 Ibrahim Nafisah1Nermine Mahmoud2Ahmed A. Ewees3Mohamed G. Khattap4Abdelghani Dahou5Safar M. Alghamdi6
Ibrahim Nafisah1Nermine Mahmoud2Ahmed A. Ewees3Mohamed G. Khattap4Abdelghani Dahou5Safar M. Alghamdi6 Ibrahim A. Fares7*Mohammed Azmi Al-Betar8,9
Ibrahim A. Fares7*Mohammed Azmi Al-Betar8,9 Mohamed Abd Elaziz7,10*
Mohamed Abd Elaziz7,10*- 1Department of Statistics and Operations Research, College of Sciences, King Saud University, Riyadh, Saudi Arabia
- 2Faculty of Human Science, Galala University, Suez, Egypt
- 3Department of Computer, Damietta University, Damietta, Egypt
- 4Technology of Radiology and Medical Imaging Program, Faculty of Applied Health Sciences Technology, Galala University, Suez, Egypt
- 5School of Computer Science and Technology, Zhejiang Normal University, Jinhua, China
- 6Department of Mathematics and Statistics, College of Science, Taif University, Taif, Saudi Arabia
- 7Department of Mathematics, Faculty of Science, Zagazig University, Zagazig, Egypt
- 8Artificial Intelligence Research Center (AIRC), College of Engineering and Information Technology, Ajman University, Ajman, United Arab Emirates
- 9Hourani Center for Applied Scientific Research, Al-Ahliyya Amman University, Amman, Jordan
- 10Faculty of Computer Science and Engineering, Galala University, Suez, Egypt
Introduction: Autism Spectrum Disorder (ASD) is a neurodevelopmental condition characterized by challenges in communication, social interactions, and repetitive behaviors. The heterogeneity of symptoms across individuals complicates diagnosis. Neuroimaging techniques, particularly resting-state functional MRI (rs-fMRI), have shown potential for identifying neural signatures of ASD, though challenges such as high dimensionality, noise, and small sample sizes hinder their clinical application.
Methods: This study proposes a novel approach for ASD detection utilizing deep learning and advanced feature selection techniques. A hybrid model combining Stacked Sparse Denoising Autoencoder (SSDAE) and Multi-Layer Perceptron (MLP) is employed to extract relevant features from rs-fMRI data in the ABIDE I dataset, which was preprocessed using the CPAC pipeline. Feature selection is enhanced through an optimized Hiking Optimization Algorithm (HOA) that integrates DynamicOpposites Learning (DOL) and Double Attractors to improve convergence toward the optimal subset of features.
Results: The proposed model is evaluated using multiple ASD datasets. The performance metrics include an average accuracy of 0.735, sensitivity of 0.765, and specificity of 0.752, surpassing the results of existing state-of-the-art methods.
Discussion: The findings demonstrate the effectiveness of the hybrid deep learning approach for ASD detection. The enhanced feature selection process, coupled with the hybrid model, addresses limitations in current neuroimaging analyses and offers a promising direction for more accurate and clinically applicable ASD detection models.
1 Introduction
Autism can be defined as a set of behavioral manifestations that include restricted activities, barriers to communication, as well as social interaction problems. A more accurate term for this condition is autism spectrum disorder (ASD) (Lord et al., 2018). Diagnosis can be made as early as 18 to 24 months, when symptoms become distinguishable from typical development and other cognitive or developmental challenges (Sayers et al., 2023). ASD is classified under neurodevelopmental disorders in the Diagnostic and Statistical Manual of Mental Disorders (DSM-5) and is associated with language impairments, poor social engagement, and limited or repetitive interests and activities. Parents of children with ASD face considerable psychological, physical, and financial burdens (John and Sala, 2018). Various tools have been used to diagnose ASD, such as the Autism Spectrum Quotient (AQ), the Childhood Autism Rating Scale (CARS-2), and the Screening Tool for Autism in Toddlers and Young Children (STAT) (Al-Hendawi et al., 2023). These assessments help identify symptoms and determine the severity of the condition, facilitating early intervention and support. However, there is a pressing need for more advanced and accurate methods, particularly those employing artificial intelligence (AI) to enhance the effectiveness of these traditional techniques.
According to the Global Burden of Disease (GBD) Study, ASD ranks among the six most common developmental disabilities in children under 5 years old. The prevalence of ASD has increased significantly in recent decades, likely due to greater awareness and improved recognition of the condition (Zeidan et al., 2022). In 2010, approximately 52 million children were diagnosed with ASD, translating to a prevalence of 7.6 per 1,000 individuals. In 2018, the Centers for Disease Control and Prevention (CDC) reported that 1 in 59 children had ASD, a figure that rose to 1 in 44 by 2020 (Zeidan et al., 2022). Studies in Europe and the United States suggest that ASD diagnoses have increased markedly over the last two decades, from 0.48% to 3.13% (Zeidan et al., 2022). However, most research on ASD prevalence in Arab countries has focused on wealthier nations. A systematic meta-analysis found that ASD prevalence rates vary across Oman, the UAE, Saudi Arabia, Bahrain, Kuwait, and Qatar (Sayers et al., 2023). In Egypt, ASD prevalence estimates have varied significantly, ranging from 5.4 per 1,000 to as high as 33.6% (Zeidan et al., 2022). However, Egyptian studies are often limited to specific regions, institutional settings, and small sample sizes.
Diagnosing ASD remains challenging due to its frequent co-occurrence with other disorders such as epilepsy, attention deficit hyperactivity disorder (ADHD), and sensory processing disorders, often resulting in delayed or missed diagnoses (Simonoff et al., 2008). Recent research estimates that 1 in 36 children in the United States are diagnosed with ASD, a figure substantially higher than in previous decades, attributable to broadened diagnostic criteria and increased public awareness (Christensen, 2016; Qin et al., 2024). This growing prevalence places considerable strain on healthcare systems, with families often incurring annual therapy and treatment costs exceeding 60, 000 per child, underscoring the critical need for accessible and advanced detection tools (Lavelle et al., 2014; Huda et al., 2024).
Traditional ASD diagnosis primarily relies on parent-reported developmental milestones and behavioral observations, which are inherently subjective and susceptible to cultural and gender biases (Patil et al., 2024; Bahathiq et al., 2022). Consequently, many adolescents and adults, especially females without intellectual disabilities, remain undiagnosed until secondary mental health issues arise (Giarelli et al., 2010). In response, neuroimaging techniques such as resting-state functional MRI (rs-fMRI) have gained prominence by revealing abnormal connectivity patterns within brain networks related to social cognition and sensory processing (Supekar et al., 2013). Yet, bringing such findings to the clinical realm necessitates surmounting the computational challenges: one rs-fMRI dataset comprises tens of thousands of regional connectivity features but scarcely over 1,000 subjects even in public databases like the Autism Brain Imaging Data Exchange (ABIDE) (Di Martino et al., 2014). Therefore, there is an urgent imperative to develop effective diagnostic methods for ASD, which not only facilitate early intervention but also play a crucial role in managing the condition's global prevalence. Implementing such diagnostic tools can provide timely support and resources, ultimately improving outcomes for individuals with ASD and their families.
Machine learning (ML) offers a promising solution by detecting subtle neural signatures associated with ASD. Nonetheless, high dimensionality and noise in neuroimaging data continue to challenge model accuracy (Mellema et al., 2022; Fares et al., 2025). Feature selection (FS) techniques, such as recursive feature elimination, have become essential for removing redundant connections while preserving biomarkers related to social attention and executive function (Mellema et al., 2022; Bahathiq et al., 2022; Fares and Abd Elaziz, 2025). Hybrid approaches that combine deep learning (DL) with FS have demonstrated notable success. For example, methods integrating the Adaptive Bacterial Foraging (ABF) algorithm with Support Vector Machine Recursive Feature Elimination (SVM-RFE) have shown high performance in ASD detection (Lamani and Benadit, 2023). Similarly, convolutional neural networks (CNNs) hybridized with Elephant Herding Optimization (EHO) algorithms have been applied to multiple fMRI datasets, yielding promising results in identifying ASD patients (Chola Raja and Kannimuthu, 2023).
However, despite such progress, various challenges remain. The biological heterogeneity of ASD implies that no neural marker is universally applicable; connectivity changes differ between toddlers and adults, between verbal and non-verbal individuals, or between those with and without genetic syndromes (Alzubaidi et al., 2023). Reproducibility is also constrained by small sample sizes and heterogeneous preprocessing pipelines at imaging sites (Schielen et al., 2024; Chola Raja and Kannimuthu, 2023).
This paper aims to propose a modified version of the autism detection model based on the strengths of DL and FS techniques. In general, the DL model combining a Stacked Sparse Denoising Autoencoder (SSDAE) and a Multi-Layer Perceptron (MLP) is used to extract the relevant features (Liu et al., 2024). Following by using an enhanced version of Hiking Optimization Algorithm (HOA) as an FS technique (Oladejo et al., 2024). This enhancement is conducted through using Dynamic Opposites Learning (DOL) (Ahmad et al., 2022) and Double Attractors (He and Lu, 2022) to enhance the convergence toward the optimal subset of relevant features. These approaches have been established in their performance in different applications. For example, DOL has applied engineering problems (Cao et al., 2023; Xu et al., 2020), job shop scheduling (Yang et al., 2022), IIR system identification (Niu Y. et al., 2022), and skin cancer detection (Dahou et al., 2023). Has applied to enhance design of structures (Kaveh and Yousefpoor, 2024), color image compression (Yao et al., 2025), and KELM diabetes classification (Zhu et al., 2025).
The contributions of this study can be stated as follows:
• Development of an autism detection approach using DL and an enhanced FS model based on a modified version of the HOA algorithm.
• Integration of SSDAE and MLP for learning feature representations from rs-fMRI data and performing feature extraction.
• Introducing a modified version of HOA using the dynamic opposite-based learning and double attractors.
• Evaluation of the performance of the developed autism detection technique on multiple datasets and comparison with other well-known methods.
The organization of this paper is given as follows: Section 2 introduces the related works of using different AI models to detect autism. Section 3 presents the basic information of the Hiking Optimization Algorithm (HOA), Dynamic-Opposite Learning (DOL), and Double Attractors. The stages of the proposed autism detection model are presented in section 4. The experimental results and discussion are introduced in Section 5. Finally, the conclusion and future works are presented in Section 6.
2 Related works
The development of AI-based models for detecting ASD has seen notable progress, particularly with the integration of FS techniques and DL algorithms. Over the past decade, various studies have explored innovative methods for leveraging neuroimaging data, such as rs-fMRI, in combination with DL approaches. This section will review the most influential works that have contributed to the development of ASD detection models, highlighting key advancements in both AI methodologies and neuroimaging techniques used in ASD diagnosis.
Earlier work of Di Martino et al. (2014) and Guan and Liu (2021) described Autism Brain Imaging Data Exchange (ABIDE), a multi-site rs-fMRI repository, allowing for high-dimensional analysis of functional connectivity in ASD, and driving development in ML techniques. Nielsen et al. (2013) displayed multisite fMRI classification with SVMs, but with high-dimensional and site-related biases limiting it. The DL transition began with graph-based techniques. Parisot et al. (2018) started with graph convolutional networks (GCNs) representing functional connectivity in brain graphs, with 70% accuracy in ABIDE through encoding non-linear relationships between regions of interest (ROIs). In parallel, Heinsfeld et al. (2018) utilized convolutional neural networks (CNNs) for raw fMRI time-series, with renewed emphasis on automatization of feature extraction in an effort to reduce manual ROI selection. Hybrid architectures soon dominated: Eslami et al. (2019) combined SVM-RFE FS with 3D CNNs, and 88% accuracy in ABIDE through isolating discriminative connections in the default mode network (DMN). Similarly, Wang et al. (2020) designed a multi-atlas feature ensemble scheme and showed FS preceding training with DL aided generalizability improvement over ABIDE sites.
FS techniques specific to neuroimaging data gained prominence. Niu X. et al. (2022) optimized site-wise feature reproducibility with LASSO regularization, while Abraham et al. (2017) proposed a deep embedded feature selection (DEFS) algorithm, training FS layers and autoencoders together, and discovering cerebellar and somatosensory connectivity to be significant biomarkers. For multi-modal data, Abbas et al. (2023) merged structural MRI and fMRI features with attention, mapping 87% accuracy for ABIDE-II. Graph-methods saw a quantum jump with Li et al. (2020), utilizing graph neural networks (GNNs) for investigating modular connectivity profiles, mapping 80% accuracy, and indicating thalamocortical impairment in ASD.
Further, hybrid meta-heuristic algorithms along with CNNs achieved 98.6% on the ABIDE dataset (Chola Raja and Kannimuthu, 2023). Likewise, DL models like YOLOv8 while performing the analysis on facial images, showed 89.64% classification accuracy with a F1-score of 89% (Gautam et al., 2023). The proposed adaptive bacterial foraging optimization along with SVM-RFE and mRMR and followed by the graph convolutional network classifier obtained an accuracy of 97.512% (Lamani and Benadit, 2023).
Liu et al. (2024) introduced MADE-for-ASD, which integrates the power of various brain atlases and demographic information with fMRI. It presented an accuracy as high as 96.40% by highlighting the essential ASD-relevant brain regions. Furthermore, this efficient model is extendable and available openly for public adoption. A meta-analysis in Ding et al. (2024) emphasized the classification performance of these deep-learning models in ascertaining the disorder amongst children; thereby it may be exploited in extending present diagnostic methodologies. Chen et al. (2024) introduced DeepASD, an adversary-regularized GNN, aligning feature distributions between modalities (fMRI + SNPs), and mapping state-of-the-art 93% AUC-ROC performance for ABIDE-II. While the study Joe (2024) proposed using AI robots integrated with visual strategies to enhance social and communication skills in children with ASD. The author employed interactive robots to deliver structured visual stimuli and personalized learning experiences to improve engagement and skill retention. The author used a tuned CNN model, and it achieved an accuracy of 96% in the detection of ASD.
The study of Khan and Katarya (2025) proposes a new scheme, WS-BiTM, fusing White Shark Optimization (WSO) for FS and Bidirectional Long Short-Term Memory (Bi-LSTM) for classification for ASD improvement. WSO is utilized for selecting significant features out of sets of datasets for autism screening, and then these are processed with Bi-LSTM for efficient sequential processing. WSO-Bi-LSTM overcomes overfitting and computational efficiency issues effectively. Baseline algorithms outdo through comparative studies with 97.6%, 96.2%, and 96.4% accuracy for datasets for toddlers, adults, and kids, respectively, and proving its efficiency as a dependable tool for ASD classification.
The contribution of Abu-Doleh et al. (2025) introduces a two-step model for improving ASD classification with volumetric brain MRI images. First, subcortical structures are extracted and processed with a 3D autoencoder in order to detect regions of interest for analysis for ASD-related analysis. Secondly, these regions are classified with a Siamese Convolutional Neural Network (SCNN). SCNN achieved 66% accuracy with regions determined with the Mutual Information FS criterion. This contribution identifies the potential for fusing SCNNs and autoencoders for brain MRI-based ASD improvement. Jabbar et al. (2025) develop an ML model for early ASD screening by combining parent-reported questionnaires plus video analysis of child behavior. They achieved high accuracy through feature engineering by using data balancing techniques. Their hybrid algorithm outperforms traditional tools in AUC (0.92). The solution enables low-cost, mobile-friendly screening, particularly beneficial in resource-limited settings where clinical access is restricted.
3 Background
Optimization algorithms play a crucial role in enhancing the effectiveness of AI models by improving FS processes and model performance. Among these, the Hiking Optimization Algorithm (HOA) has shown promise as an effective tool for solving complex optimization problems, due to its human-inspired search mechanism that mirrors the dynamics of hiking. This section will introduce the key concepts behind HOA, Dynamic-Opposite Learning (DOL), and Double Attractors, which serve as the foundational techniques for the proposed autism detection model.
3.1 Hiking Optimization Algorithm
The Hiking Optimization Algorithm (HOA) is a metaheuristic inspired by hiking, where hikers navigate varying terrains to reach a peak (Oladejo et al., 2024). Similar to the unpredictable landscapes of hiking, optimization problems feature complex search spaces. HOA uses Tobler's Hiking Function (THF) to model hikers' movement, considering terrain elevation and distance. This approach mimics hikers' strategies of avoiding steep paths to maintain a steady pace, helping agents in HOA find optimal solutions while avoiding local optima. The algorithm's human-inspired structure makes it an efficient tool for solving complex optimization problems.
3.1.1 Initialization
In the first step of the HOA, the initial positions of the hikers—analogous to search agents—are established randomly. This method ensures diversity in the search space, promoting a broad exploration of potential solutions. The position of each hiker, denoted as Xi(t), is determined within a defined search space. This space is bounded by the upper limit UBi and the lower limit LBi for each dimension j of the decision variable. The initialization process follows the equation:
where rand() is a uniformly distributed random variable within the range [0, 1].
3.1.2 Modeling hiker speed using Tobler's Hiking Function
The next step is incorporating the widely recognized Tobler's Hiking Function (THF), a mathematical model formulated by the geographer Waldo Tobler. THF is an exponential function that estimates hikers' velocity based on the terrain's steepness. This function plays a crucial role in HOA, as it simulates the movement dynamics of search agents (hikers) within the optimization space.
The velocity of a hiker i at iteration t, denoted as , is computed using the following equation:
where Si, t represents the slope of the terrain at the hiker's position. The slope itself is determined by the elevation change (dh) and the distance traveled (dx), given by:
where θi, t is the inclination angle of the terrain, constrained within the range [0°, 50°].
The integration of THF into HOA ensures that the movement of hikers (agents) is guided by realistic terrain-based constraints. In essence, steeper inclinations result in slower movement speeds, mirroring real-world hiking behaviors. By leveraging this function, HOA dynamically adjusts the step sizes of agents in the optimization process, enhancing both exploration and exploitation capabilities.
3.1.3 Exploitation phase
The exploitation phase of the HOA is responsible for refining the search process by guiding hikers (agents) toward promising regions in the optimization landscape. This phase leverages the social intelligence of hikers as a group and their individual cognitive abilities. A key parameter known as the sweep factor (SF) plays a crucial role in defining the balance between exploitation and exploration. The SF regulates the influence of the lead hiker on the movement of other hikers, controlling the extent of their deviation from the leader's trajectory. A higher SF value directs the HOA toward the exploitation phase, allowing agents to converge toward promising solutions. Conversely, a lower SF encourages exploration, enabling the algorithm to investigate diverse regions of the search space. The velocity of a hiker i at iteration t is updated by:
where γ is a random number within the range [0, 1]. and represent the actual and initial velocities of the hiker, respectively. The variable Xbest corresponds to the position of the lead hiker, representing the best solution found so far. Additionally, αi(t) denotes the sweep factor (SF), which takes values in the range [1, 3].
The updated position of hiker i at the next iteration, incorporating its velocity, is expressed as:
The complete implementation details of the Hiking Optimization Algorithm, including its initialization, velocity updates, and search mechanisms, are outlined in the pseudocode provided in Algorithm 1.

Algorithm 1. Pseudo-code of the HOA algorithm.
3.2 Dynamic-opposite learning
Metaheuristic optimization algorithms often struggle with premature convergence, leading to stagnation in local optima. Dynamic-Opposite Learning (DOL) is a recent strategy designed to enhance both exploration and exploitation by dynamically adjusting the search space (Xu et al., 2020). DOL builds upon Opposite-Based Learning (OBL) (Wang et al., 2011; Rahnamayan et al., 2007; El-Abd, 2011), which improves convergence by considering opposite solutions (Tizhoosh, 2005). Traditional OBL methods refine this concept but remain susceptible to local optima (Rahnamayan et al., 2007; Ergezer et al., 2009). To overcome this, DOL introduces an asymmetric and dynamically expanding search space, increasing population diversity and reducing stagnation. A random opposite number is used to create asymmetry, preventing premature convergence, while a weighting factor balances exploration and exploitation. By integrating DOL into metaheuristic frameworks, optimization performance is significantly enhanced, making it a powerful approach for solving complex problems.
The concept behind DOL is to expand the search space dynamically, rather than symmetrically, by introducing a random opposite number XRO, defined as:
where [a, b] represents the search domain of X. D is the dimension of X. In general, replacing the standard opposite number XO with XRO transforms the search into an asymmetric adaptive process, preventing premature convergence. A new candidate solution XDO is then selected as:
To maintain feasibility, XDO is adjusted if it falls outside the search boundaries [a, b]. However, as iterations progress, the search space may shrink, reducing the algorithm's exploitation capability. To counteract this, a weighting factor w is introduced, refining the final formulation:
where w is a positive constant ensuring an optimal balance between exploration and exploitation.
3.2.1 Dynamic opposite number
Let X be a real number in the search space, where X∈[a, b]. To introduce dynamic adaptation, the dynamic opposite number XDO is defined as:
where XO represents the opposite number of X as defined earlier in the OBL in Equation 7, w is a positive weighting factor controlling the expansion range, and rand is a random value sampled from (0, 1). The introduction of w ensures a balanced adaptation, preventing excessive search space contraction while enhancing exploration capabilities.
3.2.2 Dynamic opposite point in multi-dimensional space
Extending the DOL approach to higher dimensions, consider X = (X1, X2, …, XD) as a point in a D-dimensional search space, where each coordinate Xj falls within the predefined range [aj, bj]. The opposite point in this space is denoted by , as defined in Equation 7. The dynamic opposite point is formulated as:
3.2.3 DOL-based optimization
The proposed DOL strategy is applied iteratively to guide the optimization process. Given a population of candidate solutions X, each point undergoes transformation based on the dynamic opposite learning mechanism. The newly generated opposite candidates are assessed based on their objective function values.
The selection process follows a simple criterion:
If the fitness of XDO surpasses that of X, the new candidate is accepted. Otherwise, XDO is discarded, and the original X is retained.
To ensure boundary constraints are maintained, each must satisfy:
If any falls outside this range, it is reinitialized as a random value within [aj, bj].
3.3 Double attractors
In this section, we introduce Double attractors as one of the most important operators that are used to enhance the balancing between exploration and exploitation (He and Lu, 2022). In general, the solutions in the metaheuristic algorithms are updated their values according to the shared information and personal knowledge. Moreover, the solutions during the updating process move toward the feasible solution that is considered as an attraction point. However, the process of balance between the main phases of MH techniques, named exploration and exploitation, is considered one of the main challenges that the MH algorithms suffer from them. Therefore, DA is used to handle this challenge, and this is achieved through using two attractors named L1 and L2.
Following (He and Lu, 2022), L1 is defined as in Equation 13.
In Equation 13, pij(t) indicates the historical best value at jth dimension of Xi the iteration t. Whereas pbj(t) indicates the value of Xb among dimension j among tth iteration. ϕ1 is a parameter that linearly decreased over iterations and it is defined.
where T is the maximum number of iterations.
Moreover, the second attractor L2 is defined as:
where ϕ2 denotes a constant parameter.
Finally, the solution can be updated using either L1 and L2 as defined in Equation 16.
4 Proposed method
Building on the foundational concepts of HOA, DOL, and Double Attractors introduced in the previous section, this section presents the developed autism detection model. The model integrates DL techniques with the modified HOA to enhance the diagnostic process by extracting meaningful features from raw data and optimizing FS for improved diagnostic accuracy.
4.1 Feature extraction process
The feature extraction process in the proposed framework involves leveraging multi-atlas fMRI data to identify discriminative features for ASD diagnosis following the proposed model and process in Liu et al. (2024). Functional connectivity matrices are derived from three brain atlases (AAL, CC, EZ) using Pearson correlation coefficients, which are flattened into one-dimensional vectors. These vectors are input into a Stacked Sparse Denoising Autoencoder (SSDAE) for pre-training, where sparsity and noise constraints are applied to learn robust feature representations. The SSDAE compresses the data into a reduced encoding, which is then fine-tuned using the MLP. The final 100-unit layer of the MLP extracts learned features, which are subsequently processed by an FS algorithm to identify the most relevant features for classification. This approach ensures the extraction of meaningful and discriminative features from multi-atlas fMRI data, optimizing the model for ASD diagnosis.
4.2 Feature selection process
The modified HOA plays a pivotal role in the FS process by refining the search for the most relevant features that contribute to accurate ASD detection. By integrating dynamic OBL, HOA enhances the ability to exploit known good solutions while avoiding local optima. The introduction of DA further improves the balance between exploration and exploitation, allowing the algorithm to explore diverse regions of the feature space and converge more effectively on the most discriminative features for ASD classification. This makes the HOA an essential tool for improving the diagnostic accuracy of the proposed model, as it ensures that only the most relevant and informative features are used for classification, which directly impacts the detection of ASD.
Followed by generating a set of solutions X and using its opposition using DOL as defined in Equation 11. Then determining the best N solutions from X∪XDOL according to their fitness value. The next process is to update the solutions X using the operators of HOA and DA. This process of updating is conducted until the stop conditions are met. The details of the proposed model are given as follows.
4.2.1 First stage
This stage aims to generate a suitable population X which has N solutions based on the DOL techniques. To achieve this task, the first step is to use Equation 19 to set the initial value for these solutions.
where D denotes the dimension of X and r5∈[0, 1] refers to a random value. We apply Equation 11 to generate the opposite solutions XDO for each Xi, i = 1, 2, ..., N. Then we compute the fitness value for X and XDO, then select the best N solutions from X∪XDO to form the initial solution X. In general, this step leads to enhancing the convergence rate toward the optimal solution.
4.2.2 Second stage
This second stage aims to enhance the value of solutions X based on the operators of HOA and DA. This process is conducted by determining the best solution Xb.
The next step is to determine the selected features using the current solution Xi, and this is achieved by using the binary of Xi as defined in the following formula.
In Equation 20, r6∈[0, 1] denotes a random value. After that, we evaluate the quality of the selected features which correspond to the ones in BXi, and this is performed through computing the fitness value (Fiti) as in the following equation.
In Equation 21, |BXij| refers to the number of selected features. γ denotes the error of classification using the KNN classifier (we set K = 5). ρ∈[0, 1] refers to a parameter used to balance between the two terms of Equation 21.
The best Xb solution with the best Fit is then identified. Then we apply the operators of HOA as defined in Equations 2–5. Then we used the DA to enhance X, however, to reduce the time complexity of this stage, we used the following formula.
The steps of this stage are repeated until the stop conditions are met. Then the best solution is returned as the output of this stage.
4.2.3 Third stage
Finally, we used the testing set to assess the quality of the selected features, and this was conducted by generating the binary version of Xb is obtained using Equation 20. Then we select the relevant features from the testing set that correspond to the ones in BXb and assess the quality of those features by computing the performance metrics of the predicted values obtained using the trained KNN model. The steps of the developed model are given in Figure 1.
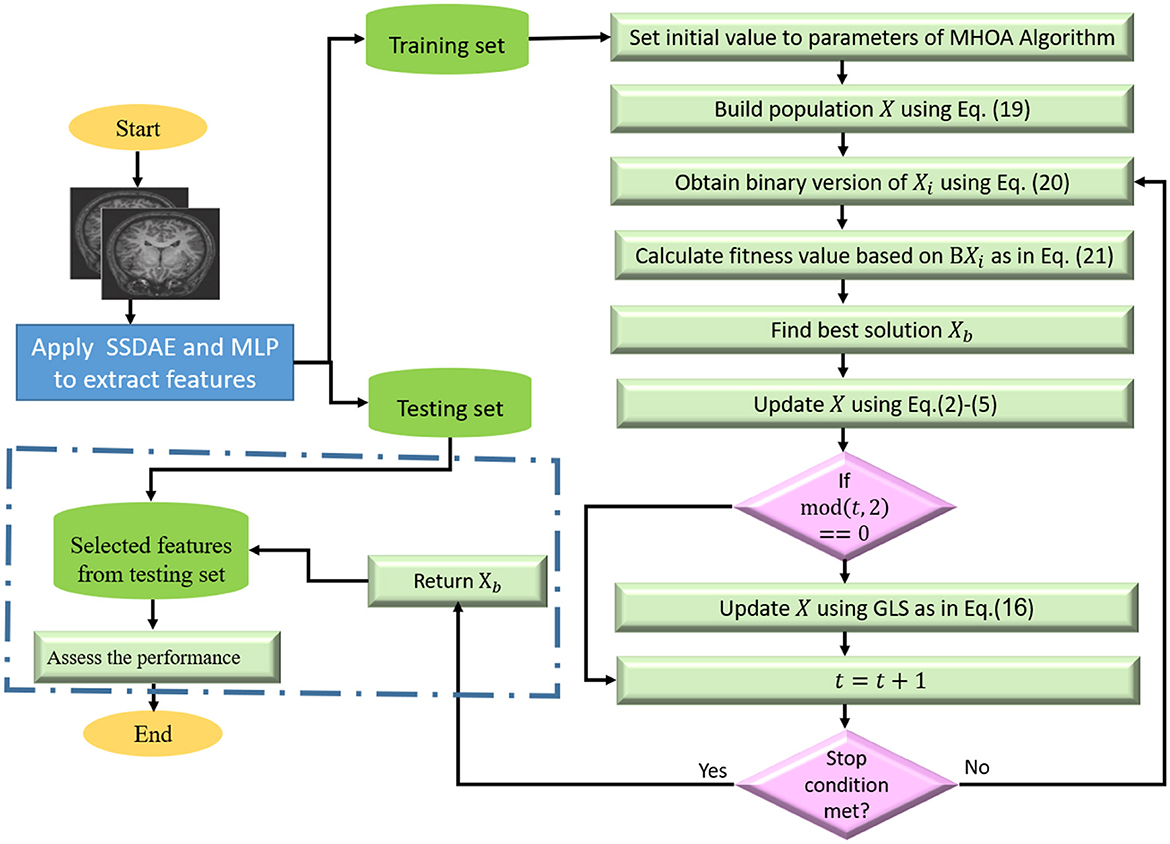
Figure 1. Phases of the developed autism detection based on the MHOA algorithm.
5 Experimental results and discussion
Having outlined the architecture and processes of the proposed autism detection model, this section presents the results of the proposed autism detection model, including a comprehensive analysis of its performance. The effectiveness of the model is evaluated through various experiments, and its performance is compared with existing models to assess its strengths and limitations.
5.1 Dataset preparation
The rs-fMRI data used in this study were sourced from the ABIDE I dataset, comprising 505 autistic individuals and 530 typical controls (TCs). The dataset includes subjects with ASD and TC, with age ranges from 10.0 to 35.0 years for ASD and 10.0 to 33.7 years for TC across different sites. The data is preprocessed using the Configurable Pipeline for the Analysis of Connectomes (CPAC) pipeline, which includes essential steps such as slice timing correction, voxel intensity normalization, motion correction, nuisance signal removal, global signal regression, band-pass filtering, and spatial registration. After preprocessing and quality control, the final dataset consists of 1,035 samples distributed as follows: 623 samples for the training set, 308 samples for the validation set, and 104 samples for the test set. Functional connectivity matrices are generated using three brain atlases (AAL, CC, EZ), and the mean time series for each ROI is calculated following (Liu et al., 2024). These matrices are flattened into one-dimensional vectors, forming the input for the feature extraction model. Finally, we derived three datasets from ABIDE I based on the EZ, AAL, and CC atlases, designated as Dataset-1, Dataset-2, and Dataset-3, respectively.
5.2 Model configurations
The model architecture integrates an SSDAE followed by an MLP. For the SSDAE, pre-training was conducted with a learning rate of 0.001 using gradient descent (GD) and a batch size of 100. Sparsity and noise constraints were applied to enhance robust feature learning, with dropout set to 0.5 to reduce overfitting. The SSDAE comprises two autoencoder layers: the first encoding layer has 1,000 units, and the second reduces the representation to 600 units. The MLP was subsequently fine-tuned with a learning rate of 0.0005 using stochastic gradient descent (SGD) and a smaller batch size of 10 to allow for finer updates. Dropout was set to 0.3 for the MLP. The final layer of the MLP includes 100 units, outputting the learned features for each atlas. The number of training iterations was selected based on convergence behavior: the first SSDAE autoencoder was trained for 700 iterations, and the second for 1,000 iterations to ensure adequate reconstruction performance.
5.3 Evaluation metrics
The effectiveness of the suggested method, along with the performance of the comparison algorithms, is assessed using the following evaluation metrics:
• Accuracy:
In this formula, TP and TN denote the true positive and true negative counts, while FP and FN represent the false positives and false negatives, respectively.
• Sensitivity:
• Standard Deviation (StDev):
Where, N refers to the total number of runs, xi denotes the individual values, and is the mean of those values.
5.4 Results and discussion
To assess the effectiveness of the proposed MHOA-based ASD detection model, experiments were conducted using multiple datasets derived from the ABIDE I database. Each dataset was preprocessed using a consistent pipeline to extract functional connectivity matrices, which were then transformed into feature vectors for analysis. The experiments used identical training and evaluation procedures across all algorithms to ensure a fair comparison.
The MHOA method was compared against six metaheuristic optimization algorithms: Hiking Optimization Algorithm (HOA), slime mold algorithm (SMA) (Ewees et al., 2023), Attraction-repulsion optimization algorithm (AROA) (Cymerys and Oszust, 2024), Harris hawk optimizer (HHO) (Abd Elaziz and Yousri, 2021), Great Wall Construction Algorithm (GWCA) (Guan et al., 2023), and gray wolf optimizer (GWO) (Helmi et al., 2021). These algorithms were selected based on their demonstrated success in FS and high-dimensional search spaces. All methods were evaluated using a k-nearest neighbors (KNN) classifier with consistent parameter settings. Evaluation metrics included accuracy, sensitivity, AUC, fitness value, and the number of selected features. The same classifier and dataset splits were applied to each method to ensure consistent benchmarking.
The proposed approach introduces a hybrid architecture combining SSDAE and MLP for feature representation, integrated with an enhanced optimization framework based on a modified Hiking Optimization Algorithm. The use of Dynamic Opposite Learning increases population diversity, while the Double Attractors mechanism improves convergence toward better feature subsets. These enhancements were specifically designed to address the high dimensionality and noise in rs-fMRI data and contribute to improved classification outcomes across the datasets.
The results, summarized in Tables 1–3, demonstrate that MHOA consistently achieved competitive performance compared to the other algorithms in most evaluation metrics.
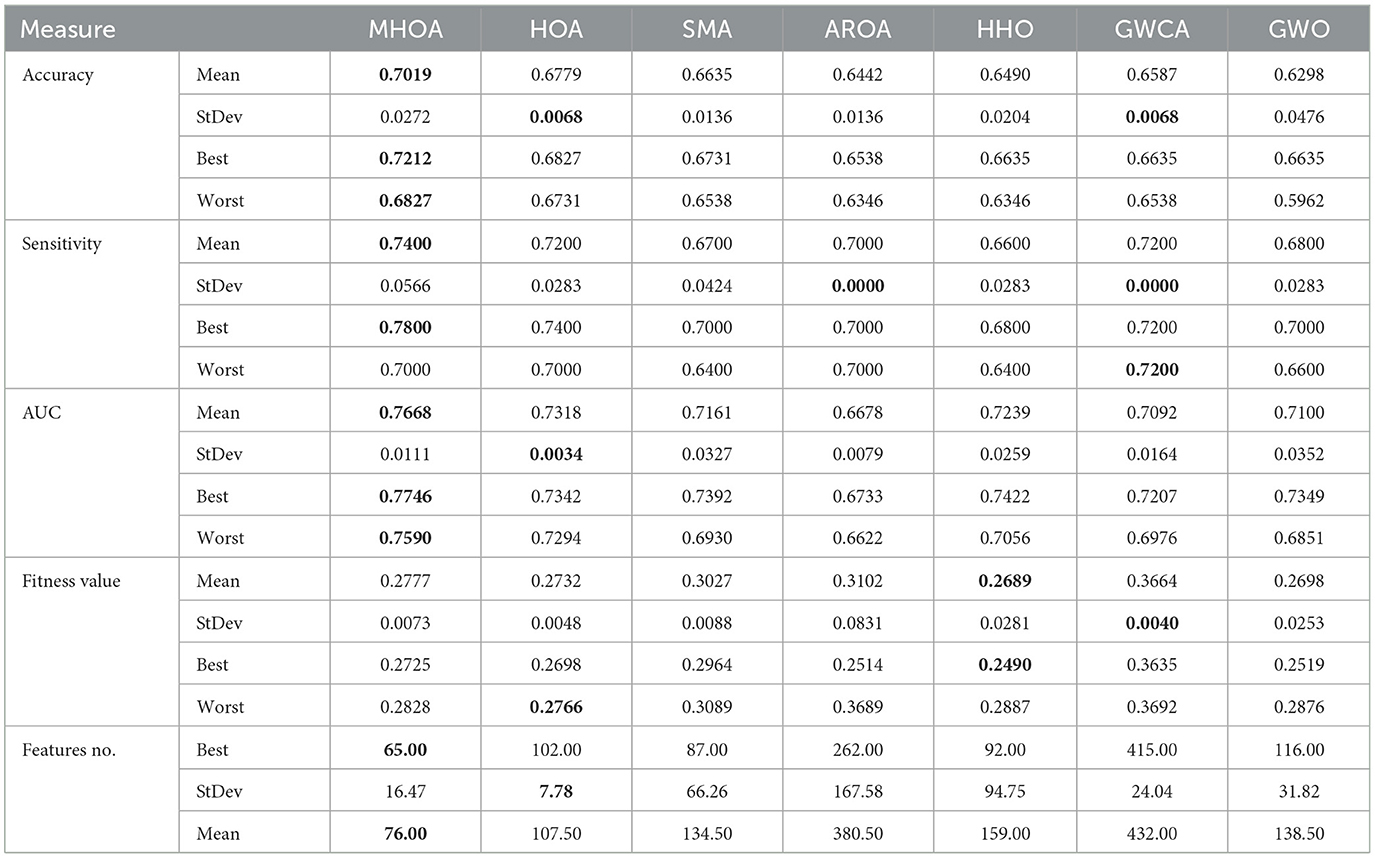
Table 1. Results of the Dataset-1.
Table 1 lists the numerical results for DATASET-1. In the table, the accuracy results demonstrated that MHOA achieved the highest mean accuracy, followed closely by HOA and SMA. The stability of MHOA was slightly lower than HOA, as indicated by its higher standard deviation. However, its best and worst accuracy values remained superior to those of the other methods. SMA exhibited moderate performance, with AROA and HHO showing lower mean values. GWO achieved the lowest accuracy.
In terms of sensitivity, MHOA ranked first, achieving the highest mean value. HOA and GWCA followed with comparable mean sensitivity scores, while AROA and GWO were positioned in the middle. HHO showed the lowest mean sensitivity. The standard deviation analysis revealed that AROA and GWCA had the most stable results, while MHOA exhibited intermediate stability. The best sensitivity values confirmed MHOA's advantage, as it reached the highest observed value, while the worst results indicated that GWCA achieved the highest stability, followed by MHOA and HOA.
Regarding the AUC metric, MHOA achieved the highest mean, indicating superior overall classification performance. HOA and HHO also showed competitive results, with SMA ranking slightly lower. AROA exhibited the lowest mean AUC. Standard deviation values indicated that HOA maintained the most stable performance, whereas SMA and GWO showed greater variability. The best and worst AUC values showed MHOA's effectiveness, as it outperformed the compared methods.
For the fitness value, HHO exhibited the best mean. HOA and GWO followed closely, with MHOA ranking slightly lower. However, the standard deviation results indicated that MHOA and HOA provided more stable optimization performance than HHO and AROA, which had higher variance. The best and worst fitness values showed that HHO maintained a strong optimization capability, while GWCA had the highest worst fitness value.
The FS results revealed that MHOA achieved the lowest number of selected features in the Best-case scenario. SMA and HOA followed, while GWCA selected the highest number of features. The standard deviation results indicated that HOA had the most stable FS followed by MHOA, while AROA and HHO exhibited greater variability. The mean values confirmed that MHOA consistently selected fewer features than the other methods and demonstrated its efficacy in reducing dimensionality while preserving classification performance. Figure 2 presents a comparison of the algorithms' performance on Dataset-1 across Accuracy, Sensitivity, and AUC metrics.
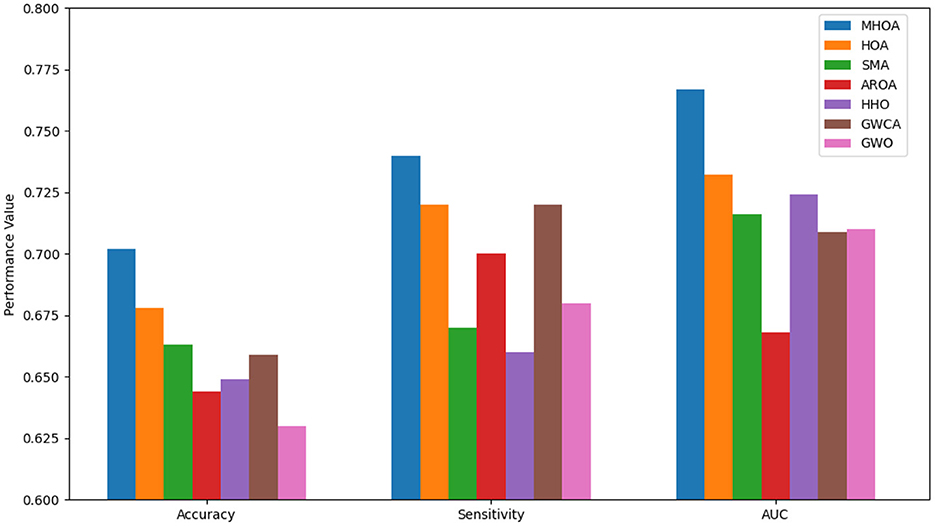
Figure 2. Results of accuracy, sensitivity, and AUC for Dataset-1.
As shown in Figure 2, the MHOA algorithm consistently outperformed other algorithms across all three key metrics: accuracy, sensitivity, and AUC. Notably, MHOA achieved the highest average accuracy of 0.7019, indicating improved classification capability. These results validate the effectiveness of combining SSDAE-based feature extraction with the modified HOA in capturing discriminative features from rs-fMRI data.
Table 2 presents the results of the DATASET-2. In the table, MHOA achieved the highest mean accuracy, followed closely by AROA, HHO, and GWCA, which exhibited similar performance. The standard deviation values showed that HOA and GWO exhibited the most stable results. MHOA outperformed other methods in the best and worst accuracy values. SMA, AROA, and HHO exhibited moderate performance, while HOA and GWO had lower rankings.
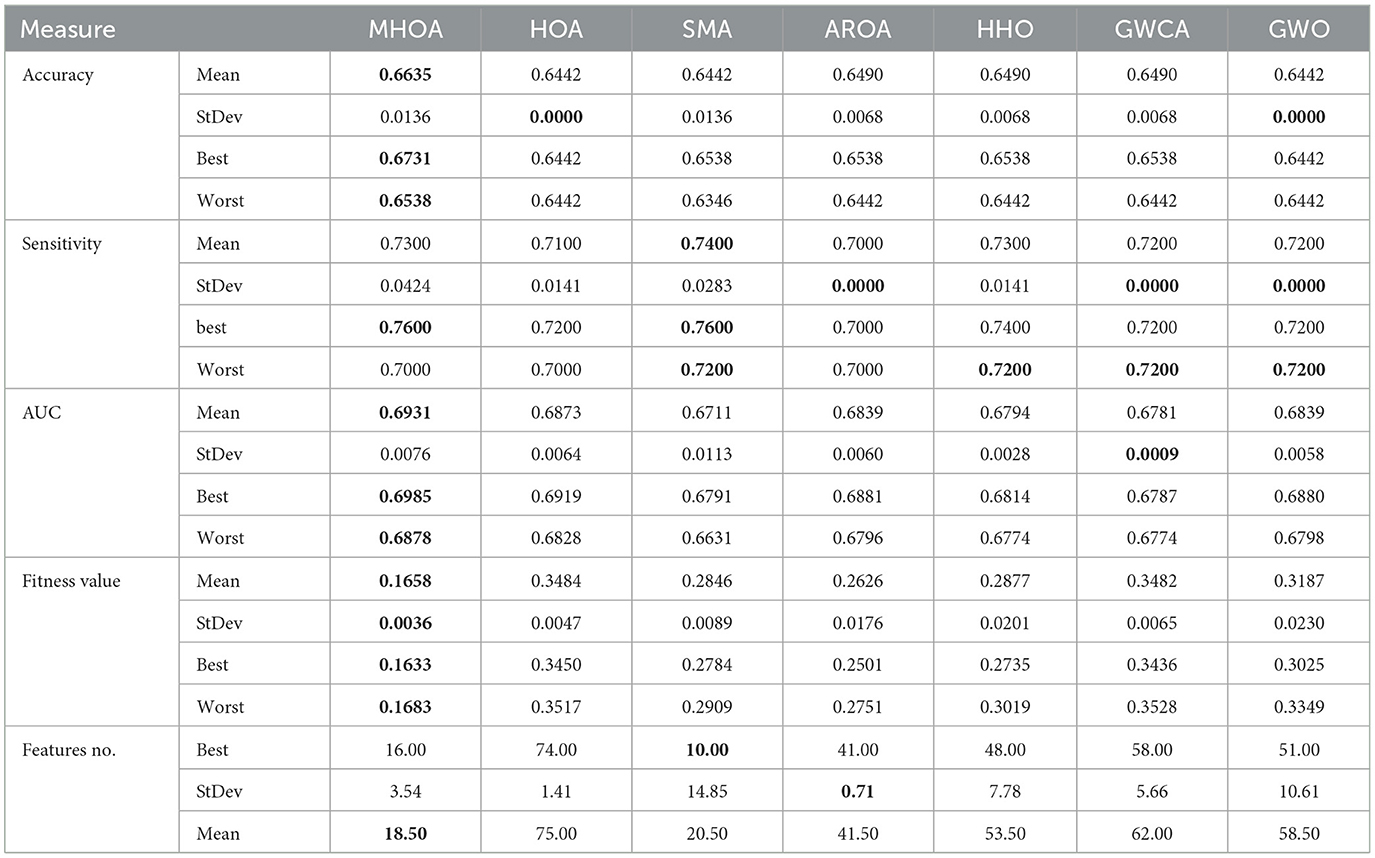
Table 2. Results of the Dataset-2.
In terms of sensitivity, SMA achieved the highest mean value, with MHOA and HHO ranking closely behind. HOA and AROA exhibited the lowest sensitivity. Standard deviation values showed that AROA, GWCA, and GWO were the most stable. The Best-case confirmed MHOA's strength, while the worst value demonstrated that SMA, HHO, GWCA, and GWO showed similar results, followed by MHOA.
Regarding the AUC metric, MHOA ranked highest in mean performance and demonstrated its superior classification capability. HOA followed closely, while SMA recorded the lowest mean AUC. Standard deviation results indicated that GWCA maintained the most stable AUC performance, whereas SMA showed greater variability. The best and worst values confirmed MHOA's consistently high performance across various scenarios.
For the fitness value, MHOA exhibited the best mean. AROA followed, while HOA recorded the highest mean value. The standard deviation analysis showed that MHOA had the most stable fitness value, whereas GWO and HHO exhibited greater variability. The best and worst fitness values further confirmed that MHOA maintained strong optimization capability, whereas HOA and GWCA showed inconsistent performance.
The FS results revealed that SMA achieved the lowest number of selected features in the best case. MHOA followed closely, while HOA selected the highest number of features. The standard deviation values indicated that AROA maintained the most stable FS, followed by HOA and MHOA, while SMA and GWO exhibited greater variability. The mean values confirmed that MHOA consistently selected fewer features than most methods and proved effective in dimensionality reduction while maintaining classification accuracy. Figure 3 presents a comparison of the algorithms' performance on Dataset-2 across Accuracy, Sensitivity, and AUC metrics.
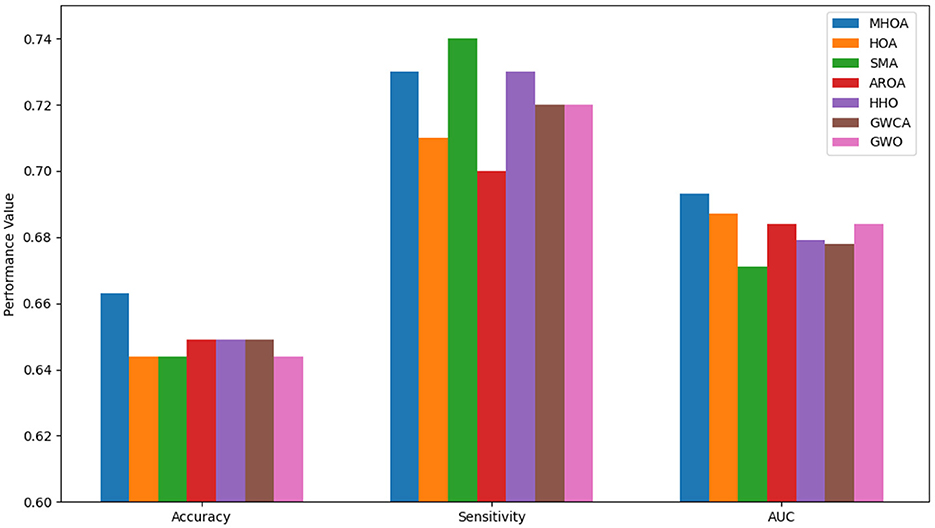
Figure 3. Results of accuracy, sensitivity, and AUC for Dataset-2.
In Figure 3, the proposed MHOA model outperforms all competing methods in terms of accuracy and AUC, demonstrating improved classification capability. Although the SMA algorithm achieved slightly higher sensitivity, MHOA exhibits a strong balance between sensitivity and accuracy, which is crucial in minimizing both false negatives and false positives in ASD detection. The GWCA and GWO models showed relatively stable sensitivity but did not match the overall classification performance of MHOA.
Table 3 presents the results and shows that MHOA achieved the highest mean accuracy. AROA and GWO followed closely, while HOA and SMA ranked lower. Standard deviation values indicated that AROA and GWO exhibited stable performance, whereas HOA and SMA showed greater variability. MHOA maintained its dominance in best and worst accuracy values, reinforcing its robustness.
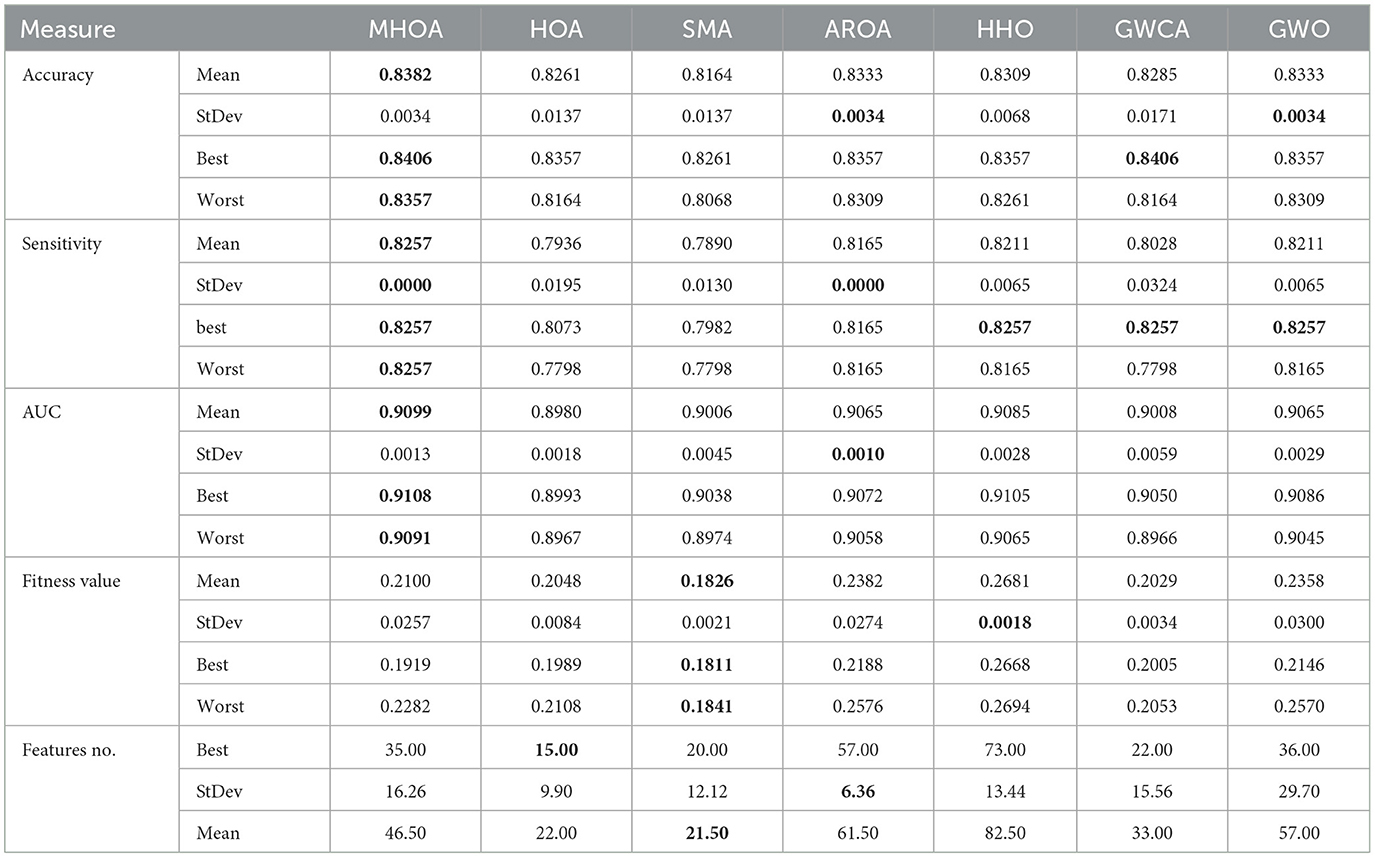
Table 3. Results of the Dataset-3.
Regarding sensitivity, MHOA ranked the highest with the best mean performance. HHO and GWO followed closely behind. HOA showed the lowest sensitivity and indicated its weakness in detecting positive instances. Standard deviation results indicated that MHOA and AROA were the most stable in sensitivity, while SMA, HOA, and GWCA exhibited higher variability. The best-case values demonstrated that MHOA consistently performed well in identifying positive instances, while HOA's worst-case results showed significant variability.
For AUC, MHOA outperformed all other algorithms in mean performance and demonstrated clear class differentiation capability. HHO and GWO ranked next, while HOA performed the weakest in AUC. Standard deviation analysis revealed that AROA exhibited the most stability in AUC performance, while SMA and GWCA showed higher fluctuations. The best and worst values confirmed that MHOA maintained good performance across different scenarios and indicated its reliability in class separation.
In terms of fitness value, SMA achieved the lowest mean. HOA and GWCA followed, while HHO recorded the highest mean. Standard deviation results showed that HHO was the most stable in optimization performance, while AROA and GWO exhibited higher variability. The best and worst values further supported SMA's optimization efficiency, while MHOA exhibited competitive performance with relatively stable optimization. HHO and AROA displayed less stability in converging to optimal solutions.
Regarding FS, HOA selected the fewest features in the best-case scenario. SMA followed closely behind, while HHO selected the highest number of features. MHOA demonstrated a balanced approach by selecting a moderate number of features, maintaining a trade-off between dimensionality reduction and classification performance. Standard deviation values revealed that AROA exhibited the most stable FS, while GWO showed the greatest variability. The mean values confirmed that HOA and SMA consistently selected fewer features, while MHOA maintained a competitive balance between FS and model performance. Figure 4 presents a comparison of the algorithms' performance on Dataset-3 across Accuracy, Sensitivity, and AUC metrics.
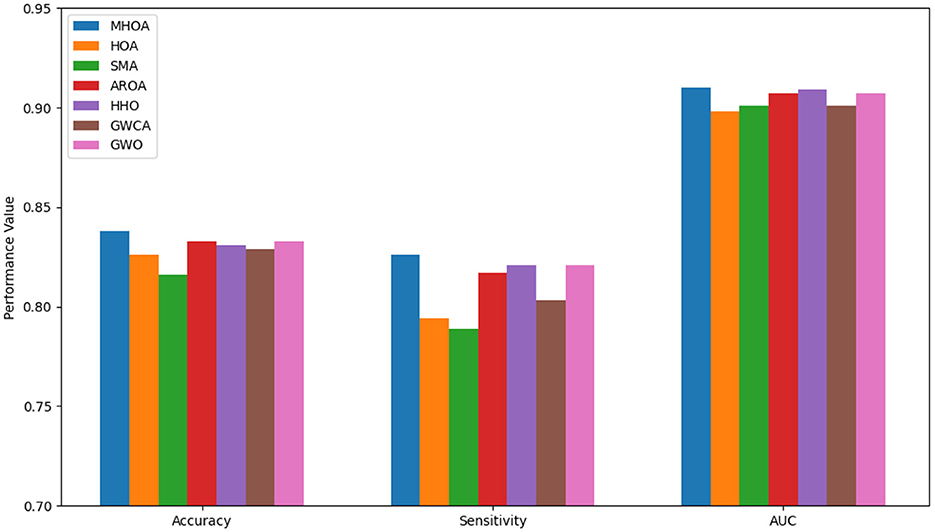
Figure 4. Results of accuracy, sensitivity, and AUC for Dataset-3.
As shown in Figure 4, the MHOA algorithm achieved the best results across all metrics. It ranked first in accuracy, followed by AROA, GWO, and HHO. In sensitivity, MHOA again led, while HHO, GWO, and AROA showed similar outcomes. For AUC, MHOA maintained the top position, with HHO, AROA, and GWO close behind. GWCA and HOA showed lower sensitivity and AUC values, and SMA ranked lowest in accuracy and sensitivity.
These observed performance rankings are further supported by the results of the Friedman test, a non-parametric statistical method commonly used to detect differences across multiple conditions when the data does not follow normal distribution assumptions. It is particularly useful in model comparison as it accounts for the ordinal nature of the data and dependencies between repeated measures. The results of the Friedman test, as shown in Table 4, reveal considerable variability in performance across the models. MHOA consistently ranks highest in accuracy, AUC, and sensitivity and shows better overall effectiveness. In contrast, GWO ranks lowest in accuracy and reflects relatively lower performance in this context. Models such as HOA, SMA, AROA, HHO, and GWCA demonstrate intermediate performance. These findings highlight differences among the models, with MHOA showing the most consistent results.

Table 4. Results of the Friedman test.
To further evaluate the performance of the developed MHOA model to detect ASD, we compared it with the results obtained in Liu et al. (2024). Since this work uses the same strategy to split ABIDE I dataset. The technique used in Liu et al. (2024) is named MADE-for-ASD, and its accuracy for CC, AAL, and EZ is 73.42%, 71.20%, and 68.74%, respectively. However, our developed MHOA based on the SSDAE model has accuracy 66.35%, 70.19%, and 83.82% for EZ, AAL, and CC, respectively. So, MADE-for-ASD is better than MHOA at EZ and AAL, whereas MHOA is better according to the results of CC split (dataset-3). In addition, the average accuracy of MADE-for-ASD and our MHOA model overall the three datasets is 71.12% and 73.45%, respectively. This indicates the high ability of the developed model to detect ASD.
In general, MHOA consistently achieved the highest accuracy and AUC across datasets and demonstrated strong classification performance. Sensitivity results confirmed its ability to identify positive instances. Its optimization performance remained competitive with relatively stable fitness values. FS analysis indicated that MHOA maintained a balance between dimensionality reduction and model effectiveness and demonstrating its reliability across diverse evaluation criteria. However, its stability in some metrics, such as fitness value and sensitivity, was lower than that of certain methods and suggesting potential improvements in robustness under varying conditions.
6 Conclusion and future works
This paper presents a novel DL model integrated with a modified version of the HOA for detecting ASD from rs-fMRI data. The proposed model enhances the accuracy of ASD detection, potentially improving early intervention strategies for individuals who may otherwise be missed by traditional methods. By combining the SSDAE and MLP, the model effectively extracts relevant features, while the enhanced HOA, utilizing dynamic opposite-based learning and double attractors, optimizes FS. The developed model demonstrates promising results, with an average accuracy of 0.735, sensitivity of 0.765, and AUC of 0.790 across various datasets, showing the potential of DL and the MHOA algorithm in automated ASD detection.
Despite the promising results, several challenges remain. The biological heterogeneity of ASD, along with variations in imaging protocols and preprocessing steps, introduces potential limitations that could affect the generalizability and reproducibility of the model. Future work could focus on addressing these challenges by incorporating multi-site datasets with consistent preprocessing pipelines to enhance the model's robustness and external validity. Additionally, the model's interpretability remains a key consideration, as understanding the decision-making process of DL models is crucial for clinical adoption. Efforts toward developing explainable AI techniques could be integrated to provide more transparent insights into the detected features and their relevance to ASD. Moreover, future research should explore the application of this approach to other neurodevelopmental disorders that exhibit overlapping symptoms with ASD, such as ADHD and intellectual disabilities. Expanding the model's applicability across a broader spectrum of neurodevelopmental conditions could facilitate the development of more generalized and efficient diagnostic tools. Furthermore, incorporating longitudinal data and examining the model's performance over time could provide deeper insights into the progression of ASD and its early detection.
In conclusion, this study lays the groundwork for a more effective, DL-based diagnostic tool for ASD, offering a promising direction for early detection and intervention. However, further refinements and validations in diverse clinical settings are necessary to ensure the model's practical applicability in real-world healthcare environments.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found here: https://www.nature.com/articles/s41598-022-09821-6.
Ethics statement
Ethical approval and written informed consent from the patients/participants or their legal guardians/next of kin were not required, as the ABIDE I is a publicly available dataset.
Author contributions
IN: Writing – original draft, Resources, Software, Data curation, Investigation, Methodology, Visualization, Conceptualization, Funding acquisition, Supervision. NM: Visualization, Writing – original draft, Methodology, Data curation, Validation, Investigation, Software. AE: Writing – review & editing, Investigation, Writing – original draft, Conceptualization, Formal analysis, Visualization, Resources, Validation. MK: Conceptualization, Investigation, Methodology, Software, Visualization, Writing – original draft, Formal analysis, Data curation, Resources. AD: Investigation, Methodology, Writing – original draft, Resources, Conceptualization, Project administration. SA: Software, Visualization, Writing – original draft, Investigation, Project administration, Methodology, Supervision, Validation. IF: Data curation, Conceptualization, Writing – original draft, Investigation, Visualization, Formal analysis. MA-B: Resources, Validation, Project administration, Methodology, Software, Investigation, Writing – original draft, Supervision. ME: Project administration, Validation, Supervision, Writing – review & editing, Investigation, Visualization, Software.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. The authors extend their appreciation to the King Salman center For Disability Research for funding this work through Research Group no KSRG-2024-297.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Gen AI was used in the creation of this manuscript.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Abbas, S. Q., Chi, L., and Chen, Y.-P. P. (2023). Deepmnf: deep multimodal neuroimaging framework for diagnosing autism spectrum disorder. Artif. Intell. Med. 136:102475. doi: 10.1016/j.artmed.2022.102475
Abd Elaziz, M., and Yousri, D. (2021). Automatic selection of heavy-tailed distributions-based synergy henry gas solubility and harris hawk optimizer for feature selection: case study drug design and discovery. Artif. Intell. Rev. 54, 4685–4730. doi: 10.1007/s10462-021-10009-z
Abraham, A., Milham, M. P., Di Martino, A., Craddock, R. C., Samaras, D., Thirion, B., et al. (2017). Deriving reproducible biomarkers from multi-site resting-state data: an autism-based example. Neuroimage 147, 736–745. doi: 10.1016/j.neuroimage.2016.10.045
Abu-Doleh, A., Abu-Qasmieh, I. F., Al-Quran, H. H., Masad, I. S., Banyissa, L. R., and Ahmad, M. A. (2025). Recognition of autism in subcortical brain volumetric images using autoencoding-based region selection method and Siamese convolutional neural network. Int. J. Med. Inform. 194:105707. doi: 10.1016/j.ijmedinf.2024.105707
Ahmad, M. F., Isa, N. A. M., Lim, W. H., and Ang, K. M. (2022). Differential evolution with modified initialization scheme using chaotic oppositional based learning strategy. Alexandria Eng. J. 61, 11835–11858. doi: 10.1016/j.aej.2022.05.028
Al-Hendawi, M., Hussein, E., Al Ghafri, B., and Bulut, S. (2023). A scoping review of studies on assistive technology interventions and their impact on individuals with autism spectrum disorder in Arab countries. Children 10:1828. doi: 10.3390/children10111828
Alzubaidi, L., Bai, J., Al-Sabaawi, A., Santamaría, J., Albahri, A. S., Al-dabbagh, B. S. N., et al. (2023). A survey on deep learning tools dealing with data scarcity: definitions, challenges, solutions, tips, and applications. J. Big Data 10:46. doi: 10.1186/s40537-023-00727-2
Bahathiq, R. A., Banjar, H., Bamaga, A. K., and Jarraya, S. K. (2022). Machine learning for autism spectrum disorder diagnosis using structural magnetic resonance imaging: promising but challenging. Front. Neuroinform. 16:949926. doi: 10.3389/fninf.2022.949926
Cao, D., Xu, Y., Yang, Z., Dong, H., and Li, X. (2023). An enhanced whale optimization algorithm with improved dynamic opposite learning and adaptive inertia weight strategy. Complex Intell. Syst. 9, 767–795. doi: 10.1007/s40747-022-00827-1
Chen, W., Yang, J., Sun, Z., Zhang, X., Tao, G., Ding, Y., et al. (2024). Deepasd: a deep adversarial-regularized graph learning method for asd diagnosis with multimodal data. Transl. Psychiatry 14:375. doi: 10.1038/s41398-024-02972-2
Chola Raja, K., and Kannimuthu, S. (2023). Deep learning-based feature selection and prediction system for autism spectrum disorder using a hybrid meta-heuristics approach. J. Intell. Fuzzy Syst. 45, 797–807. doi: 10.3233/JIFS-223694
Christensen, D. L. (2016). Prevalence and characteristics of autism spectrum disorder among children aged 8 years–autism and developmental disabilities monitoring network, 11 sites, United States, 2012. MMWR Surveill. Summ. 72, 1–14. doi: 10.15585/mmwr.ss6503a1
Cymerys, K., and Oszust, M. (2024). Attraction-repulsion optimization algorithm for global optimization problems. Swarm Evolut. Comput. 84:101459. doi: 10.1016/j.swevo.2023.101459
Dahou, A., Aseeri, A. O., Mabrouk, A., Ibrahim, R. A., Al-Betar, M. A., and Elaziz, M. A. (2023). Optimal skin cancer detection model using transfer learning and dynamic-opposite hunger games search. Diagnostics 13:1579. doi: 10.3390/diagnostics13091579
Di Martino, A., Yan, C.-G., Li, Q., Denio, E., Castellanos, F. X., Alaerts, K., et al. (2014). The autism brain imaging data exchange: towards a large-scale evaluation of the intrinsic brain architecture in autism. Mol. Psychiatry 19, 659–667. doi: 10.1038/mp.2013.78
Ding, Y., Zhang, H., and Qiu, T. (2024). Deep learning approach to predict autism spectrum disorder: a systematic review and meta-analysis. BMC Psychiatry 24, 739. doi: 10.1186/s12888-024-06116-0
El-Abd, M. (2011). “Opposition-based artificial bee colony algorithm,” in Proceedings of the 13th Annual Conference on Genetic and Evolutionary Computation, 109–116. doi: 10.1145/2001576.2001592
Ergezer, M., Simon, D., and Du, D. (2009). “Oppositional biogeography-based optimization,” in 2009 IEEE International Conference on Systems, Man and Cybernetics (IEEE), 1009–1014. doi: 10.1109/ICSMC.2009.5346043
Eslami, T., Mirjalili, V., Fong, A., Laird, A. R., and Saeed, F. (2019). ASD-diagnet: a hybrid learning approach for detection of autism spectrum disorder using fmri data. Front. Neuroinform. 13:70. doi: 10.3389/fninf.2019.00070
Ewees, A. A., Al-Qaness, M. A., Abualigah, L., Algamal, Z. Y., Oliva, D., Yousri, D., et al. (2023). Enhanced feature selection technique using slime mould algorithm: a case study on chemical data. Neural Comput. Applic. 35, 3307–3324. doi: 10.1007/s00521-022-07852-8
Fares, I. A., and Abd Elaziz, M. (2025). Explainable tabnet transformer-based on google vizier optimizer for anomaly intrusion detection system. Knowl. Based Syst. 316:113351. doi: 10.1016/j.knosys.2025.113351
Fares, I. A., Abd Elaziz, M., Aseeri, A. O., Zied, H. S., and Abdellatif, A. G. (2025). Tfkan: transformer based on kolmogorov-arnold networks for intrusion detection in IoT environment. Egyptian Inform. J. 30:100666. doi: 10.1016/j.eij.2025.100666
Gautam, S., Sharma, P., Thapa, K., Upadhaya, M. D., Thapa, D., Khanal, S. R., et al. (2023). Screening autism spectrum disorder in children using deep learning approach: Evaluating the classification model of yolov8 by comparing with other models. arXiv preprint arXiv:2306.14300.
Giarelli, E., Wiggins, L. D., Rice, C. E., Levy, S. E., Kirby, R. S., Pinto-Martin, J., et al. (2010). Sex differences in the evaluation and diagnosis of autism spectrum disorders among children. Disabil. Health J. 3, 107–116. doi: 10.1016/j.dhjo.2009.07.001
Guan, H., and Liu, M. (2021). Domain adaptation for medical image analysis: a survey. IEEE Trans. Biomed. Eng. 69, 1173–1185. doi: 10.1109/TBME.2021.3117407
Guan, Z., Ren, C., Niu, J., Wang, P., and Shang, Y. (2023). Great wall construction algorithm: a novel meta-heuristic algorithm for engineer problems. Expert Syst. Appl. 233:120905. doi: 10.1016/j.eswa.2023.120905
He, G., and Lu, X.-l. (2022). Good point set and double attractors based-qpso and application in portfolio with transaction fee and financing cost. Expert Syst. Appl. 209:118339. doi: 10.1016/j.eswa.2022.118339
Heinsfeld, A. S., Franco, A. R., Craddock, R. C., Buchweitz, A., and Meneguzzi, F. (2018). Identification of autism spectrum disorder using deep learning and the abide dataset. NeuroImage 17, 16–23. doi: 10.1016/j.nicl.2017.08.017
Helmi, A. M., Al-Qaness, M. A., Dahou, A., Damaševičius, R., Krilavičius, T., and Elaziz, M. A. (2021). A novel hybrid gradient-based optimizer and grey wolf optimizer feature selection method for human activity recognition using smartphone sensors. Entropy 23:1065. doi: 10.3390/e23081065
Huda, S., Khan, D. M., Masroor, K., Warda Rashid, A., and Shabbir, M. (2024). Advancements in automated diagnosis of autism spectrum disorder through deep learning and resting-state functional mri biomarkers: a systematic review. Cogn. Neurodyn. 18, 3585–3601. doi: 10.1007/s11571-024-10176-z
Jabbar, U., Iqbal, M. W., Alourani, A., Shinan, K., Alanazi, F., Sarwar, N., et al. (2025). Machine learning-based approach for early screening of autism spectrum disorders. Appl. Comput. Intell. Soft Comput. 2025:9975499. doi: 10.1155/acis/9975499
Joe, C. V. (2024). Exploring ai robots-based visual strategy in training children with autism disorder. J. Innov. Image Proc. 6, 40–49. doi: 10.36548/jiip.2024.1.004
John, J., and Sala, R. (2018). 043 Is the prevalence of autism spectrum disorder decreased in black and ethnic children and adolescents?. Arch. Disease Childhood 103, A17A18. doi: 10.1136/goshabs.43
Kaveh, A., and Yousefpoor, H. (2024). Chaotic Meta-Heuristic Algorithms for Optimal Design of Structures. Cham: Springer. doi: 10.1007/978-3-031-48918-1
Khan, K., and Katarya, R. (2025). Ws-bitm: Integrating white shark optimization with BI-LSTM for enhanced autism spectrum disorder diagnosis. J. Neurosci. Methods 413:110319. doi: 10.1016/j.jneumeth.2024.110319
Lamani, M. R., and Benadit, P. J. (2023). Automatic diagnosis of autism spectrum disorder detection using a hybrid feature selection model with graph convolution network. SN Comput. Sci. 5:126. doi: 10.1007/s42979-023-02439-z
Lavelle, T. A., Weinstein, M. C., Newhouse, J. P., Munir, K., Kuhlthau, K. A., and Prosser, L. A. (2014). Economic burden of childhood autism spectrum disorders. Pediatrics 133, e520–e529. doi: 10.1542/peds.2013-0763
Li, X., Zhou, Y., Dvornek, N. C., Zhang, M., Zhuang, J., Ventola, P., et al. (2020). “Pooling regularized graph neural network for fMRI biomarker analysis,” in Medical Image Computing and Computer Assisted Intervention-MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020, Proceedings, Part VII 23 (Springer), 625–635. doi: 10.1007/978-3-030-59728-3_61
Liu, X., Hasan, M. R., Gedeon, T., and Hossain, M. Z. (2024). Made-for-ASD: a multi-atlas deep ensemble network for diagnosing autism spectrum disorder. Comput. Biol. Med. 182:109083. doi: 10.1016/j.compbiomed.2024.109083
Lord, C., Elsabbagh, M., Baird, G., and Veenstra-Vanderweele, J. (2018). Autism spectrum disorder. Lancet 392, 508–520. doi: 10.1016/S0140-6736(18)31129-2
Mellema, C. J., Nguyen, K. P., Treacher, A., and Montillo, A. (2022). Reproducible neuroimaging features for diagnosis of autism spectrum disorder with machine learning. Sci. Rep. 12:3057. doi: 10.1038/s41598-022-06459-2
Nielsen, J. A., Zielinski, B. A., Fletcher, P. T., Alexander, A. L., Lange, N., Bigler, E. D., et al. (2013). Multisite functional connectivity MRI classification of autism: abide results. Front. Hum. Neurosci. 7:599. doi: 10.3389/fnhum.2013.00599
Niu, X., Gou, J., Chang, H., Lowe, M., and Zhang, F. (2022). Classification model with weighted regularization to improve the reproducibility of neuroimaging signature selection. Stat. Med. 41, 5046–5060. doi: 10.1002/sim.9553
Niu, Y., Yan, X., Wang, Y., and Niu, Y. (2022). Dynamic opposite learning enhanced artificial ecosystem optimizer for IIR system identification. J. Supercomput. 78, 13040–13085. doi: 10.1007/s11227-022-04367-w
Oladejo, S. O., Ekwe, S. O., and Mirjalili, S. (2024). The hiking optimization algorithm: a novel human-based metaheuristic approach. Knowl.-Based Syst. 296:111880. doi: 10.1016/j.knosys.2024.111880
Parisot, S., Ktena, S. I., Ferrante, E., Lee, M., Guerrero, R., Glocker, B., et al. (2018). Disease prediction using graph convolutional networks: application to autism spectrum disorder and Alzheimer's disease. Med. Image Anal. 48, 117–130. doi: 10.1016/j.media.2018.06.001
Patil, M., Iftikhar, N., and Ganti, L. (2024). Neuroimaging insights into autism spectrum disorder: structural and functional brain. Health Psychol. Res. 12:123439. doi: 10.52965/001c.123439
Qin, L., Wang, H., Ning, W., Cui, M., and Wang, Q. (2024). New advances in the diagnosis and treatment of autism spectrum disorders. Eur. J. Med. Res. 29:322. doi: 10.1186/s40001-024-01916-2
Rahnamayan, S., Tizhoosh, H. R., and Salama, M. M. (2007). “Quasi-oppositional differential evolution,” in 2007 IEEE Congress on Evolutionary Computation (IEEE), 2229–2236. doi: 10.1109/CEC.2007.4424748
Sayers, E. W., Beck, J., Bolton, E. E., Brister, J. R., Chan, J., Comeau, D. C., et al. (2023). Database resources of the national center for biotechnology information. Nucleic Acids Res. 52:D33. doi: 10.1093/nar/gkad1044
Schielen, S. J., Pilmeyer, J., Aldenkamp, A. P., and Zinger, S. (2024). The diagnosis of ASD with MRI: a systematic review and meta-analysis. Transl. Psychiatry 14:318. doi: 10.1038/s41398-024-03024-5
Simonoff, E., Pickles, A., Charman, T., Chandler, S., Loucas, T., and Baird, G. (2008). Psychiatric disorders in children with autism spectrum disorders: prevalence, comorbidity, and associated factors in a population-derived sample. J. Am. Acad. Child Adolesc. Psychiatry 47, 921–929. doi: 10.1097/CHI.0b013e318179964f
Supekar, K., Uddin, L. Q., Khouzam, A., Phillips, J., Gaillard, W. D., Kenworthy, L. E., et al. (2013). Brain hyperconnectivity in children with autism and its links to social deficits. Cell Rep. 5, 738–747. doi: 10.1016/j.celrep.2013.10.001
Tizhoosh, H. R. (2005). “Opposition-based learning: a new scheme for machine intelligence,” in International Conference on Computational Intelligence for Modelling, Control and Automation and International Conference on Intelligent Agents, Web Technologies and Internet Commerce (CIMCA-IAWTIC'06) (IEEE), 695–701. doi: 10.1109/CIMCA.2005.1631345
Wang, H., Wu, Z., Rahnamayan, S., Liu, Y., and Ventresca, M. (2011). Enhancing particle swarm optimization using generalized opposition-based learning. Inf. Sci. 181, 4699–4714. doi: 10.1016/j.ins.2011.03.016
Wang, Y., Wang, J., Wu, F.-X., Hayrat, R., and Liu, J. (2020). Aimafe: autism spectrum disorder identification with multi-atlas deep feature representation and ensemble learning. J. Neurosci. Methods 343:108840. doi: 10.1016/j.jneumeth.2020.108840
Xu, Y., Yang, Z., Li, X., Kang, H., and Yang, X. (2020). Dynamic opposite learning enhanced teaching-learning-based optimization. Knowl. Based Syst. 188:104966. doi: 10.1016/j.knosys.2019.104966
Yang, D., Wu, M., Li, D., Xu, Y., Zhou, X., and Yang, Z. (2022). Dynamic opposite learning enhanced dragonfly algorithm for solving large-scale flexible job shop scheduling problem. Knowl. Based Syst. 238:107815. doi: 10.1016/j.knosys.2021.107815
Yao, M., Chen, Z., Deng, H., Wu, X., Liu, T., and Cao, C. (2025). A color image compression and encryption algorithm combining compressed sensing, sudoku matrix, and hyperchaotic map. Nonlinear Dyn. 113, 2831–2865. doi: 10.1007/s11071-024-10334-2
Zeidan, J., Fombonne, E., Scorah, J., Ibrahim, A., Durkin, M. S., Saxena, S., et al. (2022). Global prevalence of autism: a systematic review update. Autism Res. 15, 778–790. doi: 10.1002/aur.2696
Keywords: autism detection, deep learning, resting-state functional MRI (rs-fMRI), feature selection, Hiking Optimization Algorithm, dynamic-opposite learning, double attractors
Citation: Nafisah I, Mahmoud N, Ewees AA, Khattap MG, Dahou A, Alghamdi SM, Fares IA, Azmi Al-Betar M and Abd Elaziz M (2025) Deep learning-based feature selection for detection of autism spectrum disorder. Front. Artif. Intell. 8:1594372. doi: 10.3389/frai.2025.1594372
Received: 20 March 2025; Accepted: 28 May 2025;
Published: 25 June 2025.
Edited by:
Alaa Eleyan, American University of the Middle East, KuwaitReviewed by:
Shijun Li, People's Liberation Army General Hospital, ChinaJudy Simon, SRM Arts and Science College, India
Copyright © 2025 Nafisah, Mahmoud, Ewees, Khattap, Dahou, Alghamdi, Fares, Azmi Al-Betar and Abd Elaziz. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Mohamed Abd Elaziz, YWJkX2VsX2F6aXpfbUB5YWhvby5jb20=; Ibrahim A. Fares, aWZhcmVzLmNzQGdtYWlsLmNvbQ==