 Monica Billio
Monica Billio Roberto Casarin
Roberto Casarin Michele Costola
Michele Costola Matteo Iacopini
Matteo Iacopini- 1Department of Economics, Ca' Foscari University of Venice, Venice, Italy
- 2Department of Econometrics and Data Science, Vrije Universiteit Amsterdam, Amsterdam, Netherlands
- 3Tinbergen Institute, Amsterdam, Netherlands
Networks represent a useful tool to describe relationships among financial firms and network analysis has been extensively used in recent years to study financial connectedness. An aspect, which is often neglected, is that network observations come with errors from different sources, such as estimation and measurement errors, thus a proper statistical treatment of the data is needed before network analysis can be performed. We show that node centrality measures can be heavily affected by random errors and propose a flexible model based on the matrix-variate t distribution and a Bayesian inference procedure to de-noise the data. We provide an application to a network among European financial institutions.
1. Introduction
A network can be defined as a set of nodes and edges, which represent a relationship among the nodes (Newman et al., 2006; Newman, 2018). A wide spectrum of relational, spatial, and multivariate data from many fields, such as sociology, biology, environmental, and neuroscience, admits a natural representation as a network. In mathematical terms, a network can be represented through the notion of a graph and its properties. For an introduction to graph theory and random graphs, we refer the interested reader to Bollobás (1998) and Bollobás (2001). See Jackson (2008) for an introduction to network theory in social sciences. In this paper, we will use the two terms interchangeably. As an example, in financial networks, a node represents a firm and an edge has the interpretation of a financial relationship between two firms.
In finance, the extraction of unobserved networks from time series data has attracted the attention of many researchers since the recent financial crisis (e.g., Billio et al., 2012; Diebold and Yılmaz, 2014). A large number of different methodologies have been proposed for the estimation of financial networks from firm return series (e.g., Barigozzi and Brownlees, 2019; Bräuning and Koopman, 2020), in particular in the Bayesian approach. For example, Billio et al. (2019) propose a Bayesian non-parametric Lasso prior distribution for vector autoregressive (VAR) models, which provides a sparse estimation of the VAR coefficients and classifies the non-zero coefficients into different clusters. They extract causal networks among financial assets and find that the resulting network topologies match the features of many real-world networks. Ahelegbey et al. (2016a,b) exploit graphical models to specify both the contemporaneous and the lagged causal structures in Bayesian VAR models. In a related contribution, Bianchi et al. (2019) investigate the temporal evolution in systemic risk using a Markov-switching graphical SUR model.
The inferred network structure is intrinsically contaminated by a certain degree of estimation error, which may cumulate with other sources of errors, such as model misspecification and measurement error. Consequently, the direct use of estimated networks as inputs in network analyses (e.g., Casarin et al., 2020; Wang et al., 2021) may result in misleading conclusions. This calls for the definition of suitable tools for cleaning the data from random disturbances, thus enabling to perform valid statistical analyses of the networks.
In this paper, we propose a new Bayesian model for network data with matrix-variate t errors which accounts for heavy tails (Tomarchio et al., 2020). The inferential procedure is based on data augmentation and conjugate prior distributions that allow for an efficient posterior sampling scheme. In addition to the studies on financial network extraction, our paper also contributes to the literature on matrix-variate models and financial connectedness.
Motivated by the increasing availability of large and multidimensional data, the use of matrix-variate distributions in time series econometrics has flourished during the last decade. The main domains where these models have been successfully applied include the classification of longitudinal datasets (Viroli, 2011), network analysis (Durante and Dunson, 2014; Zhu et al., 2017, 2019), factor analysis (Wang et al., 2019; Chen et al., 2020), stochastic volatility modeling (Gouriéroux et al., 2009; Golosnoy et al., 2012), and Gaussian dynamic linear modeling (Wang and West, 2009).
Finally, we aim to contribute to the financial economics literature by applying the proposed method for de-noising network data extracted from European firms' stock market returns. Then, we analyze the connectedness of the network and compare the results to those obtained from a direct analysis of the network raw data. Our simulation results provide an estimate of the bias in the network centrality measures induced by errors in the edges and show that the proposed approach is effective in correcting for the bias. Our empirical analysis confirms the presence of variability in the network edges. Furthermore, comparing network statistics between the raw network data and the filtered one, we find substantial evidence of differences in the most frequently used statistics, such as out-degree, eigenvector, betweenness, and closeness centrality measures.
The remaining of the paper is structured as follows: section 2 introduces a new linear model for matrix-valued data, then section 3 presents a Bayesian inference procedure. The results of an empirical analysis on real network data are illustrated in section 4. Finally, section 5 concludes.
2. A Matrix-Variate t Model
Let , t = 1, …, T, be a sequence of networks (Boccaletti et al., 2014), where Ht ⊂ V × V is the edge set and V = {1, …, n} is the set of nodes. In our application, is a Granger network where the nodes represent institutions from different sectors and directed edges represent financial linkages. A directed edge from node j to node i represents a Granger-causal relationship from firm j to firm i, and is associated to the element Yij, t of the adjacency matrix Yt.
The connectivity structure of a n-dimensional network can be represented through a n-dimensional square matrix Yt, called the adjacency matrix. Each element Yuv, t of the adjacency matrix is non-zero if there is an edge from institution v to institution u with u, v ∈ V, and 0 otherwise, where u ≠ v, since self-loops are not allowed.
Unfortunately, most frequently the connectivity structure among financial institutions is not directly observable, thus requiring suitable statistical tools to extract the latent network topologies that are characterized by estimation errors. For example, our data relies on a Granger causality approach to extract network observations from financial price series, which, in turn, may be contaminated by the presence of measurement noise. Overall, these multiple sources of errors may yield an imperfect observation of the true connectivity structure, calling for the adoption of a proper de-noising procedure before performing network analyses.
We propose a matrix-variate linear stochastic model to deal with measurement and estimation errors in the adjacency matrices. The noise process is assumed to follow a matrix-variate t distribution, that accounts for potentially large deviations of the observations from the mean. The proposed model is
where B ∈ ℝn × n is a matrix of coefficients and is a random error term. A random matrix X ∈ ℝp × m follows a matrix-variate t distribution, X ~ tp, m(ν, M, Σ1, Σ2), if it has probability density function
where Γp(·) is the multivariate gamma function and |·| denotes the matrix determinant. The matrix M ∈ ℝp × m is the location parameter, ν > 0 is the degrees of freedom parameter, and the positive definite matrices and are scale parameters driving the covariances between each of the p rows and the m columns of X, respectively. For further details, see Chapter 4 in Gupta and Nagar (1999). Thanks to the properties of the matrix-variate t distribution, the unconditional mean and variance of Yt are 𝔼(Yt) = B, if ν > 1, and 𝕍ar(Yt) = Σ2 ⊗ Σ1/(ν − 2), if ν > 2, where ⊗ denotes the Kronecker product.
3. Bayesian Inference
3.1. Prior Specification
In this section we describe the prior structure for the model parameters. For the coefficient matrix B, we assume a matrix normal distribution
where Ω1 = ω1In and Ω2 = ω2In, with ω1 > 0 and ω2 > 0 fixed. A random matrix Z ∈ ℝp × m follows a matrix normal distribution (Gupta and Nagar, 1999, Chapter 2), denoted by , if its probability density function is
The matrix normal distribution is equivalent to a multivariate normal distribution with a product-separable covariance structure, that is, is equivalent to , where vec(·) is a vectorization operator that stacks all the columns of a matrix into a column vector. Since Σ2 ⊗ Σ1 = (Σ2/a) ⊗ (aΣ1) for any a ≠ 0, the noise covariance matrices of the matrix-variate t distribution, Σ1, Σ2, are not identifiable and prior restrictions can be used to achieve identification. Nevertheless, in this paper we are interested in the variability of the errors as measured by the product Σ2 ⊗ Σ1, which is always identifiable. For the noise covariances, Σ1 and Σ2, we assume the following hierarchical prior distribution
where we use the shape-scale parametrization for the gamma distribution and the scale parametrization for the Wishart and inverse Wishart distributions, with densities
where κ1 and κ2 are the degrees of freedom parameters and Γn(·) is the multivariate gamma function (see Gelman et al., 2014, Appendix A, p. 577). The common scale γ allows for various degrees of prior dependence in the unconditional joint distribution of (Σ1, Σ2). Finally, since the object of interest is the mean of Yt, which is defined only for ν > 1, we assume the following gamma prior distribution truncated on the interval (1, +∞)
The gamma prior distribution has been previously considered, e.g., in Geweke (1993) and Wang et al. (2011). For the use of an improper prior, see Fonseca et al. (2008). Since we are using a proper prior distribution for B, its posterior distribution is well-defined for ν > 0 (Geweke, 1993), whereas the constraint ν > 2 is required when using improper prior distributions.
3.2. Posterior Approximation
Denote the collection of parameters with θ = (B, Σ1, Σ2, ν), and let Y = (Y1, …, YT) be the collection of all observed networks. The likelihood of the model in Equation (1) is
Since the joint posterior distribution implied by the prior assumptions in Equations (3)–(6) and the likelihood in Equation (7) is not tractable, we follow a data augmentation approach. We exploit the representation of the matrix t distribution as a scale mixture of matrix normal distributions, with Wishart mixing distribution (Thompson et al., 2020). From Theorem 4.3.1 in Gupta and Nagar (1999), if and , then X~tp, m(ν, M, Σ1, Σ2). Following Gelman et al. (2014) parametrization of the inverse Wishart, we obtain the equivalent representation and . We apply this result to Yt~tn, n(ν, B, Σ1, Σ2) and obtain the complete data likelihood
where W = (W1, …, WT) is the collection of auxiliary variables, with .
The data augmentation approach combined with our prior assumptions allows us to derive analytically the full conditional distributions of B, Σ1, Σ2, and W. Since the joint posterior distribution is not tractable, we implement an MCMC approach based on a Gibbs sampling algorithm that iterates over the following steps:
1. Draw (ν, W) from the joint posterior distribution P(ν, W|Y, B, Σ1, Σ2) with a collapsed-Gibbs step that first samples ν ~ P(ν|Y, B, Σ1, Σ2) and then W ~ P(W|Y, B, Σ1, Σ2, ν).
2. Draw vec(B) from the multivariate normal distribution P(vec(B)|Y, W, Σ1, Σ2).
3. Draw Σ1 from the Wishart distribution P(Σ1|W, ν, γ).
4. Draw Σ2 from the inverse Wishart distribution P(Σ2|Y, B, W, γ).
5. Draw γ from the gamma distribution P(γ|Σ1, Σ2).
See the Appendix for further details.
3.3. Simulation Experiments
We study the effects of the network estimation errors on the network statistics. We set the size of the network to n = 70, assume the degrees of freedom parameter takes values ν = 1, 2, …, 50, and consider two experimental settings with different levels of variance in the error term Et: (i) low variance, with Σ1 = In · 3.0 and Σ2 = In · 1.2, and (ii) high variance, with Σ1 = In · 75.0 and Σ2 = In · 1.2. The choice of the parameter settings reflects the results obtained in the empirical application.
The adjacency matrix A of the network is obtained by applying the probit transformation to the elements of B. Following common practice in the analysis of financial connectedness [e.g., see Billio et al., 2012], we fix a threshold equal to 0.05, that is aij = 𝕀(Φ(bij < 0.05)), where aij and bij are the (i, j)-th elements of A and B, respectively, 𝕀(p) is the indicator function, taking value 1 when p is true and 0 otherwise, and Φ denotes the cdf of the standard normal distribution.
We focus on four measures of node centrality commonly used in network analysis (Newman, 2018, Chapter 7): out-degree, , eigenvector centrality, , closeness centrality, , and betweenness centrality, . To define these measures, we first introduce some notation. A path is a sequence of edges which joins a sequence of distinct vertices, and a node s is said to be reachable from node t if there exists a path which starts with t and ends with s.
The out-degree on node i is the total number of outgoing connections, that is
The eigenvector centrality describes the influence of a node in a network by accounting for the centrality of all the other nodes in its neighborhood. For each node i, it is defined as
where the score is related to the score of its neighborhood Ni = {v ∈ V; aiv = 1} and λ is an eigenvalue of the adjacency matrix A. The closeness centrality accounts for connectivity patterns by indicating how easily a node can reach other nodes. For each node i, it is given by
where l(i, v) is the length of the shortest path between i and v. A related measure is the betweenness centrality, which indicates how relevant a node is in terms of connecting other nodes in the graph. Let n(u, v) be the number of shortest paths from u to v and ni(u, v) be the cardinality of the set , that is the number of shortest paths from u to v going through the node i. Then the betweenness centrality for node i is
Figure 1 shows the network statistics for the true network A, the estimated network based on , and the empirical averages of the statistics based on the raw data Yt. The main findings are summarized below:
• for heavier-tailed noise distribution (i.e., smaller ν), the bias of the empirical network statistics increases;
• the bias increases with the scale of the noise, especially for the eigenvector and betweenness centrality measures;
• as the degrees of freedom increase, the noise distribution converges to a matrix normal and the empirical averages approach the true value;
• the model proposed in Equation (1) yields correct estimates of the metrics for all values of ν, even in presence of heavy tails, with higher dispersion as the scale of the noise increases.
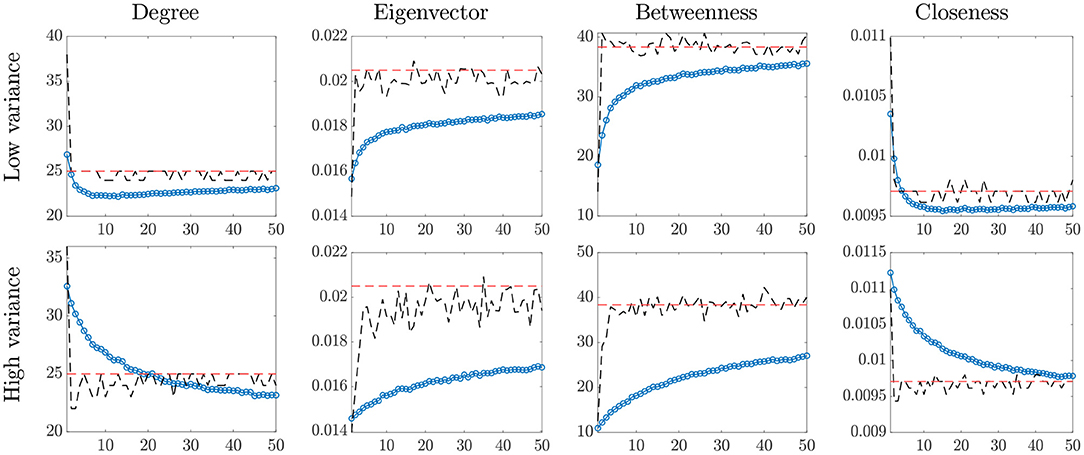
Figure 1. Network centrality statistics. In each plot: true value (red, dashed line) and temporal averages of the statistics on the raw data Yt (blue, dotted line), and statistics based on the estimated network (black, dashed line), for increasing values of the degrees of freedom, ν (horizontal axis).
Overall, these findings indicate that a direct implementation of network analysis in presence of noisy measurements may lead to misguiding conclusions. This issue can be addressed by using the proposed methodology to de-noise the network data.
4. Empirical Analysis
In this section, we provide a description of the raw time series data and of the methodology used to extract the financial networks. Then, we present the benefits of the proposed model for computing the summary statistics most widely used in applied network analysis.
4.1. Data Description
We consider the stock prices of the 70 European firms with the largest market capitalization (source: Bloomberg and Eikon/Datastream). The dataset includes 28 German, 37 French, and five Italian firms, belonging to 11 GICS sectors: Communication Services (four firms), Consumer Discretionary (15 firms), Consumer Staples (six firms), Energy (two firms), Financials (11 firms), Health Care (six firms), Industrials (10 firms), Information Technology (five firms), Materials (two firms), Real Estate (three firms), Utilities (five firms), and Food and Beverages (one firm)1.
Data are sampled from the 4th of January 2016 to the 31st of December 2019, at weekly frequency (Friday-Friday). The period after the outbreak of the COVID-19 is excluded from the analysis due to the break induced on the network structure.
We extract the network sequence using the pairwise Granger-causality test (e.g., see Billio et al., 2012) on a rolling window of 104 weekly logarithmic returns (i.e., 2 years). The auxiliary regression used is
where i, j = 1, …, n, for i ≠ j. Each entry (i, j) of the matrix Yt, denoted by Yij, t, is the p-value of the Granger test statistic. The element Yij, t represents the probability that xj, t Granger-causes xi, t. We estimate a total of 105 adjacency matrices, for the period from the 29th of December 2017 to the 31st of December 20192.
4.2. Results
In this section, we apply the model and inference proposed in sections 2, 3 to estimate the impact of the risk factors on the European financial network. We run the Gibbs sampler for 5,000 iterations after discarding the first 2,000 as burn-in3.
Figure 2 shows the de-noised directed network and two elements of the raw series. In each plot, a node represents a firm and its size is proportional to its out-degree. The red dot indicates the most central node in , that is the node with the highest out-degree in , and directed edges are represented by clockwise-oriented arcs. The node with the highest out-degree is a financial firm, whereas the most central node according to the other measures belongs to the energy sector. The largest black dot in each plot of Figure 2 represents the most degree-central institution, that is the one with highest out-degree. As shown by the position of the largest dot in the middle and right plots, the most central node varies over the sample. This supports the claim that observation contaminated by noise, if not properly filtered, may alter network analyses.
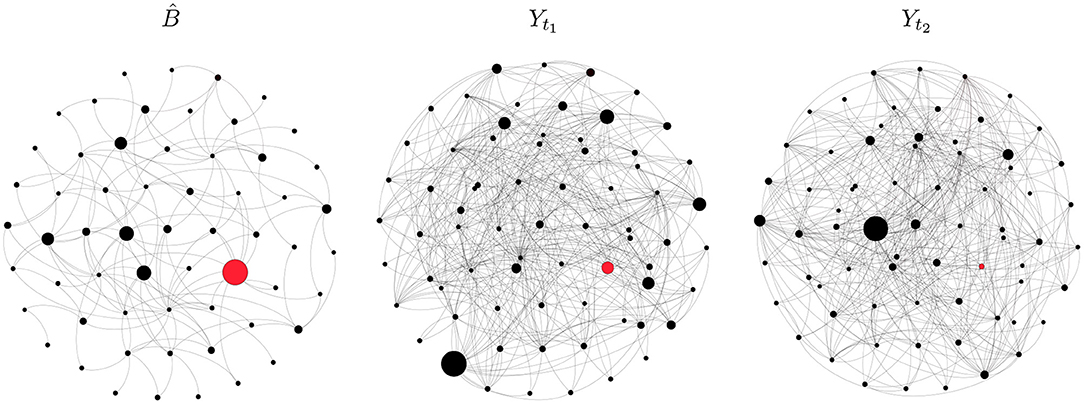
Figure 2. Graphical representation of the de-noised network (left) and raw networks at t1 = 1 (middle) and t2 = 105 (right). Black dots represent financial firms and gray arcs represent directed edges (clockwise orientation). The red dot stands for the most central institution according to degree centrality. In each plot, the size of a node is proportional to its out-degree.
The posterior density of the degrees of freedom in the left plot of Figure 3 suggests that the noise distribution is close to the Gaussian. Nonetheless, as shown in the simulation experiments, our approach is able to provide more accurate estimates of the network measures as compared to the empirical averages. This is particularly evident for the eigenvector centrality, where the empirical averages are sensitive to errors compatible with a t distribution with large degrees of freedom (see Figure 1). The right plot shows the posterior distribution of the average of the elements on the main diagonal of Σ2 ⊗ Σ1. The estimated average variance is 84.5, thus providing evidence of high variability in the network observations.
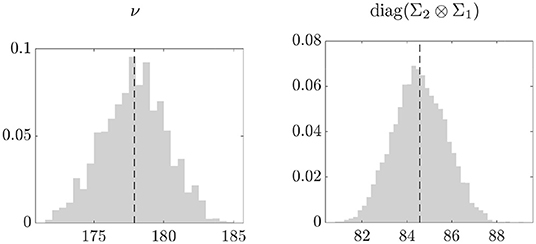
Figure 3. Posterior distribution (gray) and mean (black, dashed line) of the degrees of freedom (left) and of the average of diag(Σ2 ⊗ Σ1) (right).
As described in section 1, the presence of noise in the data can invalidate network analyses, such as the identification of the most central institution. Motivated by this fact, we assess the importance of de-noising the network data by computing the network centrality measures on the raw data and on the de-noised network obtained using the method in section 2. The results are shown in Figure 4, which reports the posterior distribution of the centrality measures computed on the de-noised network (gray, with the black line representing the posterior mean) and the temporal average of the statistics computed on the raw data (red line). We find that all centrality measures of the de-noised data differ from the temporal average of the raw data; in particular, the eigenvector and betweenness centrality based on the raw data are underestimated, while the closeness centrality is overestimated. Overall, these findings provide evidence that the presence of noise in network data may jeopardize the validity of the ensuing analyses of the network structure.
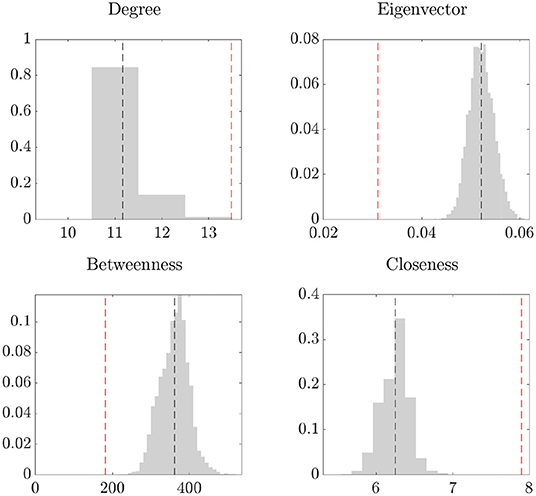
Figure 4. Network centrality statistics. In each plot: posterior distribution (gray) and mean (black, dashed line) of the statistics, and temporal averages of the statistics on the raw data Yt (red, dashed line).
5. Conclusions
A common, though often neglected, aspect of network analysis is that observations for networks might come with errors from different sources, such as estimation and measurement errors. We show that noise may invalidate the study of the network topology, such as the measurement of node centrality.
We have introduced a new matrix-variate regression framework that allows for heavy-tailed matrix-variate t errors to address this issue. The model is applied to filter out the noise from network data as a preliminary step before investigating the connectedness structure. In the presence of heavy-tailed error distributions or big scales of the variance of the noise, the proposed approach has superior performance compared to the temporal averages of the network statistics. Finally, we have applied the model to a sequence of estimated networks among European firms and find evidence of large error variance that affects the centrality measures.
More generally, our approach can be implemented to obtain robust network inference or fit benchmark random network models, such as those proposed by Erdőrigos-Rény and Albert-Barabási, thus representing a valuable tool for researchers investigating networks.
In this paper, we focus on the case where all the noisy observations contain the same set of nodes, meaning that there is no uncertainty on the network nodes. An interesting extension would be to consider observed networks having different sizes. We leave this for future research.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author/s.
Author Contributions
All authors listed have made a substantial, direct and intellectual contribution to the work, and approved it for publication.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We thank Maurizio La Mastra for excellent research assistance. This research used the SCSCF and the HPC multiprocessor cluster systems provided by the Venice Centre for Risk Analytics (VERA) at the University Ca' Foscari of Venice. MB, RC, and MC acknowledge financial support from the Italian Ministry MIUR under the PRIN project Hi-Di NET – Econometric Analysis of High Dimensional Models with Network Structures in Macroeconomics and Finance (grant agreement no. 2017TA7TYC). MI acknowledges financial support from the Marie Skłodowska-Curie Actions, European Union, Seventh Framework Program HORIZON 2020 under REA grant agreement no. 887220.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frai.2021.674166/full#supplementary-material
Footnotes
1. ^The list of the firms, the countries, and the information about their GICS sectors and industries are available upon request to the Authors.
2. ^The estimation algorithm has been parallelized and implemented in MATLAB on the High Performance Computing (HPC) cluster at Ca' Foscari University. Each node has two CPUs Intel Xeon with 20 cores 2.4 GHz and 768 GB of RAM.
3. ^The total computing time for the empirical application is about 22 h with code written in MATLAB and run on an Intel Xeon with 20 cores 2.4 GHz and 768 GB of RAM.
References
Ahelegbey, D. F., Billio, M., and Casarin, R. (2016a). Bayesian graphical models for structural vector autoregressive processes. J. Appl. Econometr. 31, 357–386. doi: 10.1002/jae.2443
Ahelegbey, D. F., Billio, M., and Casarin, R. (2016b). Sparse graphical vector autoregression: a Bayesian approach. Ann. Econ. Stat. 333–361. doi: 10.15609/annaeconstat2009.123-124.0333
Barigozzi, M., and Brownlees, C. (2019). Nets: network estimation for time series. J. Appl. Econometr. 34, 347–364. doi: 10.1002/jae.2676
Bianchi, D., Billio, M., Casarin, R., and Guidolin, M. (2019). Modeling systemic risk with Markov switching graphical sur models. J. Econometr. 210, 58–74. doi: 10.1016/j.jeconom.2018.11.005
Billio, M., Casarin, R., and Rossini, L. (2019). Bayesian nonparametric sparse VAR models. J. Econometr. 212, 97–115. doi: 10.1016/j.jeconom.2019.04.022
Billio, M., Getmansky, M., Lo, A. W., and Pelizzon, L. (2012). Econometric measures of connectedness and systemic risk in the finance and insurance sectors. J. Financ. Econ. 104, 535–559. doi: 10.1016/j.jfineco.2011.12.010
Boccaletti, S., Bianconi, G., Criado, R., Del Genio, C. I., Gómez-Gardenes, J., Romance, M., et al. (2014). The structure and dynamics of multilayer networks. Phys. Rep. 544, 1–122. doi: 10.1016/j.physrep.2014.07.001
Bräuning, F., and Koopman, S. J. (2020). The dynamic factor network model with an application to international trade. J. Econometr. 216, 494–515. doi: 10.1016/j.jeconom.2019.10.007
Casarin, R., Iacopini, M., Molina, G., ter Horst, E., Espinasa, R., Sucre, C., et al. (2020). Multilayer network analysis of oil linkages. Econometr. J. 23, 269–296. doi: 10.1093/ectj/utaa003
Chen, E. Y., Tsay, R. S., and Chen, R. (2020). Constrained factor models for high-dimensional matrix-variate time series. J. Am. Stat. Assoc. 115, 775–793. doi: 10.1080/01621459.2019.1584899
Diebold, F. X., and Yılmaz, K. (2014). On the network topology of variance decompositions: measuring the connectedness of financial firms. J. Econometr. 182, 119–134. doi: 10.1016/j.jeconom.2014.04.012
Durante, D., and Dunson, D. B. (2014). Bayesian dynamic financial networks with time-varying predictors. Statist. Probab. Lett. 93, 19–26. doi: 10.1016/j.spl.2014.06.015
Fonseca, T. C., Ferreira, M. A., and Migon, H. S. (2008). Objective bayesian analysis for the student-t regression model. Biometrika 95, 325–333. doi: 10.1093/biomet/asn001
Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., and Rubin, D. B. (2014). Bayesian Data Analysis. CRC Press.
Geweke, J. (1993). Bayesian treatment of the independent student-t linear model. J. Appl. Econometr. 8, S19–S40. doi: 10.1002/jae.3950080504
Golosnoy, V., Gribisch, B., and Liesenfeld, R. (2012). The conditional autoregressive Wishart model for multivariate stock market volatility. J. Econometr. 167, 211–223. doi: 10.1016/j.jeconom.2011.11.004
Gouriéroux, C., Jasiak, J., and Sufana, R. (2009). The Wishart autoregressive process of multivariate stochastic volatility. J. Econometr. 150, 167–181. doi: 10.1016/j.jeconom.2008.12.016
Newman, M. E., Barabási, A. L. E., and Watts, D. J. (2006). The Structure and Dynamics of Networks. Princeton, NJ: Princeton University Press.
Thompson, G. Z., Maitra, R., Meeker, W. Q., and Bastawros, A. F. (2020). Classification with the matrix-variate-t distribution. J. Comput. Graph. Statist. 29, 668–674. doi: 10.1080/10618600.2019.1696208
Tomarchio, S. D., Punzo, A., and Bagnato, L. (2020). Two new matrix-variate distributions with application in model-based clustering. Comput. Statist. Data Anal. 152:107050. doi: 10.1016/j.csda.2020.107050
Viroli, C. (2011). Finite mixtures of matrix normal distributions for classifying three-way data. Statist. Comput. 21, 511–522. doi: 10.1007/s11222-010-9188-x
Wang, D., Liu, X., and Chen, R. (2019). Factor models for matrix-valued high-dimensional time series. J. Econometr. 208, 231–248. doi: 10.1016/j.jeconom.2018.09.013
Wang, H., and West, M. (2009). Bayesian analysis of matrix normal graphical models. Biometrika 96, 821–834. doi: 10.1093/biomet/asp049
Wang, J. J., Chan, J. S., and Choy, S. B. (2011). Stochastic volatility models with leverage and heavy-tailed distributions: a Bayesian approach using scale mixtures. Comput. Statist. Data Anal. 55, 852–862. doi: 10.1016/j.csda.2010.07.008
Wang, Y. R., Li, L., Li, J. J., Huang, H., et al. (2021). Network modeling in biology: statistical methods for gene and brain networks. Statist. Sci. 36, 89–108. doi: 10.1214/20-STS792
Zhu, X., Pan, R., Li, G., Liu, Y., and Wang, H. (2017). Network vector autoregression. Ann. Statist. 45, 1096–1123. doi: 10.1214/16-AOS1476
Keywords: Bayesian, financial markets, matrix-variate distributions, networks, t distribution
JEL Classification: C11, C32, C58
MSCI Classification: 62F15, 62M10, 65C05
Citation: Billio M, Casarin R, Costola M and Iacopini M (2021) A Matrix-Variate t Model for Networks. Front. Artif. Intell. 4:674166. doi: 10.3389/frai.2021.674166
Received: 28 February 2021; Accepted: 12 April 2021;
Published: 13 May 2021.
Edited by:
Joerg Osterrieder, Zurich University of Applied Sciences, SwitzerlandReviewed by:
Andriette Bekker, University of Pretoria, South AfricaBertrand Kian Hassani, University College London, United Kingdom
Copyright © 2021 Billio, Casarin, Costola and Iacopini. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Monica Billio, YmlsbGlvQHVuaXZlLml0