 Soumya Sara Koshy
Soumya Sara Koshy L. Jani Anbarasi*
L. Jani Anbarasi*- School of Computer Science and Engineering, Vellore Institute of Technology, Chennai, India
Introduction: Breast cancer is a severe illness predominantly affecting women, and in most cases, it leads to loss of life if left undetected. Early detection can significantly reduce the mortality rate associated with breast cancer. Ultrasound imaging has been widely used for effectively detecting the disease, and segmenting breast ultrasound images aid in the identification and localization of tumors, thereby enhancing disease detection accuracy. Numerous computer-aided methods have been proposed for the segmentation of breast ultrasound images.
Methods: A deep learning-based architecture utilizing a ConvMixer-based encoder and ConvNeXT-based decoder coupled with convolution-enhanced multihead attention has been proposed for segmenting breast ultrasound images. The enhanced ConvMixer modules utilize spatial filtering and channel-wise integration to efficiently capture local and global contextual features, enhancing feature relevance and thus increasing segmentation accuracy through dynamic channel recalibration and residual connections. The bottleneck with the attention mechanism enhances segmentation by utilizing multihead attention to capture long-range dependencies, thus enabling the model to focus on relevant features across distinct regions. The enhanced ConvNeXT modules with squeeze and excitation utilize depthwise convolution for efficient spatial filtering, layer normalization for stabilizing training, and residual connections to ensure the preservation of relevant features for accurate segmentation. A combined loss function, integrating binary cross entropy and dice loss, is used to train the model.
Results: The proposed model has an exceptional performance in segmenting intricate structures, as confirmed by comprehensive experiments conducted on two datasets, namely the breast ultrasound image dataset (BUSI) dataset and the BrEaST dataset of breast ultrasound images. The model achieved a Jaccard index of 98.04% and 94.84% and a Dice similarity coefficient of 99.01% and 97.35% on the BUSI and BrEaST datasets, respectively.
Discussion: The ConvMixer and ConvNeXT modules are integrated with convolution-enhanced multihead attention, which enhances the model's ability to capture local and global contextual information. The strong performance of the model on the BUSI and BrEaST datasets demonstrates the robustness and generalization capability of the model.
1 Introduction
Breast cancer is the most frequently diagnosed and deadliest form of cancer, primarily affecting women. Breast cancer is caused by the irregular growth of abnormal cells in the breast, leading to tumors. Tumors can be classified as either benign or malignant. Benign tumors are non-cancerous and do not spread outside the breast tissues, while malignant tumors are cancerous and have the ability to metastasize beyond the breast tissues to other parts of the body. Effective policies and initiatives have reduced the percentage of women with metastatic breast cancer at diagnosis in high-income nations; nonetheless, disparity still exists, which must be addressed by raising awareness of breast cancer symptoms and promoting early detection (Fuentes et al., 2024). In economically deprived nations, the occurrence and fatality rates of breast cancer continue to increase. Early detection can significantly reduce breast cancer mortality. Research pertaining to the detection of the disease at an early stage has gained wide attention.
Due to the non-invasive, real-time, low-cost, and non-radiation nature of ultrasound imaging, it has quickly gained widespread acceptance as a breast tumor detection method. Ultrasound imaging uses sound waves instead of radiation to generate images. A precise analysis of the breast cancer images can be done by extracting only the relevant areas from the images, which is called segmentation. Breast ultrasound lesion segmentation presents a variety of challenges: (1) Poor contrast and noise present in the images make it difficult to differentiate lesions from the surrounding tissues. (2) Variations in the structure of malignant tumors make them difficult to detect. (3) Uneven distribution of benign and malignant images in the datasets.
The manual annotation of breast ultrasound images is laborious, time-intensive, and prone to inter-observer variability; an automated segmentation approach can mitigate these issues by delivering consistent and trustworthy outcomes. Computer-aided diagnostic tools for breast ultrasound images have steadily gained popularity as a means of enhancing the precision of diagnosis. Precise segmentation can augment diagnostic accuracy, facilitate quantitative lesion analysis, and aid radiologists in making more informed judgments, thereby enhancing patient outcomes. Furthermore, automating segmentation can optimize clinical procedures, decrease diagnostic duration, and facilitate radiology training by offering prompt feedback. Earlier machine-learning techniques were utilized for breast ultrasound image segmentation, for which manual intervention was required for feature extraction. This approach is time-consuming and also lacks consistency and reliability. Deep learning methods have now been widely used for breast ultrasound image segmentation, in which features are extracted automatically. Various convolutional neural network architectures, including U-Net, U-Net++, etc., show exceptional performance in ultrasound image segmentation.
A hybrid mixer framework with multihead attention (HMA-Net) is proposed for breast ultrasound image segmentation in which features are extracted from the input ultrasound images using five contiguous ConvMixer (Trockman and Kolter, 2022)-based encoder blocks (EMxi), which utilize enhanced ConvMixer for improved feature representation across channels. Convolution-enhanced multihead attention (CEMHA) acts as an intermediary between the encoder and decoder, extracting significant semantic information and effectively decreasing the number of channels, thereby reducing the computational complexity of subsequent layers. Multihead attention (Georgescu et al., 2023) enables the model to focus on divergent areas of the image simultaneously, thereby allowing the model to capture intricate patterns. The ConvNeXT-based decoder blocks (DCNxi) generate high-resolution feature maps from the compressed feature maps produced by the EMxi blocks. The ConvNeXT (Liu et al., 2022) involves enhanced convolutions with which the features can be extracted with increased efficiency compared to the conventional convolutional networks. Skip connections are established between the feature maps in the contracting path of the EMxi blocks and the corresponding layers in the DCNxi, facilitating feature merging via concatenation to restore the spatial resolution of images.
The HMA-Net model is validated on two datasets of ultrasound images. The initial dataset is called breast ultrasound image dataset (BUSI) (Al-Dhabyani et al., 2020), which consists of 780 ultrasound images in PNG format. The second dataset is a benchmark dataset, called BrEaST (Pawłowska et al., 2024), of ultrasound images. It consists of 256 breast images from 256 patients, all of which have been personally annotated by a skilled radiologist.
The major contributions of this study are as follows:
(1) ConvMixer-based encoders for efficiently extracting and summarizing the features of input images.
(2) ConvNeXT-based decoders for efficiently reconstructing feature maps based upon the intricate features received from the encoder.
(3) Channel-wise feature responses of each channel are recalibrated using the squeeze and excitation by explicitly modeling the interdependencies among channels.
(4) A computationally efficient bottleneck, combined with convolution-enhanced multihead attention, allows for the simultaneous processing of multiple components of the input sequence, capturing their intricate relationships.
(5) The encoder, decoder, and enhanced multihead attention utilize residual connections to combine high-level and low-level features. It facilitates stable and faster training by diminishing the problem of vanishing gradients.
(6) Utilization of the combined loss function (Adrian et al., 2022) enhances the ability of the model to deal with unbalanced data.
The subsequent sections are organized as follows: Section II presents a summary of the recent research in the field of breast ultrasound lesion segmentation. The architecture of the HMA-Net is elaborated in Section III. Section IV covers experimental results and discussions. Section V discusses the conclusion.
2 Related works
Researchers have extensively studied breast ultrasound image segmentation, which is the primary step in breast cancer detection. Conventional approaches used thresholding-based methods (Horsch et al., 2001), watershed-based methods (Huang and Chen, 2004), clustering-based methods (Moon et al., 2014), graph-based methods (Zhou et al., 2014), etc., for segmentation. Recently, researchers have utilized deep learning methods based on convolutional neural networks and proposed various approaches for breast ultrasound image segmentation. Üzen (2024) introduced an encoder–decoder network in which the encoder is based on ConvMixer, and the decoder utilizes classification techniques. DenseNet121 is used in the encoder part to obtain semantic and spatial information, whereas long-range contextual information is acquired with ConvMixer. The encoder merges and passes the features to the decoder, which employs a detection and classification network to obtain the classification and detection scores. The performance of the approach is analyzed using the BUSI dataset.
Zhang et al. (2023) introduced a method that includes a classification branch and a segmentation branch. The classification branch receives the encoder's output and classifies the images into normal and abnormal. The classification branch is responsible for determining whether the image is benign or cancerous, and the segmentation branch draws the outlines of the tumors. A new breast ultrasound dataset has been compiled with 1,600 images, 405 of which were benign, 372 were malignant, and the rest were normal. Xu et al. (2023) proposed a regional attentive multitask learning framework for classifying and segmenting breast ultrasound images. A regional attention module was designed in which predicted probability maps are utilized to direct the classifier to learn category-specific information in the background, peritumoral, and tumor regions, which are then combined to enhance the feature representation. The model involves a segmentation and classification network that shares the features acquired from the encoder. This study used the BUSI and UDIAT datasets.
Chen et al. (2023) presented a method in which a deeper U-Net is employed to capture feature information from ultrasound images. Between the encoder and decoder, the squeeze and excitation network, acts as a link to enhance attention. Prediction masks of the ultrasound images are refined by incorporating deep supervised constraints to the decoding network. The method is analyzed using two datasets: BUSI and Dataset B (Yap et al., 2017). Lyu et al. (2023) combined attention mechanisms and multiscale features for segmenting breast ultrasound images. The authors performed multidimensional feature extraction using a depthwise separable convolution strategy on the encoding side and utilized Global Attention Upsample feature fusion on the decoding side. The model is evaluated using two datasets (Al-Dhabyani et al., 2020; Piotrzkowska-Wróblewska et al., 2017). Almajalid et al. (2018) introduced a technique based on U-Net structure, which involves an expansive path and a contracting path. The contracting path consists of convolution layers which are then followed by max pooling for downsampling, and the ReLU activation function is applied. The expansion path includes upsampling, convolution layers, and ReLU. The input images were preprocessed using speckle reduction and contrast enhancement and then post-processed to remove the noise from the segmented images.
Cho et al. (2022) introduced a multistage approach with U-Net-based residual feature selection for segmentation, followed by a classification network. The method obtained a pixel accuracy of 96.975, intersection over union (IOU) of 73.904, and DC of 82.005 on the BUSI dataset. Vakanski et al. (2020) incorporated attention blocks into a U-Net framework, enabling the model to acquire feature representations that prioritize spatial locations with notable saliency. Tang et al. (2023) presented a fully convolutional model in which the encoder output is fed to the ConvMixer model for extracting global context information. The decoder employs multiscale attention gates to enhance salient features. On the BUSI dataset, the method obtained 73.27% IOU, precision of 84.81%, F1 score of 84.16%, recall of 84.26%, and accuracy of 97.33%. Huang et al. (2021) introduced a fuzzy-based deep learning network in which breast ultrasound images are transferred to the fuzzy domain using fuzzy membership functions, which, after decreasing the uncertainty, are fed to the initial convolutional layer. The feature maps that are obtained are also converted into the fuzzy domain. The segmented results obtained are further enhanced using conditional random fields. Data augmentation is performed using a wavelet transform. Ilesanmi et al. 92021) introduced a U-Net-based method with four decoding and four encoding blocks. The method employed variant-enhanced blocks for encoding, which comprised a combined average and max pooling technique together with batch normalization. The decoding architecture utilizes double concatenated convolutions.
Tong et al. (2021) replaced the convolution module of the attention U-Net framework's networking path with the residual modules, thereby alleviating the gradient explosion problem. AbdElhakem and Torki (2023) proposed an encoder–decoder model with the ConvMixer block as the bottleneck between the encoder and decoder. Shareef et al. (2022) introduced an enhanced tumor network with a dual encoder architecture for extracting and combining image context details at various scales. It achieves this by creating feature maps using multiple kernels. These kernels extract multiscale tumor context information while conserving tumor location information. He et al. (2023) proposed a network which combines global contextual information learnt using transformer encoder blocks with convolutional neural networks for extracting features of varying resolutions. The decoder incorporates a spatial-wise cross-attention module to reduce the semantic mismatch within the encoder. The model is evaluated on three datasets: BUSI, BUS (Ilesanmi et al., 2021), and Dataset B (Huang et al., 2020).
Zhang et al. (2024) proposed a hybrid model for breast ultrasound image segmentation utilizing the long-range dependencies of transformers and the detailed local representations of convolutional neural networks. An L-G transformer block was embedded within the skip connections of the U-shaped architecture network to integrate global contextual information. The segmentation performance was enhanced by incorporating a cross-attention block module on the decoder side to facilitate interaction among different layers. The model obtained a Dice coefficient of 88.73% for the UDIAT dataset, 89.48% for the Breast Lesion Ultrasound Image dataset (BLUI) dataset (Abbasian Ardakani et al., 2023), and 83.11% for the BUSI dataset.
Zhai et al. (2022) proposed an asymmetric semi-supervised generative adversarial network, which employs a discriminator and two generators for adversarial learning. Unlabeled cases can be utilized to enhance model training as the two generators mutually guide each other to generate segmentation-predicted masks without labels. The method was evaluated on three datasets, namely DBUI, SPDBUI, ADBUI, and SDBUI.
Lin et al. (2023) proposed a dual-stage framework for the segmentation of breast lesions, utilizing transformer and Multilayer perceptron. The segmentation performance is enhanced by combining Swin Transformer block with pyramid-squeezed attention block in a parallel configuration and introducing bidirectional interactions across branches. The performance of the model is evaluated using three public datasets, namely BUSI, MT_BUS, and BUL. The BUL dataset consists of 163 images collected from the UDIAT Diagnostic Center of the Parc Taul Corporation. MT_BUS consists of 400 breast ultrasound images, with 200 images of benign breast cancer and 200 of malignant breast cancer. Table 1 compares various breast ultrasound segmentation methods.
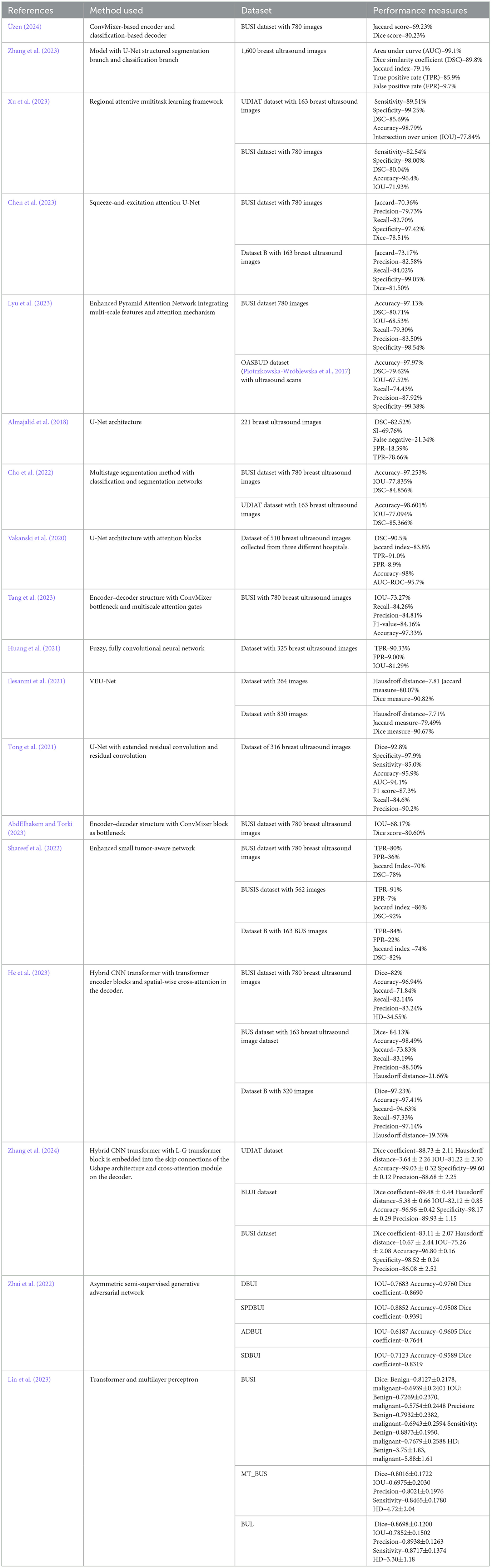
Table 1. Comparison of various breast ultrasound image segmentation methods.
3 Proposed methodology
The proposed hybrid mixer framework with multihead attention (HMA-Net) incorporates a lightweight spatial-channel mixing model within its encoder (EMx1 to EMx5) to extract robust features effectively. convolution-enhanced multihead attention module (CEMHA) serves as the bottleneck between encoder and decoder, enhancing the long-range dependencies and allowing it to focus on subtle differences for precise segmentation. In the decoder (DCNx5 to DCNx1), enhanced ConvNeXT (ECN) modules facilitate upsampling and high-resolution reconstruction, refining features and accurately capturing boundaries and contours in breast ultrasound images. Figure 1 displays the architecture of the hybrid mixer framework with multihead attention (HMA-Net).
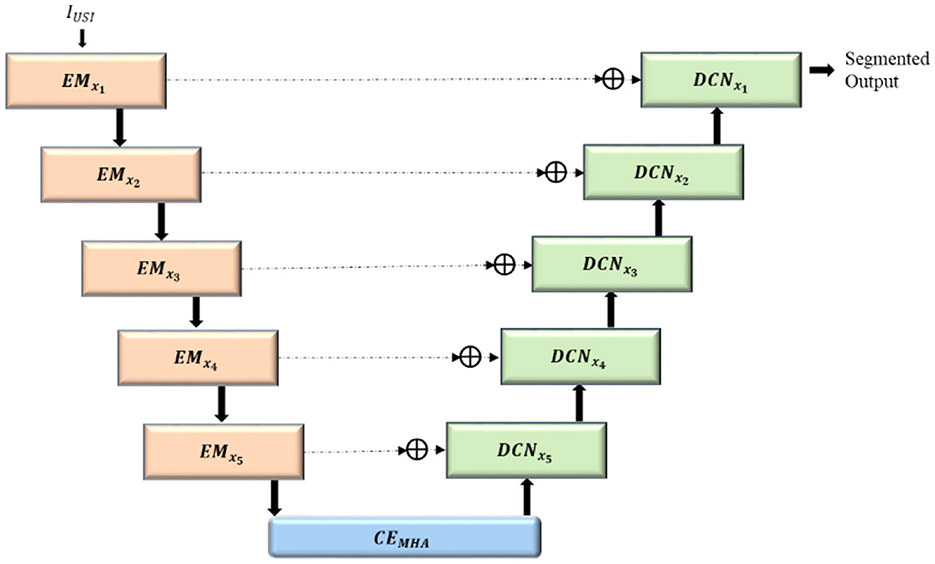
Figure 1. Architecture of the HMA-net.
3.1 ConvMixer-based encoder blocks (EMxi)
The complex features from the input ultrasound images (IUSI) are extracted using five consecutive encoder mixer blocks EMx1 to EMx5. Downsampled feature maps with reduced dimensions (OEMxi) are generated, facilitating an enhanced hierarchical representation of complex features. The enhanced ConvMixer modules (ECMs) incorporated squeeze and excitation along with residual linking for modeling channelwise interdependencies by adaptively adjusting channel feature responses. The structure of ConvMixer-based encoder block is shown in Figure 2.

Figure 2. ConvMixer-based encoder block.
3.1.1 Convolved GeLU block (CBG)
CBG block is designed to capture edge information for accurate boundary identification. The batch normalization component stabilizes training and accelerates convergence, while the Gaussian Error Linear Unit (GeLU) activation introduces enhanced non-linearity, enriching the extracted features. Convolutions with filters of size 3 × 3 are performed to generate feature maps emphasizing distinct features of the input image by extracting local features. The generated feature maps are stabilized and normalized by batch normalization (BN), accelerating faster convergence and enhancing the resilience of the model to variations in the input data distribution. Non-linearity is introduced by the GeLU activation function (γ), enhancing the ability of the model to acquire intricate relationships within the data and to make accurate predictions on unfamiliar data. The functioning of the Convolved GeLU block (CBG) is shown in Equation 1:
3.1.2 Enhanced ConvMixer module
Enhanced ConvMixer module (ECM) integrate depthwise convolutions, pointwise convolutions and squeeze and excitation to improve feature extraction and boost the representation power of the model. Local patterns in the input images are detected using depthwise convolutions (D3 × 3), where each input channel is convolved via separate convolutions instead of applying the same kernel to all channels, thus extracting spatial features while maintaining channel independence. Non-linearity is introduced by passing the feature maps through the GeLU activation function, allowing the model to learn complex patterns with improved gradient flow, thus aiding the model to learn slight variations in input features. Training is accelerated and stabilized by normalizing the non-linearly transformed feature map.
Channel-wise features are generated by pointwise convolutions (P1 × 1), by mixing the information across the channels, with the application of a 1 × 1 convolution filter to each and every pixel across all the channels. The spatial and channel features are integrated by CBG block, facilitating improved integration of information across channels, thereby boosting the network's ability to represent complex patterns. Spatial features captured by depthwise convolutions and channel features captured by 1 × 1 convolutions are enhanced by the GeLU activation function, enabling the network to learn complex patterns. The output of the convolutions is normalized using batch normalization to ensure that the activations have a reliable and consistent distribution (OIECM), as shown in Equation 2.
The attention mechanism is incorporated into the ECM module by adding squeeze-and-excitation (SE) block, thereby enhancing the model accuracy by giving higher priority to significant features and reducing the impact of less useful ones. It is a process of adaptively adjusting the weights of each feature map to selectively enhance the weight of relevant feature maps, which in turn improves the representation power of the model. Global average pooling (GAP) is applied to the feature maps thereby generating a single value for each channel, hence reducing the spatial dimensions. The global average pooled vector is mapped into a low-dimensional space using a dense layer, and the network representation capacity is enhanced by introducing non-linearity using the ReLU activation function (DRL). The reduced dimensional vector is mapped back to its original size using a fully connected layer, and the feature maps are scaled with sigmoid activation functions (DSD) to generate channel-wise weights. The channel-wise weights generated are reshaped (Rs) to match with the dimensions of the input feature map, as given in Equation 3.
The SE block's output (OSE), that is, the channel-wise weights generated are multiplied with its input feature map in order to recalibrate the feature maps, as shown in Equation 4.
Ultimately, the ECM reintegrates the recalibrated feature maps with the input using a residual link, which facilitates the flow of gradients and improves the network's ability to represent information, as in Equation 5.
The architecture of the ECM is given in Figure 3.

Figure 3. Enhanced ConvMixer module (ECM).
3.1.3 Max pooling
The feature maps from the ECM blocks are downsampled (M2X2), as in Equation 6, to enhance the learning ability of the model by capturing high-level features at varying spatial scales. Translational invariance is provided so that the model can detect lesions irrespective of their position in the image, which results in improved generalization.
3.2 Convolution-enhanced multihead attention module (CEMHA)
The convolution-enhanced multihead attention (CEMHA) emphasize the relevant features across distinct regions of the image, ensuring that the masks generated by the decoder will closely follow the lesion boundaries, thus aiding in the accurate identification of lesions. The architecture of the CEMHA module is shown in Figure 4.
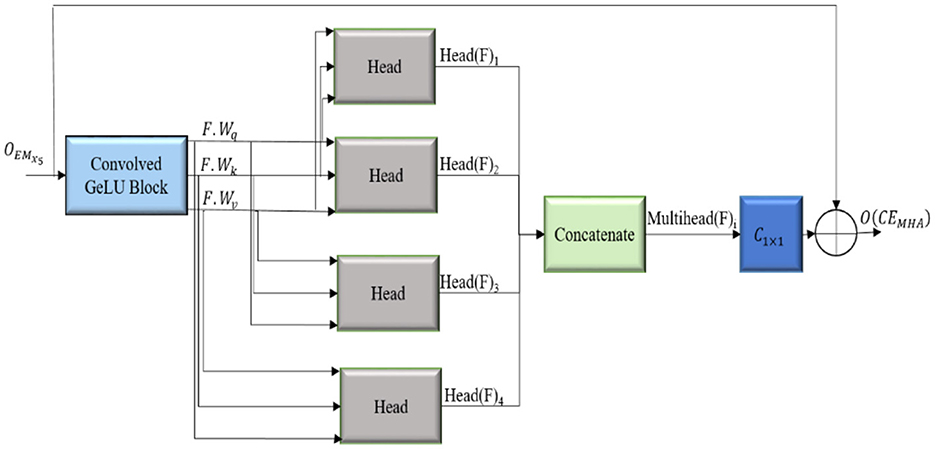
Figure 4. Architecture of the convolution enhanced multihead attention (CEMHA) module.
The downsampled feature maps from the EMxi blocks are enhanced by the convolved GeLU block, thus improving the ability of the model to process and comprehend the underlying structure of the input data and stabilizes the training process. Long-range diverse dependencies across different parts of the images are captured using four distinct heads, each of which focuses on a specific pattern in the image, thus allowing the model to maintain context by comprehending the relation between different areas of the image. The enhanced feature map F is linearly transformed into a query(F.Wq), key(F. Wk) and value (F.Wv) matrices, which, in turn, calculate the attention score. The similarity between the query and key matrices is calculated and scaled by to stabilize for larger dimensions. The attention scores are normalized using the softmax activation function (σ), and the most significant features from the input feature map are aggregated, allowing the model to integrate global and local contextual details. The computations inside each attention unit (h) are shown in Equation 7. The output dimension of each attention head is where dmodel represents the dimensionality of the model.
The attention scores calculated by the four distinct heads are merged to obtain Multihead(F)i , as in Equation 8, with output dimension dmodel, facilitating the ability of the model to concentrate on distinct segments of the input image concurrently, effectively collecting many facets of the data. The model is thus enabled to generalize better for different types of input images.
The output of the attention is transformed back to its original number of channels by convolving with a filter of size 1 × 1 (C1 × 1). The refined feature maps generated are appended with its input to enable the smooth flow of gradients throughout the network, thereby alleviating the issues of vanishing gradient problems and aiding in learning efficient representations, as shown in Equation 9.
The residual connections are integrated to enhance segmentation accuracy and training stability Equation 9. The actual input is integrated with the attention-enhanced features, allowing the model to combine both the original features and globally attended information. This approach promotes the smooth flow of gradients and reduces the vanishing gradient problem. Intricate contextual information is preserved, facilitating the precise delineation of tumor boundaries. The convolution-enhanced multihead attention with residual connections (CEMHA) ensures the balanced integration of learned attention-driven features while maintaining training stability and efficient convergence.
3.3 ConvNeXT-based decoder blocks (DCNxi)
The output feature maps from the convolution-enhanced multihead attention (O(CEMHA)) are upsampled and concatenated with the corresponding feature maps from the EMxi, which increased the resolution of the feature maps to that of the original image, and the segmentation masks were generated. The detailed architecture of the ConvNeXT-based decoder blocks (DCNxi) are shown in Figure 5. In each DCNxi block with enhanced ConvNeXT (ECN), the spatial dimensions of the downsampled refined feature map are increased by transposed convolutions (CT2 × 2) while lowering the number of channels. The upsampled feature map from the transposed convolutions is batch normalized to accelerate the training process, ensuring that the input to the succeeding GeLU activation layer has a uniform distribution.
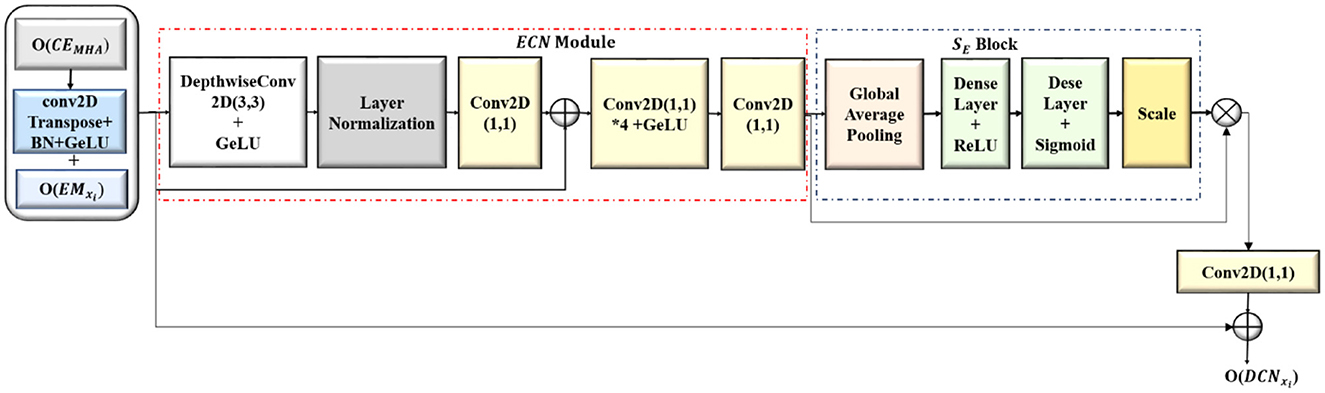
Figure 5. Architecture of the ConvNeXT-based decoder (DCNxi) block.
The downsampled feature maps from each EMxi block after center cropping (Cr(OEMxi) ) has been concatenated with the corresponding upsampled feature map from DCNxi block, resulting in a merged feature map by combining semantic information with the spatial information. This enabled the DCNxi to get a comprehensive understanding of the data, utilizing both the low level and high level features. The concatenated feature map is further refined with the Enhanced ConvNeXT (ECN) module as shown in Equation 10.
Enhanced ConvNeXT module extracts spatial features independently from each channel by convolving separately with filters of size 7 ((Dconv(x)) resulting in feature maps with better representation. The spatially significant features are normalized to mitigate the effect of internal covariance shift during training by calculating the mean and variance of the inputs of every individual sample (LN). The normalized features are mapped back to the original dimensions (C1 × 1) and the input (x) is added. The mixing of features across the channels is enhanced by two 1 × 1 convolutions, with the first convolution expanding the feature channels by 4 () which enhanced the feature refining and mixing capacity of the model before bringing it back to its original number of filter channels with the second convolution(C1 × 1). The capacity of the model to recalibrate channel-specific feature responses is improved by integrating squeeze-and-excitation (SE) block, highlighting informative features and reducing the prominence of less valuable ones, which results in enhanced segmentation accuracy and improved feature refinement while generating the image segments. The functioning of the ECN module is given in Equation 11.
3.4 Combined loss function
A combined loss function, which integrates two loss functions, is used for training the model, by which the segmentation performance can be optimized. The discrepancy between the actual label and the predicted label is measured by using the binary cross entropy function and performs best when the data distribution is uniform. However, this alone cannot be used for training where the tumor occupies only a small fraction of the image due to class imbalance.
To address this issue, dice loss is integrated with binary cross entropy. The extent to which the true mask and predicted mask overlapped is assessed using dice loss function, with an emphasis on the regions where the two intersect. The combined loss is calculated as in Equation 12.
Here, is the predicted probability, M is the total number of samples, and yi is the actual label. Binary cross entropy loss guarantees that each pixel is classified correctly and, the accurate segmentation is ensured by dice loss. The performance of the model is enhanced by the effective utilization of these two losses.
4 Experimental results and discussions
This section offers a detailed description of the dataset, experimental setup, data preprocessing and augmentation methods, evaluation metrics, ablation study, and performance evaluation. Various performance measures are utilized to access the performance of the proposed HMA-Net.
4.1 Dataset description
The proposed HMA Net model is validated on two datasets—the BUSI dataset and the BrEaST dataset. The first dataset used is BUSI, which is a public benchmark dataset with 780 PNG images categorized into three classes—benign, malignant, and normal. Each image of size 500 × 500 pixels is further enhanced by a corresponding ground truth annotation that offers precise segmentation masks for the tumors. The data were gathered from a group of 600 female patients, ranging in age from 25 to 75, during the year 2018 at the Baheya Hospital. Sample images and masks from the BUSI dataset are shown in Figure 6. The BUSI dataset presents a balanced depiction of various breast abnormalities through a varied assortment of benign, malignant, and normal cases of breast ultrasound images. It is ideal for segmentation model evaluation and training in practical clinical circumstances due to its diversity.
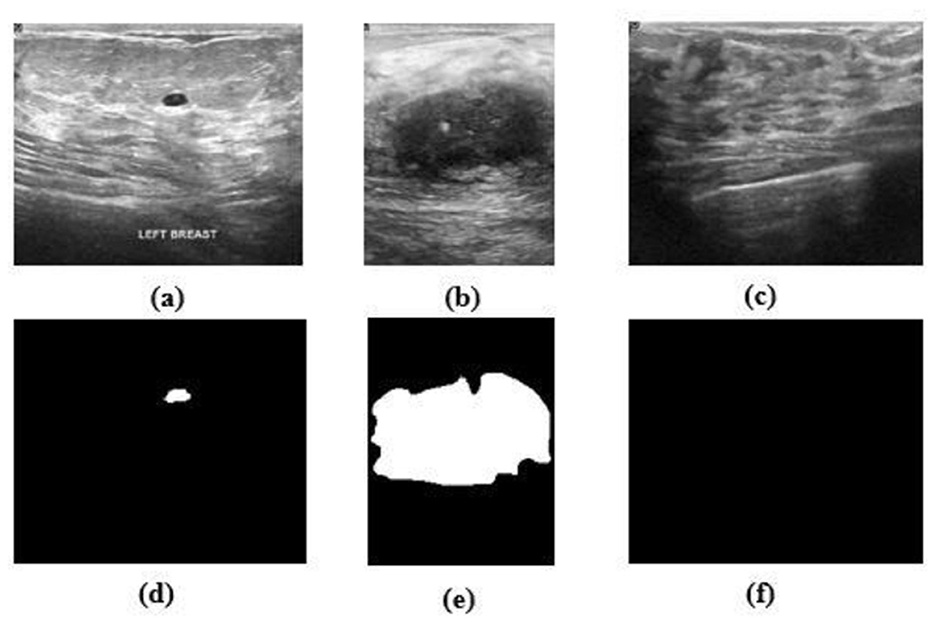
Figure 6. (a–c) Benign, malignant, and normal images from the BUSI dataset. (d–f) Masks corresponding to (a–c).
The BrEaST dataset is comprised of 256 images obtained from 256 patients. The dataset comprises 98 instances of cancer, 154 instances of benign lesions, and four instances of normal tissue images. The initial stage in constructing the dataset involved anonymising, gathering, and transferring the data. In order to safeguard the confidentiality of patients, any identifiable data have been eliminated from the images. Figure 7 shows sample images and masks from the BrEaST dataset. In order to ensure high-quality and clinically appropriate labels for both tumors and surrounding areas, the BrEaST dataset was manually annotated by skilled radiologists. For accurate model evaluation in medical image segmentation tasks, this level of precision is necessary. The dataset is divided into two parts: 20% is used for testing and 80% is used for training.
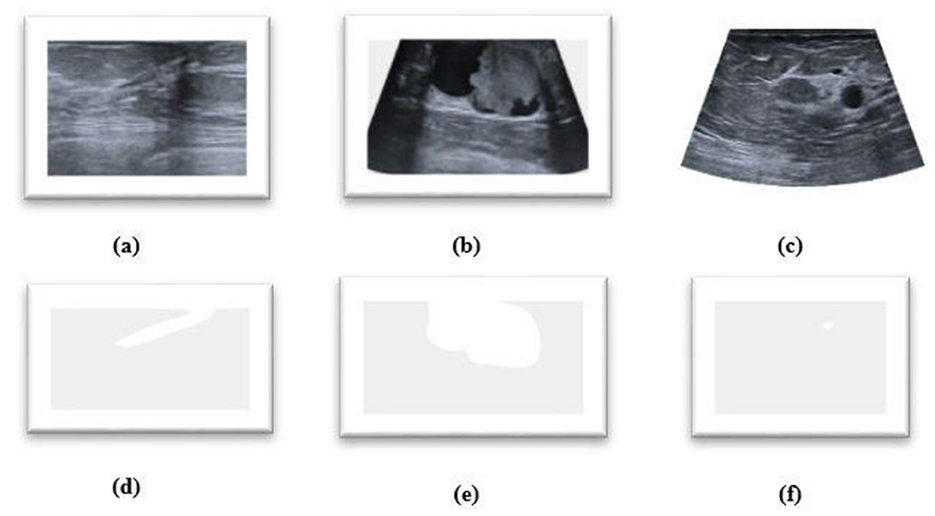
Figure 7. (a–c) Breast ultrasound images. (d–f) Masks from the BrEaST dataset.
4.2 Experimental setup
The task was implemented on a cloud computing platform known as Google Colab notebooks. The utilization of this cloud-based technology facilitated the training and execution of the deep learning model with enhanced efficiency. The HMA − Net model was implemented using the Python programming language and various important libraries, such as Keras, matplotlib, Tensorflow, OS, and sklearn, were used throughout the implementation process.
4.3 Data preprocessing and augmentation
In order to improve the effectiveness of the network training process, the size of the input image of the network structure is resized to 128 × 128. A significant amount of training data is necessary for deep neural networks in order to obtain performance levels that are adequate. The process of data augmentation is carried out with the purpose of artificially increasing the quantity of the dataset by generating new versions of the images that are already there, thus overcoming the issues that are associated with having limited data. Random flips in horizontal and vertical directions are applied to the masks and images. Images and masks are randomly shifted horizontally by up to 10% of their width and randomly shifted vertically by up to 10% of their height. Images and masks are randomly zoomed up to 20% and are randomly rotated with a rotation angle of up to 20 degrees. The pixels that move outside of the image are filled by fill_mode to the nearest, which fills the empty region with the pixel that is adjacent to it. The sample augmented data from the BUSI and BrEaST datasets are displayed in Figures 8a, b, respectively.

Figure 8. Sample augmented images and masks from the (a) BUSI dataset, (b) BrEaST dataset.
4.4 Evaluation metrics of the proposed architecture
The model is accessed using various evaluation metrics, including the Jaccard similarity index (JI), accuracy, Dice similarity coefficient (DSC), precision, recall, and AUC. The Jaccard index is employed to assess the degree of similarity or variation among sets. The Jaccard index can be used to determine how similar the predicted image is to the ground truth image. Let P be the ground truth mask and Q be the predicted mask; the Jaccard index is given as in Equation 13.
The DSC is a statistical metric employed to assess the resemblance between two sets of data. The measurement quantifies the extent to which the predicted segmentation mask and the ground truth mask overlap. The equation for DSC is given in Equation 14.
Segmentation accuracy is the metric used to evaluate the pixels that are correctly classified in the image that has been segmented. It is defined as the ratio of the total number of true positive and true negative pixels to the total number of pixels in the image, as in Equation 15.
Recall measures the ability of the model to accurately detect tumor areas. It is the percentage of actual positive cases (tumor pixels) that the segmentation model correctly identifies as positive, as given by Equation 16.
Precision is defined as the ratio of the number of pixels that are correctly predicted as tumorous to the total number of samples that are predicted as tumorous as in Equation 17.
AUC refers to area under receiver operating characteristic curve in which true positive rate (TPR) is plotted against false positive rate (FPR). The higher the AUC, the better the performance of the model.
4.5 Ablation studies
Ablation studies were implemented to investigate the impact of enhanced ConvMixer (ECM), convolution-enhanced multihead attention (CEMHA) and the enhanced ConvNeXT (ECN) modules on the segmentation of breast ultrasound images. The basic model without ConvMixer and ConvNeXT modules (Model 1) was initially implemented. ECMs were integrated next (Model 2) to assess its impact on the performance of the model. The next enhancement was to integrate enhanced ConvNeXT (Model 3), followed by the addition of a convolution-enhanced multihead attention module (HMA-Net). The efficiency of each model was evaluated on the BUSI and BrEaST datasets using the Jaccard index, DSC, accuracy, precision, and recall. Training and validation accuracy and loss curves for each model (Figures 9, 10 for Model 1, Figures 11, 12 for Model 2, and Figures 13, 14 for Model 3) along with visualizations of segmentations (Figures 15a, b for Model 1, Figures 16a, b for Model 2, and Figures 17a, b for Model 3) are also presented, demonstrating the incremental enhancement in segmentation performance across all the stages.
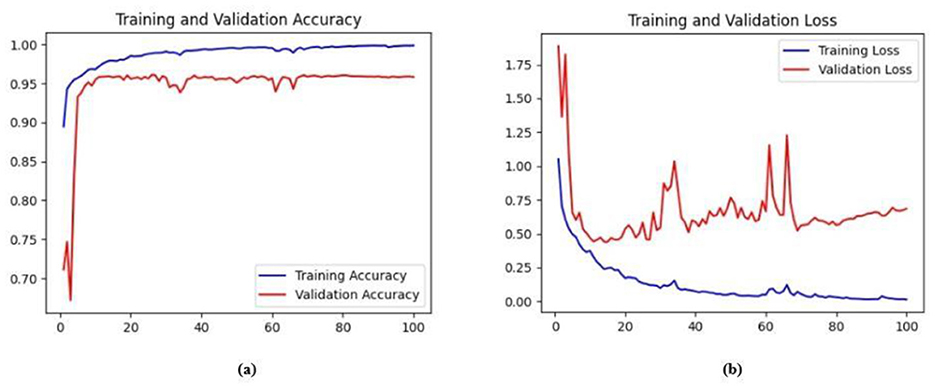
Figure 9. (a) Training and validation accuracy for Model 1 on the BUSI dataset. (b) Training and validation loss for Model 1 on the BUSI dataset.
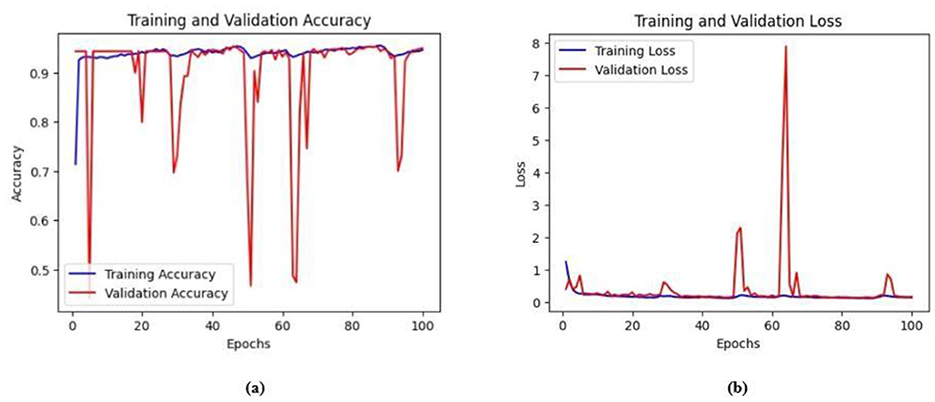
Figure 10. (a) Training and validation accuracy for Model 1 on the BrEaST dataset. (b) Training and validation loss for Model 1 on the BrEaST dataset.
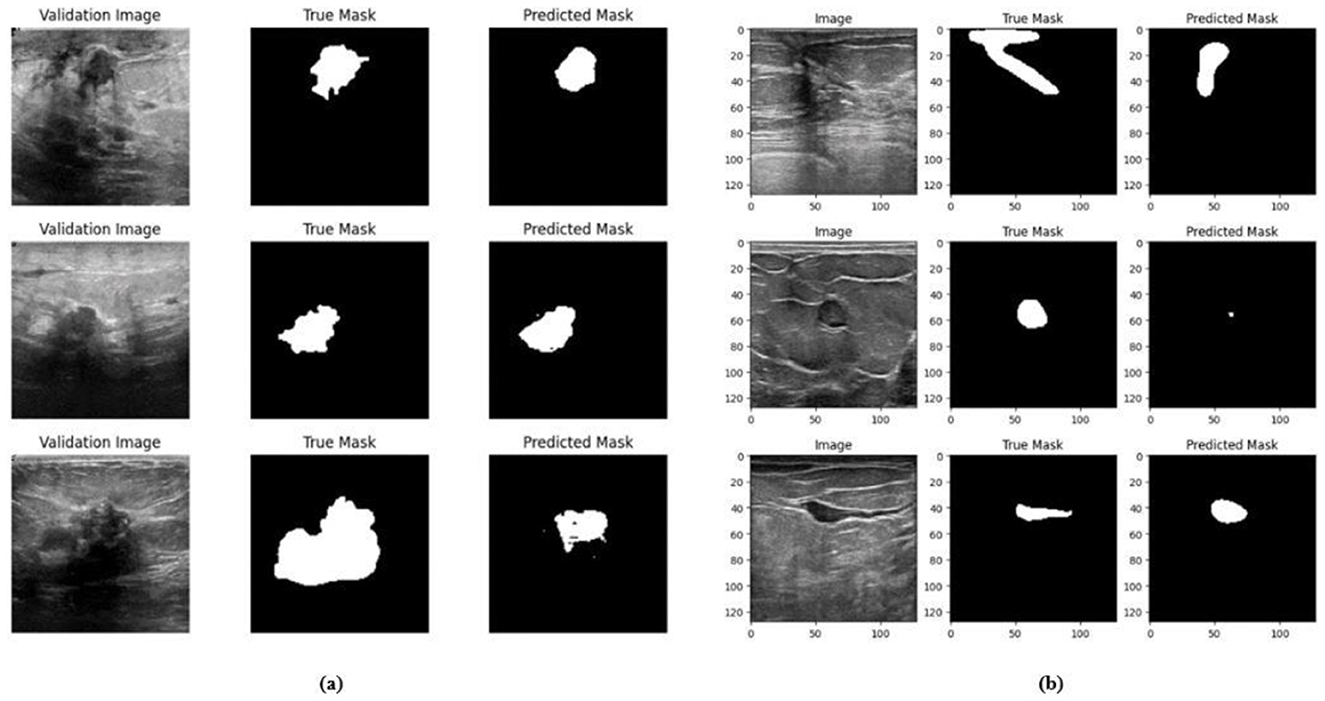
Figure 11. Visualizations of the segmentation result for the Model 1 on the (a) BUSI dataset (b) BrEaST dataset.
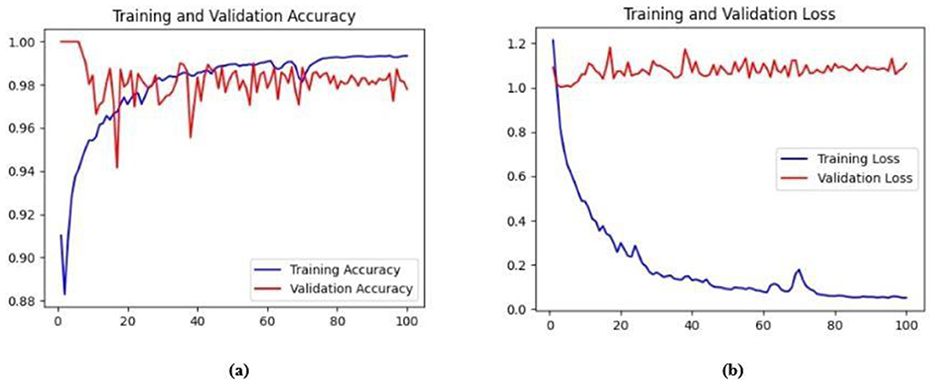
Figure 12. (a) Training and validation accuracy of Model 2 on the BUSI dataset. (b) Training and validation loss of Model 2 on the BUSI dataset.
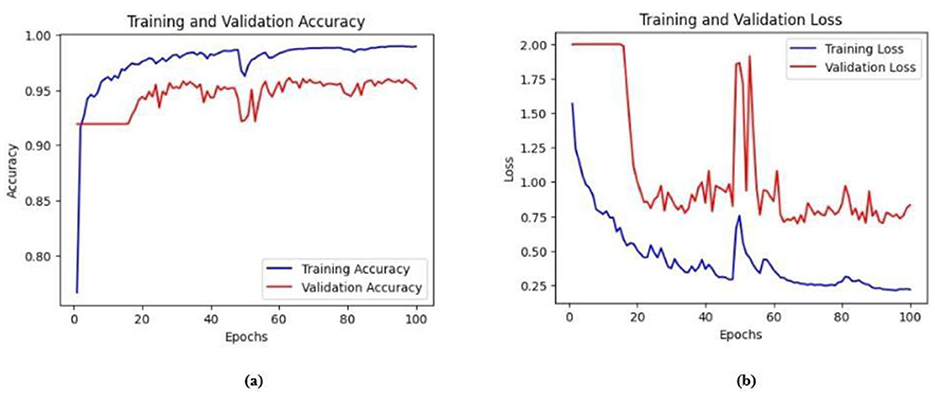
Figure 13. (a) Training and validation accuracy of Model 2 on the BrEaST dataset. (b) Training and validation loss of Model 2 on the BrEaST dataset.
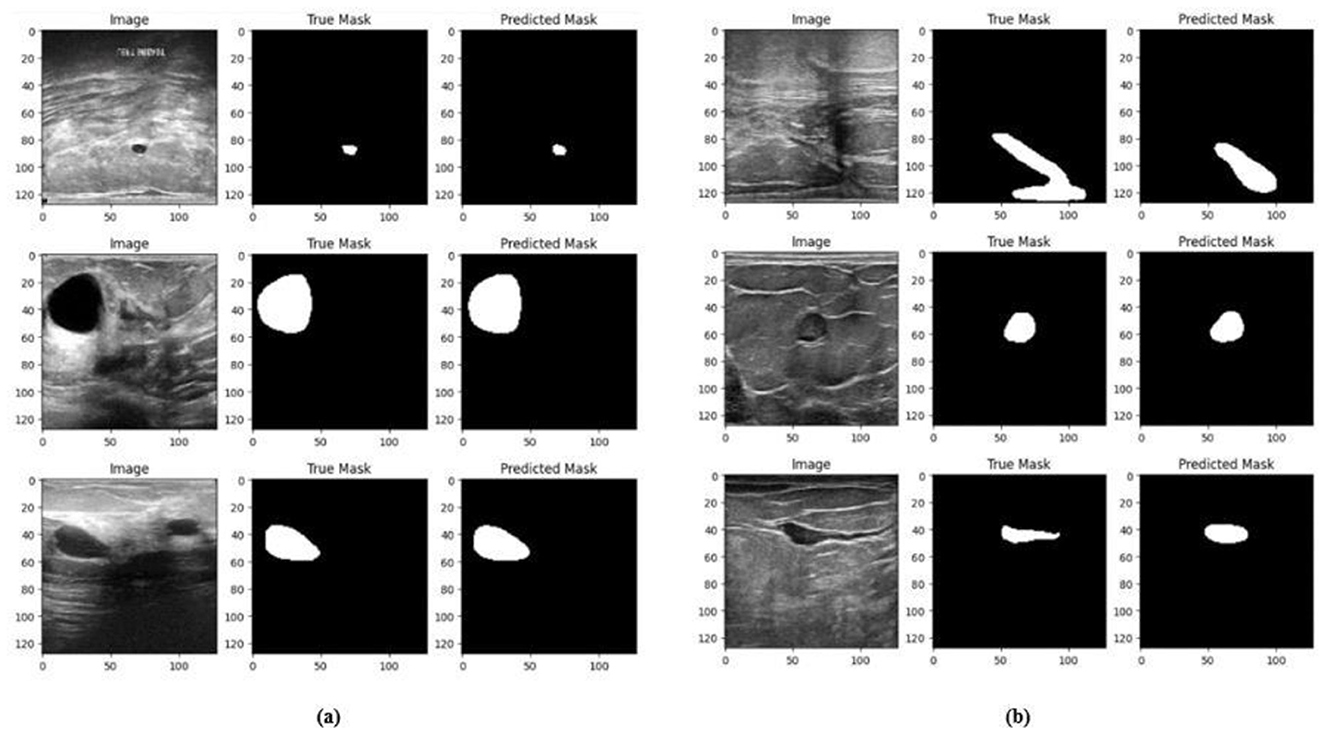
Figure 14. Visualizations of the segmentation results of Model 2 on the (a) BUSI dataset (b) BrEaST dataset.
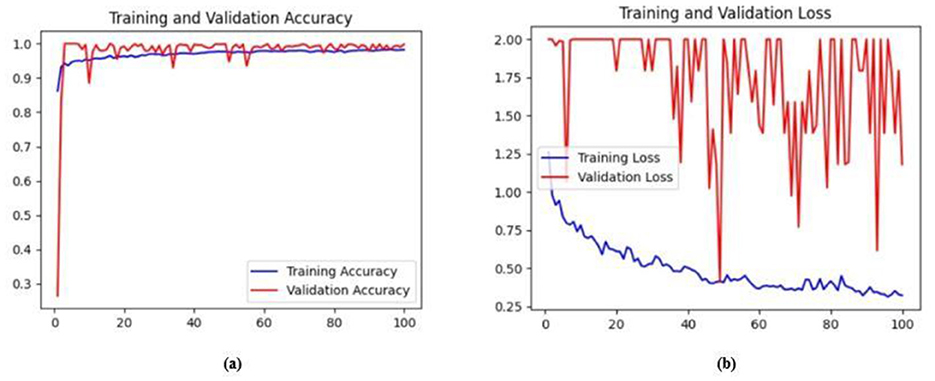
Figure 15. (a) Training and validation accuracy of Model 3 on the BUSI dataset. (b) Training and validation loss of Model 3 on the BUSI dataset.
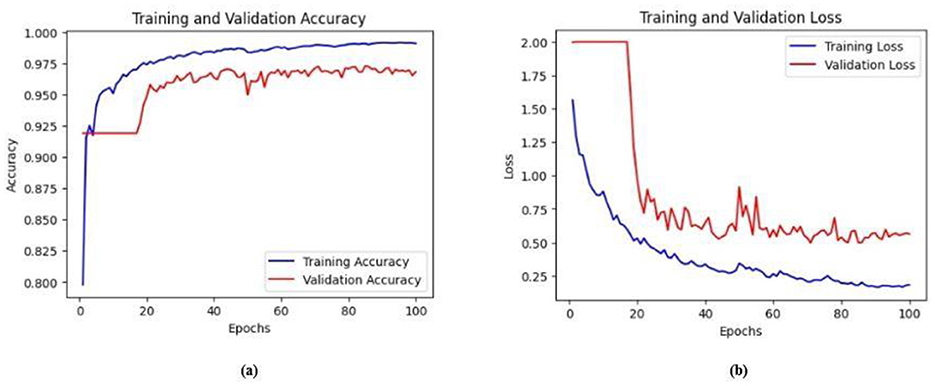
Figure 16. (a) Training and validation accuracy of Model 3 on the BrEaST dataset. (b) Training and validation loss of Model 3 on the BrEaST dataset.
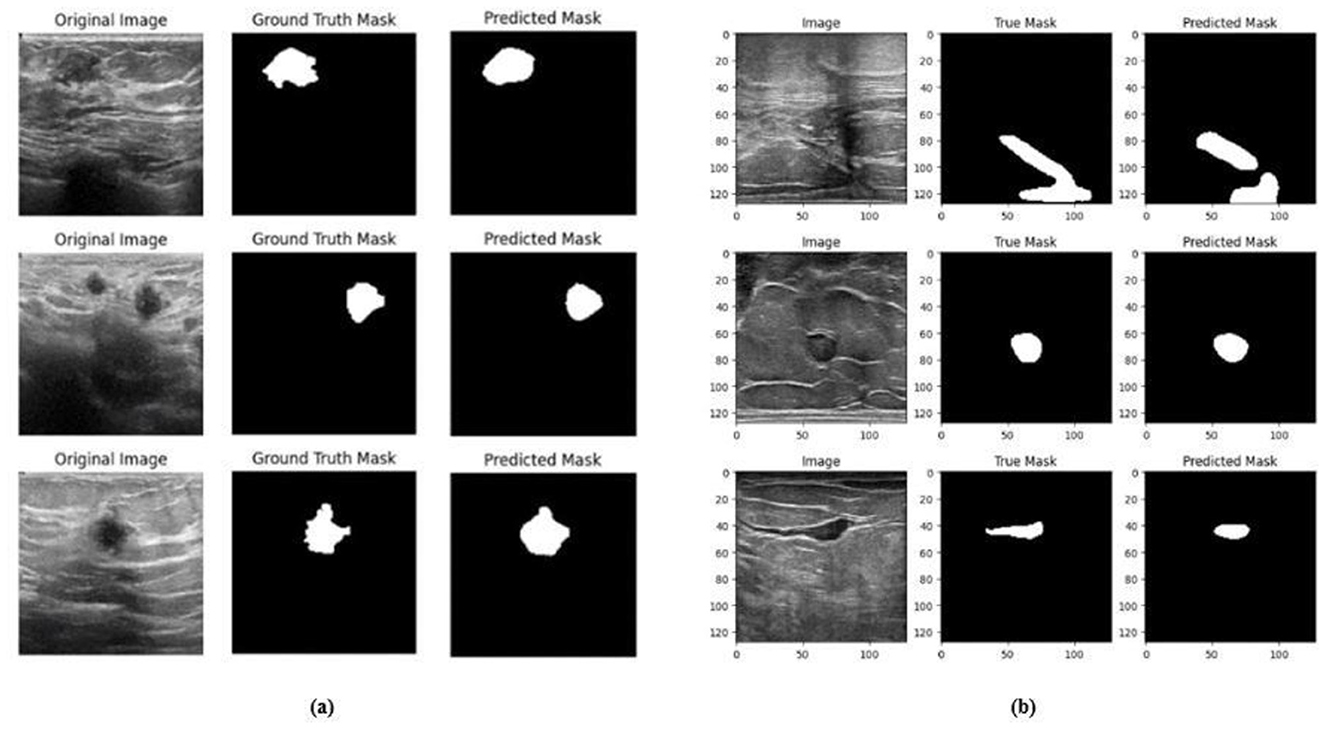
Figure 17. Visualizations of the segmentation results of Model 3 on the (a) BUSI dataset and (b) BrEaST dataset.
4.5.1 Performance analysis of model 1 (base model)
The base model has an encoder–decoder structure with symmetrical layers that perform downsampling and upsampling operations on the input image, respectively. The encoder section consists of five blocks, each consisting of a convolutional layer, batch normalization and GeLU activation. Downsampling is accomplished by employing max pooling layers. The bottleneck utilizes a simple structure that incorporates additional convolution and normalization layers. The decoder section of the model uses Conv2DTranspose layers to increase the resolution of the feature maps. This base model, without the use of ConvMixer, ConvNeXT, and a simple bottleneck with convolutions (instead of multihead attention), attained a Jaccard index of 50.47% for the BUSI dataset, and for the BrEaST dataset, the Jaccard index was 44.71%. The DSCs obtained were 67.08% for the BUSI dataset and 61.79% for the BrEaST dataset. The accuracy, precision, and recall values obtained were 95.69%, 84.29%, and 55.71% for the BUSI dataset, and 96.13%, 89.69%, and 47.13% for the BrEaST dataset, respectively. The training and validation accuracy for Model 1 on the BUSI dataset is shown in Figure 9a, and the training and validation loss is displayed in Figure 9b. The training and validation accuracy for Model 1 on the BrEaST dataset is displayed in Figure 10a, and the training and validation loss is displayed in Figure 10b. The visualizations of the segmentation results for Model 1 on the BUSI dataset are shown in Figure 11a, while the results for the BrEaST dataset are shown in Figure 11b.
4.5.2 Performance analysis of model 2 (enhanced ConvMixer modules integrated with the base model)
Enhanced ConvMixer modules were added to the encoder blocks of Model 1, significantly improving the ability of the model to capture spatial patterns. It allowed the model to effectively integrate spatial and channel information, enabling it to focus on relevant features. The integration of ECM modules also reduced the risk of vanishing gradient problems, resulting in effective training and improved performance. For the BUSI dataset, the model obtained a Jaccard index of 83.22%, a DSC of 90.84%, an accuracy of 98.52%, a precision of 91.97%, and a recall of 88.52%. For the BrEaST dataset, the Jaccard index was 80.57%, the DSC was 89.24%, the accuracy was 98.60%, the precision was 91.28%, and the recall was 87.30%.
The training and validation accuracy of Model 2 on the BUSI dataset is shown in Figure 12a, and the training and validation loss is displayed in Figure 12b. The training and validation accuracy of Model 2 on the BrEaST dataset is shown in Figure 13a, and the training and validation loss is shown in Figure 13b. The visualizations of the segmentation results obtained using Model 2 on the BUSI dataset are shown in Figure 14a, while those for the BrEaST dataset are presented in Figure 14b.
4.5.3 Performance analysis of model 3 (enhanced ConvNeXT modules integrated with model 2)
The next enhancement made was to integrate enhanced ConvNeXT (ECN) modules into the five contiguous decoder blocks of Model 2. It improves the feature representation ability of the model, and high-resolution segmentation maps can be generated by combining transposed convolutions with ConvNeXT. The model achieved a Jaccard index of 91.79%, a DSC of 95.72%, an accuracy of 99.32%, a precision of 93.36%, and a recall of 98.20% on the BUSI dataset. For the BrEaST dataset, the Jaccard index was 85.08%, the DSC was 91.94%, the accuracy was 98.94%, the precision was 93.28%, and the recall was 90.64%. The training and validation accuracy of Model 3 on the BUSI dataset is shown in Figure 15a, and the training and validation loss is displayed in Figure 15b. Similarly, the training and validation accuracy of Model 3 on the BrEaST dataset is displayed in Figure 16a, and the training and validation loss is shown in Figure 16b. The visualizations of the segmentation results of Model 3 on the BUSI dataset are displayed in Figure 17a, while the results obtained with the BrEaST dataset are shown in Figure 17b.
The Jaccard index, DSC, recall, accuracy, and precision obtained for Model 1, Model 2, and Model 3 are displayed in Table 2. Model 1 (the base model) obtained lower Jaccard and Dice scores, demonstrating its limited ability for precise segmentation. Visualization results show that the lesion boundaries are poorly defined due to the restricted expressive power of conventional convolutional layers in the encoder and decoder. The performance was enhanced with the addition of ECMs in Model 2, which utilized depthwise and pointwise convolutions for reduced computational complexity, in conjunction with squeeze and excitation to improve the integration of spatial and channel features. The model obtained higher Dice scores of 90.84% on the BUSI dataset and 89.24% on the BrEaST dataset, demonstrating improved generalization. Visualization of the segmentation results also indicates clearer tumor contours. Enhanced ConvNeXT modules were integrated within the decoder, resulting in Model 3. The ECN blocks enhanced the upsampled representations through depthwise convolution, channel mixing, and recalibration utilizing SE layers. The squeeze and excitation layer in the encoder and decoder reduces the parameter overhead while enhancing feature selection. High-resolution masks were reconstructed with sharper boundaries and reduced false positives. Intricate semantic information can be retrieved as indicated by a recall value of 98.20% on the BUSI dataset and 90.64% on the BrEaST dataset.
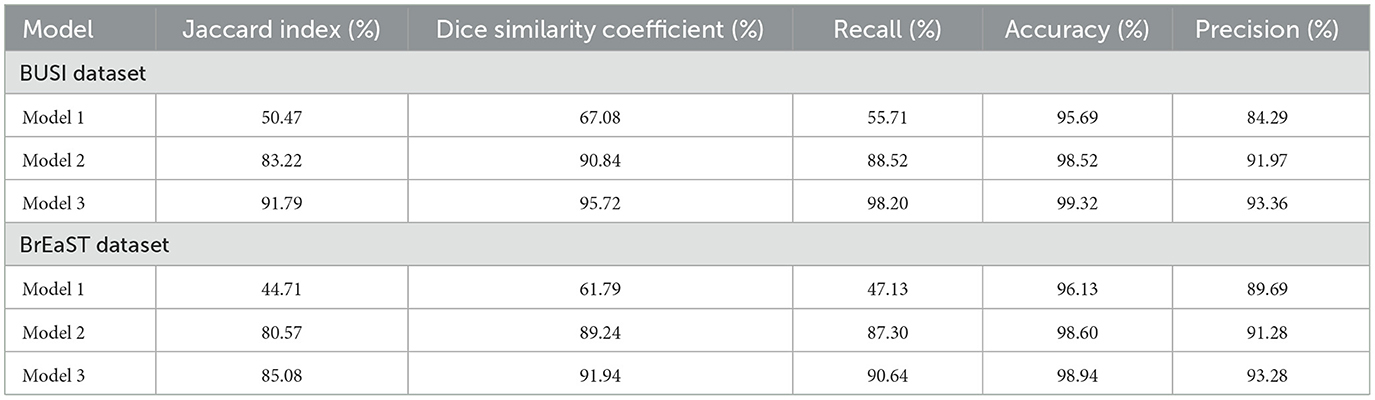
Table 2. Performance analysis of model 1, model 2, and model 3.
5 Experimental results and performance analysis of proposed HMA-Net
A detailed analysis of the proposed hybrid mixer framework with multihead attention for breast ultrasound image segmentation (HMA-Net) is carried out in this session. The HMA-Net utilized EMxi blocks with enhanced ConvMixer for capturing multiscale features at varying stages from the input ultrasound images and is converted into a sequence of more detailed and compact representations with reduced resolutions, which in turn is used by the DCNxi blocks to perform effective segmentations. The spatial resolutions of the extracted feature maps are restored to the original level of the input image by the DCNxi blocks using transposed convolutions and enhanced ConvNeXT modules. The CEMHA module with normalized convolutions and multihead attention with residual connections escalates the feature extraction property of HMA-Net by allowing the model to concentrate more on relevant features. The convolution-enhanced multihead attention allows the capture of contextual dependencies between various components of the image, thus empowering the model to differentiate minute differences in the breast ultrasound images. The implementation of spatial attention at the bottleneck via CEMHA avoids the need for spatial attention across all the layers, thereby reducing computational complexity while capturing global contextual dependencies.
For the BUSI dataset, the model achieved a Jaccard index of 98.04% and a DSC of 99.01%. The model is efficient in detecting actual tumor regions, indicated by a recall of 99.09%. Precision and accuracy obtained were 99.06% and 99.85%, respectively. This is important in medical diagnosis to prevent missed detections. The values obtained indicate the ability of the model to correctly identify both tumor and non-tumor regions. The results obtained for the BrEaST dataset are as follows. The model achieved a Jaccard index of 94.84% and a DSC of 97.35%. The model can correctly identify tumor and non-tumor regions, as demonstrated by an accuracy of 99.65% and a precision of 98.67%. The recall achieved was 96.03%. In summary, based on the evaluation of the two datasets, these findings indicate that the model has significant potential for clinical use in precisely delineating breast tumors from ultrasound images, hence assisting in the timely identification and diagnosis of breast cancer. The summary of the results obtained is shown in Table 3.
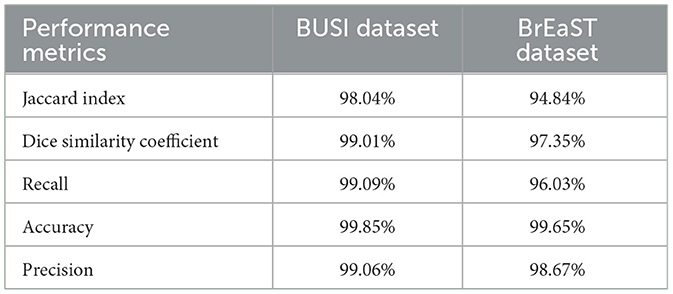
Table 3. Results obtained by the HMA-Net for the two different datasets.
The training and validation accuracy obtained for the proposed HMA-Net on the BUSI dataset is displayed in Figure 18a, and the training and validation loss obtained is displayed in Figure 18b. Figure 19a displays the training and validation accuracy obtained for the HMA-Net on the BrEaST dataset, and the training and validation loss for the BrEaST dataset is shown in Figure 19b. HMA-Net obtained AUC values of 0.9950 for the BUSI dataset and 0.9797 for the BrEaST dataset. These values indicate that the model is highly effective in differentiating background pixels from tumor regions. The AUC curve obtained for the BUSI dataset is displayed in Figure 20a, and the BrEaST dataset is presented in Figure 20b. The visualizations of the segmentation results obtained for the BUSI dataset are displayed in Figure 21a, while those for the BrEaST dataset are displayed in Figure 21b.
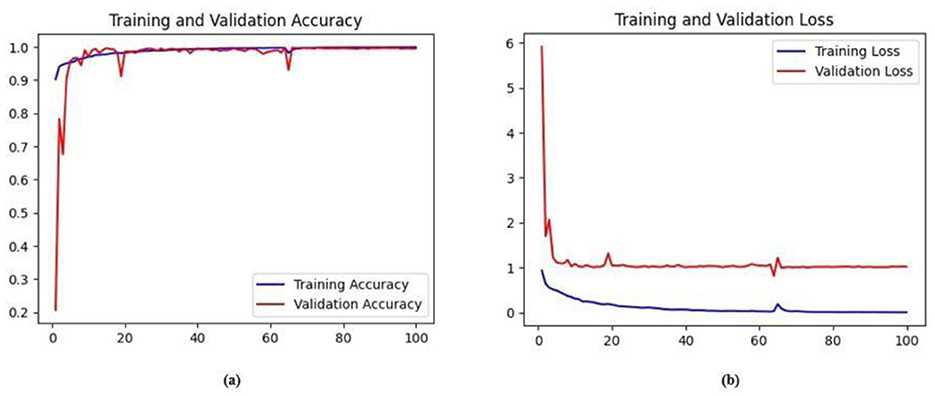
Figure 18. (a) Training and validation accuracy of the HMA-Net on the BUSI dataset. (b) Training loss and validation loss of the HMA-Net on the BUSI dataset.
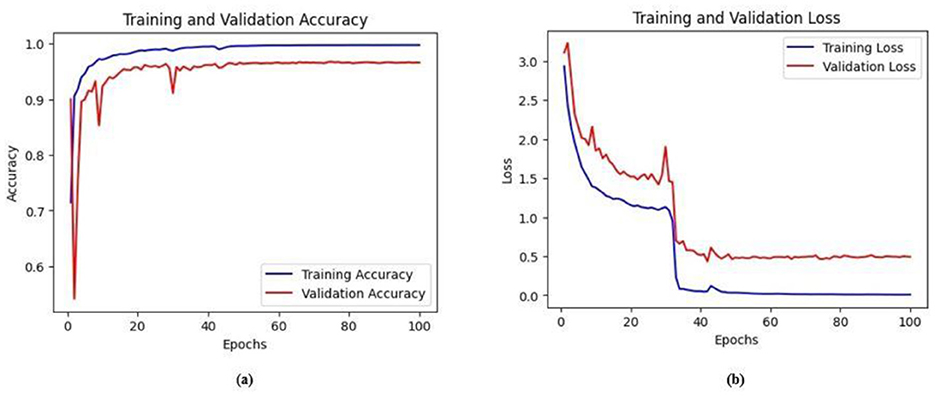
Figure 19. (a) Training and validation accuracy of the HMA-Net on the BrEaST dataset. (b) Training and validation loss of the HMA-Net on the BrEaST dataset.
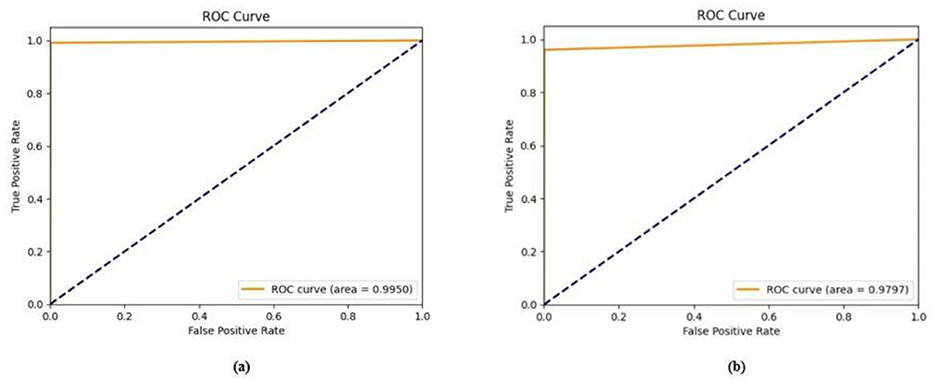
Figure 20. AUC curve obtained for the (a) BUSI dataset and (b) BrEaST dataset.
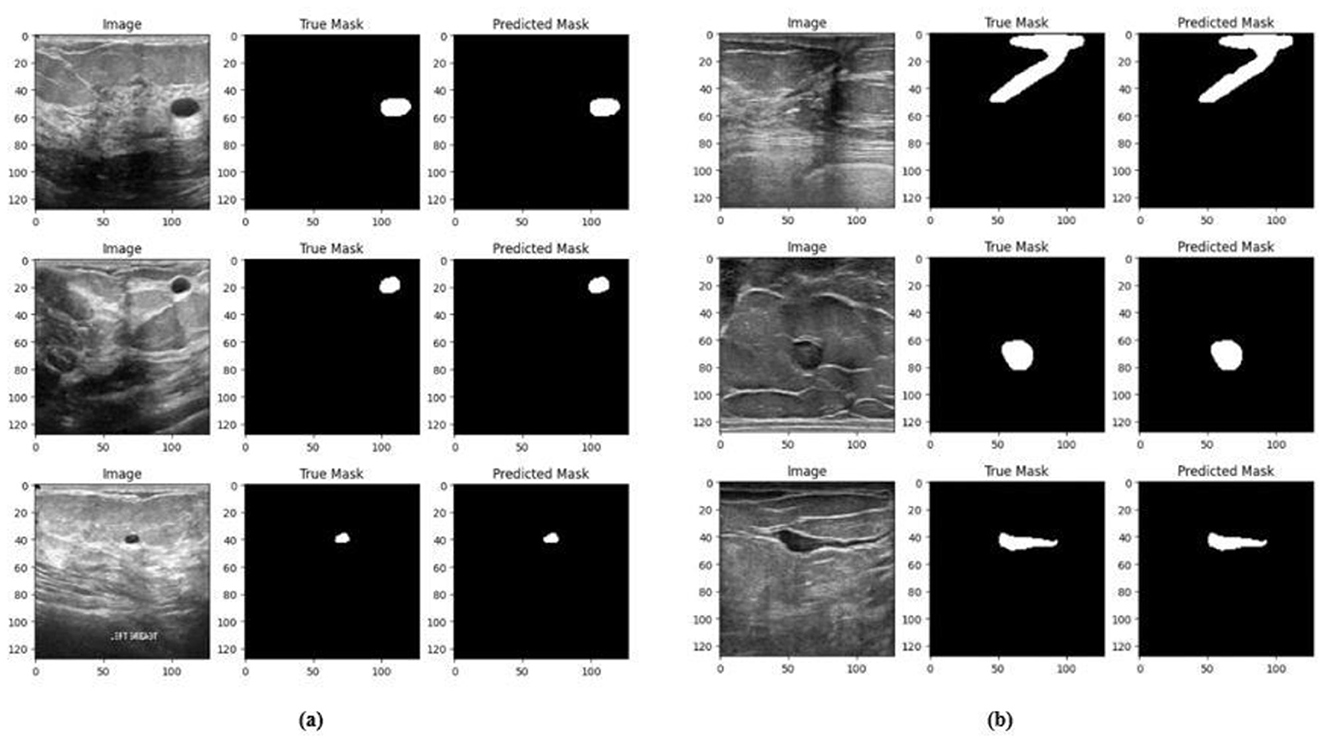
Figure 21. Visualization of the segmentation results of HMA-Net on (a) BUSI dataset and (b) BrEaST dataset.
The results obtained in Table 3 for the BUSI and BrEaST demonstrate that the proposed HMA-Net can be effectively used for the segmentation of tumor regions. The performance of the HMA-Net is due to the combined contribution of various components—ECMs in the encoder, enhanced ConvNeXT modules (ECN) in the decoder, and convolution-enhanced multihead attention (CEMHA) at the bottleneck. The ECM blocks improve spatial feature extraction using depthwise and pointwise convolutions, utilizing SE techniques for adaptive channel recalibration, enabling the model to prioritize relevant features and diminish noise. The ECN blocks further enhance the upsampled features, guaranteeing precise reconstruction of segmentation masks with more defined lesion boundaries. The local and global feature representations are merged using CEMHA module by integrating convolutional processing and multihead attention, thereby allowing the network to capture long-range relationships and contextual information essential for accurate tumor localization.
6 Comparison of the HMA-Net with the state-of-the-art architectures
Table 4 provides a comparison between the HMA-Net and the other models. The method introduced by Üzen (2024) obtained a Jaccard index of 69.23% and a DSC of 80.23% on the BUSI dataset. Zhang et al. (2023) introduced a method for breast ultrasound image classification and segmentation and obtained a DSC of 89.8%, a Jaccard index of 79.1% and a recall of 85.9%. The regional attentive multitask learning framework proposed by Xu et al. (2023) was evaluated on two datasets, obtaining DSC values of 85.69% and 80.04%, sensitivity values of 89.51% and 82.54%, specificity values of 99.25% and 98.00%, accuracy values of 98.79% and 96.4%, and IOU values of 77.84% and 71.93%. The method introduced by Chen et al. (2023) was evaluated on two different datasets to obtain Jaccard index values of 70.36% and 73.17%, DSC values of 78.51% and 81.50%, specificity values of 97.42% and 99.05%, precision values of 79.73% and 82.58%, and recall values of 82.70% and 84.02%. The method proposed by Lyu et al. (2023) was also evaluated using two datasets with the DSC values of 80.71% and 79.62%, specificity values of 98.54% and 99.38%, accuracy values of 97.13% and 97.97%, precision values of 83.5% and 87.95%, recall values of 79.3% and 74.43%, and IOU values of 68.53% and 67.52%. The method proposed by Almajalid et al. (2018) secured a DSC of 82.52%, a TPR of 78.66%, an FPR of 18.59%, and a FNR of 21.34%.
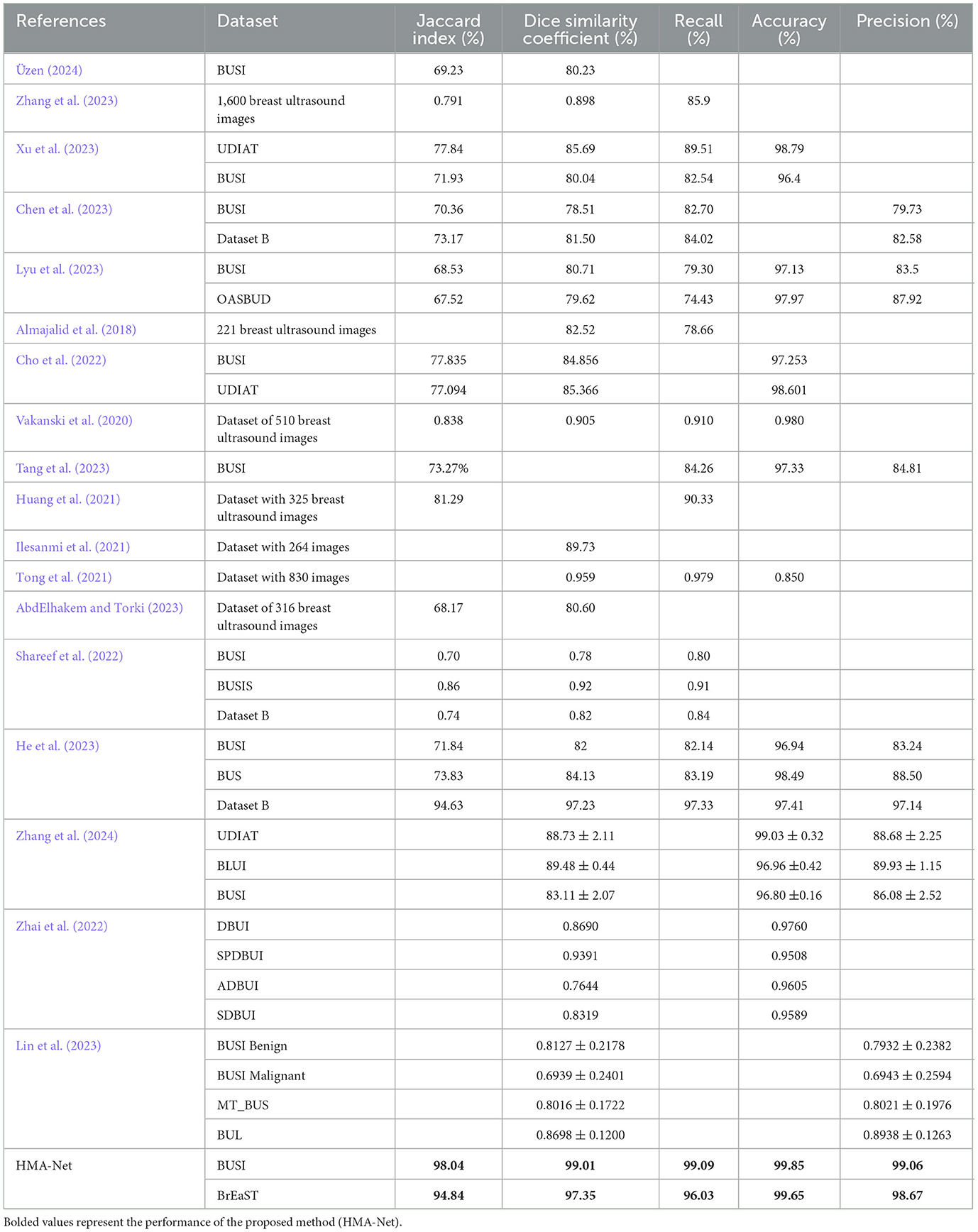
Table 4. Comparison of the HMA-Net with the state-of-the-art architectures.
The method proposed by Cho et al. (2022) obtained a pixel accuracy of 97.253%, an IOU of 77.835%, and a Dice coefficient of 84.856% on the BUSI dataset. For the UDIAT dataset, the same method achieved a pixel accuracy of 98.601%, an IOU of 77.094%, and a Dice coefficient of 85.366%. Attention blocks enhanced U-Net architecture proposed by Vakanski et al. (2020) attained a Jaccard index of 83.8%, a DSC of 90.5%, a TPR of 91.0%, an FPR of 8.9%, and an accuracy of 98.0%. The ConvMixer-based model for ultrasound image segmentation proposed by Tang et al. (2023) obtained an IOU of 84.75 ± 0.30, a recall of 91.53 ± 0.37, a precision of 92.02±0.13, an F1 score of 84.16 ± 0.47 and an accuracy of 97.33 ± 0.14 on the BUSI dataset. An IOU of 81.29%, an FPR of 9.00%, and a Recall of 90.33% were obtained for fuzzy deep learning network-based breast ultrasound image segmentation proposed by Huang et al. (2021). The method proposed by Ilesanmi et al. (2021) obtained a Dice measure of 89.73%. The method proposed by Tong et al. (2021) obtained a Dice coefficient of 95.9%, a sensitivity of 97.9%, an accuracy of 85%, and a specificity of 92.8%.
The method proposed by AbdElhakem and Torki (2023) secured an IOU of 68.17% and a Dice score of 80.60%. The model introduced by Shareef et al. (2022) was evaluated on three different datasets, obtaining Jaccard index values of 70%, 86%, and 74%, DSC values of 78%, 92%, and 82%, TPR values of 80%, 91% and 84%, and FPR values of 36%, 7%, and 22%, respectively. The hybrid convolutional neural network proposed by He et al. (2023) was also evaluated on three different datasets, achieving Jaccard index values of 71.84%, 73.83%, and 94.63%, DSCs of 82%, 84.13%, and 97.23%, accuracy values of 96.94%, 98.49%, and 97.41%, precision values of 83.24%, 88.50%, and 97.14%, and recall values of 82.14%, 83.19%, and 97.33, respectively. The model proposed by Zhang et al. (2024) obtained a Dice coefficient of 88.73% for the UDIAT dataset, 89.48% for the BLUI dataset, and 83.11% for the BUSI dataset, while the corresponding accuracy values were 99.03 ± 0.32, 96.96 ± 0.42, and 96.80 ± 0.16.
The method proposed by Zhai et al. (2022) obtained DSC of 0.8690, 0.9391, 0.7644, and 0.8319 on DBUI, SPDBU, ADBUI, and SDBUI datasets, respectively. The corresponding accuracy values of these datasets were 0.9760, 0.9508, 0.9605, and 0.9589. The method proposed by Lin et al. (2023) obtained DSCs of 0.8127 ± 0.2178, 0.6939 ± 0.2401, 0.8016 ± 0.1722, and 0.8698 ± 0.1200 on the BUSI benign, BUSI malignant, MT_BUS, and BUL datasets, respectively. In contrast, the precision values obtained were 0.7932 ± 0.2382, 0.6943 ± 0.2594, 0.8021 ± 0.1976, and 0.8938 ± 0.1263 for the same datasets.
The HMA-Net model obtained better results than prior techniques, such as U-Net, U-Net++, and ConvMixer-based architectures, by combining global and local feature extraction. The model utilized EMxi blocks integrated with ECMs to capture varied characteristics through depthwise and pointwise convolutions, while squeeze-and-excitation (SE) recalibrate channel-wise responses for improved feature representation. Enhanced ConvNeXT based DCNxi blocks further refine the upsampled features by integrating residual connections and channel mixing, facilitating the precise reconstruction of segmentation masks.
Unlike previous architectures that prioritize either local patterns or long-range dependencies, HMA-Net effectively combines both with its convolution-enhanced multihead attention (CEMHA) module, which merges convolutional operations for local feature extraction with global attention. This design enhances the delineation of ambiguous tumor boundaries in ultrasound images. Integrating attention exclusively at the bottleneck stage, rather than throughout all layers, achieves an optimal equilibrium between performance and efficiency. These distinct components jointly enhance the segmentation outcomes attained by HMA-Net on both the BUSI and BrEaST datasets, as reflected in Table 4.
7 Conclusion
Breast cancer is a prevalent issue among women nowadays and is impacting the lives of numerous individuals. Ultrasound images have now been widely used for detecting breast cancer owing to their safe and radiation-less nature. A hybrid mixer framework with multihead attention (HMA-Net) has been proposed for segmenting breast ultrasound images. The HMA-Net utilizes enhanced ConvMixer-based EMxi blocks for extracting downsampled feature maps from the input ultrasound images, and high-resolution segmentation masks are reconstructed using enhanced ConvNeXT-based DCNxi blocks. The ability of ECMs to combine the channel and spatial information is enhanced with the addition of the squeeze and excitation layer by dynamically adjusting the importance of various channels, resulting in more discriminative and detailed feature representations. The enhanced ConvNeXT modules capture complex patterns and hierarchical characteristics by which high-resolution segmentation masks can be reconstructed from low-resolution encoded features. The variations in the input data can be handled by ConvNeXT modules, and more accurate segmentation masks can be constructed by capturing local and global features. The residual linking improves the performance of the model by enhancing feature propagation and maintaining important features across layers. The convolution-enhanced multihead attention module improves the performance of the model by capturing long-range dependencies and intricate patterns from the input images. The model utilized a combined loss function, which enables the model to handle unbalanced data and to concentrate more on relevant areas. The performance of the model was evaluated using two breast ultrasound image datasets. The model obtained a Jaccard index of 98.04% and a DSC of 99.01% on the BUSI dataset. For the BrEaST dataset, the model obtained a Jaccard index of 94.84% and a DSC of 97.35%. The results obtained indicate that the model can be efficiently used for segmenting breast ultrasound images, which will help in the early detection of breast cancer. The HMA-Net model has robust segmentation capabilities and may be effortlessly incorporated into current ultrasound imaging workflows for clinical use. A practical scenario involves direct real-time implementation on ultrasound scanners and generating instantaneous segmentation masks during image acquisition. It can also be implanted in post-diagnostic systems to analyze the captured images and generate segmentation outputs prior to radiologist evaluation. This facilitates better lesion analysis, quicker interpretation, and consistent reporting in large-scale clinical environments.
The HMA-Net model has been evaluated on the BUSI and the BrEaST datasets. The BUSI dataset consists of 780 images collected from a single hospital, while the BrEaST dataset contains 256 manually annotated scans collected from five different institutions. Since these datasets have limited size and diversity, the variations present in real-world clinical situations cannot be adequately represented by this. Bigger datasets with a wider variety of image qualities, scanner types, and patient demographics should be used to validate the robustness and scalability of the proposed methodology.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
SS: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Project administration, Resources, Software, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing. LA: Conceptualization, Investigation, Methodology, Supervision, Validation, Writing – review & editing.
Funding
The author(s) declare that no financial support was received for the research and/or publication of this article. This research is funded by the Vellore Institute of Technology, Chennai, India.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Gen AI was used in the creation of this manuscript.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Abbasian Ardakani, A., Mohammadi, A., Mirza-Aghazadeh-Attari, M., et al. (2023). An open-access breast lesion ultrasound image database: applicable in artificial intelligence studies. Comput. Biol. Med. 152:106438. doi: 10.1016/j.compbiomed.2022.106438
AbdElhakem, S, Basiony, S., and Torki, M. (2023). “ConvMixer-UNet: a lightweight network for breast lesion segmentation in ultrasound images”, in 2023 20th ACS/IEEE International Conference on Computer Systems and Applications (AICCSA) (Giza: IEEE), 1–5.
Adrian, G., Carneiro, G., and González Ballester, M. A. (2022). “On the optimal combination of cross-entropy and soft dice losses for lesion segmentation with out-of-distribution robustness”, in Diabetic Foot Ulcers Grand Challenge (Cham: Springer International Publishing), 40–51.
Al-Dhabyani, W., Gomaa, M., Khaled, H., and Fahmy, A. (2020). Dataset of breast ultrasound images. Data Brief. 28:104863. doi: 10.1016/j.dib.2019.104863
Almajalid, R., Shan, J., Du, Y., and Zhang, M. (2018). “Development of a deep-learning-based method for breast ultrasound image segmentation”, in 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA) (Orlando, FL: IEEE), 1103-1108.
Chen, G., Liu, Y., Qian, J., Zhang, J., Yin, X., Cui, L., et al. (2023). DSEU-net: A novel deep supervision SEU-net for medical ultrasound image segmentation. Expert Syst. Appl. 223:119939. doi: 10.1016/j.eswa.2023.119939
Cho, S. W., Baek, N. R., and Park, K. R. (2022). Deep Learning-based Multi-stage segmentation method using ultrasound images for breast cancer diagnosis. J. King Saud Univers.-Comp. Inform. Sci. 34, 10273–10292. doi: 10.1016/j.jksuci.2022.10.020
Fuentes, J. D. M., Morgan, E., Luna Aguilar, A., de Mafra, A., Shah, R., Giusti, F., et al. (2024). Global stage distribution of breast cancer at diagnosis: a systematic review and meta-analysis. JAMA Oncol. 10, 71–78. doi: 10.1001/jamaoncol.2023.4837
Georgescu, M. I., Tudor Ionescu, R., Miron, A. I., Savencu, O., Ristea, N. C., Verga, N., et al. (2023). “Multimodal multi-head convolutional attention with various kernel sizes for medical image super-resolution,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (Waikoloa, HI: IEEE), 2195–2205.
He, Q., Yang, Q., and Xie, M. (2023). HCTNet: a hybrid CNN-transformer network for breast ultrasound image segmentation. Comp. Biol. Med. 155:106629. doi: 10.1016/j.compbiomed.2023.106629
Horsch, K., Giger, M. L., Venta, L. A., and Vyborny, C. J. (2001). Automatic segmentation of breast lesions on ultrasound. Med. Phys. 28, 1652–1659. doi: 10.1118/1.1386426
Huang, K., Zhang, Y., Cheng, H. D., Xing, P., and Zhang, B. (2021). Semantic segmentation of breast ultrasound image with fuzzy deep learning network and breast anatomy constraints. Neurocomputing 450, 319–35. doi: 10.1016/j.neucom.2021.04.012
Huang, Q., Huang, Y., Luo, Y., Yuan, F., and Li, X. (2020). Segmentation of breast ultrasound image with semantic classification of superpixels. Med. Image Analy. 61:101657. doi: 10.1016/j.media.2020.101657
Huang, Y. L., and Chen, D. R. (2004). Watershed segmentation for breast tumor in 2-D sonography. Ultrasound Med. Biol. 30, 625–632. doi: 10.1016/j.ultrasmedbio.2003.12.001
Ilesanmi, A. E., Chaumrattanakul, U., and Makhanov, S. S. (2021). A method for segmentation of tumors in breast ultrasound images using the variant enhanced deep learning. Biocybernet. Biomed. Eng. 41, 802–818. doi: 10.1016/j.bbe.2021.05.007
Lin, G., Chen, M., Tan, M., and Chen, L. (2023). A dual-stage transformer and MLP-based network for breast ultrasound image segmentation. Biocybernet. Biomed. Eng. 43, 656–671. doi: 10.1016/j.bbe.2023.09.001
Liu, Z., Mao, H., Wu, C. Y., Feichtenhofer, C., Darrell, T., Xie, S., et al. (2022). “A convnet for the 2020s,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (New Orleans, LA: IEEE), 11976–11986.
Lyu, Y., Xu, Y., Jiang, X., Liu, J., Zhao, X., Zhu, X., et al. (2023). AMS-PAN: Breast ultrasound image segmentation model combining attention mechanism and multi-scale features. Biomed. Signal Proc. Cont. 81, 104425. doi: 10.1016/j.bspc.2022.104425
Moon, W. K., Lo, C.T., Chen, R. T., Shen, Y. W., Chang, J. W., Huang, C. S., et al. (2014). Tumor detection in automated breast ultrasound images using quantitative tissue clustering. Med. Phys. 41:042901. doi: 10.1118/1.4869264
Pawłowska, A., Cwierz-Pieńkowska, A., Domalik, A., Jaguś, D., Kasprzak, P., Matkowski, R., et al. (2024). Curated benchmark dataset for ultrasound based breast lesion analysis. Scient. Data 11:148. doi: 10.1038/s41597-024-02984-z
Piotrzkowska-Wróblewska, H. K., Dobruch-Sobczak, M. B., and Nowicki, A. (2017). Open access database of raw ultrasonic signals acquired from malignant and benign breast lesions. Med. Phys. 44, 6105–6109. doi: 10.1002/mp.12538
Shareef, B., Vakanski, A., Freer, P. E., and Xian, M. (2022). Estan: Enhanced small tumor-aware network for breast ultrasound image segmentation. Healthcare 10:2262. doi: 10.3390/healthcare10112262
Tang, F., Wang, L., Ning, C., Xian, M., and Ding, J. (2023). “CMU-NET: a strong convmixer-based medical ultrasound image segmentation network,” in 2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI) (Cartagena: IEEE), 1-5.
Tong, Y., Liu, Y., Zhao, M., Meng, L., and Zhang, J. (2021). Improved U-net MALF model for lesion segmentation in breast ultrasound images. Biomed. Signal Proc. Cont. 68:102721. doi: 10.1016/j.bspc.2021.102721
Trockman, A., and Kolter, J. Z. (2022). Patches are all you need? arXiv [preprint] arXiv:2201.09792. doi: 10.48550/arXiv.2201.09792
Üzen, H. (2024). Convmixer-based encoder and classification-based decoder architecture for breast lesion segmentation in ultrasound images. Biomed. Signal Proc. Cont. 89:105707. doi: 10.1016/j.bspc.2023.105707
Vakanski, A., Xian, M., and Freer, P. E. (2020). Attention-enriched deep learning model for breast tumor segmentation in ultrasound images. Ultrasound Med. Biol. 46, 2819–2833. doi: 10.1016/j.ultrasmedbio.2020.06.015
Xu, M., Huang, K., and Qi, X. (2023). A regional-attentive multi-task learning framework for breast ultrasound image segmentation and classification. IEEE Access 11, 5377–5392. doi: 10.1109/ACCESS.2023.3236693
Yap, M. H., Pons, G., Marti, J., Ganau, S., Sentis, M., Zwiggelaar, R., et al. (2017). Automated breast ultrasound lesions detection using convolutional neural networks. IEEE J. Biomed. Health Informat. 22, 1218–1226. doi: 10.1109/JBHI.2017.2731873
Zhai, D., Hu, B., Gong, X., and Zou, H. (2022). ASS-GAN: asymmetric semi-supervised GAN for breast ultrasound image segmentation. Neurocomputing 493, 204–216. doi: 10.1016/j.neucom.2022.04.021
Zhang, H., Lian, J., Yi, Z., Wu, R., Lu, X., Ma, P., et al. (2024). HAU-Net: Hybrid CNN-transformer for breast ultrasound image segmentation. Biomed. Signal Proc. Cont. 87, 105427. doi: 10.1016/j.bspc.2023.105427
Zhang, S., Liao, M., Wang, J., Zhu, Y., Zhang, Y., Zhang, J., et al. (2023). Fully automatic tumor segmentation of breast ultrasound images with deep learning. J. Appl. Clini. Med. Phys. 24:e13863. doi: 10.1002/acm2.13863
Keywords: breast cancer, deep learning, ultrasound images, segmentation, ConvNeXt, ConvMixer
Citation: Sara Koshy S and Anbarasi LJ (2025) HMA-Net: a hybrid mixer framework with multihead attention for breast ultrasound image segmentation. Front. Artif. Intell. 8:1572433. doi: 10.3389/frai.2025.1572433
Received: 07 February 2025; Accepted: 12 May 2025;
Published: 18 June 2025.
Edited by:
Zhijie Xu, Xi'an Jiaotong-Liverpool University, ChinaReviewed by:
Yihong Wang, Xi'an Jiaotong-Liverpool University, ChinaHaiyang Zhang, Xi'an Jiaotong University, China
Copyright © 2025 Sara Koshy and Anbarasi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: L. Jani Anbarasi, amFuaWFuYmFyYXNpLmxAdml0LmFjLmlu