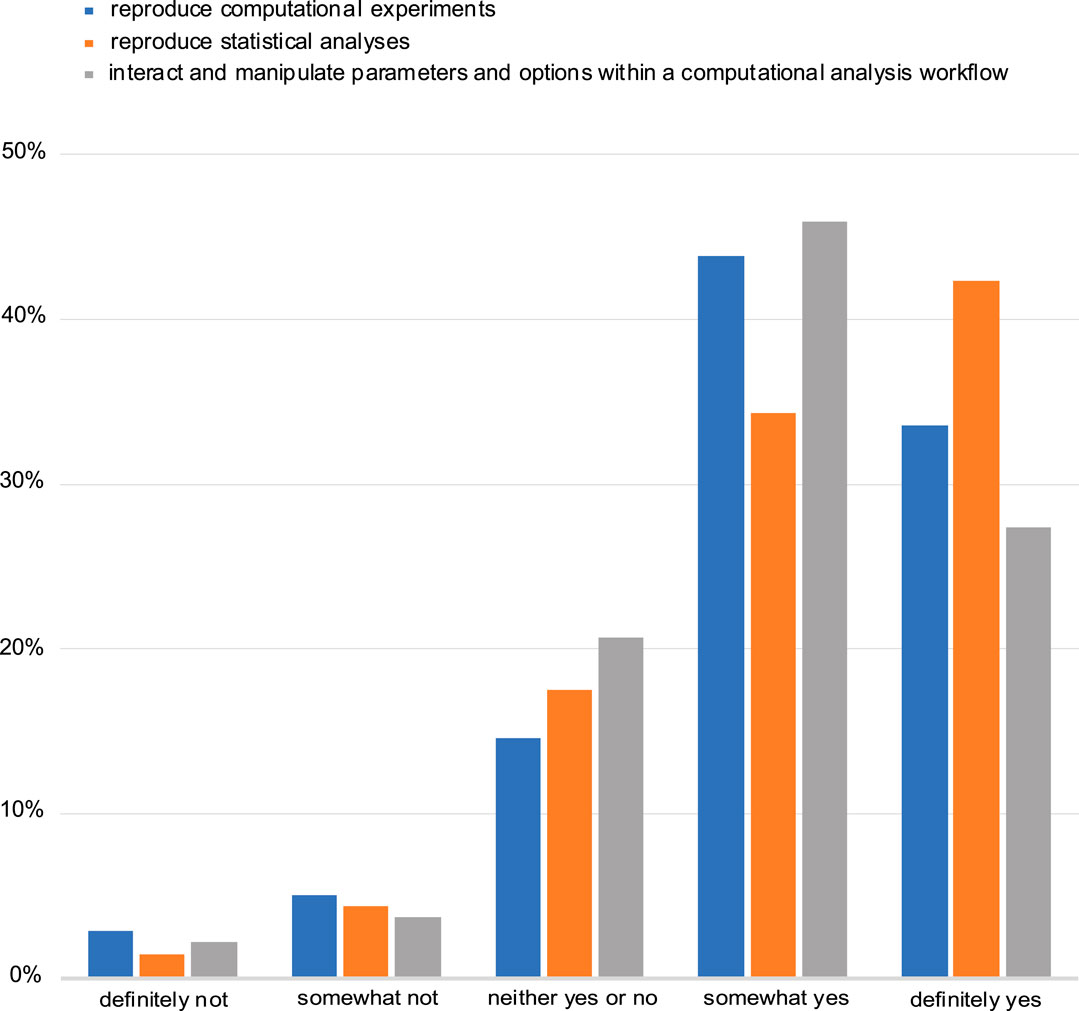
FIGURE 5. Assessment of perceived benefit for automatically reproducing computational experiments or other analyses (including statistical tests). Responses from both NBI and eLIFE for question 14.
Limitations
The findings were collected using the self-reporting method which can be limited in certain ways, especially with regards to the reported reproducibility success or lack of success of the respondents. We do not know categorically that someone reproduced experiments successfully because they checked the box. Despite the potential for confusing the exact meaning of reproducibility, which could affect the answers to questions five, six and seven, the general consensus among respondents showed that the questions were sufficiently phrased to help us divide people into two groups of assessment (successful vs not successful) for subsequent analysis.
Part of our survey sample were researchers from the NBI, and this population might not be representative of the life sciences research community. Researchers working in academic institutions may have attitudes, incentives, or infrastructure to support reproducibility that may be different from those who work in the private sector or government agencies. In addition, as the population of the NBI researchers was solely United Kingdom based, the attitudes of these researchers might differ from those in the rest of the world, even though the NBI comprises scientists who are from multiple countries and have trained and worked in global institutions. eLIFE authors work across the breadth of scientific institutions, both private and public, from the international stage, thus we believe that both eLIFE and NBI participants to be sufficiently representative for the purposes of our survey study.
Although we do not have distinct evidence that the eLIFE authors’ cohort had a predisposition to reproducibility, and the authors we surveyed were randomly selected, we acknowledge that as eLIFE is a journal that requires data sharing and is also heavily involved in reproducibility efforts, such as the Reproducibility Project: Cancer Biology. In the absence of data to the contrary, thus it is reasonable to assume that some factors might have influenced the eLIFE respondents’ opinions about reproducibility. We do not think that this fact undermines our conclusion, but it is a factor that future studies should be aware of when drawing comparisons that can shed further light on this issue.
We acknowledge that questions eight and nine were on the same page when the participants were taking the survey and seeing the two questions together might have introduced bias into their answers. Nonetheless, free text answers to question eight included answers which were not presented as options for question nine. Some respondents also declared that they were not aware of, or have not previously encountered, interactive figures (see Supplementary section free-text responses to question eight).
We have found that the response rate for studies of this nature is fairly typical and indeed, other studies (Koschke, 2003; Snell and Spencer, 2005; Federer et al., 2015; Schneider et al., 2016; Barone et al., 2017) have experienced comparable or lower rates. Ideally, we would want to aim for a higher response rate for future studies, which could be achieved by providing monetary incentives, as well as sending email reminders to the same or bigger cohort of invited people to participate in the study (James and Bolstein, 1990; Shettle and Mooney, 1999; Jobber et al., 2004).
Discussion
This study highlights the difficulties currently experienced in reproducing experiments and conveys positive attitudes of scientists toward enabling and promoting reproducibility of published experiments through interactive elements in online publications. The NBI cohort of respondents were active life sciences researchers at the time the survey was conducted, and the eLIFE cohort were researchers that have published at least once in the eLIFE journal; therefore we believe the opinions collected are representative of researchers in life sciences who are routinely reading and publishing research.
While progress has been made in publishing standards across all life science disciplines, the opinions of the respondents reflect previously published shortcomings of the publishing procedures (Müller et al., 2003; Tenopir et al., 2011; Marx, 2013; Stodden, 2015): lack of data and code provision; storage standards; not including or requiring a detailed description of the methods and code structure (i.e., code scripts, algorithms, full software packages, language used, versions of any libraries required, organisation of any modular components, configuration and deployment options) in the published papers. However, the level of interest and incentives in reproducing published research is in its infancy, or it is not the researchers’ priority (Collins and Tabak, 2014; Nosek et al., 2015). A key outcome of our survey is the acknowledgment of the large majority who understand that science becomes implicitly more reproducible if methods (including data, analysis, and code) are well-described and available. Respondents also perceive the benefit of having tools that enable the availability of data, methods and code and being able to automatically reproduce computational experiments described within the paper. Interactive figures within publications and executable documents can be such tools that allow the automatic reproducibility of computational experiments, or other analyses described within the paper, interact and manipulate parameters within the computational analysis workflow and give further insights and detailed view of the data in the figure. Despite technologies existing to aid reproducibility (Crick et al., 2014) and authors knowing they are beneficial, many scientific publications do not meet basic standards of reproducibility.
Our findings are in accordance with the current literature (Pulverer, 2015; Berg, 2018) that highlight that the lack of access to the data presented and described in research articles is one of the major reasons leading to the irreproducibility of published studies. When data is difficult to obtain, the reproducibility problem is exacerbated. A study that examined the differences between clinical and non-clinical scientists, showed that the majority of respondents did not have experience with uploading biomedical data to a repository, stemming from different social reasons not to do so: concerns and motivation around data sharing; work necessary to prepare the data (Federer et al., 2015). Even with current policies mandating data openness (National Institutes of Health, 2015; Wilkinson et al., 2016), authors still fail to include their data alongside their publication, and this can not only be attributed to technical complications, but also fear of being scooped, fear of mistakes being found in data or analyses, and fear of others using their data for their own research papers (Federer et al., 2015; Stodden, 2010; Tenopir et al., 2011, Tenopir et al., 2015). Making FAIR data practices standard, through public data deposition and subsequent publication and citation, could encourage individual researchers and communities to share and reuse data considering their individual requirements and needs (Pawlik et al., 2019). Data accessibility issues are also compounded by data becoming less retrievable with every year passing after the publication (Vines et al., 2014). This is supported by our findings where data is either not available upon publication (57%) or authors cannot be reached/are unresponsive to data provision requests (44%). This continues to be a cultural artifact of using a paper’s methods section as a description of steps to reproduce analysis, rather than a fully reproducible solution involving easy access to public data repositories, open-source code, and comprehensive documentation.
As evidenced by the respondents, the lack of data availability is a common hurdle for researchers to encounter that prevents the reproducibility of published work. Thus, the reproducibility of experiments could be improved by increasing the availability of data. Datasets are becoming larger and more complex, especially in genomics. Storage solutions for large data files and citing them within the publication document, especially those in the order of terabytes, can allow for their wider, more efficient and proper data reusability (Faniel and Zimmerman, 2011; Poldrack and Gorgolewski, 2014). Despite the potential advantage, these services can provide for data availability and accessibility, they do not implicitly solve the problem of data reusability. This is most apparent when data is too large to be stored locally or transferred via slow internet connections, or there is no route to attach metadata that describes the datasets sufficiently for reuse or integration with other datasets. There is also the question of data repository longevity - who funds the repositories for decades into the future? Currently, some researchers now have to pay data egress charges for downloading data from cloud providers (Banditwattanawong et al., 2014; Linthicum, 2018). This method presumably saves the data producers money in terms of storing large datasets publicly, but the cost is somewhat now presented to the consumer. This raises complex questions around large data generation projects that also need to be studied extensively for future impact, especially with respect to reproducibility within publications. Moreover, access to the raw data might not be enough, if the steps and other artifacts involved in producing the processed data that was used in the analysis are not provided (Pawlik et al., 2019). In addition, corresponding authors often move on from projects and institutions or the authors themselves can no longer access the data, meaning “data available on request” ceases to be a viable option to source data or explanations of methods. Restricted access to an article can also affect reproducibility by requiring paid subscriptions to read content from a publisher. Although there is precedent for requesting single articles within cross-library loan systems or contacting the corresponding author(s) directly, this, much like requesting access to data, is not without issues. Pre-print servers such as bioRxiv have been taken up rapidly (Abdill and Blekhman, 2019), especially in the genomics and bioinformatics domains, and this has the potential to remove delays in publication whilst simultaneously providing a “line in the sand” with a Digital Object Identifier (DOI) and maintaining the requirements for FAIR data. In some cases, the sensitivity of data might discourage authors from data sharing (Hollis, 2016; Figueiredo, 2017), but this reason was only reported by a small proportion of our respondents. Whilst there are efforts that attempt to apply the FAIR principles to clinical data, such as in the case of the OpenTrials database (Chen and Zhang, 2014), they are by no means ubiquitous.
Data within public repositories with specific deposition requirements (such as the EMBL-EBI European Nucleotide Archive, ebi.ac.uk/ena), might not be associated or annotated with standardised metadata that describes it accurately (Attwood et al., 2009), rather the bare minimum for deposition. Training scientists to implement data management policies effectively is likely to increase data reuse through improved metadata. In a 2016 survey of 3,987 National Science Foundation Directorate of Biological Sciences principal investigators (BIO PIs), expressed their greatest unmet training needs by their institutions (Collins and Tabak, 2014). These were in the areas of integration of multiple data (89%), data management and metadata (78%) and scaling analysis to cloud/high-performance computing (71%). The aforementioned data and computing elements are integral to the correct knowledge “how-to” for research reproducibility. Our findings indicated that those who stated they had experience in informatics also stated they are better able to attempt and reproduce results. Practical bioinformatics and data management training, rather than in specific tools, may be an effective way of reinforcing the notion that researchers’ contributions toward reproducibility are a responsibility that requires active planning and execution. This may be especially effective when considering the training requirements of wet-lab and field scientists, who are becoming increasingly responsible for larger and more complex computational datasets. Further research needs to be undertaken to better understand how researchers’ competence in computational reproducibility may be linked to their level of informatics training.
Furthermore, for transparent and reproducible science, both negative (or null) and positive results should be reported for others to examine the evidence (Franco et al., 2014; Prager et al., 2019; Miyakawa, 2020). However, there remains a perception that researchers do not get credit for reproducing the work of others or publishing negative or null results (Franco et al., 2014; Teixeira da Silva, 2015). Whilst some journals explicitly state that they welcome negative results articles (e.g., PLOS ONE “Missing Pieces” collection), this is by no means the norm in life science publishing as evidenced by low, and dropping publication rates of negative findings (Fanelli, 2012; Franco et al., 2014; Teixeira da Silva, 2015). In addition, the perception that mostly positive results are publication-worthy might discourage researchers from providing enough details on their research methodology, such as reporting any negative findings. Ideally, the publication system would enable checking of reproducibility by reviewers and editors at the peer-review stage, with authors providing all data (including raw data), a full description of methods including statistical analysis parameters, any negative findings based on previous work and open source software code (Iqbal et al., 2016). These elements can all be included within the interactive figure, such as by zooming in on over data points to reveal more information on the data, pop-up windows to give details on negative results and parameters and the figure offering re-running of the computational experiment in the case of executable documents. Peer reviewers would then be better able to check for anomalies, and editors could perform the final check to ensure that the scientific paper to be published is presenting true, valid, and reproducible research. Some respondents have suggested that if reviewers and/or editors were monetarily compensated, spending time to reproduce the computational experiments in manuscripts would become more feasible and would aid the irreproducibility issue. However, paying reviewers does not necessarily ensure that they would be more diligent in checking or trying to reproduce results (Hershey, 1992) and there must be optimal ways to ensure effective pressure is placed upon the authors and publishing journals to have better publication standards (Anon, 2013; Pusztai et al., 2013). The increasing adoption by journals of reporting standards for experimental design and results, provide a framework for harmonising the description of scientific processes to enable reproducibility. However, these standards are not universally enforced (Moher, 2018). Similarly, concrete funding within research grants for implementing reproducibility itself manifested as actionable Data Management Plans (Digital Curation Center), rather than what is currently a by-product of the publishing process, could give a level of confidence to researchers who would want to reproduce previous work and incorporate that data in their own projects.
Respondents mentioned that there are word count restrictions in papers, and journals often ask authors to shorten methods sections and perhaps move some text to supplementary information, many times placed in an unorganised fashion or having to remove it altogether. This is a legacy product of the hard-copy publishing era and readability aside; word limits are not consequential for most internet journals. Even so, if the word count limit was only applicable to the introduction, results and discussion sections, then the authors could describe methods in more detail within the paper, without having to move that valuable information in the supplementary section. When methods are citing methodology techniques as described in other papers, where those original references are hard to obtain, typically through closed access practices or by request mechanisms as noted above, then this can be an additional barrier to the reproducibility of the experiment. This suggests that there are benefits to describing the methods in detail and stating that they are similar to certain (cited) references as well as document the laboratory's expertise in a particular method (Moher et al., 2015). However, multi-institutional or consortium papers are becoming more common with ever-increasing numbers of authors on papers, which adds complexity to how authors should describe every previous method available that underpins their research (Gonsalves, 2014). There is no obvious solution to this issue. Highly specialised methods (e.g., electrophysiology expertise, requirements for large computational resources or knowledge of complex bioinformatics algorithms) and specific reagents (e.g., different animal strains), might not be readily available to other research groups (Collins and Tabak, 2014). As stated by some respondents, in certain cases the effective reproducibility of experiments is obstructed by numerical issues with very small or very large matrices or datasets, or different versions of analysis software used, perhaps to address bugs in analytical code, will cause a variation in the reproduced results.
Effects on Technical Developments
Previous studies have provided strong evidence that there is a need for better technical systems and platforms to enable and promote the reproducibility of experiments. We provide additional evidence that paper authors and readers perceive a benefit from having an interactive figure that would allow for the reproducibility of the experiment shown in the figure. An article that gives access to the data, code and detailed data analysis steps would allow for in situ reproduction of computational experiments by re-running code including statistical analyses “live” within the paper (Perkel, 2017). Whilst our study did not concentrate on how these “executable papers” may be constructed, this is an active area of development and some examples of how this may be achieved have been provided (Jupyter et al., 2018; Somers, 2018). We provide additional evidence that paper authors and readers perceive a benefit from having publication infrastructure available that would allow for the reproducibility of an experiment. As such, the findings of this survey helped the development of two prototypes of interactive figures (see Data and Code availability) and subsequently the creation of eLIFE’s first computationally reproducible document (Ghosh et al., 2017).
We also asked whether presenting published experiments through interactive figures elements in online publications might be beneficial to researchers, in order to better consume research outputs. Respondents stated they could see the benefit in having interactive figures for the readers of their papers and the papers they read and being able as authors to present their experiment analysis and data as interactive figures. Respondents endorsed articles that include interactive elements, where access to the processed and raw data, metadata, code, and detailed analysis steps, in the form of an interactive figure, would help article readers better understand the paper and the experimental design and methodology. This would, in turn, improve the reproducibility of the experiment presented in the interactive figure, especially computational experiments. The notion of data visualisation tools promoting interactivity and reproducibility in online publishing has also been discussed in the literature (Perkel, 2018). Other efforts have been exploring the availability of interactive figures for driving reproducibility in publishing in the form of executable documents (Ghosh et al., 2017; Ingraham, 2017; Rao et al., 2017; Jupyter et al., 2018). Moreover, technologies such as Jupyter Notebooks, Binder, myExperiment, CodeOcean enable the reproducibility of computational experiments associated with publications, provided by the authors as links from the paper. However, the benefit of having the interactivity and availability of reproducing experiments from within the article itself in the form of interactive figures, is that the reader can stay within the article itself and explore all the details of the data presented in the figure, download the data, play with the code or analysis that produced the figure, interact with parameters in the computational analysis workflows and computationally reproduce the experiments presented in the figure. This can enable the reader to better understand the research done presented in the interactive figure. Despite the self-reported perceived benefits of including interactive figures, the availability of this facility would not affect the respondents’ decisions on where to publish. This contradiction suggests that cultural factors (incentives, concerns authors have with sharing their data, attitudes toward open research) (Stodden, 2010; Federer et al., 2015) play an underestimated role in reproducibility.
Despite the benefits, the interactive documents and figures can provide to the publishing system for improved consumption of research outputs, and that those benefits are in demand by the scientific community, work is needed in order to promote and support their use. Given the diversity of biological datasets and ever-evolving methods for data generation and analysis, it is unlikely that a single interactive infrastructure type can support all types of data and analysis. More research into how different types of data can be supported and presented in papers with interactivity needs to be undertaken. Yet problems with data availability and data sizes will persist - many studies comprise datasets that are too large to upload and render within web browsers in a reasonable timescale. Even if the data are available through well-funded repositories with fast data transfers, e.g., the INSDC databases (insdc.org), are publishers ready to bear the extra costs of supporting the infrastructure and people required to develop or maintain such interactive systems in the long run? These are questions that need to be further investigated, particularly when considering any form of industry standardisation of such interactivity in the publishing system. Publishing online journal papers with embedded interactive figures requires alterations to infrastructure, authoring tools and editorial processes (Perkel, 2018). In some cases, the data underpinning the figures might need to be stored and managed by third parties and this means the data, as well as the figures, may not be persistent. The same argument is relevant to software availability and reuse - publishers would need to verify that any links to data and software were available and contained original unmodified datasets. As datasets become larger and more complex, and more software and infrastructure is needed to re-analyse published datasets, this will affect how infrastructure will need to be developed to underpin reproducible research. Incentives will need to be put in place to motivate investment in these efforts.
Effects on Research Policy and Practice
We show that providing tools to scientists who are not computationally aware also requires a change in research culture, as many aspects of computational reproducibility require a change in publishing behavior and competence in the informatics domain. Encouraging and incentivising scientists to conduct robust, transparent, reproducible and replicable research, such as with badges to recognise open practices should be prioritised to help solve the irreproducibility issue (Kidwell et al., 2016). Implementing hiring practices with open science at the core of research roles (Schönbrodt, 2016) will encourage attitudes to change across faculty departments and institutions. In general, as journal articles are still the dominant currency of research in terms of career development, measures of reproducibility and openness may well become more important to hiring institutions when considering candidates rather than publication placement and impact. Indeed, DORA (sfdora.org) now has many signatories, showing that research institutions are taking their role seriously in changing the previous cultural practices of closed “prestigious” science.
We believe that the attitudes highlighted in this survey reflect the growing acceptance of open publishing of code and data, in at least some disciplines. Some publishers are acknowledging that they have a part to play in the improvement of reproducibility through their publishing requirements, e.g., PLOS Computational Biology recently announced that the journal is implementing a “more-rigorous code policy that is intended to increase code sharing on publication of articles” (Cadwallader et al., 2021). Google Scholar now includes a measure of the number of publications in a researcher’s profile that meet funder mandates for open access. Whilst, not a perfect system (institutional repositories do not seem to be well covered currently), this shows that even search engines that are heavily in use by researchers to find and consume research outputs are trying to both adapt to cultural changes and automate the presentation of open reproducible science as a goal for researchers. Our survey reflects movements toward open scholarly communications and reproducible academic publishing that are being put into practice. Further work in this area should include surveys to quantitatively and qualitatively assess how these changes and developments in policy and practice are having an effect on the research culture of reproducibility in the life sciences.
Another potential solution to the reproducibility crisis is to identify quantifiable metrics of research reproducibility and its scientific impact, thus giving researchers a better understanding of how their work stands on a scale of measurable reproducibility. The current assessment of the impact of research articles is a set of quantifiable metrics that do not evaluate research reproducibility, but stakeholders are starting to request that checklists and tools are provided to improve these assessments (Wellcome Trust, 2018). It is harder to find a better approach that is based on a thoroughly informed analysis by unbiased experts in the field that would quantify the reproducibility level of the research article (Flier, 2017). That said, top-down requirements from journals and funders to release reproducible data and code may go some way to improving computational reproducibility within the life sciences, but this will also rely on the availability of technical solutions that are accessible and useful to most scientists.
Opinions are mixed regarding the extent and severity of the reproducibility crisis. Our study and previous studies are highlighting the need to find effective solutions toward solving the reproducibility issue. Steps toward modernising the publishing system by incorporating interactivity with interactive figures and by automatically reproducing computational experiments described within a paper are deemed desirable. This may be a good starting point for improving research reproducibility by reproducing experiments within research articles. This, however, does not come without its caveats, as we described above. From our findings and given the ongoing release of tools and platforms for technical reproducibility, future efforts should be spent in tackling the cultural behavior of scientists, especially when faced with the need to publish for career progression.
Data Availability Statement
All datasets presented in this study can be found below: https://doi.org/10.6084/m9.figshare.c.4436912. Prototypes of interactive figures developed by the corresponding author are available via these GitHub repositories: https://github.com/code56/nodeServerSimpleFig and https://github.com/code56/prototype_article_interactive_figure.
Ethics Statement
The studies involving human participants were reviewed and approved by UEA Computing Sciences Research Ethics Committee Approval reference: CMPREC/1819/R/13. Data were analysed anonymously, however, we did seek and received ethics approval. Written informed consent for participation was not required for this study in accordance with the national legislation and the institutional requirements.
Author Contributions
ES and RD contributed to the conception and design of the study. ES conducted the survey, collected the data and organised the database. ES and RD performed the statistical analysis. ES wrote the first draft of the manuscript. Both authors contributed to manuscript revision, read, and approved the submitted version.
Funding
This work was supported by the Biotechnology and Biological Sciences Research Council (BBSRC) through the Core Capability Grant BB/CCG1720/1 at the Earlham Institute. ES was supported by a BBSRC iCASE PhD training grant (project reference: BB/M017176/1) and eLIFE. RD was supported by the BBSRC grants BBS/E/T/000PR9817 and BBS/E/T/000PR9783. Open Access fee support was provided by the BBSRC.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We would like to thank all the respondents of the surveys for their time. We would also like to thank George Savva from the Quadram Institute (QIB, United Kingdom) for comments and suggestions for this manuscript; eLIFE Sciences Publications Ltd., with whom the corresponding author collaborates as an iCASE student; as well as Ian Mulvany, former eLIFE Head of Development, for his help in developing the survey questionnaire.
References
Abdill, R. J., and Blekhman, R. (2019). Meta-Research: Tracking the Popularity and Outcomes of All bioRxiv Preprints. eLife 8, e45133. doi:10.7554/elife.45133
Afgan, E., Baker, D., Batut, B., van den Beek, M., Bouvier, D., Čech, M., et al. (2018). The Galaxy Platform for Accessible, Reproducible and Collaborative Biomedical Analyses: 2018 Update. Nucleic Acids Res. 46 (W1), W537–W544. doi:10.1093/nar/gky379
Amstutz, P., Crusoe, M. R., Tijanić, N., Chapman, B., Chilton, J., and Heuer, M. (2016). Common Workflow Language Specifications, v1.0.2. Retrieved from: www.commonwl.org website: https://w3id.org/cwl/v1.0/.
Anon, J. (2013). Announcement: Reducing Our Irreproducibility. Nature 496 (7446), 398. doi:10.1038/496398a
Attwood, T. K., Kell, D. B., McDermott, P., Marsh, J., Pettifer, S. R., and Thorne, D. (2009). Calling International rescue: Knowledge Lost in Literature and Data Landslide!. Biochem. J. 424 (3), 317–333. doi:10.1042/bj20091474
Baker, M. (2016). Is There a Reproducibility Crisis? A Nature Survey Lifts the Lid on How Researchers View the Ciris Rocking Science and what They Think Will Help. Nature 533 (26), 353–366. doi:10.1038/533452a
Banditwattanawong, T., Masdisornchote, M., and Uthayopas, P. (2014). “Economical and Efficient Big Data Sharing with I-Cloud,” in 2014 International Conference on Big Data and Smart Computing (BIGCOMP), Bangkok, Thailand, 15–17 Janurary 2014, (IEEE), 105–110.
Baranyi, M., and Greilhuber, J. (1999). Genome Size inAllium: in Quest of Reproducible Data. Ann. Bot. 83 (6), 687–695. doi:10.1006/anbo.1999.0871
Barnes, D. G., and Fluke, C. J. (2008). Incorporating Interactive Three-Dimensional Graphics in Astronomy Research Papers. New Astron. 13 (8), 599–605. doi:10.1016/j.newast.2008.03.008
Barnes, D. G., Vidiassov, M., Ruthensteiner, B., Fluke, C. J., Quayle, M. R., and McHenry, C. R. (2013). Embedding and Publishing Interactive, 3-dimensional, Scientific Figures in Portable Document Format (Pdf) Files. PloS one 8 (9), e69446. doi:10.1371/journal.pone.0069446
Barone, L., Williams, J., and Micklos, D. (2017). Unmet Needs for Analyzing Biological Big Data: A Survey of 704 NSF Principal Investigators. PLoS Comput. Biol. 13 (10), e1005755. doi:10.1371/journal.pcbi.1005755
Begley, C. G., and Ellis, L. M. (2012). Raise Standards for Preclinical Cancer Research. Nature 483 (7391), 531–533. doi:10.1038/483531a
Bell, C. J., Dinwiddie, D. L., Miller, N. A., Hateley, S. L., Ganusova, E. E., Mudge, J., et al. (2011). Carrier Testing for Severe Childhood Recessive Diseases by Next-Generation Sequencing. Sci. translational Med. 3 (65), 65ra4. doi:10.1126/scitranslmed.3001756
Brinckman, A., Chard, K., Gaffney, N., Hategan, M., Jones, M. B., Kowalik, K., et al. (2018). Computing Environments for Reproducibility: Capturing the “Whole Tale”. Future Generation Computer Syst. 94, 854–867.
Cadwallader, L., Papin, J. A., Mac Gabhann, F., and Kirk, R. (2021). Collaborating with Our Community to Increase Code Sharing. Plos Comput. Biol. 17 (3), e1008867. doi:10.1371/journal.pcbi.1008867
Cataldo, M., Mockus, A., Roberts, J. A., and Herbsleb, J. D. (2009). Software Dependencies, Work Dependencies, and Their Impact on Failures. IIEEE Trans. Softw. Eng. 35 (6), 864–878. doi:10.1109/tse.2009.42
Chen, C. P., and Zhang, C.-Y. (2014). Data-intensive Applications, Challenges, Techniques and Technologies: A Survey on Big Data. Inf. Sci. 275, 314–347.
Chirigati, F., Rampin, R., Shasha, D., and Freire, J. (2016). “Reprozip: Computational Reproducibility with Ease,” in Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, United States, 26 June 2016–July 1 2016, (ACM (Association for Computing Machinery), 2085–2088. doi:10.1145/2882903.2899401
Christensen, G., and Miguel, E. (2018). Transparency, Reproducibility, and the Credibility of Economics Research. J. Econ. Lit. 56 (3), 920–980. doi:10.1257/jel.20171350
Claerbout, J. F., and Karrenbach, M. (1992). “Electronic Documents Give Reproducible Research a New Meaning,” in Seg Technical Program Expanded Abstracts 1992 (Stanford, CA, United States: Standford Exploration Project), 601–604.
Collins, F. S., and Tabak, L. A. (2014). Policy: Nih Plans to Enhance Reproducibility. Nature 505 (7485), 612–613. doi:10.1038/505612a
Colomb, J., and Brembs, B. (2014). Sub-strains of drosophila Canton-s Differ Markedly in Their Locomotor Behavior. F1000Res 3, 176. doi:10.12688/f1000research.4263.1
Crick, T., Hall, B. A., and Ishtiaq, S. (2017). Reproducibility in Research: Systems, Infrastructure, Culture. J. Open Res. Softw. 5. doi:10.5334/jors.73
Crick, T., Hall, B. A., Ishtiaq, S., and Takeda, K. (2014). “" Share and Enjoy": Publishing Useful and Usable Scientific Models,” in In 2014 IEEE/ACM 7th International Conference on Utility and Cloud Computing, London, UK, 8–11 December 2014, (IEEE), 957–961. doi:10.1109/UCC.2014.156
de Ruiter, P. (2017). The Significance of Reproducible Data. Retrieved from: https://www.labfolder.com/blog/the-significance-of-reproducible-data/(Accessed September 1, 2019).
Donoho, D. L. (2010). An Invitation to Reproducible Computational Research. Biostatistics 11 (3), 385–388. doi:10.1093/biostatistics/kxq028
Drummond, C. (2009). “Replicability Is Not Reproducibility: Nor Is it Good Science,” in Proceedings of the Evaluation Methods for Machine Learning Workshop at the 26th ICML., 2009, Montreal, Canada, 14–18 June 2009, (New York, United States: ACM (Association for Computing Machinery)). doi:10.1145/1553374.1553546
Eisner, D. (2018). Reproducibility of Science: Fraud, Impact Factors and Carelessness. J. Mol. Cell. Cardiol. 114, 364–368. doi:10.1287/865b2258-d578-4194-9895-d5d65d7a739c
Fanelli, D. (2012). Negative Results Are Disappearing from Most Disciplines and Countries. Scientometrics 90 (3), 891–904. doi:10.1007/s11192-011-0494-7
Faniel, I. M., and Zimmerman, A. (2011). Beyond the Data Deluge: A Research Agenda for Large-Scale Data Sharing and Reuse. Ijdc 6 (1), 58–69. doi:10.2218/ijdc.v6i1.172
Federer, L. M., Lu, Y.-L., Joubert, D. J., Welsh, J., and Brandys, B. (2015). Biomedical Data Sharing and Reuse: Attitudes and Practices of Clinical and Scientific Research Staff. PloS one 10 (6), e0129506. doi:10.1371/journal.pone.0129506
Feger, S. S., Dallmeier-Tiessen, S., Woźniak, P. W., and Schmidt, A. (2019). “Gamification in Science: A Study of Requirements in the Context of Reproducible Research,” in Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow Scotland, United Kingdom, May 4–9, 2019, (New York, United States: ACM (Association for Computing Machinery)), 1–14.
Figueiredo, A. S. (2017). Data Sharing: Convert Challenges into Opportunities. Front. Public Health 5, 327. doi:10.3389/fpubh.2017.00327
Flier, J. S. (2017). Irreproducibility of Published Bioscience Research: Diagnosis, Pathogenesis and Therapy. Mol. Metab. 6 (1), 2–9. doi:10.1016/j.molmet.2016.11.006
Franco, A., Malhotra, N., and Simonovits, G. (2014). Publication Bias in the Social Sciences: Unlocking the File Drawer. Science 345 (6203), 1502–1505. doi:10.1126/science.1255484
Fraser, H., Parker, T., Nakagawa, S., Barnett, A., and Fidler, F. (2018). Questionable Research Practices in Ecology and Evolution. PLOS ONE 13 (7), e0200303, e0200303. doi:10.1371/journal.pone.0200303
Freedman, L. P., Cockburn, I. M., and Simcoe, T. S. (2015). The Economics of Reproducibility in Preclinical Research. Plos Biol. 13 (6), e1002165. doi:10.1371/journal.pbio.1002165
Ghosh, S. S., Poline, J.-B., Keator, D. B., Halchenko, Y. O., Thomas, A. G., Kessler, D. A., et al. (2017). A Very Simple, Re-executable Neuroimaging Publication. F1000Research 6, 124. doi:10.12688/f1000research.10783.2
Goble, C. A., Bhagat, J., Aleksejevs, S., Cruickshank, D., Michaelides, D., and Newman, D. (2010). myExperiment: a Repository and Social Network for the Sharing of Bioinformatics Workflows. Nucleic Acids Res. 38 (Suppl. 2), W677–W682. doi:10.1093/nar/gkq429
Goff, S. A., Vaughn, M., McKay, S., Lyons, E., Stapleton, A. E., Gessler, D., et al. (2011). The iPlant Collaborative: Cyberinfrastructure for Plant Biology. Front. Plant Sci. 2, 34. doi:10.3389/fpls.2011.00034
Gonsalves, A. (2014). Lessons Learned on Consortium-Based Research in Climate Change and Development. (Ottawa, Canada; London, United Kingdom: International Development Research Centre; UK Aid), 1. Available at: https://idl-bnc-idrc.dspacedirect.org/bitstream/handle/10625/52501/1/IDL-52501.pdf.
Grossman, T., Chevalier, F., and Kazi, R. H. (2016). Bringing Research Articles to Life with Animated Figures. Interactions 23 (4), 52–57. doi:10.1145/2949762
Hardwicke, T. E., Mathur, M. B., MacDonald, K., Nilsonne, G., Banks, G. C., Kidwell, M. C., et al. (2018). Data Availability, Reusability, and Analytic Reproducibility: Evaluating the Impact of a Mandatory Open Data Policy at the Journal Cognition. R. Soc. Open Sci. 5 (8), 180448. doi:10.1098/rsos.180448
Hershey, N. (1992). Compensation and Accountability: The Way to Improve Peer Review. Qual. Assur. Utilization Rev. 7 (1), 23–29. doi:10.1177/106286069200700104
Higginson, A. D., and Munafò, M. R. (2016). Current Incentives for Scientists lead to Underpowered Studies with Erroneous Conclusions. PLoS Biol. 14 (11), e2000995. doi:10.1371/journal.pbio.2000995
Hollis, K. F. (2016). To Share or Not to Share: Ethical Acquisition and Use of Medical Data. AMIA Summits Translational Sci. Proc. 2016, 420.
Hull, D., Wolstencroft, K., Stevens, R., Goble, C., Pocock, M. R., Li, P., et al. (2006). Taverna: a Tool for Building and Running Workflows of Services. Nucleic Acids Res. 34 (Suppl. 2), W729–W732. doi:10.1093/nar/gkl320
Ingraham, T. (2017). Reanalyse(a)s: Making Reproducibility Easier with Code Ocean Widgets. Retrieved from. doi:10.2514/6.2017-0456https://blog.f1000.com/2017/04/20/reanaly-seas-making-reproducibility-easier-with-code-ocean-widgets/(Accessed September 6, 2019).
Ingraham, T. (2017). Researchers Can Now Publish Interactive Plotly Figures in F1000PlotlyRetrieved from: https://medium.com/plotly/researchers-can-now-publish-interactive-plotly-figures-in-f1000-87827a1b5d94 (Accessed August 7, 2019).
Ioannidis, J., and Doucouliagos, C. (2013). What's to Know about the Credibility of Empirical Economics? J. Econ. Surv. 27 (5), 997–1004. doi:10.1111/joes.12032
Ioannidis, J. P. A. (2005). Why Most Published Research Findings Are False. Plos Med. 2 (8), e124. doi:10.1371/journal.pmed.0020124
Ioannidis, J. P., Stanley, T. D., and Doucouliagos, H. (2017). The Power of Bias in Economics Research. Oxford, UK: Oxford University Press.
Iqbal, S. A., Wallach, J. D., Khoury, M. J., Schully, S. D., and Ioannidis, J. P. (2016). Reproducible Research Practices and Transparency across the Biomedical Literature. PLoS Biol. 14 (1), e1002333. doi:10.1371/journal.pbio.1002333
James, J. M., and Bolstein, R. (1990). The Effect of Monetary Incentives and Follow-Up Mailings on the Response Rate and Response Quality in Mail Surveys. Public Opin. Q. 54 (3), 346–361. doi:10.1086/269211
Jobber, D., Saunders, J., and Mitchell, V.-W. (2004). Prepaid Monetary Incentive Effects on Mail Survey Response. J. Business Res. 57 (1), 21–25. doi:10.1016/s0148-2963(02)00280-1
Jupyter, P., Bussonnier, M., Forde, J., Freeman, J., Granger, B., and Head, T. (2018). “Binder 2.0-reproducible, Interactive, Sharable Environments for Science at Scale,” in Proceedings of the 17th python in science conference, Austin, TX, United States, July 9–July 15, 2018, 113, 120. doi:10.25080/majora-4af1f417-011
Kidwell, M. C., Lazarevic, L. B., Baranski, E., Hardwicke, T. E., Piechowski, S., and Falkenberg, L.-S. and . . . others (2016). Badges to Acknowledge Open Practices: A Simple, Low-Cost, Effective Method for Increasing Transparency. PLoS Biol. 14 (5), e1002456. doi:10.1371/journal.pbio.1002456
Kim, Y. M., Poline, J. B., and Dumas, G. (2018). Experimenting with reproducibility: a case study of robustness in bioinformatics. GigaScience 7 (7), giy077. doi:10.1093/gigascience/giy077
Koschke, R. (2003). Software Visualization in Software Maintenance, Reverse Engineering, and Re-engineering: a Research Survey. J. Softw. Maint. Evol. Res. Pract. 15 (2), 87–109. doi:10.1002/smr.270
Kurtzer, G. M., Sochat, V., and Bauer, M. W. (2017). Singularity: Scientific Containers for Mobility of Computer. PloS one 12 (5), e0177459. doi:10.1371/journal.pone.0177459
Leipzig, J., Nust, D., Hoyt, C. T., Soiland-Reyes, S., Ram, K., and Greenberg, J. (2020). The Role of Metadata in Reproducible Computational Research. preprint arXiv:2006.08589.
LeVeque, R. J., Mitchell, I. M., and Stodden, V. (2012). Reproducible Research for Scientific Computing: Tools and Strategies for Changing the Culture. Comput. Sci. Eng. 14 (4), 13–17. doi:10.1109/mcse.2012.38
Liberman, M. (2015). Replicability vs. Reproducibility — or Is it the Other Way Around? Retrieved from: https://languagelog.ldc.upenn.edu/nll/?p=21956 (Accessed October 5, 2019).
Linthicum, D. (2018). Don’t Get Surprised by the Cloud’s Data-Egress Fees. Retrieved from: https://www.infoworld.com/article/3266676/dont-get-surprised-by-the-clouds-data-egress-fees.html (Accessed September 6, 2019).
Maciocci, G., Aufreiter, M., and Bentley, N. (2019). Introducing eLIFE's First Computationally Reproducible Article, Cambridge, United Kingdom: eLife Labs [Internet].
Miyakawa, T. (2020). No Raw Data, No Science: Another Possible Source of the Reproducibility Crisis. BioMed Central. doi:10.1201/9780367811044
Moher, D., Avey, M., Antes, G., and Altman, D. G. (2015). The National Institutes of Health and Guidance for Reporting Preclinical Research. BMC Med. 13 (1), 1–4. doi:10.1186/s12916-015-0321-8
Moher, D. (2018). Reporting Guidelines: Doing Better for Readers. BMC Med. 16 (1). doi:10.1186/s12916-018-1226-0
Munafo, M. R., Nosek, B. A., Bishop, D. V., Button, K. S., Chambers, C. D., Du Sert, N. P., et al. (2017). A Manifesto for Reproducible Science. Nat. Hum. Behav. 1 (1), 1–9. doi:10.1038/s41562-016-0021
National Institutes of Health (2015). Plan for Increasing Access to Scientific Publications and Digital Scientific Data from NIH Funded Scientific Research. Retrieved from https://grants.nih.gov/grants/NIH-Public-Access-Plan.pdf.
Newe, A. (2016). Enriching Scientific Publications with Interactive 3D Pdf: an Integrated Toolbox for Creating Ready-To-Publish Figures. PeerJ Computer Sci. 2, e64. doi:10.7717/peerj-cs.64
Nosek, B. A., Alter, G., Banks, G. C., Borsboom, D., Bowman, S. D., Breckler, S. J., et al. (2015). Promoting an Open Research Culture. Science 348 (6242), 1422–1425. doi:10.1126/science.aab2374
Nuijten, M. B., Bakker, M., Maassen, E., and Wicherts, J. M. (2018). Verify Original Results through Reanalysis before Replicating. Behav. Brain Sci. 41 (e143). doi:10.1017/s0140525x18000791
O'Brien, B. C., Harris, I. B., Beckman, T. J., Reed, D. A., and Cook, D. A. (2014). Standards for Reporting Qualitative Research: a Synthesis of Recommendations. Acad. Med. 89 (9), 1245–1251. doi:10.1097/ACM.0000000000000388
Oinn, T., Addis, M., Ferris, J., Marvin, D., Senger, M., Greenwood, M., et al. (2004). Taverna: a Tool for the Composition and Enactment of Bioinformatics Workflows. Bioinformatics 20 (17), 3045–3054. doi:10.1093/bioinformatics/bth361
Open Science Collaboration, (2015). PSYCHOLOGY. Estimating the Reproducibility of Psychological Science. Science 349 (6251), aac4716. doi:10.1126/science.aac4716
Pawlik, M., Hütter, T., Kocher, D., Mann, W., and Augsten, N. (2019). A Link Is Not Enough - Reproducibility of Data. Datenbank Spektrum 19 (2), 107–115. doi:10.1007/s13222-019-00317-8
Peng, R. D., Dominici, F., and Zeger, S. L. (2006). Reproducible Epidemiologic Research. Am. J. Epidemiol. 163 (9), 783–789. doi:10.1093/aje/kwj093
Peng, R. D. (2011). Reproducible Research in Computational Science. Science 334 (6060), 1226–1227. doi:10.1126/science.1213847
Perkel, J. M. (2018). Data Visualization Tools Drive Interactivity and Reproducibility in Online Publishing. Nature 554 (7690), 133–134. doi:10.1038/d41586-018-01322-9
Perkel, J. (2017). TechBlog: Interactive Figures Address Data Reproducibility: Naturejobs Blog. Retrieved from: Accessed http://blogs.nature.com/naturejobs/2017/10/20/techblog-interactive-figures-address-data-reproducibilityAugust 6, 2019).
Pettifer, S. R., Sinnott, J. R., and Attwood, T. K. (2004). UTOPIA-User-Friendly Tools for Operating Informatics Applications. Comp. Funct. Genomics 5 (1), 56–60. doi:10.1002/cfg.359
Pettifer, S., Thorne, D., McDermott, P., Marsh, J., Villeger, A., Kell, D. B., et al. (2009). Visualising Biological Data: a Semantic Approach to Tool and Database Integration. Bmc bioinformatics 10, 1–12. doi:10.1186/1471-2105-10-s6-s19
Plesser, H. E. (2018). Reproducibility vs. Replicability: a Brief History of a Confused Terminology. Front. neuroinformatics 11, 76. doi:10.3389/fninf.2017.00076
Poldrack, R. A., and Gorgolewski, K. J. (2014). Making Big Data Open: Data Sharing in Neuroimaging. Nat. Neurosci. 17 (11), 1510–1517. doi:10.1038/nn.3818
Prager, E. M., Chambers, K. E., Plotkin, J. L., McArthur, D. L., Bandrowski, A. E., Bansal, N., et al. (2019). Improving Transparency and Scientific Rigor in Academic Publishing. Wiley Online Library.
Pusztai, L., Hatzis, C., and Andre, F. (2013). Reproducibility of Research and Preclinical Validation: Problems and Solutions. Nat. Rev. Clin. Oncol. 10 (12), 720–724. doi:10.1038/nrclinonc.2013.171
Rao, S. S. P., Huang, S.-C., Glenn St Hilaire, B., Engreitz, J. M., Perez, E. M., Kieffer-Kwon, K.-R., et al. (2017). Cohesin Loss Eliminates All Loop Domains. Cell 171 (2), 305–320. doi:10.1016/j.cell.2017.09.026
Robinson, J. T., Turner, D., Durand, N. C., Thorvaldsdóttir, H., Mesirov, J. P., and Aiden, E. L. (2018). Juicebox.js Provides a Cloud-Based Visualization System for Hi-C Data. Cel Syst. 6 (2), 256–258. doi:10.1016/j.cels.2018.01.001
Schneider, M. V., Flannery, M., and Griffin, P. (2016). Survey of Bioinformatics and Computational Needs in Australia 2016. Figshare. Available from: https://figshare.com/articles/Survey_of_Bioinformatics_and_Computational_Needs_in_Australi a_2016_pdf/4307768/1.
Schonbrodt, F. (2016). Changing Hiring Practices towards Research Transparency: The First Open Science Statement in a Professorship Advertisement. Felix Schonbrodt Blog. Available from: https://www.nicebread.de/open-science-hiring-practices.
Shettle, C., and Mooney, G. (1999). Monetary Incentives in Us Government Surveys. J. Official Stat. 15 (2), 231.
Sneddon, T. P., Li, P., and Edmunds, S. C. (2012). GigaDB: Announcing the GigaScience Database. GigaScience 1 (1), 2047-217X-221X-11. doi:10.1186/2047-217x-1-11
Snell, L., and Spencer, J. (2005). Reviewers' Perceptions of the Peer Review Process for a Medical Education Journal. Med. Educ. 39 (1), 90–97. doi:10.1111/j.1365-2929.2004.02026.x
Somers, S. (2018). The Scientific Paper Is Obsolete. Retrieved from: https://www.theatlantic.com/science/archive/2018/04/the-scientific-paper-is-obsolete/556676/(Accessed September 1, 2019).
Stodden, V., Borwein, J., Bailey, D., Malm, H., Novitzky, P., and Gordijn, B. (2013a). Setting the Default to Reproducible: Reproducibility in Computational and Experimental Mathematics. Comput. Sci. ResearchSIAM News 46 (1).
Stodden, V., Guo, P., and Ma, Z. (2013b). Toward Reproducible Computational Research: an Empirical Analysis of Data and Code Policy Adoption by Journals. PloS ONE 8 (6), e67111. doi:10.1371/journal.pone.0067111
Stodden, V., McNutt, M., Bailey, D. H., Deelman, E., Gil, Y., Hanson, B., et al. (2016). Enhancing Reproducibility for Computational Methods. Science 354 (6317), 1240–1241. doi:10.1126/science.aah6168
Stodden, V., and Miguez, S. (2013). Best Practices for Computational Science: Software Infrastructure and Environments for Reproducible and Extensible Research.Available at SSRN 2322276
Stodden, V. (2015). Reproducing Statistical Results. Annu. Rev. Stat. Its Appl. 2, 1–19. doi:10.1145/2807591.2897788
Stodden, V., Seiler, J., and Ma, Z. (2018). An Empirical Analysis of Journal Policy Effectiveness for Computational Reproducibility. Proc. Natl. Acad. Sci. USA 115 (11), 2584–2589. doi:10.1073/pnas.1708290115
Stodden, V. (2010). “The Scientific Method in Practice: Reproducibility in the Computational Sciences,”. Paper No. 4773-10 (MIT Sloan Research).
Tait, A. (2017). 10 Rules for Creating Reproducible Results in Data Science - Dataconomy. Retrieved from: https://dataconomy.com/2017/07/10-rules-results-data-science (Accessed August 1, 2019).
Tang, B., Li, F., Li, J., Zhao, W., and Zhang, Z. (2018). Delta: a new web-based 3D genome visualization and analysis platform. Bioinformatics 34 (8), 1409–1410.
Teixeira da Silva, J. A. (2015). Negative Results: Negative Perceptions Limit Their Potential for Increasing Reproducibility. J. negative results Biomed. 14 (1), 1–4. doi:10.1186/s12952-015-0033-9
Tenopir, C., Allard, S., Douglass, K., Aydinoglu, A. U., Wu, L., Read, E., and Frame, M. (2011). Data Sharing by Scientists: Practices and Perceptions. PloS one 6 (6), e21101. doi:10.1371/journal.pone.0021101
Tenopir, C., Dalton, E. D., Allard, S., Frame, M., Pjesivac, I., Birch, B., and Dorsett, K. (2015). Changes in Data Sharing and Data Reuse Practices and Perceptions Among Scientists Worldwide. PloS one 10 (8), e0134826. doi:10.1371/journal.pone.0134826
Vines, T. H., Albert, A. Y. K., Andrew, R. L., Débarre, F., Bock, D. G., Franklin, M. T., et al. (2014). The Availability of Research Data Declines Rapidly with Article Age. Curr. Biol. 24 (1), 94–97. doi:10.1016/j.cub.2013.11.014
Weinländer, M., Lekovic, V., Spadijer-Gostovic, S., Milicic, B., Krennmair, G., and Plenk Jr, H. (2009). Gingivomorphometry - Esthetic Evaluation of the crown-mucogingival Complex: a New Method for Collection and Measurement of Standardized and Reproducible Data in Oral Photography. Clin. Oral Implants Res. 20 (5), 526–530. doi:10.1111/j.1600-0501.2008.01685.x
Weissgerber, T. L., Garovic, V. D., Savic, M., Winham, S. J., and Milic, N. M. (2016). From Static to Interactive: Transforming Data Visualization to Improve Transparency. PLoS Biol. 14 (6), e1002484. doi:10.1371/journal.pbio.1002484
Wellcome Trust (2018). Request for Information (RFI) A Software Tool to Assess the FAIRness of Research Outputs against a Structured Checklist of Requirements [FAIRWare]. In Wellcome.Org. Retrieved from: https://wellcome.ac.uk/sites/default/files/FAIR-checking-software-request-for-information.pdf.
Wilkinson, M. D., Dumontier, M., Aalbersberg, I. J., Appleton, G., Axton, M., and Baak, A. and . . . others (2016). The FAIR Guiding Principles for Scientific Data Management and Stewardship. Scientific data 3 (1), 1–9. doi:10.1038/sdata.2016.18
Wolstencroft, K., Haines, R., Fellows, D., Williams, A., Withers, D., Owen, S., et al. (2013). The Taverna Workflow Suite: Designing and Executing Workflows of Web Services on the Desktop, Web or in the Cloud. Nucleic Acids Res. 41 (W1), W557–W561. doi:10.1093/nar/gkt328
Yong, E. (2015). Reproducibility Problems in Genetics Research May Be Jeopardizing Lives. Retrieved from https://geneticliteracyproject.org/2015/12/17/reproducibility-problems-genetics-research-may-costing-lives.(Accesssed February 12, 2015).
Keywords: reproducibility in life sciences, replication of experiments, reproducibility of computational experiments, interactive figures, reproducibility, reproducibility metrics, open science, reproducibility survey in life sciences
Citation: Samota EK and Davey RP (2021) Knowledge and Attitudes Among Life Scientists Toward Reproducibility Within Journal Articles: A Research Survey. Front. Res. Metr. Anal. 6:678554. doi: 10.3389/frma.2021.678554
Received: 09 March 2021; Accepted: 18 May 2021;
Published: 29 June 2021.
Edited by:
Hamid R. Jamali, Charles Sturt University, AustraliaReviewed by:
Tom Crick, Swansea University, United KingdomIman Tahamtan, The University of Tennessee, United States
Copyright © 2021 Samota and Davey. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Evanthia Kaimaklioti Samota, ZXZhbnRoaWEuc2Ftb3RhQGVhcmxoYW0uYWMudWs=