Abstract
In this article, we consider local overlapping histograms of functions between discrete domains and codomains. We develop a simple algebra for local histograms. Based on a separation of overlapping domains into non-overlapping domains, we (1) show how these can be used to enumerate the size of the set of possible histograms given the local histogram domains, and (2) enumerate the number of functions, which share a specific choice of a set of local histograms. Finally, we present a decoding algorithm, which given a set of overlapping histograms, and calculate the set of functions, which share these histograms.
1. Introduction
Inspired by Koenderink and Doorn (1999), we have for many years worked with images, and features derived from local histograms, and a nagging question has been, what the degrees of freedoms remain, given a set of overlapping histograms. This paper presents a theoretical investigation into the relationship between sets of local histograms and functions between discrete domains and codomains of any dimension. We describe an algebra of histograms, which is strongly related to the algebra of sets on the function domain and multisets: Given a set of local histogram's domains, h(Xi), Xi ⊂ X, where X is the full domain, and Xi are subsets thereof, such that ⋃iXi = X, we factor X into a new set of disjoint subsets , and with this, we are able to count the number of independent histograms, which jointly describe the total set of local histograms, and which leads to a simple countable, generative model for functions drawn from these histograms. Finally, we present a simple algorithm for generating the set of functions, which share a particular set of local histograms overlapping or not.
Our work is an extension of Sporring and Darkner (2022), where 1-dimensional signals are considered and the concept of metameric classes is introduced in the concept of local histograms. The article restricts itself to binary signals from their densely overlapping histograms. In Wu et al. (2000), the authors consider normalized histogram of images filtered with Gabor kernels (Gabor, 1946), and in particular, the limiting case of the discrete domain converging to ℤ2.
This paper is organized as follows. In Section 2, we present the histogram-algebra, in Section 3 we show how the number of unique functions sharing a specific set of histograms is generated. In Section 4, we present the algorithm for calculating the set of functions, which share a given set of local histograms, and finally, Section 6 gives concluding remarks.
2. Histograms as Infintely-Additive set functions
In the following, we will define an algebra for discrete histograms of disjoint domains, and we will extend this to non-disjoint domains by repartitioning domains.
Consider discrete domain X, co-domain A, and a functions f : X → A between them, such that the histogram h : A → ℤ+
is defined. Conceptually, we think of X as d-dimensional spatial domain X = {1, 2, 3, …, n}d with side-lengths n > 0, and A as a an alphabet of m > 0 different gray values A = {1, …m}, but for the properties of possibly overlapping histograms, the interpretation of the values of X and A is not important, and X and A could as well be the set {cow, cat, fish} or color triplets {(0, 0, 0), (0, 0, 1), …}. As long as we can define a one-to-one mapping to an index set, we need only to concern ourselves with this index.
Two key properties of a histogram are that
Property 2.1. Histograms are non-negative, ∀a∈Ah(a) ≥ 0.
Property 2.2. Every value f(x), x ∈ X is counted once and only once.
A direct consequence of Property 2.2 is that
In this article, we are interested in counting possible histograms and for given histograms, counting the number of possible function. Let's start by examining the number of unique histograms that exists for a single domain and co-domain. Let be the set of unique histograms. Its size may be calculated as unordered sampling with replacement, where we visually represent each element in X with a “•” and each bin edge with a “;.” Then the string “• • •;•;;…” corresponds to the histogram [1; 2; 3; …] → [3; 1; 0; …]. For brevity, it is convenient to assume that an ordering of the alphabet exists such that we may write the before mentioned histogram simply as [3; 1; 0; …]. The string will be |X|+|A|−1 long, and all possible histograms can be produced by selecting |A| − 1 positions in this string for the “;” character. Thus, the number of unique histograms for a given domain X is given by the binomial coefficient,
In the following, we will consider possibly overlapping, local histograms over the domain X. Our expositions will be divided into first non-overlapping or disjoint domains, and then we will show how overlapping domains can be repartitioned into disjoint domains, and how these relate to the original overlapping domains.
2.1. Histograms over disjoint domains
Consider a partitioning of X into k < ∞ disjoint subdomains , where ∀i≠jXi ∩ Xj = ∅. Due to Property 2.2, h is a finitely-additive set function (Stover, 2022), and hence,
As a consequence, h∅(a) = 0, and addition of histograms of disjoint domains is commutative and associative. The subtraction hY(a) − hX(a) is a histogram when X ⊆ Y, e.g.,
omitting the argument a for brevity. However, subtracting any two histograms in general will likely produce negative values violating Property 2.1, and although useful at times, the result will not be a histogram.
Since the sets Xi are disjoint, the size of the set of all possible histograms of X is found by extending Equation (3) directly,
2.2. Partitioning of non-disjoint sets
For a set of k non-disjoint domains of , we can repartition X into disjoint domains of unique overlap of Xi
where Pk is the powerset of {1, 2, …, k}, e.g., P3 = {∅, {1}, {2}, {3}, {1, 2}, {1, 3}, {2, 3}, {1, 2, 3}}. With this notation, we find the original sets as,
Example 2.1. As an example, consider 3 sets X1, X2, and X3, there are 7 unqiue intersections as illustrated in Figure 1 together with the powerset naming convention.
Figure 1
That is, and .
Example 2.2. As a concrete example, consider the domain X = {1, 2, …, 6} and the codomain A = {1, 2, 3}, and define X1 = {1, 2, 3, 4}, X2 = {3, 4, 5, 6}. Assuming the usual ordering of integers, we can illustrate this overlap on a line as,
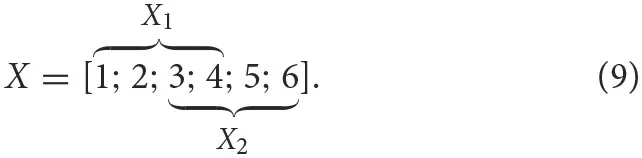
Using Equation (7) we find that P2 = {{1}, {2}, {1, 2}} and that , , and . Each of these subdomains are of size 2, and thus, the by Equation (3), number of possible histograms of each is , and the set of possible histograms is
Since there are 3 disjoint regions each with 6 possible histograms, there are 63 = 216 combinations of these. Introducing a natural extension of our notations on the domains to their corresponding histograms, one of these is,
in which case,
Since these overlapping histograms have been generated by histograms on their disjoint parts, we are sure that a function exists on X which has histograms h1 and h2. Further, since histograms are finitely-additive functions we are sure that Properties 2.1 and 2.2 are fulfilled for h1 and h2.
In the following, we will count the number of functions on disjoint domains and see how these can be combined to generate the family of functions, which share overlapping histograms generated from the disjoint domains.
3. Unique functions and their histograms on disjoint domains
For a single domain X, the total number of possible functions is given as |A||X|, and some of these have the same histogram. Conversely, given a histogram h, the set of functions, which share this histogram can be produced as the set of distinct permutations of the function,
The number of distinct functions is given by
CX is a multinomial coefficient and can be simplified to
where we for simplicity have neglected to write the subscript X and in the last term used that (|X|−h(1)−h(2)−…−h(|A|))! = 1. Like the simplified notation for h, we will also write Ci for CXi.
For the disjoint sets ∀i≠jXi ∩ Xj = ∅, the functions on Xi are independent on those on Xj, j ≠ i, and may be chosen independently. Thus, number of functions sharing H is
where CXi is Equation (14) applied to hi.
Example 3.1. As an example, consider the (ordered) alphabet A = {1, 2, 3} and the histogram hX = [1; 1; 2]. Then by Equation (2) we know that |X| = 4. Finally using Equation (15) we find that
Assuming that X is a line, we can list all possible functions which has histogram hX as,
Example 3.2. Another example, for the same alphabet as in Example 3.1 but with hX = [2; 0; 2] we follow the same procedure as in Example 3.1 to calculate , and the list possible functions on a linear domain X as,
Example 3.3. Continuing Example 2.2 with A = {1, 2, 3}, X = {1, 2, …, 6}, X1 = {1, 2, 3, 4}, X2 = {3, 4, 5, 6}, and h{1} = [1; 1; 0], h{1,2} = [1; 0; 1], h{2} = [0; 2; 0], the number of functions is computed from its non-overlapping parts are
Thus, the total number of functions for these specific histograms h0 and h1 is C{1}C{1,2}C{2} = 4, and the functions are any combination of
One of the 4 functions, which have histograms h1 and h2 specified in Equation (12) is thus .
Example 3.4. As a final example, consider a one-dimensional function over the alphabet A = {1, 2, 3} and where X = X1 ∪ X2 ∪ X3, X1 = {1, 2, 3, 4}, X2 = {2, 3, 4, 5}, X3 = {3, 4, 5, 6}. The unique partitions are then given as,
The possible histograms of the singleton domains are
and for ,
since . The total number of different histograms is,
To generate a set of functions and overlapping histograms, we choose a specific set of hI,
and thus, h1 = h{1} + h{1,2} + h{1,2,3} = [1; 2; 1], h2 = h{1,2} +h{1,2,3} +h{2,3} = [1; 2; 1], and h3 = h{1,2,3} +h{2,3} +h{3} = [2; 1; 1]. The number of functions is computed from its non-overlapping parts,
Thus, the total number of functions for these specific histograms is C{1}C{1,2}C{1,2,3}C{2,3}C{3} = 2, and the functions are any combination of
and one of the two possible functions sharing is thus f(X) = [2; 1; 0; 1; 2; 0].
In the above, we have given a method for generating histograms and functions by repartioning the domain into disjoint domains. In the following, we will investigate how to find the set of functions, which share a set of overlapping histograms.
4. Unique functions from overlapping histograms
For a set of overlapping histograms, we have yet to find a closed form solution for counting the number of functions, which share . However, by repartition their domain using Equation (7) giving |Pk| disjoint domains, we are able to recursively calculate the sets of histograms for the repartitioned domains which agree with . For each domain, we have κhI(1, |XI|), I ∈ Pk different histograms where κ is given recursively as,
Example 4.1. For example, given two overlapping subdomains X1 and X2, we repartitioning the domain using Equation (7) into , , and .
Further, if A = {1, 2}, , and , then there are the following possible combinations of histograms for h1 and h{1}:
The recursive evaluation of κ in Equation (27) for this example is visualized as the trees in Figure 2. Not that given h{1}, then h{1,2} is determined directly by Equation (5) as h1 − h{1}. For example, if h1 = [3; 1] ∧ h{1} = [1; 1] then h{1,2} = [3; 1] − [1; 1] = [2; 0].
Figure 2
Given , we can use Equation (27) to sequentially generate a tree of histograms hI which agree with . For example, starting with h1 we can calculate the set of possible histograms for (h{1}, h1 \ h{1}) pairs. Then for each h1 \ h{1} we calculate the set of possible histograms for (h{1,2}, h1\h{1}\h{1,2}) pairs and so on. In practice, we have chosen to implement a sifting algorithm instead, which will be described in the following.
Given a set overlapping domains {X0, X1, …} and their corresponding histograms {hX0, hX1, …}, we propose a sifting algorithm that considers a list of candidate functions that are iteratively updated as we consider additional local histograms. We produce candidate functions, and for a particular candidate function f, which has candidate values at positions , the next window Xn and its target histogram hXn, we identify yet to be considered region and calculate the function
If g ≥ 0 and , then we cannot refute the candidate, and g is the histogram of which agrees with the histograms h0, h1, … hn, and hence the candidate f is replaced with a new set of candidate functions extending f(Xn) with function values that have histogram g at .
The computational complexity of the algorithm is governed by the sizes of the function, the sizes of Xi, and the sweeping order of the update of the candidates. In Figure 3 are two unavoidable cases shown for a 2-dimensional domain. In the figure, Xn are denoted by the blue areas, and Xn by the green square.
Figure 3
Since each candidate appears to grown binomially by the size that , our experiments indicate that a sweeping order, where the cases where is small seems to produce fewer maximum number of candidates during the reconstruction. An upper bound on the search tree is given in Section 5. The main part of our algorithm is shown in Figure 4. The full algorithm can be downloaded from github.
Figure 4
Example 4.2. An example of a reconstruction is shown in Figure 5, where A = {0, 1, 2}, X = {0, 1, … 9}2, and Xi are 3 × 3 square windows translated in both directions with a stride of 1. In this case, there are two images, which has the same set of local histograms for m = 3.
Figure 5
5. Bound on the size of the search tree
As a measure of the Computational complexity of our sifting algorithm, we will here give an upper bound on the search tree.
Given an n×n image with intensities from an alphabet A and its local histograms hij over m × m domains, Xij, where m ≤ n, and where ij is the lower left corner of the domain. We consider the maximum case of all local (n−m+1)2 histograms produced by m × m windows translated by 1 over the image domain. Our algorithm considers the histograms in a diagonal order,
Caseh11: Our sifting algorithm will first produce the set of candidates for X11 which by (15) produces candidates. The pseudo-uniform histogram, |h(j) − h(k)| ≤ 1, j ≠ k maximizes this value. To prove this, consider two values in the histogram, where h(j) > h(k), and the denominator,
For a similiar histogram h′ which is equal to h, except h′(j) = h(j) − 1 and h′(k) = h(k) + 1, then the ratio of their corresponding denominator is,
When h(j) = h(k)+1 then otherwise , and we conclude that d is minimized for pseudo-uniform histograms. Since m2 is a constant, is maximized for pseudo-uniform histograms. Writing m2 by its integer quotient and remainder,
where q and r are whole numbers and 0 ≤ r < |A|, then the pseudo-uniform histogram will have |A| − r bins with q values and r bins with q + 1, and the largest number of candidates for the left-most part of the image is
Caseh21: Our algorithm next considers the histogram h21 for the window X21, which is a translated 1 wrt. X11, i.e., |X11 \ X21| = |X21 \ X11| = m. When hX11\X21 = hX21\X11, then none of the candidates generated by h11 can be discarded, and for each, we must consider all the additional candidates for hX21\X11. In the worst case, hX21\X11 is pseudo-uniform. Writing m in terms of its integer quotient and remainder,
where p and s are whole numbers 0 ≤ s < |A|, this gives us
additional hypotheses to consider for each existing candidate.
Caseh12: Having reach this histogram, all candidates agree with h11 and h21. Since, |X12 \ (X11 ∪ X21)| = |X12 \ X11| = m, the number of additional hypotheses for each candidate are the same as derived for case h21.
Caseh22: Having reach this histogram, all candidates agree with h11, h21, h12, h31. Since, |X22 \ (X11 ∪ X21 ∪ X12 ∪ X31)| = |X22\(X11∪X21∪X12)| = 1, and there is at most one solution for this solution corresponding to a non-negative value in difference between h22−hX22∩(X11∪X21∪X12). If this histogram difference is has negative value, then the candidate solution can be discarded, however, for simplicity's sake, we will ignore this. Thus, this case does not give additional candidates.
Bound on the number of candidate images: By the anti-diagonal order, we 1 time are in Case h00, n − m times in Case hi,1, i > 1 and in Case h1,j, j > 1, which are identical to Cases h2,1 and h1,2, and (n − m − 1)2 times in Case hi,j, i,j > 1, which are identical to Case h22. Thus, we conclude that the worst case scenario is reached when all histograms considered are pseudo-linear, in which case a maximum of
hypotheses must be considered. Examples of the number of hypotheses by the above equation for a small set of n, A, and m are given below
| n | |A| | m | #Hypotheses |
| 10 | 2 | 2 | 393216 |
| 10 | 2 | 3 | 602654094 |
| 10 | 3 | 2 | 786432 |
| 10 | 3 | 3 | 131651795681280 |
| 11 | 2 | 2 | 1572864 |
| 11 | 2 | 3 | 5423886846 |
| 11 | 3 | 2 | 3145728 |
| 11 | 3 | 3 | 4739464644526080 |
Note: In practice, the number of hypotheses in memory is considerably smaller. Consider the case of n = 3 and m = 2. The initial 3 histograms h11, h21, and h12 generates hypotheses for the m2 − 1 = 3 values in |X22 ∩ (X11 ∪ X21 ∪ X12)|, for which there are only different histograms, and h22 must be out of the possible histograms. Similarly, if the histogram difference contains zero-values, then any candidate, which has a non-zero value at the corresponding histogram point can be discarded. This happens often, when m2 < |A|.
6. Conclusion
In this article, we have considered locally overlapping histograms of functions from discrete domains and codomains of any dimension. Histograms of signals and images have been studied in the literature extensively, and particularly, the seminal work on locally orderless images (Koenderink and Doorn, 1999), the notion of local histograms has gained a solid theoretical basis. The authors' work map discrete functions and histograms into the continuous domain, in a manner that makes differentiation of discrete functions well-posed. Their work, however, left the essential question unanswered: what is the expression power of histograms? In Sporring and Darkner (2022) a partial answer is given to this question for binary signals with densely overlapping histograms, and in this article, we extend this work for non-binary discrete functions of any dimension and with windows of any overlap, and in this article we have:
Presented a simple algebra for histograms of discrete domain and co-domains based on non-overlapping sets.
For a given set of covering sets in the domain, we have given a constructive method for identifying unique, non-overlapping sets which cover the domain.
We have given an equation for the size of the set of all possible histograms based on the set of unique, non-overlapping domain sets.
For a specific set of histograms of the individual unique, overlapping and non-overlapping sets, we have given
• an equation for calculating the corresponding histograms of any set in the domain and
• an equation for counting the total number of functions with these histograms.
Presented an algorithm, which given a set of overlapping histograms, produce the set of functions, which share these histograms.
Understanding the expression power of local histograms is not done. For one, we still seek to connect the results obtained for discrete functions with the continuous domain.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher. All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Statements
Data availability statement
The code is publicly available at: https://github.com/sporring/reconstructionFromHistograms.
Author contributions
JS and SD: conceptualization and writing—review and editing. JS: formal analysis, methodology, software, and writing—original draft. Both authors have read and agreed to the published version of the manuscript.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
1
GaborD. (1946). Theory of communication. Part 1: the analysis of information. J. Inst. Electr. Eng.93, 429–441. 10.1049/ji-3-2.1946.0074
2
KoenderinkJ. J.DoornA. J. V. (1999). The structure of locally orderless images. Int. J. Comput. Vis.31, 159–168.
3
SporringJ.DarknerS. (2022). Reconstructing binary signals from local histograms. Entropy24, 433. 10.3390/e24030433
4
StoverC. (2022). Finite Additivity. From MathWorld–A Wolfram Web Resource, created by Eric W. Weisstein. Available online at: https://mathworld.wolfram.com/FiniteAdditivity.html
5
WuY. N.ZhuS. C.LiuX. (2000). Equivalence of julesz ensembles and frame models. Int. J. Comput. Vis.38, 247–265. 10.1023/A:1008199424771
Summary
Keywords
infinitely-additive set functions, multisets, counting histograms and functions, locally orderless histograms, reconstruction from histograms
Citation
Sporring J and Darkner S (2022) An algebra for local histograms. Front. Comput. Sci. 4:939563. doi: 10.3389/fcomp.2022.939563
Received
09 May 2022
Accepted
19 October 2022
Published
17 November 2022
Volume
4 - 2022
Edited by
Yi-Zhe Song, University of Surrey, United Kingdom
Reviewed by
Shancheng Zhao, Jinan University, China; Ruoyi Du, Beijing University of Posts and Telecommunications (BUPT), China
Updates
Copyright
© 2022 Sporring and Darkner.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jon Sporring sporring@di.ku.dk
This article was submitted to Computer Vision, a section of the journal Frontiers in Computer Science
Disclaimer
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.