Abstract
Whether it is to initially deploy a network or to restore the connectivity in a partitioned one, the question of the optimal Relay Node (RN) placement arises. This problem is already challenging when considering a static homogeneous network. However, diversity in transmission parameters within the network can induce diversity in transmission ranges, imposing the consideration of heterogeneity in the network. Furthermore, if the nodes are moving, the RN placement scheme must manage a smooth repositioning of the RNs without any large jumps or major restructuring. This paper introduces an effective strategy for deploying the minimum number of RNs in order to restore the connectivity between the nodes of a partitioned heterogeneous network. Through the statistical analysis of results from numerous randomly generated scenarios, the proposed Barycenter-focused Relay nodes placement for Heterogeneous wireless Networks (BRHEN) algorithm is shown to be an improvement on other similar approaches in terms of the number of RNs and the latency. Additionally, BRHEN exhibits stability in the positions and number of RNs when small displacements are applied to the Initial Nodes (INs). This characteristic makes this method suitable for scenarios with moving INs.
1 Introduction
Modern wireless networks are inherently heterogeneous, incorporating diverse types of nodes with varying capabilities, communication ranges, and energy constraints. This heterogeneity introduces significant challenges in maintaining network connectivity, optimizing performance, and ensuring efficient data transmission. A critical aspect of network management in such environments is the strategic placement of Relay Nodes (RNs), which serve to improve connectivity, extend network coverage, and enhance overall reliability.
Effective relay node placement becomes particularly crucial in scenarios where network partitions arise due to node failures, mobility, or energy depletion. Conventional relay placement methods often assume homogeneous network conditions, failing to account for the diverse characteristics of nodes present in real-world deployments. However, in heterogeneous networks—such as those found in Internet of Things (IoT) ecosystems, heterogeneous cellular networks (HetNets), and next-generation wireless communication systems (Parihar et al. 2024a; Parihar et al. 2024b; Swami et al., 2022) — a homogeneous approach to RN placement is insufficient. Instead, adaptive placement strategies that consider node diversity, transmission power, and network topology dynamics are essential for maintaining seamless connectivity and optimizing performance.
Given these challenges, an effective relay node placement method that explicitly accounts for network heterogeneity is essential. Existing approaches often fail to fully address the impact of node diversity and mobility on RN deployment strategies, highlighting the need for more adaptive solutions. In the following, we review the current state of research on relay node placement, by examining the methodologies proposed to handle network heterogeneity, and by identifying key gaps that motivate the need for improved strategies.
A wide range of scenarios requiring RN deployment can be found in the literature. For example, in Ladosz et al. (2018) they are used to reconnect segmented networks or isolated users, as well as to build a relay network for a search and rescue mission in Yanmaz (2021) or in a disaster area in ur Rahman et al. (2018). In Wang et al. (2019), Yang et al. (2016) and Grönkvist et al. (2022), they are also considered to enhance wireless traffic in cellular networks and to enable a higher frequency network in military and tactical situations. Other examples of RN uses can be found in Wu et al. (2017), in which the question of energy efficiency is studied in a scenario in which a mobile node is used to relay the data from several mobile sensing robots; and in Cao et al. (2016) where they discuss a relay selection scheme to improve the end-to-end symbol error rate between two nodes. These RNs can be ground nodes, Unmanned Aerial Vehicles (UAVs) or even Intelligent Reflecting Surfaces (IRSs) as proposed in Swami and Bhatia (2021). Nonetheless, the challenge of optimally placing these relays in order to minimize their number, maximize throughput, and, in the event of a non-static network, minimize RN movements and topology changes persists.
To minimize the number of relays, Yanmaz (2021) used the Steiner Tree Problem with Minimum number of Steiner Points and the Bounded Edge-Length (STP-MSPBEL) method of Lin and Xue (1999), Cheng et al. (2008). Given a set of points and a maximum edge size (line segment between two points), the Steiner Tree Problem (STP) is the placement of the minimum number of additional points so that there is a path from each point to the others via edges. This problem has been shown to be NP-Hard by Lin and Xue (1999). STP-MSPBEL is a well-known approach to solving the STP, with a performance ratio of 5 — this indicates that the result is at most 5 times the optimal solution, or put differently, at most 5 times the minimum number of additional points. Since the development of that method, new approaches have been developed with a lower performance ratio and better results. The best-known scheme with a proved good performance ratio to date is the k-restricted Loss-Contracting Algorithm (k-LCA), which is polynomial in time and has a performance ratio of Robins and Zelikovsky (2005). Other algorithms, developed for segmented wireless sensor networks, such as CORP (Cell-based Optimized Relay node Placement) Lee and Younis (2010a), ORC (Optimized Relay node placement algorithm using a minimum Steiner tree on the Convex hull) Lee and Younis (2010b) and DORMS (Distributed algorithm for Optimized Relay node placement using Minimum Steiner tree) Lee and Younis (2010c), are able to achieve similar results in terms of minimizing the number of additional nodes while being computationally lighter.
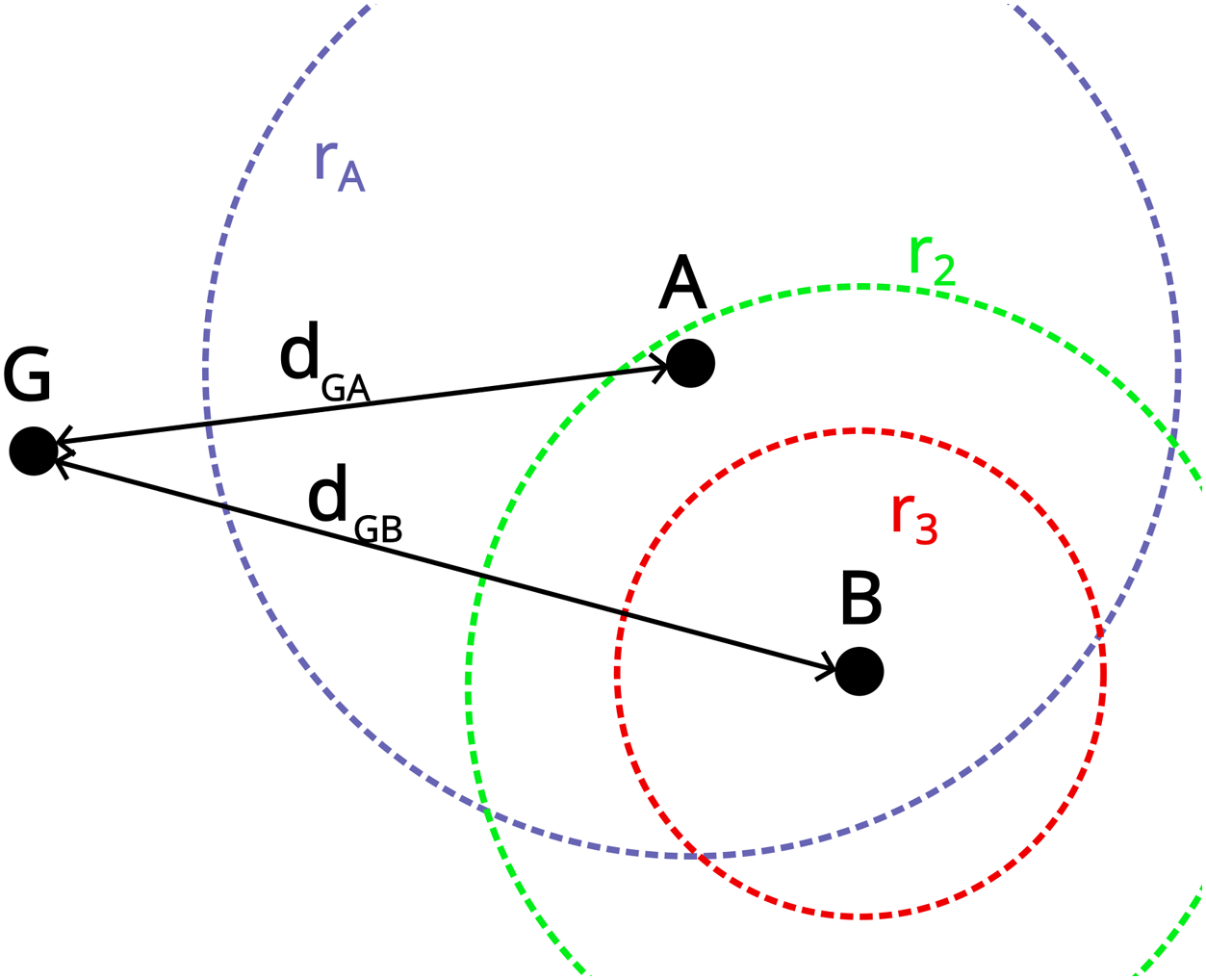
These methods consider the network to be homogeneous, i.e., all the nodes have the same range. However, this may not be the case, e.g., in modern scenarios combining emerging technologies such as in (Parihar et al., 2024a, Parihar et al., 2024b; Swami et al., 2022), or in a simple scenario where a Wireless Sensor Network (WSN) is segmented and RNs are deployed to restore the connectivity between the segments as in (Lee and Younis, 2010a; Lee and Younis, 2010b; Lee and Younis, 2010c), the RNs may have a different range than the initial nodes (INs). A third example is a tactical scenario in which some units are limited to handheld radios with a power of 5 W, whil others have a vehicular support and radio with a power of 10 W and one of 20 W. If units are out of range, relays must be deployed to connect the network (see Figure 1). A heterogeneous network with three different ranges is to be considered for the INs, in addition to the relay range.
FIGURE 1

Schematic view of a partitioned heterogeneous network where . Only and are in range from each other.
Some methods have considered heterogeneity to some extent: MST-1tRN (Minimum spanning tree based approximation algorithm for single-Tiered Relay Node placement) Lloyd and Xue (2007), NAP Liu et al. (2019), and Xie et al. (2020) using the Adaptive Whale Optimization (AWO) method account for transmission range differences between INs and RNs. Going further, Han et al. (2010) and Deyab et al. (2011) introduce heterogeneity in the set of INs and even in the set of RNs for the latter.
The STP is a viewpoint where the nodes remain stationary. A scenario with moving nodes requires dynamic adaptability. A straightforward approach is to take each moment (separated by an arbitrary time ) as a snapshot and compute the positions of the RNs using the chosen algorithm. To be highly responsive—as necessary for highly mobile nodes—the algorithm must be time efficient. Moreover, it must be capable of performing the calculations with the necessary precision for the positions. The grid-based approaches CORP and ORC—although more effective than most—have a resolution of , where represents the node’s range, and so are inappropriate to account for mobility. A grid-less approach is required.
The first major contribution of this paper is a method for a balanced placement of the RN(s) with an associated range to connect two nodes and having possibly different communication ranges, and , respectively. It is called Optimized Relay Placement for one Heterogeneous link or ORPHe. This can be implemented in STP-MST(BEL) and MST-1tRN during the node placement phase to account for network heterogeneity. The second and main contribution of this paper is a heuristic algorithm for heterogeneous networks inspired by the CORP algorithm: the Barycenter-focused Relay placement for HEterogeneous wireless Networks or BRHEN. Our method takes into account the heterogeneity and does not rely on a grid. It is shown to be more effective for minimizing the number of relays for heterogeneous networks than MST-1tRN enhanced with balanced placement and than the CORP method.
This paper is organized as follows. Section 2 provides a detailed description of the proposed methods and algorithms. The performance is evaluated in Section 3 before discussing the applicability of the BRHEN method in Section 4. The paper ends with the conclusion in Section 5 and the future works in Section 6.
2 The proposed methods
Before we begin to describe and analyze our algorithms, let us state a couple of definitions.
DEFINITION 2.1A node is a point with an associated range which defines the distance at which the point can emit and be received—i. e., a node is defined by the triplet . A relay is merely a node, but not an initial one.1
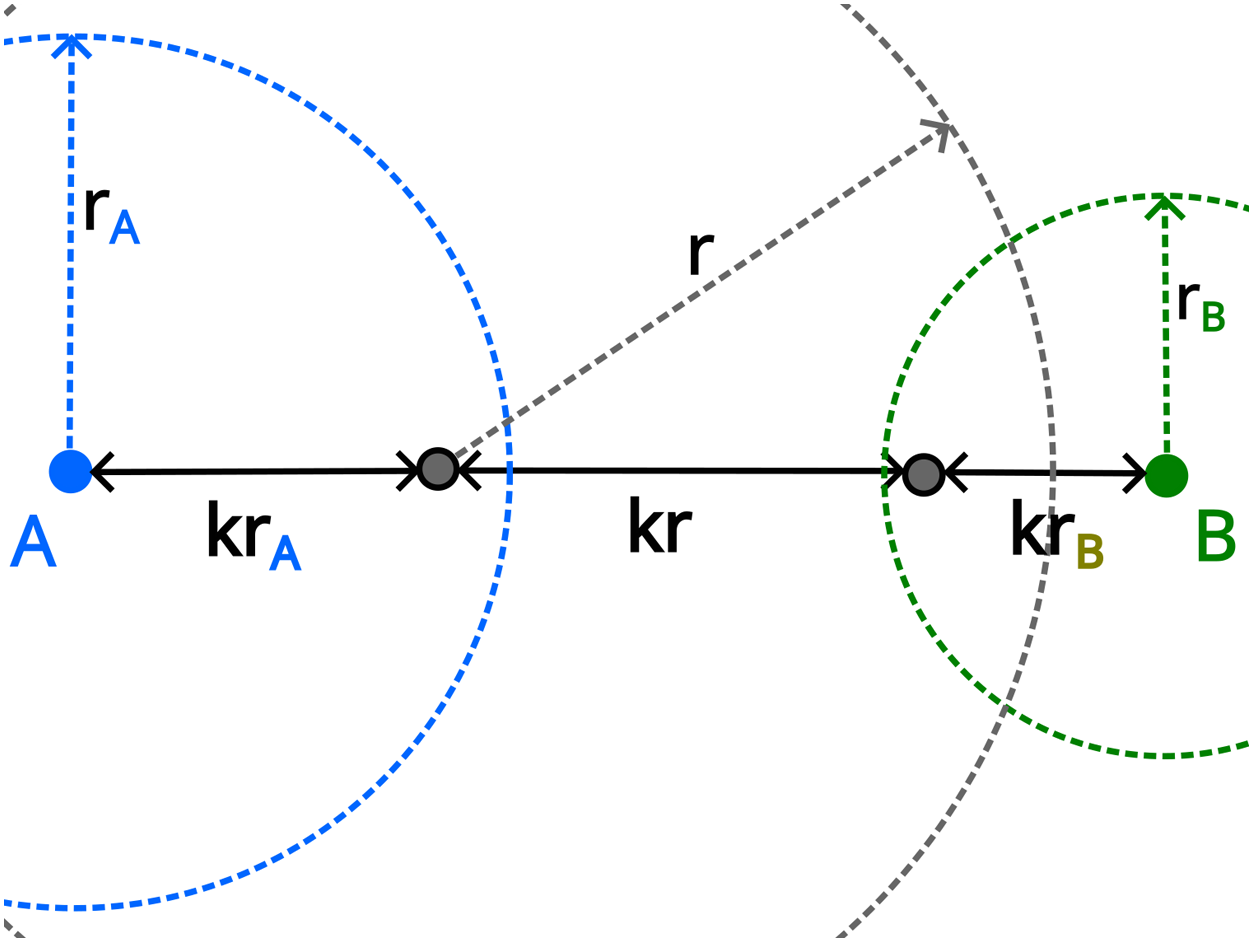
DEFINITION 2.2Two nodes are said to be connected or to be neighbors when the distance between them is less than the ranges of both nodes (see Figure 2).
FIGURE 2
Schematic of two nodes with different ranges illustrated by the dotted circles. If , and regard each other as neighbors and the farthest from the barycenter is marked as connected (given that it is not already marked).
2.1 Optimized Relay Placement for one heterogeneous link (ORPHe)
A method for placing one or multiple relays with a fixed communication range between two nodes, and with possibly different respective ranges and will be described in the following. The pseudocode is displayed in Algorithm 1.
The goal is to have a balanced placement. This means that the distance between each successive node is treated in the same way. To do so, we first consider the maximum distance between two successive nodes. It will be equal to the smaller of their ranges. This distance will be reduced by a positive real factor less than or equal to one that depends only on (a) the distance between and , and (b) on the values of the ranges , and . Thus, this factor is common to all links between and . This approach prevents a link from becoming weak while another one may afford to lose some strength.
In the following, the distance between two points and will be denoted . Because it is a recurring value, the distance between and will be treated as an exception and referred to as .
A method for the case where is proposed in Lloyd and Xue (2007), whereas a generalization with no restrictions on the ranges, except that they are positive is proposed in Han et al. (2010). The latter defines , . It also defines , the number of relays. if and are in range, i.e., , and otherwise. If , place the relay at from towards . If , after placing the first relay near , place a second at from towards . The remaining relays should be evenly distributed between the first and second relays.
Even if it is sufficient to provide the connection between and , some links may be under strain, while the others have room to spare. For example, if , the relay next to will be as far from as it can be, while if the distance between the relays will be less than .
For our method, and similarly to Han et al. (2010), we define and , then the required number of relays is computed with . If , the factor is defined as . The position of the relays starting from are given bywith and , . Here , , . For other values of the indices, , and (with ) are the coordinates and the range of the relay counting from node . The relays are assumed to have the same range , thus . A scenario with two relays is illustrated in Figure 3.
FIGURE 3
RN (in grey) placement between two INs with different ranges (blue and green) with the ORPHe method. The distance between two nodes is the maximal distance, given by , or , reduced by a common factor .
Equation 1 provides us with an iterative way of positioning RNs to increase Signal-to-Noise Ratio (SNR) across all links, instead of just those between the RNs.
In Algorithm 1, this method is used to realign a set of nodes, or a segment, . Its first and last nodes, and respectively, are the ones that will play the role of and . This algorithm returns the new segment with new elements, except for the first and the last.
2.2 The BRHEN approach
In this section, the concept of segment associated with an IN is used. It refers to the set which includes the IN and all of the relays that are successively placed starting from that node. Two segments will be considered neighbors if at least one node from the first segment is a neighbor of at least one node from the second segment.
The proposed BRHEN approach is a heuristic method for heterogeneous networks that aims to connect all INs using the minimum number of relays. After a first initialization, BRHEN operates in rounds. A round begins with a search for neighbors, followed by a relocation of the current relays to improve link stability if a neighbor is found. If the segment is not connected, the round concludes with the placement of a new relay. Only when the last two unconnected segments see each other as neighbors does the algorithm exit the loop and returns the complete set of nodes. For reference, the pseudocode is displayed in Algorithm 2.
In the Following, the details of these steps will be unfolded. The set of INs will be referred to as and each IN is associated to a index , with , the number of INs. Figure 4 provides a visual example with 7 INs. The INs all have a range of 200 m, with the exception of , which has a range of 100 m. The RNs have a range of 300 m. A color is assigned to each .
FIGURE 4
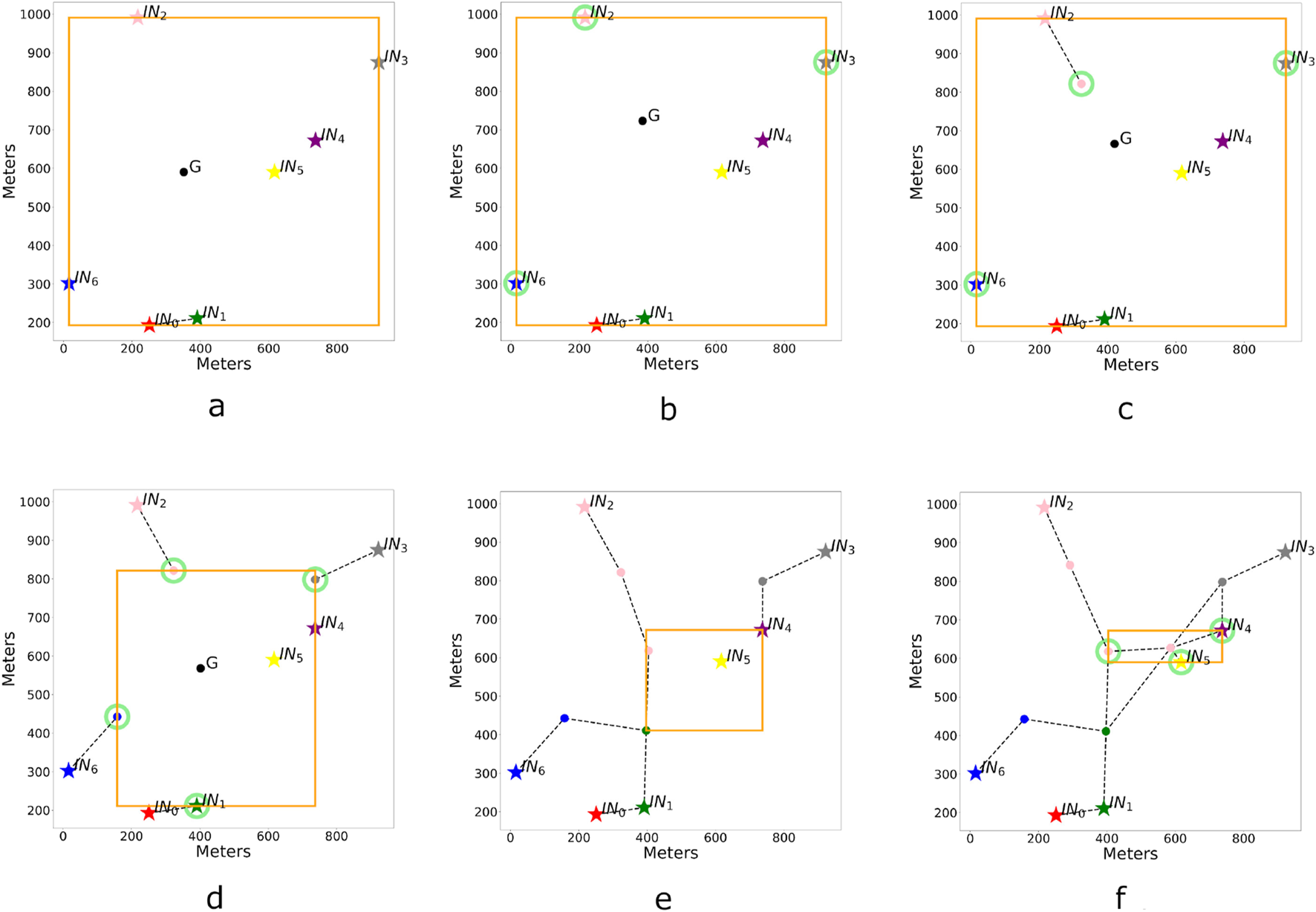
Some steps of the BRHEN algorithm are given above. The dashed lines represent the possibility of connection. And the side of the orange rectangle highlights the considered nodes for relay placement (a) Initialization phase: defining the first BNs. sees as a neighbor, the farthest from is marked as connected. (b) Circled in green: the eligible nodes after discarding the connected one. (c) First relay placement: there are now two elements in . This relay replaces in becoming the eligible node for . (d) Start of the second round. (e) Start of round 3, only the segments 1, 2 and 4 are not connected, but 1 will be marked as connected before 2 places the last relay necessary for the network to be complete (f) Shows the final outcome. has been rearranged by the ORPHe algorithm between its first and third element.
Algorithm 1
Input:
Output:
1: ,
2:
3:
4: ifthen
5:
6: else ifthen
7:
8: end if
9:
10: ifthen
11: return
12: end if
13:
14: ,
15: , ,
16: for to do
17: , ,
18: end for
19:
20: return
2.2.1 Initialization
BRHEN assigns a segment with the corresponding index to each initial node, i.e., the segment is the set with the initial node and all the relays that are successively placed starting from that node. The elements of the segment will be ordered with the initial node being the first and the most recently added relay being the last—if no relay has been added yet, the initial node is also the last.
The information of the set of is copied into three different sets at the beginning of the algorithm, each with a different function. is the set of the last node or relay from each segment, its elements will be substituted with the newly added relays for the corresponding segment during the round. For each segment: records the entire segment from its initial node to the last relay placed and holds the part of the segment from its last element that had a neighbor to its last element—until a neighbor is found, it is the same as . represents the set of the segments that are connected. Each time two segments become neighbors, only one will be added to . The loop can now start and run until all the segments are connected, i.e., until .
Before using an example for a better understanding of the algorithm, let us first detail some of its key steps.
Algorithm 2
Input:
Output:
1: ,
2:
3: whiledo
4: ,
5:
6: fordo
7: ifthen
8: Break
9: end if
10: fordo
11: ifthen
12: ifthen
13:
14: else ifthen
15:
16: end if
17: ,
18: end if
19: end for
20: if then
21: return
22: end if
23: ifthen
24:
25:
26: ifthen
27: ,
28: else
29:
30: end if
31: , ,
32: end if
33: end for
34: end while
2.2.2 Key steps
2.2.2.1 Remark
During a round of the BRHEN algorithm, different segments will in turn be the focus as the index will vary. When a segment is the focus, its last element, , is the true focus. It will be referred to as the considered node in the details of the key steps.
2.2.2.2 Border nodes (BNs) identification
The Border Nodes (BNs) are selected from the nodes that were not previously BNs and belong to an unconnected segment. Within this set of nodes, those having coordinates corresponding to at least one extremum (, , , ) become the BNs. This selection is done inside the function which takes and as variables and gives back the indices of the elements of that constitute the BNs.
2.2.2.3 Barycenter
The BRHEN algorithm uses the (unweighted) barycenter of the eligible nodes to provide a direction towards which the RNs will be placed and to use as reference for selecting the connected segment when necessary. The eligible nodes for the barycenter computation will always be part of . We define a function which takes as input the set of the indices of the elements of to be considered and outputs the point using the following formulae for the coordinates:with the sums spanning all the elements to be considered and denoting the number of elements.
2.2.2.4 Finding the neighbors
To determine if a segment is connected to the currently considered segment, , a search for neighbors of is initiated. A node (with range ) from a different segment and the considered node are neighbors if the distance between them is less than the smallest range of the two nodes — see Figure 2 where . Because there is no a priori knowledge about which element of is the closest, this evaluation is done for each element of . One neighbor is sufficient for the two segments to be connected.
The function that checks for a neighbor in another segment is called in the pseudo-code. It takes as input the considered node and a segment and returns if there is a neighbor or otherwise. This function has to be applied to all the segments with for the search to be complete. If two segments are neighbors, one of them ( or ) will be marked as connected.
2.2.2.5 Choosing which segment to mark as connected
The simplest approach to determine which segment is marked as connected is to consistently mark the same segment, either the one identified by or the one identified by . Nonetheless, an indicator that it is converging is that each new relay gets closer to . The closer we get to in one step, the faster it converges. Applying the simplest approach fails to guarantee that the segment that remains unconnected is the nearest one to (whether it is or ). With this in mind, a more elaborate selection strategy has been implemented. There are two cases.
The first one occurs when is closer to than the last element of , and that the segment has not yet been marked as connected. If the two conditions are met, is added to and is, from now on, marked as connected. The second case occurs when is closer to than . In this situation, is marked as connected and added to (see Figure 2). We now have and this segment cannot be considered for marking other neighbor segments as connected nor for placing RNs.
This strategy provides a way to keep the closest segment to , thus moving more effectively towards the other segments. Since two nodes do not mark each other as neighbors, this approach will prevent all segments from being marked as connected while the network is not yet connected (before a path from each node to all the others is available). This method will end with the two last segments meeting each other and one remaining out of . Thus, the end of the loop is reached when .
2.2.2.6 Realignment of the current segment
This part is optional, although it is implemented in order to reduce the distance between the nodes. Using the placement method for one heterogeneous link described above, it is ensured that all the distances between the nodes of the current segment are less than the maximum range by a positive factor .
Here is an example to illustrate how this realignment works in the algorithm. Let and . Inputting in the ORPHe algorithm (with the range for the RNs), the algorithm will output a better positioning for the RNs as , with and being new positions. Then the new positions are substituted to the previous ones in which is now . Finally, is reinitialized to contain only the last element of , . The set must contain at least three elements for that process to take place.
The function called in the pseudo-code performs this task. The function takes and as inputs, changes the elements in and reinitializes as described above.
A similar realignment can be performed on the current segment but it is more tedious because the neighbor node may not be the last element of . Therefore, the realignment can only be done from the first element of to the neighbor element. The function that takes into account this information is called .
2.2.2.7 RN placement
The BRHEN algorithm determines the RN placement direction based on the position of the barycenter of the eligible nodes. The eligible nodes are the with which were not marked as connected during the round—i.e., . There is the possibility that this set now contains only the index of the considered segment. In that case, the positioning of a new RN is bypassed since the barycenter is at the same position as the considered node rendering the concept of direction towards the barycenter void.
If the distance between the considered node and the barycenter is greater than the smaller range between that of and that of a RN—i.e., if — the RN is placed at a distance corresponding to towards , using the following formulae for the coordinates:Otherwise, if the RN is placed at the barycenter with and . The new nodes will replace the current element and will be added to and as their last element.
2.2.3 Detailed workings with example
This description of the workings of the BRHEN algorithm uses the scenario presented in Figure 4 as reference.
2.2.3.1 First round
The round starts by identifying the BNs with the function. Since it is the first time, is the set of initial nodes and is empty. The function thus considers all the INs and its output, the set , contains the indices of the INs which are BNs. This set is and it is used to compute a first barycenter . Figure 4a shows in orange the rectangle defined by the BNs and which encloses all the other yet unconsidered nodes.
Beginning with the index 0, the search for neighbors of is initiated and one is found in . The segment of the farthest node from is marked as connected and . Now that the considered segment is marked as connected, it is no longer eligible for RN placement and will not be considered for future barycenter computations. The connection between the two nodes is represented by a dashed line joining them in Figure 4.
The next segment is now considered with the index 2, has no neighbors and is eligible for a RN placement. The barycenter of all eligible nodes (, , , circled in green in Figure 4b) is computed, and a RN is placed in that direction at a distance from (see Figure 4c). This new node becomes the new , making it the eligible element of the second segment for the next barycenter computations. In turn, segments 3 and 6 go through the same process, finding no neighbors and placing a RN each.
2.2.3.2 Subsequent rounds
The second round starts with a connected segment and three new nodes as illustrated in Figure 4d. The new BNs are circled in green. is not one of them, as it is slightly inside the orange rectangle. In this round, will place a RN after finding no other neighbor than , and so will . will connect with and as the former will be farther from the barycenter will be marked as connected. Similarly for , it will connect with the new and its segment will be marked as connected. Thus, by the end of the second round and the third round will start with the structure shown in Figure 4e.
In the third round, only and will be considered first. However, will see as a neighbor and its segment will be marked as connected leaving alone. The realignment functions are applied to both and , but only has enough elements for the functions to modify its content. The realignment can be seen by comparing Figures 4e, f. being alone, in this round there is no eligible node for RN placement. Furthermore, the short range of , prevents from connecting with it.
The fourth round starts with the same set of as the previous one, but with being connected, the BNs and the eligible nodes are different. will place the final RN on the barycenter because and all other eligible nodes will see it as neighbor. In its turn, will be marked as connected as it finds as neighbor and closer to . The set of connected segments is now . Therefore, the condition of is met, and the algorithm returns the set containing all the nodes in the network.
2.3 Algorithms analysis
In this subsection, original proofs for the validity of the formulae used in the ORPHe algorithm and the convergence of BRHEN algorithm are given.
2.3.1 Analysis of ORPHe
Property 2.3 The coordinates of a point on the line between two different points and , at the distance from and in the direction of , are given by with and . Therefore, the relation between the coordinates of and is provided by a term composed of (a) the ratio between the distance and the distance between and and (b) the difference between their coordinates .
Proposition 2.4 If and and both are not equal to zero, there is a real factor such that there is a point on the line defined by and — two different points — which is at a distance and from and , respectively. Its coordinates are given by is unique and equal to and the position of is determined by substituting with the sum of the ranges in Equation 4. This allows us to find a point that reduces (or extends) both distancesandby the same factor.Proof. The proof will be done only for the coordinate, as it is similar for the coordinate. Equating the result from Property 2.3 for a point on the line defined by and at a distance from with its result for a point on the same line at a distance from , yieldsThus, the coordinate of the point is given bywith .
Remark 2.5 In the following, we will consider the connectivity of the nodes. Since all relays will have the same range and the initial nodes and may have distinct ranges, for the connectivity between an initial node and a relay, we must consider the smaller range as the maximum distance between the two. Thus, from now on, and will be by default and , respectively.
Proposition 2.6 Let and be two unconnected nodes with ranges and , respectively. The minimum number of additional nodes with range for and to be connected is given by Where is the distance between the two unconnected nodes, and are the ranges considered for these nodes (see Remark 2.5), whileis the range of the additional nodes.Proof. After placing a node towards at a distance of from and a node towards at a distance of from , the remaining distance between those two relays is . The minimum number of segments of length needed to cover that distance is . Finally, the first two relays are added to obtain the total number of relays: .
Let and be two unconnected nodes with respective ranges and and be the number of additional nodes. Let us assign an index to each additional node that will be placed between and starting from . Thus, and refer to the closest to and the closest to , respectively. For any number of nodes, , with range to be placed in between and , the coordinates of the node , are given by The coordinates can also be expressed using the coordinates of the previous node:with,andfor.
Furthermore, all nodes are connected for .
Equation 8 give the positions of all the RNs from the position of one of the INs depending on its index, whereas Equation 9 are the iterative formulae that give the position of the subsequent RNs from the previous one (or from the IN for the first RN).
Proof. Firstly, the placement of the th relay from towards can be thought of as the placement of the only relay between and with new respective ranges defined as and . The definition of from Proposition 2.4 isThen, with Equation 5 we can express the coordinates of the node — shown only for the coordinate as it is similar for the — as .with , and for . Secondly, with from Equation 7, the distance between two consecutive nodes and for , is given byThus, the distance between the two consecutive nodes and is smaller than the range of and the connectivity is guaranteed for .
Proposition 2.8 Let us consider the maximum range of each node to be the distance within which a desired channel capacity is ensured and assume two different propagation channels, one being between an IN and a RN and the other one between two RN, with possibly different Path-Loss Exponents (PLEs). Let us also assume that all the RNs have the same range. Finally that the bandwidth used by each node is the same and that we have an Additive White Gaussian Noise (AWGN). Then, the ORPHe placement method is an improvement on a method leaving some distances between nodes to be maximal and is optimal for the special case where the two PLE are identical. Proof. For an AWGN channel the channel capacity is given bywhere is the bandwidth. This capacity is a function of the SNR which is inversely proportional to , with , the distance from the source and , the PLE. The range of each node is defined by the distance at which a certain is ensured and this is the same for each node. However, if the bandwidth is the same for all links, equal values of correspond to equal values of SNR. Let and be the PLE of the RN-RN and IN-RN channels, respectively, and let and be the two INs. Then, the different SNRs can be expressed aswith , and taking into account the transmission power, the fading, the bandwidth, and the frequency of each node.Since the idea behind the ranges is that they give the same capacity, substituting with the appropriate range yieldsIn our case, we haveand we want to reduce the distances between the nodes such thatwith , , and , , . Substituting those distances to the ’s in Equation 11 yieldsHowever, from the last equality of Equation 11 and that of Equation 12, we get that , leaving only and to be determined. The first equality of the identical equations yields or . Thus, we have the following set of equationsLet us demonstrate that, for the optimal SNR, the equalities are to be conserved when modifying the distances. If they were not, we might have, for example,The channel capacity of the link between and is limited by the lowest capacity of the different hops, i.e., the right hand side. As previously, with Equation 11, we deduce that . This means thatBecause the right-hand side is the result when assuming the equality of the SNR, we can conclude that assuming the equality is optimal.Three different cases are to be analyzed: , and .
2.3.1.1 Case
Equation 14 becomes and Equation 13 yields . This is the definition of in the ORPHe algorithm, thus in the ORPHe algorithm the use of a unique coefficient is the same as assuming that the PLE are the same for all links and it is the optimal placement in that case.
2.3.1.2 Case
Substituting to in Equation 13, yieldsGiven that and , we have . Then the value of the coefficient , which is solution of Equation 13, will be less than that of the first case (which will be referred to as from now on). With this in mind, we may qualitatively compare the SNRs that would be obtained by assuming a unique PLE, with the ones that would be obtained with different PLE. For the latter, the equality on the SNR still holds. However, substituting to both and yieldssince . As a consequence, the SNR between the RNs will be the limiting factor for the channel capacity. On the other hand, considering the two PLE yieldsComparing the limiting SNR from two previous results to the limiting SNR when nothing is done (Equation 11) gives the following successive inequalitiesThe first inequality is because and the second one because .
2.3.1.3 Case
Substituting to in Equation 13 allows us to follow the same reasoning with as in the previous case with . Here , Equation 14 becomessince and the optimal SNR is
Finally, comparing the limiting SNRs yieldsThe first inequality is due to and the second one to .
Thus, assuming that the channels have the same LPE for determining a coefficient to reduce the distance between the node as is implicitly done in the ORPHe algorithm, is suboptimal yet enhances, nonetheless, the channel capacity compared to leaving some distances between nodes to be maximal.
2.3.2 Analysis of BRHEN
Property 2.9 The barycenter of points is always inside the rectangle defined by the extrema in and coordinates of those points, In addition, it is equal to an extremum in or if all the points have the same or coordinate, respectively.Proof. The proof will only be done for the coordinate, as it is similar for the coordinate. We can establish an upper bound to the value of by substituting all with for in the definition of . It yieldsThe lower bound is obtained by substituting all for . It yields .It is equal if all the have the same value , indicating that all the points are on a vertical line.For the coordinate, it is equal to the extrema if all the points are on a horizontal line.This property guarantees that the new relays placed from the border nodes towards their barycenter remain within the rectangle defined by those nodes. This means that the next border identification, which only takes into account the nodes not considered yet, will have nodes strictly inside the previous rectangle to consider. As a result, the algorithm converges as the rectangles become smaller.
3 Performance evaluation
This section assesses the effectiveness of BRHEN by comparing performance across multiple metrics using simulations. The results show that BRHEN performs better in terms of the number of relays placed when the Initial Nodes (INs) are heterogeneous with respect to the communication ranges and when the relays have yet a different range. The simulations also indicate that BRHEN performs better in terms of average hop count between two INs once the network is established. Therefore, the resulting topography produces a lower data delivery latency. An analysis of the behavior of each method for large-scale networks shows that BRHEN handles large and dense networks better than its counterparts. The data also show that BRHEN is computationally light and that it is stable with regard to the positions and the number of RNs when the INs are randomly displaced by up to 10% of the smallest range. Additionally, in the last two subsections, we studied the effect of the order of consideration of the different segments on the resulting network and the effect of applying the ORPHe method within the BRHEN algorithm.
3.1 Validation simulations
The performance of BRHEN is compared to two baseline approaches. This subsection introduces the simulations setup, the performance metrics and the baseline approaches used for comparisons.
3.1.1 Simulations setup and performance metrics
The simulations consider a partitioned network with INs, with different ranges
and
, while the relays to be placed for network restoration have a range
. The performance is evaluated by varying the following three parameters.
• Relative communication ranges of the nodes (, , ): The communication range has a great influence on the number of relays by reducing both the distance left to cover and the number of relays necessary to cover it. Here, since multiple ranges are dealt with, the performance will be assessed for (a) ranges growing with the same factor, the mutual growth coefficient , and (b) for the two largest ranges growing relatively to the smallest ones, i.e., proportionally to the separate growth coefficient .
• Number of Initial Nodes: The number of INs to connect is also expected to influence the number of relays to deploy.
• INs displacement: Each IN of the set is displaced in a random direction by meters. This parameter is used to evaluate the stability of the BRHEN algorithm with respect to moving INs.
We assessed the impact of these parameters on the following eight metrics.
• Number of Relay Nodes: This is the main goal of the optimization and the clearest visualization of the performance of BRHEN.
• Average Hop count: This will assess the connectivity of the resulting topology. It is calculated as the sum of the number of hops needed to connect each IN to every other through the shortest path—without counting everything twice—divided by the number of connections to make .
• Number of roundsand computation time: The objectives of these metrics are to show that the algorithm converges in a low number of rounds and that it is computationally light.
• Mean RN displacementand Probability ofto change: These metrics are used in order to assess the stability of the BRHEN method and compare the state of the network before and after random displacements of the INs
• Difference between first and best number of RNs: Used to visualize the improvement on the resulting when applying the BRHEN algorithm while considering the INs and their segments in different sequences.
• Smallest SNR improvement : This metric shows the smallest improvement among the various links in a segment following realignment with the ORPHe algorithm. The parameters and the metrics are summerized in Tables 1, 2, respectively.
TABLE 1
| Parameter | Symbol | Effect |
|---|---|---|
| Mutual growth coef | All ranges are multiplied by it | |
| Separate growth coef | and grows with it | |
| Number of INs | The density of INs grows with it | |
| INs displacement | INs moved by that amount |
Simulation parameters.
TABLE 2
| Metric | Symbol |
|---|---|
| Number of RNs | |
| Average hop count | |
| Number of rounds | |
| Computing time | |
| Mean RN displacement | |
| Probability of to change | |
| Difference btw first and best | |
| Smallest SNR improvement |
Simulation metrics.
3.1.2 Baseline approaches
• CORP: This algorithm considers a homogeneous set of INs with a communication range . It also assumes the RNs to have the same range. CORP is a cell-based method, and the map is divided into cells with a size corresponding to the range. The greatest distance between two adjacent cells is set to . Since it corresponds to the diagonal, the dimension of the square cells is . This method operates similarly to BRHEN, as the latter’s main steps were inspired by CORP. The key distinction is in the use of cells and in the consideration of different cells for the best placement of a new RN for the CORP part. The algorithm takes in the positions of the set of INs, which must correspond to the center of a cell. To each IN corresponds an index and a segment. The first step is a search for the INs defining the rectangle which encapsulates all the INs. It will then start a loop that will continue until the set of Border Nodes (BNs) is empty. In a second loop, for each BN, it first searches the adjacent cells of each BN for neighbors. If one of a different segment is found, one of the two segments is marked as connected and will not be considered hereafter. If the number of RNs in the marked segment is greater than the number of RNs necessary for connecting its IN and its last RN in a straight line, the segment is pruned—i.e., the RNs are placed in the straight line and equidistant from each other. The second step is to evaluate each adjacent cell as a possible position for a new RN. This is done by calculating the sum of the distances between the considered cell and the other BNs. When it is done for all the BNs, the algorithm starts again from the search for the new BNs in the set including all the nodes except the ones already considered.
• MST-1tRN (enhanced): The basic idea behind this algorithm is to compute a MST and populate the edges of the MST with the required number of RNs. The MST yields a set of edges connecting the nodes such that there is a path from each node to the others with the minimum total length. In Lloyd and Xue (2007), it is assumed that all nodes have the same range and the relays have a range . Thus, it does not support a heterogeneous set of INs. This is easily alleviated by applying the ORPHe method for populating the edges. This enhanced version will be our baseline approach as an algorithm that can manage a heterogeneous network.
To ensure that all methods worked under the same initial conditions in the following simulations, cells were used to place the INs. In addition, since CORP works with a unique range, this range must be the smallest; otherwise, some nodes in neighboring cells would not be connected. This is the reason why the size of a cell is defined by .
3.2 Comparison of the different methods
In order to test the BRHEN method in a more general way, the scenarios are randomly generated. The INs are placed one by one with a random selection of a unused cell in a square area with a given side length (in number of cells). Each IN is randomly assigned a range (1 cell diagonal) or which is greater by a given factor and the relays have the greatest range . The factors for and are 1.5 and 2, respectively, except for the tests where the factors are the variable parameters. For each value of the variable parameters, 1,000 random scenarios are generated, and the statistical results are the focus of the analysis. is assigned to the RNs because we assume that they are Unmanned Aerial Vehicles (UAVs) using their ability to be swiftly deployed anywhere. The establishment of a Line of Sight (LOS) between each other justifies their greater range.
The and the metrics are first evaluated with increasing ranges—which is equivalent to a decreasing number of cells covering the area. Thus, we decrease the side length of the square area from 16 cells to 9 cells, which corresponds to a 78 per cent increase in range, or a growth coefficient . It is evaluated for a fixed 7 INs. The second evaluation on those metrics is done with the same number of INs and a side of 12 cells, but the factors between and the other ranges (, ) increase. The values are given by and , where takes the values from 2 to 9 by increments of one. The third test on those metrics is when the side is fixed to 12 cells. The factors are also fixed to 1.5 and 2, and the number of INs increases by one from 5 to 12. The last metric is the number of rounds done in BRHEN for the network to be connected. It is evaluated for 7, 8 and 9 INs with increasing ranges as the number of cells decreases from 16 to 9.
In the following results, displayed in Figures 5–10, it should be noted that the great variance in the results is due, to a large extent, to the fact that the scenarios are generated completely randomly. This randomness means that all the INs might be placed as a cluster somewhere in the map or very disparate. Alternatively, every INs could have the smaller (or larger) range. This would influence, for example, the number of RNs of all the methods in a similar way.
FIGURE 5
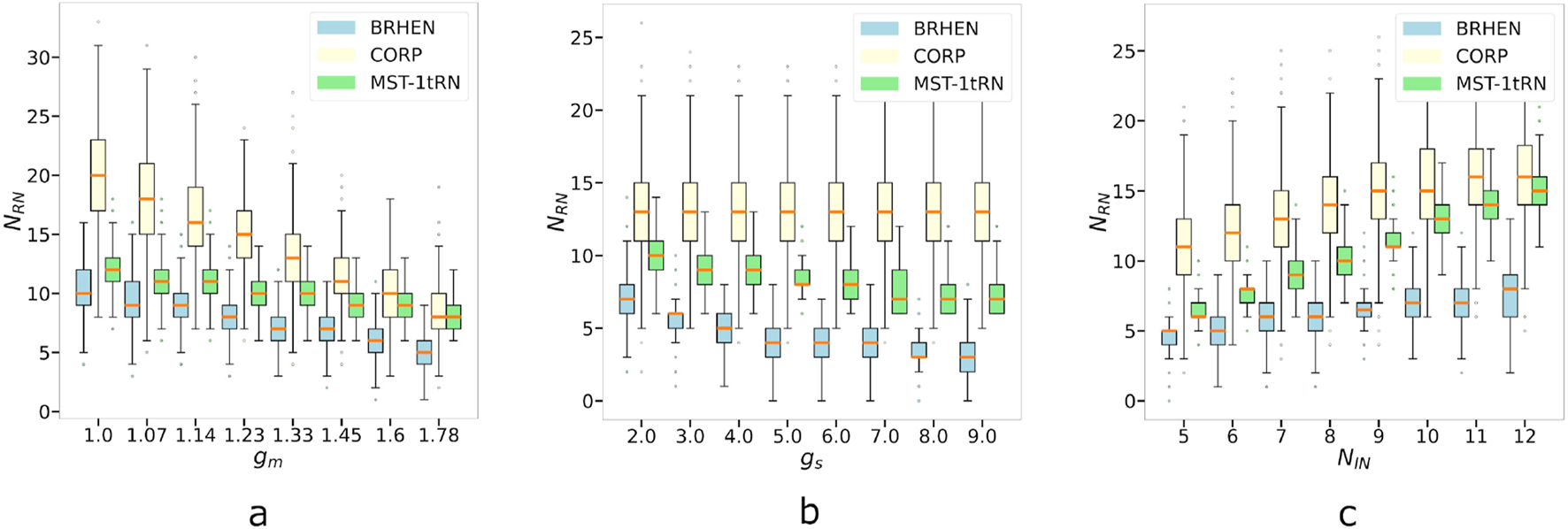
Results comparison regarding the evolution of the number of relays in function of (a) the growth of all the ranges with respect to the size of the map, with and . (b) The growth of the difference between the ranges, represented by the increase of the ratio , and (c) the number of initial nodes (INs).
FIGURE 6
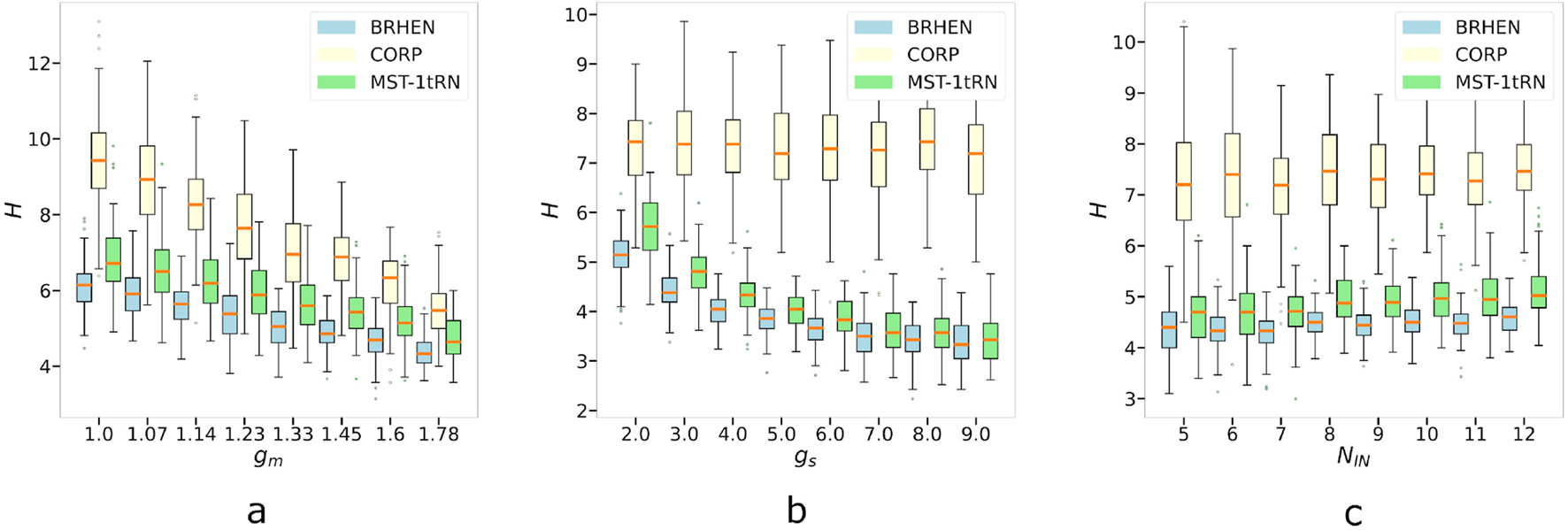
Results comparison regarding the evolution of the average hop count in function of (a) the growth of all the ranges with respect to the size of the map, with and . (b) The growth of the difference between the ranges, represented by the increase of the ratio , and (c) the number of initial nodes (INs).
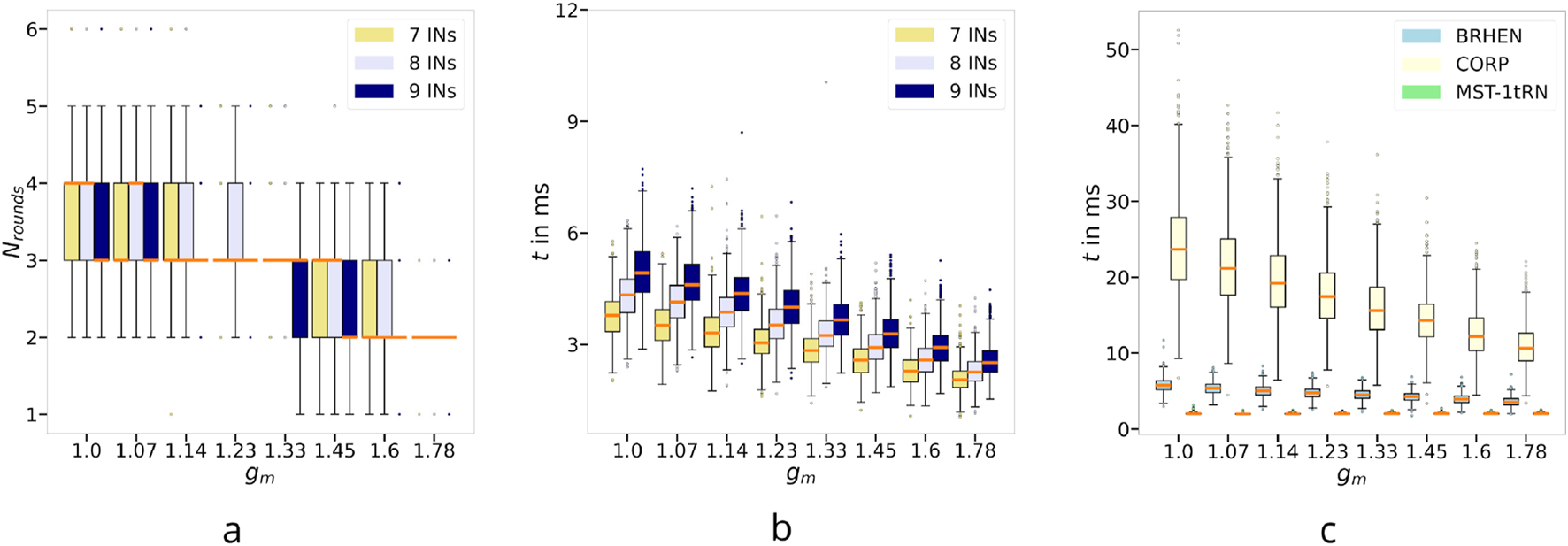
FIGURE 7
(a) Number of rounds in function of the range for different number of INs. (b) BRHEN computation time in milliseconds (ms) as a function of the range for different number of INs. (c) Comparison of the computing time of BRHEN (blue), CORP (yellow) and MST-1tRN (green).
FIGURE 8
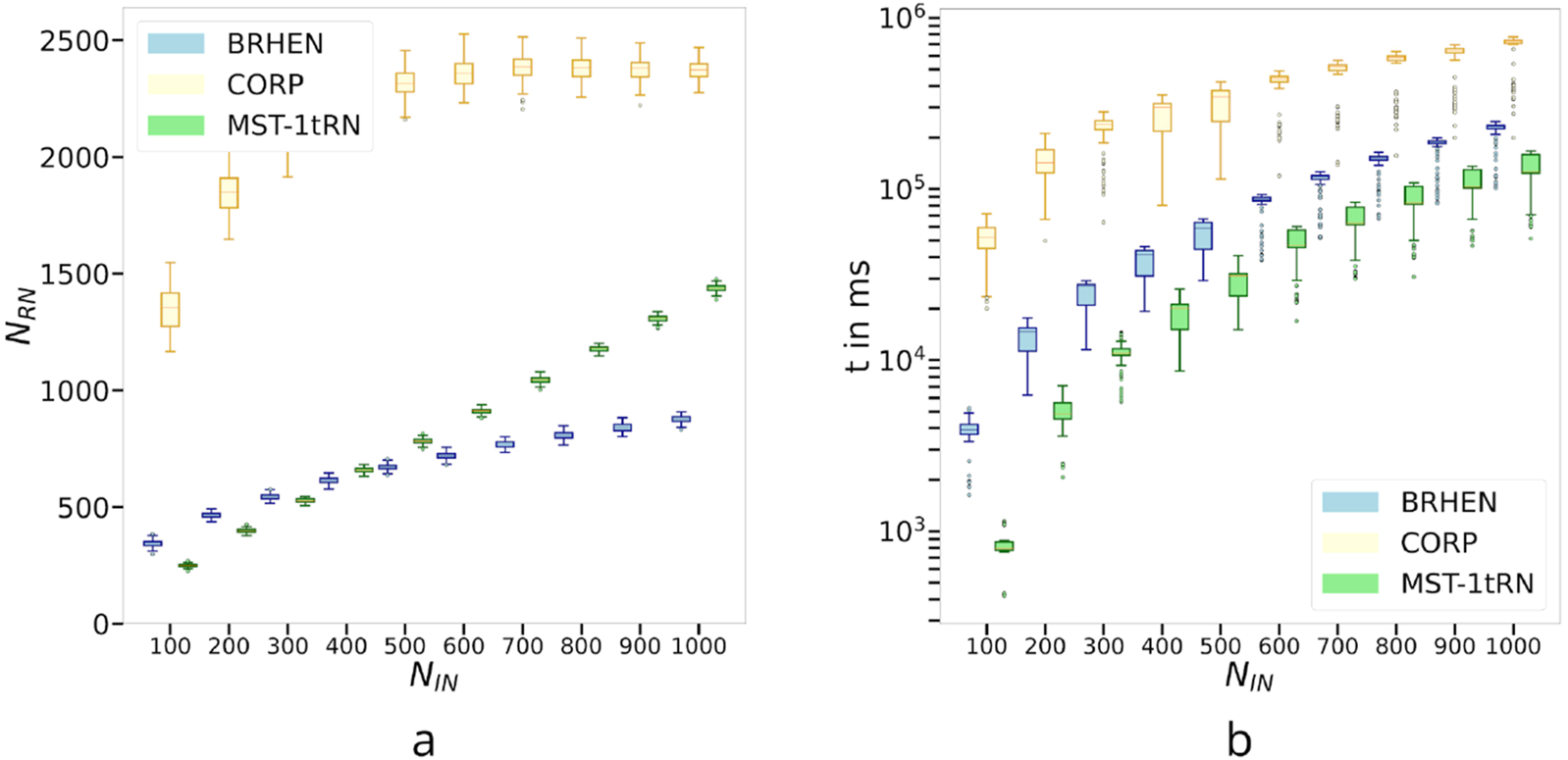
The large-scale behavior of the three considered methods for (a) the number of relay nodes placed and (b) the computation time in milliseconds.
FIGURE 9
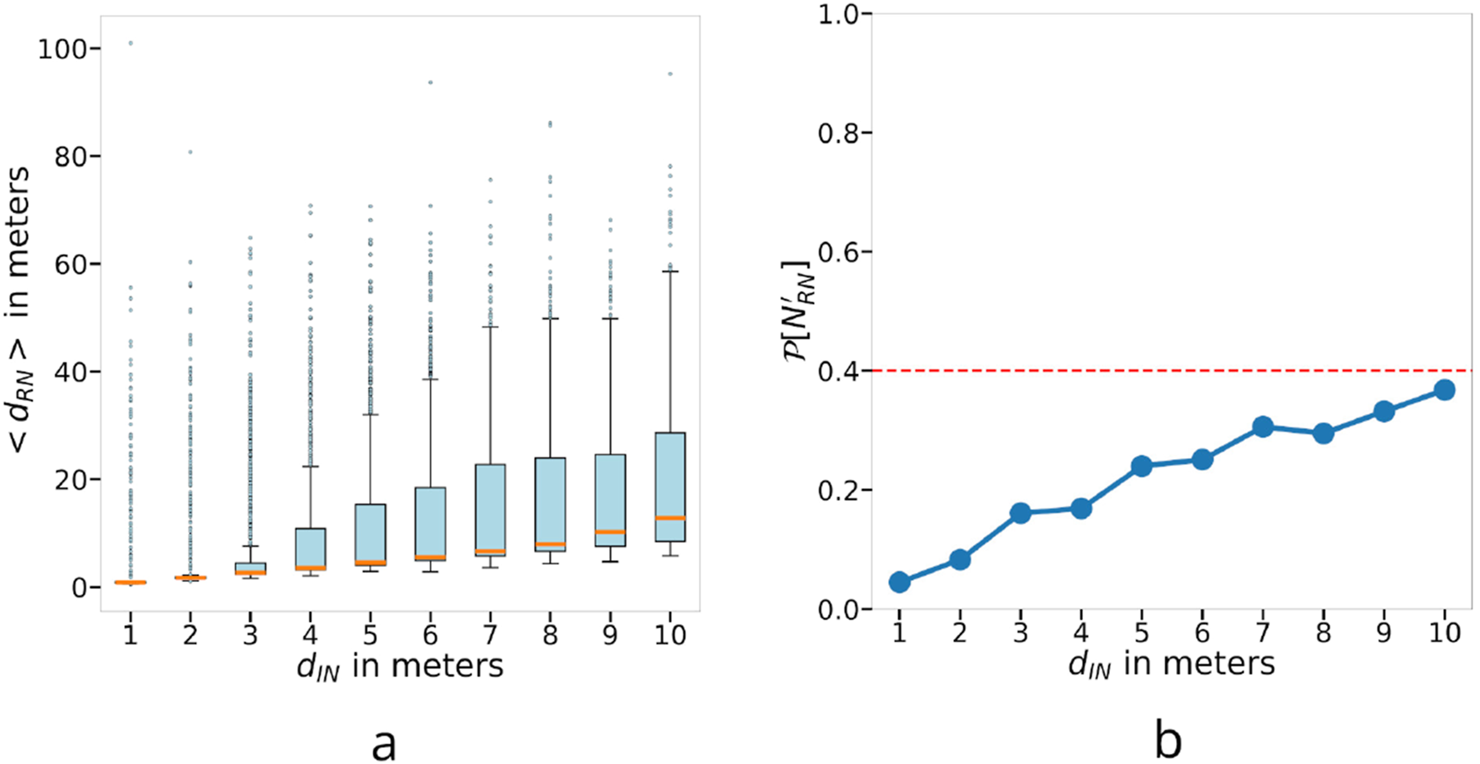
Assessment of the stability of the BRHEN approach. (a) Mean RN displacement in meters as a function of the distance of the IN displacements. (b) Probability that the number of RN changes when the INs are displaced.
FIGURE 10
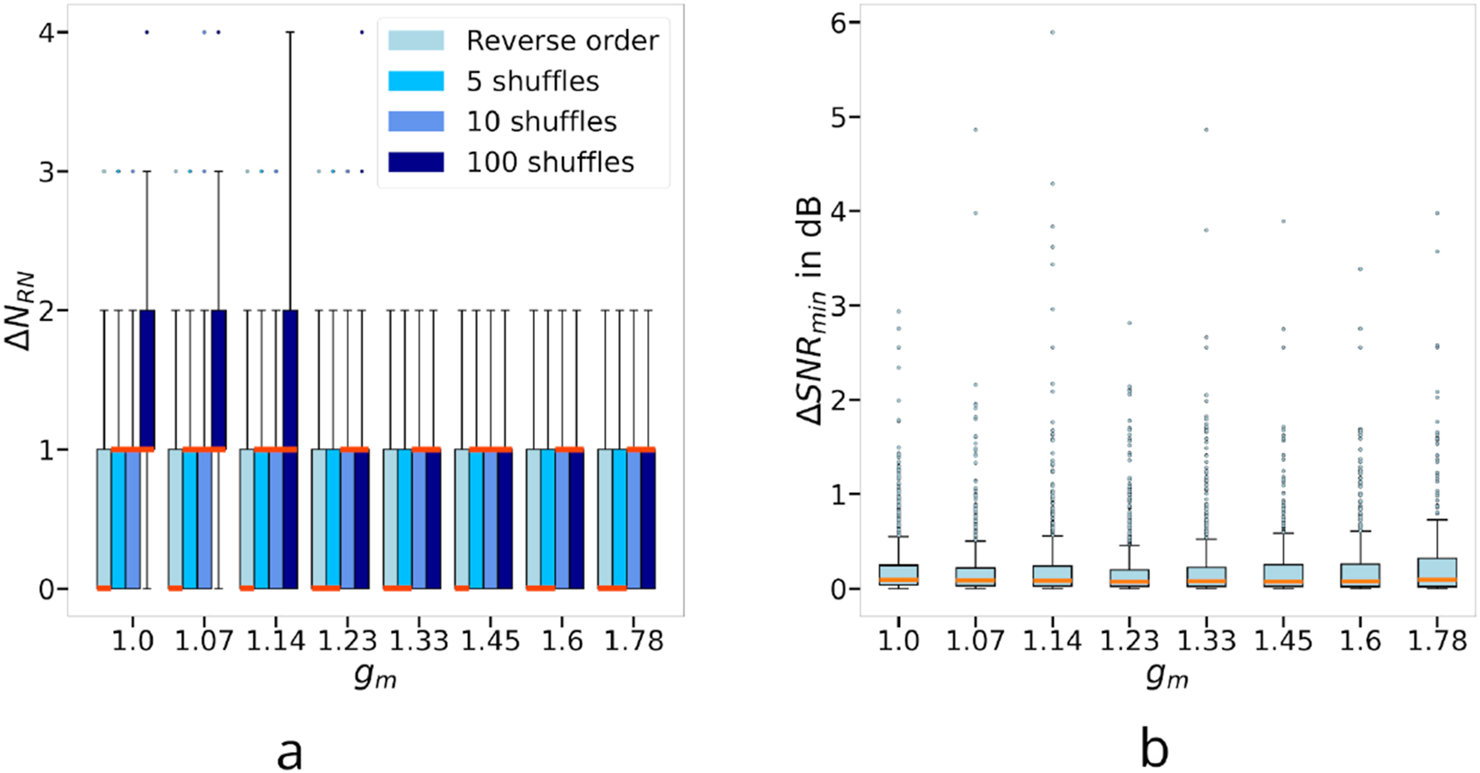
(a) Comparison of the difference in between the result using the initial ordering of segment consideration (0–6) and using the best result among multiple different segment ordering considerations (shuffled segment numbers). (b) Improvement of SNR after realignment using the ORPHe method.
3.2.1 Number of RNs
3.2.1.1 Behavior for increasing , and
As it is expected with increasing ranges, all the methods see their decrease as the ranges become larger (see Figure 5a). However, the decrease rate depends on the method. CORP starts with a number of RNs significantly larger than other approaches, with results centered around 20 RNs, but its large decrease rate allows it to close the gap between CORP and MST-1tRN—which decreases the slowest. Both methods have a centered around 10 after an increase in the ranges by a factor of 1.78. Nevertheless, the produced by BHREN is consistently almost half that of CORP and keeps the lowest number of RN among the approaches, starting around 10 and ending around 5.
3.2.1.2 Behavior for and growing with respect to
Figure 5b shows that obtained by CORP stays constant while the two greater ranges, and , become larger—as it is expected since is constant and the CORP method scales with it. On the other hand, the counts of BRHEN and MST-1tRN decrease. They do so at approximately the same rate, thus keeping the same gap between them as and increase. BRHEN is the most effective approach, with the bulk initially about 7 RNs and decreasing to about 4. It is followed by MST-1tRN with about 10 to about seven and CORP has the largest number of RNs, staying centered around 13 RNs.
3.2.1.3 Behavior for an increasing number of INs
Finally, Figure 5c depicts the number of RNs required to connect an increasing number of INs. The three methods see their increase with the number of INs. Here again, CORP is the least effective. However, the count of MST-1tRN grows more rapidly, and by the time the number of INs reaches 12, the bulk of the results from MST-1tRN are within the bulk of the results from CORP. BHREN has a lower increase rate than the other approaches and maintains the lowest number of RNs for all the values of the number of INs, staying around half the results from CORP.
3.2.2 Average hop count
3.2.2.1 Behavior for increasing , and
Figure 6a shows that the average hop counts follows the same pattern as the number of RNs, which is also expected. The notable difference is that MST-1tRN has a decreasing rate similar to that of BRHEN, which keeps MST-1tRN centered around one additional hop from BRHEN.
3.2.2.2 Behavior for and growing with respect to
It can be seen in Figure 6b that stays constant for CORP, similarly to the results (same reason). However, for BRHEN and MST-1tRN, the results are closer. BRHEN has a lower count for smaller ranges, but MST-1tRN closes the gap for the upper values of the ranges. While remains centered around 7 for CORP, it is around 5 and around 6 for BRHEN and MST-1tRN, respectively, for the lower range ratio and both are centered under 4 for the largest ratio.
3.2.2.3 Behavior for an increasing the number of INs
In Figure 6c, the average hop count behaves quite differently from the number of RNs. The results are fairly constant for all the approaches. The results of CORP are again almost double that of BRHEN. MST-1tRN generates a slightly higher average hop count than BRHEN.
3.2.3 Number of rounds
The number of rounds performed by the BRHEN algorithm have been counted for different numbers of INs and as a function of the ranges. Figure 7a shows that BRHEN converges in a few rounds for any number of INs. In addition, the number of rounds is inversely proportional to the ranges of the nodes.
3.2.4 Computation time
Similarly to the number of rounds, the computation times of the BRHEN algorithm have been recorded for different numbers of INs and as a function of the range. In Figure 7b, it can be seen that the computation time decreases with increasing ranges for all INs. It is expected because the number of relays—thus the number calculations for the positions—and the number of rounds decrease with increasing ranges. The higher computation time for larger number of INs is also expected, since the number of relays grows with the number of INs.
For a comparison of the computing time of BRHEN with the other methods, see Figure 7c. It shows that the simplest method, MST-1tRN, is the fastest method. Its time stays mostly constant even if the ranges are growing due to the fact that the heavier computational task is finding the edges of the MST—which does not involve the ranges. BRHEN is heavier than MST-1tRN, but nothing compared to the CORP method, which needs to evaluate 9 cells to select the better one.
3.3 Scalability
Let us now analyze the behavior of the different methods for larger-scale networks. To do so, we multiplied by 10 the dimensions of the square area which gives rise to cells where we randomly placed 100 to 1,000 INs. The diagonal of 1 cell still corresponds to . The INs have a randomly assigned range of either or . The RNs have a range of . For the following results, the statistics are from 100 iterations for each number of INs. Figure 8 compares the performance of the three considered methods in terms of the number of relay nodes, , and the computation time, , in milliseconds.
The behavior of is presented in Figure 8a. We can see that the CORP method struggles with the up-scaling having to place around 1,500 RNs when there are 100 INs and around 2,700 for 1,000 INs. On the other hand, BRHEN and MST-1tRN require around 400 and 250 INs, respectively. Although MST-1tRN produces better results under 400 INs, with its nonlinear growth, BRHEN has a lower beyond the 400 INs mark. MST-1tRN requires almost 1,500 RNs, while BRHEN only requires around 750 RNs for 1,000 INs. From this change of trend and the nonlinear growth of BRHEN, we can infer that MST-1tRN is more efficient in lower density networks, while BRHEN is for higher density networks. CORP also exhibits this non-linear growth.
The computation time of the three methods behaves similarly as can be observed in Figure 8b. They grow similarly with but their orders of magnitude are different. The lightest method is MST-1tRN which starts at around 200 m for 100 INs and ends at ms. BRHEN and CORP start at 1,500 m and ms, and end at and , respectively. The MST-1tRN method remains the lightest even on a larger scale.
3.4 Stability
To manage mobile INs, a RN placement algorithm must produce positions that are stable with respect to the displacements of the INs. In order to assess this stability, for each scenario, the positions of the RNs were compared to the ones of the same scenario after all the INs are moved a certain distance in a randomly chosen direction. The stability is evaluated for different values of the distance, labeled .
Two metrics are used for the assessment. The first metric is the average distance between the positions of the initial scenario and the disrupted scenario of each RN—or mean RN displacement. As is easily conceivable, INs moving towards each other or in opposite directions can induce a variation of . Thus, the second metric is the probability that changes.
For each value of , 1,000 scenarios are randomly generated in the same way as for the previous results. However, since the scenarios do not have to be appropriate for a cell-based method, the map is chosen to be a square with a side length of 1,000 m and the ranges are meters, and . varies from 1 to 10 m. It is 1–10 percent of . For each value, it produces a variation in distance between the INs of 0–2 times — 0 being the two considered INs displaced towards the same direction, and 2 towards the opposite directions. In this case, it represents 20 percent of .
3.4.1 Results
It can be seen in Figure 9a that the majority of the data spread more as the grows. Nonetheless, the median remains about equal to . The spreading is expected as the growth of increases the probability that the disrupted scenario has a completely different structure—e.g., the first border nodes are different or two nodes are now neighbors. However, this probability exists even for a small . This is reflected in the decrease in the number of outliers and their values. On the other hand, the highest values appear to be independent of and may be related to the ratios between the ranges or between the scale of the ranges and the scale of the map.
Figure 9b gives the probability that varies after the perturbation. As expected, this metric increases with . This is also due to the growing probability to have a completely different structure. Nonetheless, even for meters, it stays below 40 percent.
Now, if we add information on the time within which these displacements occur, we obtain a value for the velocity of the INs. The RNs would have to reach their new position in the same amount of time to prevent the network from partitioning momentarily during these displacements. Therefore, we can study the required RN speed from the results presented in Figure 9a. We can see that the median of is around the same value as and the third quartile is slightly above . Thus, as long as the RNs can move freely around the same speed as the INs, we have a probability that the RNs can keep up with the changes in positions. Otherwise, a momentary partitioning might occur during that time frame. However, if the RN’s are significantly more mobile than the INs, say twice as mobile, it almost achieves the probability mark.
In order to give a more concrete example, for the chosen range values of meters , . Taking the worst scenario presented in Figure 9a where meters (or of ). For simplicity, we chose to assume that the displacements occur within 1 s, i.e., the INs are moving at 10 m/s. To obtain around probability that the RNs have time to adjust without possible momentary partitions in the network, the RNs need to reach 20 m/s (or 72 km/h). If we consider UAVs as RNs, this is an achievable speed, even for small ones. Nevertheless, the more reasonable speed of 10 m/s (or 36 km/h) will already reach . If we double the ranges, we now have . Since is now 5% of , this scenario corresponds to in Figure 9a. 10 m/s and 20 m/s will now allow us to reach between and , and almost , respectively. Let us point out that the temporary partition that would arise would last around the same time frame as assumed for the displacement.
3.5 Influence of segment consideration order
Upon initiating a scenario, the INs are given a random (or arbitrary) segment number. The BRHEN algorithm uses these numbers to consider the segments in the standard order. However, that order will influence the overall structure of the resulting network, and nothing guarantees that the given order is yielding the best result.
One way to get closer to the best result is to shuffle the segment consideration order a given number of times and take the best of all the outputs. In the following, the output with the least number of RN will be considered the best. We applied this method for 1 shuffle (a simple reversal of the order), 5, 10 and 100 shuffles, using the same parameter and the same number of random scenarios for each parameter value as in Subsection 3.2. This allows us to take the results presented in Figure 5 as a reference for with one run. We obtain a statistical distribution of the number of RNs that we can save by doing each number of shuffles. It is represented by , with , the initial result, and , the smallest number obtained among the initial result and the ones given by the different shuffles. The results are presented in Figure 10a.
We can see that from a small number of shuffles (1–5) we already get an appreciable probability that one less RN is deployed. For small values of (small ranges with respect to the area), proceeding to a great number of shuffles can lead to a high probability of reducing even more. Nevertheless, this advantage fades with increasing (with greater ranges). This is expected since decreases with growing , thus there are fewer RN that might be superfluous.
These results suggest that doing a few runs of the BRHEN algorithm with shuffled segment orderings has a non-negligible probability of resulting in a better RN layout. Since BRHEN is computationally light, it is a reasonable option. However, for relatively large ranges with respect to the area, a representative sample can consist of only a few shuffled runs.
3.6 Use of the ORPHe method and its effects
With Proposition 2.8, we have shown that using the ORPHe method to place RNs between two nodes allowed the overall SNR between the two to be improved. Here we show that when applied as a realignment method within the BHREN algorithm, we obtain a slight SNR improvement within the segment.
To do so, we are using the same simulation setup as in Subsection 3.2 with as the parameter. Each time a realignment occurs within BRHEN, we calculate the difference between the smallest SNR in the segment being realigned before and after as . Since the ranges are assumed to have been computed to achieve a desired SNR (i.e., a desired modulation), is set. To find , we use Equation 10. Applying the corresponding PLE for a link and the corresponding range, we can extract the coefficient of that link from the before case, then use and the new distance between the two nodes to obtain the new SNR of that link. Thus, for each link, we use the formula:
with depending on the type of link and the smallest range of the two nodes (which defines the before distance between the two). The improvement in SNR is given by the second term and will be the smallest value of the second term within the links in the realigned segment. From each BRHEN run, we take the average of those improvements. For the simulations, since does not depend on it is unnecessary to specify it. We only have to set the different PLEs and since the RNs are assumed to be UAVs, we have set between RNs (i.e., assuming LOS) and between INs and RNs. Figure 10b shows the statistics of the 1,000 scenarios for each value of .
The data suggest that there is always a slight improvement in SNR in the realigned segment after using ORPHe. The median is around 0.1 dB, but in some isolated cases, it can be several dB, with a maximum improvement obtained of 6 dB. The results are mostly the same for all values of , this is expected since the relative growth of the ranges might reduce the number of nodes placed, and thus the number of realignments needed. However, the mean improvement of these realignments remains mostly unchanged.
4 Applicability of the BRHEN algorithm
The BRHEN algorithm is a heuristic method that is suitable for 1-tiered heterogeneous networks. The heterogeneity appears in the form of the variety of ranges it takes into account. Behind the difference in ranges is hidden a difference in emitting power, sensibility, propagation path, or a combination of those. In cases where the line between two nodes is not horizontal (such as between air and ground), the range that should be applied is the length of the path as it appears on the horizontal plane.
For example, the placement of ground stations for a permanent or temporary network. The difference in range here will be due to the difference in emitting power and sensibility. Another example is with UAVs as RNs, they enjoy free space LOS propagation for the links between each other, resulting in a greater range between them than between ground nodes with the same radio setup.
This second use-case can be pushed further into the realm of Non-Terrestrial Networks (NTN). However, using greater ranges will result in the need to take into account the Earth’s curvature. Using a conformal projection, which keeps the angles—thus the direction toward the barycenter—true, will allow the method to stick to the Cartesian formulation. Nevertheless, the distances are distorted along the meridians. Due to this, for large areas that span several degrees in latitude, a more complex formulation must be developed for the different steps of the BRHEN algorithm.
5 Conclusion
This paper investigates the methods allowing to manage the RN placement for heterogeneous networks, focusing on their effectiveness regarding the number of Relay Nodes (RNs) placed, the average hop count for the delay, the computation time, and the stability of the placement when the network is nonstatic.
Two algorithms are proposed: ORPHe (Optimized Relay Placement for one Heterogeneous link) for an enhanced RN placement between two disconnected nodes and BRHEN (Barycenter-focused Relay node placement for HEterogeneous wireless Network). They can manage a heterogeneous set of INs and RNs with a different set of communication properties. In addition, it does not require the definition of cells—which limits the precision of the computed positions.
Whether in terms of number of RNs used or in terms of the average hop count for two INs to communicate, the simulations results show the advantage of the BRHEN method over two other approaches for heterogeneous networks. Moreover, BRHEN is shown to be computationally light and to have a relatively good stability. These are important features for mobile networks, since the positions have to be updated frequently—the higher the velocities, the higher the frequency—and the updated RN positions have to be reasonably close to the previous ones. This is an important feature allowing to keep the integrity of the network during readjustments using mobile RNs with reasonable speed.
6 Future works
As a follow-up, strategies to optimally cope with the displacements of the INs need to be explored. First, study predictive IN movements first and, ultimately, deal with unexpected IN motion. Other future work will focus on the implementation of terrain and signal propagation loss in the placement selection process before conducting measurement during field trials for validation.
Statements
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author contributions
EG: Conceptualization, Data curation, Formal Analysis, Investigation, Software, Writing – original draft, Writing – review and editing. VL: Writing – review and editing. BL: Writing – review and editing. MB: Writing – review and editing.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This research is funded by the Royal Military Academy of Belgium.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1.^The information of the height, , is hidden in as the range will be influenced by the propagation channel. If the INs and the RNs have different heights, can be viewed as the projection on the horizontal plane of the 3D .
References
1
Cao R. Gao H. Lv T. Yang S. Huang S. (2016). Phase-rotation-aided relay selection in two-way decode-and-forward relay networks. IEEE Trans. Veh. Technol.65, 2922–2935. 10.1109/TVT.2015.2442622
2
Cheng X. Du D.-Z. Wang L. Xu B. (2008). Relay sensor placement in wireless sensor networks. Wirel. Netw.14, 347–355. 10.1007/s11276-006-0724-8
3
Deyab T. M. Baroudi U. Selim S. Z. (2011). “Optimal placement of heterogeneous wireless sensor and relay nodes,” in 2011 7th international wireless communications and mobile computing conference, 65–70. 10.1109/IWCMC.2011.5982508
4
Grönkvist J. Hansson A. Hägglund K. Komulainen A. Sköld M. (2022). Low-altitude uavs for significantly increased data rate in tactical ad hoc networks. Procedia Comput. Sci.205, 107–116. 10.1016/j.procs.2022.09.012
5
Han X. Cao X. Lloyd E. L. Shen C.-C. (2010). Fault-tolerant relay node placement in heterogeneous wireless sensor networks. IEEE Trans. Mob. Comput.9, 643–656. 10.1109/TMC.2009.161
6
Ladosz P. Oh H. Chen W.-H. (2018). Trajectory planning for communication relay unmanned aerial vehicles in urban dynamic environments. J. Intelligent Robotic Syst.89, 7–25. 10.1007/s10846-017-0484-y
7
Lee S. Younis M. (2010a). Optimized relay placement to federate segments in wireless sensor networks. IEEE J. Sel. Areas Commun.28, 742–752. 10.1109/JSAC.2010.100611
8
Lee S. Younis M. (2010b). “Qos-aware relay node placement for connecting disjoint segments in wireless sensor networks,” in 2010 6th IEEE International Conference on Distributed Computing in Sensor Systems Workshops (DCOSSW), Santa Barbara, CA, USA, 21-23 June 2010, 1–6. 10.1109/DCOSSW.2010.5593290
9
Lee S. Younis M. (2010c). Recovery from multiple simultaneous failures in wireless sensor networks using minimum steiner tree. J. Parallel Distributed Comput.70, 525–536. 10.1016/j.jpdc.2009.12.004
10
Lin G. Xue G. (1999). Steiner tree problem with minimum number of Steiner points and bounded edge-length. Inf. Process. Lett.69, 53–57. 10.1016/s0020-0190(98)00201-4
11
Liu G. Lu K. Li J. (2019). “Approximation algorithm for relay node placement in singled-tiered wireless sensor networks,” in 2019 IEEE 4th International Conference on Advanced Robotics and Mechatronics (ICARM), Toyonaka, Japan, 03-05 July 2019, 162–167. 10.1109/ICARM.2019.8834312
12
Lloyd E. L. Xue G. (2007). Relay node placement in wireless sensor networks. IEEE Trans. Comput.56, 134–138. 10.1109/TC.2007.250629
13
Parihar A. S. Baghel A. Swami P. Bhatia V. (2024a). “On performance of swipt empowered noma-hetnet with non-linear energy harvesting,” in 2024 national conference on communications (NCC), 1–6. 10.1109/NCC60321.2024.10485896
14
Parihar A. S. Singh K. Bhatia V. Li C.-P. Duong T. Q. (2024b). Performance analysis of noma-enabled active ris-aided mimo heterogeneous iot networks with integrated sensing and communication. IEEE Internet Things J.11, 28137–28152. 10.1109/JIOT.2024.3416951
15
Robins G. Zelikovsky A. (2005). Tighter bounds for graph steiner tree approximation. SIAM J. Discrete Math.19, 122–134. 10.1137/S0895480101393155
16
Swami P. Bhatia V. (2021). “Impact of distance on outage probability in irs-noma for beyond 5g networks,” in 2021 IEEE 18th Annual Consumer Communications Networking Conference (CCNC), Las Vegas, NV, USA, 09-12 January 2021, 1–2. 10.1109/CCNC49032.2021.9369548
17
Swami P. Mishra M. K. Bhatia V. Ratnarajah T. Trivedi A. (2022). Performance analysis of sub-6 ghz/mmwave noma hybrid-hetnets using partial csi. IEEE Trans. Veh. Technol.71, 12958–12971. 10.1109/TVT.2022.3198144
18
ur Rahman S. Kim G.-H. Cho Y.-Z. Khan A. (2018). Positioning of uavs for throughput maximization in software-defined disaster area uav communication networks. J. Commun. Netw.20, 452–463. 10.1109/JCN.2018.000070
19
Wang Z. Duan L. Zhang R. (2019). Adaptive deployment for uav-aided communication networks. IEEE Trans. Wirel. Commun.18, 4531–4543. 10.1109/TWC.2019.2926279
20
Wu Y. Zhang B. Yang S. Yi X. Yang X. (2017). “Energy-efficient joint communication-motion planning for relay-assisted wireless robot surveillance,” in IEEE INFOCOM 2017 - IEEE Conference on Computer Communications, Atlanta, GA, USA, 01-04 May 2017, 1–9. 10.1109/INFOCOM.2017.8057072
21
Xie J. Zhang B. Zhang C. (2020). A novel relay node placement and energy efficient routing method for heterogeneous wireless sensor networks. IEEE Access8, 202439–202444. 10.1109/ACCESS.2020.2984495
22
Yang S. Xu X. Alanis D. Xin Ng S. Hanzo L. (2016). Is the low-complexity mobile-relay-aided ffr-das capable of outperforming the high-complexity comp?IEEE Trans. Veh. Technol.65, 2154–2169. 10.1109/TVT.2015.2416333
23
Yanmaz E. (2021). Dynamic relay selection and positioning for cooperative uav networks. IEEE Netw. Lett.3, 114–118. 10.1109/LNET.2021.3080403
Summary
Keywords
relay node placement, heterogeneous network, mobile networks, unmanned aerial vehicle, heuristic method, steiner tree
Citation
Guffens E, Le Nir V, Lauwens B and Becquaert M (2025) Heuristic method for relay node placement in heterogeneous wireless network. Front. Commun. Netw. 6:1567560. doi: 10.3389/frcmn.2025.1567560
Received
27 January 2025
Accepted
09 April 2025
Published
30 April 2025
Volume
6 - 2025
Edited by
Rosdiadee Nordin, Sunway University, Malaysia
Reviewed by
Pragya Swami, Indian Institute of Technology Indore, India
Ahmad Bazzi, New York University Abu Dhabi, United Arab Emirates
Updates
Copyright
© 2025 Guffens, Le Nir, Lauwens and Becquaert.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Eliott Guffens, eliott.guffens@mil.be
Disclaimer
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.