 Benn Macdonald
Benn Macdonald Dirk Husmeier
Dirk Husmeier- School of Mathematics and Statistics, University of Glasgow, Glasgow, UK
Parameter inference in mathematical models of biological pathways, expressed as coupled ordinary differential equations (ODEs), is a challenging problem in contemporary systems biology. Conventional methods involve repeatedly solving the ODEs by numerical integration, which is computationally onerous and does not scale up to complex systems. Aimed at reducing the computational costs, new concepts based on gradient matching have recently been proposed in the computational statistics and machine learning literature. In a preliminary smoothing step, the time series data are interpolated; then, in a second step, the parameters of the ODEs are optimized, so as to minimize some metric measuring the difference between the slopes of the tangents to the interpolants, and the time derivatives from the ODEs. In this way, the ODEs never have to be solved explicitly. This review provides a concise methodological overview of the current state-of-the-art methods for gradient matching in ODEs, followed by an empirical comparative evaluation based on a set of widely used and representative benchmark data.
1. Introduction
The elucidation of the structure and dynamics of biopathways is a central objective of systems biology. A standard approach is to view a biopathway as a network of biochemical reactions, which is modeled as a system of ordinary differential equations (ODEs). Following Barenco et al. (2006), this system can typically be expressed as1:
where i ∈ {1, … , n} denotes one of n components (henceforth referred to as “species”) in the biopathway, xi(t) denotes the concentration of species i at time t, δi is a decay rate and x(t) is a vector of concentrations of all system components that influence or regulate the concentration of species i at time t. If, for instance, species i is an mRNA, then x(t) may contain the concentrations of transcription factors (proteins) that bind to the promoter of the gene from which i is transcribed. The regulation is modeled by the regulation function g. Depending on the species involved, g may define different types of regulatory interactions, e.g., mass action kinetics, Michaelis–Menten kinetics, allosteric Hill kinetics, etc. All of these interactions depend on a vector of kinetic parameters, ρ i. For complex biopathways, only a small fraction of ρ i can typically be measured. Hence, the explication of the biopathway dynamics requires the majority of kinetic parameters to be inferred from observed (typically noisy and sparse) time course concentration profiles. In principle, this can be accomplished with standard techniques from machine learning and statistical inference. These techniques are based on first quantifying the difference between predicted and measured time course profiles by some appropriate metric to obtain the likelihood of the data. The parameters are then either optimized to maximize the likelihood (or a regularized version thereof), or sampled from a distribution based on the likelihood (the posterior distribution).
However, the nature of the ODE-based model in equation (1) renders the inference problem computationally challenging in two respects. First, the ODE system often does not permit closed-form solutions. One therefore has to resort to numerical simulations every time the kinetic parameters ρ i are adapted, which is computationally onerous. Second, the likelihood function in the space of parameters ρ i is typically not unimodal, but suffers from multiple local optima. Hence, even if a closed-form solution of the ODEs existed, inference by maximum likelihood would face an NP-hard optimization problem, and Bayesian inference would suffer from poor mixing and convergence of the Markov chain Monte Carlo (MCMC) simulations.
Conventional inference methods involve numerically integrating the system of ODEs to produce a signal, which is compared to the data by some appropriate metric defined by the chosen noise model, allowing for the calculation of a likelihood. This process is repeated as part of an iterative optimization or sampling procedure to produce estimates of the parameters. Figure 1A is a graphical representation of the model for these conventional inference methods. For a given set of initial concentrations of the entire system X(0) and set of ODE parameters θ [where θ = (θ1, … , θn) and θi = (ρ i, δi)], a signal can be produced by integration of the ODEs. As mentioned previously, for many ODE systems a closed-form solution does not exist, so in practice, numerical integration is implemented instead. Assuming an appropriate noise model (for example, a Gaussian additive noise model) with standard deviation (SD) of the observational error σ, the differences between the resultant signal and the data Y can be used to calculate the likelihood of the parameters θ. The process is repeated for different parameters θ until the maximum likelihood of the parameters is found (in the classical approach) or until convergence to the posterior distribution is reached (in the Bayesian approach). However, the computational costs involved with repeatedly numerically solving the ODEs are large.
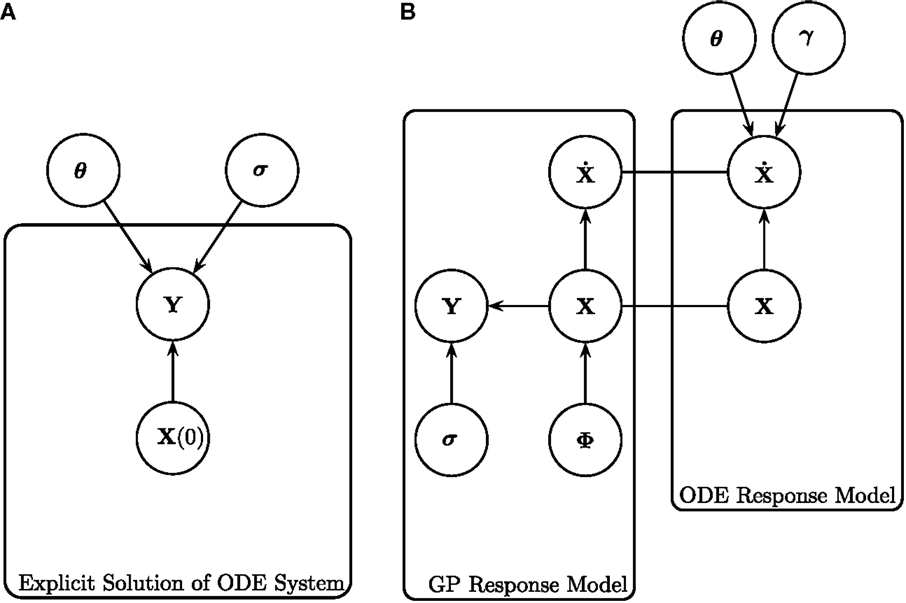
Figure 1. Graphical representations of (left) the explicit solution of the ODE system, as shown in Calderhead et al. (2008), and (right) gradient matching with Gaussian processes, as proposed in Calderhead et al. (2008) and Dondelinger et al. (2013). (A) Explicit solution of the ODE system, as shown in Calderhead et al. (2008). The noisy data signals Y are described by some initial concentration X(0), ODE parameters θ and observational errors with SD σ. For a given set of initial concentrations X(0) and set of ODE parameters θ, the ODEs can be integrated to produce a signal, which is then compared to the data signal by some metric defined by the chosen noise model. (B) Gradient matching with Gaussian processes, as proposed in Calderhead et al. (2008) and Dondelinger et al. (2013). The gradients are compared from two modeling approaches; the Gaussian process model and the ODEs themselves. The distribution of Y is given in equation (4), the Gaussian process on X defined in equation (5), the derivatives of the Gaussian process in equation (10), the ODE model in equation (2), and the gradient matching in equation (17). All symbols are detailed in Section 2.1.
To reduce the computational complexity, several authors have adopted an approach based on gradient matching [e.g., Calderhead et al. (2008) and Liang and Wu (2008)]. The idea is based on the following two-step procedure. In a preliminary smoothing step, the time series data are interpolated; then, in a second step, the parameters θ of the ODEs are optimized so as to minimize some metric measuring the difference between the slopes of the tangents to the interpolants, and the θ-dependent time derivatives from the ODEs. In this way, the ODEs never have to be solved explicitly, and the typically unknown initial conditions are effectively profiled over. A disadvantage of this two-step scheme is that the results of parameter inference critically hinge on the quality of the initial interpolant. A better approach, first suggested in Ramsay et al. (2007), is to regularize the interpolants by the ODEs themselves. Dondelinger et al. (2013) applied this idea to the non-parametric Bayesian approach of Calderhead et al. (2008), using Gaussian processes (GPs), and demonstrated that it substantially improves the accuracy of parameter inference and robustness with respect to noise. As opposed to Ramsay et al. (2007), all smoothness hyperparameters are consistently inferred in the framework of non-parametric Bayesian statistics, dispensing with the need to adopt heuristics and approximations.
This review compares the current state-of-the-art in gradient matching, specifically in the context of parameter inference in ODEs. This comparison aids in understanding the difference between key components of methods without confounding influence from other modeling choices. For instance, we compare the inference paradigm of the parameter that governs the degree of mismatch between the gradients of the interpolants and ODEs [using the method in Dondelinger et al. (2013)] with a tempering approach [from the method in Macdonald and Husmeier (2015)], using the same interpolation scheme (namely, Gaussian processes). This way, we are able to gain an understanding as to what approach may be more suitable, without concern that differences may be due to interpolation choice. If the ODEs provide the correct mathematical description of the system, ideally there should be no difference between the interpolant gradients and those predicted from the ODEs. In practice, however, forcing the gradients to be equal is likely to cause parameter inference techniques to converge to a local optimum of the likelihood. A parallel tempering scheme is the natural way to deal with such local optima, as opposed to inferring the degree of mismatch, since different tempering levels correspond to different strengths of penalizing the mismatch between the gradients. A parallel tempering scheme (which uses smoothed versions of the posterior distribution as well as the usual posterior distribution, see Section 2.2 for more details) was explored by Campbell and Steele (2012).
When comparing one method to another, in order to assess the strengths and weaknesses of an approach, often results are not directly comparable, since different approaches use different methodological paradigms. For example, if the method by Campbell and Steele (2012) (which uses B-splines interpolation) was compared to Dondelinger et al. (2013) (which uses a GP approach) in order to examine the difference between parallel tempering and inference of the parameter controlling the degree of mismatch between the gradients, then the results would be confounded by the choice of interpolation scheme. In this review, we present a comparative evaluation of parallel tempering versus inference in the context of gradient matching for the same modeling framework, i.e., without any confounding influence from the model choice. We also compare the method of Bayesian inference with Gaussian processes with other methodological paradigms, within the specific context of adaptive gradient matching, which is highly relevant to current computational systems biology. We look at the methods of: Campbell and Steele (2012), who carry out parameter inference using adaptive gradient matching and B-splines interpolation; González et al. (2013), who implement a reproducing kernel Hilbert space (RKHS) and penalized maximum likelihood approach in a non-Bayesian fashion; Ramsay et al. (2007), who optimize the gradient mismatch, interpolant, and ODE parameters using a hierarchical regularization method and penalize the difference between the gradients using B-splines in a non-Bayesian approach; Dondelinger et al. (2013), who use adaptive gradient matching with Gaussian processes, inferring the degree of mismatch between the gradients; and Macdonald and Husmeier (2015), who use adaptive gradient matching with Gaussian processes and temper the parameter that controls the degree of mismatch between the gradients.
2. Methodology
2.1. Adaptive Gradient Matching with Gaussian Processes
The following covers the background of methodology for Dondelinger et al. (2013), and Macdonald and Husmeier (2015), which combines the former method with a parallel tempering scheme for the gradient mismatch parameter (the details on parallel tempering will be given in Section 2.2).
Consider a set of T arbitrary timepoints t1 < … < tT, and a set of noisy observations Y = (y(t1), … , y(tT)), where y(t) = x(t) + ε(t), n = dim(x(t)), X = (x(t1), … , x(tT)), y(t) is the data vector of the observations of all species concentrations at time t, x(t) is the vector of the concentrations of all species at time t, y i is the data vector of the observations of species concentrations i at all timepoints, x i is the vector of concentrations of species i at all timepoints, yi(t) is the observed datapoint of the concentration of species i at time t, xi(t) is the concentration of species i at time t and ε is multivariate Gaussian noise, . The signals of the system are described by ordinary differential equations
or alternatively, represented in scalar form
where is the vector containing the ODE gradients for species i at all timepoints, fi (t) = (fi(t1),… ,fi(tT))Τ, θi = (ρ i, δi), ρ i is a vector of kinetic parameters, δi is a decay rate parameter and fi (x(t), θi, t) = gi (x(t), ρ i,t) −δi xi. Then,
and the matrices X and Y are of dimension n by T. Following Calderhead et al. (2008), we place a Gaussian process (GP) prior on x i,
where μ i is a mean vector, for simplicity set as the sample mean, and is a positive definite matrix of covariance functions with hyperparameters ϕi. Since differentiation is a linear operation, a Gaussian process is closed under differentiation, and the joint distribution of the state variables x i and their time derivatives i is multivariate Gaussian with mean vector (μ i, 0)Τ and covariance functions
where are the elements of the covariance matrix . Using elementary transformations of Gaussian distributions [for example, see page 87 of Bishop (2006)], the conditional distribution for the state derivatives is then
where
Assuming additive Gaussian noise with a state-specific error variance γi, from equation (2) we get
Calderhead et al. (2008), and Dondelinger et al. (2013) link the interpolant in equation (10) with the ODE model in equation (12) using a product of experts approach, as illustrated in Figure 1B, obtaining the following distribution
The joint distribution is therefore
where γ is the vector containing all the gradient mismatch parameters and p(θ), p(ϕ), p(γ) are the priors over the respective parameters. Dondelinger et al. (2013) show that you can marginalize over the derivatives to get a closed-form solution to
Using equations (4) and (15), our full joint distribution becomes
where the likelihood p(Y|X, σ) is defined in equation (4) and p(σ2) is the prior over the variances of the observational error. Dondelinger et al. (2013) show
where and f i is the vector containing the gradients from the ODEs for species i. The sampling is conducted using MCMC, where the whitening approach of Murray and Adams (2010) is used to efficiently sample in the joint space of GP hyperparameters ϕ and latent variables X. The concept of gradient matching with Gaussian processes can be seen graphically in Figure 1B. The data Y are explained by the latent variables X, which are modeled by a Gaussian process with hyperparameters ϕ, and SD of the observational errors σ. The gradients from the ODE model are compared to those from the Gaussian process, subject to some degree of mismatch controlled by parameter γ, dispensing with the need to explicitly solve the ODEs.
2.2. Parallel Tempering
A challenging problem, which sampling methods face, is that of local optima. The aim of sampling is to represent fully the configuration space weighted by the volume of the corresponding posterior density peaks. In order to do this, the sampling algorithm implemented must be able to adequately explore the posterior distribution. If this landscape is rugged, with many local optima and low-probability barriers separating areas of high posterior probability, mixing and convergence of the Markov chain Monte Carlo simulations can be poor. For example, consider the Metropolis–Hastings algorithm, which proposes a move and computes the acceptance probability pmove by taking the ratio of the posterior densities of the proposed state to the current state. If pmove > 1, the algorithm accepts the proposed move. If pmove < 1, the proposed state is accepted with probability pmove. If then, the parameter location of the algorithm is currently situated at a local optimum, then the proposed move could result in a small pmove. Theoretically, the algorithm will eventually be able to move the parameter location out of this region; however, in practice, this could take a considerable amount of time. If the total number of MCMC iterations has been specified in advance, the simulation could finish before the parameter position of the algorithm has escaped the local optimum and explored the remainder of the region. Entrapment in local optima can mislead established convergence tests and erroneously indicate a sufficient degree of convergence.
Parallel tempering is a method that tackles the problem of local optima. It involves running multiple MCMC simulations at different levels or “temperatures”2 of the likelihood in parallel. Low “temperatures” flatten the posterior landscape, making it easier to explore the region, since the peaks have been smoothed. This can be seen graphically in Figure 2. As the “temperature” is increased to the highest value, the landscape becomes more rugged and eventually the original posterior landscape is recovered (see bottom of Figure 2).
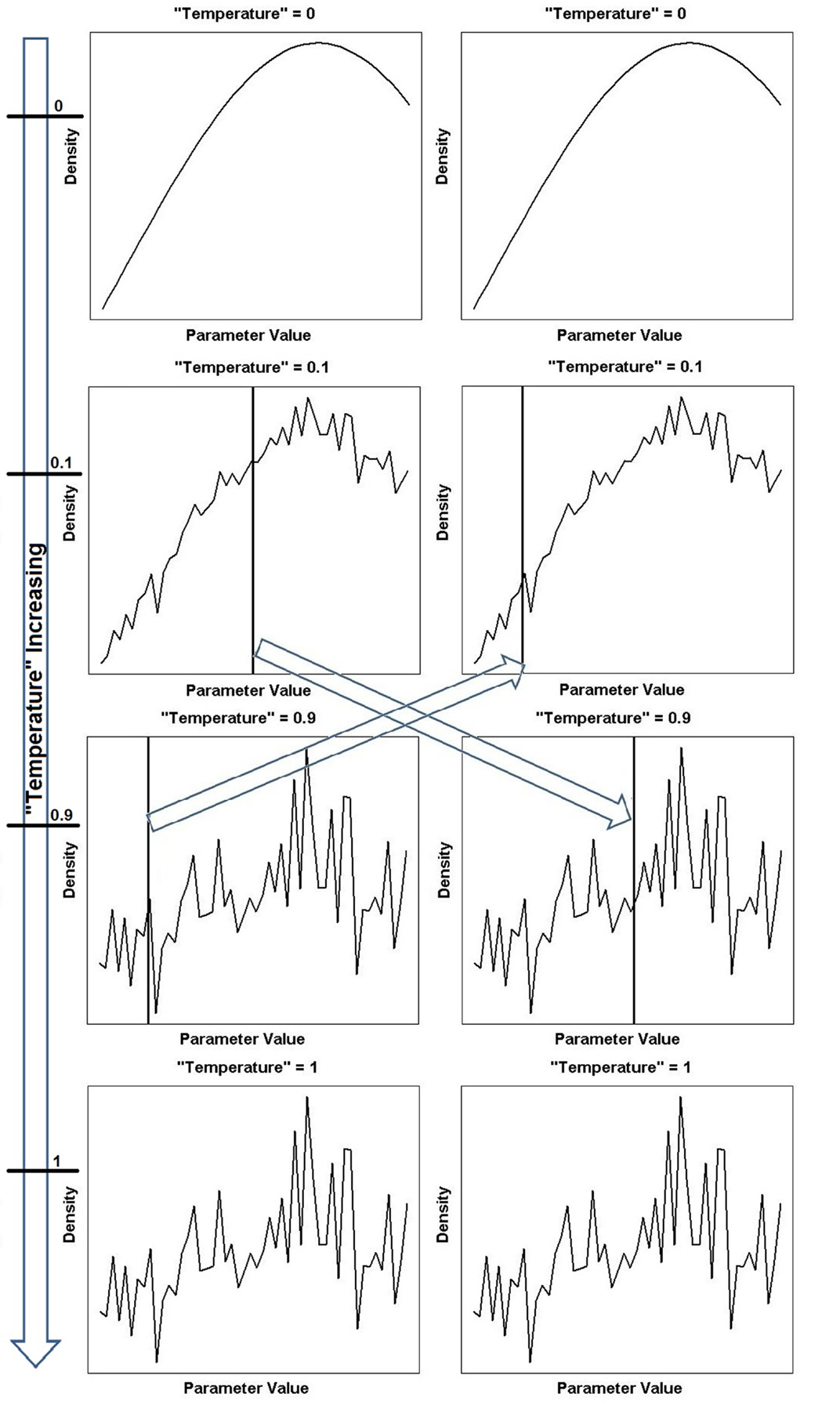
Figure 2. Continued A one-dimensional illustration of equation (18) showing different power posterior distributions for different levels or “temperatures” of the likelihood. The posterior landscape is smoother at lower “temperatures” (corresponding to chains closer to the prior) and becomes increasingly rugged until the true posterior landscape is recovered for “temperature” = 1. The arrow on the far left depicts the increase in “temperature” and the horizontal ticks mark the specific “temperature” of that chain. Two chains (“temperature” = 0.1 and “temperature” = 0.9) have been chosen to swap parameter locations (locations indicated by vertical line). The left column shows the parameter locations of the tempering algorithm before the swap and the right column shows the parameter locations of the tempering algorithm after the swap. The swapping of locations is indicated by the arrows in the center of the figure.
At every MCMC iteration, two “temperature” chains are chosen and the parameter locations where the sampling algorithm is currently situated are swapped, see middle of Figure 2. This way, the algorithm can move the parameter position from a local optimum to somewhere else on the posterior landscape, dispensing with the need to gradually navigate away from the region and the problems associated with doing so.
Consider a series of “temperatures”, 0 = β(1) < … < β(M) = 1 and a power posterior distribution of our ODE parameters [Friel and Pettitt (2008)]
Equation (18) reduces to the prior for β(j) = 0 (see top of Figure 2), and becomes the posterior when β(j) = 1 (see bottom of Figure 2), with 0 < β(j) < 1 creating a distribution between our prior and posterior (see Figure 2). The M β(j) annealed likelihoods in equation (18) are used as the target densities of M parallel MCMC chains [Campbell and Steele (2012)]. At each MCMC step, each “temperature” chain independently performs a Metropolis–Hastings step to update θ(j), the parameter vector associated with temperature β(j)
where q( ) is the proposal distribution and the superscripts “proposed” and “current” indicate whether the algorithm is being evaluated at the proposed or current state. Also, at each MCMC step, two chains are randomly selected, and a proposal to exchange parameters is made, with acceptance probability
A graphical representation of the swap moves between chains can be seen in Figure 2.
The method by Macdonald and Husmeier (2015) focuses on the intrinsic slack parameter γi [see equation (12)], which theoretically should be γi = 0, since this corresponds to no mismatch between the gradients. In practice, it is allowed to take on larger values, γi > 0, to prevent the inference scheme from getting stuck in sub-optimal states. However, rather than inferring γi like a model parameter, as carried out in Dondelinger et al. (2013), other authors [e.g., Campbell and Steele (2012)] propose that γi should be gradually set to zero, since values closer to zero force the gradients to be more similar and tie the interpolants closer to the ODEs. It is possible to abruptly set the values to zero, rather than gradually; however, this is likely to cause the parameter inference techniques to converge to a local optimum of the likelihood. To this end, Macdonald and Husmeier (2015) combine the gradient matching with Gaussian processes approach in Dondelinger et al. (2013) with the tempering approach in Campbell and Steele (2012) and temper this parameter to zero.
We choose values of γi and assign them to the variance parameter in equation (12) for each “temperature” β(j), such that chains closer to the prior (β(j) closer to 0) allow the gradients from the interpolant to have more freedom to deviate from those predicted by the ODEs (which corresponds to a larger γi), chains closer to the posterior (β(j) closer to 1) more closely match the gradients (corresponding to a smaller γi), and for the chain corresponding to β(M) = 1, we wish that the mismatch is approximately zero (γi ≈ 0). Since γi corresponds to the variance of our state-specific error [see equation (12)], as γi → 0, we have less mismatch between the gradients, and as γi gets larger, the gradients have more freedom to deviate from one another. Hence, we temper γi toward zero. Now, each β(j) chain in equation (18) has a γi(j) [where the superscript (j) indicates the gradient mismatch parameter associated with “temperature” β(j)] fixed in place for the strength of the gradient mismatch.
Continuing the notation, anything with a superscript (j) is the associated variable or fixed parameter for “temperature” chain β(j). The ODE model in equation (12) now becomes
where this distribution is evaluated at each of the j chains. Following equations (13)–(16), we obtain for the joint distribution
Equation (22) is calculated for each of the j chains. The particular schedules used for γi in this review are given in Table 1. For more details on tempering, see Calderhead and Girolami (2009) and Mohamed et al. (2012). The computational times for the methods from Dondelinger et al. (2013) and Macdonald and Husmeier (2015), in comparison to numerically integrating the ODEs, can be found in Table 2.
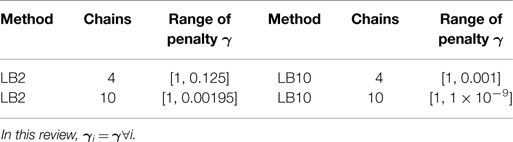
Table 1. Ranges of the penalty parameter γi for LB2 and LB10.
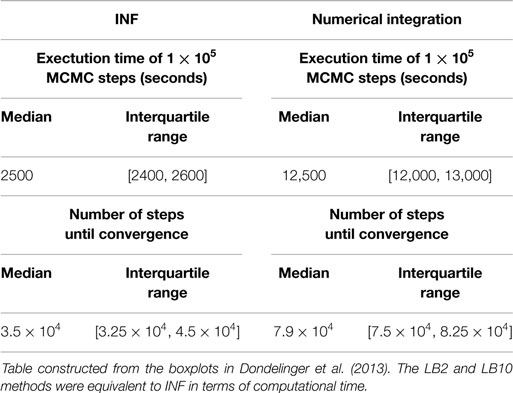
Table 2. Computational times for INF and a method that numerically integrates the ODEs for the protein signaling transduction pathway in equations (63)–(67).
2.3. B-Splines
Splines are used for function interpolation, where the function of interest is approximated by a weighted linear combination of basis functions. These basis functions, called “splines”, are “local” polynomials, where the exact functional form depends on the particular type of spline that is used (for example, a truncated power basis). See Hastie et al. (2009) for an overview of different types of splines.
The advantage of spline interpolation over global polynomial interpolation is that the interpolation error can be made small even when using low degree polynomials for the splines. This, in particular, avoids the problem of Runge’s phenomenon, in which oscillations can occur between data points when interpolating using high degree polynomials.
B-splines interpolation takes the form
where m + 1 is the number of basis functions, d is the degree of polynomial, αi is a coefficient and ϕi,d (t) is the ith basis function of polynomial degree d evaluated at time t. For some vector of fixed points called knots [denoted τ, where x(t) is continuous at each knot], the basis functions are calculated with the following recursive formulae
The coefficients αi are then estimated by
where is the vector containing all the coefficients (and αi would correspond to the (i + 1)th position in the vector) and Φ is the matrix containing all the basis functions
One can aim to avoid over-fitting by penalizing the 2nd derivative of the function x(t) (known as penalized splines), making our objective function
where λ controls the amount of trade-off between the data fit and penalty term. In this case, the coefficients αi are estimated by
where D is the solution to the penalty in equation (28) (the integral of the square of the second derivative of x). It is possible to change the penalty term in equation (28) to some other penalty form (this is known as P-splines), where the D in equation (29) would be updated accordingly.
2.4. Smooth Functional Tempering
Here, we detail the method for parameter inference used in Campbell and Steele (2012). In their paper, the authors discuss two types of smooth functional tempering, one that needs to infer the initial conditions of the species concentrations and one that does not. This review uses the method that does not need to infer the initial conditions. If the initial conditions are unknown, then they must be inferred as an extra parameter in the inference procedure; however, the method described in this section effectively profiles over the initial conditions, dispensing with the need to infer them. This reduces the complexity of the procedure, which is more appealing. The reader can refer to the original publication should they wish to implement the former procedure. The choice of interpolation scheme for the concentrations x i is B-splines. For an introduction to parallel tempering, see Section 2.2.
The posterior distribution of the parameters is
where the superscript j denotes those variables associated with “temperature” β(j), the likelihood, p(Y|X(j), σ2(j)) = N(X(j), σ2(j)), is tempered in the same way as in equation (18), λ = (λ1, … , λn) and p(X(j)|θ(j), λ(j)) is
which is analogous to
For details on tempering, see Section 2.2. In equation (31), is the gradient mismatch parameter for species i corresponding to “temperature” β(j) (similar to the mismatch parameter in Section 2.1). The is chosen in advance and fixed to each “temperature” β(j) such that , where values closer to 0 allow the gradients to be more different to one another and values closer to ∞ restrict them from being different.
Sampling from equation (30) is performed using MCMC.
2.5. Penalized Likelihood with Hierarchical Regularization
Ramsay et al. (2007) aim to conduct parameter inference in ODEs using a penalized likelihood approach and a hierarchical regularization in order to tune the gradient mismatch parameter and parameters of their interpolation scheme (splines). They perform parameter inference in a hierarchical three level approach. At level 1, they optimize the gradient mismatch parameter, in order to ensure the estimates of the coefficients of their interpolant are properly regularized by the mismatch to the ODEs. In their paper, they adjust the gradient mismatch parameter manually using numerical and visual heuristics, but suggest a way it could be achieved through generalized cross-validation, which we will detail. At level 2, the coefficients of the interpolant are optimized. While optimizing for the parameters in the final step, each time the ODE parameters and observational noise parameters are changed, they re-optimize the coefficients of the interpolant, by penalizing the differences between the gradients, which allows the ODEs to regulate the interpolant. At level 3, the ODE and observational noise parameters are estimated using a sum of squares criterion. This criterion is optimized directly for the ODE and observational noise parameters, but it is also optimized implicitly, since the sum of squares incorporates x i, which itself was optimized with respect to these parameters at level 2. A flow chart of these three levels can be found in Figure 3.
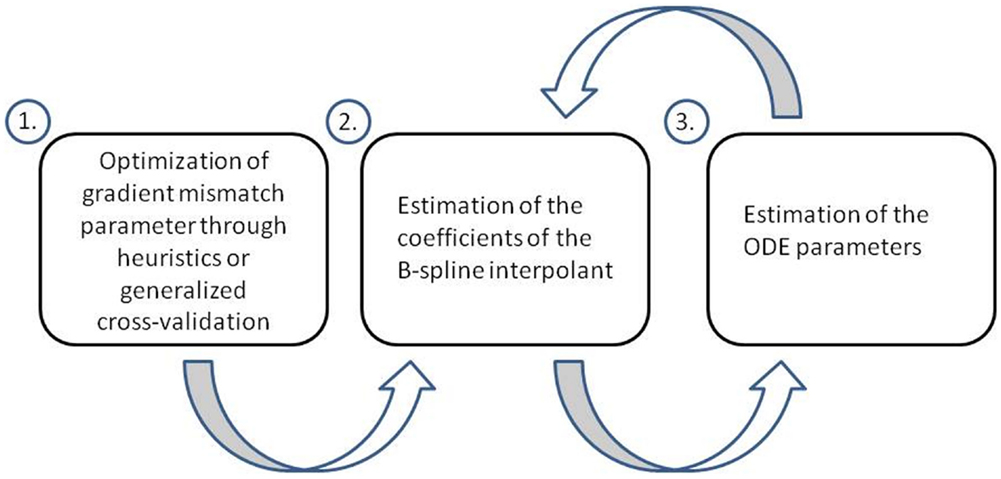
Figure 3. Flow chart of the three level approach employed by Ramsay et al. (2007). At level 1, the gradient mismatch parameter is optimized either by visual or numerical heuristics or through generalized cross-validation. At level 2, the coefficients of the interpolant are estimated (splines in this method). At level 3, the ODE parameters are estimated. Levels 2 and 3 are iterated using a pseudo-delta method (see Section 2.5 for details).
At level 1 of the three hierarchical levels, the gradient mismatch parameter is configured. To avoid the need for heuristics, Ramsay et al. (2007) suggest the use of generalized cross-validation, since the estimation of the state variables for some gradient mismatch parameter λ is usually a non-linear problem and so standard cross-validation methods are not applicable. Generalized cross-validation takes the form
where y i is the data for species i, x i is the interpolant corresponding to species i, n is the number of species and T is the number of timepoints. The derivatives in the denominator can be expressed as
where α are the estimated coefficients of the splines interpolant [see equation (29)]. Calculating these derivatives takes the dependency of the data y and the ODE parameters θ into account, since . The estimates of λ will be calculated by minimizing equation (33) over values of λ.
The second level involves estimating the coefficients of the splines interpolant using the following criterion
where is the gradient of the interpolant for species i and wi are weights to normalize the sum of squares of different species (so that species on varying scales of measurement do not distort the sum of squares with very large or very small residuals that are simply a consequence of their magnitude or unit of measurement). Large values of λi mean that the gradients have to more closely match one another (since the difference between them will need to tend to 0, to compensate for the large penalty a large λi would produce), whereas small values would allow the gradients to differ more. The penalty term in equation (35) allows the mismatch between the gradients to regularize the estimates of the interpolant coefficients.
At the third level, the ODE parameters are optimized using the sum of squares criterion
To optimize equation (36) with respect to θ, Ramsay et al. (2007) find the solution of the gradient
Since the function α(θ) is not explicitly available, is calculated by application of the implicit function theorem of differential calculus. This gives
2.6. Reproducing Kernel Hilbert Space
Here, we provide background for reproducing kernel Hilbert spaces (RKHS) that are used in González et al. (2013), and how they compare to Gaussian processes. RKHS interpolation is a useful tool in statistical learning, since a property of reproducing kernel Hilbert spaces, known as the representer theorem (details to follow), means that every function in an RKHS can be written as a linear combination of the kernel function evaluated at the training points. This provides a computationally fast process for interpolation, which is particularly useful in gradient matching, since the original purpose of gradient matching is to obtain a computational speed-up over methods involving calculating numerical solutions to the ODEs.
By Mercer’s theorem [Mercer (1909)], we are able to represent a kernel that produces a positive definite covariance matrix in terms of eigenvalues λs and eigenfunctions vs
These vs form an orthonormal basis for a function space
The inner product between two functions and in the space in equation (40) is defined as
which Murphy (2012) shows implies that
This is known as the reproducing property and the space of functions H is called a reproducing kernel Hilbert space. Now consider the minimization problem
where J(f) is the objective function and ||f ||H is the norm in Hilbert space
The desired function used for interpolation should be simple and provide a good fit to the data. Complex functions with respect to the kernel in equation (39) will produce large norms, since they will need many eigenfunctions to represent them, and therefore be more heavily penalized in equation (43). Schöelkopf and Smola (2002) show that the desired function must have the following form
This is known as the representer theorem. To solve for c, we combine equation (45) with equation (43), giving us
where K is a matrix of kernel elements for all combinations of observed timepoints. Minimizing with respect to c gives us
Hence,
where t* is the timepoint at which one wants to make predictions and k* is the vector of kernel elements for all combinations of t* and ts. This form is the same as a posterior mean of a Gaussian process predictive distribution.
2.7. Penalized Likelihood with RKHS
The goal of González et al. (2013) is to create a penalized likelihood function that incorporates the information of the ODEs, then using the properties of reproducing kernel Hilbert spaces to perform parameter estimation in a computationally fast manner. They consider ODEs of the form
or alternatively, represented in scalar form
where x i is the vector of mRNA concentrations for species i, δi is the degradation rate of the mRNA concentrations for species i, Z is the matrix containing the concentrations of all proteins [transcription factors (TFs)] at all timepoints, z(t) is the vector containing the concentrations of all proteins at timepoint t, ρ i is a parameter vector that governs the amount of regulation that the TFs have on the ith gene and gi(t) = (gi(t1), … , gi(tT))Τ. Note the difference between equations (50) and (1). In equation (1), the regulatees can themselves act as regulators, corresponding to genes coding for transcription factors acting on other genes. In equation (50), regulators (Z) and regulatees are separated in what is effectively a bi-partite regulatory network structure. The ODE in equation (49) depends on the state variables x i only by a linear decay term δi. Consider a differencing matrix D, where
and . We can then approximate equation (49) as
To demonstrate how Dx i is computed, as an example let us consider x i = (x(t1), … , x(t5))Τ and t = (1, 2, … , 5)Τ. Then,
Writing P = D + δi I (I here is the identity matrix) gives us the following penalty to be incorporated into the likelihood term
Equation (52) implies that Px i − gi(Z, ρ i, t) = 0. Rather than solving this equation explicitly, it is used as a penalty term within a regression context, i.e., the term in equation (43) will be replaced by equation (54). However, equation (54) cannot be expressed as a norm of x i within the RKHS framework, since x i = 0 does not necessarily imply that Ω(x i) = 0. The authors therefore transform the state variables x i (and subsequently y i) in order to make them compatible. Consider instead
It is straightforward to see that multiplying both sides of equation (55) by P and taking squared norms gives us the exact form of equation (54) . Likewise, the data are transformed by
to correspond with . The penalty term in equation (54) now becomes
Equation (57) is now a proper norm, since when , this implies . Denote K = (PΤP)−1. K is a matrix of kernel elements that define a unique RKHS. Hence,
[where c is given in equation (47), and equation 58 is used as the term in the far right of equation 46, see Section 2.6 for details]. By using equations (47) and (48), we obtain closed-form expressions for the transformed state variables [and the original expressions can be recovered using equation (55)]
where λ is a penalty parameter, and Σ is the covariance matrix of the data [which generalizes equation (47) since the observational error of our data may not be independent between species]. In practice, not all ODEs are of the form in equation (50), which only depends on the state variables by a linear decay term. Hence, the authors need to transform any ODE that is not of this form into 2 parts. Terms in part (1) will have a dependency on the state variables only by a linear decay term and can be modeled using the RKHS method and estimated by equation (59). Terms in part (2) cannot fit this framework and are modeled using splines. For example, consider in the FitzHugh–Nagumo ODEs (for more details, see Section 4)
where the square brackets denote the time-dependent concentration for that species, the dot over the V is shorthand for the temporal derivative of V and ψ is a parameter. Since the state variables do not only depend on a linear decay term, equation (60) needs to be transformed. Part (1) will be expressed by , where now the dependency on the state variables is only by a linear decay term and hence can be fitted using the RKHS method. Part (2) will be , which is fitted using splines, where and are spline estimates for [V] and [R], respectively.
The penalized log-likelihood function can now be expressed by
where αi is the vector containing the coefficients from the spline interpolant for species i, see equation (26). Given that the gradient matching is dependent on the differencing operator, it is important to note that points further apart in time will produce continually poorer estimates of the gradient and thus poorer gradient matching. González et al. (2013) attempt to circumvent this issue by data augmentation. They infer the latent variables at additional unobserved timepoints with the expectation maximization (EM) algorithm, which emulates more datapoints, in order to obtain more accurate gradient estimates. Parameter estimation in an approximate penalized maximum likelihood sense can be carried out with standard non-linear optimization algorithms, such as quasi-Newton or conjugate gradients.
3. Summary of Methods
This section provides a brief summary of the methods throughout the review, as described in Section 2. Since many methods and settings are used in this review for comparison purposes, for ease of reading, abbreviations are used. Table 3 is a reference for those methods and an overview of the methods follows.
INF (Section 2.1): this method conducts parameter inference using adaptive gradient matching and Gaussian processes. The penalty mismatch parameter γ (where γ is the vector of mismatch penalty parameter values at different “temperatures”) is inferred rather than tempered.
LB2 (Sections 2.1 and 2.2): this method conducts parameter inference using adaptive gradient matching and Gaussian processes. The penalty mismatch parameter γ is tempered in log base 2 increments, see Table 1 for details.
LB10 (Sections 2.1 and 2.2): as with LB2, parameter inference is conducted using adaptive gradient matching and Gaussian processes; however, the penalty mismatch parameter γ is tempered in log base 10 increments, see Table 1 for details.
C&S (Section 2.4): parameter inference is carried out using adaptive gradient matching and tempering of the mismatch parameter. The choice of interpolation scheme is B-splines.
RAM (Section 2.5): this technique uses a non-Bayesian optimization process for parameter inference. The method penalizes the difference between the gradients using splines and a hierarchical 3 level regularization approach is used to configure the tuning parameters.
GON (Section 2.7): parameter inference is conducted in a non-Bayesian fashion, implementing a reproducing kernel Hilbert space (RKHS) and penalized likelihood approach. Comparisons between RKHS and GPs have been previously explored conceptually [for example, see Rasmussen and Williams (2006) and Murphy (2012)], and in this review we analyze them empirically in the specific context of gradient matching. The RKHS gradient matching method in González et al. (2013) obtains the interpolant gradient using a differencing operator.
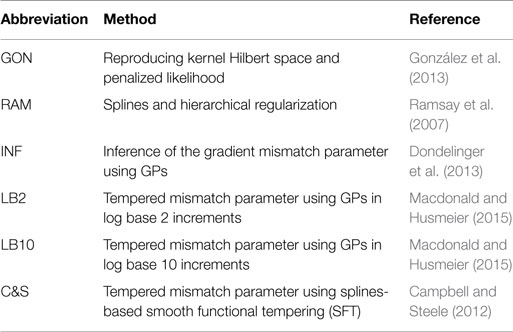
Table 3. Abbreviations of the methods used throughout this review.
Table 4 outlines particular settings with some of the methods in Table 3. The ranges of the penalty parameter for γ, for LB2 and LB10 methods, are given in Table 1. The increments are equidistant on the log scale. The M βis from 0 to 1 are set by taking a series of equidistant M values and raising them to the power 5 [Friel and Pettitt (2008)].
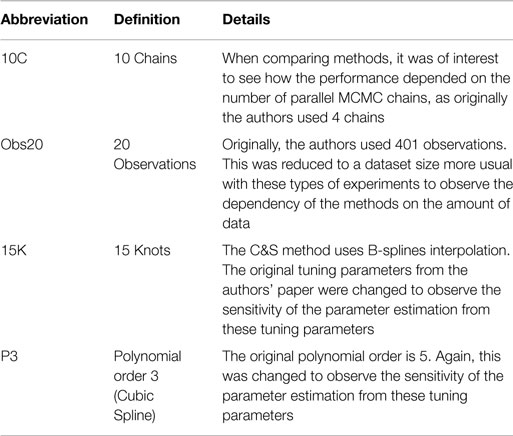
Table 4. Particular settings of Campbell and Steele (2012)’s method.
4. Data
4.1. FitzHugh–Nagumo
These equations model the voltage potential across the cell membrane of the axon of giant squid neurons [FitzHugh (1961); Nagumo et al. (1962)]. There are two “species”: voltage (V) and recovery variable (R), and 3 parameters; α, β, and ψ. The square brackets denote the time-dependent concentration for that species and a dot over a symbol is shorthand for the temporal derivative of that symbol:
An example of the signals produced from these ODEs can be found in Figure 4.
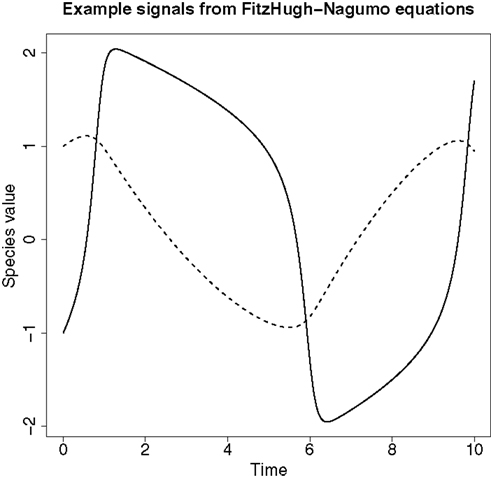
Figure 4. An example of the signals produced from the FitzHugh–Nagumo ODEs in equation (62). The solid line represents the signal for species V and the dashed line represents the signal for species R.
4.2. Protein Signaling Transduction Pathway
These equations model protein signaling transduction pathways in a signal transduction cascade, where the free parameters are kinetic parameters governing how quickly the proteins (“species”) convert to one another [Vyshemirsky and Girolami (2008)]. There are 5 “species” (S, dS, R, RS, Rpp) and 6 parameters (k1, k2, k3, k4, V, Km). The system describes the phosphorylation of a protein, R → Rpp [equation (67)], catalyzed by an enzyme S, via an active protein complex [RS, equation (66)], where the enzyme is subject to degradation [S → dS, equation (64)]. The chemical kinetics are described by a combination of mass action kinetics [equations (63), (64), and (66)] and Michaelis–Menten kinetics [equations (65) and (67)]. A graphical representation of this system can be seen in Figure 5. The square brackets denote the time-dependent concentration for that species and a dot over a symbol is shorthand for the temporal derivative of that symbol:
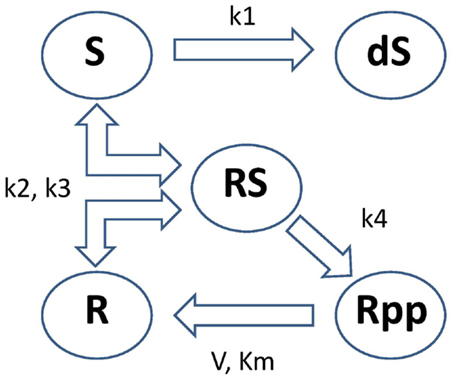
Figure 5. Graphical representation of the protein signaling transduction pathway in equations (63)–(67). There are 5 “species” (S, dS, R, RS, Rpp) and 6 parameters (k1, k2, k3, k4, V, Km). The system describes the phosphorylation of a protein, R → Rpp [equation (67)], catalyzed by an enzyme S, via an active protein complex [RS, equation (66)], where the enzyme is subject to degradation [S → dS, equation (64)]. Figure adapted from Vyshemirsky and Girolami (2008).
An example of a typical signal produced from these ODEs can be found in Figure 6.
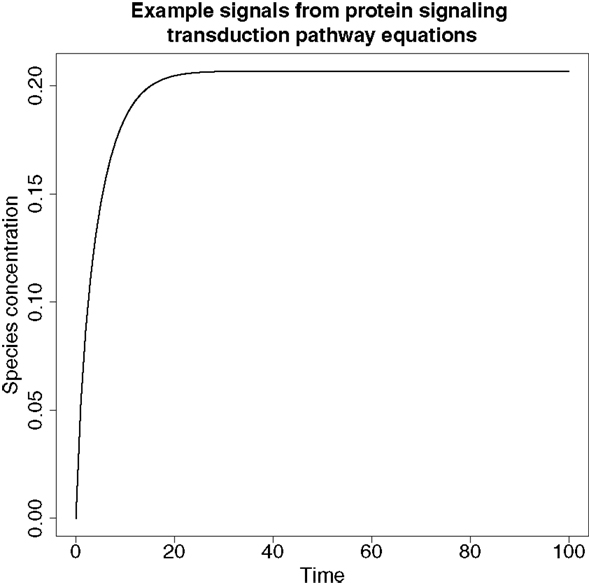
Figure 6. An example of a signal produced from the protein signaling transduction pathway in equation (64). The signal represents species dS and shows a rapid change in concentration before it plateaus, which is a feature typical of the remaining species’ signals in equations (63)–(67).
5. Simulation
For those methods for which software was unavailable at the time [Ramsay et al. (2007); González et al. (2013)], results were compared directly with the results from the original publications. To this end, test data were generated in the same way as described by the authors. For methods for which software was available at the time [Campbell and Steele (2012); Dondelinger et al. (2013); Macdonald and Husmeier (2015)], the evaluation was repeated twice, first on data equivalent to those used in the original publications, and again on new data generated with different (more realistic) parameter settings. For comparisons with Bayesian methods, the authors’ specifications for the priors on the ODE parameters were used. For comparisons with non-Bayesian methods, the methods of Dondelinger et al. (2013) and Macdonald and Husmeier (2015) were applied with the parameter prior from Campbell and Steele (2012), since the ODE model was the same.
5.1. Reproducing Kernel Hilbert Space Method (Section 2.7)
The method was tested on the FitzHugh–Nagumo data (see Section 4) with the following parameters: α = 0.2; β = 0.2, and ψ = 3. Starting from initial values of (−1, −1) for the two “species”, 50 timepoints were generated over the time course [0, 20], producing 2 periods, with iid Gaussian noise (SD = 0.1) added. Fifty independent datasets were generated in this way.
5.2. Splines and Hierarchical Regularization Method (Section 2.5)
This method was included in the study by González et al. (2013), and the results in this review are from the original paper. For a proper comparison, the methods of Dondelinger et al. (2013) and Macdonald and Husmeier (2015) were applied in the same way as in for the comparison with González et al. (2013).
5.3. Tempered Mismatch Parameter Using Splines-Based Smooth Functional Tempering (Section 2.4)
The method was tested on the FitzHugh–Nagumo system with the following parameter settings: α = 0.2; β = 0.2, and ψ = 3, starting from initial values of (−1, 1) for the two “species” [note the different starting values to the set-up in González et al. (2013)]. Four hundred and one observations were simulated over the time course [0, 20] (producing 2 periods) and Gaussian noise was added with SD {0.5, 0.4} to each respective “species”. The original settings were used for inferring the ODE parameters: splines of polynomial order 5 with 301 knots; four parallel tempering chains associated with gradient mismatch parameters {10, 100, 1000, 10,000}; parameter prior distributions for the ODE parameters: α ∼ N(0, 0.42), β ∼ N(0, 0.42), and .
In addition to comparing the methods of Dondelinger et al. (2013) and Macdonald and Husmeier (2015) with these original settings, the following modifications were made to test the robustness of the procedures with respect to these (rather arbitrary) choices. The number of observations was reduced from 401 to 20 over the time course [0, 10] (producing 1 period) to reflect more closely the amount of data typically available from current systems biology projects. For these smaller datasets, the number of knots for the splines was reduced to 15 (keeping the same proportionality of knots to datapoints as before), and a different polynomial order was tested: 3 instead of 5. Due to the high computational costs of the Campbell and Steele (2012) method (roughly weeks for a run), only 3 MCMC simulations on 3 independent datasets could be run. The respective posterior samples were combined, to approximately marginalize over datasets, and thereby remove their potential particularities. For a fair comparison, the tempering schedule in Campbell and Steele (2012) was applied to the methods of Dondelinger et al. (2013) and Macdonald and Husmeier (2015) such that 4 parallel chains were used rather than 10.
5.4. Inference of the Gradient Mismatch Parameter Using GPs (Section 2.1)
The methods of Dondelinger et al. (2013) and Macdonald and Husmeier (2015) were applied in the same way as in the original publication of Dondelinger et al. (2013), selecting the same kernels and parameter/hyperparameter priors. Data were generated from the protein signal transduction pathway, described in Section 4, with the following settings; ODE parameters: (k1 = 0.07, k2 = 0.6, k3 = 0.05, k4 = 0.3, V = 0.017, Km = 0.3); initial values of the species: (S = 1, dS = 0, R = 1, RS = 0, Rpp = 0); 15 timepoints covering one period, {0, 1, 2, 4, 5, 7, 10, 15, 20, 30, 40, 50, 60, 80, 100}. Multiplicative iid Gaussian noise of SD = 0.1 was used to distort the signals, in order to reflect observational error that would be obtained in experiments. For Bayesian inference, a Γ(4, 0.5) prior was used for the ODE parameters. For the GP, we used the same kernel as in Dondelinger et al. (2013); see below for details. In addition to this ODE system, these methods were also applied to the set-ups previously described for the FitzHugh–Nagumo model.
5.5. Choice of Kernel
For the GP, a suitable kernel needs to be chosen, which defines a prior distribution in function space. Two kernels are considered in this review [to match the authors’ set-ups in Dondelinger et al. (2013)], the radial basis function (RBF) kernel
with hyperparameters and l2, and the sigmoid variance kernel
with hyperparameters , a and b [Rasmussen and Williams (2006)].
To choose initial values for the hyperparameters, a standard GP regression model (i.e., without the ODE part) is fitted using maximum likelihood. The interpolant is then inspected to decide whether it adequately represents the prior knowledge of the signal. For the data generated from the FitzHugh–Nagumo model, the RBF kernel provides a good fit to the data. For the protein signaling transduction pathway, the non-stationary nature of the data is not represented properly with the RBF kernel, which is stationary [Rasmussen and Williams (2006)], in confirmation of the findings in Dondelinger et al. (2013). Following Dondelinger et al. (2013), the sigmoid variance kernel was used, which is non-stationary [Rasmussen and Williams (2006)] and this provided a considerably improved fit to the data.
5.6. Other Settings
Finally, the values for the variance mismatch parameter of the gradients, γ, needs to be configured for the method in Macdonald and Husmeier (2015). Log base 2 and log base 10 increments were used (initializing at 1), since studies that indicate reasonable values are limited [see Calderhead et al. (2008) and Friel and Pettitt (2008)]. All parameters were initialized with a random draw from the respective priors (apart from GON and RAM, which did not use priors).
6. Results
We present the results in the same way the authors of the methods we are comparing presented them in the original papers. For the methods we had obtained the authors’ code for, we also present the root mean square (RMS) values in function space. First, the signal was reconstructed with the sampled parameters and then the true signal was subtracted (signal created with true parameters and no observational noise added). The RMS was calculated on these residuals. It is important to assess the methods on this criterion as well as looking at the parameter uncertainty, as some parameters might only be weakly identifiable, corresponding to ridges in the likelihood landscape. In other words, large uncertainty in parameter estimates may not necessarily imply a poor performance by a method, if the reconstructed signals for all groups of sampled parameters were close to the truth.
All distributions of the results in this section are displayed graphically as boxplots, which display whiskers that extend from the lower (Q1) and upper (Q3) quartiles of the box, to boundaries defined by Q1 − 1.5(Q3 − Q1) and Q3 + 1.5(Q3 − Q1). All values outside these boundaries are considered outliers and drawn as a circle.
6.1. Reproducing Kernel Hilbert Space (Section 2.7) and Hierarchical Regularization (Section 2.5) Methods
For this configuration, to judge the performance of the methods, we used the same concept as in GON to examine our results. For each parameter, the absolute value of the difference between an estimate and the true parameter was computed and the distribution across the datasets was examined. For the LB2, LB10, and INF methods, the median of the sampled parameters was used since it is a robust estimator. Looking at Figure 7, the LB2, LB10, and INF methods do as well as the GON method for 2 parameters (INF doing slightly worse for ψ) and outperform it for 1 parameter. All methods outperform the RAM method.
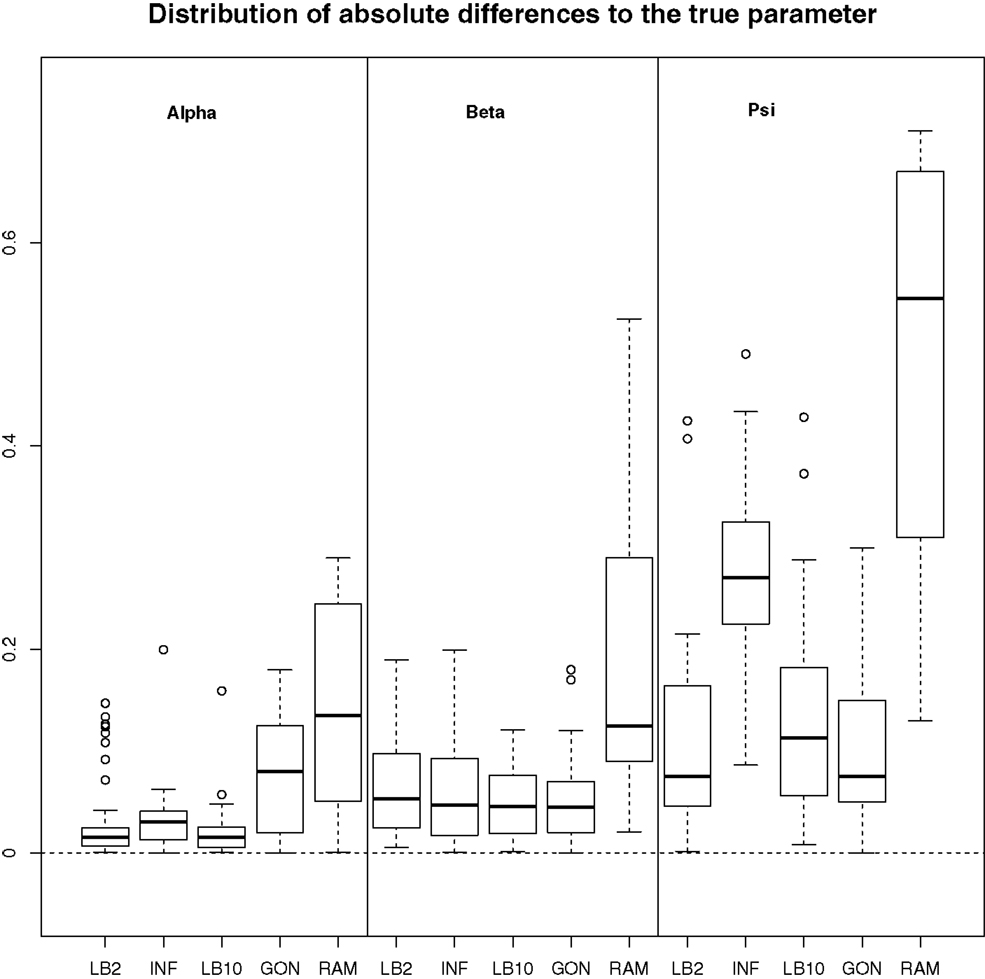
Figure 7. Boxplots of the distributions of the absolute differences of an estimate to the true parameter over 50 datasets. The three sections from left to right represent the parameters α, β, and ψ from equation (62). Within each section, the boxplots from left to right are: LB2 method, INF method, LB10 method, GON’s method [boxplot reconstructed from González et al. (2013)], and RAM’s method [boxplot reconstructed from González et al. (2013)]. For an explanation of the boxplot form, see the beginning of Section 6. Figure reconstructed from Macdonald and Husmeier (2015).
6.2. Tempered Mismatch Parameter Using Splines-Based Smooth Functional Tempering (Section 2.4)
For this set-up, the entire posterior distributions were examined. The posterior distributions were averaged over datasets in order to present the overall performance of each method, not confounded by the particular observational error that was added to a dataset. The C&S method shows good performance over all parameters in the one case where the number of observations is 401, the number of knots is 301, and the polynomial order is 3 (cubic spline), since the bulk of the average posterior distributions of the sampled parameters surrounds the true parameters in Figures 8 and 10 and is close to the true parameter in Figure 9. However, these settings require a great deal of “hand-tuning” or time expensive cross-validation and would be very difficult to set when using real data. The sensitivity of the splines-based method can be seen in the other settings, where the results deteriorate. It is also important to note that when the dataset size was reduced, the cubic spline performed very badly. This inconsistency makes these methods very difficult to apply in practice. The LB2, LB10, and INF methods consistently outperform the C&S method with the bulk of the average posterior distributions overlapping or being closer to the true parameters. On the set-up with 20 observations, for 4 chains and 10 chains, the INF method produced largely different estimates over the datasets, as depicted by the wide boxplots and long tails. The long tails in all of these distributions are due to the combination of estimates from different datasets.
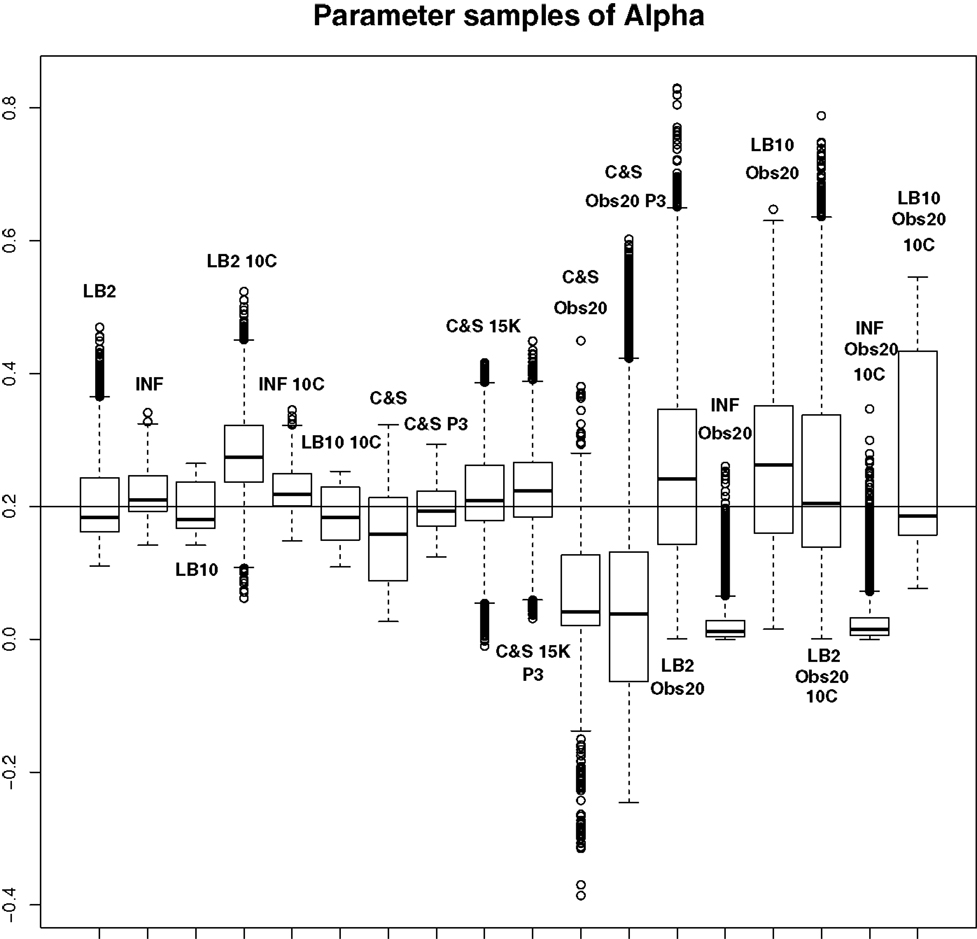
Figure 8. Average posterior distributions of parameter α from equation (62) over 3 datasets. From left to right: LB2, INF, LB10, LB2 10C, INF 10C, LB10 10C, C&S, C&S P3, C&S 15K, C&S 15K P3, C&S Obs20, C&S Obs20 P3, LB2 Obs20, INF Obs20, LB10 Obs20, LB2 Obs20 10C, INF Obs20 10C, and LB10 Obs20 10C. The solid line is the true parameter. For definitions, see Tables 3 and 4. For an explanation of the boxplot form, see the beginning of Section 6. Figure reconstructed from Macdonald and Husmeier (2015).
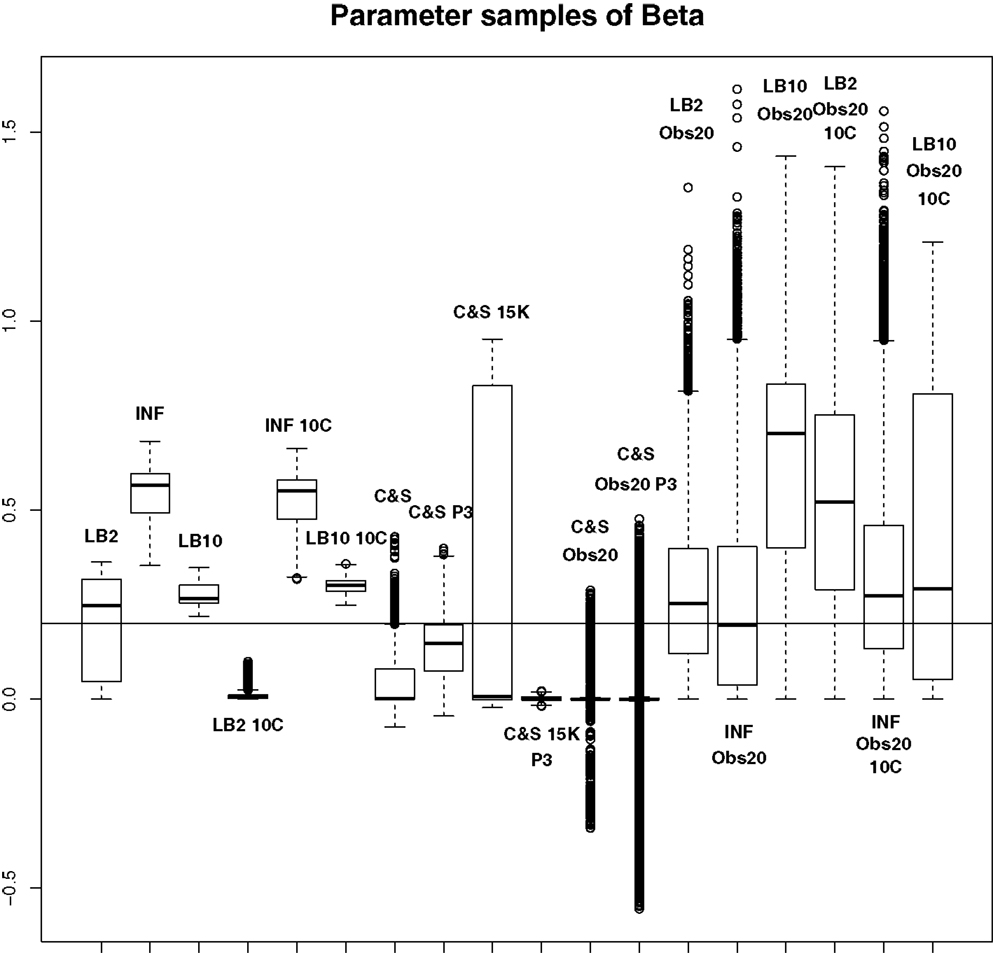
Figure 9. Average posterior distributions of parameter β from equation (62) over 3 datasets. From left to right: LB2, INF, LB10, LB2 10C, INF 10C, LB10 10C, C&S, C&S P3, C&S 15K, C&S 15K P3, C&S Obs20, C&S Obs20 P3, LB2 Obs20, INF Obs20, LB10 Obs20, LB2 Obs20 10C, INF Obs20 10C, and LB10 Obs20 10C. The solid line is the true parameter. For definitions, see Tables 3 and 4. For an explanation of the boxplot form, see the beginning of Section 6. Figure reconstructed from Macdonald and Husmeier (2015).
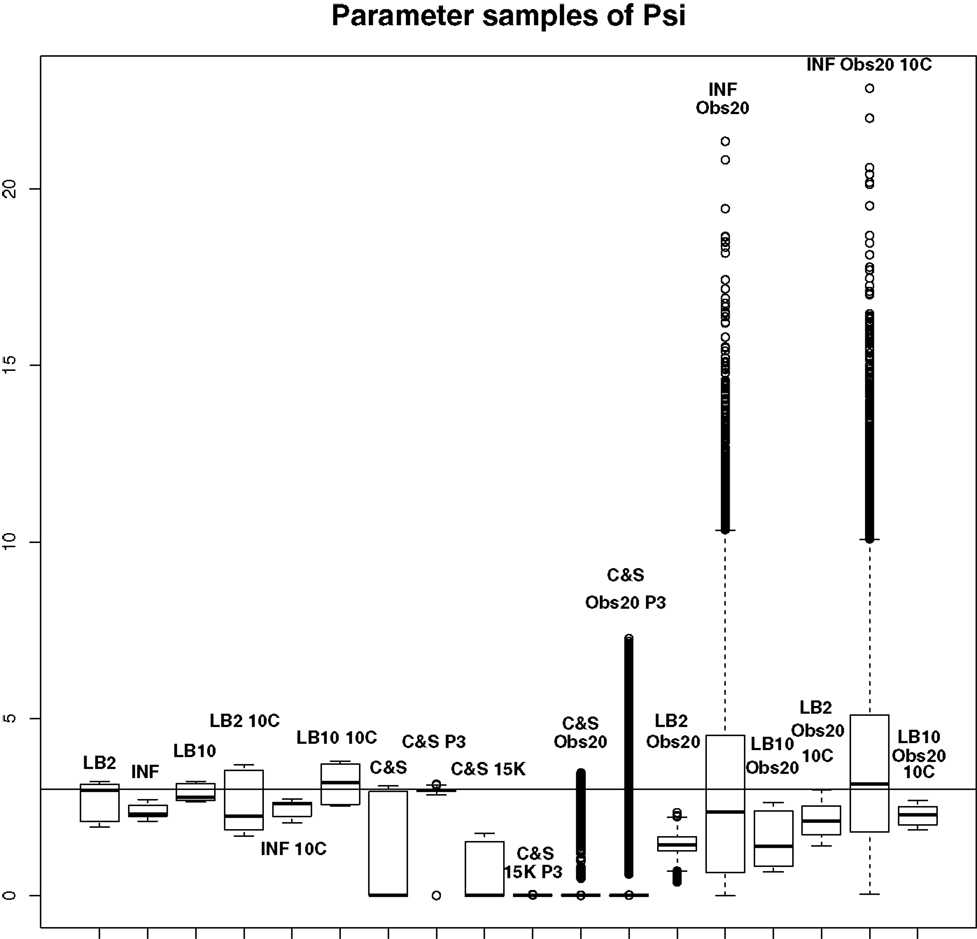
Figure 10. Average posterior distributions of parameter ψ from equation (62) over 3 datasets. From left to right: LB2, INF, LB10, LB2 10C, INF 10C, LB10 10C, C&S, C&S P3, C&S 15K, C&S 15K P3, C&S Obs20, C&S Obs20 P3, LB2 Obs20, INF Obs20, LB10 Obs20, LB2 Obs20 10C, INF Obs20 10C, and LB10 Obs20 10C. The solid line is the true parameter. For definitions, see Tables 3 and 4. For an explanation of the boxplot form, see the beginning of Section 6. Figure reconstructed from Macdonald and Husmeier (2015).
By examining Figure 11, we can see how the methods perform in function space. The RMS values for some of the C&S set-ups were very large, so for graphical viewing purposes, we applied a squashing function
where f (RMS) = RMS for RMS << 1, and f (RMS) = 1 for RMS → ∞. The RMS values have been monotonically transformed and values closer to 0 show better performance, whereas values closer to 1 show poorer performance. These results reinforce what we saw from the parameter estimates. The C&S performs well only in the one case where there was a large number of datapoints (401) and a cubic spline was used. The other set-ups for C&S perform very poorly, including the case where the cubic spline was used with a smaller dataset size. The LB2, INF, and LB10 methods perform well and similarly across the different set-ups, with LB10 performing slightly better in some scenarios.
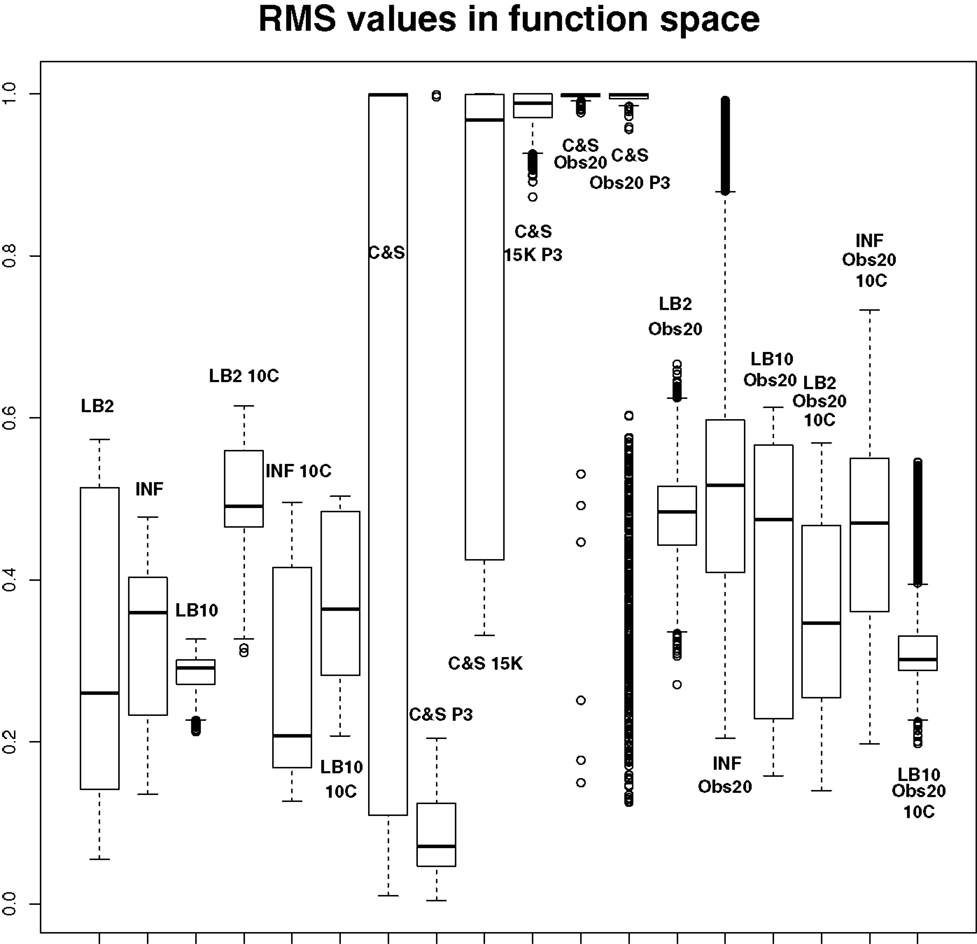
Figure 11. Average posterior distributions of RMS values in function space, calculated on the residuals of the true signal (signal produced with true parameters and no observational error) minus the signal produced with the posterior sampled parameters. For viewing purposes, a squashing function has been applied to the RMS values, see equation (70). Larger values show poorer reconstructed signals. From left to right: LB2, INF, LB10, LB2 10C, INF 10C, LB10 10C, C&S, C&S P3, C&S 15K, C&S 15K P3, C&S Obs20, C&S Obs20 P3, LB2 Obs20, INF Obs20, LB10 Obs20, LB2 Obs20 10C, INF Obs20 10C, and LB10 Obs20 10C. For definitions, see Tables 3 and 4. For an explanation of the boxplot form, see the beginning of Section 6.
6.3. Inference of the Gradient Mismatch Parameter Using GPs (Section 2.1)
In order to see how the tempering method in Macdonald and Husmeier (2015) performs in comparison to the INF method, we can examine the results from the protein signaling transduction pathway (see Section 4), as well as comparing the results in the previous set-ups. The distributions of the posterior parameter samples minus the true values for the protein signaling transduction pathway are shown in Figure 12. The INF method was unable to converge properly for some of the datasets. In order to present the average performance of the methods, for INF, LB2, and LB10, the root mean square (RMS) of the difference between the posterior parameter samples and the true values was calculated across all datasets. The results from the dataset which produced the median RMS are shown for each method.
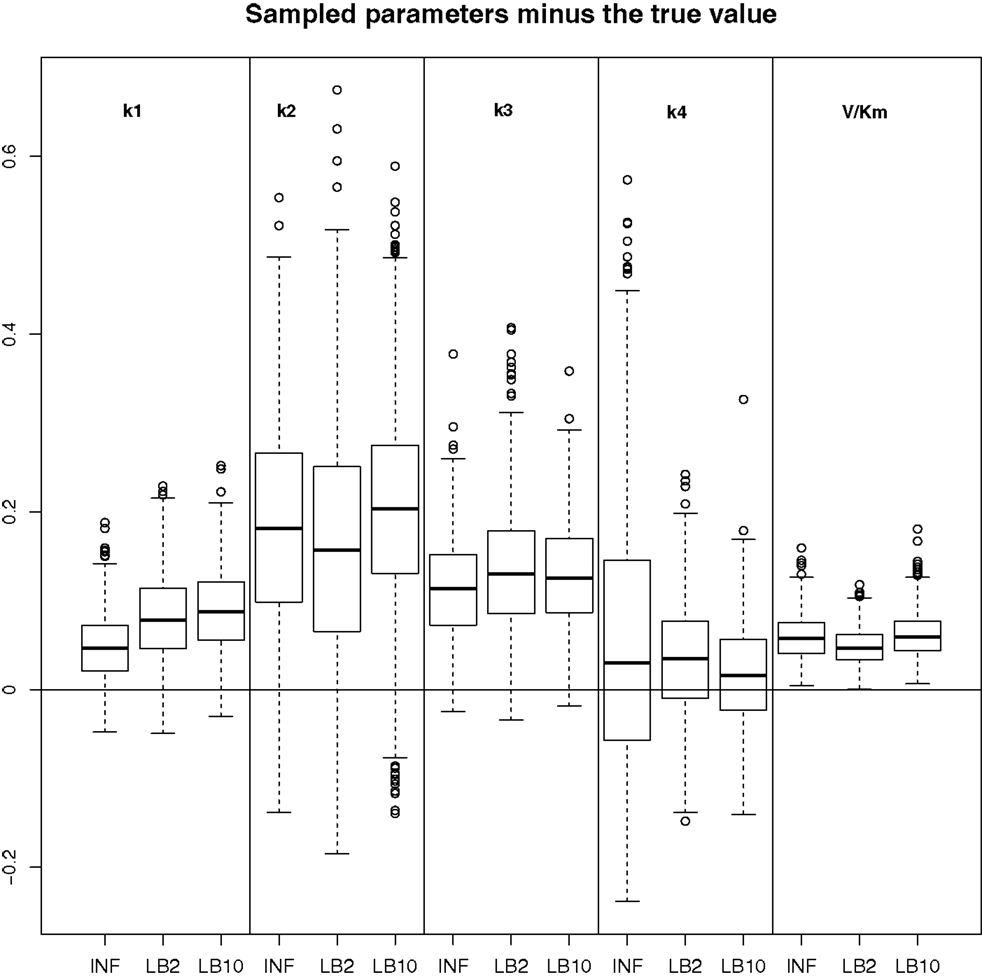
Figure 12. Results from the dataset that showed the average RMS of the posterior parameter samples minus the true values for the INF, LB2, and LB10 methods. The posterior distributions are of the sampled parameters from equations (63)–(67) minus their true values. The horizontal line shows zero difference. For an explanation of the boxplot form, see the beginning of Section 6. Figure reconstructed from Macdonald and Husmeier (2015).
By examining Figure 12, we can see that for each parameter, the bulk of the distributions is close to the true value and so the methods are performing reasonably. Overall, there does not appear to be a significant difference between the INF, LB2, and LB10 methods for this model. Figure 13 shows the distribution of RMS values for INF, LB2, and LB10 methods in terms of deviance from the true time series. All three methods perform similarly to one another, with RMS values close to zero.
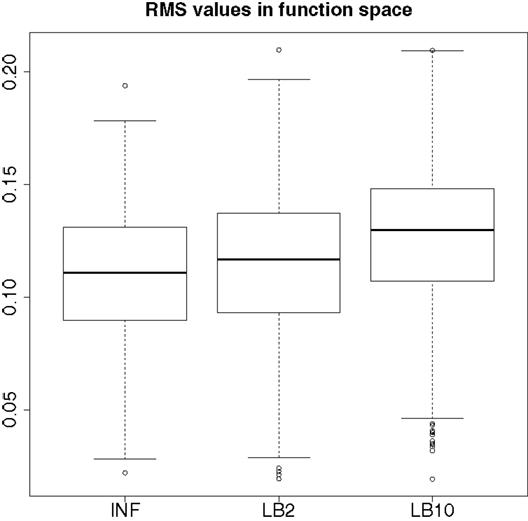
Figure 13. Posterior distributions of RMS values for the ODE model in equations (63)–(67). The RMS values are calculated on the residuals of the true signal (signal produced with true parameters and no observational error) minus the signal produced from the sampled parameters. For an explanation of the boxplot form, see the beginning of Section 6.
For the set-up in Sections 2.7 and 2.5: Figure 14 shows the Expected Cumulative Distribution Functions (ECDFs) of the absolute difference of the posterior parameter samples to the true values, for INF, LB2, and LB10. Included are the p-values for 2-sample, 1-sided Kolmogorov–Smirnov tests. If a distribution’s ECDF is significantly higher than another, this constitutes as better parameter estimation. A higher curve means that a method has more values that lie in the lower range of absolute error.
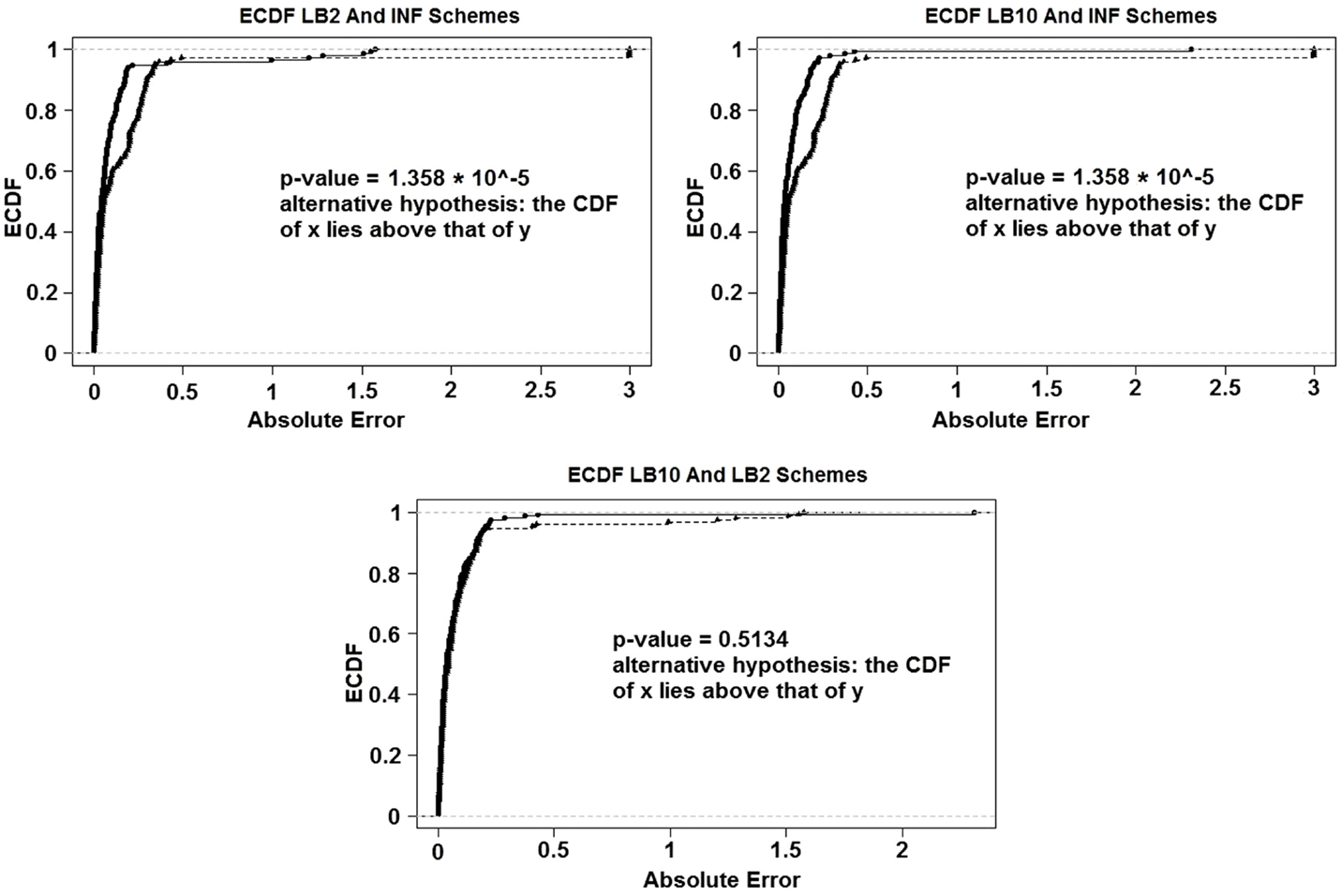
Figure 14. ECDFs of the absolute errors of the parameter estimation. Top left – ECDFs for LB2 and INF, top right – ECDFs for LB10 and INF, and bottom – ECDFs for LB10 and LB2. Included are the p-values for 2-sample, 1-sided Kolmogorov–Smirnov tests. For definitions, see Tables 3 and 4. Figure reconstructed from Macdonald and Husmeier (2015).
Figure 14 shows that both the LB2 and LB10 methods outperform the INF method, shown by p-values of less than the standard significance level of 0.05. Therefore, we conclude that the CDFs for LB2 and LB10 are significantly higher than those for INF. Since we are dealing with absolute errors, this means that the parameter estimates from the LB2 and LB10 methods are closer to the true parameters than the INF method. The LB2 and LB10 methods show no significant difference to each other.
For the set-up in Section 2.4: The LB2 and LB10 methods do well over all the parameters and dataset sizes, with most of the mass of the distributions surrounding or being situated close to the true parameters. The LB2 does better than the LB10 for 4 parallel chains (distributions overlapping the true parameter for all three parameters) and the LB10 outperforms the LB2 for 10 parallel chains (distribution overlapping true parameter in Figure 8, being closer to the true parameter in Figure 9, and narrower and more symmetric around the true parameter in Figure 10). The INF method’s bulk of parameter sample distributions is located close to the true parameters for all dataset sizes. However, the decrease in uncertainty is at the expense of bias. When reducing the dataset to 20 observations, for 4 and 10 chains, the inference deteriorates and is outperformed by the LB2 and LB10 methods. This could be due to the parallel tempering scheme constraining the mismatch between the gradients in chains closer to the posterior, allowing for better estimates of the parameters.
7. Discussion
We have carried out a comparative evaluation of various state-of-the-art gradient matching methods. These methods are based on different statistical modeling and inference paradigms: non-parametric Bayesian statistics with Gaussian processes (INF, LB2, and LB10), hierarchical regularization using splines interpolation (RAM), splines-based smooth functional tempering (C&S), and penalized likelihood based on reproducing kernel Hilbert spaces (GON). We have also compared the antagonistic paradigms of Bayesian inference (INF) versus parallel tempering (LB2 and LB10) of slack parameters in the specific context of adaptive gradient matching. We discuss aspects of the methodology and empirical findings separately.
7.1. Methodology
The GON method, due to the RKHS framework, is fast to implement. This is an attractive property, since the main motivation for gradient matching methods was to obtain a computational speed-up over techniques that calculate the numerical solution to the ODEs. This method hinges on obtaining better estimates of the interpolant gradient by use of the EM algorithm, so great care needs to be had when implementing this step. Care also needs to be exercised in fitting the splines estimates of the species for terms of the ODEs that cannot be fit with the RKHS approach. This step is not optimized within the penalized likelihood of equation (61) and so poor splines estimates could deteriorate the results. The 3 level hierarchy of the RAM method, for first configuring the tuning parameters and then for performing parameter estimation, is sensible. Since gradient matching methods rely on a good estimate of the interpolant, focusing on the tuning parameters should achieve more robust parameter estimates of the ODEs. This 3 level approach, however, does increase the computational complexity and the RAM method does not achieve a good speed-up over the numerical solution methods. The C&S method’s use of parallel tempering of both the likelihood and gradient mismatch parameter is intuitive, and allows the MCMC to explore with a reduced chance of getting stuck on local optima. This method uses B-splines interpolation, which can be difficult in practice to configure the tuning parameters for. The INF method has the advantage that the interpolant hyperparameters can be inferred from the data, since it uses Gaussian process interpolation. The inference approach to the gradient mismatch parameter, as opposed to tempering, however, could be overflexible and drive the parameter to values where the coupling between the gradients is too weak. The LB2 and LB10 methods avoid this by using a tempering scheme to drive the parameter to the theoretically correct value (0 corresponding to no mismatch between the gradients). However, currently, there is no way of optimizing the specific step size and increment schedule.
7.2. Empirical Findings
The GON method produces estimates that are close to the true parameters in terms of absolute uncertainty. This, however, was for the case with small observational noise (Gaussian iid noise SD = 0.1), and it would be interesting to see how the parameter estimation accuracy is affected by the increase of noise. The RAM method performs worse than the rest of the methods it was compared to, across all parameters. The C&S method does well only in the one case, where the number of observations is very high (higher than what would be expected in these types of experiments) and the tuning parameters are finely adjusted (which in practice is very difficult and time-consuming). When the number of observations was reduced, all settings for this method deteriorated significantly. It is important also to note that the settings that we found to be optimal were slightly different than in the original paper, which highlights the sensitivity and lack of robustness of the splines-based method. The INF method shows a reasonable performance in terms of consistently producing results close to the true parameters, across all the set-ups we have examined. However, this technique’s decrease in uncertainty is at the expense of bias. The LB2 and LB10 methods show the best performance across the set-ups. The parameter accuracy is unbiased across the different ODE models and the different settings of those models. The parallel tempering seems to be quite robust, performing similarly across the various set-ups. We have explored four different schedules for the parallel tempering scheme (as shown in Table 1). Overall, the performance of parallel tempering has been found to be reasonably robust with respect to a variation of the schedule.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This work was supported by EPSRC (EP/L020319/1). We are grateful to Dr. Catherine Higham and Dr. Caroline Haig for helpful discussions and feedback on the manuscript.
Footnotes
- ^We do not make the baseline transcription rate explicit in our notation, but include it in the function gi(.).
- ^By “temperature”, we mean a tempering parameter that defines the degree of flattening of the likelihood. Formally, our “temperature” is equivalent to an inverse temperature in Statistical Physics.
References
Barenco, M., Tomescu, D., Brewer, D., Callard, R., Stark, J., and Hubank, M. (2006). Ranked prediction of p53 targets using hidden variable dynamic modeling. Genome Biol. 7, R25. doi: 10.1186/gb-2006-7-3-r25
Calderhead, B., and Girolami, M. (2009). Estimating Bayes factors via thermodynamic integration and population MCMC. Comput. Stat. Data Anal. 53, 4028–4045. doi:10.1016/j.csda.2009.07.025
Calderhead, B., Girolami, M., and Lawrence, N. (2008). “Accelerating Bayesian inference over non-linear differential equations with Gaussian processes,” in Neural Information Processing Systems (NIPS), 22.
Campbell, D., and Steele, R. (2012). Smooth functional tempering for nonlinear differential equation models. Comput. Stat. 22, 429–443. doi:10.1007/s11222-011-9234-3
Dondelinger, F., Filippone, M., Rogers, S., and Husmeier, D. (2013). “ODE parameter inference using adaptive gradient matching with Gaussian processes,” in Journal of Machine Learning Research Workshop and Conference Proceedings (JMLR WCP): The 16th International Conference on Artificial Intelligence and Statistics (AISTATS), Vol. 31, 216–228.
FitzHugh, R. (1961). Impulses and physiological states in models of nerve membrane. Biophys. J. 1, 445–466. doi:10.1016/S0006-3495(61)86902-6
Friel, N., and Pettitt, A. (2008). Marginal likelihood estimation via power posteriors. J. R. Stat. Soc. Series B Stat. Methodol. 70, 589–607. doi:10.1111/j.1467-9868.2007.00650.x
González, J., Vujačić, I., and Wit, E. (2013). Inferring latent gene regulatory network kinetics. Stat. Appl. Genet. Mol. Biol. 12, 109–127. doi:10.1515/sagmb-2012-0006
Hastie, T., Tibshirani, R., and Freidman, J. (2009). The Elements of Statistical Learning. New York: Springer.
Liang, H., and Wu, H. (2008). Parameter estimation for differential equation models using a framework of measurement error in regression models. J. Am. Stat. Assoc. 103, 1570–1583. doi:10.1198/016214508000000797
Macdonald, B., and Husmeier, D. (2015). “Computational inference in systems biology,” in Bioinformatics and Biomedical Engineering: Third International Conference, IWBBIO 2015. Proceedings, Part II. Series: Lecture Notes in Computer Science (9044) eds. F. Ortuño and I. Rojas (Granada: Springer), 276–288.
Mercer, J. (1909). Functions of positive and negative type, and their connection with the theory of integral equations. Philos. Trans. R. Soc. Lond. A 209, 415–446. doi:10.1098/rsta.1909.0016
Mohamed, L., Calderhead, B., Filippone, M., Christie, M., and Girolami, M. (2012). “Population MCMC methods for history matching and uncertainty quantification,” in Computational Geosciences (Netherlands: Springer International publishing), 423–436.
Murray, I., and Adams, R. (2010). “Slice sampling covariance hyperparameters of latent Gaussian models,” in Advances in Neural Information Processing Systems (NIPS), 23.
Nagumo, J., Arimoto, S., and Yoshizawa, S. (1962). An active pulse transmission line simulating a nerve axon. Proc. Inst. Radio Eng. 50, 2061–2070.
Ramsay, J., Hooker, G., Campbell, D., and Cao, J. (2007). Parameter estimation for differential equations: a generalized smoothing approach. J. R. Stat. Soc. Series B Stat. Methodol. 69, 741–796. doi:10.1111/j.1467-9868.2007.00610.x
Rasmussen, C., and Williams, C. (2006). Gaussian Processes for Machine Learning. Cambridge: MIT Press.
Schöelkopf, B., and Smola, A. (2002). Support Vector Machines, Regularisation, Optimisation and Beyond. Cambridge: MIT Press.
Keywords: ordinary differential equations, gradient matching, Gaussian processes, reproducing kernel Hilbert space, parallel tempering, B-splines
Citation: Macdonald B and Husmeier D (2015) Gradient Matching Methods for Computational Inference in Mechanistic Models for Systems Biology: A Review and Comparative Analysis. Front. Bioeng. Biotechnol. 3:180. doi: 10.3389/fbioe.2015.00180
Received: 15 June 2015; Accepted: 23 October 2015;
Published: 20 November 2015
Edited by:
Marcio Luis Acencio, Universidade Estadual Paulista, BrazilReviewed by:
Adriano Velasque Werhli, Universidade Federal do Rio Grande, BrazilPaulo F. A. Mancera, Universidade Estadual Paulista, Brazil
Copyright: © 2015 Macdonald and Husmeier. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Benn Macdonald, Yi5tYWNkb25hbGQuMUByZXNlYXJjaC5nbGEuYWMudWs=, Yi5tYWNkb25hbGQucmVzZWFyY2hAZ21haWwuY29t;
Dirk Husmeier, ZGlyay5odXNtZWllckBnbGFzZ293LmFjLnVr