 Martin Komaritzan
Martin Komaritzan Stephan Wenninger
Stephan Wenninger Mario Botsch
Mario Botsch- Computer Graphics Group, TU Dortmund University, Dortmund, Germany
3D morphable models are widely used to describe the variation of human body shapes. However, these models typically focus on the surface of the human body, since the acquisition of the volumetric interior would require prohibitive medical imaging. In this paper we present a novel approach for creating a volumetric body template and for fitting this template to the surface scan of a person in a just a few seconds. The body model is composed of three surface layers for bones, muscles, and skin, which enclose the volumetric muscle and fat tissue in between them. Our approach includes a data-driven method for estimating the amount of muscle mass and fat mass from a surface scan, which provides more accurate fits to the variety of human body shapes compared to previous approaches. We also show how to efficiently embed fine-scale anatomical details, such as high resolution skeleton and muscle models, into the layered fit of a person. Our model can be used for physical simulation, statistical analysis, and anatomical visualization in computer animation and medical applications, which we demonstrate on several examples.
1 Introduction
Virtual humans are present in our everyday lives. They can be found in movies, computer games, and commercials. In addition, they are employed in a rapidly growing number of applications in virtual reality (VR) and augmented reality (AR), even ranging to computational medicine. All these applications benefit from realistic virtual representations of human.
If we look at a human, its appearance is mostly determined by everything we can directly see (skin, hair, cloth, etc.). Hence, it is not surprising that research has focused on capturing, analyzing, and animating surface models of humans. Consequently, there is a vast amount of surface-based capturing approaches, suitable for almost every level of detail and budget: From complex multi-camera photogrammetry setups that capture finest-scale wrinkles of the human face (Riviere et al., 2020) over approaches that compute ready-to-animate models from simple smart-phone videos (Wenninger et al., 2020) to machine learning approaches that reconstruct a virtual model from a single image (Weng et al., 2019). For the purpose of creating convincing animations of and interactions with those models, large amounts of 3D captured data have been collected to build sophisticated surface-based models (Anguelov et al., 2005; Loper et al., 2015; Bogo et al., 2017). Those models compensate for the fact that humans are not empty hulls or homogeneous solids by capturing and analyzing more and more data of that surface hull. Another way to approach this is to model volumetric virtual humans by incorporating (discrete approximations of) their interior anatomical structures. While surface-based models might be sufficient for many applications, for others (e.g., surgery simulation) a volumetric model is an essential prerequisite.
While detailed volumetric models of the human body exist (Ackerman, 1998; Christ et al., 2009; Zygote, 2020), they can be very tedious to work with. Since they usually consist of hundreds of different bones and muscles, merely creating a volumetric tetrahedral mesh for simulation purposes can be frustratingly difficult. Moreover, those models represent average humans and transferring their volumetric structure and anatomical details to a specific human model (e.g., a scanned person) is not straightforward. Although there are a couple of approaches for transferring the interior anatomy from a volumetric template model into a surface-based virtual human (Dicko et al., 2013; Kadleček et al., 2016), these methods either deform bone structures in a non-plausible manner (Dicko et al., 2013) or require a complex numerical optimization (Kadleček et al., 2016).
In this paper we present a robust and efficient method for transferring an interior anatomy template into a surface mesh in just a couple of seconds. A key component is a simple decomposition of the human body into three layers that are bounded by surfaces sharing the same triangulation: the skin surface defines the outer shape of the human, the muscle surface envelopes its individual muscles, and the skeleton surface wraps the subject’s skeleton (see Figure 1 middle). The muscle layer is hence enclosed in between the skeleton and muscle surface, and the subcutaneous fat tissue by the muscle surface and skin surface. This layered template model is derived from the Zygote body model (Zygote, 2020), which provides an accurate representation of both the male and female anatomy. We propose simple and fast methods for fitting the layered template to surface scans of humans and for transferring the high-resolution anatomical details (Zygote, 2020) into these fitted layers (see Figure 1 right). Our method is robust, efficient, and fully automatic, which we demonstrate on about 1,700 scans from the European CAESAR dataset (Robinette et al., 2002).

FIGURE 1. Starting from the surface of a human (left), we fit a three-layered model consisting of a skin, muscle, and skeleton layer (middle), which enables physical simulations in a simple and intuitive way. terior structures, such as individual models of muscles and bones, can also be transferred using our layered model (right).
Our approach enriches simple surface scans by plausible anatomical details, which are suitable for educational visualizations and volumetric simulations. We note, however, that due to the lack of true volumetric information, it is not a replacement of volumetric imaging techniques in a medical context. Our main contributions are:
• A novel approach for creating a layered volumetric template defined by skin, muscle, and bone surfaces, which all have the same triangulation, thereby making volumetric tessellation straightforward.
• A robust and efficient method for transferring the layered volumetric template model into a given surface scan of a human in just a couple of seconds.
• A regressor that extracts the amount of muscle and fat mass of a subject from the skin surface only, thereby making manual specification of muscle and fat distribution unnecessary.
• Our approach takes differences between male and female anatomy into account by deriving individual volumetric templates and individual muscle/fat regressors for men and women.
2 Related Work
Using a layered volumetric model of a virtual character has been shown beneficial compared to a surface-only model in multiple previous works. Deul and Bender (2013) compute a simple layered model representing a bone, muscle, and fat layer, which they use for a multi-layered skinning approach. Simplistic layered models have also been used to extend the SMPL surface model (Loper et al., 2015) in order to support elastic effects in skinning animations (Kim et al., 2017; Romero et al., 2020). Compared to these works, our three layers yield an anatomically more accurate representation of the human body, while still being simpler and more efficient than complex irregular tetrahedralizations. Saito et al. (2015) show that a layer that envelopes muscles yields more convincing muscle growth simulations and reduces the number of tetrahedral elements required in their computational model. They also show how to simulate different variations of bone sizes, muscle mass and fat mass for a virtual character.
When it comes to the generation of realistic personalized anatomical structures from a given skin surface, most previous works focus on the human head: Ichim et al. (2016) register a template skull model to a surface-scan of the head in order to build a combined animation model using both physics-based and blendshape-based face animation. Ichim et al. (2017) also incorporate facial muscles and a muscle activation model to allow more advanced face animation effects. Gietzen et al. (2019), Achenbach et al. (2018) use volumetric CT head scans and surface-based head scans in order to learn a combined statistical model of the head surface, the skull surface, and the enclosed soft tissue, which allows them to estimate the head surface from the skull shape and vice versa. Regarding the other parts of the body, Zhu et al. (2015) propose an anatomical model of the upper and lower limbs that can be fit to surface scans and is able to reconstruct motions of the limbs.
To our knowledge, there are just two former approaches for generating an anatomical model of the complete core human body (torso, arms, legs) from a given skin surface. In their pioneering work, Dicko et al. (2013) transfer the anatomic details from a template model to various humanoid target models, ranging from realistic body shapes to stylized non-human characters. They transfer the template’s anatomy through a harmonic space warp and per-bone affine transformations, which, however, might distort muscles and bones in an implausible way. Different distributions of subcutaneous fat can be (and have to be) painted manually into a special fat texture. The work of Kadleček et al. (2016) is most closely related to our approach. They build an anatomically plausible volumetric model from a set of 3D scans of a person in different poses. An inverse physics simulation is used to fit a volumetric anatomical template model to the set of surface scans, where custom constraints prevent muscles and bones from deforming in an unnatural manner. We discuss the main differences of our approach and Dicko et al. (2013), Kadleček et al. (2016) in Section 4.
Estimating the body composition from surface measures or 3D surface scans (like we do in Section 3.3) has been tackled before. There are numerous formulas for computing body fat percentage (BF), or body composition in general, from certain circumferences, skinfold thicknesses, age, gender, height, weight, and density measurements. Prominent examples are the skinfold equations, or the Siri- and Brozek formulas (Siri, 1956; Brožek et al., 1963; Jackson and Pollock, 1985). These formulas, however, either rely on anthropometric measurements that have to be taken by skilled personnel or on measuring the precise body density via expensive devices, such as BOD PODs (Fields et al., 2002). Ng et al. (2016) compute BF based on a 3D body scan of the subject, but their formula is tailored toward body scans and measurements taken with the Fit3D Scanner (Fit3D, 2021). Even with the help of the authors we could not successfully apply their formulas to scans taken with different systems, since we could always find examples resulting in obviously wrong (or even negative) BF. Recently, Maalin et al. (2020) showed that modeling body composition through body fat alone is an inferior measure for defining the shape of a person compared to a combined model of fat mass and muscle mass. We therefore adapt their data to estimate fat mass and muscle mass from surface scans alone (Section 3.3). Incorporating these estimations into the volumetric fitting process allows us to determine how much of the soft tissue layer is described by muscle tissue more plausibly than Kadleček et al. (2016).
3 Methods
Our approach consists of three main contributions: First, the generation of the volumetric three-layer template, described in Section 3.2, where we derive the skin, muscle, and skeleton layers from the male and female Zygote model (Zygote, 2020). Second, an efficient method for fitting this layered model (including all contained anatomical details) (in)to a given human surface scan (Section 3.4). Third, the estimation of a person’s body composition, i.e., how much of the person’s soft tissue is described by muscles and fat (Section 3.3). By adapting the BeyondBMI dataset (Maalin et al., 2020) to our template, we derive this information from the surface scan alone and use it to inform the volumetric template fitting. Figure 2 shows an overview of the whole process, starting from the different input data sets, the template model and the muscle/fat regressor, to the final personalized anatomical fit.
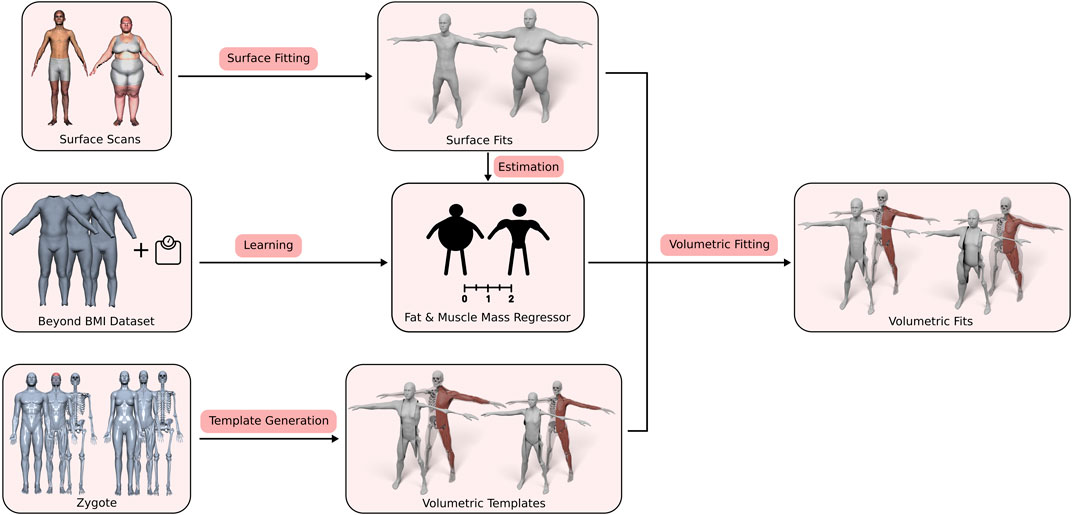
FIGURE 2. Overview of our volumetric template fitting approach. From the Zygote model (Zygote, 2020), we build layered volumetric templates for the male and female anatomy. By adapting the BeyondBMI dataset (Maalin et al., 2020) we learn a model for estimating fat and muscle mass from a surface model. Given a person’s surface scan, we then estimate its fat/muscle mass and use this information to fit the volumetric template (in)to the surface scan, which yields the personalized anatomical model.
3.1 Data Preparation
In our approach we make use of several publicly or commercially available datasets for model generation, model learning, and evaluation:
• Zygote: The Zygote model (Zygote, 2020) provides high-resolution models for the male and female anatomy. We use their skin, muscle, and skeleton models for building our layered template.
• BeyondBMI: Maalin et al. (2020) scanned about 400 people and additionally measured their fat mass (FM), muscle mass (MM), and body mass index (BMI) using a medical-grade eight-electrode bioelectrical impedance analysis. They provide annotated (synthetic) scans of 100 men and 100 women, each computed by averaging shape and annotations of two randomly chosen subjects. From this data we learn a regressor that estimates fat and muscle mass from the skin surface.
• Hasler: The dataset of Hasler et al. (2009) contains scans of 114 subjects in 35 different poses, captured by a 3D laser scanner. The scans are annotated with fat and muscle mass percentage as measured by a consumer-grade impedance spectroscopy body fat scale. We use this dataset to evaluate the regressor learned from the BeyondBMI data.
• CAESAR: The European subset of the CAESAR scan database (Robinette et al., 2002) consists of 3D scans (with about 70 selected landmarks) equipped with annotations (e.g., weight, height, BMI) of about 1,700 subjects in a standing pose. We use this data to evaluate our overall fitting procedure.
All these data sources use different model representations, i.e., either different mesh tessellations or even just point clouds. In a preprocessing step we therefore re-topologize the skin surfaces of these datasets to a common triangulation by fitting a surface template using the non-rigid surface-based registration of Achenbach et al. (2017).
This approach is based on an animation-ready, fully rigged, statistical template model. Its mesh tessellation (about 21k vertices), animation skeleton, and skinning weights come from the Autodesk Character Generator (Autodesk, 2014). It uses a 10-dimensional PCA model representing the human body shape variation and we will call it the surface template in the following. In a preprocessing step we fit the surface template to all input surface scans to achieve a common triangulation and thereby establish dense correspondence. This fitting process is guided by a set of landmarks, which are either specified manually or provided by the dataset. A nonlinear optimization then determines alignment (scaling, rotation, translation), body shape (PCA parameters), and pose (inverse kinematics on joint angles) in order to minimize squared distances of user-selected landmarks and automatically determined closest point correspondences in a non-rigid ICP manner (Bouaziz et al., 2014b). Once the model parameters are optimized, a fine-scale out-of-model deformation improves the matching accuracy and results in the final template fit. For more details we refer to (Achenbach et al., 2017).
3.2 Generating the Volumetric Template
We use the male and female Zygote body model (Zygote, 2020) as a starting point for our volumetric model. Our volumetric template is defined by the skeleton surface
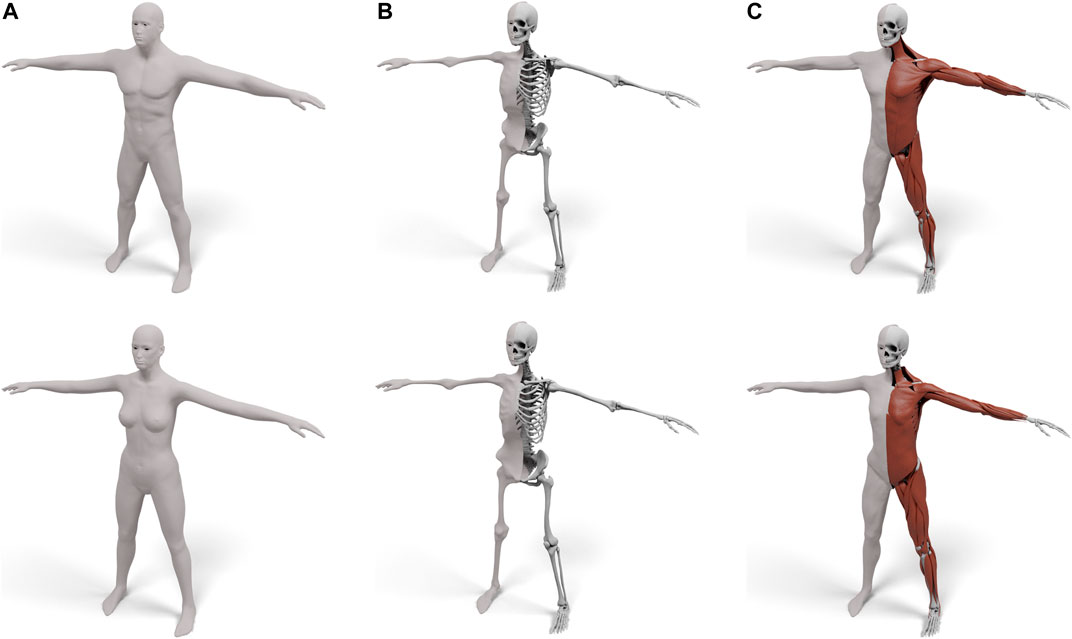
FIGURE 3. Our layered template for both male (top) and female (bottom): the skin surface (A), the skeleton surface enveloping the skeleton (B), and the muscle surface enveloping both muscles and skeleton (C). For (B) and (C) the left half shows the enveloping surface, the right half the enveloped anatomical details.
The three surfaces
The following two sections describe how to generate the skeleton surface
3.2.1 The Skeleton Surface
The skeleton surface
We generate the skeleton surface
The regularization is formulated as a discrete bending energy that penalizes the change of mean curvature, measured as the change of length of the Laplacian:
where
The fitting term penalizes the squared distance of vertices
The target positions
Closest point correspondences are updated in each iteration of the minimization to the closest position on
Near complicated regions, like the armpit or the rib-cage, the skin has to stretch considerably to deform toward the skeleton wrap. As a consequence, corresponding triangles
We define a per-vertex score penalizing misalignment of corresponding vertices
A 2D example of this is shown on the right, where the closest correspondence of
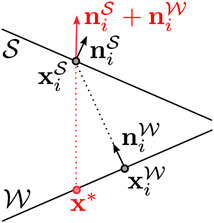
Fixed correspondences are responsible for reducing these tangential shifts and thereby improving the prism shapes. We determine them for some vertices at the beginning of the fit as explained in the following and keep them fixed throughout the optimization. Since the alignment error increases faster if the distance between skin surface and skeleton wrap is small, we specify fixed correspondences for vertices on
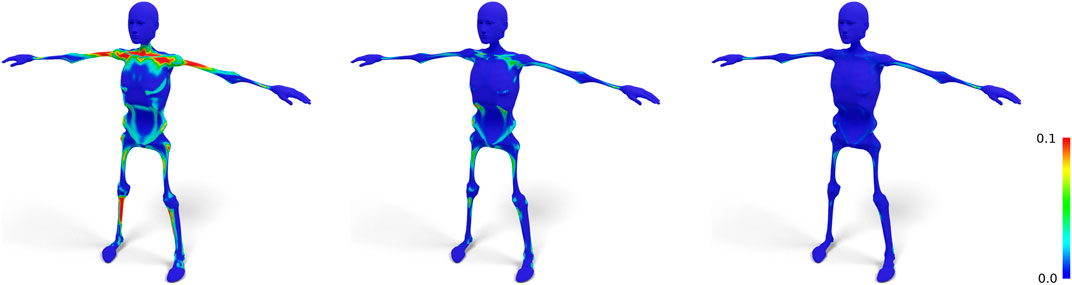
FIGURE 4. Standard nonrigid registration from skin to skeleton (left) results in a bad tangential alignment of corresponding triangles, causing sheared prisms, which we visualize by color-coding the alignment error (Eq. 4). Using fixed correspondences reduces this error (center). Also shifting closest point correspondences with bad alignment reduces the error even further (right).
Closest point correspondences can also drag vertices to locations with high alignment error. In each iteration of the nonrigid ICP, we compute
In the process of moving the surface
3.2.2 The Muscle Surface
We generate the muscle surface
3.3 Estimating Fat Mass and Muscle Mass
Having generated the volumetric layered template, we want to be able to fit it to a given surface scan of a person. To regularize this under-determined problem, we first have to estimate how much of the person’s soft tissue is explained by fat mass (FM) and muscle mass (MM), respectively. This is a challenging problem since we want to capture a single surface scan of the person only and therefore cannot rely on information provided by additional hardware, such as a DXA scanner or a body fat scale. Kadleček et al. (2016) handle this problem by describing the person’s shape primarily through muscles, i.e., by growing muscles as much as possible and defining the remaining soft tissue volume as fat. This strategy results in adipose persons having considerably more muscle mass than leaner people. Although there is a certain correlation between total body mass (and also BMI) and muscle mass – because the higher weight has a training effect especially on the muscles of the lower limbs (Tomlinson et al., 2016) – this general trend is not sufficient to define the body composition of people.
Maalin et al. (2020) measured both FM and MM using a medical-grade eight-electrode bio-electrical impedance analysis and acquired a 3D surface scan. From this data, they built a model that can vary the shape of a person based on specified muscle or fat variation, similar to Piryankova et al. (2014). Our model should perform the inverse operation, i.e., estimate FM and MM from a given surface scan. We train our model on their BeyondBMI dataset (Section 3.1), which consists of scans of 100 men and 100 women captured in an approximate A-pose (see Figure 5), each annotated with FM, MM, and BMI.
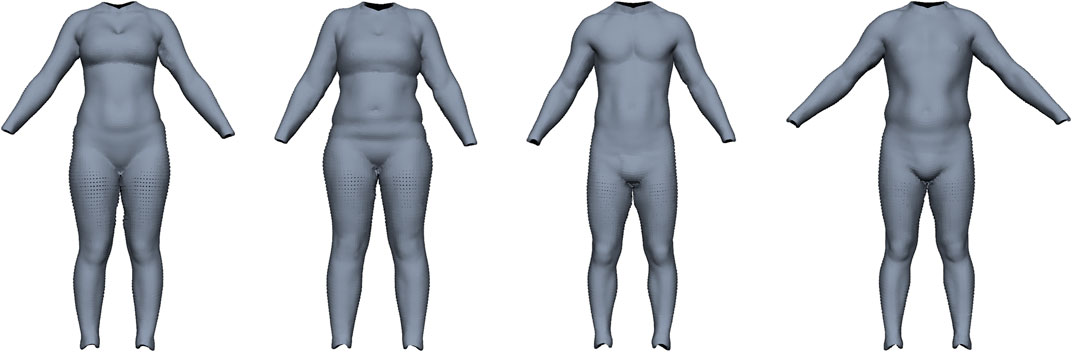
FIGURE 5. Examples for the BeyondBMI dataset provided by Maalin et al. (2020) consisting of scans of 100 men and 100 women, annotated with fat mass, muscle mass, and BMI. The scans lack geometric data for head, hands, and feet and are captured in approximate A-pose (with noticeable variation in pose).
By applying the surface fitting described in Section 3.1 to the BeyondBMI dataset, we make their scans compatible to our template and un-pose their scans to a common T-pose, thereby making any subsequent statistical analysis pose-invariant. After re-excluding the head, hands, and feet of our surface template, we are left with
and perform PCA on the data matrix
For a first evaluation of this model, we perform a leave-one-out test on the BeyondBMI dataset, i.e., excluding each scan once, building the regressors as described above from the remaining
We compared the linear model to a support vector regression (using scikit-learn (Pedregosa et al., 2011) with default parameters and RBF kernels), but in contrast to Hasler et al. (2009) we found that for the BeyondBMI dataset this approach performs considerably worse:
Whenever we fit the volumetric model to a given body scan, as explained in the next section, we first use the proposed linear regressors to estimate the person’s fat mass and muscle mass and use this information to generate the muscle and fat layers in Section 3.4.3.
3.4 Fitting the Volumetric Template to Surface Scans
Given a surface scan, we transfer the template anatomy into it through the following steps: First, we fit our surface template to the scan, which establishes one-to-one correspondence with the volumetric template and puts the scan into the same T-pose as the template (Section 3.1). After this pre-processing, we deform the volumetric template to match the scanned subject. To this end, we adjust global scaling and per-bone local scaling, such that body height and limb lengths of template and scan match (Section 3.4.1). This is followed by a quasi-static deformation of the volumetric template that considers the skin surface
3.4.1 Global and Local Scaling
Fitting the surface template to the scanner data puts the latter into the same alignment (rotation, translation) and the same pose as the volumetric template. The next step is to correct the mismatch in scale by adjusting body height and limb lengths of the volumetric template.
This scaling does influence all three of the template’s surfaces. Since the shape of the skeleton surface
The global scaling is determined from the height difference of scan and template and is applied to all vertices of the template model. It therefore scales all bone lengths and bone diameters uniformly. Directly scaling with the height ratio of scan and template, however, can result in bones too thin or too thick for extreme target heights. Thus, we damp the height ratio
After the global scaling, the local scaling further adjusts the limb lengths of the template to match those of the scan. The (fully rigged) surface-based template has been fit to both the scan (Section 3.1) and the template (Section 3.2). This fit provides a simple skeleton graph (used for skinning animation) for both models. We use the length mismatch of the respective skeleton graph segments to determine the required scaling for upper and lower arms, upper and lower legs, feet, and torso. We scale these limbs in their corresponding bone directions (or the spine direction for the torso) using the bone stretching of Kadleček et al. (2016). As mentioned before, this changes the limb lengths but not the bone diameters.
This two-step scaling process is visualized in Figure 6. As a result, the scaled template matches the scan with respect to alignment, pose, body height, and limb lengths. Its layer surfaces, which we denote by

FIGURE 6. Scaling the template (opaque) to match the scan (semi-transparent): The pre-processing aligns the scan with the template and puts it into the same pose (left). Body height and limb lengths of the template are then adjusted by a global uniform scaling (center), followed by local scaling for limbs and spine (right).
3.4.2 Skeleton Fitting
Given the coarse registration of the previous step, we now fit the skin surface
The first term is responsible for keeping the skeleton surface (approximately) rigid and uses the same formulation as Eq. 2, with
The second term prevents strong deformations of the prism elements
where
Third, we detect all collisions
where
3.4.3 Muscle Fitting
Having determined the skin surface
The average muscle surface is transferred from the scaled template
The first term tries to preserve the shape of the scaled template’s muscle surface
where
Having transferred the average muscle surface, we next grow/shrink muscles as much as possible in order to define the maximum/minimum muscle surfaces. Since certain muscle groups might be better developed than others, we perform the muscle growth/shrinkage separately for the major muscle groups, namely upper legs (including buttocks), lower legs, upper arms, lower arms, chest, abdominal muscles, shoulders, and back. Muscles are built from fibers and grow perpendicular to the fiber direction. In all cases relevant for us, the fibers are approximately perpendicular to the direction from
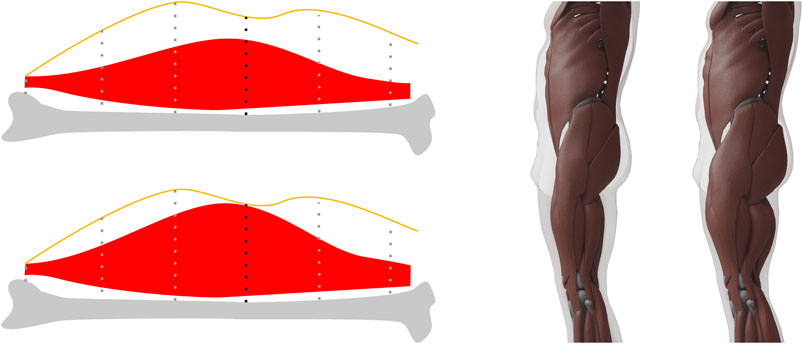
FIGURE 7. Left. When computing the maximum muscle surface, we move muscle vertices toward the skin by an amount proportional to their muscle potential, which for each vertex is the length of the dotted line intersected with the muscle. The vertex with the black dotted line defines the maximum allowed stretch in this example. Right: An example of our minimum and maximum muscle layers for the same target. These two surfaces define the lower and upper limit for the muscle mass and vice versa for the fat mass.
We determine the final muscle surface
The resulting masses require some corrections though: First, we have to add the visceral fat (VAT), which is not part of our fat layer but resides in the abdominal cavity. We estimate the VAT mass
We correct the muscle mass by subtracting the mass
There are other terms like the fat of head, hands, and toes, which could be added, or the volume of blood vessels and tendons, which could be subtracted. We assume those terms to be negligible.
Since the total volume of the soft tissue layer
with the density ratio
The minimum/maximum muscle surface yields a maximum/minimum fat layer mass. The optimized fat layer mass is clamped to meet this range, thereby defining the final fat layer mass. We then choose the linear interpolant between the minimum and maximum muscle surface that matches this fat mass, which we find through bisection search.
We did this for the scans of 100 men and 100 women from the BeyondBMI dataset (Maalin et al., 2020), where we know the true values for FM and MM from measurements, and optimized the value of k for this dataset, yielding
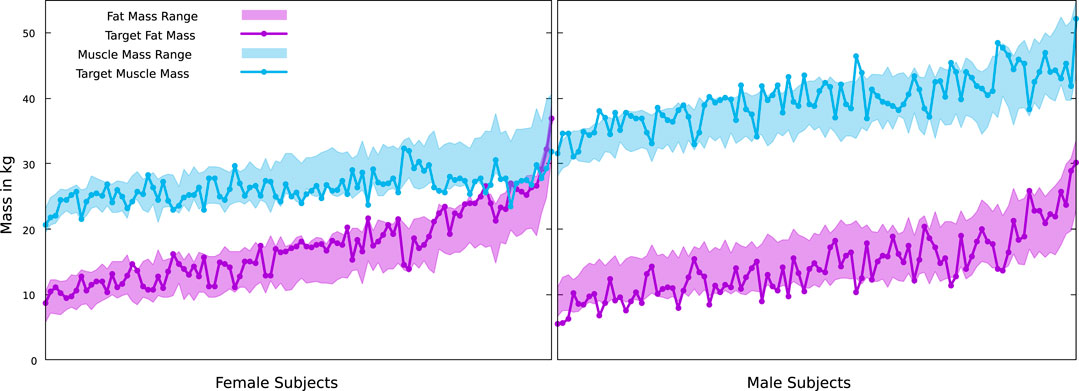
FIGURE 8. True muscle and fat masses for the female and male subjects of the BeyondBMI dataset, plotted on top of the possible ranges defined by our minimum and maximum muscle surfaces. Note that our minimal fat mass is coupled to the maximal muscle mass and vice versa.
3.4.4 Transferring Original Anatomical Data
After fitting the skin surface
Dicko et al. (2013) also employ a space warp for their, which they discretized by interpolating values
We follow the same idea, but use a space warp based on triharmonic radial basis functions (RBFs) (Botsch and Kobbelt, 2005), which have been shown to yield higher quality deformations with lower geometric distortion than many other warps (including FEM-based harmonic warps) (Sieger et al., 2013). The RBF warp is defined as a sum of n RBF kernels and a linear polynomial:
where
In order to warp the high-resolution bone model from the template to the scan, we setup the RBF warp to reproduce the deformation
4 Results and Applications
Generating a personalized anatomical model for a given surface scan of a person consists of the following steps: First, the surface template is registered to the scanner data (triangle mesh or point cloud) as described in Section 3.1 and Achenbach et al. (2017). After manually selecting 10–20 landmarks, this process takes about 50 s. Fitting the surface template establishes dense correspondence with the surface of the volumetric template and puts the scan into the same T-pose as the volumetric template. Fitting the volumetric template by transferring the three layer surfaces (Sections 3.4.1; 3.4.2; 3.4.3) takes about 15 s. Transferring the high-resolution anatomical models of bones and muscles (145k vertices) takes about 4.5 s for solving the linear system (which is an offline pre-processing) and 0.5 s for transforming the vertices (Section 3.4.4). Timings were measured on a desktop workstation, equipped with an Intel Core i9 10850K CPU and a Nvidia RTX 3070 GPU.
Dicko et al. (2013), Kadleček et al. (2016) are the two approaches most closely related to ours. Dicko et al. (2013) also use a space warp for transferring anatomical details, but since they only use the skin surface as constraint, the interior geometry can be strongly distorted. To prevent this, they restrict bones to affine transformations, which, however, might still contain unnatural shearing modes and implausible scaling. Our space warp yields a higher smoothness due to the use of
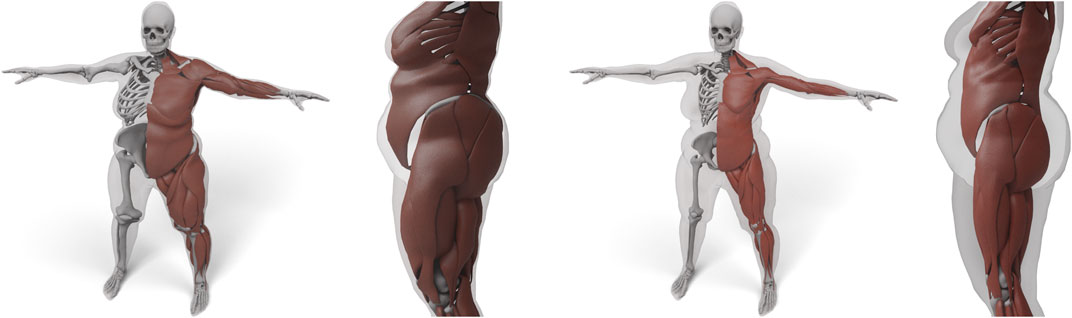
FIGURE 9. Result of transferring the anatomy by using just the skin layer and a harmonic basis (left). Here, both muscles and bones deform too much to fit overweight targets. We use the additional muscle and skeleton layer and a triharmonic basis (right) to prevent unnatural deformations.
Compared to Kadleček et al. (2016), we require a single input scan only, since we infer (initial guesses for) joint positions and limb lengths from the full-body PCA of Achenbach et al. (2017). Putting the scan into T-pose prevents us from having to solve bone geometry and joint angles simultaneously, which makes our approach much faster than theirs (15 s vs. 30 min). Moreover, our layered model yields a conforming volumetric tessellation with constant and homogeneous per-layer materials, which more effectively prevents bones from penetrating skin or muscles. In their approach the rib cage often intersects the muscle layer for thin subjects as mentioned by Kadleček et al. (2016) in the limitations and shown in Figure 12 (bottom row) of their work. Furthermore, we automatically derive the muscle/fat body composition from the surface scan, which yields more plausible results than growing muscles as much as possible (Kadleček et al., 2016), since the latter leads to more corpulent people always having more muscles. Our model extracts the amount of muscle and fat using data of real humans and can therefore adopt to the variety of human shapes (low FM and high MM, high FM and low MM, and everything in between). Finally, we support both male and female subjects by employing individual anatomical templates and muscle/fat regressors for men and women.
4.1 Evaluation on Hasler Dataset
In order to further evaluate the generalization abilities of the linear FM/MM models (Section 3.3) to other data sources, we estimate FM and MM for a subset of registered scans from the Hasler dataset (Hasler et al., 2009) and measure the prediction error. We selected scans of 10 men and 10 women, making sure to cover the extremes of the weight, height, fat, and muscle percentage distribution present in the data.
For the female sample, the predictions show a mean absolute error of
Given the FM and MM values of a target from our regressor, we choose the optimal muscle surface between the minimal and maximal muscle surface as explained in Section 3.4.3. Comparing the final FM and MM of the volumetric model to the ground truth measurements of the Hasler dataset we get end-to-end errors of
4.2 Evaluation on CAESAR Dataset
In order to demonstrate the flexibility and robustness of our method, we evaluate it by generating anatomical models for all scans of the European Caesar data set (Robinette et al., 2002), consisting of 919 scans of women and 777 scan of men, with height range 131–218 cm for men and from 144 to 195 cm for women (we restricted to scans with complete annotation and taken in standing pose). A few examples for men and women can be seen in Figures 1, 10, 11.
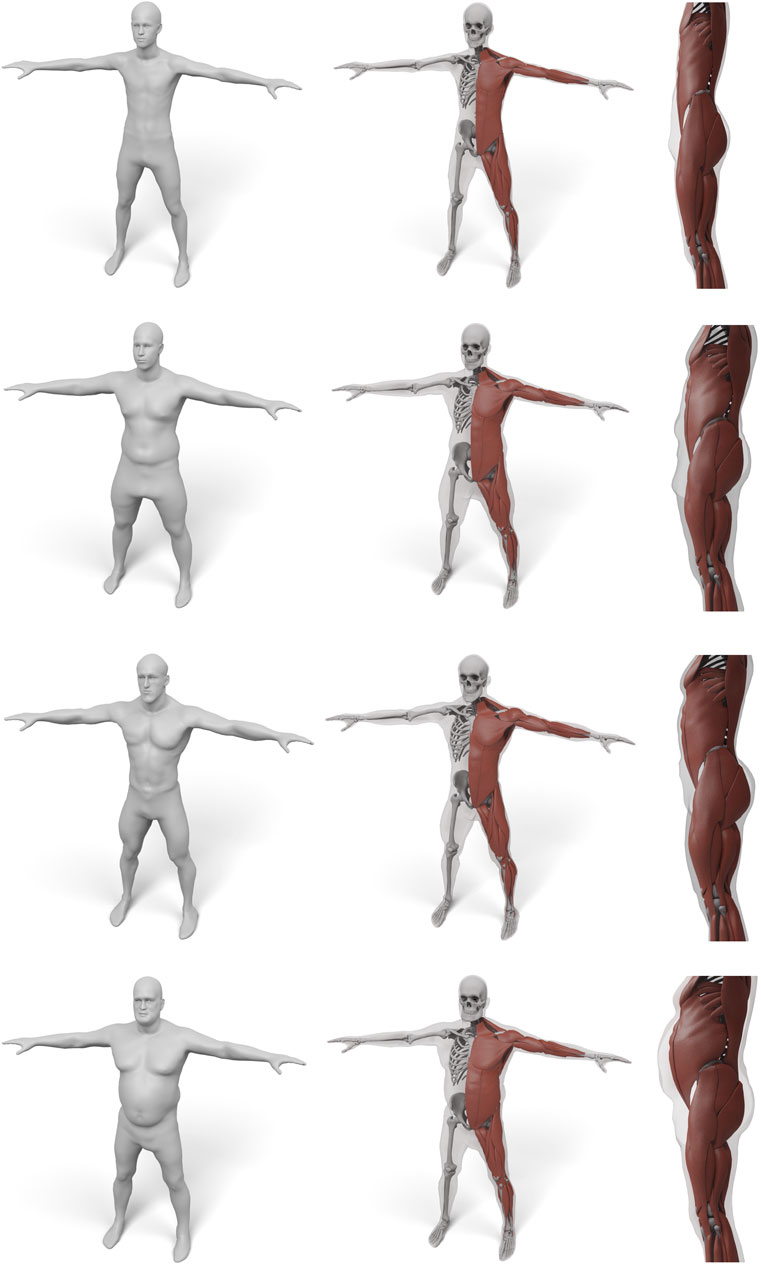
FIGURE 10. Some examples for various male body shape types. For each input surface the transferred muscles and skeleton are shown in front and side view.
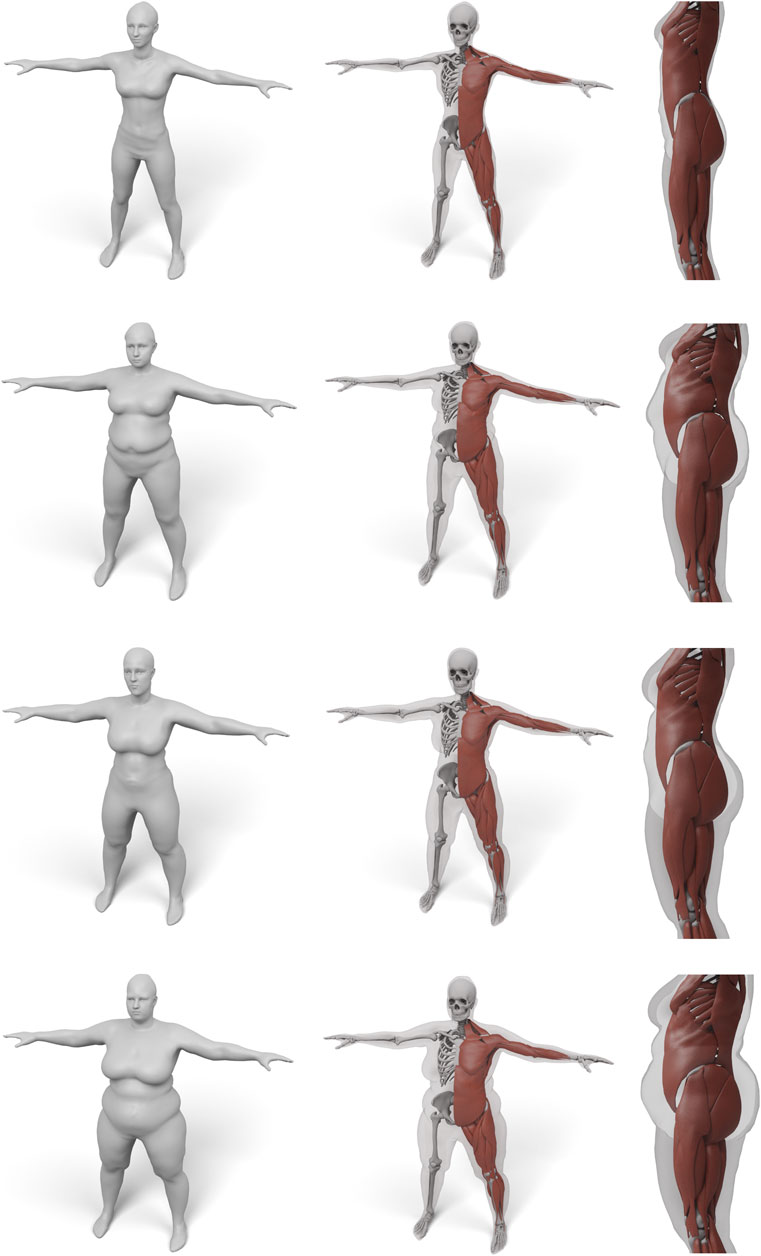
FIGURE 11. Some examples for various female body shape types. For each input surface the transferred muscles and skeleton are shown in front and side view.
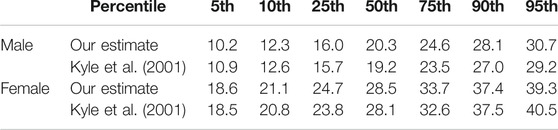
For the about 1,700 CAESAR scans, our muscle and fat mass regressors yield just one slightly negative value for the fat mass of the thinnest male (body weight 48 kg, height 1.72 m, BMI 16.14
The CAESAR dataset does not include ground truth data for fat and muscle mass of the scanned individuals. Thus, in order to further evaluate the plausibility of our estimated body composition, we compare it to known body fat percentiles. Percentiles are used as guidelines in medicine and provide statistical reference values one can compare individual measurements to. For instance, a
4.3 Physics-Based Character Animation
One application of our model is simulation-based character animation (Deul and Bender, 2013; Komaritzan and Botsch, 2018; Komaritzan and Botsch, 2019), where the transferred volumetric layers can improve the anatomical plausibility. We demonstrate the potential by extending the Fast Projective Skinning (FPS) of Komaritzan and Botsch (2019). FPS already uses a simplified volumetric skeleton built from spheres and cylinders, a skeleton surface wrapping this simple skeleton, and one layer of volumetric prism elements spanned between skin and skeleton surface. Whenever the skeleton is posed, the vertices of the skeleton surface are moved, and a projective dynamics simulation of the soft tissue layer updates the skin surface.
We replace their synthetic skeleton by our more realistic version and split their soft tissue layer into our separate muscle and fat layers. This enables us to use different stiffness values for the fat and muscle layers (the latter being three times larger). Moreover, our skeleton features a realistic rib-cage, whereas FPS only uses a simplified spine in the torso region. As a result, our extended version of FPS yields more realistic results in particular in the torso and belly region, as shown in Figure 12.
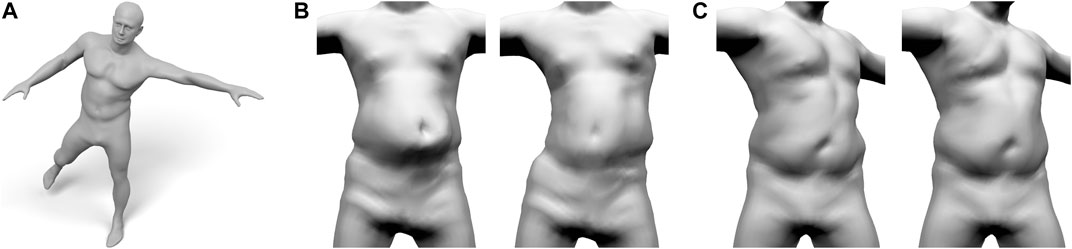
FIGURE 12. Our layered anatomical model can be animated using an extension of Fast Projective Skinning (FPS), as shown in (A). When the character performs a jump to the left (B), our realistic skeleton correctly restricts the dynamic jiggling to the belly region (B-Left), while the original FPS deforms the complete torso (B-Right). For a static twist of the torso (C), the rib-cage of our layered model keeps the chest region rather rigid and concentrates the deformation to the belly (C-left). Without a proper anatomical model, the deformation of FPS is distributed over the complete torso (C-right).
4.4 Simulation of Fat Growth
Our anatomical model can also be used to simulate an increase of body fat, where its volumetric nature provides advantages over existing surface-based methods.
In their computational bodybuilding approach, Saito et al. (2015) also propose a method for growing fat. They, however, employ a purely surface-based approach that conceptually mimics blowing up a rubber balloon. This is modeled by a pressure potential that drives skin vertices outwards in normal direction, regularized by a co-rotated triangle strain energy. The user can (and should) specify a scalar field that defines where and how strong the skin surface should be “blown up”, which is used to modulate the per-vertex pressure forces. Despite the regularization we sometimes noticed artifacts at the boundary of the fat growing region and therefore add another regularization through Eq. 2. This approach allows the user to tune the amount of subcutaneous fat, but unless a carefully designed growth field is specified, the fat growth looks rather uniform and balloon-like (see Figures 10, 11 in Saito et al., 2015).
Every person has an individual fat distribution and gaining weight typically intensifies these initial fat depots. We model this behavior by scaling up the local prism volumes of our fat layer. Each fat prism can be split into three tetrahedra, which define volumetric elements
with the Laplacian regularization of Eq. 2, the displacement regularization
and the volume fitting term
where
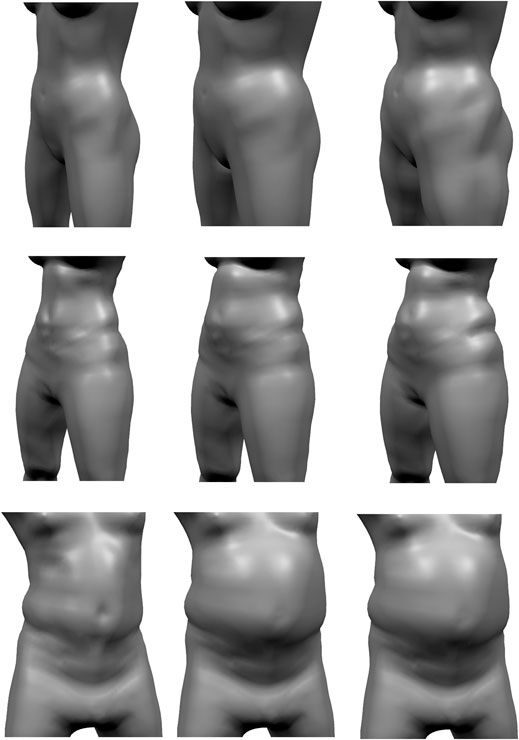
FIGURE 13. Given a reconstructed model (left), the pressure-based fat growth of Saito et al. (2015) leads to a more uniform increases in fat volume (center), while our volume-based fat growth increases the initial fat distribution.

FIGURE 14. Examples of our fat growth simulation, with input models shown in the top row and their weight-gained version in the bottom row.
Our volume-based fat growth has another advantage: If we want to grow fat on a very skinny person, the initial (negligible) fat distribution does not provide enough information on where to grow fat, such that both approaches would do a poor job. But since we can easily fit the volumetric template to several subjects, we can “copy” the distribution of fat prism volumes from another person and “paste” it onto the skinny target, which simply replaces the target volumes in (Eq. 16). This enables to fat transfer between different subjects, which is shown in Figure 15.

FIGURE 15. Examples of “fat transfer”. The two subjects (top/bottom) on the left have a very low amount of body fat. Therefore, scaling their fat volumes is not suitable for fat growth. Instead, we copy the fat distributions of other subjects (shown as small insets) and transfer them to the skinny targets.
5 Conclusion
We created a simple layered volumetric template of the human anatomy and presented an approach for fitting it to surface scans of men and women of various body shapes and sizes. Our method generates plausible muscle and fat layers by estimating realistic muscle and fat masses from the surface scan alone. In addition to the layered template, we also showed how to transfer internal anatomical structures, such as bones and muscles, using a high-quality space warp. Compared to previous work, our method is fully automatic and considerably faster, enabling the simple generation of personalized anatomical models from surface body scans. Besides educational visualization, we demonstrated the potential of our model for physics-based character animation and anatomically plausible fat growth simulation.
Our approach has some limitations: First, we do not generate individual layers for head, hands and toes, where in particular the head would require special treatment. Combining our layered body model with the multi-linear head model of Achenbach et al. (2018) is therefore a promising direction for future work. Second, our regressors for fat and muscle mass could be further optimized by training on more body scans with known body composition. Given more and more accurate training data, as for instance provided by DXA scans, we could extend the fat/muscle estimations to individual body parts. Third, we do not model tendons and veins. Those would have to be included in all layers and could be transferred in the same way as high-resolution muscle and bone models. Fourth, the fact that the three layers of our model share the same topology/connectivity can also be considered a limitation, since we cannot use different, adaptive mesh resolutions in different layers. A promising direction for future work is the use of our anatomical model for generating synthetic training data for statistical analysis and machine learning applications, where the simple structure of our layered model can be beneficial.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Author Contributions
MK is the first author and responsible for most of the implementation and also wrote the first draft of the manuscript. SW wrote and implemented some of the sections (Section 3.1; Section 3.3). MB is responsible for the implementation of Section 3.4.4. and generally supervised the implementation and manuscript generation. All authors contributed to manuscript revision, read, and approved the submitted version.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors are grateful to Jascha Achenbach for valuable discussion and implementation hints and to Hendrik Meyer for his help with the renderings of our models. This research was supported by the German Federal Ministry of Education and Research (BMBF) through the project ViTraS (ID 16SV8225). The scale and ruler emojis in Figure 2 are designed by OpenMoji (https://openmoji.org) and provided through CC BY-SA 4.0 License.
References
Achenbach, J., Waltemate, T., Latoschik, M. E., and Botsch, M. (2017). “Fast Generation of Realistic Virtual Humans,” in Proc. of ACM Symposium on Virtual Reality Software and Technology. Berlin: Springer, 1–10.
Achenbach, J., Brylka, R., Gietzen, T., Zum Hebel, K., Schömer, E., Schulze, R., et al. (2018). “A Multilinear Model for Bidirectional Craniofacial Reconstruction,” in Proc. of Eurographics Workshop on Visual Computing for Biology and Medicine. Berlin: Springer, 67–76.
Anguelov, D., Srinivasan, P., Koller, D., Thrun, S., Rodgers, J., and Davis, J. (2005). SCAPE: Shape completion and animation of people. ACM Trans. Graph. 24, 408–416. doi:10.1145/1073204.1073207
Autodesk (2014). Character Generator. Available at: https://charactergenerator.autodesk.com/ [Dataset] (September 21, 2014).
Aydin Kabakci, A. D., Buyukmumcu, M., Yilmaz, M. T., Cicekcibasi, A. E., Akin, D., and Cihan, E. (2017). An Osteometric Study on Humerus. Int. J. Morphol. 35, 219–226. doi:10.4067/s0717-95022017000100036
Bogo, F., Romero, J., Pons-Moll, G., and Black, M. J. (2017). “Dynamic FAUST: Registering Human Bodies in Motion,” in Proc. of IEEE Conference on Computer Vision and Pattern Recognition, 5573–5582. Boca Raton. CRC Press.
Botsch, M., and Kobbelt, L. (2005). Real-time Shape Editing Using Radial Basis Functions. Comput. Graphics Forum 24, 611–621. doi:10.1111/j.1467-8659.2005.00886.x
Botsch, M., Kobbelt, L., Pauly, M., Alliez, P., and Lévy, B. (2010). Polygon Mesh Processing. Boca Raton. CRC Press.
Bouaziz, S., Deuss, M., Schwartzburg, Y., Weise, T., and Pauly, M. (2012). Shape-up: Shaping Discrete Geometry with Projections. Comput. Graph. Forum 31, 1657–1667. doi:10.1111/j.1467-8659.2012.03171.x
Bouaziz, S., Martin, S., Liu, T., Kavan, L., and Pauly, M. (2014a). Projective Dynamics: Fusing Constraint Projections for Fast Simulation. ACM Trans. Graphics 33, 1–11. doi:10.1145/2601097.2601116
Bouaziz, S., Tagliasacchi, A., and Pauly, M. (2014b). Dynamic 2D/3D Registration. Eurographics Tutorials 14, 1–17. doi:10.1118/1.4830428
Brochu, T., Edwards, E., and Bridson, R. (2012). Efficient Geometrically Exact Continuous Collision Detection. ACM Trans. Graphics 31, 1–7. doi:10.1145/2185520.2185592
Brožek, J., Grande, F., Anderson, J. T., and Keys, A. (1963). Densitometric Analysis of Body Composition: Revision of Some Quantitative Assumptions. Ann. N. Y Acad. Sci. 110, 113–4010. doi:10.1111/j.1749-6632.1963.tb17079.x
Christ, A., Kainz, W., Hahn, E. G., Honegger, K., Zefferer, M., Neufeld, E., et al. (2009). The Virtual Family—Development of Surface-Based Anatomical Models of Two Adults and Two Children for Dosimetric Simulations. Phys. Med. Biol. 55, N23–N38. doi:10.1088/0031-9155/55/2/n01
Dayal, M. R., Steyn, M., and Kuykendall, K. L. (2008). Stature Estimation from Bones of South African Whites. South Afr. J. Sci. 104, 124–128. doi:10.1520/jfs13760j
Deul, C., and Bender, J. (2013). “Physically-based Character Skinning,” in Proc. Of Virtual Reality Interactions and Physical Simulations. Berlin: Springer.
Deuss, M., Deleuran, A. H., Bouaziz, S., Deng, B., Piker, D., and Pauly, M. (2015). ShapeOp – a Robust and Extensible Geometric Modelling Paradigm. Proc. Des. Model. Symp. 14, 505–515. doi:10.1007/978-3-319-24208-8_42
Dicko, A.-H., Liu, T., Gilles, B., Kavan, L., Faure, F., Palombi, O., et al. (2013). Anatomy Transfer. ACM Trans. Graphics 32, 1–8. doi:10.1145/2508363.2508415
Fields, D. A., Goran, M. I., and McCrory, M. A. (2002). Body-composition Assessment via Air-Displacement Plethysmography in Adults and Children: a Review. Am. J. Clin. Nutr. 75, 453–467. doi:10.1093/ajcn/75.3.453
Fit3D (2021). Fit3d Scanner Systems. Available at: https://fit3d.com/ (October 2, 2020).
Gietzen, T., Brylka, R., Achenbach, J., Zum Hebel, K., Schömer, E., Botsch, M., et al. (2019). A Method for Automatic Forensic Facial Reconstruction Based on Dense Statistics of Soft Tissue Thickness. PloS one 14, e0210257. doi:10.1371/journal.pone.0210257
Guennebaud, G., and Jacob, B. (2018). Eigen V3. Available at: http://eigen.tuxfamily.org (December 4, 2020).
Hasler, N., Stoll, C., Sunkel, M., Rosenhahn, B., and Seidel, H.-P. (2009). A Statistical Model of Human Pose and Body Shape. Comput. Graphics Forum 28, 337–346. doi:10.1111/j.1467-8659.2009.01373.x
Heymsfield, S. B., Heo, M., Thomas, D., and Pietrobelli, A. (2011). Scaling of Body Composition to Height: Relevance to Height-Normalized Indexes. Am. J. Clin. Nutr. 93, 736–740. doi:10.3945/ajcn.110.007161
Ichim, A.-E., Kavan, L., Nimier-David, M., and Pauly, M. (2016). “Building and Animating User-specific Volumetric Face Rigs.,” in Symposium on Computer Animation. Berlin: Springer, 107–117.
Ichim, A.-E., Kadleček, P., Kavan, L., and Pauly, M. (2017). Phace: Physics-Based Face Modeling and Animation. ACM Trans. Graphics 36, 1–14. doi:10.1145/3072959.3073664
Jackson, A. S., and Pollock, M. L. (1985). Practical Assessment of Body Composition. The Physician and Sportsmedicine 13, 76–90. doi:10.1080/00913847.1985.11708790
Kadleček, P., Ichim, A.-E., Liu, T., Křivánek, J., and Kavan, L. (2016). Reconstructing Personalized Anatomical Models for Physics-Based Body Animation. ACM Trans. Graphics 35, 1–13. doi:10.1145/2980179.2982438
Kim, M., Pons-Moll, G., Pujades, S., Bang, S., Kim, J., Black, M. J., et al. (2017). Data-driven Physics for Human Soft Tissue Animation. ACM Trans. Graphics 36 (541–54), 12. doi:10.1145/3072959.3073685
Komaritzan, M., and Botsch, M. (2018). Projective Skinning. Proc. ACM Comput. Graphics Interactive Tech. 1, 27. doi:10.1145/3203203
Komaritzan, M., and Botsch, M. (2019). Fast Projective Skinning. Proc. ACM Motion, Interaction Games 22 (1–22), 10. doi:10.1145/3359566.3360073
Kyle, U. G., Genton, L., Slosman, D. O., and Pichard, C. (2001). Fat-free and Fat Mass Percentiles in 5225 Healthy Subjects Aged 15 to 98 Years. Nutrition 17, 534–541. doi:10.1016/s0899-9007(01)00555-x
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., and Black, M. J. (2015). SMPL: A Skinned Multi-Person Linear Model. ACM Trans. Graphics 34, 1–16. doi:10.1145/2816795.2818013
Maalin, N., Mohamed, S., Kramer, R. S., Cornelissen, P. L., Martin, D., and Tovée, M. J. (2020). Beyond BMI for Self-Estimates of Body Size and Shape: A New Method for Developing Stimuli Correctly Calibrated for Body Composition. Behav. Res. Methods 14, 121. doi:10.3758/s13428-020-01494-1
Ng, B. K., Hinton, B. J., Fan, B., Kanaya, A. M., and Shepherd, J. A. (2016). Clinical Anthropometrics and Body Composition from 3D Whole-Body Surface Scans. Eur. J. Clin. Nutr. 70, 1265–1270. doi:10.1038/ejcn.2016.109
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., et al. (2011). Scikit-learn: Machine Learning in Python. J. Machine Learn. Res. 12, 2825–2830. doi:10.1002/9781119557500.ch5
Piryankova, I., Stefanucci, J., Romero, J., de la Rosa, S., Black, M., and Mohler, B. (2014). Can I Recognize My Body’s Weight? the Influence of Shape and Texture on the Perception of Self. ACM Trans. Appl. Perception 11, 1–18. doi:10.1145/2628257.2656424
Riviere, J., Gotardo, P., Bradley, D., Ghosh, A., and Beeler, T. (2020). Single-shot High-Quality Facial Geometry and Skin Appearance Capture. ACM Trans. Graphics 39, 1–12. doi:10.1145/3386569.3392464
Robinette, K. M., Blackwell, S., Daanen, H., Boehmer, M., and Fleming, S. (2002). Civilian American and European Surface Anthropometry Resource (CEASAR), Final Report,” in Summary. Tech. Rep. 1. New York, NY: Sytronics Inc.
Romero, C., Otaduy, M. A., Casas, D., and Perez, J. (2020). Modeling and Estimation of Nonlinear Skin Mechanics for Animated Avatars. Comput. Graphics Forum 39, 77–88. doi:10.1111/cgf.13913
Saito, S., Zhou, Z.-Y., and Kavan, L. (2015). Computational Bodybuilding: Anatomically-Based Modeling of Human Bodies. ACM Trans. Graphics 34, 1–12. doi:10.1145/2766957
Shoemake, K., and Duff, T. (1992). “Matrix Animation and Polar Decomposition,” in Proceedings of the Conference on Graphics Interface, Boca Raton: CRC Press. 258–264.
Sieger, D., Menzel, S., and Botsch, M. (2013). “High Quality Mesh Morphing Using Triharmonic Radial Basis Functions,” in Proceedings of the 21st International Meshing Roundtable, Boca Raton: CRC Press. 1–15. doi:10.1007/978-3-642-33573-0_1
Siri, W. E. (1956). “Body Composition from Fluid Spaces and Density: Analysis of Methods,” in Tech. Rep. Ucrl-, 3349. New York, NY: Lawrence Berkeley National Laboratory.
Tomlinson, D., Erskine, R., Morse, C., Winwood, K., and Onambélé-Pearson, G. (2016). The Impact of Obesity on Skeletal Muscle Strength and Structure through Adolescence to Old Age. Biogerontology 17, 467–483. doi:10.1007/s10522-015-9626-4
Weng, C.-Y., Curless, B., and Kemelmacher-Shlizerman, I. (2019). “Photo Wake-Up: 3D Character Animation from a Single Photo,” in Proc. of IEEE Conference on Computer Vision and Pattern Recognition, Boca Raton: CRC Press. 1–15.
Wenninger, S., Achenbach, J., Bartl, A., Latoschik, M. E., and Botsch, M. (2020). “Realistic Virtual Humans from Smartphone Videos,” in Proc. of ACM Symposium on Virtual Reality Software and Technology. New York, NY: Lawrence Berkeley National Laboratory, 1–11.
Zhu, L., Hu, X., and Kavan, L. (2015). Adaptable Anatomical Models for Realistic Bone Motion Reconstruction. Comput. Graphics Forum 34, 459–471. doi:10.1111/cgf.12575
Ziylan, T., and Murshid, K. A. (2002). An Analysis of Anatolian Human Femur Anthropometry. Turkish J. Med. Sci. 32, 231–235. doi:10.1127/anthranz/64/2006/389
Zygote (2020). Definitions. Available at: https://www.zygote.com (December 10, 2019).
Appendix: implementation details
For minimization of the energies (Eqs 1, 5, 8), we use the projective framework of Bouaziz et al. (2012) and Bouaziz et al. (2014a), implemented through an adapted local/global solver from the ShapeOp library (Deuss et al., 2015). It has the advantages of being unconditionally stable, easy-to-use and flexible enough to handle a wide range of energies. Here we give the weights for the different energy terms and give implementation details.
We fit the skin surface
We first initialize
For fitting the skeleton surface of the template to a surface scan, we minimize Eq. 5
where
In order to fit the templates muscle surface to the target, we perform the minimization of (Eq. 8)
We initialize
Keywords: virtual human, anatomy, non rigid registration, virtual reality, human shape analysis
Citation: Komaritzan M, Wenninger S and Botsch M (2021) Inside Humans: Creating a Simple Layered Anatomical Model from Human Surface Scans. Front. Virtual Real. 2:694244. doi: 10.3389/frvir.2021.694244
Received: 12 April 2021; Accepted: 08 June 2021;
Published: 05 July 2021.
Edited by:
Yajie Zhao, University of Southern California, United StatesReviewed by:
John Dingliana, Trinity College Dublin, IrelandDominique Bechmann, Université de Strasbourg, France
Copyright © 2021 Komaritzan, Wenninger and Botsch. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Martin Komaritzan, bWFydGluLmtvbWFyaXR6YW5AdHUtZG9ydG11bmQuZGU=