 Xiaotong Qu
Xiaotong Qu Chengbo Wang
Chengbo Wang Ruijia Zhao
Ruijia Zhao Mingxing Fang2,4,5
Mingxing Fang2,4,5- 1Integrated Transport Institute, Transportation Engineering College, Dalian Maritime University, Dalian, China
- 2Anhui Engineering Research Center on Information Fusion and Control of Intelligent Robot, Wuhu, China
- 3Department of Automation, School of Information Science and Technology, University of Science and Technology of China, Hefei, China
- 4School of Physics and Electronic Information, Anhui Normal University, Wuhu, China
- 5Anhui Provincial Joint Key Laboratory on Information Fusion of Intelligent Automotive Cabin, Wuhu, China
Incomplete data significantly hampers risk analysis for high-sea maritime accidents (HSMAs). This paper introduces a novel multi-source data-driven Bayesian network (DDBN) framework to address this limitation. This framework initially integrates heterogeneous data from multiple sources, including accident reports, ship characteristics, environmental conditions, etc. The structural learning of the DDBN employs a hybrid, tri-source enhanced methodology. Informed by a two-stage risk evolution theory, this approach integrates evidence from structured data, text analysis, and expert knowledge to construct a unified network structure, ensuring that derived causal relationships align with both statistical evidence and domain expertise. Subsequently, the Expectation-Maximization algorithm is employed for parameter estimation to handle missing data. The findings indicate that although the accident type, sea area and ship type all contribute to the risk level of HSMAs, the gross tonnage is the most critical factor that directly affects the likelihood of an accident. The DDBN model achieves an accident prediction accuracy of 84.0%, with both precision and recall exceeding 75%. Furthermore, DDBN-based scenario analysis proactively identifies high-risk scenarios associated with specific accident types and gross tonnage, offering maritime authorities and operators an enhanced tool for risk assessment. This study provides a scientific basis for formulating targeted HSMA prevention strategies.
1 Introduction
With its advantages of low cost and high efficiency, maritime transport accounts for more than 80% of global trade (Goerlandt and Montewka, 2015; Wang et al., 2024a; Liu et al., 2025). However, the development of large-scale and high-speed ships has brought severe challenges to maritime security, especially in the high-sea area. The high-sea area usually refers to remote sea areas far away from the coastline and unable to quickly obtain land support (Xie et al., 2021). According to statistics, from 2014 to 2022, a total of 698 merchant ships over 100 tons were lost globally (Allianz Global Corporate & Specialty Company, 2024). Among more than 23,000 maritime casualties, 20.8% occurred in the high sea, with a rising trend year by year (European Maritime Safety Agency, 2023). Although maritime regulators, shipowners and other stakeholders have made tremendous efforts to enhance safety levels in terms of supervision, ship design improvements and risk management, accidents in the high sea still occur frequently. For example, on February 16, 2022, the cargo ship Felicity Ace caught fire near the Azores in the Atlantic Ocean. Although rescue efforts were made, the complexity of the high-sea environment and the out-of-control fire ultimately led to the total loss of the ship and more than 3,000 vehicles on board, with economic losses of more than $400 million (Göksu et al., 2023). Another pertinent case occurred on January 21, 2023, when a pump operator sustained a critical head injury while on duty at sea. The absence of prompt medical intervention was cited as a contributing factor to the worker’s death two days later (International Maritime Organization, 2023). These examples highlight that accidents in the high sea often lead to catastrophic consequences, including ship lost, loss of life, environmental pollution, and supply chain disruptions. Exacerbating this problem is that only a few ports and shipyards worldwide are equipped to handle such accidental ships (Xu et al., 2024). Therefore, there is an urgent need to develop scientific, rigorous and targeted risk analysis methods to assist decision makers in effectively identifying potential risks and thereby improve the safety level of high-sea navigation.
Addressing the severe challenges and inherent risks of maritime navigation necessitates the development of advanced risk analysis methods to enhance maritime safety. Traditional risk analysis techniques, such as Fault Tree Analysis (FTA) and risk matrix, have indeed played an important role in dealing with specific scenarios with clear causal chains and sufficient historical data (Cem Kuzu et al., 2019; Huang et al., 2023). However, these traditional methods exhibit significant limitations within the complex high-sea environment, which is characterized by data sparsity, diverse information sources, and high uncertainty. Specifically, their efficacy is often compromised by difficulties in integrating heterogeneous data, diminished reliability with incomplete or missing data, and an inability to adequately capture the non-linear, time-varying interactions among risk factors. Consequently, to address these deficiencies, leveraging the burgeoning volume of maritime data for risk analysis has emerged as a prominent trend, fostering the innovation and application of data-driven methodologies in maritime safety. These methods, especially machine learning and probabilistic graphical models, have shown great potential in mining potential patterns in complex data, handling uncertainties, and modeling complex dependencies between variables (Chen et al., 2023; Li et al., 2023; Fan et al., 2024). Among many data-driven technologies, Bayesian networks (BNs) have attracted much attention due to their unique advantages: (1) they can effectively integrate quantitative and qualitative information from different sources; (2) they can still perform robust probabilistic reasoning in the absence of data; (3) they explicitly model the potential causal or correlation relationships between variables and build highly interpretable risk models, which is crucial for understanding the mechanism of accidents (Marcot and Penman, 2019). These characteristics make BNs an ideal tool for addressing the challenges of data heterogeneity, incompleteness, and relationship complexity in high-sea accident risk analysis.
In view of this, this paper proposes a multi-source DDBN framework, which aims to make full use of the core advantages of BNs and innovatively adopt a hybrid, three-source enhanced methodology to provide an accurate and comprehensive analysis method for accident risks in the high sea. The main innovations of this paper are as follows.
1. To the best of the author’s knowledge, this is the first model to quantitatively assess the risk of HSMAs informed by a two-stage risk evolution perspective. It comprehensively considers factors including the ship, environment, management, and human elements, effectively filling the gap in maritime accident assessment from the high-sea perspective.
2. A new adaptive variable state definition method combining domain knowledge has been developed, which can objectively and accurately divide the state based on data characteristics, laying the foundation for DDBN modeling.
3. Most importantly, a hybrid three-source enhanced structural learning method is proposed. The new method innovatively integrates structured data patterns, text mining insights, and expert knowledge to build a network structure that is more consistent with causal logic and reality.
The rest of this paper is organized as follows. Section 2 provides a literature review on maritime accident research and maritime applications of BN. Section 3 introduces the proposed risk analysis framework, multi-source data, and related method. Section 4 provides the results and discussion of the high-sea accident risk analysis. Finally, Section 5 concludes the paper.
2 Literature review
Maritime safety is a critical global concern, attracting significant research focused on risk analysis, management, maritime accident, and policy (Luo and Shin, 2019; Chen et al., 2020; Xu et al., 2023). However, extant research has predominantly focused on port and coastal water scenarios (Pan et al., 2021; Wang et al., 2024b). This predominant focus has resulted in maritime accidents within the challenging high-sea environment remaining comparatively understudied. The unique characteristics of the high sea, such as vast distances, harsh conditions, pervasive data limitations, and complex Search and Rescue (SAR) logistics, present distinct difficulties for comprehensive risk analysis (Song et al., 2023). Consequently, addressing HSMAs represents a significant research gap requiring dedicated investigation.
Maritime accidents arise from complex interactions among human factors, adverse environmental conditions, and ship failures, with strong coupling between these elements hindering effective risk assessment (Deng et al., 2021). To address this, the International Maritime Organization’s (IMO) Formal Safety Assessment (FSA) framework (Zhou et al., 2020) provides structured decision support. Driven by the FSA methodology, traditional risk analysis approaches, utilizing quantitative techniques like FTA and qualitative methods such as the Human Factors Analysis and Classification System (HFACS), are widely applied in maritime accidents. For instance (Chen et al., 2013), employed HFACS for a detailed investigation and classification of human factors in maritime accidents. In turn (Zhang et al., 2019), combined the strengths of HFACS with FTA to identify collision risk factors for icebreakers operating in ice-covered waters. Nevertheless, a significant limitation of these traditional approaches lies in their inherent challenges in rigorously managing uncertainty and adequately modeling the intricate probabilistic causal dependencies among diverse risk factors, which is essential for robust risk understanding and prediction.
To overcome these limitations, BNs have emerged as a powerful probabilistic graphical modeling approach, adept at representing complex dependencies and reasoning effectively under uncertainty (Afenyo et al., 2017; Jiang and Lu, 2020b). Their suitability for handling uncertainty and integrating diverse information sources in maritime safety management and decision support has been well-documented (Hänninen, 2014).
While early BN applications in maritime safety were primarily expert-driven (Fu et al., 2023; Li et al., 2024), the advent of maritime Big Data, characterized by increasing volume, velocity, and variety from sources like Automatic Identification System (AIS), Vessel Traffic Services (VTS), sensor networks, and textual incident reports (Chen et al., 2020; Wang et al., 2024a), has significantly fueled a shift towards data-driven methods. These approaches leverage Big Data analytics techniques to learn network structure and parameters automatically from extensive and heterogeneous historical records, thereby reducing subjectivity and potentially uncovering complex, hidden dependencies. For instance (Fan et al., 2020), employed a data-driven BN on large-scale incident datasets to assess human factor risks, identifying key contributors across accident types. In the same year (Jiang and Lu, 2020a), utilized a dynamic BN learned from extensive spatio-temporal accident data to evaluate risks in specific sea lanes. Two years later (Fu et al., 2022), also demonstrated the synergy of BNs with other accident analysis techniques like AcciMap to enhance causal identification in stranding accidents, often drawing insights from combined data sources.
Despite advancements showcasing DDBN utility, significant obstacles persist, particularly when analyzing complex high-sea accidents within the current maritime Big Data landscape. Addressing high-sea specific risks, effectively managing diverse and incomplete multi-source data, and ensuring learned structures align with domain knowledge are critical unmet challenges (Xu et al., 2024). These challenges constitute the starting point and core focus of this study.
To address these specific issues, this study proposes a novel multi-source DDBN framework designed for the high-sea environment. The framework systematically handles the heterogeneity and incompleteness of the data, especially adopting the Expectation-Maximization (EM) algorithm for parameter estimation. The structure learning adopts a hybrid three-source enhanced algorithm and integrates structured data patterns, text mining insights, and expert knowledge to enhance causal validity. The goal of this study is to develop an accurate and reliable tool with plausible causal relationships for assessing and mitigating accident risks in challenging high-sea environments.
3 Materials and methods
Section 3 outlines the materials and methods used in this study to assess the risk of HSMAs. Initially, section 3.1 presents the overall risk analysis framework that guided the research process. Section 3.2 then describes the relevant materials used. Finally, building upon this foundation, Section 3.3 details the key methodological steps, including the identification and state definition of risk influencing factors (RIFs), the construction of the DDBN model, its rigorous validation, and the subsequent sensitivity analysis.
3.1 Risk analysis framework
The mechanism of HSMAs is complex, involving multi-source heterogeneous information such as the ship’s own status and external environmental conditions, and has the characteristics of uncertainty and high complexity. To address these multifaceted challenges, this paper introduces a systematic DDBN-based risk analysis framework, depicted in Figure 1. The framework aims to ensure the rigor of risk analysis through a structured process and ultimately provide reliable decision support for high-sea navigation safety. The framework is divided into four key steps: (1) Data preparation focuses on integrating multi-source heterogeneous data and defining key RIFs. (2) DDBN model construction involves building the probabilistic risk model using a tri-source enhanced structural learning method and parameter estimation. (3) Model validation and analysis aims to assess the model’s predictive accuracy, logical coherence, and the sensitivity of key RIFs. (4) Model application utilizes the model for risk inference and scenario simulation to identify high-risk situations and support accident prevention decisions.
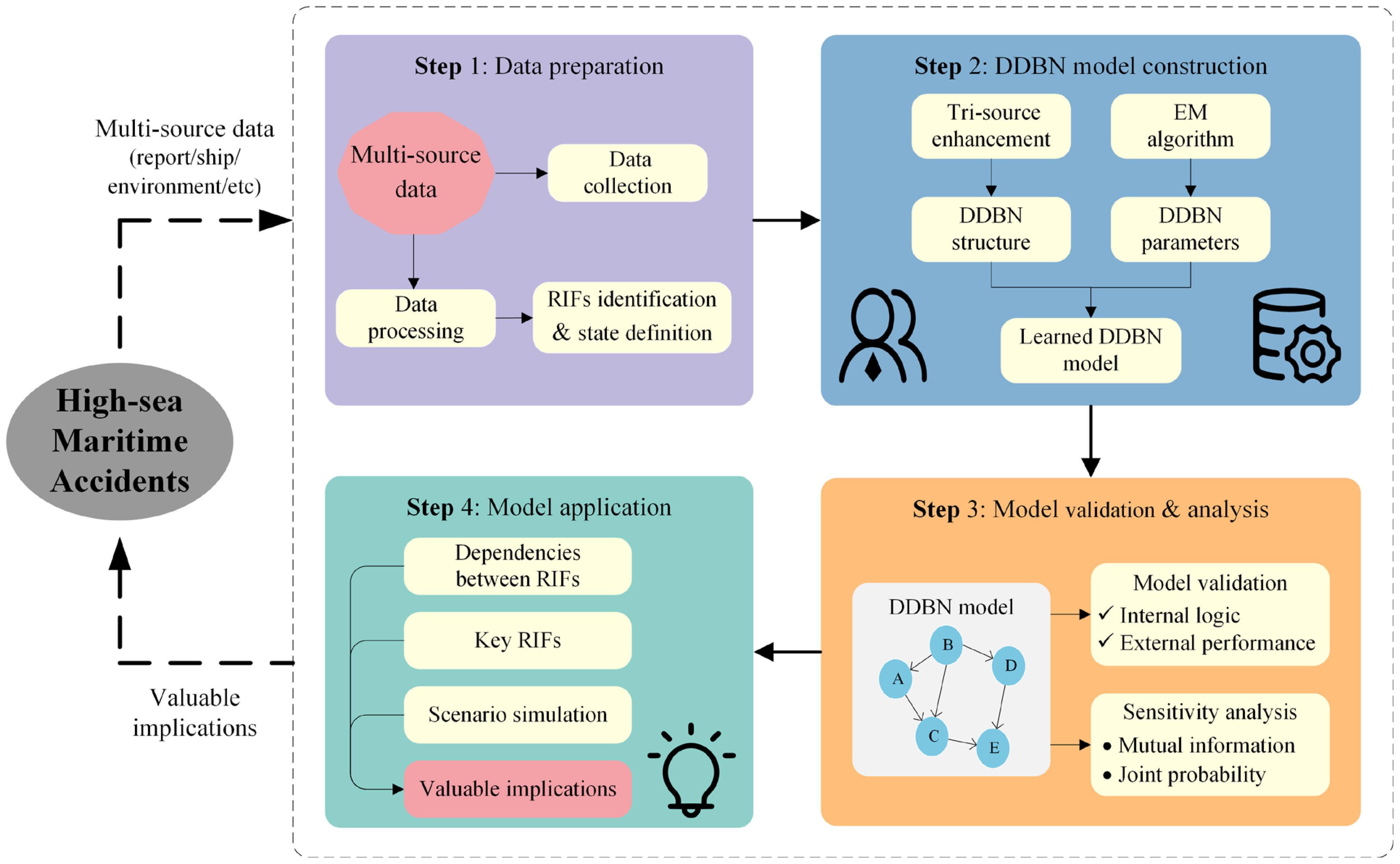
Figure 1. DDBN-based risk analysis framework for HSMAs.
3.2 Materials
3.2.1 Study scope and definitions
This study statistically analyzes global maritime accidents from 2005 to 2022 based on navigational area and accident risk, with the findings presented in Figure 2. For this analysis, navigational areas are categorized as inland waters, internal waters, territorial sea, and the high sea. Accident risk, following IMO standard MSC-MEPC.3/Circ.1, is categorized as very serious, serious, or less serious. In this study, we define ‘high-risk accidents’ as those resulting in ‘very serious’ consequences. Thus, the ‘High-risk accidents ratio’ in Figure 2 denotes the proportion of ‘very serious’ accidents to the total number of accidents within a given water area.
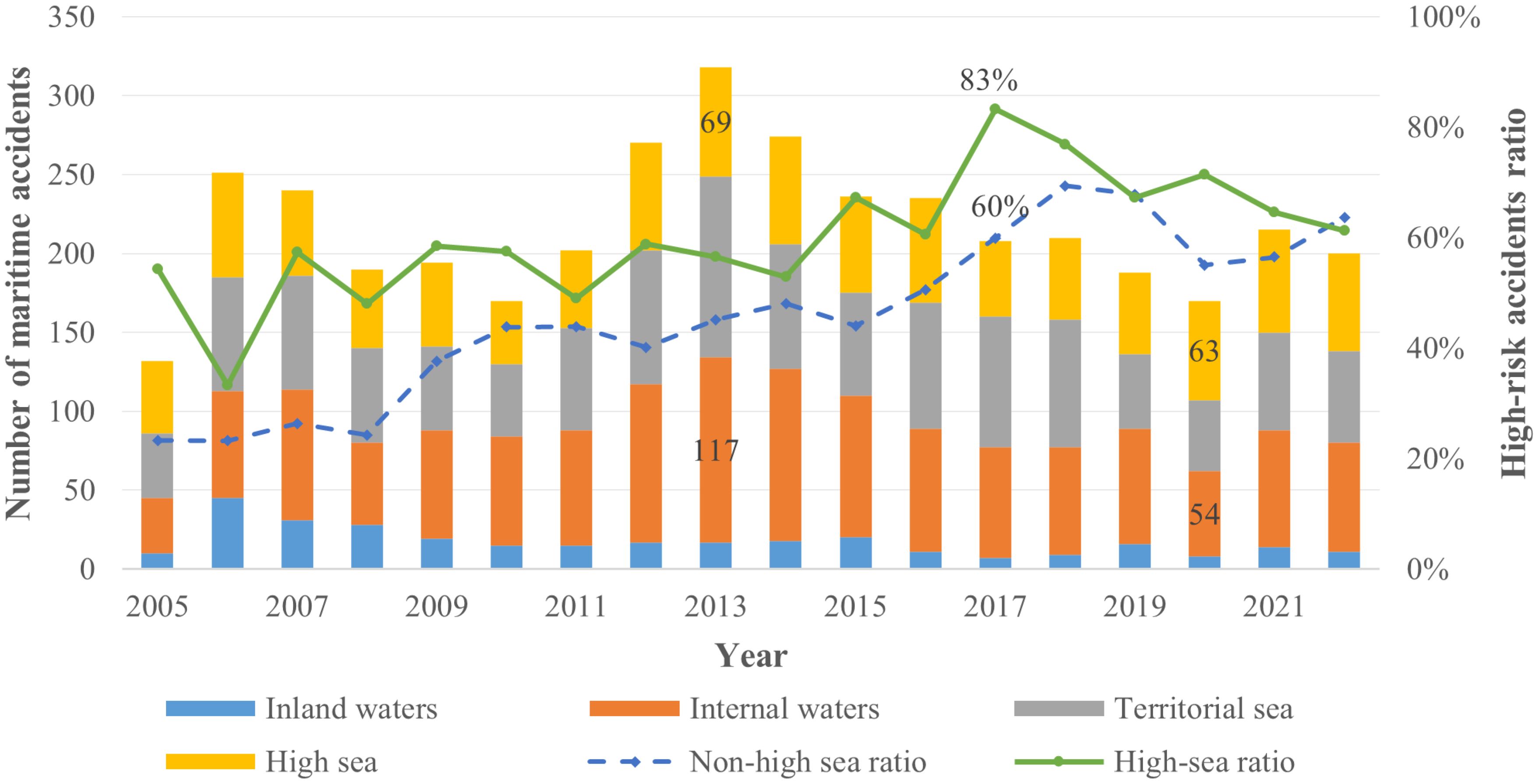
Figure 2. Annual maritime accidents by navigational areas and high-risk ratios.
Figure 2 illustrates an overall downward trend in total global maritime accidents since 2013, indicative of continuous improvements in global maritime safety governance. Notably, however, the number of accidents in the high sea did not correspondingly decrease significantly during this period, even remaining relatively stable in some years. For example, comparing data from 2013 (117 inland water accidents, 69 high-sea accidents) with 2020 (54 inland water accidents, 63 high-sea accidents) clearly shows that safety challenges in high-sea areas remain severe and are relatively independent of this general trend.
Further analysis reveals that HSMAs exhibit not only limited quantitative improvement but also a propensity for more severe consequences. Indeed, data indicate that the proportion of high-risk accidents in high-sea areas (the ‘High-sea ratio’) generally exceeds that in non-high-sea areas. In 2017, for instance, the high-risk accident ratio in high-sea areas was approximately 83%, significantly surpassing the circa 60% in non-high-sea areas for that year. This high-risk profile is commonly attributed to the inherently adverse natural conditions of the high seas, limitations in the geographical accessibility of rescue assets, and the relative deficiencies in emergency response and logistical support capabilities. In view of the persistence of high-sea accidents, the extreme severity of their repercussions, and the unique genesis of their risks, this study designates the risk analysis of HSMAs as its core research focus.
3.2.2 Multi-source data collection and processing
A comprehensive HSMA dataset is constructed for this study, employing a multi-source data fusion strategy. The primary data, comprising high-sea accident summaries and investigation reports (2014-2022), originates from the IMO’s Global Integrated Shipping Information System (GISIS). This core dataset is augmented by meteorological/hydrological data from the European Centre for Medium-Range Weather Forecasts (ECMWF), vessel specifications from the Electronic Quality Shipping Information System (EQUASIS) and Lloyd’s Register Fairplay (LRF), and port proximity data from public port authority records. Data linkage accuracy across these diverse sources is ensured via IMO and Maritime Mobile Service Identity (MMSI) numbers, establishing a foundation for comprehensively capturing multi-dimensional RIFs including ship, environment, management, and human.
Adhering to predefined spatio-temporal boundaries, the data collection phase involves gathering detailed qualitative and quantitative information for each HSMA case. Where necessary, cross-database record linkage, again utilizing IMO and MMSI numbers, is performed to consolidate all pertinent information for individual ships and incidents. This meticulous approach ensures the consistency and completeness of the dataset before its subsequent analysis.
The collected data subsequently underwent a meticulous two-stage (TS) processing workflow to ensure its quality and suitability for modeling. Stage one focused on data cleaning and completion, which involved the removal of duplicate and irrelevant entries, alongside the imputation of missing values for key variables using supplementary data sources. Stage two consisted of data validation and filtering, where records exhibiting internal inconsistencies, ambiguous information, or insufficient detail were manually reviewed and excluded. Completion of these procedures yielded a final dataset of 472 HSMA cases, forming the empirical foundation for the construction and analysis of the DDBN model.
3.3 Methods
3.3.1 RIFs identification and state definition
Identifying RIFs for HSMAs is a fundamental step in constructing a robust risk analysis model. This study employes a systematic, multi-source approach to identify these RIFs, which primarily encompassed: (1) an extensive literature review focusing on the causative factors of maritime accidents and established safety frameworks; (2) an in-depth analysis of high-sea accident investigation reports from the IMO’s GISIS database; and (3) iterative consultation and validation with domain experts. From a system safety theory perspective, the identified potential RIFs were subsequently categorized into four main dimensions: ship, environment, management, and human.
These identified RIFs collectively determine the safety level of high-sea navigation. To effectively represent these factors within the DDBN model, this study integrates both quantitative data and qualitative knowledge. Table 1 systematically summarizes the RIFs selected for this research, detailing their categorization, data processing types, and the rationale for their inclusion, critically including their selection basis. The ‘Selection basis’ column in Table 1 clarifies the primary and secondary evidence supporting the inclusion of each RIF. To ensure the reliability and relevance of expert knowledge throughout crucial phases such as RIF selection, state definition, and model structure optimization, a panel of experts with extensive experience in pertinent domains is consulted; their professional backgrounds are provided in Table A1.
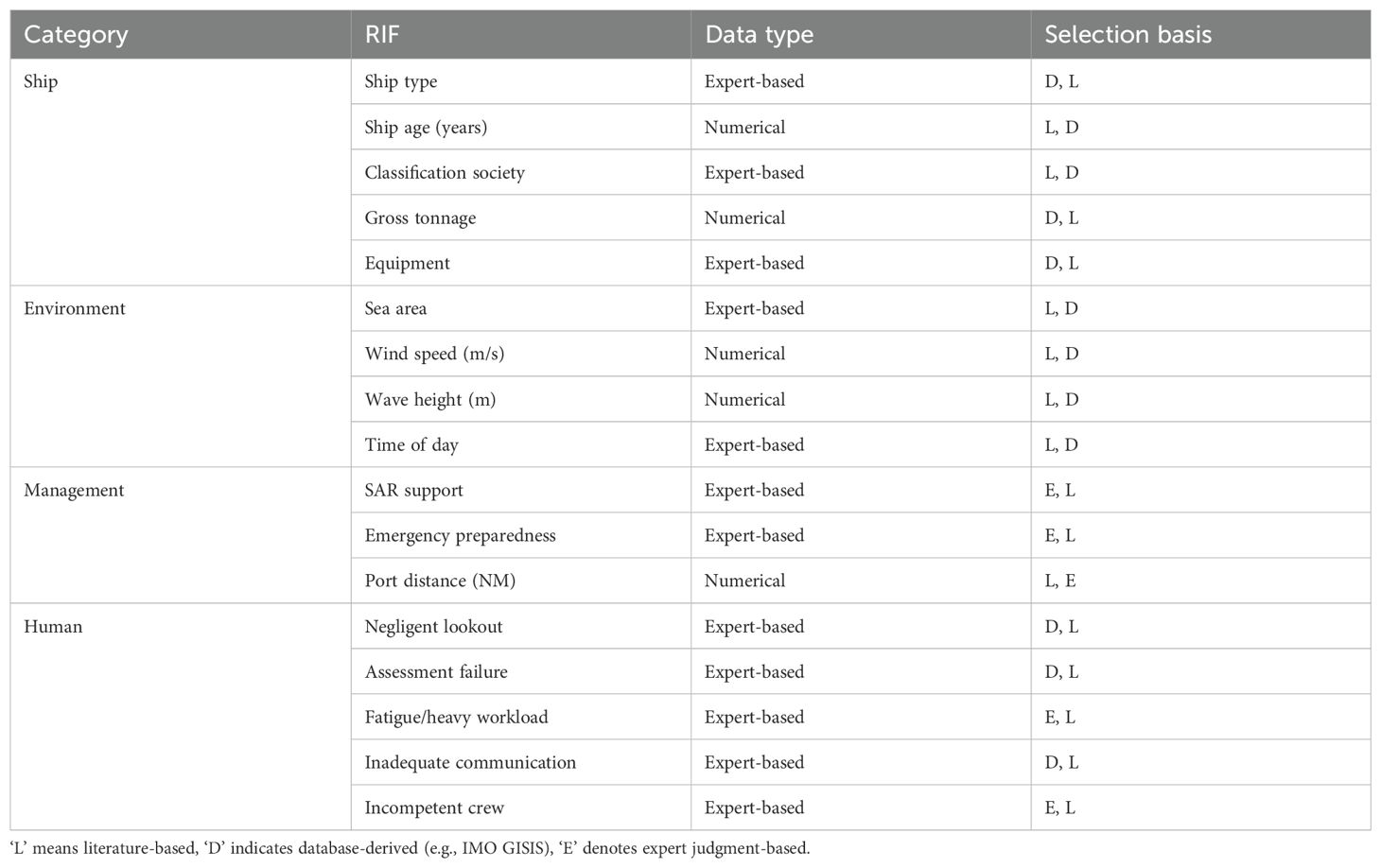
Table 1. RIFs for HSMAs: categories, data types, and selection basis.
Subsequent to RIF identification, defining discrete states for each node is crucial in BN modeling. To overcome limitations of traditional expert-defined thresholds, such as subjectivity, this study employes a Stratified Expert-Integrated Discretization (SEID) method. For ‘expert-based’ RIFs with clear standards (e.g., ‘Classification society’ as ‘Registered’/’Unregistered’), SEID adopts these predefined categories. For ‘numerical’ RIFs (e.g., ‘Ship age’), initial intervals are partitioned using supervised discretization, such as our Supervised Cause-based Interval Merging (SCIM) method (Chen et al., 2024), which leverages accident cause distributions within intervals.
These initial data-driven partitions then undergo expert validation. Experts assess the practical significance and operational relevance of intervals, adjusting boundaries to align with critical safety thresholds or established maritime practices not algorithmically captured. For example, a statistically derived ship age bracket might be refined to reflect maintenance cycles. This hybrid SEID process balances data objectivity with expert insight, enhancing the credibility and utility of node state definitions, detailed for the final 19 nodes in Table A2.
3.3.2 DDBN model construction
A DDBN model is defined by a network structure, G, and a set of parameters, . For any given set of n variables, X = {X1 ,…, Xn}, their joint probability distribution over specific instantiations, , can be factorized using the chain rule, as shown in Equation 1:
Here, denotes the set of parent nodes of in the graph G. The conditional probability distributions, , are parameterized by . For discrete variables, these distributions are typically represented as Conditional Probability Tables (CPTs). This factorization forms the fundamental basis for performing probabilistic inference and prediction with BNs.
In this study, we employ a hybrid, tri-source enhanced algorithm for learning the network structure G; subsequently, the EM algorithm is utilized to estimate the parameters from multi-source data, which may contain missing values. The subsequent subsections will respectively detail the structural learning and parameter estimation algorithms employed.
Structural learning for BNs, which involves defining the directed acyclic graph G, primarily relies on two main approaches: data-driven algorithms and expert knowledge-based construction. Data-driven methods, such as Tree-Augmented Naive Bayes (TAN), excel at discovering statistical dependencies but may overlook contextual information or deeper causal relationships (Kamal and Çakır, 2022). Conversely, approaches that depend solely on expert knowledge are challenged by subjectivity and potential incompleteness. Consequently, hybrid methods have emerged, aiming to integrate data-derived evidence with expert insights to construct more robust and reliable network structures (Fan et al., 2024).
To this end, this study proposes a novel hybrid structural learning algorithm, termed the Tri-Source Enhanced Two-Stage (TSETS) algorithm. Figure 3 illustrates a comparison of network structures derived from: Figure 3a Naive Bayes (NB) and Figure 3b TAN, representing common BN learning approaches; Figure 3c a foundational TS structure that serves as a precursor; and Figure 3d the final, optimized structure obtained through the TSETS algorithm. These structures, particularly NB, TAN, and TS, also serve as baselines for the performance evaluation discussed later.
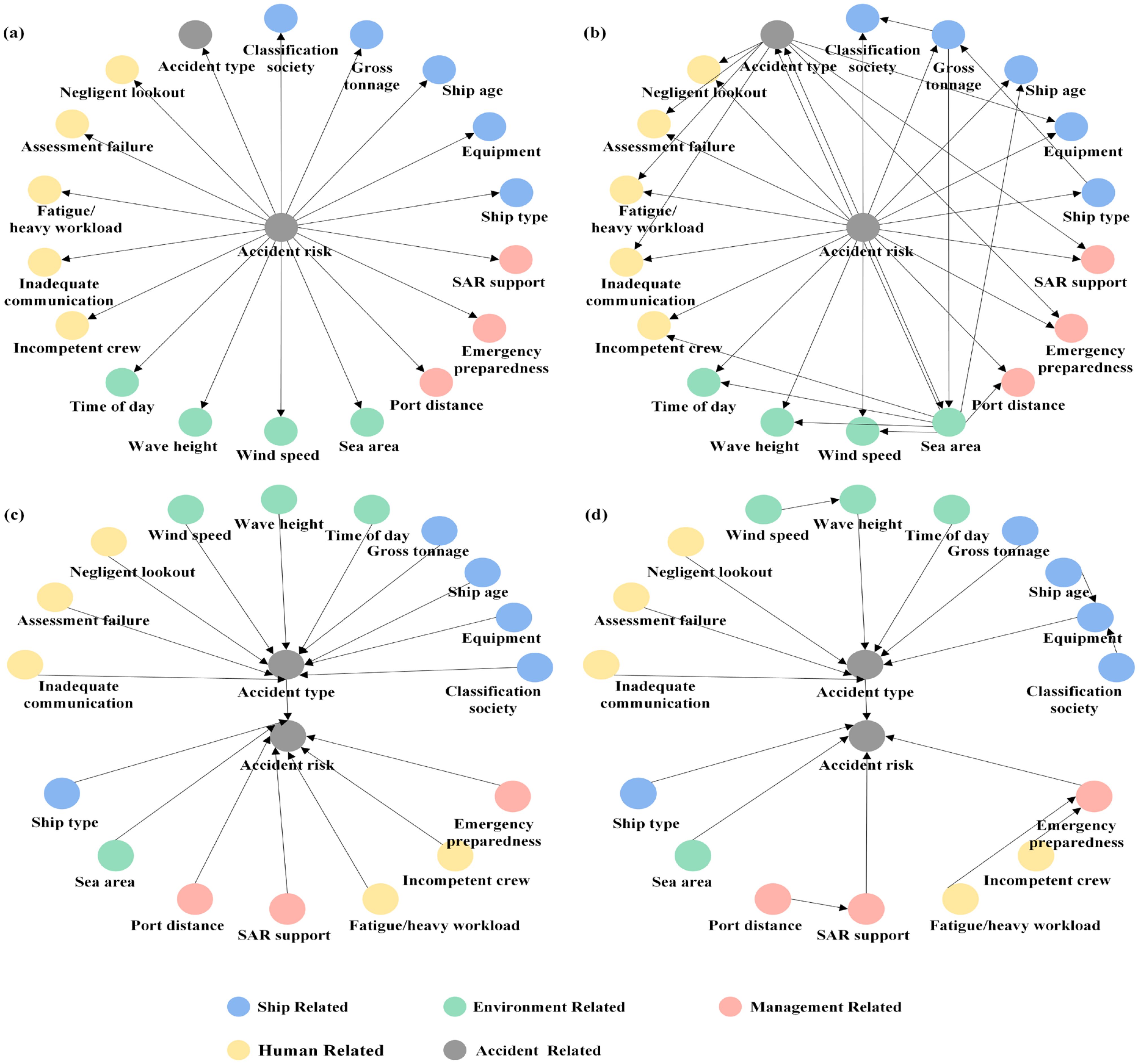
Figure 3. The structure of NB (a), TAN (b), TS (c) and TSETS (d).
The core of the TSETS algorithm lies in the systematic, multi-source evidence-driven enhancement and refinement of a given TS foundational structure (as depicted in Figure 3c). This method innovatively integrates three distinct types of information sources: statistical dependency patterns derived from structured data, relationships extracted from unstructured textual narratives, and domain expert judgments. The specific procedural steps of the TSETS algorithm are detailed in Table 2.

Table 2. Process of the TSETS Algorithm.
Once the final DDBN structure, G, is established, the subsequent critical task is parameter learning to determine the conditional probability distribution for each node. The presence of incomplete data in this study’s dataset, exemplified by missing vessel information for fishing boats and unrecorded occurrence times for some accidents, renders standard Maximum Likelihood Estimation (MLE) methods inapplicable. Consequently, the widely-used EM algorithm (Yang et al., 2019) is adopted for parameter estimation, as it is particularly well-suited for learning parameters in probabilistic models with missing data.
The essence of the EM algorithm is to find the maximum likelihood estimate for parameters by iteratively processing an incomplete dataset X, which comprises an observed part (A) and a missing part (B). The EM algorithm consists of two steps: the Expectation (E) step and the Maximization (M) step. These are detailed as follows:
E-step: Given the current parameter estimate , calculate the expectation of the complete-data log-likelihood function with respect to the conditional distribution of the missing data B given A and . This expected log-likelihood, often denoted as the Q-function, is defined as:
M-step: Maximize the Q-function with respect to to obtain the updated parameter estimate :
The algorithm iterates between the E-step and M-step until converges. Upon convergence, the algorithm terminates and outputs the optimal DDBN parameters . Otherwise, the E and M steps are repeated.
3.3.3 Model validation
Following the construction of the DDBN model, its rigorous validation is a critical step for assessing reliability and effectiveness. This study employs a dual-dimension validation strategy, integrating an internal logical consistency review with an external predictive performance evaluation.
The internal logical consistency review is primarily conducted using an axiomatic approach (Fan et al., 2023; Li et al., 2023). Axiom 1 stipulates that a slight increase or decrease in the prior probability of a parent node should induce a corresponding directional change in the posterior probability of its child node. Axiom 2 mandates that the overall impact of a combination of evidence must be no less than the impact of any subset of that evidence.
External performance evaluation focuses on quantifying the DDBN model’s predictive accuracy and generalization capability on unseen data (Jiang et al., 2020). This study utilizes randomly allocated training and test sets to calculate four standard performance metrics derived from a confusion matrix (Table 3). In addition to overall accuracy (i.e. Equation 4), particular emphasis is placed on precision (i.e. Equation 5), recall (i.e. Equation 6), and the F1-score (i.e. Equation 7). These metrics are employed to comprehensively assess the model’s predictive performance and discriminatory power, especially when addressing potential class imbalance in the data.

Table 3. The confusion matrix.
3.3.4 Sensitivity analysis
Initially, a preliminary sensitivity analysis is conducted using Mutual Information (MI) to quantify the strength of statistical dependence between each RIF and the target node. MI effectively identifies key RIFs that have a significant influence on the target node. The MI is calculated as shown in Equation 8:
where T denotes the target node, and R represents any given RIF. is the joint probability distribution of T and R, while and are the marginal probability distributions of T and R, respectively. A higher MI value indicates a stronger statistical association between the RIF and the target node.
Secondly, for the key RIFs identified and ranked by their MI values, a parameter sensitivity analysis is conducted. This analysis involved sequentially setting each state of a selected key RIF as deterministic evidence (i.e., 100% probability) and then utilizing Bayesian network inference to calculate the posterior probability of the target node, ‘accident risk,’ under that specific condition. By comparing the variations in the target node’s probability as the RIF assumes different states, the specific degree of impact and the influence patterns of each particular state of that RIF on the ‘accident risk’ probability could be precisely and quantitatively revealed. This process thereby provided stakeholders with valuable insights and decision support for identifying critical risk points and formulating targeted risk mitigation strategies.
4 Results and discussion
4.1 Learned DDBN model
First, we construct the DDBN network structure using the TSETS algorithm, as detailed in Table 2. Second, we employ the EM algorithm, formulated in Equations 2, 3, to learn the CPT for each node. Finally, the TSETS-based model for high-sea accident risk proposed in this study is depicted in Figure 4.
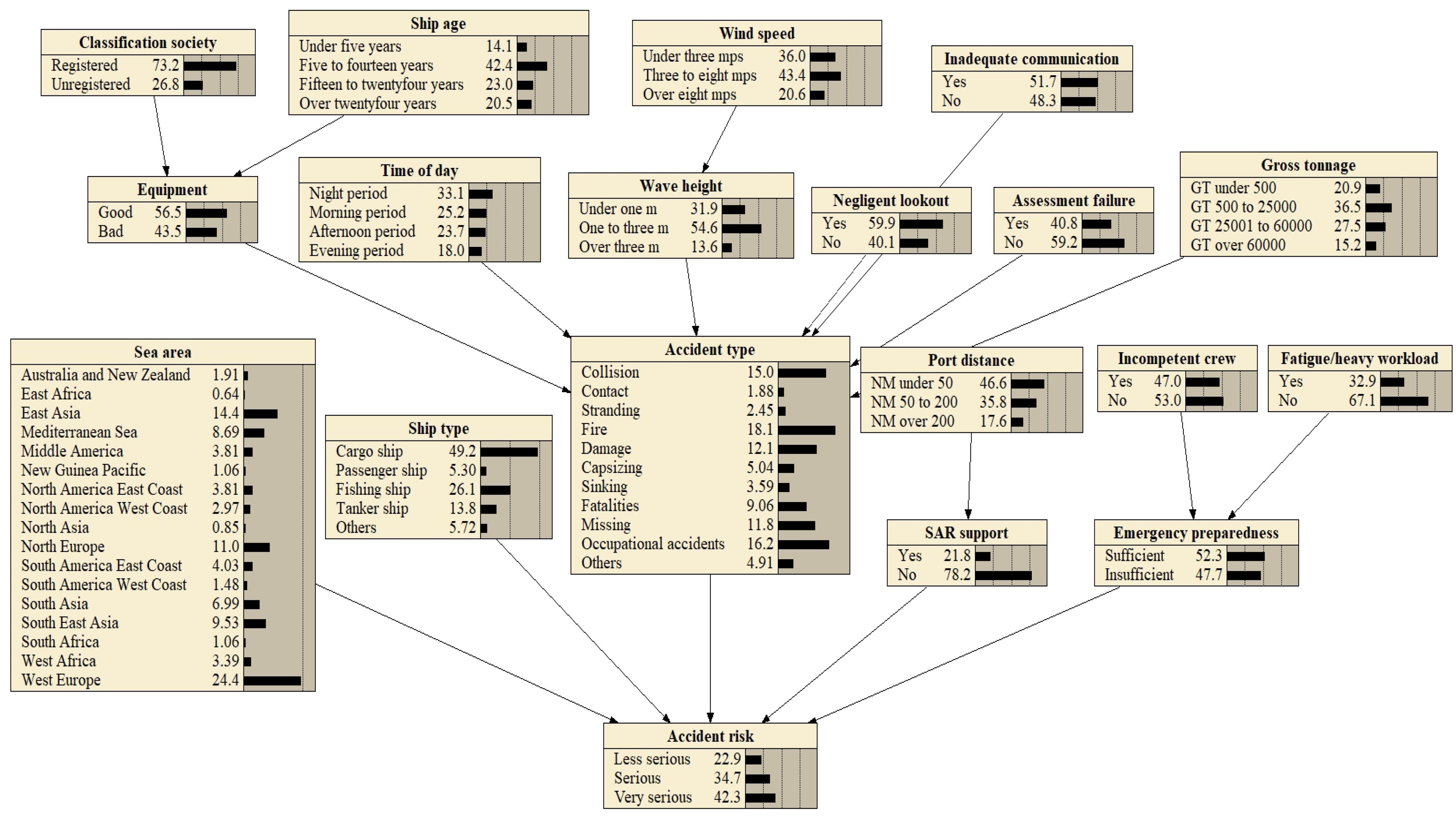
Figure 4. The TSETS-based DDBN model created for HSMAs.
Figure 4 reveals several new patterns concerning the occurrence of HSMAs. Firstly, fire (18.1%) emerge as the most common type, followed by occupational accidents (16.2%) and collision (15.0%). Secondly, the probability of ships experiencing ‘very serious’ consequences from accidents in the high sea is notably high, at approximately 42.3%. These findings suggest that stakeholders should enhance the training of ocean-going seafarers and conduct regular safety drills, encompassing first aid and firefighting. Crucially, maintaining a proper lookout is essential for ensuring safe vessel navigation, even in the high sea. The subsequent analysis will examine the specific circumstances of HSMA occurrence from four dimensions: ship, environment, management, and human factors, to aid stakeholders in formulating targeted accident prevention measures.
Cargo ships (49.2%) are the ship type most frequently involved in high-sea accidents, followed by fishing ships (26.1%). Ships aged between 5 and 14 years (42.4%) exhibit the highest likelihood of experiencing high-sea accidents, and equipment failure is present in 43.5% of accident-involved ships. Among ships involved in high-sea accidents, 26.8% are not registered with a classification society, and those with a gross tonnage (GT) between 500 and 25,000 account for the largest proportion (36.5%). Therefore, stakeholders should strengthen safety management for cargo ships and fishing ships. Furthermore, ship age, GT, and classification society registration can serve as key reference points when selecting ocean-going ships.
Western Europe (24.4%) is the sea area with the highest incidence of high-sea accidents, followed by East Asia (14.4%). The accident occurrence rate is highest during the early morning hours, accounting for approximately 33.1% of incidents. While 20.6% of high-sea accidents occur in strong wind conditions, only 13.6% take place in heavy sea conditions. Therefore, vigilance must be maintained even in favorable wind and sea conditions, and seafarers should intensify monitoring, particularly during nighttime navigation. For high-frequency accident areas in the high seas, regulatory oversight and emergency response capabilities ought to be appropriately enhanced.
Although only 17.6% of accident-involved ships are located more than 200 nautical miles from port at the time of the incident, merely 21.8% of ships in high-sea accidents receive SAR support. Furthermore, only 52.3% of ocean-going ships demonstrate effective emergency preparedness. Consequently, there is a need to strengthen high-sea safety training and accelerate the development of high-sea emergency support infrastructure to ensure rapid and effective assistance can be accessed following an accident.
Lack of communication, negligent lookout, fatigue/heavy workload, incompetent crew, and assessment failures are identified as the primary human factors contributing to the occurrence of high-sea accidents. Therefore, communication training should be enhanced to improve the efficiency and accuracy of intra-crew communication. Additionally, providing necessary mental health counseling is recommended to help seafarers cope with the occupational stress of working at sea.
4.2 Model performance and validation
The DDBN model’s internal logical consistency is verified using a two-axiom approach. For this, ‘classification society’ and ‘ship age’ are selected as risk nodes, and ‘equipment’ (initial ‘bad’ state probability: 43.5%) serves as the target node. When the probability of the risk node ‘classification society’ being ‘unregistered’ is notionally increased by 10 percentage points (which implies a corresponding 10 percentage point decrease for the ‘registered’ state), the ‘bad’ state probability of ‘equipment’ rises from 43.5% to 43.9%. This outcome satisfies Axiom 1. Subsequently, while maintaining this evidence, applying a similar 10 percentage points notional probability increase to ‘ship age’ being ‘over twenty-four years’ further elevates the ‘equipment’ ‘bad’ state probability from 43.9% to 44.4%. This incremental increase in the target node’s risk with cumulative adverse evidence aligns with Axiom 2, thus confirming the model’s logical coherence.
External performance evaluation (Table 4) compares the proposed TSETS structure with NB, TAN, and a foundational TS structure. These baselines were selected to provide a comprehensive benchmark: NB serves as a simple probabilistic classifier baseline, TAN represents a standard data-driven BN learning approach, and the TS structure allows for direct assessment of the improvements gained from TSETS’s tri-source enhancement. While purely data-driven approaches like TAN exhibit strong predictive metrics (e.g., TAN OA: 0.860), they may overlook deeper causal understanding. In contrast, our TSETS algorithm enhances a foundational structure by systematically integrating statistical patterns, textual insights, and expert knowledge, achieving a robust overall accuracy of 84.0% and a high F1-score (0.870) for ‘very serious’ accidents. This compelling balance between strong predictive performance and superior causal plausibility and interpretability, led to the selection of the TSETS algorithm for learning the DDBN topology in this study.
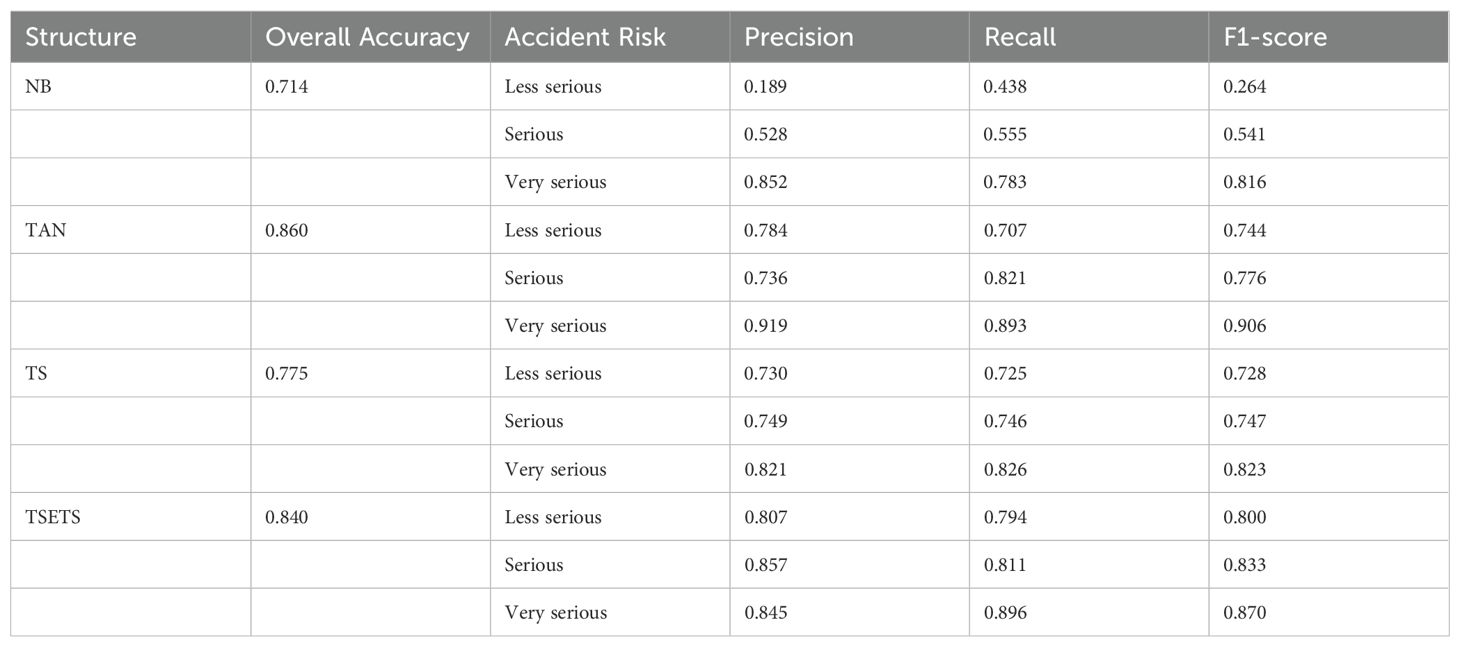
Table 4. Performance comparison of different DDBN structures.
4.3 Sensitivity analysis results
This study employs the MI method to conduct sensitivity analysis, with the MI calculation detailed in Section 3.3.4. MI is a statistical measure that quantifies the degree of mutual dependence between two nodes, where a higher MI value signifies a stronger interrelation. Table 5 presents the sensitivity analysis results for two target nodes: ‘accident risk’ and ‘accident type.’
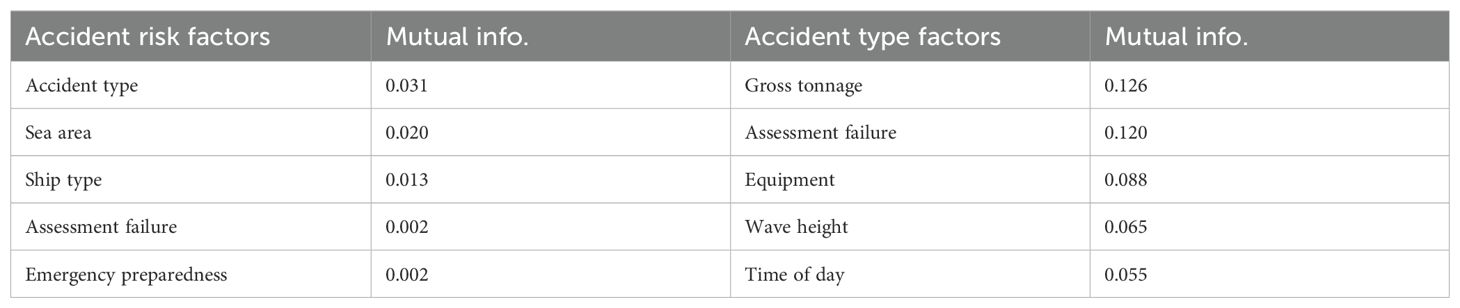
Table 5. Top factors affecting accident risk and accident type.
According to the MI values presented in Table 5, when ‘accident risk’ serves as the target node, ‘accident type’ exhibits the strongest influence, with an MI value of 0.031. Furthermore, variables with MI values ranging between 0.01 and 0.03, namely ‘sea area’ and ‘ship type,’ also demonstrate a significant impact on ‘accident risk.’ Conversely, the ‘assessment failure’ and ‘emergency preparedness’ variables exert a relatively weaker influence on the target node, with their respective MI values being only 0.002.
When ‘accident type’ serves as the target node, ‘gross tonnage’ exerts the most substantial influence, with a MI value of 0.126. This is closely followed by ‘assessment failure,’ with an MI value of 0.120, indicating that ‘assessment failure’ is a strong influencer of ‘accident type.’ Furthermore, variables with MI values ranging between 0.05 and 0.1—namely ‘equipment,’ ‘wave height,’ and ‘time of day’—also demonstrate a significant impact on ‘accident type.’
In summary, the MI values reveal that ‘assessment failure’ is a significant influencing factor for both ‘accident type’ and ‘accident risk.’ Additionally, ‘sea area’ notably impacts ‘accident type.’ These observations collectively underscore the appropriateness and necessity of incorporating risk factors such as ‘sea area’ and ‘assessment failure’ into the risk analysis framework for HSMAs.
4.4 Scenario simulation and analysis
Scenario analysis allows for the exploration of how different states of RIFs potentially impact high-sea risk, thereby yielding valuable insights. Based on the preceding sensitivity analysis results, this study separately investigates the potential impact of different GT states on accident types (first stage) and the potential impact of different accident types on overall accident risk (second stage), as depicted in Figures 5, 6, respectively.
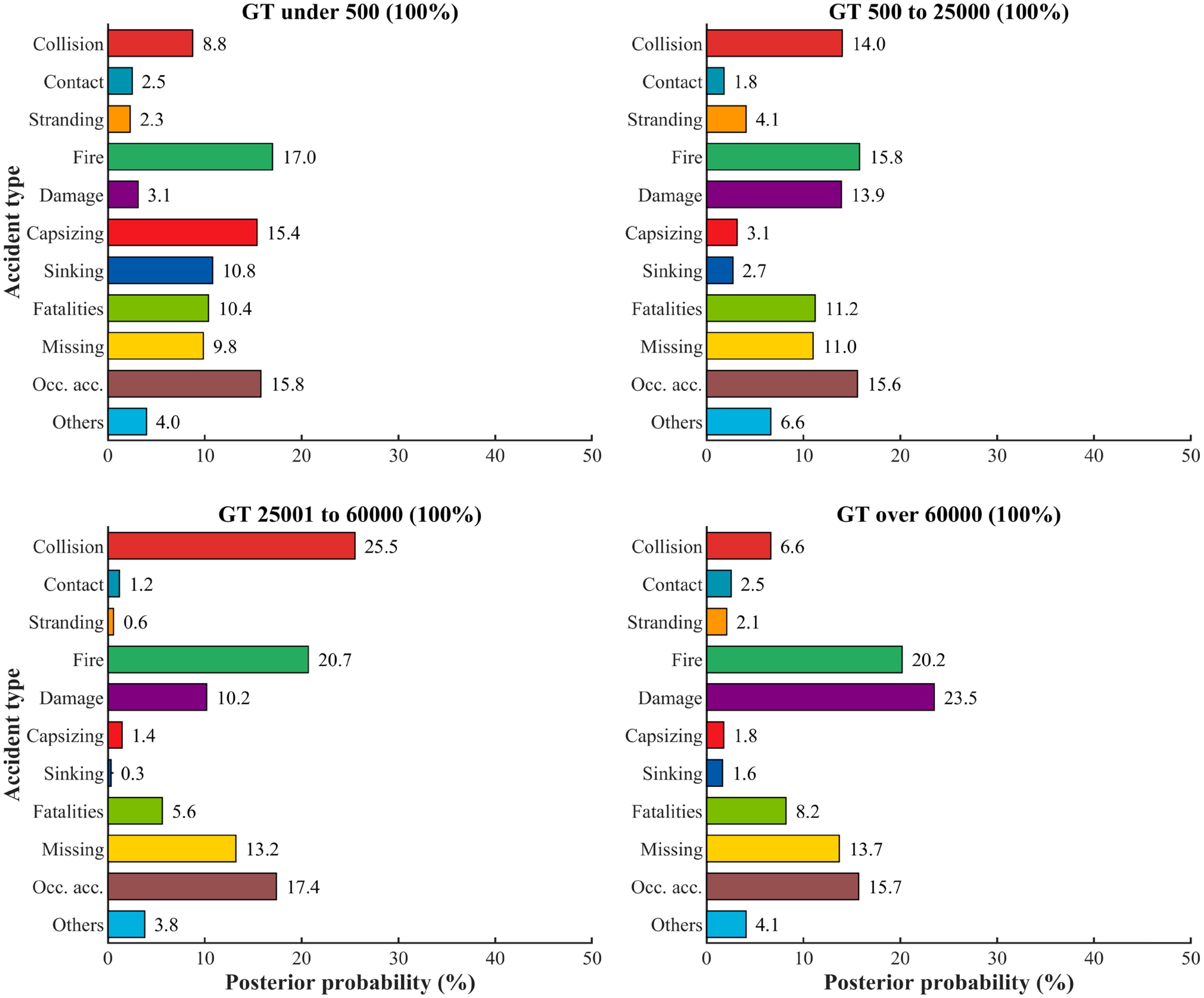
Figure 5. Probability distribution of accident types by GT in scenario one.
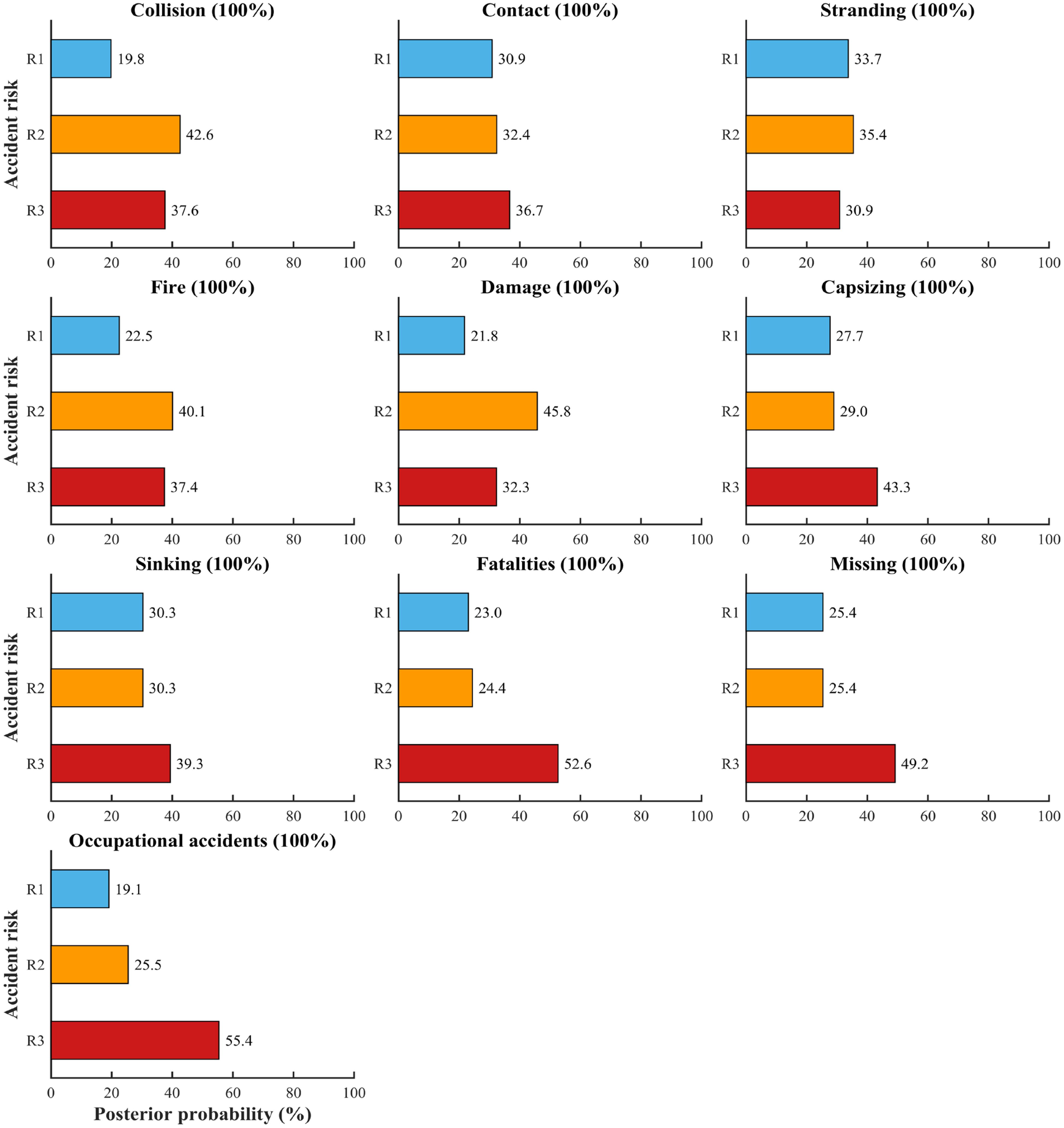
Figure 6. Probability distribution of accident risk by accident types in scenario two.
Scenario 1 simulates the probability of various high-sea accident types resulting from different GT categories. As shown in Figure 5, if the GT state is set to ‘GT under 500,’ a comparison with baseline data reveals that ‘fire,’ ‘occupational accident,’ and ‘capsizing’ are common accident types for this GT. Concurrently, the occurrence probabilities of ‘capsizing’ and ‘sinking’ accidents increase significantly under this condition.
Furthermore, sequentially setting GT states to ‘GT 500 to 25000,’ ‘GT 25001 to 60000,’ and ‘GT over 60000’ reveals a clear shift in dominant accident types. While fire is a primary concern for smaller ships (‘GT under 500’ and ‘GT 500 to 25000’), the risk profile transitions towards collisions becoming more prevalent for large ships (‘GT 25001 to 60000’). For very large ships (‘GT over 60000’), damage incidents emerge as the most significant accident type, notably surpassing fire in frequency, while collisions become relatively less common. This progression reveals that variations in ship size, with their attendant operational characteristics and risk profiles, are critical determinants in shaping the profile of prevalent maritime accident types. Notably, ‘fire’ and ‘occupational accidents’ consistently exhibit high occurrence proportions across all GT categories considered.
Consequently, maritime stakeholders are encouraged to consider these GT category-specific variations when guiding shipping companies to enhance their safety management systems and strengthen personnel competency. In turn, shipping companies are advised to prioritize the robust management of fire and occupational safety risks on board their ships.
Scenario 2 simulates the potential for different accident types to result in ‘very serious’ high-sea accident outcomes, as depicted in Figure 6. In these bar charts, R1, R2, and R3 represent the posterior probabilities of the accident risk being ‘less serious,’ ‘serious,’ and ‘very serious,’ respectively, given a specific accident type is set to 100% occurrence. If the ‘accident type’ state is set to ‘collision,’ a comparison of data from Figures 4, 6 reveals that the posterior probability of a ‘very serious’ outcome decreases from an average of 42.3% to 37.6%. This indicates that the severity impact of collision-related incidents in the high sea is lower than the overall average.
Furthermore, when the ‘accident type’ state is sequentially set to collision, grounding, fire, damage, capsizing, sinking, fatality, missing, and occupational accident, the respective posterior probabilities of a ‘very serious’ outcome are 36.7%, 30.9%, 37.4%, 32.3%, 43.3%, 39.3%, 52.6%, 49.2%, and 55.4%. This demonstrates that different accident types have varying impacts on accident risk. For instance, occupational accidents and fatalities significantly increase the likelihood of a ‘very serious’ outcome. In contrast, actual collisions in the high sea result in the lowest severity impact among the types analyzed.
Consequently, maritime stakeholders should prioritize strengthening preventive measures specifically targeting occupational accidents and incidents leading to fatalities, given their high propensity to result in very serious consequences. Concurrently, the development of differentiated emergency response plans tailored to specific accident types is also of critical importance.
4.5 Study limitations
This study has certain limitations that warrant discussion.
Firstly, while the proposed DDBN model integrates data and expert knowledge, mitigating deficiencies of purely data-driven or expert-based approaches, challenges persist regarding human and management factors. Data for these human and management factors are often subjective, which hinders the acquisition of fully objective, quantifiable data and introduces uncertainty that could affect model precision. The subjectivity in quantifying human factors thus remains a primary limitation. Future research could explore advanced human factor quantification (e.g., NLP on reports) and incorporate uncertainty-handling methodologies like fuzzy logic or Dempster-Shafer theory within the DDBN framework (Göksu et al., 2023). Achieving such advanced quantification via NLP, however, would critically depend on access to extensive and consistently structured textual accident data.
Secondly, the proposed DDBN, while effective for static scenario analysis, inherently lacks support for high-frequency, real-time risk prediction due to its fundamentally static structure. This precludes leveraging dynamic data streams for rapid risk updates, thus not fully meeting practical demands for proactive risk management. The model’s insufficient real-time predictive capability is therefore another key limitation. Addressing this necessitates developing dynamic BNs integrated with real-time data (e.g., AIS, sensor feeds) and adaptive machine learning algorithms for continuous model updating and inference (Fan et al., 2024). However, ensuring the real-time computational feasibility and managing the evolving complexity of such dynamic BNs may present significant implementation hurdles.
5 Conclusions
To address the gap in maritime accident analysis from a high-sea perspective, this study proposes a risk analysis framework based on a multi-source DDBN. This framework is designed not only to assess and predict the risk of HSMAs but also to furnish stakeholders with insights for developing effective prevention strategies. Methodologically, the framework first integrates heterogeneous data from sources such as accident reports, ship information, and environmental data. A hybrid, tri-source enhanced algorithm is then employed for structural learning to obtain a network structure consistent with causal logic and real-world conditions. Subsequently, the EM algorithm is used to calculate the conditional probabilities of the DDBN. Key RIFs are then identified based on sensitivity analysis results derived from MI. Finally, we conduct scenario analysis, guided by these sensitivity findings, to reveal potential risks under different conditions. The principal findings of this study include:
1. The three RIFs with the greatest impact on accident risk are accident type, sea area and ship type, while the three RIFs with the greatest impact on accident type are GT, assessment failure and equipment.
2. Occupational accidents are associated with the highest severity impact, whereas collisions result in the lowest severity impact.
3. The most common accident types are fire for small to medium-sized ships, collisions for large ships, and damage for very large ships.
4. The proposed DDBN risk model successfully performs causal reasoning for accidents in complex scenarios, achieving a case inference accuracy of approximately 84.0%.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material. Further inquiries can be directed to the corresponding author.
Author contributions
XQ: Conceptualization, Methodology, Software, Validation, Visualization, Writing – original draft, Writing – review & editing. CW: Conceptualization, Funding acquisition, Methodology, Writing – original draft, Writing – review & editing. RZ: Funding acquisition, Validation, Writing – review & editing. MF: Visualization, Writing – review & editing. XX: Conceptualization, Methodology, Validation, Writing – original draft, Writing – review & editing.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This research was funded by the Anhui Engineering Research Center on Information Fusion and Control of Intelligent Robot Open Fund, grant number IFCIR2024002; the National Natural Science Foundation of China, grant number 72204035; the Fundamental Research Funds for the Central Universities, grant number 3132023175.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be constructed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fmars.2025.1631650/full#supplementary-material
Supplementary Table 1 | Professional background and relevant expertise of the expert panel.
Supplementary Table 2 | State definitions for nodes in the DDBN model.
References
Afenyo M., Khan F., Veitch B., and Yang M. (2017). Arctic shipping accident scenario analysis using Bayesian Network approach. Ocean Eng. 133, 224–230. doi: 10.1016/j.oceaneng.2017.02.002
Allianz Global Corporate & Specialty Company (2024). Safety and shipping review 2024. Available online at: https://commercial.allianz.com/content/dam/onemarketing/commercial/commercial/reports/Commercial-Safety-Shipping-Review-2024.pdf (Accessed May 19, 2025).
Cem Kuzu A., Akyuz E., and Arslan O. (2019). Application of Fuzzy Fault Tree Analysis (FFTA) to maritime industry: A risk analysing of ship mooring operation. Ocean Eng. 179, 128–134. doi: 10.1016/j.oceaneng.2019.03.029
Chen S., Wall A., Davies P., Yang Z., Wang J., and Chou Y. (2013). A Human and Organisational Factors (HOFs) analysis method for marine casualties using HFACS-Maritime Accidents (HFACS-MA). Saf. Sci. 60, 105–114. doi: 10.1016/j.ssci.2013.06.009
Chen X., Ma X., Jia L., Zhang Z., Chen F., and Wang R. (2024). Causative analysis of freight railway accident in specific scenes using a data-driven Bayesian network. Reliabil. Eng. Sys. Saf. 243, 109781. doi: 10.1016/j.ress.2023.109781
Chen X., Wei C., Xin Z., Zhao J., and Xian J. (2023). Ship Detection under Low-Visibility Weather Interference via an Ensemble Generative Adversarial Network. J. Mar. Sci. Eng. 11, 2065. doi: 10.3390/jmse11112065
Chen X., Wu S., Shi C., Huang Y., Yang Y., Ke R., et al. (2020). Sensing data supported traffic flow prediction via denoising schemes and ANN: A comparison. IEEE Sens. J. 20, 14317–14328. doi: 10.1109/JSEN.2020.3007809
Deng J., Liu S., Xie C., and Liu K. (2021). Risk coupling characteristics of maritime accidents in chinese inland and coastal waters based on N-K model. J. Mar. Sci. Eng. 10, 4. doi: 10.3390/jmse10010004
European Maritime Safety Agency (2023). Annual overview of marine casualties and incidents. Available online at: https://www.emsa.europa.eu/publications/reports/item/5052-annual-overview-of-marine-casualties-and-incidents.html (Accessed May 19, 2025).
Fan S., Blanco-Davis E., Yang Z., Zhang J., and Yan X. (2020). Incorporation of human factors into maritime accident analysis using a data-driven Bayesian network. Reliabil. Eng. Sys. Saf. 203, 107070. doi: 10.1016/j.ress.2020.107070
Fan H., Gong X., and Lyu J. (2023). Resilience assessment of strait/canal: A rule-based Bayesian network framework. Transport. Res. Part D: Transport. Environ. 124, 103960. doi: 10.1016/j.trd.2023.103960
Fan H., Lyu J., He X., Li B., Ji Y., and Chang Z. (2024). A novel object-oriented Bayesian network on risk assessment of sea lanes of communication. Ocean Eng. 300, 117347. doi: 10.1016/j.oceaneng.2024.117347
Fu S., Gu S., Zhang Y., Zhang M., and Weng J. X. (2023). Towards system-theoretic risk management for maritime transportation systems: A case study of the yangtze river estuary. Ocean Eng. 286, 115637. doi: 10.1016/j.oceaneng.2023.115637
Fu S., Yu Y., Chen J., Xi Y., and Zhang M. (2022). A framework for quantitative analysis of the causation of grounding accidents in arctic shipping. Reliabil. Eng. Sys. Saf. 226, 108706. doi: 10.1016/j.ress.2022.108706
Goerlandt F. and Montewka J. (2015). Maritime transportation risk analysis: Review and analysis in light of some foundational issues. Reliabil. Eng. Sys. Saf. 138, 115–134. doi: 10.1016/j.ress.2015.01.025
Göksu B., Yüksel O., and Şakar C. (2023). Risk assessment of the Ship steering gear failures using fuzzy-Bayesian networks. Ocean Eng. 274, 114064. doi: 10.1016/j.oceaneng.2023.114064
Hänninen M. (2014). Bayesian networks for maritime traffic accident prevention: Benefits and challenges. Accid. Anal. Prev. 73, 305–312. doi: 10.1016/j.aap.2014.09.017
Huang X., Wen Y., Zhang F., Han H., Huang Y., and Sui Z. (2023). A review on risk assessment methods for maritime transport. Ocean Eng. 279, 114577. doi: 10.1016/j.oceaneng.2023.114577
International Maritime Organization (2023). Global integrated shipping information system. Available online at: https://gisis.imo.org/Public/Default.aspx (Accessed May 19, 2025).
Jiang M. and Lu J. (2020a). Maritime accident risk estimation for sea lanes based on a dynamic Bayesian network. Marit. Policy Manage. 47, 649–664. doi: 10.1080/03088839.2020.1730995
Jiang M. and Lu J. (2020b). The analysis of maritime piracy occurred in Southeast Asia by using Bayesian network. Transport. Res. Part E: Logist. Transport. Rev. 139, 101965. doi: 10.1016/j.tre.2020.101965
Jiang M., Lu J., Yang Z., and Li J. (2020). Risk analysis of maritime accidents along the main route of the Maritime Silk Road: a Bayesian network approach. Marit. Policy Manage. 47, 815–832. doi: 10.1080/03088839.2020.1730010
Kamal B. and Çakır E. (2022). Data-driven Bayes approach on marine accidents occurring in Istanbul strait. Appl. Ocean Res. 123, 103180. doi: 10.1016/j.apor.2022.103180
Li H., Ren X., and Yang Z. (2023). Data-driven Bayesian network for risk analysis of global maritime accidents. Reliabil. Eng. Sys. Saf. 230, 108938. doi: 10.1016/j.ress.2022.108938
Li P., Wang Y., and Yang Z. L. (2024). Risk assessment of maritime autonomous surface ships collisions using an FTA-FBN model. Ocean Eng. 309, 118444. doi: 10.1016/j.oceaneng.2024.118444
Liu X., Qiu L., Fang Y., Wang K., Li Y., and Rodríguez J. (2025). Event-driven based reinforcement learning predictive controller design for three-phase NPC converters using online approximators. IEEE Trans. Power Electron. 40, 4914–4926. doi: 10.1109/TPEL.2024.3510731
Luo M. and Shin S. (2019). Half-century research developments in maritime accidents: Future directions. Accid. Anal. Prev. 123, 448–460. doi: 10.1016/j.aap.2016.04.010
Marcot B. G. and Penman T. D. (2019). Advances in Bayesian network modelling: Integration of modelling technologies. Environ. Modell. Software 111, 386–393. doi: 10.1016/j.envsoft.2018.09.016
Pan W., Xie X., He P., Bao T., and Li M. (2021). An automatic route design algorithm for intelligent ships based on a novel environment modeling method. Ocean Eng. 237, 109603. doi: 10.1016/j.oceaneng.2021.109603
Song Y., Zhao R., and Xie X. (2023). Pricing game between repair-and-support ships and shipyards under multiple repair tasks on a remote ocean. Expert Syst. Appl. 219, 119630. doi: 10.1016/j.eswa.2023.119630
Wang C., Wang N., Gao H., Wang L., Zhao Y., and Fang M. (2024a). Knowledge transfer enabled reinforcement learning for efficient and safe autonomous ship collision avoidance. Int. J. Mach. Learn. Cyber. 15, 3715–3731. doi: 10.1007/s13042-024-02116-4
Wang C., Zhang X., Gao H., Bashir M., Li H., and Yang Z. (2024b). Optimizing anti-collision strategy for MASS: A safe reinforcement learning approach to improve maritime traffic safety. Ocean Coast. Manage. 253, 107161. doi: 10.1016/j.ocecoaman.2024.107161
Xie X., Zhao R., and Zhu Y. (2021). Conceptual design and parametric optimization of self-propelled semi-submersible repair ships: a novel equipment providing maintenance and repair support at sea. J. Mar. Sci. Technol. 26, 243–256. doi: 10.1007/s00773-020-00733-6
Xu M., Ma X., Zhao Y., and Qiao W. (2023). A systematic literature review of maritime transportation safety management. J. Mar. Sci. Eng. 11, 2311. doi: 10.3390/jmse11122311
Xu X., Xie X., Wei P., and Wang Y. (2024). A hybrid method for the capability evaluation of a far-sea naval ship repair and maintenance system based on binary semantic information and the evidential reasoning approach. Expert Syst. Appl. 248, 123373. doi: 10.1016/j.eswa.2024.123373
Yang Y., Gao X., Guo Z., and Chen D. (2019). Learning Bayesian networks using the constrained maximum a posteriori probability method. Pattern Recognit. 91, 123–134. doi: 10.1016/j.patcog.2019.02.006
Zhang M., Zhang D., Goerlandt F., Yan X., and Kujala P. (2019). Use of HFACS and fault tree model for collision risk factors analysis of icebreaker assistance in ice-covered waters. Saf. Sci. 111, 128–143. doi: 10.1016/j.ssci.2018.07.002
Keywords: maritime safety, maritime accidents, data-driven Bayesian network, risk analysis, high sea, incomplete data
Citation: Qu X, Wang C, Zhao R, Fang M and Xie X (2025) Multi-source data-driven Bayesian network for risk analysis of maritime accidents in the high sea. Front. Mar. Sci. 12:1631650. doi: 10.3389/fmars.2025.1631650
Received: 20 May 2025; Accepted: 10 June 2025;
Published: 25 June 2025.
Edited by:
Maohan Liang, National University of Singapore, SingaporeCopyright © 2025 Qu, Wang, Zhao, Fang and Xie. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Chengbo Wang, d2FuZ2NiMjNAdXN0Yy5lZHUuY24=